Schemathesis: catch crashes, validate specs, and save time
![]()




Documentation: https://schemathesis.readthedocs.io/en/stable/
Chat: https://discord.gg/R9ASRAmHnA
Schemathesis is a tool that automates your API testing to catch crashes and spec violations. Built on top of the widely-used Hypothesis framework for property-based testing, it offers the following advantages:
🕒 Time-Saving
Automatically generates test cases, freeing you from manual test writing.
🔍 Comprehensive
Utilizes fuzzing techniques to probe both common and edge-case scenarios, including those you might overlook.
🛠️ Flexible
Supports OpenAPI, GraphQL, and can work even with partially complete schemas. Only the parts describing data generation or responses are required.
🎛️ Customizable
Customize the framework by writing Python extensions to modify almost any aspect of the testing process.
🔄 Reproducible
Generates code samples to help you quickly replicate and investigate any failing test cases.
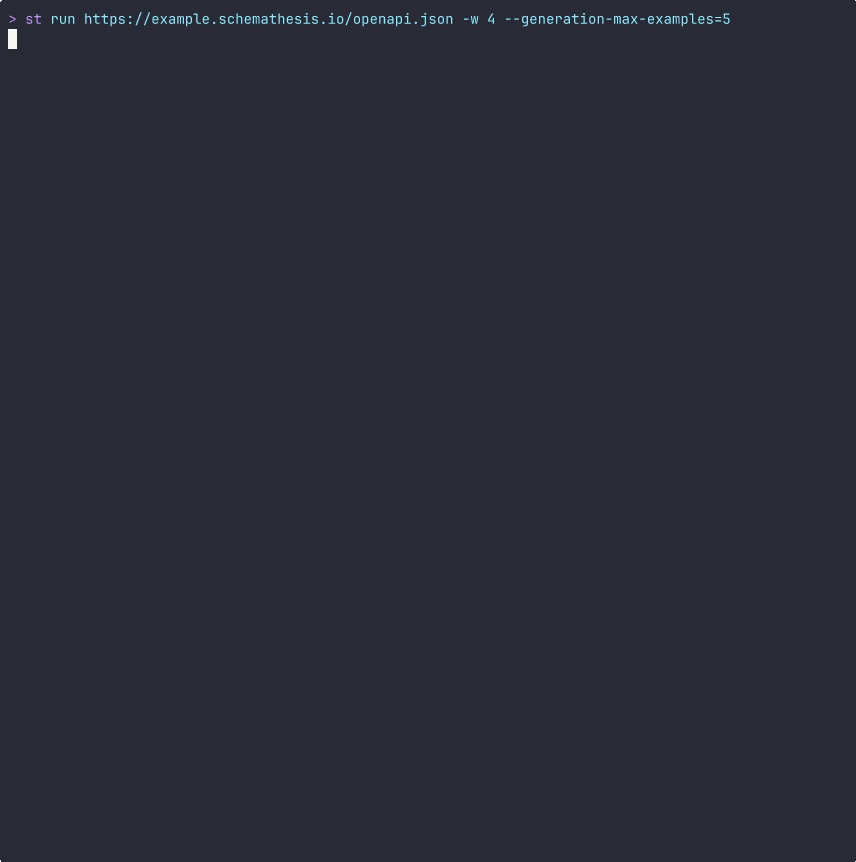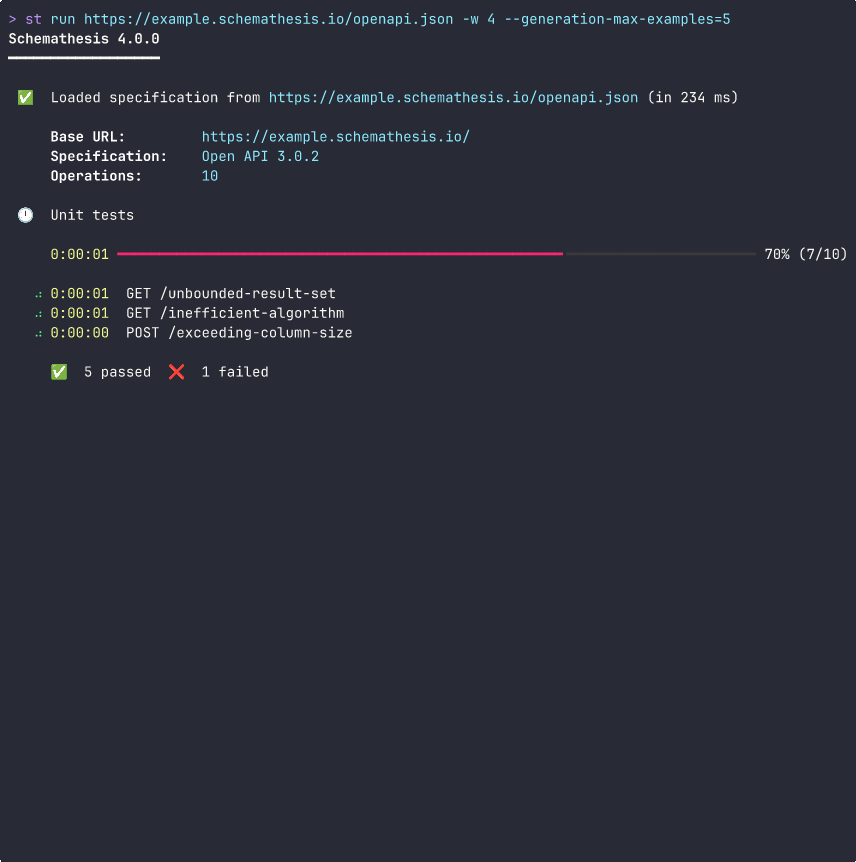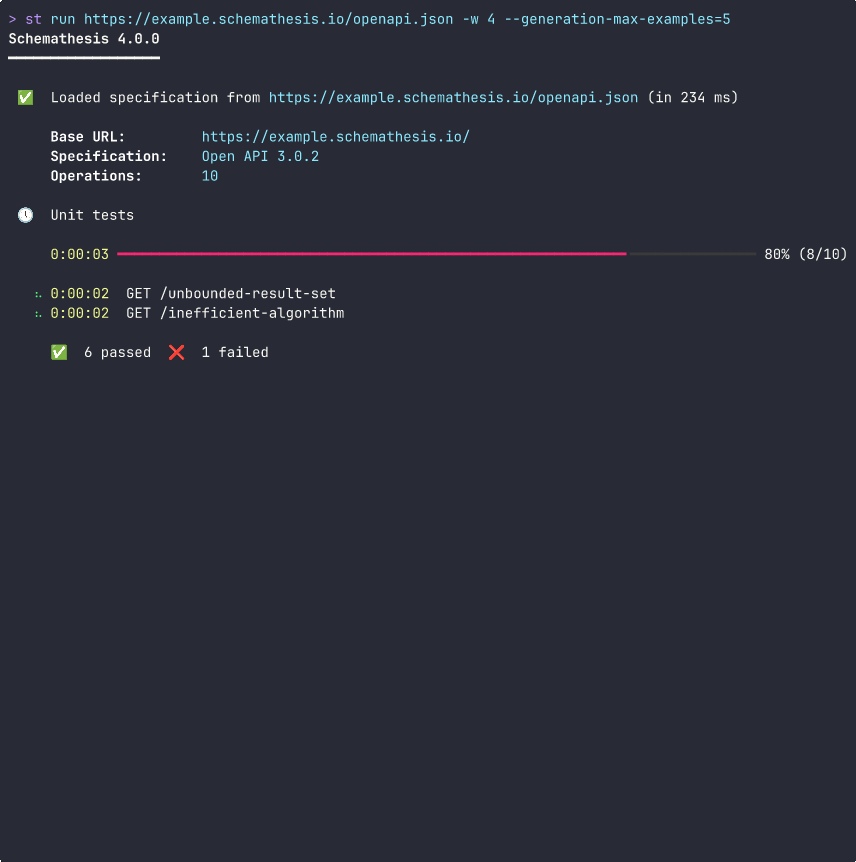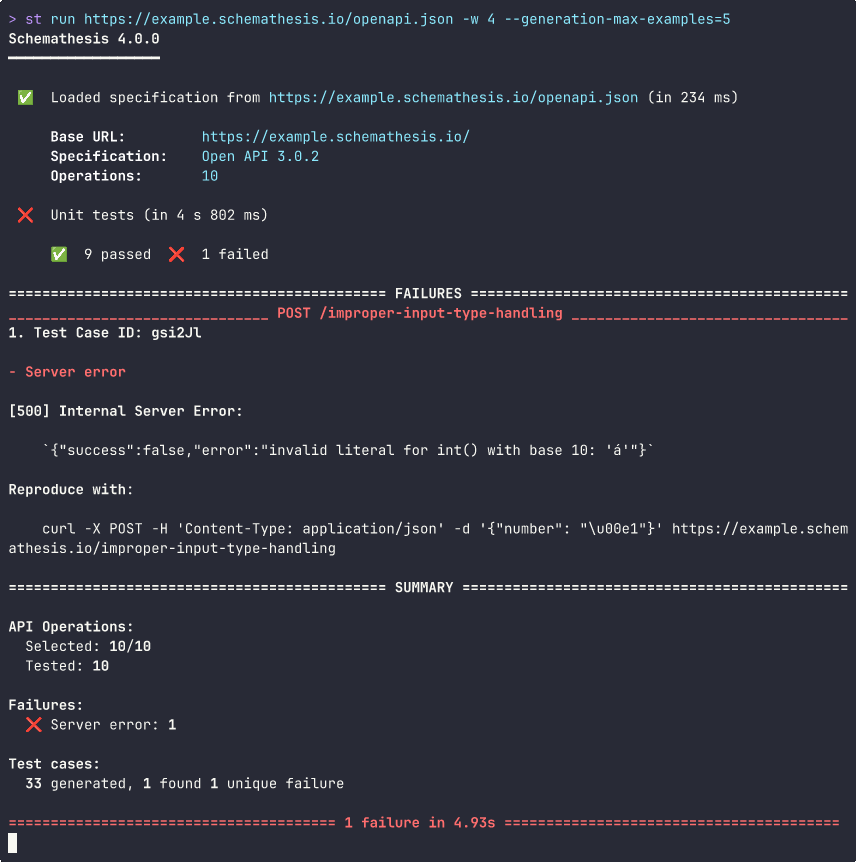
