dict_dim = 33261
emb_dim = 128
hid_dim = 128
hid_dim2 = 96
win_size = 3
unpad_data = fluid.layers.sequence_unpad(text_a, length=text_a_lens)
emb = fluid.layers.embedding(input=unpad_data, size=[dict_dim, emb_dim])
conv = fluid.nets.sequence_conv_pool(
input=emb,
num_filters=hid_dim,
filter_size=win_size,
act="tanh",
pool_type="max")
# full connect layer
fc_1 = fluid.layers.fc(input=[conv], size=hid_dim2)
# softmax layer
prediction = fluid.layers.fc(input=[fc_1], size=cfg.num_labels, act="softmax")
if is_inference:
feed_targets_name = [text_a.name, text_a_lens.name]
return feed_targets_name, prediction
cost = fluid.layers.cross_entropy(input=prediction, label=label)
avg_cost = fluid.layers.mean(x=cost)
graph_vars = collections.OrderedDict()
graph_vars["loss"] = avg_cost
graph_vars["classify_infer"] = prediction
graph_vars["label"] = label
return py_reader, graph_vars
def __init__(self, config, create_net):
print('BaseModel init....')
self.config = config
if config.use_cuda:
place = fluid.CUDAPlace(int(os.getenv('FLAGS_selected_gpus', '0')))
self.dev_count = fluid.core.get_cuda_device_count()
else:
place = fluid.CPUPlace()
self.dev_count = int(os.environ.get('CPU_NUM', multiprocessing.cpu_count()))
self.executor = fluid.Executor(place)
self.startup_prog = fluid.Program()
self.key_dict_manger = global_key_manager.key_dict_manager
# multi nodes
self.num_trainers = 1
self.trainer_id = 0
self.is_fleet = False
self.create_net = create_net
# Todo: replace by warmup_proportion
self.warmup_steps = 0
self.build_reader()
logging.debug("finish build reader")
if not self.config.use_cuda:
self.init_fleet(config.is_local)
self.build_program()
logging.debug("finish build graph")
logging.debug("PADDLE_IS_LOCAL:%d" % config.is_local)
if self.config.use_cuda:
self.prepare_nccl2_env(config.is_local)
logging.debug("finish prepare nccl2 env")
# run startup_prog after transpile for nccl2
self.executor.run(self.startup_prog)
else:
self.prepare_fleet_2(config.is_local)
logging.debug("finish prepare fleet env")
self.load_pretrained_models()
self.build_executor()
logging.debug("finish build executor")
# should be executed after self.build_reader() is called
if self.reader.label_map:
self.config.label_id2text = {id_label:text_label for text_label, id_label in self.reader.label_map.items()}
self.print_config()
def print_config(self):
print("*********************************** Task Config **************************************")
for k, v in self.config.__dict__.items():
print("{0}:{1}".format(k, v))
print("**************************************************************************************")
# TODO:need override
def init_reader(self):
print("init reader...")
def extend_graph_vars(self, create_net):
""" add metrics for standard classify task
"""
def wrapper(* config, **kwconfig):
pyreader, graph_vars = create_net(*config, **kwconfig)
for k, v in graph_vars.items():
v.persistable = True
return pyreader, graph_vars
return wrapper
def build_reader(self):
self.init_reader()
if not self.reader:
print("reader not init.")
