The Jupyter notebooks contain large images therefore they may not load properly on Github page. Therefore, it is best to Git clone to view in your local machine.

This is the code repository for Hands-On Image Generation with TensorFlow : A practical guide to generating images and videos using deep learning ,published by Packt.
as recommended by Francois Chollet, Google AI, Creator of Keras
"All TensorFlow/Keras, with very readable code examples. Includes a section on StyleGAN, which will come in handy ... it's well explained."
The emerging field of Generative Adversarial Networks (GANs) has made it possible to generate indistinguishable images from existing datasets. With this hands-on book, you’ll not only develop image generation skills but also gain a solid understanding of the underlying principles.
Starting with an introduction to the fundamentals of image generation using TensorFlow, this book covers Variational Autoencoders (VAEs) and GANs. You’ll discover how to build models for different applications as you get to grips with performing face swaps using deepfakes, neural style transfer, image-to-image translation, turning simple images into photorealistic images, and much more. You’ll also understand how and why to construct state-of-the-art deep neural networks using advanced techniques such as spectral normalization and self-attention layer before working with advanced models for face generation and editing. You'll also be introduced to photo restoration, text-to-image synthesis, video retargeting, and neural rendering. Throughout the book, you’ll learn to implement models from scratch in TensorFlow 2.x, including PixelCNN, VAE, DCGAN, WGAN, pix2pix, CycleGAN, StyleGAN, GauGAN, and BigGAN.
By the end of this book, you'll be well versed in TensorFlow and be able to implement image generative technologies confidently.
This book covers the following exciting features:
- Train on face datasets and use them to explore latent spaces for editing new faces
- Get to grips with swapping faces with deepfakes
- Perform style transfer to convert a photo into a painting
- Build and train pix2pix, CycleGAN, and BicycleGAN for image-to-image translation
- Use iGAN to understand manifold interpolation and GauGAN to turn simple images into photorealistic images
- Become well versed in attention generative models such as SAGAN and BigGAN
- Generate high-resolution photos with Progressive GAN and StyleGAN
You can also checkout on my blog for detailed book overview
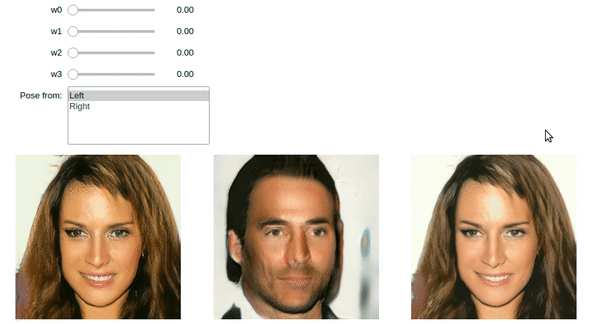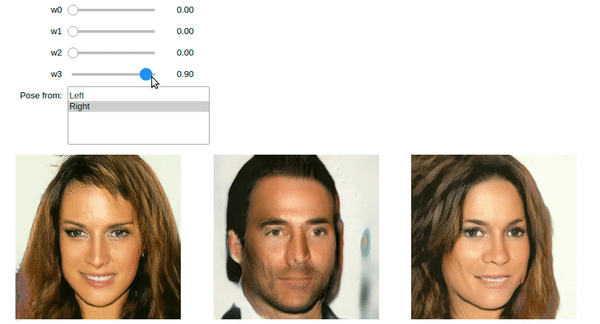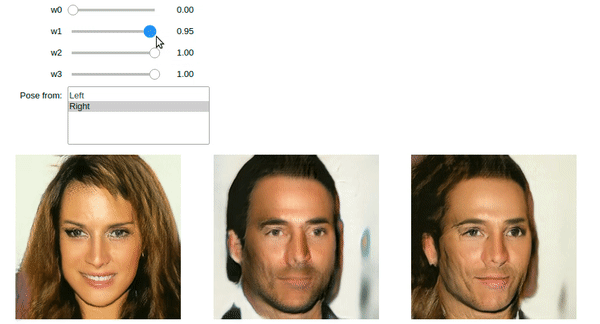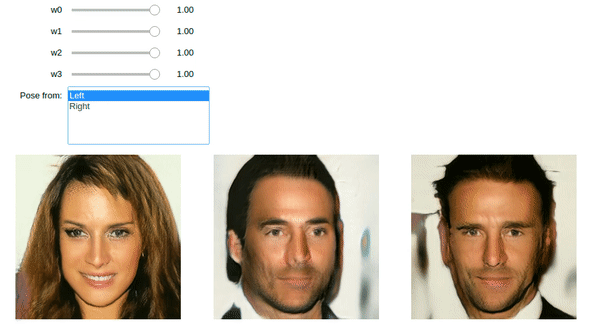
The images above were generated using StyleGAN code in the book. You too can do it using the Jupyter notebook and pretrained model provided.
