2017 年做软件开发工程师至今,技术成长可以分为两个阶段。
2018 年到 2020 年在做 移动端 Hybrid 相关工作。
主要产出如下:
2020 年至今在做 沙箱(泛指代码执行环境) 相关工作。
目前主要产出如下:

如果我的产出帮到了你,欢迎打赏点零花钱 (⁎⁍̴̛ᴗ⁍̴̛⁎)

|

|
个人微信(伸手党勿扰)

|
:honeybee: 记录技术成长过程中思考与沉淀
2017 年做软件开发工程师至今,技术成长可以分为两个阶段。
2018 年到 2020 年在做 移动端 Hybrid 相关工作。
主要产出如下:
2020 年至今在做 沙箱(泛指代码执行环境) 相关工作。
目前主要产出如下:
如果我的产出帮到了你,欢迎打赏点零花钱 (⁎⁍̴̛ᴗ⁍̴̛⁎)
|
|
|
个人微信(伸手党勿扰)
|
|





























































































































文章首发于我的博客 #110
距离发布如何私有化部署 CodeSandbox 沙箱的文章《搭建一个属于自己的在线 IDE》 已经过了一年多的时间,最开始是为了在区块复用平台上能够实时构建前端代码并预览效果。不过在去年云音乐内部启动的基于源码的低代码平台项目中,同样有在线实时构建前端应用的需求,最初是采用从零开发沙箱的方式,不过自研沙箱存在以下几点问题:
灵活性较差
被构建应用的 npm 依赖需要提前被打包到沙箱本身的代码中,无法做到在构建过程中动态从服务获取应用依赖内容;
兼容性较差
被构建应用的技术选型比较受限,比如不支持使用 less 等;
未实现与平台的隔离
低代码平台和沙箱没有用类似 iframe 作为隔离,会存在沙箱构建页面的全局变量或者样式上被外部的低代码平台污染的问题。
当然如果继续在这个自研沙箱上继续开发,上面提到的问题还是可以逐步被解决的,只是需要投入更多的人力。
而 CodeSandbox 作为目最主流且成熟度较高的在线构建沙箱,不存在上面列出的问题。而且实现代码全部开源,也不存在安全问题。于是便决定采用私有化部署的 CodeSandbox 来替换低代码平台的自研沙箱,期间工作主要分为下面两方面:
针对低代码平台的定制化需求
例如为了实现组件的拖拽到沙箱构建的页面中,需要对沙箱构建好的页面进行跨 iframe 的原生事件监听,以便进一步计算拖拽的准确位置。
提升沙箱构建速度
由于低代码平台需要在线搭建应用,存在两个特点:首先是需要构建完整的前端应用代码而非某些代码片段,其次是需要频繁地修改应用代码并实时查看效果,因此对沙箱的构建性能有较高要求。
其中在提升沙箱构建速度的过程中一波三折:从最初花费接近 2 分钟构建一个包含 antd 依赖的简单中后台应用,一步步优化到 1 秒左右实现秒开,甚至已经比 CodeSandbox 官网的沙箱构建速度还要更快。
补充:上面提到两个平台的文章介绍如下,感兴趣的可以自行查看:
低代码平台: 网易云音乐低代码体系建设思考与实践
区块复用平台: 跨项目区块复用方案实践
下面就来介绍下 CodeSandbox 沙箱性能优化过程,在正式开始之前,为了方便读者更容易理解,先简要介绍下沙箱的构建过程。
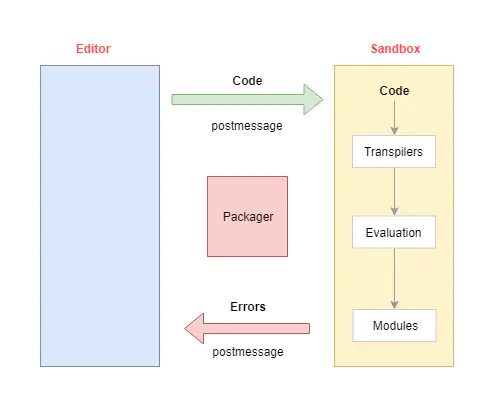
CodeSandbox 本质上是在浏览器中运行的简化版 Webpack,下面是整个沙箱的架构图,主要包含两部分:在线 Bundler 部分和 Packager 服务。
其中使用方只需引入封装好的 Sandbox 组件即可,组件内部会创建 iframe 标签来加载部署好的沙箱页面,页面中的 js 代码就是沙箱的核心部分 -- 在线 Bundler。沙箱构建流程中首先是 Sandbox 组件将需要包含被构建应用源代码的 compile 指令通过 postMessage 传递给 iframe 内的在线 Bundler,在线 Bundler 在接收到 compile 指令后便开始构建应用,最开始会预先从 npm 打包服务获取应用的 npm 依赖内容。
下面分别对沙箱构建的三个阶段 -- 依赖预加载阶段、编译阶段、执行阶段,进行详细阐述。
由于在浏览器环境中很难安装前端应用的 node_modules 资源,所以编译阶段需要从服务端获取依赖的 npm 包的模块资源,通过 npm 包的入口文件字段(package#main 等)和 meta 信息计算 npm 包中指定模块在 CDN 上的具体路径,然后请求获取模块内容。举个例子:
如果前端应用的某视图模块 demo.js 引用了 react 依赖,如下图:
import React from 'react';
const Demo = () => (<div>Demo</div>);
export default Demo;在编译完 demo.js 模块后会继续编译该模块的依赖 react,首先会从 CDN 上获取 react 的 package.json 模块内容和 react 的 meta 信息:
https://unpkg.com/[email protected]/package.json
https://unpkg.com/[email protected]/?meta
然后计算得到 react 包入口文件的具体路径(整个过程也就是 file resolve 的过程),从 CDN 上请求该模块内容:
https://unpkg.com/[email protected]/index.js
接着继续编译该模块及其依赖,如此递归编译直到将应用中所有被引用到的依赖模块编译完成。
可见浏览器端实现的沙箱在整个编译应用过程中需要不断从 CDN 上获取 npm 包的模块内容,产生非常多的 HTTP 请求,也就是传说中的 HTTP 请求瀑布流。又因为浏览器对同一域名下的并发 HTTP 请求数量有限制(例如针对 HTTP/1.x 版本的 HTTP 请求,其中 Chrome 浏览器限制数量为 6 个),最终导致整个编译过程非常耗时。
为了解决这个问题,于是便有了依赖预加载阶段 -- 即在开始编译应用之前,沙箱先从 npm 打包服务中请求应用依赖的 npm 包内容,而打包服务会将 npm 包的被导出的模块打包成一个 JSON 模块返回,该模块也被称为 Manifest。 例如下面就是 react 包的 Manifest 模块的链接和截图:
https://prod-packager-packages.codesandbox.io/v2/packages/react/17.0.2.json
这样获取每个 npm 包的内容只需要发送一个 HTTP 请求就可以了。
在依赖预加载阶段,沙箱会请求应用中所有依赖包的 Manifest,然后合并成一个 Manifest。目的是为了在接下来的编译阶段,沙箱只需要从 Manifest 中查找 npm 包的某个具体模块即可。当然如果在 Manifest 中找不到,沙箱还是会从 CDN 上请求该模块以确保编译过程顺利进行。
上面提到的 npm 打包服务(也称 Packager 服务)的基本原理如下:
先通过 yarn 将指定 npm 包安装到磁盘上,然后解析 npm 包入口文件的 AST 中的 require 语句,接着递归解析被 require 模块,最终将所有被引用的模块打包到 Manifest 文件中输出(目的是为了剔除 npm 包中多余模块,例如文档等)。
简而言之依赖预加载阶段就是为了避免在编译阶段产生大量请求导致编译时间过长。和 Vite 的依赖预构建的部分目标是相同的 -- 依赖预构建。
注意:这里之所以如此详细地介绍依赖预加载阶段存在的必要性和运行机制,主要是为了后面阐述沙箱性能优化部分做铺垫。读者读到性能优化部分有些不理解的话,可以再返回来温习下。
简单来说编译阶段就是从应用的入口文件开始,对源代码进行编译,解析 AST,找出下级依赖模块,然后递归编译,最终形成一个依赖关系图。其中模块之间互相引用遵循的是 CommonJS 规范。
补充:关于模拟 CommonJS 的内容可以参考下面关于 Webpack 的文章,由于篇幅问题这里就不展开了:webpack系列 —— 模块化原理-CommonJS
和编译阶段一样,也是从入口文件开始,使用 eval 执行入口文件,如果执行过程中调用了 require,则递归 eval 被依赖的模块。
到此沙箱的构建过程就阐述完了,更多详细内容可参考以下文章:
接下来就进入到本文的主题 -- 如何提升沙箱的构建速度。整个过程会以文章开头提到的包含 antd 依赖的简单中后台应用的构建为例,阐述如何逐步将构建速度从 2 分钟优化到 1s 左右。主要有以下四个方面:
缓存 Packager 服务打包结果
减少编译阶段单个 npm 包模块请求数量
开启 Service-Worker + CacheStorage 缓存
实现类 Webpack Externals 功能
通过对沙箱构建应用过程的分析,首先发现的问题是在依赖预加载阶段从 Packager 服务请求 antd 包的 Manifest 耗时 1 分钟左右,有时甚至会有请求超时的情况。根据前面对 Packager 服务原理的阐述,可以判断出导致耗时的原因主要是 antd 包(包括其依赖)体积较大,无论是下载 antd 包还是从 antd 包入口文件递归打包所有引用的模块都会非常耗时。
对此可以将 Packager 服务的打包结果缓存起来,沙箱再次请求时则直接从缓存中读取并返回,无需再走下载+打包的过程。其中缓存的具体方式读者可根据自身情况来决定。至于首次打包过慢问题,可以针对常用的 npm 包提前请求 Packager 服务来触发打包,以保证在构建应用过程中可以快速获取到 npm 包的 Manifest。
在缓存了 Packager 服务打包结果之后,应用的构建时间就从近 2 分钟优化到了 70s 左右。
继续分析沙箱在编译阶段的网络请求时,会发现会有大量的 antd 包和 @babel/runtime 包相关的模块请求,如下图所示:
