picfile's People
Contributors

Watchers
picfile's Issues
将java项目部署到docker容器中运行-CSDN博客
docker部署一个简单的javaweb项目到容器中运行
(无任mysql 等其他依赖)
1.将项目打成jar包, 通过xftp 上传linux 某目录,此处在/data/app目录下
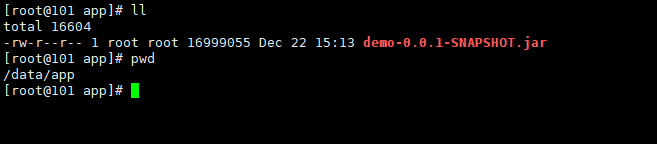
2.在jar包所在的位置创建一个Dockerfile 文件 (保证jar包和Dockerfile 在同一个目录下)
2.1创建Dockerfile文件
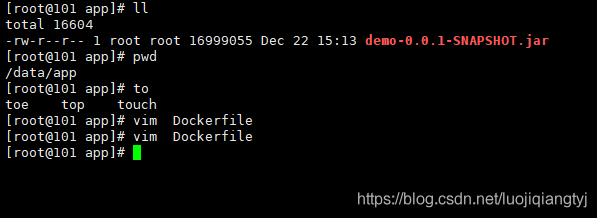
2.2在DockerFile文件里加入一下代码
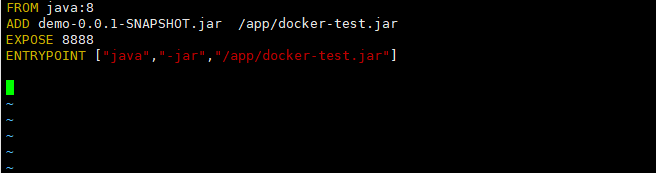
`FROM java:8
ADD demo-0.0.1-SNAPSHOT.jar /app/docker-test.jar
EXPOSE 8888
ENTRYPOINT ["java","-jar","/app/docker-test.jar"]`
* 1
* 2
* 3
* 4
命令解释:
FROM java:8 :
指定从镜像仓库中拉取 java 镜像, :8 表示版本
ADD demo-0.0.1-SNAPSHOT.jar /app/docker-test.jar
指定将当前目录的demo-0.0.1-SNAPSHOT.jar(我们自己上传上来的jar) 添加到等会要创建的容器的 /app目录下 并且取名为docker-test.jar
EXPOSE 8888 : 将容器的指定端口暴露出去 (因为作者的spring项目的service 端口是指定的8888 所以此处将8888端口暴露出去)
ENTRYPOINT [“java”,"-jar","/app/docker-test.jar"]
指定创建镜像的时候要执行的命令:这里的意思是 启动的时候会执行 java -jar /app/docker -test.jar命令(以jar包的形式 启动 /app/docker-test.jar 因为我们在文件中指定了将我们的jar包复制到容器的 /app目录下并且取名 docker-test.jar 所以这里运行的正是前面我们ADD 命令中的jar包)
3.指定刚才的创建的镜像创建容器
3.1运行以下命令:
意思是创建一个docker镜像名字为java -app Dockerfile 所在路径为当前路径
-t 指定名称 为java-app
. 表示指定Dockerfile文件的路径为当前的路径
`[root@101 app]`
* 1
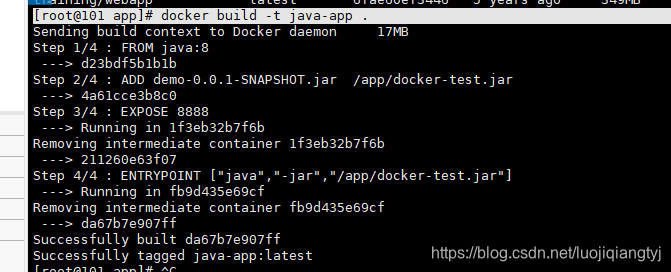
3.2查看镜像是否创建成功
`docker images`
* 1
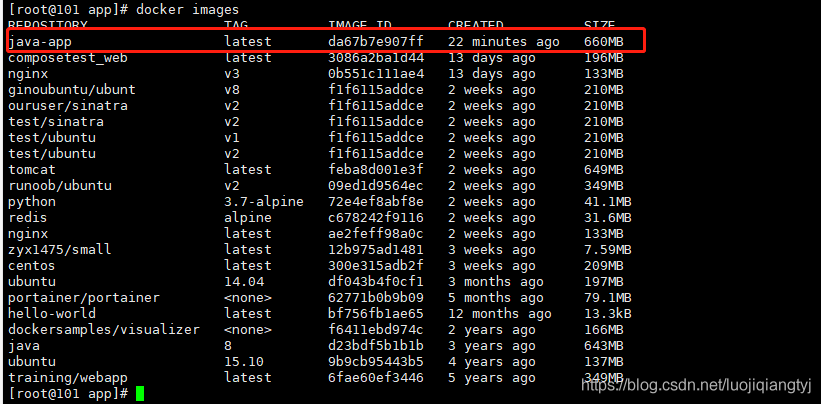
4.创建容器
-d表示后台运行
-p 指定端口 映射关系 (将容器的8888端口映射到8081)
–name 指定创建容器的名称(java-web)
java app 指定创建容器的镜像为java-app(即我们刚刚创建的)
`[root@101 app]`
* 1

5.测试访问
访问地址: http://106.13.5.101:8081/web

最后附上个人的笔记地址:👇链接👇
(33条消息) selenium+opencv实现模拟登陆(滑块验证码)_selenium滑块验证_plexming的博客-CSDN博客
很多网站登录登陆时都要用到滑块验证码,在某些场景例如使用爬虫爬取信息时常常受到阻碍,想着用opencv的模板匹配试试能不能实现模拟登陆。本来觉得网上资料多应该还蛮容易,但实际上手还是搞了蛮久,在这里记录一下整个流程,网站无所谓主要是要有滑动验证码:
python 3.9, selenium和Opencv相关依赖,用于抓取图片的requests包,具体安装这里不多讲了,其中selenium用的火狐版本。
整体流程就是这个样子:访问网站->点击登录->输入账号密码->搞定滑块验证->登录网站,其中最大的难点是滑块验证码,但在此之前我们当然要先让selenium自动打开网站把账号密码输好,我们通过find_element()方法定位输入框之后执行操作,元素的各个属性F12就可以找到:

代码如下:
options = webdriver.FirefoxOptions()driver = webdriver.Firefox(options=options)driver.find_element("link text", "登录").click()name = driver.find_element("id", "name-input")name.send_keys("账号######") pw = driver.find_element("id", "password-input")pw.send_keys("密码#########") driver.find_element("id", "submit").click()
为了做后续处理我们需要把滑块验证码相关图片抓到本地,网上关于滑块验证码这块很多都是用原图和有缺口的图对比来确定缺口位置的,但是我并没有找到原图,这里用到的是有缺口的背景图和滑块图,如下:
滑块图:

有缺口的背景图:

这里爬图是selenium定位之后用requests包爬的,注意验证码和登陆界面不在一个iframe里,selenium记得切到对应iframe才能定位到图片,代码如下:
driver.switch_to.frame('tcaptcha_iframe')img = driver.find_element("id", "slideBg").get_attribute('src')'Accept': "application/json, text/plain, */*",'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"r = requests.get(img, headers=headers)with open('img.png', 'wb') as f:block = driver.find_element("id", "slideBlock").get_attribute('src')r = requests.get(block, headers=headers)with open('block.png', 'wb') as f:
接下来就是重点,如何确定缺口位置来定位滑动验证码该往哪滑。这里主要用到OpenCV的模板匹配。 首先对滑块也就是稍后匹配时用到的模板进行处理,这里主要就是把形状轮廓提取出来然后去掉多余的东西,先把原图变成灰度图:
tpl_gray = cv2.cvtColor(tpl, cv2.COLOR_BGR2GRAY)

可以看到边缘有一圈阴影部分,我们需要把周围这圈去掉,遍历找到黑色像素点把它变成和周围一样。
width, height = tpl_gray.shape
处理后变成了这样,然后把中间主体部分涂黑,也就是将图片二值化。
binary = cv2.inRange(tpl_gray, 96, 96) kernel = np.ones((8, 8), np.uint8)template = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel)
处理完毕得到理想的模板图:
接下来对带有缺口的背景图进行处理,这个过程稍微麻烦一点,不过思路还是比较清晰的,还是先转化成灰度图再二值化,这里有一个问题,不同验证码图片之间差距很大,有的颜色很显眼,有的却很清淡,比如下面这两差别太大了,这就导致在二值化的过程中很难有一个固定的参数。


这里我根据图片的平均灰度值设定了几个区间,对不同区间的验证码图片传入不同参数进行二值化:
mean_val, _, _, _ = cv2.mean(img) gauss = cv2.GaussianBlur(img, [5, 5], 0) img_gray = cv2.cvtColor(gauss, cv2.COLOR_BGR2GRAY) cv2.imshow("111", img_gray) ret, target = cv2.threshold(img_gray, 105, 255, cv2.THRESH_BINARY)elif avg_mean(img) > 102: ret, target = cv2.threshold(img_gray, 95, 255, cv2.THRESH_BINARY) ret, target = cv2.threshold(img_gray, 85, 255, cv2.THRESH_BINARY)
处理过的结果大概像这样:

效果还是不错的,清晰的凸显了缺口位置,最后把背景图和模板传入opencv的模板匹配方法,记录下匹配到的坐标即可。
result = cv2.matchTemplate(target, template, cv2.TM_CCOEFF_NORMED)min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)right_down = (left_up[0] + height, left_up[1] + width)cv2.rectangle(img, left_up, right_down, (0, 0, 255), 2)
这里框出来看看效果:

识别出位置之后就要算出滑块移动了多少距离,我们可以看到滑块初始状态距离边缘有26个像素:

同时抓下来的图片相比在网页中放大了一倍,所以真实滑动距离是:
(left_up - 26*2)/2
于是用selenium的actionchains模拟拖动滑块:
drag = driver.find_element("id", "tcaptcha_drag_button") ActionChains(driver).click_and_hold(on_element=drag).perform() ActionChains(driver).move_to_element_with_offset(to_element=drag, xoffset=l, yoffset=0).perform() ActionChains(driver).release().perform()
这样整个流程就搞定了,理论上这样简单粗暴的自动拖过去在很多时候会不奏效,还需要模拟人手动拖动,不过因为我做测试的时候直接就成功了,所以没写下去,整体思路大概是加速减速停几秒或者中间触发几个mouse_up(),mouse_down()事件。
下面是测试时用到的脚本,selenium部分和主函数,拿某个CTF靶场做的测试,仅供参考,根据实际网站不同肯定得改改:
from selenium import webdriverfrom selenium.webdriver.common.action_chains import ActionChains drag = driver.find_element("id", "tcaptcha_drag_button") ActionChains(driver).click_and_hold(on_element=drag).perform() ActionChains(driver).move_to_element_with_offset(to_element=drag, xoffset=l, yoffset=0).perform() ActionChains(driver).release().perform()def login_in(username, password):'Accept': "application/json, text/plain, */*",'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" driver.find_element("link text", "登录").click() name = driver.find_element("id", "name-input") pw = driver.find_element("id", "password-input") driver.find_element("id", "submit").click() driver.switch_to.frame('tcaptcha_iframe') img = driver.find_element("id", "slideBg").get_attribute('src') r = requests.get(img, headers=headers)with open('img.png', 'wb') as f: block = driver.find_element("id", "slideBlock").get_attribute('src') r = requests.get(block, headers=headers)with open('block.png', 'wb') as f:if __name__ == '__main__': options = webdriver.FirefoxOptions() driver = webdriver.Firefox(options=options) length = block_loc.match(image, tpl)
Opencv部分:
mean_val, _, _, _ = cv2.mean(img) tpl_gray = cv2.cvtColor(tpl, cv2.COLOR_BGR2GRAY) width, height = tpl_gray.shape binary = cv2.inRange(tpl_gray, 96, 96) kernel = np.ones((8, 8), np.uint8) template = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel) gauss = cv2.GaussianBlur(img, [5, 5], 0) img_gray = cv2.cvtColor(gauss, cv2.COLOR_BGR2GRAY) ret, target = cv2.threshold(img_gray, 105, 255, cv2.THRESH_BINARY) elif avg_mean(img) > 102: ret, target = cv2.threshold(img_gray, 95, 255, cv2.THRESH_BINARY) ret, target = cv2.threshold(img_gray, 80, 255, cv2.THRESH_BINARY) result = cv2.matchTemplate(target, template, cv2.TM_CCOEFF_NORMED) min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result) right_down = (left_up[0] + height, left_up[1] + width) cv2.rectangle(img, left_up, right_down, (0, 0, 255), 2) length = (left_up[0] - 26*2)/2
(34条消息) Nacos注册中心的部署与用法详细介绍_nacos部署_张维鹏的博客-CSDN博客
我们知道微服务彼此间独立部署、具有清晰的边界,服务间通过远程调用来构建复杂的业务功能。而服务册中心在微服务项目中扮演着非常重要的角色,那么注册中心又是什么,使用服务注册中心可以解决微服务中的哪些问题呢?
1、什么是注册中心:
注册中心是微服务架构中的纽带,类似于“通讯录”,它记录了服务和服务地址的映射关系。在分布式架构中,服务会注册到这里,当服务需要调用其它服务时,就到这里找到服务的地址并进行调用。注册中心本质上是为了解耦服务提供者和服务消费者。对于任何一个微服务,原则上都应存在或者支持多个提供者,这是由微服务的分布式属性决定的,更进一步,为了支持弹性扩缩容特性,一个微服务的提供者的数量和分布往往是动态变化的,也是无法预先确定的。因此,原本在单体应用阶段常用的静态LB机制就不再适用了,需要引入额外的组件来管理微服务提供者的注册与发现,而这个组件就是服务注册中心。
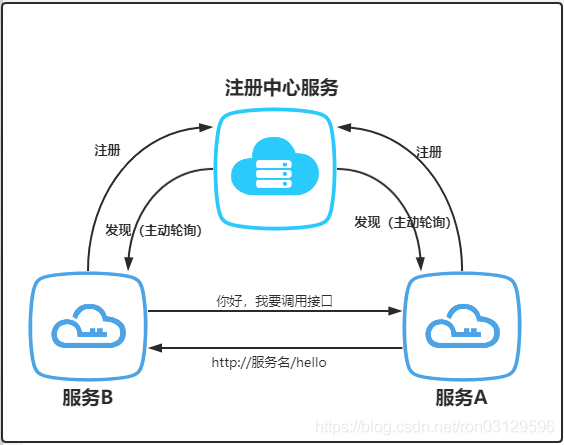
2、注册中心的核心功能:
- 服务注册:服务实例将自身服务信息注册到注册中心
- 服务发现:服务实例通过注册中心,获取到注册到其中的服务实例的信息,通过这些信息去请求它们提供的服务
- 服务剔除:服务注册中心将出问题的服务自动剔除到可用列表之外,使其不会被调用到
3、注册中心解决的问题:
(1)屏蔽、解耦服务之间相互依赖的细节:
服务之间的远程调用必须要知道对方IP、端口。但是该调用方式存在明显的问题,如被调用的IP、端口变化后,调用方也要同步修改。通过服务发现,将服务之间IP与端口的依赖转化为服务名的依赖,服务名可以根据具体微服务业务来做标识。
(2)对服务进行动态管理:
在微服务架构中,服务数量多且依赖错综复杂,无论是服务主动停止、意外挂掉,还是因为流量增加对服务扩容,这些服务状态上的动态变化,都需要尽快的通知到被调用方,被调用方才采取相应的措施。所以,对于服务注册中心要实时管理服务的数据与状态,包括服务的注册上线、服务主动下线,异常服务的剔除。
(3)降低服务端负载均衡中间件的压力:
当服务越来越多时,服务 URL 配置管理变得非常困难,服务端的负载均衡中间件,比如 F5、Nginx 压力也越来越大。通过服务注册中心,就可以实现动态地注册和发现服务,使服务的位置透明,并通过在消费方获取服务提供方地址列表,实现软负载均衡和 Failover,降低对服务端的负载均衡中间件,也能减少部分成本。
4、服务的发现与注册的实现模式:
上面提到,硬件的 F5、软件的 Nginx 也可以实现服务的发现,那么这与注册中心的服务发现有什么区别呢?这其实是服务发现与注册的两种实现模式:服务端的发现模式 和 客户端的发现模式。F5、Nginx 属于服务端的发现模式,服务注册中心属于客户端的发现模式,两种模式各有优缺点,也适用于不同的场景,对于大型应用一般会有多层负载,外层用服务器端负载均衡,内部用客户端负载均衡。接下来我们就具体看看两种服务发现模式是怎么样的:
(1)服务端的发现模式:
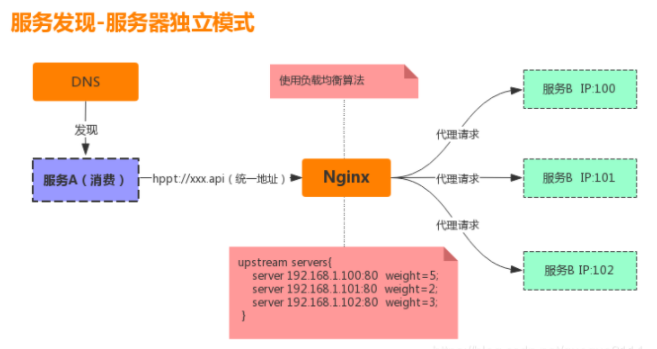
服务端的发现模式是通过使用一个中间的服务器,来屏蔽被调用服务的复杂性与变动性,当有新的服务加入或老服务剔除时,只需要修改中间服务器上的配置即可,此模式的显著特点是:引入独立的中间代理服务器来屏蔽真实服务的具体细节。
如下图所示:当服务A要调用服务B时,先通过 DNS 域名解析找到 Nginx 服务器,然后将请求发送给Nginx,因为在 Nginx 上配置了服务B的真实访问地址,Nginx 收到请求后根据负载均衡算法,将请求转发到某个真实的服务B,服务B将请求结果返回给 Nginx,Nginx 再将返回结果给服务A,整个请求流程结束。当然中间服务器不一定非得是 Nginx,还可以是基于硬件的 F5,也可以是工作在传输层的 IP 负载均衡等。
该模式的优点是:配置集中在独立的中间服务器端完成,对代码没有任何入侵,也不存在跨平台跨语言的问题。但缺点也很明显,因为所有请求都需要穿透中间服务器,所以中间服务器会成为一个单点,对性能也会有所影响。
(2)客户端的发现模式:
我们再看看客户端的发现模式,服务A调用服务B时,不需要通过中间服务器,而是在自己进程内维护了服务B的信息,再通过负载算法选择一个服务B直接调用。那服务A具体是怎么维护服务B的信息呢?为此引入了服务注册中心的概念,当服务B启动时向注册中心注册自己(将自己的信息发送到注册中心的注册表里),服务A再从注册中心获取所有注册的服务,这就是客户端模式的基本原理。
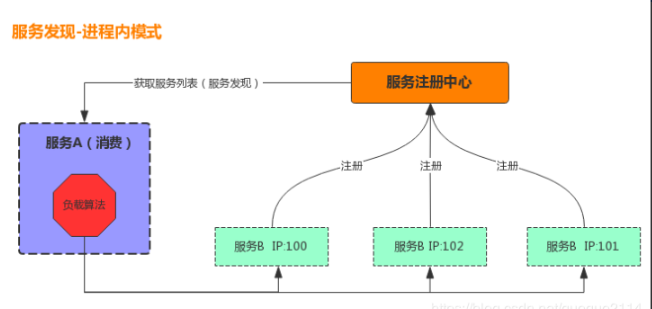
客户端模式因为在进程内直接调用服务,也叫做进程内负载,由于不需要穿透中间服务器,所以客户端模式的性能损耗比较小。但是,需要在服务内部维护服务注册信息,负载算法等,有一定的代码入侵性,对于跨平台,跨语言的支持不太友好。
5、服务注册表:
微服务架构中,所有的服务启动后都通过注册中心来注册自己,同时把注册中心里面的服务信息拉回本地,后续调用时就直接检查本地的服务和节点信息来进行服务节点的调用。每个服务节点都会来注册中心进行服务注册,那注册信息是如何在服务端保存的呢,其实就是注册表,服务注册的时候把自己的信息上报上来,然后注册中心把注册表,返回给客户端,那服务之间就知道要调用服务的节点了。
服务注册表需要高可用而且随时更新。客户端能够缓存从服务注册表中获取的服务地址,然而,这些信息最终会过时,客户端也就无法发现服务实例。因此,服务注册表会包含若干服务端,并使用复制协议保持一致性。服务注册表不能是单点,否则存在单点故障,当服务注册表有多台服务器的时需要考虑服务注册表的信息在多台机器上的实时同步和一致。
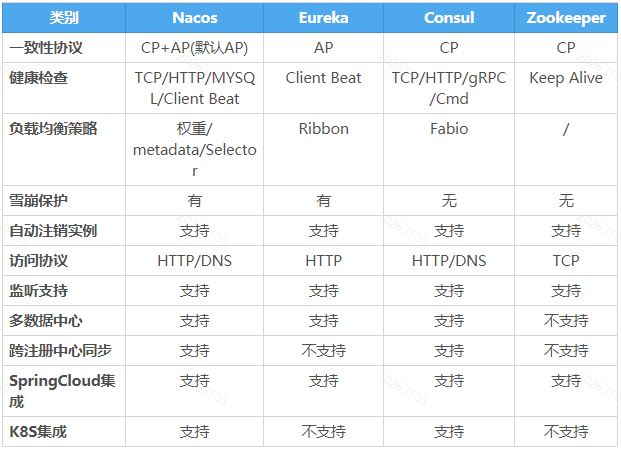
(1)Zookeeper 和 Consul 遵循 CP 原则,保证了强一致性和分区容错性,放弃可用性,在分布式环境中,如果涉及数据存储的场景,数据一致性应该是首先被保证的,但对于服务发现来说,可用性才是最核心的,针对同一个服务,即使注册中心的不同节点保存的服务提供者信息不相同,也并不会造成灾难性的后果。因为对于服务消费者来说,能消费才是最重要的,消费者拿到不正确的服务实例信息后尝试消费一下,也胜过因为无法获取实例信息而不去消费而导致系统异常
(2)Eureka 遵循 AP 原则,保证可用性,放弃数据一致性,基本能满足注册中心所需的核心功能,但 Eureka 2.x 版本已停止开发,并且宣布如果继续使用的话,风险自负。
(3)Nacos 同时支持 AP 与 CP,默认是 AP,同时功能更丰富,与 SpringCloud Alibaba 的兼容性更好,使用更简单灵活,可以满足更多的业务场景,且支持 K8S 的集成。
不同的服务注册中心组件的应用场景不同,读者可以根据自己的业务情况进行选型。但下文我们主要以 Nacos 注册中心为例进行介绍,其他几种注册中心读者自行上网查阅
1、Nacos 注册中心的搭建:
我们先去 Nacos 的 Github(Tags · alibaba/nacos · GitHub)下载我们所需的 Nacos 版本,可以选择 windows 或者 Linux,如下图:

由于当时在搭建项目的时候,考虑到与 SpringBoot 和 SpringCloud 的版本对应问题,我这里是下载了 2.0.0 的版本进行搭建,读者可以根据自己的情况选择对应的 Nacos 版本。

1.1、Windows 环境:
下载并解压 nacos-server-2.0.0.zip,解压完成后进入 /bin 目录,可以看到下面两个脚本:
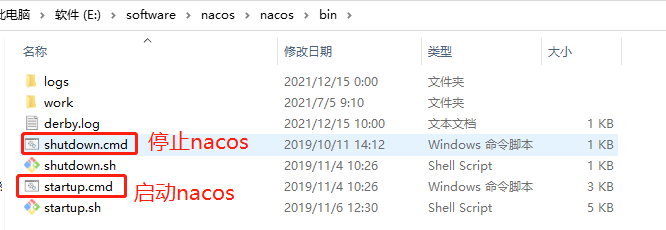
windows 环境直接运行 startup.cmd 启动项目,出现以下界面则启动完成:
在浏览器输入 http://localhost:8848/nacos 进入Nacos的登录界面,用户名与密码默认都是 nacos,登录成功后界面如下:
1.2、Linux 环境:
Nacos 在 Linux 环境下的启停跟在 windows 环境的启停基本一致,先下载 nacos-server-2.0.0.tar.zip 压缩包,然后上传到 Linux 服务器上进行解压(解压命令:tar -zxvf nacos-server-2.0.0.tar.gz),解压完成后同样进入 /bin 目录执行启动命令(单机模式启动命令:sh startup.sh -m standalone),启动完成后再访问 nacos 控制台地址(http://服务器ip地址:8848/nacos/index.html)验证是否成功启动即可。
2、SpringBoot 整合 Nacos 进行服务注册发现:
我们首先看一下 nacos 的简单架构图:
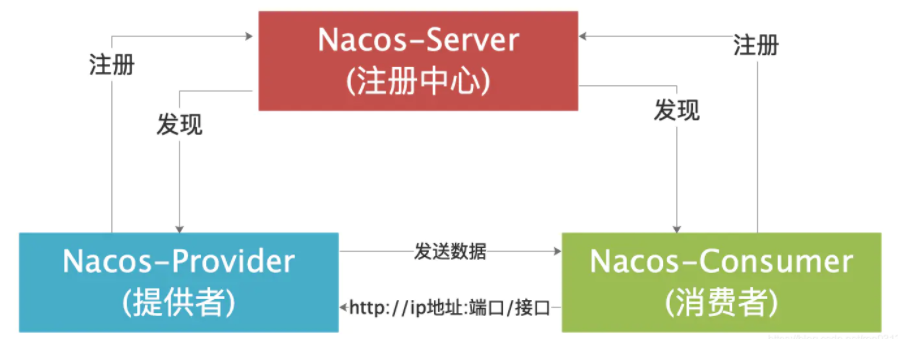
参照上面的架构图,我们分别创建两个模块,分别是 cloud-producer-server(服务提供者)、cloud-consumer(服务消费者),职责如下:
- cloud-producer-server:注册进入nacos-server,对外暴露服务
- cloud-consumer:注册进入nacos-server,调用 cloud-producer-server 的服务
创建这两个模块前,我们先声明项目的版本信息:
<spring-boot.version>2.3.2.RELEASE</spring-boot.version><spring-cloud.version>Hoxton.SR9</spring-cloud.version><spring-cloud-alibaba.version>2.2.6.RELEASE</spring-cloud-alibaba.version><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>${spring-boot.version}</version><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><!-- 声明 springCloud Alibaba 版本 --><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>${spring-cloud-alibaba.version}</version>
2.1、创建服务提供者 cloud-producer-server:
(1)引入maven依赖:
<!-- 引入阿里的nacos作为服务注册中心 --><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
(2)添加 nacos 相关的配置信息:
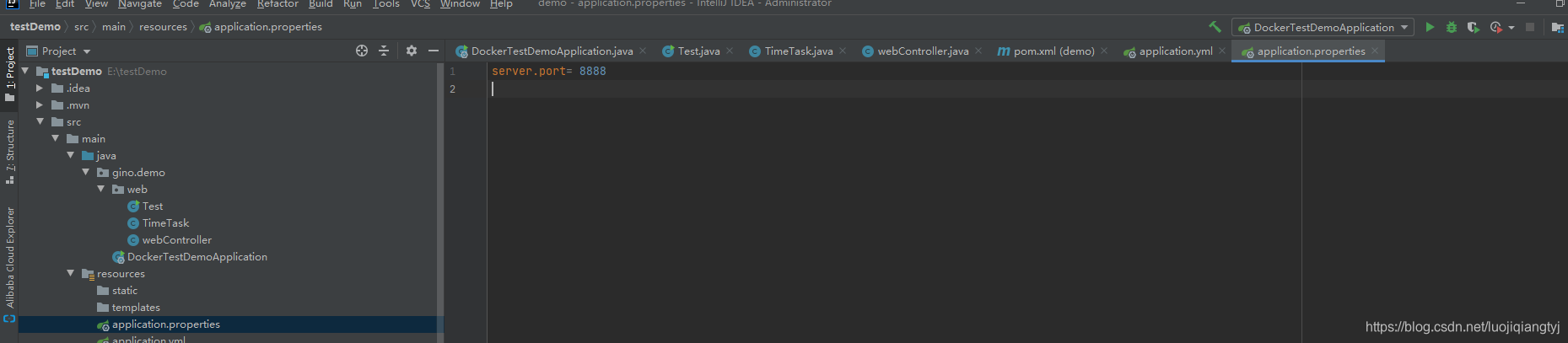
在 application.properties 配置文件指定服务名称、端口号、nacos-server 的地址信息,如下:
spring.application.name = cloud-producer-serverserver.servlet.context-path = /${spring.application.name}spring.cloud.nacos.discovery.server-addr = localhost:8848spring.cloud.nacos.discovery.namespace = 91b5489b-d009-4725-86fa-534f760b4d04spring.cloud.nacos.discovery.register-enabled = true
(3)开启服务注册发现的功能:
在主 Application 启动类加入 @EnableDiscoveryClient 注解开启服务注册发现的功能,如下:
public class ProducerApplicationpublic static void main(String[] args) SpringApplication.run(ProducerApplication.class, args);
(4)实现个演示功能:
cloud-producer-server 作为服务提供者注册到 nacos 中,肯定需要提供个服务来供消费者 cloud-consumer 调用,下面简单写一个演示接口:
@RequestMapping (value = "/")public class CloudControllerpublic String getSum(@RequestParam (value = "num1") Integer num1, @RequestParam (value = "num2") Integer num2)return "success:两数求和结果=" + (num1 + num2);
(5)启动项目:
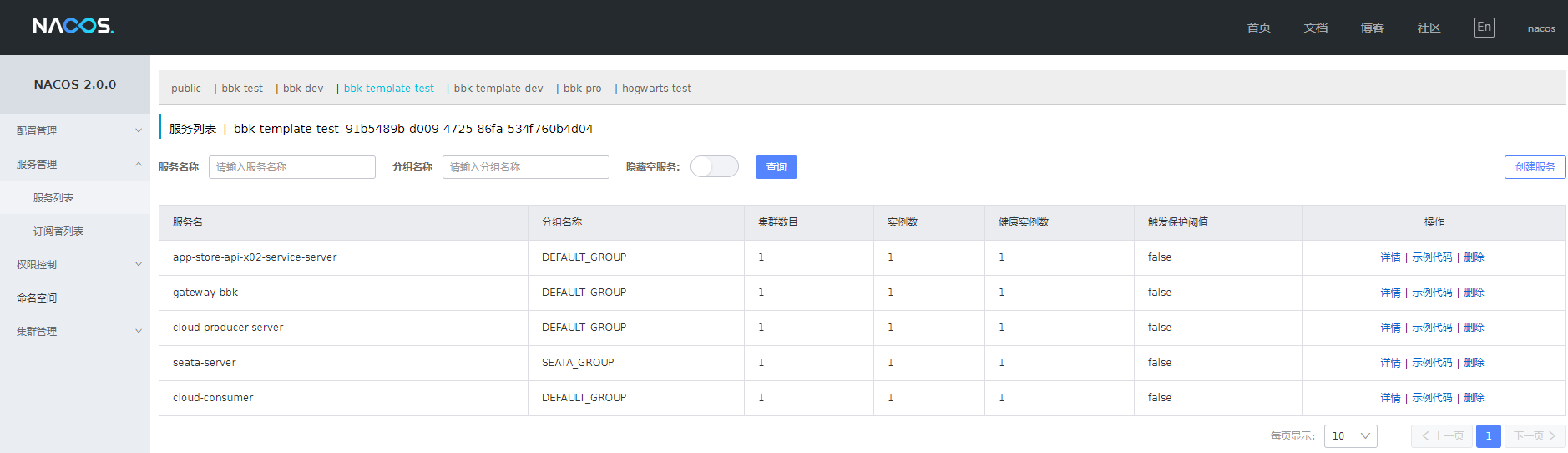
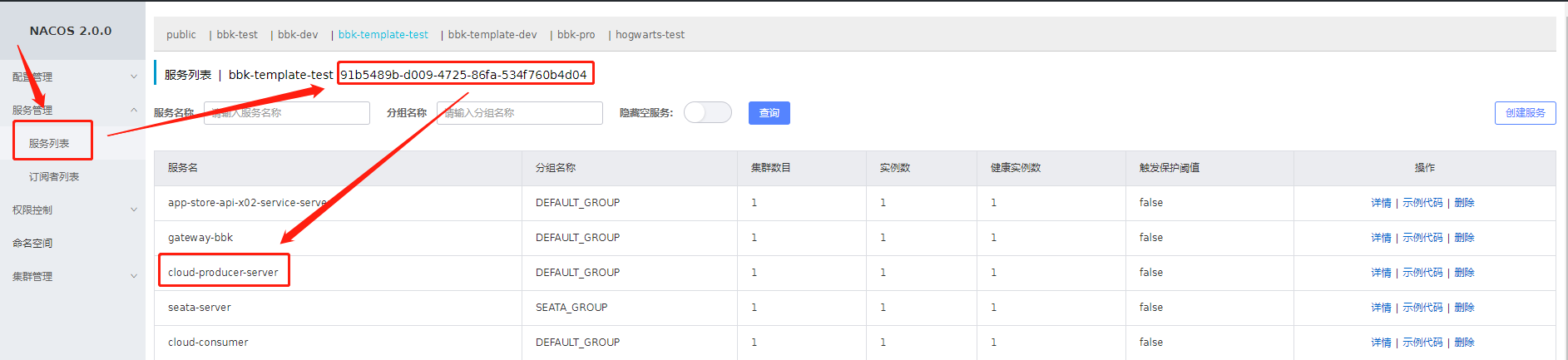
启动项目之后,我们进入 nacos 控制台,在 nacos 的 “服务管理->服务列表” 的 “91b5489b-d009-4725-86fa-534f760b4d04” 空间中将会发现注册进入的 cloud-producer-server 这个服务,如下图:
2.2、创建服务消费者 cloud-consumer:
服务消费者的创建步骤与服务提供者基本一致
(1)引入maven依赖:
<!-- 引入阿里的nacos作为服务注册中心 --><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
(2)添加 nacos 相关的配置信息:
spring.application.name = cloud-consumerspring.cloud.nacos.discovery.server-addr = localhost:8848spring.cloud.nacos.discovery.namespace = 91b5489b-d009-4725-86fa-534f760b4d04spring.cloud.nacos.discovery.register-enabled = true
(3)开启服务注册发现的功能:
public class ConsumerApplicationpublic static void main(String[] args)SpringApplication.run(ConsumerApplication.class, args);
(4)调用服务提供方的演示功能:
cloud-producer-server 服务提供方提供一个演示功能,那我们如何调用该功能呢?其实 Nacos 集成了 Ribbon(有关 Ribbon 的详细介绍请参考这篇文章:https://blog.csdn.net/a745233700/article/details/122916856),因此我们便能使用 Ribbon 的负载均衡来调用服务,步骤如下:
① 创建 RestTemplate,使用 @LoadBalanced 注解标注开启负载均衡:
public RestTemplate restTemplate(){return new RestTemplate();
② 通过 RestTemplate 请求远程服务地址并接收返回值
@RequestMapping (value = "api/invoke")public class InvokeControllerprivate RestTemplate restTemplate;@ApiOperation (value = "RestTemplate", notes = "使用RestTemplate进行远程服务调用,并使用Ribbon进行负载均衡")@GetMapping ("getByRestTemplate")public String getByRestTemplate(Integer num1, Integer num2)String url = "http://cloud-producer-server/cloud-producer-server/getSum"; MultiValueMap<String, Object> params = new LinkedMultiValueMap<>(); params.add("num1", num1); params.add("num2", num2);return restTemplate.postForObject(url, params, String.class);
(5)启动测试,查看nacos注册中心控制面板情况
启动成功后将会在 nacos 中的服务列表中看到 cloud-consumer,如下图:

