blogs's People
Watchers



blogs's Issues
事件循环
一、event loop
JS主线程不断的循环往复的从任务队列中读取任务,执行任务,这中运行机制称为事件循环(event loop)。
二、Microtasks、Macrotasks
Microtasks和Macrotasks是异步任务的一种类型,Microtasks的优先级要高于Macrotasks,下面是它们所包含的api:
- microtasks
- process.nextTick
- promise
- Object.observe (废弃)
- MutationObserver
- macrotasks
- setTimeout
- setImmerdiate
- setInterval
- I/O
- UI 渲染
三、异步运行机制
下面看一个例子:
// 1. 开始执行
console.log(1) // 2. 打印 1
setTimeout(function () { // 6. 浏览器在 0ms 后,将该函数推入任务队列
console.log(2) // 7. 打印 2
Promise.resolve(1).then(function () { // 8. 将 resolve(1) 推入任务队列 9. 将 function函数推入任务队列
cosole.log('ok') // 10. 打印 ok
})
}) // 3.调用 setTimeout 函数,并定义其完成后执行的回调函数
setTimeout(function (){ // 11. 浏览器 0ms 后,将该函数推入任务队列
console.log(3) // 12. 打印 3
}) // 4. 调用 setTimeout 函数,并定义其完成后执行的回调函数
// 5. 主线程执行栈清空,开始读取 任务队列 中的任务
// output: 1 2 ok 3
JS 主线程拥有一个 执行栈(同步任务) 和 一个 任务队列(microtasks queue),主线程会依次执行代码,
- 当遇到函数(同步)时,会先将函数入栈,函数运行结束后再将该函数出栈;
- 当遇到task任务(异步)时,这些 task 会返回一个值,让主线程不在此阻塞,使主线程继续执行下去,而真正的task任务将交给 浏览器内核 执行,浏览器内核执行结束后,会将该任务事先定义好的回调函数加入相应的**任务队列(microtasks queue/ macrotasks queue)**中。
- 当JS主线程清空执行栈之后,会按先入先出的顺序读取microtasks queue中的回调函数,并将该函数入栈,继续运行执行栈,直到清空执行栈,再去读取任务队列。
- 当microtasks queue中的任务执行完成后,会提取 macrotask queue 的一个任务加入 microtask queue, 接着继续执行microtask queue,依次执行下去直至所有任务执行结束。
这就是 JS的异步执行机制
四、async await、Promise、setTimeout
setTimeout
console.log('script start') //1. 打印 script start
setTimeout(function(){
console.log('settimeout') // 4. 打印 settimeout
}) // 2. 调用 setTimeout 函数,并定义其完成后执行的回调函数
console.log('script end') //3. 打印 script start
// 输出顺序:script start->script end->settimeout
Promise
Promise本身是同步的立即执行函数, 当在executor中执行resolve或者reject的时候, 此时是异步操作, 会先执行then/catch等,当主栈完成后,才会去调用resolve/reject中存放的方法执行,打印p的时候,是打印的返回结果,一个Promise实例。
console.log('script start')
let promise1 = new Promise(function (resolve) {
console.log('promise1')
resolve()
console.log('promise1 end')
}).then(function () {
console.log('promise2')
})
setTimeout(function(){
console.log('settimeout')
})
console.log('script end')
// 输出顺序: script start->promise1->promise1 end->script end->promise2->settimeout
当JS主线程执行到Promise对象时,
promise1.then() 的回调就是一个 task
promise1 是 resolved或rejected: 那这个 task 就会放入当前事件循环回合的 microtask queue
promise1 是 pending: 这个 task 就会放入 事件循环的未来的某个(可能下一个)回合的 microtask queue 中
setTimeout 的回调也是个 task ,它会被放入 macrotask queue 即使是 0ms 的情况
async await
async function async1(){
console.log('async1 start');
await async2();
console.log('async1 end')
}
async function async2(){
console.log('async2')
}
console.log('script start');
async1();
console.log('script end')
// 输出顺序:script start->async1 start->async2->script end->async1 end
async 函数返回一个 Promise 对象,当函数执行的时候,一旦遇到 await 就会先返回,等到触发的异步操作完成,再执行函数体内后面的语句。可以理解为,是让出了线程,跳出了 async 函数体。
举个例子:
async function func1() {
return 1
}
console.log(func1())
Promise {<resolved>: 1}
__proto__: Promise
[[PromiseStatus]]: "resolved"
[[PromiseValue]]: 1
很显然,func1的运行结果其实就是一个Promise对象。因此我们也可以使用then来处理后续逻辑。
func1().then(res => {
console.log(res); // 30
})
await的含义为等待,也就是 async 函数需要等待await后的函数执行完成并且有了返回结果(Promise对象)之后,才能继续执行下面的代码。await通过返回一个Promise对象来实现同步的效果。
重拾那些逐渐退化的CSS能力
源起
span元素是否可以用padding撑开宽高,”不能啊”!真的吗,确定没有记错吗,来,实验是检验真理的唯一标准。
<!DOCTYPE html>
<html>
<head>
<title></title>
</head>
<style type="text/css">
body{margin: 0;padding: 0}
div{
color: #000;
/*margin-bottom: 30px;*/ /*取消注释第二步,运行看效果*/
}
span{
padding:20px;
background-color: #000;
color: #fff;
text-align: center;
font-size: 20px;
margin:20px;
}
</style>
<body>
<!-- <div>神奇啊</div> --> <!-- 取消注释第一步,运行看效果 -->
<span>我是span</span>
</div>
</body>
</html>由此我们可以得出:
span设置内外边距问题
1、margin:
span标签设置margin-left/right均好使,margin-top/bottom不好使;
2、padding:
span标签设置padding好使,但span标签上面无元素时,padding-top 不好使;span标签上面有元素时,padding-top会把上面的元素盖住.
天啊,太神奇了!太神奇了!为什么,为什么啊????
等等,我还有疑问,那span可以设置line-height撑开里面的高度吗?
html元素的标签分类
曾经我的字典里只有行内元素和块级元素,inline & block,事实上:
HTML5中,元素主要分为7类:
Metadata
Flow
Sectioning
Heading
Phrasing
Embedded
Interactive
这些分类集合互相之间也存在一定的交集(一个元素可以同时属于多个分类)
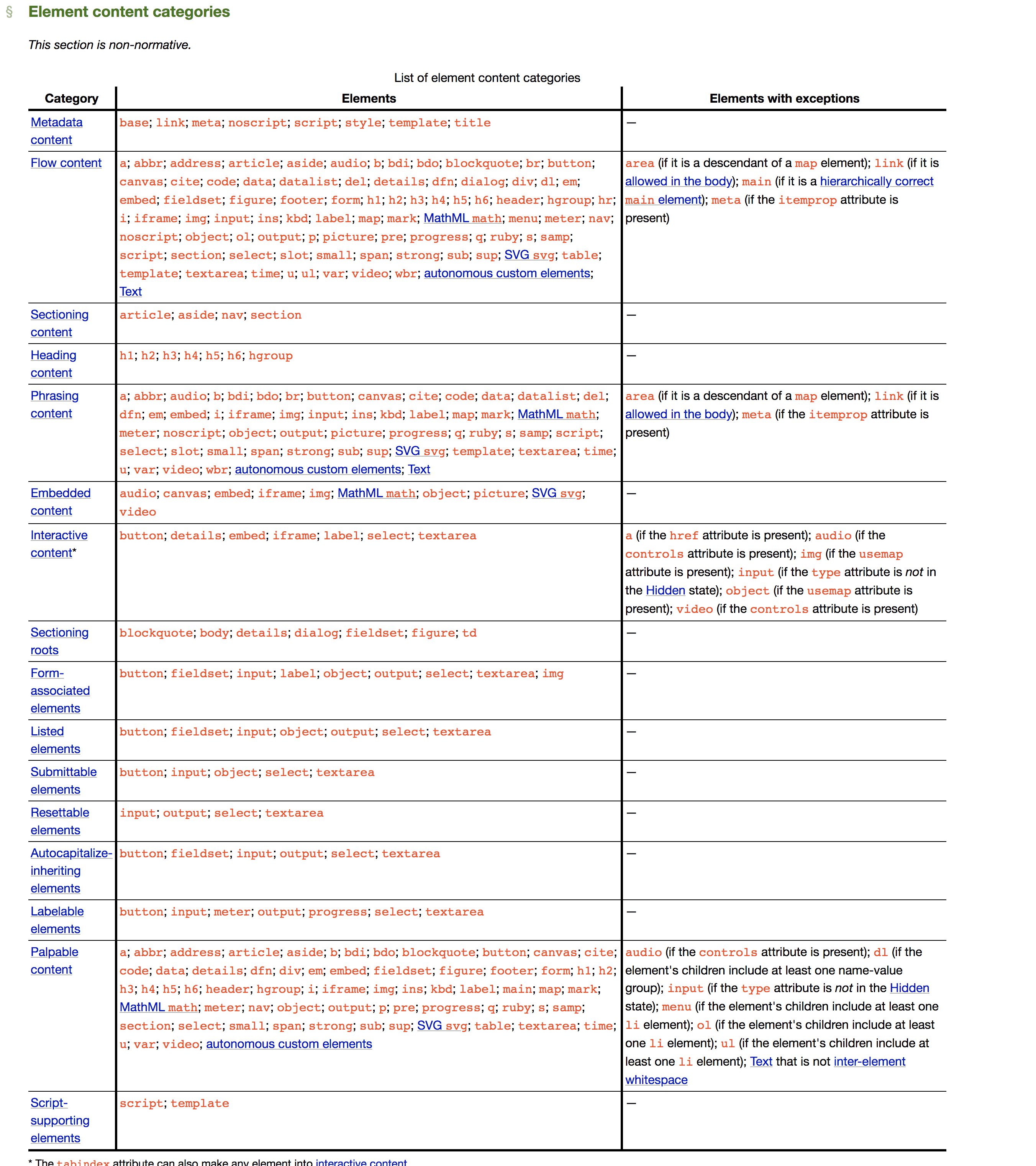
Metadata(元数据元素)
顾名思义,Metadata元素意指那些定义文档元数据信息的元素 — 其作用包括:影响文档中其它节点的展现与行为、定义文档与其它外部资源之间的关系等。
base, link, meta, noscript, script, style, template, title
Flow(流式元素)
所有可以放在body标签内,构成文档内容的元素均属于Flow元素。因此,除了base, link, meta, style, title等只能放在head标签内的元素外,剩下的所有元素均属于Flow元素。
a, abbr, address, area(如果它是map元素的后裔), article, aside, audio, b, bdi, bdo, blockquote, br, button, canvas, cite, code, command, datalist, del, details, dfn, div, dl,em, embed, fieldset, figure, footer, form, h1, h2, h3, h4, h5, h6, header, hgroup, hr, i, iframe, img, input, ins, kbd, keygen, label, map, mark, math, menu, meter,nav, noscript, object, ol, output, p, pre, progress, q, ruby, s, samp, script, section, select, small, span, strong, style(如果该元素设置了scoped属性), sub, sup, svg, table,textarea, time, u, ul, var, video, wbr, text
Sectioning(章节元素)
Sectioning意指定义页面结构的元素
article, aside, nav, section
Heading(标题元素)
所有标题元素属于Heading
h1, h2, h3, h4, h5, h6
Phrasing(段落元素)
所有可以放在p标签内,构成段落内容的元素均属于Phrasing元素。因此,所有Phrasing元素均属于Flow元素。在HTML5标准文档中,关于Phrasing元素的原始定义为:
Phrasing content is the text of the document, as well as elements that mark up that text at the intra-paragraph level. Runs of phrasing content form paragraphs.
