myprototypewhat / take-down Goto Github PK
View Code? Open in Web Editor NEW记一些平时的笔记 有笔记 有源码解析
记一些平时的笔记 有笔记 有源码解析









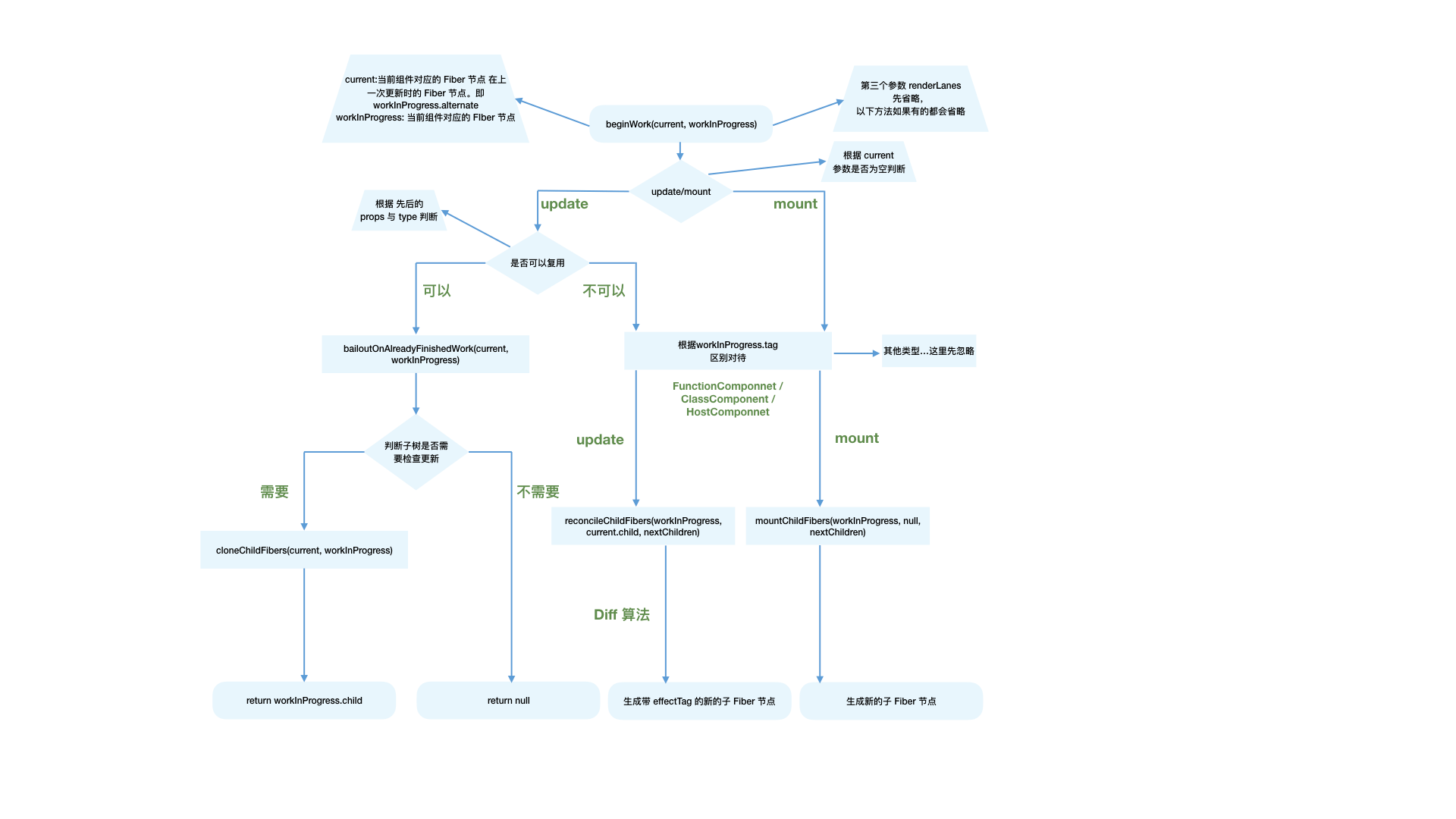
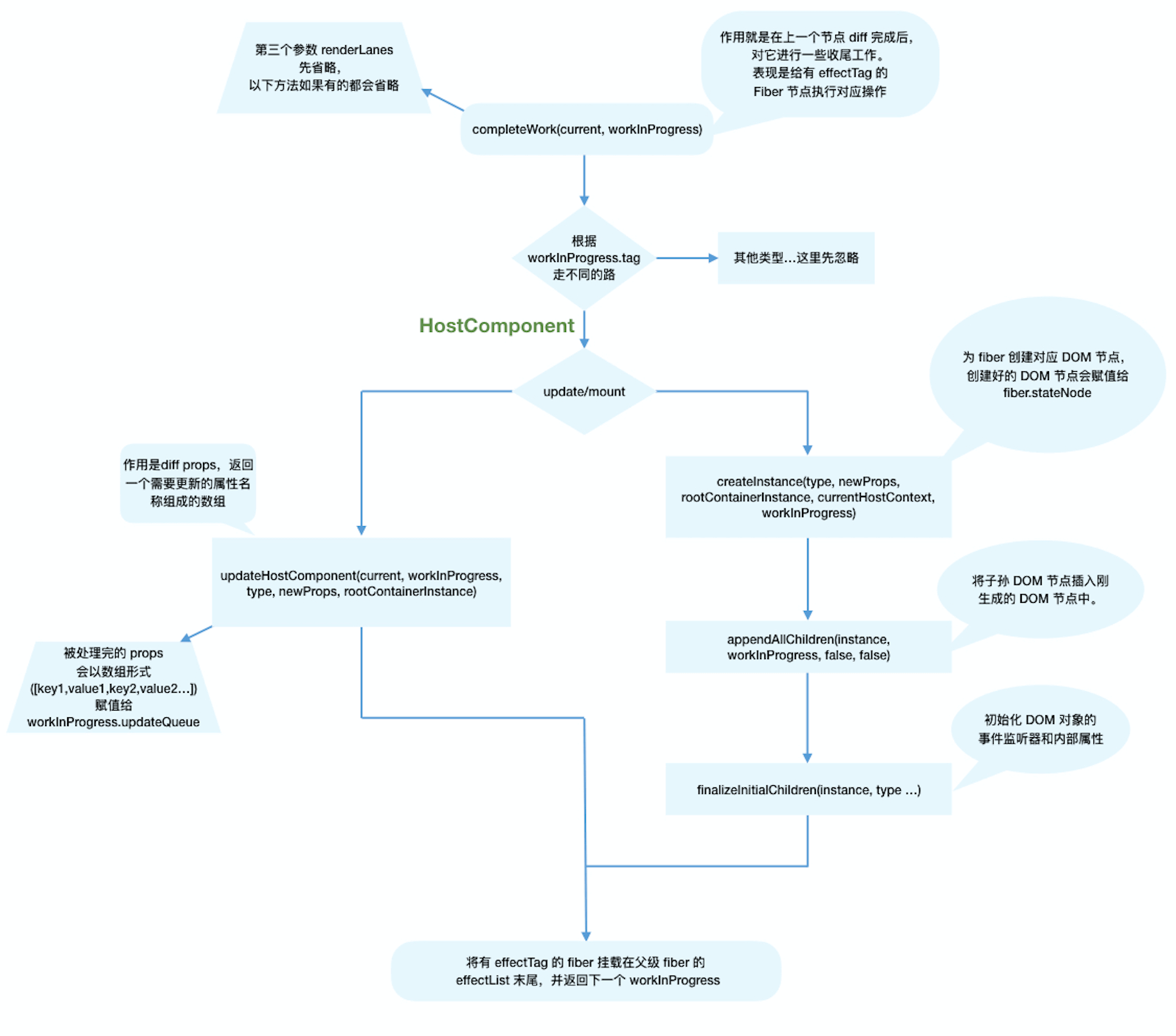
入口
path:packages/reactivity/src/reactive.ts
export const enum ReactiveFlags { // 初始都为undefined SKIP = '__v_skip', //无需响应的对象 IS_REACTIVE = '__v_isReactive', //响应式对象 IS_READONLY = '__v_isReadonly', //只读数据 RAW = '__v_raw' //取原始对象 } const enum TargetType { INVALID = 0, // 无效 COMMON = 1, // Array/Object COLLECTION = 2 // map/set/weakMap/weakSet }
export function reactive(target: object) {
// 如果尝试观察只读代理,请返回只读版本。
if (target && (target as Target)[ReactiveFlags.IS_READONLY]) {
return target
}
return createReactiveObject(
target,
false,
mutableHandlers,
mutableCollectionHandlers,
reactiveMap
)
}createReactiveObject
// 机翻下英文注释就能看明白...
function createReactiveObject(
target: Target,
isReadonly: boolean,// reactive函数调用传参为false
baseHandlers: ProxyHandler<any>,
collectionHandlers: ProxyHandler<any>,
proxyMap: WeakMap<Target, any>
) {
if (!isObject(target)) {
// if (__DEV__) {
// console.warn(`value cannot be made reactive: ${String(target)}`)
// }
return target
}
// 目标已是代理,请返回它。
// 此处调用会触发getter
if (
target[ReactiveFlags.RAW] &&
!(isReadonly && target[ReactiveFlags.IS_REACTIVE])
) {
return target
}
// 目标已具有相应的代理
// 每个 proxy 都会被保存在 proxyMap
const existingProxy = proxyMap.get(target)
if (existingProxy) {
return existingProxy
}
function targetTypeMap(rawType: string) {
switch (rawType) {
case 'Object':
case 'Array':
return TargetType.COMMON
case 'Map':
case 'Set':
case 'WeakMap':
case 'WeakSet':
return TargetType.COLLECTION
default:
return TargetType.INVALID
}
}
function getTargetType(value: Target) {
return value[ReactiveFlags.SKIP] || !Object.isExtensible(value)
? TargetType.INVALID // 0
// toRawType => Object.prototype.toString.call(value).slice(8,-1)
: targetTypeMap(toRawType(value)) // 1|2
}
// 0直接返回target
const targetType = getTargetType(target)
if (targetType === TargetType.INVALID) {
return target
}
// 添加代理
const proxy = new Proxy(
target,
// 1=>baseHandlers 2->collectionHandlers
targetType === TargetType.COLLECTION ? collectionHandlers : baseHandlers
)
// target -> proxy
proxyMap.set(target, proxy)
return proxy
}baseHandlers
packages/reactivity/src/baseHandlers.tsexport const mutableHandlers: ProxyHandler<object> = {
get,
set,
deleteProperty,
has,
ownKeys
}getter
const get = createGetter()
function createGetter(isReadonly = false, shallow = false) {
return function get(target: Target, key: string | symbol, receiver: object) {
if (key === ReactiveFlags.IS_REACTIVE) {
return !isReadonly
} else if (key === ReactiveFlags.IS_READONLY) {
return isReadonly
} else if (
// 如果key==='__v_raw' && receiver===reactiveMap(也就是上文的proxyMap).get(target)
key === ReactiveFlags.RAW &&
receiver ===
(isReadonly
? shallow
? shallowReadonlyMap
: readonlyMap
: shallow
? shallowReactiveMap
: reactiveMap
).get(target)
) {
// 当target[__v_raw]取值时 返回target
return target
}
// isArray = Array.is
const targetIsArray = isArray(target)
// hasOwn = Object.prototype.hasOwnProperty.call
// 判断 target是数组,并且调用了数组的方法
// arrayInstrumentations是 一个对象{[数组方法]:function(){}}
if (!isReadonly && targetIsArray && hasOwn(arrayInstrumentations, key)) {
return Reflect.get(arrayInstrumentations, key, receiver)
}
const res = Reflect.get(target, key, receiver)
// isSymbol = typeof val === 'symbol'
const builtInSymbols = new Set(
Object.getOwnPropertyNames(Symbol)
.map(key => (Symbol as any)[key])
.filter(isSymbol)
)
if (isSymbol(key) ? builtInSymbols.has(key) : isNonTrackableKeys(key)) {
// 如果key是Symbol,则判断key是否是symbol内置属性
// 否则判断key是否在__proto__,__v_isRef,__isVue属性上
return res
}
if (!isReadonly) {
// 不是制只读
track(target, TrackOpTypes.GET, key)
}
if (shallow) {
return res
}
if (isRef(res)) {
// 判断是否被ref修饰过
// ref展开-不适用于数组+整数键。
const shouldUnwrap = !targetIsArray || !isIntegerKey(key)
return shouldUnwrap ? res.value : res
}
if (isObject(res)) {
// 将返回值也转换为代理。
// 我们在这里执行isObject检查以避免无效值警告。
// 这里还需要延迟访问只读和被动,以避免循环依赖。
// 返回proxy,并在上方判断该对象是否被代理,如果被代理直接返回改
return isReadonly ? readonly(res) : reactive(res)
}
return res
}
}arrayInstrumentations:
function createArrayInstrumentations() {
const instrumentations: Record<string, Function> = {}
// instrument identity-sensitive Array methods to account for possible reactive
// values
;(['includes', 'indexOf', 'lastIndexOf'] as const).forEach(key => {
instrumentations[key] = function (this: unknown[], ...args: unknown[]) {
const arr = toRaw(this) as any
for (let i = 0, l = this.length; i < l; i++) {
track(arr, TrackOpTypes.GET, i + '')
}
// 我们首先使用原始参数运行该方法(可能是被动的)
const res = arr[key](...args)
if (res === -1 || res === false) {
// 如果不起作用,请使用原始值再次运行它。
return arr[key](...args.map(toRaw))
} else {
return res
}
}
})
//避免无限调用
;(['push', 'pop', 'shift', 'unshift', 'splice'] as const).forEach(key => {
instrumentations[key] = function (this: unknown[], ...args: unknown[]) {
pauseTracking()
// 触发getter,获取原始值调用对应函数
const res = (toRaw(this) as any)[key].apply(this, args)
resetTracking()
return res
}
})
return instrumentations
}effect:
path:packages/reactivity/src/effect.ts
track:
let activeEffect // ReactiveEffect实例
let trackOpBit = 1
export function track(target: object, type: TrackOpTypes, key: unknown) {
if (!isTracking()) {
// 没有依赖
// 看到此处 ,如果是单纯的get、set 没有使用effect的话,建议跳过下面部分,直接看set
return
}
// targetMap: target -> depsMap
let depsMap = targetMap.get(target)
if (!depsMap) {
targetMap.set(target, (depsMap = new Map()))
}
// depsMap: key -> dep
let dep = depsMap.get(key)
const createDep = (effects?: ReactiveEffect[]): Dep => {
// Set 防止重复
const dep = new Set<ReactiveEffect>(effects) as Dep
// 用来标记该属性上次和本次在哪些effect中使用过,再通过对比进行删除和新增。
dep.w = 0
dep.n = 0
return dep
}
if (!dep) {
depsMap.set(key, (dep = createDep()))
}
const eventInfo = __DEV__
? // debugger用,不需要关注
{ effect: activeEffect, target, type, key }
: undefined
trackEffects(dep, eventInfo)
}
export function isTracking() {
return shouldTrack && activeEffect !== undefined
}
export function trackEffects(
dep: Dep,
debuggerEventExtraInfo?: DebuggerEventExtraInfo
) {
let shouldTrack = false
// effectTrackDepth: 当前递归跟踪的effect数。 用来记录当前effect是第几层,每当有effect执行就++effectTrackDepth,执行完毕就--effectTrackDepth
// maxMarkerBits=30:按位轨迹标记最多支持30级递归。选择此值是为了使现代JS引擎能够在所有平台上使用SMI。当递归深度更大时,返回到使用完全清理。
if (effectTrackDepth <= maxMarkerBits) {
// 判断本次是否标记过
if (!newTracked(dep)) {
// trackOpBit 可以理解为唯一ID
dep.n |= trackOpBit // set newly tracked
// 判断原来是否标记过
shouldTrack = !wasTracked(dep)
}
} else {
// Full cleanup mode.
shouldTrack = !dep.has(activeEffect!)
}
if (shouldTrack) {
dep.add(activeEffect)
activeEffect!.deps.push(dep)
if (__DEV__ && activeEffect!.onTrack) {
activeEffect!.onTrack(
Object.assign(
{
effect: activeEffect!
},
debuggerEventExtraInfo
)
)
}
}
}effect:
export function effect<T = any>(
fn: () => T,
options?: ReactiveEffectOptions
): ReactiveEffectRunner {
if ((fn as ReactiveEffectRunner).effect) {
// 拿到原始fn
fn = (fn as ReactiveEffectRunner).effect.fn
}
const _effect = new ReactiveEffect(fn)
if (options) {
// extend = Object.assign
extend(_effect, options)
if (options.scope) recordEffectScope(_effect, options.scope)
}
if (!options || !options.lazy) {
// 没有lazy参数,立即执行run
_effect.run()
}
const runner = _effect.run.bind(_effect) as ReactiveEffectRunner
runner.effect = _effect
return runner
}ReactiveEffect
const effectStack=[]
class ReactiveEffect {
constructor(fn, scheduler = null, scope) {
this.fn = fn;
this.scheduler = scheduler;
this.active = true;
this.deps = [];
// effectScope 相关处理逻辑
recordEffectScope(this, scope);
}
run() {
if (!this.active) {
// 没有激活,说明我们调用了effect stop 函数,
return this.fn();
}
if (!effectStack.includes(this)) {
try {
effectStack.push((activeEffect = this));
enableTracking();
// 根据递归的深度记录位数
trackOpBit = 1 << ++effectTrackDepth;
if (effectTrackDepth <= maxMarkerBits) {
// 给依赖打标记
initDepMarkers(this);
}
else {
// 超过 maxMarkerBits 则 trackOpBit 的计算会超过最大整形的位数,
// 降级为 cleanupEffect
cleanupEffect(this);
}
return this.fn();
}
finally {
// fn执行完成之后
if (effectTrackDepth <= maxMarkerBits) {
// 完成依赖标记
finalizeDepMarkers(this);
}
// 恢复到上一级
trackOpBit = 1 << --effectTrackDepth;
resetTracking();
// 出栈
effectStack.pop();
const n = effectStack.length;
// 指向栈最后一个 effect
activeEffect = n > 0 ? effectStack[n - 1] : undefined;
}
}
}
stop() {
if (this.active) {
cleanupEffect(this);
if (this.onStop) {
this.onStop();
}
this.active = false;
}
}
}
const initDepMarkers = ({ deps }) => {
if (deps.length) {
for (let i = 0; i < deps.length; i++) {
deps[i].w |= trackOpBit; // 标记依赖已经被收集
}
}
};例子:
get了Vue.createApp({
setup(){
const state=reactive({a:1})
effect(()=>{
console.log(state.a)
})
return {state}
}
}).mount('#app')proxyMap={target:proxy}、 targetMap={target:depsMap}、depsMap={key:dep}、dep={Set[ReactiveEffect实例],n,w}reactive:创建proxy,getter中收集依赖,setter中触发effect,effect:创建ReactiveEffect实例,执行run函数,state.a触发getter,触发track,根据target,key找出对应dep,将ReactiveEffect实例添加进dep,ReactiveEffect实例deps数组推入depReactiveEffect.deps,也就是dep,更w,n属性,effectStack出栈,activeEffect指向effectStack栈顶Setter
function createSetter(shallow = false) {
return function set(
target: object,
key: string | symbol,
value: unknown,
receiver: object
): boolean {
let oldValue = (target as any)[key]
if (!shallow && !isReadonly(value)) {
// 获取新旧真实数据
value = toRaw(value)
oldValue = toRaw(oldValue)
if (!isArray(target) && isRef(oldValue) && !isRef(value)) {
// 处理ref数据
oldValue.value = value
return true
}
} else {
// 在浅层模式下,无论是否是reactive,对象都按原样设置
}
// 判断有效key
const hadKey =
isArray(target) && isIntegerKey(key)
? Number(key) < target.length
: hasOwn(target, key)
const result = Reflect.set(target, key, value, receiver)
// 如果目标是原型链中的某个东西,则不要触发
// receiver是proxy实例对象,原值为Proxy {...target}
// 此时Reflect.set执行过后,receiver变为Proxy {key:value}
// proxyMap中相应的target也更改为{key:value}
// toRaw获取__v_raw,会触发getter,返回proxyMap.get(target)
if (target === toRaw(receiver)) {
if (!hadKey) {
trigger(target, TriggerOpTypes.ADD, key, value)
} else if (hasChanged(value, oldValue)) {
// 对比新旧值是否改变
// hasChanged = !Object.is
trigger(target, TriggerOpTypes.SET, key, value, oldValue)
}
}
return result
}
}trigger:
export function trigger(
target: object,
type: TriggerOpTypes,
key?: unknown,
newValue?: unknown,
oldValue?: unknown,
oldTarget?: Map<unknown, unknown> | Set<unknown>
) {
const depsMap = targetMap.get(target)
if (!depsMap) {
// 没有被收集
return
}
let deps: (Dep | undefined)[] = []
if (type === TriggerOpTypes.CLEAR) {
// 正在清除集合
// 触发target中所有effect
deps = [...depsMap.values()]
} else if (key === 'length' && isArray(target)) {
// 对修改数组length的处理
depsMap.forEach((dep, key) => {
if (key === 'length' || key >= (newValue as number)) {
deps.push(dep)
}
})
} else {
if (key !== void 0) {
deps.push(depsMap.get(key))
}
// 在ADD | DELETE | Map.SET 时也运行迭代键
switch (type) {
case TriggerOpTypes.ADD:
if (!isArray(target)) {
deps.push(depsMap.get(ITERATE_KEY))
if (isMap(target)) {
deps.push(depsMap.get(MAP_KEY_ITERATE_KEY))
}
} else if (isIntegerKey(key)) {
// new index added to array -> length changes
deps.push(depsMap.get('length'))
}
break
case TriggerOpTypes.DELETE:
if (!isArray(target)) {
deps.push(depsMap.get(ITERATE_KEY))
if (isMap(target)) {
deps.push(depsMap.get(MAP_KEY_ITERATE_KEY))
}
}
break
case TriggerOpTypes.SET:
if (isMap(target)) {
deps.push(depsMap.get(ITERATE_KEY))
}
break
}
}
const eventInfo = __DEV__
? { target, type, key, newValue, oldValue, oldTarget }
: undefined
if (deps.length === 1) {
if (deps[0]) {
if (__DEV__) {
triggerEffects(deps[0], eventInfo)
} else {
triggerEffects(deps[0])
}
}
} else {
const effects: ReactiveEffect[] = []
for (const dep of deps) {
if (dep) {
effects.push(...dep)
}
}
if (__DEV__) {
triggerEffects(createDep(effects), eventInfo)
} else {
triggerEffects(createDep(effects))
}
}
}triggerEffects:
export function triggerEffects(
dep: Dep | ReactiveEffect[],
debuggerEventExtraInfo?: DebuggerEventExtraInfo
) {
// spread into array for stabilization
for (const effect of isArray(dep) ? dep : [...dep]) {
// effect = ReactiveEffect{}
// 遍历依赖执行
if (effect !== activeEffect || effect.allowRecurse) {
if (__DEV__ && effect.onTrigger) {
effect.onTrigger(extend({ effect }, debuggerEventExtraInfo))
}
if (effect.scheduler) {
effect.scheduler()
} else {
effect.run()
}
}
}
}[TOC]
src/immer.ts
// src/immer.ts#L23
const immer = new Immer()
// src/immer.ts#L44
export const produce: IProduce = immer.produce// produce(baseState, recipe: (draftState) => void): nextState
import produce from "immer"
const baseState = [
{
title: "Learn TypeScript",
done: true
},
{
title: "Try Immer",
done: false
}
]
const nextState = produce(baseState, draftState => {
draftState.push({title: "Tweet about it"})
draftState[1].done = true
})produce中对象的更改不会导致原值更改
expect(baseState.length).toBe(2)
expect(nextState.length).toBe(3)
// same for the changed 'done' prop
expect(baseState[1].done).toBe(false)
expect(nextState[1].done).toBe(true)
// unchanged data is structurally shared
expect(nextState[0]).toBe(baseState[0])
// ...but changed data isn't.
expect(nextState[1]).not.toBe(baseState[1])接下来看源码,看着不长,但是引用的函数较多
export class Immer implements ProducersFns {
......