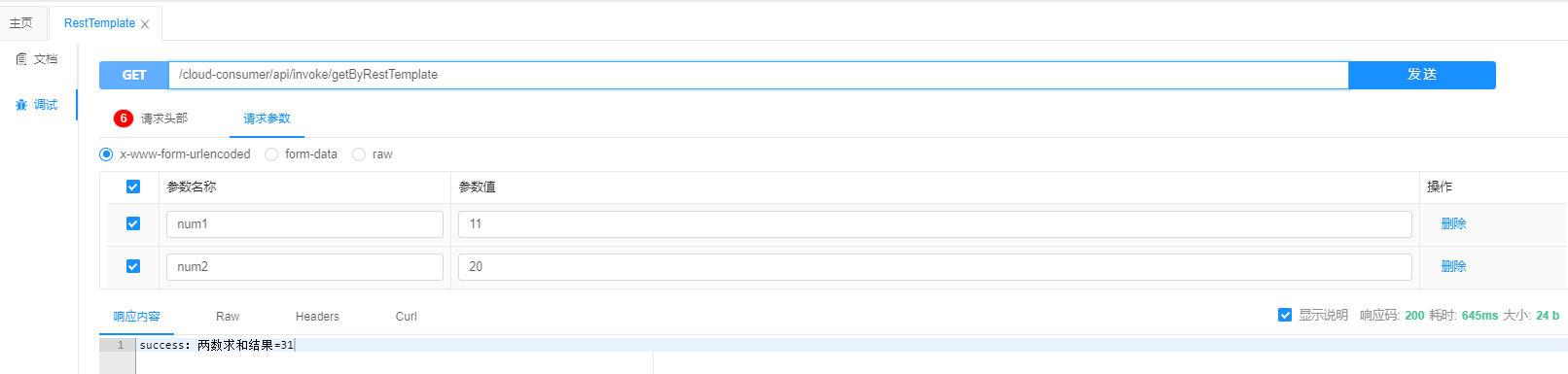
那么接下来就测试下服务能否调的通?访问服务消费方的 api/invoke/getByRestTemplate接口,可以看到请求结果如下:
3、Nacos 的集群化部署:
前面的介绍中,我们并未对 Nacos 服务端做任何特殊的配置,一切均以默认的单机模式运行,但是单机运行模式仅适用于学习与测试环境,对于有高可用要求的生产环境显然是不合适的。那我们怎么搭建支持高可用的集群环境呢?
在搭建 Nacos 集群前,我们需要先修改 Nacos 的数据持久化配置为 MySQL 存储。默认情况下,Nacos 使用内嵌的数据库 Derby实现数据的存储,这种情况下,如果启动多个默认配置下的 Nacos 节点,数据存储是存在一致性问题的。为了解决这个问题,Nacos 采用了集中式存储的方式来支持集群化部署,但目前 Nacos 只支持 MySQL 的存储,且版本要求:5.6.5+
3.1、Nacos 配置的持久化:
(1)初始化 MySQL 数据库:
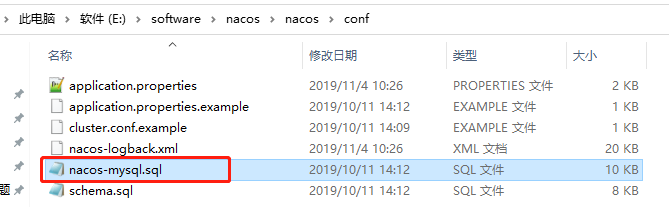
首先在 MySQL 中新建一个数据库 nacos-config(名称随意),然后执行 Nacos 中的SQL脚本,该脚本是 Nacos-server 的 conf 文件夹中的 nacos-mysql.sql,如下图:
执行该脚本,将会自动创建表,如下图:

(2)修改 conf/application.properties 配置文件:
Nacos-server 也是一个Spring Boot 项目,想要连接自己的数据库,当然要配置数据源了,配置文件同样在 Nacos-server 中的 conf 目录下,如下图:
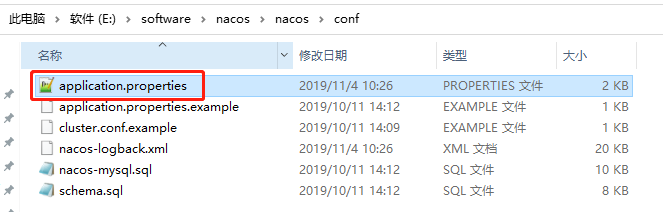
只需要将 application.properties 中的 Mysql 配置成自己的数据源并重启 Nacos-server 即可 ,如下:
spring.datasource.platform=mysql# 注意MySQL8.0以上版本指定url时一定要带入serverTimezone参数db.url.0=jdbc:mysql://localhost:3306/nacos_config?serverTimezone=Asia/Shanghai&characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=truenacos.cmdb.dumpTaskInterval=3600nacos.cmdb.eventTaskInterval=10nacos.cmdb.labelTaskInterval=300nacos.cmdb.loadDataAtStart=false
3.2、Nacos 集群化部署:
Nacos 官方推荐在生产环境使用集群模式部署,这样可以避免单点故障,集群化部署的架构图如下:
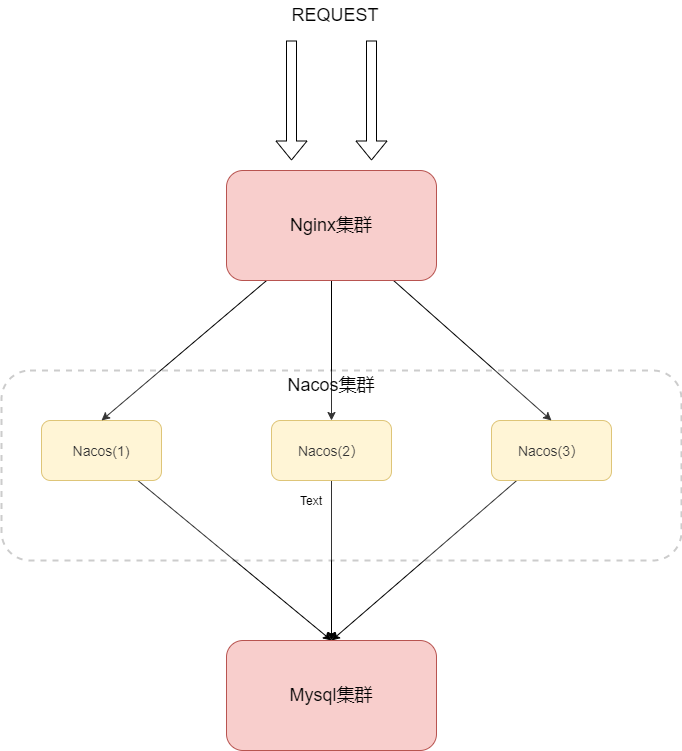
请求先通过 Nginx 集群进行转发到 Nacos 集群中,当然为了保持高可用,数据库也需要是集群模式。那么接下来我们就演示下搭建 Nacos 集群的方法。
由于条件限制,我们仅在一台服务器上启动三个Nacos服务演示。Nacos的端口分别为8848、8849、8850。
(1)修改端口号:
Nacos 默认的端口号是 8848,那么如何修改端口呢?只需要修改 conf 目录下的 application.properties 中的 server.port 即可,如下图:

(2)修改集群配置:
那么如何配置集群呢?在 conf 目录下有一个 cluster.conf.example 文件,如下图:
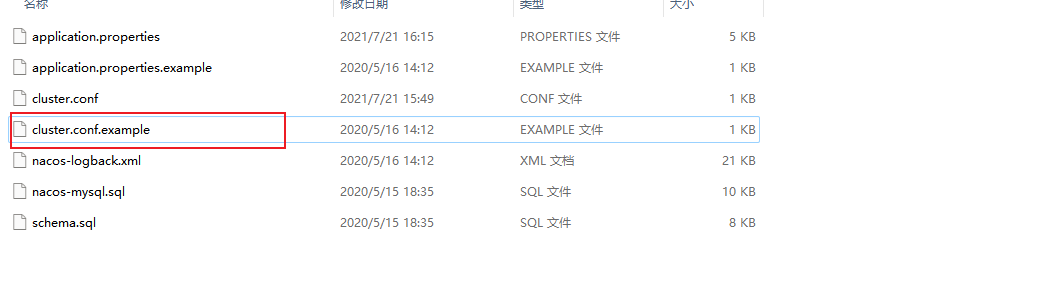
只需要将 cluster.conf.example 这个文件复制一份为 cluster.conf 放在 conf 目录下,其中配置的内容如下:
172.16.1.84:8848
172.16.1.84:8849
172.16.1.84:8850
(3)修改数据源:
这个在持久化的那里已经讲过了,只需要将 application.properties 中的数据源替换掉,如下:
spring.datasource.platform=mysql# 注意MySQL8.0以上版本指定url时一定要带入serverTimezone参数db.url.0=jdbc:mysql://localhost:3306/nacos_config?serverTimezone=Asia/Shanghai&characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=truenacos.cmdb.dumpTaskInterval=3600nacos.cmdb.eventTaskInterval=10nacos.cmdb.labelTaskInterval=300nacos.cmdb.loadDataAtStart=false
(4)启动Nacos:
经过上述的步骤 Nacos 集群已经配置好了,启动 Nacos 成功后,访问任意一个端口的 Nacos 服务,在 “集群管理->节点列表” 中将会看到自己搭建的三个节点,如下图:
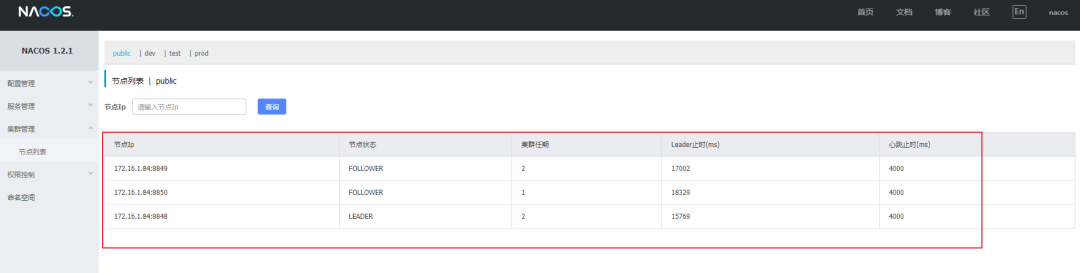
至此,Nacos集群算是搭建完成了
(5)Nginx 中的配置:
此处就不演示Nginx集群搭建了,直接在单机的Nginx中配置。直接修改nginx的conf文件,内容如下:
(6)项目中配置 server-addr:
既然搭建了集群,那么项目中也要配置一下,有两种方式,下面分别介绍:
第一种:通过直连的方式配置,如下:
name: cloud-producer-server # nacos的服务地址,nacos-server中IP地址:端口号 server-addr: 172.16.1.84:8848,172.16.1.84:8849,172.16.1.84:8850
第二种:直接连接Nginx,如下:
name: cloud-producer-server # nacos的服务地址,nacos-server中IP地址:端口号server-addr: 172.16.1.84:80
Nacos 集群搭建非常简单,唯一的配置就是在 cluster.conf 中设置三个 Nacos 服务的地址。
相关阅读:
常见的服务器架构入门:从单体架构、EAI 到 SOA 再到微服务和 ServiceMesh
常见分布式理论(CAP、BASE)和一致性协议(Gosssip协议、Raft一致性算法)
SpringCloud OpenFeign 远程HTTP服务调用用法与原理
Sentinel-Dashboard 与 apollo 规则的相互同步
Spring Cloud Gateway 服务网关的部署与使用详细介绍
Spring Cloud Gateway 整合 sentinel 实现流控熔断
Spring Cloud Gateway 整合 knife4j 聚合接口文档
参考文章:
idea中定义日志模板_idea自定义代码提示 日志输出模版_斜月三的博客-CSDN博客
在开发过程中,充分利用idea的一些功能,能够让开发达到事半功倍的效果。今天介绍两种日志模板的定义。
两种类型日志
类型一(多用于类下面)、
private static final Logger logger = LoggerFactory.getLogger(OptionalTest.class);
类型二(多用于方法中)、
log.info("OptionalTest类,main方法,15行:{}","");
开始之前,先File->Settings->Editor->Live Templates->点击右侧+号->Template Group
创建一个自己的模板组,可以用来存方自己创建的模板。我这边建了一个模板组叫myself。

之后选中自己创建的模板组,继续点击+号,选择Live Template,就可以创建自己的模板了,如下:

1. Abbreviation:就是你想用的缩写;
2. Description:就是你想添加的描述;
3. Template text:把你想要的模板写上;
4.
5. Edit Variables:这里就可以在Expression中选择代表的变量,定义4中的变量所代表的含义,如下:

一路OK,设置完成,接下来看成果:

在类中输入logger,右边可以看到刚才定义的描述,enter确认,就会自动补全如下:

之后导入Logger和LoggerFactory依赖就可以了,如下:

好了,之后就可以自由使用了,啦啦啦德玛西亚。
对于配置类型二:log.info("OptionalTest类,main方法,15行:{}","");
几乎是同样的道理,话不多说,看图:

上面定义的这些参数,都是在Edit variables中配置的,如下:

无非是参数多几个而已,有时间的话可以好好了解Expression中的参数,各种代表什么意思等等,对开发是非常有帮助的,如下只是展示了一小部分:

ok,设置好后,来看看效果(我这边用了lombok的@slf4j注解,所以就不用定义logger了):

点击enter确认,效果如下:

看,最后还可以写上自己的文字描述这个log的意义:

方便吧!好了,定义自己的模板就是这种方法,灵活运用,举一反三,大佬就是你自己!
最后,不以时迁者,松柏也。加油!
有赞滑块简易分析_qq_30710677的博客-CSDN博客

于 2022-04-15 11:22:18 首次发布
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
基本的滑块流程可以分为以下几步
请求一个地址url0 获取返回值 其中包含 关键字符串 还有一个token 用于认证
然后使用token 获取 图片的url
根据滑块操作 对轨迹数据进行加密获取 并和 token 一同请求 成功 true 失败 false
认证成功后 token就会变成ticket 也就是通行证 并参与后续的请求
首先是获取关键参数

