![]()
![]()
![]()
An English-to-Gallifreyan transliterator, based on Sherman's Gallifreyan created by Loren Sherman.
Note that Sherman's Gallifreyan is a fan-made cipher and is not affiliated with the BBC show Doctor Who.
The goal of Gallifreyo is to be able to recreate the first image from the official guide to Sherman's Gallifreyan — a transliteration of "hello sweetie" — to a reasonable degree of accuracy.
This target image is simple but complex. It is a good indication of how well Gallifreyo handles a range of requirements:
- low-level requirements like word positioning and sizing, letters and vowels, and sentence formation
- medium-level requirements like dots, lines, and variance between letter types
- high-level requirements like double-letter and -vowel merging, sentence outlining, and word interlocking
It's just missing punctuation, paragraphs (multiple sentences), and numbers.
| Theirs | Ours (v0.2.0) |
|---|---|
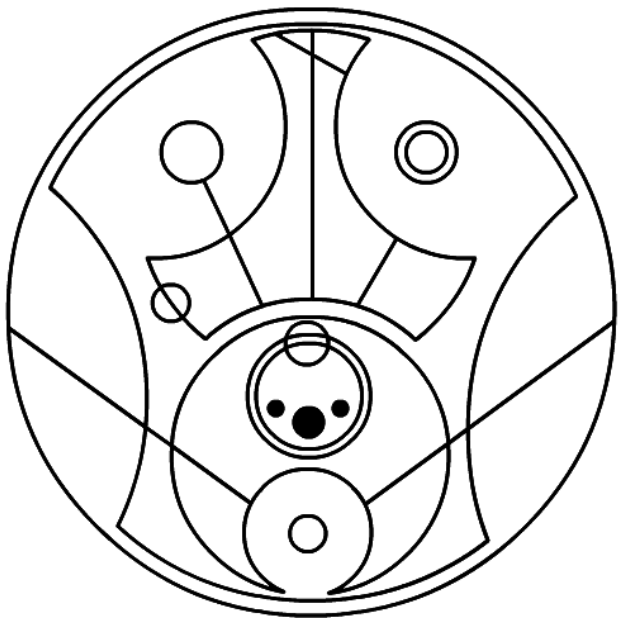 |
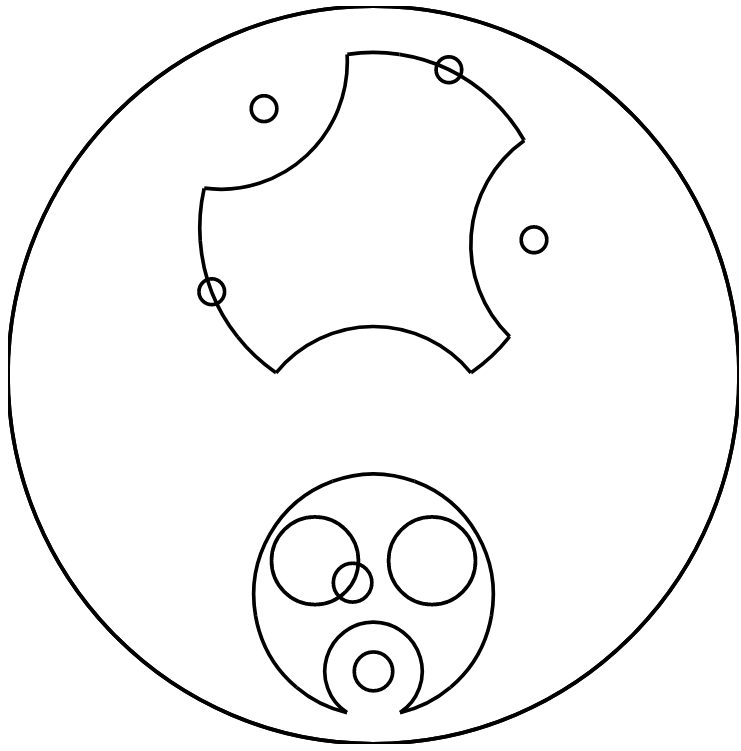 |
Obviously, Gallifreyo is incomplete.
Gallifreyo is licensed under MIT.
Images produced by Gallifreyo are subject to the same licence of the text that created them — if you wrote the text yourself, you own the copyright.