With a summary right in your PRs:
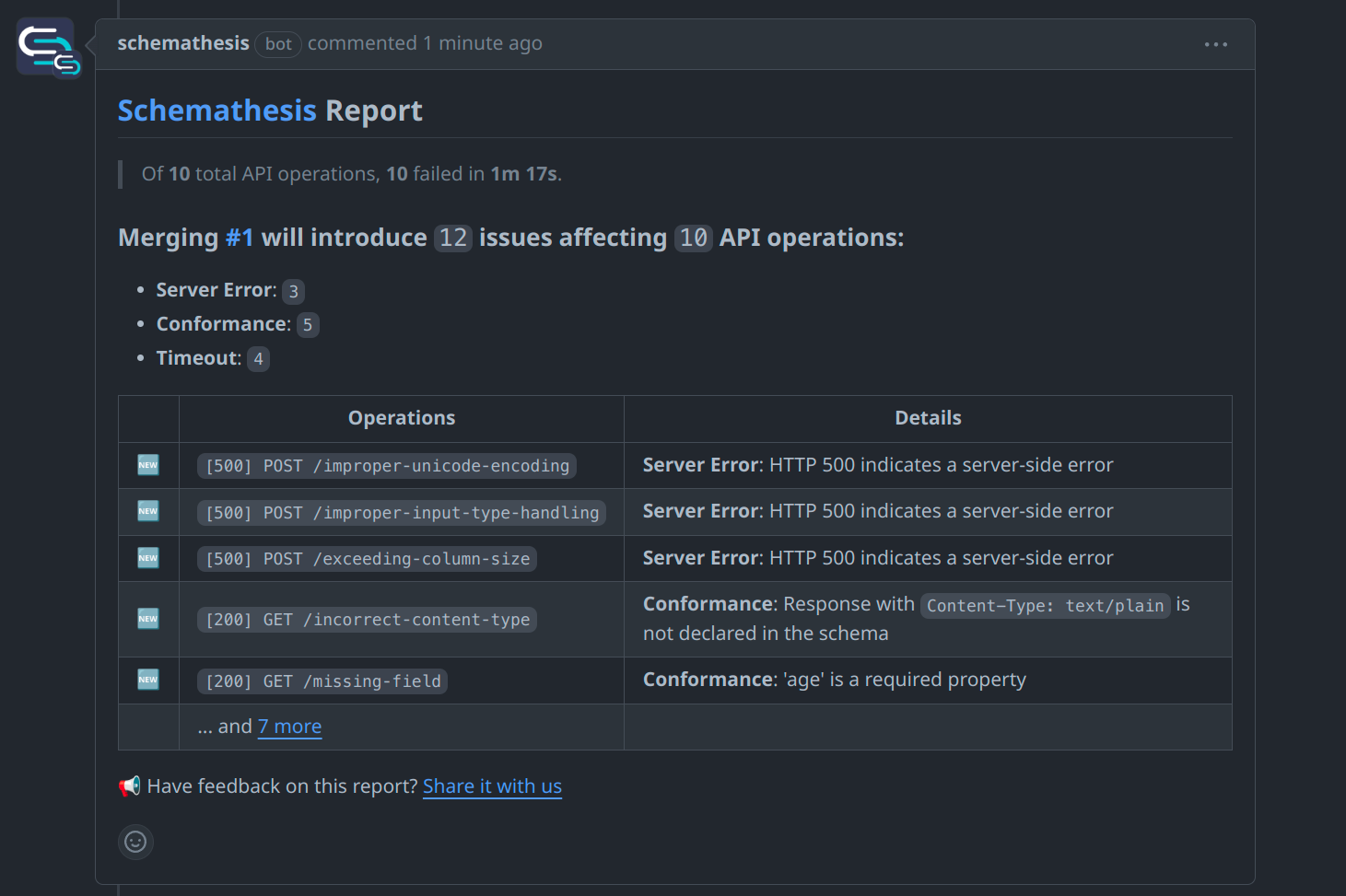
Choose from multiple ways to start testing your API with Schemathesis.
💡 Your API schema can be either a URL or a local path to a JSON/YAML file.
Quick and easy for those who prefer the command line.
Python
- Install via pip:
python -m pip install schemathesis - Run tests
st run --checks all https://example.schemathesis.io/openapi.jsonDocker
- Pull Docker image:
docker pull schemathesis/schemathesis:stable - Run tests
docker run schemathesis/schemathesis:stable
run --checks all https://example.schemathesis.io/openapi.jsonFor more control and customization, integrate Schemathesis into your Python codebase.
- Install via pip:
python -m pip install schemathesis - Add to your tests:
import schemathesis
schema = schemathesis.from_uri("https://example.schemathesis.io/openapi.json")
@schema.parametrize()
def test_api(case):
case.call_and_validate()💡 See a complete working example project in the /example directory.
GitHub Actions
Run Schemathesis tests as a part of your CI/CD pipeline.
