透過自然語處理(Natural Language Processing, NLP)方式,分析及拆解使用者提出的問題,由SEC QA資料蒐尋出最近似的答案
- 文本朗讀(Text to speech)/ 語音合成(Speech synthesis)
- 語音識別(Speech recognition)
自動分詞(word segmentation)- 詞性標註(Part-of-speech tagging)
- 句法分析(Parsing)
- 自然語言生成(Natural language generation)
文本分類(Text categorization)信息檢索(Information retrieval)- 信息抽取(Information extraction)
- 文字校對(Text-proofing)
- 問答系統(Question answering)
- 機器翻譯(Machine translation)
- 自動摘要(Automatic summarization)
- 文字蘊涵(Textual entailment)
- 基於統計原理,如 TFIDF、LSI、LDA...,以詞袋 (Bag Of Word, BOW)形式表現
- 基於深度學習,如word2vec、doc2vec, 以詞向量 (Word Embedding)形式表現
舉例
句子1: 我喜歡AI,不喜歡BI
句子2: 我不喜歡AI,也不喜歡BI
第一步 分詞 (jieba)
句子1: 我 / 喜歡 / AI / 不 / 喜歡 / BI
句子2: 我 / 不 / 喜歡 / AI / 也 / 不 / 喜歡 / BI
第二步 列出所有詞
我,喜歡,不,AI,BI,也
第三步 分別計算TF
| 我 | 喜歡 | 不 | AI | BI | 也 | |
|---|---|---|---|---|---|---|
| 句子1 | 1 | 2 | 1 | 1 | 1 | 0 |
| 句子2 | 1 | 2 | 2 | 1 | 1 | 1 |
句子1: [1, 2, 1, 1, 1, 0], 句子2: [1, 2, 2, 1, 1, 1]
tf - idf 是一種統計方法,此原理為評估一個字詞對於一個檔案集,或一個語料庫中的其中一份檔案的重要程度,這個概念十分重要。
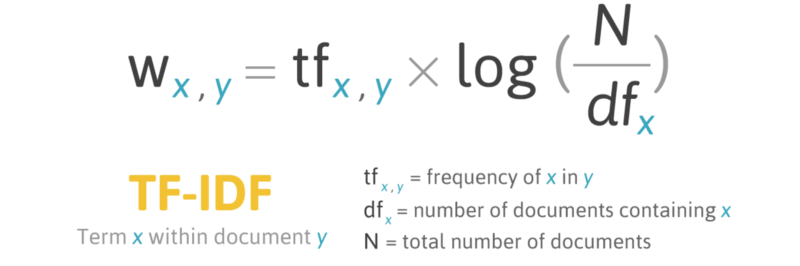
餘絃相似度(cosine similarity)是資訊檢索中常用的相似度計算方式,可用來計算文件之間的相似度, 也可以計算詞彙之間的相似度,更可以計算查詢字串與文件之間的相似度。
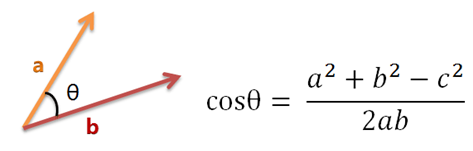
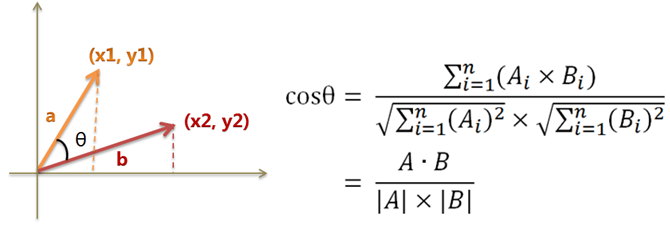
- 資料預處理: 語料庫中所有問題進行中文分詞,去除重複、停用字及低詞頻雜訊
- 所有分詞結果整理成一個集合並計算IDF
- 將每個問題轉換為向量(bow)並計算TFIDF
- 將user提出的問題轉換為向量(bow)並計算TFIDF
- 計算兩者餘弦相似度(越接近1表越相似),回傳最相似的結果
- 資料預處理: 語料庫中所有問題進行中文分詞,去除重複、停用字及低詞頻雜訊
- 分詞結果整理成一個集合並轉換為字典檔 (word -> id)
- 透過字典檔將語料庫轉換為向量格式
- 將語料庫轉換為TFIDF model
- 透過TFIDF model建立LSI Model並指定topic數量
- 根據topics計算建立索引
- 將user提出的問題轉換為向量(bow)並透過建立好的lsi model計算出最相似的答案
是利用 SVD ( Singular Value Decomposition )把文件從高維空間投影到低維空間(topics),在這個空間內進行文本相似性的比較。與詞組之間語意上的關聯相比, LSI 更關注的是詞組之間「隱含」的關聯
-
python 3
-
Modules: gensim / jieba / wordcloud / pandas / matplotlib
pip install -r require_pkg.txt -
Run
Demo.ipynbwith jupyter notebook
docker run -p 8888:8888 shihxuancheng/ai_exercise