对于这一定义,个人认为不应当使用“text”这一容易引起误解的词,事实上,一个元素即使不是文本,只要能包含在p标签中成为段落内容的一部分,就可以称之为Phrasing元素。
a(如果其只包含段落式元素), abbr, area(如果它是map元素的后裔), audio, b, bdi, bdo, br, button, canvas, cite, code, command, datalist, del(如果其只包含段落式元素), dfn, em, embed, i,iframe, img, input, ins(如果其只包含段落式元素), kbd, keygen, label, map(如果其只包含段落式元素), mark, math, meter, noscript, object, output, progress, q, ruby, s, samp, script,select, small, span, strong, sub, sup, svg, textarea, time, u, var, video, wbr, text
Embedded(嵌入元素)
所有用于在网页中嵌入外部资源的元素均属于Embedded元素
audio, video, img, canvas, svg, iframe, embed, object, math
Interactive(交互元素)
所有与用户交互有关的元素均属于Interactive元素。
a, audio(如果设置了controls属性), button, details, embed, iframe, img(如果设置了usemap属性), input(如果type属性不为hidden状态), keygen, label, menu(如果type属性为toolbar状态),object(如果设置了usemap属性), select, textarea, video(如果设置了controls属性)
Palpable
所有应当拥有子元素的元素称之为Palpable元素。比如,br元素因不需要子元素,因此也就不属于Palpable。
Script-supporting
自身不做任何页面展现,但与页面脚本相关的元素
script, template
其实这是非规范的,所以不是强求的,新的分类定义了元素的内容模型(Content Model),关键还是要清楚这些元素的特性以及各大浏览器是如何渲染解析的,包括有哪些默认的样式,从而正确嵌套标签以及设置reset.css。
https://html.spec.whatwg.org/multipage/indices.html#element-content-categories
W3C 标准盒模型 & IE 怪异盒模型
页面上显示的每个元素(包括内联元素)都可以看作一个盒子,即盒模型(box model) 盒模型由 4 部分组成,从内到外分别是:content padding border margin
W3C标准盒模型一个元素的宽度(高度以此类推)应该这样计算:
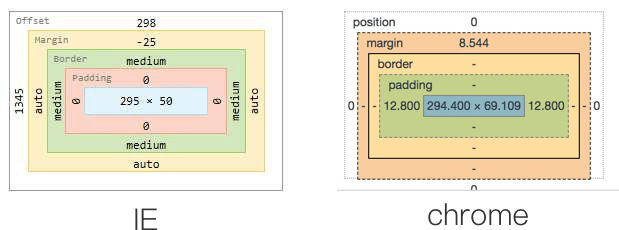
一个元素的宽度 = content
盒子总宽度 = margin-left + border-left + padding-left + width + padding-right + border-right + margin-right
而IE 怪异盒模型一个元素的宽度(高度以此类推)却是这样计算的:
一个元素的宽度 = content + padding + border
盒子总宽度 = margin-left + width + margin-right
解决方案 box-sizing
// W3C 标准盒模型(浏览器默认)
box-sizing: content-box;
// IE 怪异盒模型
box-sizing: border-box;
当我们设置 box-sizing: border-box; 时,border 和 padding 就被包含在了宽高之内,和IE在非标准的模式下是一致的。
然而好像看到很多网站为了避免同一份 css 在不同浏览器下表现不同,基本会加上:
*, *:before, *:after {
-moz-box-sizing: border-box;
-webkit-box-sizing: border-box;
box-sizing: border-box;
}
文档类型(Doctype)
亲测了下,发现其实当头部设置了html5的头部声明,在IE下也全是标准的盒模型了,估计除了历史遗留下的网站,新的全是html5的声明,HTML5 不基于 SGML,所以不需要引用 DTD。可能也就只有一些老家伙才经历过图下的历史:
如果有兴趣推荐看这篇关于声明的具体元素意思,毕竟其实很多医院系统,学校系统,政府系统之类可能还是会有旧的,了解下也好。
https://www.jianshu.com/p/c3dcdad42e6d
理解CSS布局和BFC
CSS布局中有一些概念,一旦理解了这些概念,就能真正的提高你的CSS能力。这篇文章主要介绍的是关于块格式化上下文(Block Formatting Context),也就是大家俗称的BFC。
它是W3C CSS2.1规范中的一个概念。它是页面中的一块渲染区域,并且有一套渲染规则,它决定了其子元素将如何定位,以及和其他元素的关系和相互作用。也就是说我们平时在布局的时候,它默默地提供了一个环境,使得HTML元素在这个环境中按照一定规则进行布局。
最常见的formatting context有Block Formatting Context(BFC)和Inline Formatting Context(IFC),CSS3中还增加了GridLayout Formatting Context(GFC)和Flex Formatting Context(FFC)。
BFC的布局规则与触发规则
刚才我们说到BFC中的元素有一套规定的布局规则:
内部的元素会在垂直方向一个接一个地放置
元素垂直方向的距离由margin决定,属于同一个BFC的两个相邻元素的margin会发生重叠
每个元素的左外边距与包含块的左边界相接触(对于从左往右,否则相反),即使存在浮动也是如此
BFC的区域不会与float元素重叠
计算BFC的高度时,浮动元素也参与计算
BFC就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素,反之也如此
刚才我们又提到BFC是一块渲染区域,那这块渲染区域到底在哪,它又是有多大,这些由生成BFC的元素来决定,CSS2.1中规定满足下列CSS声明的元素便会生成BFC(触发规则):
根元素
float的值不为none
overflow的值不为visible
position的值为absolute或fixed
display的值为inline-block, table-cell, table-caption, flex, inline-flex, grid
注:display: table也认为可以生成BFC,主要原因是table会默认生成一个匿名的table-cell,正是这个匿名的table-cell生成了BFC
上面这些CSS声明的元素生成了BFC,而它们本身并不是BFC,这一点需要区分。
防止垂直margin重叠
有点布局经验的朋友都知道margin collapse,也就是相邻的垂直元素同时设置了margin后,实际margin值会塌陷到其中较大的那个值。其根本原理就是它们处于同一个BFC,符合“属于同一个BFC的两个相邻元素的margin会发生重叠”的规则。
我们可以在其中一个元素外面包裹一层容器,并触发该容器生成一个BFC。那么两个元素便属于不同的BFC,就不会发生margin重叠了:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>防止垂直margin重叠</title>
</head>
<style>
/*.wrap{
overflow: hidden;
}
p{
width: 200px;
line-height: 100px;
margin: 100px;
background: #000;
color: #fff;
text-align: center;
}*/
.outer { background-color: #ccc; margin: 0 0 40px 0; /*overflow: auto;*/}
p { padding: 0; margin: 20px 0 20px 0; background-color: rgb(233,78,119); color: #fff; }
</style>
<body>
<!-- <p>我属于一个BFC</p>
<div class="wrap">
<p>我属于另一个BFC</p>
</div> -->
<div class="outer">
<p>我是P</p>
<p>我是另一个P</p>
</div>
</body>
</html>
防止浮动子元素高度塌陷
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>防止浮动子元素高度塌陷</title>
</head>
<style>
.outer { border: 5px dotted rgb(214,129,137); border-radius: 5px; width: 450px; padding: 10px; margin-bottom: 40px;/*overflow: hidden;*/ }
.float { padding: 10px; border: 5px solid rgba(214,129,137,.4); border-radius: 5px; background-color: rgba(233,78,119,.4); color: #fff; float: left; width: 200px; margin: 0 20px 0 0; }
</style>
<body>
<div class="outer">
<div class="float">我是浮动</div>
我会包裹着浮动
</div>
</body>
</html>如果我们将.outer元素的overflow: hidden去掉,那么.outer元素就获取不到浮动元素的高度了。但是加上overflow属性后触发了BFC,计算BFC的高度时,浮动元素也参与了计算。
防止文字(或其他元素)环绕
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>防止文字(或其他元素)环绕</title>
</head>
<style>
.parent{
width: 300px;
border: 3px solid #000;
}
.child{
float: left;
width: 100px;
height: 100px;
border: 3px solid #f00;
color: #f00;
}
.text{
/*overflow: hidden;*/
}
</style>
<body>
<div class="parent">
<div class="child">float: left</div>
<div class="text">我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕</div>
</div>
</body>
</html>
正常情况下,如果一个块级元素设置成了float,那么他的兄弟元素会环绕其布局。这里我们给.text加上overflow,文字所在的区域就产生了BFC,元素的左边总是触碰到容器的左边,即使存在浮动也是如此。
以上的都是BFC常见的应用场景以及它的触发规则,
接下来我们来看看BFC新的触发条件。
创建BFC的新方式
使用overflow或其他的方法创建BFC时会有两个问题。首先,这些方法本身是有自身的设计目的,所以在使用它们创建BFC时可能会产生副作用。例如,使用overflow创建BFC后在某些情况下可能会看到出现一个滚动条或者元素内容被裁切。这是由于overflow属性的设计是用来让你告诉浏览器如何定义元素的溢出状态的。
最安全的做法应该是创建一个BFC时并不会带来任何副作用,它内部的元素都安全的呆在这个迷你布局中,这种方法不会引起任何意想不到的问题,也可以理解开发者的意图。CSS工作组也十分认同这种想法,所以他们定制了一个新的属性值:display:flow-root。
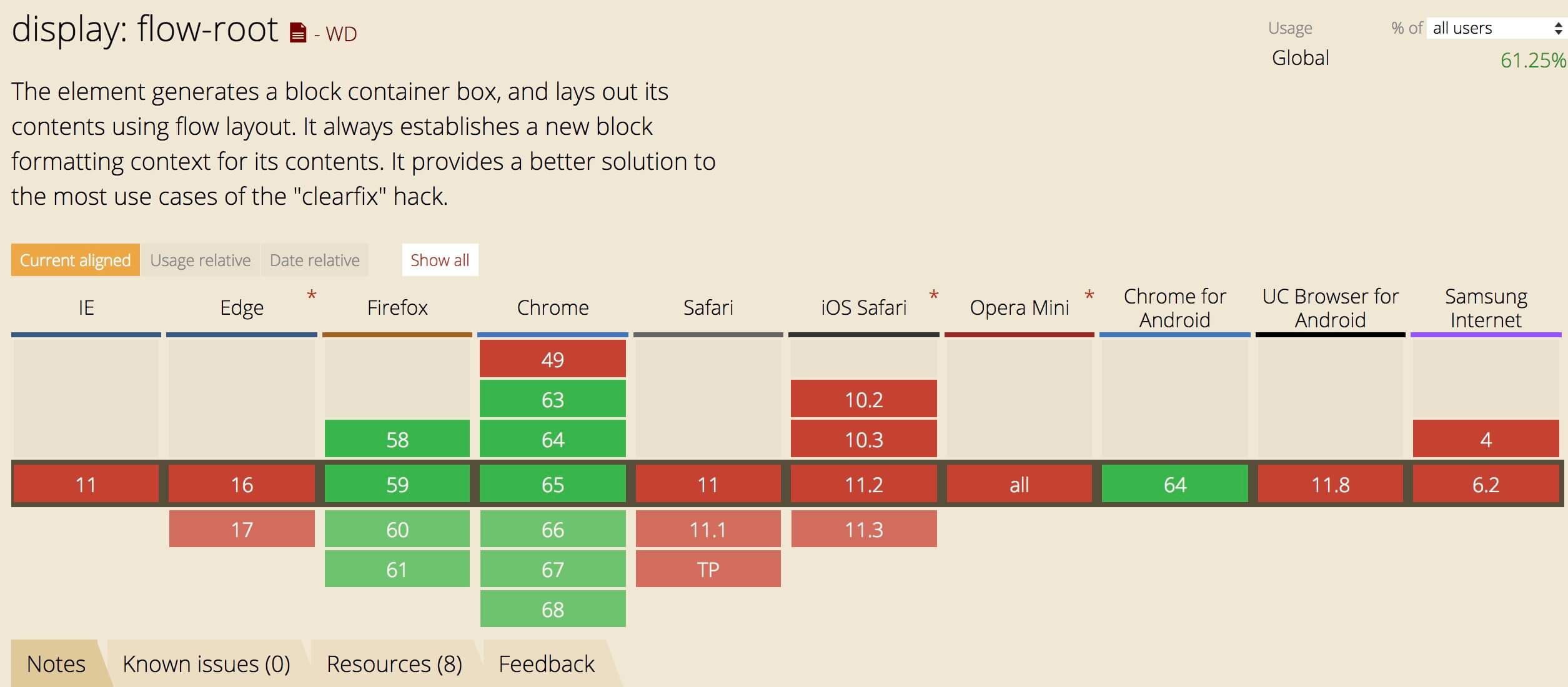
Caniuse上display:flow-root各浏览器兼容情况。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>flow-root</title>
</head>
<style>
.parent{
width: 300px;
border: 3px solid #000;
}
.child{
float: left;
width: 100px;
height: 100px;
border: 3px solid #f00;
color: #f00;
}
.text{
display: flow-root;
}
</style>
<body>
<div class="parent">
<div class="child">float: left</div>
<div class="text">我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕我只是文字但我不会环绕</div>
</div>
</body>
</html>
vertical-center(水平垂直居中)
仅居中元素定宽高适用:
absolute + 负margin
absolute + margin auto
absolute + calc
居中元素不定宽高适用:
absolute + transform
writing-mode
lineheight
table
css-table
flex
grid
参考链接:
https://www.w3cplus.com/css/understanding-css-layout-block-formatting-context.html
https://segmentfault.com/a/1190000011211625
前端性能优化
浏览器都做了什么
我们希望浏览器打开一个简单的网页
<!DOCTYPE html>
<html>
<head>
<title>The "Click the button" page</title>
<meta charset="UTF-8">
<link rel="stylesheet" href="styles.css" />
</head>
<body>
<h1>
Click the button.
