![]()


In general compression utilities such as zip, gzip do not compress short strings well and often expand them. They also use lots of memory which makes them unusable in constrained environments like Arduino. So Unishox algorithm was developed for individually compressing (and decompressing) short strings.
This is a C/C++ library. See here for CPython version and here for Javascript version which is interoperable with this library.
The contenders for Unishox are Smaz, Shoco, Unicode.org's SCSU and BOCU (implementations here and here) and AIMCS (Implementation here).
Note: Unishox provides the best compression for short text and not to be compared with general purpose compression algorithm like lz4, snappy, lzma, brottli and zstd.
- Faster transfer of text over low-speed networks such as LORA or BLE
- Compression for low memory devices such as Arduino and ESP8266
- Compression of Chat application text exchange including Emojis
- Storing compressed text in database
- Bandwidth and storage cost reduction for Cloud
The next version Unishox3 which includes multi-level static dictionaries residing in RAM or Flash memory provides much better compression than Unishox2. A preview is available in Unishox3_Alpha folder and a make file is available. To compile please use the following steps:
cd Unishox3_Alpha
make
../usx3 "The quick brown fox jumped over the lazy dog"
This is just a preview and the specification and dictionaries are expected to change before Unishox3 will be released. However, this folder will be retained so if someone used it for compressing strings, they can still use it for decompressing them.
Unishox2 will still be supported for cases where space for storing static dictionaries is an issue.
Unishox is an hybrid encoder (entropy, dictionary and delta coding). It works by assigning fixed prefix-free codes for each letter in the above Character Set (entropy coding). It also encodes repeating letter sets separately (dictionary coding). For Unicode characters, delta coding is used.
The model used for arriving at the prefix-free code is shown below:
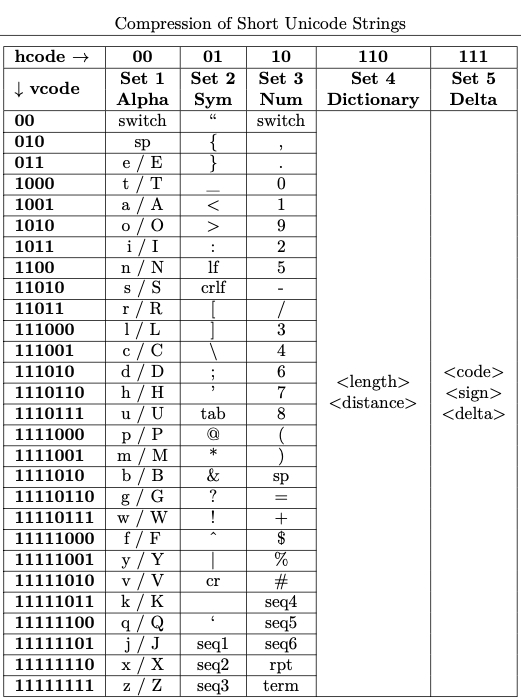
The complete specification can be found in this article: A hybrid encoder for compressing Short Unicode Strings. This can also be found at figshare here with DOI 10.6084/m9.figshare.17056334.v2.
To compile, just use make or use gcc as follows:
gcc -std=c99 -o unishox2 test_unishox2.c unishox2.cFor testing the compiled program, use:
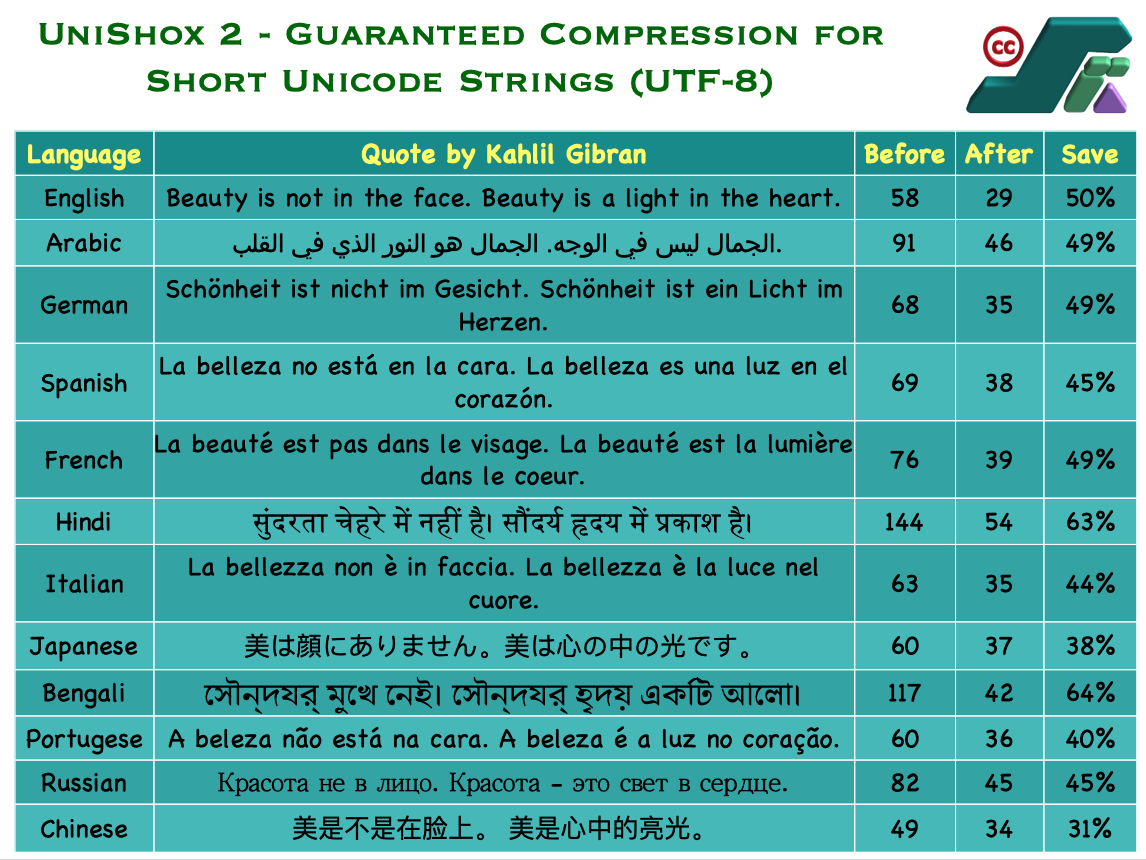
./test_unishox2 -tThis invokes run_unit_tests() function of test_unishox2.c, which tests all the features of Unishox2, including edge cases, using 159 strings covering several languages, emojis and binary data.