根据上面沙箱原理部分的讲解可以知道,依赖预加载阶段就是为了避免在编译阶段产生大量 npm 单模块请求而设计的,那为什么还会有这么多的请求呢?原因总结来说有两个:
Packager 服务和沙箱构建时确定 npm 包的入口文件不同
npm 包本身没有指定入口文件或入口文件不能关联所有编译时会用到的模块
以 antd 包的为例,该包本身的依赖大部分为内部组件 rc-xxx,其 package.json 同时包含两个字段 main 和 module,以 rc-slider 为例,下面是该包的 package.json 有关入口文件定义部分(注意其中入口文件名没有后缀):
{
"main": "./lib/index",
"module": "./es/index",
"name": "rc-slider",
"version": "10.0.0-alpha.4"
}我们已经知道了 Packager 服务是从 npm 包的入口文件开始,递归将所有被引用的模块打包成 Manifest 返回的。其中 module 字段优先级高于 main 字段,所以 Packager 服务会以 ./es/index.js 作为入口文件开始打包。但在完成 Manifest 打包后和正式返回给沙箱前,还会校验 package.json 中 module 字段定义的入口文件是否在 npm 包中真实存在,如果不存在则会将 module 字段从 package.json 中删除。
不幸的是检验入口文件是否真实存在的逻辑中没有考虑到文件名没有后缀的情况,而恰好该 npm 包的 module 字段没有写文件后缀,所以在返回的 Manifest 中 rc-slider 的 package.json 的 module 字段被删除了。
接下来是浏览器侧的沙箱开始编译应用,编译到 rc-slider 依赖时,由于 rc-slider 的 package.json 的 module 字段被删除,所以是按照 main 字段指定的 ./lib/index.js 模块作为入口文件开始编译,但是 Manifest 中只有 es 目录下的模块,所以只能在编译过程中从 CDN 动态请求 lib 下的模块,由此产生了大量 HTTP 请求阻塞编译。
有关 Packager 服务没有兼容入口文件名无后缀的问题,笔者已经向 CodeSandbox 官方提交 PR 修复了,点击查看。
接下来再看另外一个例子 -- ramda 包的 package.json 中有关入口文件部分:
{
"exports": {
".": {
"require": "./src/index.js",
"import": "./es/index.js",
"default": "./src/index.js"
},
"./es/": "./es/",
"./src/": "./src/",
"./dist/": "./dist/"
},
"main": "./src/index.js",
"module": "./es/index.js",
"name": "ramda",
"version": "0.28.0"
}Packager 服务是 module 字段指定的 ./es/index.js 作为入口开始打包的,但编译阶段中沙箱却最终选择 export 中 . 的 default 指定的 ./src/index.js 作为入口开始编译,进而也产生了大量的单个模块的请求。
问题的本质就是【Packager 服务打包 npm 包时】和【沙箱构建应用时】确定 npm 包入口文件的策略并不完全一致,想要根治该问题就要对其两侧的确定入口文件的策略。
沙箱侧确定入口文件的逻辑在 packages/sandpack-core/src/resolver/utils/pkg-json.ts 中。
Packager 服务侧相关逻辑在 functions/packager/packages/find-package-infos.ts / functions/packager/packages/resolve-required-files.ts / functions/packager/utils/resolver.ts 中。
读者可自行决定选择 以 Packager 服务侧还是沙箱侧的 npm 入口文件的确定策略 作为统一标准,总之一定要保证两侧的策略是一致的。
首先分析下 @babel/runtime 包,通过该包的 package.json 可以发现其并没有定义入口文件,一般使用该包都是直接引用包中的具体模块,例如 var _classCallCheck = require("@babel/runtime/helpers/classCallCheck");,所以按照 Packager 服务的打包原理是无法将该包中的编译时会用到的模块打包到 Manifest 中的,最终导致编译阶段产生大量单个模块的请求。
对此笔者也只是采用特殊情况特殊处理的方式:在打包没有定义入口文件或入口文件不能关联所有编译时会用到的模块的 npm 包时,在 npm 打包过程中手动将指定目录下或指定模块打包到 Manifest 中。例如对于 @babel/runtime 包来说,就是在打包过程中将其根目录下的所有文件都手动的打包到 Manifest 中。目前还没有更好的解法,如果读者有更好的解法欢迎留言。
当然如果是内部的 npm 包,也可以在 package.json 中增加类似 sandpackEntries 的自定义字段,即指定多个入口文件,便于 Packager 服务将编译阶段用到的模块尽可能都打包到 Manifest 中。例如针对低代码平台的组件可能会分为正常模式和设计模式,其中设计模式是为了在低代码平台更方便的拖动组件和配置组件参数等,会在 index.js 之外再定义 designer.js 作为设计模式下组件入口文件,这种情况就可以指定多个入口文件(多个入口概念仅针对 Packager 服务)。相关改造是在 functions/packager/packages/resolve-required-files.ts 中的 resolveRequiredFiles 函数,如下图所示:
通过减少编译阶段单个 npm 包模块请求数量,应用的构建时间从 70s 左右降到了 35s 左右。
笔者在分析大量 npm 包单个模块请求问题时,也在 CodeSandbox 官方站点的沙箱中构建完全相同的应用,并没有遇到这个问题,后来才发现官网只是将已经请求过的资源缓存起来。也就是说在第一次使用 CodeSandbox 或在浏览器隐身模式下构建应用,还是会遇到大量 HTTP 请求问题。
那么官网是如何缓存的呢?首先通过 Service-Worker 拦截应用构建过程中的请求,如果发现是需要被缓存的资源,则先从 CacheStorage 中查找是否已缓存过,没有则继续请求远端服务,并将请求返回的内容缓存一份到 CacheStorage 中;如果查找到对应缓存,则直接从 CacheStorage 读取并返回,从而减少请求时间。
如下图所示,CodeSandbox 缓存内容主要包括:
沙箱页面的静态资源模块
从 Packager 服务请求的 npm 包的 Manifest
从 CDN 请求的 npm 包单个模块内容
不过 CodeSandbox 在对外提供的沙箱版本中将缓存功能关闭了,我们需要开启该功能,相关代码在 packages/app/src/sandbox/index.ts 中,如下图所示:
另外该缓存功能是通过 SWPrecacheWebpackPlugin 插件实现的 -- 在打包 CodeSandbox 沙箱代码时,启用 SWPrecacheWebpackPlugin 插件并向其传入具体的缓存策略配置,然后会在构建物中自动生成 service-worker.js 脚本,最后在沙箱运行时注册执行该脚本即可开启缓存功能。这里我们需要做的是将其中缓存策略的地址修改成我们私有化部署的沙箱对应地址即可,具体模块在 packages/app/config/webpack.prod.js 中:
补充:SWPrecacheWebpackPlugin 插件主要是作用避免手动编写 Service Worker 脚本,开发者只需要提供具体的缓存策略即可,更多细节可点击下面链接:https://www.npmjs.com/package/sw-precache-webpack-plugin
开启浏览器侧的缓存之后,应用的构建时间基本可以稳定到 12s 左右。
以上三个方面的优化基本都是在网络方面 -- 或增加缓存或减少请求数量。那么编译和执行代码本身是否可以进一步优化呢?接下来就一起来分析下。
笔者在使用浏览器调试工具调试沙箱的编译过程时发现一个问题:即使应用中仅仅使用了 antd 包的一个组件,例如:
import React from 'react';
import { Button } from 'antd';
const Btn = () => (<Button>Click Me</Button>);
export default Btn;但仍会编译 antd 包内所有组件关联的模块,最终导致编译时间过长。经过排查发现主要原因是 antd 的入口文件中引用了全部组件。下面是 es 模式下的入口文件 antd/es/index.js 的部分代码:
export { default as Affix } from './affix';
export { default as Anchor } from './anchor';
export { default as AutoComplete } from './auto-complete';
...根据上面编译阶段和执行阶段的讲解我们可以知道,沙箱会从 antd 入口文件开始对所有被引用的模块进行递归编译和执行。
因为沙箱也使用 babel 编译 js 文件,所以笔者最开始想到的是在编译 js 文件时集成 babel-plugin-import 插件,该插件的作用就是实现组件的按需引入,点击查看插件更多细节。下面的代码编译效果会更直观一些:
