Di masa sekarang ini, kuantitas transaksi data yang terjadi setiap menitnya meningkat secara eksponensial. Jumlah data yang berada dalam internet menjadi semakin banyak dan dari sekian banyaknya data tersebut tidak semuanya sesuai dengan yang diinginkan pengguna[1]. Data yang sangat besar itu jika tidak diproses dengan baik akan terbuang percuma. Dalam beberapa kasus, pengguna perlu melakukan pencarian beberapa kali sebelum menemukan hal yang mereka cari. Untuk itu, diperlukan suatu sistem yang memberikan rekomendasi kepada pengguna terkait dengan informasi yang mereka inginkan berdasarkan informasi relevan yang diambil dari informasi pengguna.
Sistem rekomendasi dapat menyaring informasi dari internet dan menyarankan informasi yang paling sesuai dengan yang dibutuhkan pengguna sesuai preferensi mereka. Sistem rekomendasi ini secara luas dibagi menjadi tiga jenis, yaitu content-based filtering, collaborative filtering, dan hybrid method[2]. Dari ketiga jenis tersebut, yang akan dipakai dalam proyek ini adalah content-based filtering dan collaborative filtering untuk proses pemberian saran atau rekomendasi movie/film kepada pengguna. Hal ini sangat penting untuk diterapkan agar pengguna merasa nyaman dan senang, sehingga mereka dapat tetap memakai layanan/aplikasi yang dibuat.
Berdasarkan kondisi yang telah diuraikan sebelumnya, akan dikembangkan suatu sistem rekomendasi untuk memberikan rekomendasi atau saran terkait movie/film sesuai dengan preferensi atau film yang telah ditonton sebelumnya. Sebelum itu, berikut adalah pernyataan masalah dan tujuan atau goals yang ingin diraih.
- Berdasarkan data mengenai pengguna, bagaimana membuat sistem rekomendasi yang dipersonalisasi dengan teknik content-based filtering?
- Dengan data rating yang Anda miliki, bagaimana perusahaan dapat merekomendasikan film lain yang mungkin disukai dan belum pernah ditonton oleh pengguna?
- Menghasilkan sejumlah rekomendasi film yang dipersonalisasi untuk pengguna dengan teknik content-based filtering.
- Menghasilkan sejumlah rekomendasi film yang sesuai dengan preferensi pengguna dan belum pernah ditonton sebelumnya dengan teknik collaborative filtering.
- Menggunakan pendekatan content-based filtering dengan mencari hubungan antara fitur genre dengan judul film menggunakan cosine similarity.
- Menggunakan pendekatan collaborative filtering dengan mencari hubungan antara user, movie, dan rating menggunakan model neural network.
Dataset yang digunakan dalam proyek ini adalah data film yang dirilis sejak tahun 1996 sampai 2016. Dataset ini terdiri dari satu folder berisi empat file kecil untuk diolah dan satu file berisi metadata dari kumpulan film. Empat file yang ada di dalam folder itu adalah links.csv, movies.csv, ratings.csv, dan tags.csv. Namun, dari empat file tersebut, yang digunakan untuk membentuk sistem rekomendasi hanya movies.csv dan ratings.csv. File movies.csv memiliki 9742 baris dan 3 kolom, sementara file ratings.csv memiliki 100836 baris dan 4 kolom.
Adapun sumber asli data ini diambil dari Movie lens, tetapi kemudian diolah dan saya mendapat hasil olahan tersebut dari kaggle, sumber data dapat diakses melalui tautan berikut: Movie Recommendation Data
- movies: merupakan identitas film/movie
- movieId: kode unik pengidentifikasi film/movie
- title: judul film/movie
- genres: genre film/movie
- ratings: merupakan penilaian user terhadap movie
- userId: kode unik untuk identitas user yang melakukan penilaian
- movieId: kode unik pengidentifikasi film/movie yang dinilai
- rating: rating atau penilaian film/movie
- timestamp: waktu dilakukannya penilaian
Hal yang pertama perlu dilakukan setelah memuat dataset yaitu mengetahui isi, info, dan deskripsi dari data. Proses eksplorasi data ini dilakukan pada kedua variabel movies dan ratings.
