The Reddit Sentiment Analysis Data Pipeline is designed to collect comments from Reddit using the Reddit API, process them using Apache Spark, store the processed data in Cassandra, and visualize sentiment scores of various subreddits in Grafana. The pipeline leverages containerization and utilizes a Kubernetes cluster for deployment, with infrastructure management handled by Terraform. Finally, Kafka is used as a message broker to provide low latency, scalability & availability.
NOTE: This project was (fortunately?) created right before the Reddit API terms and policies changed drastically making it a paid service as of now. So, just a heads up, I haven't tested the pipeline with a paid account yet and it may not work as expected. Feel free to make a PR if you happen to find any required changes.
- Project Overview
- Table of Contents
- Architecture
- Installation and Setup
- Improvements
- Acknowledgements
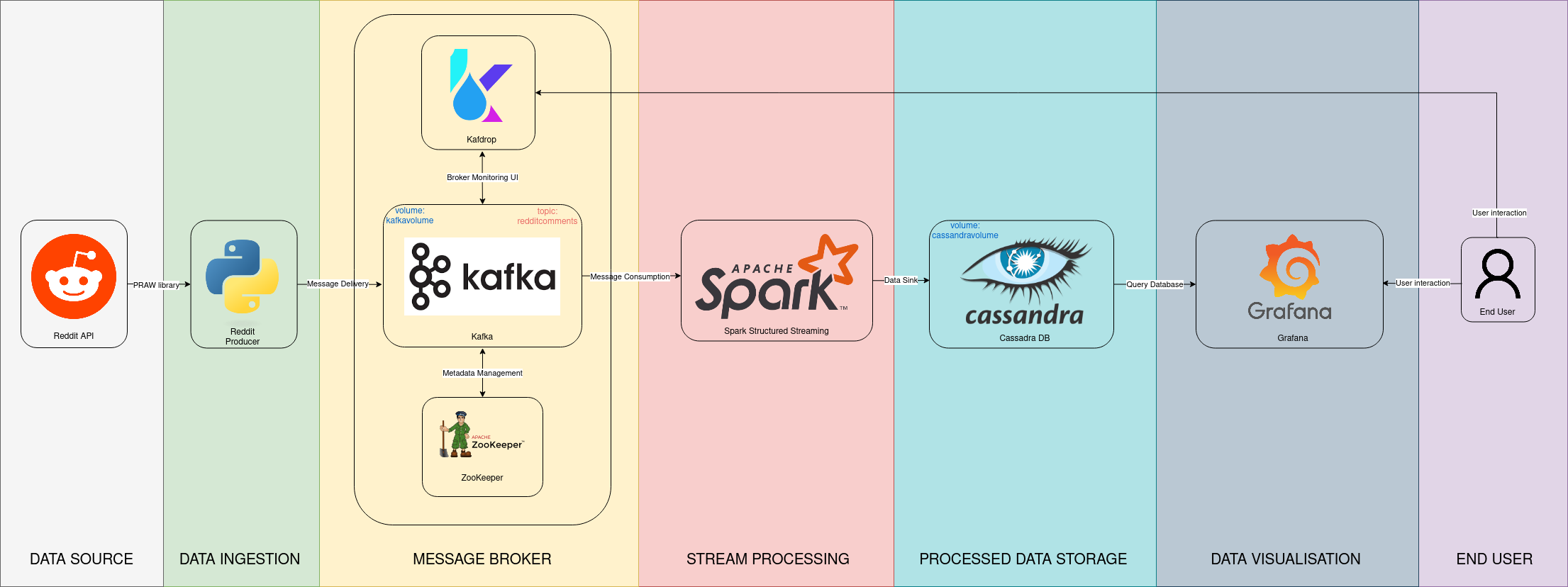
All applications in the above architecture are containerized into Docker containers, which are orchestrated by Kubernetes - and its infrastructure is managed by Terraform. The docker images for each application are available publically in the Docker Hub registry. Further details about each layer is provided below:
-
Data Ingestion : A containerized Python application called reddit_producer connects to Reddit API using credentials provided in the
secrets/credentials.cfgfile. It takes the received messages (reddit comments) and converts them into a JSON format. These transformed messages are then sent and stored in a Kafka broker. PRAW python library is used for interacting with Reddit API. -
