snwagh / falcon-public Goto Github PK
View Code? Open in Web Editor NEWImplementation of protocols in Falcon
Implementation of protocols in Falcon

























































































I ran AlexNet on ImageNet in LAN. Here is what i got:
P0:
./Falcon.out 0 files/IP_LAN files/keyA files/keyAB files/keyAC AlexNet ImageNet Semi-honest
Loading data done.....
Forward 0 completed...
...
Forward 18 completed...
Delta last layer completed.
Delta 18 completed...
...
Delta 1 completed...
Update Eq. 18 completed...
...
Update Eq. 1 completed...
First layer update Eq. completed.
----------------------------------------------
Wall Clock time for AlexNet train: 7155.25 sec
CPU time for AlexNet train: 7042.8 sec
----------------------------------------------
----------------------------------------------
Total communication: 1777.36MB (sent) and 1777.36MB (recv)
Total calls: 2495 (sends) and 2495 (recvs)
----------------------------------------------
----------------------------------------------
Communication, AlexNet train, P0: 3171.3MB (sent) 3171.3MB (recv)
Rounds, AlexNet train, P0: 808(sends) 808(recvs)
----------------------------------------------
----------------------------------------------
Run details: 3PC (P0), 1 iterations, batch size 128
Running Semi-honest AlexNet train on ImageNet dataset
----------------------------------------------
----------------------------------------------
(1) CNN Layer 56 x 56 x 3
7 x 7 (Filter Size)
1 , 3 (Stride, padding)
128 (Batch Size)
56 x 56 x 64 (Output)
----------------------------------------------
(2) CNN Layer 56 x 56 x 64
5 x 5 (Filter Size)
1 , 2 (Stride, padding)
128 (Batch Size)
56 x 56 x 64 (Output)
----------------------------------------------
(3) Maxpool Layer 56 x 56 x 64
2 (Pooling Size)
2 (Stride)
128 (Batch Size)
----------------------------------------------
(4) ReLU Layer 50176 x 128
----------------------------------------------
(5) BN Layer 50176 x 128
----------------------------------------------
(6) CNN Layer 28 x 28 x 64
5 x 5 (Filter Size)
1 , 2 (Stride, padding)
128 (Batch Size)
28 x 28 x 128 (Output)
----------------------------------------------
(7) Maxpool Layer 28 x 28 x 128
2 (Pooling Size)
2 (Stride)
128 (Batch Size)
----------------------------------------------
(8) ReLU Layer 25088 x 128
----------------------------------------------
(9) BN Layer 25088 x 128
----------------------------------------------
(10) CNN Layer 14 x 14 x 128
3 x 3 (Filter Size)
1 , 1 (Stride, padding)
128 (Batch Size)
14 x 14 x 256 (Output)
----------------------------------------------
(11) CNN Layer 14 x 14 x 256
3 x 3 (Filter Size)
1 , 1 (Stride, padding)
128 (Batch Size)
14 x 14 x 256 (Output)
----------------------------------------------
(12) Maxpool Layer 14 x 14 x 256
2 (Pooling Size)
2 (Stride)
128 (Batch Size)
----------------------------------------------
(13) ReLU Layer 12544 x 128
----------------------------------------------
(14) FC Layer 12544 x 1024
128 (Batch Size)
----------------------------------------------
(15) ReLU Layer 1024 x 128
----------------------------------------------
(16) FC Layer 1024 x 1024
128 (Batch Size)
----------------------------------------------
(17) ReLU Layer 1024 x 128
----------------------------------------------
(18) FC Layer 1024 x 200
128 (Batch Size)
----------------------------------------------
(19) ReLU Layer 200 x 128
----------------------------------------------
P1:
./Falcon.out 1 files/IP_LAN files/keyB files/keyBC files/keyAB AlexNet ImageNet Semi-honest
Loading data done.....
Forward 0 completed...
...
Forward 18 completed...
Delta last layer completed.
Delta 18 completed...
...
Delta 1 completed...
Update Eq. 18 completed...
...
Update Eq. 1 completed...
First layer update Eq. completed.
