PyQt5界面,Scrapy+Selenium将爬取的信息保存到Excel文件
一、部署虚拟环境,有虚拟环境的可忽略
这个项目的虚拟环境采用pipenv
安装
pip install -i https://pypi.douban.com/simple pipenv
创建环境
cd D:\(所在文件夹)\ExcelCrawl
pipenv install
进入虚拟环境
pipenv shell
二、安装所需要的库、包
cd D:\(所在文件夹)\ExcelCrawl
pip install -i https://pypi.doubanio.com/simple/ -r requirements.txt
三、运行项目
运行里面的main.py文件即可
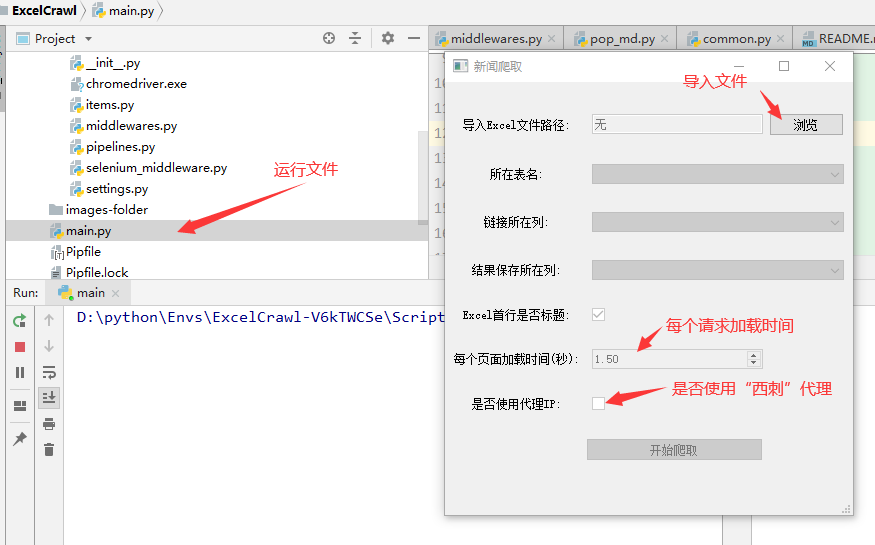
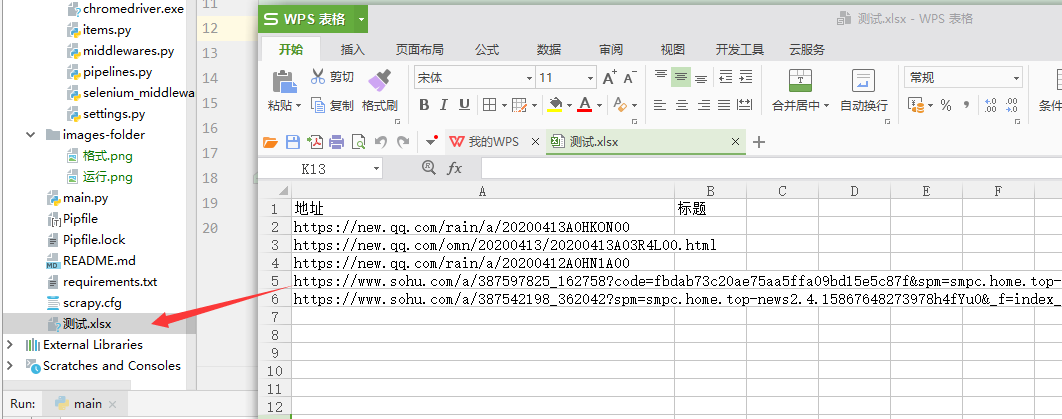
例子:这里我给大家留了一个text.xlsx用来测试
导入文件
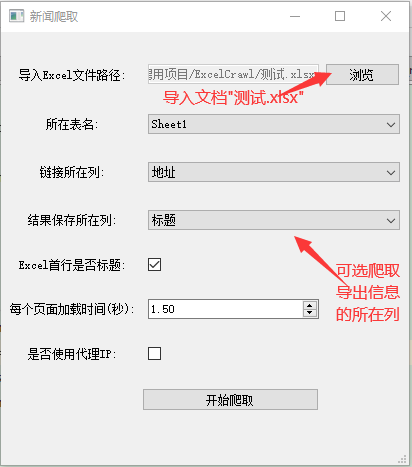
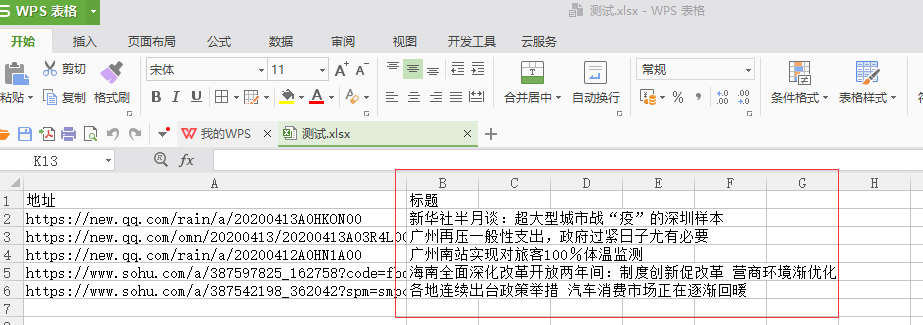
运行,稍等片刻(这里用的是selenium,可加载js渲染的网站适合大多数网站,同时防止访问频繁而被禁IP,看个人需求,静态页面的可不用这种设置)
如果需要修改、添加其他新闻,或想爬更多信息可在以下修改:




