- Overview
- Dataset Overview
- Data Preprocessing and EDA
- Model Fitting
- Results
Discussing daily events or important topic you care about can be difficult. The threat of abuse and harassment online means that many people stop expressing themselves and give up on seeking different opinions. Platforms struggle to effectively facilitate conversations, leading many communities to limit or completely shut down user comments.
As a student with great interest in Natural Language Processing, as well as a strong believer in making online discussion more productive and respectful, my aim is to build a model that is capable of detecting different types of toxicity like threats, obscenity, insults, and identity-based hate to control the hatred over the internet. This model would help various platforms to create a safe environment for a healthy conversation.
The dataset we are using consists of comments from Wikipedia’s talk page edits. These comments have been labeled by human raters for toxic behavior. The types of toxicity are:
- toxic
- severe_toxic
- obscene
- threat
- insult
- identity_hate
There are 159,571 observations in the training dataset and 153,164 observations in the testing dataset.
Since all of our data are text comments, we wrote our own simple_tokenizer() function, removing punctuations and special characters and lemmatizing the comments. After benchmarking between different vectorizers (TFIDFVectorizer and CountVectorizer), we chose TFIDFVectorizer, which provides us with better performance.
So Tf-idf stands for term frequency-inverse document frequency, and the tf-idf weight is a weight often used in information retrieval and text mining. This weight is a statistical measure used to evaluate how important a word is to a document in a collection or corpus. The importance increases proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus. Variations of the tf-idf weighting scheme are often used by search engines as a central tool in scoring and ranking a document's relevance given a user query.
Due to aforementioned reason, tfidfVectorizer is the best vector generator in our scenario.
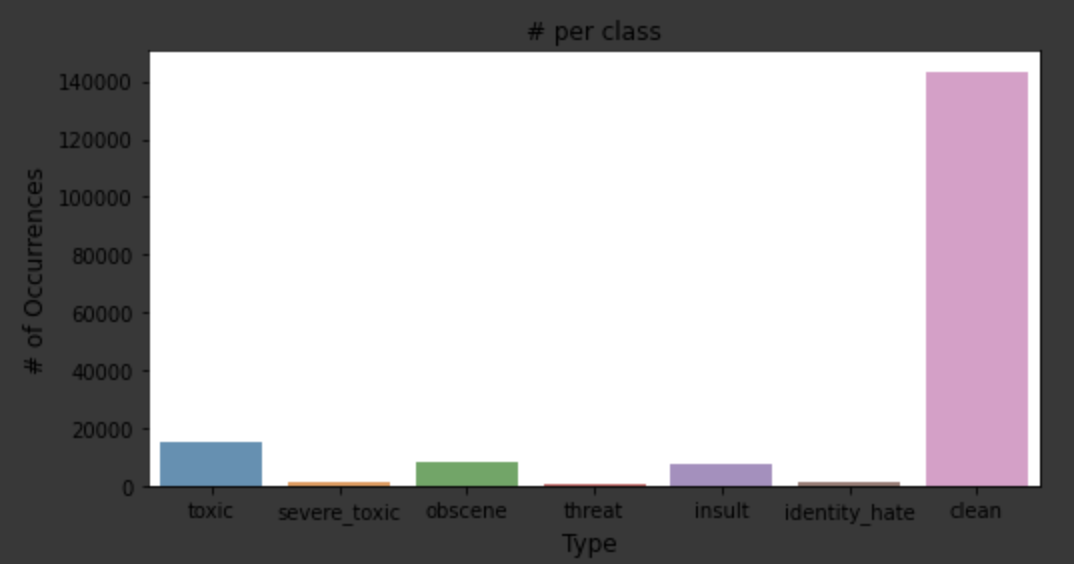
We have an imbalanced class problem. The dataset contains only 9.5% Toxic comments while there are only ~1% Severe Toxic comments.

