oscar-project / corpus Goto Github PK
View Code? Open in Web Editor NEWcorpus issues.
License: Apache License 2.0
corpus issues.
License: Apache License 2.0







How much data is shared between the two versions? Do they overlap in time? Is the new version a superset of the earlier version?
Thanks in advance!
It seems to only have non linguistic content.
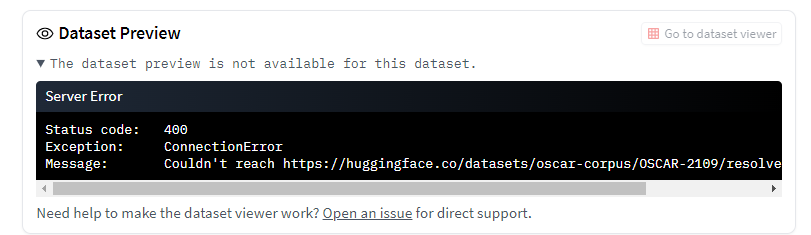
There seems to be an issue with reaching certain files when addressing the new dataset version via HuggingFace:
The code I used:
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "unshuffled_deduplicated_af")
The resulting error:
---------------------------------------------------------------------------
ConnectionError Traceback (most recent call last)
/tmp/ipykernel_24000/136913172.py in <module>
1 from datasets import load_dataset
2
----> 3 dataset = load_dataset("oscar-corpus/OSCAR-2109", "unshuffled_deduplicated_af")
~/env_test/lib/python3.7/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, script_version, **config_kwargs)
1613 revision=revision,
1614 use_auth_token=use_auth_token,
-> 1615 **config_kwargs,
1616 )
1617
~/env_test/lib/python3.7/site-packages/datasets/load.py in load_dataset_builder(path, name, data_dir, data_files, cache_dir, features, download_config, download_mode, revision, use_auth_token, script_version, **config_kwargs)
1440 download_config.use_auth_token = use_auth_token
1441 dataset_module = dataset_module_factory(
-> 1442 path, revision=revision, download_config=download_config, download_mode=download_mode, data_files=data_files
1443 )
1444
~/env_test/lib/python3.7/site-packages/datasets/load.py in dataset_module_factory(path, revision, download_config, download_mode, force_local_path, dynamic_modules_path, data_files, **download_kwargs)
1154 f"Couldn't find '{path}' on the Hugging Face Hub either: {type(e1).__name__}: {e1}"
1155 ) from None
-> 1156 raise e1 from None
1157 else:
1158 raise FileNotFoundError(
~/env_test/lib/python3.7/site-packages/datasets/load.py in dataset_module_factory(path, revision, download_config, download_mode, force_local_path, dynamic_modules_path, data_files, **download_kwargs)
1133 download_config=download_config,
1134 download_mode=download_mode,
-> 1135 dynamic_modules_path=dynamic_modules_path,
1136 ).get_module()
1137 else:
~/env_test/lib/python3.7/site-packages/datasets/load.py in get_module(self)
843 def get_module(self) -> DatasetModule:
844 # get script and other files
--> 845 local_path = self.download_loading_script()
846 dataset_infos_path = self.download_dataset_infos_file()
847 imports = get_imports(local_path)
~/env_test/lib/python3.7/site-packages/datasets/load.py in download_loading_script(self)
828 def download_loading_script(self) -> str:
829 file_path = hf_hub_url(path=self.name, name=self.name.split("/")[1] + ".py", revision=self.revision)
--> 830 return cached_path(file_path, download_config=self.download_config)
831
832 def download_dataset_infos_file(self) -> str:
~/env_test/lib/python3.7/site-packages/datasets/utils/file_utils.py in cached_path(url_or_filename, download_config, **download_kwargs)
303 use_etag=download_config.use_etag,
304 max_retries=download_config.max_retries,
--> 305 use_auth_token=download_config.use_auth_token,
306 )
307 elif os.path.exists(url_or_filename):
~/env_test/lib/python3.7/site-packages/datasets/utils/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only, use_etag, max_retries, use_auth_token)
592 raise FileNotFoundError("Couldn't find file at {}".format(url))
593 _raise_if_offline_mode_is_enabled(f"Tried to reach {url}")
--> 594 raise ConnectionError("Couldn't reach {}".format(url))
595
596 # Try a second time
ConnectionError: Couldn't reach https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/resolve/main/OSCAR-2109.py
The error seems to exist on the dataset page itself (link).
