mmcdole / gofeed Goto Github PK
View Code? Open in Web Editor NEWParse RSS, Atom and JSON feeds in Go
License: MIT License
Parse RSS, Atom and JSON feeds in Go
License: MIT License











































































































































































Starting parsing content:encoded for Item.Content for RSS feeds.
Sample code:
package main
import (
"fmt"
"log"
"github.com/mmcdole/gofeed"
)
func main() {
feedData :=
`<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<item>
<title>Test</title>
<description>Some description</description>
</item>
</channel>
</rss>`
fp := gofeed.NewParser()
feed, err := fp.ParseString(feedData)
if err != nil {
log.Fatalf("cannot parse feed: %v", err)
}
fmt.Printf("%s\n", feed.Items[0].Description)
}
If I run it: vendor/github.com/mmcdole/gofeed/detector.go:7:2: use of internal package not allowed
I also tried with a url feed with same result.
The following example entry, included within a valid Atom feed, should create a gofeed.Item with the following content.
<atom:entry>
<atom:title>Parsing Atom with gofeed</atom:title>
<atom:link href="https://example.com/blog/2016/04/18/parsing-atom-with-gofeed" />
<atom:updated>2016-04-18T00:00:00+00:00</atom:updated>
<atom:id>https://example.com/blog/2016/04/18/parsing-atom-with-gofeed</atom:id>
<atom:content type="html">
<p>This is a directly included child element, no wrapping in a DIV element.</p>
<div class="not-root"><p>This DIV is part of the post content, wholly unrelated to what RFC 4287 might say about DIVs.</p></div>
</atom:content>
</atom:entry>for _, item := range feed.Items {
fmt.Println(item.Content)
}
// <p>This is a directly included child element, no wrapping in a DIV element.</p>\n\n<div class="not-root"><p>This DIV is part of the post content, wholly unrelated to what RFC 4287 might say about DIVs.</p></div>for _, item := range feed.Items {
fmt.Println(item.Content)
}
// <p>This DIV is part of the post content, wholly unrelated to what RFC 4287 might say about DIVs.</p>The problematic feed is https://terinstock.com/atom.xml. The author is alright.
2. If the value of "type" is "html", the content of atom:content MUST NOT contain child elements and SHOULD be suitable for handling as HTML. The HTML markup MUST be escaped; for example, "<br>" as "<br>". The HTML markup SHOULD be such that it could validly appear directly within an HTML <DIV> element. Atom Processors that display the content MAY use the markup to aid in displaying it. 3. If the value of "type" is "xhtml", the content of atom:content MUST be a single XHTML div element [XHTML] and SHOULD be suitable for handling as XHTML. The XHTML div element itself MUST NOT be considered part of the content. Atom Processors that display the content MAY use the markup to aid in displaying it. The escaped versions of characters such as "&" and ">" represent those characters, not markup.
Of course, a DIV is valid within a DIV, but it's not required for type html. Even if the content was wrapped with a DIV, it should be considered part of the content, for the html type.
Feed parsed
http://www.larevuedudigital.com/feed/ -> Failed to detect feed type
Hey Matthew, thanks for your help over on the feedparser issue tracker!
Mark Pilgrim claimed copyright over the feedparser XML unit tests released them under the 2-clause BSD license. In addition, I've spent the last six years cleaning up and adding new XML unit tests. However, I didn't see any copyright attribution nor the text of the 2-clause BSD license, both of which are mandatory in order to use the XML unit tests.
Would you update the gofeed documentation so that it clearly identifies both Mark Pilgrim and myself as the XML unit test copyright owners and identify that the unit test files are released under the terms of the 2-clause BSD license?
Thanks!
This malformed feed has a self-closing feed tag at the beginning of it. Need to iterate through other sibling elements if the first element is empty?