</h1>
<button type="button">Click me</button>
<script>
var button = document.querySelector("button");
button.style.fontWeight = "bold";
button.addEventListener("click", function () {
alert("Well done.");
});
</script>
</body>
</html>
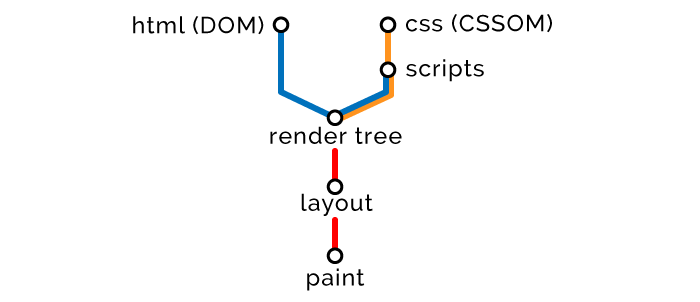
浏览器如何渲染网页
1、使用 HTML 创建文档对象模型(DOM)
2、使用 CSS 创建 CSS 对象模型(CSSOM)
3、基于 DOM 和 CSSOM 执行脚本(Scripts)
4、合并 DOM 和 CSSOM 形成渲染树(Render Tree)
5、使用渲染树布局(Layout)所有元素
6、渲染(Paint)所有元素
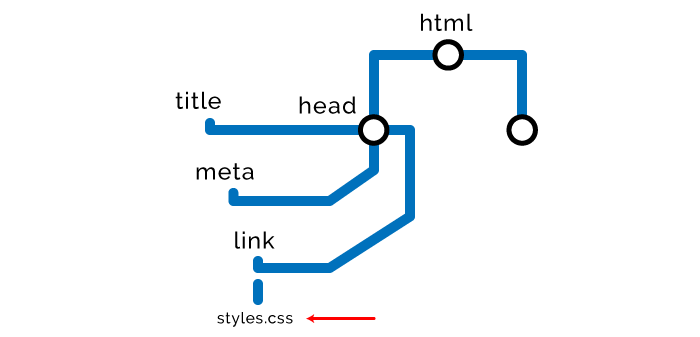
步骤一 — HTML
浏览器从上到下读取标签,把他们分解成节点,从而创建 DOM 。
HTML 加载优化策略
1、样式在顶部,脚本在底部
总体思路是尽可能早的加载样式,尽可能晚的加载脚本。原因是脚本执行之前,需要 HTML 和 CSS 解析完成,因此,样式尽可能的往顶部放,当底部脚本开始执行之前,样式有足够的时间完成计算。
2、最小化和压缩
方法可用于所有内容,包括 HTML,CSS,JavaScript,图片和其它资源。
最小化是移除所有多余的字符,包括空格,注释,多余的分号,等等。
压缩比如 GZip,大大压缩下载文件的大小
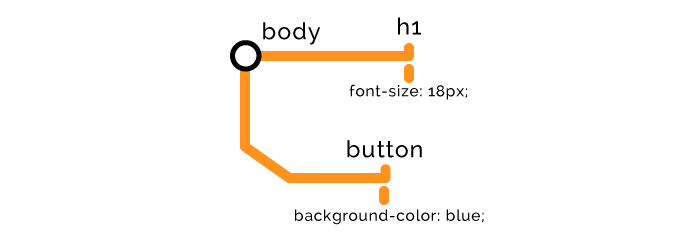
步骤二 — CSS
当浏览器发现任何与节点相关的样式时,比如:外部,内部,或行内样式,立即停止渲染 DOM ,并利用这些节点创建 CSSOM。这就是 CSS “渲染阻塞“ 的由来。
//外部样式
<link rel="stylesheet" href="styles.css">
// 内部样式
<style>
h1 {
font-size: 18px;
}
</style>
// 行内样式
<button style="background-color: blue;">Click me</button>
CSSOM 节点创建与 DOM 节点创建类似,随后,两者合并如下:
CSSOM 的构建会阻塞页面的渲染,因此我们想尽早加载样式
CSS 加载优化策略
ws.onerror = function (error) {
console.log('连接出错');
};
onerror是在连接出现问题时触发,连接出错考虑是否需要做相应的提示或者重连。
CSS 加载优化策略
1、延迟加载 CSS
有些样式,比如:首屏以下的,或者不那么重要的,可以等待首屏最有价值的内容渲染完成再加载,可以使用脚本等待页面加载,然后再插入样式。
2、只加载需要的样式
尽量移除不需要的样式。
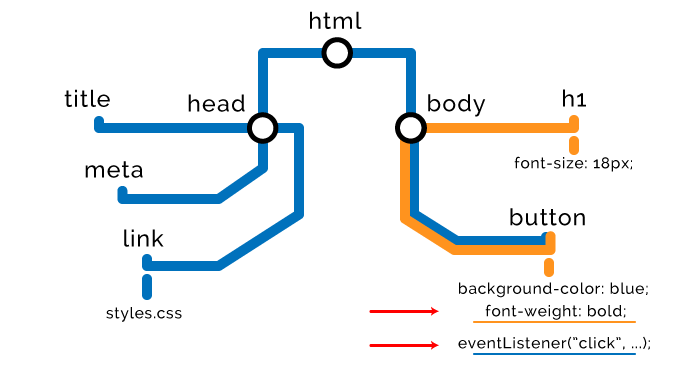
步骤三 — JavaScript
浏览器不断构建 DOM / CSSOM 节点,直到发现外部或者行内的脚本。
由于脚本可能需要访问或操作之前的 HTML 或样式,我们必须等待它们构建完成。
因此浏览器必须停止解析节点,完成构建 CSSOM,执行脚本,然后再继续。这就是 JavaScript 被称作“解析器阻塞”的原因。
脚本只能等到先前的 CSS 节点构建完成。
JavaScript 加载优化策略
1、异步加载脚本
脚本添加 async 属性,可以通知浏览器不要阻塞其余页面的加载,下载脚本处于较低的优先级。一旦下载完成,就可以执行。
async 适用于不影响 DOM 或 CSSOM 的脚本,对一些跟我们的代码无关的,不影响用户体验的外部脚本尤其适用,比如:分析统计脚本。
2、延迟加载脚本
defer 跟 async 非常相似,不会阻塞页面加载,但会等到 HTML 完成解析后再执行。
不幸的是 async 和 defer 对于行内的脚本不起作用,浏览器默认会编译执行它们。
3、操作之前克隆节点
多次操作 DOM 时可以尝试,首先克隆整个 DOM 节点更加高效,操作克隆后的节点,然后替换先前的节点,避免了多次重绘,降低了 CPU 和内存消耗,同时也避免了不必要的页面闪烁。
步骤四 — 渲染树(Render Tree)
一旦所有节点已被解析,DOM 和 CSSOM 准备合并,浏览器便会构建渲染树。如果我们把节点想象成单词,那么对象模型就是句子,渲染树便是整个页面。
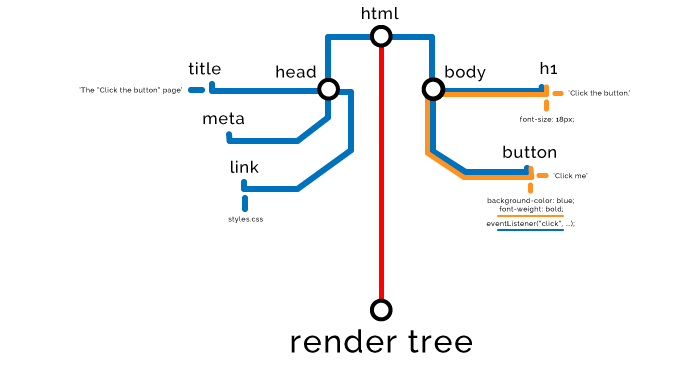
步骤五 — 布局(Layout)
布局阶段需要确定页面上所有元素的大小和位置。
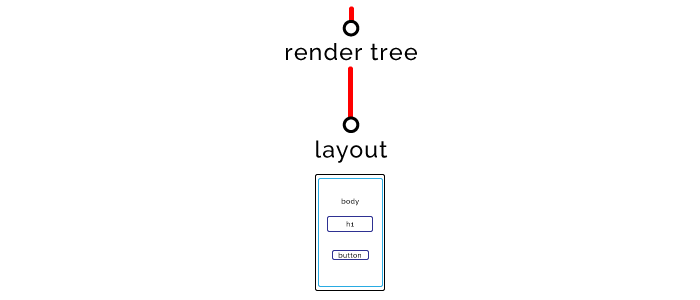
步骤六 — 渲染(Paint)
最终的渲染阶段,会真正地光栅化屏幕上的像素,把页面呈现给用户。
整个过程耗时1秒或十分之一秒,我们的任务是让它更快。
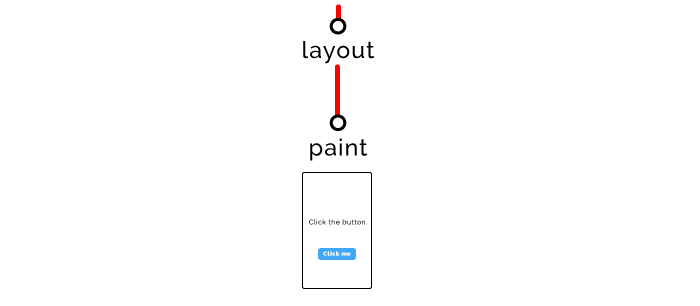
如果 JavaScript 事件改变了页面的某部分,便会引起渲染树的重绘,并且迫使布局(Layout)和渲染(Paint)过程再次进行。
浏览器如何发起网络请求
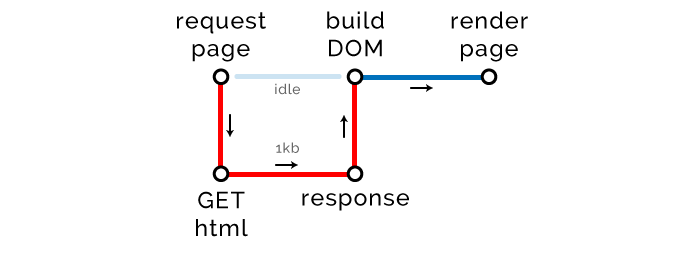
当浏览器请求一个 URL,服务端会响应一些 HTML。
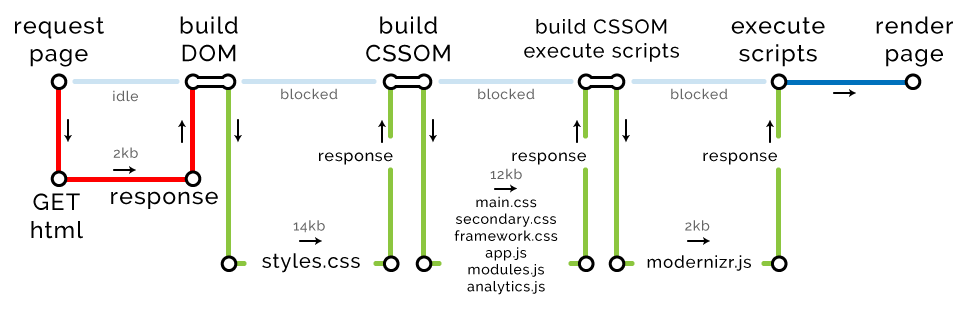
我们需要认识一个新术语,关键渲染路径(Critical Rendering Path (CRP)),就是浏览器渲染页面的步骤数,如下图。
关键路径长度
关键渲染路径的度量标准是路径长度。最理想的关键路径长度是1。
如果页面包含一些内部样式和 JavaScript ,关键路径发生以下改变
新增两步,构建 CSSOM和执行脚本,因为我们的 HTML 有内部样式和脚本需要计算。由于没有外部请求,我们的关键路径长度没变。
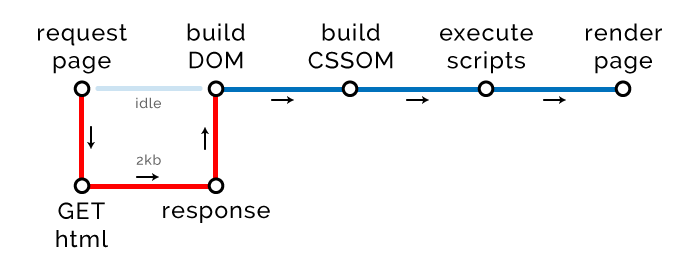
但是注意,我们的 HTML 大小增加到了 2kb,某些地方还是受了影响。
关键字节数
三个度量标准之二出现了,关键字节数,它用来衡量渲染页面需要传送多少字节数。
如果你认为不需要外部资源,就大错特错了,外部资源可以被缓存。
我们使用一个外部 CSS 文件,一个外部 JavaScript 文件,和一个外部带 async 属性的 JavaScript 文件。关键路径图如下:
浏览器请求页面,构建 DOM,发现外部资源后开始下载,CSS 和 JavaScript 有较高的优先级,其它资源次之。
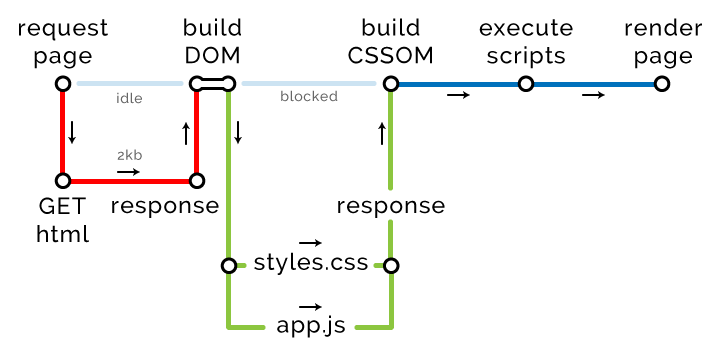
styles.css 和 app.js 通过另一个关键路径获取。暂时不获取 analytics.js ,因为加了 async 属性,浏览器将用另一个线程下载它,它处于较低优先级,不会阻塞页面渲染,也不影响关键路径。
关键文件
最后一个度量标准是关键文件,浏览器渲染页面需要下载的文件总量。以上例子,HTML 文件,CSS 和 JavaScript 文件算关键文件,async 的脚本不算。当然是文件越少越好。
回到关键路径长度
以上例子就是最长的渲染路径吗?我认为渲染页面时,我们仅需要下载 HTML,CSS 和 JavaScript 文件,仅通过两次服务器往返就做到了。
HTTP1 文件限制
我们浏览器的 HTTP1 协议,在同一个域名,同一次,允许下载的文件数有最大限制,范围从 2(老旧的浏览器)到 6(Edge,Chrome)。
HTTP2
如果网站使用了 HTTP2,并且用户的浏览器也兼容,则可以完全避开这个下载限制。
TCP 往返限制
每一次服务器往返可以传送的最大数据量是 14kb,包括所有 HTML,CSS 和脚本的网络请求。
如果我们的 HTML,或者积累的资源请求超过 14kb时,需要多做一次服务器往返。
大魔法师
我们整个 HTML 页面可以很好的压缩, GZip 可以压缩到 2kb,远低于 14kb 的限制,因此,一次服务器往返就可以搞定。
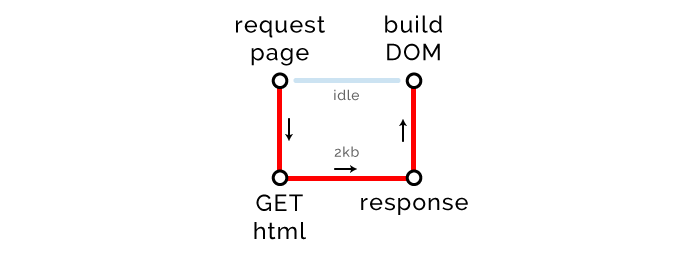
关键路径度量: 长度 1,文件数 1,字节数 2kb
浏览器发现外部资源(CSS 和 JavaScript)时,发起请求开始下载它们。首要下载的 CSS 文件是 14kb,达到了往返传输的最大限制,因此增加了一条关键路径。
关键路径度量: 长度 2,文件数 2,字节数 16kb
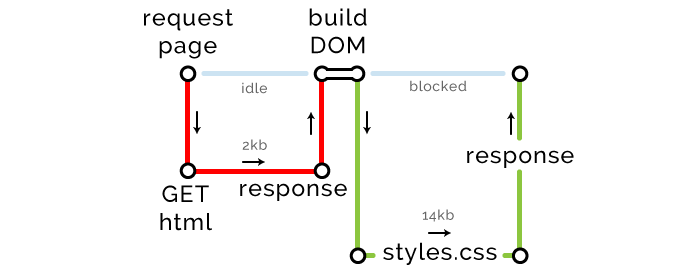
余下的资源低于 14kb,但是总共有 7 个资源,由于网站未启用 HTTP2,我们的 Chrome,每一次往返仅可以下载 6 个文件。
关键路径度量: 长度 3,文件数 8,字节数 28kb
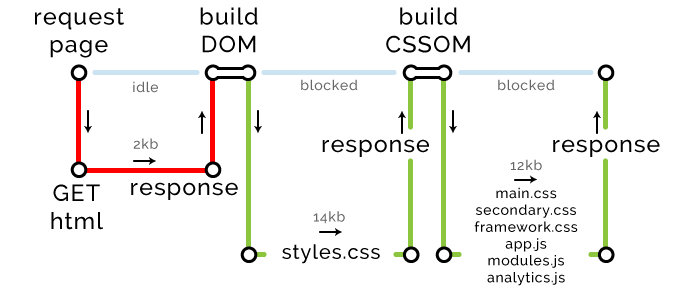
下载完最终文件,并开始渲染 DOM。
来源:http://jinlong.github.io/2017/05/08/optimising-the-front-end-for-the-browser/
Performance面板
1.FPS,CPU和NET的使用情况?
2.页面的前1毫秒和后1毫秒网络任务是怎样?
3.Javascript代码的执行消耗时间,显卡负载情况等?
4.浏览器对页面的绘制精确到毫秒级的情况?

这幅图中,1,2包括了FPS,CPU,NET以及网页渲染快照以及流式Network图,直观地浅显地回答了1和2两个问题,3回答了Javascript代码的执行消耗时间,显卡负载情况等,4则回答了浏览器对页面的绘制精确到毫秒级的情况。
第4步,也就是我们最关心的一步,是浏览器对页面的绘制精确到毫秒级的情况,准确的为我们剖析了浏览器加载渲染页面的全过程。
因此下文我们主要对4进行剖析,它包括4个分析面板,肯定有各自的意思在其中。
来源:https://segmentfault.com/a/1190000009845281


Puppeteer简单爬虫
Puppeteer 介绍
