Your Name
(Image1)[https://user-images.githubusercontent.com/16946028/163627966-dc0b4e18-d7ac-4d75-889f-2844926d11be.png]
Url of an image to represent you (or attach to the issue)
Level of Pulsar understanding
100 (beginner)|200 (intermediate)|300 (advanced)
Content (don't worry about formatting, the site moderators can help)
In today’s modern age of social media and online interconnectivity, real-time information relies on efficient systems that quickly and consistently distribute data to a wide range of consumers.
Pulsar and Kafka are both industry-standard messaging systems.
In 2011, LinkedIn developed Apache Kafka and published it as an open source system. Since then, it has surged in popularity and established itself as the industry standard for a highly scalable publish/subscribe (pub/sub) messaging platform. It’s still a fantastic free and open source technology for distributed streaming applications. However, there’s now an alternative.
Apache Pulsar began as a Yahoo project in 2013. It was open sourced in 2016 and adopted by the Apache Software Foundation. It’s a cloud-native distributed messaging and streaming platform. Hundreds of businesses — including Verizon Media, Tencent, Comcast, and Overstock to name a few — have embraced this solution.
In this article, we'll evaluate the features, architectures, performance, and use cases of Apache Pulsar versus Kafka, to help you decide which is the better solution for you.
Apache Pulsar Versus Apache Kafka
Speed and Performance
Pulsar is considerably faster than Kafka. It can provide higher throughput with reduced latency in real-world situations.
Confluent found that Kafka offers the lowest latency at higher throughputs, with high availability and durability. Kafka’s efficiency and fewer moving parts also lower its cost.
However, StreamNative countered that Confluent’s tests used a narrow set of parameters that did not measure Pulsar’s performance accurately. StreamNative’s benchmarks actually indicate that Pulsar surpasses Kafka in tasks that are more useful in the real world, like streaming messages and events.
For example, Pulsar’s catch-up read throughput was 3.5 times faster. Unlike Kafka, Pulsar was unaffected by increasing the number of partitions and changing durability levels. Pulsar also had lower latency — at milliseconds versus Kafka’s seconds — and was less impacted by the number of topics and subscriptions.
Pulsar also comes out on top when it comes to pricing and performance according toGigaOm: with a 35 percent higher performance at a lower 3-year cost than Kafka and 81 percent savings when handling higher data volumes.
Geo-Replication
Pulsar's most significant native capability,geo-replication, truly differentiates it from Kafka. Geo-replication systems use geographically-distributed data centers to increase availability and disaster resilience. The built-in geo-replication function can synchronize data between clusters usually located in various geographical regions by duplicating topics. This approach aids diverse service availability needs, such as disaster recovery, data migration, and data backup.
Because Pulsar’s geo-replication is built-in, it does not require complicated setups or add-ons. If you publish a message to a topic in a replicated namespace, Pulsar automatically copies the message to the selected location or multiple locations.
Cloud-Native Approach
Cloud-native means building, running, and distributing applications on the cloud’s distributed computing architecture. Developers build cloud-native applications using various technologies, including Docker, APIs, serverless functions, and microservices. Kubernetes is the industry standard for cloud-native orchestration.
Apache Pulsar integrates seamlessly with Kubernetes, supporting rolling upgrades, automatic monitoring, and horizontal scalability. Its multilayer architecture also integrates well with cloud infrastructures, separating computing (which is handled by brokers) from storage (which is managed by Apache BookKeeper).
Pulsar is cloud-native at its core. Kafka wasn’t a fully cloud-native solution from the start, so you need services like Confluent Operator to work with cloud services.
Messaging and Event-Streaming Architecture
Apache Pulsar's multi-layered design completely decouples the message routing and storage layers, allowing each to scale independently. It also integrates the advantages of classic messaging systems such as RabbitMQ with the benefits of publish/subscribe systems such as Kafka.
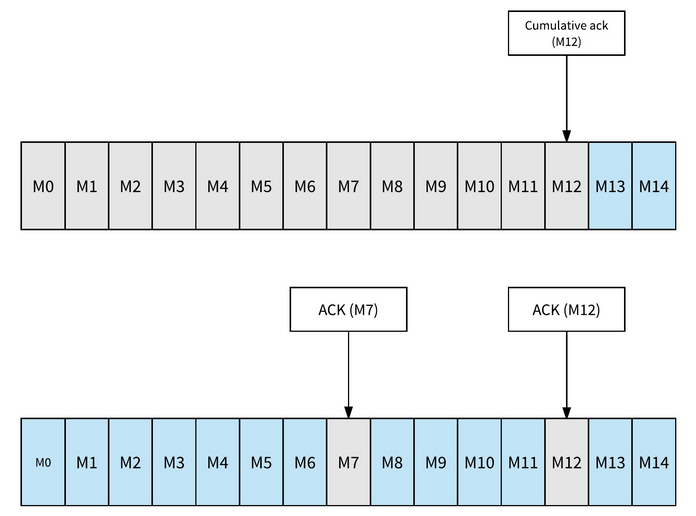
The publish/subscribe pattern lies at Pulsar’s heart. Producers publish messages to the server, and consumers must subscribe to receive the notifications.
