nemo2011 / bilibili-api Goto Github PK
View Code? Open in Web Editor NEW哔哩哔哩常用API调用。支持视频、番剧、用户、频道、音频等功能。原仓库地址:https://github.com/MoyuScript/bilibili-api
Home Page: https://nemo2011.github.io/bilibili-api/
License: GNU General Public License v3.0
哔哩哔哩常用API调用。支持视频、番剧、用户、频道、音频等功能。原仓库地址:https://github.com/MoyuScript/bilibili-api
Home Page: https://nemo2011.github.io/bilibili-api/
License: GNU General Public License v3.0






![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")


































































































































Python 版本: 3.9.13
模块版本: 10.1.0/10.2.0b5
运行环境: Ubuntu 20.04.4 LTS
模块路径: bilibili_api.video_uploader
**报错信息:'分块上传失败'
{'name': 'PRE_CHUNK', 'data': {'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x7f8264089c70>, 'offset': 807403520, 'chunk_number': 77, 'total_chunk_count': 496}}
{'name': 'PRE_CHUNK', 'data': {'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x7f8264089c70>, 'offset': 817889280, 'chunk_number': 78, 'total_chunk_count': 496}}
{'name': 'PRE_CHUNK', 'data': {'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x7f8264089c70>, 'offset': 828375040, 'chunk_number': 79, 'total_chunk_count': 496}}
{'name': 'CHUNK_FAILED', 'data': {'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x7f8264089c70>, 'offset': 807403520, 'chunk_number': 77, 'total_chunk_count': 496, 'info': '分块上传失败'}}
{'name': 'CHUNK_FAILED', 'data': {'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x7f8264089c70>, 'offset': 828375040, 'chunk_number': 79, 'total_chunk_count': 496, 'info': '分块上传失败'}}
{'name': 'CHUNK_FAILED', 'data': {'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x7f8264089c70>, 'offset': 817889280, 'chunk_number': 78, 'total_chunk_count': 496, 'info': '分块上传失败'}}
自6月27日左右开始,位于不同省份,使用不同账号,但运行环境相同的机器,均出现这种现象。原MoyuScript的是一开始两年左右没这个问题,6月27出现首次后,尝试继续使用了一段时间,因为是概率性的(下面有解释)。后来更换到这个新的库,依旧会出现这种情况。
比如这个496块差不多5G的视频投稿,他会从0到496,不断上传,不断返回这个分块上传失败,再从0开始循环。时间久了(持续上传10小时左右)甚至会被B站暂时封ip,返回403,才会停下来。(虽然显示分块上传失败,网关显示上行速度是有常规投稿上传时的速度的)
已经触发这个现象而失败的文件,无论怎么上传,都会这样。如果改一下文件名(文件名纯数字),再运行一次,就有概率能成功。它是要么全程没问题,要么一上来就出现这个分块上传失败,直至结束。如果改名字后运行还是失败,再改一下名字,再上传,还是有概率成功。大概是60-70%的概率能成功。
Python 版本: 3.8.5
模块版本: 3.1.3
运行环境: Linux
无论是在3.1.3的bilibili_api.utils.Verify,抑或是当前最新版的bilibili_api.utils.Credential,用户认证都需要用到Cookies中的SESSDATA和bili_jct。尽管这种方式和大多SDK的AK/SK认证不同,但在过去两年左右时间里,我们的服务使用bilibili_api进行自动上传视频总是能成功,这归功于Cookies中的SESSDATA和bili_jct在很长一段时间保持不变。
但最近,总会因为SESSDATA和bili_jct频繁变动,导致自动上传视频失败。
因此,我想了解了解SESSDATA和bili_jct的刷新机制,以及如何去避免因SESSDATA和bili_jct刷新而造成的上传失效,或者还有其他方法能实现用户持久的认证吗?
希望能尽快收到回复,感谢!