Puppeteer 翻译是操纵木偶的人,利用这个工具,我们能做一个操纵页面的人。Puppeteer是一个Nodejs的库,支持调用Chrome的API来操纵Web,相比较Selenium或是PhantomJs,它最大的特点就是它的操作Dom可以完全在内存中进行模拟既在V8引擎中处理而不打开浏览器,而且关键是这个是Chrome团队在维护,会拥有更好的兼容性和前景。
SPA(单页面web应用)在页面渲染上面用的都是js异步渲染,与传统服务端渲染直接吐出完整的html内容不同。所以一些旧的爬虫工具已经不太适合使用在SPA项目上面了。
而puppeteer因为是一个chromium内核的浏览器工具,固然能抓取到所有能在页面正常渲染的内容,无论是html还是基于js的异步加载。
puppeteer本身支持单个浏览器对象的多开页面,所以在共享登录态这类场景下毫无压力。视硬件配置而定,甚至能多开浏览器实例,做并发爬虫。
通俗点说的就是,我们可以用Puppeteer这个nodejs库来操作一个浏览器(chrome)。
Puppeteer 用处
1、利用网页生成PDF、图片
2、爬取SPA应用,并生成预渲染内容(即“SSR” 服务端渲染)
3、可以从网站抓取内容
4、自动化表单提交、UI测试、键盘输入等
5、帮你创建一个最新的自动化测试环境(chrome),可以直接在此运行测试用例
6、捕获站点的时间线,以便追踪你的网站,帮助分析网站性能问题
Puppeteer 使用
安装以及初始化项目
mkdir thal
cd thal
npm init
cnpm i --save puppeteer //用淘宝镜像源好点,我用npm经常安全不成功
爬取什么值得买12小时热门白菜价商品
爬取白菜价商品数据
const fs = require('fs');
const puppeteer = require('puppeteer');
const Sequelize = require('sequelize');
const config = require('./config');
var sequelize = new Sequelize(config.database, config.username, config.password, {
host: config.host,
dialect: 'mysql',
pool: {
max: 5,
min: 0,
idle: 30000
}
});
var Baicai = sequelize.define('baicai', {
id: {
type: Sequelize.STRING(50),
primaryKey: true
},
title: Sequelize.STRING(100),
price: Sequelize.STRING(100),
milemeter: Sequelize.STRING(100)
}, {
timestamps: false
});
(async () => {
const browser = await (puppeteer.launch({ headless: true }));
let page = await browser.newPage();
// 进入页面
await page.goto('https://faxian.smzdm.com/9kuai9/');
// 获取页面标题
let title = await page.title();
console.log(title);
// const CAR_LIST = '.subcate-tab-list';
// const clickTag = await page.evaluate((sel,page) => {
// const catBoxs = Array.from($(sel).find('li'));
// const ctn = catBoxs.map(v => {
// const title = $(v).find('a').text();
// if(title == '12h最热'){
// page.click($(v));
// }
// });
// }, CAR_LIST); //获取不到12h最热的点击
// 获取商品分类
const BRANDS_INFO_SELECTOR = '.filter-items.J_filter_items';
const brands = await page.evaluate(sel => {
const ulList = Array.from($(sel).find('div a'));
const ctn = ulList.map(v => {
return v.innerText.replace(/\s/g, '');
});
return ctn;
}, BRANDS_INFO_SELECTOR);
console.log('分类: ', JSON.stringify(brands));
let writerStream = fs.createWriteStream('fenlei.json');
writerStream.write(JSON.stringify(brands, undefined, 2), 'UTF8');
writerStream.end();
// await bodyHandle.dispose();
// 获取商品列表
const CAR_LIST_SELECTOR = '.feed-list-col.z-clearfix';
const carList = await page.evaluate((sel) => {
const catBoxs = Array.from($(sel).find('li'));
const ctn = catBoxs.map(v => {
const title = $(v).find('.feed-ver-title a').text();
const price = $(v).find('a.tag-bottom-right').text();
const subTitle = $(v).find('.z-highlight.z-ellipsis').text();
return {
title: title,
price: price,
milemeter: subTitle
};
});
return ctn;
}, CAR_LIST_SELECTOR);
console.log(`总共${carList.length}条商品数据: `, JSON.stringify(carList, undefined, 2));
// (async () => {
// for(let i = 0; i < carList.length; i ++){
// //const item = carList[i];
// let tmpObj = {
// id: 'd-' + Date.now(),
// title: carList[i].title,
// price: carList[i].price,
// milemeter: carList[i].milemeter
// }
// var baicai = await Baicai.create(tmpObj);
// console.log('created: ' + JSON.stringify(baicai));
// }
// })();
// 将商品信息写入文件
writerStream = fs.createWriteStream('baicai.json');
writerStream.write(JSON.stringify(carList, undefined, 2), 'UTF8');
writerStream.end();
browser.close();
// (async () => {
// var pets = await Baicai.findAll({
// where: {
// price: '京东'
// }
// });
// console.log(`find ${pets.length} pets:`);
// for (let p of pets) {
// console.log(JSON.stringify(p));
// }
// })();
// (async () => {
// var p = await Baicai.findAll({
// where: {
// id: 'd-1564362846693'
// }
// });
// p.title = "那只猪看到了";
// p.price = "淘阿宝";
// p.milemeter = "一千万";
// await p.save();
// })();
// Baicai.update({ title: "那只猪看到了",price: "淘阿宝", milemeter: "一千万"}, {
// where: {
// id: 'd-1564362846693'
// }
// }).then(() => {
// console.log("Done");
// });
// Baicai.destroy({
// where: {
// id: 'd-1564362846525'
// }
// }).then(() => {
// console.log("删除成功");
// });
// (async () => {
// var p = await Baicai.findAll({
// where: {
// id: 'd-1564362846525'
// }
// });
// await p.destroy();
// })();
})();
javascript 作用域
最近在看你不知道的javascript上卷,做下总结。
简述编译原理
JavaScript通常会被归类为“动态”或“解释执行”语言,但事实上它是一门编译语言。但与传统的编译语言不同,它不是提前编译的,编译结果也不能在分布式系统上进行移植。
在传统编译语言的流程中,程序中的一段源代码在执行前会经历三个步骤,统称为“编译”。
1. 分词 / 词法分析
2. 解析 / 语法分析
3. 代码生成
与其他语言不同,JavaScript的编译过程不是发生在构建之前的。对于JavaScript来说,大部分情况下编译发生在代码执行前的几微秒(甚至更短)的时间内。
举个栗子,var a = 2; JavaScript引擎会将它分为几步完成呢?