----------------------------------------------
Wall Clock time for AlexNet train: 7155.26 sec
CPU time for AlexNet train: 6951.5 sec
----------------------------------------------
----------------------------------------------
Communication, AlexNet train, P1: 3171.3MB (sent) 3171.3MB (recv)
Rounds, AlexNet train, P1: 808(sends) 808(recvs)
----------------------------------------------
----------------------------------------------
Run details: 3PC (P1), 1 iterations, batch size 128
Running Semi-honest AlexNet train on ImageNet dataset
----------------------------------------------
----------------------------------------------
(1) CNN Layer 56 x 56 x 3
7 x 7 (Filter Size)
1 , 3 (Stride, padding)
128 (Batch Size)
56 x 56 x 64 (Output)
----------------------------------------------
(2) CNN Layer 56 x 56 x 64
5 x 5 (Filter Size)
1 , 2 (Stride, padding)
128 (Batch Size)
56 x 56 x 64 (Output)
----------------------------------------------
(3) Maxpool Layer 56 x 56 x 64
2 (Pooling Size)
2 (Stride)
128 (Batch Size)
----------------------------------------------
(4) ReLU Layer 50176 x 128
----------------------------------------------
(5) BN Layer 50176 x 128
----------------------------------------------
(6) CNN Layer 28 x 28 x 64
5 x 5 (Filter Size)
1 , 2 (Stride, padding)
128 (Batch Size)
28 x 28 x 128 (Output)
----------------------------------------------
(7) Maxpool Layer 28 x 28 x 128
2 (Pooling Size)
2 (Stride)
128 (Batch Size)
----------------------------------------------
(8) ReLU Layer 25088 x 128
----------------------------------------------
(9) BN Layer 25088 x 128
----------------------------------------------
(10) CNN Layer 14 x 14 x 128
3 x 3 (Filter Size)
1 , 1 (Stride, padding)
128 (Batch Size)
14 x 14 x 256 (Output)
----------------------------------------------
(11) CNN Layer 14 x 14 x 256
3 x 3 (Filter Size)
1 , 1 (Stride, padding)
128 (Batch Size)
14 x 14 x 256 (Output)
----------------------------------------------
(12) Maxpool Layer 14 x 14 x 256
2 (Pooling Size)
2 (Stride)
128 (Batch Size)
----------------------------------------------
(13) ReLU Layer 12544 x 128
----------------------------------------------
(14) FC Layer 12544 x 1024
128 (Batch Size)
----------------------------------------------
(15) ReLU Layer 1024 x 128
----------------------------------------------
(16) FC Layer 1024 x 1024
128 (Batch Size)
----------------------------------------------
(17) ReLU Layer 1024 x 128
----------------------------------------------
(18) FC Layer 1024 x 200
128 (Batch Size)
----------------------------------------------
(19) ReLU Layer 200 x 128
----------------------------------------------
P2:
./Falcon.out 2 files/IP_LAN files/keyC files/keyAC files/keyBC AlexNet ImageNet Semi-honest
Loading data done.....
Forward 0 completed...
...
Forward 18 completed...
Delta last layer completed.
Delta 18 completed...
...
Delta 1 completed...
Update Eq. 18 completed...
...
Update Eq. 1 completed...
First layer update Eq. completed.
----------------------------------------------
Wall Clock time for AlexNet train: 7155.25 sec
CPU time for AlexNet train: 6733.12 sec
----------------------------------------------
----------------------------------------------
Communication, AlexNet train, P2: 4024.69MB (sent) 4024.69MB (recv)
Rounds, AlexNet train, P2: 879(sends) 879(recvs)
----------------------------------------------
----------------------------------------------
Run details: 3PC (P2), 1 iterations, batch size 128
Running Semi-honest AlexNet train on ImageNet dataset
----------------------------------------------
----------------------------------------------
(1) CNN Layer 56 x 56 x 3
7 x 7 (Filter Size)
1 , 3 (Stride, padding)
128 (Batch Size)
56 x 56 x 64 (Output)
----------------------------------------------
(2) CNN Layer 56 x 56 x 64
5 x 5 (Filter Size)
1 , 2 (Stride, padding)
128 (Batch Size)
56 x 56 x 64 (Output)
----------------------------------------------
(3) Maxpool Layer 56 x 56 x 64
2 (Pooling Size)
2 (Stride)
128 (Batch Size)
----------------------------------------------
(4) ReLU Layer 50176 x 128
----------------------------------------------
(5) BN Layer 50176 x 128
----------------------------------------------
(6) CNN Layer 28 x 28 x 64
5 x 5 (Filter Size)
1 , 2 (Stride, padding)
128 (Batch Size)
28 x 28 x 128 (Output)