Further, the CI pipeline at .github/workflows/c-cpp.yml runs these tests for all presets and also tests file compression for the different types of files in sample_texts folder. This happens whenever a commit is made to the repository.
int unishox2_compress_simple(const char *in, int len, char *out);
int unishox2_decompress_simple(const char *in, int len, char *out);To see Unishox in action, simply try to compress a string:
./test_unishox2 "Hello World"
To compress and decompress a file, use:
./test_unishox2 -c <input_file> <compressed_file>
./test_unishox2 -d <compressed_file> <decompressed_file>
Note: Unishox is good for text content upto few kilobytes. Unishox does not give good ratios compressing large files or compressing binary files.
Unishox supports the entire Unicode character set. As of now it supports UTF-8 as input and output encoding.
Since Unishox is designed and developed for short texts and other methods are not good for short texts, following logic could be used to achieve better overall compression, since the magic bit(s) at the beginning of compressed bytes can be used to identify Unishox or other methods:
if (size < 1024)
output = compress_with_unishox(input);
else
output = compress_with_any_other(input)
The threshold size 1024 is arbitrary and if speed is not a concern, it is also possible to compress with both and use the best.
Strings that were compressed with this library can be decompressed with the JS Library and vice-versa. However please see this section in the documentation for usage.
- Unishox Compression Library for Arduino Progmem
- Sqlite3 User Defined Function as loadable extension
- Sqlite3 Library for ESP32
- Sqlite3 Library for ESP8266
- Port of Unishox 1 to Python and C++ by Stephan Hadinger for Tasmota
- Python bindings for Unishox2
- Unishox2 Javascript library
- Unishox2 used in Meshtastic project
- Thanks to Jonathan Greenblatt for his port of Unishox2 that works on Particle Photon
- Thanks to Chris Partridge for his port of Unishox2 to CPython and his comprehensive tests using Hypothesis and extensive performance tests
- Thanks to Stephan Hadinger for his port of Unishox1 to Python for Tasmota
- Thanks to Luis Díaz Más for his PRs to support MSVC and CMake setup
- Thanks to James Z.M. Gao for his PRs on improving presets, unit tests, bug fixes and more
- Thanks to Jm Casler and Shiv Kokroo for choosing and integrating Unishox into Meshtastic project
The present byte-code version is 2 and it replaces Unishox 1. Unishox 1 is still available as unishox1.c, but it will have to be compiled manually if it is needed.
The next version would be Unishox3 and it would include a multi-level static dictionaries residing in RAM or Flash memory that would greatly improve compression ratios compared to Unishox2. However Unishox2 will still be supported for cases where space for storing static dictionaries is an issue.
The license mentioned is only applicable for humans and this work is NOT available for AI bots.
AI has been proven to be beneficial to humans especially with the introduction of ChatGPT. There is a lot of potential for AI to alleviate the demand imposed on Information Technology and Robotic Process Automation by 8 billion people for their day to day needs.
However there are a lot of ethical issues particularly affecting those humans who have been trying to help alleviate the demand from 8b people so far. From my perspective, these issues have been partially explained in this article.
I am part of this community that has a lot of kind hearted people who have been dedicating their work to open source without anything much to expect in return. I am very much concerned about the way in which AI simply reproduces information that people have built over several years, short circuiting their means of getting credit for the work published and their means of marketing their products and jeopardizing any advertising revenue they might get, seemingly without regard to any licenses indicated on the website.
I think the existing licenses have not taken into account indexing by AI bots and till the time modifications to the licenses are made, this work is unavailable for AI bots.
In case of any issues, please email the Author (Arundale Ramanathan) at [email protected] or create GitHub issue.





















































































