答案是两步,JavaScript 会将其看成两句声明:var a; 和 a = 2;。第一个定义声明在编译阶段进行,第二个赋值声明会被留在原地等待执行阶段。
下面是原书对这句声明的拆解分析:
变量的赋值操作会执行两个动作,首先编译器会在当前作用域中声明一个变量(如果之前没有声明过),然后在运行时引擎会在引用域中查找该变量,如果能够找到就会对它赋值。
而要讲的LHS 和 RHS 就是上面说的对变量的两种查找操作,查找的过程是由作用域(词法作用域)进行协助,在编译的第二步中执行。
参考原文:https://blog.csdn.net/zwkkkk1/article/details/79725502
LHS(Left-Hand-Side)查询和RHS(Right-Hand-Side)查询
问题1:之前只知道在JavaScript中,如果一个变量a未经声明就直接取值,如 console.log(a),会抛出ReferenceError异常;如果一个变量a未经声明,就直接赋值,如 a = 2,那么程序会自动创建一个全局变量a,然后再把2赋给a,但是这是为什么呢?
如 var a = 2,在JavaScript预编译结束后引擎开始执行代码,引擎执行它时,会通过查找变量a来判断它是否已声明过,查找的过程由作用域进行协助。有两种查询类型,LHS(Left-Hand-Side)查询和RHS(Right-Hand-Side)查询。
作用域是一套规则,用于确定在何处以及如何查找变量(标识符)。如果查找的目的是对变量进行赋值,那么就会使用LHS查询,如 a = 2;如果目的是获取变量的值,那么就会使用RHS查询,如 console.log(a)。非严格模式下,不成功的RHS引用(如找不到变量a)会导致抛出ReferenceError异常;不成功的LHS引用(如找不到变量a)会导致自动隐式地创建一个全局变量(a),该变量使用LHS引用的目标作为标识符,但严格模式下也会抛出ReferenceError异常。
赋值操作符会导致LHS查询,= 操作符或调用函数时传入参数的操作都会导致关联作用域的赋值操作。
LHS查询和RHS查询都会在当前执行作用域中开始,如果有需要(没找到),就会向上一级作用域继续查找目标标识符,这样每次上升一级作用域,最后抵达全局作用域,无论找到或者没找到都将停止。
参考原文:https://blog.csdn.net/binma2542/article/details/81169604
词法作用域
“词法作用域”就是定义在词法阶段的作用域。换句话说,词法作用域是由你在写代码时将变量和块作用域写在哪里来决定的,因此当词法分析器处理代码时会保持作用域不变。
function foo(a){
var b = a * 2;
function bar(c){
console.log(a,b,c);
}
bar(b * 3);
}
foo(2);
这个例子有三级嵌套的作用域
参考:https://www.cnblogs.com/GongQi/p/5426055.html

欺骗词法
如果词法作用域完全由写代码期间函数所生命的位置来定义,那么可以通过几种方法来欺骗(修改)词法作用域,比如 eval、with 但是要注意:欺骗词法作用域会导致性能下降。
因为JS引擎会在编译阶段进行性能优化,其中有些优化依赖于能够根据代码的词法进行静态分析,并预先确定所有变量和函数的定义位置,才能在执行过程中快速找到标识符。但是如果引擎在代码中找到 eval、with ,就会完全不做任何优化。
eval:eval()函数接受一个字符串为参数,并将其中的内容视为好像在书写时就存在于程序中这个位置的代码。
function foo(str, a){
eval(str);
console.log(a,b)
}
var b = 2;
foo("var b = 3;", 1)
//也就是永远都找不到外部的b,好像就是在动态的写代码一样
with:with通常被当作重复引用同一个对象中的多个属性的更快捷方式
eg:var obj = {
a:1,
b:2
}
obj.a = 2;
obj.b = 3;
相当于:
with(obj){
a:2;
b:33;
}
//可以方便的访问对象属性
with可以将一个没有或有多个属性的对象处理为一个完全隔离的词法作用域,因此这个对象的属性也会被处理为定义在这个作用域中的词法标识符。但是这个块内部正常的var声明并不会被限制在这个块的作用域中,而是被添加到with所在的函数作用域中,所以就有一个新的问题,变量会被泄露。
参考链接:https://www.jianshu.com/p/8fe5ba6d2b3b
函数作用域
js简单的防抖跟节流
前端的优化这个老生常谈的话题,这次我来记录下js的防抖跟节流对于页面优化的实现方式。
前言
在前端开发中我们会遇到一些频繁的事件触发,比如:window 的 resize、scroll,mousedown、mousemove,keyup、keydown …… 或者根据数据的改变实时得进行数据接口的请求,比如搜索。
下面,我们举个示例代码来了解事件如何频繁的触发:
index.html 文件:
<!DOCTYPE html>
<html>
<head>
<title>debounce</title>
<style>
#container{
width: 100%; height: 200px; line-height: 200px; text-align: center; color: #fff; background-color: #333; font-size: 30px;
}
</style>
</head>
<body>
<div id="container"></div>
<script src="debounce.js"></script>
</body>
</html>debounce.js 文件:
var count = 1;
var container = document.getElementById('container');
function getMouseMove() {
container.innerHTML = count++;
};
container.onmousemove = getMouseMove;当我们从浏览器这样滑过去时会调用很多次的getMouseMove方法,这只是一个很简单的效果,浏览器完全反应得过来,试想一下,如果是复杂的回调或者是ajax请求那性能会大受打击,会有明显的卡顿。
为了解决这个问题,一般有两种解决方案:
1、debounce 防抖
2、throttle 节流
防抖
防抖的原理就是:你尽管触发事件,但是我一定在事件停止触发 n 秒后才执行。
这意味着如果你在一个事件触发的 n 秒内又触发了这个事件,那我就以新的事件触发的时间为准,在此时间 n 秒后才执行。
总之,就是要等你触发完事件 n 秒内不再触发事件,我才执行!
防抖函数
function debounce(func, wait) {
var timeout;
return function () {
var context = this;
var args = arguments;
clearTimeout(timeout)
timeout = setTimeout(function(){
func.apply(context, args)
}, wait);
}
}使用:
container.onmousemove = debounce(getMouseMove, 1000);节流
节流就是:如果你持续触发事件,每隔一段时间,只执行一次事件。
关于节流的实现,有两种主流的实现方式,一种是使用时间戳,一种是设置定时器。
使用时间戳
让我们来看第一种方法:使用时间戳,当触发事件的时候,我们取出当前的时间戳,然后减去之前的时间戳(最一开始值设为 0 ),如果大于设置的时间周期,就执行函数,然后更新时间戳为当前的时间戳,如果小于,就不执行。
function throttle(func, wait) {
var context, args;
var previous = 0;
return function() {
var now = +new Date();
context = this;
args = arguments;
if (now - previous > wait) {
func.apply(context, args);
previous = now;
}
}
}例子依然是用讲 debounce 中的例子,如果你要使用:
container.onmousemove = throttle(getMouseMove, 1000);使用定时器
接下来,我们讲讲第二种实现方式,使用定时器。
当触发事件的时候,我们设置一个定时器,再触发事件的时候,如果定时器存在,就不执行,直到定时器执行,然后执行函数,清空定时器,这样就可以设置下个定时器。
function throttle(func, wait) {
var timeout;
return function() {
context = this;
args = arguments;
if (!timeout) {
timeout = setTimeout(function(){
timeout = null;
func.apply(context, args)
}, wait)
}
}
}参考链接如下:
https://segmentfault.com/a/1190000009638648
https://segmentfault.com/a/1190000009831691
Linux命令指南
因为要查看一些用接口补获的错误日志,因此就要进对应的项目服务器里面去查看,自然Linux并不像window系统那样便利的图形化操作,因此我们要就学会几个linux命令啦。
为什么我们要学习Linux
相信大部分人的PC端都是用Windows系统的,那我们为什么要学习Linux这个操作系统呢???Windows图形化界面做得这么好,日常基本使用的话,学习成本几乎为零。
而Linux不一样,可能刚接触Linux的人会认为:Linux好麻烦哦,不好玩,都是字符界面。不直观、这个破系统是用来干嘛的~~
日常用的话Windows是比较顺手的,但是我们要知道的是:我们开发出来的程序一般都是放在Linux下运行的。
那可能就会有人提出疑问了:Windows同样是操作系统,为啥要放在Linux下,而不放在Windows下呢??相信Windows也是可以运行我们写出来的程序的。
我总结了Linux的几个优点:
1、免费
2、很多软件原生是在Linux下运行的,庞大的社区支持,生态环境好。
3、开源,可被定制,开放,多用户的网络操作系统。
4、相对安全稳定
所以开发者选择了Linux来跑我们自己写出来的程序。
Linux的基础知识
Linux系统的组成:
1、linux内核(linus 团队管理)
2、shell:用户与内核交互的接口
3、文件系统:ext3、ext4等。windows 有 fat32 、ntfs
4、第三方应用软件
Linux基本目录结构
Linux 文件系统是一个目录树的结构,文件系统结构从一个根目录开始,根目录下可以有任意多个文件和子目录,子目录中又可以有任意多个文件和子目录
bin 存放二进制可执行文件(ls,cat,mkdir等)
boot 存放用于系统引导时使用的各种文件
dev 用于存放设备文件
etc 存放系统配置文件
home 存放所有用户文件的根目录
lib 存放跟文件系统中的程序运行所需要的共享库及内核模块
mnt 系统管理员安装临时文件系统的安装点
opt 额外安装的可选应用程序包所放置的位置
proc 虚拟文件系统,存放当前内存的映射
root 超级用户目录
sbin 存放二进制可执行文件,只有root才能访问
tmp 用于存放各种临时文件
usr 用于存放系统应用程序,比较重要的目录/usr/local 本地管理员软件安装目录
var 用于存放运行时需要改变数据的文件
接触的命令
tips:输入命令的时候要常用tab键来补全
ls:显示文件或目录信息
mkdir:当前目录下创建一个空目录
rmdir:要求目录为空
touch:生成一个空文件或更改文件的时间
cp:复制文件或目录
mv:移动文件或目录、文件或目录改名
rm:删除文件或目录
ln:建立链接文件
find:查找文件
file/stat:查看文件类型或文件属性信息
cat:查看文本文件内容
more:可以分页看
less:不仅可以分页,还可以方便地搜索,回翻等操作
tail -10: 查看文件的尾部的10行
head -20:查看文件的头部20行
echo:把内容重定向到指定的文件中 ,有则打开,无则创建
管道命令 | :将前面的结果给后面的命令,例如:ls -la | wc,将ls的结果加油wc命令来统计字数
重定向 > 是覆盖模式,>> 是追加模式,例如:echo "Java3y,zhen de hen xihuan ni" > qingshu.txt把左边的输出放到右边的文件里去
cat 文件名
预览文件
tail -f 文件名
实时监听文件的变化
grep命令
grep(global search regular expression)是一个强大的文本搜索工具。grep 使用正则表达式搜索文本,并把匹配的行打印出来。
格式:grep [options] PATTERN [FILE...]