----------------------------------------------
(7) Maxpool Layer 28 x 28 x 128
2 (Pooling Size)
2 (Stride)
128 (Batch Size)
----------------------------------------------
(8) ReLU Layer 25088 x 128
----------------------------------------------
(9) BN Layer 25088 x 128
----------------------------------------------
(10) CNN Layer 14 x 14 x 128
3 x 3 (Filter Size)
1 , 1 (Stride, padding)
128 (Batch Size)
14 x 14 x 256 (Output)
----------------------------------------------
(11) CNN Layer 14 x 14 x 256
3 x 3 (Filter Size)
1 , 1 (Stride, padding)
128 (Batch Size)
14 x 14 x 256 (Output)
----------------------------------------------
(12) Maxpool Layer 14 x 14 x 256
2 (Pooling Size)
2 (Stride)
128 (Batch Size)
----------------------------------------------
(13) ReLU Layer 12544 x 128
----------------------------------------------
(14) FC Layer 12544 x 1024
128 (Batch Size)
----------------------------------------------
(15) ReLU Layer 1024 x 128
----------------------------------------------
(16) FC Layer 1024 x 1024
128 (Batch Size)
----------------------------------------------
(17) ReLU Layer 1024 x 128
----------------------------------------------
(18) FC Layer 1024 x 200
128 (Batch Size)
----------------------------------------------
(19) ReLU Layer 200 x 128
----------------------------------------------
Firstly, the "Total communication" seems not equal to the sum of all parties communication.
Secondly, it was much more time consuming than I expected.
Btw, I also ran AlexNet on CIFAR10, it cost 77.6502 sec and total communication was 665.514MB (sent).
Any clue?
hellow snwagh.
I read the algorithm 5 for computing pow in your paper, but when I read the implementation of the code, I found that the fourth step of algorithm 5 in paper is c=1, and the code shows c=0 here I am puzzled about this. Can you help me? Thank you very much
Hello, @snwagh . I have a question about this function. I guess it is used to compute the dot product between two vectors a and b , i.e. ab=c, where c is a number. However, this function requests c.size() == size. Is something wrong with it? Thank you!
Hey, snwagh.
I have been reading your paper Falcon. I am interested in how to use randomness functions of AESObject in Falcon.
e.g.
let partyA and partyB have r1, partyB and partyC have r2, and partyC and partyA have r3.
std::make_pair(0,0);
# AESObject
myType get64Bits();
smallType get8Bits();
Hello, I would like to train a neural network using a falcon and then make a prediction. Is this possible with the current functionality?
Function "test" loads a pre-trained model, can I save the model after training with falcon?
Hello @snwagh, I have found an error in your code.
In line 1150 and 1151 of Functionalities.cpp, the last parameter of sendVector and receiveVector should be sizeLong instead of size.
This mistake makes the communication amount per ReLU 31 bytes less than the correct value and also influences the wall clock time in the stats. Because all shares of the common randomnesses are set to 0 in Precompute.cpp(which is also inappropriate), the mistake above does not have an impact on the prediction result. But the experiment results in Table 2,3,4,5,7 are all incorrect, let alone the follow-up works that make comparison with Falcon.
The correct communication amount per ReLU in semi-honest setting should be 73 bytes, but the theoretical results in the Appendix neither in Table 8(which is 32l) nor in Table 9(which is 4kn) agree with this value.
Hi Snwagh
When I use different commands and arguments, there is no change in the Rolling accuracy (100%). Could you give some tips for it or did I run it in wrong way?
./Falcon.out 2 files/IP_localhost files/keyC files/keyAC files/keyBC AlexNet CIFAR10 Semi-honest >/dev/null &
./Falcon.out 1 files/IP_localhost files/keyB files/keyBC files/keyAB AlexNet CIFAR10 Semi-honest >/dev/null &
./Falcon.out 0 files/IP_localhost files/keyA files/keyAB files/keyAC AlexNet CIFAR10 Semi-honest
argc == 9
Loading data done.....
Rolling accuracy: 128 out of 128 (100 %)
MPC Output over uint32_t:
Thank you very much!
Hi, I am training LeNet on localhost for 15 iterations. I got the results like in the picture, where it shows the total communication is 900 Mb, but the communication for P0 is already 1673.28 MB. Is there anything wrong with this?