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc0 in position 73: invalid start byte
代码:
import asyncio
from bilibili_api import video
async def main():
# 实例化 Video 类
v = video.Video(bvid="BV1uv411q7Mv")
# 获取信息
info = await v.get_info()
# 打印信息
print(info)
if name == 'main':
asyncio.get_event_loop().run_until_complete(main())
如题,例如BV1GJ411x7h7,返回-404
Python 版本: 3.9
模块版本: x.x.x
**运行环境:*MacOS
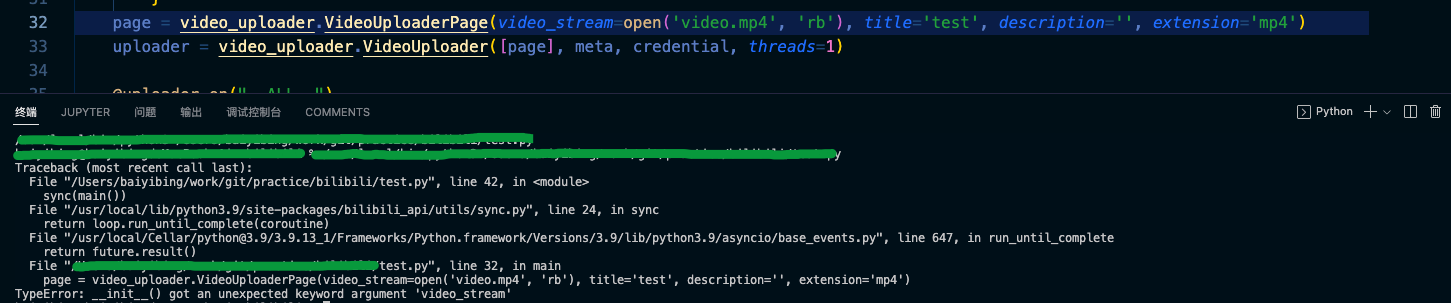
上传视频示例报错
**Python 版本: 3.8.6
**模块版本:3.1.3
**运行环境:Linux/MacOS
在release3.1.3中,可以通过调用user.get_videos_g({uid})来获取用户的所有投稿视频信息,但在2022-09-21 18:00后,使用这个方法开始开始出现异常,以下是我在MacOS上执行失败的一段错误日志:
Traceback (most recent call last):
File "", line 1, in
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/bilibili_api/user.py", line 118, in get_videos_g
data = get_videos_raw(uid=uid, order=order, pn=page, verify=verify)
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/bilibili_api/user.py", line 158, in get_videos_g
data = utils.get(url=api["url"], params=params, cookies=verify.get_cookies())
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/bilibili_api/utils.py", line 418, in get
resp = request("GET", url=url, params=params, cookies=cookies, headers=headers, data_type=date_type, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/bilibili_api/utils.py", line 394, in request
raise exceptions.BilibiliException(con["code"], msg)
bilibili_api.exceptions.BilibiliException: 错误代码:-401, 信息:非法访问
考虑到bilibili版本迭代速度过快,而release 3.1.3一直以来都能满足我们的服务需求,所以想请教下不切换版本的情况下是否还能获取到一个用户所发布的所有投稿信息
没想到还真有人接手做了,看了一圈貌似还可以。原仓库主要是我实在是没精力去维护了,要不在原仓库给你引个流?[狗头]
不介意的话也可以把原仓库转给你,我偶尔冒泡帮个忙。
Python 版本: 3.9
模块版本: 12.5.1
运行环境: Linux
github_code.txt是源代码,return_information.txt是返回的结果,因为这个错误卡一天了,可以帮忙看看吗?非常感谢。
是这样的, 个人闲时会玩玩OW这个游戏,官方OWL联赛会根据观看时长赠送皮肤,个人又没有那么多时间挂时长,于是想写个脚本仍服务器上挂一下,无论怎样都不会增加时长,请问B站增加观看时长的api有了解吗,个人可以自行添加。
我翻了下B站直播相关的油猴脚本有调用heartbeat/webHeartBeat这个api的,我增加了一下发现没有什么用。
下面是主要逻辑
credential = Credential(sessdata, bili_jct, buvid3, dedeuserid)
room_id = xxxx
room = live.LiveRoom(room_id, credential)
sync(room.get_user_info_in_room())
room_info = sync(room.get_room_info())
print(f"进入{room_info['anchor_info']['base_info']['uname']}直播间, 标题【{room_info['room_info']['title']}】")
sync(room.get_room_play_info_v2(live_qn=live.ScreenResolution.FLUENCY))
danmaku = live.LiveDanmaku(room_id, False, credential)
@danmaku.on("ALL")
async def danmaku_all(event):
pass
# print(event)
def heartbeat():
while True:
sync(room.get_room_info())
# 包装的 webHeartBeat 这个api
print(sync(room.heartbeat()))
time.sleep(60)
threading.Thread(target=heartbeat).start()
sync(danmaku.connect())Python 版本: 3.10
模块版本: 12.4.0
下载视频示例报错 ”for chunk in resp.iter_bytes(1024):“
报错内容'ClientResponse' object has no attribute 'iter_bytes',看了最新的ClientResponse好像确实没有这个成员,应该是示例没更新,但是新版本应该怎样表示分块大小呢?
