The official pytorch implemention of the paper "Res2Net: A New Multi-scale Backbone Architecture"
Our paper is accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).
- 2020.10.20 PaddlePaddle version Res2Net achieves 85.13% top-1 acc. on ImageNet: PaddlePaddle Res2Net.
- 2020.8.21 Online demo for detection and segmentation using Res2Net is released: http://mc.nankai.edu.cn/res2net-det
- 2020.7.29 The training code of Res2Net on ImageNet is released https://github.com/Res2Net/Res2Net-ImageNet-Training (non-commercial use only)
- 2020.6.1 Res2Net is now in the official model zoo of the new deep learning framework Jittor.
- 2020.5.21 Res2Net is now one of the basic bonebones in MMDetection v2 framework https://github.com/open-mmlab/mmdetection. Using MMDetection v2 with Res2Net achieves better performance with less computational cost.
- 2020.5.11 Res2Net achieves about 2% performance gain on Panoptic Segmentation based on detectron2 with no trick. We have released our code on: https://github.com/Res2Net/Res2Net-detectron2.
- 2020.2.24 Our Res2Net_v1b achieves a considerable performance gain on mmdetection compared with existing backbone models. We have released our code on: https://github.com/Res2Net/mmdetection. Detailed comparision between our method and HRNet, which previously generates best results, could be found at: https://github.com/Res2Net/mmdetection/tree/master/configs/res2net
- 2020.2.21: Pretrained models of Res2Net_v1b with more than 2% improvement on ImageNet top1 acc. compared with original version of Res2Net are released! Res2Net_v1b achieves much better performance when transfer to other tasks such as object detection and semantic segmentation.
We propose a novel building block for CNNs, namely Res2Net, by constructing hierarchical residual-like connections within one single residual block. The Res2Net represents multi-scale features at a granular level and increases the range of receptive fields for each network layer. The proposed Res2Net block can be plugged into the state-of-the-art backbone CNN models, e.g. , ResNet, ResNeXt, BigLittleNet, and DLA. We evaluate the Res2Net block on all these models and demonstrate consistent performance gains over baseline models.
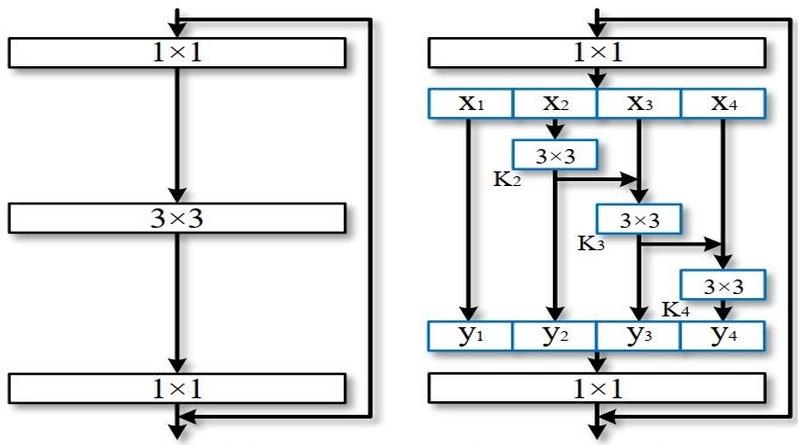
Res2Net module
PyTorch>=0.4.1
git clone https://github.com/gasvn/Res2Net.git
from res2net import res2net50
model = res2net50(pretrained=True)
Input image should be normalized as follows:
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
(By default, the model will be downloaded automatically. If the default download link is not available, please refer to the Download Link listed on Pretrained models.)
| model | #Params | MACCs | top-1 error | top-5 error | Link |
|---|---|---|---|---|---|
| Res2Net-50-48w-2s | 25.29M | 4.2 | 22.68 | 6.47 | OneDrive |
| Res2Net-50-26w-4s | 25.70M | 4.2 | 22.01 | 6.15 | OneDrive |
| Res2Net-50-14w-8s | 25.06M | 4.2 | 21.86 | 6.14 | OneDrive |
| Res2Net-50-26w-6s | 37.05M | 6.3 | 21.42 | 5.87 | OneDrive |
| Res2Net-50-26w-8s | 48.40M | 8.3 | 20.80 | 5.63 | OneDrive |
| Res2Net-101-26w-4s | 45.21M | 8.1 | 20.81 | 5.57 | OneDrive |
| Res2NeXt-50 | 24.67M | 4.2 | 21.76 | 6.09 | OneDrive |
| Res2Net-DLA-60 | 21.15M | 4.2 | 21.53 | 5.80 | OneDrive |
| Res2NeXt-DLA-60 | 17.33M | 3.6 | 21.55 | 5.86 | OneDrive |
| Res2Net-v1b-50 | 25.72M | 4.5 | 19.73 | 4.96 | Link |
| Res2Net-v1b-101 | 45.23M | 8.3 | 18.77 | 4.64 | Link |
| Res2Net-v1d-200-SSLD | 76.21M | 15.7 | 14.87 | 2.58 | PaddlePaddleLink |
- Res2Net_v1b is now available.
- You can load the pretrained model by using
pretrained = True.
The download link from Baidu Disk is now available. (Baidu Disk password: vbix)
Other applications such as Classification, Instance segmentation, Object detection, Semantic segmentation, Salient object detection, Class activation map,Tumor segmentation on CT scans can be found on https://mmcheng.net/res2net/ .
If you find this work or code is helpful in your research, please cite:
@article{gao2019res2net,
title={Res2Net: A New Multi-scale Backbone Architecture},
author={Gao, Shang-Hua and Cheng, Ming-Ming and Zhao, Kai and Zhang, Xin-Yu and Yang, Ming-Hsuan and Torr, Philip},
journal={IEEE TPAMI},
year={2021},
doi={10.1109/TPAMI.2019.2938758},
}
If you have any questions, feel free to E-mail me via: shgao(at)live.com
The code is released under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License for Noncommercial use only. Any commercial use should get formal permission first.
















