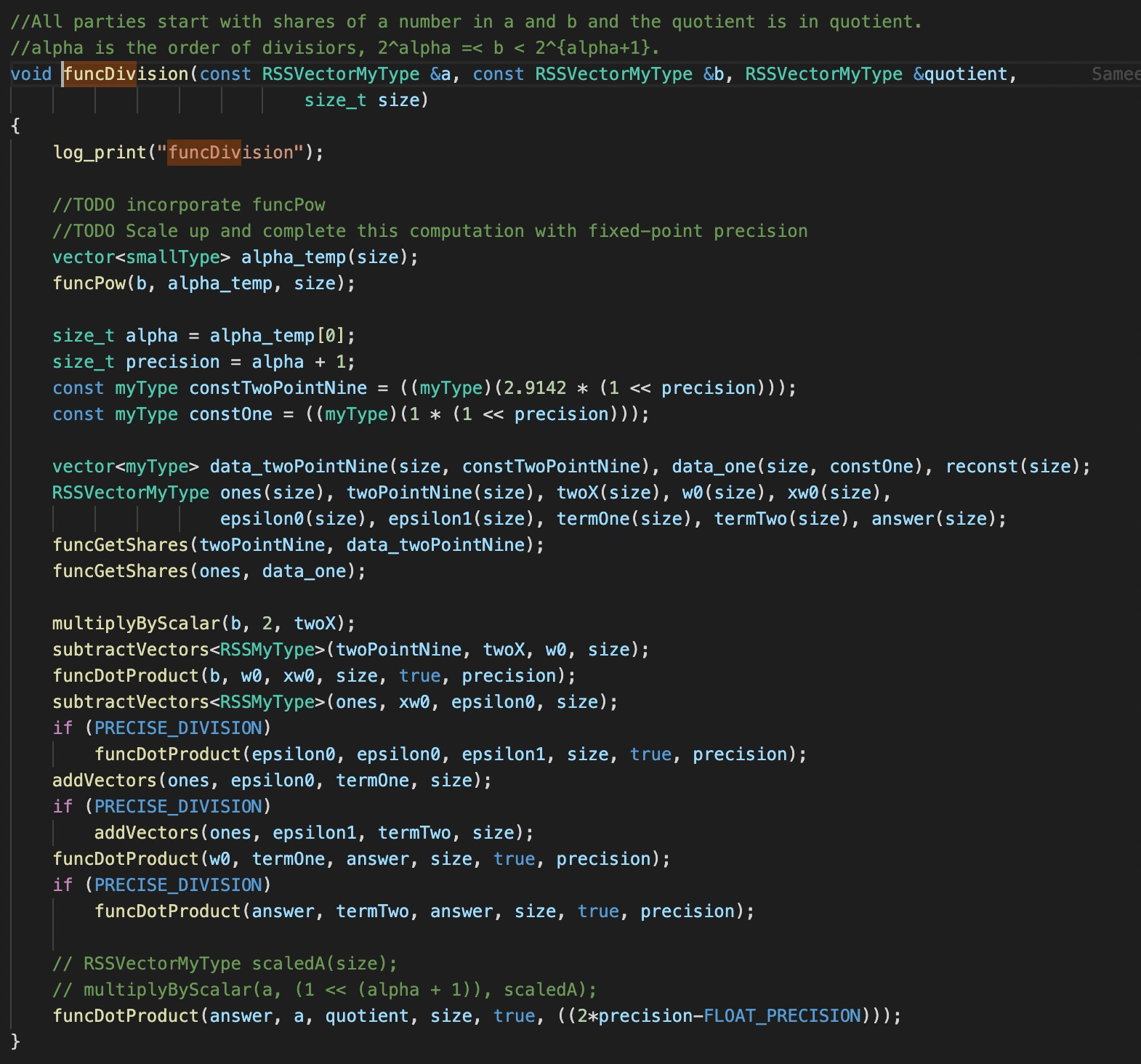
Hi, @snwagh . The funcDivsion functionality computes c=a/b. After increasing the bit-width by changing to uint64_t, I try to run some tests in Debugdivision code as follows
void debugDivision() {
vector<myType> data_a = {floatToMyType(255), floatToMyType(256),
floatToMyType(255)},
data_b = {floatToMyType(255), floatToMyType(256),
floatToMyType(255)};
size_t size = data_a.size();
RSSVectorMyType a(size), b(size), quotient(size);
vector<myType> reconst(size);
funcGetShares(a, data_a);
funcGetShares(b, data_b);
funcDivision(a, b, quotient, size);
#if (!LOG_DEBUG)
funcReconstruct(a, reconst, size, "a", true);
funcReconstruct(b, reconst, size, "b", true);
funcReconstruct(quotient, reconst, size, "Quot", true);
print_myType(reconst[0], "Quotient[0]", "FLOAT");
print_myType(reconst[1], "Quotient[1]", "FLOAT");
print_myType(reconst[2], "Quotient[2]", "FLOAT");
#endif
}It returns as follows:
a: 2088960 2097152 2088960
b: 2088960 2097152 2088960
Quot: 8137 8131 8137
Quotient[0]: 0.993286
Quotient[1]: 0.992554
Quotient[2]: 0.993286It seems good.