Setelah mengetahui isi dan info dari data movies, bisa dilihat bahwa dalam judul (title) film terdapat tahun ketika film tersebut rilis. Fitur ini dapat dipisah untuk menampakan persebaran tahun dari film-film tersebut. Selain itu, setelah memisahkan fitur tahun ini, kita dapat melihat bahwa film terlama dirilis pada tahun 1902 dan film terbaru (dalam dataset) dirilis pada tahun 2018, serta didapat pula bahwa ada beberapa film yang tidak diketahui tahun rilisnya. Berikut grafik persebaran tahunnya.
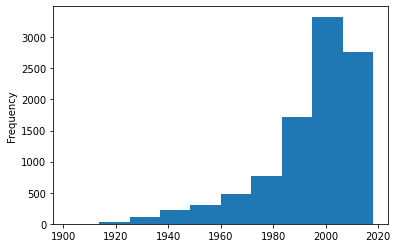
Gambar 1. Distribusi tahun rilis film
Setelah mengetahui isi, info, dan deskripsi dari data ratings, didapat beberapa informasi seperti:
- Tidak semua film mendapat rating oleh pengguna atau user. Dilihat dari jumlah film yang diberi rating kurang dari jumlah film yang ada di variabel
movies. - Rating minimum adalah 0.5 dan rating maksimum adalah 5.0
- User paling banyak memberi rating 4.0 dan paling sedikit memberi rating 0.5. Berikut grafiknya.
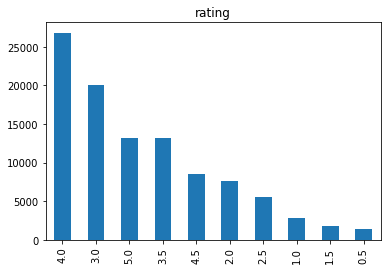
Gambar 2. Distribusi rating
Data preparation yang dilakukan dalam proyek ini dibagi menjadi dua, yaitu untuk content-based filtering dan collaborative filtering.
- Menggabungkan ratings dengan movies dengan menggunakan perintah
mergeyang ada padapandas.Dataframe. Ini digunakan agar semua dataset digunakan untuk proses pembuatan model. - Menghapus missing value. Terdapat missing value pada fitur
yearsetelah dilakukan pemisahan antara fitur judul dan tahun rilis film. Data yang kosong itu akan dihapus karena tahun rilis film tidak bisa digantikan dengan mean, median, ataupun modus. Untuk menghapusnya gunakan perintahdropna()yang ada padapandas.Dataframe. - Drop duplicate dan membuat dataframe baru. Drop duplicate yang dimaksud adalah untuk menghilangkan duplikasi pada fitur
titlekarena hanya diperlukan data unique untuk proses pemodelan. Untuk menghilangkan duplikasi gunakan perintahdrop_duplicates()yang ada padapandas.Dataframe. Namun, sebelum proses menghilangkan duplikasi tersebut, lakukan pengurutan terlebih dahulu pada fiturmovieIdmenggunakan perintahsort_values()dari librarypandas.Dataframe. Kemudian buat dataframe baru bernamamovies_newdari data unique tersebut, cukup ambil fiturmovieId,title,genres, danyearuntuk digunakan pada proses pemodelan content-based filtering.
- Encoding
userIddanmovieId. Encoding atau mengkodekan kedua fitur ini bertujuan untuk mempermudah proses training, spliting, dan pemberian rekomendasi dengan menjadikannya dalam bentuk integer berurutan yang unique. - Membagi data untuk training dan validasi. Sebelum proses pembagian data, acak dataset dengan menggunakan perintah
sampledengan parameterfrac=1danrandom_state=55. Kemudian data dibagi dengan rasio 80% data latih dan 20% data validasi. Pembagian dataset ini dilakukan untuk menghindari terjadinya overfitting pada data latih ketika diterapkan pada kasus nyata.