模块路径: bilibili_api.live
如 https://live.bilibili.com/3010,id实际上为8633637。
建议解决方法:
直接向https://live.bilibili.com/{room_display_id}发送Get请求,在resp中存在真实room_id。
Python 版本: 3.9 / NodeJS 版本: 无
模块版本: 11.5.1 (python/JS&TS)
运行环境: Debian 11 x86_64 Kernel: 5.10.0-14-amd64
模块路径: ./.local/lib/python3.9/site-packages
解释器(Python): python
报错信息:
Exception in thread Thread-9:
Traceback (most recent call last):
File "/home/appleUqaq/haku-qqbot/plugins/commands/bilibili.py", line 1, in <module>
import bilibili_api
File "/home/appleUqaq/.local/lib/python3.9/site-packages/bilibili_api/__init__.py", line 17, in <module>
nest_asyncio.apply()
File "/home/appleUqaq/.local/lib/python3.9/site-packages/nest_asyncio.py", line 16, in apply
loop = loop or asyncio.get_event_loop()
File "/home/appleUqaq/.local/lib/python3.9/site-packages/nest_asyncio.py", line 45, in _get_event_loop
loop = events.get_event_loop_policy().get_event_loop()
File "/usr/lib/python3.9/asyncio/events.py", line 642, in get_event_loop
raise RuntimeError('There is no current event loop in thread %r.'
RuntimeError: There is no current event loop in thread 'Thread-9'.报错代码:
import bilibili_api还有一个问题,就是如果执行多次用 lsof | grep CLOSE_WAIT 查找则会出现CLOSE_WAIT,会导致 OSError: Too many open files ,因为不会异步,所以用的都是bilibili_api.sync()

Windows10 python3.10
安装失败
Python 版本:3.9
模块版本:bilibili-api-python 12.1.0
报错信息:
{'name': 'PRE_CHUNK', 'data': {'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x117db95b0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 1}}
{'name': 'CHUNK_FAILED', 'data': {'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x117db95b0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 1, 'info': '分块上传失败'}}
报错代码:
credential = video_uploader.Credential(sessdata=SESSDATA, bili_jct=BILI_JCT, buvid3=BUVID3)
# 具体请查阅相关文档
meta = {
"copyright": 2,
"source": v_url,
"cover": v_cover,
"desc": v_desc,
"desc_format_id": 0,
"dynamic": "自动化上传测试",
"interactive": 0,
"open_elec": 1,
"no_reprint": 1,
"subtitles": {
"lan": "",
"open": 1
},
"tag": ','.join(v_tag),
"tid": 171,
"title": v_title,
"up_close_danmaku": False,
"up_close_reply": False
}
page = video_uploader.VideoUploaderPage(path=video_path, title=v_title, description=v_desc)
uploader = video_uploader.VideoUploader([page], meta, credential, v_cover)
在此处写正文
Python 版本: 3.x
模块版本: x.x.x
运行环境: Windows / Linux
Traceback (most recent call last):
File ".\bilisearch.py", line 175, in <module>
asyncio.get_event_loop().run_until_complete(main())
File "D:\Program Files\anaconda3\envs\autopub\lib\asyncio\base_events.py", line 608, in run_until_complete
return future.result()
File ".\bilisearch.py", line 158, in main
r = await misc.web_search_by_type(k,'video')
File "D:\Program Files\anaconda3\envs\autopub\lib\site-packages\bilibili_api\misc.py", line 36, in web_search_by_type
return await request('GET', url=api["url"], params=params)
File "D:\Program Files\anaconda3\envs\autopub\lib\site-packages\bilibili_api\utils\network.py", line 111, in request
async with session.request(**config) as resp:
File "D:\Program Files\anaconda3\envs\autopub\lib\site-packages\aiohttp\client.py", line 1117, in __aenter__
self._resp = await self._coro
File "D:\Program Files\anaconda3\envs\autopub\lib\site-packages\aiohttp\client.py", line 520, in _request
conn = await self._connector.connect(
File "D:\Program Files\anaconda3\envs\autopub\lib\site-packages\aiohttp\connector.py", line 535, in connect
proto = await self._create_connection(req, traces, timeout)
