pythonlessons / tensorflow-2.x-yolov3 Goto Github PK
View Code? Open in Web Editor NEWYOLOv3 implementation in TensorFlow 2.3.1
Home Page: https://pylessons.com/
License: MIT License
YOLOv3 implementation in TensorFlow 2.3.1
Home Page: https://pylessons.com/
License: MIT License



























































































































This has been really helpful, thank you!
I'm having an issue using checkpoint learning on colab, it's not working and returns an error;
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/network.py in _is_hdf5_filepath(filepath)
AttributeError: 'bool' object has no attribute 'endswith'
The MP4 file:
video_path = "./IMAGES/street_drive.mp4"
in detection_demo.py is not versioned, maybe you can add in README the url to download it.
Hello,
Thank you very much for writing all this code, it is incredible. Unfortunately I can't seem to find the save file of the retrained weights. This is my final readout after running train.py with the newly configured config file. I did have it set to 30 epochs so it did do the full amount.
epoch:30 step: 92/93, lr:0.000001, giou_loss: 4.07, conf_loss: 1.96, prob_loss: 0.48, total_loss: 6.52
epoch:30 step: 0/93, lr:0.000001, giou_loss: 0.58, conf_loss: 1.65, prob_loss: 0.11, total_loss: 2.35
epoch:30 step: 1/93, lr:0.000001, giou_loss: 3.67, conf_loss: 2.23, prob_loss: 0.46, total_loss: 6.36
giou_val_loss: 3.37, conf_val_loss: 2.31, prob_val_loss: 0.36, total_val_loss: 6.05
i train a dataset but cant run custom
File "/home/pi/.local/lib/python3.8/site-packages/tensorflow/python/keras/engine/training.py", line 2785, in _is_hdf5_filepath
return (filepath.endswith('.h5') or filepath.endswith('.keras') or
AttributeError: 'bool' object has no attribute 'endswith'
2020-08-19 12:52:07.347401: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
Traceback (most recent call last):
File "C:\Users\sid_a\anaconda3\envs\pytorch\lib\site-packages\tensorflow_core\python\framework\ops.py", line 1610, in _create_c_op
c_op = c_api.TF_FinishOperation(op_desc)
tensorflow.python.framework.errors_impl.InvalidArgumentError: Duplicate node name in graph: 'ones'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "object_tracker.py", line 34, in
yolo = Create_Yolo(input_size=YOLO_INPUT_SIZE)
File "C:\Users\sid_a\PycharmProjects\MTO_Highway_Analysis\TensorFlow-2.x-YOLOv3-master\yolov3\yolov4.py", line 391, in Create_Yolo
pred_tensor = decode(conv_tensor, NUM_CLASS, i)
File "C:\Users\sid_a\PycharmProjects\MTO_Highway_Analysis\TensorFlow-2.x-YOLOv3-master\yolov3\yolov4.py", line 420, in decode
xy_grid = tf.meshgrid(tf.range(output_size), tf.range(output_size))
File "C:\Users\sid_a\anaconda3\envs\pytorch\lib\site-packages\tensorflow_core\python\ops\array_ops.py", line 2954, in meshgrid
mult_fact = ones(shapes, output_dtype)
File "C:\Users\sid_a\anaconda3\envs\pytorch\lib\site-packages\tensorflow_core\python\ops\array_ops.py", line 2583, in ones
output = fill(shape, constant(one, dtype=dtype), name=name)
File "C:\Users\sid_a\anaconda3\envs\pytorch\lib\site-packages\tensorflow_core\python\ops\array_ops.py", line 171, in fill
result = gen_array_ops.fill(dims, value, name=name)
File "C:\Users\sid_a\anaconda3\envs\pytorch\lib\site-packages\tensorflow_core\python\ops\gen_array_ops.py", line 3601, in fill
"Fill", dims=dims, value=value, name=name)
File "C:\Users\sid_a\anaconda3\envs\pytorch\lib\site-packages\tensorflow_core\python\framework\op_def_library.py", line 793, in _apply_op_helper
op_def=op_def)
File "C:\Users\sid_a\anaconda3\envs\pytorch\lib\site-packages\tensorflow_core\python\framework\func_graph.py", line 548, in create_op
compute_device)
File "C:\Users\sid_a\anaconda3\envs\pytorch\lib\site-packages\tensorflow_core\python\framework\ops.py", line 3429, in _create_op_internal
op_def=op_def)
File "C:\Users\sid_a\anaconda3\envs\pytorch\lib\site-packages\tensorflow_core\python\framework\ops.py", line 1773, in init
control_input_ops)
File "C:\Users\sid_a\anaconda3\envs\pytorch\lib\site-packages\tensorflow_core\python\framework\ops.py", line 1613, in _create_c_op
raise ValueError(str(e))
ValueError: Duplicate node name in graph: 'ones'
Do you know a possible reason for this error when trying to run object_tracker.py? The error seems to be with Create_Yolo function in yolov4.py.
Also instead of using TensorFlow 2.2, I am using TensorFlow 2.0 since TensorFlow 2.2 kept giving me a DLL Import Error.
Hello,
I just wanted to thank you for all of the hard work you've put into producing, maintaining, and giving tutorials on your code. I am working on a project and would like to use your code if possible. Apparently, without a license, no one can really legally use your code (https://opensource.stackexchange.com/questions/1720/what-can-i-assume-if-a-publicly-published-project-has-no-license). I was wondering if you would be willing to add a license for the project?
Thanks again,
Steven
Hello,
first a big thank you for your tutorial and the repository. They are great.
I cloned your repository, installed the requirements.txt, downloaded the yolov4.weights and changed in configs.py line 13 "yolov3" to "yolov4".