import { Button } from 'antd';
↓ ↓ ↓ ↓ ↓ ↓
var _button = require('antd/lib/button');集成该插件后发现沙箱构建速度的确有所提升,但随着应用使用的组件增多,构建速度会越慢。那么是否有更好的方式来减少甚至不需编要译模块呢?有,实现类 Webpack Externals 功能,下面是整个功能的原理:
1. 在编译阶段跳过 antd 包的编译,以减少编译时间。
2. 在执行阶段开始之前先通过 script 标签全局加载和执行 antd 的 umd 形式的构建物,如此以来 antd 包中导出的内容就被挂载到 window 对象上了。接下来在执行编译后的代码时,如果发现需要引用的antd 包中的组件,则从 window 对象获取返回即可。由于不再需要执行 antd 包所有组件关联的模块,所以执行阶段的时间也会减少。
注:这里涉及到 Webpack Externals 和 umd 模块规范的概念,由于篇幅问题就不在这里细说了,有兴趣可通过下面链接了解:
思路有了,接下来就开始对 CodeSandbox 源码进行改造:
首先是编译阶段的改造,当编译完某个模块时,会添加该模块的依赖然后继续编译。在添加依赖时,判断如果依赖是被 external 的 npm 包则直接退出,以阻断进一步对该依赖的编译。
具体代码在 packages/sandpack-core/src/transpiled-module/transpiled-module.ts,改动如下图所示:
然后是执行阶段的改造,因为 CodeSandbox 最终是将所有模块编译成 CommonJS 模块然后模拟 CommonJS 的环境来执行(上面的沙箱构建过程部分有提到)。所以只需要在模拟的 require 函数中判断如果是被 external 的 npm 包引用模块,直接从 window 对象获取返回即可。
具体代码在 packages/sandpack-core/src/transpiled-module/transpiled-module.ts,改动如下图所示:
另外在沙箱开始执行编译后的代码之前,需要动态创建 script 标签来加载和执行 antd 包 umd 形式的构建物,幸运的是 CodeSandbox 已经提供了动态加载外部 js/css 资源的能力,不需要额外开发。只需要将需要 js/css 资源的链接通过 externalResources 参数传给沙箱即可。
最后就需要在 sandbox.config.json 文件中配置相关参数即可,如下图所示:
{
"externals": {
"react": "React",
"react-dom": "ReactDOM",
"antd": "antd"
},
"externalResources": [
"https://unpkg.com/[email protected]/umd/react.development.js",
"https://unpkg.com/[email protected]/umd/react-dom.development.js",
"https://unpkg.com/[email protected]/dist/antd.min.js",
"https://unpkg.fn.netease.com/[email protected]/dist/antd.css"
]
}补充:
sandbox.config.json文件中的内容会在沙箱构建获取到,该文件是放在被构建应用的根目录下。点击查看 configuration 详情。
最终经过上面四个方面的优化,沙箱只需 1s 左右即可完成对整个应用的构建,效果如下图所示:
那么沙箱的构建性能优化方案是否就已经接近完美了呢?
答案当然是否定的,读者可以试想下,随着构建应用的规模变大,需要编译和执行的模块也会增多,CodeSandbox 沙箱这种通过应用的入口文件递归编译所有引用模块,然后再从应用入口文件递归执行所有引用模块的模式,必然还会导致整个构建时间不可避免地增加。
那么是否有更好的方式呢?最近很流行的 Vite 提供了一种思路:在应用代码执行过程中,通过 ES Module 方式引用了其他模块,浏览器会发起一个请求获取该模块,服务器拦截请求匹配到对应模块后对其进行编译并返回。这种不需要对应用模块进行提前全量编译,按需动态编译的方式会极大缩应用构建时间,应用越复杂构建速度的优势越明显。
笔者正在尝试改造 Vite 使其能够运行在浏览器中,过程中的收获会总结到沙箱系列下一篇文章中 -- 《搭建一个浏览器版 Vite 沙箱》,沙箱原型的实现代码也会同步到 https://github.com/mcuking/vitesandbox-client 中,敬请期待!
在用户端的浏览器中实现可以运行代码(涵盖前端 / Node 服务等应用的代码)的沙箱环境,相对在服务端容器中运行代码的方式,具有不占用服务资源、运营成本低、启动速度快等优势,在很多应用场景下都可以创造可观的价值。另外浏览器版沙箱也是为数不多的富前端应用,整个沙箱应用的主体功能都是在浏览器中实现,对前端开发工作提出了更大的挑战。
下图是笔者这两年在沙箱领域的一些尝试,欢迎感兴趣的同学一起交流:https://github.com/mcuking/blog
文章首发于我的博客 #96
Wasm 解释器项目地址:
https://github.com/mcuking/wasmc
从去年年底开始笔者决定深入 WebAssembly(为了书写方便,接下来简称为 Wasm)这门技术,在读《WebAssembly 原理与核心技术》这本书的过程中(这本书详细讲解了 Wasm 的解释器和虚拟机的工作原理以及实现思路),萌生了实现一个 Wasm 解释器的想法,于是就有了这个项目。接下来我们就直奔主题,看下到底如何实现一个 Wasm 解释器。
在具体阐述解释器实现过程之前,首先介绍下 Wasm 相关的背景知识。
Wasm 是一种底层类汇编语言,能在 Web 平台上以趋近原生应用的速度运行。C/C++/Rust 等语言将 Wasm 作为编译目标语言,可以将已有的代码移植到 Web 平台中运行,以提升代码复用度。
而 Wasm 官网给出的定义是 —— WebAssembly(缩写为 Wasm)是一种基于栈式虚拟机的二进制指令格式。Wasm 被设计成为一种编程语言的可移植编译目标,可以通过将其部署到 Web 平台上,使其为客户端和服务端应用程序提供服务。
其中将 Wasm 定义为一种虚拟指令集架构 V-ISA(Virtual-Instruction Set Architecture),关于这方面的解读,请参考下面执行阶段的内容。
接着来看下 Wasm 的一些特点:
Tip: 关于 Wasm 的更多详细介绍可参考笔者翻译的文章 《WebAssembly 的后 MVP 时代的未来:一棵卡通技能树(译)》
Wasm 目前已经在浏览器端的图像处理、音视频处理、游戏、IDE、可视化、科学计算等,以及非浏览器端的 Serverless、区块链、IoT 等领域有一定的应用。如果想要了解更多有关 Wasm 应用的内容,可以关注笔者的另一个 GitHub 仓库:
https://github.com/mcuking/Awesome-WebAssembly-Applications
Wasm 技术目前有 4 份规范:
本文主要介绍的 Wasm 解释器主要是运行在非浏览器环境,因此无需关注 JavaScript API 和 Web API 规范。
另外目前实现的版本并没有涉及到 WASI(后续有计划支持),所以目前只需要关注 核心规范 即可。
Wasm 模块主要有以下 4 种表现形式:
下图就是使用 C 语言编写的阶乘函数,以及对应的 Wasm 文本格式和二进制格式。
而内存格式和具体的 Wasm 解释器的实现有关,例如本项目的内存格式大致如下(在后面执行阶段部分会详细讲解):
各个格式之间的关联如下:
最后推荐一个名为 WebAssembly Code Explorer 的站点,可以更直观地查看 Wasm 二进制格式和文本格式之间的关联。
https://wasdk.github.io/wasmcodeexplorer/
通过上面的介绍,相信大家对 Wasm 技术已经有了大致的了解。接下来我们从分析 Wasm 二进制文件的执行流程开始,探讨解释器的实现思路。
Wasm 二进制文件被执行主要分 3 个阶段:解码、验证、执行
Tip: 本项目实现的解释器,并没有一个单独的验证阶段。而是将具体的验证分布在解码阶段或执行阶段中进行,例如在解码阶段验证是否存在非法的段 ID,在执行阶段验证函数的参数或返回值的类型或数量是否和函数签名匹配等。
另外实例化过程在解码阶段就完成了,执行阶段仅需要进行函数调用即可。
所谓实例化,主要内容就是为内存段、表段等申请空间,记录所有函数(自定义的函数和导入的函数)的入口地址,然后将模块的所有信息记录到一个统一的数据结构module中。
接下来我们就分别对解码阶段和执行阶段的实现细节进行详细阐述。
和其他二进制格式(例如 Java 类文件)一样,Wasm 二进制格式也是以魔数和版本号开头,之后就是模块的主体内容,这些内容根据不同用途被分别放在不同的段(Section) 中。一共定义了 12 种段,每种段分配了 ID(从 0 到 11)。除了自定义段之外,其他所有段都最多只能出现一次,且须按照 ID 递增的顺序出现。ID 从 0 到 11 依次有如下 12 个段:
自定义段、类型段、导入段、函数段、表段、内存段、全局段、导出段、起始段、元素段、代码段、数据段
Tip: 其中不同段之间的排序是有一定依据的,主要目的是为了进行流编译 —— 即一边下载 Wasm 模块一边将其编译到机器码,详细信息可查阅文章 《Making WebAssembly even faster: Firefox’s new streaming and tiering compiler》
换句话说,每一个不同的段都描述了这个 Wasm 模块的一部分信息。而模块内的所有段放在一起,便描述了这个 Wasm 模块的全部信息:
Tip: 在上面的 Wasm 二进制格式的段中,表段应该比会较难以理解,这里特地对其说明下。
在 Wasm 设计**中,与执行过程相关的代码段/栈等元素和内存是完全分离的,这与通常的体系结构中代码段/数据段/堆/栈全都处在统一编址内存空间情况完全不同,函数地址对 Wasm 程序来说是不可见的,更不要说将函数当作变量一样传递、修改和调用。
表是实现这一机制的关键,表用于存储对象引用,目前对象只能是函数,也就是说目前表中只是用来存储函数索引值。Wasm 程序只能通过表中的索引,找到对应函数索引值来调用函数,并且运行时的栈数据也不保存在内存对象中。由此彻底杜绝了 Wasm 代码越界执行的可能,最糟糕情况不过是在内存对象中产生一堆错误数据而已。
知道了每个段对应的用途以及每个段的具体编码格式(详细的编码格式可查看 module.c 中的 load_module 函数中的注释),我们就可以对 Wasm 二进制文件进行解码,将其“翻译”成内存格式,也就是将模块的所有信息记录到一个统一的数据结构中 —— module,module 结构如下图所示:
Tip: 为了节约空间,让二进制文件更加紧凑,Wasm 二进制格式采用 LEB128(Little Endian Base 128) 来编码列表长度、索引等整数值。LEB128 是一种变长编码格式,32 位整数编码后会占 1 到 5 个字节,64 位整数编码后会占 1 到 10 个字节。越小的整数编码后占用的字节数越少。由于像列表长度、索引这样的整数通常都比较小,所以采用 LEB128 编码就可以起到节约空间的作用。
LEB128 有两个特点:1. 采用小端序表示,即低位字节在前,高位字节在后;2. 采用 128 进制,即每 7 位为一组(一个字节的后 7 位),空出来的最高位是标识位,1 表示还有后续字节,0 表示没有。
LEB128 有两个变体,分别用来编码无符号整数和有符号整数,具体实现可查阅 https://github.com/mcuking/wasmc/blob/master/source/utils.c 中的read_LEB函数。
最后展示下解码阶段对应的部分实际代码截图如下:
更多细节建议查阅 https://github.com/mcuking/wasmc/blob/master/source/module.c 中的 load_module 函数,其中有丰富的注释讲解。
经过了上面的解码阶段,我们可以从 Wasm 二进制文件中得到涵盖执行阶段所需要的全部信息的内存格式,接下来我们来一起探索如何基于上面的内存格式实现执行阶段。在正式开始之前,首先需要介绍下栈式虚拟机的相关知识作为铺垫。
官网对 Wasm 的定义 —— Wasm 是基于栈式虚拟机的二进制指令格式。也就是说 Wasm 不仅仅是一门编程语言,也是一套虚拟机体系结构规范。那么什么是虚拟机,什么又是栈式虚拟机呢?
虚拟机是软件对硬件的模拟,借助操作系统和编译器提供的功能模拟硬件的工作,这里主要指对硬件 CPU 的模拟。虚拟机执行指令主要有以下 3 个步骤:
执行指令流中的一条条指令,就是不断循环执行上面的三个步骤。循环执行的过程中需要有一个标志来记录当前已经执行到哪一条指令,也就是程序计数器 PC (Program Count) —— 用于保存下一条待执行指令的地址。
Tip: 提供给 Wasm 虚拟机解释执行的不是平台相关的机器码,而是由 Wasm 自定义的一套指令集所构成的字节码,主要是为了实现跨平台的目的 —— 用软件去模拟 CPU,并定义一套类似 CPU 指令集的自定义指令集,这样只需要虚拟机本身的程序针对不同平台适配即可,而运行在虚拟机上的程序则无需关心跑在哪个平台上。
Wasm 指令主要分为 5 大类:
每条指令包含两部分信息:操作码和操作数。
下图是 Wasm 部分指令的操作码助记符的枚举,完成版请查阅 https://github.com/mcuking/wasmc/blob/master/source/opcode.h。
另外 GitHub 上有一个可视化表格比较直观地展示了 Wasm 所有的操作码,感兴趣的同学可以点击查看下。
https://pengowray.github.io/wasm-ops/
关于操作数的内容会在下面的栈式虚拟机部分介绍。
虚拟机又大致分为两种:寄存器虚拟机和栈式虚拟机。
接下来我们就详细介绍下栈式虚拟机的工作机制。
栈式虚拟机主要特点是拥有一个操作数栈,Wasm 绝大部分指令都是在操作数栈上执行某种操作,例如下面的指令:
f32.sub:表示从操作数栈弹出 2 个 32 位浮点数,计算它们的差并将结果压入到操作数栈顶。
其中从操作数栈弹出的 2 个 32 位浮点数就是操作数,下面是具体定义:
操作数,也称动态操作数,是指在运行时位于操作数栈顶并被指令操纵的数。
我们再看另一个指令的例子:
i32.const 3:表示压入索引为 3 的 32 位整数类型的局部变量到操作数栈顶。
而这个数值 3 就是立即数,下面是具体定义:
立即数,也称静态立即参数 / 静态操作数,立即数是直接硬编码在指令里的(也就是字节码里),紧跟在操作码后面。大部分 Wasm 指令是没有立即数的,欲知 Wasm 指令中具体哪些指令是带有立即数的,请查阅 https://github.com/mcuking/wasmc/blob/master/source/module.c 中的
skip_immediate函数。
上面讨论的仅仅是一条指令的执行,下面我们在看下一个函数在栈式虚拟机上是如何被执行的:
如下图所示:
由此可见,函数调用时参数传递和返回值获取,以及函数体中的指令执行,都是通过操作数栈来完成的。
从上面的描述中可以看出,函数调用经常是嵌套的,例如函数 A 调用函数 B,函数 B 调用函数 C。因此需要另外一个栈来维护函数之间的调用关系信息 —— 调用栈(Call Stack)。
调用栈是由一个个独立的栈帧组成,每次函数调用,都会向调用栈压入一个栈帧(注意:为了阐述的简洁明了,仅讨论函数情况,其他例如 If / Loop 等控制块暂不在本文讨论中)。每次函数执行结束,都会从调用栈弹出对应栈帧并销毁。一连串的函数调用,就是不停创建和销毁栈帧的过程。但在任一时刻,只有位于调用栈顶的栈帧是活跃的,也就是所谓的当前栈帧。
每个栈帧包括以下内容:
Tip: 目前这个解释器定义的栈帧中比没有类似 JVM 虚拟机栈帧中的局部变量表,而是将参数、局部变量和操作数都放在了操作数栈上,主要目的有两个:
- 实现简单,不需要额外定义局部变量表,可以很大程度简化代码。
- 让参数传递变成无操作 NOP,可以让两个栈帧的操作数栈有一部分数据是重叠的,这部分数据就是参数,这样自然就起到了参数在不同函数之间传递的作用。
经过上面的铺垫,相信大家对栈式虚拟机有了一定的认识。最后我们用一个实际示例来阐述下整个执行过程:
下面这个 Wasm 文本格式中的有两个函数:compute 函数和 add 函数,其中 add 函数主要是接收两个数(类型分别是 32 位整数和 32 位浮点数),计算两数之和。compute 函数中调用了两次 add 函数,注意第二次调用 add 函数时,操作数栈上已经保存了上次调用 add 函数时的返回结果(再一次印证了两个函数关联的栈帧是共用同一个完整的操作数栈的,可以很便捷地实现函数之间参数的传递),所以这次仅需要传入第二个参数即可。
(module
(func $compute (result i32)
i32.const 13 ;; 向操作数栈压入 13
f32.const 42.0 ;; 向操作数栈压入 42.0
call $add ;; 调用 $add 函数得到 55
f32.const 10.0 ;; 向操作数栈压入 10.0
call $add ;; 再调用 $add 函数得到 65
)
(func $add(param $a i32) (param $b f32) (result i32)
i32.get_local $a ;; 将类型为 32 位整数的局部变量 $a 压入到操作数栈
f32.get_local $b ;; 将类型为 32 位浮点数的局部变量 $b 压入到操作数栈
i32.trunc_f32_s ;; 将当前操作数栈顶的 32 位浮点数 $b 截断为 32 有符号位整数(截掉小数部分)
i32.add ;; 将操作数栈顶和次栈顶的 32 位整数从操作数栈弹出,并计算两者之和然后将和压入操作数栈
)
(export "compute" (func $compute))
(export "add" (func $add))
)对应的就是其执行过程的示意图如下:
最后展示下执行阶段对应的部分实际代码截图如下:
可以看到虚拟机的取指、译码、执行三个阶段,可以使用 while 循环和 switch-case 语句来简单地实现。更多细节建议查阅 https://github.com/mcuking/wasmc/blob/master/source/interpreter.c 中的 interpreter 函数,其中有丰富的注释讲解。
以上就是 Wasm 解释器实现中的核心内容,当然这仅仅是 Wasm 解释器的最基本的功能 —— 简单地逐条解析并执行指令,没有像其他专业的解释器那样提供 JIT 功能 —— 即先解释执行字节码来快速启动,然后再通过 JIT 将其编译成平台相关的机器码,以提升后面代码执行的速度(注:JIT 的具体实现过程因解释器而异)。
所以用本项目的解释器解释执行 Wasm 代码,速度上并没有太多优势。但也正是由于其实现比较简单,所以源码更易读,并且其中有丰富的注释,所以非常适合对 Wasm 有兴趣的读者快速了解该技术的核心原理。
文章首发于我的博客 #39
JSBridge 项目以 js 与 android 通信为例,讲解 JSBridge 实现原理,下面提到的方法在 iOS(UIWebview 或 WKWebview)均有对应方法。
两种 native 调用 js 方法,注意被调用的方法需要在 JS 全局上下文上
