







Inseq is a Pytorch-based hackable toolkit to democratize the access to common post-hoc interpretability analyses of sequence generation models.
Inseq is available on PyPI and can be installed with pip:
pip install inseqInstall extras for visualization in Jupyter Notebooks and 🤗 datasets attribution as pip install inseq[notebook,datasets].
Dev Installation
To install the package, clone the repository and run the following commands:cd inseq
make poetry-download # Download and install the Poetry package manager
make install # Installs the package and all dependenciesIf you have a GPU available, use make install-gpu to install the latest torch version with GPU support.
For library developers, you can use the make install-dev command to install and its GPU-friendly counterpart make install-dev-gpu to install all development dependencies (quality, docs, extras).
After installation, you should be able to run make fast-test and make lint without errors.
FAQ Installation
-
Installing the
tokenizerspackage requires a Rust compiler installation. You can install Rust from https://rustup.rs and add$HOME/.cargo/envto your PATH. -
Installing
sentencepiecerequires various packages, install withsudo apt-get install cmake build-essential pkg-configorbrew install cmake gperftools pkg-config.
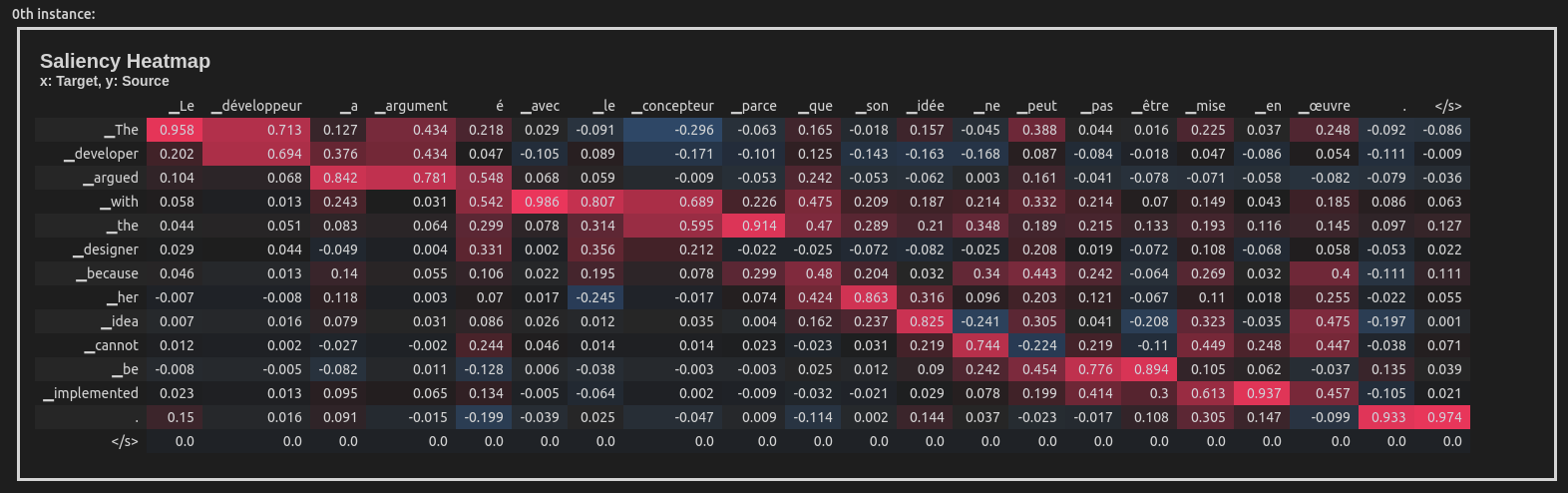
This example uses the Integrated Gradients attribution method to attribute the English-French translation of a sentence taken from the WinoMT corpus:
import inseq
model = inseq.load_model("Helsinki-NLP/opus-mt-en-fr", "integrated_gradients")
out = model.attribute(
"The developer argued with the designer because her idea cannot be implemented.",
n_steps=100
)
out.show()This produces a visualization of the attribution scores for each token in the input sentence (token-level aggregation is handled automatically). Here is what the visualization looks like inside a Jupyter Notebook:
Inseq also supports decoder-only models such as GPT-2, enabling usage of a variety of attribution methods and customizable settings directly from the console:
import inseq
model = inseq.load_model("gpt2", "integrated_gradients")
model.attribute(
"Hello ladies and",
generation_args={"max_new_tokens": 9},
n_steps=500,
internal_batch_size=50
).show()
-
Feature attribution of sequence generation for most
ForConditionalGeneration(encoder-decoder) andForCausalLM(decoder-only) models from 🤗 Transformers -
Support for single and batched attribution using multiple gradient-based feature attribution methods from Captum
-
Post-hoc aggregation of feature attribution maps via
Aggregatorclasses. -
Attribution visualization in notebooks, browser and command line.
-
Command line interface for attributing single examples or entire 🤗 datasets.
-
Custom attribution of target functions, supporting advanced usage for cases such as contrastive and uncertainty-weighted feature attributions.
-
Extract and visualize custom scores (e.g. probability, entropy) for every generation step alongsides attribution maps.
-
Attention-based and occlusion-based feature attribution methods (documented in #107 and #108).
-
Interoperability with other interpretability libraries like ferret.
-
Rich and interactive visualizations in a tabbed interface, possibly using Gradio Blocks.
The Inseq library also provides useful client commands to enable repeated attribution of individual examples and even entire 🤗 datasets directly from the console. See the available options by typing inseq -h in the terminal after installing the package.
For now, two commands are supported:
-
ìnseq attribute: Wraps theattributemethod shown above, requires explicit inputs to be attributed. -
inseq attribute-dataset: Enables attribution for a full dataset using Hugging Facedatasets.load_dataset.
Both commands support the full range of parameters available for attribute, attribution visualization in the console and saving outputs to disk.
Example: The following command can be used to perform attribution (both source and target-side) of Italian translations for a dummy sample of 20 English sentences taken from the FLORES-101 parallel corpus, using a MarianNMT translation model from Hugging Face transformers. We save the visualizations in HTML format in the file attributions.html. See the --help flag for more options.
inseq attribute-dataset \
--model_name_or_path Helsinki-NLP/opus-mt-en-it \
--attribution_method saliency \
--do_prefix_attribution \
--dataset_name inseq/dummy_enit \
--input_text_field en \
--dataset_split "train[:20]" \
--viz_path attributions.html \
--batch_size 8 \
--hide
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")