File "D:\Program Files\anaconda3\envs\autopub\lib\site-packages\aiohttp\connector.py", line 890, in _create_connection
_, proto = await self._create_proxy_connection(req, traces, timeout)
File "D:\Program Files\anaconda3\envs\autopub\lib\site-packages\aiohttp\connector.py", line 1073, in _create_proxy_connection
transport, proto = await self._create_direct_connection(
File "D:\Program Files\anaconda3\envs\autopub\lib\site-packages\aiohttp\connector.py", line 1011, in _create_direct_connection
raise ClientConnectorError(req.connection_key, exc) from exc
aiohttp.client_exceptions.ClientConnectorError: Cannot connect to host {proxy}:80 ssl:default [getaddrinfo failed]
proxypool='https://proxypool.scrape.center/random'
proxy = requests.get(proxypool).text
print(proxy,'========')
settings.proxy = "http://{proxy}" # 里头填写你的代理地址
r = await misc.web_search_by_type(k,'video')
Python 版本: 3.10
模块版本: x.x.x
运行环境: Windows / Linux / MacOS
资源类型改成VIDEO,oid改成某某av号是能成功的,但是评论动态不行。(oid填的是动态页的t.bilibili.com/和?spm_id_from...之间的一串数,字符串和int值都试过)
报错内容:
接口返回错误代码:-404,信息:啥都木有。
{'code': -404, 'message': '啥都木有', 'ttl': 1, 'data': None}
代码内容:
#coding=gbk
from bilibili_api import login, user, sync,comment
print("请登录:")
credential = login.login_with_qrcode()
try:
credential.raise_for_no_bili_jct() # 判断是否成功
credential.raise_for_no_sessdata() # 判断是否成功
except:
print("登陆失败。。。")
exit()
print("欢迎,", sync(user.get_self_info(credential))['name'], "!")
text=r"text"
async def main():
c = await comment.send_comment(text=text,oid='xxx' ,type_=comment.CommentResourceType.DYNAMIC,credential=credential)
print('success')
sync(main())
Python 版本: 3.10
**模块版本:latest
运行环境: Windows / Linux
模块路径: bilibili_api.bangumi
解释器(Python): pypi
from bilibili_api import bangumi
b = bangumi.Bangumi(media_id=1635, credential=credential)
KeyError: up_info
js: vue-cli 3**
**模块版本:文档上的第一个例子
**运行环境:vscode
在此处写正文
Python 版本: 3.x
运行环境: Windows
from bilibili_api import article, sync
async def main():
ar = article.Article(14693531)
await ar.fetch_content()
with open('article.md', 'w', encoding='utf8') as f:
f.write(ar.markdown())
sync(main())比如抓取14693531这篇文章,地址:https://www.bilibili.com/read/cv14693531/?from=readlist ,引用内容和引用间内容会丢失。
抓取其他文章时,出现引用内容后的一部分正文内容,也会被转为引用
bilibili_api 在 pyinstaller 打包的时候需要把许多的数据(如分区数据、API 数据)打进 exe 文件里面,目前 setup.py 已经添加了在 Pyinstaller 打包的时候自动把 bilibili_api 的相关文件打包进去的功能。
如果你在运行打包后的 exe 程序时出现:'NoneType' object is not subscriptable,则代表 bilibili_api 的数据没有打包进去。请按照如下步骤解决:
dist-packages 目录或 site-packages 目录)python 模块目录/PyInstaller/hooks 下新建文件 hook-bilibili_api.py。hook-bilibili_api.py 文件中写入:from PyInstaller.utils.hooks import collect_data_files
datas = collect_data_files("bilibili_api")执行完以下步骤一般就能解决问题了。如果你的问题仍然没有解决,请发出你的 exe 文件的错误, PyInstaller 日志, 以便解决问题。

Python 版本: 3.10.3
模块版本: 9.1.0
运行环境: Windows / Linux
使用VideoUploader传入了多个VideoUploaderPage对象时在提交视频时失败,提示超出当前可用分p视频数上限,请问分p这一块是有什么限制吗
pages = []
for filename in os.listdir(dirname):
filepath = os.path.join(dirname, filename)
page = video_uploader.VideoUploaderPage(filepath, meta['title'], meta['desc'])
pages.append(page)
uploader = video_uploader.VideoUploader(pages=pages, meta=meta, credential=myCredential)
await uploader.start()Python 版本: 3.10
模块版本: dev
运行环境: Linux
getSubList APIhttp://space.bilibili.com/ajax/tags/getSubList
url 参数:
| 参数名 | 类型 | 内容 | 必要性 | 备注 |
|---|---|---|---|---|
| mid | num | 目标用户 UID | 必要 |
在 查询用户关注的 TAG 的相关Api中, ajax 重定向没有被 预定的工具库处理,另外处理后也因为没有 code 字段不能被解析。
暂时没有
看了 search 模块,好像没有对排序属性的设置,或许可以整合一个功能更完善的 search 模块?
