We embarked on an exciting project to build a robust data pipeline that would consume data from a trusted source - https://www.kaggle.com/datasets/rounakbanik/the-movies-dataset?datasetId=3405.
In this dataset we have movie rating given by the users with the dates. I wanted to find out the distribution of average ratings given by user and then in the second step I wanted to find the distribution of average ratings for each month in each year that is wanted to explore the relation between month, year and ratings. Below is the link for report, it might stop working if my GCP free trial expires then for that reference I have attached the screenshot and video for the same.
https://lookerstudio.google.com/reporting/238f176c-a729-47ce-94aa-830857ae5ec7/page/0aVND
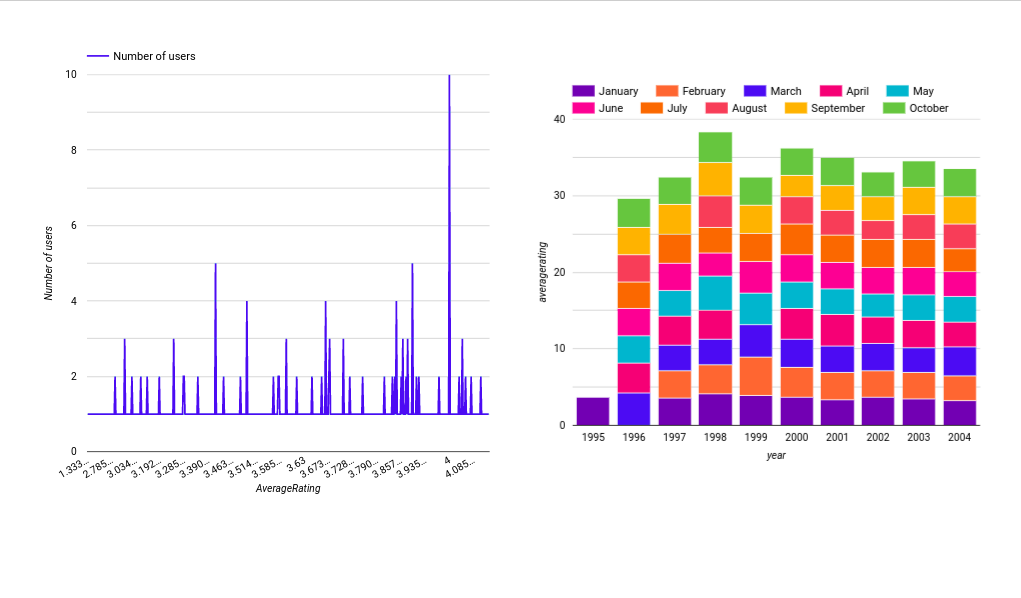 First graph represents the distribution of average ratings accoding to number of users and second graph represent the rating distribution with each month for each year. We can clearly see that average rating are roughly same for each month in each year.
First graph represents the distribution of average ratings accoding to number of users and second graph represent the rating distribution with each month for each year. We can clearly see that average rating are roughly same for each month in each year.
Let's get into technical aspects of this project.
To kick off the process, we fetched the data from the provided URL and downloaded it onto an GCP virtual machine. From there, we uploaded the data to GCS, where we leveraged external tables to create new tables in BigQuery.
Thanks to the power of Prefect, we seamlessly orchestrated the entire process, while Terraform played a pivotal role in setting up the necessary infrastructure. Once we had the data securely stored, we applied transformation on the BigQuery table using DataProc in GCP. The outcome of this process was a brand new set of tables, which we used for dashboarding purposes.
In a nutshell, we were able to build a top-notch data pipeline that streamlined the entire data collection, transformation, and visualization process. Setting up virtual machine and other infra.
+---------------+ +---------------+
| | | |
| Data | | GCP |
| Provider | | |
| | | (GCS, |
+-------+-------+ | BigQuery, |
| | DataProc) |
| | |
| +-------+-------+
| |
| |
+--------+ +-----+-----+ +--------+--------+
| | | | | |
|Virtual +--+ GCS +-------------+ BigQuery |
| Machine| | | | |
+--------+ +-----+-----+ +-----------------+
| |
| |
| |
| |
+------+-------+ +------+-------+
| | | |
| Prefect | | DataProc |
| | | |
+--------------+ +--------------+
| |
| |
+---------------+ |
| | |
| Terraform +---------------+
| |
+---------------+
Following were the requirements for the project.
