An Open Source search engine + web crawler. Can be used to cache specific websites or the entire web. This is part of a project for caching specific sites of the web on to a raspberry Pi and make information freely available in remote areas where internet access is difficult to provide.
This is a work in progress and at it's very initial stages, not fit for production use. For single websites however this search engine works very well.
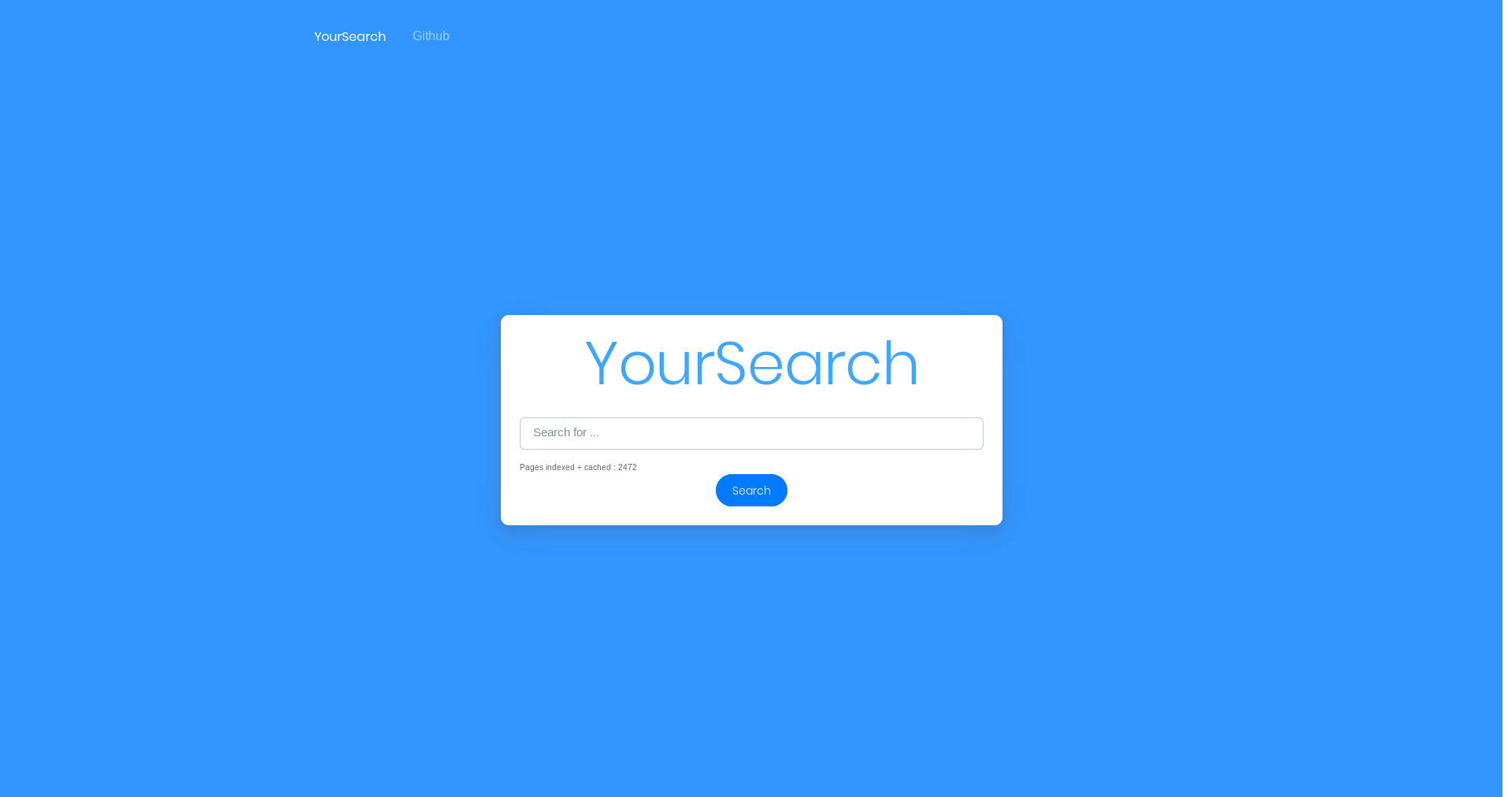
Results
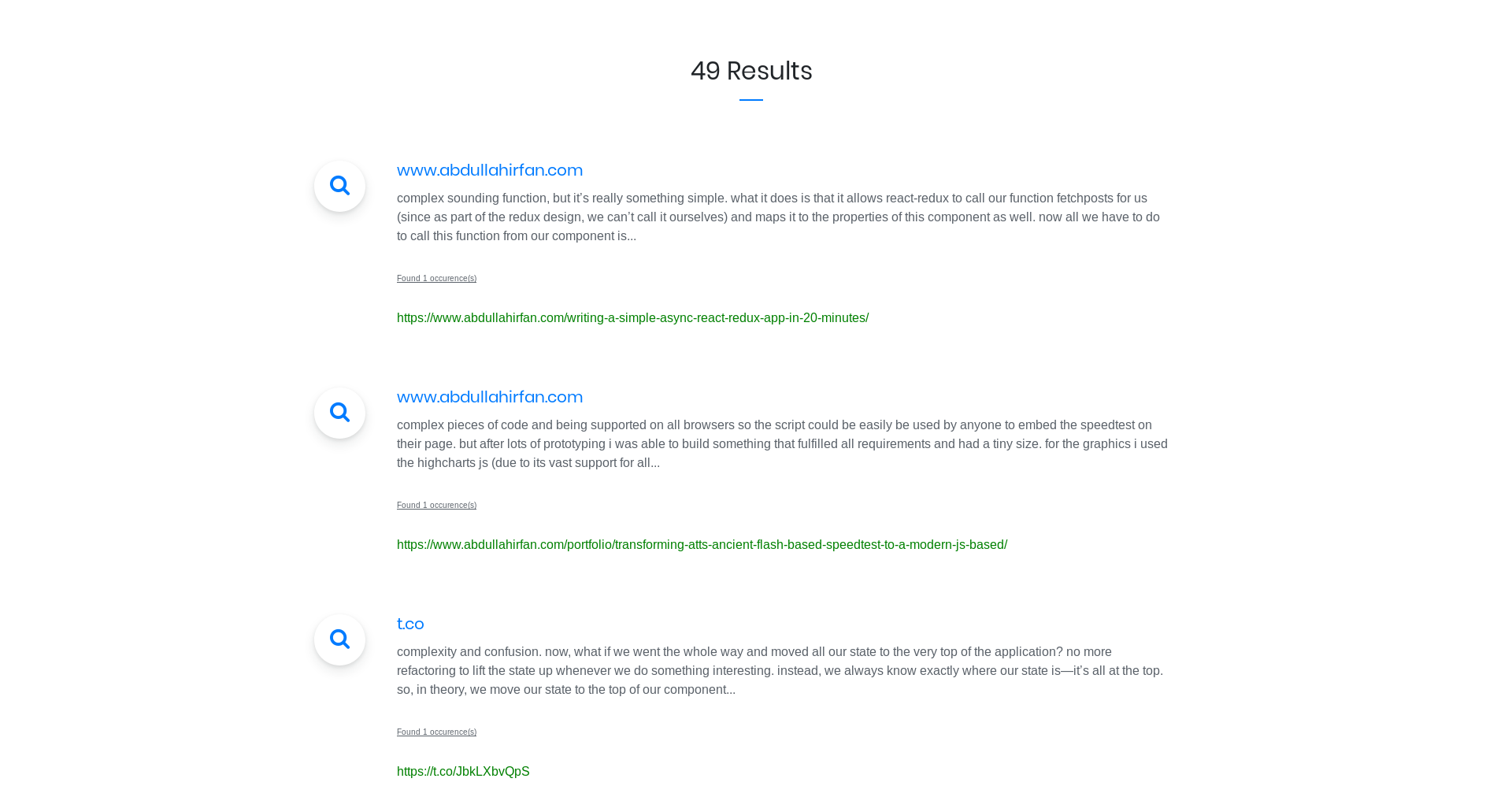
The search engine has 2 components ; a crawler and the server. The crawler crawls the web and sends crawled page contents back to the server. The server stores these contents in a database. Whenever a user wants to search anything, the server performs a database search operation over the stored contents.
- Indexing is slow.
- Change database backend from MySQL to something fast; maybe Mongodb.
- Secure communication between server and crawler
Server : PHP7 + MySQL.
Client : Runs everywhere
-
Build the main.go file in the crawler folder:
go build main.go -
Setup a LEMP server
-
Setup the webserver online, by copying contents from the webserver folder.
-
Import db.sql into your MySQL database.
-
Go to application/config/database.php to change database credentials to your db server.
-
Test to see if its working by visitng your-server-ip/index.php/Api
-
Change links in the
config.jsonfile to point to your server, change the starting url too. -
Run the crawler :
./main ./. The first argument to the crawler is the path to the directory which contains the config.json file. (PS: You can run multiple crawlers at once) -
Visit your-server-ip to view the search page and see progress of the number of pages indexed.