But if I change the first element of data_a and data_b as follows:
vector<myType> data_a = {floatToMyType(300), floatToMyType(256),
floatToMyType(255)},
data_b = {floatToMyType(300), floatToMyType(256),
floatToMyType(255)};I got this error result:
a: 2457600 2097152 2088960
b: 2457600 2097152 2088960
Quot: -8188 -8176 -8175
Quotient[0]: -0.999512
Quotient[1]: -0.998047
Quotient[2]: -0.997925I am so confused about the result. Is anything wrong with my understanding?
Hi,
I am trying to run the experiments on the LAN setting to reproduce the results in the Table 4 of the paper. I have changed the appropriate settings in makefile. I have also changed the IP addresses in files/IP_LAN and god. However, I always got the error "Not managing to connect" after running make command, like in the picture attached.
Thank you very much.

Hi, I discovered while running inference that the funcRELUPrime function produces inconsistent sharing of b when printed by different parties. Since the random number is 0, the final calculation result is correct.
I added the following code in funcRELUPrime to get the result
void funcRELUPrime(const RSSVectorMyType &a, RSSVectorSmallType &b, size_t size)
{
log_print("funcRELUPrime");
RSSVectorMyType twoA(size);
RSSVectorSmallType theta(size);
for (int i = 0; i < size; ++i)
twoA[i] = a[i] << 1;
// cout << "Wrap: \t\t" << funcTime(funcWrap, twoA, theta, size) << endl;
funcWrap(twoA, theta, size);
for (int i = 0; i < size; ++i)
{
b[i].first = theta[i].first ^ (getMSB(a[i].first));
b[i].second = theta[i].second ^ (getMSB(a[i].second));
}
// cout << "---------------------------------------------------------"<<endl;
// for (size_t i = 0; i < 50; ++i){
// cout << (int)b[i].first << " ";
// }
// cout << endl;
// for (size_t i = 0; i < 50; ++i){
// cout << (int)b[i].second << " ";
// }
// cout << endl;
// print_vector(b, "FLOAT", "b - v", 50);
// cout << "---------------------------------------------------------"<<endl;
}
The b shares should be consistent across all parties after the funcRELUPrime function is executed.
The b shares are inconsistent, as demonstrated by the following outputs from different parties:
0 0 1 1 0 0 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 0 0 1 1 1 0 0 1 1 0 0 0 0 1 1 0 0 0 0 0 1 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
b - v
0 0 1 1 0 0 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 0 0 1 1 1 0 0 1 1 0 0 0 0 1 1 0 0 0 0 0 1 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
b - v
0 0 1 1 0 0 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 0 0 1 1 1 0 0 1 1 0 0 0 0 1 1 0 0 0 0 0 1 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 0 0 1 1 0 1 1 1 1 1 1 1 1 1 0 1 0 1 1 1 1 1 0 1 1 1 1 0 0 0 1 1 0 0 1 1 1 1 0 0 1 1 1 1 1 0 1 1
b - v
1 1 0 0 1 1 0 1 1 1 1 1 1 1 1 1 0 1 0 1 1 1 1 1 0 1 1 1 1 0 0 0 1 1 0 0 1 1 1 1 0 0 1 1 1 1 1 0 1 1
Hi, I was trying to conduct the experiment on Linux servers, but I could not get the results from the paper. For the smaller networks, the computation time is almost ignorable, and the main overhead comes from the transmission. For example, for a network like Sarda, in the WAN setting of 70ms ping time between servers and 40MB/s speed, I spent 2.16s purely in data transmission during inference (counted through adding timers in sendVector and receiveVector, computation cost < 0.05s), while the paper reports only 0.76s in total. One thing I notice is that in my case the time cannot simply match adding the round delay + transmission time, and this is very likely to be caused by the vector being split into several packages and costed several rounds during transmission due to the transmission protocol settings.