mWebview.loadUrl("javascript: func()");mWebview.evaluateJavascript("javascript: func()", new ValueCallback<String>() {
@Override
public void onReceiveValue(String value) {
return;
}
});| 方式 | 优点 | 缺点 |
|---|---|---|
| loadUrl | 兼容性好 | 1. 会刷新页面 2. 无法获取 js 方法执行结果 |
| evaluateJavascript | 1. 性能好 2. 可获取 js 执行后的返回值 | 仅在安卓 4.4 以上可用 |
三种 js 调用 native 方法
即由 h5 发出一条新的跳转请求,native 通过拦截 URL 获取 h5 传过来的数据。
跳转的目的地是一个非法不存在的 URL 地址,例如:
"jsbridge://methodName?{"data": arg, "cbName": cbName}"具体示例如下:
"jsbridge://openScan?{"data": {"scanType": "qrCode"}, "cbName": "handleScanResult"}"h5 和 native 约定一个通信协议,例如 jsbridge, 同时约定调用 native 的方法名 methodName 作为域名,以及后面带上调用该方法的参数 arg,和接收该方法执行结果的 js 方法名 cbName。
具体可以在 js 端封装相关方法,供业务端统一调用,代码如下:
window.callbackId = 0;
function callNative(methodName, arg, cb) {
const args = {
data: arg === undefined ? null : JSON.stringify(arg),
};
if (typeof cb === 'function') {
const cbName = 'CALLBACK' + window.callbackId++;
window[cbName] = cb;
args['cbName'] = cbName;
}
const url = 'jsbridge://' + methodName + '?' + JSON.stringify(args);
...
}以上封装中较为巧妙的是将用于接收 native 执行结果的 js 回调方法 cb 挂载到 window 上,并为防止命名冲突,通过全局的 callbackId 来区分,然后将该回调函数在 window 上的名字放在参数中传给 native 端。native 拿到 cbName 后,执行完方法后,将执行结果通过 native 调用 js 的方式(上面提到的两种方法),调用 cb 传给 h5 端(例如将扫描结果传给 h5)。
至于如何在 h5 中发起请求,可以设置 window.location.href 或者创建一个新的 iframe 进行跳转。
function callNative(methodName, arg, cb) {
...
const url = 'jsbridge://' + method + '?' + JSON.stringify(args);
// 通过 location.href 跳转
window.location.href = url;
// 通过创建新的 iframe 跳转
const iframe = document.createElement('iframe');
iframe.src = url;
iframe.style.width = 0;
iframe.style.height = 0;
document.body.appendChild(iframe);
window.setTimeout(function() {
document.body.removeChild(iframe);
}, 800);
}native 会拦截 h5 发出的请求,当检测到协议为 jsbridge 而非普通的 http/https/file 等协议时,会拦截该请求,解析出 URL 中的 methodName、arg、 cbName,执行该方法并调用 js 回调函数。
下面以安卓为例,通过覆盖 WebViewClient 类的 shouldOverrideUrlLoading 方法进行拦截,android 端具体封装会在下面单独的板块进行说明。
import android.util.Log;
import android.webkit.WebView;
import android.webkit.WebViewClient;
public class JSBridgeViewClient extends WebViewClient {
@Override
public boolean shouldOverrideUrlLoading(WebView view, String url) {
JSBridge.call(view, url);
return true;
}
}如下代码:
window.location.href = "jsbridge://callNativeNslog?{"data": "111", "cbName": ""}";
window.location.href = "jsbridge://callNativeNslog?{"data": "222", "cbName": ""}";js 此时的诉求是在同一个运行逻辑内,快速的连续发送出 2 个通信请求,用客户端本身 IDE 的 log,按顺序打印 111,222,那么实际结果是 222 的通信消息根本收不到,直接会被系统抛弃丢掉。
原因:因为 h5 的请求归根结底是一种模拟跳转,跳转这件事情上 webview 会有限制,当 h5 连续发送多条跳转的时候,webview 会直接过滤掉后发的跳转请求,因此第二个消息根本收不到,想要收到怎么办?js 里将第二条消息延时一下。
//发第一条消息
location.href = "jsbridge://callNativeNslog?{"data": "111", "cbName": ""}";
//延时发送第二条消息
setTimeout(500,function(){
location.href = "jsbridge://callNativeNslog?{"data": "222", "cbName": ""}";
});但这并不能保证此时是否有其他地方通过这种方式进行请求,为系统解决此问题,js 端可以封装一层队列,所有 js 代码调用消息都先进入队列并不立刻发送,然后 h5 会周期性比如 500 毫秒,清空一次队列,保证在很快的时间内绝对不会连续发 2 次请求通信。
如果需要传输的数据较长,例如方法参数很多时,由于 URL 长度限制,仍以丢失部分数据。
即由 h5 发起 alert confirm prompt,native 通过拦截 prompt 等获取 h5 传过来的数据。
因为 alert confirm 比较常用,所以一般通过 prompt 进行通信。
约定的传输数据的组合方式以及 js 端封装方法的可以类似上面的 拦截 URL Schema 提到的方式。
function callNative(methodName, arg, cb) {
...
const url = 'jsbridge://' + method + '?' + JSON.stringify(args);
prompt(url);
}native 会拦截 h5 发出的 prompt,当检测到协议为 jsbridge 而非普通的 http/https/file 等协议时,会拦截该请求,解析出 URL 中的 methodName、arg、 cbName,执行该方法并调用 js 回调函数。
下面以安卓为例,通过覆盖 WebChromeClient 类的 onJsPrompt 方法进行拦截,android 端具体封装会在下面单独的板块进行说明。
import android.webkit.JsPromptResult;
import android.webkit.WebChromeClient;
import android.webkit.WebView;
public class JSBridgeChromeClient extends WebChromeClient {
@Override
public boolean onJsPrompt(WebView view, String url, String message, String defaultValue, JsPromptResult result) {
result.confirm(JSBridge.call(view, message));
return true;
}
}这种方式没有太大缺点,也不存在连续发送时信息丢失。不过 iOS 的 UIWebView 不支持该方式(WKWebView 支持)。
即由 native 将实例对象通过 webview 提供的方法注入到 js 全局上下文,js 可以通过调用 native 的实例方法来进行通信。
具体有安卓 webview 的 addJavascriptInterface,iOS UIWebview 的 JSContext,iOS WKWebview 的 scriptMessageHandler。
下面以安卓 webview 的 addJavascriptInterface 为例进行讲解。
首先 native 端注入实例对象到 js 全局上下文,代码大致如下,具体封装会在下面的单独板块进行讲解:
public class MainActivity extends AppCompatActivity {
private WebView mWebView;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mWebView = (WebView) findViewById(R.id.mWebView);
...