return
if self.config.do_train:
self.train_data_generator = self.reader.data_generator(
data_path=self.config.train_set,
batch_size=self.config.batch_size,
epoch=self.config.epoch,
shuffle=True,
phase="train")
if self.config.do_test:
self.test_data_generator = self.reader.data_generator(
data_path=self.config.test_set,
batch_size=self.config.batch_size,
epoch=1,
shuffle=False)
if self.config.do_val:
self.dev_data_generator = self.reader.data_generator(
data_path=self.config.dev_set,
batch_size=self.config.batch_size,
epoch=1,
shuffle=False)
if self.config.do_predict:
self.predict_data_generator = self.reader.data_generator(
data_path=self.config.predict_set,
batch_size=self.config.batch_size,
epoch=1,
shuffle=False,
phase="predict")
def build_program(self):
self.define_train_program()
self.define_test_program()
self.define_infer_program()
self.set_reader_provider()
def build_executor(self):
if self.is_fleet:
exec_strategy = fluid.ExecutionStrategy()
exec_strategy.num_threads = int(os.getenv("CPU_NUM"))
build_strategy = fluid.BuildStrategy()
build_strategy.async_mode = False
if int(os.getenv("CPU_NUM")) > 1:
build_strategy.reduce_strategy = fluid.BuildStrategy.ReduceStrategy.Reduce
self.train_exe = fluid.ParallelExecutor(
use_cuda=self.config.use_cuda,
loss_name=self.graph_vars["loss"].name,
main_program=self.train_program,
build_strategy=build_strategy,
exec_strategy=exec_strategy)
else:
exec_strategy = fluid.ExecutionStrategy()
exec_strategy.num_iteration_per_drop_scope = self.config.num_iteration_per_drop_scope
if self.config.use_fast_executor:
exec_strategy.use_experimental_executor = True
self.train_exe = fluid.ParallelExecutor(
use_cuda=self.config.use_cuda,
loss_name=self.graph_vars["loss"].name,
exec_strategy=exec_strategy,
main_program=self.train_program,
num_trainers=self.num_trainers,
trainer_id=self.trainer_id)
# TODO: need override
def loss_optimizer(self):
print("init loss_optimizer")
if not self.config.use_cuda and not self.config.is_local:
print("is fleet ....")
self.optimizer = fluid.optimizer.Adam(learning_rate=self.config.learning_rate)
else:
optimizer, scheduled_lr = optimization(
loss=self.graph_vars["loss"],
warmup_steps=self.warmup_steps,
num_train_steps=1000,
learning_rate=self.config.learning_rate,
train_program=self.train_program,
startup_prog=self.startup_prog,
weight_decay=self.config.weight_decay,
scheduler=self.config.lr_scheduler,
use_fp16=self.config.use_fp16,
loss_scaling=self.config.loss_scaling)
self.optimizer = optimizer
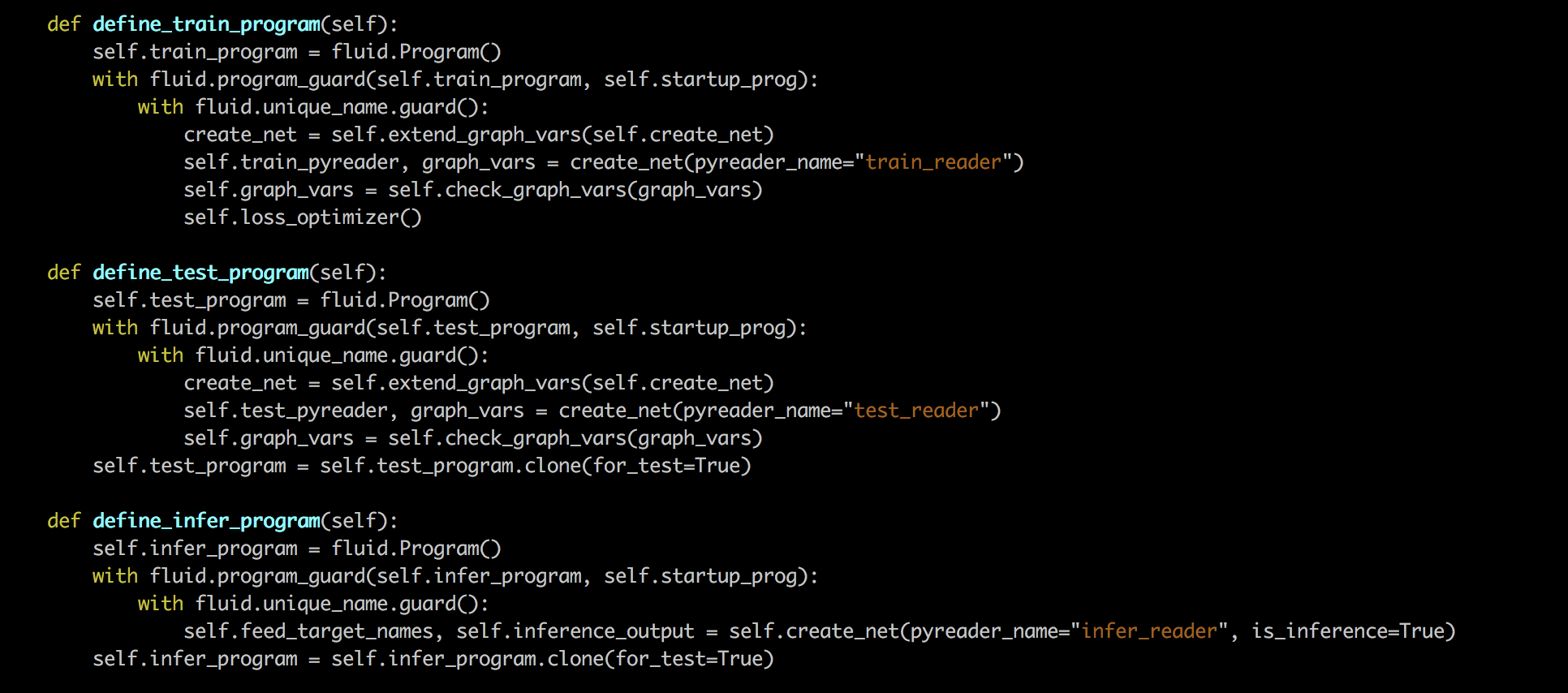
def define_train_program(self):
if self.is_fleet:
