go get rsc.io/pdf
rsc / pdf Goto Github PK
View Code? Open in Web Editor NEWPDF reader
License: BSD 3-Clause "New" or "Revised" License
PDF reader
License: BSD 3-Clause "New" or "Revised" License
go get rsc.io/pdf































































































































Correct me if I am using this library incorrectly but I seem to get the text (string) output of a PDF page and it does not include spaces between characters.
func ParsePDF() (text string) {
fileName := "./someFolder/testPDF.pdf"
reader, err := pdf.Open(fileName)
if err != nil {
// log the error
}
foundEnd := 0
pageNum := 1
text = ""
for foundEnd < 1 {
page := reader.Page(pageNum)
if page.V.IsNull() {
foundEnd++
break
} else {
content := page.Content()
textStruct := content.Text
for _, v := range textStruct {
text += v.S
}
pageNum++
}
}
return text
}
When I call this method that wraps the code of this library, the result is a correct text and characters, but with no space characters. I believe this is related to: https://github.com/rsc/pdf/blob/master/page.go#L422
Is there a particular reason spaces are being ignored? Am I just using the library incorrectly?
Do we have workaround for big-endian UCS-2 decoder?
panic: unsupported PDF: encryption version V=4
I met a pdf with PKCS protection which I had to decrypt it with a pfx cert. I hope you could add a feature to decode it.
I have this valid PDF which I can read and I can even parse it with nodejs. When I try to read it I get this:
not a PDF file: missing %%EOF
Any idea?
Documenting the issue at least, so people with similar goals with me would know it exists.
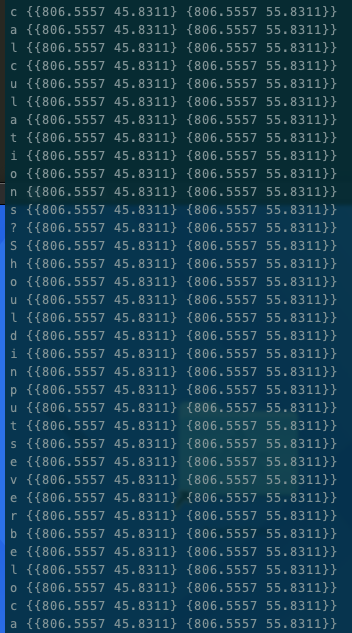
Basically when some fonts are decoded, it is analyzed character by character, however, all those characters would have the same position coordinates...See screenshot below.
I might dig into it and try to fix it. We'll see.
I have the following Go program that uses this library:
package main
import (
"fmt"
"os"
"strconv"
"rsc.io/pdf"
)
func main() {
if len(os.Args) < 2 || os.Args[1] == "-h" || os.Args[1] == "--help" {
fmt.Println("usage: pdfpage file.pdf [pnum]")
os.Exit(1)
}
reader, err := pdf.Open(os.Args[1])
if err != nil {
fmt.Println(err)
os.Exit(2)
}
if len(os.Args) == 3 {
var pnum int
var err error
if pnum, err = strconv.Atoi(os.Args[2]); err != nil {
pnum = 1
}
fmt.Printf("PAGE %d\n", pnum)
printPage(reader, pnum)
} else {
for pnum := 1; pnum <= reader.NumPage(); pnum++ {
fmt.Printf("PAGE %d\n", pnum)
printPage(reader, pnum)
fmt.Println("")
}
}
}
func printPage(reader *pdf.Reader, pnum int) {
page := reader.Page(pnum)
if page.V.IsNull() {
fmt.Printf("failed to read page %d\n", pnum)
os.Exit(3)
}
for _, chunk := range page.Content().Text {
fmt.Printf("x=%06.2f y=%06.2f w=%06.2f %q %s %.1fpt\n",
chunk.X, chunk.Y, chunk.W, chunk.S, chunk.Font,
chunk.FontSize)
}
}This builds and runs fine and for many PDFs gives the expected output (although it is rather slow).