The feed I am trying to parse has a few nodes that are using a different namespace. The library causes the whole feed to be parsed into the extension map instead of just those few nodes. Ideally, I'd like to be able to access the content from the Item slice and discard the extension map.
The feed in question is http://feeds.feedburner.com/blogspot/RLXA
The feed to parse properly, with extensions limited to only the single offending node.
The whole feed is put inside the extension map.
Parsing the following will cause the entry to be in the extension map.
<?xml version="1.0" encoding="UTF-8"?>
<feed xmlns="http://www.w3.org/2005/Atom">
<title type="text">Foo</title>
<subtitle type="html">Bar</subtitle>
<author>
<name>Foo</name>
</author>
<blah:link href="foo" rel="self" type="application/atom+xml" xmlns:blah="http://www.w3.org/2005/Atom"/>
<entry>
<id>Foo</id>
<title type="text">title</title>
<content type="html">foo</content>
</entry>
</feed>
but removing the following line will marshal it into the feed struct flawlessly.
<blah:link href="foo" rel="self" type="application/atom+xml" xmlns:blah="http://www.w3.org/2005/Atom"/>
Note: Please include any links to problem feeds, or the feed content itself!
Currently when the feed encounters an unexpected token, I get an error message such as this:
(master) % gotest f /Users/mmcdole/Downloads/feeds/1016.dat
Error: Expected StartTag or EndTag but got Text
I'd like to improve these error messages to give more context about the location and source of the error.
Attaching a broken feed file as an example.
1016.txt
Hi,
i'm trying to parse this feed https://ctftime.org/event/list/upcoming/rss/
As you can see each item has tags like weight but i can't find a way to parse them, looking at the doc i can't find anything about that
The following feed is failing to parse due to issues with the <enclosure> tag. Need to look into this feed further.
I need to research how to get our code-coverage CI tool to include the aggregate coverage for all of gofeed's packages. Having it just be the coverage for the gofeed package doesn't seem as useful.
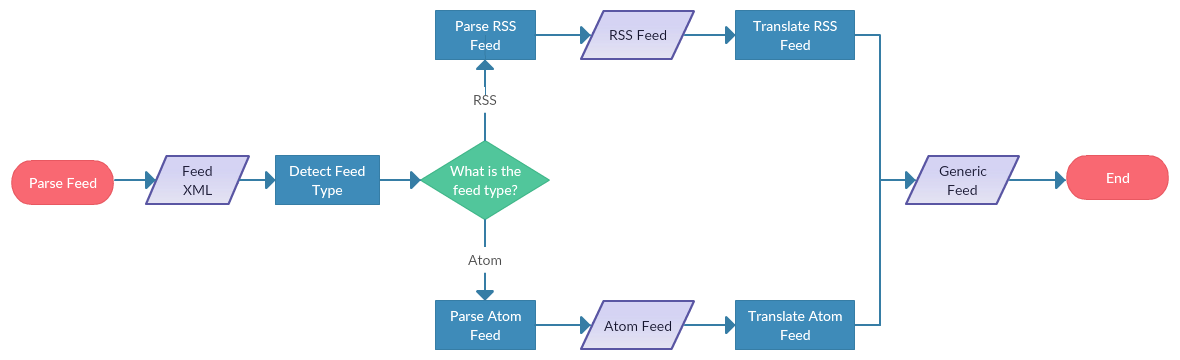 ! seems to have confused Atom and RSS feeds.
! seems to have confused Atom and RSS feeds.
I believe RSS feeds is being parsed by RSS parser, not Atom.
Any plans on supporting the JSON Feed format?
Obviously JSON is easy enough to parse on it's own, but it would be great to be able to have it just work with this out of the box.
I expect feed.Categories to be ["News & Politics"].
feed.Categories is: [Jon Favreau POTUS Donald Trump politics Tommy Vietor Dan Pfeiffer Jon Lovett Pod Save America News & Politics].
Please see unit test here: https://gist.github.com/armhold/96be9635883fd417b6cb82ab445abddd
This feed comes from: http://feeds.feedburner.com/pod-save-america.