When I started the detection_demo.py the following error occurred:
2020-09-07 07:43:52.622543: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
Traceback (most recent call last):
File "C:/Users/aaron/Documents/YOLOv4/TensorFlow-2.x-YOLOv3/detection_demo.py", line 15, in
import tensorflow as tf
File "C:\Users\aaron\AppData\Local\Programs\Python\Python36\lib\site-packages\tensorflow_init_.py", line 41, in
from tensorflow.python.tools import module_util as module_util
File "C:\Users\aaron\AppData\Local\Programs\Python\Python36\lib\site-packages\tensorflow\python_init.py", line 84, in
from tensorflow.python import keras
File "C:\Users\aaron\AppData\Local\Programs\Python\Python36\lib\site-packages\tensorflow\python\keras_init_.py", line 27, in
from tensorflow.python.keras import models
File "C:\Users\aaron\AppData\Local\Programs\Python\Python36\lib\site-packages\tensorflow\python\keras\models.py", line 24, in
from tensorflow.python.keras import metrics as metrics_module
File "C:\Users\aaron\AppData\Local\Programs\Python\Python36\lib\site-packages\tensorflow\python\keras\metrics.py", line 37, in
from tensorflow.python.keras.engine import base_layer
File "C:\Users\aaron\AppData\Local\Programs\Python\Python36\lib\site-packages\tensorflow\python\keras\engine\base_layer.py", line 51, in
from tensorflow.python.keras import initializers
File "C:\Users\aaron\AppData\Local\Programs\Python\Python36\lib\site-packages\tensorflow\python\keras\initializers_init_.py", line 127, in
populate_deserializable_objects()
File "C:\Users\aaron\AppData\Local\Programs\Python\Python36\lib\site-packages\tensorflow\python\keras\initializers_init_.py", line 85, in populate_deserializable_objects
generic_utils.populate_dict_with_module_objects(
AttributeError: module 'tensorflow.python.keras.utils.generic_utils' has no attribute 'populate_dict_with_module_objects'
(tf2) PS D:\TF2_YOLOv3\TensorFlow-2.x-YOLOv3-master> python detection_demo.py 2020-07-01 00:12:42.907737: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
Traceback (most recent call last):
File "detection_demo.py", line 29, in
load_yolo_weights(yolo, Darknet_weights) # use Darknet weights
File "D:\TF2_YOLOv3\TensorFlow-2.x-YOLOv3-master\yolov3\utils.py", line 59, in load_yolo_weights
conv_weights = conv_weights.reshape(conv_shape).transpose([2, 3, 1, 0])
ValueError: cannot reshape array of size 55195 into shape (128,64,3,3)
Hi! I wanna train yolov3-tiny custom model.
I has google cloud platform instance and here is environment.
OS : Ubuntu 18.04
GPU : Tesla K80
cuda : 10.0
cuDNN : 7.4.2
nvidia driver version : 450
Tensorflow version : 2.0.0 gpu
nvidia-smi and nvcc are successfully worked.
Gpu list is successfully loaded on python prompt.
But it can not on train.py
What happened??
Here is error.
tensorflow/stream_executor/cuda/cuda_driver.cc:300] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Here is result that I load gpu on python prompt
Python 3.7.9 (default, Sep 5 2020, 20:35:59)
[GCC 7.5.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf
/usr/local/lib/python3.7/site-packages/pandas/compat/__init__.py:120: UserWarning: Could not import the lzma module
. Your installed Python is incomplete. Attempting to use lzma compression will result in a RuntimeError.
warnings.warn(msg)
>>> gpus=tf.config.experimental.list_physical_devices('GPU')
2020-09-06 00:22:39.765471: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dyn
amic library libcuda.so.1
2020-09-06 00:22:42.146957: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read
from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-06 00:22:42.147888: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties
:
name: Tesla K80 major: 3 minor: 7 memoryClockRate(GHz): 0.8235
pciBusID: 0000:00:04.0
2020-09-06 00:22:42.148244: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dyn
amic library libcudart.so.10.0
2020-09-06 00:22:42.150090: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dyn
amic library libcublas.so.10.0
2020-09-06 00:22:42.151637: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dyn
amic library libcufft.so.10.0
2020-09-06 00:22:42.151987: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dyn
amic library libcurand.so.10.0
2020-09-06 00:22:42.153944: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dyn
amic library libcusolver.so.10.0
2020-09-06 00:22:42.155584: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dyn
amic library libcusparse.so.10.0
2020-09-06 00:22:42.161431: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dyn
amic library libcudnn.so.7
2020-09-06 00:22:42.161581: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read
from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-06 00:22:42.163090: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read
from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-06 00:22:42.163816: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1746] Adding visible gpu devices: 0
When I tried to run train.py
root@instance-1:/home/TensorFlow-2.x-YOLOv3# python3 train.py
/usr/local/lib/python3.7/site-packages/pandas/compat/__init__.py:120: UserWarning: Could not import the lzma module
. Your installed Python is incomplete. Attempting to use lzma compression will result in a RuntimeError.
warnings.warn(msg)
2020-09-06 00:24:33.931352: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dyn
amic library libcuda.so.1
2020-09-06 00:24:36.422085: E tensorflow/stream_executor/cuda/cuda_driver.cc:318] failed call to cuInit: CUDA_ERROR
_NO_DEVICE: no CUDA-capable device is detected
2020-09-06 00:24:36.422153: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:169] retrieving CUDA diagnostic i
nformation for host: instance-1
I think lzma module issue does not matter.
My issue is that the program doesn't detect that i have CUDA install and i can´t train my model with GPU
I have the cuda v10.1 and tf 2.3
2020-08-13 12:22:54.085076: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll
2020-08-13 12:22:55.554754: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library nvcuda.dll
2020-08-13 12:22:55.579834: E tensorflow/stream_executor/cuda/cuda_driver.cc:314] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
2020-08-13 12:22:55.583787: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:169] retrieving CUDA diagnostic information for host: MSI
2020-08-13 12:22:55.584068: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:176] hostname: MSI
2020-08-13 12:22:55.585746: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the following CPU instructions in performance-critical operations: AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2020-08-13 12:22:55.593980: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x2450a543890 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2020-08-13 12:22:55.594301: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
Thank you @pythonlessons for the detailed steps and neat documentation.
I wanted to evaluate my custom trained model. I have the weight file, renamed as "yolov3.weights" for simplicity and pasted in "model_data".
I changed the following
I tried running the "evaluate.py", it was taking a Long time, my GPU resource was not used. Therefore I tried with 300 Images to check if I get the desired Output as mentioned. But I got the following error, even though , the "coco.names" file contains the class CAR and one of my Images had a CAR object in the Picture.
Traceback (most recent call last):
File "evaluate_mAP.py", line 282, in <module>
get_mAP(yolo, testset, score_threshold=0.05, iou_threshold=0.50)
File "evaluate_mAP.py", line 157, in get_mAP
json_pred[gt_classes.index(class_name)].append({"confidence": str(score), "file_id": str(index), "bbox": str(bbox)})
ValueError: 'car' is not in list
could not debug, request update/support.
Thank you in advance
I am creating custom datasets, with hight resolution to detect all the strawberry growing stages for my Msc project, I got the pictures and using LabelIMG to label each. I already trained yolo v3 for a F1 car deception before. but now I am getting this error
I am thinking about the image size could be the problem, but I already had label more than 1000 images and I will need to resize the image and annotation.
I was looking in Github for a script to test all the images before start the training to avoid wasting time. Any ideas on how to address this issues?
what is your suggestion? I need to use my own pictures to perform this training.