Terdapat dua model berbeda yang disajikan dalam proyek ini, yaitu content-based filtering dan collaborative filtering.
Tahap pertama yang dilakukan ketika membuat model ini yaitu menyiapkan mengambil data yang sudah disiapkan pada proses sebelumnya (movies_new) dan mengambil sampel data untuk digunakan pada tahap rekomendasi. Kemudian siapkan TFIDF Vectorizer atau TfidfVectorizer yang diambil dari library sklearn.feature_extraction.text untuk membuat matriks fitur berdasarkan data genres.
Tahap kedua yaitu menghitung cosine similarity yang diambil dari library sklearn.metrics.pairwise dengan memasukkan tfidf_matrix sebagai argumennya. Kemudian buat dataframe dari dari cosine similarity tersebut dengan data title sebagai indeks dan kolomnya.
Tahap ketiga yaitu membuat fungsi untuk melakukan rekomendasi berdasarkan judul film dan dataframe yang ada di tahap kedua sebagai dasarnya. Ambil top-n recommendation kemudian drop judul film yang diberikan agar tidak muncul dalam rekomendasi. Langkah terakhir yaitu mengambil data sampel yang sudah disiapkan sebelumnya dan memasukkan judul filmnya ke dalam fungsi. Maka rekomendasi judul film yang mirip akan diberikan beserta genrenya.
Content-based filtering memiliki kelebihan yaitu dapat merekomendasikan film baru tanpa perlu menunggu pengguna lain untuk melakukan rating pada suatu film karena rekomendasi dilakukan berdasarkan konten, dalam hal ini genre, dari film tersebut. Kelemahan dari metode ini adalah terbatasnya rekomendasi hanya pada film-film yang mirip atau berhubungan, sehingga sulit untuk menghasilkan rekomendasi film yang tidak terduga (serendipitous recommendation).
Hasil rekomendasi dari 5 sampel:
Recommendation for: Double Team => Action
Tabel 1.1. Rekomendasi content-based filtering untuk judul film "Double Team"
| title | genres | |
|---|---|---|
| 0 | Avalanche | Action |
| 1 | Five Deadly Venoms | Action |
| 2 | No Holds Barred | Action |
| 3 | Only the Strong | Action |
| 4 | Fair Game | Action |
Recommendation for: By the Gun => Crime|Drama|Thriller
Tabel 1.2. Rekomendasi content-based filtering untuk judul film "By the Gun"
| title | genres | |
|---|---|---|
| 0 | Mr. Brooks | Crime|Drama|Thriller |
| 1 | Dancer Upstairs, The | Crime|Drama|Thriller |
| 2 | Villain | Crime|Drama|Thriller |
| 3 | Fresh | Crime|Drama|Thriller |
| 4 | Deadly Outlaw: Rekka (a.k.a. Violent Fire) (Ji... | Crime|Drama|Thriller |
Recommendation for: Night on Earth => Comedy|Drama
Tabel 1.3. Rekomendasi content-based filtering untuk judul film "Night on Earth"
| title | genres | |
|---|---|---|
| 0 | Boys on the Side | Comedy|Drama |
| 1 | Last Detail, The | Comedy|Drama |
| 2 | Paper, The | Comedy|Drama |
| 3 | Full Monty, The | Comedy|Drama |
| 4 | Carnal Knowledge | Comedy|Drama |
Recommendation for: Mexican, The => Action|Comedy
Tabel 1.4. Rekomendasi content-based filtering untuk judul film "Mexican, The"
| title | genres | |
|---|---|---|
| 0 | Tuxedo, The | Action|Comedy |
| 1 | Game Over, Man! | Action|Comedy |
| 2 | Beverly Hills Ninja | Action|Comedy |
| 3 | Disorganized Crime | Action|Comedy |
| 4 | National Security | Action|Comedy |
Recommendation for: Dangerous Minds => Drama
Tabel 1.5. Rekomendasi content-based filtering untuk judul film "Dangerous Minds"
| title | genres | |
|---|---|---|
| 0 | The Fundamentals of Caring | Drama |
| 1 | Men of Honor | Drama |
| 2 | Tangerines | Drama |
| 3 | Mommy | Drama |
| 4 | Way Back, The | Drama |
Tahap pertama yaitu membuat kelas RecommenderNet dengan keras model class. Model ini menghitung skor kecocokan antara pengguna dan film dengan teknik embedding. Setelah proses embedding antara user dan movie selesai, perkalian dot product antara keduanya akan dilakukan. Selain itu, di sini juga ditambahkan bias untuk setiap user dan movie. Skor kecocokan ditetapkan dalam skala [0,1] dengan menggunakan fungsi aktivasi sigmoid.