However I have a few PDFs which produce a panic:
PAGE 1
panic: malformed PDF: reading at offset 0: stream not present
goroutine 1 [running]:
rsc.io/pdf.(*buffer).errorf(0xc4200d3948, 0x507f70, 0x27, 0xc4200d36d0, 0x2, 0x2)
/home/mark/app/go/src/rsc.io/pdf/lex.go:82 +0x74
rsc.io/pdf.(*buffer).reload(0xc4200d3948, 0x8)
/home/mark/app/go/src/rsc.io/pdf/lex.go:95 +0x193
rsc.io/pdf.(*buffer).readByte(0xc4200d3948, 0x599da0)
/home/mark/app/go/src/rsc.io/pdf/lex.go:71 +0x69
rsc.io/pdf.(*buffer).readToken(0xc4200d3948, 0xc42000aca0, 0x1000)
/home/mark/app/go/src/rsc.io/pdf/lex.go:135 +0x4a
rsc.io/pdf.Interpret(0xc42006e060, 0x37, 0x4d78a0, 0xc42000ab60, 0xc4200d3b08)
/home/mark/app/go/src/rsc.io/pdf/ps.go:64 +0x1c6
rsc.io/pdf.Page.Content(0xc42006e060, 0x37, 0x4db2e0, 0xc420014810, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)
/home/mark/app/go/src/rsc.io/pdf/page.go:613 +0x326
main.printPage(0xc42006e060, 0x1)
/home/mark/app/go/src/pdfpage2/main.go:47 +0xa8
main.main()
/home/mark/app/go/src/pdfpage2/main.go:35 +0x25d
I also have a 647 page PDF for which the program outputs the first 22 pages, then outputs PAGE 23 and then just sits there eating memory and using ~25% CPU. That particular page has some Japanese characters but I don't know if they are Unicode text or paths.
From code of https://github.com/rsc/pdf/blob/master/page.go#L421
I see you skip all character, why do you do it. Not sure I got your idea but when reading all text form pdf, we can't use the content and the result's very useless.

hi,
it seems rsc.io/pdf can not be retrieved with go get (short of using the -insecure flag):
$ go get -v -u rsc.io/pdf
Fetching https://rsc.io/pdf?go-get=1
https fetch failed: Get https://rsc.io/pdf?go-get=1: x509: certificate signed by unknown authority
package rsc.io/pdf: unrecognized import path "rsc.io/pdf" (https fetch: Get https://rsc.io/pdf?go-get=1: x509: certificate signed by unknown authority)
could this be fixed?
-s
https://github.com/rsc/pdf/blob/master/page.go#L22
The GoDoc for this function says that it's 1-indexed, but the comment on L22 says it's 0-indexed. When calling the method as such:
r.Page(0)
we land in an infinite loop, because the initial num-- adjustment puts num at -1, and therefore we never find a page. Maybe an error condition should be returned in case a 0 is passed as an argument?
as title say,i cant use this lib to read chinese charactors pdf
Hi @rsc. First off: Cool library, thanks for making it!
Do you have any plans to support more PDF versions, or improve on any of the bugs listed on godoc? I would love to have a proper library in Go for parsing PDF documents instead of having to rely on Python's PDFMiner.
I would also love to help out, but I am not sure where to start. I do not know anything about the black magic that seems to be the inner workings of PDF documents.
Greetings,
Given a PDF file that has a loop (ex: pages found from "Kids" have entries for "Parent" pointing back), how to I traverse the graph without getting stuck?
I tried saving the Values that I have visited, but they are not == to the new Values.
I received a PDF from clippercard.com that has "%PDF-1.3 " as the first line - note the space character after the "3". This causes rsc.io/pdf to fail to parse the PDF file. The PDF file in question has a number of space characters at the end of lines which cause the PDF library to alternately return these errors, depending on which space characters you fix:
not a PDF file: invalid header
malformed PDF: cross-reference table not found: ref
malformed PDF file: missing final startxref
Chrome, Mozilla Firefox and Preview.app have no problem displaying the PDF in question.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.