Did your experiment specifically set some parameters or rules for the Linux data transmission to perform better in large packages? Would you mind sharing those settings so I can better reproduce the results you have? Of course, if you have some other theory for the difference, please let me know! I'm not using an Amazon server as in the paper, would that potentially caused this kind of huge difference?
Thanks!
network = "VGG16";
dataset = "CIFAR10"; // or ImageNet
Segmentation fault is detected when pushing back the 31st layer (an FC layer) to layers. This occurred on my two machines so I think it's a machine issue. Tried to fix it myself but didn't quite get the reason for the issue. I see the repo is updated a lot since I first checked, please do investigate this issue to see if the bug can be reproduced.
Hi,
So I saw the previous discussion on #9 and I made some edit to the functions that I could get reasonable results for SecureML and Sarda (~96% each). However I still could not get good results for LeNet and MiniONN. So just want to know how the accuracy results in the paper were created? Was there something like quantization scripts? Thanks!
Hello! I read the paper Falcon: Honest-Majority Maliciously Secure Framework for Private Deep Learning. I wonder how to generate the common randomness in Algorithm wrap3, which I didn't find in code, i.e the shares of a random number x and the shares of the carry bit.
In your code, you just set r = 0 and rPrime = 0, which is unsecure. Can you tell me how to generate r and rPrime correctly?
Hi all,
I was trying to get the accuracy as done in one of the previous issues #8 but I realized the NeuralNetwork::getAccuracy() function has been commented out and as a result temp_groundTruth is not updated. I am always getting 100% accuracy since both counter[0] and counter[1] have same values. Can anyone please help to fix this issue?
Thanks
Hi, i find the division test result is error, everybody meet such problem?
In the test, a = 3.2 b=9.7, the result should be a / b = 0.32, but the code result is 0.0198,
Is there some errors in my test?

Hey @snwagh .
I try to test the AlexNet and VGG16 which takes CIFAR-10 and ImageNet datasets as training data. Is there data loader for these two datasets?
And i notice that the input size of CIFAR-10 for AlexNet is modified to 33x33, which is here. I wonder why this modification is made and how does this affect the dataloader, zero padding the raw input from 32x32 to 33x33?
From the look of the code (especially neural network part), I got an impression that parties are actually computing on the same inputs (rather than having their own secret inputs and sharing them in MPC fashion). Please correct me if I am wrong.
I also found the following lines in the neural network code (secondary.cpp)
//Some day check if this is right. It seems that all
//parties use the same data which is not right.
How do I make parties compute on shares created on their secret inputs? kindly refer to an example file I might have missed
Hi,
How can I define the number of training epochs for different networks? I have found that there is a variable named NUM_ITERATIONS in main.cpp, but not sure what it is, and also we cannot change it in makefile either.
Thank you.
I want to test the falcon and found 4 four IP addresses in files/IP_localhost, and I want to know the corresponding relationship between these IP addresses and PC0, PC1, and PC2, and how to change the communication port. Can the Falcon run in the network environment just by changing the IP address in files/IP_localhost?
Thanks a lot.
Hey, snwagh.
I have been reading your paper of Falcon and found this repo. And I am interested in how you perform the computation of Batch Normalization.