正在写
https://github.com/Nemo2011/bilibili-api/blob/main/bilibili_api/data/channel.json
包含的分区信息有些旧了。
最新版的主页可以考虑用
https://s1.hdslb.com/bfs/static/laputa-home/client/assets/index.6d9f1875.js
这个文件内的_t[channellist]变量转换。不过和以前的字典的键值有些减少。
Python 版本: 3.10
模块版本: x.x.x (PYTHON/JS&TS)
运行环境: Windows /
输出
{'room_display_id': 21409991, 'room_real_id': 2199971, 'type': 'DANMU_MSG', 'data': {'cmd': 'DANMU_MSG', 'info': [[0, 1, 25, 16777215, 1659962555600, 124775867, 0, '178d1d3f', 0, 0, 0, '', 0, '{}', '{}', {'mode': 0, 'show_player_type': 0, 'extra': '{"send_from_me":false,"mode":0,"color":16777215,"dm_type":0,"font_size":25,"player_mode":1,"show_player_type":0,"content":"cddrjgtfj","user_hash":"395124031","emoticon_unique":"","bulge_display":0,"recommend_score":0,"main_state_dm_color":"","objective_state_dm_color":"","direction":0,"pk_direction":0,"quartet_direction":0,"anniversary_crowd":0,"yeah_space_type":"","yeah_space_url":"","jump_to_url":"","space_type":"","space_url":""}'}, {'activity_identity': '', 'activity_source': 0, 'not_show': 0}], 'cddrjgtfj', [291426330, '残存の影子', 0, 0, 0, 10000, 1, ''], [15, '旅行', '地球频道', 9196015, 12478086, '', 0, 12478086, 12478086, 12478086, 0, 1, 290515513], [10, 0, 9868950, '>50000', 1], ['', ''], 0, 0, None, {'ts': 1659962555, 'ct': 'CB0A8807'}, 0, 0, None, None, 0, 210]}}
但是我希望能输出
残存の影子说:cddrjgtfj
感谢继续维护开发这个项目啊,好用,提个功能上的建议
另一个获取关注列表的接口
接口参考 SocialSisterYi/bilibili-API-collect#521
此接口的好处是可以获取到隐藏关注列表的用户的关注,不知道是否长期有效。
可以考虑优先用原接口,如果检测到用户设置了隐藏,就根据get_followings的参数是否用第二个接口再次尝试。
user模块get_followings和get_followers需要ps参数
虽然只能获取到前5页,不过ps参数决定每页返回的用户数目,所以最多可以返回5*50=250个用户。
不加ps参数的话,只能获取到100个。
同时,get_all_followings里面也可以改一下
Python 版本: 3.8
模块版本: 12.5.2
运行环境: Linux
今天在使用LiveDanmuku时突然发现卡在了获取真实房间号 stderr.log:
[2022-10-08 13:12:40,289][WARNING]创建主数据库容器成功
[2022-10-08 13:12:40,718][WARNING]创建缓存数据库容器成功
[2022-10-08 13:12:40,784][WARNING]获取用户-----------会话成功
[-----------][2022-10-08 13:12:40,790][INFO] 准备连接直播间 --------
[-----------][2022-10-08 13:12:40,791][DEBUG] 正在获取真实房间号
在怀疑是不是存在接口更新导致失效,还是说ip被墙这种,但是测试过的其他api一律有效,唯独卡死在这里的获取。
没用过ASync IO, 先放个需求在这。 等整明白了我看看能不能自己实现再PR过来
DownloadUID DownloadTag 之类的接口函数和下载回调Python 版本: 3.9
模块版本: 13.3.0
运行环境: Windows
使用 dynamic 的 repost() ,转发他人的转发动态
比如我想转发ID为 732728181152284690 的动态,执行结果却转发了它的源动态 732714338481078288
应该如何解决呢?
