
![]()
![]()

Swirl Metasearch adapts and distributes user queries to anything with a search API - search engines, databases, noSQL engines, cloud/SaaS services, etc. - and uses AI (Large Language Models) to re-rank the unified results without extracting or indexing anything. It includes OAuth2 support for Microsoft 365 alongside integration with enterprise services such as Atlassian Jira and Confluence, JetBrains YouTrack, HubSpot and more.
Using the Galaxy UI, knowledge workers can systematically review the best results from all configured services including Apache Solr, ChatGPT, Elastic, OpenSearch, PostgreSQL, Google BigQuery, plus generic HTTP/GET/POST with configurations for premium services like Google's Programmable Search Engine, Miro and Northern Light Research.

Built on the Python/Django stack, Swirl is intended for use by anyone who wants to solve multi-silo search problems without moving, re-indexing or re-permissioning sensitive information.
-
To run Swirl in Docker, you must have the latest Docker app for MacOS, Linux, or Windows installed and running locally.
-
Windows users must also install and configure either the WSL 2 or the Hyper-V backend, as outlined in the System Requirements for installing Docker Desktop on Windows.
curl https://raw.githubusercontent.com/swirlai/swirl-search/main/docker-compose.yaml -o docker-compose.yaml
- In MacOS or Linux, run the following command from the Console:
docker-compose pull && docker-compose up
- In Windows, run the following command from PowerShell:
docker compose up
After a few minutes the following or similar should appear:
ssdtest-app-1 | Command successful!
ssdtest-app-1 | __S_W_I_R_L__2_._5_._1________________________________________________________
ssdtest-app-1 |
ssdtest-app-1 | Warning: logs directory does not exist, creating it
ssdtest-app-1 | Start: redis -> redis-server ./redis.conf ... Ok, pid: 28
ssdtest-app-1 | Start: celery-worker -> celery -A swirl_server worker --loglevel INFO ... Ok, pid: 34
ssdtest-app-1 | Start: celery-beats -> celery -A swirl_server beat --scheduler django_celery_beat.schedulers:DatabaseScheduler ... Ok, pid: 45
ssdtest-app-1 | Updating .swirl... Ok
ssdtest-app-1 |
ssdtest-app-1 | PID TTY TIME CMD
ssdtest-app-1 | 28 ? 00:00:00 redis-server
ssdtest-app-1 | 34 ? 00:00:02 celery
ssdtest-app-1 | 45 ? 00:00:02 celery
ssdtest-app-1 |
ssdtest-app-1 | Command successful!
ssdtest-app-1 | 2023-08-29 13:16:11,070 INFO Starting server at tcp:port=8000:interface=0.0.0.0
ssdtest-app-1 | 2023-08-29 13:16:11,074 INFO HTTP/2 support not enabled (install the http2 and tls Twisted extras)
ssdtest-app-1 | 2023-08-29 13:16:11,075 INFO Configuring endpoint tcp:port=8000:interface=0.0.0.0
ssdtest-app-1 | 2023-08-29 13:16:11,079 INFO Listening on TCP address 0.0.0.0:8000
- Open this URL with a browser: http://localhost:8000 (or http://localhost:8000/galaxy)
If the search page appears, click Log Out at the top, right. The Swirl login page will appear:

-
Enter the username
adminand passwordpassword, then clickLogin. -
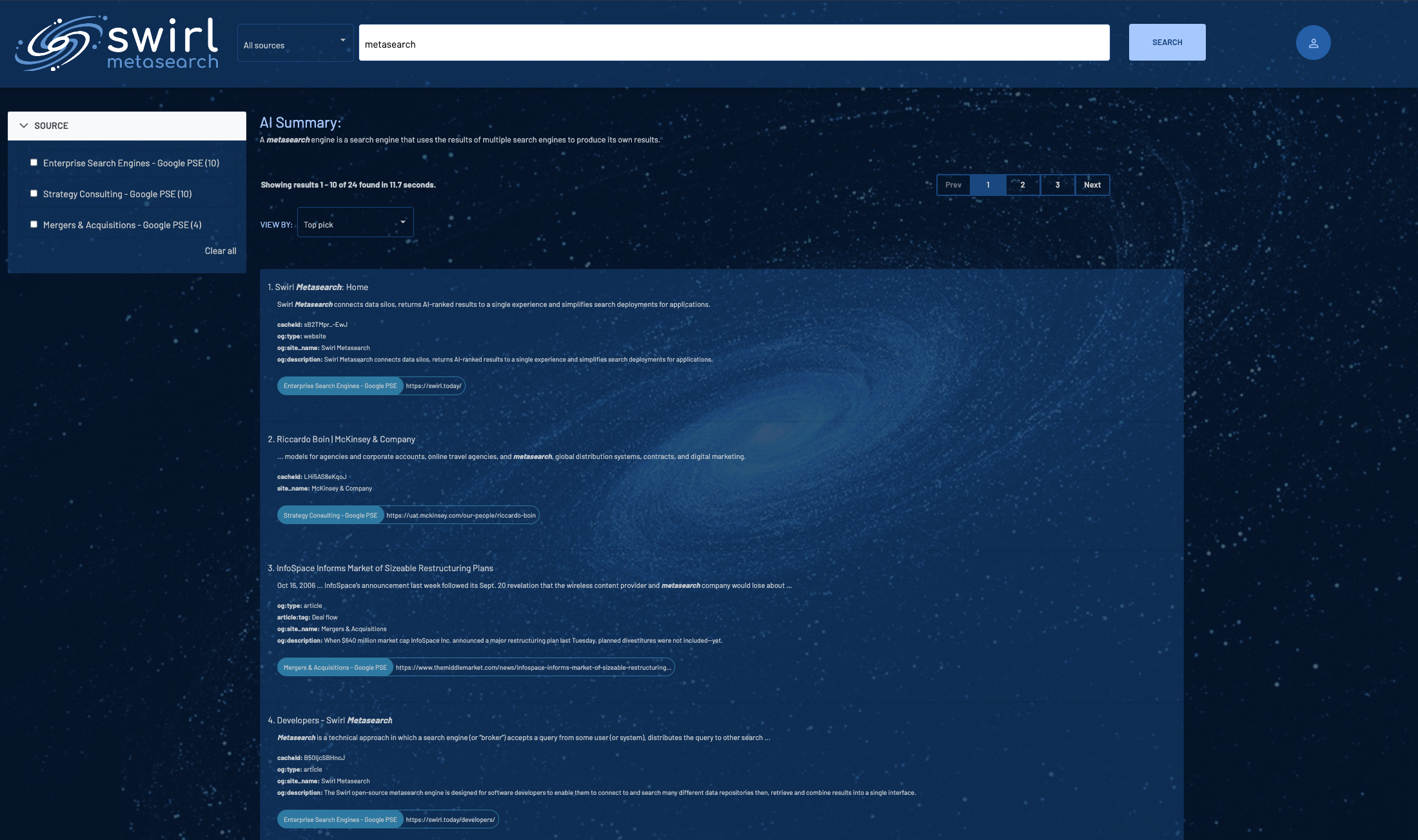
Enter a search in the search box and press the
Searchbutton. Ranked results appear in just a few seconds:
- To view the raw JSON, open http://localhost:8000/swirl/search/
The most recent Search object will be displayed at the top. Click on the result_url link to view the full JSON Response.
🔑 Swirl includes four (4) Google Programmable Search Engines (PSEs) to get you up and running right away. The credentials for these are shared with the Swirl Community.
🔑 Using Swirl with Microsoft 365 requires installation and approval by an authorized company Administrator. For more information, please review the M365 Guide or contact us.
-
Check out the details of our latest release!
-
Head over to the Quick Start Guide and install Swirl locally!
-
SearchProvider configurations for all included Connectors. They can be organized with the active, default and tags properties.
-
Adaptation of the query for each provider such as rewriting
NOT termto-term, removing NOTted terms from providers that don't support NOT, and passing down the AND, + and OR operators. -
Optional subscribe feature to continuously monitor any search for new results
-
Pipelining of Processor stages for real-time adaptation and transformation of queries, responses and results
-
Results stored in SQLite3 or PostgreSQL for post-processing, consumption and/or analytics
-
Built-in Query Transformation support, including re-writing and replacement
-
Matching on word stems and handling of stopwords via NLTK
-
Duplicate detection on field or by configurable Cosine Similarity threshold
-
Re-ranking of unified results using Cosine Vector Similarity based on spaCy's large language model and NLTK
-
Result mixers order results by relevancy, date or round-robin (stack) format, with optional filtering of just new items in subscribe mode
-
Page through all results requested, re-run, re-score and update searches using URLs provided with each result set
-
Sample data sets for use with SQLite3 and PostgreSQL
-
Optional search/result expiration service to limit storage use
Have an idea for a new feature, bug fix, or enhancement to Swirl? Great, we'd love to see it! To ensure a proper code review, all contributions to the project must go through a GitHub pull request.
We follow a rough approximation of the Gitflow branching model. Changes for the next release go on the develop branch. When submitting PRs to Swirl, please create a branch off of develop with a name that describes the change you're working on.
For more general information about contributing to projects on Github, visit the GitHub documentation on this very subject.
Thanks for your help!
For information about Swirl as a managed service, please contact us!
Home | Quick Start | User Guide | Admin Guide | M365 Guide | Developer Guide | Developer Reference
-
Email: [email protected] with issues, requests, questions, etc. - we'd love to hear from you!