Antonio
The Issue:
Traceback (most recent call last):
File "C:/Users/ms/Documents/YOLOv4/TensorFlow-2.x-YOLOv3/train.py", line 184, in
main()
File "C:/Users/ms/Documents/YOLOv4/TensorFlow-2.x-YOLOv3/train.py", line 53, in main
load_yolo_weights(Darknet, Darknet_weights) # use darknet weights
File "C:\Users\ms\Documents\YOLOv4\TensorFlow-2.x-YOLOv3\yolov3\utils.py", line 71, in load_yolo_weights
assert len(wf.read()) == 0, 'failed to read all data'
AssertionError: failed to read all data
`
And my configs.py
YOLO_TYPE = "yolov4" # yolov4 or yolov3
YOLO_FRAMEWORK = "tf" # "tf" or "trt"
YOLO_V3_WEIGHTS = "model_data/yolov3.weights"
YOLO_V4_WEIGHTS = "model_data/yolov4.weights"
YOLO_V3_TINY_WEIGHTS = "model_data/yolov3-tiny.weights"
YOLO_V4_TINY_WEIGHTS = "model_data/yolov4-tiny.weights"
YOLO_TRT_QUANTIZE_MODE = "INT8" # INT8, FP16, FP32
YOLO_CUSTOM_WEIGHTS = "C:/Users/ms/Documents/YOLOv4/TensorFlow-2.x-YOLOv3/checkpoints"
YOLO_COCO_CLASSES = "C:/Users/ms/Documents/YOLOv4/TensorFlow-2.x-YOLOv3/SW/sw.names"
YOLO_STRIDES = [8, 16, 32]
YOLO_IOU_LOSS_THRESH = 0.5
YOLO_ANCHOR_PER_SCALE = 3
YOLO_MAX_BBOX_PER_SCALE= 100
YOLO_INPUT_SIZE = 416
if YOLO_TYPE == "yolov4":
YOLO_ANCHORS = [[[12, 16], [19, 36], [40, 28]],
[[36, 75], [76, 55], [72, 146]],
[[142,110], [192, 243], [459, 401]]]
if YOLO_TYPE == "yolov3":
YOLO_ANCHORS = [[[10, 13], [16, 30], [33, 23]],
[[30, 61], [62, 45], [59, 119]],
[[116, 90], [156, 198], [373, 326]]]
TRAIN_YOLO_TINY = False
TRAIN_SAVE_BEST_ONLY = True # saves only best model according validation loss (True recommended)
TRAIN_SAVE_CHECKPOINT = True # saves all best validated checkpoints in training process (may require a lot disk space) (False recommended)
TRAIN_CLASSES = "C:/Users/ms/Documents/YOLOv4/TensorFlow-2.x-YOLOv3/SW/sw.names"
TRAIN_ANNOT_PATH = "C:/Users/ms/Documents/YOLOv4/TensorFlow-2.x-YOLOv3/SW/Train_1.txt" #"mnist/mnist_train.txt"
TRAIN_LOGDIR = "log"
TRAIN_CHECKPOINTS_FOLDER = "C:/Users/ms/Documents/YOLOv4/TensorFlow-2.x-YOLOv3/checkpoints"
TRAIN_MODEL_NAME = f"{YOLO_TYPE}_custom"
TRAIN_LOAD_IMAGES_TO_RAM = True # With True faster training, but need more RAM
TRAIN_BATCH_SIZE = 4
TRAIN_INPUT_SIZE = 416
TRAIN_DATA_AUG = True
TRAIN_TRANSFER = True
TRAIN_FROM_CHECKPOINT = False # "checkpoints/yolov3_custom"
TRAIN_LR_INIT = 1e-4
TRAIN_LR_END = 1e-6
TRAIN_WARMUP_EPOCHS = 2
TRAIN_EPOCHS = 100
TEST_ANNOT_PATH = "C:/Users/ms/Documents/YOLOv4/TensorFlow-2.x-YOLOv3/SW/Test_1.txt"
TEST_BATCH_SIZE = 4
TEST_INPUT_SIZE = 416
TEST_DATA_AUG = False
TEST_DECTECTED_IMAGE_PATH = "C:/Users/ms/Documents/YOLOv4/TensorFlow-2.x-YOLOv3/IMAGES"
TEST_SCORE_THRESHOLD = 0.3
TEST_IOU_THRESHOLD = 0.45
`
Where is my problem?
Every file exist at the right place.
Hi! My question here is if i can add a new class in a trained model and dont need to retrain all the model again with the new class and the old classes.
Hey,
The detection runs great without any issue (amazing work!), but when I used the object_tracker.py for testing, I get an error stating
"KeyError: "The name 'images:0' refers to a Tensor which does not exist. The operation, 'images', does not exist in the graph."
Am I missing something ?
screenshot of the terminal:

I trained my dataset , generated some weights files, and I use convert_to_pb.py to convert my custom weights to *.pb file.
always fail!
using default config with yolov3,Convert_to_pb.py always be fine.
(tf2_py374) D:\Tensorflow2\darknet\build\darknet\x64\TensorFlow_2.x_YOLOv3>python Convert_to_pb.py
2020-09-12 20:49:24.892145: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll
2020-09-12 20:49:26.573650: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library nvcuda.dll
2020-09-12 20:49:26.594044: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce RTX 2060 computeCapability: 7.5
coreClock: 1.755GHz coreCount: 30 deviceMemorySize: 6.00GiB deviceMemoryBandwidth: 312.97GiB/s
2020-09-12 20:49:26.597994: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll
2020-09-12 20:49:26.602725: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cublas64_10.dll
2020-09-12 20:49:26.607236: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cufft64_10.dll
2020-09-12 20:49:26.611288: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library curand64_10.dll
2020-09-12 20:49:26.616769: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cusolver64_10.dll
2020-09-12 20:49:26.620259: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cusparse64_10.dll
2020-09-12 20:49:26.628963: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudnn64_7.dll
2020-09-12 20:49:26.631240: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0
2020-09-12 20:49:26.632461: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the following CPU instructions in performance-critical operations: AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2020-09-12 20:49:26.640920: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x1a6fc17cf50 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2020-09-12 20:49:26.643947: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
2020-09-12 20:49:26.645725: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce RTX 2060 computeCapability: 7.5
coreClock: 1.755GHz coreCount: 30 deviceMemorySize: 6.00GiB deviceMemoryBandwidth: 312.97GiB/s
2020-09-12 20:49:26.650759: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll
2020-09-12 20:49:26.652231: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cublas64_10.dll
2020-09-12 20:49:26.655432: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cufft64_10.dll
2020-09-12 20:49:26.657607: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library curand64_10.dll
2020-09-12 20:49:26.666303: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cusolver64_10.dll
2020-09-12 20:49:26.671663: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cusparse64_10.dll
2020-09-12 20:49:26.674852: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudnn64_7.dll
2020-09-12 20:49:26.680977: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0
2020-09-12 20:49:27.102780: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1257] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-09-12 20:49:27.105822: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1263] 0
2020-09-12 20:49:27.107148: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1276] 0: N
2020-09-12 20:49:27.108402: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1402] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 4594 MB memory) -> physical GPU (device: 0, name: GeForce RTX 2060, pci bus id: 0000:01:00.0, compute capability: 7.5)
2020-09-12 20:49:27.115270: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x1a6a1ddc200 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
2020-09-12 20:49:27.118053: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): GeForce RTX 2060, Compute Capability 7.5
2020-09-12 20:49:28.575087: W tensorflow/core/util/tensor_slice_reader.cc:95] Could not open model_data\yolov3_custom_63000\yolov3_custom_63000.weights: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
Traceback (most recent call last):
File "Convert_to_pb.py", line 38, in <module>
yolo.load_weights(YOLO_CUSTOM_WEIGHTS) # use custom weights
File "D:\Programs\Anaconda3\envs\tf2_py374\lib\site-packages\tensorflow\python\keras\engine\training.py", line 2204, in load_weights
with h5py.File(filepath, 'r') as f:
File "D:\Programs\Anaconda3\envs\tf2_py374\lib\site-packages\h5py\_hl\files.py", line 408, in __init__
swmr=swmr)
File "D:\Programs\Anaconda3\envs\tf2_py374\lib\site-packages\h5py\_hl\files.py", line 173, in make_fid
fid = h5f.open(name, flags, fapl=fapl)
File "h5py\_objects.pyx", line 54, in h5py._objects.with_phil.wrapper
File "h5py\_objects.pyx", line 55, in h5py._objects.with_phil.wrapper
File "h5py\h5f.pyx", line 88, in h5py.h5f.open
OSError: Unable to open file (file signature not found)
YOLO_CUSTOM_WEIGHTS = "model_data/yolov3_custom_63000/yolov3_custom_63000.weights" # False # "checkpoints/yolov3_custom" # used in evaluate_mAP.py and custom model detection, if not using leave False
TRAIN_CLASSES = "model_data/yolov3_custom_63000/coco_custom.names" # "mnist/mnist.names"
I train YOLOv3-Tiny on own dataset all work OK.
