

SeaORM is a relational ORM to help you build web services in Rust with the familiarity of dynamic languages.

Please help us with maintaining SeaORM by completing the SeaQL Community Survey 2024!

Integration examples:
- Actix v4 Example
- Axum Example
- GraphQL Example
- jsonrpsee Example
- Loco TODO Example / Loco REST Starter
- Poem Example
- Rocket Example / Rocket OpenAPI Example
- Salvo Example
- Tonic Example
- Seaography Example
-
Async
Relying on SQLx, SeaORM is a new library with async support from day 1.
-
Dynamic
Built upon SeaQuery, SeaORM allows you to build complex dynamic queries.
-
Testable
Use mock connections and/or SQLite to write tests for your application logic.
-
Service Oriented
Quickly build services that join, filter, sort and paginate data in REST, GraphQL and gRPC APIs.
use sea_orm::entity::prelude::*;
#[derive(Clone, Debug, PartialEq, DeriveEntityModel)]
#[sea_orm(table_name = "cake")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub name: String,
}
#[derive(Copy, Clone, Debug, EnumIter, DeriveRelation)]
pub enum Relation {
#[sea_orm(has_many = "super::fruit::Entity")]
Fruit,
}
impl Related<super::fruit::Entity> for Entity {
fn to() -> RelationDef {
Relation::Fruit.def()
}
}// find all models
let cakes: Vec<cake::Model> = Cake::find().all(db).await?;
// find and filter
let chocolate: Vec<cake::Model> = Cake::find()
.filter(cake::Column::Name.contains("chocolate"))
.all(db)
.await?;
// find one model
let cheese: Option<cake::Model> = Cake::find_by_id(1).one(db).await?;
let cheese: cake::Model = cheese.unwrap();
// find related models (lazy)
let fruits: Vec<fruit::Model> = cheese.find_related(Fruit).all(db).await?;
// find related models (eager)
let cake_with_fruits: Vec<(cake::Model, Vec<fruit::Model>)> =
Cake::find().find_with_related(Fruit).all(db).await?;let apple = fruit::ActiveModel {
name: Set("Apple".to_owned()),
..Default::default() // no need to set primary key
};
let pear = fruit::ActiveModel {
name: Set("Pear".to_owned()),
..Default::default()
};
// insert one
let pear = pear.insert(db).await?;
// insert many
Fruit::insert_many([apple, pear]).exec(db).await?;use sea_orm::sea_query::{Expr, Value};
let pear: Option<fruit::Model> = Fruit::find_by_id(1).one(db).await?;
let mut pear: fruit::ActiveModel = pear.unwrap().into();
pear.name = Set("Sweet pear".to_owned());
// update one
let pear: fruit::Model = pear.update(db).await?;
// update many: UPDATE "fruit" SET "cake_id" = NULL WHERE "fruit"."name" LIKE '%Apple%'