- Problem description 0 points: Problem is not described 1 point: Problem is described but shortly or not clearly 2 points: Problem is well described and it's clear what the problem the project solves
- Cloud 0 points: Cloud is not used, things run only locally 2 points: The project is developed in the cloud 4 points: The project is developed in the cloud and IaC tools are used(done)
- Data ingestion (choose either batch or stream) Batch / Workflow orchestration 0 points: No workflow orchestration 2 points: Partial workflow orchestration: some steps are orchestrated, some run manually 4 points: End-to-end pipeline: multiple steps in the DAG, uploading data to data lake(done)
- Data warehouse 0 points: No DWH is used 2 points: Tables are created in DWH, but not optimized 4 points: Tables are partitioned and clustered in a way that makes sense for the upstream queries (with explanation)(done)
- Transformations (dbt, spark, etc) 0 points: No tranformations 2 points: Simple SQL transformation (no dbt or similar tools) 4 points: Tranformations are defined with dbt, Spark or similar technologies(done)
- Dashboard 0 points: No dashboard 2 points: A dashboard with 1 tile 4 points: A dashboard with 2 tiles(done)
- Reproducibility 0 points: No instructions how to run code at all 2 points: Some instructions are there, but they are not complete 4 points: Instructions are clear, it's easy to run the code, and the code works(done)
There were certain requirements for this project. I tried to fulfill all of them, even if something is missing please let me know.
Prerequisites
The following requirements are needed to reproduce the project:
Go to GCP console and create a project. After you create the project, you will need to create a Service Account with the following roles:
BigQuery Admin
Storage Admin
Storage Object Admin
Viewer
Download the Service Account credentials file, rename it to google_credentials.json and store it in your home folder, in $HOME/.google/credentials/
IMPORTANT: if you're using a VM as recommended, you will have to upload this credentials file to the VM.
You will also need to activate the following APIs:
https://console.cloud.google.com/apis/library/iam.googleapis.com
https://console.cloud.google.com/apis/library/iamcredentials.googleapis.com
From your project's dashboard, go to Cloud Compute > VM instance
Create a new instance:
Any name of your choosing
Pick your favourite region.
IMPORTANT: make sure that you use the same region for all of your Google Cloud components.
Pick a E2 series instance. A e2-standard-4 instance is recommended (4 vCPUs, 16GB RAM)
Change the boot disk to Ubuntu. The Ubuntu 20.04 LTS version is recommended. Also pick at least 30GB of storage.
Leave all other settings on their default value and click on Create.
To SSH to your VM, generate SSH key on your local computer. Mine is Ubuntu therefore I used
ssh-keygen -t rsa -f ~/.ssh/de-zoomkey -C shivam -b 2048
Your ~/.ssh folder will now have two files namely de-zoomkey and de-zoomkey.pub for private and public part respectively. Add thebucket-deproject public key to your project metadata in
https://console.cloud.google.com/compute/metadata
Follow below command to ssh to your instance with below command.
ssh -i ~/.ssh/de-zoomkey [email protected]
Explain about using VS code
Upload the credentials.json file downloaded in step 1. to instance and update bashrc as follows.
open bashrc like nano ~/.bashrc and add the line
export GOOGLE_APPLICATION_CREDENTIALS="<path/to/authkeys>.json"
Exit nano with Ctrl+X. Follow the on-screen instructions to save the file and exit.
Log out of your current terminal session and log back in, or run source ~/.bashrc to activate the environment variable.
Install Gcloud from /https://cloud.google.com/sdk/docs/install for your version .
Download Gcloud SDK from this link and install it according to the instructions for your OS.
Run gcloud init from a terminal and follow the instructions.