// 将 NativeMethods 类下面的提供给 js 的方法转换成 hashMap
JSBridge.register("JSBridge", NativeMethods.class);
// 将 JSBridge 的实例对象注入到 js 全局上下文中,名字为 _jsbridge,该实例对象下有 call 方法
mWebView.addJavascriptInterface(new JSBridge(mWebView), "_jsbridge");
}
}
public class NativeMethods {
// 用来供 js 调用的方法
public static void methodName(WebView view, JSONObject arg, CallBack callBack) {
}
}
public class JSBridge {
private WebView mWebView;
public JSBridge(WebView webView) {
this.mWebView = webView;
}
private static Map<String, HashMap<String, Method>> exposeMethods = new HashMap<>();
// 静态方法,用于将传入的第二个参数的类下面用于提供给 javacript 的接口转成 Map,名字为第一个参数
public static void register(String exposeName, Class<?> classz) {
...
}
// 实例方法,用于提供给 js 统一调用的方法
@JavascriptInterface
public String call(String methodName, String args) {
...
}
}然后 h5 端可以在 js 调用 window._jsbridge 实例下面的 call 方法,传入的数据组合方式可以类似上面两种方式。具体代码如下:
window.callbackId = 0;
function callNative(method, arg, cb) {
let args = {
data: arg === undefined ? null : JSON.stringify(arg)
};
if (typeof cb === 'function') {
const cbName = 'CALLBACK' + window.callbackId++;
window[cbName] = cb;
args['cbName'] = cbName;
}
if (window._jsbridge) {
window._jsbridge.call(method, JSON.stringify(args));
}
}以安卓 webview 的 addJavascriptInterface 为例,在安卓 4.2 版本之前,js 可以利用 java 的反射 Reflection API,取得构造该实例对象的类的內部信息,并能直接操作该对象的内部属性及方法,这种方式会造成安全隐患,例如如果加载了外部网页,该网页的恶意 js 脚本可以获取手机的存储卡上的信息。
在安卓 4.2 版本后,可以通过在提供给 js 调用的 java 方法前加装饰器 @JavascriptInterface,来表明仅该方法可以被 js 调用。
| 方式 | 优点 | 缺点 |
|---|---|---|
| 拦截 Url Schema(假请求) | 无安全漏洞 | 1. 连续发送时消息丢失 2. Url 长度限制,传输数据大小受限 |
| 拦截 prompt alert confirm | 无安全漏洞 | iOS 的 UIWebView 不支持该方式 |
| 注入 JS 上下文 | 官方提供,方便简捷 | 在安卓 4.2 以下有安全漏洞 |
native 与 h5 交互部分的代码在上面已经提到了,这里主要是讲述 native 端如何封装暴露给 h5 的方法。
首先单独封装一个类 NativeMethods,将供 h5 调用的方法以公有且静态方法的形式写入。如下:
public class NativeMethods {
public static void showToast(WebView view, JSONObject arg, CallBack callBack) {
...
}
}接下来考虑如何在 NativeMethods 和 h5 之前建立一个桥梁,JSBridge 类因运而生。
JSBridge 类下主要有两个静态方法 register 和 call。其中 register 方法是用来将供 h5 调用的方法转化成 Map 形式,以便查询。而 call 方法主要是用接收 h5 端的调用,分解 h5 端传来的参数,查找并调用 Map 中的对应的 Native 方法。
首先在 JSBridge 类下声明一个静态属性 exposeMethods,数据类型为 HashMap 。然后声明静态方法 register,参数有字符串 exposeName 和类 classz,将 exposeName 和 classz 的所有静态方法 组合成一个 map,例如:
{
jsbridge: {
showToast: ...
openScan: ...
}
}代码如下:
private static Map<String, HashMap<String, Method>> exposeMethods = new HashMap<>();
public static void register(String exposeName, Class<?> classz) {
if (!exposeMethods.containsKey(exposeName)) {
exposeMethods.put(exposeName, getAllMethod(classz));
}
}由上可知我们需要定义一个 getAllMethod 方法用来将类里的方法转化为 HashMap 数据格式。在该方法里同样声明一个 HashMap,并将满足条件的方法转化成 Map,key 为方法名,value 为方法。
其中条件为 公有 public 静态 static 方法且第一个参数为 Webview 类的实例,第二个参数为 JSONObject 类的实例,第三个参数为 CallBack 类的实例。 (CallBack 是自定义的类,后面会讲到)
代码如下:
private static HashMap<String, Method> getAllMethod(Class injectedCls) {
HashMap<String, Method> methodHashMap = new HashMap<>();
Method[] methods = injectedCls.getDeclaredMethods();
for (Method method: methods) {
if(method.getModifiers()!=(Modifier.PUBLIC | Modifier.STATIC) || method.getName()==null) {
continue;
}
Class[] parameters = method.getParameterTypes();
if (parameters!=null && parameters.length==3) {
if (parameters[0] == WebView.class && parameters[1] == JSONObject.class && parameters[2] == CallBack.class) {
methodHashMap.put(method.getName(), method);
}
}
}
return methodHashMap;
}由于注入 JS 上下文和两外两种,h5 端传过来的参数形式不同,所以处理参数的方式略有不同。
下面以拦截 Prompt 的方式为例进行讲解,在该方式中 call 接收的第一个参数为 webView,第二个参数是 arg,即 h5 端传过来的参数。还记得拦截 Prompt 方式时 native 端和 h5 端约定的传输数据的方式么?