self.train_program = fleet.main_program
else:
self.train_program = fluid.Program()
with fluid.program_guard(self.train_program, self.startup_prog):
with fluid.unique_name.guard():
create_net = self.extend_graph_vars(self.create_net)
self.train_pyreader, graph_vars = create_net(pyreader_name="train_reader")
self.graph_vars = self.check_graph_vars(graph_vars)
self.loss_optimizer()
def define_test_program(self):
self.test_program = fluid.Program()
with fluid.program_guard(self.test_program, self.startup_prog):
with fluid.unique_name.guard():
create_net = self.extend_graph_vars(self.create_net)
self.test_pyreader, graph_vars = create_net(pyreader_name="test_reader")
self.graph_vars = self.check_graph_vars(graph_vars)
self.test_program = self.test_program.clone(for_test=True)
def define_infer_program(self):
self.infer_program = fluid.Program()
with fluid.program_guard(self.infer_program, self.startup_prog):
with fluid.unique_name.guard():
self.feed_target_names, self.inference_output = self.create_net(pyreader_name="infer_reader", is_inference=True)
self.infer_program = self.infer_program.clone(for_test=True)
def check_graph_vars(self, graph_vars):
keys = list(graph_vars.keys())
for k in keys:
if not self.key_dict_manger.check_key_legitimacy(k):
del graph_vars[k]
print("after check ", graph_vars)
return graph_vars
def load_pretrained_models(self):
config = self.config
exe = self.executor
if config.do_train:
if config.init_checkpoint and config.init_parameters:
raise ValueError(
"ERROR: config 'init_checkpoint' and 'init_parameters' "
"both are set! Only one of them should be set. "
"if you want warmstart checkpoint keep its learning_rate and moments, plese set 'init_checkpoint'. "
"if you want warmstart checkpoint with only its parameters, and you want reset a new learning_rate "
"by config, plese set 'init_parameters'")
if config.init_checkpoint:
init_checkpoint(
exe,
config.init_checkpoint,
main_program=self.train_program,
use_fp16=config.use_fp16)
elif config.init_parameters:
init_parameters(
exe,
config.init_parameters,
main_program=self.train_program,
use_fp16=config.use_fp16)
elif config.do_val or config.do_test or config.do_predict:
if config.init_checkpoint:
init_checkpoint(
exe,
config.init_checkpoint,
main_program=self.train_program,
use_fp16=config.use_fp16)
elif config.init_parameters:
init_parameters(
exe,
config.init_parameters,
main_program=self.train_program,
use_fp16=config.use_fp16)
else:
raise ValueError("config 'init_checkpoint' or 'init_paramters' should be set if"
"only doing validation or testing or predict!")