I haven't really dug into the code yet, so it's possible I'm doing something dumb here. But I think gofeed is accidentally adding the next line of the xml to feed.Categories.
Are you aware that http.Get can return a non-nil response that still needs closing even if err is non-nil as well? Not doing so leaks. http://devs.cloudimmunity.com/gotchas-and-common-mistakes-in-go-golang/index.html#close_http_resp_body
I seemed to have introduced a regression in parsing CDATA sections. It is including the CDATA prefix itself in the parsed content. I assume this was introduced when I fixed the naked markup issues.
I also need to add some more tests for both parsers around CDATA parsing.
If the connection to the given url is hanging, the httpClient should timeout.
Ideally the desired timeout could be an argument with a reasonable default
the connection hangs
find a url with really slow network and try parsing it.
Note: Please include any links to problem feeds, or the feed content itself!
the link that hung for me was http://rss.shanghaidaily.com/Portal/mainSite/Handler.ashx?i=7
the function that's hanging for me is ParseURL in parser.go
The atom.Parser needs to be modified to support resolving relative urls specified with xml:base.
Add relative url tests as well.
Be able to run go feed
When i try to 'go build', i am seeing this error.
'package gofeed
imports github.com/mmcdole/gofeed/internal/shared: use of internal package not allowed'
My go version is 'go version go1.5.1 darwin/amd64'
run go build
Note: Please include any links to problem feeds, or the feed content itself!
I am new to go. Did i miss anything?
Parsing https://www.reddit.com/r/games/.rss should work with an appropriate delay in making requests (Reddit asks for 2 seconds between bot requests).
To further describe the issue, this could be resolved if we had the option of defining our own user-agent strings (or any headers for that matter) when calling gofeed.ParseURL(url string) or when constructing our parser with gofeed.NewParser() .
Returns 429 Too Many Requests, as Reddit filters requests that do not have user-agent strings.
The first request will work, after which Reddit will block all new requests for a period of time.
fp := gofeed.NewParser()
feed, err := fp.ParseURL("https://www.reddit.com/r/games/.rss")
if err != nil {
fmt.Println(err.Error())
return
}
// This first request will work
fmt.Println(feed.Title)
time.Sleep(5 * time.Second)
// This second request will fail because no user-agent string is defined for the request
secondfeed, err := fp.ParseURL("https://www.reddit.com/r/games/.rss")
if err != nil {
fmt.Println(err.Error())
return
}
fmt.Println(secondfeed.Title)
Note: Please include any links to problem feeds, or the feed content itself!
The xml:lang attribute is not being parsed currently to populate the Language field of atom.Parser.
We are also missing Atom unit tests for the Language field.
many times i have ERROR: EOF
for eample :http://basijnews.ir/fa/rss/39: EOF
The feed is apparently a valid Atom 1.0 feed according to the W3C. https://validator.w3.org/feed/check.cgi?url=http%3A%2F%2Fwww.qdep.org%2Ffeed%2Fatom%2F
Error message: "Failed to detect feed type".
Try parsing http://www.qdep.org/feed/atom/ on commit 1bc2cbeba25b7b594430cff43d7c9e9367cfdca0
xref : matrix-org/go-neb#187
Since all the structs are here, are there any plans to use them to create feeds?
Failed to parse the following feed:
http://feeds.feedburner.com/gestalten_tv
when i start parser with 30 feed url i have error:
socket: too many open files
Failed to parse the following feed:
http://feeds.feedburner.com/YalePressPodcastITunes
When calling ParseURL() on a feed URL, if the server returns an error (e.g. 404), ParseURL() should return this error.
ParseURL() returns "Failed to detect feed type".
Simple example: use ParseURL() on http://boinkor.net/atom.xml (should return 404).
Feeds are XML documents. Character data can contains both predefined entites (such as <) and numerical character references (e.g. "). These references must be decoded; for example, " has to be decoded to ". encoding/xml does it properly.