Make sure that your project is selected with the command gcloud config list
1. Run sudo apt install docker.io to install it.
2 .Change your settings so that you can run Docker without sudo:
2.a. Run sudo groupadd docker
2.b. Run sudo gpasswd -a $USER docker
2.c. Log out of your SSH session and log back in.
2.d. Run sudo service docker restart
2.e. Test that Docker can run successfully with docker run hello-world
3. Installing **Terraform**
Use this link, https://developer.hashicorp.com/terraform/downloads to install terraform for your setup. I have anyways written the commands below.
3.1. wget -O- https://apt.releases.hashicorp.com/gpg | gpg --dearmor | sudo tee /usr/share/keyrings/hashicorp-archive-keyring.gpg
3.2. echo "deb [signed-by=/usr/share/keyrings/hashicorp-archive-keyring.gpg] https://apt.releases.hashicorp.com $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/hashicorp.list
3.3.sudo apt update && sudo apt install terraform
Now, terraform is installed.
Go to Terraform folder, execute below steps to initialise GCP bucket and BigQuery dataset.
4. Terraform command executions
4.1 Initialize Terraform:
terraform init
4.2 Plan the infrastructure and make sure that you're creating a bucket in Cloud Storage as well as a dataset in BigQuery
terraform plan
4.3 If the plan details are as expected, apply the changes.
terraform apply
Now, you should have a bucket named bucket-deproject and bigquery dataset namely dataset_movie
All the code for data ingestion is inside the file full_prefect_flow.py inside prefect folder. It works by fetching the data from url. We download it locally, transform certain columns such as converting the time to datetime object. We then upload saved data from local to GCS. Then we create the external table in BigQuery. All this has been done inside the flow namely, "cloud_storage_flow".
We also need to create blocks for accessing GCS services via Prefect, code for the same has been written inside make_block.py file inside the Prefect folder. All of this runs via docker.
Running everything via docker
1. Go to main project folder and run
docker build -t project_image .
2. Run container
docker run -p 4200:4200 project_image
Below is an image for the prefect flow.
 This will create the table named movies_data inside BigQuery.We will use this in next step.
This will create the table named movies_data inside BigQuery.We will use this in next step.
Now, we created an external table in Bigquery. We will need to partition it based upon date as it will help us reducing the cost of time based queries.
'''
CREATE OR REPLACE TABLE projectmovies-381510.dataset_movie.movies_data_par
PARTITION BY
DATE(datetime_column) AS
SELECT *,
PARSE_DATETIME('%Y-%m-%d %H:%M:%S', timestamp) AS datetime_column
FROM
projectmovies-381510.dataset_movie.movies_data;
'''
This creates a new column namely datetime_columns and we partition according to that.
We now have our partitioned table like

We need to do some transformation on this table. First transformation we need is to get the the average rating per user and second transformation we need to carry out is average rating for each month for each year in the dataset. These transformation were carried out using Spark. I specifically use GCP's DataProc for that. We will use GCP's DataProc cluster for executing the transformation and we will save the transformed tables back to BigQuery.
This tutorial can be helpful to learn about DataProc
8.1 Run the following command to set your project id:
gcloud config set project <project_id>
8.2 Set the region of your project by choosing one from the list here. An example might be us-central1.
gcloud config set dataproc/region <region>
8.3 Pick a name for your Dataproc cluster and create an environment variable for it, my cluster name was cluster-project.
CLUSTER_NAME=<cluster_name>
8.4 Creating a Dataproc Cluster by executing the following command:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--worker-machine-type n1-standard-2 \
--num-workers 2 \
--image-version 1.5-debian \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--optional-components=ANACONDA \
--enable-component-gateway
8.5 Change the directory to spark inside the folder and execute the below command.
gcloud dataproc jobs submit pyspark --cluster cluster-project --jars gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar --driver-log-levels root=FATAL getting_data_from_redshift.py
It will take some good amount of time to carry out these jobs. After this you will get two tables namely, year_month_avg_rating and avg_rating. We then used lookerstudio to display the report from these Bigquery tables.
And with this the project is finally over. All thanks to this amazing course https://github.com/DataTalksClub/data-engineering-zoomcamp