然后进行滑块操作

显然其中的userBehaviorData是加密的参数 解决方法有很多 直接全局搜索或者跟踪堆栈 都是可以的,
这里因为是很有特征的字符串 所以 直接搜索

在这里就可以一步一步跟踪了
之后就是分析轨迹拼接参数
先看成果吧

目前完成了py和易语言的程序
由于全部基于opencv 所以准确率非常高
后续继续更新吧
极验滑块 3代4代
Python-Opencv 识别滑块验证码缺口位置(三)_js opencv缺口识别_码王吴彦祖的博客-CSDN博客
Python-Opencv 识别滑块验证码缺口位置
本篇主要围绕opencv中的两个部分:模板匹配
之前的两篇文章讲过利用边缘检测来提取滑块的轮廓,当遇到提取的轮廓有多条时,在去筛选,到最后的效果也不一定很好,所以可以使用另一种方法来检测却缺口,有的滑块,是包含一个小图,和一个大图的,小图是从大图中的一部分抠出来的,这个时候,就可以用到opencv中的模板匹配功能,模板匹配,可以将小图,匹配到大图中缺口的那个区域,这样,也能达到检测滑块缺口的效果,下面来看实战
首先是数据集




上述的数据集可能需要注意一下,在你把下图拿下来之后,可以看到,我的小图,上下两边还会有白色的填充区域存在,那么在进行模板匹配之后的效果可能不会很好,所以先要对小图进行一些处理&
文章知识点与官方知识档案匹配,可进一步学习相关知识
【微服务笔记(十)】之Spring Cloud Gateway网关,路由,过滤器_spring.cloud.gateway.routes.filters_开发小鸽的博客-CSDN博客
本文章由公号【开发小鸽】发布!欢迎关注!!!
一. Spring Cloud Gateway网关
(一) 概述
Spring Cloud Gateway是Spring自己开发的网关服务,基于Filter链提供网关基本功能:安全,监控,限流,能够为微服务架构提供简单,有效且统一的API路由管理。
(二) 原理
Spring Cloud Gateway组件的核心是过滤器,通过这些过滤器可以将客户端发送的请求路由到对应的微服务。Spring Cloud Gateway是设置在微服务前端的防火墙和代理器,能够隐藏微服务节点的ip端口信息,从而加强安全保护。一切来自客户端的请求或者是服务内部调用,只要是对服务的请求都可以经过网关,然后通过网关来验证,路由。
(三) 概念
1. 路由(route)
路由信息由一个ID,一个目的URL,一组断言工厂,一组Filter组成。如果路由断言为真,说明请求URL和配置路由匹配。
2. 断言(Predicate)
断言函数允许开发者自定义匹配来气Http Request中的任何信息。
3. 过滤器(Filter)
Filter分为两种,一种是Gateway Filter, 一种是Global Filter,过滤器会对请求和响应进行修改处理。
(四) Gateway项目实战
1. 需求分析
需求是将包含有/user的URL请求路由到http://localhost:8080/user/id中
2. 创建工程
创建一个Maven工程springcloud-gateway。
3. 添加依赖
需要添加两个依赖,一个是gateway的,还有一个是Eureka client的,因为gateway本身也是一个服务,需要注册到Eureka Server中。
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
<version></version>
</dependency>
</dependencies>4. 创建引导类即配置文件
在引导类上添加@EnableDiscoveryClient注解表示能够发现Eureka Server,并注册到Eureka Server中。
package com.gateway;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@SpringBootApplication
@EnableDiscoveryClient
public class GatewayApp {
public static void main(String[] args) {
SpringApplication.run(GatewayApp.class, args);
}
}设置application.yml,基础的设置不用过多说明,主要是网关gateway的配置。在gateway的routes下有多个路由,每个路由表示一种路由方式。id表示路由的id,可以任意编写;uri表示要代理的服务地址,即路由到的服务地址;predicates表示断言,可以有多个断言,断言即判断请求是否满足断言的条件,如Path路径中含有/user时就进行路由。
server:
port: 8084
spring:
application:
name: api-gateway
cloud:
gateway:
routes:
#路由id
- id: user-service-route
#代理的服务地址
uri: http://127.0.0.1:8080
#路由断言
predicates:
- Path=/user5. 测试
通过访问网关的端口8084,并且在路径中添加/user/7,符合路由的断言,那么该请求就会被路由到8080的服务地址,并且路径中的/user/7同样被添加到访问服务的请求URL中,访问成功。
二. 面向服务的路由
(一) 概述
当同一个服务有多个实例的话,需要使用动态路由来从网关路由到相应的服务地址,这就需要修改之前设置的网关的uri,使用服务的服务名称来动态路由。当uri使用的协议为lb时,网关将使用LoadBalncerClient把user-service通过eureka解析为实际的主机和端口,并进行Ribbon负载均衡。
(二) 修改网关配置
修改网关的配置文件,将路由的uri修改为 lb://服务名称 这种格式。
uri: lb://user-service三. 路由前缀处理
(一) 概述
用户发送请求到网关时,不一定是正确的请求地址,可能会有所偏差,这时就需要我们来为用户修正请求地址了。
(二) 添加前缀
通过配置路由的过滤器PrefixPath,实现映射路径中地址的添加。添加如下参数:
Spring:
cloud:
gateway:
routes:
- id: user-service-route
uri: lb://user-service
predicates:
-Path=上面的配置中,断言的路径是所有路径,它将所有的路径都放进来,但是在过滤器中添加了路径的前缀 /user,即为所有进来的请求路径中都添加了/user 前缀,如请求为localhost:8084/7,进来以后就变为了localhost:8084/user/7。
(三) 去除前缀
同理,通过配置StripPrefix,可以将映射路径中地址的前缀去除。StipPrefix的值为要去掉前缀的个数,以”/”为分割线。如请求路径为/api/user/**,那么当StripPrefix为1时,就去掉/api,当StipPrefix为2时,就去掉/api/user。
Spring:
cloud:
gateway:
routes:
-id: user-service-route
uri: lb://user-service
predicates:
-Path=/api/user四. 过滤器
(一) 概述
过滤器为网关实现请求的鉴权功能,Gateway自带了几十个过滤器,能够为用户的请求修改很多参数。如:AddRequestHeader能够对匹配上的请求添加Header,AddRequestParematers能够为匹配上的请求路由添加参数,AddResponseHeader能够为从网关上返回的响应添加Header。
(二) AddResponseHeader过滤器示例
在网关的配置文件中添加过滤器的配置,本次添加的是全局的默认过滤器,对所有路由都有效,如下所示:
spring:
cloud:
gateway:
routes:
…
default-filters:
-AddResponseHeader=X-Response-Foo, Bar过滤器的值为两个,第一个是要添加的参数名,第二个是该参数的值。
(三) 过滤器类型
1. 局部过滤器
通过spring.cloud.gateway.routes.filters 配置在具体的路由下面,只作用在当前路由上,自带的过滤器都可以配置或者自定义的过滤器。像我们上面配置spring.cloud.gateway.default-filters可以对所有的路由生效,这是一种全局的过滤器,但是这些过滤器的实现都是要实现GatewayFilterFactory接口的。
2. 全局过滤器
全局过滤器不需要再配置文件中配置,作用在所有的路由中,实现GlobalFilter接口即可。
(四) 过滤器执行生命周期
在过滤器执行的前后可以执行一些操作,即通过过滤器的GatewayFilterChain执行filter方法的前后来实现。
如,请求鉴权时,在执行filter方法之前,进行鉴定访问权限,执行过滤器后,如果没有权限,就返回空。同样的,在异常处理时,执行filter方法后,记录异常并返回异常。
(五) 自定义局部过滤器
1. 需求分析
编写并配置一个自定义的局部过滤器,该过滤器可以通过配置文件中的参数名称获取请求的参数值。如将请求http://locahost:8084/user/8?name=xx中的参数name的值获取并且输出到控制台。注意,自定义过滤器的名称是由固定的后缀GatewayFilterFactory的,前面可以添加自定义的名称,如在前面加上MyParam,则自定义过滤器的名称为MyParamGatewayFilterFactory,在配置时只需要配置MyParam即可。
2. 配置文件
在网关的配置中添加自定义的过滤器,如下所示:
spring:
cloud:
gateway:
routes:
-id:user-service-route
uri: lb://user-service
predicates:
-Path=/api/user3. 创建自定义过滤器
(1)创建配置类
创建自定义的过滤器MyParamGatewayFilterFactory,过滤器都要继承一个抽象类AbstractGatewayFilterFactory<>,需要传入一个泛型,我们在配置中配置了参数name,但是无法得知name的值的类型。因此需要创建一个配置类,动态地获取参数name的值,并将该类传到泛型的位置。
public class MyParamGatewayFilterFactory extends AbstractGatewayFilterFactory<MyParamGatewayFilterFactory.Config>{
public static class Config{
private String param;
public String getParam(){
return param;
}
public void setParam(String param){
this.param=param;
}
}
}(2)添加构造函数
public MyParamGatewayFilterFactory(){
super(Config.class);
}(3)添加shortcutFieldOrder函数
该函数的作用是将配置类中的参数添加到列表中,这样才能够从配置文件中读取数据。注意PARAM-NAME的值要和配置类中的参数名一致,都为param。
static final String PARAM_NAME = “param”;
public List<String> shortcutFieldOrder(){
return Arrays.asList(PARAM_NAME);
}(4)重写apply方法
apply方法是过滤器的逻辑所在,如何过滤是该方法编写的内容。传入配置类作为参数,通过获取请求Request,判断请求参数中是否包含了我们需要的参数,如果有,就打印该参数。注意,此时在配置类中的config.param指的就是我们在网关的配置中填入的name参数。
@Override
public GatewayFilter apply(Config config) {
return (exchange, chain) -> {
ServerHttpRequest request = exchange.getRequest();
if(request.getQueryParams().containsKey(config.param)){
request.getQueryParams().get(config.param).forEach(value-> System.out.printf("局部过滤器 : %s = %s", config.param, value ));
}
return chain.filter(exchange);
};
}(5) 测试
正常地通过网关进行访问,当我们在访问的url后面添加name参数时,如localhost:8084/7?name=xx控制台就会打印name参数的值xx了。
(六) 自定义全局过滤器
1. 需求分析
定义一个全局过滤器,检查请求地址是否携带token参数,若token参数存在则放行;如果token参数不存在则设置返回的状态码为:未授权不再继续执行。
2. 创建全局过滤器
全局过滤器需要继承GlobalFilter类,如果想让过滤器的执行有序的话,还要继承Ordered类。重写filter方法与getOrder方法,filter方法中编写的是过滤器的过滤逻辑,判断获取请求的参数中是否有token参数,如果有则继续执行,如果没有则停止执行。getOrder方法是用于过滤器的排序,返回的值越小就越先执行。
public class MyGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
System.out.println("去哪聚过滤器: ");
String token = exchange.getRequest().getQueryParams().getFirst("token");
if(StringUtils.isBlank(token)){
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete();
}
return chain.filter(exchange);
}
@Override
public int getOrder() {
return 1;
}
}(七) Gateway的跨域问题
跨域问题是在JS的请求中,如果访问的地址与当前服务器的域名,ip或者端口号不一致则成为跨域请求,若不能跨域则无法获取到请求地址的返回结果。因此,我们需要在网关中解决跨域问题,直接在网关中配置即可,配置有哪些服务是可以跨域请求的。配置如下:
Spring:
cloud:
gateway:
globalcors:
cors-configurations:
'[/**]':
#表示允许访问的服务器地址
allowedOrigins:
- "http://doc.spring.io"
allowedMethods:
- GETallowedOrigins表示指定允许访问的服务器地址
allowedMethods表示允许的方法
‘[/**]’表示对所有访问到网关服务器的请求地址。
因此上面的配置表示可以允许来自http://docs.spring.io的get请求方法获取服务数据。
(八) Gateway的高可用
在服务内部之间访问时,可以通过启动多个Gateway服务,形成集群自动负载均衡。在外部访问Gateway时,这些请求无法通过Eureka进行负载均衡,需要使用其他的服务网关来对Gateway进行代理,如Nginx。
(九) Gateway与Feign的区别
Gateway用于外部请求对微服务的调用,Feign则是将当前微服务的部分服务接口暴露出来,主要用于各个微服务之间的服务调用。
(32条消息) Y赞滑块逆向_肥宅胖的博客-CSDN博客
好久没写文章了,最近刚转正比较忙,今天有空把业务中写过的一个滑块来给大家讲讲吧。
话不多说直接上网站:aHR0cHMlM0EvL2FjY291bnQueW91emFuLmNvbS9sb2dpbg==
直接开搞:
第一步;抓包分析:

我们多刷新抓几次包分析可以得到下面这些结论:
token:统一请求标识
bizType:固定
bizData:
captchaType:固定
userBechaviorData:轨迹加密**
我们发现token是前面返回的那么整个接口加密就剩一个userBehaviorData了
那就简单了啊 我们直接全局搜索:

找到位置打上断点,在滑一次滑块。
在控制台输出一下加密的值:

然后输出一下加密后的结果:

果然是这个地方,那我们只需要构造出来加密参数,和扣出加密算法就行了。
来
喽他!
加密参数的分析:
“{“cx”:230,“cy”:43,“scale”:0.5,“slidingEvents”:[{“mx”:40,“my”:211,“ts”:1595474135296},{“mx”:1,“my”:0,“ts”:39},{“mx”:3,“my”:0,“ts”:8},{“mx”:5,“my”:0,“ts”:9},{“mx”:5,“my”:0,“ts”:7},{“mx”:7,“my”:0,“ts”:9},{“mx”:9,“my”:-1,“ts”:7},{“mx”:14,“my”:-1,“ts”:9},{“mx”:14,“my”:-1,“ts”:7},{“mx”:14,“my”:-2,“ts”:9},{“mx”:14,“my”:-2,“ts”:7},{“mx”:17,“my”:-1,“ts”:9},{“mx”:20,“my”:-1,“ts”:8},{“mx”:20,“my”:-1,“ts”:8},{“mx”:24,“my”:0,“ts”:8},{“mx”:20,“my”:-2,“ts”:8},{“mx”:20,“my”:-1,“ts”:8},{“mx”:17,“my”:-1,“ts”:8},{“mx”:13,“my”:0,“ts”:8},{“mx”:11,“my”:0,“ts”:8},{“mx”:15,“my”:0,“ts”:7},{“mx”:11,“my”:0,“ts”:8},{“mx”:9,“my”:0,“ts”:8},{“mx”:6,“my”:0,“ts”:8},{“mx”:3,“my”:1,“ts”:10},{“mx”:3,“my”:0,“ts”:6},{“mx”:1,“my”:0,“ts”:8}]}”
我们观察到他的json格式都为x,y,t 格式
“cx”:230,“cy”:43,“scale”:0.5
前面这里我们猜测cx=230为滑块缺口,cy=43为鼠标点击高度,scale=0.5为滑动时间。
[{“mx”:40,“my”:211,“ts”:1595474135296}
后面这一部分json我们猜测是在一段时间是收集x和y和t的移动距离
ts在[6,7,8,9,10]这个区间里,那么我们只需要将全部x坐标加起来等于230,就知道他是不是这样检测的。
我们发现结果不等于,所以我们暂时不知道他是检测什么的遇到这种情况我们直接写死试试,最后发现果然
他自己都不会检测这个轨迹。
所以我们直接保存一条轨迹出来,替换里面的时间戳和终点坐标就行。
def distcance(juli):
x='{"cx":'+str(int((juli)/2))+',"cy":18,"scale":0.5,"slidingEvents":[{"mx":40,"my":196,"ts":'+str(int(time.time()*1000))+'}' \
',{"mx":1,"my":0,"ts":1},{"mx":1,"my":-1,"ts":8},{"mx":1,"my":0,"ts":8},{"mx":4,"my":0,"ts":9},{"mx":3,"my":-1,"ts":7},' \
'{"mx":7,"my":-1,"ts":8},{"mx":12,"my":-1,"ts":7},{"mx":12,"my":-1,"ts":9},{"mx":19,"my":-2,"ts":7},{"mx":22,"my":-1,"ts":9},' \
'{"mx":31,"my":-2,"ts":7},{"mx":33,"my":-1,"ts":8},{"mx":35,"my":-2,"ts":8},{"mx":38,"my":0,"ts":8},{"mx":42,"my":-2,"ts":8},' \
'{"mx":43,"my":0,"ts":8},{"mx":43,"my":0,"ts":8},{"mx":44,"my":0,"ts":8},{"mx":46,"my":0,"ts":8},{"mx":38,"my":0,"ts":8},' \
'{"mx":38,"my":0,"ts":8},{"mx":33,"my":-1,"ts":8},{"mx":25,"my":-2,"ts":8},{"mx":19,"my":0,"ts":8},{"mx":15,"my":0,"ts":8},' \
'{"mx":9,"my":-1,"ts":8},{"mx":11,"my":0,"ts":8},{"mx":4,"my":-1,"ts":8},{"mx":6,"my":0,"ts":8},{"mx":1,"my":0,"ts":8}]}'
with open(r'get_data.js', 'r', encoding='UTF-8')as f:
ua_js = f.read().encode().decode("gbk", 'ignore')
js_data = execjs.compile(ua_js)
key = js_data.call('get', x)
return key
参数分析完了 ,我们来分析加密函数:
逆向userBechaviorData算法
为对称加密AES,采用cbc填充方式,iv为偏移值
我们可用python进行改写,也可以直接扣js
这里我们采用直接扣去js的方法

