
English / 中文
Takin is an Java-based, open-source system designed to measure online or test environmental performance test for full-links, Especially for microservices. Through ArchGuadian, middlewares and applications can identify real online traffic and test traffic, ensure that they enter the right databases.
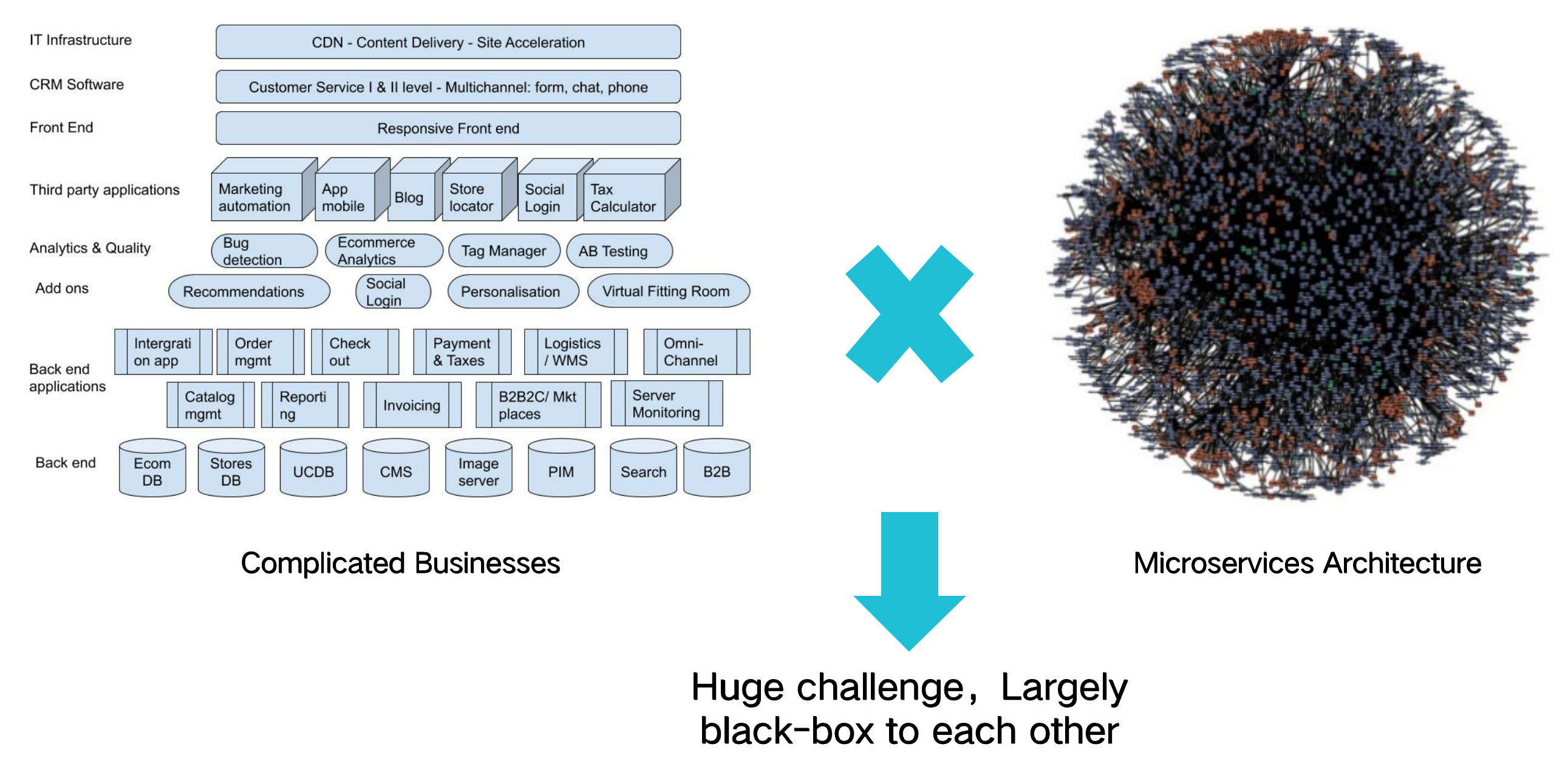
Microservices Architecture is used commonly nowadays and it always make system complex to understand for humans. Moreover, businesses are also very complex in huge system. Business complexity and system complexity make it difficult to :
- Keep entire system highly available
- Maintain Research & Development efficiency.
In order to keep system high available, we usually make performance test on test environment or online single-service. However, test environment is very different from online environment, single-service can't stand for the whole service-links. They can't guarantee system performance.
Microservices Are Complex
Compare with monolithic application, Microservices architecture increases complexity for business system. It may maintain multiple tools and frameworks.
Business Systems Are Complex
Businesses involve different sections and many of them are long-process and complicated, such as E-Commerce businesses.
The Microservices Relation Is Complex
In a microservices architecture system with a lot of business services, the calling relation between services is very complicated. Every change may affect the availability of the entire system and make developers difficult to release new versions Frequently.