某个栏目近期投稿API,有吗?
https://www.bilibili.com/v/knowledge/business
从网页抓到的例子是
https://s.search.bilibili.com/cate/search?main_ver=v3&search_type=video&view_type=hot_rank©_right=-1&new_web_tag=1&order=click&cate_id=207&page=1&pagesize=30&time_from=20220501&time_to=20220730
这里只能拿到过去大概3个月的数据,有没有办法可以拿到更久的?
Python 版本: 3.x
使用标准测试框架,更方便的管理项目和覆盖率测试
要做个项目 找到了MoyuScript/bilibili-api,看到已经不维护了 心里凉凉,又发现这个项目,希望能维护下去,贴个赞赏码出来表示下支持。
刚接触爬虫,目前扫码登录仅能获取uid,sessdata以及bilijct等,有大佬教一下通过扫码登录获取uuid的思路吗(谢了
Python 版本: 3.9
模块版本: 12.1.0
运行环境: Windows
假设我想添加一个接口用于获取创作激励的稿件收入信息,我应当将其加入User类吗?还是应该将创作中心相关接口单独作为一个模块?
在测试submit_subtitle这个函数时,网页会返回一些错误原因,但是ResponseCodeException并没有提取/返回所有有效信息,导致排查困难。
比如,经常收到报错:
接口返回错误代码:79014,信息:字幕超过限制。
但是网页返回的其实包含了其他有效信息:
{'code': 79014, 'message': '字幕超过限制', 'ttl': 1, 'data': [{'line': 580, 'error_msg': '字幕时间点超过视频时间长度'}]}
在代码中如果加上self.raw就可以返回全部信息。
bilibili-api/bilibili_api/exceptions/ResponseCodeException.py
Lines 10 to 29 in 2c6f8da
另外,关于字幕的操作,目前只有提交字幕这一个api,是否可以增加其他操作字幕的api,比如查看/退回/删除等?
感谢!
b站 cookies 可能因超过时限、退出登录等原因失效,需要及时检测重新登陆。
向 https://api.bilibili.com/x/web-interface/nav 发送 Get 请求,若 resp['code'] 值为 0 ,则登陆有效,反之失效。
Python 版本: All
模块版本: All
运行环境: All
我此前长期使用的方式是携带着Cookies然后使用selenium打开主页维持一段时间(但是拒绝一切的图像文件啥的接受)。然后重保存整个Cookies的。因为懒所以一直没分析过具体会是api还是主页的请求本身是一个动态页面,导致在获取template的同时就更新该会话的登录状态,还是因为发送了某个心跳请求,或是登录接口本身做校验。
简而言之,我需要最小化自动登录(签到)的手续(对于Cookies的有效性校验我有方法,但是自动登录经过上次有出错的前提下我不保证一定成功,因此废弃该方案,但凡Cookies失效就拉Error,主动更新一遍Cookies)。

如图,我用的是api示例直接复制粘贴,,在pyc里直接运行是正常的
在此处写正文
Traceback (most recent call last):
.................
ep = bangumi.Episode(675686)
File "/home/xxx/miniconda3/envs/biliMonitor/lib/python3.8/site-packages/bilibili_api/bangumi.py", line 212, in __init__
raise ApiException("未找到番剧信息")
bilibili_api.exceptions.ApiException.ApiException: 未找到番剧信息
在对特殊类型,如ep675686进行
ep = bangumi.Episode(675686)
print(ep.get_aid())
会发生 404 错误
from bilibili_api import bangumi, sync
from bilibili_api.bangumi import Bangumi
async def main():
ep = bangumi.Episode(675686)
# 打印 bv 号674245
print(ep.get_aid())
sync(main())
ep 对应页面不可访问,match取空
pattern = re.compile(r"window.__INITIAL_STATE__=(\{.*?\});")
match = re.search(pattern, content)
利用子 Api ,不可访问的 ep 剧集 所属番剧信息也是可以得到的,是否可以改善 Bangumi ?