Message Broker : The Kafka broker (kafkaservice pod), recieves messages from the reddit_producer. The Kafka broker is accompanied by the Kafdrop applicatino, which acts as Kafka mointoring tool through UI. When Kafka starts, another container named
kafkainitcreates the topicredditcomments. The zookeeper pod is launched before Kafka for managing Kafka metadata. -
Stream Processer : A Spark deployment in the Kubernetes cluster is started for consuming and processing the data from the Kafka topic
redditcomments. The PySpark scriptspark/stream_processor.pyconsumes and aggregates the data to put it in the data sink i.e. Cassandra tables. -
Processed Data Storage : A Cassandra cluster is used to store and serve the processed data from the above spark job. When Cassandra starts, another container named
cassandrainitcreates the keyspaceredditand tablescomments&subreddit_sentiment_avg. Raw comments data is written inreddit.commentstable and the aggregated data is written inreddit.subreddit_sentiment_avgtable. The NLTK python library is used to prepare a sentiment score for each comment and the score is aggregated for each subreddit in the last minute. -
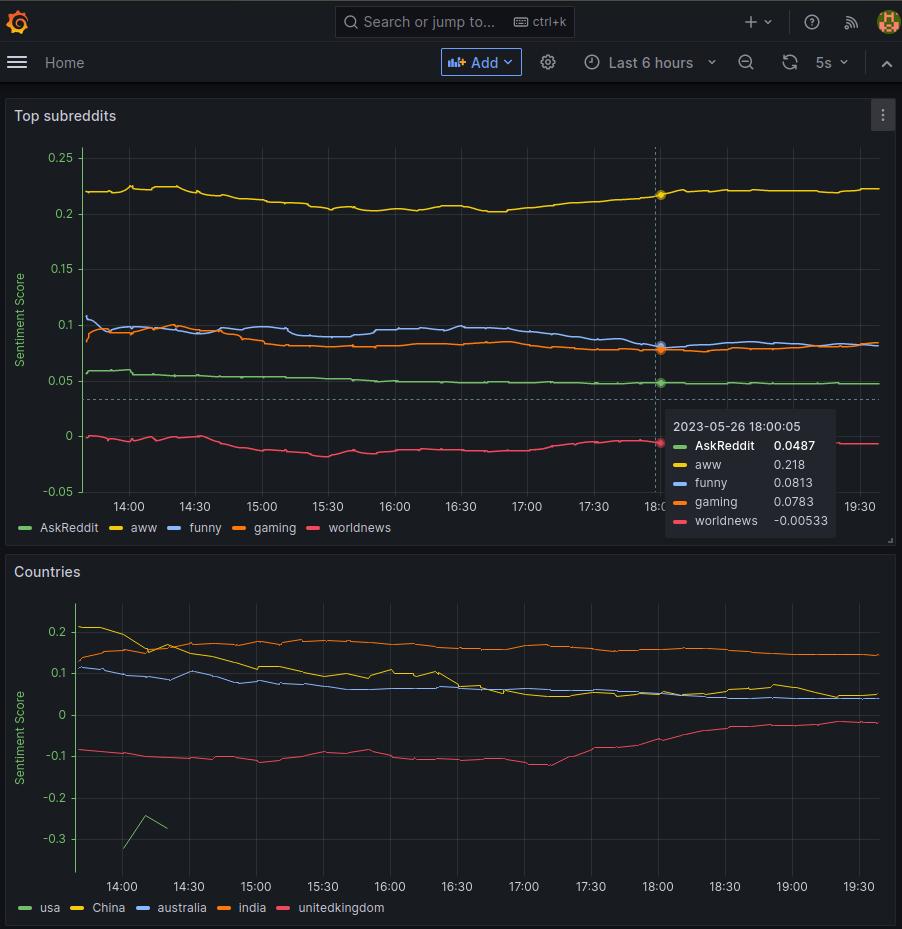
Data Visualisation : Grafana establishes a connection with the Cassandra database. It queries the aggregated data from Cassandra and presents it visually to users through a dashboard. The dashboard shows the following panels for analysis:
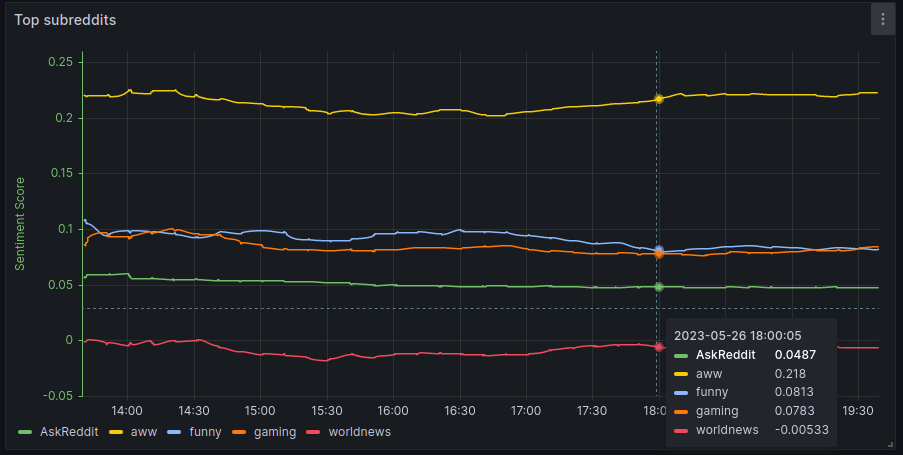
Top subreddits: Showcase the real-time sentiment scores of a few top subreddits of all time.