But if I run python3 detection_custom.py throw this error:
Traceback (most recent call last):
File "detection_custom.py", line 31, in <module>
yolo.load_weights(YOLO_CUSTOM_WEIGHTS) # use custom weights
File "/home/mario/.local/lib/python3.7/site-packages/tensorflow/python/keras/engine/training.py", line 2182, in load_weights
status = self._trackable_saver.restore(filepath, options)
File "/home/mario/.local/lib/python3.7/site-packages/tensorflow/python/training/tracking/util.py", line 1320, in restore
checkpoint=checkpoint, proto_id=0).restore(self._graph_view.root)
File "/home/mario/.local/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py", line 209, in restore
restore_ops = trackable._restore_from_checkpoint_position(self) # pylint: disable=protected-access
File "/home/mario/.local/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py", line 914, in _restore_from_checkpoint_position
tensor_saveables, python_saveables))
File "/home/mario/.local/lib/python3.7/site-packages/tensorflow/python/training/tracking/util.py", line 297, in restore_saveables
validated_saveables).restore(self.save_path_tensor, self.options)
File "/home/mario/.local/lib/python3.7/site-packages/tensorflow/python/training/saving/functional_saver.py", line 340, in restore
restore_ops = restore_fn()
File "/home/mario/.local/lib/python3.7/site-packages/tensorflow/python/training/saving/functional_saver.py", line 316, in restore_fn
restore_ops.update(saver.restore(file_prefix, options))
File "/home/mario/.local/lib/python3.7/site-packages/tensorflow/python/training/saving/functional_saver.py", line 111, in restore
restored_tensors, restored_shapes=None)
File "/home/mario/.local/lib/python3.7/site-packages/tensorflow/python/training/saving/saveable_object_util.py", line 127, in restore
self.handle_op, self._var_shape, restored_tensor)
File "/home/mario/.local/lib/python3.7/site-packages/tensorflow/python/ops/resource_variable_ops.py", line 311, in shape_safe_assign_variable_handle
shape.assert_is_compatible_with(value_tensor.shape)
File "/home/mario/.local/lib/python3.7/site-packages/tensorflow/python/framework/tensor_shape.py", line 1134, in assert_is_compatible_with
raise ValueError("Shapes %s and %s are incompatible" % (self, other))
ValueError: Shapes (255,) and (18,) are incompatible
Config:
# YOLO options
YOLO_TYPE = "yolov3" # yolov4 or yolov3
YOLO_FRAMEWORK = "tf" # "tf" or "trt"
YOLO_V3_WEIGHTS = "model_data/yolov3.weights"
YOLO_V4_WEIGHTS = "model_data/yolov4.weights"
YOLO_V3_TINY_WEIGHTS = "model_data/yolov3-tiny.weights"
YOLO_V4_TINY_WEIGHTS = "model_data/yolov4-tiny.weights"
YOLO_TRT_QUANTIZE_MODE = "INT8" # INT8, FP16, FP32
YOLO_CUSTOM_WEIGHTS = "checkpoints/yolov3_custom_Tiny" # "checkpoints/yolov3_custom" # used in evaluate_mAP.py and custom model detection, if not using leave False
# YOLO_CUSTOM_WEIGHTS also used with TensorRT and custom model detection
YOLO_COCO_CLASSES = "model_data/coco/coco.names"
YOLO_STRIDES = [8, 16, 32]
YOLO_IOU_LOSS_THRESH = 0.5
YOLO_ANCHOR_PER_SCALE = 3
YOLO_MAX_BBOX_PER_SCALE = 100
YOLO_INPUT_SIZE = 416
if YOLO_TYPE == "yolov4":
YOLO_ANCHORS = [[[12, 16], [19, 36], [40, 28]],
[[36, 75], [76, 55], [72, 146]],
[[142,110], [192, 243], [459, 401]]]
if YOLO_TYPE == "yolov3":
YOLO_ANCHORS = [[[10, 13], [16, 30], [33, 23]],
[[30, 61], [62, 45], [59, 119]],
[[116, 90], [156, 198], [373, 326]]]
# Train options
TRAIN_YOLO_TINY = True
TRAIN_SAVE_BEST_ONLY = True # saves only best model according validation loss (True recommended)
TRAIN_SAVE_CHECKPOINT = False # saves all best validated checkpoints in training process (may require a lot disk space) (False recommended)
TRAIN_CLASSES = "tools/dataset/list.names"
TRAIN_ANNOT_PATH = "tools/dataset/list_train.txt"
TRAIN_LOGDIR = "log"
TRAIN_CHECKPOINTS_FOLDER = "checkpoints"
TRAIN_MODEL_NAME = f"{YOLO_TYPE}_custom"
TRAIN_LOAD_IMAGES_TO_RAM = True # With True faster training, but need more RAM
TRAIN_BATCH_SIZE = 4
TRAIN_INPUT_SIZE = 416
TRAIN_DATA_AUG = True
TRAIN_TRANSFER = False
TRAIN_FROM_CHECKPOINT = False # "checkpoints/yolov3_custom"
TRAIN_LR_INIT = 1e-4
TRAIN_LR_END = 1e-6
TRAIN_WARMUP_EPOCHS = 2
TRAIN_EPOCHS = 3
# TEST options
TEST_ANNOT_PATH = "tools/dataset/list_test.txt"
TEST_BATCH_SIZE = 4
TEST_INPUT_SIZE = 416
TEST_DATA_AUG = False
TEST_DECTECTED_IMAGE_PATH = ""
TEST_SCORE_THRESHOLD = 0.3
TEST_IOU_THRESHOLD = 0.45
#YOLOv3-TINY and YOLOv4-TINY WORKAROUND
if TRAIN_YOLO_TINY:
YOLO_STRIDES = [16, 32, 64]
YOLO_ANCHORS = [[[10, 14], [23, 27], [37, 58]],
[[81, 82], [135, 169], [344, 319]],
[[0, 0], [0, 0], [0, 0]]]
I was wondering if i can save the model that i generate when I trained in the yolov4 format instead of saving in a keras format, or tranfser the keras model to yolov4.
