Machine learning is quite a fascinating subfield of computer science so I decided to learn more about it. This repository contains some of the code that I have written in order to introduce myself to various concepts of machine learning.
Who knows, maybe one day this will become an open source machine learning library... It may not be the TensorFlow but this code should give you a basic understanding of the fundamentals. I will try to comment the code the best I can and give some basic theory behind the concepts in this README file.
NOTE: Readers should be familiar with linear algebra and calculus.
In statistics, linear regression is an approach for modeling the relationship between a scalar dependent variable 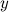

In a nutshell this means that for any two given data sets of points 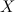





In this case we are investigating 

i.e. we are trying to find a set of coefficients 

We measure how well

where 


where 
In order to find the coefficients 

where alpha is the learning rate. When we substitute our cost function we get:

The idea behind this is that 
which will be the best set of coefficients for our relation
Instead of our output vector
We use sigmoid function as our hypothesis representation


Cost function is:

This cost function is chosen because it approaches infinity if 

Using the cost function above our algorithm to find the coefficients looks like this:

- Coursera machine learning course
- Deep Learning book by Ian Goodfellow Yoshua Bengio and Aaron Courville