我们跟进去发现:
他所有的方法都在这个里面

但是我们直接抠下来并不能直接用,因为他被
void 0 === (r = function(t, e, n) {})
包着的我们需要自己稍微改写下:
var wGdk = function(t, e, n) {
var r;
var r, o, i = i || function(t, e) {
var n = {}, r = n.lib = {}, o = function() {}, i = r.Base = {
extend: function(t) {
o.prototype = this;
var e = new o;
return t && e.mixIn(t), e.hasOwnProperty("init") || (e.init = function() {
e.$super.init.apply(this, arguments)
}), e.init.prototype = e, e.$super = this, e
},
create: function() {
var t = this.extend();
return t.init.apply(t, arguments), t
},
init: function() {},
mixIn: function(t) {
for (var e in t)
t.hasOwnProperty(e) && (this[e] = t[e]);
t.hasOwnProperty("toString") && (this.toString = t.toString)
},
clone: function() {
return this.init.prototype.extend(this)
}
}, u = r.WordArray = i.extend({
init: function(t, e) {
t = this.words = t || [], this.sigBytes = null != e ? e : 4 * t.length
},
toString: function(t) {
return (t || c).stringify(this)
},
concat: function(t) {
var e = this.words,
n = t.words,
r = this.sigBytes;
if (t = t.sigBytes, this.clamp(), r % 4) for (var o = 0; o < t; o++)
e[r + o >>> 2] |= (n[o >>> 2] >>> 24 - o % 4 * 8 & 255) << 24 - (r + o) % 4 * 8;
else if (65535 < n.length) for (o = 0; o < t; o += 4)
e[r + o >>> 2] = n[o >>> 2];
else e.push.apply(e, n);
return this.sigBytes += t, this
},
clamp: function() {
var e = this.words,
n = this.sigBytes;
e[n >>> 2] &= 4294967295 << 32 - n % 4 * 8, e.length = t.ceil(n / 4)
},
clone: function() {
var t = i.clone.call(this);
return t.words = this.words.slice(0), t
},
random: function(e) {
for (var n = [], r = 0; r < e; r += 4)
n.push(4294967296 * t.random() | 0);
return new u.init(n, e)
}
}),
a = n.enc = {}, c = a.Hex = {
stringify: function(t) {
var e = t.words;
t = t.sigBytes;
for (var n = [], r = 0; r < t; r++) {
var o = e[r >>> 2] >>> 24 - r % 4 * 8 & 255;
n.push((o >>> 4).toString(16)), n.push((15 & o).toString(16))
}
return n.join("")
},
parse: function(t) {
for (var e = t.length, n = [], r = 0; r < e; r += 2)
n[r >>> 3] |= parseInt(t.substr(r, 2), 16) << 24 - r % 8 * 4;
return new u.init(n, e / 2)
}
}, s = a.Latin1 = {
stringify: function(t) {
var e = t.words;
t = t.sigBytes;
for (var n = [], r = 0; r < t; r++)
n.push(String.fromCharCode(e[r >>> 2] >>> 24 - r % 4 * 8 & 255));
return n.join("")
},
parse: function(t) {
for (var e = t.length, n = [], r = 0; r < e; r++)
n[r >>> 2] |= (255 & t.charCodeAt(r)) << 24 - r % 4 * 8;
return new u.init(n, e)
}
}, f = a.Utf8 = {
stringify: function(t) {
try {
return decodeURIComponent(escape(s.stringify(t)))
} catch (t) {
throw Error("Malformed UTF-8 data")
}
},
parse: function(t) {
return s.parse(unescape(encodeURIComponent(t)))
}
}, l = r.BufferedBlockAlgorithm = i.extend({
reset: function() {
this._data = new u.init, this._nDataBytes = 0
},
_append: function(t) {
"string" == typeof t && (t = f.parse(t)), this._data.concat(t), this._nDataBytes += t.sigBytes
},
_process: function(e) {
var n = this._data,
r = n.words,
o = n.sigBytes,
i = this.blockSize,
a = o / (4 * i);
if (e = (a = e ? t.ceil(a) : t.max((0 | a) - this._minBufferSize, 0)) * i, o = t.min(4 * e, o), e) {
for (var c = 0; c < e; c += i)
this._doProcessBlock(r, c);
c = r.splice(0, e), n.sigBytes -= o
}
return new u.init(c, o)
},
clone: function() {
var t = i.clone.call(this);
return t._data = this._data.clone(), t
},
_minBufferSize: 0
});
r.Hasher = l.extend({
cfg: i.extend(),
init: function(t) {
this.cfg = this.cfg.extend(t), this.reset()
},
reset: function() {
l.reset.call(this), this._doReset()
},
update: function(t) {
return this._append(t), this._process(), this
},
finalize: function(t) {
return t && this._append(t), this._doFinalize()
},
blockSize: 16,
_createHelper: function(t) {
return function(e, n) {
return new t.init(n).finalize(e)
}
},
_createHmacHelper: function(t) {
return function(e, n) {
return new p.HMAC.init(t, n).finalize(e)
}
}
});
var p = n.algo = {};
return n
}(Math);
o = (r = i).lib.WordArray, r.enc.Base64 = {
stringify: function(t) {
var e = t.words,
n = t.sigBytes,
r = this._map;
t.clamp(), t = [];
for (var o = 0; o < n; o += 3)
for (var i = (e[o >>> 2] >>> 24 - o % 4 * 8 & 255) << 16 | (e[o + 1 >>> 2] >>> 24 - (o + 1) % 4 * 8 & 255) << 8 | e[o + 2 >>> 2] >>> 24 - (o + 2) % 4 * 8 & 255, u = 0; 4 > u && o + .75 * u < n; u++)
t.push(r.charAt(i >>> 6 * (3 - u) & 63));
if (e = r.charAt(64)) for (; t.length % 4;)
t.push(e);
return t.join("")
},
parse: function(t) {
var e = t.length,
n = this._map;
(r = n.charAt(64)) && -1 != (r = t.indexOf(r)) && (e = r);
for (var r = [], i = 0, u = 0; u < e; u++)
if (u % 4) {
var a = n.indexOf(t.charAt(u - 1)) << u % 4 * 2,
c = n.indexOf(t.charAt(u)) >>> 6 - u % 4 * 2;
r[i >>> 2] |= (a | c) << 24 - i % 4 * 8, i++
}
return o.create(r, i)
},
_map: "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
},
function(t) {
function e(t, e, n, r, o, i, u) {
return ((t = t + (e & n | ~e & r) + o + u) << i | t >>> 32 - i) + e
}
function n(t, e, n, r, o, i, u) {
return ((t = t + (e & r | n & ~r) + o + u) << i | t >>> 32 - i) + e
}
function r(t, e, n, r, o, i, u) {
return ((t = t + (e ^ n ^ r) + o + u) << i | t >>> 32 - i) + e
}
function o(t, e, n, r, o, i, u) {
return ((t = t + (n ^ (e | ~r)) + o + u) << i | t >>> 32 - i) + e
}
for (var u = i, a = (s = u.lib).WordArray, c = s.Hasher, s = u.algo, f = [], l = 0; 64 > l; l++)
f[l] = 4294967296 * t.abs(t.sin(l + 1)) | 0;
s = s.MD5 = c.extend({
_doReset: function() {
this._hash = new a.init([1732584193, 4023233417, 2562383102, 271733878])
},
_doProcessBlock: function(t, i) {
for (var u = 0; 16 > u; u++) {
var a = t[c = i + u];
t[c] = 16711935 & (a << 8 | a >>> 24) | 4278255360 & (a << 24 | a >>> 8)
}
u = this._hash.words;
var c = t[i + 0],
s = (a = t[i + 1], t[i + 2]),
l = t[i + 3],
p = t[i + 4],
h = t[i + 5],
d = t[i + 6],
v = t[i + 7],
g = t[i + 8],
y = t[i + 9],
m = t[i + 10],
b = t[i + 11],
x = t[i + 12],
w = t[i + 13],
_ = t[i + 14],
S = t[i + 15],
O = e(O = u[0], j = u[1], D = u[2], P = u[3], c, 7, f[0]),
P = e(P, O, j, D, a, 12, f[1]),
D = e(D, P, O, j, s, 17, f[2]),
j = e(j, D, P, O, l, 22, f[3]);
O = e(O, j, D, P, p, 7, f[4]), P = e(P, O, j, D, h, 12, f[5]), D = e(D, P, O, j, d, 17, f[6]), j = e(j, D, P, O, v, 22, f[7]), O = e(O, j, D, P, g, 7, f[8]), P = e(P, O, j, D, y, 12, f[9]), D = e(D, P, O, j, m, 17, f[10]), j = e(j, D, P, O, b, 22, f[11]), O = e(O, j, D, P, x, 7, f[12]), P = e(P, O, j, D, w, 12, f[13]), D = e(D, P, O, j, _, 17, f[14]), O = n(O, j = e(j, D, P, O, S, 22, f[15]), D, P, a, 5, f[16]), P = n(P, O, j, D, d, 9, f[17]), D = n(D, P, O, j, b, 14, f[18]), j = n(j, D, P, O, c, 20, f[19]), O = n(O, j, D, P, h, 5, f[20]), P = n(P, O, j, D, m, 9, f[21]), D = n(D, P, O, j, S, 14, f[22]), j = n(j, D, P, O, p, 20, f[23]), O = n(O, j, D, P, y, 5, f[24]), P = n(P, O, j, D, _, 9, f[25]), D = n(D, P, O, j, l, 14, f[26]), j = n(j, D, P, O, g, 20, f[27]), O = n(O, j, D, P, w, 5, f[28]), P = n(P, O, j, D, s, 9, f[29]), D = n(D, P, O, j, v, 14, f[30]), O = r(O, j = n(j, D, P, O, x, 20, f[31]), D, P, h, 4, f[32]), P = r(P, O, j, D, g, 11, f[33]), D = r(D, P, O, j, b, 16, f[34]), j = r(j, D, P, O, _, 23, f[35]), O = r(O, j, D, P, a, 4, f[36]), P = r(P, O, j, D, p, 11, f[37]), D = r(D, P, O, j, v, 16, f[38]), j = r(j, D, P, O, m, 23, f[39]), O = r(O, j, D, P, w, 4, f[40]), P = r(P, O, j, D, c, 11, f[41]), D = r(D, P, O, j, l, 16, f[42]), j = r(j, D, P, O, d, 23, f[43]), O = r(O, j, D, P, y, 4, f[44]), P = r(P, O, j, D, x, 11, f[45]), D = r(D, P, O, j, S, 16, f[46]), O = o(O, j = r(j, D, P, O, s, 23, f[47]), D, P, c, 6, f[48]), P = o(P, O, j, D, v, 10, f[49]), D = o(D, P, O, j, _, 15, f[50]), j = o(j, D, P, O, h, 21, f[51]), O = o(O, j, D, P, x, 6, f[52]), P = o(P, O, j, D, l, 10, f[53]), D = o(D, P, O, j, m, 15, f[54]), j = o(j, D, P, O, a, 21, f[55]), O = o(O, j, D, P, g, 6, f[56]), P = o(P, O, j, D, S, 10, f[57]), D = o(D, P, O, j, d, 15, f[58]), j = o(j, D, P, O, w, 21, f[59]), O = o(O, j, D, P, p, 6, f[60]), P = o(P, O, j, D, b, 10, f[61]), D = o(D, P, O, j, s, 15, f[62]), j = o(j, D, P, O, y, 21, f[63]);
u[0] = u[0] + O | 0, u[1] = u[1] + j | 0, u[2] = u[2] + D | 0, u[3] = u[3] + P | 0
},
_doFinalize: function() {
var e = this._data,
n = e.words,
r = 8 * this._nDataBytes,
o = 8 * e.sigBytes;
n[o >>> 5] |= 128 << 24 - o % 32;
var i = t.floor(r / 4294967296);
for (n[15 + (o + 64 >>> 9 << 4)] = 16711935 & (i << 8 | i >>> 24) | 4278255360 & (i << 24 | i >>> 8), n[14 + (o + 64 >>> 9 << 4)] = 16711935 & (r << 8 | r >>> 24) | 4278255360 & (r << 24 | r >>> 8), e.sigBytes = 4 * (n.length + 1), this._process(), n = (e = this._hash).words, r = 0; 4 > r; r++)
o = n[r], n[r] = 16711935 & (o << 8 | o >>> 24) | 4278255360 & (o << 24 | o >>> 8);
return e
},
clone: function() {
var t = c.clone.call(this);
return t._hash = this._hash.clone(), t
}
}), u.MD5 = c._createHelper(s), u.HmacMD5 = c._createHmacHelper(s)
}(Math),
function() {
var t, e = i,
n = (t = e.lib).Base,
r = t.WordArray,
o = (t = e.algo).EvpKDF = n.extend({
cfg: n.extend({
keySize: 4,
hasher: t.MD5,
iterations: 1
}),
init: function(t) {
this.cfg = this.cfg.extend(t)
},
compute: function(t, e) {
for (var n = (a = this.cfg).hasher.create(), o = r.create(), i = o.words, u = a.keySize, a = a.iterations; i.length < u;) {
c && n.update(c);
var c = n.update(t).finalize(e);
n.reset();
for (var s = 1; s < a; s++)
c = n.finalize(c), n.reset();
o.concat(c)
}
return o.sigBytes = 4 * u, o
}
});
e.EvpKDF = function(t, e, n) {
return o.create(n).compute(t, e)
}
}(), i.lib.Cipher || function(t) {
var e = (d = i).lib,
n = e.Base,
r = e.WordArray,
o = e.BufferedBlockAlgorithm,
u = d.enc.Base64,
a = d.algo.EvpKDF,
c = e.Cipher = o.extend({
cfg: n.extend(),
createEncryptor: function(t, e) {
return this.create(this._ENC_XFORM_MODE, t, e)
},
createDecryptor: function(t, e) {
return this.create(this._DEC_XFORM_MODE, t, e)
},
init: function(t, e, n) {
this.cfg = this.cfg.extend(n), this._xformMode = t, this._key = e, this.reset()
},
reset: function() {
o.reset.call(this), this._doReset()
},
process: function(t) {
return this._append(t), this._process()
},
finalize: function(t) {
return t && this._append(t), this._doFinalize()
},
keySize: 4,
ivSize: 4,
_ENC_XFORM_MODE: 1,
_DEC_XFORM_MODE: 2,
_createHelper: function(t) {
return {
encrypt: function(e, n, r) {
return ("string" == typeof n ? v : h).encrypt(t, e, n, r)
},
decrypt: function(e, n, r) {
return ("string" == typeof n ? v : h).decrypt(t, e, n, r)
}
}
}
});
e.StreamCipher = c.extend({
_doFinalize: function() {
return this._process(!0)
},
blockSize: 1
});
var s = d.mode = {}, f = function(t, e, n) {
var r = this._iv;
r ? this._iv = void 0 : r = this._prevBlock;
for (var o = 0; o < n; o++)
t[e + o] ^= r[o]
}, l = (e.BlockCipherMode = n.extend({
createEncryptor: function(t, e) {
return this.Encryptor.create(t, e)
},
createDecryptor: function(t, e) {
return this.Decryptor.create(t, e)
},
init: function(t, e) {
this._cipher = t, this._iv = e
}
})).extend();
l.Encryptor = l.extend({
processBlock: function(t, e) {
var n = this._cipher,
r = n.blockSize;
f.call(this, t, e, r), n.encryptBlock(t, e), this._prevBlock = t.slice(e, e + r)
}
}), l.Decryptor = l.extend({
processBlock: function(t, e) {
var n = this._cipher,
r = n.blockSize,
o = t.slice(e, e + r);
n.decryptBlock(t, e), f.call(this, t, e, r), this._prevBlock = o
}
}), s = s.CBC = l, l = (d.pad = {}).Pkcs7 = {
pad: function(t, e) {
for (var n, o = (n = (n = 4 * e) - t.sigBytes % n) << 24 | n << 16 | n << 8 | n, i = [], u = 0; u < n; u += 4)
i.push(o);
n = r.create(i, n), t.concat(n)
},
unpad: function(t) {
t.sigBytes -= 255 & t.words[t.sigBytes - 1 >>> 2]
}
}, e.BlockCipher = c.extend({
cfg: c.cfg.extend({
mode: s,
padding: l
}),
reset: function() {
c.reset.call(this);
var t = (e = this.cfg).iv,
e = e.mode;
if (this._xformMode == this._ENC_XFORM_MODE) var n = e.createEncryptor;
else n = e.createDecryptor, this._minBufferSize = 1;
this._mode = n.call(e, this, t && t.words)
},
_doProcessBlock: function(t, e) {
this._mode.processBlock(t, e)
},
_doFinalize: function() {
var t = this.cfg.padding;
if (this._xformMode == this._ENC_XFORM_MODE) {
t.pad(this._data, this.blockSize);
var e = this._process(!0)
} else e = this._process(!0), t.unpad(e);
return e
},
blockSize: 4
});
var p = e.CipherParams = n.extend({
init: function(t) {
this.mixIn(t)
},
toString: function(t) {
return (t || this.formatter).stringify(this)
}
}),
h = (s = (d.format = {}).OpenSSL = {
stringify: function(t) {
var e = t.ciphertext;
return ((t = t.salt) ? r.create([1398893684, 1701076831]).concat(t).concat(e) : e).toString(u)
},
parse: function(t) {
var e = (t = u.parse(t)).words;
if (1398893684 == e[0] && 1701076831 == e[1]) {
var n = r.create(e.slice(2, 4));
e.splice(0, 4), t.sigBytes -= 16
}
return p.create({
ciphertext: t,
salt: n
})
}
}, e.SerializableCipher = n.extend({
cfg: n.extend({
format: s
}),
encrypt: function(t, e, n, r) {
r = this.cfg.extend(r);
var o = t.createEncryptor(n, r);
return e = o.finalize(e), o = o.cfg, p.create({
ciphertext: e,
key: n,
iv: o.iv,
algorithm: t,
mode: o.mode,
padding: o.padding,
blockSize: t.blockSize,
formatter: r.format
})
},
decrypt: function(t, e, n, r) {
return r = this.cfg.extend(r), e = this._parse(e, r.format), t.createDecryptor(n, r).finalize(e.ciphertext)
},
_parse: function(t, e) {
return "string" == typeof t ? e.parse(t, this) : t
}
})),
d = (d.kdf = {}).OpenSSL = {
execute: function(t, e, n, o) {
return o || (o = r.random(8)), t = a.create({
keySize: e + n
}).compute(t, o), n = r.create(t.words.slice(e), 4 * n), t.sigBytes = 4 * e, p.create({
key: t,
iv: n,
salt: o
})
}
}, v = e.PasswordBasedCipher = h.extend({
cfg: h.cfg.extend({
kdf: d
}),
encrypt: function(t, e, n, r) {
return n = (r = this.cfg.extend(r)).kdf.execute(n, t.keySize, t.ivSize), r.iv = n.iv, (t = h.encrypt.call(this, t, e, n.key, r)).mixIn(n), t
},
decrypt: function(t, e, n, r) {
return r = this.cfg.extend(r), e = this._parse(e, r.format), n = r.kdf.execute(n, t.keySize, t.ivSize, e.salt), r.iv = n.iv, h.decrypt.call(this, t, e, n.key, r)
}
})
}(),
function() {
for (var t = i, e = t.lib.BlockCipher, n = t.algo, r = [], o = [], u = [], a = [], c = [], s = [], f = [], l = [], p = [], h = [], d = [], v = 0; 256 > v; v++)
d[v] = 128 > v ? v << 1 : v << 1 ^ 283;
var g = 0,
y = 0;
for (v = 0; 256 > v; v++) {
var m = (m = y ^ y << 1 ^ y << 2 ^ y << 3 ^ y << 4) >>> 8 ^ 255 & m ^ 99;
r[g] = m, o[m] = g;
var b = d[g],
x = d[b],
w = d[x],
_ = 257 * d[m] ^ 16843008 * m;
u[g] = _ << 24 | _ >>> 8, a[g] = _ << 16 | _ >>> 16, c[g] = _ << 8 | _ >>> 24, s[g] = _, _ = 16843009 * w ^ 65537 * x ^ 257 * b ^ 16843008 * g, f[m] = _ << 24 | _ >>> 8, l[m] = _ << 16 | _ >>> 16, p[m] = _ << 8 | _ >>> 24, h[m] = _, g ? (g = b ^ d[d[d[w ^ b]]], y ^= d[d[y]]) : g = y = 1
}
var S = [0, 1, 2, 4, 8, 16, 32, 64, 128, 27, 54];
n = n.AES = e.extend({
_doReset: function() {
for (var t = (n = this._key).words, e = n.sigBytes / 4, n = 4 * ((this._nRounds = e + 6) + 1), o = this._keySchedule = [], i = 0; i < n; i++)
if (i < e) o[i] = t[i];
else {
var u = o[i - 1];
i % e ? 6 < e && 4 == i % e && (u = r[u >>> 24] << 24 | r[u >>> 16 & 255] << 16 | r[u >>> 8 & 255] << 8 | r[255 & u]) : (u = r[(u = u << 8 | u >>> 24) >>> 24] << 24 | r[u >>> 16 & 255] << 16 | r[u >>> 8 & 255] << 8 | r[255 & u], u ^= S[i / e | 0] << 24), o[i] = o[i - e] ^ u
}
for (t = this._invKeySchedule = [], e = 0; e < n; e++)
i = n - e, u = e % 4 ? o[i] : o[i - 4], t[e] = 4 > e || 4 >= i ? u : f[r[u >>> 24]] ^ l[r[u >>> 16 & 255]] ^ p[r[u >>> 8 & 255]] ^ h[r[255 & u]]
},
encryptBlock: function(t, e) {
this._doCryptBlock(t, e, this._keySchedule, u, a, c, s, r)
},
decryptBlock: function(t, e) {
var n = t[e + 1];
t[e + 1] = t[e + 3], t[e + 3] = n, this._doCryptBlock(t, e, this._invKeySchedule, f, l, p, h, o), n = t[e + 1], t[e + 1] = t[e + 3], t[e + 3] = n
},
_doCryptBlock: function(t, e, n, r, o, i, u, a) {
for (var c = this._nRounds, s = t[e] ^ n[0], f = t[e + 1] ^ n[1], l = t[e + 2] ^ n[2], p = t[e + 3] ^ n[3], h = 4, d = 1; d < c; d++) {
var v = r[s >>> 24] ^ o[f >>> 16 & 255] ^ i[l >>> 8 & 255] ^ u[255 & p] ^ n[h++],
g = r[f >>> 24] ^ o[l >>> 16 & 255] ^ i[p >>> 8 & 255] ^ u[255 & s] ^ n[h++],
y = r[l >>> 24] ^ o[p >>> 16 & 255] ^ i[s >>> 8 & 255] ^ u[255 & f] ^ n[h++];
p = r[p >>> 24] ^ o[s >>> 16 & 255] ^ i[f >>> 8 & 255] ^ u[255 & l] ^ n[h++], s = v, f = g, l = y
}
v = (a[s >>> 24] << 24 | a[f >>> 16 & 255] << 16 | a[l >>> 8 & 255] << 8 | a[255 & p]) ^ n[h++], g = (a[f >>> 24] << 24 | a[l >>> 16 & 255] << 16 | a[p >>> 8 & 255] << 8 | a[255 & s]) ^ n[h++], y = (a[l >>> 24] << 24 | a[p >>> 16 & 255] << 16 | a[s >>> 8 & 255] << 8 | a[255 & f]) ^ n[h++], p = (a[p >>> 24] << 24 | a[s >>> 16 & 255] << 16 | a[f >>> 8 & 255] << 8 | a[255 & l]) ^ n[h++], t[e] = v, t[e + 1] = g, t[e + 2] = y, t[e + 3] = p
},
keySize: 8
});
t.AES = e._createHelper(n)
}(), i.pad.Iso10126 = {
pad: function(t, e) {
var n = (n = 4 * e) - t.sigBytes % n;
t.concat(i.lib.WordArray.random(n - 1)).concat(i.lib.WordArray.create([n << 24], 1))
},
unpad: function(t) {
t.sigBytes -= 255 & t.words[t.sigBytes - 1 >>> 2]
}
}
return i
}
function get(t1) {
var e = new wGdk,
r = e.enc.Utf8.parse("youzan.com.aesiv"),
o = e.enc.Utf8.parse("youzan.com._key_");
var t = e.enc.Utf8.parse(t1)
return e.AES.encrypt(t, o, {
mode: e.mode.CBC,
padding: e.pad.Iso10126,
iv: r
}).toString()
}
图像识别的代码网上到处都是,这就不给了
有什么疑问可以私聊我。qq:1374522338
木木哒。
idea中定义日志模板_idea自定义代码提示 日志输出模版_斜月三的博客-CSDN博客
在开发过程中,充分利用idea的一些功能,能够让开发达到事半功倍的效果。今天介绍两种日志模板的定义。
两种类型日志
类型一(多用于类下面)、
private static final Logger logger = LoggerFactory.getLogger(OptionalTest.class);
类型二(多用于方法中)、
log.info("OptionalTest类,main方法,15行:{}","");
开始之前,先File->Settings->Editor->Live Templates->点击右侧+号->Template Group
创建一个自己的模板组,可以用来存方自己创建的模板。我这边建了一个模板组叫myself。
之后选中自己创建的模板组,继续点击+号,选择Live Template,就可以创建自己的模板了,如下:
1. Abbreviation:就是你想用的缩写;
2. Description:就是你想添加的描述;
3. Template text:把你想要的模板写上;
4.
5. Edit Variables:这里就可以在Expression中选择代表的变量,定义4中的变量所代表的含义,如下:
一路OK,设置完成,接下来看成果:
在类中输入logger,右边可以看到刚才定义的描述,enter确认,就会自动补全如下:
之后导入Logger和LoggerFactory依赖就可以了,如下:
好了,之后就可以自由使用了,啦啦啦德玛西亚。
对于配置类型二:log.info("OptionalTest类,main方法,15行:{}","");
几乎是同样的道理,话不多说,看图:
上面定义的这些参数,都是在Edit variables中配置的,如下:
无非是参数多几个而已,有时间的话可以好好了解Expression中的参数,各种代表什么意思等等,对开发是非常有帮助的,如下只是展示了一小部分:
ok,设置好后,来看看效果(我这边用了lombok的@slf4j注解,所以就不用定义logger了):
点击enter确认,效果如下:
看,最后还可以写上自己的文字描述这个log的意义:
方便吧!好了,定义自己的模板就是这种方法,灵活运用,举一反三,大佬就是你自己!
最后,不以时迁者,松柏也。加油!
springboot整合之版本号统一管理_springboot版本号_极速小乌龟的博客-CSDN博客
特别说明:本次项目整合基于idea进行的,如果使用Eclipse可能操作会略有不同,不过总的来说不影响。
springboot整合mybatis-plus+durid数据库连接池
springboot整合之logback日志配置
springboot整合pagehelper分页
springboot整合本地缓存
springboot整合redis + redisson
springboot整合elasticsearch
springboot整合rabbitMq
springboot整合canal实现缓存一致性
springboot整合springSecurity(前后端不分离版本)
相信小伙伴们对于版本号的管理都很熟悉了,那我们在springboot中常见的版本管理有几种方式呢?
这种方式也是我们项目中常用的方式,首先这样以来我们能对项目中的ja包版本号进行统一的管理,以后修改版本号都会比较方便。而且这样会减少很多不必要的问题。所以强烈推荐这种管理方式。至于会减少什么问题我们稍后会详细说一说。