"jsbridge://openScan?{"data": {"scanType": "qrCode"}, "cbName":"handleScanResult"}"call 方法首先会判断字符串是否以 jsbridge 开头(native 端和 h5 端之间约定的传输数据的协议名),然后该字符串转成 Uri 格式,然后获取其中的 host 名,即方法名,获取 query,即方法参数和 js 回调函数名组合的对象。最后查找 exposeMethods 的映射,找到对应的方法并执行该方法。
public static String call(WebView webView, String urlString) {
if (!urlString.equals("") && urlString!=null && urlString.startsWith("jsbridge")) {
Uri uri = Uri.parse(urlString);
String methodName = uri.getHost();
try {
JSONObject args = new JSONObject(uri.getQuery());
JSONObject arg = new JSONObject(args.getString("data"));
String cbName = args.getString("cbName");
if (exposeMethods.containsKey("JSBridge")) {
HashMap<String, Method> methodHashMap = exposeMethods.get("JSBridge");
if (methodHashMap!=null && methodHashMap.size()!=0 && methodHashMap.containsKey(methodName)) {
Method method = methodHashMap.get(methodName);
if (method!=null) {
method.invoke(null, webView, arg, new CallBack(webView, cbName));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
return null;
}js 调用 native 方法成功后,native 有必要返回给 js 一些反馈,例如接口是否调用成功,或者 native 执行后的得到的数据(例如扫码)。所以 native 需要执行 js 回调函数。
执行 js 回调函数方式本质是 native 调用 h5 的 js 方法,方式仍旧是上面提到的两种方式 evaluateJavascript 和 loadUrl。简单来说可以直接将 js 的回调函数名传给对应的 native 方法,native 执行通过 evaluateJavascript 调用。
但为了统一封装调用回调的方式,我们可以定义一个 CallBack 类,在其中定义一个名为 apply 的静态方法,该方法直接调用 js 回调。
注意:native 执行 js 方法需要在主线程上。
public class CallBack {
private String cbName;
private WebView mWebView;
public CallBack(WebView webView, String cbName) {
this.cbName = cbName;
this.mWebView = webView;
}
public void apply(JSONObject jsonObject) {
if (mWebView!=null) {
mWebView.post(() -> {
mWebView.evaluateJavascript("javascript:" + cbName + "(" + jsonObject.toString() + ")", new ValueCallback<String>() {
@Override
public void onReceiveValue(String value) {
return;
}
});
});
}
}
}到此为止 JSBridge 的大致原理都讲完了。但功能仍可再加完善,例如:
native 执行 js 方法时,可接受 js 方法中异步返回的数据,比如在 js 方法中请求某个接口在返回数据。直接调用 webview 提供的 evaluateJavascript,在第二个参数的类 ValueCallback 的实例方法 onReceiveValue 并不能接收到 js 异步返回的数据。
后面有空 native 调用 js 方式会继续完善的,最后以一句古语互勉:
路漫漫其修远兮 吾将上下而求索
在上一篇文章 《云音乐低代码:基于 CodeSandbox 的沙箱性能优化》 中有提到过 CodeSandbox 方案在构建规模较大的前端应用比较耗时的问题,并在文章结尾提到会尝试采用 bundless 构建模式来解决这个问题。而本文就是来介绍笔者在这块的实践成果 —— 对 Vite 进行改造使其可以运行在浏览器中,并结合其他技术实现一套基于浏览器的 bundless 在线实时构建沙箱方案。
在正式开始介绍本方案之前,先阐述下目前主流的沙箱方案以及存在的问题。
针对通用的应用进行实时构建可以采用云端沙箱(Cloud Sandbox)模式。该方案首先会在服务器中出初始化一个代码运行环境(Docker 或 microVM 等),然后将需要被构建的应用代码从指定位置(例如某个 git 代码仓库)拷贝到该运行环境中,安装依赖,最后执行构建命令对应用进行构建。该种模式对应用所采用的编程语言等没有特定要求,完全等同于本地环境。目前 CodeSandbox 的 Cloud templates 生成的应用就是采用这种模式来进行构建。
占用服务器资源较多:因为该模式下代码最终运行在服务器中,构建的应用代码越多,所占用服务器资源也就会越多
首次构建时间较长:应用代码首次构建时需要在服务器中初始化代码运行环境,所以首次构建过程比较费时(后续可通过容器保活/文件缓存等方式优化二次构建时长)。
如果仅构建前端应用,则可以将应用的编译构建的过程迁移到浏览器中进行,最终的构建结果直接在浏览器中执行 —— 渲染出最终的页面,也就是浏览器端沙箱(Browser Sandbox)模式。目前 CodeSandbox 的 Browser templates 生成的应用就是采用这种模式来进行构建。
CodeSandbox 本质上是在浏览器中运行的简化版 Webpack,下面是该沙箱方案构建应用的步骤:
从 npm 打包服务获取被构建应用的 npm 依赖内容。
从应用的入口文件开始,对源代码进行编译, 解析 AST,找出下级依赖模块,然后递归编译,最终形成一个依赖关系图。其中模块之间互相引用遵循的是 CommonJS 规范。
和编译阶段一样,也是从入口文件开始,使用 eval 执行入口文件,如果执行过程中调用了 require,则递归 eval 被依赖的模块。
本方案主要对 Vite / esm.sh 等开源方案的改造,再结合 Web Worker / Service Worker / Broadcast Channel / Cache Storage / iframe 等浏览器技术,以实现在浏览器中对前端应用按照 bundless 模式进行实时构建的目的。
首先介绍下本方案中最核心的部分 —— 如何改造 Vite 使其可以行在浏览器中。
在介绍具体的改造细节之前,让我们先了解下 Vite 的基本原理,以便更好地理解具体的改造方案。下面摘取了 Vite 官网的部分介绍文案:
Vite 是一种新型前端构建工具,能够显著提升前端开发体验。作为一个基于浏览器原生 ESM 的构建工具,它省略了开发环境的打包过程,利用浏览器去解析 imports,在服务端按需编译返回。同时,在开发环境拥有速度快到惊人的模块热更新,且热更新的速度不会随着模块增多而变慢。
当冷启动开发服务器时,基于打包器的方式启动必须优先抓取并构建整个应用,然后才能提供服务,如下图所示。
而 Vite 则通过在一开始将应用中的模块区分为 依赖 和 源码 两类,改进了开发服务器启动时间,如下图所示。
Vite 将会使用 esbuild 预构建依赖。esbuild 使用 Go 编写,并且比以 JavaScript 编写的打包器预构建依赖快 10-100 倍。
Vite 以原生 ESM 方式提供源码。这实际上是让浏览器接管了打包程序的部分工作:Vite 只需要在浏览器请求源码时进行转换并按需提供源码。根据情景动态导入代码,即只在当前屏幕上实际使用时才会被处理。
为了使 Vite 运行在浏览器中,首先需要将其源码使用打包器进行打包,本方案打包器采用的是 Webpack,然后在浏览器中通过 Script 标签加载或者 Web Worker 动态 import 加载并执行,以达到在浏览器运行 Vite 的目的。
接下来就看下这个过程中,需要解决哪些问题。
首先 Vite 是一个 Node 应用,其中使用到了很多 Node 原生模块,例如 fs / path 等,而浏览器中并不存在这些模块。对此本方案在使用 Webpack 对 Vite 源码打包的过程中,将其中的 Node 原生模块使用对应在浏览器的 polyfill 包进行替换,例如使用 path-browserify 包来替换 Node 原生模块 path。
其中有部分 Node 原生模块和对应的浏览器 polyfill 包提供的 API 不完全一致,例如 Node 的原生模块 url 和对应的 polyfill 包 node-url,对此需要在 node-url 包基础上进行二次封装,以确保其提供的 API 和对应原生模块完全一致。相关代码如下:
import { parse } from 'node-url';
const URL = globalThis.URL;
const URLSearchParams = globalThis.URLSearchParams;
function pathToFileURL(path) {
return new URL(path, 'file://');
}
function fileURLToPath(url) {
if (url.protocol === 'file:') {
return url.pathname;
}
throw new Error(`fileURLToPath(${url})`);
}
export {
URL,
URLSearchParams,
parse,
pathToFileURL,
fileURLToPath
};将 Node 原生模块映射成 polyfill 包的配置如下所示:
resolve: {
alias: {
fs: path.resolve(__dirname, 'src/utils/polyfill/fs.js'),
module: path.resolve(__dirname, 'src/utils/polyfill/module.js'),
url: path.resolve(__dirname, 'src/utils/polyfill/url.js'),
'perf_hooks': path.resolve(__dirname, 'src/utils/polyfill/perfHooks.js'),
esbuild: path.resolve(__dirname, 'src/utils/polyfill/esbuild.js'),
...
},
fallback: {
assert: require.resolve('assert'),
buffer: require.resolve('buffer'),
'safe-buffer': require.resolve('buffer'),
crypto: require.resolve('crypto-browserify'),
os: require.resolve('os-browserify/browser'),
path: require.resolve('path-browserify'),
...
},
}其次 Vite 在对应用进行构建时,需要使用文件系统进行文件的读写。但由于安全问题浏览器无法直接操作用户计算机的磁盘文件系统,对此本方案采用 memfs 实现的内存文件系统来进行替代。memfs 提供的 API 和 node 的原生 fs 模块基本一致,相关二次封装代码如下:
import { fs } from 'memfs';
export const promises = fs.promises;
export default fs;另外 Vite 在启动时会进行依赖预构建 —— 使用 esbuild 对 node_modules 中应用依赖模块进行按照 ESM 模块化格式转换和打包处理,并将处理结果保存在 node_modules 下的 .vite 目录中,以便在后面的应用构建过程中复用,提升二次构建速度。由此可见 Vite 的依赖预构建过程非常依赖 node_modules。
虽然上面有提到本方案采用了 memfs 实现的内存文件系统,但是由于应用的 node_modules 规模一般都会非常庞大,将完整的 node_modules 写入到内存中会非常占用内存。对此本方案采取的解决办法是剥离 Vite 的依赖预构建功能,并将对依赖的打包迁移到服务端中进行。
这里就要提到 esm.sh 服务,该服务是一种将 npm 包中所有模块按 ESM 模块化方式进行转化,然后进行内容分发的服务,其中最核心的依赖处理也是通过 esbuild 实现的。是采用 go 语言实现的开源项目,仓库地址 https://github.com/ije/esm.sh。
本方案的依赖处理就是通过该服务完成的,具体做法是自定义 Vite 的 optimize 过程,在解析模块中对 npm 包的裸模块导入时,例如当解析 import React from 'react' 时,该插件会将其替换成 import React from 'https://esm.sh/[email protected]'。浏览器在解析到 import 部分时,会发起 HTTP 请求 https://esm.sh/[email protected]。esm.sh 服务在接收到请求后,会对 react 包内的模块按照 ESM 模块化进行转换,然后返回给浏览器中的页面。由于 esm.sh 服务本身会有缓存策略,另外前端应用中的大部分依赖基本相同,因此可以很快地从缓存中获取上次的转换结果并直接返回,跳过了依赖处理的过程。所以在沙箱的实际运行中发现依赖处理阶段非常迅速,不会占用整个应用构建过程过多的时间。
其中自定义 Vite 的 optimize 过程的核心代码如下:
async function optimizeDeps(config, tree, newDeps) {
...
for (const depName of Object.keys(deps)) {
data.optimized[depName] = {
file: genNpmUrl(depName, deps, tree),
needsInterop: false
};
}
return data;
}
async function runOptimize(channel, server, { ref, tree }, addInitError) {
...
try {
server._isRunningOptimizer = true;
server._optimizeDepsMetadata = await optimizeDeps(config, tree);
server.moduleGraph.onFileChange(filePath);
} finally {
server._isRunningOptimizer = false;
}
...