Tahap kedua yaitu proses inisialisasi, compile, dan train model. Lakukan inisialisasi model menggunakan kelas RecommenderNet di tahap pertama dengan num_users, num_movie, dan 50 (embedding size) sebagai parameternya. Lalu compile model dengan loss function menggunakan BinaryCrossentropy, optimizer menggunakan Adam dengan learning rate 0.001, dan metrik menggunakan RootMeanSquaredError atau RMSE. Terakhir lakukan training model menggunakan dataframe yang telah dipisah untuk proses latih dan validasi dengan epochs sebanyak 30 dan batch size sebesar 128.
Tahap ketiga yaitu mendapatkan rekomendasi film. Untuk mendapatkan rekomendasi film, pertama ambil user acak dan definisikan variabel movie_not_visited yang merupakan daftar film yang belum pernah dilihat oleh pengguna dan yang akan dijadikan rekomendasi. Selanjutnya gunakan model.predict() untuk mendapatkan rekomendasi filmnya. Maka akan tampil 10 rekomendasi film yang sesuai dengan preferensi pengguna.
Collaborative filtering memiliki kelebihan yaitu dapat bekerja meskipun konten yang berhubungan dengan item atau user sangat sedikit atau bahkan tidak ada. Sedangkan kelemahannya adalah pendekatan ini sangat memerlukan parameter rating untuk melakukan rekomendasi, sehingga jika ada item yang baru dimasukkan, sistem tidak akan merekomendasikan item tersebut. Masalah ini dinamakan sebagai cold-start problem.
Hasil rekomendasi untuk user:
Showing recommendations for users: 413
===========================
Movies with high ratings from user
--------------------------------
Pulp Fiction => Comedy|Crime|Drama|Thriller
Fight Club => Action|Crime|Drama|Thriller
Casino => Crime|Drama
Remember the Titans => Drama
Shanghai Noon => Action|Adventure|Comedy|Western
--------------------------------
Top 10 movie recommendation
--------------------------------
Amadeus => Drama
Grand Day Out with Wallace and Gromit, A => Adventure|Animation|Children|Comedy|Sci-Fi
City of God (Cidade de Deus) => Action|Adventure|Crime|Drama|Thriller
Pianist, The => Drama|War
Boot, Das (Boat, The) => Action|Drama|War
Seventh Seal, The (Sjunde inseglet, Det) => Drama
Touch of Evil => Crime|Film-Noir|Thriller
Glory => Drama|War
Streetcar Named Desire, A => Drama
Manhattan => Comedy|Drama|Romance
Atau jika ditampilkan dalam bentuk tabel, hasil rekomendasinya seperti yang ditunjukkan dalam tabel 2.
Tabel 2. Rekomendasi collaborative filtering untuk user 413
| title | genres | |
|---|---|---|
| 1 | Amadeus | Adventure|Animation|Children|Comedy|Sci-Fi |
| 2 | Grand Day Out with Wallace and Gromit, A | Adventure|Animation|Children|Comedy|Sci-Fi |
| 3 | City of God (Cidade de Deus) | Action|Adventure|Crime|Drama|Thriller |
| 4 | Pianist, The | Drama|War |
| 5 | Boot, Das (Boat, The) | Action|Drama|War |
| 6 | Seventh Seal, The (Sjunde inseglet, Det) | Drama |
| 7 | Touch of Evil | Crime|Film-Noir|Thriller |
| 8 | Glory | Drama|War |
| 9 | Streetcar Named Desire, A | Drama |
| 10 | Manhattan | Comedy|Drama|Romance |
Metriks yang digunakan dalam model content-based filtering adalah precision. Metriks ini menghitung jumlah item rekomendasi yang relevan jika dibandingkan dengan semua item yang direkomendasikan. Adapun formulanya dapat ditulis sebagaimana ditunjukkan pada gambar 3.