/**
* @param {any} base - the initial state
* @param {Function} producer - function that receives a proxy of the base state as first argument and which can be freely modified
* @param {Function} patchListener - optional function that will be called with all the patches produced here
* @returns {any} a new state, or the initial state if nothing was modified
*/
produce: IProduce = (base: any, recipe?: any, patchListener?: any) => {
// curried invocation
// base 和 recipe参数 互换
// 上述例子走不到这个判断
if (typeof base === "function" && typeof recipe !== "function") {
const defaultBase = recipe
recipe = base
const self = this
return function curriedProduce(
this: any,
base = defaultBase,
...args: any[]
) {
return self.produce(base, (draft: Drafted) => recipe.call(this, draft, ...args)) // prettier-ignore
}
}
// 错误信息 6: "The first or second argument to `produce` must be a function"
if (typeof recipe !== "function") die(6)
// 错误信息 7: "The third argument to `produce` must be a function or undefined"
if (patchListener !== undefined && typeof patchListener !== "function")
die(7)
let result
// 判断对象是否是是Draftable
if (isDraftable(base)) {
// 生成作用域,一个对象对应一个作用域
// this是Immer类的实例
const scope = enterScope(this)
// 添加proxy代理,这个是重点之一
const proxy = createProxy(this, base, undefined)
let hasError = true
try {
// 执行回调
result = recipe(proxy)
hasError = false
} finally {
// finally 而不是 catch + rethrow 更好地保留原始堆栈
// revokeScope:终止当前scope的所有proxy,将currentScope变量赋值为scope.parent_
if (hasError) revokeScope(scope)
else leaveScope(scope)
}
if (typeof Promise !== "undefined" && result instanceof Promise) {
return result.then(
result => {
usePatchesInScope(scope, patchListener)
return processResult(result, scope)
},
error => {
// 同上
revokeScope(scope)
throw error
}
)
}
usePatchesInScope(scope, patchListener)
return processResult(result, scope)
} else if (!base || typeof base !== "object") {
result = recipe(base)
if (result === undefined) result = base
if (result === NOTHING) result = undefined
if (this.autoFreeze_) freeze(result, true)
if (patchListener) {
const p: Patch[] = []
const ip: Patch[] = []
getPlugin("Patches").generateReplacementPatches_(base, result, p, ip)
patchListener(p, ip)
}
return result
} else die(21, base)
}对类型的判断,没啥注释,一看就懂
export function isDraftable(value: any): boolean {
if (!value) return false
return (
isPlainObject(value) ||
Array.isArray(value) ||
!!value[DRAFTABLE] ||
!!value.constructor[DRAFTABLE] ||
isMap(value) ||
isSet(value)
)
}isPlainObject:
const objectCtorString = Object.prototype.constructor.toString()
export function isPlainObject(value: any): boolean {
if (!value || typeof value !== "object") return false
const proto = Object.getPrototypeOf(value)
if (proto === null) {
return true
}
const Ctor =
Object.hasOwnProperty.call(proto, "constructor") && proto.constructor
if (Ctor === Object) return true
return (
typeof Ctor == "function" &&
// 字符串的比较主要是为了解决不同js环境,例如iframe
Function.toString.call(Ctor) === objectCtorString
)
}DRAFTABLE:
export const DRAFTABLE: unique symbol = hasSymbol
? Symbol.for("immer-draftable")
: ("__$immer_draftable" as any)isMap\isSet:
// hasMap\hasSet 是否有map set的构造函数
export function isMap(target: any): target is AnyMap {
return hasMap && target instanceof Map
}
export function isSet(target: any): target is AnySet {
return hasSet && target instanceof Set
}let currentScope: ImmerScope | undefined
export function enterScope(immer: Immer) {
return (currentScope = createScope(currentScope, immer))
}
function createScope(
parent_: ImmerScope | undefined,
immer_: Immer
): ImmerScope {
return {
// 保存着每次通过createProxy生成的proxy对象
// 例1
drafts_: [],
parent_,
immer_,
// 每当修改后的draft包含来自另一个范围的draft时,我们需要防止自动冻结,以便最终确定无主draft。
canAutoFreeze_: true,
unfinalizedDrafts_: 0
}
}例1
const obj = {a: {c: 1}, b: 1}
const produce = immer.produce
const p2 = produce(a, draft => {
draft.a.c = 3
})
// 此时
// scope.drafts_=>[Proxy,Proxy]
// 数组第一项proxy是代理变量obj创建的,第二项是代理obj.a创建的重点之一,为数据添加proxy
src/core/proxy.ts#L50
// src/types/types-internal.ts#L20
export const enum Archtype {
Object,
Array,
Map,
Set
}
// src/types/types-internal.ts#L27
export const enum ProxyType {
ProxyObject,
ProxyArray,
Map,
Set,
ES5Object,
ES5Array
}
// src/utils/common.ts#L160
export function latest(state: ImmerState): any {
// 优先返回copy_,因为copy_保存的是base更改之后的拷贝
return state.copy_ || state.base_
}
// src/utils/common.ts#L118
export function has(thing: any, prop: PropertyKey): boolean {
return getArchtype(thing) === Archtype.Map
// 区分map
// 判断是否有这个属性
? thing.has(prop)
: Object.prototype.hasOwnProperty.call(thing, prop)
}
// src/utils/common.ts#L101
export function getArchtype(thing: any): Archtype {
/* istanbul ignore next */
// 如果只是一个plainObject,则state为undefined
const state: undefined | ImmerState = thing[DRAFT_STATE]
return state
? state.type_ > 3
? state.type_ - 4 // cause Object and Array map back from 4 and 5
: (state.type_ as any) // others are the same
: Array.isArray(thing)
? Archtype.Array
: isMap(thing)
? Archtype.Map
: isSet(thing)
? Archtype.Set
// 例如 如果原数据是对象,最终判断会落在这
: Archtype.Object
}export function createProxy<T extends Objectish>(
immer: Immer,
value: T,
parent?: ImmerState
): Drafted<T, ImmerState> {
// 前提条件:createProxy应该由isDraftable保护,所以我们知道我们可以安全地起草
// 判断对象的类型,使用不同的方法
const draft: Drafted = isMap(value)
? getPlugin("MapSet").proxyMap_(value, parent)
: isSet(value)
? getPlugin("MapSet").proxySet_(value, parent)
// 是否支持proxy
: immer.useProxies_
? createProxyProxy(value, parent)
: getPlugin("ES5").createES5Proxy_(value, parent)
const scope = parent ? parent.scope_ : getCurrentScope()
scope.drafts_.push(draft)
return draft
}
export function getCurrentScope() {
// 错误信息 0: "Illegal state"
if (__DEV__ && !currentScope) die(0)
return currentScope!
}createProxyProxy(value, parent)
export function createProxyProxy<T extends Objectish>(
base: T,
parent?: ImmerState
): Drafted<T, ProxyState> {
const isArray = Array.isArray(base)
const state: ProxyState = {
// 类型判断
type_: isArray ? ProxyType.ProxyArray : (ProxyType.ProxyObject as any),
// 跟踪与哪个produce调用相关联。
scope_: parent ? parent.scope_ : getCurrentScope()!,
// 对浅层和深层变化都适用。
modified_: false,
// 在最终确定期间使用。
finalized_: false,
// 跟踪已赋值 (true) 或删除 (false) 的属性。
assigned_: {},
// The parent draft state.
parent_: parent,
// The base state.
base_: base,
// proxy代理对象
draft_: null as any, // set below
// base更改值之后的副本
copy_: null,
// 用来撤销proxy
revoke_: null as any,
isManual_: false
}
// 并不是以原数据作为proxy的target,而是使用state
let target: T = state as any
let traps: ProxyHandler<object | Array<any>> = objectTraps
if (isArray) {
target = [state] as any
traps = arrayTraps
}
// Proxy.revocable()方法可以用来创建一个可撤销的代理对象。
const {revoke, proxy} = Proxy.revocable(target, traps)
state.draft_ = proxy as any
state.revoke_ = revoke
return proxy as any
}
// src/core/proxy.ts#L241
function readPropFromProto(state: ImmerState, source: any, prop: PropertyKey) {
// 获取对应属性描述符
const desc = getDescriptorFromProto(source, prop)
// 返回对应值
return desc
? `value` in desc
? desc.value
: // This is a very special case, if the prop is a getter defined by the
// prototype, we should invoke it with the draft as context!
desc.get?.call(state.draft_)
: undefined
}
// src/core/proxy.ts#L252
// 遍历原型链,获取对应属性描述符
function getDescriptorFromProto(
source: any,
prop: PropertyKey
): PropertyDescriptor | undefined {
// 'in' checks proto!
if (!(prop in source)) return undefined
let proto = Object.getPrototypeOf(source)
while (proto) {
const desc = Object.getOwnPropertyDescriptor(proto, prop)
if (desc) return desc
proto = Object.getPrototypeOf(proto)
}
return undefined
}Object:objectTraps
export const objectTraps: ProxyHandler<ProxyState> = {
get(state, prop) {
if (prop === DRAFT_STATE) return state
// 拿到原数据
const source = latest(state)
if (!has(source, prop)) {
// 判断是否有该属性
// 如果没有就往原型链上查
return readPropFromProto(state, source, prop)
}
// 获取值
const value = source[prop]
if (state.finalized_ || !isDraftable(value)) {
// state.finalized_后面讲
// 如果value不是一个可以被draft的对象,直接返回值
return value
}
// 比较value和base的引用
if (value === peek(state.base_, prop)) {
// state.copy_浅拷贝state,base_
prepareCopy(state)
// 为copy_中对应的props添加proxy
return (state.copy_![prop as any] = createProxy(
state.scope_.immer_,
value,
state
))
}
return value
},
// 直接看代码吧,使用最新数据进行判断
// ------------
has(state, prop) {
return prop in latest(state)
},
ownKeys(state) {
return Reflect.ownKeys(latest(state))
},
// ------------
set(
state: ProxyObjectState,
prop: string /* 严格来说不是,但有助于TS */,
value
) {
const desc = getDescriptorFromProto(latest(state), prop)
if (desc?.set) {
// 特殊情况:如果这个写入被 setter 捕获,我们必须用正确的上下文触发它
desc.set.call(state.draft_, value)
return true
}
if (!state.modified_) {
// 当前state是否经过修改
const current = peek(latest(state), prop)
// 获取state
const currentState: ProxyObjectState = current?.[DRAFT_STATE]
// 特殊情况,如果将原值赋值给draft,可以直接忽略这个赋值
// 例1
if (currentState && currentState.base_ === value) {
state.copy_![prop] = value
state.assigned_[prop] = false
return true
}
// Object.is
// 值相等 && (value不为undefined 或者 base上有该属性)
// 需要判断原数据没有prop 和 prop值为undefined的区别
// 如果原数据上没有prop,current值也会是undefined
if (is(value, current) && (value !== undefined || has(state.base_, prop)))
// 无需更改,可以忽略
return true
// 拷贝
prepareCopy(state)
// 修改当前state.modified_ 以及 parent.modified_ 为 true
markChanged(state)
}
if (
// 排除设置值为自身引用的情况
// Fixes immerjs/immer#648 https://github.com/immerjs/immer/issues/648
state.copy_![prop] === value &&
// 排除0===-0
typeof value !== "number" &&
// 特殊情况 处理新的prop值为undefined情况
(value !== undefined || prop in state.copy_)
)
return true
// @ts-ignore
state.copy_![prop] = value
state.assigned_[prop] = true
return true
},
// delete 操作符的捕捉器
deleteProperty(state, prop: string) {
// The `undefined` check is a fast path for pre-existing keys.
if (peek(state.base_, prop) !== undefined || prop in state.base_) {
state.assigned_[prop] = false
prepareCopy(state)
markChanged(state)
} else {
// if an originally not assigned property was deleted
delete state.assigned_[prop]
}
// @ts-ignore
if (state.copy_) delete state.copy_[prop]
return true
},
// Note: We never coerce `desc.value` into an Immer draft, because we can't make
// the same guarantee in ES5 mode.
// 可拦截 Object.getOwnPropertyDescriptor()、Reflect.getOwnPropertyDescriptor()
getOwnPropertyDescriptor(state, prop) {
const owner = latest(state)
const desc = Reflect.getOwnPropertyDescriptor(owner, prop)
if (!desc) return desc
return {
writable: true,
configurable: state.type_ !== ProxyType.ProxyArray || prop !== "length",
enumerable: desc.enumerable,
value: owner[prop]
}
},
defineProperty() {
die(11)
},
getPrototypeOf(state) {
return Object.getPrototypeOf(state.base_)
},
setPrototypeOf() {
die(12)
}
}例1
const a = {a: {c: 1}, b: 2}
const p1 = produce(a, draft => {
draft.a = a.a
})Array:
src/core/finalize.ts#L20
重点,将更改之后的结果输出
export function processResult(result: any, scope: ImmerScope) {
scope.unfinalizedDrafts_ = scope.drafts_.length
// 基于base生成的proxy,会在scope.drafts_第一项
const baseDraft = scope.drafts_![0]
const isReplaced = result !== undefined && result !== baseDraft
if (!scope.immer_.useProxies_)
getPlugin("ES5").willFinalizeES5_(scope, result, isReplaced)
if (isReplaced) {
if (baseDraft[DRAFT_STATE].modified_) {
revokeScope(scope)
die(4)
}
if (isDraftable(result)) {
// Finalize the result in case it contains (or is) a subset of the draft.
result = finalize(scope, result)
if (!scope.parent_) maybeFreeze(scope, result)
}
if (scope.patches_) {
getPlugin("Patches").generateReplacementPatches_(
baseDraft[DRAFT_STATE].base_,
result,
scope.patches_,
scope.inversePatches_!
)
}
} else {
// 计算最终值
result = finalize(scope, baseDraft, [])
}
revokeScope(scope)
if (scope.patches_) {
scope.patchListener_!(scope.patches_, scope.inversePatches_!)
}
return result !== NOTHING ? result : undefined
}src/core/finalize.ts#L57
function finalize(rootScope: ImmerScope, value: any, path?: PatchPath) {
// 不要在递归数据结构中递归
// 判断value是否冻结,兼容ie (Fixes #600)
if (isFrozen(value)) return value
const state: ImmerState = value[DRAFT_STATE]
// 一个普通的对象,可能需要冻结,可能包含draft
if (!state) {
// 遍历,根据格式判断分为两种:
// Object.keys().forEach \ .forEach
each(
value,
(key, childValue) =>
finalizeProperty(rootScope, state, value, key, childValue, path),
true // See #590, 不要递归到不可枚举的非draft对象
)
return value
}
// 永远不要最终确定另一个范围拥有的drafts
if (state.scope_ !== rootScope) return value
// 未修改的,返回(冻结的)原值
if (!state.modified_) {
maybeFreeze(rootScope, state.base_, true)
return state.base_
}
// 还没有最终确定,现在就开始吧
if (!state.finalized_) {
state.finalized_ = true
state.scope_.unfinalizedDrafts_--
const result =
// For ES5, create a good copy from the draft first, with added keys and without deleted keys.
state.type_ === ProxyType.ES5Object || state.type_ === ProxyType.ES5Array
? (state.copy_ = shallowCopy(state.draft_))
: state.copy_
// Finalize all children of the copy
// For sets we clone before iterating, otherwise we can get in endless loop due to modifying during iteration, see #628
// Although the original test case doesn't seem valid anyway, so if this in the way we can turn the next line
// back to each(result, ....)
each(
state.type_ === ProxyType.Set ? new Set(result) : result,
(key, childValue) =>
finalizeProperty(rootScope, state, result, key, childValue, path)
)
// everything inside is frozen, we can freeze here
maybeFreeze(rootScope, result, false)
// first time finalizing, let's create those patches
if (path && rootScope.patches_) {
getPlugin("Patches").generatePatches_(
state,
path,
rootScope.patches_,
rootScope.inversePatches_!
)
}
}
return state.copy_
}尽量用最白的话讲明白~
目录:
export default function createStore(reducer, preloadedState, enhancer)
暴露createStore函数,返回:
return {
dispatch,
subscribe,
getState,
replaceReducer,
[$$observable]: observable
}createStore大致有三种使用:
createStore(reducer)
createStore(reducer,applyMiddleware(...middleware))
createStore(reducer,initialState,applyMiddleware(...middleware))接下来就逐个分析一下~
if (
(typeof preloadedState === 'function' && typeof enhancer === 'function') ||
(typeof enhancer === 'function' && typeof arguments[3] === 'function')
) {...}
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState
preloadedState = undefined
}
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {...}
// 这里的 enhancer 是 applyMiddleware(...) 执行后的高阶函数
return enhancer(createStore)(reducer, preloadedState)
}
if (typeof reducer !== 'function') {...}
let currentReducer = reducer //当前的reducer
let currentState = preloadedState// 拿到当前 State
let currentListeners = [] // 初始化 listeners 用于放置监听函数,用于保存快照供当前 dispatch 使用
let nextListeners = currentListeners //引用传值 指向当前 listeners,在需要修改时复制出来修改为下次快照存储数据,不影响当前订阅
let isDispatching = false// 用于标记是否正在进行 dispatch,用于控制 dispatch 依次调用不冲突
/**
* 这是currentListeners的浅拷贝,所以我们可以使用nextListeners作为调度时的临时列表。
* 这样可以防止消费者在dispatch过程中 订阅/取消订阅 调用时出现任何错误
*/
//在一段时间内始终没有新的订阅或取消订阅的情况下,nextListeners 与 currentListeners 可以共用内存
// 确保可以改变 nextListeners。没有新的listener 可以始终用同一个引用
function ensureCanMutateNextListeners() {
// 需要写入新的监听之前调用,如果是指向同一个地址的话,就把nextListeners复制出来
if (nextListeners === currentListeners) {
nextListeners = currentListeners.slice()
}
}类型判断,除了排除特定的type之外,还有另外一个目的就是,满足参数灵活。
获取当前的state,没什么好说的
function getState() {
if (isDispatching) {
throw new Error(
'You may not call store.getState() while the reducer is executing. ' +
'The reducer has already received the state as an argument. ' +
'Pass it down from the top reducer instead of reading it from the store.'
/**
* 在Reducer执行时不能调用store.getState()
* reducer已收到state作为参数。
* 从顶端reducer往下递送,而不是从店里读出。
*/
)
}
return currentState
}向监听列表中添加监听函数,返回值为取消监听函数
如果在调用dispatch时订阅或取消订阅,则不会对当前正在进行的dispatch产生任何影响。但是,下一个dispatch调用(无论是否嵌套)将使用订阅列表的最新快照。
function subscribe(listener) {
if (typeof listener !== 'function') {...}
if (isDispatching) {...}
let isSubscribed = true
ensureCanMutateNextListeners()
nextListeners.push(listener)
return function unsubscribe() {
if (!isSubscribed) { //防止多次触发
return
}
if (isDispatching) {
throw new Error(
//在Reducer正在执行时,您不能取消对存储侦听器的订阅
'You may not unsubscribe from a store listener while the reducer is executing. ' +
'See https://redux.js.org/api-reference/store#subscribe(listener) for more details.'
)
}
isSubscribed = false
ensureCanMutateNextListeners()
const index = nextListeners.indexOf(listener)
nextListeners.splice(index, 1) //去除队列中相对应的listener
currentListeners = null
}
}listener是否是function,否则报错dispatch状态,true则报错,在reducer中不能调用。ensureCanMutateNextListeners(),判断当前监听队列是否和临时监听队列是否相同引用,如果相同则通过slice复制出来一份,赋值给nextListeners,此举为了不混淆当前的监听队列。unsubscribe依旧触发ensureCanMutateNextListeners,然后找到对应的listener(在subscribe函数时形成闭包)在数组中的index,删除。currentListeners = null(较老的版本没有这句) 这句没太搞懂为什么这么写,有大佬明白的麻烦给说下,谢了~执行reducer之后获取最新的state,并且依次执行监听队列函数
function dispatch(action) {
if (!isPlainObject(action)) {...}
if (typeof action.type === 'undefined') {...}
if (isDispatching) {...}
try {
isDispatching = true
currentState = currentReducer(currentState, action) //currentReducer 传入的reducer
} finally {
isDispatching = false
}
/**
* 更新最新的监听对象,相当于:
currentListeners = nextListeners
const listeners = currentListeners
如果再次触发订阅,则会执行ensureCanMutateNextListeners(),然后再次把nextListeners复制出来,添加监听
*/
const listeners = (currentListeners = nextListeners) //在生成了currentState之后遍历当前的监听列表,逐个执行
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
return action //返回当前action
}扁平对象type是否为undefined,是则报错dispatch,是则报错true,通过reducer处理之后或者 最新的state监听:
将nextListeners直接赋值给currentListeners,统一当前的监听列表,然后遍历执行监听函数
替换reducer
function replaceReducer(nextReducer) { //替换reducer的同时会dipatch`@@redux/REPLACE${randomString()}`
if (typeof nextReducer !== 'function') {
throw new Error('Expected the nextReducer to be a function.')
}
currentReducer = nextReducer
/**
* 此操作与ActionTypes.INIT具有相似的效果。
* 新旧rootReducer中存在的任何Reducer都将收到以前的状态。这将使用旧状态树中的任何相关数据有效地填充新状态树。
*/
dispatch({ type: ActionTypes.REPLACE }) //初始化state
}将reducer替换之后,dispatch一下,更新state。一般不会用到
目前没见过有用这个的...
function observable() {
const outerSubscribe = subscribe //创建一个外部的订阅函数
return {
/**
* 最小观察者订阅方法。
* @param {object} 可用作观察者的任何对象。
* 观察者对象应该有一个`next`方法
* @returns {Subscription} 具有`unsubscribe`方法的对象,
* 该方法可用于从存储中取消订阅可观察对象,并防止观察对象进一步发送值。
*
*/
subscribe(observer) {
if (typeof observer !== 'object' || observer === null) {
throw new TypeError('Expected the observer to be an object.')
}
function observeState() { //如果传入的observer对象有next函数,就执行next()并将当前state放入函数中
if (observer.next) {
observer.next(getState())
}
}
observeState()
const unsubscribe = outerSubscribe(observeState) //给当前监听的数组加上observeState函数
return { unsubscribe }
},
/**
* Redux 内部没有用到这个方法,在测试代码 redux/test/createStore.spec.js 中有出现。
* https://github.com/benlesh/symbol-observable
*/
[$$observable]() {
return this
}
}
}这部分用到了一个包symbol-observable感兴趣的可以去看下
最后dispatch({ type: ActionTypes.INIT })
创建存储时,将dispatch 'INIT',以便每个reducer返回其初始状态。这有效地填充了初始state tree。
1. 讲解一下HTTPS的工作原理
HTTPS在传输数据之前需要客户端(浏览器)与服务端(网站)之间进行一次握手,在握手过程中将确立双方加密传输数据的密码信息。TLS/SSL协议不仅仅是一套加密传输的协议,更是一件经过艺术家精心设计的艺术品,TLS/SSL中使用了非对称加密,对称加密以及HASH算法。握手过程的简单描述如下:
浏览器将自己支持的一套加密规则发送给网站。
网站从中选出一组加密算法与HASH算法,并将自己的身份信息以证书的形式发回给浏览器。证书里面包含了网站地址,加密公钥,以及证书的颁发机构等信息。
获得网站证书之后浏览器要做以下工作:
4.网站接收浏览器发来的数据之后要做以下的操作:
5.浏览器解密并计算握手消息的HASH,如果与服务端发来的HASH一致,此时握手过程结束,之后所有的通信数据将由之前浏览器生成的随机密码并利用对称加密算法进行加密。
2. 如何遍历一个dom树
function traversal(node) {
//对node的处理
if (node && node.nodeType === 1) {
console.log(node.tagName);
}
var i = 0,
childNodes = node.childNodes,
item;
for (; i < childNodes.length; i++) {
item = childNodes[i];
if (item.nodeType === 1) {
//递归先序遍历子节点
traversal(item);
}
}
}3. new操作符都做了什么
1、 创建一个空对象,并且 this 变量引用该对象,// lat target = {};
2、继承了函数的原型。// target.proto = func.prototype;
3、属性和方法被加入到 this 引用的对象中。并执行了该函数func// func.call(target);
4、新创建的对象由 this 所引用,并且最后隐式的返回 this 。// 如果func.call(target)返回的res是个对象或者function 就返回它
function new(func) {
let target = {};
target.__proto__ = func.prototype;
let res = func.call(target);
if (res && typeof(res) == "object" || typeof(res) == "function") {
return res;
}
return target;
}4. 前端如何进行seo优化
5. 前后端分离的项目如何seo
补充:
@xianshannan :
引用下知乎上别人的回答
那么我们首先得了解Search Engine才能谈如何做到让页面被收录,这里就拿最常见的百度和google来举例吧。
百度是不支持收录SPA的页面的,而且SPA的网站对于百度的spider来说等于是只有1个页面,那么如何做到让这种搜索引擎收录页面呢?
首先我们可以自行提交sitemap,让蜘蛛主动去爬,但是遇到sitemap中的URL,到达指定页面后页面只有一段js怎么办,我们可以利用比如标签来进行最简单的优化,比如在noscript里打印出当前页面一些关键的信息点,但是这个做法大家一看就非常的蠢,因为正常用户并不需要这些内容,占用下载量,而且不好维护。
那么我们如何判断当前页面是否支持运行javascript呢?
前端已做到,用noscript,后端不行,那么只好针对百度的spider做UA判断了,这也就是大家常见的一些解决方案,使用phantomjs或者nginx代理,来对spider访问的页面进行特殊的处理,达到被收录的效果。那么这么做其实是有一些副作用的,比如你收录的页面和用户正常访问的页面差别较大是有被搜索引擎K掉的风险的,
所以更多的做法还是选择首屏使用ssr的方式渲染,先通过后端路由保证页面的主要信息可以被服务器端输出,然后其他的功能,包括用户之后的路由跳转控制,再使用前端路由来做,曾经的项目经验在新浪博客手机版中也是这么做的,当然当时没有ssr,是后端直接渲染的模板,用户访问后,再进行交互则再采用前后端分离和前端路由控制来完成。
然后就是google的搜索引擎,是支持hashtag再rewrite访问你的静态版的,但是毕竟只有google支持,所以正规的做法都是使用pushState来对页面URL做前端的后续无刷新控制,对爬虫和所有用户提供任何入口的ssr或者首屏的直接渲染,才是最完美的SEO支持方案。
本人也比较认同 ssr 的处理方式,当然 ssr 的成本相对高。
6. 讲解一下https对称加密和非对称加密。
对称加密: 发送方和接收方需要持有同一把密钥,发送消息和接收消息均使用该密钥。相对于非对称加密,对称加密具有更高的加解密速度,但双方都需要事先知道密钥,密钥在传输过程中可能会被窃取,因此安全性没有非对称加密高。
非对称加密: 接收方在发送消息前需要事先生成公钥和私钥,然后将公钥发送给发送方。发送放收到公钥后,将待发送数据用公钥加密,发送给接收方。接收到收到数据后,用私钥解密。 在这个过程中,公钥负责加密,私钥负责解密,数据在传输过程中即使被截获,攻击者由于没有私钥,因此也无法破解。 非对称加密算法的加解密速度低于对称加密算法,但是安全性更高。
几个名词要理清
安装 React、 React-dom 类型定义文件
yarn add @types/react
yarn add @types/react-dom
定义state:
interface IProps {
color: string,
size?: string,
}
interface IState {
count: number,
}
class App extends React.PureComponent<IProps, IState> {
readonly state: Readonly<IState> = {
count: 1,
}
render () {
return (
<div>Hello world</div>
)
}
componentDidMount () {
this.state.count = 2
}
}
export default App在 React 的声明文件中 已经定义了一个 SFC 类型,使用这个类型可以避免我们重复定义 children、 propTypes、 contextTypes、 defaultProps、displayName 的类型。
使用 SFC 进行无状态组件开发。
import { SFC } from 'react'
import { MouseEvent } from 'react'
import * as React from 'react'
interface IProps {
onClick (event: MouseEvent<HTMLDivElement>): void,
}
const Button: SFC<IProps> = ({onClick, children}) => {
return (
<div onClick={onClick}>
{ children }
</div>
)
}
export default Button大家可以想到直接把 event 设置为 any 类型,但是这样就失去了我们对代码进行静态检查的意义。
function handleEvent(event: any) { console.log(event.clientY) }
试想下当我们注册一个 Touch 事件,当我们通过 event.clientY 访问时就有问题了,因为 Touch 事件的 event 对象并没有 clientY 这个属性。
常用 Event 事件对象类型:
import { MouseEvent } from 'react’
interface IProps {
onClick (event: MouseEvent<HTMLDivElement>): void,
}Promise 是一个泛型类型,T 泛型变量用于确定使用 then 方法时接收的第一个回调函数(onfulfilled)的参数类型。
interface IResponse<T> {
message: string,
result: T,
success: boolean,
}
async function getResponse (): Promise<IResponse<number[]>> {
return {
message: '获取成功',
result: [1, 2, 3],
success: true,
}
}
getResponse()
.then(response => {
console.log(response.result)
})一般我们都是先定义类型,再去赋值使用,但是使用 typeof 我们可以把使用顺序倒过来。
const options = {
a: 1
}
type Options = typeof options使用 **Partial **将所有的 props 属性都变为可选值
type Partial<T> = { [P in keyof T]?: T[P] };
上面代码的意思是 keyof T 拿到 T 所有属性名, 然后 in 进行遍历, 将值赋给 P , 最后 T[P]取得相应属性的值,中间的 ? 用来进行设置为可选值。
如果 props 所有的属性值都是可选的我们可以借助 Partial 这样实现。
(keyof 是索引类型查询操作符。假设T是一个类型,那么keyof T产生的类型是T的属性名称字符串字面量类型构成的联合类型。)
import { MouseEvent } from 'react'
import * as React from 'react'
interface IProps {
color: 'red' | 'blue' | 'yellow',
onClick (event: MouseEvent<HTMLDivElement>): void,
}
const Button: SFC<Partial<IProps>> = ({onClick, children, color}) => {
return (
<div onClick={onClick}>
{ children }
</div>
)TypeScript2.8引入了条件类型,条件类型可以根据其他类型的特性做出类型的判断。
T extends U ? X : Y
原先
interface Id { id: number, /* other fields */ }
interface Name { name: string, /* other fields */ }
declare function createLabel(id: number): Id;
declare function createLabel(name: string): Name;
declare function createLabel(name: string | number): Id | Name;使用条件类型之后
type IdOrName<T extends number | string> = T extends number ? Id : Name;
declare function createLabel<T extends number | string>(idOrName: T): T extends number ? Id : Name;通过传入的类型判断,如果T是number 那么就为Id,否则为Name
从 T 中排除那些可以赋值给 U 的类型。
type Exclude<T, U> = T extends U ? never : T;
实例:
type T = Exclude<1|2|3|4|5, 3|4> // T = 1|2|5
此时 T 类型的值只可以为 1 、2 、 5 ,当使用其他值时 TS 会进行错误提示。
Error:(8, 5) TS2322: Type '3' is not assignable to type '1 | 2 | 5’.