Hi,
I tried doing a training on some small datasets to see how the code worked. When I first ran the larger set, it is only about 4gigs of images, the terminal locked up after a period and either hung or threw an error like this:
cv2.error: OpenCV(4.3.0) C:\projects\opencv-python\opencv\modules\core\src\alloc.cpp:73: error: (-4:Insufficient memory) Failed to allocate 24883200 bytes in function 'cv::OutOfMemoryError'
This also caused cuddn linkage issues which I resolved by restarting. I then tried a 1 gig byte training set and the same issue. When I looked at the code in dataset.py the problem may like in the lines starting and 64.
if TRAIN_LOAD_IMAGES_TO_RAM:
image = cv2.imread(image_path)
I am not sure if this is the issue but loading my datasets not memory could cause this issue. Is there a flag to not allow it to put the full set into memory?
I should not that my system is running dual xeons, has 32 gig of ram, and a RTX 2080 TI founders edition with 11g of ram.,
x_INPUT_SIZE=416 -> 416, 416
to
x_INPUT_SIZE=780 -> 780, 780
my images are all. 780, 480
@pythonlessons
Thank you for the well informative Repo. I would like to calculate the Recall vs Precision for my Model. Is there any possibility of your support or even some information on that will be helpful.
I have trained a model for detecting license plate. I have used 69 images for training and 25 for testing
parameter used :
TRAIN_BATCH_SIZE = 10
TRAIN_LR_INIT = 9e-5
TRAIN_LR_END = 9e-7
TRAIN_EPOCHS = 10
the last lines of training are :
giou_val_loss: 1.83, conf_val_loss: 215.04, prob_val_loss: 1.10, total_val_loss: 217.97
calculating mAP45...
0.000% = license-plate AP
mAP = 0.000%, 6.86 FPS.
Where am i going wrong?
Text should have all predictions with co-ordinates, class name, confidence
I use tensorflow/2.0.0-py36-gpu and get the error below when I run detection_demo.py:
File "detection_demo.py", line 32, in <module>
detect_image(yolo, image_path, output_path, input_size=input_size, show=True, rectangle_colors=(255,0,0))
File "TensorFlow-2.x-YOLOv3/yolov3/utils.py", line 255, in detect_image
pred_bbox = YoloV3.predict(image_data)
File "/apps/tensorflow/2.0.0-py36-gpu/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training.py", line 909, in predict
use_multiprocessing=use_multiprocessing)
File "/apps/tensorflow/2.0.0-py36-gpu/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_arrays.py", line 722, in predict
callbacks=callbacks)
File "/apps/tensorflow/2.0.0-py36-gpu/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_arrays.py", line 189, in model_iteration
f = _make_execution_function(model, mode)
File "/apps/tensorflow/2.0.0-py36-gpu/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_arrays.py", line 565, in _make_execution_function
return model._make_execution_function(mode)
File "/apps/tensorflow/2.0.0-py36-gpu/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training.py", line 2190, in _make_execution_function
self._make_predict_function()
File "/apps/tensorflow/2.0.0-py36-gpu/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training.py", line 2180, in _make_predict_function
**kwargs)
File "/apps/tensorflow/2.0.0-py36-gpu/lib/python3.6/site-packages/tensorflow_core/python/keras/backend.py", line 3773, in function
return EagerExecutionFunction(inputs, outputs, updates=updates, name=name)
File "/apps/tensorflow/2.0.0-py36-gpu/lib/python3.6/site-packages/tensorflow_core/python/keras/backend.py", line 3657, in __init__
raise ValueError('Unknown graph. Aborting.')
Any clues for the error above?
So earlier I was getting the same issue from issue #45
E tensorflow/stream_executor/cuda/cuda_driver.cc:318] failed call to cuInit: CUDA_ERROR
_NO_DEVICE: no CUDA-capable device is detected
Here is my sytem config for reference:
Ubuntu 18.04 LTS
i7- 9th GEN
GTX 1660 Ti 6GB (notebook)
16 GB RAM
CUDA Toolkit - 10.1.243
cudnn - 7.6.5
Driver version 450.66 (It doesnt work with r418 either)
No other programs running in background
I tried the fix reccomened by FussnerS and am now getting a new error.
swastik@G531G:~/Documents/TensorFlow-2.x-YOLOv3$ python train.py
2020-09-09 11:24:28.420718: I tensorflow/core/platform/cpu_feature_guard.cc:143] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
2020-09-09 11:24:28.445247: I tensorflow/core/platform/profile_utils/cpu_utils.cc:102] CPU Frequency: 2599990000 Hz
2020-09-09 11:24:28.445783: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x564df49d7b30 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2020-09-09 11:24:28.445815: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
2020-09-09 11:24:28.446370: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1
2020-09-09 11:24:28.458470: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.458703: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1561] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce GTX 1660 Ti computeCapability: 7.5
coreClock: 1.59GHz coreCount: 24 deviceMemorySize: 5.80GiB deviceMemoryBandwidth: 268.26GiB/s
2020-09-09 11:24:28.458815: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
2020-09-09 11:24:28.459771: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10
2020-09-09 11:24:28.460699: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10
2020-09-09 11:24:28.460898: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10
2020-09-09 11:24:28.461914: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10
2020-09-09 11:24:28.462462: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10
2020-09-09 11:24:28.464652: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7
2020-09-09 11:24:28.464724: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.465068: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.465261: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1703] Adding visible gpu devices: 0
2020-09-09 11:24:28.465282: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
2020-09-09 11:24:28.519237: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1102] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-09-09 11:24:28.519280: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1108] 0
2020-09-09 11:24:28.519296: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1121] 0: N
2020-09-09 11:24:28.519459: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.519734: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.519970: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.520200: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1247] Created TensorFlow device (/device:GPU:0 with 5052 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1660 Ti, pci bus id: 0000:01:00.0, compute capability: 7.5)
2020-09-09 11:24:28.521529: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x564df7fd1160 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
2020-09-09 11:24:28.521541: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): GeForce GTX 1660 Ti, Compute Capability 7.5
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 2658484180504880421
, name: "/device:XLA_CPU:0"
device_type: "XLA_CPU"
memory_limit: 17179869184
locality {
}
incarnation: 12809034059942815785
physical_device_desc: "device: XLA_CPU device"
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 5298053440
locality {
bus_id: 1
links {
}
}
incarnation: 11980719283488140266
physical_device_desc: "device: 0, name: GeForce GTX 1660 Ti, pci bus id: 0000:01:00.0, compute capability: 7.5"
, name: "/device:XLA_GPU:0"
device_type: "XLA_GPU"
memory_limit: 17179869184
locality {
}
