revsys / revsys-nuremberg Goto Github PK
View Code? Open in Web Editor NEWLicense: MIT License
License: MIT License












Remove redundant double-quoting of search-query notification below transcript search box

2- A second search without leaving the search page (ie first search for anything, then for example change the search text entry to "author:hitler" and click search) does not have the author fly-out expanding, a hover on a author name shows nothing.
(This last comment seems to be also reported by Paul in issue #195)
Originally posted by @nessita in #12 (comment)
The current properties table as given has their data de-normalized and contains a lot of duplication. We should use the existing processing of that to group properties and their qualifiers to populate a new, likely, table or some sort of intermediary storage.
The search unit tests are asserting over search results values that depend on number of indexed documents, number of returned pages, etc.
This makes the tests likely failing after a Solr schema change or a reindex of new/updated documents.
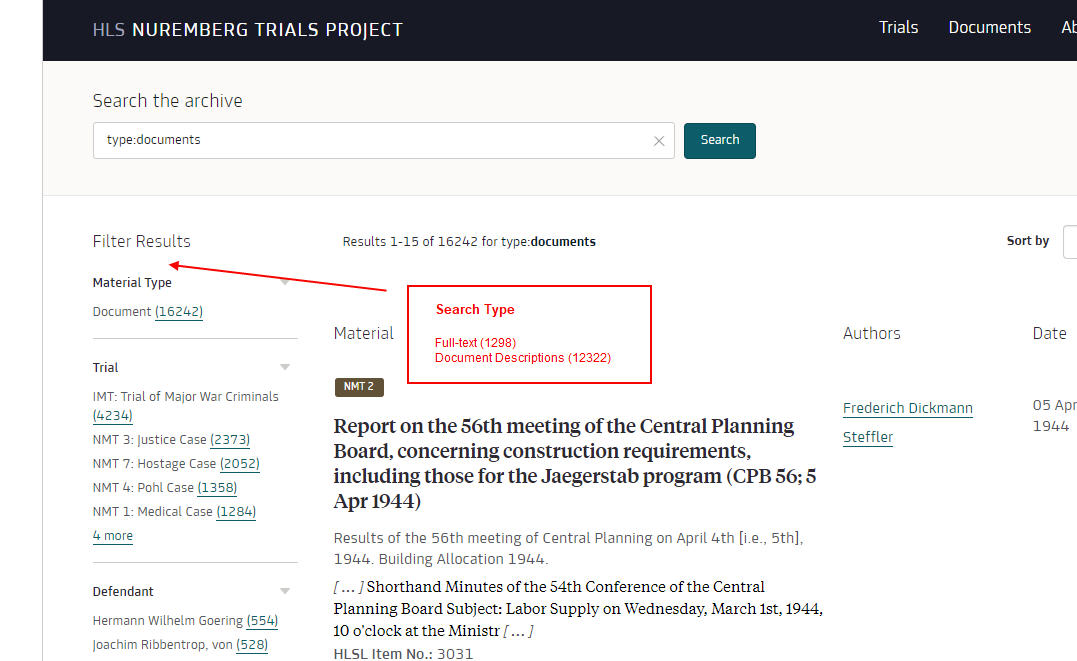
Please add facet of "Search Type" to facet listing on search-results page (first facet to be listed); the instance numbers are just examples, of course:
In full-text exact-phrase query, ellipsis incorrectly separates terms of exact phrase, instead of separating snippet instances of exact phrase found in the document


Low priority, but eventually I'll need the project we recently took over installed to provide a /health/ endpoint
If no results are returned, replace current "Results 0-0 of 0" with "No results"

Overview texts for trials IMT and NMT 9 are available at:
https://docs.google.com/document/d/1UHOG9icSbp-WKQixuWP3Ys6sFCQCwAlk1yQU9pGrTlQ/edit
https://docs.google.com/document/d/1a4pS7ndgNzb2YXH7Fu7057Cpzq4pFql_cCGTpYbIdUY/edit
These need to be converted to HTML and formatted in a similar manner to the existing trials. There are template placeholders for these two that were added in #154
The page format should follow existing trial pages, such as https://github.com/revsys/revsys-nuremberg/blob/main/web/nuremberg/content/templates/content/nmt_1_intro.html.
Query box's "x" at far right should be protected by padding from being overlapped by extended query string

HLSL item number search retrieves false positives


When user clicks on View link in transcript page viewer, the page image does not come up. This is working in the legacy site.