请问我想要输出"谢谢熱血赠送的2个辣条、1个PK票",该如何操作?
@room.on('COMBO_SEND')经常触发不动
@room.on('SEND_GIFT')不支持数量统计
`
from bilibili_api import live, sync
room = live.LiveDanmaku(2xxxx)
@room.on('SEND_GIFT')
async def on_gift1(event):
礼物名=event['data']['data']['giftName']
送礼人=event['data']['data']['uname']
礼物数 = event['data']['data']['num']
print(送礼人+礼物名+str(礼物数))
sync(room.connect())
`
具体要求:
1收到礼物后观察n秒,假如n秒内没有收到同一用户的礼物,就print()
2如果在观察的时候再次收到该用户礼物,则重置观察时间(再观察n秒),循环直到执行1
3不同用户的礼物互不干扰,每位用户的观察时间独立
4同一用户多个礼物可以合并一起输出
思考:
1while循环:浪费资源,堵住线程
2新建线程:目标3可能会有问题
3批量创建线程,一位用户一个线程去观察:不会......没找到代码实现方法
全局变量
主线程 子线程
发现礼物创建子线程----------------------------计时n秒
发现礼物,礼物数+x,重启子线程----------------计时n秒
发现礼物,礼物数+x,重启子线程----------------计时n秒
n秒了还没礼物----------------------------------print,结束子线程
Python 版本:3.10.6 / NodeJS 版本:16
模块版本: python(python/JS&TS)
运行环境: Linux
模块路径: `bilibili_api.audio, sync, get_session
解释器(Python): cpython
报错信息:
AttributeError: 'bytes' object has no attribute 'read'```
**报错代码:**
这里填写报错代码
---
chunk = await resp.content.read(1024)
Python 版本: 3.8
模块版本: 12.5.0
运行环境: Linux
模块路径: bilibili_api.login
解释器(Python): cpython
报错代码:
def login_with_sms(phonenumber: PhoneNumber, code: str):
"""
验证码登录
Args:
phonenumber(string): 手机号类
code(string) : 验证码
Returns:
Credential: 凭据类
"""
global captcha_id
sess = get_session()
api = API["sms"]["login"]
if captcha_id == None:
raise LoginError("请申请或重新申请发送验证码")
return_data = json.loads(
sync(
sess.request(
"POST",
url=api["url"],
data={
"tel": phonenumber.number,
"cid": phonenumber.code,
"code": code,
"source": "main_web",
"captcha_key": captcha_id,
"keep": "true",
},
)
).text
)
if return_data["code"] == 0:
captcha_id = None
url = return_data["data"]["url"]
cookies_list = url.split("?")[1].split("&")
sessdata = ""
bili_jct = ""
dede = ""
for cookie in cookies_list:
if cookie[:8] == "SESSDATA":
sessdata = cookie[9:]
if cookie[:8] == "bili_jct":
bili_jct = cookie[9:]
if cookie[:11].upper() == "DEDEUSERID=":
dede = cookie[11:]
c = Credential(sessdata, bili_jct, dedeuserid=dede)
return c
else:
raise LoginError(return_data["message"])当触发安全机制时,其中return_data返回的是:
{'is_new': False, 'status': 5, 'message': '安全风险控制', 'url': '***', 'hint': '', 'in_reg_audit': 0, 'refresh_token': '', 'timestamp': 0}即使return_data["code"] == 0
修复建议:
对return_data的status进行校验,以抛出异常。或者安全风险控制有进一步进行修正的登录过程。
接口是 user.get_videos,msg为空,可能是偶发的,这个错误码遇到过吗?
user里的get_user_info获取的用户信息里的jointime都是0,有其他的获取方式嘛
如标题@_@
不清楚现在有没有,翻了一下changelog好像没有
Python 版本: 3.10.4
模块版本: 10.0.1
运行环境: Kubuntu 22.04 LTS
模块路径: bilibili_api.user
报错信息:
Traceback (most recent call last):
File "<unrelated>.py", line 8, in <module>
from bilibili_api.user import User, BangumiType
File "<unrelated>/.venv/lib/python3.10/site-packages/bilibili_api/user.py", line 11, in <module>
from pytest import param
ModuleNotFoundError: No module named 'pytest'
requirements.txt 中没有依赖 pytest 但仍导入导致报错。(而且导入之后并未使用)
类似于下面这种,没找到相应的API
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