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2201", use_auth_token=True)
The OSCAR 2019 Central Bikol corpus is too small and of a bad quality.
The 21.09 version has to be checked.
Source: Quality at a Glance.
Hi would it possible to include support for Tigrinya language in the corpus.
I can help if needed.
The OSCAR 2019 Chavacano corpus is too small and of a bad quality.
The 21.09 version has to be checked.
Source: Quality at a Glance.
According to OSCAR document:
meta.headers.warc-target-uri: string URI from where the content has been fetched
When checking some records on Vietnamese subset, I found that text fields doesn't come from meta.headers.warc-target-uri
import datasets
dataset = datasets.load_dataset('oscar-corpus/OSCAR-2109', "deduplicated_vi", use_auth_token=HF_TOKEN)
Downloading and preparing dataset oscar2109/deduplicated_vi to /root/.cache/huggingface/datasets/oscar-corpus___oscar2109/deduplicated_vi/2021.9.0/f99db7058ca20335499dad39cda92ee05d57d8aa943fe651fdc5676101ee1e8f...
Downloading: 100%
7.42k/7.42k [00:00<00:00, 161kB/s]
13628679/0 [49:47<00:00, 5363.82 examples/s]
Dataset oscar2109 downloaded and prepared to /root/.cache/huggingface/datasets/oscar-corpus___oscar2109/deduplicated_vi/2021.9.0/f99db7058ca20335499dad39cda92ee05d57d8aa943fe651fdc5676101ee1e8f. Subsequent calls will reuse this data.
100%
1/1 [01:50<00:00, 110.41s/it]
# wait ~ 50 mins on colab
!rm -rf ~/.cache/huggingface/datasets/downloads/*> dataset['train'][10000000] # Wrong
{'id': 10000000,
'meta': {'headers': {'content-length': 43729,
'content-type': 'text/plain',
'warc-block-digest': 'sha1:UPBAHYJIQJ4L7PGUTQ4P2HMK362EJI3C',
'warc-date': '2021-03-03T11:48:41Z',
'warc-identified-content-language': 'eng,vie',
'warc-record-id': '<urn:uuid:ff775a03-e278-4bb0-b66f-4ff5ddd108df>',
'warc-refers-to': '<urn:uuid:02979651-d9ca-4830-a483-6e24b4e02238>',
'warc-target-uri': 'https://chipi.vn/blogs/tin-thoi-trang/ao-tam-ho-phan-chan-nguc-lua-chon-cua-nhung-co-nang-ua-ho-bao',
'warc-type': 'conversion'},
'nb_sentences': 14,
'offset': 2523135},
'text': 'Combo Sách Quản Trị : Kế Toán Quản Trị (Managerial Accounting) + Quản Trị Trong Thời Khủng Hoảng - Chiến Lược Biến Đổi Những Mối Đe Dọa Thành Cơ Hội Phát Triển | Tiki\nTrang chủNhà Sách TikiSách tiếng ViệtSách kinh tếSách quản trị, lãnh đạoCombo Sách Quản Trị : Kế Toán Quản Trị (Managerial Accounting) + Quản Trị Trong Thời Khủng Hoảng - Chiến Lược Biến Đổi Những Mối Đe Dọa Thành Cơ Hội Phát Triển\nGiống như ngọn hải đăng cần mẫn dẫn đường cho người thủy thủ, Kế toán quản trị đã dẫn dắt hàng triệu người đọc dấn thân khám phá “vùng biển” kế toán quản trị. Tổng hợp 12 chủ điểm quan trọng cùng cách truyền đạt súc tích, dễ hiểu, cuốn sách sẽ đem đến cho người đọc một góc nhìn vừa bao quát, vừa chi tiết nhưng cũng rất thực tế về kế toán quản trị. Các chương trong sách bao gồm:\nRay H. Garrison là Giáo sư Kế toán của Đại học Brigham. Ông cũng là cố vấn quản trị của nhiều công ty kế toán trong khu vực và toàn liên bang Hoa Kỳ.\nEric W. Noreen hiện đang giảng dạy tại khoa Kế toán, Trường Kinh doanh Fox thuộc Đại học Temple. Ông là tác giả của nhiều bài báo về kế toán quản trị được đăng trên các tạp chí quốc tế có uy tín.