Following the work in pull request #31, the ad-hoc added javascript and the improvised CSS should be improved.
Use this image for when we don't have an author image.
Fields with null values should not display in document metadata viewer

When POSTing in the dev site using the advanced view search form, we get a 403 with CSRF verification failed. Request aborted..
The CSRF token is indeed present and rendered in the template, and is also POSTed along the form fields:
csrfmiddlewaretoken=SOME_SECRET_STR&keywords=&title=&author=&defendant=&issue=&trial=&language=¬es=&source=&evidence=&evidence_num=&evidence_suffix=&exhibit=&exhibit_num=&book=&book_num=
There may be something else going on, potentially some settings related to CSRF tokens may need review.
The advanced search help page is available after #137 was landed, but we need to link it from somewhere.
When using the search form, the search input field has the magnifier glass overlapping the text:

In full-text search, matching based on stem matches should not be allowed.


There seems like the CSS for the missing images placeholder for documents may be broken or buggy. See for example https://nuremberg.law.harvard.edu/documents/2683#p.1 which looks like this:

In the dev site, this same doc https://nuremberg.revsys.dev/documents/2683#p.1 looks like this:

We commented out this test in this PR #227
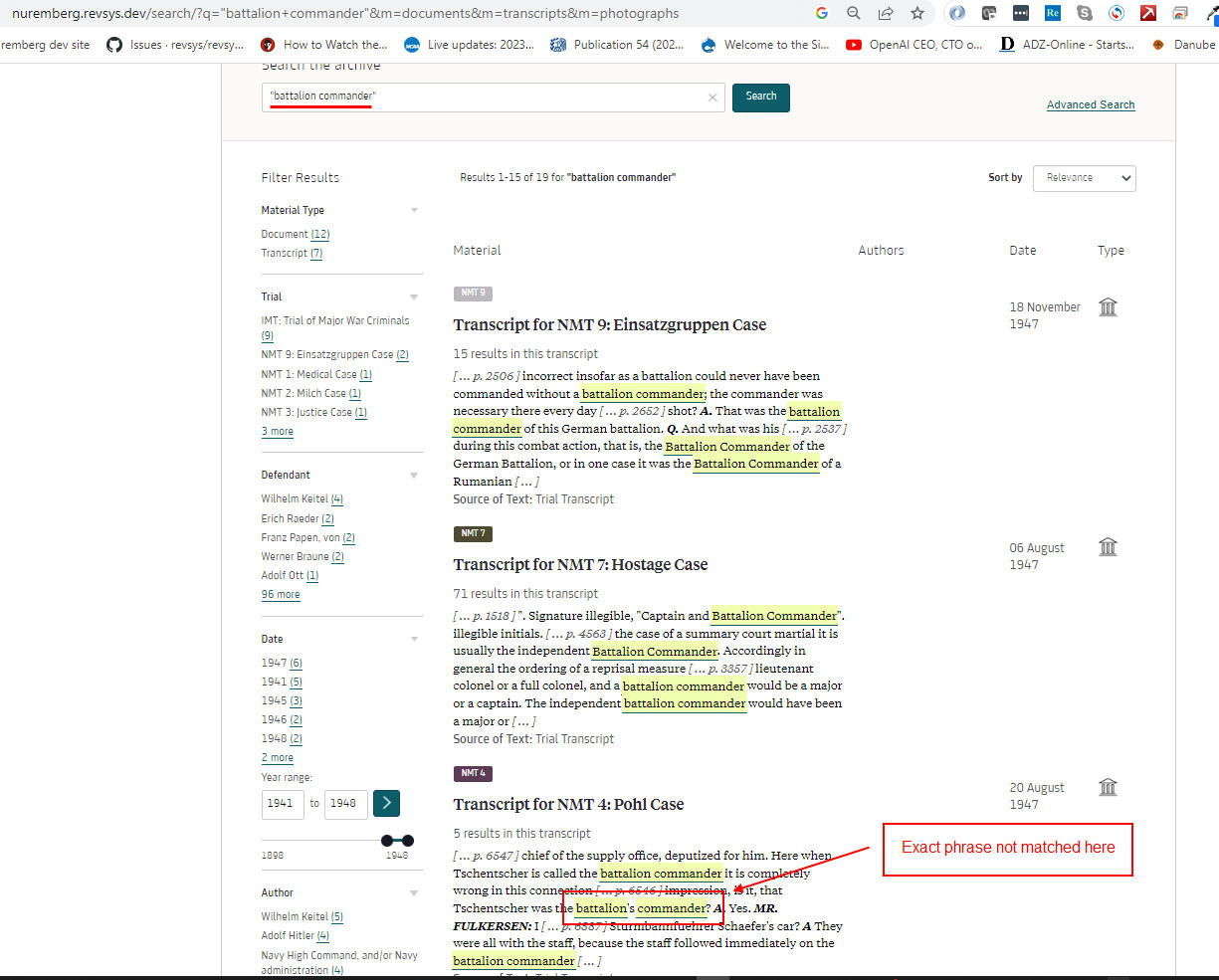
In full-text exact phrase searching, many false positives being returned, as in screenshots below.