最常见的就是坐标引入也很简单,如下,直接在pom文件中粘贴就好了。比如下面这个,我们就是引入了swagger-bootstrap-ui的1.9.6版本。
<groupId>com.github.xiaoymin</groupId><artifactId>swagger-bootstrap-ui</artifactId>
那么为什么不推荐这种方式来管理jar包版本号呢? 那就是这种管理方式可能会导致jar包引入不是我们想要的。想要搞明白这个问题我觉得有必要先了解一下spring-boot-starter-parent是如何管理jar包的。
就拿下面的mysql驱动来说.

在当前项目下我们并没有设置mysql链接驱动的版本号,但是springboot却帮我们自动引入了8.0.25.那么他是怎么做到的呢?
首先就是spring-boot-starter-parent继承了spring-boot-dependencies。spring-boot-dependencies对一些常用的jar包进行了统一的版本号管理。如果有疑问的可以ctrl然后点击一下spring-boot-starter-parent.然后看到下面这个pom文件,其实这个就是spring-boot-starter-parent的pom文件.在这个文件中可以很清晰的看到spring-boot-starter-parent继承了spring-boot-dependencies。

然后我们接着按住ctrl,点击spring-boot-dependencies,进入到spring-boot-dependencies的pom文件看一下.可以看到许多常见的jar包版本号springboot都已经帮我们维护好了.而且这些版本号跟当前版本都是兼容的.这样对于我们开发者来说相当的方便,而且不用自己去处理jar包和springboot版本不兼容问题.
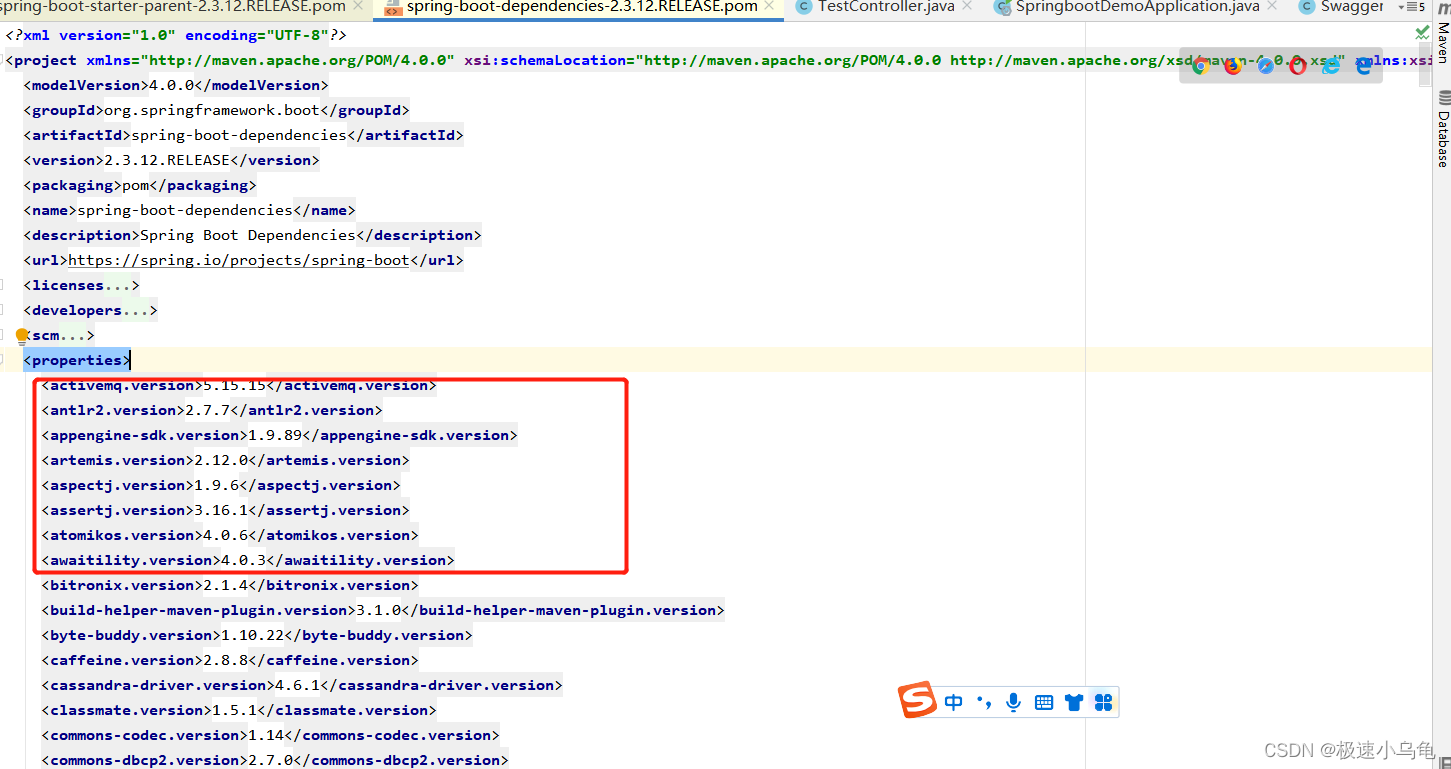
然后我们在文件中查找MySQL的版本号:

可以看到当前的mysql版本号就是8.0.25。这就是为啥我们在springboot中不用写版本号但是spring boot却能帮我们自动导入相应版本号jar包的原因。
熟话说事情都有两面性,对于spring boot通过spring-boot-dependencies来进行常用jar包版本号管理也是如此。比如我们现在项目使用的是7.10.2版本的ElasticSearch,但是按照spring boot官方给的说明,我们现在用的是spring boot 2.3.X对应的是7.6.2版本。