docker:
- VM memory requirement : 8G
- Docker mirror size : 2.1 G
If docker configuration doesn't set AliYun docker source :
vim /etc/docker/daemon.json
Add following configuration:
{
"registry-mirrors": ["https://q2gr04ke.mirror.aliyuncs.com"]
}
restart service
systemctl daemon-reload
Pull docker
# docker url : registry.cn-hangzhou.aliyuncs.com/shulie-takin/takin:v1.0.0
docker pull registry.cn-hangzhou.aliyuncs.com/shulie-takin/takin:v1.0.1
docker run -e APPIP=your ip address -p 80:80 -p 2181:2181 -p 29900-29999:29900-29999 registry.cn-hangzhou.aliyuncs.com/shulie-takin/takin:v1.0.1-
Parameter:-d start in background,-p port.
The Initiation of docker need about 10 mins because it need install necessary components. -d can ignore installment information of components in background. If you dont't want to open your server's port, you can use --net=host and make sure it and host server are in the same network。 -
Open http://APPIP/web
-
PS:If Nginx shows 502, the problem mostly is caused when the docker container has just been started, you only need to configure it correctly, and then wait a little (1-2 min) while to refresh and try again.
after installation:
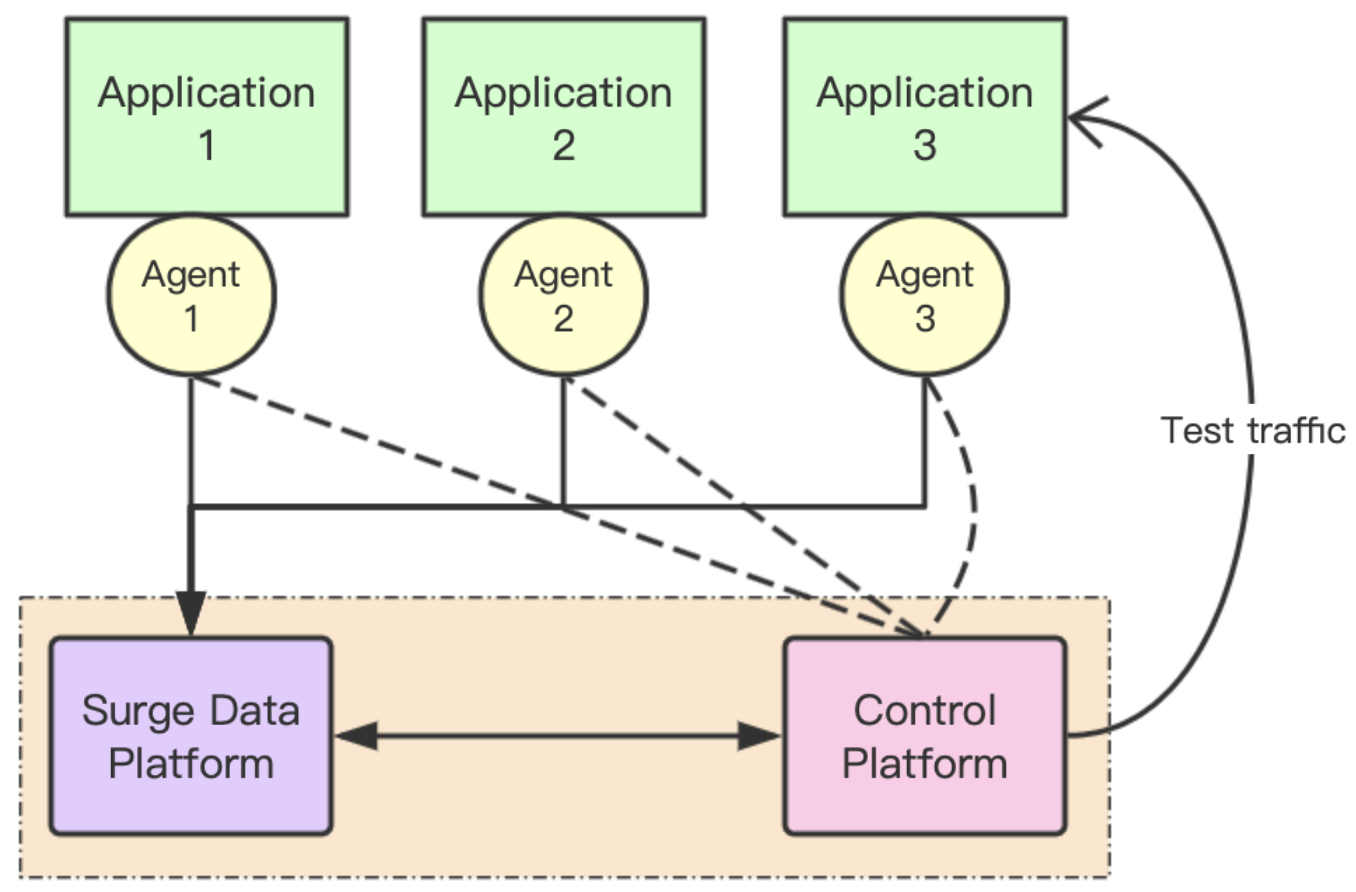
Takin consists of Agent, Web App and Surge Data.
- see Agent
- see Takin-surge-deploy
- see Takin-amdb
- see Takin-common
- see Takin-web
- see Takin-web-ui
- see Takin-cloud
- see Takin-pressure-engine
- see Takin-jmeter
Mailing List: Mail to [email protected]
Wechat group

QQ group: **118098566**
QR code:

Dingding group:

WeChat Official Account:


Takin is under the Apache 2.0 license. See the LICENSE file for details.









































































































































































