WIP
- Big O - describes the upper bound
- Big Omega - describes the lower bound
- Big Theta - describes the tight bound
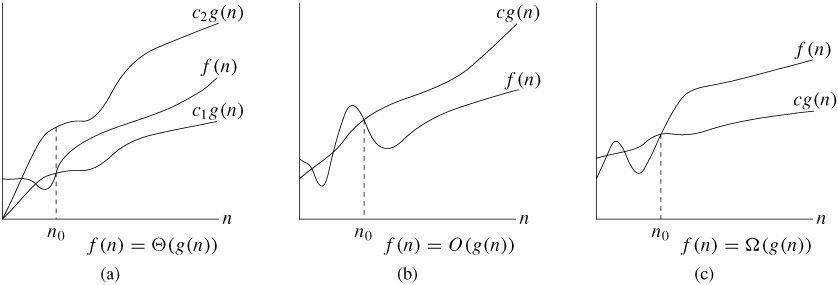
Graphical representation showing how (a) has a tight bound between a function g(n) times a constant c1 and another constant c2. Simplified example 3n2 < 5n2 < 8n2. (b) describes the upper bound. (c) describes lower bound.
- Best case - Perfect world / Best situation (all elements in
insertion sortare in order = O(n) - Worst case - Worst situation (no elements in
insertion sortare in order = O(n2) - Average case - What will likely be the case. Usually is the same as the worst case (
insertion sortmore likely to be out of order so O(n2)
Note: Determing best case and worst case isn't too hard but average case requires intuition.
Big O/Omega/Theta DOES NOT correspond to worst/best/average case. The worst/best/average case will describe Big O/Omega/Theta. An easy way to understand this is using insertion sort. If all elements are ordered, then applying insertion sort will have a best case scenario and an upper bound of O(n) while if all elements are not in order, this would be the worst possible case and cause the upper bound to be O(n2). Still dealing with Big O but depending on the situation, the best, worst, and average case varies.
Drop the non-dominant term - When faced with an algorithm that takes O(n2 + n) time, we drop the n as it is irrelevant. The n2 scales much faster than n - when looking at Big O, we look how it scales to infinity (asymptote) and at a certain point, the n will become a non-factor. A note though is that this is only the case if we are use the same variable; using two different variables means we don't know which scales faster than the other. An example is O(n + m), we don't know if n > m or n < m so O(n + m) is the best upper bound we can determine.
for (i from 0 to a)
do something in O(1) time
for (j from 0 to b)
do something in O(1) time
How many times are we doing O(1) in the first for loop? a times so the total time would be O(a). The same logic would be applied to the second for loop to yeild O(b). Since we do not have a way to view if a > b or vice versa (which would allow us to drop the non-dominant term), the total time would O(a + b).
Asymptote - We care about how the algorithms scale to infinity. Many algorithms may be faster although not apparent such as 999n vs n2. This is equivalent to O(n) and O(n2) respectively. Setting n = 1 will yield a faster result for the O(n2). Only when n > 999 will n2 take more time but the goal is not to see how an algorithm works for specific cases but as it scales to infinity.
Space vs Time complexity
The amount of time it takes to perform an algorithm given that each operation takes O(1) time. Say we are adding 10 values in a for loop:
a = 0
for (i in range 0 to n):
a += i
The a += i calculation takes a constant time O(1) determined by specific hardware. How many times are we doing this calculation? It is not a constant value, n could be anything so the number of times we have to perform the a += i calculation is the variable n times = n * O(1) which is simply O(n).
Now for example the n was swapped with a 10:
a = 0
for (i in range 0 to 10):
a += i
The number of times we have to do this a += i calculation is 10 times which is a constant - no matter how many times we perform this algorithm, it will always take the same amount of time and therefore the time complexity is O(1): constant time.
The amount of space the computer needs to perform the algorithm. This is a tricky subject unless you have a good foundation of how memory is stored in RAM.
The best way to look at this is through examples.
Say we define an array of size n. This will allocate memory large enough for the array. Clearly the amount of space required is O(n).
Note: This will differ depending on whether the allocated memory is of size integer, double, custom class, etc but remember we do not care about that since we only care about how it grows to infinity - looking at 16 bytes * n, the 16 isn't that important the closer n reaches infinity.
But say we look at the previous example:
a = 0
for (i in range 0 to n):
a += i
The amount of space required is actually O(1) because, while we are adding n number of times, the only value we have to store in memory is the new value of a and i - we don't scale the amount of space required in memory regardless of how many times we are adding.