# TODO: need to override
def set_reader_provider(self):
print("set pyreader data provider.")
# self.use_lod_tensor = True
# self.train_pyreader.decorate_tensor_provider(self.train_data_generator)
# self.test_pyreader.decorate_tensor_provider(self.test_data_generator)
def prepare_nccl2_env(self, is_local):
if not is_local:
port = os.getenv("PADDLE_PORT", "6174")
trainers = os.getenv("PADDLE_TRAINERS") # ip,ip...
logging.debug("trainers form env:{}".format(trainers))
trainer_endpoints = []
for trainer_ip in trainers.split(","):
trainer_endpoint = ":".join([trainer_ip, port])
trainer_endpoints.append(trainer_endpoint)
trainer_endpoints = ",".join(trainer_endpoints)
logging.debug("trainers endpoints:{}".format(trainer_endpoints))
#eplist = []
#for ip in pserver_ips.split(","):
# eplist.append(':'.join([ip, port]))
#pserver_endpoints = ",".join(eplist) # ip:port,ip:port...
num_trainers = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
current_endpoint = os.getenv("POD_IP") + ":" + port
logging.debug("current_endpoint: {}".format(current_endpoint))
trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
config = fluid.DistributeTranspilerConfig()
config.mode = "nccl2"
t = fluid.DistributeTranspiler(config=config)
#t.transpile(trainer_id, pservers=pserver_endpoints, trainers=trainers)
t.transpile(trainer_id, trainers=trainer_endpoints, current_endpoint=current_endpoint, \
program=self.train_program, startup_program=self.startup_prog)
self.num_trainers = num_trainers
self.trainer_id = trainer_id
logging.debug("nccl_num_trainers:{} nccl_trainer_id:{}".format(self.num_trainers, self.trainer_id))
def init_fleet(self, is_local):
if not is_local:
trainer_id = int(os.environ["PADDLE_TRAINER_ID"])
print("trainer_id:", trainer_id)
trainers = int(os.environ["PADDLE_TRAINERS"])
print("trainers:", trainers)
training_role = os.environ["PADDLE_TRAINING_ROLE"]
training_role = role_maker.Role.WORKER if training_role == "TRAINER" else role_maker.Role.SERVER
num_trainers = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
self.num_trainers = num_trainers
self.trainer_id = trainer_id
ports = os.getenv("PADDLE_PSERVER_PORTS")
print("ports:", ports)
pserver_ip = os.getenv("PADDLE_PSERVER_IP", "")
print("pserver_ip:", pserver_ip)
pserver_endpoints = []
for port in ports.split(","):
pserver_endpoints.append(':'.join([pserver_ip, port]))
role = role_maker.UserDefinedRoleMaker(current_id=trainer_id, role=training_role, worker_num=trainers,
server_endpoints=pserver_endpoints)
fleet.init(role_maker=role)
self.startup_prog = fleet.startup_program
def prepare_fleet_2(self, is_local):
if not is_local:
strategy = DistributeTranspilerConfig()
# strategy.sync_mode = bool(int(os.getenv("DISTRIBUTED_SYNC_MODE")))
strategy.sync_mode = True
optimizer = fleet.distributed_optimizer(self.optimizer, strategy)
optimizer.minimize(self.graph_vars["loss"])
print("minimize fleet2 ...")
if fleet.is_server():
# with open("pserver.proto.{}".format(fleet.server_endpoints()[fleet.server_index()]), "w") as f:
# f.write(str(fleet.main_program))
fleet.init_server()
fleet.run_server()
elif fleet.is_worker():
fleet.init_worker()
self.executor.run(self.startup_prog)
# train_loop(fleet.main_program, fleet.worker_index() == 0)
# fleet.stop_worker()
print("fleet_num_trainers:{} fleet_trainer_id:{}".format(self.num_trainers, self.trainer_id))
self.is_fleet = True
else:
self.executor.run(self.startup_prog)
def prepare_fleet(self, is_local):
if not is_local:
pserver_endpoints = os.getenv("PADDLE_PSERVER_ENDPOINTS")
pserver_endpoints = pserver_endpoints.split(",")
role = role_maker.UserDefinedRoleMaker(
current_id=int(os.getenv("CURRENT_ID")),
role=role_maker.Role.WORKER if bool(int(os.getenv("IS_WORKER"))) else role_maker.Role.SERVER,
worker_num=int(os.getenv("WORKER_NUM")),
server_endpoints=pserver_endpoints
)
fleet.init(role_maker=role)
strategy = DistributeTranspilerConfig()
strategy.sync_mode = bool(int(os.getenv("DISTRIBUTED_SYNC_MODE")))
optimizer = fleet.distributed_optimizer(self.optimizer, strategy)
optimizer.minimize(self.graph_vars["loss"])
print("minimize fleet ...")