In the publish/subscribe design pattern, message publishers don’t deliver messages to specific subscribers. Instead, message consumers subscribe to topics of interest. Each time a publisher publishes a message linked with that topic, Pulsar promptly sends it to all subscribers.
Pulsar’s all-in-one platform offers publish/subscribe systems, queues, and streams all in one place, offering an advantage over Kafka’s publish/subscribe-only system.
Available Clients
Pulsar exposes a client API with language bindings for Java, Go, Python, C++, and C#. The client API optimizes and encapsulates Pulsar's client-broker communication protocol and exposes a simple and intuitive API for applications to use.
Because Kafka is older, it has more developed client libraries. However, it’s only a matter of time before Pulsar catches up given its fast-developing community.
Additionally, if you cannot locate a client library for your preferred language, you can use Pulsar's WebSocket proxy. You can also usePulsar Beam, a standalone service enabling applications to interact with Apache Pulsar using HTTP.
As we can see, Kafka may be a better choice depending on which language you use, although Pulsar has its workarounds.
Storage
Kafka employs a distributed commit log as its storage layer. Pulsar, in contrast, employs anindex-based storage method that maintains data in a tree structure, allowing quick access when addressing individual messages.
Both Pulsar and Kafka provide long-term or permanent message storage. However, their mechanisms differ. Kafka stores data in logs shared across brokers, while Pulsar stores data in Apache BookKeeper.
Kafka’s storage costs are higher than Pulsar, which provides tiered storage. This tiered storage lets you keep outdated and infrequently accessed data on low-cost storage alternatives.
Pulsar also allows you to add new brokers without altering or re-partitioning the data. Additionally, it addresses latency while working with massive data sets using a quorum-based replication technique resulting in more consistent latencies.
So, while both Pulsar and Kafka offer long-term storage, Pulsar’s approach may be more cost-effective.
Brokers
Pulsar and Kafka operate as clusters, with nodes called brokers. Brokers can act as either leaders or replicas to offer the system high availability and fault tolerance.
Kafka has many significant limitations compared to Pulsar. Most significantly, its broker-tied storage limits scalability.
Each broker in Kafka maintains a complete partition log. Brokers must synchronize data with all other brokers responsible for the same partition and their duplicates. In contrast, Pulsar keeps the state outside the brokers, separating them from the data storage layer.
Apache Pulsar's stateless brokers are a significantly competitive feature over Kafka. You can launch them rapidly and in vast numbers to meet increased demand.
Documentation and Community Support
While both solutions may accomplish your objectives, other factors like access to support and community resources are often equally or more relevant.
Kafka's community is far more extensive and active than Pulsar's because of Kafka’s popularity and longstanding presence. Therefore, many enterprises consider Kafka a more logical choice.
Yet, Pulsar has rich documentation. Plus, its community is also growing daily as more organizations migrate from Kafka and other messaging systems to Pulsar for its built-in features and improvements over Kafka.
Pulsar Use Cases
Pulsar excels in various applications, including real-time machine learning using Pulsar Functions. It offers many advantages, such as its quorum-based replication algorithm for consistent latency, tiered storage, and distinct storage and broker layers.
Pulsar Functions is an integrated, easy-to-use stream processor. It helps reduce the operational complexity of configuring and managing a stand-alone stream processing engine such as Apache Heron or Apache Storm. Extending Pulsar’s architecture with an additional engine can handle more complex use cases.
Pulsar excels in stream processing for various applications, including real-time health monitoring, financial transaction processing, Internet of things (IoT) stream analysis, and more. Additionally, Pulsar's focus on machine learning and artificial intelligence make it a more viable option for modern enterprises valuing data as a strategic resource.
Conclusion
Pulsar is gaining traction among modern enterprises seeking a more current, innovative solution that fulfills modern requirements. Additionally, Pulsar features a Kafka-compatible API, making migration simple for developers.
Pulsar is user-friendly and feature-rich, plus it’s more scalable and faster than Kafka. It alleviates the discomfort and operational expenses associated with deploying several systems offering similar services.
Although there may be times when Kafka comes out on top, such as for built-in language support — overall, Pulsar looks more suitable for most use cases.