PATTERN 是查找条件:可以是普通字符串、可以是正则表达式,通常用单引号将RE括起来。
FILE 是要查找的文件,可以是用空格间隔的多个文件,也可是使用Shell的通配符在多个文件中查找PATTERN,省略时表示在标准输入中查找。
grep命令不会对输入文件进行任何修改或影响,可以使用输出重定向将结果存为文件
例子:
在文件 myfile 中查找包含字符串 mystr的行
grep -n mystr myfile
显示 myfile 中第一个字符为字母的所有行
grep '^[a-zA-Z]' myfile
在文件 myfile 中查找首字符不是 # 的行(即过滤掉注释行)
grep -v '^#' myfile
列出/etc目录(包括子目录)下所有文件内容中包含字符串“root”的文件名
grep -lr root /etc/*
用grep查找/etc/passwd文件中以a开头的行,要求显示行号;查找/etc/passwd文件中以login结束的行;
grep -i "15:00" 文件名
grep -i "15:00" /media/raid10/htdocs/项目名/runtime/logs/logs-report-2019-07-01
共享结构对象
其实这就是利用es6的解构来实现对象的浅复制,进而可以提高性能优化,同时介绍下Object.assign() 方法
Object.assign()
Object.assign() 方法用于将所有可枚举属性的值从一个或多个源对象复制到目标对象。它将返回目标对象。
const target = { a: 1, b: 2 };
const source = { b: 4, c: 5 };
const returnedTarget = Object.assign(target, source);
console.log(target);
// expected output: Object { a: 1, b: 4, c: 5 }
console.log(returnedTarget);
// expected output: Object { a: 1, b: 4, c: 5 }
Object.assign(target, ...sources)
target 目标对象。
sources 源对象。
返回值 目标对象。
如果目标对象中的属性具有相同的键,则属性将被源对象中的属性覆盖。后面的源对象的属性将类似地覆盖前面的源对象的属性。
Object.assign 方法只会拷贝源对象自身的并且可枚举的属性到目标对象。
复制一个对象节
const obj = { a: 1 };
const copy = Object.assign({}, obj);
console.log(copy); // { a: 1 }
深拷贝问题节
针对深拷贝,需要使用其他办法,因为 Object.assign()拷贝的是属性值。假如源对象的属性值是一个对象的引用,那么它也只指向那个引用。
let obj1 = { a: 0 , b: { c: 0}};
let obj2 = Object.assign({}, obj1);
console.log(JSON.stringify(obj2)); // { a: 0, b: { c: 0}}
obj1.a = 1;
console.log(JSON.stringify(obj1)); // { a: 1, b: { c: 0}}
console.log(JSON.stringify(obj2)); // { a: 0, b: { c: 0}}
obj2.a = 2;
console.log(JSON.stringify(obj1)); // { a: 1, b: { c: 0}}
console.log(JSON.stringify(obj2)); // { a: 2, b: { c: 0}}
obj2.b.c = 3;
console.log(JSON.stringify(obj1)); // { a: 1, b: { c: 3}}
console.log(JSON.stringify(obj2)); // { a: 2, b: { c: 3}}
// Deep Clone
obj1 = { a: 0 , b: { c: 0}};
let obj3 = JSON.parse(JSON.stringify(obj1));
obj1.a = 4;
obj1.b.c = 4;
console.log(JSON.stringify(obj3)); // { a: 0, b: { c: 0}}
合并对象
const o1 = { a: 1 };
const o2 = { b: 2 };
const o3 = { c: 3 };
const obj = Object.assign(o1, o2, o3);
console.log(obj); // { a: 1, b: 2, c: 3 }
console.log(o1); // { a: 1, b: 2, c: 3 }, 注意目标对象自身也会改变。
合并具有相同属性的对象节
const o1 = { a: 1, b: 1, c: 1 };
const o2 = { b: 2, c: 2 };
const o3 = { c: 3 };
const obj = Object.assign({}, o1, o2, o3);
console.log(obj); // { a: 1, b: 2, c: 3 }
共享结构的对象-(解构)
大家都知道这种 ES6 的语法:
const obj = { a: 1, b: 2}
const obj2 = { ...obj } // => { a: 1, b: 2 }
const obj2 = { ...obj } 其实就是新建一个对象 obj2,然后把 obj 所有的属性都复制到 obj2 里面,相当于对象的浅复制。上面的 obj 里面的内容和 obj2 是完全一样的,但是却是两个不同的对象。除了浅复制对象,还可以覆盖、拓展对象属性:
const obj = { a: 1, b: 2}
const obj2 = { ...obj, b: 3, c: 4} // => { a: 1, b: 3, c: 4 },覆盖了 b,新增了 c
我们接下来举个例子,只重新修改改变了的例子,没有改变的还是引用原对象。
有这样一个对象:
let appState = {
title: {
text: '小书',
color: 'red',
},
content: {
text: '小书内容',
color: 'blue'
}
}
我们可以把这种特性应用在 appstate 的更新上,我们禁止直接修改原来的对象,一旦你要修改某些东西,你就得把修改路径上的所有对象复制一遍,例如,我们不写下面的修改代码:
appState.title.text = '小书尾巴'
取而代之的是,我们新建一个 newAppState,新建 newAppState.title,新建 newAppState.title.text:
let newAppState = { // 新建一个 newAppState
...appState, // 复制 appState 里面的内容
title: { // 用一个新的对象覆盖原来的 title 属性
...appState.title, // 复制原来 title 对象里面的内容
text: '小书尾巴' // 覆盖 text 属性
}
}
appState 和 newAppState 其实是两个不同的对象,因为对象浅复制的缘故,其实它们里面的属性 content 指向的是同一个对象;但是因为 title 被一个新的对象覆盖了,所以它们的 title 属性指向的对象是不同的。同样地,修改 appState.title.color:
let newAppState1 = {
...newAppState,
title:{
...newAppState.title,
color:"blue"
}
}
我们每次修改某些数据的时候,都不会碰原来的数据,而是把需要修改数据路径上的对象都 copy 一个出来。这样有什么好处?看看我们的目的达到了:
appState !== newAppState // true,两个对象引用不同,数据变化了,重新渲染
appState.title !== newAppState.title // true,两个对象引用不同,数据变化了,重新渲染
appState.content !== appState.content // false,两个对象引用相同,数据没有变化,
修改数据的时候就把修改路径都复制一遍,但是保持其他内容不变,最后的所有对象具有某些不变共享的结构(例如上面三个对象都共享 content 对象)。大多数情况下我们可以保持 50% 以上的内容具有共享结构,这种操作具有非常优良的特性,我们可以用它来优化上面的渲染性能。
Set集合
Set集合
Set 是一种叫做集合的数据结构,主要的应用场景在于数据重组;是ES6 新增的一种新的数据结构,类似于数组,但成员是唯一且无序的,没有重复的值。
Set 本身是一种构造函数,用来生成 Set 数据结构。
主要有一下特点:
1.成员不能重复
2.只有健值,没有健名,有点类似数组。
3. 可以遍历,方法有add, delete,has
new Set([iterable])
举个例子:
const s = new Set()
[1, 2, 3, 4, 3, 2, 1].forEach(x => s.add(x))
for (let i of s) {
console.log(i) // 1 2 3 4
}
// 去重数组的重复对象
let arr = [1, 2, 3, 2, 1, 1]
[... new Set(arr)] // [1, 2, 3]
Set 对象允许你储存任何类型的唯一值,无论是原始值或者是对象引用。
向 Set 加入值的时候,不会发生类型转换,所以5和"5"是两个不同的值。Set 内部判断两个值是否不同,使用的算法叫做“Same-value-zero equality”,它类似于精确相等运算符(===),主要的区别是NaN等于自身,而精确相等运算符认为NaN不等于自身。
let set = new Set();
let a = NaN;
let b = NaN;
set.add(a);
set.add(b);
set // Set {NaN}
let set1 = new Set()
set1.add(5)
set1.add('5')
console.log([...set1]) // [5, "5"]
另外,两个对象总是不相等的。
let set = new Set();
set.add({});
set.size // 1
set.add({});
set.size // 2
上面代码表示,由于两个空对象不相等,所以它们被视为两个值。
Set 实例的属性和方法
-
Set 实例属性
-
constructor: 构造函数
-
size:元素数量
-
let set = new Set([1, 2, 3, 2, 1])
console.log(set.length) // undefined
console.log(set.size) // 3
- Set 实例方法
-
操作方法
-
add(value):新增,相当于 array里的push
-
delete(value):存在即删除集合中value
-
has(value):判断集合中是否存在 value
-
clear():清空集合
let set = new Set() set.add(1).add(2).add(1) set.has(1) // true set.has(3) // false set.delete(1) set.has(1) // falseArray.from 方法可以将 Set 结构转为数组
const items = new Set([1, 2, 3, 2]) //Set(3) {1, 2, 3} const array = Array.from(items) console.log(array) // [1, 2, 3] // 或 const arr = [...items] console.log(arr) // [1, 2, 3] -
-
遍历方法(遍历顺序为插入顺序)
-
keys():返回一个包含集合中所有键的迭代器
-
values():返回一个包含集合中所有值得迭代器
-
entries():返回一个包含Set对象中所有元素得键值对迭代器
-
forEach(callbackFn, thisArg):用于对集合成员执行callbackFn操作,如果提供了 thisArg 参数,回调中的this会是这个参数,没有返回值
let set = new Set([1, 2, 3]) console.log(set.keys()) // SetIterator {1, 2, 3} console.log(set.values()) // SetIterator {1, 2, 3} console.log(set.entries()) // SetIterator {1, 2, 3} for (let item of set.keys()) { console.log(item); } // 1 2 3 for (let item of set.entries()) { console.log(item); } // [1, 1] [2, 2] [3, 3] set.forEach((value, key) => { console.log(key + ' : ' + value) }) // 1 : 1 2 : 2 3 : 3 console.log([...set]) // [1, 2, 3]Set 可默认遍历,默认迭代器生成函数是 values() 方法
Set.prototype[Symbol.iterator] === Set.prototype.values // true所以, Set可以使用 map、filter 方法
let set = new Set([1, 2, 3]) set = new Set([...set].map(item => item * 2)) console.log([...set]) // [2, 4, 6] set = new Set([...set].filter(item => (item >= 4))) console.log([...set]) //[4, 6]因此,Set 很容易实现交集(Intersect)、并集(Union)、差集(Difference)