Add this YAML configuration to your GitHub Actions:
api-tests:
runs-on: ubuntu-22.04
steps:
- uses: schemathesis/action@v1
with:
schema: "https://example.schemathesis.io/openapi.json"
# OPTIONAL. Add Schemathesis.io token for pull request reports
token: ${{ secrets.SCHEMATHESIS_TOKEN }}For more details, check out our GitHub Action repository.
💡 See our GitHub Tutorial for a step-by-step guidance.
GitHub App
Receive automatic comments in your pull requests and updates on GitHub checks status. Requires usage of our SaaS platform.
- Install the GitHub app.
- Enable in your repository settings.
Schemathesis CLI integrates with Schemathesis.io to enhance bug detection by optimizing test case generation for efficiency and realism. It leverages various techniques to infer appropriate data generation strategies, provide support for uncommon media types, and adjust schemas for faster data generation. The integration also detects the web server being used to generate more targeted test data.
Schemathesis.io offers a user-friendly UI that simplifies viewing and analyzing test results. If you prefer an all-in-one solution with quick setup, we have a free tier available.
Here’s a simplified overview of how Schemathesis operates:
- Test Generation: Using the API schema to create a test generator that you can fine-tune to your testing requirements.
- Execution and Adaptation: Sending tests to the API and adapting through statistical models and heuristics to optimize subsequent cases based on responses.
- Analysis and Minimization: Checking responses to identify issues. Minimizing means simplifying failing test cases for easier debugging.
- Stateful Testing: Running multistep tests to assess API operations in both isolated and integrated scenarios.
- Reporting: Generating detailed reports with insights and cURL commands for easy issue reproduction.
Our study, presented at the 44th International Conference on Software Engineering, highlighted Schemathesis's performance:
-
Defect Detection: identified a total of 755 bugs in 16 services, finding between 1.4× to 4.5× more defects than the second-best tool in each case.
-
High Reliability: consistently operates seamlessly on any project, ensuring unwavering stability and reliability.