从 T 中提取那些可以赋值给 U 的类型。
type Extract<T, U> = T extends U ? T : never;
type T = Extract<1|2|3|4|5, 3|4> // T = 3|4
此时T类型的值只可以为 3 、4 ,当使用其他值时 TS 会进行错误提示:
Error:(8, 5) TS2322: Type '5' is not assignable to type '3 | 4'.
从 T 中取出一系列 K 的属性。
type Pick<T, K extends keyof T> = {
[P in K]: T[P];
};
假如我们现在有一个类型其拥有 name 、 age 、 sex 属性,当我们想生成一个新的类型只支持 name 、age 时可以像下面这样:
interface Person {
name: string,
age: number,
sex: string,
}
let person: Pick<Person, 'name' | 'age'> = {
name: '小王',
age: 21,
}将 K 中所有的属性的值转化为 T 类型。
type Record<K extends keyof any, T> = {
[P in K]: T;
};
};
将 name 、 age 属性全部设为 string 类型。
let person: Record<'name' | 'age', string> = {
name: '小王',
age: '12',
}从对象 T 中排除 key 是 K 的属性。
由于 TS 中没有内置,所以需要我们使用 Pick 和 Exclude 进行实现。
type Omit<T, K> = Pick<T, Exclude<keyof T, K>>
排除 name 属性。
interface Person {
name: string,
age: number,
sex: string,
}
let person: Omit<Person, 'name'> = {
age: 1,
sex: '男'
}排除 T 为 null 、undefined。
type NonNullable<T> = T extends null | undefined ? never : T;
type T = NonNullable<string | string[] | null | undefined>;
获取函数 T 返回值的类型。。
type ReturnType<T extends (...args: any[]) => any> = T extends (...args: any[]) => infer R ? R : any;
infer R 相当于声明一个变量,接收传入函数的返回值类型。
type T1 = ReturnType<() => string>; // string
type T2 = ReturnType<(s: string) => void>; // void yield/generator
yield* 后面可跟String\Array\Generator可迭代的对象function* foo() {
yield* [1, 2];
yield* "12";
yield* [
function* () {
yield 1;
},
function* () {
yield 2;
},
];
}
const f=foo()
console.log(g.next());//{value: 1, done: false}
console.log(g.next());//{value: 2, done: false}
console.log(g.next());//{value: "1", done: false}
console.log(g.next());//{value: "2", done: false}
console.log(g.next());//{value: ƒ*, done: false}
console.log(g.next());//{value: ƒ*, done: false}
console.log(g.next());//{value: undefined, done: true}yield 后面跟generator 并不会执行generator函数现有写法
const f1=async ()=>{
console.log('f1')
const data=await f2()
console.log('data',data)
}
const f2=async ()=>{
return await 'f2'
}babel之后
"use strict";
function asyncGeneratorStep(gen, resolve, reject, _next, _throw, key,arg) {
try {
// 执行next
var info = gen[key](arg);
var value = info.value;
} catch (error) {
reject(error);
return;
}
if (info.done) {
// 更改promise状态
resolve(value);
} else {
// 如果value是一个promise,会在执行promise改变状态之后执行_next/_throw
Promise.resolve(value).then(_next, _throw);
}
}
function _asyncToGenerator(fn) {
return function () {
// 保存this和参数
var self = this,
args = arguments;
return new Promise(function (resolve, reject) {
var gen = fn.apply(self, args);
function _next(value) {
asyncGeneratorStep(gen, resolve, reject, _next, _throw,"next",value);
}
function _throw(err) {
asyncGeneratorStep(gen, resolve, reject, _next, _throw, "throw", err);
}
// 每次执行前先执行一次next
_next(undefined);
});
};
}
const f1 = /*#__PURE__*/ (function () {
// f1的函数体被变成generator函数并被_asyncToGenerator包裹
var _ref = _asyncToGenerator(function* () {
console.log("f1");
// await被编译成yield
const data = yield f2();
console.log("data",data); // f2
});
return function f1() {
// 保证this指向正确
return _ref.apply(this,arguments);
};
})();
const f2 = /*#__PURE__*/ (function () {
var _ref2 = _asyncToGenerator(function* () {
return yield "f2";
});
return function f2() {
return _ref2.apply(this,arguments);
};
})();
f1();_asyncToGenerator返回一个函数执行后,返回一个promise是为了在done=false时时候,被Promise.resolve包裹(上文执行到yield f2()时,f1的value为f2返回的promise),从而等待异步操作完成之后再执行next
基于《重构2》一书中的**
前部分为概念叙述,可直接跳过看例子
用户侧关注的行为不应改变
总之,重构可以帮助我们更好的掌握代码,而不是一味的完成某些事情(功能)
三次法则:第一次做某件事的时候只管去做;第二次做类似的事情就会反感,但也能接受;第三次再做类似的事情时,你就应该重构
事不过三,三则重构
——《重构2》
code review时的重构通常合适的命名要比写代码更难 [滑稽]
这个不用很常见,不过多赘述
据我们的经验,活的最长、最好的程序,其中的函数都比较短
——《重构2》
将一个函数内部拆分成多个功能模块(函数),简洁兼并语义化
function printOwing(invoice) {
let outstanding = 0;
printBanner();
// calculate outstanding
for (const o of invoice.orders) {
outstanding += o.amount;
}
// record due date
const today = Clock.today;
invoice.dueDate = new Date(
today.getFullYear(),
today.getMonth(),
today.getDate() + 30
);
//print details
console.log(`name: ${invoice.customer}`);
console.log(`amount: ${outstanding}`);
console.log(`due : ${invoice.dueDate.toLocaleDatestring()}`);
}invoice)是一个数据结构,然而代码中又有修改这个数据结构的部分,所以可以将其提炼出来为一个函数outstanding),将初始化变量和使用变量的地方两者靠近。如果这个局部变量不止在一处使用,则将使用变量的逻辑提炼为一个函数,并且返回出变量function printOwing(invoice) {
printBanner()
let outstanding=calculateOutstanding(invoice)
recordDueDate(invoice)
pringDetails(invoice,outstanding)
}
// ...小函数省略也可将calculateOutstanding(invoice)作为参数,即:
pringDetails(invoice,calculateOutstanding(invoice))calculateOutstanding内用到的invoice参数不会因为代码位置的变化而变化recordDueDate)与提炼函数恰恰相反,将一个提炼出的函数再拆开放回原函数
function getRating(driver){
return moreThanFiveLateDeliveries(driver)? 2 : 1
}
function moreThanFiveLateDeliveries(driver){
return driver.numberOfLateDeliveries > 5
}moreThanFiveLateDeliveries内部的代码放回getRating中同样清晰已读,那么应该去掉这个函数。moreThanFiveLateDeliveries内部代码是递归调用、多返回点、内联之后出现局部变量无法访问等复杂情况,内联函数这种重构手法并不适合。从目前例子来看,**可以总结为:为了更好的语义化,为了更好的间接性,为了更好的一目了然,
这章主要大概讲解重构的**,当然重构还有更多种的方法,包括封装。
未完待续
《重构2》[美]马丁.福勒(Martin Fowler)
function-bind.js
module.exports = Function.bind || function bind(that /* , ...args */) {
// 判断是否是一个函数
var F = aCallable(this);
var Prototype = F.prototype;
// 拿到除that之外的函数
var partArgs = arraySlice(arguments, 1);
// 返回的函数
var boundFunction = function bound(/* args... */) {
// 拼接参数
var args = concat(partArgs, arraySlice(arguments));
// 重点!!
// 判断this是否是boundFunction的实例
// 函数bind之后的函数再new出一个实例,这个实例其实是通过,原函数new出的实例,并不会更改this指向
return this instanceof boundFunction ? construct(F, args.length, args) : F.apply(that, args);
};
// 继承this函数的原型
if (isObject(Prototype)) boundFunction.prototype = Prototype;
return boundFunction;
};var construct = function (C, argsLength, args) {
if (!hasOwn(factories, argsLength)) {
for (var list = [], i = 0; i < argsLength; i++) list[i] = 'a[' + i + ']';
// 通过Function创建函数
// 创建出的函数为
// ƒ anonymous(C,a
// ) {
// return new C(a[0],a[1])
// }
factories[argsLength] = Function('C,a', 'return new C(' + join(list, ',') + ')');
} return factories[argsLength](C, args);
};例子
function a(){}
function b(){}
const c=a._bind(b)
const d=new c('a','c','d')d为a函数bind之后的函数new出的实例对象
construct函数返回出的函数为
ƒ anonymous(C,a) {
// C是通过boundFunction闭包保存的例子中的a函数
return new C(a[0],a[1],a[2])
}几乎支持所有浏览器都支持class写法
例子1
class A{
constructor(){
this.a=1
}
static state={}
static fnStatic(){}
props={a:1}
props={a:2}
m2=()=>{}
fn(){}
}编译后:
"use strict";
function _classCallCheck(instance, Constructor) {
if (!(instance instanceof Constructor)) {
// 执行检测
// 如果直接A()调用报错
throw new TypeError("Cannot call a class as a function");
}
}
function _defineProperties(target, props) {
for (var i = 0; i < props.length; i++) {
var descriptor = props[i];
descriptor.enumerable = descriptor.enumerable || false;
descriptor.configurable = true;
if ("value" in descriptor) descriptor.writable = true;
Object.defineProperty(target, descriptor.key, descriptor);
}
}
function _createClass(Constructor, protoProps, staticProps) {
// 类函数,绑定在prototype上
if (protoProps) _defineProperties(Constructor.prototype, protoProps);
// 静态函数绑定在自身上
if (staticProps) _defineProperties(Constructor, staticProps);
// 将prototype更改为只读
Object.defineProperty(Constructor, "prototype", { writable: false });
return Constructor;
}
function _defineProperty(obj, key, value) {
if (key in obj) {
// 如果key已存在就重置,更改修饰符
Object.defineProperty(obj, key, {
value: value,
enumerable: true,
configurable: true,
writable: true,
});
} else {
obj[key] = value;
}
return obj;
}
var A = /*#__PURE__*/ (function () {
function A() {
_classCallCheck(this, A);
// 在new的时候会执行这部分代码
_defineProperty(this, "props", {
a: 1,
});
_defineProperty(this, "props", {
a: 2,
});
_defineProperty(this, "m2", function () {});
this.a = 1;
}
// 绑定属性
_createClass(
A,
[
{
key: "fn",
value: function fn() {},
},
],
[
{
key: "fnStatic",
value: function fnStatic() {},
},
]
);
return A;
})();
// 静态属性,挂在自身
_defineProperty(A, "state", {});例子2
class B extends A {
constructor() {
super();
this.props=1
}
}编译后(省略上文A编译后代码)
"use strict";
function _typeof(obj) {
"@babel/helpers - typeof";
return (
(_typeof =
"function" == typeof Symbol && "symbol" == typeof Symbol.iterator
? function (obj) {
return typeof obj;
}
: function (obj) {
return obj &&
"function" == typeof Symbol &&
obj.constructor === Symbol &&
obj !== Symbol.prototype
? "symbol"
: typeof obj;
}),
_typeof(obj)
);
}
function _inherits(subClass, superClass) {
if (typeof superClass !== "function" && superClass !== null) {
// 函数类型判断
throw new TypeError("Super expression must either be null or a function");
}
Object.defineProperty(subClass, "prototype", {
// 构建subClass.prototype,已superClass.prototype为__proto__
// 也就是 subClass.prototype.__proto__ ==={
// ...superClass.prototype,
// constructor:subClass
// }
value: Object.create(superClass && superClass.prototype, {
constructor: { value: subClass, writable: true, configurable: true }
}),
writable: false
});
// subClass.__proto__ === superClass
// 继承静态属性
if (superClass) _setPrototypeOf(subClass, superClass);
}
function _setPrototypeOf(o, p) {
_setPrototypeOf =
Object.setPrototypeOf ||
function _setPrototypeOf(o, p) {
o.__proto__ = p;
return o;
};
return _setPrototypeOf(o, p);
}
function _createSuper(Derived) {
var hasNativeReflectConstruct = _isNativeReflectConstruct();
return function _createSuperInternal() {
// 拿到B的__proto__
// 注意 这时的__proto__就是function A(){}
var Super = _getPrototypeOf(Derived),
result;
if (hasNativeReflectConstruct) {
// 这里的this指向的是B实例
// NewTarget = function B(){}
var NewTarget = _getPrototypeOf(this).constructor;
// 相当于
// var result = Object.create(NewTarget.prototype);===>> result.__proto__ = NewTarget.prototype
// Super.apply(result, arguments);
// 在B实例上挂在属性
result = Reflect.construct(Super, arguments, NewTarget);
// 这样调用保证new.target不丢失
} else {
// 如果不支持Reflect就.apply执行
result = Super.apply(this, arguments);
}
return _possibleConstructorReturn(this, result);
};
}
function _possibleConstructorReturn(self, call) {
// 构造函数可能返回的值
// 类似new一个实例对象,当构造函数中返回对象或者函数,则这个实例是值为返回值
if (call && (_typeof(call) === "object" || typeof call === "function")) {
return call;
} else if (call !== void 0) {
// void 0 = undefined 前提是undefined值未被更改
throw new TypeError(
"Derived constructors may only return object or undefined"
);
}
return _assertThisInitialized(self);
}
function _assertThisInitialized(self) {
// 在super前调用this
if (self === void 0) {
throw new ReferenceError(
"this hasn't been initialised - super() hasn't been called"
);
}
return self;
}
function _isNativeReflectConstruct() {
// 检测Reflect是否可用
if (typeof Reflect === "undefined" || !Reflect.construct) return false;
if (Reflect.construct.sham) return false;
if (typeof Proxy === "function") return true;
try {
// Reflect.construct() 方法的行为有点像 new 操作符 构造函数 , 相当于运行 new target(...args).
Boolean.prototype.valueOf.call(
Reflect.construct(Boolean, [], function () {})
);
return true;
} catch (e) {
return false;
}
}
function _getPrototypeOf(o) {
_getPrototypeOf = Object.setPrototypeOf
? Object.getPrototypeOf
: function _getPrototypeOf(o) {
return o.__proto__ || Object.getPrototypeOf(o);
};
return _getPrototypeOf(o);
}
// ..... 忽略部分上文重复代码
var A = /*#__PURE__*/ (function () {
function A() {
_classCallCheck(this, A);
_defineProperty(this, "props", {
a: 1
});
_defineProperty(this, "props", {
a: 2
});
this.a = 1;
}
// ..... 忽略部分上文重复代码
})();
_defineProperty(A, "state", {});
var B = /*#__PURE__*/ (function (_A) {
// 处理原型链
_inherits(B, _A);
var _super = _createSuper(B);
function B() {
var _this;
_classCallCheck(this, B);
// 执行父类构造函数并且将父类this上的属性挂载在上面
_this = _super.call(this);
_this.props = 2;
// _this.__proto__===B.prototype
// _this.__proto__.__proto__===A.prototype
return _this;
}
return _createClass(B);
})(A);
new B()super这个位置能引出另一个问题,看下面的例子
例子3:
class B extends A{
constructor(){
this.props=2
super()
}
}
new B()编译后:
...
var B = /*#__PURE__*/ (function (_A) {
_inherits(B, _A);
var _super = _createSuper(B);
function B() {
var _this;
_classCallCheck(this, B);
// 重点在这
// 因为this在super前调用,所以this还未初始化,此时为undefined
// 执行报错
_this.props = 2;
return (_this = _super.call(this));
}
return _createClass(B);
})(A);例子4
class B extends A{
constructor(){
console.log(this)
}
}
new B()编译后
var B = /*#__PURE__*/ (function (_A) {
_inherits(B, _A);
var _super = _createSuper(B);
function B() {
var _this;
_classCallCheck(this, B);
// 此时_assertThisInitialized执行直接报错
console.log(_assertThisInitialized(_this));
return _possibleConstructorReturn(_this);
}
return _createClass(B);
})(A);先看官方例子:
App.tsx
export default function App() {
return (
<div>
<h1>Basic Example</h1>
<p>
This example demonstrates some of the core features of React Router
including nested <code><Route></code>s,{" "}
<code><Outlet></code>s, <code><Link></code>s, and using a
"*" route (aka "splat route") to render a "not found" page when someone
visits an unrecognized URL.
</p>
{/* Routes nest inside one another. Nested route paths build upon
parent route paths, and nested route elements render inside
parent route elements. See the note about <Outlet> below. */}
<Routes>
<Route path="/" element={<Layout />}>
<Route index element={<Home />} />
<Route path="about" element={<About />} />
<Route path="dashboard" element={<Dashboard />} />
{/* Using path="*"" means "match anything", so this route
acts like a catch-all for URLs that we don't have explicit
routes for. */}
<Route path="*" element={<NoMatch />} />
</Route>
</Routes>
</div>
);
}main.tsx
import React from "react";
import ReactDOM from "react-dom";
import { BrowserRouter } from "react-router-dom";
import "./index.css";
import App from "./App";
ReactDOM.render(
<React.StrictMode>
<BrowserRouter>
<App />
</BrowserRouter>
</React.StrictMode>,
document.getElementById("root")
);可以看到 BrowserRouter是入口,那么就先从BrowserRouter开始看
export function BrowserRouter({
basename,
children,
window,
}: BrowserRouterProps) {
let historyRef = React.useRef<BrowserHistory>();
if (historyRef.current == null) {
historyRef.current = createBrowserHistory({ window });
}
let history = historyRef.current;
let [state, setState] = React.useState({
action: history.action,
location: history.location,
});
// 当history更改时重新监听
// 当切换路由时会触发setState
React.useLayoutEffect(() => history.listen(setState), [history]);
return (
<Router
basename={basename}
children={children}
location={state.location}
navigationType={state.action}
navigator={history}
/>
);
}很短很好理解,主要就是通过 history库中 createBrowserHistory函数创建history实例,然后通过historyRef保存,返回Router组件
接下来看 Router组件
packages/react-router/lib/components.tsx#L172
// line:172
export function Router({
basename: basenameProp = "/",
children = null,
location: locationProp,
navigationType = NavigationType.Pop,
navigator,
static: staticProp = false,
}: RouterProps): React.ReactElement | null {
invariant(
// 不能嵌套<Router>
!useInRouterContext(),
`You cannot render a <Router> inside another <Router>.` +
` You should never have more than one in your app.`
);
// 规范basename
let basename = normalizePathname(basenameProp);
// 设置navigationContext
let navigationContext = React.useMemo(
() => ({ basename, navigator, static: staticProp }),
[basename, navigator, staticProp]
);
if (typeof locationProp === "string") {
// 如果为字符串则转换成对象
locationProp = parsePath(locationProp);
}
let {
pathname = "/",
search = "",
hash = "",
state = null,
key = "default",
} = locationProp;
let location = React.useMemo(() => {
// 将pathname上的basename去掉返回出来,并且判断做一些判断
let trailingPathname = stripBasename(pathname, basename);
if (trailingPathname == null) {
return null;
}
return {
pathname: trailingPathname,
search,
hash,
state,
key,
};
}, [basename, pathname, search, hash, state, key]);
warning(
location != null,
`<Router basename="${basename}"> is not able to match the URL ` +
`"${pathname}${search}${hash}" because it does not start with the ` +
`basename, so the <Router> won't render anything.`
);
if (location == null) {
// 因为pathname没有以basename开头,所以无法匹配,不会渲染任何东西
return null;
}
return (
// 一共注入两个context——NavigationContext和LocationContext
<NavigationContext.Provider value={navigationContext}>
<LocationContext.Provider
children={children}
value={{ location, navigationType }}
/>
</NavigationContext.Provider>
);
}normalizePathname:
const normalizePathname = (pathname: string): string =>
pathname.replace(/\/+$/, "").replace(/^\/*/, "/");
// '/a/b/c' => '/a/b/c'
// '/a/b/c/' => '/a/b/c'
// 'a/b/c////' => '/a/b/c'
// 给第一位的零或多个'/'替换成'/' ,去掉最后一位的多个'/'parsePath:
let pathPieces = parsePath("/the/path?the=query#the-hash");
// pathPieces = {
// pathname: '/the/path',
// search: '?the=query',
// hash: '#the-hash'
// }stripBasename
export function stripBasename(
pathname: string,
basename: string
): string | null {
if (basename === "/") return pathname;
if (!pathname.toLowerCase().startsWith(basename.toLowerCase())) {
// 判断是否以basename开头
return null;
}
let nextChar = pathname.charAt(basename.length);
if (nextChar && nextChar !== "/") {
// pathname不能以 basename/ 开头
return null;
}
// 截取basename后面一段
return pathname.slice(basename.length) || "/";
}Router组件同样很好理解,注入navigationContext,对location做处理,之后当做context注入。相当于一个外层容器,初始化好一些数据供内部组件使用。<Router>它是一个上下文提供者,为应用程序的其余部分提供路由信息。
接下来我们来看 Routes组件
packages/react-router/lib/components.tsx#L252
export function Routes({
children,
location,
}: RoutesProps): React.ReactElement | null {
return useRoutes(createRoutesFromChildren(children), location);
}很短很简单,主要是引用了两个函数,使用useRoutes这个hooks来渲染,通过createRoutesFromChildren生成hooks接受的routes数据结构
packages/react-router/lib/components.tsx#L270
export function createRoutesFromChildren(
children: React.ReactNode
): RouteObject[] {
let routes: RouteObject[] = [];
React.Children.forEach(children, (element) => {
if (!React.isValidElement(element)) {
// 忽略非有效元素。可以更容易地在路由配置中内联条件。
return;
}
if (element.type === React.Fragment) {
// 支持展开Fragment
routes.push.apply(
routes,
createRoutesFromChildren(element.props.children)
);
return;
}
// 如果子组件不是Route,则报错
invariant(
element.type === Route,
`[${
typeof element.type === "string" ? element.type : element.type.name
}] is not a <Route> component. All component children of <Routes> must be a <Route> or <React.Fragment>`
);
// 创建路由对象
let route: RouteObject = {
caseSensitive: element.props.caseSensitive,
element: element.props.element,
index: element.props.index,
path: element.props.path,
};
// 如果有children就递归
if (element.props.children) {
route.children = createRoutesFromChildren(element.props.children);
}
routes.push(route);
});
// 最后返回出这个数组
return routes;
}就是一个遍历的过程,很简单。最后返回的是一个数组,符合useRoutes第一个参数数据结构的数组
packages/react-router/lib/hooks.tsx#L266
export function useRoutes(
routes: RouteObject[],
locationArg?: Partial<Location> | string
): React.ReactElement | null {
invariant(
// 首先检测是否在LocationContext.provider下
useInRouterContext(),
// TODO: This error is probably because they somehow have 2 versions of the
// router loaded. We can help them understand how to avoid that.