\nPeter C. Brewer hiện là giảng viên khoa Kế toán, Trường Đại học Wake Forest. Ông đã có 19 năm là Giáo sư Kế toán của Trường Đại học Miami và có hơn 40 bài báo trong lĩnh vực kế toán quản trị trên\nQuản trị trong thời khủng hoảng là một trong những cuốn sách kinh điển về quản trị. Cuốn sách tập trung hoàn toàn vào các hành động, chiến lược và cơ hội, những điều các nhà quản trị có thể làm, nên làm và phải làm trong những thời kỳ biến động, khủng hoảng. Trong cuốn sách này, Peter F. Drucker trả lời một cách chính xác và rõ ràng 3 câu hỏi:\n\nĐinh TịFirst News - Trí ViệtĐại Mai Books-Công Ty Cổ Phần Văn Hóa Đông ANhà Sách Đại MaiNhã Nam Kim ĐồngCrabit KidbooksCty TNHH Sách WABOOKSCông Ty CP Văn Hóa Nhân VănNXB Chính Trị Quốc Gia Sự ThậtNXB Kim ĐồngNXB TrẻNXB Âm NhạcNhiều công ty phát hànhNhà Sách Hồng ÂnNhà Xuất Bản Kim ĐồngThái HàTân Việt\nCombo 4 cuốn truyện tranh song ngữ - Truyện tranh ngụ ngôn dành cho thiếu nhi song ngữ Anh - Việt ( Kiến và chim + sư tử và chuột nhắt+ sói và sóc + chuột , gà trống và mèo )\nCánh Én Tuổi Thơ - 90 Bài Hát Thiếu Nhi Về Thế Giới Loài Vật- Có Phần Hòa Âm Dành Cho Người Chơi Đàn (Kèm Cd)\nCombo sách khoa học điển hình dành cho trẻ: 100 bí ẩn đáng kinh ngạc về lịch sử - 100 things to know about history +100 bí ẩn đáng kinh ngạc về số, máy tính và mã hóa - 100 things to know about numbers, computers & coding\n\nVé máy bay đi Đức giá rẻ. Nằm ở vị trí trung tâm Châu Âu, và được bao bọc bởi 9 quốc gia, Đức đã trở thành một trong những điểm du lịch hấp dẫn cho mọi du khách khi đến thăm Châu Âu. Hôm nay Tìm chuyến bay sẽ đưa bạn đến Đức, quốc gia có lịch sử phát triển lâu đời, nền văn hóa phong phú, nơi có nhiều bảo tàng lịch sử, nghệ thuật, những công trình kiến trúc nổi tiếng đặc biệt là các lâu đài. Ngoài ra Đức còn có cảnh sắc thiên nhiên tươi đẹp, và nhiều lễ hội sôi động. Hi vọng bạn sẽ có nhiều trải nghiệm khó quên khi đến nước Đức.'}
> dataset['train'][2000] # Wrong
{'id': 2000,
'meta': {'headers': {'content-length': 2519,
'content-type': 'text/plain',
'warc-block-digest': 'sha1:XWZHMUSNYWHL7VEOM4BHSUCHY3N52523',
'warc-date': '2021-02-25T14:14:34Z',
'warc-identified-content-language': 'vie,eng',
'warc-record-id': '<urn:uuid:eca6a11d-d7e2-440c-af2b-2286e6c3a096>',
'warc-refers-to': '<urn:uuid:4e96c6d3-80db-41c0-a07d-ada90a97080e>',
'warc-target-uri': 'https://u-os.org/banh-ngon-mien-tay-banh-cu-cai',
'warc-type': 'conversion'},
'nb_sentences': 1,
'offset': 18147},
'text': 'Trong các hạng mục thi công xây dựng chắc chắn không thể thiếu được chống thấm. Một công trình nhà ở có nhiều vị trí cần chống thấm nhưng đáng quan tâm nhất là chống thấm sàn mái. Đây là khu vực phải tiếp xúc với nước, chịu ảnh hưởng trực tiếp của khí hậu tác động đến kết cấu, thẩm mỹ và tuổi thọ công trình. Hiểu rõ tầm quan trọng ấy, hôm nay chongthamvietthai sẽ mang đến bạn 5 loại vật liệu chống thấm sàn mái tốt nhất, với tuổi thọ trên 25 năm.'}
You can find my code here colab
I wonder if there's a reason behind the small size of Swahili 7MB in the latest release and 13 MB overall
ps: There's a Swahili Wikipedia with 68K articles. If you need help to extract text from the dump let me know, I can forward you some scripts. https://sw.wikipedia.org/
This issue serves as a discussion/checklist elaboration for the next OSCAR version to come.