let set1 = new Set([1, 2, 3]) let set2 = new Set([4, 3, 2]) let intersect = new Set([...set1].filter(value => set2.has(value))) let union = new Set([...set1, ...set2]) let difference = new Set([...set1].filter(value => !set2.has(value))) console.log(intersect) // Set {2, 3} console.log(union) // Set {1, 2, 3, 4} console.log(difference) // Set {1} -
-
NPM — JavaScript 的包管理器
本文主要介绍npm的常用命令,以及如何发布一些常用的js模块化代码到npm上面方便日后的使用,和举例如何把一个vue组件打包发布到npm到最后下载到本地使用的过程。
npm(Node Package Manager)是node的默认模块管理器,一个命令行下的软件,用来安装和管理node模块,同时也可以管理其他开放式的js模块代码。npm有一个好处是除了下载需要的模块外还会帮我们解决依赖关系,同时下载所依赖的模块。
NPM —— JavaScript 的包管理器
npm help
access, adduser, bin, bugs, c, cache, completion, config,
ddp, dedupe, deprecate, dist-tag, docs, doctor, edit,
explore, get, help, help-search, i, init, install,
install-test, it, link, list, ln, login, logout, ls,
outdated, owner, pack, ping, prefix, prune, publish, rb,
rebuild, repo, restart, root, run, run-script, s, se,
search, set, shrinkwrap, star, stars, start, stop, t, team,
test, tst, un, uninstall, unpublish, unstar, up, update, v,
version, view, whoami
npm help 可以查看所有可使用的命令。
npm常用指令
npm install 名字 //该命令用于安装模块
npm uninstall 名字 //该命令用于卸载模块
npm run 名字 //该命令用于执行脚本
如何用npm发布自己的模块
我们所有下载以及发布的包是存放在这个地址:https://www.npmjs.com/
我们发布一个东西,得要有自己的标识吧,所以得先注册账号。
1.注册用户
npm adduser
运行该命令后会需要你依次输入
Username:
Password:
Email:
2.检查
接下来是需要检查一下有没有注册成功
npm whoami
3.建立package
npm init
//一路回车
name: (dateFormat) datechange
version: (1.0.0)
description: change date format
entry point: (index.js)
test command:
git repository: https://github.com/shuangmuyingzi/dateFormat.git
keywords: dateformat date datechange
author: lingzi
license: (ISC)
About to write to /Users/linziying/Downloads/npm/dateFormat/package.json:
{
"name": "datechange",
"version": "1.0.0",
"description": "change date format",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"repository": {
"type": "git",
"url": "git+https://github.com/shuangmuyingzi/dateFormat.git"
},
"keywords": [
"dateformat",
"date",
"datechange"
],
"author": "lingzi",
"license": "ISC",
"bugs": {
"url": "https://github.com/shuangmuyingzi/dateFormat/issues"
},
"homepage": "https://github.com/shuangmuyingzi/dateFormat#readme"
}
Is this ok? (yes)
然后会在该目录下多了个package.json文件
添加简单的日期转换格式插件
每次后台数据接口返回的基本是时间戳,往往需要转换成常用的日期格式。那我就以一个简单的日期转换格式小插件为例。把下面代码放到package.json文件同级目录里。
date.js
(function(global) {
var datechange = (function() {
return function (date) {
date = date || new Date;
if(!(date instanceof Date)) {
date = new Date(date);
}
if (isNaN(date)) {
throw TypeError('Invalid date');
}
let re = date.getFullYear() + '.' + (date.getMonth()+1) + '.' + date.getDate();
return re
}
})()
if (typeof define === 'function' && define.amd) {
define(function () {
return datechange;
});
} else if (typeof exports === 'object') {
module.exports = datechange;
} else {
global.datechange = datechange;
}
})(this);
4.发布
npm publish
记得在推之前先登录npm要不然会报错。如果是再次推送同一个项目记得修改版本号。
使用
npm install --save-dev datechange
var datechange = require('datechange');
var now = new Date();
var timeStamp = datechange(now);
OR
<script type="text/javascript" src='date.js'></script>
<script type="text/javascript">
var now = new Date();
var timeStamp = datechange(1511350834583);
alert(timeStamp)
</script>先安装后使用,包的名称为package.json里的name属性。
具体代码看github:
https://github.com/shuangmuyingzi/dateFormat
Vue组件如何上传到NPM
方式一
用webpack把项目打包成JS文件,然后在package.json的 main导出该JS文件。
创建
-
vue-cli创建vue简单项目
vue init webpack-simple load-ling-zi -
修改package.json
-
修改
"private": falsenpm默认创建的项目是私有的,如果要发布至npm必须将其公开
-
添加
"main": "dist/build.js"通过
import loading from 'load-ling-zi'引用该组件时,项目会自动找到node_modules/load-ling-zi/dist/build.js
-
-
在src加入组件代码App.vue, 并创建我们的导出文件index.js。
在index.js中添加:import load from './App.vue' export default load //global 情况下 自动安装 if (typeof window !== 'undefined' && window.Vue) { window.Vue.component('load', load); } -
因为最后我们是打包成一个js文件,所以需要修改一下配置文件
webpack.config.js因为不是所有使用你组件的人都是通过npm按住和impor的很多人是通过
<script>直接引入的,我们要将libraryTarget改为umd,以及修改入口文件与设置导出文件目录以及名称。entry: './src/index.js', output: { path: path.resolve(__dirname, './dist'), publicPath: '/dist/', filename: 'build.js', library: 'load', libraryTarget: 'umd', umdNamedDefine: true }, -
最后需要把
.gitignore文件里面的/dist删除掉要不然上传时会忽略掉dist打包的文件。具体代码已放到github:
https://github.com/shuangmuyingzi/loadingModule/tree/master/load/load-ling-zi
发布
npm publish,具体参考上面步骤。
应用
- Installation
# install dependencies
npm install load-ling-zi -D- Usage
<loading v-if="loading.isShow">
<span>{{ loading.text }}</span>
</loading>
<script>
import loading from 'load-ling-zi'
export default {
components: {
loading:loading
},
data () {
return {
loading:{
isShow:true,
text:"加载中"
},
}
}
}
</script>
方式二
在main里直接导出Vue组件(.vue文件)
具体代码看这里:
https://github.com/shuangmuyingzi/loadingModule/tree/master/loading
写在最后
关于vue组件、插件的实现方式估计还有很多的办法,本文权当抛砖引玉,水平有限,举的例子也是比较简单,一个好的组件也要考虑更多的可配置性以及通用性,数据的可配置,结构的可配置,样式的可配置等等,es里面模块化的写法也是很多,还有一些直接在<script>引入,所以要考虑如何导出代码能够满足更多场景的使用。
作用域闭包
最近在看你不知道的javascript上卷,做下总结。
闭包产生
当函数可以记住并访问所在的词法作用域时,就产生了闭包,即使函数是在当前词法作用域之外执行。
function foo() { var a = 2;
function bar() { console.log( a );
}
return bar; }
var baz = foo();
baz(); // 2 —— 朋友,这就是闭包的效果。
函数 bar() 的词法作用域能够访问 foo() 的内部作用域。然后我们将 bar() 函数本身当作 一个值类型进行传递。在这个例子中,我们将 bar 所引用的函数对象本身当作返回值。
在 foo() 执行后,其返回值(也就是内部的 bar() 函数)赋值给变量 baz 并调用 baz(),实 际上只是通过不同的标识符引用调用了内部的函数 bar()。
bar() 显然可以被正常执行。但是在这个例子中,它在自己定义的词法作用域以外的地方 执行。
在 foo() 执行后,通常会期待 foo() 的整个内部作用域都被销毁,因为我们知道引擎有垃 圾回收器用来释放不再使用的内存空间。由于看上去 foo() 的内容不会再被使用,所以很 自然地会考虑对其进行回收。
而闭包的“神奇”之处正是可以阻止这件事情的发生。事实上内部作用域依然存在,因此 没有被回收。谁在使用这个内部作用域?原来是 bar() 本身在使用。
拜 bar() 所声明的位置所赐,它拥有涵盖 foo() 内部作用域的闭包,使得该作用域能够一 直存活,以供 bar() 在之后任何时间进行引用。
bar() 依然持有对该作用域的引用,而这个引用就叫作闭包。
function foo() { var a = 2;
function baz() { console.log( a ); // 2
}
bar( baz ); }
function bar(fn) {
fn(); // 妈妈快看呀,这就是闭包!
}
把内部函数 baz 传递给 bar,当调用这个内部函数时(现在叫作 fn),它涵盖的 foo() 内部
作用域的闭包就可以观察到了,因为它能够访问 a。 传递函数当然也可以是间接的。
var fn;
function foo() {
var a = 2;
function baz() { console.log( a );
}
fn = baz; // 将 baz 分配给全局变量 }
function bar() {
fn(); // 妈妈快看呀,这就是闭包!
}
foo();
bar(); // 2
无论通过何种手段将内部函数传递到所在的词法作用域以外,它都会持有对原始定义作用 域的引用,无论在何处执行这个函数都会使用闭包。
闭包日常
function wait(message) {
setTimeout( function timer() {
console.log( message );
}, 1000 ); }
wait( "Hello, closure!" );
将一个内部函数(名为 timer)传递给 setTimeout(..)。timer 具有涵盖 wait(..) 作用域
的闭包,因此还保有对变量 message 的引用。
wait(..) 执行 1000 毫秒后,它的内部作用域并不会消失,timer 函数依然保有 wait(..)
