This repository is now read-only. Work has been moved to the Pear project, see for frontend and
for backend




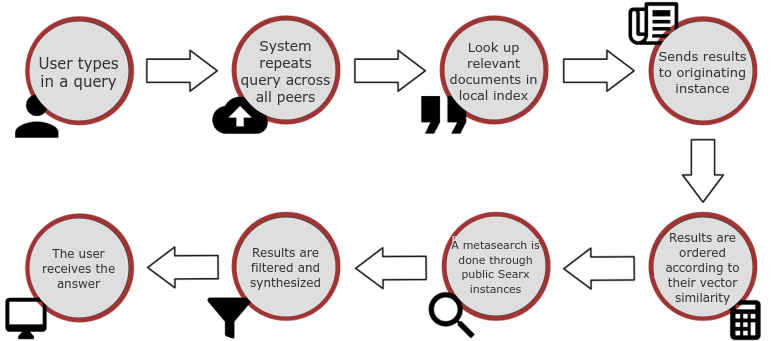
FUTURE is a completely stand alone, open-source search engine that's focused on privacy and decentralization, so that any user can also self-host their own instance to contribute to a shared index of web pages accessible through any one of them. Given the small index that it currently has, it also works as a meta-search engine, mixing its own results with others from public Searx instances, to be capable of answering any request properly. Here is a small presentation that serves to show why FUTURE is different, better and how it accomplishes that.
The decentralization aspect of the search engine is a core feature as it allows anyone to expand the index and improve the service, while also increasing reliability by redundancy. Currently the main node is located at https://wearebuildingthefuture.com.
If you are planning to host your own instance, we strongly encourage you to consider using Uberspace as they offer an excellent service and instances for a fair price.
Documentation is available on-line at https://wearebuildingthefuture.readthedocs.io/en/latest/ and in the docs directory.
After cloning the repository, add a config.py file, which will allow you to customize important parts of your instance without directly modifying the source code and struggling with updates. It is suggested to start with this configuration template, which is essentially equal to the one used for the main instance:
#!/usr/bin/env python3
# -*- coding: utf8 -*-
import secrets
from web3 import Web3
from tranco import Tranco
t = Tranco(cache=True, cache_dir='.tranco')
WTF_CSRF_ENABLED = True
SECRET_KEY = secrets.token_urlsafe(16)
HOST_NAME = "my_public_future_instance" # THE NAMES 'private' and 'wearebuildingthefuture.com' are reserved for private and main nodes, respectively.
SEED_URLS = ["http://" + x for x in t.list().top(1000)]
PEER_PORT = 3000
HOME_URL = "wearebuildingthefuture.com"
LIMIT_DOMAINS = None
ALLOWED_DOMAINS = []
CONCURRENT_REQUESTS = 10
CONCURRENT_REQUESTS_PER_DOMAIN = 2.0
CONCURRENT_ITEMS = 100
REACTOR_THREADPOOL_MAXSIZE = 20
DOWNLOAD_MAXSIZE = 10000000
AUTOTHROTTLE = True
TARGET_CONCURRENCY = 2.0
MAX_DELAY = 30.0
START_DELAY = 1.0
DEPTH_PRIORITY = 1
LOG_LEVEL = 'INFO'
CONTACT = "[email protected]"
MAINTAINER = "Roberto Treviño Cervantes"
FIRST_NOTICE = "Written and Mantained By <a href='https://keybase.io/rtrevinnoc'>Roberto Treviño</a>"
SECOND_NOTICE = "Proudly Hosted on <a href='https://uberspace.de/en/'>Uberspace</a>"
DONATE = "<a href='https://www.buymeacoffee.com/searchatfuture'>DONATE</a>"
COLABORATE = "<a href='https://github.com/rtrevinnoc/FUTURE'>COLABORATE</a>"
CACHE_TIMEOUT = 15
CACHE_THRESHOLD = 100
COMPLEMENTARY_VECTOR_CACHE = -1
try:
WEB3API = Web3(Web3.HTTPProvider('http://127.0.0.1:8545'))
ETHEREUM_ACCOUNT = WEB3API.eth.accounts[0]
CONTRACT_CODE = 'future-token/build/contracts/FUTURE.json'
CONTRACT_ADDRESS = "0x2ebDA3D6B2F24aE57164b0384daa9af2C0D17323"
except:
passNOTE: In case you want to use a docker container, simpy run the following commands before everything else below (Or use the pre-built image from DockerHub):
docker build -t future .
docker run -i -t -p 3000:3000 future bashAfter you have configurated your FUTURE instance, but before you can start the server, you will be required to add a minimum of ~25 urls to your local index, by executing:
chmod +x bootstrap.sh
./bootstrap.sh
./build_index.shAt any point in time, you can check how much webpages are in your local index by executing:
python3 count_index.pyAnd eventually, you can interrupt the crawler by executing:
./save_index.shNaturally, you can restart it using ./build_index.sh. And with this, you can start your development server with:
./future.pyHowever, if you are planning to contribute to the shared index by making your instance public, it is recommended to use uWSGI. We suggest using this configuration template, with touch uwsgi.ini, as it is used on the main instance.
[uwsgi]
module = future:app
pidfile = future.pid
http-socket = :3000
chmod-socket = 660
strict = true
master = true
enable-threads = true
vacuum = true ; Delete sockets during shutdown
single-interpreter = true
die-on-term = true ; Shutdown when receiving SIGTERM (default is respawn)
need-app = true
disable-logging = true ; Disable built-in logging
log-4xx = true ; but log 4xx's anyway
log-5xx = true ; and 5xx's
cheaper-algo = busyness
processes = 6 ; Maximum number of workers allowed
cheaper = 1 ; Minimum number of workers allowed
cheaper-initial = 2 ; Workers created at startup
cheaper-overload = 1 ; Length of a cycle in seconds
cheaper-step = 1 ; How many workers to spawn at a time
cheaper-busyness-multiplier = 30 ; How many cycles to wait before killing workers
cheaper-busyness-min = 20 ; Below this threshold, kill workers (if stable for multiplier cycles)
cheaper-busyness-max = 70 ; Above this threshold, spawn new workers
cheaper-busyness-backlog-alert = 4 ; Spawn emergency workers if more than this many requests are waiting in the queue
cheaper-busyness-backlog-step = 2 ; How many emergency workers to create if there are too many requests in the queueFinally, start your public node to contribute to the shared network with the following command:
uwsgi uwsgi.iniBelow are listed all the projects upon which FUTURE rests.
| Name | License |
|---|---|
| Flask | BSD 3-Clause |
| Werkzeug | BSD 3-Clause |
| SymSpell | MIT |
| Polyglot | GPL v3 |
| Beautifulsoup | BSD 2-Clause |
| BSON Python bindings | Apache 2.0 |
| NumPy | BSD 3-Clause |
| GeoPy | MIT |
| SciKit Learn | BSD 3-Clause |
| Pandas | BSD 3-Clause |
| Gensim | LGPL 2.1 |
| NLTK | Apache 2.0 |
| Scrapy | BSD License |
| H5PY | BSD 3-Clause |
| LMBD | OpenLDAP |
| LMBD Python bindings | OpenLDAP |
| tldextract | BSD 3-Clause |
| WTForms | BSD 3-Clause |
| Flask_wtf | BSD 3-Clause |
| HNSWLib | Apache 2.0 |
| JQuery | MIT |
| JQuery UI | MIT |
| Particles JS | MIT |
| Ionicons | MIT |
| Source Sans Pro | OFL 1.1 |
| GloVe | Apache 2.0 |
| SPARQLWrapper | W3C License |
| TextScrambler | BSD-like |





