Fruit::update_many()
.col_expr(fruit::Column::CakeId, Expr::value(Value::Int(None)))
.filter(fruit::Column::Name.contains("Apple"))
.exec(db)
.await?;let banana = fruit::ActiveModel {
id: NotSet,
name: Set("Banana".to_owned()),
..Default::default()
};
// create, because primary key `id` is `NotSet`
let mut banana = banana.save(db).await?;
banana.name = Set("Banana Mongo".to_owned());
// update, because primary key `id` is `Set`
let banana = banana.save(db).await?;// delete one
let orange: Option<fruit::Model> = Fruit::find_by_id(1).one(db).await?;
let orange: fruit::Model = orange.unwrap();
fruit::Entity::delete(orange.into_active_model())
.exec(db)
.await?;
// or simply
let orange: Option<fruit::Model> = Fruit::find_by_id(1).one(db).await?;
let orange: fruit::Model = orange.unwrap();
orange.delete(db).await?;
// delete many: DELETE FROM "fruit" WHERE "fruit"."name" LIKE 'Orange'
fruit::Entity::delete_many()
.filter(fruit::Column::Name.contains("Orange"))
.exec(db)
.await?;Seaography is a GraphQL framework built on top of SeaORM. Seaography allows you to build GraphQL resolvers quickly. With just a few commands, you can launch a GraphQL server from SeaORM entities!
Starting 0.12, seaography integration is built into sea-orm. While Seaography development is still in an early stage, it is especially useful in prototyping and building internal-use admin panels.
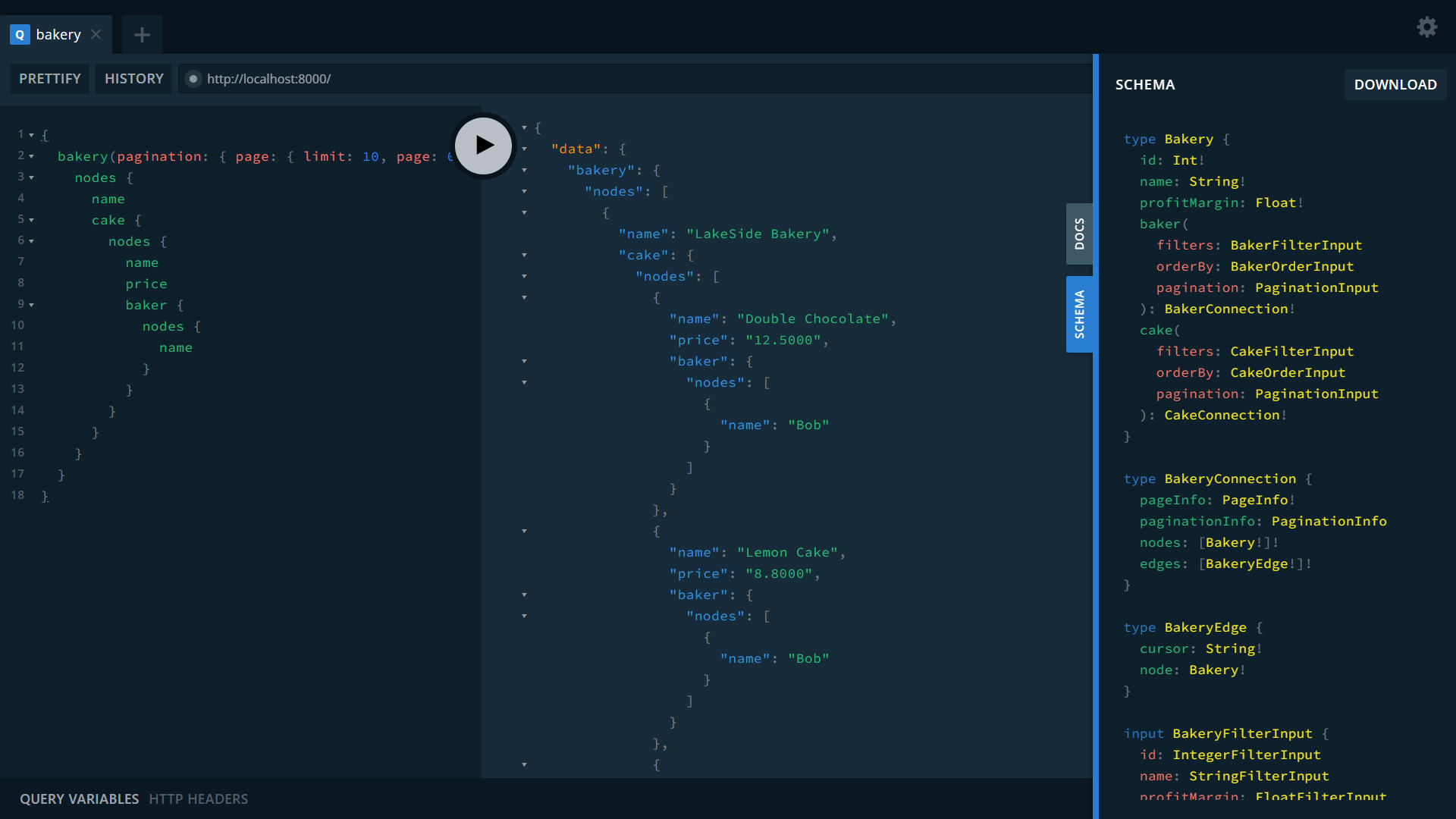
Look at the Seaography Example to learn more.
See Built with SeaORM. Feel free to submit yours!
Licensed under either of
- Apache License, Version 2.0 (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in the work by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.
SeaORM is a community driven project. We welcome you to participate, contribute and together help build Rust's future.
A big shout out to our contributors!

SeaQL.org is an independent open-source organization run by passionate developers. If you enjoy using our libraries, please star and share our repositories. If you feel generous, a small donation via GitHub Sponsor will be greatly appreciated, and goes a long way towards sustaining the organization.
We invite you to participate, contribute and together help build Rust's future.

A friend of Ferris, Terres the hermit crab is the official mascot of SeaORM. His hobby is collecting shells.

































































































































































