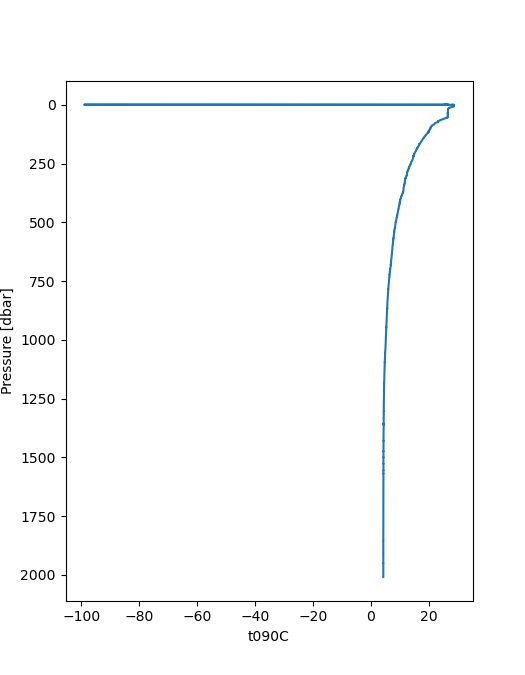
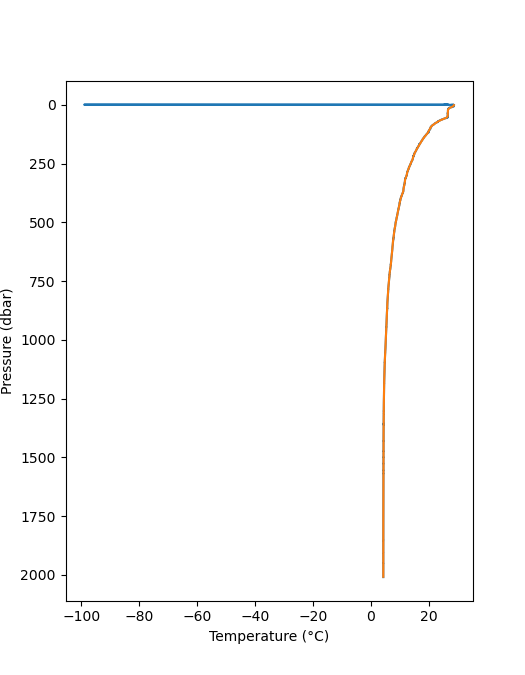
We have not discovered the problem with error message, but we could fix the problem with our input file.
.virtualenvs/zurf/local/lib/python2.7/site-packages/ctd/ctd.pyc in from_cnv(fname, compression, below_water, lon, lat)
200 f.close()
201
--> 202 cast.set_index('prDM', drop=True, inplace=True)
203 cast.index.name = 'Pressure [dbar]'
204
.virtualenvs/zurf/local/lib/python2.7/site-packages/pandas/core/frame.pyc in set_index(self, keys, drop, append, inplace, verify_integrity)
2915 names.append(None)
2916 else:
-> 2917 level = frame[col]._values
2918 names.append(col)
2919 if drop:
.virtualenvs/zurf/local/lib/python2.7/site-packages/pandas/core/frame.pyc in __getitem__(self, key)
2057 return self._getitem_multilevel(key)
2058 else:
-> 2059 return self._getitem_column(key)
2060
2061 def _getitem_column(self, key):
.virtualenvs/zurf/local/lib/python2.7/site-packages/pandas/core/frame.pyc in _getitem_column(self, key)
2064 # get column
2065 if self.columns.is_unique:
-> 2066 return self._get_item_cache(key)
2067
2068 # duplicate columns & possible reduce dimensionality
.virtualenvs/zurf/local/lib/python2.7/site-packages/pandas/core/generic.pyc in _get_item_cache(self, item)
1384 res = cache.get(item)
1385 if res is None:
-> 1386 values = self._data.get(item)
1387 res = self._box_item_values(item, values)
1388 cache[item] = res
.virtualenvs/zurf/local/lib/python2.7/site-packages/pandas/core/internals.pyc in get(self, item, fastpath)
3541
3542 if not isnull(item):
-> 3543 loc = self.items.get_loc(item)
3544 else:
3545 indexer = np.arange(len(self.items))[isnull(self.items)]
.virtualenvs/zurf/local/lib/python2.7/site-packages/pandas/indexes/base.pyc in get_loc(self, key, method, tolerance)
2134 return self._engine.get_loc(key)
2135 except KeyError:
-> 2136 return self._engine.get_loc(self._maybe_cast_indexer(key))
2137
2138 indexer = self.get_indexer([key], method=method, tolerance=tolerance)
pandas/index.pyx in pandas.index.IndexEngine.get_loc (pandas/index.c:4433)()
pandas/index.pyx in pandas.index.IndexEngine.get_loc (pandas/index.c:4279)()
pandas/src/hashtable_class_helper.pxi in pandas.hashtable.PyObjectHashTable.get_item (pandas/hashtable.c:13742)()
pandas/src/hashtable_class_helper.pxi in pandas.hashtable.PyObjectHashTable.get_item (pandas/hashtable.c:13696)()
KeyError: 'prDM'
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-4-afa11aeac91a> in <module>()
----> 1 a = ctd.DataFrame.from_cnv('tccvini/sampling/25-01-17/stations_25-01-2017_RAW.cnv')
.virtualenvs/envpy3/lib/python3.5/site-packages/ctd/ctd.py in from_cnv(fname, compression, below_water, lon, lat)
161 f = read_file(fname, compression=compression)
162 header, config, names = [], [], []
--> 163 for k, line in enumerate(f.readlines()):
164 line = line.strip()
165 if '# name' in line: # Get columns names.
.virtualenvs/envpy3/lib/python3.5/codecs.py in decode(self, input, final)
319 # decode input (taking the buffer into account)
320 data = self.buffer + input
--> 321 (result, consumed) = self._buffer_decode(data, self.errors, final)
322 # keep undecoded input until the next call
323 self.buffer = data[consumed:]
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe1 in position 71: invalid continuation byte




![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")






![pre-commit-ci[bot] avatar](https://avatars.githubusercontent.com/in/68672?v=4 "pre-commit-ci[bot]")


























