`useRoutes() may be used only in the context of a <Router> component.`
);
// 获取RouteContext,因为上文并没有RouteContext,
// 所以可以看出Routes和Route都是是可以嵌套的
let { matches: parentMatches } = React.useContext(RouteContext);
// 获取matches最后一个,获取对应参数
let routeMatch = parentMatches[parentMatches.length - 1];
let parentParams = routeMatch ? routeMatch.params : {};
let parentPathname = routeMatch ? routeMatch.pathname : "/";
let parentPathnameBase = routeMatch ? routeMatch.pathnameBase : "/";
let parentRoute = routeMatch && routeMatch.route;
// 相当于 locationFromContext = React.useContext(LocationContext).location;
let locationFromContext = useLocation();
let location;
if (locationArg) {
// 这个操作跟Router中的location处理类似
let parsedLocationArg =
typeof locationArg === "string" ? parsePath(locationArg) : locationArg;
invariant(
parentPathnameBase === "/" ||
parsedLocationArg.pathname?.startsWith(parentPathnameBase),
`When overriding the location using \`<Routes location>\` or \`useRoutes(routes, location)\`, ` +
`the location pathname must begin with the portion of the URL pathname that was ` +
`matched by all parent routes. The current pathname base is "${parentPathnameBase}" ` +
`but pathname "${parsedLocationArg.pathname}" was given in the \`location\` prop.`
);
// 赋值
location = parsedLocationArg;
} else {
// 如果没传这个参数就默认取LocationContext中de
location = locationFromContext;
}
let pathname = location.pathname || "/";
// 获取剩余pathname
let remainingPathname =
parentPathnameBase === "/"
? pathname
// 截取从父路径开始的后半段pathname
: pathname.slice(parentPathnameBase.length) || "/";
// matchRoutes 路由匹配的核心算法
let matches = matchRoutes(routes, { pathname: remainingPathname });
// 渲染函数
return _renderMatches(
matches &&
// 与父级的合并操作
matches.map((match) =>
Object.assign({}, match, {
params: Object.assign({}, parentParams, match.params),
pathname: joinPaths([parentPathnameBase, match.pathname]),
pathnameBase:
match.pathnameBase === "/"
? parentPathnameBase
: joinPaths([parentPathnameBase, match.pathnameBase]),
})
),
parentMatches
);
}RouteContext
export const RouteContext = React.createContext<RouteContextObject>({
outlet: null,
matches: [],
});packages/react-router/lib/router.ts#L141
matchRoutes针对给定的一组路由运行路由匹配算法,location以查看哪些路由(如果有)匹配。如果找到匹配项,RouteMatch则返回一个数组,每个匹配的路由对应一个对象。
这是 React-Router 匹配算法的核心。useRoutes在内部使用它来确定哪些路径与当前位置匹配。在想要手动匹配一组路由的某些情况下,它也很有用。
export function matchRoutes(
routes: RouteObject[],
locationArg: Partial<Location> | string,
basename = "/"
): RouteMatch[] | null {
// 相同的操作上文已有叙述
let location =
typeof locationArg === "string" ? parsePath(locationArg) : locationArg;
let pathname = stripBasename(location.pathname || "/", basename);
if (pathname == null) {
return null;
}
// routes数组拍平
let branches = flattenRoutes(routes);
// 降序排列
rankRouteBranches(branches);
let matches = null;
for (let i = 0; matches == null && i < branches.length; ++i) {
// 注意这里的 matches==null
// 只要其中一个未匹配到则进入下一轮循环,匹配到则结束循环
matches = matchRouteBranch(branches[i], pathname);
}
return matches;
}rankRouteBranches
function rankRouteBranches(branches: RouteBranch[]): void {
// 降序排列
branches.sort((a, b) =>
a.score !== b.score
? b.score - a.score // 分数高的优先
: compareIndexes(
a.routesMeta.map((meta) => meta.childrenIndex),
b.routesMeta.map((meta) => meta.childrenIndex)
)
);
}compareIndexes
function compareIndexes(a, b) {
// 判断是否是同级
let siblings =
a.length === b.length && a.slice(0, -1).every((n, i) => n === b[i]);
return siblings
? // 同级则判断最后一位
a[a.length - 1] - b[b.length - 1]
: // 否则,按索引对非同级进行排序是没有意义的,所以它们的排序是相等的
0;
}只看代码可能不太直观,举个例子
{
path: "/courses",
element: " <Courses />",
children: [
// 同级
// 上文 a[a.length - 1] - b[b.length - 1] 指的是
// childrenIndex的对比 ,/a index为0 /b index为1
{ path: "/courses/a", element: "<Course />" },
{ path: "/courses/b", element: "<Course />" },
],
},packages/react-router/lib/router.ts#L179
关键部分
function flattenRoutes(
routes: RouteObject[],
branches: RouteBranch[] = [],
parentsMeta: RouteMeta[] = [],
parentPath = ""
): RouteBranch[] {
routes.forEach((route, index) => {
let meta: RouteMeta = {
// 相对路径
relativePath: route.path || "",
// 区分大小写
caseSensitive: route.caseSensitive === true,
childrenIndex: index,
route,
};
if (meta.relativePath.startsWith("/")) {
// 如果路径以 / 开头并且没有包含父路径则报错
invariant(
meta.relativePath.startsWith(parentPath),
`Absolute route path "${meta.relativePath}" nested under path ` +
`"${parentPath}" is not valid. An absolute child route path ` +
`must start with the combined path of all its parent routes.`
);
// 将父路径截掉,保留后半段
// 例1
meta.relativePath = meta.relativePath.slice(parentPath.length);
}
// 与父路径合并路径
let path = joinPaths([parentPath, meta.relativePath]);
// 类似于把meta push到了parentsMeta数组,但是不会改变原数组(parentsMeta)
let routesMeta = parentsMeta.concat(meta);
// Add the children before adding this route to the array so we traverse the
// route tree depth-first and child routes appear before their parents in
// the "flattened" version.
if (route.children && route.children.length > 0) {
// 索引路由,也称默认子路由,该路由不能有子路由
invariant(
route.index !== true,
`Index routes must not have child routes. Please remove ` +
`all child routes from route path "${path}".`
);
flattenRoutes(route.children, branches, routesMeta, path);
}
// 没有路径的路由本身不应该匹配,除非它们是索引路由
if (route.path == null && !route.index) {
return;
}
branches.push({ path, score: computeScore(path, route.index), routesMeta });
});
return branches;
}例1
{
path:'/', // 父路径为'',相当于 '/'.slice(0) => '/'
children:[
{
path:'/a' // => a
}
]
}
// 如果子路径带/ 则要写父路径joinPaths
export const joinPaths = (paths: string[]): string =>
// 路径通过/拼接,并且将多个 // 替换为 /
paths.join("/").replace(/\/\/+/g, "/");computeScore
packages/react-router/lib/router.ts#L251
const paramRe = /^:\w+$/;
const dynamicSegmentValue = 3;
const indexRouteValue = 2;
const emptySegmentValue = 1;
const staticSegmentValue = 10;
const splatPenalty = -2;
const isSplat = (s: string) => s === "*";
function computeScore(path: string, index: boolean | undefined): number {
let segments = path.split("/");
// 初始分数为路径深度
let initialScore = segments.length;
if (segments.some(isSplat)) {
// 只要有*,则
initialScore += splatPenalty;
}
if (index) {
// 如果是索引路由
initialScore += indexRouteValue;
}
return segments
// 挑出不带星号的
.filter((s) => !isSplat(s))
// 计算分数
.reduce(
(score, segment) =>
score +
// 动态路径,例如: /:id
(paramRe.test(segment)
? dynamicSegmentValue
: segment === ""
// 空字符串
? emptySegmentValue
: staticSegmentValue),
initialScore
);
}例如:
path='/' // => 分数:4 segments=['','']
path='/abc' // => 分数:13 segments=['','abc']举个例子:
let routes = [
{
path: "/",
element:' <Layout />',// branches第6次push
children: [
{ index: true, element: '<Home />' }, // branches第1次push 因为是索引路由,所以score多加了2
{
path: "/courses",
element:' <Courses />',// branches第4次push
children: [
{ index: true, element: '<CoursesIndex />' }, // branches第2次push
{ path: "/courses/:id", element: '<Course />' },// branches第3次push
],
},
{ path: "*", element: '<NoMatch />' },// branches第5次push
],
},
];
flattenRoutes(routes)输出结果

排序之后

routesMeta为父-子的顺序,在后面匹配时会遍历 routesMeta
packages/react-router/lib/router.ts#L291
查找匹配的路由分支
function matchRouteBranch<ParamKey extends string = string>(
branch: RouteBranch,
pathname: string
): RouteMatch<ParamKey>[] | null {
let { routesMeta } = branch;
let matchedParams = {};
let matchedPathname = "/";
let matches: RouteMatch[] = [];
for (let i = 0; i < routesMeta.length; ++i) {
// 一层层路径遍历匹配
let meta = routesMeta[i];
let end = i === routesMeta.length - 1;
// 剩余路径
let remainingPathname =
// 匹配路径
// pathname = `${matchedPathname}xxx`,remainingPathname = 'xxx'
matchedPathname === "/"
? pathname
: pathname.slice(matchedPathname.length) || "/";
let match = matchPath(
{ path: meta.relativePath, caseSensitive: meta.caseSensitive, end },
remainingPathname
);
// 只要有一层未匹配到则跳出当前循环,routesMeta是一个数组,从0到最后一项顺序为父->子
if (!match) return null;
Object.assign(matchedParams, match.params);
let route = meta.route;
matches.push({
params: matchedParams,
pathname: joinPaths([matchedPathname, match.pathname]),
pathnameBase: normalizePathname(
joinPaths([matchedPathname, match.pathnameBase])
),
route,
});
if (match.pathnameBase !== "/") {
// 匹配到对应层级的路径之后,要把这个层级算上,以便下次循环匹配remainingPathname
// 例如 /a/b/c matchedPathname=> / => /a => /a/b => /a/b/c
matchedPathname = joinPaths([matchedPathname, match.pathnameBase]);
}
}
return matches;
}packages/react-router/lib/router.ts#L388
matchPath将路由路径与 URL 路径名匹配并返回有关匹配的信息。当您需要手动运行路由器的匹配算法以确定路由路径是否匹配时,这很有用。如果模式与给定的路径名不匹配,则返回 null
useMatch钩子在内部使用此函数来匹配相对于当前位置的路由路径。
export function matchPath<
ParamKey extends ParamParseKey<Path>,
Path extends string
>(
pattern: PathPattern<Path> | Path,
pathname: string
): PathMatch<ParamKey> | null {
if (typeof pattern === "string") {
pattern = { path: pattern, caseSensitive: false, end: true };
}
// 编译路径,根据对应的路径生成对应的匹配正则
let [matcher, paramNames] = compilePath(
pattern.path,
pattern.caseSensitive,
pattern.end
);
// 与当前路径匹配
let match = pathname.match(matcher);
// 没匹配到不作处理
if (!match) return null;
let matchedPathname = match[0];
// 其实就是去掉结尾任意数量的 /
let pathnameBase = matchedPathname.replace(/(.)\/+$/, "$1");
// 捕获组 其实就是参数(动态参数或者*)
let captureGroups = match.slice(1);
let params: Params = paramNames.reduce<Mutable<Params>>(
(memo, paramName, index) => {
// 直接根据index在捕获组中匹配,参数有可能被编码,所以先decode
if (paramName === "*") {
let splatValue = captureGroups[index] || "";
// 去掉参数后的路径
pathnameBase = matchedPathname
.slice(0, matchedPathname.length - splatValue.length)
.replace(/(.)\/+$/, "$1");
}
// 解码
memo[paramName] = safelyDecodeURIComponent(
captureGroups[index] || "",
paramName
);
return memo;
},
{}
);
return {
params,
pathname: matchedPathname,
pathnameBase,
pattern,
};
}conpilePath
全是正则匹配,不了解的可以先恶补下正则,主要有这几种 (?:) (?=) \b
function compilePath(
path: string,
caseSensitive = false,
end = true
): [RegExp, string[]] {
warning(
// 例如 '/abc*' 路径被视为 '/abc/*'
path === "*" || !path.endsWith("*") || path.endsWith("/*"),
`Route path "${path}" will be treated as if it were ` +
`"${path.replace(/\*$/, "/*")}" because the \`*\` character must ` +
`always follow a \`/\` in the pattern. To get rid of this warning, ` +
`please change the route path to "${path.replace(/\*$/, "/*")}".`
);
let paramNames: string[] = [];
let regexpSource =
"^" +
path
// 0次或多次 / 和 零次或者一次 *
.replace(/\/*\*?$/, "") // 忽略 / and /*, 我们将在下面处理它
.replace(/^\/*/, "/") // 确保最前面有 /
.replace(/[\\.*+^$?{}|()[\]]/g, "\\$&") // Escape特殊正则字符
.replace(/:(\w+)/g, (_: string, paramName: string) => {
// 例:/a/:id/
// paramName = id
paramNames.push(paramName);
// 将:id替换
return "([^\\/]+)";
});
if (path.endsWith("*")) {
// 以*结尾
paramNames.push("*");
regexpSource +=
path === "*" || path === "/*"
? "(.*)$" // 已匹配首字母/,只匹配其余的
: "(?:\\/(.+)|\\/*)$"; // 不要在参数[“*”]中包含/ (?:) 非捕获组
} else {
regexpSource += end
? "\\/*$" // 匹配到结尾时,忽略尾部斜杠
: //否则,请匹配单词边界。单词边界限制父路由仅匹配其自己的单词,仅此而已,
//例如父路由“/home”不应匹配“/home2”。
// 此外,允许以“.`、`-`、` ~`、` ~`”开头的路径,
// 和url编码的实体,但不使用匹配路径中的字符,以便它们可以与嵌套路径匹配。
// 例 可匹配 /abc/d%22
"(?:(?=[.~-]|%[0-9A-F]{2})|\\b|\\/|$)";
}
// 创建正则
let matcher = new RegExp(regexpSource, caseSensitive ? undefined : "i");
return [matcher, paramNames];
}packages/react-router/lib/hooks.tsx#L377
export function _renderMatches(
matches: RouteMatch[] | null,
parentMatches: RouteMatch[] = []
): React.ReactElement | null {
if (matches == null) return null;
return matches.reduceRight((outlet, match, index) => {
// 使用reduceRight,遍历渲染
return (
<RouteContext.Provider
children={
match.route.element !== undefined ? match.route.element : outlet
}
value={{
outlet,
matches: parentMatches.concat(matches.slice(0, index + 1)),
}}
/>
);
}, null as React.ReactElement | null);
}为什么使用reduceRight,还是上面的例子,例如当前路由为/courses,传入的matches的数据结构为

const a=()=>{
console.log(this)
}
const obj={
a:1,
fn(){
const arrow=()=>{
console.log(this.a)
}
}
}
obj.fn() // 1转义后(spec:true):
"use strict";
var _this = void 0;
function _newArrowCheck(innerThis, boundThis) {
if (innerThis !== boundThis) {
throw new TypeError("Cannot instantiate an arrow function");
}
}
var a = function a() {
// 检查this,也就是为什么箭头函数不能new
_newArrowCheck(this, _this);
console.log(this);
}.bind(void 0);
var obj = {
a: 1,
fn: function fn() {
var _this2 = this;
var arrow = function arrow() {
_newArrowCheck(this, _this2);
console.log(this.a);
}.bind(this);
}
};
obj.fn(); // 1var xx=function xx(){} 形式,同时在函数外层创建_this并在函数内使用;无法变量提升。_newArrowCheck检查是this是否相同,被new时报错。Scheduler顾名思义就是一个调度器,负责React中任务的调度。众所周知 JS 是单线程,通过task和micro task来调度任务的执行。
核心概念分为三个:时间切片、任务切片和优先级调度
小顶堆的数据结构(不过多介绍)熟悉 JS 的同学肯定知道跟浏览器渲染帧相关的两个API:requestIdleCallback(浏览器空闲时调用,下文简称rIC)和requestAnimationFrame(每一帧绘制之前调用,下文简称rAF),两个 api 看似可以达到不占用主线程,优先浏览器渲染,不阻塞的效果,但是真的适用吗?很显然,都有缺陷。
rIC
兼容性太差,Safari直接不兼容...
执行时间不一定:浏览器空闲时执行间隔为50ms,也就是 20FPS,一秒执行 20 次,这显然间隔太长了。
例如:持续滚动页面,这时执行的间隔时间就会非常不稳定
还有一点,当页面至于后台时,干脆不执行了...
rAF
rAF是官方推荐用于做流畅动画的api,所以它的回调执行在页面渲染更新前。执行顺序可能在宏任务(task)前或者后(涉及到EventLoop,篇幅问题不过多介绍)。rAF在各个平台的浏览器表现不一。React可能执行两次更新综上所述,React 团队打算自己实现一个策略,用于时间分片。最终使用MessageChannel实现
执行顺序,microTask > messageChannel > setTimeout,messageChannel为dom event,所以优先级要大于setTimeout
为什么用task而不用microTask?不用microTask的原因是,microTask将在页面更新前全部执行完,达不到将主线程还给浏览器的目的。
task就会执行所有microTask,并且在这个过程中新增的microTask都会一并执行,所以React的渲染如果在microTask中,无法中断,
React在中断渲染之后会检查是否还有任务,如果有就再次调度一个performConcurrentWorkOnRoot,根据事件循环来看这时再有microTask会立即执行,所以每次都会执行完全部任务,无法达到一个tick执行一个task的目的为什么不使用setTimeout?因为setTimeout(_,0)即使设置为0,还会有**4ms的问题**。在MessageChannel无法使用的时候,降级使用setTimeout
为什么不使用postMessage?因为postMessage会因为持续的滚动等操作被阻塞住。浏览器会为了保证用户交互的响应,将四分之三的优先权给了鼠标键盘事件,其余的时间会交给其他的task,所以就导致了持续的滚动阻塞了postMessage,Vue 2.0.0-rc.7有个issue就是描述这个问题的。
Scheduler被单独拆成一个包,放在React项目中,目录为react/packages/scheduler/src/forks/Scheduler.js
根据优先级对应不同timeout
var maxSigned31BitInt = 1073741823;
// Times out immediately
var IMMEDIATE_PRIORITY_TIMEOUT = -1;
// Eventually times out
var USER_BLOCKING_PRIORITY_TIMEOUT = 250;
var NORMAL_PRIORITY_TIMEOUT = 5000;
var LOW_PRIORITY_TIMEOUT = 10000;
// Never times out
var IDLE_PRIORITY_TIMEOUT = maxSigned31BitInt;全局函数
// 获取currentTime(当前时间)
let getCurrentTime = () => performance.now();
// 延时器
const localSetTimeout = typeof setTimeout === "function" ? setTimeout : null;
// 清除延时器
const localClearTimeout =
typeof clearTimeout === "function" ? clearTimeout : null;
// 环境支持的话
const isInputPending = navigator.scheduling.isInputPending.bind(
navigator.scheduling
);任务相关变量
var taskQueue = [];
var timerQueue = [];
// 当前任务
var currentTask = null;
// 当前任务优先级
var currentPriorityLevel = NormalPriority;
// flushWork中设置为true,表示当前任务正在执行,防止再次进入
var isPerformingWork = false;
// 表示任务是否被调度,调用requestHostCallback函数前设置为false(触发postMessage之前),在flushWork中设置为false
var isHostCallbackScheduled = false;
// 表示是否有延时器正在执行,延时器执行完毕之后设置为false
var isHostTimeoutScheduled = false;
...
// 代表当前postMessage触发的回调正在执行
let isMessageLoopRunning = false;
// scheduledHostCallback = flushWork
let scheduledHostCallback = null;
// 延时器id
let taskTimeoutID = -1;简单来说,任务分为两个堆——taskQueue和timerQueue,两个变量都是js数组形式的小顶堆,taskQueue根据expirationTime(过期时间)由小到大排序,timerQueue根据startTime(开始时间)由大到小排序
taskQueue和timerQueue分别表示任务需要立刻执行和延迟执行,通过(startTime>currentTime)来判断任务是添加进taskQueue中还是timerQueue
任务对象的属性
var newTask = {
// 自增的id,用来判断插入顺序,当sortIndex相同时,通过id判断优先级执行顺序
id: taskIdCounter++,
// performSyncWorkOnroot等,react render阶段的入口函数
callback,
// 优先级
priorityLevel,
// 开始时间 startTime=currentTime+delay(如果有的话)
startTime,
// 过期时间(startTime+timeout) timeout为不同优先级预设的时间
expirationTime,
// 堆排序的主要依据,timerQueue中为startTime,taskQueue中为expirationTime
sortIndex: -1,
};入口函数,分成四个部分
startTime,如果有delay就加上timeoutexpirationTime,创建任务对象(newTask)startTime > currentTime来判断是push进timerQueue中还是taskQueuefunction unstable_scheduleCallback(priorityLevel, callback, options) {
// 第一部分
var currentTime = getCurrentTime();
var startTime;
if (typeof options === "object" && options !== null) {
var delay = options.delay;
if (typeof delay === "number" && delay > 0) {
startTime = currentTime + delay;
} else {
startTime = currentTime;
}
} else {
startTime = currentTime;
}
// 第二部分
var timeout;
switch (priorityLevel) {
case ImmediatePriority:
timeout = IMMEDIATE_PRIORITY_TIMEOUT;
break;
case UserBlockingPriority:
timeout = USER_BLOCKING_PRIORITY_TIMEOUT;
break;
case IdlePriority:
timeout = IDLE_PRIORITY_TIMEOUT;
break;
case LowPriority:
timeout = LOW_PRIORITY_TIMEOUT;
break;
case NormalPriority:
default:
timeout = NORMAL_PRIORITY_TIMEOUT;
break;
}
// 第三部分
var expirationTime = startTime + timeout;
var newTask = {
id: taskIdCounter++,
callback,
priorityLevel,
startTime,
expirationTime,
sortIndex: -1,
};
if (enableProfiling) {
newTask.isQueued = false;
}
// 第四部分
if (startTime > currentTime) {
// 延迟任务.
newTask.sortIndex = startTime;
// push时会根据startTime进行排序
push(timerQueue, newTask);
if (peek(taskQueue) === null && newTask === peek(timerQueue)) {
// taskQueue中没有任务,并且timerQueue中有任务,拿到优先级最高的任务(当前任务)(startTime最小)
if (isHostTimeoutScheduled) {
// 如果当前有上一个被通过setTimeout延迟执行的任务就取消掉
cancelHostTimeout();
} else {
// 如果没有,就设置为true,代表当前有被调度的任务
isHostTimeoutScheduled = true;
}
// 将延迟任务通过setTimeout变为立即执行任务
requestHostTimeout(handleTimeout, startTime - currentTime);
}
} else {
newTask.sortIndex = expirationTime;
push(taskQueue, newTask);
// 如果当前没有正在调度的任务,并且没有正在执行的任务
if (!isHostCallbackScheduled && !isPerformingWork) {
isHostCallbackScheduled = true;
// 立即执行
requestHostCallback(flushWork);
}
}
return newTask;
}这部分代码很简单,就是一个延时器
function requestHostTimeout(callback, ms) {
// callback = handleTimeout
taskTimeoutID = localSetTimeout(() => {
callback(getCurrentTime());
}, ms);
}判断当前是否有被调度的任务,如果有就取出timeQueue第一位,继续等待执行,如果没有就直接调度该任务
function handleTimeout(currentTime) {
// 当前延时器回调执行了,isHostTimeoutScheduled为false代表释放当前延时器,下一个延时任务可以被调度
isHostTimeoutScheduled = false;
// 将timerQueue中已经过期了的任务插入到taskQueue中
advanceTimers(currentTime);
// 判断当前是否有被调度的任务
if (!isHostCallbackScheduled) {
// 没有并且taskQueue中有任务
if (peek(taskQueue) !== null) {
// 开始调度taskQueue中的任务
isHostCallbackScheduled = true;
requestHostCallback(flushWork);
} else {
// 有则取出继续等待调度
const firstTimer = peek(timerQueue);
if (firstTimer !== null) {
requestHostTimeout(handleTimeout, firstTimer.startTime - currentTime);
}
}
}
}将timerQueue中已经过期了的任务插入到taskQueue中
function advanceTimers(currentTime) {
// 检查不再延迟的任务,并将其添加到队列中。
let timer = peek(timerQueue);
// 遍历timerQueue
while (timer !== null) {
if (timer.callback === null) {
// 任务被取消,出堆
pop(timerQueue);
} else if (timer.startTime <= currentTime) {
// 计时器响了。转移到任务队列。
pop(timerQueue);
// 因为要插进taskQueue,所以要重新计算sortIndex
timer.sortIndex = timer.expirationTime;
push(taskQueue, timer);
} else {
// 后面的任务的时间有剩余
return;
}
timer = peek(timerQueue);
}
}以上是调度timerQueue的过程,其中执行的函数和调度taskQueue中函数有重复,放在下面讲解
入参为flushWork,将flushwork赋值给全局变量,并且触发消息通知
function requestHostCallback(callback) {
// callback = flushWork
scheduledHostCallback = callback;
if (!isMessageLoopRunning) {
isMessageLoopRunning = true;
// 执行postMessage
schedulePerformWorkUntilDeadline();
}
}对于设备环境做了兼容
let schedulePerformWorkUntilDeadline;
if (typeof localSetImmediate === "function") {
// Node.js 和 old IE.
schedulePerformWorkUntilDeadline = () => {
localSetImmediate(performWorkUntilDeadline);
};
} else if (typeof MessageChannel !== "undefined") {
// DOM and Worker environments.