Explore the full paper at https://ieeexplore.ieee.org/document/9793781 or pre-print at https://arxiv.org/abs/2112.10328
"The world needs modern, spec-based API tests, so we can deliver APIs as-designed. Schemathesis is the right tool for that job."
"Schemathesis is the only sane way to thoroughly test an API."
"The tool is absolutely amazing as it can do the negative scenario testing instead of me and much faster! Before I was doing the same tests in Postman client. But it's much slower and brings maintenance burden."
"Schemathesis is the best tool for fuzz testing of REST API on the market. We are at Red Hat use it for examining our applications in functional and integrations testing levels."
"There are different levels of usability and documentation quality among these tools which have been reported, where Schemathesis clearly stands out among the most user-friendly and industry-strength tools."
We welcome contributions in code and are especially interested in learning about your use cases. Understanding how you use Schemathesis helps us extend its capabilities to better meet your needs.
Feel free to discuss ideas and questions through GitHub issues or on our Discord channel. For more details on how to contribute, see our contributing guidelines.
Your feedback is essential for improving Schemathesis. By sharing your thoughts, you help us develop features that meet your needs and expedite bug fixes.
- Why Give Feedback: Your input directly influences future updates, making the tool more effective for you.
- How to Provide Feedback: Use this form to share your experience.
- Data Privacy: We value your privacy. All data is kept confidential and may be used in anonymized form to improve our test suite and documentation.
Thank you for contributing to making Schemathesis better! 👍
If you're a large enterprise or startup seeking specialized assistance, we offer commercial support to help you integrate Schemathesis effectively into your workflows. This includes:
- Quicker response time for your queries.
- Direct consultation to work closely with your API specification, optimizing the Schemathesis setup for your specific needs.
To discuss a custom support arrangement that best suits your organization, please contact our support team at [email protected].
- Deriving Semantics-Aware Fuzzers from Web API Schemas by @Zac-HD and @Stranger6667
- Description: Explores the automation of API testing through semantics-aware fuzzing. Presented at ICSE 2022.
- Date: 20 Dec 2021
- Auto-Generating & Validating OpenAPI Docs in Rust: A Streamlined Approach with Utoipa and Schemathesis by identeco
- Description: Demonstrates OpenAPI doc generation with Utoipa and validating it with Schemathesis.
- Date: 01 Jun 2023
- Testing APIFlask with schemathesis by @pamelafox
- Description: Explains how to test APIFlask applications using Schemathesis.
- Date: 27 Feb 2023
- Using Hypothesis and Schemathesis to Test FastAPI by @amalshaji
- Description: Discusses property-based testing in FastAPI with Hypothesis and Schemathesis.
- Date: 06 Sep 2022
- How to use Schemathesis to test Flask API in GitHub Actions by @lina-is-here
- Description: Guides you through setting up Schemathesis with Flask API in GitHub Actions.
- Date: 04 Aug 2022
- Using API schemas for property-based testing (RUS) about Schemathesis by @Stranger6667
- Description: Covers the usage of Schemathesis for property-based API testing.
- Date: 07 Sep 2021
- Schemathesis: property-based testing for API schemas by @Stranger6667
- Description: Introduces property-based testing for OpenAPI schemas using Schemathesis.
- Date: 26 Nov 2019
- API Fuzzing: What it is and why you should use it by José Haro Peralta
- Description: A comprehensive overview and demo of Schemathesis.
- Date: 14 Feb 2023
- Schemathesis tutorial with an accompanying video by Red Hat
- Description: Provides a hands-on tutorial for API testing with Schemathesis.
- Date: 09 Feb 2023
- Effective API schemas testing from DevConf.cz by @Stranger6667
- Description: Talks about using Schemathesis for property-based API schema testing.
- Date: 24 Mar 2021
- API-schema-based testing with schemathesis from EuroPython 2020 by @hultner
- Description: Introduces property-based API testing with Schemathesis.
- Date: 23 Jul 2020
This project is licensed under the terms of the MIT license.




![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")











































































































