incarnation: 5307793851066346902
physical_device_desc: "device: XLA_GPU device"
]
2020-09-09 11:24:28.522030: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.522225: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1561] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce GTX 1660 Ti computeCapability: 7.5
coreClock: 1.59GHz coreCount: 24 deviceMemorySize: 5.80GiB deviceMemoryBandwidth: 268.26GiB/s
2020-09-09 11:24:28.522249: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
2020-09-09 11:24:28.522257: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10
2020-09-09 11:24:28.522264: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10
2020-09-09 11:24:28.522273: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10
2020-09-09 11:24:28.522281: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10
2020-09-09 11:24:28.522289: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10
2020-09-09 11:24:28.522296: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7
2020-09-09 11:24:28.522322: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.522517: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.522695: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1703] Adding visible gpu devices: 0
GPUs [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
2020-09-09 11:24:28.572536: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.572786: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1561] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce GTX 1660 Ti computeCapability: 7.5
coreClock: 1.59GHz coreCount: 24 deviceMemorySize: 5.80GiB deviceMemoryBandwidth: 268.26GiB/s
2020-09-09 11:24:28.572843: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
2020-09-09 11:24:28.572854: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10
2020-09-09 11:24:28.572862: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10
2020-09-09 11:24:28.572888: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10
2020-09-09 11:24:28.572920: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10
2020-09-09 11:24:28.572942: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10
2020-09-09 11:24:28.572950: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7
2020-09-09 11:24:28.572981: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.573183: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.573364: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1703] Adding visible gpu devices: 0
2020-09-09 11:24:28.573406: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1102] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-09-09 11:24:28.573411: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1108] 0
2020-09-09 11:24:28.573415: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1121] 0: N
2020-09-09 11:24:28.573458: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.573663: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-09 11:24:28.573852: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1247] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 5052 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1660 Ti, pci bus id: 0000:01:00.0, compute capability: 7.5)
skipping conv2d_74
skipping conv2d_66
skipping conv2d_58
2020-09-09 11:24:45.025499: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7
2020-09-09 11:24:45.477260: E tensorflow/stream_executor/cuda/cuda_dnn.cc:329] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
2020-09-09 11:24:45.489178: E tensorflow/stream_executor/cuda/cuda_dnn.cc:329] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
Traceback (most recent call last):
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/ops/gen_nn_ops.py", line 926, in conv2d
"dilations", dilations)
tensorflow.python.eager.core._FallbackException: Expecting int64_t value for attr strides, got numpy.int32
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "train.py", line 195, in
main()
File "train.py", line 150, in main
results = train_step(image_data, target)
File "train.py", line 88, in train_step
pred_result = yolo(image_data, training=True)
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer.py", line 968, in call
outputs = self.call(cast_inputs, *args, **kwargs)
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/keras/engine/network.py", line 719, in call
convert_kwargs_to_constants=base_layer_utils.call_context().saving)
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/keras/engine/network.py", line 888, in _run_internal_graph
output_tensors = layer(computed_tensors, **kwargs)
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer.py", line 968, in call
outputs = self.call(cast_inputs, *args, **kwargs)
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/keras/layers/convolutional.py", line 207, in call
outputs = self._convolution_op(inputs, self.kernel)
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/ops/nn_ops.py", line 1106, in call
return self.conv_op(inp, filter)
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/ops/nn_ops.py", line 638, in call
return self.call(inp, filter)
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/ops/nn_ops.py", line 237, in call
name=self.name)
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/ops/nn_ops.py", line 2014, in conv2d
name=name)
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/ops/gen_nn_ops.py", line 933, in conv2d
data_format=data_format, dilations=dilations, name=name, ctx=_ctx)
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/ops/gen_nn_ops.py", line 1022, in conv2d_eager_fallback
ctx=ctx, name=name)
File "/home/swastik/anaconda3/envs/tf2/lib/python3.6/site-packages/tensorflow/python/eager/execute.py", line 60, in quick_execute
inputs, attrs, num_outputs)
tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above. [Op:Conv2D]
.
.
.
Also, I should mention that earlier the model was training on my CPU after showing the error (same as #45 ). Now it just fails.
Hi
Great work sir.
while training on a class from google open dataset
have been facing this following issue
epoch: 1 step: 3432/3434, lr:0.000100, giou_loss: 1.99, conf_loss: 5.01, prob_loss: 10.97, total_loss: 17.97
epoch: 1 step: 3433/3434, lr:0.000100, giou_loss: 2.27, conf_loss: 6.15, prob_loss: 11.99, total_loss: 20.41
epoch: 1 step: 0/3434, lr:nan, giou_loss: 2.14, conf_loss: 6.32, prob_loss: 12.02, total_loss: 20.48
epoch: 1 step: 1/3434, lr:nan, giou_loss: 2.78, conf_loss: 5.77, prob_loss: 13.06, total_loss: 21.61
giou_val_loss: nan, conf_val_loss: nan, prob_val_loss: nan, total_val_loss: nan
Hi,
I am wondering if anyone can assist. I have run into an issue which I don't think is a bug persay but rather an issue with how the graph is being constructed or maybe not being cleared. I downloaded the code and weights and ran detection_demo.py and this is the error message I get.
ValueError: Tensor("Placeholder:0", shape=(?, ?, ?, ?), dtype=float32) must be from the same graph as Tensor("conv2d/kernel:0", shape=(), dtype=resource).
The error is coming from line 66 of load_yolo_weights in utils.py. This is the code in that block that gives the error
if i not in range2: conv_layer.set_weights([conv_weights]) bn_layer.set_weights(bn_weights) else: conv_layer.set_weights([conv_weights, conv_bias])
I am using TF2.3 and installed all the requirements via conda. I would appreciate any advice.
When I execute this statement.python detection_demo.py.Show this error.

Then i changed pred_bbox = YoloV3.predict(image_data) to pred_bbox = YoloV3(image_data).Then the prediction succeeded.
