- Develop a log ingestor system that can efficiently handle vast volumes of log data.
- Offer a simple interface for querying this data using full-text search or specific field filters.
- The logs should be ingested (in the log ingestor) over HTTP, on port
3000.
- Develop a mechanism to ingest logs in the provided format.
- Ensure scalability to handle high volumes of logs efficiently.
- Mitigate potential bottlenecks such as I/O operations, database write speeds, etc.
- Make sure that the logs are ingested via an HTTP server, which runs on port
3000by default.
- Offer a user interface (Web UI or CLI) for full-text search across logs.
- Include filters based on:
- level
- message
- resourceId
- timestamp
- traceId
- spanId
- commit
- metadata.parentResourceId
- Aim for efficient and quick search results.
The following are some sample queries that will be executed for validation.
- Find all logs with the level set to "error".
- Search for logs with the message containing the term "Failed to connect".
- Retrieve all logs related to resourceId "server-1234".
- Filter logs between the timestamp "2023-09-10T00:00:00Z" and "2023-09-15T23:59:59Z". (Bonus)
- Clone this repository.
- Install Docker Desktop.
- Run
docker-compose up --buildin the root directory of the project. This process takes a a minute or two to complete, for the first time. - You might have to stop the containers and run the command again, because the Cassandra containers sometimes takes some time to create superusers upon first time container start, because of which the consumer fails.
- The Web UI will be available at
http://localhost:3000/static/index.html.
- The Web UI is very basic, and is only meant for testing the API.
- Web UI running on port
3000. - Include filters based on:
- level
- message
- resourceId
- timestamp
- traceId
- spanId
- commit
- metadata.parentResourceId
- Implement search within specific date ranges.
- Allow combining multiple filters.
- Provide real-time log ingestion and searching capabilities.
- Containerized approach to solving the problem statement.
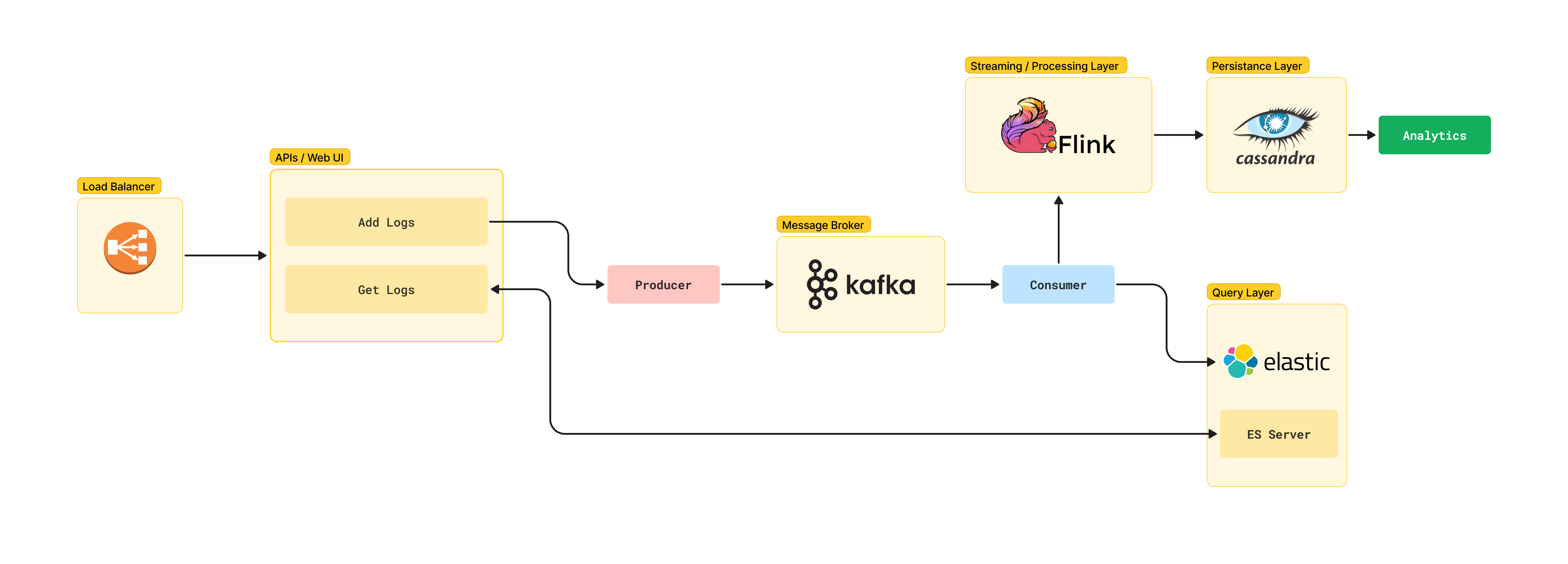
- Given the non-blocking & async I/O of FastAPI, it is used as the web framework. This will help in ingesting logs at a faster rate.
- Apache Kafka is used as the message broker. It will help in decoupling the ingestion and querying process.
- Apache Cassandra is used as the database. It is a NoSQL database and is highly scalable. It will help in storing the logs in a distributed manner. It also provides a fast read/write speed, i.e. high throughput.
- Query interface is built upon Elasticsearch. It is a distributed, RESTful search and analytics engine. It helps in providing a fast search result. Elasticsearch works wonders with large databases, with high processing speeds.
- The logs are ingested via an HTTP server, which runs on port
3000by default.
- The current architecture is a very basic implementation of the problem statement.
- Depending upon the scale, the entire architecture can be scaled horizontally.
- Load Balancing can be implemented to handle high volumes of logs efficiently. We might use AWS ELB.
- Apache Flink can be setup between Kafka and Cassandra for streaming, processing and analytics.
- Cassandra can be used as a Data Lake, and Apache Spark can be used for analytics.
- JWT Authentication can be implemented for the Web UI. (didn't have time)
- Regex filters can be implemented on Elasticsearch. (didn't have time)
Kaustav Mukhopadhyay
- Linkedin: @kaustavmukhopadhyay
- Github: @muKaustav