// 由于setTimeout的4ms延迟,所以使用MessageChannel
const channel = new MessageChannel();
const port = channel.port2;
channel.port1.onmessage = performWorkUntilDeadline;
schedulePerformWorkUntilDeadline = () => {
port.postMessage(null);
};
} else {
// 非浏览器环境使用setTimeout
schedulePerformWorkUntilDeadline = () => {
localSetTimeout(performWorkUntilDeadline, 0);
};
}MessageChannel为例,执行schedulePerformWorkUntilDeadline会触发performWorkUntilDeadline执行,但是会放在下一轮事件循环中执行作为postMessage触发的回调,主要负责执行全局变量scheduledHostCallback,通过返回值判定是否触发下一轮postMessage
const performWorkUntilDeadline = () => {
// scheduledHostCallback 在 requestHostCallback 中被赋值为 flushWork
if (scheduledHostCallback !== null) {
const currentTime = getCurrentTime();
// 获取函数真正执行的当前时间,提供给后续时间片判断(shouldYieldToHost函数)
startTime = currentTime;
const hasTimeRemaining = true;
// 故意不使用try-catch,因为这会使一些调试技术变得更加困难。
// 相反,如果'scheduledHostCallback'出现错误,
// 那么'hasMoreWork'将保持为true,我们将继续工作循环。
let hasMoreWork = true;
try {
// scheduledHostCallback = flushWork
hasMoreWork = scheduledHostCallback(hasTimeRemaining, currentTime);
} finally {
if (hasMoreWork) {
// 代表当前任务没结束(返回一个函数、报错、)
schedulePerformWorkUntilDeadline();
} else {
// 重置全局变量
isMessageLoopRunning = false;
scheduledHostCallback = null;
}
}
} else {
isMessageLoopRunning = false;
}
};核心,负责执行 workLoop 并且返回执行结果,在执行结束后重置全局变量
function flushWork(hasTimeRemaining, initialTime) {
// 设为false,为了能够执行requestHostCallback,调度下次任务
isHostCallbackScheduled = false;
if (isHostTimeoutScheduled) {
// 如果当前有延时器就取消掉,当前任务优先级更高
// 因为接下来执行callback前后会再次执行advanceTimers,并且执行callback也是会有时间损耗的
isHostTimeoutScheduled = false;
cancelHostTimeout();
}
// 任务开始执行
isPerformingWork = true;
const previousPriorityLevel = currentPriorityLevel;
try {
// 直接看这里,返回值为外部函数作用域的hasMoreWork变量
return workLoop(hasTimeRemaining, initialTime);
} finally {
// 任务执行完成之后重置全局变量
currentTask = null;
currentPriorityLevel = previousPriorityLevel;
isPerformingWork = false;
}
}核心,任务循环,真正执行callback的地方。在执行callback前后都会执行advanceTimers,确保taskQueue中任务的优先级
function workLoop(hasTimeRemaining, initialTime) {
// initialTime为 postMessage触发回调当时的时间
// hasTimeRemaining 始终为true
let currentTime = initialTime;
// 检测是否有过期的任务,放在taskQueue队列中
advanceTimers(currentTime);
currentTask = peek(taskQueue);
while (currentTask !== null) {
if (
currentTask.expirationTime > currentTime &&
(!hasTimeRemaining || shouldYieldToHost())
) {
// 此判断代表任务还未过期,但是没时间了(5ms已过),终止循环
// shouldYieldToHost 判断为
// if(getCurrentTime() - startTime < frameInterval(默认5ms)) return false ,执行到现在还没到5ms,不需要暂停
// shouldYieldToHost 还有对isInputPending情况的判断,兼容性不高不做考虑
// navigator.scheduling.isInputPending为react团队和chrome团队协商出的api,主要用于判断当前是否有input等事件正在执行,有兴趣可以了解下
break;
}
const callback = currentTask.callback;
if (typeof callback === "function") {
currentTask.callback = null;
currentPriorityLevel = currentTask.priorityLevel;
// 当前任务是否超时
const didUserCallbackTimeout = currentTask.expirationTime <= currentTime;
// 拿到返回
// 任务切片
const continuationCallback = callback(didUserCallbackTimeout);
currentTime = getCurrentTime();
if (typeof continuationCallback === "function") {
// 如果是个函数,更新callback,作为下一轮事件循环使用
currentTask.callback = continuationCallback;
} else {
// 判断当前任务是否是最高优先级任务,是则pop
if (currentTask === peek(taskQueue)) {
pop(taskQueue);
}
}
// 检测是否有过期的任务,放在taskQueue队列中
advanceTimers(currentTime);
} else {
// 任务被取消,出堆
pop(taskQueue);
}
// 更新currentTask继续循环
currentTask = peek(taskQueue);
}
if (currentTask !== null) {
// 走到这个判断会有两种情况
// callback返回一个函数 或者 达到当前deadline(默认5ms的限制)
return true;
} else {
const firstTimer = peek(timerQueue);
if (firstTimer !== null) {
// taskQueue中已经没有可执行的任务了,取出timerQueue中的任务,进行调度
requestHostTimeout(handleTimeout, firstTimer.startTime - currentTime);
}
return false;
}
}总结下大致流程:通过将任务划分成立即执行和延迟执行两个堆,立即执行的堆中任务会通过MessageChannel触发,延迟执行的堆会通过setTimeout将任务延迟到对应事件后添加进taskQueue中触发。
每次 workLoop 都会从taskQueue中取出任务,执行任务,如果任务执行完之后还有剩余时间,则继续执行,直到没有剩余时间或者任务队列为空。如果 5ms 到了,但是还有任务,则通过 postMessage 开启下一轮 workLoop。达到让出主线程的能力
Http:
Https:
传输层安全协议(TSL) 或 安全套接层协议(SSL) 对通讯协议进行加密,也就是 HTTP + SSL(TLS) = HTTPSssl通信后,ssl再和tcp通信私钥A和公钥A,公钥A传给浏览器密钥X,用公钥A将密钥X加密,传给服务器私钥A解密出密钥X,这样双方都有密钥X密钥X进行加密解密每次进行HTTPS请求时都必须在SSL/TLS层进行握手传输密钥吗?
sessionID,在TSL握手阶段传给浏览器sessionID下每次请求都会携带sessionID,服务器通过sessionID找到对应的密钥,进行加密解密操作中间人攻击
私钥A和公钥A,公钥A传给浏览器公钥A换成自己的公钥B(同时也拥有私钥B),传给浏览器密钥X,使用公钥B加密密钥X密钥X,其根本原因是浏览器无法确认收到的公钥是不是网站自己的如何证明浏览器拿到的公钥一定是该网站的公钥?
数字证书
数字证书CA机构申领一份数字证书,数字证书中由公钥信息、持有者信息等,服务器把证书传给浏览器,浏览器从证书中获取对应网站的公钥证书本身的传输过程中,如何防止被篡改?
数字签名
数字签名公钥和私钥明文数据T获取hash值私钥加密,得到数字签名s明文和数字签名共同组成数字证书,颁发给网站明文T和数字签名s公钥将数字签名进行解密,得到hash值hash算法将明文T进行hash,得到计算后的hash值hash值相等,证书可信网站B也拿到了CA机构认证的证书,它想劫持网站A的信息。于是它成为中间人拦截到了A传给浏览器的证书,然后替换成自己的证书,传给浏览器,之后浏览器就会错误地拿到B的证书里的公钥了,会有这种情况吗?请求网站的域名与证书中的域名进行比对,就知道有没有被掉包SSL/TSL:
SSL被更名为TLS网站和公司信息 绑定到加密密钥,每一个密钥对都有一个私有密钥一个共有密钥,用私钥解密公钥加密的信息对称加密和 非对称加密 两种形式。对称加密
AES-128, AES-192、AES-256 和 ChaCha20。非对称加密
RSA 加密算法是最重要的、最出名的一个HTTP请求报文
请求⾏:
GET /index.html HTTP/1.1。请求头部:
空⾏
请求体
post put等请求携带的数据HTTP响应报文
HTTP/1.1 200 OK 。UDP
应用层将数据传递给传输层的 UDP 协议,UDP 只会给数据增加一个 UDP 头,标识下是 UDP 协议,然后就传递给网络层了UDP对应用程序交下来的报文,在添加首部后就向下交付IP层。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。因此,应用程序必须选择合适大小的报文TCP和UDP的区别
TCP是一个面向连接的、可靠的、基于字节流的传输层协议,UDP是一个面向无连接的传输层协议UDP 相比TCP三大核心特征:
TCP三次握手
发送能力和接收能力CLOSED状态,服务端监听某个端口,变成LISTEN状态SYN=1报文段(同步位),随机产生sep(初始序列号),要求建立连接,变成SYN-SENT状态SYN和ACK(acknowledgement 确认)都为1,以及ack( Acknowledge number确认号)(对应客户端的seq+1),为自己随机产生seq,变成SYN-RCVD状态ACK=1以及ack(对应服务端seq+1),状态变成ESTABLISHEDACK和ack,对比ack是否和seq值相同,状态变成ESTABLISHED,连接建立TCP四次挥手
ESTABLISHED状态,当客户端主动关闭,服务端被动关闭(双方都可主动与另一方释放连接)FIN=1,seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1)客户端进入FIN-WAIT-1ACK=1、ack=u+1并生成seq=v,状态变为CLOSE-WAIT。服务器通知上层的应用进程,客户端向服务器的方向连接关闭,此时TCP连接处于半关闭状态,虽然此时客户端已经没有数据要发送了,但是服务器如果要发送数据给客户端,客户端还是要接受。FIN-WAIT-2状态。等待服务器发送连接释放报文。FIN=1、ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,进入LAST-ACK状态.TIME-WAIT状态,然后发送 ACK=1 ack=w+1 给服务端,而自己的序列号是seq=u+1。MSL(Maximum Segment Lifetime,报文最大生存时间)(4分钟), 在这段时间内如果客户端没有收到服务端的重发请求,那么表示 ACK 成功到达,挥手结束,否则客户端重发 ACK。2XX(Success 成功状态码)
201 - Created 文档创建成功,比如新增一个user成功
202 - Accepted 请求已被接受,但相应的操作可能尚未完成。这用于后台操作,例如数据库压缩等异步操作
204 - No Content 该状态码表示客户端发送的请求已经在服务器端正常处理了,但是没有返回的内容,响应报文中不包含实体的主体部分。一般用于只需要从客户端往服务器端发送信息,而服务器端不需要往客户端发送内容时使用。
206 Partial Content 该状态码表示客户端进行了范围请求,而服务器端执行了这部分的 GET 请求。响应报文中包含由 Content-Range 指定范围的实体内容。
3XX(表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。)
300 - Multiple Choices 针对请求,服务器可执行多种操作
301 - Moved Permanently 请求的网页已永久移动到新位置
302 - redirect 代表暂时性转移,一些旧客户端会将请求方法错误的更改为GET(尽管302标准禁止post变化get,但实际使用时大家并不太遵守)(http1.0的协议状态码)
303 - See Other 该状态码表示由于请求对应的资源存在着另一个URI,应使用GET方法定向获取请求的资源(302状态码有着相同的功能,但是303明确表示客户端应当采用GET方法获取资源,把POST请求变为GET请求进⾏重定向)(http1.1的协议状态码)
304 - Not Modified 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容
305 - Use Proxy 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
307 - Temporary Redirect 代表暂时性转移,不会更改请求方法和消息主体(与302有相同的含义)(http1.1的协议状态码)
4XX(Client Error 客户端错误状态码)
400 - Bad Request 参数错误401 - Unauthorized 未被授权403 - Forbidden 请求被拒绝405 - Method Not Allowed 请求类型错误,例如不支持post但用post请求406 - Not Acceptable 服务器不支持请求的content-type413 - Request Entity Too Large 请求体太大不支持,一般是上传的文件超出了限定导致的5XX(Server Error 服务器错误状态码)
500 - Internal Server Error 表示服务端在执行请求时发生了错误。 可能是服务器或者应用存在bug503 - Service Unavailable 服务不可用,现在无法处理请求。强缓存
status code: 200不和服务器交互
协商缓存
status code: 304强缓存失效就走协商缓存
与服务器交互
响应头 Last-Modified响应头 EtagEtag / If-None-Match优先级高于Last-Modified / If-Modified-Since,同时存在则只有Etag / If-None-Match生效缓存位置
图像和网页等资源主要缓存在disk cache,操作系统缓存文件(如.JS)等资源大部分都会缓存在memory cache中。具体操作浏览器自动分配,看谁的资源利用率不高就分给谁。Memory Cache 胜在容量和存储时效性上。HTTP/2 中的内容,当以上三种缓存(以上两种和service-worker)都没有命中时,它才会被使用。它只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在Chrome浏览器中只有5分钟左右,同时它也并非严格执行HTTP头中的缓存指令。二进制分帧层
HTTP2是二进制协议,他采用二进制格式传输数据而不是1.x的文本格式。1.1响应是文本格式,而2.0把响应划分成了两个帧,HEADERS(首部)和DATA(消息负载)多路复用
HTTP2建立一个TCP连接,一个连接上面可以有任意多个流(stream),所有的通信都在一个TCP连接上完成,真正实现了请求的并发头部压缩
HTTP2为此采用HPACK压缩格式来压缩首部。头部压缩需要在浏览器和服务器端之间:
例如要传输method:GET,那我们只需要传输静态字典里面method:GET对应的索引值就可以了,一个字节搞定。
像user-agent、cookie这种静态字典里面只有首部名称而没有值的首部,第一次传输需要user-agent在静态字典中的索引以及他的值,值会采用静态Huffman编码来减小体积。第一次传输过user-agent之后呢,浏览器和服务器端就会把它添加到自己的动态字典中。后续传输就可以传输索引了,一个字节搞定。
服务器端推送
index.htm,服务器端能够额外推送.js和.css。参考:
HTTP Request Header 常见的请求头:
HTTP Responses Header 常见的响应头:
参考:
GET方法URL长度限制的原因
get方法请求的url长度进行限制,这个限制是特定的浏览器及服务器对它的限制。2083字节(2K+35)。由于IE浏览器对URL长度的允许值是最小的,所以开发过程中,只要URL不超过2083字节GET和POST的请求的区别
应用场景: GET 请求是一个幂等的请求,一般 Get 请求用于对服务器资源不会产生影响的场景,比如说请求一个网页的资源。而 Post 不是一个幂等的请求,一般用于对服务器资源会产生影响的情景,比如注册用户这一类的操作
Get 请求缓存,但很少对 Post 请求缓存。Get 请求的报文中实体部分为空,Post 请求的报文中实体部分一般为向服务器发送的数据。Get 请求可以将请求的参数放入 url 中向服务器发送,这样的做法相对于 Post 请求来说是不太安全的,因为请求的 url 会被保留在历史记录中。url 长度的限制,所以会影响 get 请求发送数据时的长度。这个限制是浏览器规定的,并不是 RFC 规定的。post 的参数传递支持更多的数据类型。POST和PUT请求的区别
PUT请求是向服务器端发送数据,从而修改数据的内容,但是不会增加数据的种类等,也就是说无论进行多少次PUT操作,其结果并没有不同。(可以理解为时更新数据)POST请求是向服务器端发送数据,该请求会改变数据的种类等资源,它会创建新的内容。(可以理解为是创建数据)OPTIONS请求方法及使用场景
HTTP请求方法;CORS 跨域资源共享时,对于复杂请求,就是使用 OPTIONS 方法发送嗅探请求,以判断是否有对指定资源的访问权限。参考:
DNS 协议是什么
DNS完整的查询过程
DNS查询过程例子
www.baidu.com的 IP 地址DNS服务器向根域名服务器发送一个请求,根域名服务器返回负责 .com 的顶级域名服务器的 IP 地址的列表DNS 服务器再向其中一个负责 .com 的顶级域名服务器发送一个请求,负责 .com 的顶级域名服务器返回负责 .baidu 的权威域名服务器的 IP 地址列表迭代查询与递归查询
OSI七层模型
OSI参考模型中最靠近用户的一层,是为计算机用户提供应用接口,也为用户直接提供各种网络服务。我们常见应用层的网络服务协议有:HTTP,HTTPS,FTP,POP3、SMTP等。应用层数据的编码和转换功能**,确保一个系统的应用层发送的数据能被另一个系统的应用层识别base64对数据进行编解码。如果按功能来划分,base64应该是工作在表示层。表示层实体之间的通信会话。TCP UDP就是在这一层。端口号既是这里的“端”。IP寻址来建立两个节点之间的连接,为源端的运输层送来的分组,选择合适的路由和交换节点,正确无误地按照地址传送给目的端的运输层。这一层就是我们经常说的IP协议层。IP协议是Internet的基础。网络层规定了数据包的传输路线,而传输层则规定了数据包的传输方式。网络层与数据链路层的对比,通过上面的描述,我们或许可以这样理解,网络层是规划了数据包的传输路线,而数据链路层就是传输路线。不过,在数据链路层上还增加了差错控制的功能。对等层进行通信,这种通信方式称为对等层通信**。在每一层通信过程中,使用本层自己协议进行通信**。Array.prototype.flat
function flat(/* depthArg = 1 */) {
// 函数名花里胡哨的,其实很好理解
// 拿到参数
var depthArg = arguments.length ? arguments[0] : undefined;
// if(this==undefined) 判断,否返回Objec(this)
var O = toObject(this);
// lengthOfArrayLike => toLength(obj.length)
// 其实就是拿到数组的length 规范length的边界为有效整数(2 ** 53 - 1)
var sourceLen = lengthOfArrayLike(O);
// 相当于new Array(0)
// 拿到数组的构造函数 并new 不赘述,感兴趣可以去看源码实现
var A = arraySpeciesCreate(O, 0);
// 核心
A.length = flattenIntoArray(A, O, O, sourceLen, 0, depthArg === undefined ? 1 : toIntegerOrInfinity(depthArg));
return A;
}Array.prototype.flatMap
function flatMap(callbackfn /* , thisArg */) {
var O = toObject(this);
var sourceLen = lengthOfArrayLike(O);
var A;
// typeof callbackfn == 'function'
aCallable(callbackfn);
A = arraySpeciesCreate(O, 0);
// 与flat不同的是多了个callbackfn和thisArg depthArg写死为1
A.length = flattenIntoArray(A, O, O, sourceLen, 0, 1, callbackfn, arguments.length > 1 ? arguments[1] : undefined);
return A;
}flattenIntoArray:
/**
*
* @param {*} target 目标数组
* @param {*} original 原数组,用于mapper
* @param {*} source 当前遍历数组
* @param {*} sourceLen 当前遍历数组长度
* @param {*} start target中下一位索引值
* @param {*} depth 拍平深度
* @param {*} mapper 遍历函数
* @param {*} thisArg 遍历函数上下文
* @returns
*/
var flattenIntoArray = function (target, original, source, sourceLen, start, depth, mapper, thisArg) {
var targetIndex = start;
var sourceIndex = 0;
// 绑定函数上下文
var mapFn = mapper ? bind(mapper, thisArg) : false;
var element, elementLen;
// 开始遍历
while (sourceIndex < sourceLen) {
// 判断索引有效
if (sourceIndex in source) {
// 处理遍历函数返回值,没有遍历函数则返回当前项
// 每次遇到数组时都会执行
element = mapFn ? mapFn(source[sourceIndex], sourceIndex, original) : source[sourceIndex];
// 遇到数组并且存在有效depth
if (depth > 0 && isArray(element)) {
elementLen = lengthOfArrayLike(element);
// 递归
targetIndex = flattenIntoArray(target, original, element, elementLen, targetIndex, depth - 1) - 1;
} else {
// 如果拍平结束或者不是数组
// 判断数组长度的有效值
if (targetIndex >= 0x1FFFFFFFFFFFFF) throw TypeError('Exceed the acceptable array length');
// 设置对应值
target[targetIndex] = element;
}
// 索引++
targetIndex++;
}
sourceIndex++;
}
return targetIndex;
};targetIndex是关键,始终穿插在各层数组中记录索引,例如:
[1,[2,3]]
第一轮循环,targetIndex=0 target赋值之后 targetIndex++
第二轮循环,为数组,递归遍历[2,3],不为数组 target[targetIndex]=2 => target[1]=2
然后 targetIndex++
然后 target[targetIndex]=3 => target[2]=3
target=[1,2,3]Array.prototype.fill:
function toIntegerOrInfinity(argument) {
// 转换为number
// +undefined = NaN
// +null = 0
var number = +argument;
// eslint-disable-next-line no-self-compare -- safe
// 取小值 例如 1.1取1 -1.1取-2
// number !== number 判断NaN情况
// number === 0 判断0和null情况
return number !== number || number === 0 ? 0 : (number > 0 ? floor : ceil)(number);
}
function toAbsoluteIndex(index, length) {
// 先对第一个参数取整
var integer = toIntegerOrInfinity(index);
// 小于0取0 大于0取自身
return integer < 0 ? max(integer + length, 0) : min(integer, length);
}
function fill(value /* , start = 0, end = @length */) {
// if(this==undefined) 判断,否返回Objec(this)
var O = toObject(this);
// 与数组length与2**53-1 取小值(Math.min)
var length = lengthOfArrayLike(O);
var argumentsLength = arguments.length;
// start参数初始化
var index = toAbsoluteIndex(argumentsLength > 1 ? arguments[1] : undefined, length);
var end = argumentsLength > 2 ? arguments[2] : undefined;
// end参数初始化 默认为length
var endPos = end === undefined ? length : toAbsoluteIndex(end, length);
// 遍历填充值
while (endPos > index) O[index++] = value;
return O;
}O[index++] = value; 直接赋值操作,如果value为引用类型,一旦`value某些属性更改,那么所有填充的值都会被更改Array.prototype.{ forEach, map, filter, some, every, find, findIndex, filterReject }以上函数的核心实现函数
var createMethod = function (TYPE) {
var IS_MAP = TYPE == 1;
var IS_FILTER = TYPE == 2;
var IS_SOME = TYPE == 3;
var IS_EVERY = TYPE == 4;
var IS_FIND_INDEX = TYPE == 6;
var IS_FILTER_REJECT = TYPE == 7;
var NO_HOLES = TYPE == 5 || IS_FIND_INDEX;
return function ($this, callbackfn, that, specificCreate) {
// if(this==undefined) 判断,否返回Objec(this)
var O = toObject($this);
var self = IndexedObject(O);
// callbackfn绑定上下文,一般是第三个参数
var boundFunction = bind(callbackfn, that);
// 取数组length与2**53-1 取小值(Math.min)
var length = lengthOfArrayLike(self);
var index = 0;
// 创建数组
// 具体实现有兴趣可以查看相关源码
var create = specificCreate || arraySpeciesCreate;
// 创建最终返回结果
// map => new Array(length)
// filter/filterReject => new Array(0)
// 其余为 undefined
var target = IS_MAP ? create($this, length) : IS_FILTER || IS_FILTER_REJECT ? create($this, 0) : undefined;
var value, result;
for (;length > index; index++) if (NO_HOLES || index in self) {
// find/findIndex 或者 有效索引
value = self[index];
// 执行callbackfn拿到结果
result = boundFunction(value, index, O);
if (TYPE) {
// 排除了forEach
if (IS_MAP) target[index] = result; // map修改索引对应值
else if (result) switch (TYPE) {
// 只要出现一次true
case 3: return true; // some 只要有一项返回true就返回true
case 5: return value; // find 直接返回值
case 6: return index; // findIndex 直接返回值的索引
case 2: push(target, value); // filter => target.push(value)
} else switch (TYPE) {
// 只要出现一次false
case 4: return false; // every
case 7: push(target, value); // filterReject
}
}
}
// findIndex没找到返回-1
// 如果是every此时result应该全为true,所以返回false
// 如果是some此时result应该全为false,所以判断是否是every函数即可
// 除此之外的函数都返回target
return IS_FIND_INDEX ? -1 : IS_SOME || IS_EVERY ? IS_EVERY : target;
};
};
module.exports = {
// `Array.prototype.forEach` method
// https://tc39.es/ecma262/#sec-array.prototype.foreach
forEach: createMethod(0),
// `Array.prototype.map` method
// https://tc39.es/ecma262/#sec-array.prototype.map
map: createMethod(1),
// `Array.prototype.filter` method
// https://tc39.es/ecma262/#sec-array.prototype.filter
filter: createMethod(2),
// `Array.prototype.some` method
// https://tc39.es/ecma262/#sec-array.prototype.some
some: createMethod(3),
// `Array.prototype.every` method
// https://tc39.es/ecma262/#sec-array.prototype.every
every: createMethod(4),
// `Array.prototype.find` method
// https://tc39.es/ecma262/#sec-array.prototype.find
find: createMethod(5),
// `Array.prototype.findIndex` method
// https://tc39.es/ecma262/#sec-array.prototype.findIndex
findIndex: createMethod(6),
// `Array.prototype.filterReject` method
// https://github.com/tc39/proposal-array-filtering
filterReject: createMethod(7)
};IndexedObject
fails(function () {
// 针对非数组(如ES3)和不可枚举的旧V8字符串的回退
// throws an error in rhino, see https://github.com/mozilla/rhino/issues/346
// eslint-disable-next-line no-prototype-builtins -- safe
// 判断字符串是否可枚举
return !Object('z').propertyIsEnumerable(0);
}) ? function (it) {
// 如果是字符串,切分为数组
return classof(it) == 'String' ? split(it, '') : Object(it);
} : Object;result = boundFunction(value, index, O);遍历函数第三个参数一般为原始数组,很少用到
流程:遍历数组,先排除没有返回值的,some,find,findIndex,every 函数都为短路判断,只要出现一次false/true就返回。
es.array.reduce.js
var $reduce = require('../internals/array-reduce').left;
$({ target: 'Array', proto: true, forced: !STRICT_METHOD || CHROME_BUG }, {
// 关注下面这部分
reduce: function reduce(callbackfn /* , initialValue */) {
var length = arguments.length;
return $reduce(this, callbackfn, length, length > 1 ? arguments[1] : undefined);
}
});array-reduce.js
var createMethod = function (IS_RIGHT) {
/**
* that 上下文
* callbackfn 回调函数
* argumentsLength 参数长度
* memo 上一轮循环返回值
*/
return function (that, callbackfn, argumentsLength, memo) {
// typeof callbackfn === ‘function’
aCallable(callbackfn);
// var O = Object(that)
var O = toObject(that);
// 判断是String还是Array,是String则split为数组
var self = IndexedObject(O);
// 返回数组长度
var length = lengthOfArrayLike(O);
// 初始化索引,reduceRight初始索引为最后一项
var index = IS_RIGHT ? length - 1 : 0;
// 判断每次循环+1\-1
var i = IS_RIGHT ? -1 : 1;
// 如果reduce/reduceRight入参只有一项,没有初始值时
if (argumentsLength < 2) while (true) {
if (index in self) {
// 则memo为数组第一项/最后一项
memo = self[index];
index += i;
break;
}
index += i;
if (IS_RIGHT ? index < 0 : length <= index) {
throw TypeError('Reduce of empty array with no initial value');
}
}
for (;IS_RIGHT ? index >= 0 : length > index; index += i) if (index in self) {
// 执行回调
memo = callbackfn(memo, self[index], index, O);
}
return memo;
};
};
module.exports = {
// `Array.prototype.reduce` method
// https://tc39.es/ecma262/#sec-array.prototype.reduce
left: createMethod(false),
// `Array.prototype.reduceRight` method
// https://tc39.es/ecma262/#sec-array.prototype.reduceright
right: createMethod(true)
};array-from.js
module.exports = function from(arrayLike /* , mapfn = undefined, thisArg = undefined */) {
// if(this==undefined) 判断,否返回Objec(this)