If you feel this book is for you, get your copy today!

Please use this bibtex for citation
@book{cheong2020hands,
title={Hands-On Image Generation with TensorFlow: A practical guide to generating images and videos using deep learning},
author={Cheong, S.Y.},
isbn={9781838826789},
url={https://books.google.co.uk/books?id=tGcREAAAQBAJ},
year={2020},
publisher={Packt Publishing}
}
- Getting started with Image generation with TensorFlow
- Variational Autoencoder
- Generative Adversarial Network
- Image-to-Image Translation
- Style Transfer
- AI Painter
- High Fidelity Face Generation
- Self-Attention for Image Generation
- Video Synthesis 10 .Road Ahead
The code in this book uses tensorflow_gpu==2.2.0, and is compatitible with version up to 2.3.0
The code will look like the following:
content_image = self.preprocess(content_image_input)
style_image = self.preprocess(style_image_input)
self.content_target = self.encoder(content_image)
self.style_target = self.encoder(style_image)
adain_output = AdaIN()([self.content_target[-1], self.style_target[-1]])
self.stylized_image = self.postprocess(self.decoder(adain_output))
self.stn = Model([content_image_input, style_image_input], self.stylized_image)
python3 -m venv ./venv/imgentf2
source ./venv/imgentf2/bin/activate
pip3 install --upgrade pip
pip3 install -r requirements.txt
python -m ipykernel install --user --name=imgentf2
jupyter nbextension enable --py widgetsnbextension
Following is what you need for this book: This book is a step-by-step guide to show you how to implement generative models in TensorFlow 2.x from scratch. You’ll get to grips with the image generative technology by covering autoencoders, style transfer, and GANs as well as fundamental and state-of-the-art models. You should have basic knowledge of deep learning training pipelines, such as training convolutional neural networks for image classification. This book will mainly use highlevel Keras APIs in TensorFlow 2, which is easy to learn. Should you need to refresh or learn TensorFlow 2, there are many free tutorials available online, such as the one on the official TensorFlow website, https://www.tensorflow.org/tutorials/keras/classification.
With the following software and hardware list you can run all code files present in the book (Chapter 1-10).
| Chapter | Software required | OS required |
|---|---|---|
| 1 - 10 | TensorFlow 2.2, GPU with minimum 4 GB memory | Windows, Mac OS X, and Linux (Any) |
Training deep neural networks is computationally intensive. You can train the first few simple models using the CPU only. However, as we progress to more complex models and datasets in later chapters, the model training could take a few days before you start to see satisfactory results. To get the most out of this book, you should have access to the GPU to accelerate the model training time. There are also free cloud services, such as Google's Colab, that provide GPUs on which you can upload and run the code.
We also provide a PDF file that has color images of the screenshots/diagrams used in this book. Click here to download it.
Soon Yau Cheong is an AI consultant and the founder of Sooner.ai Ltd. With a history of being associated with industry giants such as NVIDIA and Qualcomm, he provides consultation in the various domains of AI, such as deep learning, computer vision, natural language processing, and big data analytics. He was awarded a full scholarship to study for his PhD at the University of Bristol while working as a teaching assistant. He is also a mentor for AI courses with Udacity.
I hope you will enjoy reading my book. If you do, I would be most grateful if you could write a book review on Amazon.
Please feel free to connect with me on www.linkedin.com/in/soonyau. Please add a note saying that you've read my book and I will gladly accept your connection request.
If you have already purchased a print or Kindle version of this book, you can get a DRM-free PDF version at no cost.
Simply click on the link to claim your free PDF.