相信很多小伙伴在开发中也遇到过这种问题。面对这种问题我们有两种选择,第一种是替换spring boot的版本。这种情况下我们的elastic search肯定是不会有问题的,但是能确保其他jar包不出问题吗?或者项目能够正常运行吗?更可怕的是能正常运行部分功能不正常?所以我们只能是替换spring boot帮我们配置好的版本号。
这也就是为啥我们说不推荐第二种jar包版本管理的原因,因为第二种方式没办法覆盖,但是第一种properties版本号管理可以覆盖。
这样说可能不是很清楚,接下来我们动手实验一下就清晰了。首先我们按照第二种方式引入elasticsearch的依赖。
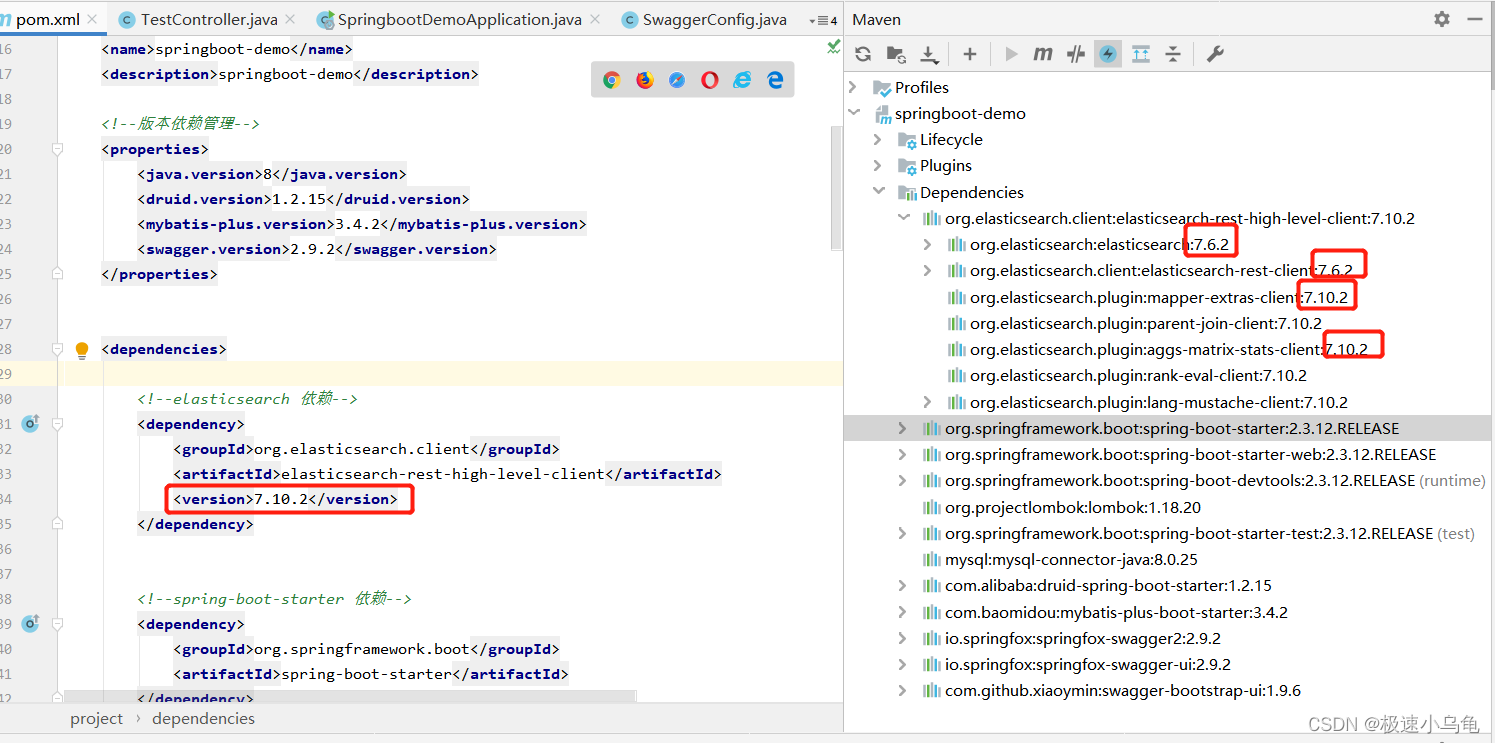
可以看到版本中不但有7.10.2的依赖,竟然还有我们没有引入的7.6.2的依赖,这也就是很多小伙伴开发中”明明是按照别人的博客CV过来的为啥别人的正常到了我这里就不能用了呢“的原因所在。
然后我们来按照第一种方式来配置一下:
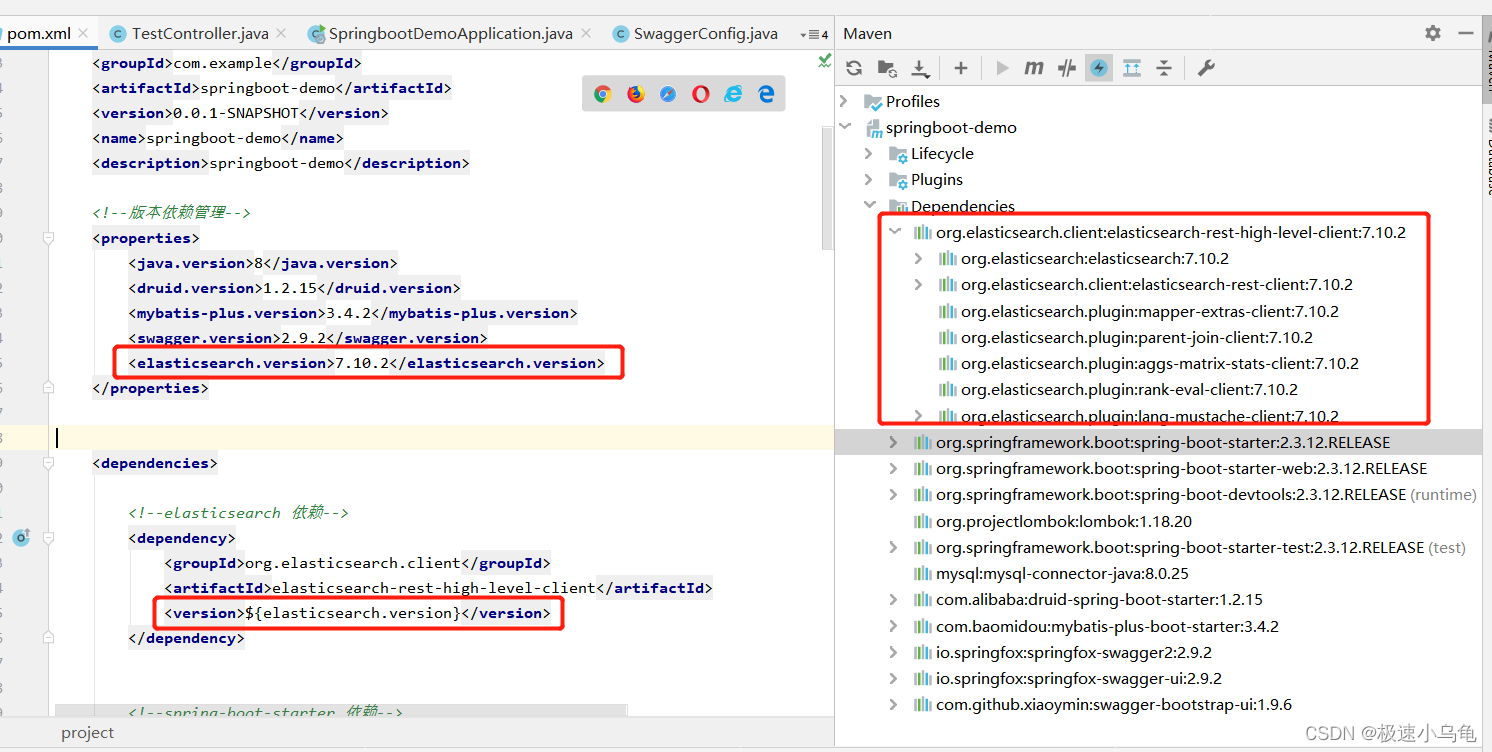
可以看到现在我们的依赖中7.6.2的版本就消失了。
所以强烈建议大家使用第一种jar包管理方式。不要使用第二种。避免不必要的麻烦。因为在spring boot中默认当前项目的properties会比spring-boot-dependencies中的properties优先级要高,所以能够覆盖原来的默认版本号。这样以来就能够减少很多不必要的麻烦。小伙伴们你们学到了吗!!!,如果文章对你有所帮助的话,可以点赞关注~
MyBatis-Plus——超详细讲解配置文件_mybatis-plus.mapper-locations-CSDN博客
📢📢📢📣📣📣
哈喽!大家好,我是【一心同学】,一位上进心十足的【**Java领域博主】!**😜😜😜
✨【一心同学】的写作风格:喜欢用【通俗易懂】的文笔去讲解每一个知识点,而不喜欢用【高大上】的官方陈述。
✨【一心同学】博客的领域是【面向后端技术】的学习,未来会持续更新更多的【后端技术】以及【学习心得】。
✨如果有对【后端技术】感兴趣的【小可爱】,欢迎关注【一心同学】💞💞💞
❤️❤️❤️**感谢各位大可爱小可爱!**❤️❤️❤️
目录
8.5 autoMappingUnknownColumnBehavior
前言
在我们的【MyBatis-Plus】中有许多【配置】,也就是当我们需要用到的时候,会在配置文件中进行编写的属性,本篇博客将会讲解这些配置的【作用】,以及简单【使用】。
1、mapperLocations
- 类型:String[]
- 默认值:["classpath*:/mapper/**/*.xml"]
介绍:扫描MyBatis Mapper 所对应的 XML 文件位置,如果在 Mapper 中有自定义方法(XML 中有自定义实现),需要进行该配置,告诉 Mapper 所对应的 XML 文件位置,Maven 多模块项目的扫描路径需以 classpath: 开头 (即加载多个 jar 包下的 XML 文件)。*
mybatis-plus.mapper-locations=classpath*:**/mapper/xml/*.xml
2、typeAliasesPackage
- 类型:String
- 默认值:null
介绍:MyBaits 别名包扫描路径,通过该属性可以给包中的类注册别名,注册后在 Mapper 对应的 XML 文件中可以直接使用类名,而不用使用全限定的类名(即 XML 中调用的时候不用包含包名)。
mybatis-plus.type-aliases-package=com.caochenlei.mpdemo.pojo
3、typeHandlersPackage
- 类型:String
- 默认值:null
介绍:TypeHandler 扫描路径,如果配置了该属性,SqlSessionFactoryBean 会把该包下面的类注册为对应的 TypeHandler,TypeHandler 通常用于自定义类型转换。
mybatis-plus.type-handlers-package=com.caochenlei.mpdemo.type
4、typeEnumsPackage
- 类型:String
- 默认值:null
介绍:枚举类 扫描路径,如果配置了该属性,会将路径下的枚举类进行注入,让实体类字段能够简单快捷的使用枚举属性。
mybatis-plus.type-enums-package=com.caochenlei.mpdemo.myenum
5、checkConfigLocation
- 类型:boolean
- 默认值:false
介绍:启动时是否检查 MyBatis XML 文件的存在,默认不检查。
mybatis-plus.check-config-location=false
6、executorType
- 类型:ExecutorType
- 默认值:simple
介绍:通过该属性可指定 MyBatis 的执行器,MyBatis 的执行器总共有三种:
- ExecutorType.SIMPLE:该执行器类型不做特殊的事情,为每个语句的执行创建一个新的预处理语句(PreparedStatement)
- ExecutorType.REUSE:该执行器类型会复用预处理语句(PreparedStatement)
- ExecutorType.BATCH:该执行器类型会批量执行所有的更新语句
mybatis-plus.executor-type=simple
7、configurationProperties
- 类型:Properties
- 默认值:null
介绍:指定外部化 MyBatis Properties 配置,通过该配置可以抽离配置,实现不同环境的配置部署。
8、configuration
- 类型:Configuration
- 默认值:null
介绍:原生 MyBatis 所支持的配置,本部分(Configuration)的配置大都为 MyBatis 原生支持的配置,这意味着您可以通过 MyBatis XML 配置文件的形式进行配置。
8.1 mapUnderscoreToCamelCase
- 类型:boolean
- 默认值:true
介绍:是否开启自动驼峰命名规则(camel case)映射,即从经典数据库列名 A_COLUMN(下划线命名) 到经典 Java 属性名 aColumn(驼峰命名) 的类似映射。
此属性在 MyBatis 中原默认值为 false,在 MyBatis-Plus 中,此属性也将用于生成最终的 SQL 的 select body,如果您的数据库命名符合规则无需使用 @TableField 注解指定数据库字段名。
mybatis-plus.configuration.map-underscore-to-camel-case=true
8.2 defaultEnumTypeHandler
- 类型:Class<? extends TypeHandler
- 默认值:org.apache.ibatis.type.EnumTypeHandler
介绍:默认枚举处理类,如果配置了该属性,枚举将统一使用指定处理器进行处理。
注意事项
其取值可以有以下几种,可以使用内置,也可以自定义:
- org.apache.ibatis.type.EnumTypeHandler : 存储枚举的名称
- org.apache.ibatis.type.EnumOrdinalTypeHandler : 存储枚举的索引
- com.baomidou.mybatisplus.extension.handlers.MybatisEnumTypeHandler : 枚举类需要实现IEnum接口或字段标记@EnumValue注解.(3.1.2以下版本为EnumTypeHandler)
mybatis-plus.configuration.default-enum-type-handler=org.apache.ibatis.type.EnumTypeHandler
8.3 aggressiveLazyLoading
- 类型:boolean
- 默认值:true
介绍:当设置为 true 的时候,懒加载的对象可能被任何懒属性全部加载,否则,每个属性都按需加载。需要和 lazyLoadingEnabled 一起使用。
mybatis-plus.configuration.aggressive-lazy-loading=truemybatis-plus.configuration.lazy-loading-enabled=true
8.4 autoMappingBehavior
- 类型:AutoMappingBehavior
- 默认值:partial
介绍:MyBatis 自动映射策略,通过该配置可指定 MyBatis 是否并且如何来自动映射数据表字段与对象的属性,总共有 3 种可选值:
- AutoMappingBehavior.NONE:不启用自动映射
- AutoMappingBehavior.PARTIAL:只对非嵌套的 resultMap 进行自动映射
- AutoMappingBehavior.FULL:对所有的 resultMap 都进行自动映射
mybatis-plus.configuration.auto-mapping-behavior=partial
8.5 autoMappingUnknownColumnBehavior
- 类型:AutoMappingUnknownColumnBehavior
- 默认值:NONE
介绍:MyBatis 自动映射时未知列或未知属性处理策略,通过该配置可指定 MyBatis 在自动映射过程中遇到未知列或者未知属性时如何处理,总共有 3 种可选值:
- AutoMappingUnknownColumnBehavior.NONE:不做任何处理 (默认值)
- AutoMappingUnknownColumnBehavior.WARNING:以日志的形式打印相关警告信息
- AutoMappingUnknownColumnBehavior.FAILING:当作映射失败处理,并抛出异常和详细信息
mybatis-plus.configuration.auto-mapping-unknown-column-behavior=none
8.6 localCacheScope
- 类型:String
- 默认值:SESSION
介绍:Mybatis一级缓存,默认为 SESSION。
- SESSION:session级别缓存,同一个session相同查询语句不会再次查询数据库
- STATEMENT:关闭一级缓存
注意事项
单服务架构中(有且仅有只有一个程序提供相同服务),一级缓存开启不会影响业务,只会提高性能。 微服务架构中需要关闭一级缓存,原因:Service1先查询数据,若之后Service2修改了数据,之后Service1又再次以同样的查询条件查询数据,因走缓存会出现查处的数据不是最新数据。
mybatis-plus.configuration.local-cache-scope=session
8.7 cacheEnabled
- 类型:boolean
- 默认值:true
介绍:开启Mybatis二级缓存,默认为 true。
mybatis-plus.configuration.cache-enabled=true
8.8 callSettersOnNulls
- 类型:boolean
- 默认值:false
介绍:指定当结果集中值为 null 的时候是否调用映射对象的 Setter(Map 对象时为 put)方法,通常运用于有 Map.keySet() 依赖或 null 值初始化的情况。
理解
通俗的讲,即 MyBatis 在使用 resultMap 来映射查询结果中的列,如果查询结果中包含空值的列,则 MyBatis 在映射的时候,不会映射这个字段,这就导致在调用到该字段的时候由于没有映射,取不到而报空指针异常。
当您遇到类似的情况,请针对该属性进行相关配置以解决以上问题。
注意:基本类型(int、boolean 等)是不能设置成 null 的。
mybatis-plus.configuration.call-setters-on-nulls=false
8.9 configurationFactory
- 类型:Class<?>
- 默认值:null
介绍:指定一个提供 Configuration 实例的工厂类。该工厂生产的实例将用来加载已经被反序列化对象的懒加载属性值,其必须包含一个签名方法
static Configuration getConfiguration()。(从 3.2.3 版本开始)
mybatis-plus.configuration.configuration-factory=
9、MyBatis的配置属性
由于其属性很多,我们这里只列出MyBatis的settings的标签属性,其余可以自己进行查看。
我们这里以日志打印为例,一般使用驼峰命名对应 “ - ”
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
| 设置 | 描述 | 取值 | 默认值 |
| cacheEnabled | 该配置是影响所有映射器中配置缓存的全局开关。 | true | false | true |
| lazyLoadingEnabled | 该配置是延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。在特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态。 | true | false | false |
| aggressiveLazyLoading | 当启用时,对任意延迟属性的调用会使带有延迟加载属性的对象完整加载,反之,每种属性将会按需加载。 | true | false | false
(true in ≤3.4.1) |
| multipleResultSetsEnabled | 是否允许单一语句返回多结果集,需要兼容驱动。 | true | false | true |
| useColumnLabel | 使用列标签代替列名。不同的驱动会有不同的表现,具体可参考相关驱动文档或通过测试这两种不同的模式来观察所用驱动的结果。 | true | false | true |
| useGeneratedKeys | 允许JDBC 支持自动生成主键,需要驱动兼容。如果设置为 true,则这个设置强制使用自动生成主键,尽管一些驱动不能兼容但仍可正常工作(比如 Derby)。 | true | false | false |
| autoMappingBehavior | 指定 MyBatis 应如何自动映射列到字段或属性。
NONE:表示取消自动映射。
PARTIAL:表示只会自动映射,没有定义嵌套结果集和映射结果集。
FULL:表示会自动映射任意复杂的结果集,无论是否嵌套。 | NONE
PARTIAL
FULL | PARTIAL |
| autoMappingUnknownColumnBehavior | 指定自动映射当中未知列(或未知属性类型)时的行为。 默认是不处理,只有当日志级别达到 WARN 级别或者以下,才会显示相关日志,如果处理失败会抛出 SqlSessionException异常。 | NONE
WARNING
FAILING | NONE |
| defaultExecutorType | 配置默认的执行器。
SIMPLE:是普通的执行器。
REUSE:会重用预处理语句。
BATCH:执行器将重用语句并执行批量更新。 | SIMPLE
REUSE
BATCH | SIMPLE |
| defaultStatementTimeout | 设置超时时间,它决定驱动等待数据库响应的秒数。 | 任意正整数值 | Not Set (null) |
| defaultFetchSize | 设置数据库驱动程序默认返回的条数限制,此参数可以重新设置。 | 任意正整数值 | Not Set (null) |
| defaultResultSetType | 指定按语句设置忽略它的滚动策略。(Since: 3.5.2) | FORWARD_ONLY
SCROLL_SENSITIVE
SCROLL_INSENSITIVE
DEFAULT
(same behavior with ‘Not Set’) | Not Set (null) |
| safeRowBoundsEnabled | 允许在嵌套语句中使用分页(RowBounds)。
如果允许,设置 false。 | true | false | false |
| safeResultHandlerEnabled | 允许在嵌套语句中使用分页(ResultHandler)。
如果允许,设置false | true | false | true |
| mapUnderscoreToCamelCaseEnables | 是否开启自动驼峰命名规则映射,即从经典数据库列名 A_COLUMN 到经典 Java 属性名 aColumn 的类似映射。 | true | false | false |
| localCacheScope | MyBatis 利用本地缓存机制(Local Cache)防止循环引用(circular references)和加速关联复嵌套査询。
SESSION:这种情况下会缓存一个会话中执行的所有查询。
STATEMENT:代表本地会话仅用在语句执行上,对相同 SqlScssion 的不同调用将不会共享数据。 | SESSION | STATEMENT | SESSION |
| jdbcTypeForNull | 当没有为参数提供特定的 JDBC 类型时,为空值时指定 JDBC 类型。某些驱动需要指定列的 JDBC 类型,多数情况直接用一般类型即可,比如 NULL、VARCHAR 或 OTHER。 | JdbcType 枚举值 | OTHER |
| lazyLoadTriggerMethods | 指定哪个对象的方法触发一次延迟加载。 | 一个逗号分隔的方法名称列表 | equals,clone,
hashCode,toString |
| defaultScriptingLanguage | 指定动态 SQL 生成的默认语言。 | 类型别名或指定类的全名称 | org.apache.
ibatis.scripting.
xmltags.XMLLang |
| defaultEnumTypeHandler | 指定默认情况下用于枚举的TypeHandler。(Since: 3.4.5) | 类型别名或指定类的全名称 | org.apache.
ibatis.type.
EnumTypeHandler |
| callSettersOnNulls | 指定当结果集中值为 null 时,是否调用映射对象的 setter(map 对象时为 put)方法,这对于 Map.keySet() 依赖或 null 值初始化时是有用的。注意,基本类型(int、boolean 等)不能设置成 null。 | true | false | false |
| returnInstanceForEmptyRowMyBatis | 默认情况下,MyBatis在返回行的所有列都为null时返回null。启用此设置后,MyBatis将返回空实例。注意,它也适用于嵌套结果(即collectioin和association)。(Since: 3.4.2) | true | false | false |
| logPrefix | 指定 MyBatis 增加到日志名称的前缀。 | 任何字符串 | Not set |
| logImpl | 指定 MyBatis 所用日志的具体实现,未指定时将自动査找。 | SLF4J
LOG4J
LOG4J2
JDK_LOGGING
COMMONS_LOGGING
STDOUT_LOGGING
NO_LOGGING | Not set |
| proxyFactory | 指定 MyBatis 创建具有延迟加载能力的对象所用到的代理工具。 | CGLIB | JAVASSIST | JAVASSIST
(MyBatis 3.3 or above) |
| vfsImpl | 指定 VFS 的实现类。 | 自定义VFS实现的类的全名称,用逗号分隔。 | Not set |
| useActualParamName | 允许使用方法签名中的名称作为语句参数名称。 为了使用该特性,你的项目必须采用 Java 8 编译,并且加上 -parameters 选项。(Since: 3.4.1) | true | false | true |
| configurationFactory | 指定提供配置实例的类。返回的配置实例用于加载反序列化对象的惰性属性。此类必须具有签名静态配置getConfiguration() 的方法。(Since: 3.2.3) | 类型别名或指定类的全名称 | Not set |
| shrinkWhitespacesInSql | 从SQL中删除多余的空白字符。注意,这也会影响SQL中的文字字符串。(Since 3.5.5) | true | false | false |
10、globalConfig
- 类型:com.baomidou.mybatisplus.core.config.GlobalConfig
- 默认值:GlobalConfig::new
介绍:MyBatis-Plus 全局策略配置。
- 类型:boolean
- 默认值:true
介绍:是否控制台 print mybatis-plus 的 LOGO。
mybatis-plus.global-config.banner=true
10.2 enableSqlRunner
- 类型:boolean
- 默认值:false
介绍:是否初始化 SqlRunner(com.baomidou.mybatisplus.extension.toolkit.SqlRunner)
mybatis-plus.global-config.enable-sql-runner=false
10.3 superMapperClass
- 类型:Class
- 默认值:com.baomidou.mybatisplus.core.mapper.Mapper.class
介绍:通用Mapper父类(影响sqlInjector,只有这个的子类的 mapper 才会注入 sqlInjector 内的 method)
mybatis-plus.global-config.super-mapper-class=com.baomidou.mybatisplus.core.mapper.Mapper
10.4 dbConfig
- 类型:com.baomidou.mybatisplus.core.config.GlobalConfig$DbConfig
- 默认值:null
介绍:MyBatis-Plus 全局策略中的 DB 策略配置。
10.4.1 idType
- 类型:com.baomidou.mybatisplus.annotation.IdType
- 默认值:ASSIGN_ID
介绍:全局默认主键类型。
mybatis-plus.global-config.db-config.id-type=assign_id
10.4.2 tablePrefix
- 类型:String
- 默认值:null
介绍:表名前缀。
mybatis-plus.global-config.db-config.table-prefix=tbl_
10.4.3 schema
- 类型:String
- 默认值:null
mybatis-plus.global-config.db-config.schema=
10.4.4 columnFormat
- 类型:String
- 默认值:null
介绍:字段 format,例:
%s,(对主键无效)
mybatis-plus.global-config.db-config.column-format=
10.4.5 propertyFormat
- 类型:String
- 默认值:null
介绍:entity 的字段(property)的 format,只有在 column as property 这种情况下生效例:
%s,(对主键无效)。
mybatis-plus.global-config.db-config.property-format=
10.4.6 tableUnderline
- 类型:boolean
- 默认值:true
介绍:表名是否使用驼峰转下划线命名,只对表名生效。
mybatis-plus.global-config.db-config.table-underline=true
10.4.6 capitalMode
- 类型:boolean
- 默认值:false
介绍:大写命名,对表名和字段名均生效。
mybatis-plus.global-config.db-config.capital-mode=false
10.4.7 logicDeleteField
- 类型:String
- 默认值:null
介绍:全局的entity的逻辑删除字段属性名,(逻辑删除下有效)。
mybatis-plus.global-config.db-config.logic-delete-field=
10.4.8 logicDeleteValue
- 类型:String
- 默认值:1
介绍:逻辑已删除值,(逻辑删除下有效)。
mybatis-plus.global-config.db-config.logic-delete-value=1
10.4.9 logicNotDeleteValue
- 类型:String
- 默认值:0
介绍:逻辑未删除值,(逻辑删除下有效)。
mybatis-plus.global-config.db-config.logic-not-delete-value=0
10.4.10 insertStrategy
- 类型:com.baomidou.mybatisplus.annotation.FieldStrategy
- 默认值:NOT_NULL
介绍:字段验证策略之 insert,在 insert 的时候的字段验证策略。
mybatis-plus.global-config.db-config.insert-strategy=not_null
10.4.11 updateStrategy
- 类型:com.baomidou.mybatisplus.annotation.FieldStrategy
- 默认值:NOT_NULL
介绍:字段验证策略之 update,在 update 的时候的字段验证策略。
mybatis-plus.global-config.db-config.update-strategy=not_null
10.4.12 selectStrategy
- 类型:com.baomidou.mybatisplus.annotation.FieldStrategy
- 默认值:NOT_NULL
介绍:字段验证策略之 select,在 select 的时候的字段验证策略既 wrapper 根据内部 entity 生成的 where 条件。
mybatis-plus.global-config.db-config.select-strategy=not_null
11、 配置小结
mybatis-plus.mapper-locations=classpath*:**/mapper/xml/*.xmlmybatis-plus.type-aliases-package=com.caochenlei.mpdemo.pojomybatis-plus.type-handlers-package=com.caochenlei.mpdemo.typemybatis-plus.type-enums-package=com.caochenlei.mpdemo.enummybatis-plus.check-config-location=falsemybatis-plus.executor-type=simple#mybatis-plus.configurationmybatis-plus.configuration.map-underscore-to-camel-case=truemybatis-plus.configuration.default-enum-type-handler=org.apache.ibatis.type.EnumTypeHandlermybatis-plus.configuration.aggressive-lazy-loading=truemybatis-plus.configuration.lazy-loading-enabled=truemybatis-plus.configuration.auto-mapping-behavior=partialmybatis-plus.configuration.auto-mapping-unknown-column-behavior=nonemybatis-plus.configuration.local-cache-scope=sessionmybatis-plus.configuration.cache-enabled=truemybatis-plus.configuration.call-setters-on-nulls=falsemybatis-plus.configuration.configuration-factory=mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl#mybatis-plus.global-configmybatis-plus.global-config.banner=truemybatis-plus.global-config.enable-sql-runner=falsemybatis-plus.global-config.super-mapper-class=com.baomidou.mybatisplus.core.mapper.Mapper#mybatis-plus.global-config.db-configmybatis-plus.global-config.db-config.id-type=assign_idmybatis-plus.global-config.db-config.table-prefix=tbl_mybatis-plus.global-config.db-config.schema=mybatis-plus.global-config.db-config.column-format=mybatis-plus.global-config.db-config.property-format=mybatis-plus.global-config.db-config.table-underline=truemybatis-plus.global-config.db-config.capital-mode=falsemybatis-plus.global-config.db-config.logic-delete-field=mybatis-plus.global-config.db-config.logic-delete-value=1mybatis-plus.global-config.db-config.logic-not-delete-value=0mybatis-plus.global-config.db-config.insert-strategy=not_nullmybatis-plus.global-config.db-config.update-strategy=not_nullmybatis-plus.global-config.db-config.select-strategy=not_null
小结
以上的【MyBatis-Plus配置详解】是一心同学是在网上阅读了不少【文章】,同时也有参考了几位【牛人】的讲解,最后【整理】出来的,大家也看到,这配置是非常的多,我们只需要大概知道其配置有什么功能,然后在开发过程中直接【应用】即可。
如果这篇【文章】有帮助到你,希望可以给【一心同学】点个赞👍,创作不易,相比官方的陈述,我更喜欢用【通俗易懂】 的文笔去讲解每一个知识点,如果有对【后端技术】感兴趣的小可爱,也欢迎关注❤️❤️❤️ 【一心同学】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】 💕💕!
IDEA 注释模板这样搞
一、类注释
打开 IDEA 的 Settings,点击 Editor-->File and Code Templates,点击右边 File 选项卡下面的 Class,在其中添加图中红框内的内容:
/**
* @author jitwxs
* @date ${YEAR}年${MONTH}月${DAY}日 ${TIME}
*/
在我提供的示例模板中,说明了作者和时间,IDEA 支持的所有的模板参数在下方的 Description 中被列出来。
保存后,当你创建一个新的类的时候就会自动添加类注释。如果你想对接口也生效,同时配置上图中的 Interface 项即可。
二、方法注释
不同于目前网络上互相复制粘贴的方法注释教程,本文将实现以下功能:
- 根据形参数目自动生成
@param注解 - 根据方法是否有返回值智能生成
@Return注解
相较于类模板,为方法添加注释模板就较为复杂,首先在Settings中点击Editor-->Live Templates。点击最右边的+,首先选择2. Template Group...来创建一个模板分组:

在弹出的对话框中填写分组名,我这里叫做 userDefine:

然后选中刚刚创建的模板分组userDefine,然后点击+,选择1. Live Template:

此时就会创建了一个空的模板,我们修改该模板的Abbreviation、Description和Template text。需要注意的是,Abbreviation必须为*,最后检查下Expand with的值是否为 Enter 键。

上图中·Template text内容如下,请直接复制进去,需要注意首行没有/,且\*是顶格的。
*
*
* @author jitwxs
* @date $date$ $time$$param$ $return$
*/注意到右下角的No applicable contexts yet了吗,这说明此时这个模板还没有指定应用的语言:

点击Define,在弹框中勾选Java,表示将该模板应用于所有的 Java 类型文件。

还记得我们配置Template text时里面包含了类似于$date$这样的参数,此时 IDEA 还不认识这些参数是啥玩意,下面我们对这些参数进行方法映射,让 IDEA 能够明白这些参数的含义。点击Edit variables按钮:

为每一个参数设置相对应的Expression:

需要注意的是,date和time的Expression使用的是 IDEA 内置的函数,直接使用下拉框选择就可以了,而param这个参数 IDEA 默认的实现很差,因此我们需要手动实现,代码如下:
groovyScript("def result = '';def params = \"${_1}\".replaceAll('[\\\\[|\\\\]|\\\\s]', '').split(',').toList(); for(i = 0; i < params.size(); i++) {if(params[i] != '')result+='* @param ' + params[i] + ((i < params.size() - 1) ? '\\r\\n ' : '')}; return result == '' ? null : '\\r\\n ' + result", methodParameters())另外return这个参数我也自己实现了下,代码如下:
groovyScript("return \"${_1}\" == 'void' ? null : '\\r\\n * @return ' + \"${_1}\"", methodReturnType())注:你还注意到我并没有勾选了
Skip if defined属性,它的意思是如果在生成注释时候如果这一项被定义了,那么鼠标光标就会直接跳过它。我并不需要这个功能,因此有被勾选该属性。
点击 OK 保存设置,大功告成!三、检验成果3.1 类注释类注释只有在新建类时才会自动生成,效果如下:

将演示以下几种情况:
- 无形参
- 单个形参
- 多个形参
- 无返回值
- 有返回值

三、Q & A
(1)为什么模板的Abbreviation一定要叫\*?Expand with要保证是 Enter 键?
答:因为 IDEA 模板的生成逻辑是模板名 + 生成键,当生成键是 Enter 时,我们输入* + Enter就能够触发模板。这也同时说明了为什么注释模板首行是一个*了,因为当我们先输入/*,然后输入* + Enter,触发模板,首行正好拼成了/**,符合 Javadoc 的规范。
(2)注释模板中为什么有一行空的\*?
答:因为我习惯在这一行写方法说明,所以就预留了一行空的写,你也可以把它删掉。
(3)注释模板中$time$$param$这两个明明不相干的东西为什么紧贴在一起?
答:首先网上提供的大部分 param 生成函数在无参情况下仍然会生成一行空的@param,因此我对param 函数的代码进行修改,使得在无参情况下不生成@param,但是这就要求$param$要和别人处在同一行中,不然没法处理退格。
(4)为什么 return 参数不使用methodReturnType(), 而要自己实现?
答:methodReturnType()在无返回值的情况下会返回 void,这并没有什么意义,因此我对 methodReturnType() 返回值进行了处理,仅在有返回值时才生成。
(5)为什么$return$不是单独一行?
答:因为当methodReturnType()返回 null 时,无法处理退格问题,原因同第三点。

idea激活码 webstorm永久激活 pycharm clion phpstorm
淘宝
¥8.88
去购买

idea激活码 webstorm永久激活 pycharm clion phpstorm
淘宝
¥8.88
去购买
编辑于 2021-11-14 · 著作权归作者所有
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.