var O = toObject(arrayLike);
// 判断是否是构造函数
// 判断this不是function或者调用reflect.construct(function(){},[],this),返回false,否则返回true
var IS_CONSTRUCTOR = isConstructor(this);
var argumentsLength = arguments.length;
var mapfn = argumentsLength > 1 ? arguments[1] : undefined;
var mapping = mapfn !== undefined;
// 相当于 mapfn = mapfn.bind(thisArg,argumentsLength > 2 ? arguments[2] : undefined)
if (mapping) mapfn = bind(mapfn, argumentsLength > 2 ? arguments[2] : undefined);
// 获取迭代器或者默认迭代器
// 相当于 O[Symbol['iterator']]
var iteratorMethod = getIteratorMethod(O);
var index = 0;
var length, result, step, iterator, next, value;
// 如果目标是不可迭代的或者它是一个带有默认迭代器的数组
if (iteratorMethod && !(this == Array && isArrayIteratorMethod(iteratorMethod))) {
// 相当于 iteratorMethod.call(O),iterator为迭代器执行之后的对象
iterator = getIterator(O, iteratorMethod);
next = iterator.next;
// 如果有构造函数,则new,否则为[]
result = IS_CONSTRUCTOR ? new this() : [];
// (step = iterator.next()).done
for (;!(step = call(next, iterator)).done; index++) {
// 相当于 value = mapfn(step.value,index)
value = mapping ? callWithSafeIterationClosing(iterator, mapfn, [step.value, index], true) : step.value;
// result插入对应值
createProperty(result, index, value);
}
} else {
length = lengthOfArrayLike(O);
// 创建对应长度的数组
result = IS_CONSTRUCTOR ? new this(length) : Array(length);
for (;length > index; index++) {
// 遍历插入对应值
value = mapping ? mapfn(O[index], index) : O[index];
createProperty(result, index, value);
}
}
result.length = index;
return result;
};根据数组长度不同,用到了两个算法,分别是插入和归并
es.array.sort.js
var getSortCompare = function (comparefn) {
return function (x, y) {
// 使用陷阱,注意undefined的情况
if (y === undefined) return -1;
if (x === undefined) return 1;
if (comparefn !== undefined) return +comparefn(x, y) || 0;
// 没有comparefn默认从大到小排序
return toString(x) > toString(y) ? 1 : -1;
};
};
sort: function sort(comparefn) {
if (comparefn !== undefined) aCallable(comparefn);
var array = toObject(this);
// 通过判断版本判断是否使用原生sort,以及对Chakra和v8的错误情况判断
if (STABLE_SORT) return comparefn === undefined ? un$Sort(array) : un$Sort(array, comparefn);
var items = [];
var arrayLength = lengthOfArrayLike(array);
var itemsLength, index;
for (index = 0; index < arrayLength; index++) {
// 相当于items.push(array[index])
if (index in array) push(items, array[index]);
}
// 重点
// internalSort就是下文的mergeSort函数 负责计算排序
// getSortCompare负责初始化比较函数
internalSort(items, getSortCompare(comparefn));
itemsLength = items.length;
index = 0;
while (index < itemsLength) array[index] = items[index++];
while (index < arrayLength) delete array[index++];
return array;
}array-sort.js
插入和归并就不多介绍了
var mergeSort = function (array, comparefn) {
var length = array.length;
var middle = floor(length / 2);
// 长度小于8,使用插入排序,大于则使用归并排序
return length < 8 ? insertionSort(array, comparefn) : merge(
array,
mergeSort(arraySlice(array, 0, middle), comparefn),
mergeSort(arraySlice(array, middle), comparefn),
comparefn
);
};
var insertionSort = function (array, comparefn) {
// 插入排序
var length = array.length;
var i = 1;
var element, j;
while (i < length) {
j = i;
element = array[i];
while (j && comparefn(array[j - 1], element) > 0) {
array[j] = array[--j];
}
if (j !== i++) array[j] = element;
} return array;
};
var merge = function (array, left, right, comparefn) {
// 归并排序
var llength = left.length;
var rlength = right.length;
var lindex = 0;
var rindex = 0;
while (lindex < llength || rindex < rlength) {
array[lindex + rindex] = (lindex < llength && rindex < rlength)
? comparefn(left[lindex], right[rindex]) <= 0 ? left[lindex++] : right[rindex++]
: lindex < llength ? left[lindex++] : right[rindex++];
} return array;
};实现构造函数(resolve情况)\Promise.resolve,未实现函数后续再更新
const share = new WeakMap();
var PENDING = 0;
var FULFILLED = 1;
var REJECTED = 2;
let call = Function.prototype.call;
call = Function.prototype.call ? call.bind(call) : () => {};
function bind(fn, state, wrapper) {
return function (value) {
fn(state, value, wrapper);
};
}
function getInternalState(key) {
return share.get(key);
}
var Queue = function () {
this.head = null;
this.tail = null;
};
Queue.prototype = {
add: function (item) {
var entry = { item: item, next: null };
if (this.head) this.tail.next = entry;
else this.head = entry;
this.tail = entry;
},
get: function () {
var entry = this.head;
if (entry) {
this.head = entry.next;
if (this.tail === entry) this.tail = null;
return entry.item;
}
},
};
function internal(callback) {
if (share.get(this)) {
return share.raw;
}
share.set(this, {
done: false,
notified: false,
parent: false,
reactions: new Queue(),
rejection: false,
state: PENDING,
value: undefined,
raw: this,
});
}
function callReaction(reaction, state) {
var value = state.value;
var ok = state.state == FULFILLED;
// 对应then中参数 reaction.ok没传默认为true
var handler = ok ? reaction.ok : reaction.fail;
var resolve = reaction.resolve;
var reject = reaction.reject;
var domain = reaction.domain;
var result, then, exited;
try {
if (handler) {
// then(有参数)情况
if (!ok) {
//
if (state.rejection === UNHANDLED) onHandleUnhandled(state);
state.rejection = HANDLED;
}
// FULFILLED并且then(没有第一个参数)情况
if (handler === true) result = value;
else {
// node环境下
if (domain) domain.enter();
// 执行then中函数
result = handler(value); // can throw
if (domain) {
domain.exit();
exited = true;
}
}
if (result === reaction.promise) {
// result对应resolve()中传递的参数
// result为当前promise实例
reject(TypeError("Promise-chain cycle"));
}
// thenable情况
// else if ((then = isThenable(result))) {
// call(then, result, resolve, reject);
// }
else resolve(result);
} else reject(value); // ok为false 并且then中未传第二个参数
} catch (error) {
if (domain && !exited) domain.exit();
reject(error);
}
}
function notify(state, isReject) {
if (state.notified) return;
state.notified = true;
queueMicrotask(function () {
var reactions = state.reactions;
var reaction;
while ((reaction = reactions.get())) {
callReaction(reaction, state);
}
state.notified = false;
if (isReject && !state.rejection) onUnhandled(state);
});
}
function newPromiseCapability(C) {
let resolve, reject;
this.promise = new C(function ($$resolve, $$reject) {
resolve = $$resolve;
reject = $$reject;
});
this.resolve = resolve;
this.reject = reject;
}
function isCallable(argument) {
return typeof argument == "function";
}
function isObject(it) {
return typeof it == "object" ? it !== null : isCallable(it);
}
var isThenable = function (it) {
var then;
return isObject(it) && isCallable((then = it.then)) ? then : false;
};
function PromiseConstructor(executor) {
internal.call(this);
const state = getInternalState(this);
executor(bind(internalResolve, state), bind(internalReject, state));
}
function internalResolve(state, value, wrapper) {
if (state.done) return;
state.done = true;
if (wrapper) state = wrapper;
if (state.raw === value) return; // 报错
// 忽略thenable情况
var then = isThenable(value);
if (then) {
queueMicrotask(function () {
var wrapper = { done: false };
// try {
call(
then,
value,
bind(internalResolve, wrapper, state),
bind(internalReject, wrapper, state)
);
// }
// catch (error) {
// internalReject(wrapper, error, state);
// }
});
} else {
state.value = value;
state.state = FULFILLED;
notify(state, false);
}
}
function internalReject() {}
PromiseConstructor.prototype.then = function (onFulfilled, onRejected) {
var state = getInternalState(this);
var reaction = new newPromiseCapability(PromiseConstructor);
state.parent = true;
reaction.ok = isCallable(onFulfilled) ? onFulfilled : true;
reaction.fail = isCallable(onRejected) && onRejected;
// node环境
// reaction.domain = IS_NODE ? process.domain : undefined;
if (state.state == PENDING) state.reactions.add(reaction);
// 如果当前state为pending则将新创建的promise实例添加进队列
// 否则就当成微任务处理
else
queueMicrotask(function () {
callReaction(reaction, state);
});
// 链式调用
return reaction.promise;
};
PromiseConstructor.resolve = function resolve(x) {
const p = new newPromiseCapability(PromiseConstructor);
p.resolve(x);
return p.promise;
};
const p = new PromiseConstructor((res) => {
console.log(1);
setTimeout(() => {
res(2);
}, 1000);
})
.then((res) => {
console.log("res", res);
return PromiseConstructor.resolve("a");
})
.then((res) => {
console.log(res);
});p.then1().then2()state(state),执行resolve(或延迟执行,视调用情况而定),触发notify(),将会遍历reactions,并执行callReactionthen1创建state1,并new出一个拥有promise功能的对象(p1),将其放在state.reactions中,返回p1.promisethen2创建state2,并new出一个拥有promise功能的对象(p2),将其放在state1.reactions,返回p2.promisenotify挂载的微任务触发,执行callReaction,执行对应的reactions,拿到执行结果result,然后执行resolve,触发下一个notifyreaction保存resolve或reject之后需要触发的函数(也就是then的两个参数)notify用来触发reaction,因为notify会将reaction触发时机变为微任务,所以可以顺利的通过then函数添加reactionthen函数返回一个promise时,这个promise会被执行then,即使没有主动调用thenresolve(internalResolve)函数,只会在第一个new Promise时显式调用[TOC]
参考:
一个
DOM节点在某一时刻最多会有4个节点和他相关。
current Fiber。如果该DOM节点已在页面中,current Fiber代表该DOM节点对应的Fiber节点。workInProgress Fiber。如果该DOM节点将在本次更新中渲染到页面中,workInProgress Fiber代表该DOM节点对应的Fiber节点。DOM节点本身。JSX对象。即ClassComponent的render方法的返回结果,或FunctionComponent的调用结果。JSX对象中包含描述DOM节点的信息。
Diff算法的本质是对比1和4,生成2。
为了降低算法复杂度,React的diff会预设三个限制:
只对同级元素进行Diff。如果一个DOM节点在前后两次更新中跨越了层级,那么React不会尝试复用他。
两个不同类型的元素会产生出不同的树。如果元素由div变为p,React会销毁div及其子孙节点,并新建p及其子孙节点。
开发者可以通过 key prop来暗示哪些子元素在不同的渲染下能保持稳定。考虑如下例子:
// 更新前
<div>
<p key="ka">ka</p>
<h3 key="song">song</h3>
</div>
// 更新后
<div>
<h3 key="song">song</h3>
<p key="ka">ka</p>
</div>如果没有key,React会认为div的第一个子节点由p变为h3,第二个子节点由h3变为p。这符合限制2的设定,会销毁并新建。
但是当我们用key指明了节点前后对应关系后,React知道key === "ka"的p在更新后还存在,所以DOM节点可以复用,只是需要交换下顺序。
实现:
- 当
newChild类型为object、number、string,代表同级只有一个节点- 当
newChild类型为Array,同级有多个节点
我们从Diff的入口函数reconcileChildFibers出发,该函数会根据newChild(即JSX对象)类型调用不同的处理函数。
// 根据newChild类型选择不同diff函数处理
function reconcileChildFibers(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChild: any,
): Fiber | null {
const isObject = typeof newChild === 'object' && newChild !== null;
if (isObject) {
// object类型,可能是 REACT_ELEMENT_TYPE 或 REACT_PORTAL_TYPE
switch (newChild.$$typeof) {
case REACT_ELEMENT_TYPE:
// 调用 reconcileSingleElement 处理
// // ...省略其他case
}
}
if (typeof newChild === 'string' || typeof newChild === 'number') {
// 调用 reconcileSingleTextNode 处理
// ...省略
}
if (isArray(newChild)) {
// 调用 reconcileChildrenArray 处理
// ...省略
}
// 一些其他情况调用处理函数
// ...省略
// 以上都没有命中,删除节点
return deleteRemainingChildren(returnFiber, currentFirstChild);
}单节点Diff:
不论当前节点个数,此次更新的节点为单个的情况
以object类型为例,会进入reconcileSingleElement函数
const isObject = typeof newChild === 'object' && newChild !== null;
if (isObject) {
// 对象类型,可能是 REACT_ELEMENT_TYPE 或 REACT_PORTAL_TYPE
switch (newChild.$$typeof) {
case REACT_ELEMENT_TYPE:
// 调用 reconcileSingleElement 处理
// ...其他case
}
}reconcileSingleElement:
function reconcileSingleElement(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
element: ReactElement
): Fiber {
const key = element.key;
let child = currentFirstChild;
// 首先判断是否存在对应DOM节点
while (child !== null) {
// 上一次更新存在DOM节点,接下来判断是否可复用
// 首先比较key是否相同
if (child.key === key) {
// key相同,接下来比较type是否相同
switch (child.tag) {
// ...省略case
default: {
if (child.elementType === element.type) {
// type相同则表示可以复用
// 返回复用的fiber
return existing;
}
// type不同则跳出switch
break;
}
}
// 代码执行到这里代表:key相同但是type不同
// 将该fiber及其兄弟fiber标记为删除
deleteRemainingChildren(returnFiber, child);
break;
} else {
// key不同,将该fiber标记为删除
deleteChild(returnFiber, child);
}
child = child.sibling;
}
// 创建新Fiber,并返回 ...省略
}总结:
key,key相同,判断type,相同则复用,不同则删除当前fiber和兄弟fiber
fiber?
key相同,type不同。既然唯一的可能性(key代表唯一标识)都不能复用,那么剩下的fiber都没有机会了,自然被删除。key不同则删除当前fiber多节点Diff:
一个JSX对象,children属性为数组,就会走到reconcileChildrenArray函数
{
$$typeof: Symbol(react.element),
key: null,
props: {
children: [
{$$typeof: Symbol(react.element), type: "li", key: "0", ref: null, props: {…}, …}
{$$typeof: Symbol(react.element), type: "li", key: "1", ref: null, props: {…}, …}
{$$typeof: Symbol(react.element), type: "li", key: "2", ref: null, props: {…}, …}
{$$typeof: Symbol(react.element), type: "li", key: "3", ref: null, props: {…}, …}
]
},
ref: null,
type: "ul"
}几种情况:
节点更新:
// 之前
<ul>
<li key="0" className="before">0<li>
<li key="1">1<li>
</ul>
// 之后 情况1 —— 节点属性变化
<ul>
<li key="0" className="after">0<li>
<li key="1">1<li>
</ul>
// 之后 情况2 —— 节点类型更新
<ul>
<div key="0">0</div>
<li key="1">1<li>
</ul>节点新增或减少
节点位置变化
同级多个节点的Diff,一定属于以上三种情况中的一种或多种。
实现:
React团队发现,在日常开发中,更新组件相较于新增和删除,发生的频率更高。所以Diff会优先判断当前节点是否属于更新。
注意
在我们做数组相关的算法题时,经常使用双指针从数组头和尾同时遍历以提高效率,但是这里却不行。
虽然本次更新的
JSX对象newChildren为数组形式,但是和newChildren中每个组件进行比较的是current fiber,同级的Fiber节点是由sibling指针链接形成的单链表,即不支持双指针遍历。即
newChildren[0]与fiber比较,newChildren[1]与fiber.sibling比较。所以无法使用双指针优化。
基于以上原因,Diff算法的整体逻辑会经历两轮遍历:
第一轮遍历:处理更新的节点。
let i = 0,遍历newChildren,将newChildren[i]与oldFiber比较,判断DOM节点是否可复用。
如果可复用,i++,继续比较newChildren[i]与oldFiber.sibling,可以复用则继续遍历。
如果不可复用,分两种情况:
key不同导致不可复用,立即跳出整个遍历,第一轮遍历结束。
// 之前
<li key="0">0</li>
<li key="1">1</li>
<li key="2">2</li>
// 之后
<li key="0">0</li>
<li key="2">1</li>
<li key="1">2</li>key === 2的节点发现key改变,不可复用,跳出遍历,等待第二轮遍历处理。oldFiber剩下key === 1、key === 2未遍历,newChildren剩下key === 2、key === 1未遍历key相同type不同导致不可复用,会将oldFiber标记为DELETION,并继续遍历
// 之前
<li key="0" className="a">0</li>
<li key="1" className="b">1</li>
// 之后 情况1 —— newChildren与oldFiber都遍历完
<li key="0" className="aa">0</li>
<li key="1" className="bb">1</li>
// 之后 情况2 —— newChildren没遍历完,oldFiber遍历完
// newChildren剩下 key==="2" 未遍历
<li key="0" className="aa">0</li>
<li key="1" className="bb">1</li>
<li key="2" className="cc">2</li>
// 之后 情况3 —— newChildren遍历完,oldFiber没遍历完
// oldFiber剩下 key==="1" 未遍历
<li key="0" className="aa">0</li>如果newChildren遍历完(即i === newChildren.length - 1)或者oldFiber遍历完(即oldFiber.sibling === null),跳出遍历,第一轮遍历结束。
第二轮遍历:处理剩下的不属于更新的节点。
newChildren和oldFiber同时遍历完
更新。此时Diff结束。newChildren没遍历完,oldFiber遍历完
DOM节点都复用了,这时还有新加入的节点,意味着本次更新有新节点插入,我们只需要遍历剩下的newChildren为生成的workInProgress fiber依次标记Placement。newChildren遍历完,oldFiber没遍历完
oldFiber,依次标记Deletion。newChildren和oldFiber都没遍历完
处理移动的节点
由于有节点改变了位置,所以不能再用位置索引i对比前后的节点,那么我们需要使用key。
为了快速的找到key对应的oldFiber,我们将所有还未处理的oldFiber存入以key为key,oldFiber为value的Map中。(这地方有些像vue2的diff)
const existingChildren = mapRemainingChildren(returnFiber, oldFiber);接下来遍历剩余的newChildren,通过newChildren[i].key就能在existingChildren中找到key相同的oldFiber。
标记节点是否移动
我们需要明确:节点是否移动是以什么为参照物?
参照物是:最后一个可复用的节点在oldFiber中的位置索引(用变量lastPlacedIndex表示)。
方便理解,两个例子:
剩余oldFiber生成map(key:index),遍历剩余newChildren,在oldFiber中匹配key找到对应老节点index
在Demo中我们简化下书写,每个字母代表一个节点,字母的值代表节点的key
// 之前
abcd
// 之后
acdb
===第一轮遍历开始===
a(之后)vs a(之前)
key不变,可复用
此时 a 对应的oldFiber(之前的a)在之前的数组(abcd)中索引为0
所以 lastPlacedIndex = 0;
继续第一轮遍历...
c(之后)vs b(之前)
key改变,不能复用,跳出第一轮遍历
此时 lastPlacedIndex === 0;
===第一轮遍历结束===
===第二轮遍历开始===
newChildren === cdb,没用完,不需要执行删除旧节点
oldFiber === bcd,没用完,不需要执行插入新节点
将剩余oldFiber(bcd)保存为map
// 当前oldFiber:bcd
// 当前newChildren:cdb
继续遍历剩余newChildren(在map中找相同key)
key === c 在 oldFiber中存在
const oldIndex = c(之前).index;
此时 oldIndex === 2; // 之前节点为 abcd,所以c.index === 2
比较 oldIndex 与 lastPlacedIndex;
如果 oldIndex >= lastPlacedIndex 代表该可复用节点不需要移动
并将 lastPlacedIndex = oldIndex;
如果 oldIndex < lastplacedIndex 该可复用节点之前插入的位置索引小于这次更新需要插入的位置索引,代表该节点需要向右移动
在例子中,oldIndex 2 > lastPlacedIndex 0,
则 lastPlacedIndex = 2;
c节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:bd
// 当前newChildren:db
key === d 在 oldFiber中存在
const oldIndex = d(之前).index;
oldIndex 3 > lastPlacedIndex 2 // 之前节点为 abcd,所以d.index === 3
则 lastPlacedIndex = 3;
d节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:b
// 当前newChildren:b
key === b 在 oldFiber中存在
const oldIndex = b(之前).index;
oldIndex 1 < lastPlacedIndex 3 // 之前节点为 abcd,所以b.index === 1
则 b节点需要向右移动
===第二轮遍历结束===// 之前
abcd
// 之后
dabc
===第一轮遍历开始===
d(之后)vs a(之前)
key改变,不能复用,跳出遍历
===第一轮遍历结束===
===第二轮遍历开始===
newChildren === dabc,没用完,不需要执行删除旧节点
oldFiber === abcd,没用完,不需要执行插入新节点
将剩余oldFiber(abcd)保存为map
继续遍历剩余newChildren
// 当前oldFiber:abcd
// 当前newChildren dabc
key === d 在 oldFiber中存在
const oldIndex = d(之前).index;
此时 oldIndex === 3; // 之前节点为 abcd,所以d.index === 3
比较 oldIndex 与 lastPlacedIndex;
oldIndex 3 > lastPlacedIndex 0
则 lastPlacedIndex = 3;
d节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:abc
// 当前newChildren abc
key === a 在 oldFiber中存在
const oldIndex = a(之前).index; // 之前节点为 abcd,所以a.index === 0
此时 oldIndex === 0;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 0 < lastPlacedIndex 3
则 a节点需要向右移动
继续遍历剩余newChildren
// 当前oldFiber:bc
// 当前newChildren bc
key === b 在 oldFiber中存在
const oldIndex = b(之前).index; // 之前节点为 abcd,所以b.index === 1
此时 oldIndex === 1;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 1 < lastPlacedIndex 3
则 b节点需要向右移动
继续遍历剩余newChildren
// 当前oldFiber:c
// 当前newChildren c
key === c 在 oldFiber中存在
const oldIndex = c(之前).index; // 之前节点为 abcd,所以c.index === 2
此时 oldIndex === 2;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 2 < lastPlacedIndex 3
则 c节点需要向右移动
===第二轮遍历结束===React-router-dom v6
BrowserRouter,通过createBrowserHistory创建history实例(history库提供),执行history.listen监听路由变化,返回Router组件React-router
Router,Routes以及多个路由相关hooksRouter注入两个context,并格式化props中相关参数。Routes将children转化为routes数组,并作为参数放在useRoutes中执行useRoutes内部读取context中数据(这也说明为什么useRoutes要放在<Router>下使用),并会通过分数规则判断路由匹配,交由_renderMatches渲染_renderMatches注入一个context,并渲染出对应组件参考
react中事件是合成事件,统一绑定在document,事件回调为dispatchEventdocument上的对应事件,从原生事件找到对应的合成事件,并从事件池中取出该合成事件的实例对象,并覆盖属性,作为事件对象,如果没有就创建一个(React17取消了事件对象的复用)dom节点,从dom节点找到最近的React组件实例,从而找到了一条由这个实例父节点不断向上组成的链, 这个链就是我们要触发合成事件的链,父-> 子,模拟捕获阶段,触发所有props中含有onClickCaptures的实例子-> 父,模拟冒泡阶段,触发所有 props 中含有 onClick 的实例。React 会在派发事件时打开批量更新, 此时所有的 setState 都会变成异步。React onClick/onClickCapture, 实际上都发生在原生事件的冒泡阶段。(React17支持原生捕获事件)参考:
虚拟DOM在React中有个正式的称呼——Fiber,用Fiber来取代React16虚拟DOM这一称呼
起源:
React15及以前,Reconciler采用递归的方式创建虚拟DOM,递归过程是不能中断的。如果组件树的层级很深,递归会占用线程很多时间,造成卡顿。React16将递归的无法中断的更新重构为异步的可中断更新,由于曾经用于递归的虚拟DOM数据结构已经无法满足需要。于是,全新的Fiber架构应运而生。含义:
React15的Reconciler采用递归的方式执行,数据保存在递归调用栈中,所以被称为stack Reconciler。React16的Reconciler基于Fiber节点实现,被称为Fiber Reconciler。Fiber节点对应一个React element,保存了该组件的类型(函数组件/类组件/原生组件...)、对应的DOM节点等信息。Fiber节点保存了本次更新中该组件改变的状态、要执行的工作(需要被删除/被插入页面中/被更新...)结构:
function FiberNode(
tag: WorkTag,
pendingProps: mixed,
key: null | string,
mode: TypeOfMode,
) {
// 作为静态数据结构的属性
this.tag = tag; // Fiber对应组件的类型 Function/Class/Host...