if fleet.is_server():
with open("pserver.proto.{}".format(fleet.server_endpoints()[fleet.server_index()]), "w") as f:
f.write(str(fleet.main_program))
fleet.init_server()
fleet.run_server()
elif fleet.is_worker():
fleet.init_worker()
self.executor.run(fleet.startup_program)
# train_loop(fleet.main_program, fleet.worker_index() == 0)
# fleet.stop_worker()
else:
self.executor.run(self.startup_prog)
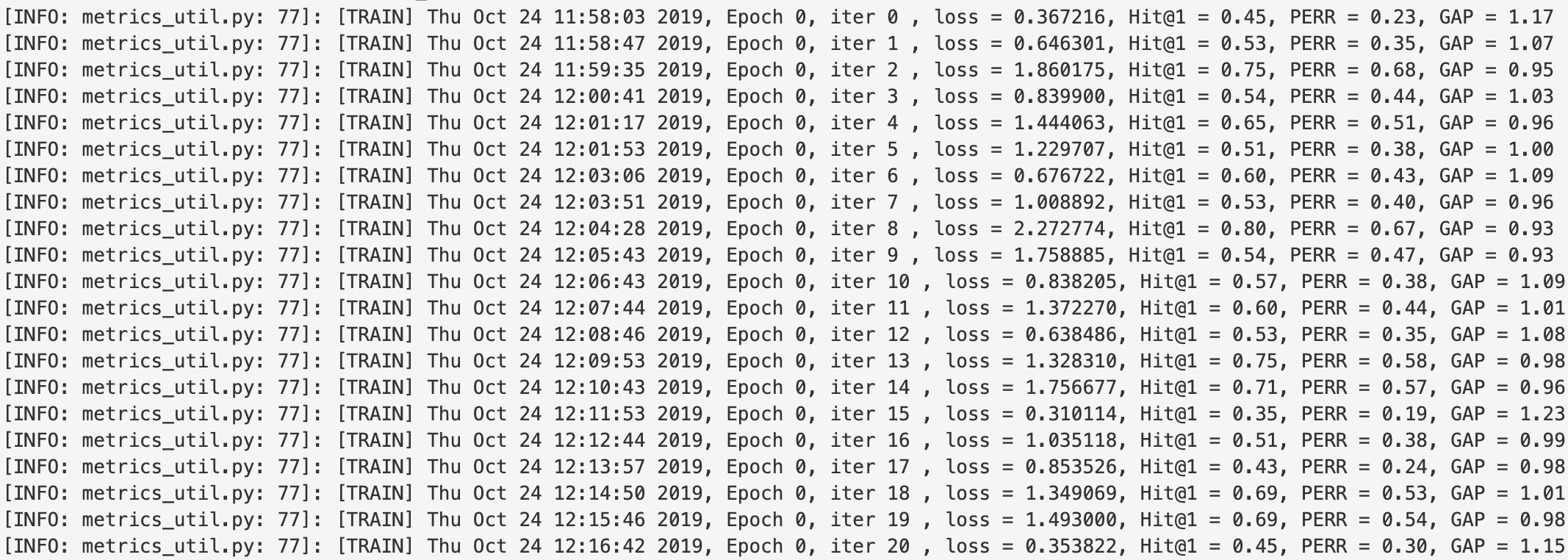
def train(self):
print("start train....")