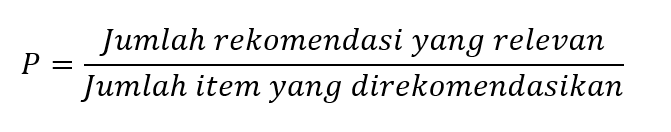
Gambar 3. Formula precision
Kemudian untuk perhitungannya dilakukan secara manual ditunjukkan pada gambar 4.
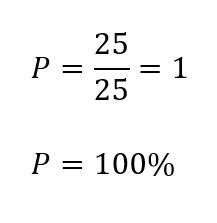
Gambar 4. Perhitungan precision
Jika dilihat dari metriks yang ada di gambar 4, dapat disimpulkan bahwa model sudah baik karena nilai precision sudah mencapai nilai 100% atau dalam kata lain sudah sangat presisi.
Metriks yang digunakan dalam model collaborative filtering adalah Root Mean Square Error (RMSE). Metriks ini dihitung dengan mengkuadratkan error (prediksi – observasi) dibagi dengan jumlah data, lalu diakarkan. Secara umum metriks ini memiliki cara kerja yang sama dengan MAE dan MSE yakni menghtung tingkat error antar nilai prediksi dan nilai sebenarnya. Adapun formulanya dapat ditulis sebagaimana ditunjukkan pada gambar 5.
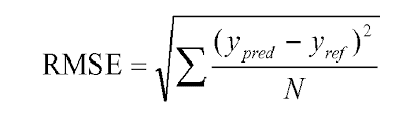
Gambar 5. Formula Root Mean Square Error (RMSE)
Adapun visualisasi metriksnya dapat dilihat pada gambar 6.
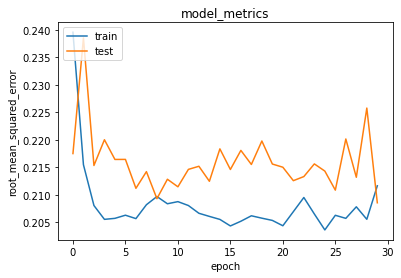
Gambar 6. Visualisasi metriks RMSE terhadap model
Jika dilihat dari metriks yang ada di gambar 6, dapat disimpulkan bahwa model sudah cukup baik karena nilai RMSE sudah cukup rendah yakni sekitar 0.20-0.21.
Sistem rekomendasi film yang telah dibuat dengan menggunakan pendekatan content-based filtering dan collaborative filtering sudah cukup bagus dan sudah memenuhi goals untuk menghasilkan sejumlah rekomendasi film yang dipersonalisasi untuk pengguna. Model content-based filtering sudah memiliki presisi yang sangat bagus, sementara model collaborative filtering sudah memiliki RMSE yang cukup kecil, sehingga dapat dikatakan bahwa kedua model sudah mencapai goals yang diinginkan. Namun, tidak menutup kemungkinan untuk kedua model ini memperoleh improvement untuk menghasilkan rekomendasi yang lebih baik.
[1] Z. Wang, X. Yu, N. Feng, and Z. Wang, “An improved collaborative movie recommendation system using computational intelligence,” J. Vis. Lang. Comput., vol. 25, no. 6, pp. 667–675, 2014, doi: 10.1016/j.jvlc.2014.09.011.
[2] S. Reddy, S. Nalluri, S. Kunisetti, S. Ashok, and B. Venkatesh, Content-based movie recommendation system using genre correlation, vol. 105. Springer Singapore, 2019. doi: 10.1007/978-981-13-1927-3_42.