this.key = key; // key属性
this.elementType = null; // 大部分情况同type,某些情况不同,比如FunctionComponent使用React.memo包裹
this.type = null; // 对于 FunctionComponent,指函数本身,对于ClassComponent,指class,对于HostComponent(原生html标签),指DOM节点tagName
this.stateNode = null; // Fiber对应的真实DOM节点
// 用于连接其他Fiber节点形成Fiber树
this.return = null; // 指向父级Fiber节点
this.child = null; // 指向子Fiber节点
this.sibling = null; // 指向右边第一个兄弟Fiber节点
this.index = 0;
this.ref = null;
// 作为动态的工作单元的属性
// 保存本次更新造成的状态改变相关信息
this.pendingProps = pendingProps;
this.memorizedProps = null;
this.updateQueue = null; //fiber 上的更新队列执行一次 setState 就会往这个属性上挂一个新的更新, 每条更新最终会形成一个链表结构,最后做批量更新
this.memorizedState = null;
this.dependencies = null;
this.mode = mode;
// Effect相关
// 保存本次更新会造成的DOM操作
this.effectTag = NoEffect; // 表示当前 fiber 要进行何种更新(更新、删除等)
this.nextEffect = null; // 指向下个需要更新的fiber
this.firstEffect = null; // 指向所有子节点里,需要更新的 fiber 里的第一个
this.lastEffect = null; // 指向所有子节点中需要更新的 fiber 的最后一个
// 调度优先级相关
this.lanes = NoLanes;
this.childLanes = NoLanes;
// 指向该fiber在另一次更新时对应的fiber(workInProgress fiber树)
this.alternate = null;
}参考:
在React中最多会同时存在两棵Fiber树。当前屏幕上显示内容对应的Fiber树称为current Fiber树,正在内存中构建的Fiber树称为workInProgress Fiber树。
current Fiber树中的Fiber节点被称为current fiber,workInProgress Fiber树中的Fiber节点被称为workInProgress fiber,他们通过alternate属性连接。
currentFiber.alternate === workInProgressFiber;
workInProgressFiber.alternate === currentFiber;即当workInProgress Fiber树构建完成交给Renderer渲染在页面上后,应用根节点的current指针指向workInProgress Fiber树,此时workInProgress Fiber树就变为current Fiber树。
流程梳理——mount时
function App() {
const [num, add] = useState(0);
return (
<p onClick={() => add(num + 1)}>{num}</p>
)
}
ReactDOM.render(<App/>, document.getElementById('root'));首次执行ReactDOM.render会创建fiberRootNode(源码中叫fiberRoot)和rootFiber。其中fiberRootNode是整个应用的根节点,rootFiber是<App/>所在组件树的根节点。
之所以要区分fiberRootNode与rootFiber,是因为在应用中我们可以多次调用ReactDOM.render渲染不同的组件树,他们会拥有不同的rootFiber。但是整个应用的根节点只有一个fiberRootNode。fiberRootNode的current会指向当前页面上已渲染内容对应Fiber树,即current Fiber树。
fiberRootNode.current = rootFiber;页面中还没有挂载任何DOM,fiberRootNode.current指向的rootFiber没有任何子Fiber节点(即current Fiber树为空)。
进入render阶段,根据组件返回的JSX在内存中依次创建Fiber节点并连接在一起构建Fiber树,被称为workInProgress Fiber树(下图中右侧的树)
在构建workInProgress Fiber树时会尝试复用current Fiber树中已有的Fiber节点内的属性,在首屏渲染时只有rootFiber存在对应的current fiber(即rootFiber.alternate)。
图中右侧已构建完的workInProgress Fiber树在commit阶段渲染到页面后,fiberRootNode的current指针指向workInProgress Fiber树使其变为current Fiber 树。
流程梳理——update时
点击p节点触发状态改变,这会开启一次新的render阶段并构建一棵新的workInProgress Fiber 树。

和mount时一样,workInProgress fiber的创建可以复用current Fiber树对应的节点数据。(这个决定是否复用的过程就是Diff算法)
workInProgress Fiber 树在render阶段完成构建后进入commit阶段渲染到页面上。渲染完毕后,workInProgress Fiber 树变为current Fiber 树。
参考:
编译成React.createElement
export function createElement(type, config, children) {
let propName;
const props = {};
let key = null;
let ref = null;
let self = null;
let source = null;
if (config != null) {
// 将 config 处理后赋值给 props
// ...省略
}
const childrenLength = arguments.length - 2;
// 处理 children,会被赋值给props.children
// ...省略
// 处理 defaultProps
// ...省略
return ReactElement(
type,
key,
ref,
self,
source,
ReactCurrentOwner.current,
props,
);
}
const ReactElement = function(type, key, ref, self, source, owner, props) {
const element = {
// 标记这是个 React Element
$$typeof: REACT_ELEMENT_TYPE,
type: type,// 执行组件自身,类组件指向类,函数组件指向函数
key: key,
ref: ref,
props: props,
_owner: owner,
};
return element;
};JSX被ReactElement生成为一个element对象。JSX是一种描述当前组件内容的数据结构
element对象不包含他不包含组件schedule、reconcile、render所需的相关信息。比如如下信息就不包括在JSX中:
优先级state标记这些内容都包含在Fiber节点中。
所以,在组件mount时,Reconciler根据JSX描述的组件内容生成组件对应的Fiber节点。
在update时,Reconciler将JSX与Fiber节点保存的数据对比,生成组件对应的Fiber节点,并根据对比结果为Fiber节点打上标记
参考:
beginWork负责从父到子遍历,当子为null的时候,执行completeWork,如果当前有sibling,就返回sibling继续执行beginWork
render阶段开始于performSyncWorkOnRoot或performConcurrentWorkOnRoot方法的调用。这取决于本次更新是同步更新还是异步更新。
// performSyncWorkOnRoot会调用该方法
function workLoopSync() {
while (workInProgress !== null) {
performUnitOfWork(workInProgress);
}
}
// performConcurrentWorkOnRoot会调用该方法
function workLoopConcurrent() {
while (workInProgress !== null && !shouldYield()) {
performUnitOfWork(workInProgress);
}
}shouldYield。如果当前浏览器帧没有剩余时间,shouldYield会中止循环,直到浏览器有空闲时间后再继续遍历。workInProgress代表当前已创建的workInProgress fiber。performUnitOfWork方法会创建下一个Fiber节点并赋值给workInProgress,并将workInProgress与已创建的Fiber节点连接起来构成Fiber树。performUnitOfWork的工作可以分为两部分:“递”和“归”。通过遍历的方式实现可中断的递归
递阶段
首先从rootFiber开始向下深度优先遍历。为遍历到的每个Fiber节点调用beginWork方法 。
该方法会根据传入的Fiber节点创建子Fiber节点,并将这两个Fiber节点连接起来。
当遍历到叶子节点(即没有子组件的组件)时就会进入“归”阶段。
归阶段
在“归”阶段会调用completeWork 处理Fiber节点。
当某个Fiber节点执行完completeWork,如果其存在兄弟Fiber节点(即fiber.sibling !== null),会进入其兄弟Fiber的“递”阶段。
如果不存在兄弟Fiber,会进入父级Fiber的“归”阶段。
“递”和“归”阶段会交错执行直到“归”到rootFiber。至此,render阶段的工作就结束了
例子:
function App() {
return (
<div>
i am
<span>KaSong</span>
</div>
)
}
ReactDOM.render(<App />, document.getElementById("root"));对应Fiber树结构:
1. rootFiber beginWork
2. App Fiber beginWork
3. div Fiber beginWork
4. "i am" Fiber beginWork
5. "i am" Fiber completeWork
6. span Fiber beginWork
7. span Fiber completeWork
8. div Fiber completeWork
9. App Fiber completeWork
10. rootFiber completeWork
// 之所以没有 “KaSong” Fiber 的 beginWork/completeWork
// 是因为作为一种性能优化手段,针对只有单一文本子节点的Fiber,React会特殊处理。beginWork:
function beginWork(
current: Fiber | null, // 当前组件对应的Fiber节点
workInProgress: Fiber, // 当前组件对应的Fiber节点
renderLanes: Lanes, // 优先级相关
): Fiber | null {
// ...省略函数体
}组件mount时,由于是首次渲染,是不存在当前组件对应的Fiber节点在上一次更新时的Fiber节点,即mount时current === null。所以我们可以通过current === null ?来区分组件是处于mount还是update。
// update时:如果current存在可能存在优化路径,可以复用current(即上一次更新的Fiber节点)
if (current !== null) {
// ...省略
// 复用current
return bailoutOnAlreadyFinishedWork(
current,
workInProgress,
renderLanes,
);
} else {
didReceiveUpdate = false;
}
// mount时:根据tag不同,创建不同的子Fiber节点
switch (workInProgress.tag) {
case IndeterminateComponent:
// ...省略
case LazyComponent:
// ...省略
case FunctionComponent:
// ...省略
case ClassComponent:
// ...省略
case HostRoot:
// ...省略
case HostComponent:
// ...省略
case HostText:
// ...省略
// ...省略其他类型
}
}因此,beginWork的工作可以分为两部分:
update时:如果current存在,在满足一定条件时可以复用current节点,这样就能克隆current.child作为workInProgress.child,而不需要新建workInProgress.child。
我们可以看到,满足如下情况时就可以直接复用前一次更新的子Fiber,不需要新建子Fiber:(didReceiveUpdate=true)
oldProps === newProps && workInProgress.type === current.type,即props与fiber.type不变!includesSomeLane(renderLanes, updateLanes),即当前Fiber节点优先级不够,会在讲解Scheduler时介绍if (current !== null) {
const oldProps = current.memoizedProps;
const newProps = workInProgress.pendingProps;
if (
oldProps !== newProps ||
hasLegacyContextChanged() ||
(__DEV__ ? workInProgress.type !== current.type : false)
) {
didReceiveUpdate = true;
} else if (!includesSomeLane(renderLanes, updateLanes)) {
didReceiveUpdate = false;
switch (workInProgress.tag) {
// 省略处理
}
return bailoutOnAlreadyFinishedWork(
current,
workInProgress,
renderLanes,
);
} else {
didReceiveUpdate = false;
}
} else {
didReceiveUpdate = false;
}mount时:除fiberRootNode以外,current === null。会根据fiber.tag不同,创建不同类型的子Fiber节点
fiber.tag不同,进入不同类型Fiber的创建逻辑。对于我们常见的组件类型,如(FunctionComponent/ClassComponent/HostComponent),最终会进入reconcileChildren方法。
reconcileChildren
Reconciler模块的核心部分
对于mount的组件,他会创建新的子Fiber节点
对于update的组件,他会将当前组件与该组件在上次更新时对应的Fiber节点比较(也就是俗称的Diff算法),将比较的结果生成新Fiber节点
export function reconcileChildren(
current: Fiber | null,
workInProgress: Fiber,
nextChildren: any,
renderLanes: Lanes
) {
if (current === null) {
// 对于mount的组件
workInProgress.child = mountChildFibers(
workInProgress,
null,
nextChildren,
renderLanes,
);
} else {
// 对于update的组件
workInProgress.child = reconcileChildFibers(
workInProgress,
current.child,
nextChildren,
renderLanes,
);
}
}最终他会生成新的子Fiber节点并赋值给workInProgress.child,作为本次beginWork返回值 ,并作为下次performUnitOfWork执行时workInProgress的传参。
mountChildFibers与reconcileChildFibers这两个方法的逻辑基本一致。唯一的区别是:reconcileChildFibers会为生成的Fiber节点带上effectTag属性,而mountChildFibers不会。
effectTag
render阶段的工作是在内存中进行,当工作结束后会通知Renderer需要执行的DOM操作。要执行DOM操作的具体类型就保存在fiber.effectTag中。你可以从这里 看到effectTag对应的DOM操作
// DOM需要插入到页面中
export const Placement = /* */ 0b00000000000010;
// DOM需要更新
export const Update = /* */ 0b00000000000100;
// DOM需要插入到页面中并更新
export const PlacementAndUpdate = /* */ 0b00000000000110;
// DOM需要删除
export const Deletion = /* */ 0b00000000001000;通过二进制表示effectTag,可以方便的使用位操作为fiber.effectTag赋值多个effect
那么,如果要通知Renderer将Fiber节点对应的DOM节点插入页面中,需要满足两个条件:
fiber.stateNode存在,即Fiber节点中保存了对应的DOM节点(fiber.effectTag & Placement) !== 0,即Fiber节点存在Placement effectTag我们知道,mount时,fiber.stateNode === null,且在reconcileChildren中调用的mountChildFibers不会为Fiber节点赋值effectTag。那么首屏渲染如何完成呢?
fiber.stateNode会在completeWork中创建mountChildFibers也会赋值effectTag,那么可以预见mount时整棵Fiber树所有节点都会有Placement effectTag。那么commit阶段在执行DOM操作时每个节点都会执行一次插入操作,这样大量的DOM操作是极低效的。mount时只有rootFiber会赋值Placement effectTag,在commit阶段只会执行一次插入操作。beginWork流程图
completeWork:
function completeWork(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
): Fiber | null {
const newProps = workInProgress.pendingProps;
switch (workInProgress.tag) {
case IndeterminateComponent:
case LazyComponent:
case SimpleMemoComponent:
case FunctionComponent:
case ForwardRef:
case Fragment:
case Mode:
case Profiler:
case ContextConsumer:
case MemoComponent:
return null;
case ClassComponent: {
// ...省略
return null;
}
case HostRoot: {
// ...省略
updateHostContainer(workInProgress);
return null;
}
case HostComponent: {
// ...省略
return null;
}类似beginWork,completeWork也是针对不同fiber.tag调用不同的处理逻辑。
处理HostComponent:
和beginWork一样,我们根据current === null ?判断是mount还是update。
同时针对HostComponent,判断update时我们还需要考虑workInProgress.stateNode != null ?(即该Fiber节点是否存在对应的DOM节点)
case HostComponent: {
popHostContext(workInProgress);
const rootContainerInstance = getRootHostContainer();
const type = workInProgress.type;
if (current !== null && workInProgress.stateNode != null) {
// update的情况
// ...省略
} else {
// mount的情况
// ...省略
}
return null;
}mount的情况:
为Fiber节点生成对应的DOM节点
将子孙DOM节点插入刚生成的DOM节点中
与update逻辑中的updateHostComponent类似的处理props的过程
// mount的情况
// ...省略服务端渲染相关逻辑
const currentHostContext = getHostContext();
// 为fiber创建对应DOM节点
const instance = createInstance(
type,
newProps,
rootContainerInstance,
currentHostContext,
workInProgress,
);
// 将子孙DOM节点插入刚生成的DOM节点中
appendAllChildren(instance, workInProgress, false, false);
// DOM节点赋值给fiber.stateNode
workInProgress.stateNode = instance;
// 与update逻辑中的updateHostComponent类似的处理props的过程
if (
finalizeInitialChildren(
instance,
type,
newProps,
rootContainerInstance,
currentHostContext,
)
) {
markUpdate(workInProgress);
}mount时只会在rootFiber存在Placement effectTag。那么commit阶段是如何通过一次插入DOM操作(对应一个Placement effectTag)将整棵DOM树插入页面的呢?
原因就在于completeWork中的appendAllChildren方法,每次调用时都会将已生成的子孙DOM节点插入当前生成的DOM节点下,当completeWork函数执行到rootfiber时,appendAllChildren已经构建好了一个完整dom的(未渲染)
update的情况:
当update时,Fiber节点已经存在对应DOM节点,所以不需要生成DOM节点。需要做的主要是处理props,比如:
onClick、onChange等回调函数的注册style propDANGEROUSLY_SET_INNER_HTML propchildren prop我们去掉一些当前不需要关注的功能(比如ref)。可以看到最主要的逻辑是调用updateHostComponent方法。
if (current !== null && workInProgress.stateNode != null) {
// update的情况
updateHostComponent(
current,
workInProgress,
type,
newProps,
rootContainerInstance,
);
}在updateHostComponent内部,被处理完的props会被赋值给workInProgress.updateQueue,并最终会在commit阶段被渲染在页面上。
workInProgress.updateQueue = (updatePayload: any);
// updatePayload=[props[key],props[value]]
// 偶数索引的值为变化的prop key,奇数索引的值为变化的prop value。你可以从这里看到updateHostComponent方法定义。
effectList
作为DOM操作的依据,commit阶段需要找到所有有effectTag的Fiber节点并依次执行effectTag对应操作。难道需要在commit阶段再遍历一次Fiber树寻找effectTag !== null的Fiber节点么?
为了解决这个问题,在completeWork的上层函数completeUnitOfWork中,每个执行完completeWork且存在effectTag的Fiber节点会被保存在一条被称为effectList的单向链表中。
effectList中第一个Fiber节点保存在fiber.firstEffect,最后一个元素保存在fiber.lastEffect。
类似appendAllChildren,在“归”阶段,所有有effectTag的Fiber节点都会被追加在effectList中,最终形成一条以rootFiber.firstEffect为起点的单向链表。
nextEffect nextEffect
rootFiber.firstEffect -----------> fiber -----------> fibercompleteWork流程图
结尾:
至此,render阶段全部工作完成。在performSyncWorkOnRoot函数中fiberRootNode被传递给commitRoot方法,开启commit阶段工作流程。
commitRoot(root);参考:
rootFiber.firstEffect为开始保存了一条需要执行副作用的链表effectList,在commit阶段执行
除此之外,一些生命周期钩子(比如componentDidXXX)、hook(比如useEffect)需要在commit阶段执行。
commit阶段的主要工作(即Renderer的工作流程)分为三部分:
DOM操作前)DOM操作)DOM操作后)commit阶段的完整代码)在before mutation阶段之前和layout阶段之后还有一些额外工作,涉及到比如useEffect的触发、优先级相关的重置、ref的绑定/解绑。
before mutation阶段之前
before mutation之前主要做一些变量赋值,状态重置的工作。
这一长串代码我们只需要关注最后赋值的firstEffect,在commit的三个子阶段都会用到他。
do {
// 触发useEffect回调与其他同步任务。由于这些任务可能触发新的渲染,所以这里要一直遍历执行直到没有任务
flushPassiveEffects();
} while (rootWithPendingPassiveEffects !== null);
// root指 fiberRootNode
// root.finishedWork指当前应用的rootFiber
const finishedWork = root.finishedWork;
// 凡是变量名带lane的都是优先级相关
const lanes = root.finishedLanes;
if (finishedWork === null) {
return null;
}
root.finishedWork = null;
root.finishedLanes = NoLanes;
// 重置Scheduler绑定的回调函数
root.callbackNode = null;
root.callbackId = NoLanes;
let remainingLanes = mergeLanes(finishedWork.lanes, finishedWork.childLanes);
// 重置优先级相关变量
markRootFinished(root, remainingLanes);
// 清除已完成的discrete updates,例如:用户鼠标点击触发的更新。
if (rootsWithPendingDiscreteUpdates !== null) {
if (
!hasDiscreteLanes(remainingLanes) &&
rootsWithPendingDiscreteUpdates.has(root)
) {
rootsWithPendingDiscreteUpdates.delete(root);
}
}
// 重置全局变量
if (root === workInProgressRoot) {
workInProgressRoot = null;
workInProgress = null;
workInProgressRootRenderLanes = NoLanes;
} else {
}
// 将effectList赋值给firstEffect
// 由于每个fiber的effectList只包含他的子孙节点
// 所以根节点如果有effectTag则不会被包含进来
// 所以这里将有effectTag的根节点插入到effectList尾部
// 这样才能保证有effect的fiber都在effectList中
let firstEffect;
if (finishedWork.effectTag > PerformedWork) {
if (finishedWork.lastEffect !== null) {
finishedWork.lastEffect.nextEffect = finishedWork;
firstEffect = finishedWork.firstEffect;
} else {
firstEffect = finishedWork;
}
} else {
// 根节点没有effectTag
firstEffect = finishedWork.firstEffect;
} const FancyButton = React.forwardRef((props, ref) => (
<button ref={ref} className="FancyButton">
{props.children}
</button>
));
// You can now get a ref directly to the DOM button:
const ref = React.createRef();
<FancyButton ref={ref}>Click me!</FancyButton>;
FordRef创建一个Reaction组件,将它接收到的ref属性转发到树中的另一个组件。
这种技术并不常见,但在两种情况下特别有用:
1.高阶组件的ref是转发
2.将refs转发到DOM组件
class MyComponent extends React.Component {
constructor(props) {
super(props);
this.inputRef = React.createRef();
}
render() {
return <input type="text" ref={this.inputRef} />;
}
componentDidMount() {
this.inputRef.current.focus();
}
}
createRef创建一个ref,它可以通过ref属性附加到Reaction元素。
可以简写为<></>
React.cloneElement()克隆并返回一个新的 ReactElement (内部子元素也会跟着克隆),新返回的元素会保留有旧元素的 props、ref、key。可以传入三个参数
1.要克隆的ReactElement;2.需要新添加的属性props;3.重新设置的子节点(会替换掉原本的子节点)
注意:当第二个参数传入名字为key值属性时,克隆后的组件拿不到this.props.key的值
render() {
let span = <span ref="span">aaa</span>;
let spanChange = React.cloneElement(span, {name:'aaa'} ,<em>bbb</em>);
return (
<div>
{spanChange}
</div>
);
}
//结果:<span name="aaa"><em>bbb</em><span>
forceUpdate() 就是重新运行render,有些变量不在state上,但是又想达到变量更新,重新render的效果的时候,就可以使用此方法手动触发render
ReactDOM.createPortal将组件渲染到父节点之外的节点
ReactDOM.createPortal(<App></App>,Node)
返回子元素中的组件总数,等于传递给map或forEach的回调调用次数。
React.Children.count(children)
render: function() {
console.log(React.Children.count(this.props.children)); //2
return (
<ol>
{
this.props.children.forEach(function (child) { //和这个次数一样
return <li>{child}</li>
})
}
</ol>
);
}
React.Children.map(this.props.children,function(child){
return <li>{child}</li>
})
在每一个直接子级(包含在 children 参数中的)上调用 fn 函数,此函数中的 this 指向 上下文。
如果 children 是一个内嵌的对象或者数组,它将被遍历:不会传入容器对象到 fn 中。
如果 children 参数是 null 或者 undefined,那么返回 null 或者 undefined 而不是一个空对象。
React.Children.only(object children)
console.log(React.Children.only(this.props.children[0]));
返回children中仅有的子级。否则抛出异常。
only方法接受的参数只能是一个对象,不能是多个对象(数组)
https://github.com/caitp/TC39-Proposals/blob/trunk/tc39-reflect-isconstructor-iscallable.md
分为两个函数,分别是isCallable \ isConstructor
很简单,看下述注释就行
isCallable
core-js/packages/core-js/modules/esnext.function.is-callable.js
// eslint-disable-next-line es-x/no-object-getownpropertydescriptor -- safe
var getOwnPropertyDescriptor = Object.getOwnPropertyDescriptor;
var classRegExp = /^\s*class\b/;
var exec = uncurryThis(classRegExp.exec);
var isClassConstructor = function (argument) {
try {
// `Function#toString` throws on some built-it function in some legacy engines
// (for example, `DOMQuad` and similar in FF41-)
// 判断环境支持和排除class
if (!DESCRIPTORS || !exec(classRegExp, inspectSource(argument))) return false;
} catch (error) { /* empty */ }
// 拿到prototype
var prototype = getOwnPropertyDescriptor(argument, 'prototype');
// 判断prototype是否可写,普通函数的prototype是可写的,class相反
return !!prototype && hasOwn(prototype, 'writable') && !prototype.writable;
};
// `Function.isCallable` method
$({ target: 'Function', stat: true, sham: true, forced: true }, {
isCallable: function isCallable(argument) {
// $iCallable: typeof argument == 'function'
return $isCallable(argument) && !isClassConstructor(argument);
}
});isConstructor
core-js/packages/core-js/modules/esnext.function.is-constructor
core-js/packages/core-js/internals/is-constructor.js
var uncurryThis = require('../internals/function-uncurry-this');
// fails:通过执行try catch包裹返回入参函数执行结果,如果报错返回true
var fails = require('../internals/fails');
var isCallable = require('../internals/is-callable');
// 相当于Object.prototype.toString.call.slice(argument,8,-1)
var classof = require('../internals/classof');
// 获取内部函数
var getBuiltIn = require('../internals/get-built-in');
// inspectSource:返回argument.toString()
var inspectSource = require('../internals/inspect-source');
var noop = function () { /* empty */ };
var empty = [];
// 拿到Reflect.construct函数
var construct = getBuiltIn('Reflect', 'construct');
var constructorRegExp = /^\s*(?:class|function)\b/;
var exec = uncurryThis(constructorRegExp.exec);
var INCORRECT_TO_STRING = !constructorRegExp.exec(noop);
var isConstructorModern = function isConstructor(argument) {
if (!isCallable(argument)) return false;
try {
construct(noop, empty, argument);
return true;
} catch (error) {
return false;
}
};
var isConstructorLegacy = function isConstructor(argument) {
if (!isCallable(argument)) return false;
switch (classof(argument)) {
case 'AsyncFunction':
case 'GeneratorFunction':
case 'AsyncGeneratorFunction': return false;
}
try {
// we can't check .prototype since constructors produced by .bind haven't it
// `Function#toString` throws on some built-it function in some legacy engines
// (for example, `DOMQuad` and similar in FF41-)
// 某些环境,通过.bind函数生成的函数没有Function#toString值
// 如果argument是一个箭头函数,通过exec正则匹配后返回false
return INCORRECT_TO_STRING || !!exec(constructorRegExp, inspectSource(argument));
} catch (error) {
return true;
}
};
isConstructorLegacy.sham = true;
// `IsConstructor` abstract operation
// https://tc39.es/ecma262/#sec-isconstructor
module.exports = !construct || fails(function () {
// 可以看到通过判断环境支持分为两种模式,
// 如果环境支持construct
// isConstructorLegacy
// isConstructorModern
var called;
return isConstructorModern(isConstructorModern.call)
|| !isConstructorModern(Object)
|| !isConstructorModern(function () { called = true; })
|| called;
}) ? isConstructorLegacy : isConstructorModern;可以看到最后有很多判断,下面逐个分析下
isConstructorModern(isConstructorModern.call)
TypeError: function call() { [native code] } is not a constructorfalse!isConstructorModern(Object)
false!isConstructorModern(function () { called = true; })
constructapi调用,入参的函数是不会被执行的,也就是called为undefinedfalse三种情况个人理解是为了判断js执行环境,排除[native code]函数、检测Object构造函数返回情况、检测入参函数是否会被调用
[email protected]
legacy mode
调用this.updater.enqueueSetState
enqueueSetState简单来说就是负责创建Update和调度Update
enqueueSetState(inst, payload, callback) {
// 通过组件实例获取对应fiber
const fiber = getInstance(inst);
const eventTime = requestEventTime();
const suspenseConfig = requestCurrentSuspenseConfig();
// 获取优先级
const lane = requestUpdateLane(fiber, suspenseConfig);
// 创建update
const update = createUpdate(eventTime, lane, suspenseConfig);
update.payload = payload;
// 赋值回调函数
if (callback !== undefined && callback !== null) {
update.callback = callback;
}
// 将update插入updateQueue
enqueueUpdate(fiber, update);
// 调度update,调度一次更新,内部执行performSyncWorkOnRoot(同步情况下)
scheduleUpdateOnFiber(fiber, lane, eventTime);
}通过createUpdate创建update对象,通过enqueueUpdate将update插入到对应fiber.updateQueue
scheduleUpdateOnFiber调用更新,主要做了以下事情
ensureRootIsScheduledReact上下文中ensureRootIsScheduled:
(if)如果有当前正在执行的任务,(if) 判断当前优先级是否更改,没有更改则复用当前任务,直接return。(else) 如果优先级更改则取消当前任务(else)调度任务,重新创建一个任务,执行scheduleLegacySyncCallback(**performSyncWorkOnRoot.bind**(null, root));执行ensureRootIsScheduled完成后,判断执行上下文,判断是否在react的掌握之中
setState外部套了setTimeout会走到这个判断里,直接执行performSyncWorkOnRootsetTimeout中的setState执行一次就render一次当js线程空闲时通过postMessgae通知scheduler开始调度,简单来说就是执行performSyncWorkOnRoot
performSyncWorkOnRoot->workLoopSync->while(workInProgress!==null)->beginWork
在beginWork中的更新阶段中的updateClassComponent函数中的updateClassInstance函数中processUpdateQueue函数中getStateFromUpdate函数中,state的值会更新
通过遍历fiber.updateQueue.firstBaseUpdate链表执行getStateFromUpdate函数,计算state
https://github.com/tc39/proposal-promise-allSettled
core-js/packages/core-js/modules/es.promise.all-settled.js
function allSettled(iterable) {
var C = this;
// 创建一个对象,capability属性为
// {
// promise : promise实例
// resolve : promise实例resolve函数
// reject : promise实例reject函数
// }
var capability = newPromiseCapabilityModule.f(C);
var resolve = capability.resolve;
var reject = capability.reject;
// perform:
// function (exec) {
// try {
