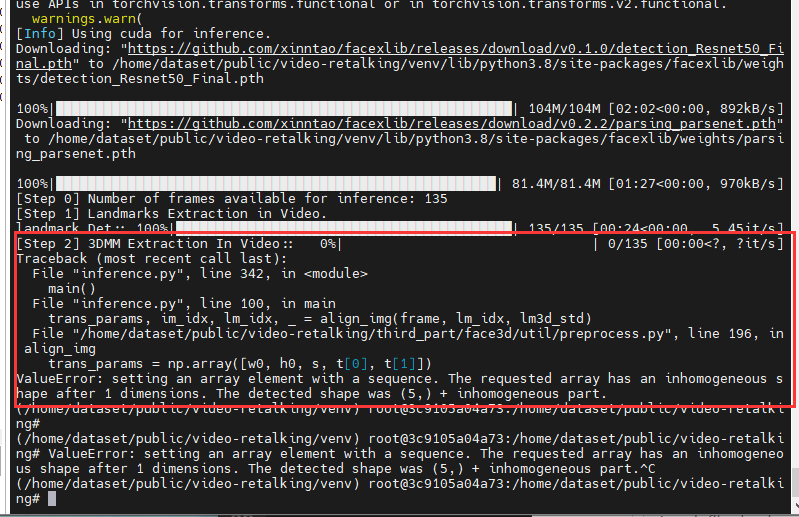
I'll leave the error log below but from what I understand my image size is too big for face detection on my gpu, I only have a 4GB GPU
using the following code
python inference.py --face examples/face/12.mp4 --audio examples/audio/3.wav --outfile results/1_6.mp4 --face_det_batch_size 2 --LNet_batch_size 2 --one_shot
I don't really want to be resizing my video as I want to preserve qaulity can i do something else like increase batch sizes or crop my video somehow (please if you are replying with code add to the lines I provided above if possible)
FaceDet:: 0%| | 0/204 [00:01<?, ?it/s]
Recovering from OOM error; New batch size: 1 | 0/204 [00:00<?, ?it/s]
FaceDet:: 0%| | 0/407 [00:00<?, ?it/s]
[Step 6] Lip Synthesis:: 0%| | 0/204 [01:36<?, ?it/s]
Traceback (most recent call last):
File "C:\Users\leolo\video-retalking\utils\inference_utils.py", line 118, in face_detect
predictions.extend(detector.get_detections_for_batch(np.array(images[i:i + batch_size])))
File "C:\Users\leolo\video-retalking\third_part\face_detection\api.py", line 66, in get_detections_for_batch
detected_faces = self.face_detector.detect_from_batch(images.copy())
File "C:\Users\leolo\video-retalking\third_part\face_detection\detection\sfd\sfd_detector.py", line 42, in detect_from_batch
bboxlists = batch_detect(self.face_detector, images, device=self.device)
File "C:\Users\leolo\video-retalking\third_part\face_detection\detection\sfd\detect.py", line 69, in batch_detect
olist = net(imgs)
File "C:\Users\leolo\.conda\envs\video_retalking\lib\site-packages\torch\nn\modules\module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\leolo\video-retalking\third_part\face_detection\detection\sfd\net_s3fd.py", line 71, in forward
h = F.relu(self.conv1_1(x))
File "C:\Users\leolo\.conda\envs\video_retalking\lib\site-packages\torch\nn\modules\module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\leolo\.conda\envs\video_retalking\lib\site-packages\torch\nn\modules\conv.py", line 443, in forward
return self._conv_forward(input, self.weight, self.bias)
File "C:\Users\leolo\.conda\envs\video_retalking\lib\site-packages\torch\nn\modules\conv.py", line 439, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: CUDA out of memory. Tried to allocate 960.00 MiB (GPU 0; 4.00 GiB total capacity; 1.96 GiB already allocated; 0 bytes free; 2.67 GiB reserved in total by PyTorch)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "inference.py", line 342, in <module>
main()
File "inference.py", line 211, in main
for i, (img_batch, mel_batch, frames, coords, img_original, f_frames) in enumerate(tqdm(gen, desc='[Step 6] Lip Synthesis:', total=int(np.ceil(float(len(mel_chunks)) / args.LNet_batch_size)))):
File "C:\Users\leolo\.conda\envs\video_retalking\lib\site-packages\tqdm\std.py", line 1178, in __iter__
for obj in iterable:
File "inference.py", line 292, in datagen
face_det_results = face_detect(full_frames, args, jaw_correction=True)
File "C:\Users\leolo\video-retalking\utils\inference_utils.py", line 121, in face_detect
raise RuntimeError('Image too big to run face detection on GPU. Please use the --resize_factor argument')
RuntimeError: Image too big to run face detection on GPU. Please use the --resize_factor argument