I have the following two questions:
the implementation of BN seems to be just a single division
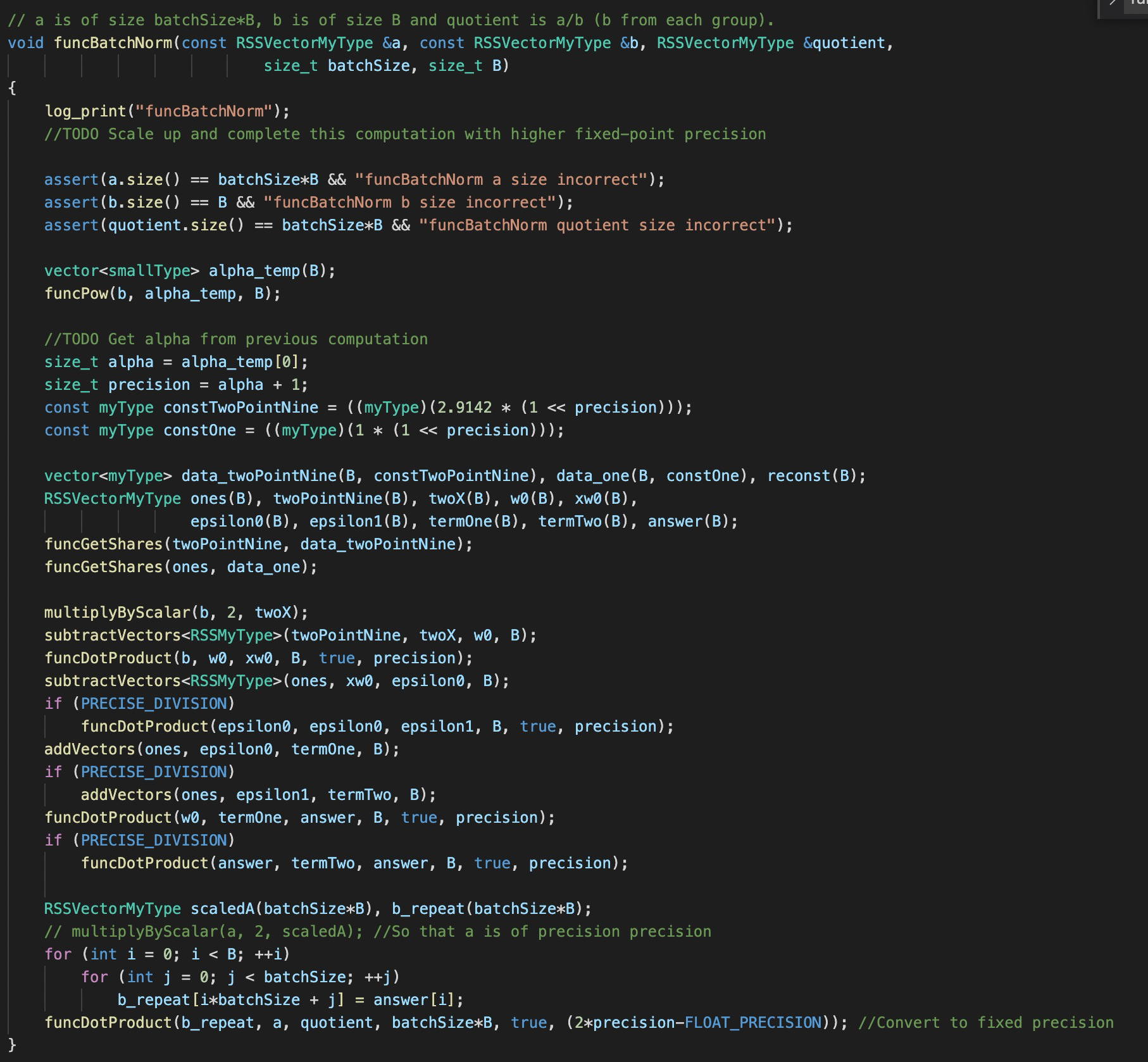
the protocol of Pow seems to reveal the information of the exponent, i.e., \alpha
the BIT_SIZE in your paper is 32, which seems to be too small. How you guarantee the accuracy or say precision? IS the BN actually essential to your ML training and inference?
As used in the picture:
1、Post_processing.ipynb:

2、secondary.cpp

Hi Wagh
I use preloading data to execute the Falcon inference phase in the LAN environment. But the communication obtained through the source code is very large (the specific output is shown in the figure below). This one is too far from the results in Table 2 in your paper. Did I miss something in the calculation process? Could you guide me on how to calculate the communication?

Very grateful for your help!
I see funcGetShares() in Functionalities.cpp, but from my understanding, for a given input a it is not randomizing the shares into 3 parts and distributing. Instead it only assigns the value a to party A (first) and party C(second) and party B is always initialized with 0. Shouldn't all shares be randomized and then sent to parties as 2-out-of-3 replicated sharing ?? Please correct me If I am wrong, I am unable to understand how shares are getting created
Hi, when conducting the experiment I see these two values are very different (CPU time seems to be smaller). Which one is reported in the paper? And why are they so different (especially in small networks)?
Is there an in-built method which can help me save the model parameters after training is completed?
If not, can you suggest some pointers. I have tried using the test() method in Secondary.cpp but I wasn't able to see any output written to any file (it should've written to file in "/files/preload/...").
Now I am trying to use this codebase to realize the training of the "SecureML" neural network over the MNIST dataset, but I have encountered some problems. Please could you advise me what I should do?