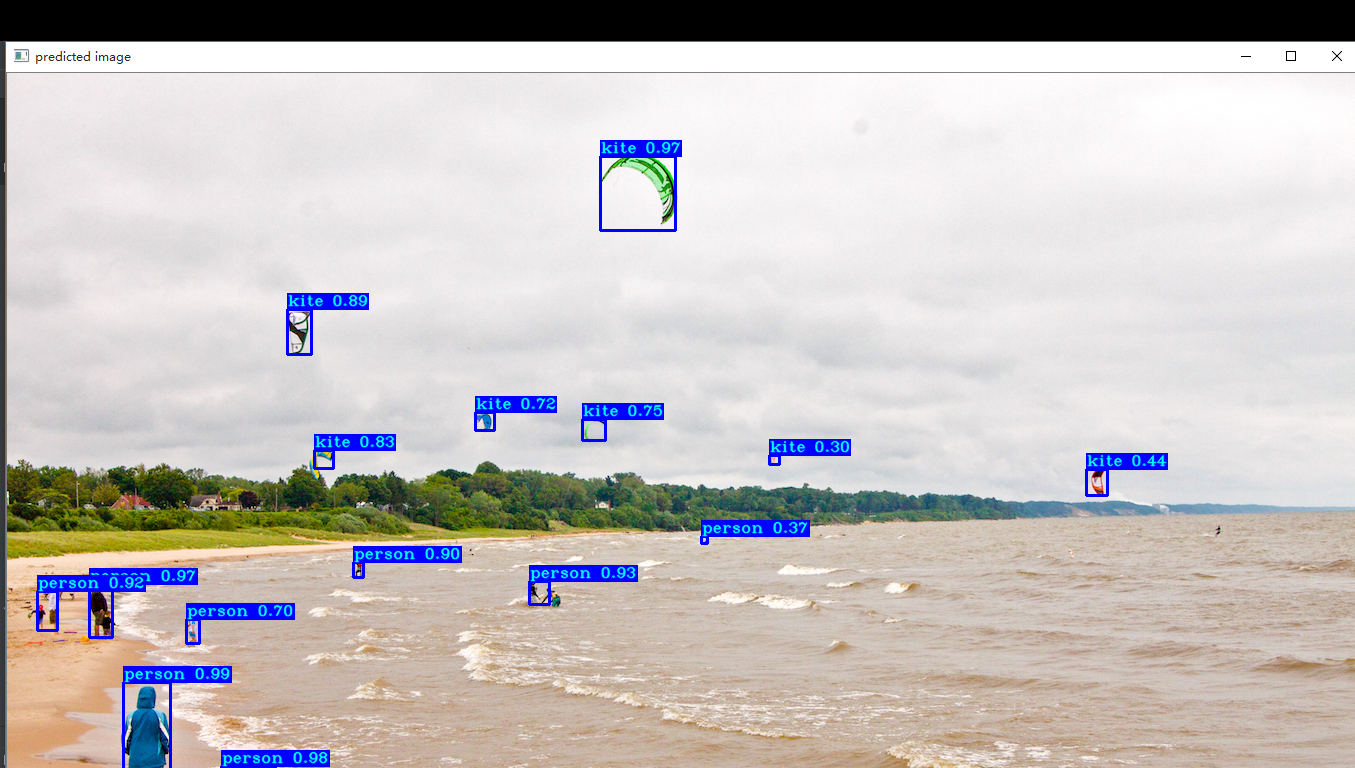
Why does YoloV3.predict(image_data) fail?
Hi sir
Can you help me in code for conversion of predictions to text format for detect_image and detect_video
Thanks in advance
Thanks for sharing the code! The calibration_input function for int8 passes noise currently. how do we pass the appropriate calibration data?
thanks!
`epoch:49 step: 0/19, lr:0.000052, giou_loss: 2.64, conf_loss: 11.12, prob_loss: 0.08, total_loss: 13.83
epoch:49 step: 1/19, lr:0.000052, giou_loss: 2.31, conf_loss: 10.61, prob_loss: 0.08, total_loss: 12.99
giou_val_loss: nan, conf_val_loss: 12.31, prob_val_loss: 0.06, total_val_loss: nan
epoch:50 step: 2/19, lr:0.000052, giou_loss: 1.96, conf_loss: 10.34, prob_loss: 0.09, total_loss: 12.38
epoch:50 step: 3/19, lr:0.000052, giou_loss: 2.51, conf_loss: 11.29, prob_loss: 0.08, total_loss: 13.87
epoch:50 step: 4/19, lr:0.000052, giou_loss: 2.17, conf_loss: 10.95, prob_loss: 0.06, total_loss: 13.18`
I changed the TRAIN_EPOCHS = 10 and TRAIN_BATCH_SIZE = 16 but the model is still using default values of 100 epochs and batch size of 8 in training. I am sure the configs file is saved with updated values.
I set up everything on colab itself (didn't upload to drive from my system), could that be the reason?
Traceback (most recent call last):
File "detection_demo.py", line 31, in <module>
load_yolo_weights(yolo, Darknet_weights) # use Darknet weights
File "/content/drive/My Drive/TensorFlow-2.x-YOLOv3/yolov3/utils.py", line 68, in load_yolo_weights
conv_weights = conv_weights.reshape(conv_shape).transpose([2, 3, 1, 0])
ValueError: cannot reshape array of size 391694 into shape (512,256,3,3)
I train a yolov3 model but in detection_demo.py give an error. This error occur in load yolov3.weights file. Take numbers that inside the model but in last layer the remaining numbers size is not equal to last layers size. I did not any changes in model file except traning changes.
What should I do if I just want to test car without retraining,I tried to train car only, but the loss was 10 to 20 and couldn't go down
Hi, I got this error while running the demo file in windows 10 system.
any solution?
Traceback (most recent call last):
File ".\detection_demo.py", line 29, in
load_yolo_weights(yolo, Darknet_weights) # use Darknet weights
File "E:\DEV\Project_Alot\Image_Detect\TensorFlow-2.x-YOLOv3\yolov3\utils.py", line 59, in load_yolo_weights
conv_weights = conv_weights.reshape(conv_shape).transpose([2, 3, 1, 0])
ValueError: cannot reshape array of size 391694 into shape (512,256,3,3)
Trained the model in one class Person
changed in configs.py
YOLO_CUSTOM_WEIGHTS = "checkpoints/yolov4_custom_Person_yolov4_tiny_Tiny"
and run detection_custom.py
and I get an execution

when I run the dectection_custom, it runs and produces the image with annotation, but the terminal doesn't end and I can't even force end it with ^C. what might be an issue?
I am running on windows with one GPU. the terminal has the following lines:
(base) PS C:\Users\Michael\python-yolo> python detection_custom.py
2020-09-16 17:53:23.444365: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll
2020-09-16 17:53:25.421163: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library nvcuda.dll
2020-09-16 17:53:25.454644: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce RTX 2070 computeCapability: 7.5
coreClock: 1.455GHz coreCount: 36 deviceMemorySize: 8.00GiB deviceMemoryBandwidth: 327.88GiB/s
2020-09-16 17:53:25.462018: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll
2020-09-16 17:53:25.475301: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cublas64_10.dll
2020-09-16 17:53:25.481780: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cufft64_10.dll
2020-09-16 17:53:25.486138: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library curand64_10.dll
2020-09-16 17:53:25.496971: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cusolver64_10.dll
2020-09-16 17:53:25.502632: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cusparse64_10.dll
2020-09-16 17:53:25.519524: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudnn64_7.dll
2020-09-16 17:53:25.522089: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0
2020-09-16 17:53:25.524340: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the following CPU instructions in performance-critical operations: AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2020-09-16 17:53:25.537301: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x27a8f8c0180 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2020-09-16 17:53:25.541399: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
2020-09-16 17:53:25.544288: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce RTX 2070 computeCapability: 7.5
coreClock: 1.455GHz coreCount: 36 deviceMemorySize: 8.00GiB deviceMemoryBandwidth: 327.88GiB/s
2020-09-16 17:53:25.550240: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll
2020-09-16 17:53:25.553248: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cublas64_10.dll
2020-09-16 17:53:25.556447: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cufft64_10.dll
2020-09-16 17:53:25.561298: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library curand64_10.dll
2020-09-16 17:53:25.566129: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cusolver64_10.dll
2020-09-16 17:53:25.570766: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cusparse64_10.dll
2020-09-16 17:53:25.574098: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudnn64_7.dll
2020-09-16 17:53:25.576873: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0
2020-09-16 17:53:26.092160: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1257] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-09-16 17:53:26.100505: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1263] 0
2020-09-16 17:53:26.102892: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1276] 0: N
2020-09-16 17:53:26.105094: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1402] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 6228 MB memory) -> physical GPU (device: 0, name: GeForce RTX 2070, pci bus id: 0000:01:00.0, compute capability: 7.5)
2020-09-16 17:53:26.115019: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x27ab3bbbd30 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
2020-09-16 17:53:26.119188: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): GeForce RTX 2070, Compute Capability 7.5
2020-09-16 17:53:35.679618: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudnn64_7.dll
2020-09-16 17:53:36.559770: W tensorflow/stream_executor/gpu/redzone_allocator.cc:314] Internal: Invoking GPU asm compilation is supported on Cuda non-Windows platforms only
Relying on driver to perform ptx compilation.