For prosecution document no. link in document metadata, add trial number to link query to prevent search results including same-numbered prosecution document for all trials in which such a document is available. Link should only retrieve documents referencing this trial's document.

Add print style sheet for those that remove the UI at least.
Following the priority list to bind document's full-text with images, the current implementation applies all criteria except the language match:
As there can be multiple images available, we would like to use the metadata from the highest-ranked item from the following priority tree, if the full-text document is in English. If the full-text document is in German, d. and e. rise -- in that order -- to just below a.:
A. Exhibit document (from any trial). In case of "a tie" for multiple documents with exhibit codes for the same evidence code, the following trial priority should be used:
B. English translation (EF doc)
C. Staff Evidence analysis (EF doc)
D. German typescript (EF doc)
E. German photostat (EF doc)
If no correlation can be found, then simply list the Title, DocID and Source from the full-text data table.
Make it like wikipedia hover over links.
On smaller screens (especially mobile phones), it may be best to take over the whole screen and have a close button.
On larger screens, it should disappear when no longer hovering over it.
Full-text highlighting missing from transcript snippet results for exact-phrase query

Paul asked if we could add in image rotation to allow a user to rotate in 90 degree increments (or something workable like that) to handle cases where the metadata about orientation is wrong.
Currently, only F4 and F8 checks are enabled for flake8, we should slowly work towards adding more checks, or even fix enough so we can instead define the ignored checks and work towards reducing that list later.
In some cases, text content extends beyond edge of page on right

When user clicks on "Full-text View" link in document image view, often (not always) the link doesn't execute, timing out with error: "502 Bad Gateway"


laundry list of pre-deployment observations, things added (towards deployment) or removed
We used to use Solr snapshots to restore the index while testing in GHA to speed up the test suite. This has been replaced by a baked Solr image with the index built in it.
Remove "Back to all results" link from all transcript pages.

In order to avoid hitting wikidata for every image in every author fly-out, we should download and store the images referenced in properties.
Images should be downloaded once and not overwritten to ensure they can be changed/modified.
For example, doc https://nuremberg.revsys.dev/documents/483-cross-reference-for-document-ps?mode=text shows how the text viewport is not contained to a fixed height. We should make this section has a fixed height and have the text inside it be scroll-able.
Following issue revsys/revsys-nuremberg-deprecated#57, I conducted a simple URL audit and found a few URLs within the content app that would need fixing/reviewing:
href="http://nuremberg.law.harvard.edu/php/docs_swi.php?DI=1&text=transcript" in nmt_1_intro.html:389Full-text search: hit counts incorrect for both single-term and exact-phrase searches




In document metadata sidebar, suppress transcript citation link when page number of citation = 0


Remove transcript note below transcript tag on right


It seems that the fly-out isn't invoked when hovering over an author's name if I've navigated to the page via the search-results pager at the bottom of the search-results page. This often also happens when clicking on the author's name to bring up all their search results and then hovering over the author's name in the search-results listing. In both cases, refreshing the window resets the hover functionality so that it works again. It also seems to work when clicking on a search result to open the associated document page and then hovering over the author's name on the right-hand metadata bar.
Attempting to slide the mouse pointer from the hover position over the author's name to the adjoining fly-out often fails, with the fly-out closing before the mouse pointer can reach the fly-out.
See attached screenshot of fly-out with dead space to the left of the image within the fly-out's block of text. This seems to be a result of being unable to accommodate the full length of a continuous-string URL in the space to the left of the image, with the result that the space is left blank until the URL can then be fitted in the space whose top border is flush with the bottom of the image. I've read that it's possible to break a URL with an inner <br/> tag in cases such as this without affecting the integrity (clickability) of the URL itself. Do you think this might work? Or would you have some other thoughts on how to avoid creating the blank block within the fly-out's text?

From Paul:
I'd like to standardize the materials-type icons used in the app. Currently, we use one set of icons in the "Access the Collection" section of the landing page and an entirely different set inside the application. I'd like to completely dispense with the icons in the Access the Collection section and use the ones from the interior of the application for transcripts and photographs and the attached new one for documents. I'd also like to substitute the new document icon for the one currently being used inside the app, the latter of which is more suggestive of a folder than a document. I'm using a public domain version of the new document icon.
The icon image:

Places where it should be replaced:


Full-text highlighting: should also include document title as well as document body

When displaying full-text document, replace default value of "Source of Text" with value taken from tblNurembergDocTexts.SourceCitation to reflect the source of the text displayed instead of the source for the document metadata

Add "Search the archive" above search box for the document viewer (both image-based and full-text document viewers) and "Search this transcript" above search box for transcript viewer (to make clear to user the context in which entered search will be executed). And supply "Search" button to right of all search boxes (as on landing and search-results pages).

Dates: use year when month and day are unavailable, and use year and month when day is unavailable.


A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}