Gofeed decodes predefined entities (internal/shared/parseutils.go: DecodeEntities) but ignores numerical character references. Lots of feeds include html data which are encoded since they are included in a XML document. For example, feed generators often encode " with " instead of ".
package main
import (
"fmt"
"log"
"github.com/mmcdole/gofeed"
)
func main() {
feedData :=
`<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<item>
<title>Test</title>
<description><a> "b" "c"</description>
</item>
</channel>
</rss>`
fp := gofeed.NewParser()
feed, err := fp.ParseString(feedData)
if err != nil {
log.Fatalf("cannot parse feed: %v", err)
}
fmt.Printf("%s\n", feed.Items[0].Description)
}This prints <a> "b" "c" instead of <a> "b" "c".
I'm not 100% sure about this but I think the logic to parse the <itunes:image> element into ITunesFeedExtension.Image and ITunesItemExtension.Image may need an update.
All the feeds I'm parsing seem to be using a self-closing tag with the image URL contained in the href attribute. Currently the parser calls parseTextExtension("image", extensions) which returns an empty string.
I've modified a copy of gofeed I'm using to do something similar to the <itunes:owner> and <itunes:category> parsers:
func parseImage(extensions map[string][]Extension) (image string) {
if extensions == nil {
return
}
matches, ok := extensions["image"]
if !ok || len(matches) == 0 {
return
}
image = matches[0].Attrs["href"]
return
}
Thanks so much for creating this library. It is fantastic.
rss_feed with this xml encoding detect error
<title>RSS Title</title>When parsing this RSS feed, the iTunesExt.Summary field should be correctly populated for each item in the feed.
The iTunesExt.Summary field is blank for every item.
Parse the feed and inspect the resulting rss.Item values. You could also look at the translated gofeed.Item values.
The problem appears to be in the parseExtensionElement function. The function takes an XML node (in this case an <itunes:summary> tag) and uses it to create a new ext.Extension. It iterates over any child nodes and, if the child is of type text, sets the Value of the new Extension to the text node's value. Note that if the parent node contains multiple child nodes of type text, only the final node's value is retained.
In this particular feed, the item-level <itunes:summary> tags all contain three text nodes. The first and last are blank while the middle node holds the actual text. Currently this text is being overwritten with the final blank string.
If you view the source for the feed you will see that there are extra line breaks around the text in the <itunes:summary> tags. These line breaks are not present on any other tags (all of which are being parsed correctly as far as I can tell). Perhaps the line breaks are causing the spurious text nodes.
I fixed this in my vendored version of the code by changing this line:
e.Value = strings.TrimSpace(p.Text)
to this:
e.Value += strings.TrimSpace(p.Text)
But I'm not familiar with the project. Maybe this quick fix isn't the best approach. Let me know what you think (I can submit a PR if you'd like).
Hello,
When a feed does not specify the author, the gofeed parser does not bother zeroing the
item.Author.Name and item.Author.Email fields.
item.Author.Name -> ""
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x6842a1]
goroutine 1 [running]:
main.main()
/home/src/go/feedparser/main.go:52 +0x251
A feed which doesn't set the author field is the linux kernel feed "https://www.kernel.org/feeds/kdist.xml"
Would ActivityStreams support be considered? It's the basis for ActivityPub, which the Mastodon network is built on.
(Sorry, I originally posted this on #80 and realized it should probably be a separate item.)
Parse content
Check http://blog.octo.com/category/architecture-et-technologies/feed/
error in channel: XML syntax error on line 574: illegal character code U+000C
XML syntax error on line 574: illegal character code U+000C
Take the chance to address the non-idiomatic method names while I still cant before hitting 1.0.
See the following reddit comment for details:
https://www.reddit.com/r/golang/comments/4e8say/gofeed_a_fast_and_robust_rss_and_atom_parser/d1y8vif
When I try to use item.PublishedParsed in goroutine, error occurs like
panic: runtime error: invalid memory address or nil pointer dereference [recovered] panic: runtime error: invalid memory address or nil pointer dereference [signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x69193e]
item.PublishedParsed is a *time.Time type.
But on official golang doc https://golang.org/pkg/time/#Time, it should be time.Time
Programs using times should typically store and pass them as values, not pointers. That is, time variables and struct fields should be of type time.Time, not *time.Time. A Time value can be used by multiple goroutines simultaneously.
Is my problem relative to this ?
Thank you
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.