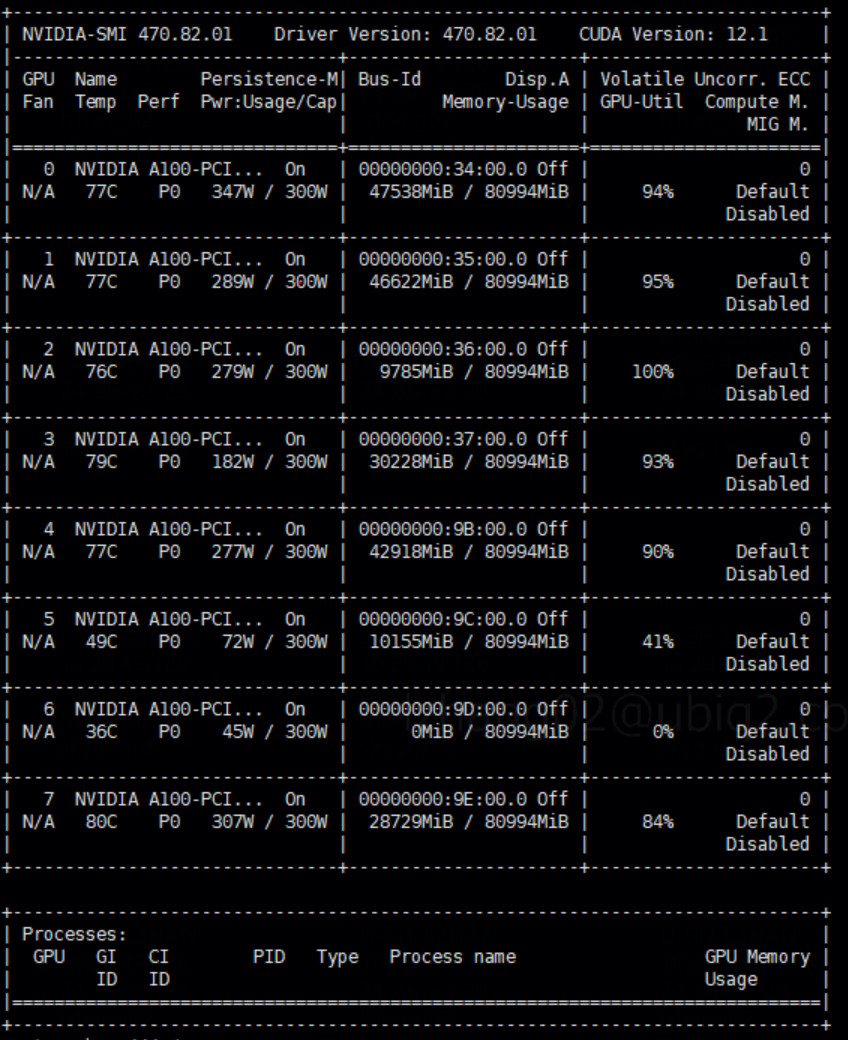
Golang bindings are provided for NVIDIA Data Center GPU Manager (DCGM). DCGM is a set of tools for managing and monitoring NVIDIA GPUs in cluster environments. It's a low overhead tool suite that performs a variety of functions on each host system including active health monitoring, diagnostics, system validation, policies, power and clock management, group configuration and accounting.
You will also find samples for these bindings in this repository.
Checkout the Contributing document!
- Please let us know by filing a new issue
- You can contribute by opening a pull request