This Repository is Archived – Use cfbfastR
A scraping and aggregating package using the CollegeFootballData API
cfbscrapR is an R package for working with CFB data. It is an R API
wrapper around https://collegefootballdata.com/. It provides users the
capability to retrieve data from a plethora of endpoints and supplement
that data with additional information (Expected Points Added/Win
Probability added).
Note: The API ingests data from ESPN as well as other sources. For details on those source, please go the website linked above. Sometimes there are inconsistencies in the underlying data itself. Please report issues here or to https://collegefootballdata.com/.
You can install cfbscrapR from
GitHub with:
# Then can install using the devtools package from either of the following:
devtools::install_github(repo = "saiemgilani/cfbscrapR")
# or the following (these are the exact same packages):
devtools::install_github(repo = "meysubb/cfbscrapR")For more information on the package and function
reference,
please see the cfbscrapR documentation
website.
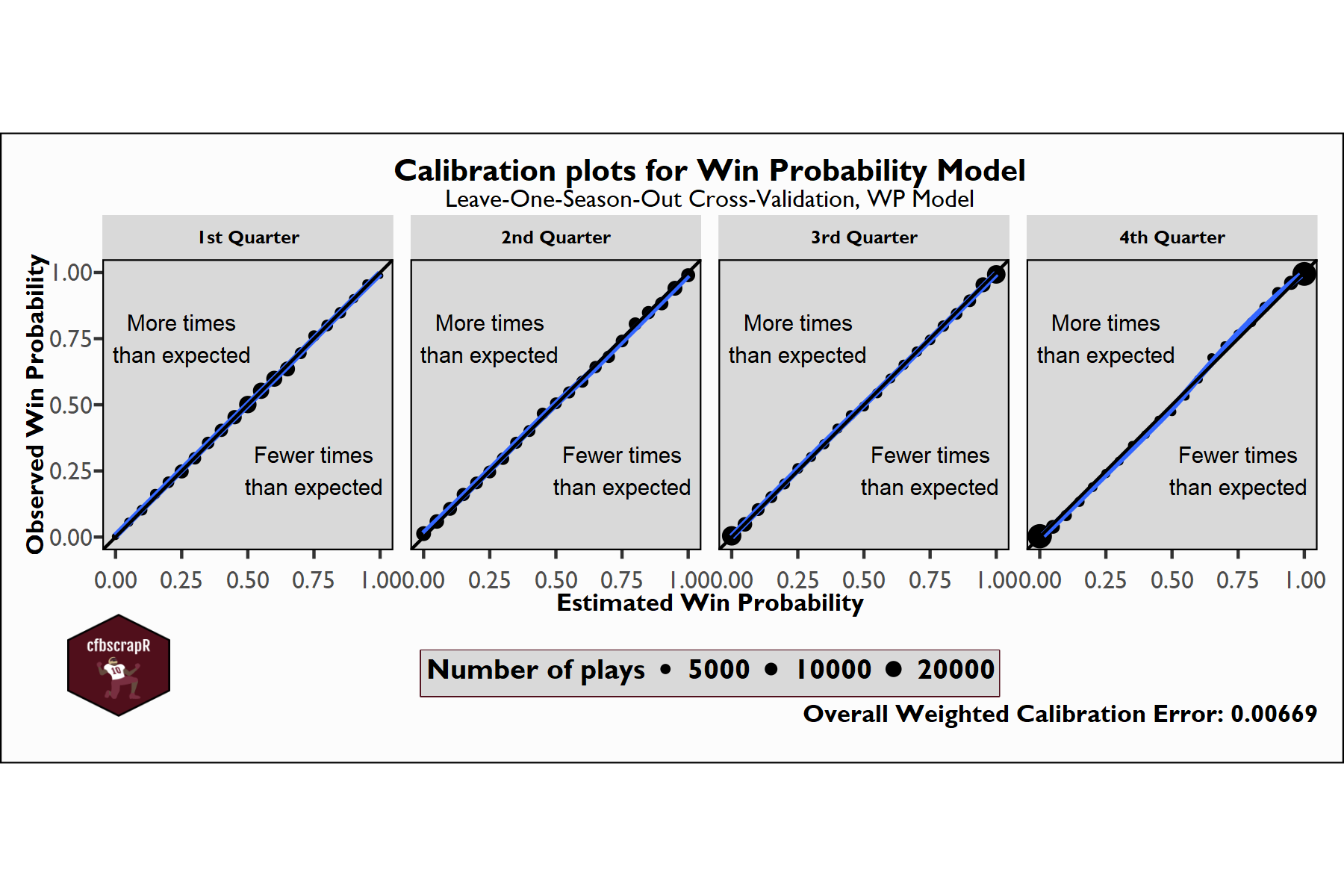
If you would like to learn more about the Expected Points and Win
Probability models, please refer to the cfbscrapR
tutorials
or for the code repository where the models are built, click
here

- Added Eric Hess’s Visualizing Team Talent Using Player Recruiting Rankings vignette
- Added
cfb_calendar()function from API - Updated
cfb_team_roster()to reflect new parameters.
- Updated
cfb_game_box_advanced()to incorporate new columns from API.
This was a big update!
- Updated expected points models and win probability models
- Add player and yardage columns to
cfb_pbp_data()pull thanks to a great deal of help from @NickTice - Add spread values to the
cfb_pbp_data()pull - Add drive detailed result with attempts at creating more accurate drive result labels
- Added series and first down variables
- Added argumentation to allow for San Jose State to be entered
without accent into
cfb_pbp_data()functionteamargument.








