Common Big Os:
- O(n)
- O(n2)
- O(n3)
- O(log n)
- O(n log n)
- O(!n)
- O(2^n) (tree like structure)
But there are many more. For interviews, it is best to widen view to any possibility.
- Collection of data elements known as nodes that point to each other using pointers.
- Nodes are generally comprised of a
headandnextelement - May be a singly linked list (each node points to the next node) or doubly linked list (each nodes points to the next node and the previous node)
- Linked lists questions are likely to use recursion and runner technique - must be able to implement either
Understand and be able to implement the following (best to implement using using head (forces better understanding of linked lists):
push_front(value)pop_front()push_back(value)pop_back()value_at(index)print_nodes()reverse_nodes()- use recursion for O(n) time complexity
Recursive call psuedo code - must know this:
if (i == n)
return node
curr_node = recursive_call(i++, n->next);
return curr_node
Runner technique psuedo code:
hare, rabbit = curr_node
while (curr_node != NULL)
hare += 2 nodes
rabbit += 1 node
C++ need to knows:
list<type> linked_listlist<type>::iterator itnext(it)prev(it)*it - get elementlinked_list.sort()for (list<type>::iterator it = linked_list.begin(); it != linked_list.end(); ++it) {}
- Access: O(n)
- Search: O(n)
- Insertion: O(1)
- Deletion: O(1)
need to work on the below - currently what is there is old stuff I wrote
- Stores fixed-size sequeuntial data of the same type.
- May be dynamic array which means the size of the array dynamically changes depending on the size of the array - possibly double array size or increase array size by one
- Multidimensional arrays can hold a large amount of data depending on the number of dimensions used but using more than 3 is ill-advised
- Access: O(1)
- Search: O(n)
- Insertion: n/a or O(n) if dynamic array
- Deletion: n/a or O(n) if dynamic array
int foo[] = {3,5,6};foo[2] = 24;
- Collection of data elments with two main operations: push and pop.
- Push adds an element to the stack
- Pop removes an element from the stack
- Uses LIFO (last in, first out)
- Often uses arrays
- Access: O(n)
- Search: O(n)
- Insertion: O(1)
- Deletion: O(1)
- Collection of data elments with two main operations: enqueue and dequeue.
- Enqueue inserts data elements to the back of the queue
- Dequeue removes data elements from the front of the queue
- Uses FIFO (First in, first out)
- Preserves order
- Often uses circular arrays or linked lists
- Access: O(n)
- Search: O(n)
- Insertion: O(1)
- Deletion: O(1)
- Trres are data structures that are made of nodes or verticies and edges without any cycles.
- Know the following:
- Root
- Child
- Parent
- Degree
- Edge
- Depth
- A complete tree is one that has every node filled up except the last - meaning there are no gaps within the tree, they all as far left as possible
- Data structure to keep elements in sorted order for fast lookup
- Each parent can have at most 2 children
- Traverse tree from root until data element - makes comparisons based on the node's key value and traverses either left or right - this means it will at most operations and will result in logarithmic lookup, insertion, and deletion
- Three forms of traversal:
- Pre-order traversal:
- Display current node data
- Traverse left subtree by recursively calling pre-order function
- Traverse right subtree by recursively calling pre-order function
- In-order traversal:
- Display current node data
- Traverse left subtree by recursively calling in-order function
- Traverse right subtree by recursively calling in-order function
- Post-order traversal:
- Display current node data
- Traverse left subtree by recursively calling post-order function
- Traverse right subtree by recursively calling post-order function
- Pre-order traversal:
- Access: O(log n)
- Search: O(log n)
- Insertion: O(log n)
- Deletion: O(log n)
- Complete binary tree that satisfies either one of the heaps properties:
- min-heap property: the value of the node is greater than or equal to the value of its parent
- max-heap property: the value of the node is less than or equal to the value of its parent
- Easy to remember, min means the minimum value is the root, max means the maximum value is the root
- Access: O(log n)
- Search: O(log n)
- Insertion: O(log n)
- Deletion: O(log n)
- Composed of three elements:
- Key - used to get element data
- Hashing function - used to determine where the data element should go and where to find it
- Buckets - contains the data
- Keys are associated with a value for example, the key
344, once inserted into the hashing function, will always return"hello world" - Collisions occur when multiple keys try to use the same bucket
- Access: O(1)
- Search: O(1)
- Insertion: O(1)
- Deletion: O(1)
To do, hash tables
Searching: breadth first vs depth first Sorting algorithms: Bubble sort, selection sort, insertion sort, merge sort, heap sort bit manipulation file i/o classes/OOP