Modify $PATH to customize ptxas location.
This message will be only logged once.
2020-09-16 17:53:36.592507: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cublas64_10.dll
I wanna train custom model, so I followed guide.
I changed config.py YOLO_INPUT_SIZE 416 to 608(accrording to guide).
Than error occured.
ValueError: Dimension 1 in both shapes must be equal, but are 38 and 26. Shapes are [4,38,38] and [4,26,26]. for '{{node concat_6}} = ConcatV2[N=2, T=DT_FLOAT, Tidx=DT_INT32, _cloned=true](inputs, inputs_1, concat_6/axis)' with input shapes: [4,38,38,128], [4,26,26,256], [] and with computed input tensors: input[2] = <-1>.
How can I fix it?? Doesn't it need to change?
epoch: 0 step: 97/100, lr:0.000048, giou_loss: 7.67, conf_loss: 199.07, prob_loss: 9.08, total_loss: 215.82
epoch: 0 step: 98/100, lr:0.000049, giou_loss: 9.68, conf_loss: 200.08, prob_loss: 10.70, total_loss: 220.46
epoch: 0 step: 99/100, lr:0.000049, giou_loss: 6.33, conf_loss: 201.52, prob_loss: 8.38, total_loss: 216.23
epoch: 0 step: 0/100, lr:0.000050, giou_loss: 8.88, conf_loss: 196.33, prob_loss: 14.15, total_loss: 219.36
epoch: 0 step: 1/100, lr:0.000050, giou_loss: 8.39, conf_loss: 193.57, prob_loss: 9.26, total_loss: 211.23
Traceback (most recent call last):
File "train.py", line 173, in
main()
File "train.py", line 145, in main
for image_data, target in testset:
File "/Users/jelaleddin/TensorFlow-2.x-YOLOv3/yolov3/dataset.py", line 97, in next
label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes = self.preprocess_true_boxes(bboxes)
File "/Users/jelaleddin/TensorFlow-2.x-YOLOv3/yolov3/dataset.py", line 220, in preprocess_true_boxes
label[i][yind, xind, iou_mask, :] = 0
IndexError: index 13 is out of bounds for axis 1 with size 13
I am getting this error, what can be the reason of such problem?Please write a comment if you have faced same issue
i train use yolov4 but get error
" Duplicate node name in graph: 'ones' " in yolov4.py line 420
After finishing the training, I get an unboundlocalerror: local variable 'save directory' referenced before assignment.
How can I resolve this issue?
File "E:\TensorFlow-2.x-YOLOv3\yolov3\utils.py", line 370, in detect_realtime
image = cv2.putText(image, "Time: {:.1f}FPS".format(fps), (0, 30),
UnboundLocalError: local variable 'image' referenced before assignment
you need to change the "image" to "frame" inside putText()
Hi,
trying to run convert_to_trt.py
getting 'ImportError: cannot import name 'trt_convert' from 'tensorflow.python.compiler.tensorrt''
am i missing a package or something, i have tensor flow 2.3.0 as per the requirements file
Hi, thanks for the elegant work on describing how train a custom TF2 YOLOv3 model, I try to train Yolov3 Tiny model with custom database(license plate), and generated a checkpoints folder. After that try to use Convert_to_pb.py to convert the model to Tensorflow format(with yolov3_Tiny-416 folder/saved_model.pb generated). My goal is to convert to TFLite format, so I use the two commands below
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) # path to the SavedModel directory
tflite_model = converter.convert()
Program will be terminated in converter.convert. I knew TFLite convert support is still in your todo list. But could you have a look first for this request?
[updated]
refer https://www.tensorflow.org/lite/guide/ops_select, TFLite convert workable.
Thanks
Angus
Hi Sir,
Thank you for great work.
I am trying to evaluate the mAP for Yolov3 but i am facing a issue with the coordinate of the grounth truth and prediction Bounding Box.
For example the grouth truth for a object in a image of MS-coco are "167.89 182.09 301.96 205.34" and the coordinate predicted by the utils.py for bounding box are "170.19602966 181.54490662 469.15988159 397.06906128".
I think the format for the grouth truth and prediction are not matching which results in wrong mAP. Please appreciate your help as i am a beginner in computer vision domain.
Thank you
Hitesh
Hi, thank you for your work and your tutorials. I've got a problem.
I train my own data set, and after the end of the first Epoch, I've got this Error:
epoch: 0 step: 87/89, lr:0.000049, giou_loss: 3.94, conf_loss: 172.47, prob_loss: 7.58, total_loss: 183.99
epoch: 0 step: 88/89, lr:0.000049, giou_loss: 5.02, conf_loss: 173.52, prob_loss: 10.47, total_loss: 189.01
epoch: 0 step: 0/89, lr:0.000050, giou_loss: 3.95, conf_loss: 166.17, prob_loss: 7.58, total_loss: 177.70
epoch: 0 step: 1/89, lr:0.000051, giou_loss: 3.95, conf_loss: 166.40, prob_loss: 9.05, total_loss: 179.41
Traceback (most recent call last):
File "train.py", line 173, in
main()
File "train.py", line 145, in main
for image_data, target in testset:
File "/home/bryan/Documents/TensorFlow-2.x-YOLOv3/yolov3/dataset.py", line 97, in next
label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes = self.preprocess_true_boxes(bboxes)
File "/home/bryan/Documents/TensorFlow-2.x-YOLOv3/yolov3/dataset.py", line 220, in preprocess_true_boxes
label[i][yind, xind, iou_mask, :] = 0
IndexError: index 13 is out of bounds for axis 1 with size 13
I don't think that my test dataset are wrong. Could you help me ?
Thank for reading.
Traceback (most recent call last):
File "train.py", line 173, in
main()
File "train.py", line 133, in main
for image_data, target in trainset:
File "C:\Users\Administrator\Desktop\TensorFlow-2.x-YOLOv3-master\yolov3\dataset.py", line 122, in next
batch_image[num, :, :, :] = image
ValueError: could not broadcast input array from shape (411,416,3) into shape (416,416,3)
Trained yolo_tiny on 3 object classes that are: carrot, cucumber and zucchini. But detection works only for that class which is first mentioned on class names txt file
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.