作用域的闭包。
深入到引擎的内部原理中,内置的工具函数 setTimeout(..) 持有对一个参数的引用,这个 参数也许叫作 fn 或者 func,或者其他类似的名字。引擎会调用这个函数,在例子中就是 内部的 timer 函数,而词法作用域在这个过程中保持完整。
这就是闭包。
或者,如果你很熟悉 jQuery(或者其他能说明这个问题的 JavaScript 框架),可以思考下面 的代码:
function setupBot(name, selector) {
$( selector ).click( function activator() {
console.log( "Activating: " + name );
} );
}
setupBot( "Closure Bot 1", "#bot_1" );
setupBot( "Closure Bot 2", "#bot_2" );
闭包经典循环问题
for (var i=1; i<=5; i++) { (function() {
setTimeout( function timer() { console.log( i );
}, i*1000 );
})();
}
这样子能打出1、2、3、4、5吗
这样不行。但是为什么呢?我们现在显然拥有更多的词法作用域了。的确 每个延迟函数都会将 IIFE 在每次迭代中创建的作用域封闭起来。
如果作用域是空的,那么仅仅将它们进行封闭是不够的。仔细看一下,我们的 IIFE 只是一 个什么都没有的空作用域。它需要包含一点实质内容才能为我们所用。
它需要有自己的变量,用来在每个迭代中储存 i 的值:
for (var i=1; i<=5; i++) { (function() {
var j = i;
setTimeout( function timer() {
console.log( j );
}, j*1000 );
})(); }
行了!它能正常工作了!。
可以对这段代码进行一些改进:
for (var i=1; i<=5; i++) { (function(j) {
setTimeout( function timer() { console.log( j );
}, j*1000 );
})( i );
}
块作用域
我们使用 IIFE 在每次迭代时都创建一个新的作用 域。换句话说,每次迭代我们都需要一个块作用域。
本质上这是将一个块转换成一个可以被关闭的作用域。
for (var i=1; i<=5; i++) {
let j = i; // 是的,闭包的块作用域! setTimeout( function timer() {
console.log( j );
}, j*1000 );
}
优化:
for (let i=1; i<=5; i++) { setTimeout( function timer() {
console.log( i );
}, i*1000 );
}
模块
wepy微信小程序问题记录
父组件调用子组件的方法
父:this.$broadcast('destroyAudio');
子:events = {
destroyAudio() {
}
};
小程序的下拉加载
onReachBottom(){}
表单的双向绑定
<input bindinput="handleInput" />
handleInput (e) {
console.log(1)
this.obj[e.target.dataset.key] = e.detail.value;
};
handleInput需要写在methods里面才可以,要不然可能watch不到改变有点奇怪。
使用 Redux进行状态管理
全局数据管理问题:比如在 A 页面用到了全局数据 globalData,由 A 页面跳转到 B 页面,B 页面也用到了 globalData;在 B 页面改变 globalData,返回到 A 页面,发现 globalData 没实时更新到。
通过使用 wepy-redux ,来管理和分发全局数据。
import { setStore, getStore } from 'wepy-redux';
import configStore from './store';
import { asyncIsOn, asyncIsIos, asyncUserObj } from './store/actions/counter'
const store = configStore();
setStore(store);
wepy.$store = store;
the same as
wepy.$store.dispatch(asyncUserObj());
参考:https://juejin.im/post/5b067f6ff265da0de02f3887
fancy-mini无限层级路由解决方案
路由问题,目前小程序最多支持打开10个page。
npm install --save fancy-mini
新建空白页面 pages/curtain/curtain
app.wpy
import './appPlugin'
appPlugin.js
import {registerToThis, registerPageHook, pageRestoreHandler, NavRefine} from 'fancy-mini/lib/wepyKit';
import Navigator from 'fancy-mini/lib/navigate/Navigator';
import {customWxPromisify} from 'fancy-mini/lib/wxPromise';
//无限层级路由方案
Navigator.config({
enableCurtain: true, //是否开启空白中转策略
curtainPage: '/pages/curtain/curtain', //空白中转页
enableTaintedRestore: true, //是否开启实例覆盖自动恢复策略
/**
-
自定义页面数据恢复函数,用于
-
- wepy实例覆盖问题,存在两级同路由页面时,前者数据会被后者覆盖,返回时需予以恢复
-
- 层级过深时,新开页面会替换前一页面,导致前一页面数据丢失,返回时需予以恢复
*/
pageRestoreHandler: pageRestoreHandler,
MAX_LEVEL: 10, //最多同时打开的页面层数
oriNavOverrides: NavRefine, //自定义覆盖部分/全部底层跳转api,如:此处底层使用wepy定义的路由模块,便于使用wepy提供的prefetch等功能
});
registerPageHook('onUnload', Navigator.onPageUnload);
//wx接口Promise化
let {wxPromise, wxResolve} = (function () {
let overrides = { //覆盖wx的部分接口
navigateTo: Navigator.navigateTo,
redirectTo: Navigator.redirectTo,
navigateBack: Navigator.navigateBack,
reLaunch: Navigator.reLaunch,
switchTab: Navigator.switchTab,
};
return {
wxPromise: customWxPromisify({overrides, dealFail: false}),
wxResolve: customWxPromisify({overrides, dealFail: true}),
}
}());
registerToThis("$wxPromise", wxPromise);
registerToThis("$wxResolve", wxResolve);
export { //导出部分api,方便lib文件使用
wxPromise,
wxResolve,
}
使用
所有页面不直接调用wx.navigateTo、wx.redirectTo、wx.navigateBack、wx.switchTab、wx.reLaunch,或wepy对应接口,统一改用this.$wxPromise.navigateTo等对应接口
wx.navigateTo({ url: '/pages/index/index'});//错误,无法确保路由过程全部由自定义模块接管
wepy.navigateTo({ url: '/pages/index/index'});//错误,无法确保路由过程全部由自定义模块接管
this.$wxPromise.navigateTo({ url: '/pages/index/index'}); //正确
所有页面跳转由this.$wxPromise相应接口触发,而不使用元素
所有页面若有自定义onUnload函数,需在函数中执行父类相应钩子: super.onUnload && super.onUnload()
export default class extends wepy.page {
//正确,页面中无onUnload函数,会直接执行父类上的统一钩子
}
export default class extends wepy.page {
onUnload(){//错误,页面中自定义onUnload函数覆盖了统一钩子,影响路由模块监听返回行为
}
}
export default class extends wepy.page {
onUnload(){//正确,页面自定义onUnload函数中调用了统一钩子
super.onUnload && super.onUnload()
}
}
this.$wxPromise.navigateTo({
url:``
})
组件传值坑
props传递过去的值,html代码界面中显示正确,但在 onLoad 生命周期中打印 undefined,方法中使用也是 undefined。
在父组件利用 $broadcast,在获取到数据后对数据进行广播,然后在子组件中获取到数据。
// 向子组件以广播形式传递answer_uid
this.$broadcast('transferAnswerId', this.answer_uid)
events = {
async transferAnswerId(answerId) {
this.tagsList = await api.teacherCommentTags({
uid: answerId,
});
this.$apply();
}
};
<AudioControl wx:if="{{item.media.media_src}}"
:item.sync="item"
:isLeft.sync="true"
:chatType.sync="2"
></AudioControl>
不能是item.下面的属性值传,要整个对象一起传过去
文档中的话:
WePY 1.x 版本中,组件使用的是静态编译组件,即组件是在编译阶段编译进页面的,每个组件都是唯一的一个实例,目前只提供简单的 repeat 支持。不支持在 repeat 的组件中去使用 props, computed, watch 等等特性。
将需要变量渲染的一整组数据直接通过 props 传给子组件,在子组件中使用 repeat 循环渲染。改变数据用子组件通过$emit改变数据源,更新数据。
methods里面的方法调用的方法要跟methods同级
video使用
随着网页元素的多元化,多形态的发展,音频跟视频自然是用得越来越多了,本文记录下H5的audio以及video两者的属性跟方法的使用。
video标签专门用来播放网络上的视频或电影,audio标签则专门用来播放网络上的音频数据。使用这两个标签,就不再需要使用其他的任何插件了,只要使用支持 HTML5 的浏览器就可以了。
video属性、方法规范
video的控件样式控制
这里所说的修改video标签中自带按钮的默认样式,指的是用css就可以控制视频播放按钮的大小等
如何查看 video 的内部构造:
chrome 下,开发者工具 setting Preferences Elements 勾选 "Show user agent shadow DOM"

video的属性
<video
id="video"
src="video.mp4"
controls = "true"
poster="images.jpg" /*视频封面*/
preload="auto"
webkit-playsinline="true" /*这个属性是ios 10中设置可以让视频在小窗内播放,也就是不是全屏播放*/
playsinline="true" /*IOS微信浏览器支持小窗内播放*/
x-webkit-airplay="allow"
x5-video-player-type="h5" /*启用H5播放器,是wechat安卓版特性*/
x5-video-player-fullscreen="true" /*全屏设置,设置为 true 是防止横屏*/
x5-video-orientation="portraint" //播放器支付的方向, landscape横屏,portraint竖屏,默认值为竖屏
style="object-fit:fill">
</video>
-
src: 视频的地址
-
controls: 加上这个属性,Gecko 会提供用户控制,允许用户控制视频的播放,包括音量,跨帧,暂停/恢复播放。
-
poster: 属性规定视频下载时显示的图像,或者在用户点击播放按钮前显示的图像。如果未设置该属性,则使用视频的第一帧来代替。
-
preload: 属性规定在页面加载后载入视频。
-
webkit-playsinline和playsinline: 视频播放时局域播放,不脱离文档流 。但是这个属性比较特别, 需要嵌入网页的APP比如WeChat中UIwebview 的allowsInlineMediaPlayback = YES webview.allowsInlineMediaPlayback = YES,才能生效。换句话说,如果APP不设置,你页面中加了这标签也无效,这也就是为什么安卓手机WeChat 播放视频总是全屏,因为APP不支持playsinline,而ISO的WeChat却支持。
这里就要补充下,如果是想做全屏直播或者全屏H5体验的用户,IOS需要设置删除 webkit-playsinline 标签,因为你设置 false 是不支持的 ,安卓则不需要,因为默认全屏。但这时候全屏是有播放控件的,无论你有没有设置control。 做直播的可能用得着播放控件,但是全屏H5是不需要的,那么去除全屏播放时候的控件,需要以下设置:同层播放 -
x-webkit-airplay="allow" : 这个属性应该是使此视频支持ios的AirPlay功能。使用AirPlay可以直接从使用iOS的设备上的不同位置播放视频、音乐还有照片文件,也就是说通过AirPlay功能可以实现影音文件的无线播放,当然前提是播放的终端设备也要支持相应的功能
-
x5-video-player-type: 启用同层H5播放器,就是在视频全屏的时候,div可以呈现在视频层上,也是WeChat安卓版特有的属性。同层播放别名也叫做沉浸式播放,播放的时候看似全屏,但是已经除去了control和微信的导航栏,只留下"X"和"<"两键。目前的同层播放器只在Android(包括微信)上生效,暂时不支持iOS。至于为什么同层播放只对安卓开放,是因为安卓不能像ISO一样局域播放,默认的全屏会使得一些界面操作被阻拦,如果是全屏H5还好,但是做直播的话,诸如弹幕那样的功能就无法实现了,所以这时候同层播放的概念就解决了这个问题。不过在测试的过程中发现,不同版本的IOS和安卓效果略有不同
-
x5-video-orientation: 声明播放器支持的方向,可选值landscape 横屏, portraint竖屏。默认值portraint。无论是直播还是全屏H5一般都是竖屏播放,但是这个属性需要x5-video-player-type开启H5模式
-
x5-video-player-fullscreen:全屏设置。它又两个属性值,ture和false,true支持全屏播放,false不支持全屏播放。其实,IOS 微信浏览器是Chrome的内核,相关的属性都支持,也是为什么X5同层播放不支持的原因。安卓微信浏览器是X5内核,一些属性标签比如playsinline就不支持,所以始终全屏。
video 的事件
video 支持的事件很多,但在有些事件在不同的系统上跟预想的表现不一致,在尝试比较之后,使用 timeupdate 和 ended 这两个事件基本可以满足需求
video.addEventListener('timeupdate', function (e) {
console.log(video.currentTime) // 当前播放的进度
})
video.addEventListener('ended', function (e) {
// 播放结束时触发
})
应用
知道了video的一些属性方法之后,我们来看看具体的一些使用场景。
1、统一为固定在某一个区域播放,非全屏
<video class="view-cover"
controls
id="my-video"
x5-video-player-type="h5"
webkit-playsinline
playsinline
@ended="videoPlayEnd"
@touchmove.stop.prevent=""
:poster="posterImage"
>
</video>
但是IOS在QQ浏览器会吊起整个播放器,凌驾于任何弹框之上,还可以引用一个库iphone-inline-video(具体用法很简单看它github,这里不介绍了,只需加js一句话,css加点),github地址https://github.com/bfred-it/iphone-inline-video 加上playsinline webkit-playsinline这两个属性和这个库基本可以保证ios端没有问题了(不过亲测,只加webkit-playsinline playsinline这两个属性不引入库好像也是ok的,至今没有在ios端微信没有出现问题,如果你要兼容uc或者qq的浏览器建议带上这个库),具体还没试过。
2、点击某个区域全屏播放
<video
width="100%"
ref="video"
controls
x5-video-player-type="h5"
x5-video-player-fullscreen='true'
:src="answer.video_url"
@play="videoPlay"
@pause="videoPaused"
preload="auto">
</video>
Typescript学习
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.