I fixed the data importing of the codebase, and the training label and testing label used the one-hot representation. could you help me confirm that this input format is correct? In addition, do I need to perform other preprocessing on the training data before importing the data?
I used the He-Initialization method to initialize the parameters(weights).
The following figure shows the training accuracy of 10 epochs, and the result is very unsatisfactory. Could you give me some valuable suggestions?

In addition, Can functions "backward","computeDelta" and "updateEquations" in the codebase be used directly?
In the paper, the division protocol a/b shown in Algorithm 6 leaks the range of the divisor b.
How to ensure the security of this protocol?
As I understand, all the functions in Precompute.cpp (currently) are just initializing values to 0, can you give a one liner for these functions and how to re-write them ??
hi. I tried to download and parse the MNIST dataset on falcon-public/MNIST/ , and I got the results like it. I have searched the Internet for this error. Some people say that it is because the parameter in the stoi function is not a string that can be converted into an integer.

Can someone help me solve this problem?
An array of 500 decimals of type flaot,
First, scale it to mytype type,
Call Falcon's multiplication operation for each number in the array to calculate the square of each number
Then add up the decimals represented by mytype, and are also represented by mytype,
It is found that the and corresponding plaintext of mytype are about 200 smaller than the plaintext calculated directly by flaot
Is the error caused by the continuous accumulation of the data in the multiplication step and the real product?
However, if you scale the 500 float data into mytype, and then add it up, you will find no error, so I'd like to ask you
Hello,
I noticed l times u[i] needs to be computed in the loop, so it use l invocations of Mult. Why communication rounds of Private Compare are (logl +2) rather than (l+2)?
I don't find the files/train_data_A etc.
why do every party get the same data?
In the paper, the division protocol a/b shown in Algorithm 6 leaks the range of the divisor b.
How to ensure the security of this protocol?
Hello!
I was trying to test the code on three machines under LAN. Is changing the IP_LAN and the makefile of choosing LAN setting all I need to do? After doing so, I tried to run make zero/one/two on the three machines but after data loading, no further responses are given and it seems no data are transferred.
If I'm doing wrong would you mind telling me the right way to do so? Thanks a lot!
If two floating point numbers float f = 7.7338 and float e = 6.7338,First, scale the two numbers, then call matrix multiplication funcMatMul (), and find that the product is wrong.
However, if float f = 2.7338 and float e = 3.7338, the result of the product is correct. Does funcmatmul() require the size range of numbers?
And it doesn't match the paper(falcon), which you mentioned that falcon improve the efficiency by abount 2X.
Do you have any advice? Thanks every much
hello ,I have put the .csv file into the ~/Downloads/mnist_train/ and ~/Downloads/mnist_test/ . when I bash the run.sh, I cannot generate the right datase and the output file TRAINING_DATA_A is all 0. I don't know where is wrong?
Hello, @snwagh . FALCON is a nice code! Thank you for your work! Recently, I want to find a way to transform RSSVectorSmallType (is a bit vector on Z_67) to RSSVectorMyType (bit vector on Z_L). But I have not idea yet. Do you have any advice? Thanks.
Hello. I am a student interested in MPC and I've executed the tutorial.
Now I plan to reconduct the experiments in your paper, but I don't know how to do it.
Maybe you can give me some help? Thank you!
Hello,
I am an undergraduate student who are working on privacy-preserving machine learning for my graduation thesis. By testing the code downloaded from the repo, I found that the getAccuracy() in NeuralNetwork.cpp is not implemented, and it always showed an accuracy of 100%, which is quite weird. Can anyone kindly provide some solution on how I can fix it?
Thank you very much!
ENV: Ubuntu 18.04 with all requirements installed (g++ make libssl-dev).
After setting up the environment (make -j), I tried running the default example (running make example with SecureML with MNIST and Semi-honest in the main.cpp), getting a segmentation fault error. I also tried make command with the proper config variables in the makefile, with the same result.
make terminal
#./BMRPassive.out 2 files/IP_localhost files/keyC files/keyAC files/keyBC >/dev/null &
#./BMRPassive.out 1 files/IP_localhost files/keyB files/keyBC files/keyAB >/dev/null &
#./BMRPassive.out 0 files/IP_localhost files/keyA files/keyAB files/keyAC
#Loading data done.....
#Binding: Address already in use
#makefile:36: recipe for target 'terminal' failed
#make: *** [terminal] Segmentation fault (core dumped)To obtain more info, I ran make valg, and I saved the resulting log hoping it will be of help.
output.log
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.