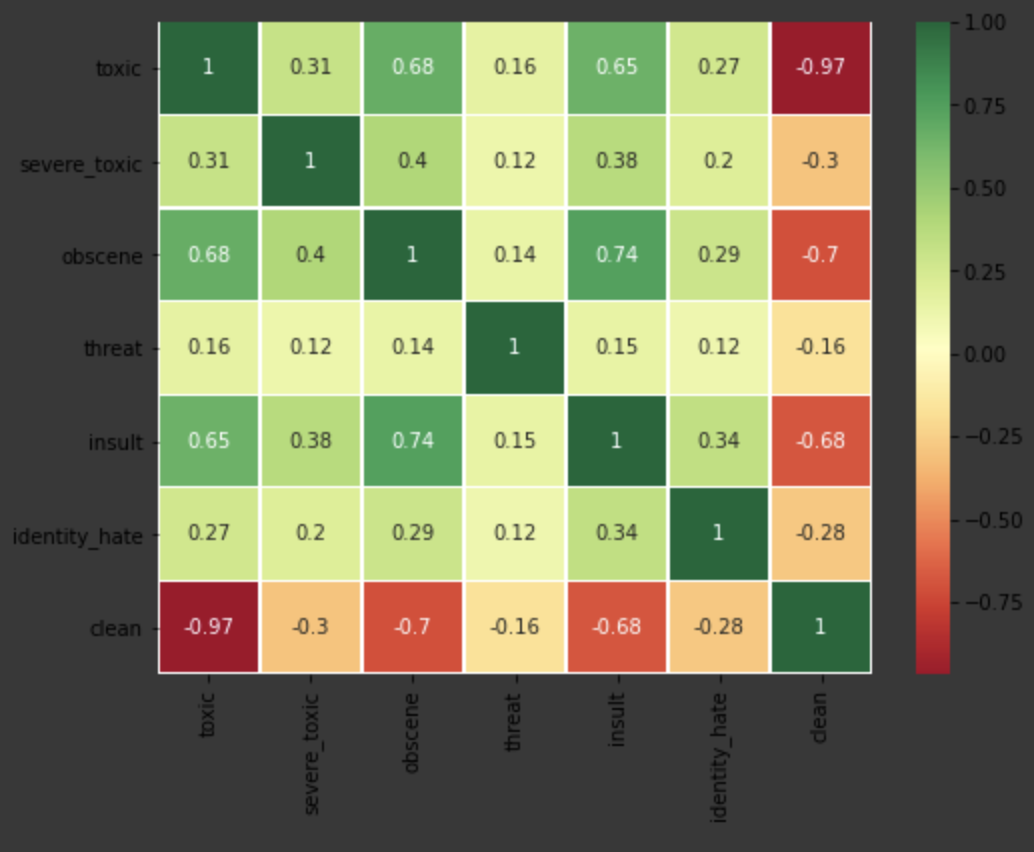
Apart from all this lets visualize how correlated our classes are. Clearly there is correlation between Toxic and Insult Comments as well as Insult and Obscene Comments and Toxic and Obscene Comments.
Lets visualize few words from Toxic, Insult and Obscene comments. The images below gives us evidence that toxic, Insult and Obscene comments have similar words in them namely "F-CK F-CK", "NI--ER NI--ER", "H-TE H-TE" Etc..
Toxic: 
Obscene: 
Insult: 
So after fitting a TFIDF vector on our training comment. We began the work of selecting the best model for our classification task.
We started with splitting our dataset into train and test in the ratio of 2:1. So since we have an imbalanced class problem, we will be using SMOTE technique to balance our classes before making predictions to have a better fit on our training dataset.
We used namely three classifiers Linear Regression, Multi-nomial Naives Bayes and Random Forest with cross validation with 3 folds. The accuracy results are as follows:
Logistic: 90%
MultinomialNB: 91%
RandomForest: 88%
Since MultinomialNB assumes independent factors, we moved on with Logistic Regression Classifier with an accuracy of 90% on our balanced dataset. For deployment we created a Flask Application and generated pickle files for our classifier models for each type.
A Sample response for a toxic comment would be:

A Sample response for a non toxic comment would be:

We will be keeping the option open for various platforms to determine till what extent the probabilities of each type can be tolerated. And Thus, decided to send probabilities of all type instead of sending labels as Toxic or Non-Toxic.
Later we deployed the app on the Heroku Server on toxic-nlp.herokuapp.com. Once deployed, various organizations can integrate and use the web service to control hatred over their respective platforms thus resulting in a much safer environment for a healthy conversation.
- Try more ways of vectorizing text data.
- Go deeper on feature engineering : Spelling corrector, Sentiment scores, n-grams, etc.
- Advanced models (e.g., lightgbm).
- Deep learning model (e.g., LSTM, Bi-LSTM).
- Embedding Techniques