// return { error: false, value: exec() };
// } catch (error) {
// return { error: true, value: error };
// }
// };
// catch掉同步执行的错误,在最后通过reject抛出
var result = perform(function () {
var promiseResolve = aCallable(C.resolve);
// 存放结果的数组
var values = [];
// 对应values索引
var counter = 0;
// 剩余几个未完成
var remaining = 1;
// 遍历iterable数组,执行第二个参数
iterate(iterable, function (promise) {
var index = counter++;
// 是否被调用
var alreadyCalled = false;
// 每次循环先++
remaining++;
// 相当于Promise.resolve(promise).then()
call(promiseResolve, C, promise).then(function (value) {
if (alreadyCalled) return;
alreadyCalled = true;
values[index] = { status: 'fulfilled', value: value };
// 如果没有剩余就resolve
--remaining || resolve(values);
}, function (error) {
// then第二个参数,用于捕获reject
if (alreadyCalled) return;
alreadyCalled = true;
values[index] = { status: 'rejected', reason: error };
// 同样的减减操作
--remaining || resolve(values);
});
});
// 由于remaining初始是1,所以再次--
--remaining || resolve(values);
});
if (result.error) reject(result.value);
// 返回promise用于后续链式调用
return capability.promise;
}perform函数捕获同步错误,最后通过reject抛出.then第二个入参Promise.all源码很类似,都是通过 counter对应结果数组索引 remaining对应未完成数量,不同在于前者 .then第二个入参为 capability.rejecthttps://github.com/tc39/proposal-accessible-object-hasownproperty
core-js/packages/core-js/modules/es.object.has-own.js
var uncurryThis = require('../internals/function-uncurry-this');
var toObject = require('../internals/to-object');
var hasOwnProperty = uncurryThis({}.hasOwnProperty);
// `HasOwnProperty` abstract operation
// https://tc39.es/ecma262/#sec-hasownproperty
// eslint-disable-next-line es-x/no-object-hasown -- safe
module.exports = Object.hasOwn || function hasOwn(it, key) {
return hasOwnProperty(toObject(it), key);
};uncurryThis包装 hasOwnPropertyhttps://github.com/tc39/proposal-global
core-js/packages/core-js/internals/global.js
很简单,不用注释了
var check = function (it) {
return it && it.Math == Math && it;
};
// https://github.com/zloirock/core-js/issues/86#issuecomment-115759028
module.exports =
// eslint-disable-next-line es-x/no-global-this -- safe
check(typeof globalThis == 'object' && globalThis) ||
check(typeof window == 'object' && window) ||
// eslint-disable-next-line no-restricted-globals -- safe
check(typeof self == 'object' && self) ||
check(typeof global == 'object' && global) ||
// eslint-disable-next-line no-new-func -- fallback
(function () { return this; })() || Function('return this')();https://github.com/tc39/proposal-promise-any
core-js/packages/core-js/modules/es.promise.any.js
var PROMISE_ANY_ERROR = 'No one promise resolved';
// `Promise.any` method
// https://tc39.es/ecma262/#sec-promise.any
$({ target: 'Promise', stat: true }, {
any: function any(iterable) {
var C = this;
var AggregateError = getBuiltIn('AggregateError');
var capability = newPromiseCapabilityModule.f(C);
var resolve = capability.resolve;
var reject = capability.reject;
var result = perform(function () {
var promiseResolve = aCallable(C.resolve);
var errors = [];
var counter = 0;
var remaining = 1;
var alreadyResolved = false;
iterate(iterable, function (promise) {
var index = counter++;
var alreadyRejected = false;
remaining++;
call(promiseResolve, C, promise).then(function (value) {
if (alreadyRejected || alreadyResolved) return;
alreadyResolved = true;
// 只要有一个成功就resolve
resolve(value);
}, function (error) {
if (alreadyRejected || alreadyResolved) return;
alreadyRejected = true;
errors[index] = error;
// 全错才会reject
--remaining || reject(new AggregateError(errors, PROMISE_ANY_ERROR));
});
});
--remaining || reject(new AggregateError(errors, PROMISE_ANY_ERROR));
});
if (result.error) reject(result.value);
return capability.promise;
}
});Promise.allSettled逻辑非常相似,不同的是注释的地方,逻辑不同AggregateError是一种错误类型,可以多种错误包含在一起,感兴趣可以去了解下mdnhttps://github.com/tc39/proposal-relative-indexing-method
core-js/packages/core-js/proposals/relative-indexing-method.js
给所有可索引类(Array, String, TypedArray)加上at函数
以 Array为例,其余的感兴趣可以自行了解下
// `Array.prototype.at` method
// https://github.com/tc39/proposal-relative-indexing-method
$({ target: 'Array', proto: true }, {
at: function at(index) {
var O = toObject(this);
var len = lengthOfArrayLike(O);
var relativeIndex = toIntegerOrInfinity(index);
var k = relativeIndex >= 0 ? relativeIndex : len + relativeIndex;
return (k < 0 || k >= len) ? undefined : O[k];
}
});
// 设置Symbol.unscopables
// addToUnscopables:
// function (key) {
// ArrayPrototype[UNSCOPABLES][key] = true;
// };
// 在with环境中at属性不会暴露,感兴趣可以去查下mdn
addToUnscopables('at');toIntegerOrInfinity:
// `ToIntegerOrInfinity` abstract operation
// https://tc39.es/ecma262/#sec-tointegerorinfinity
module.exports = function (argument) {
var number = +argument;
// eslint-disable-next-line no-self-compare -- safe
// NaN情况 取靠近0的整数
return number !== number || number === 0 ? 0 : (number > 0 ? floor : ceil)(number);
};https://github.com/tc39/proposal-string-matchall
core-js/packages/core-js/modules/es.string.match-all.js
var MATCH_ALL = wellKnownSymbol('matchAll');
var REGEXP_STRING = 'RegExp String';
var REGEXP_STRING_ITERATOR = REGEXP_STRING + ' Iterator';
var setInternalState = InternalStateModule.set;
var getInternalState = InternalStateModule.getterFor(REGEXP_STRING_ITERATOR);
var RegExpPrototype = RegExp.prototype;
var TypeError = global.TypeError;
var getFlags = uncurryThis(regExpFlags);
var stringIndexOf = uncurryThis(''.indexOf);
var un$MatchAll = uncurryThis(''.matchAll);
// 判断是否可以支持没有全局标志的正则
var WORKS_WITH_NON_GLOBAL_REGEX = !!un$MatchAll && !fails(function () {
un$MatchAll('a', /./);
});
// 设置正则表达式迭代器
// 篇幅太长不过多解释,大概流程就是:
// RegExpStringIterator函数为构造函数,设置构造函数的prototype.__proto__[Symbol.iterator]
// 感兴趣可自行查看
var $RegExpStringIterator = createIteratorConstructor(function RegExpStringIterator(regexp, string, $global, fullUnicode) {
setInternalState(this, {
type: REGEXP_STRING_ITERATOR,
regexp: regexp,
string: string,
global: $global,
unicode: fullUnicode,
done: false
});
}, REGEXP_STRING, function next() {
var state = getInternalState(this);
if (state.done) return { value: undefined, done: true };
var R = state.regexp;
var S = state.string;
var match = regExpExec(R, S);
if (match === null) return { value: undefined, done: state.done = true };
if (state.global) {
if (toString(match[0]) === '') R.lastIndex = advanceStringIndex(S, toLength(R.lastIndex), state.unicode);
return { value: match, done: false };
}
state.done = true;
return { value: match, done: false };
});
var $matchAll = function (string) {
// R为正则
var R = anObject(this);
// S为被匹配的字符串
var S = toString(string);
var C, flagsValue, flags, matcher, $global, fullUnicode;
// 拿到构造函数,会通过[Symbol.species]来获取,感兴趣可以看下
C = speciesConstructor(R, RegExp);
// 正则标志位
flagsValue = R.flags;
// isPrototypeOf(RegExpPrototype, R):断正则的原型是否是RegExp.prototype
if (flagsValue === undefined && isPrototypeOf(RegExpPrototype, R) && !('flags' in RegExpPrototype)) {
flagsValue = getFlags(R);
}
flags = flagsValue === undefined ? '' : toString(flagsValue);
// R.source值为正则去掉标志符号和两遍的斜杠
matcher = new C(C === RegExp ? R.source : R, flags);
// 是否含有g标志
$global = !!~stringIndexOf(flags, 'g');
// 是否含有u标志
fullUnicode = !!~stringIndexOf(flags, 'u');
// lastIndex用来指定下一次匹配的起始索引
matcher.lastIndex = toLength(R.lastIndex);
return new $RegExpStringIterator(matcher, S, $global, fullUnicode);
};
// `String.prototype.matchAll` method
// https://tc39.es/ecma262/#sec-string.prototype.matchall
$({ target: 'String', proto: true, forced: WORKS_WITH_NON_GLOBAL_REGEX }, {
// 入口,从这块开始看
matchAll: function matchAll(regexp) {
// 检查this是否是undefined
var O = requireObjectCoercible(this);
var flags, S, matcher, rx;
if (regexp != null) {
// 如果有参数
if (isRegExp(regexp)) {
// 参数是一个正则
// 判断'flags'属性是否存在于RegExp.prototype中
// flags属性返回一个字符串,由当前正则表达式对象的标志组成。
flags = toString(requireObjectCoercible('flags' in RegExpPrototype
? regexp.flags
// 同样是获取标志,只不过是通过判断global,ignoreCase等属性,有兴趣可自行了解
: getFlags(regexp)
));
// 如果正则中未含有g标记,报错
if (!~stringIndexOf(flags, 'g')) throw TypeError('`.matchAll` does not allow non-global regexes');
}
if (WORKS_WITH_NON_GLOBAL_REGEX) return un$MatchAll(O, regexp);
// 相当于regexp[Symbol.matchAll]
matcher = getMethod(regexp, MATCH_ALL);
// 如果matcher为undefined && PURE模式 && regexp为正则
if (matcher === undefined && IS_PURE && classof(regexp) == 'RegExp') matcher = $matchAll;
if (matcher) return call(matcher, regexp, O);
// 同样判断是否支持 没有全局标志的正则的matchAll函数
} else if (WORKS_WITH_NON_GLOBAL_REGEX) return un$MatchAll(O, regexp);
// 走到此处有几种情况,例如
// regexp===null && WORKS_WITH_NON_GLOBAL_REGEX===false
// regexp不为正则
// 等
S = toString(O);
rx = new RegExp(regexp, 'g');
return IS_PURE ? call($matchAll, rx, S) : rx[MATCH_ALL](S);
}
});在设置迭代器的时候是这么设置的
// 简写
// 通常写法:
{
[Symbole.iterator]=function(){
return {
next(){.....}
}
},
}
// corejs中是这么写的
{
[Symbole.iterator]=function(){
return this
},
next:function next(){}
}参考:
为了既实现 Webpack 打包的功能,又只实现核心代码。我们对这个流程做一些简化
例子
// webpack.config.js
const resolve = dir => require('path').join(__dirname, dir)
module.exports = {
// 入口文件地址
entry: './src/index.js',
// 输出文件地址
output: {
path: resolve('dist'),
fileName: 'bundle.js'
},
// loader
module: {
rules: [
{
test: /\.(js|jsx)$/,
// 编译匹配include路径的文件
include: [
resolve('src')
],
use: 'babel-loader'
}
]
},
plugins: [
new HtmlWebpackPlugin()
]
}入口
const Compiler = require('./compiler')
function webpack(config, callback) {
// 此处应有参数校验
const compiler = new Compiler(config)
// 开始编译
compiler.run()
}
module.exports = webpack构建配置信息
class Compiler {
constructor(config, _callback) {
const { entry, output, module, plugins } = config;
// 入口
this.entryPath = entry;
// 输出文件路径
this.distPath = output.path;
// 输出文件名称
this.distName = output.fileName;
// 需要使用的loader
this.loaders = module.rules;
// 需要挂载的plugin
this.plugins = plugins;
// 根目录
this.root = process.cwd();
// 编译工具类Compilation
this.compilation = {};
// 入口文件在module中的相对路径,也是这个模块的id
this.entryId = getRootPath(this.root, entry, this.root);
this.hooks = {
// 生命周期事件
beforeRun: new AsyncSeriesHook(["compiler"]), // compiler代表我们将向回调事件中传入一个compiler参数
afterRun: new AsyncSeriesHook(["compiler"]),
beforeCompile: new AsyncSeriesHook(["compiler"]),
afterCompile: new AsyncSeriesHook(["compiler"]),
emit: new AsyncSeriesHook(["compiler"]),
failed: new AsyncSeriesHook(["compiler"]),
};
this.mountPlugin();
}
// 注册所有的plugin
mountPlugin() {
for (let i = 0; i < this.plugins.length; i++) {
const item = this.plugins[i];
if ("apply" in item && typeof item.apply === "function") {
// 注册各生命周期钩子的发布订阅监听事件
item.apply(this);
}
}
}
// 当运行run方法的逻辑之前
run() {
// 在特定的生命周期发布消息,触发对应的订阅事件
this.hooks.beforeRun.callAsync(this); // this作为参数传入,对应之前的compiler
.......
}
}每一个 plugin Class 都必须实现一个 apply 方法,这个方法接收 compiler 实例,然后将真正的钩子函数挂载到 compiler.hook 的某一个声明周期上。
如果我们声明了一个hook但是没有挂载任何方法,在 call 函数触发的时候是会报错的。但是实际上 Webpack 的每一个生命周期钩子除了挂载用户配置的 plugin ,都会挂载至少一个 Webpack 自己的 plugin,所以不会有这样的问题。更多关于 tapable 的用法也可以移步 Tapable
之后:
run函数中先触发beforeRun、run两个钩子
然后调用complie函数,调用beforeComplie、complie钩子,创建Compilation
编译
Compilation,这个类主要是执行编译工作
在 Compilation 的构造函数中,先接收来自Compiler 下发的信息并且挂载在自身属性中
class Compilation {
constructor(props) {
const {
entry,
root,
loaders,
hooks
} = props
this.entry = entry
this.root = root
this.loaders = loaders
this.hooks = hooks
}
// 开始编译
async make() {
await this.moduleWalker(this.entry)
}
// dfs遍历函数
async moduleWalker(){ }
async loaderParse(){ }
}因为我们需要将打包过程中引用过的文件都编译到最终的代码包里,所以需要声明一个深度遍历函数 moduleWalker (这个名字是原作者者(@凹凸实验室)取的,不是webpack官方取的),顾名思义,这个方法将会从入口文件开始,依次对文件进行第一步和第二步编译,并且收集引用到的其他模块,递归进行同样的处理
第一步是使用所有满足条件的 loader 对其进行编译并且返回编译之后的源代码
第二步相当于是 Webpack 自己的编译步骤,目的是构建各个独立模块之间的依赖调用关系。我们需要做的是将所有的 require 方法替换成 Webpack 自己定义的 __webpack_require__ 函数。因为所有被编译后的模块将被 Webpack 存储在一个闭包的对象 moduleMap 中,而 __webpack_require__ 函数则是唯一一个有权限访问 moduleMap 的方法。
一句话解释 __webpack_require__的作用就是:
文件地址 -> 文件内容 的关系替换成了 对象的key -> 对象的value(文件内容) 这样的关系。在完成第二步编译的同时,会对当前模块内的引用进行收集,并且返回到 Compilation 中, 这样moduleWalker 才能对这些依赖模块进行递归的编译。当然其中大概率存在循环引用和重复引用,我们会根据引用文件的路径生成一个独一无二的 key 值,在 key 值重复时进行跳过。
moduleWalker
moduleMap = {};
// import moduleName from 'xxModule'
// key为文件路径,value为一个可执行的函数,函数内容其实就是模块中导出的内容
/**
* modules = {
* './src/index.js': function () {},
* './src/num.js': function () {},
* './src/tmp.js': function () {}
* }
*/
// 根据依赖将所有被引用过的文件都进行编译
async moduleWalker(sourcePath) {
if (sourcePath in this.moduleMap) return;
// 在读取文件时,我们需要完整的以.js结尾的文件路径
sourcePath = completeFilePath(sourcePath);
const [sourceCode, md5Hash] = await this.loaderParse(sourcePath);
const modulePath = getRootPath(this.root, sourcePath, this.root);
// 获取模块编译后的代码和模块内的依赖数组
const [moduleCode, relyInModule] = this.parse(
sourceCode,
path.dirname(modulePath)
);
// 将模块代码放入ModuleMap
this.moduleMap[modulePath] = moduleCode;
this.assets[modulePath] = md5Hash;
// 再依次对模块中的依赖项进行解析
for (let i = 0; i < relyInModule.length; i++) {
await this.moduleWalker(relyInModule[i], path.dirname(relyInModule[i]));
}
}loaderParse
async loaderParse(entryPath) {
// 用utf8格式读取文件内容
let [ content, md5Hash ] = await readFileWithHash(entryPath)
// 获取用户注入的loader
const { loaders } = this
// 依次遍历所有loader
for(let i=0;i<loaders.length;i++) {
const loader = loaders[i]
const { test : reg, use } = loader
if (entryPath.match(reg)) {
// 判断是否满足正则或字符串要求
// 如果该规则需要应用多个loader,从最后一个开始向前执行
if (Array.isArray(use)) {
// 遍历use
while(use.length) {
const cur = use.pop()
const loaderHandler =
typeof cur.loader === 'string'
// loader也可能来源于package包例如babel-loader
// 从node_module中引入
? require(cur.loader)
: (
typeof cur.loader === 'function'
? cur.loader : _ => _
)
content = loaderHandler(content)
}
} else if (typeof use.loader === 'string') {
const loaderHandler = require(use.loader)
content = loaderHandler(content)
} else if (typeof use.loader === 'function') {
const loaderHandler = use.loader
content = loaderHandler(content)
}
}
}
return [ content, md5Hash ]
}于是,在获得了 loader 处理过的代码之后,理论上任何一个模块都已经可以在浏览器或者单元测试中直接使用了。但是我们的代码是一个整体,还需要一种合理的方式来组织代码之间互相引用的关系。
parse
parse 函数中我们需要做的事情其实很简单,就是将所有模块中的 require 方法的函数名称替换成 __webpack_require__ 即可。我们在这一步使用的是 babel 全家桶。
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const types = require('@babel/types')
const generator = require('@babel/generator').default
...
// 解析源码,替换其中的require方法来构建ModuleMap
parse(source, dirpath) {
const inst = this
// 将代码解析成ast
const ast = parser.parse(source)
const relyInModule = [] // 获取文件依赖的所有模块
traverse(ast, {
// 遍历ast
// 检索所有的词法分析节点,当遇到函数调用表达式的时候执行,对ast树进行改写
CallExpression(p) {
// 有些require是被_interopRequireDefault包裹的
// 所以需要先找到_interopRequireDefault节点
if (p.node.callee && p.node.callee.name === '_interopRequireDefault') {
const innerNode = p.node.arguments[0]
if (innerNode.callee.name === 'require') {
inst.convertNode(innerNode, dirpath, relyInModule)
}
} else if (p.node.callee.name === 'require') {
inst.convertNode(p.node, dirpath, relyInModule)
}
}
})
// 将改写后的ast树重新组装成一份新的代码, 并且和依赖项一同返回
const moduleCode = generator(ast).code
return [ moduleCode, relyInModule ]
}
/**
* 将某个节点的name和arguments转换成我们想要的新节点
*/
convertNode = (node, dirpath, relyInModule) => {
node.callee.name = '__webpack_require__'
// 参数字符串名称,例如'react', './MyName.js'
let moduleName = node.arguments[0].value
// 生成依赖模块相对【项目根目录】的路径
let moduleKey = completeFilePath(getRootPath(dirpath, moduleName, this.root))
// 收集module数组
relyInModule.push(moduleKey)
// 将__webpack_require__的参数字符串替换为moduleKey,因为这个字符串也是对应模块的moduleKey,需要保持统一,
// 因为ast树中的每一个元素都是babel节点,所以需要使用'@babel/types'来进行生成
node.arguments = [ types.stringLiteral(moduleKey) ]
}emit 生成bundle文件
执行到这一步, compilation 的使命其实就已经完成了。如果我们平时有去观察生成的 js 文件的话,会发现打包出来的样子是一个立即执行函数,主函数体是一个闭包,闭包中缓存了已经加载的模块 installedModules ,以及定义了一个 __webpack_require__ 函数,最终返回的是函数入口所对应的模块。而函数的参数则是各个模块的 key-value 所组成的对象。
我们在这里通过 ejs 模板去进行拼接,将之前收集到的 moduleMap 对象进行遍历,注入到ejs模板字符串中去。
为了方便我们使用 eval 函数将字符串解析成直接可读的代码。当然这只是求快的方式,对于 JS 这种解释型语言,如果一个一个模块去解释编译的话,速度会非常慢。事实上真正的生产环境会将模块内容封装成一个 IIFE(立即自执行函数表达式)
// template.ejs
(function(modules) { // webpackBootstrap
// 缓存模块
var installedModules = {};
function __webpack_require__(moduleId) {
// 检查是否被缓存
if(installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// 创建新模块(并将其放入缓存)
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
// 执行模块功能
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// 将模块标记为已加载
module.l = true;
// 返回模块的导出
return module.exports;
}
// 加载输入模块并返回导出
return __webpack_require__(__webpack_require__.s = "<%-entryId%>");
})({
// 遍历之前得到的 moduleMap
<%for(let key in modules) {%>
"<%-key%>":
(function(module, exports, __webpack_require__) {
eval(
`<%-modules[key]%>`
);
}),
<%}%>
});
//__webpack_require__ 模块加载,先判断 installedModules 是否已加载,加载过了就直接返回 exports 数据,没有加载过该模块就通过 modules[moduleId].call(module.exports, module, module.exports, __webpack_require__) 执行模块并且将 module.exports 给返回。类似这种:
/**
* 发射文件,生成最终的bundle.js
*/
emitFile() { // 发射打包后的输出结果文件
// 首先对比缓存判断文件是否变化
const assets = this.compilation.assets
const pastAssets = this.getStorageCache()
if (loadsh.isEqual(assets, pastAssets)) {
// 如果文件hash值没有变化,说明无需重写文件
// 只需要依次判断每个对应的文件是否存在即可
// 这一步省略!
} else {
// 缓存未能命中
// 获取输出文件路径
const outputFile = path.join(this.distPath, this.distName);
// 获取输出文件模板
// const templateStr = this.generateSourceCode(path.join(__dirname, '..', "bundleTemplate.ejs"));
const templateStr = fs.readFileSync(path.join(__dirname, '..', "template.ejs"), 'utf-8');
// 渲染输出文件模板
const code = ejs.render(templateStr, {entryId: this.entryId, modules: this.compilation.moduleMap});
this.assets = {};
this.assets[outputFile] = code;
// 将渲染后的代码写入输出文件中
fs.writeFile(outputFile, this.assets[outputFile], function(e) {
if (e) {
console.log('[Error] ' + e)
} else {
console.log('[Success] 编译成功')
}
});
// 将缓存信息写入缓存文件
fs.writeFileSync(resolve(this.distPath, 'manifest.json'), JSON.stringify(assets, null, 2))
}
}例子:
配置(commonjs和es module混用):
webpack.config.js
const path = require('path')
module.exports = {
entry: path.resolve(__dirname, './test.js'),
// 为了利于分析打包后的代码,这里选择开发模式
mode: 'development',
output: {
path: path.resolve(__dirname, './dist'),
filename: 'test.js'
}
}m.js
exports.fn=()=>{
console.log('m')
}test.js
import m from './m'
m.fn()
console.log('test')打包之后
(() => {
// webpackBootstrap
var __webpack_modules__ = {
"./esModule.js": (
__unused_webpack_module,
__webpack_exports__,
__webpack_require__
) => {
"use strict";
__webpack_require__.r(__webpack_exports__);
/* harmony export */
__webpack_require__.d(__webpack_exports__, {
/* harmony export */
esFn: () => esFn,
/* harmony export */
});
const esFn = () => {
console.log("esFn");
};
//# sourceURL=webpack:///./esModule.js?"
},
"./m.js": (__unused_webpack_module, exports) => {
exports.fn = () => {
console.log("m");
};
//# sourceURL=webpack:///./m.js?"
},
"./test.js": (
__unused_webpack_module,
__webpack_exports__,
__webpack_require__
) => {
"use strict";
__webpack_require__.r(__webpack_exports__);
/* harmony import */ var _m__WEBPACK_IMPORTED_MODULE_0__ =
__webpack_require__("./m.js");
/* harmony import */ var _esModule__WEBPACK_IMPORTED_MODULE_1__ =
__webpack_require__("./esModule.js");
_m__WEBPACK_IMPORTED_MODULE_0__.fn();
// 执行绑在module.exports上的esFn get属性
(0, _esModule__WEBPACK_IMPORTED_MODULE_1__.esFn)();
console.log("test");
//# sourceURL=webpack:///./test.js?'
},
};
// 模块缓存
var __webpack_module_cache__ = {};
function __webpack_require__(moduleId) {
// 检查模块是否在缓存中
var cachedModule = __webpack_module_cache__[moduleId];
if (cachedModule !== undefined) {
return cachedModule.exports;
}
// 创建新模块(并将其放入缓存)
var module = (__webpack_module_cache__[moduleId] = {
// no module.id needed
// no module.loaded needed
exports: {},
});
// 执行模块功能
__webpack_modules__[moduleId](module, module.exports, __webpack_require__);
return module.exports;
}
(() => {
__webpack_require__.d = (exports, definition) => {
for (var key in definition) {
if (
__webpack_require__.o(definition, key) &&
!__webpack_require__.o(exports, key)
) {
// 将esFn绑在module.exports上的get属性
Object.defineProperty(exports, key, {
enumerable: true,
get: definition[key],
});
}
}
};
})();
(() => {
__webpack_require__.o = (obj, prop) =>
Object.prototype.hasOwnProperty.call(obj, prop);
})();
(() => {
// define __esModule on exports
__webpack_require__.r = (exports) => {
if (typeof Symbol !== "undefined" && Symbol.toStringTag) {
Object.defineProperty(exports, Symbol.toStringTag, {
value: "Module",
});
}
Object.defineProperty(exports, "__esModule", { value: true });
};
})();
// 入口
// 加载输入模块并返回导出
debugger
var __webpack_exports__ = __webpack_require__("./test.js");
})();总结
test.js)开始,放入缓存map,并执行__webpack_modules__对应函数,获取m.js和esModule.js的exportses-module写法被编译成:
[SymBole.toStringTag]='Module',__esModule=true,并将导出的esFn函数通过getter挂载在exports属性上test.js引入的函数PureComponent:
相当于一个HOC,将组件的shouldComponentUpdate覆盖
在shouldComponentUpdate中执行浅比较,遍历第一层,使用Object.is比较值和引用地址
缺点:
如果引用类型为多层,浅比较则失效
如果JSX中,往子组件传入的props为下文这样,会导致失效
<Son value={value||[]}> // 每次渲染都是一个新的数组,引用地址改变React.memo:
props 变更(preProps,nextProps),返回值与shouldComponentUpdate相反Context:
value值变化时会引发所有使用Context组件的更新懒加载:React.lazy等(常见于路由懒加载)
虚拟列表
受控组件细化
state属性,从而引发渲染,可将与受控组件相关的逻辑单独摘出,这样state更新只会引发部分渲染独立数据请求
手动批量更新
unstable_batchedUpdates:react-dom 中提供了unstable_batchedUpdates方法进行手动批量更新
const handerClick = () => {
Promise.resolve().then(()=>{
unstable_batchedUpdates(()=>{
setB( { ...b } )
setC( c+1 )
setA( a+1 )
})
})
}
// 三次更新合并为一次上文是因为在legacy模式下。将ReactDom.render改为createRoot也可解决上述问题
useMemo、useCallback:防止内次渲染导致重新生成该变量key:避免将key赋值为索引type或者tagName操作:type更改会导致该元素及其子元素节点被删除,并重新创建新节点A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.