We shoud aim to fix existing bugs/problems as well as adding potential features.
adult is too strong for something we know has a lot of false positives. Also, with the inclusion of model based filtering, we'll have to find a way to specify annotation source.The West Flemish corpus contains only two words, making it completely unusable.
Copied from: huggingface/datasets#3704
As mentioned in the comments, potentially related to: #15
The only way that I got a simple wc -w on the raw texts from git-lfs in the repo at https://huggingface.co/datasets/oscar-corpus/OSCAR-2109 to exactly match wc -w on all the texts exported from the loaded dataset was to fix all three issues mentioned below, plus not stripping all trailing whitespace. Just pairing the text/meta filenames was not sufficient.
The oscar-corpus/OSCAR-2109 data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are emptyFor deduplicated_fi, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with wc -w for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For deduplicated_no all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For deduplicated_mk it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the wc -w counts to line up exactly with the data splits table, but for comparison the wc -w count for deduplicated_mk on the raw texts is 134,545,424.
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data.
Hello there,
Since the Oscar is limited by the fasttext language classifier which was trained on Wikipedia, the datasets contain also the sentences in other languages. For instance, Tajik (tg.txt) language contains large chunks of Uzbek sentences in Cyrillic script.
for ex:
File: tg.txt Line: 660247: Маҳаллий расмийлар агар у пахта теримига чиқмаса, набираси учун тўланадиган нафақадан маҳрум этилиши билан таҳдид қилишгани.
if you do simple check using fasttext
import fasttext
model = fasttext.load_model('lid.176.ftz')
print(model.predict('Маҳаллий расмийлар агар у пахта теримига чиқмаса, набираси учун тўланадиган нафақадан маҳрум этилиши билан таҳдид қилишгани.', k=2))
Output will be
#(('__label__tg', '__label__bg'), array([0.38605371, 0.14384778]))
Which indicates that it is Tajik but in fact it is not, so a "nutritional table" on website should be created warning people about the issues.
The OSCAR 2019 Neapolitan corpus is too small and of a bad quality.
The 21.09 version has to be checked.
Source: Quality at a Glance.
Hello. Thanks for great job. I want to know the meaning of 'harmful pp', and is it smaller the better?
Hello all, and thank you for the great research project.
I have a question about pages that are missing from the Oscar dataset for a particular language. For instance, this page: https://www.bmbf.de/bmbf/de/service/leichte-sprache/leichte-sprache_node.html is missing from the German dataset, while there are other pages from this domain (bmbf.de) in the data, and this page is only one click from the homepage.
After asking this question on discourse, I understand that the Common Crawl isn't complete, and uses random sampling. It would still be good to know the sampling strategy used, e.g., what % of websites are typically crawled, and if this is weighed by some popularity factor? (I couldn't find this information mentioned on their website).
For the specific URL referenced above, I additionally queried the full index (via the Athena interface) and saw that it has never been crawled. This IMO is an unfortunate limitation for some research questions.
It might thus be nice to share information about other large-scale crawl projects/datasets that could be used in place of CC.
The OSCAR 2019 Northern Frisian corpus is too small and of a bad quality.
The 21.09 version has to be checked.
Source: Quality at a Glance.
At https://github.com/bigscience-workshop/bigscience we found 3835 records full of backslashes in OSCAR-en
My suspicion is that OSCAR downloaded a single webpage which was comprised of say 4B backslashes. It then happily sliced it into 0.5M-long records (which I deduce is its max doc length) and thus introduced thousands of records of just backslashes.