self.train_pyreader.start()
steps = 0
time_begin = time.time()
while True:
try:
steps += 1
if steps % self.config.skip_steps != 0:
self.train_exe.run(fetch_list=[])
else:
if self.config.verbose:
print("train pyreader queue size: %d, " % self.train_pyreader.queue.size())
outputs, current_learning_rate = self.evaluate(self.train_exe,
self.train_program,
self.train_pyreader,
self.graph_vars,
"train",
steps)
num_train_examples = self.reader.get_num_examples(self.config.train_set)
current_example, current_epoch = self.reader.get_train_progress()
time_end = time.time()
used_time = time_end - time_begin
log_info = "current_learning_rate: %f, " % current_learning_rate
log_info += "epoch: %d, progress: %d/%d, step: %d, " % (
current_epoch, current_example, num_train_examples, steps)
log_info += "speed: %f steps/s" % (self.config.skip_steps / used_time)
print(log_info)
try:
if outputs:
import paddlecloud.visual_util as visualdl
x_dic = {"x_name": "step", "x_value": steps}
y_ls = []
for key, value in outputs.items():
y = {}
y["y_name"] = key
y["y_value"] = value
y_ls.append(y)
visualdl.show_fluid_trend(x_dic, y_ls, tag="train")
except Exception:
print("import paddlecloud.visual_util failed")
time_begin = time.time()
if steps % self.config.save_steps == 0:
save_checkpoint_path = os.path.join(self.config.checkpoints, "step_" + str(steps))
fluid.io.save_persistables(self.executor, save_checkpoint_path, self.train_program)
print("save checkpoinmts to %s" % save_checkpoint_path)
save_inference_model_path = os.path.join(self.config.save_inference_model_path, "step_" + str(steps))
fluid.io.save_inference_model(
save_inference_model_path,
self.feed_target_names,
[self.inference_output],
self.executor,
main_program=self.infer_program)
print("save inference model to %s" % save_inference_model_path)
if steps % self.config.validation_steps == 0:
# evaluate dev set
if self.config.do_val:
self.do_test_val("dev", steps)
# evaluate test set
if self.config.do_test:
self.do_test_val("test", steps)
except fluid.core.EOFException:
save_path = os.path.join(self.config.checkpoints, "step_" + str(steps))
fluid.io.save_persistables(self.executor, save_path, self.train_program)
save_inference_model_path = os.path.join(self.config.save_inference_model_path, "step_" + str(steps))
fluid.io.save_inference_model(
save_inference_model_path,
self.feed_target_names,
[self.inference_output],
self.executor,
main_program=self.infer_program)
print("save inference model to %s" % save_inference_model_path)
self.train_pyreader.reset()
break
# final eval on dev set
if self.config.do_val:
print("Final validation result:")
self.do_test_val("dev", steps)
# final eval on test set
if self.config.do_test:
print("Final test result:")
self.do_test_val("test", steps)
def do_test_val(self, eval_phase, step):
if eval_phase == "dev":
data_generator = self.dev_data_generator
elif eval_phase == "test":
data_generator = self.test_data_generator
elif eval_phase == "predict":
data_generator = self.predict_data_generator
else:
raise ValueError("%s is illegal" % eval_phase)
if self.use_lod_tensor:
self.test_pyreader.decorate_paddle_reader(data_generator)
else:
self.test_pyreader.decorate_tensor_provider(data_generator)
outputs, current_learning_rate = self.evaluate(self.executor,
self.test_program,
self.test_pyreader,
self.graph_vars,
eval_phase,
step)
try:
if outputs and len(outputs) != 0:
import paddlecloud.visual_util as visualdl
x_dic = {"x_name": "step", "x_value": step}
y_ls = []
for key, value in outputs.items():
y = {}
y["y_name"] = key
y["y_value"] = value
y_ls.append(y)
visualdl.show_fluid_trend(x_dic, y_ls, tag=eval_phase)
except Exception:
print("import paddlecloud.visual_util failed")
# TODO: need override
def evaluate(self, exe, program, pyreader, graph_vars, eval_phase, step):
print("evaluate in base model...")
def predict(self):
# Todo:
logging.debug("start do predict")
self.do_test_val("predict", 0)














![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")