




Privacy Meter is an open-source library to audit data privacy in statistical and machine learning algorithms. The tool can help in the data protection impact assessment process by providing a quantitative analysis of the fundamental privacy risks of a (machine learning) model. It uses state-of-the-art inference techniques to audit a wide range of machine learning algorithms for classification, regression, computer vision, and natural language processing. Privacy Meter generates extensive reports about the aggregate and individual privacy risks for data records in the training set, at multiple levels of access to the model.
Machine learning is playing a central role in automated decision-making in a wide range of organizations and service providers. The data, which is used to train the models, typically contain sensitive information about individuals. Although the data in most cases cannot be released, due to privacy concerns, the models are usually made public or deployed as a service for inference on new test data. For a safe and secure use of machine learning models, it is important to have a quantitative assessment of the privacy risks of these models, and to make sure that they do not reveal sensitive information about their training data. This is of great importance as there has been a surge in the use of machine learning in sensitive domains such as medical and finance applications.
Data Protection regulations, such as GDPR and AI governance frameworks, require personal data to be protected when used in AI systems, and that the users have control over their data and awareness about how it is being used. For example, Article 35 of GDPR requires organizations to systematically analyze, identify and minimize the data protection risks of a project, especially when the project involves innovative technologies such as Artificial Intelligence, Machine Learning, and Deep Learning. Thus, proper mechanisms need to be in place to quantitatively evaluate and verify the privacy of individuals in every step of the data processing pipeline in AI systems.
ML Privacy Meter is a Python library (privacy_meter) that enables quantifying the privacy risks of machine learning models. The tool provides privacy risk scores which help in identifying data records among the training data that are at high risk of being leaked through the model parameters or predictions.
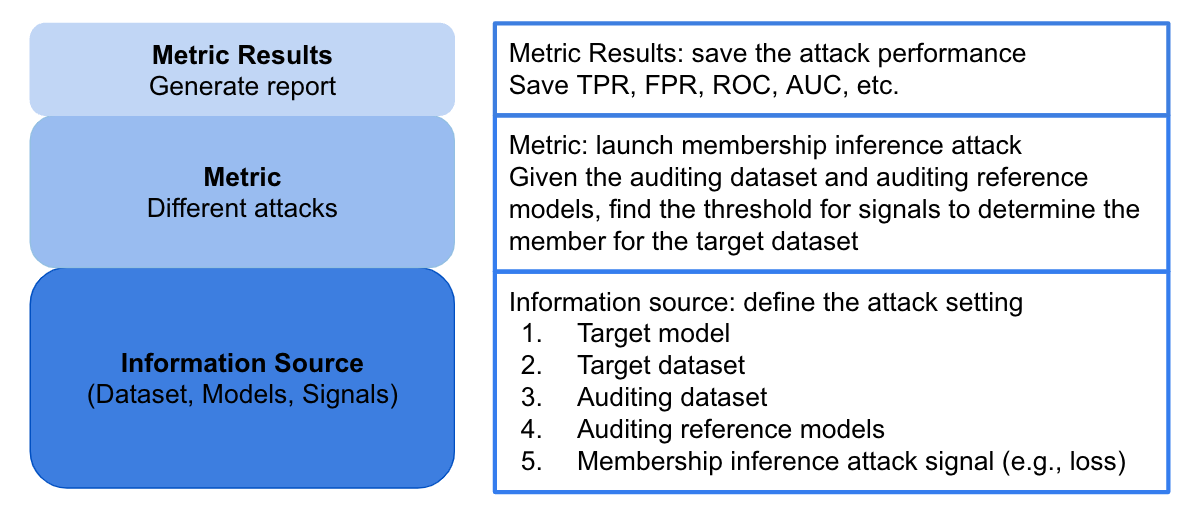
The core of the Privacy Meter consists of three parts: Information Source, Metric and Metric Results.
Privacy Meter supports Python >=3.6 and works with tensorflow>=2.4.0 and torch>=1.10.0.
You can install privacy-meter using pip for the latest stable version of the tool:
pip install privacy-meterWe offer two types of tutorials: basic usage (in the basic folder) and advanced usage (in the advanced folder). The goal of the basic tutorials is to provide users with a seamless experience in working with various predefined privacy games, algorithms, and signals. These components represent state-of-the-art membership inference attacks and can be configured easily without requiring users to write code (See instructions here). On the other hand, the advanced usage is tailored for professional users who seek to conduct sophisticated auditing. It allows them to utilize both pre-existing and customized algorithms, signals, and models, empowering them to perform advanced auditing tasks at a higher level of complexity and customization. Specifically, we provide the following tutorials for advanced usage:
- Understanding low-level APIs: Acquire a fundamental understanding of the Privacy Meter by executing a population attack on the CIFAR10 dataset.
- Understanding low-level APIs: Enhance your knowledge by conducting a reference attack on the CIFAR10 dataset.
- Implementing a simple white-box attack using the Privacy Meter.
- Expanding the Privacy Meter to encompass OpenVINO models.
- Integrating the Privacy Meter with HuggingFace models.
- Auditing Data Privacy in Machine Learning: A Comprehensive Introduction at CCS 2022, by Reza Shokri.
- Auditing Data Privacy in Machine Learning at USENIX Enigma 2022, by Reza Shokri.
- Machine Learning Privacy Meter Tool at HotPETS 2020, by Sasi Kumar Murakonda.
If you wish to add new ways of analyzing the privacy risk or add new model support, please follow our guidelines.
Please feel free to join our Slack Channel to provide your feedback and your thoughts on the project!
To cite this repository, please include the following references (or you can download the bib file).
-
Sasi Kumar Murakonda, Reza Shokri. MLPrivacy Meter: Aiding Regulatory Compliance by Quantifying the Privacy Risks of Machine Learning in Workshop on Hot Topics in Privacy Enhancing Technologies (HotPETs), 2020.
-
Jiayuan Ye, Aadyaa Maddi, Sasi Kumar Murakonda, Reza Shokri. Enhanced Membership Inference Attacks against Machine Learning Models in Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, 2022.
-
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, Florian Tramer. Membership Inference Attacks From First Principles in IEEE Symposium on Security and Privacy, 2022.
-
Milad Nasr, Reza Shokri, and Amir Houmansadr. Comprehensive Privacy Analysis of Deep Learning: Stand-alone and Federated Learning under Passive and Active White-box Inference Attacks in IEEE Symposium on Security and Privacy, 2019.
-
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership Inference Attacks against Machine Learning Models in IEEE Symposium on Security and Privacy, 2017.
The tool is designed and developed at NUS Data Privacy and Trustworthy Machine Learning Lab. We also welcome contributions from the community.



![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")



































































































