Checking that the original indeed contains these records:
pip install datasets)python -c "from datasets import load_dataset; load_dataset('oscar', 'unshuffled_deduplicated_en', split='train', keep_in_memory=False, cache_dir='cache')"
cd cache/downloads
find . -type f -size +50k | xargs -n1 gunzip -c | fgrep -a '\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\' | tee data-with-many-slashes.txt
$ perl -lne 'm|(\\{10000,})| && print length $1' data-with-many-slashes.txt | wc -l
4245
Look at the lengths:
perl -lne 'm|(\\{10000,})| && print length $1' data-with-many-slashes.txt | sort -V
The largest number is 524287 (Which is the most common record)
Hi guys,
after downloading and extracting the Turkish part of the OSCAR 21.09 release, I've found some sentences with encoding errors:

I did a grep -c "�" tr_part_* over the complete corpus, here are some stats:
| Filename | Affected number of lines |
|---|---|
| tr_part_1.txt | 1579 |
| tr_part_2.txt | 1575 |
| tr_part_3.txt | 1560 |
| tr_part_4.txt | 1603 |
| tr_part_5.txt | 1527 |
| tr_part_6.txt | 1674 |
| tr_part_7.txt | 1869 |
| tr_part_8.txt | 1628 |
| tr_part_9.txt | 1618 |
| tr_part_10.txt | 1656 |
| tr_part_11.txt | 1559 |
| tr_part_12.txt | 1739 |
| tr_part_13.txt | 1895 |
| tr_part_14.txt | 1598 |
| tr_part_15.txt | 1504 |
| tr_part_16.txt | 1549 |
| tr_part_17.txt | 1469 |
| tr_part_18.txt | 1424 |
| tr_part_19.txt | 1348 |
| tr_part_20.txt | 1200 |
| tr_part_21.txt | 1719 |
| tr_part_22.txt | 1364 |
| tr_part_23.txt | 1404 |
| tr_part_24.txt | 1565 |
| tr_part_25.txt | 1482 |
| tr_part_26.txt | 1689 |
| tr_part_27.txt | 1487 |
| tr_part_28.txt | 1539 |
| tr_part_29.txt | 1624 |
| tr_part_30.txt | 1444 |
| tr_part_31.txt | 1412 |
| tr_part_32.txt | 1530 |
| tr_part_33.txt | 1310 |
| tr_part_34.txt | 163 |
From tr_part_1.txt I took one example from line 369:
Sitemize �yelik ve i�eri�in indirilmesi tamamen �cretsizdir. Sitemizde payla��lan t�m dok�manlar (Tezler, makaleler, ders notlar�, s�nav soru cevaplar, projeler) payla��mc�lar�n bireysel �al��malar� olup telif haklar� kendilerine aittir ya da a��k bir �ekilde kamusal alana yerle�tirilmi� dok�manlar�n birer kopyalar�d�r. Ki�ilerin bireysel �al��malar�n� sitemizde y�klemesinde, sitemizde payla��ma te�vik eden puanlama sisteminin de etkisi b�y�kt�r. Bunlara ra�men hala size ait olan ve burada bulunmas�na izin vermedi�iniz dok�manlar varsa ileti�im b�l�m�nden y�neticilere bildirmeniz durumunda derhal silineceklerdir.
I extracted the corresponding meta data line (hopefully right) from tr_meta_part_1.jsonl:
{"headers":{"warc-type":"conversion","warc-record-id":"<urn:uuid:7426b39c-a6c9-4f21-b496-39e447af11fa>","content-type":"text/plain","warc-identified-content-language":"tur,eng","warc-date":"2021-03-09T03:48:37Z","warc-target-uri":"http://www.elektrotekno.com/forum-67.html","warc-refers-to":"<urn:uuid:e3e4a0d4-cff5-4c74-b6e4-788bb49cd27a>","warc-block-digest":"sha1:RMMGZX4322A5YTPZBEYMHADF6TDTYLVI","content-length":"3068"},"offset":368,"nb_sentences":1}As you can see on the actual page hyperlink the encoding is broken by default:

HTML content type header is:
<meta http-equiv="Content-Type" content="text/html; charset=windows-1254" />
However, if I manually switch my Chrome to use "Turkish (Windows-1254)" it's working:



From the official site , the Yue Chinese dataset should have 2.2KB data.
7 training instances is obviously not a right number.
As I can read Yue Chinese, I call tell the last instance is definitely not something that would appear on Common Crawl.
And even if you don't read Yue Chinese, you can tell the first six instance are problematic.
(It is embarrassing, as the 7 training instances look exactly like something from a pornographic novel or flitting messages in a chat of a dating app)
It might not be the problem of the huggingface/datasets implementation, because when I tried to download the dataset from the official site, I found out that the zip file is corrupted.
I will try to inform the host of OSCAR corpus later.
Awy a remake about this dataset in huggingface/datasets is needed, perhaps after the host of the dataset fixes the issue.
the post is copied from a post about the same issue on huggingface's repository: huggingface/datasets#2396
There is a mistake on the example inside Use in dataset library.
The second parameter to load_dataset function is given as unshuffled_deduplicated_af. This should be deduplicated_af.
The OSCAR 2019 Somali corpus is too small and of a bad quality.
The 21.09 version has to be checked.
Source: Quality at a Glance.
The Wu Chinese dataset is not in wu chinese.
Its quality needs to be evaluated: is it another language, or is it completely gibberish?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.