Countries: Showcase the real-time sentiment scores of subreddits based on a few countries.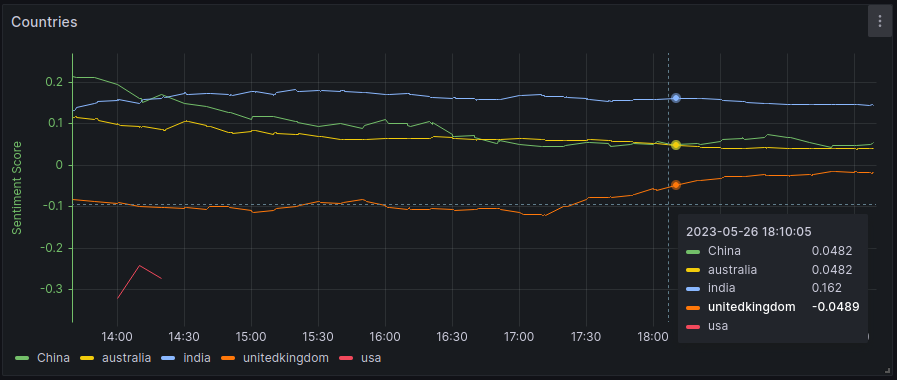
The pipeline was tested with the following local system configuration:
- minikube: v1.30.1
- Docker Engine: 24.0.1
- Terraform: v1.4.6
- OS: Ubuntu 22.04.2 LTS
- RAM: 16 GB
- CPU cores: 16
- Graphics card: AMD Ryzen 7 PRO 4750G with Radeon Graphics
To setup the pipeline locally, first you will have to add a credentials file for accessing reddit API with mkdir secrets && touch secrets/credentials.cfg. Then populate the credentials.cfg file with the following template:
[reddit]
username=<reddit username>
password=<reddit password>
user_agent=<dev_application_name>
client_id=<dev_application_client_id>
client_secret=<dev_application_client_secret>
You may have to create a reddit developer application at https://www.reddit.com/prefs/apps/ to get the above credentials. Once the credential file is ready, start the minikube cluster and apply the terraform configuration as follows:
# Remove the current cluster, start a new one along with the dashboard
$ minikube delete
$ minikube start --no-vtx-check --memory 10240 --cpus 6
$ minikube dashboard
$ cd terraform-k8s
$ terraform apply -auto-approveThe infrastructure setup progress can be monitored in the minikube dashboard or with the following kubectl command:
$ watch -n 1 kubectl get pods -n redditpipelineAfter the complete infrastructure is up and running, run the following command to get the exposed URL for grafana dashboard
$ minikube service grafana -n redditpipeline --url
http://192.168.49.2:30001
The grafana dashboard can be accessed with the above link. In case, there are authorization errors at the start, login into grafana UI with username: admin, password: admin
Similarly the exposed URL for Kafdrop UI can be retrieved and accessed as follows:
$ minikube service kafdrop -n redditpipeline --url
http://192.168.49.2:30000
-
Cassandra and Kafka initialisation: The initialisation containers stay running after the initialisation is finished due to restart policy of other containers within the same pod. A separate deployment for intitialisation containers was considered but due to the lack of option
restart_policy=Neverinkubernetes_deploymentterraform resource (github issue). Furthermore, kubernetes_job resource can be considered for this purpose. -
Optimise Dockerfiles: Certain dockerfiles can be further optimised to build only the final few layers in the case of relevant script modification. This should reduce the running time of the CI script.
-
CI pipeline: Currently, a script
docker_image_publish.shis being used to build and push various docker images to docker hub. However, a better and automated CI pipeline can be implemented based on Github Actions. -
Different Cassandra Users: A separate read-only user in Cassandra should be made for Grafana dashboard queries.
-
Code cleanup and Integration testing: Further code cleanup and refactoring in various scripts is required along with integration testing for various parts in the infrastructure.
- Finnhub Streaming Data Pipeline Project
- Docker Images - Cassandra, Grafana, Apache Spark-Py, Confluentinc Zookeeper, Confluentinc Kafka, Kafdrop
- Libraries - Kafka-Python, NLTK, PRAW














































