}在具体落地时遇到一些问题,下面就详细阐述下问题和解决办法。
首先是对私有 npm 包的处理,很多公司都会有用来存放内部的 npm 包的私有 npm 源,而 esm.sh 服务是无法获取到这类 npm 包的。解决办法也比较简单,由于 esm.sh 服务内是通过 yarn 来下载 npm 包然后进行接下来的处理的,因此只需要将 esm.sh 服务部署到公司内网环境,使得其可以通过 yarn 下载到内部 npm 包即可。
其次是如果不对 esm.sh 服务的 npm 处理结果进行打包,则会触发请求瀑布流问题,导致整个沙箱构建过程发出成千上百个请求,严重阻塞构建过程。例如请求 https://esm.sh/[email protected] 时,实际仅仅返回的是 ant 包的本身的内容,但 antd 又依赖很多其他 npm 包(例如 rc 组件包),结果就会触发很多额外请求,反而使得整个构建过程非常缓慢。对此需要将 antd 包以及其依赖的 npm 包的内容统一打包好后再返回,可以在 esm.sh 请求地址后追加 bundle 参数,例如 https://esm.sh/[email protected]?bundle。esm.sh 服务会将 bundle 参数透传给内部的 esbuild,后者在转换 npm 模块后还会再完成打包后才输出。
最后是多个 npm 包依赖相同的 npm 包,例如很多 UI 包都会依赖 react,如果每个 npm 包都将 react 依赖打包进去,会使得构建出来的页面执行多份 react 包代码导致报错。又例如很多 UI 包还会依赖比较大个组件库例如 antd,如果每个 UI 包都要将 antd 打包进去,则会导致打包过程非常耗时且打包产物较大最终影响依赖加载速度,导致沙箱构建应用的速度变慢;另外有些 npm 包会有一些副作用,例如在全局初始化一些变量,多次加载执行也会导致变量重复初始化,之前的赋值丢失的情况。
对此 Node 环境下运行的 Vite 在依赖预构建阶段会将共同依赖单独抽离出来进行打包。而本方案中采用的是先在 esm.sh 请求后追加 external 参数,例如 https://esm.sh/[email protected]?bundle&external=antd,esm.sh 服务会将 external=antd 参数透传给内部的 esbuild,后者在打包时会忽略掉 antd 依赖,仍保留原本的引用,例如 import * as k from 'antd';。
接下来再利用浏览器提供的 Import maps 技术,该技术允许开发者控制 js 的 import 语句或者 import() 表达式获取的库的 url,因此可以将对 antd 库的引用指向 esm.sh 服务,相关设置代码如下:
<script type="importmap">
{
"imports": {
"antd": "https://esm.sh/[email protected]?bundle"
}
}
</script>最后 Vite 在构建应用时需要使用 HTTP 服务器来处理和响应来自浏览器页面中的请求。例如浏览器中的页面发起请求 http://xxx/xxx/A.js 后,Vite 会在服务器中接收该请求,然后定位到在源码中的对应模块编译该模块,最后将编译后的代码转换为 Response 对象返回给浏览器中的页面。但在浏览器中并不能运行 HTTP 服务器,于是本方案中采用浏览器的 Service Worker 技术来模拟一个 HTTP 服务器,Service Worker 技术可以拦截并修改页面访问和资源请求,本质上充当 Web 应用程序、浏览器与网络之间的代理服务器。
具体做法是先使用一个 Web Worker 线程来运行 Vite,然后注册 Service Worker 拦截页面请求,并将请求信息转发给运行在 Web Worker 的 Vite,Vite 根据请求信息确定对应模块并编译,然后将编译后的代码返回给 Service Worker,Service Worker 再将编译后的代码作为请求响应返回给页面。
Service Worker 的相关逻辑实现如下:
import { registerRoute } from 'workbox-routing';
import Channel from '$utils/channel';
registerRoute(
// 使用正则表达式匹配来自 iframe 页面的请求
/^https?:\/\/[^]*\/([^/]{32})\/preview\/([^/]*)(\/.*)$/,
async ({ request, url, params }) => {
const [ busid, wcid, pathname ] = params;
const { href } = url;
let channel = ChannelMap.get(busid);
if (!channel) {
channel = new Channel(busid);
ChannelMap.set(busid, channel);
}
// 将拦截到 iframe 页面内的请求信息通过 Broadcast Channel 发送给 Vite Worker 线程
const res = await channel.request('serve-request', {
wcid,
pathname: pathname.replace(/#.*$/, ''),
rawUrl: href,
accept: request?.headers?.get('accept')
});
// 在收到运行在 Web Worker 的 Vite 对某个模块编译完成的消息后,会从 Cache Storage 中取出包含编译后的代码的 Response 对象
if (res.cache) {
const viteCache = await caches.open('vite');
return viteCache.match(href).finally(() => viteCache.delete(href));
}
// 作为请求响应返回给 iframe 中的页面,从而使得编译后的代码在浏览器中执行
return res.notfound ? new Response('Not found',{
status: 404,
statusText: 'NOT FOUND'
}) : new Response(res.error || 'Error',{
status: 500,
statusText: 'SERVER ERROR'
});
}
);在介绍如何改造 Vite 使其运行在浏览器后,接下来将详细阐述运行在浏览器的 Vite 是如何与 Web Worker / Service Worker / Broadcast Channel / Cache Storage / iframe / esm.sh 等技术一起配合,实现对前端应用按照 bundless 模式进行构建的。
整个沙箱构建过程如上图所示,主要分以下几个步骤:
初始化运行 Vite 的 Web Worker 线程(后面简称 Vite Worker 线程),并将需要被构建的前端应用源码发送给 Vite Worker 线程。
初始化并注册用于拦截页面请求的 Service Worker 线程,来模拟 Node 环境下 Vite 所使用的 HTTP 服务器,该步骤和步骤 1 没有依赖关系,可同时进行。
Service Worker 线程注册成功后,创建 iframe 标签来加载被构建应用的页面。
其中 iframe 的页面 URL 设置需要加上特殊的前置路径,例如 <iframe src='/preview/index.html'/>,目的是为了在 Service Worker 线程拦截页面请求时可以区分该请求是来自主页面还是 iframe 标签加载的页面。因被构建的前端应用页面是由 iframe 标签来加载,所以只需要对来自 iframe 页面的请求进行响应处理即可。
前面三个步骤相当于沙箱启动时的准备阶段,接下来则正式进入到沙箱的构建阶段。
Service Worker 拦截来自 iframe 页面的请求,例如 http://xxx/preview/index.html。
Servie Worker 将拦截到 iframe 页面内的请求信息(例如请求 url、请求头 accept 字段等)通过 Broadcast Channel 发送给 Vite Worker 线程。
运行在 Web Worker 线程的 Vite 根据页面的请求信息,从被构建应用的源码找到对应源代码进行编译,然后将编译后的代码转换成 Response 对象存储在 Cache Storage 中,并通知 Service Worker 线程。
Service Worker 在收到 Vite Worker 线程对某个模块编译完成的消息后,会从 Cache Storage 中取出包含编译后的代码的 Response 对象,作为请求响应返回给 iframe 中的页面,从而使得编译后的代码在浏览器中执行。
例如在处理 http://xxx/preview/A.js 请求时,Vite 先从前端应用源码中确定到具体模块 A.js,然后使用 babel / esbuild 等工具对 A.js 进行编译并将编译后的代码返回给浏览器。在浏览器执行 A.js 编译后的代码时,如果其中有通过 ESM import 方式引用其他模块,例如 import { foo } from 'B.js',则会发出一个对 B.js 模块的 HTTP 请求 http://xxx/preview/B.js,然后继续被 Service Worker 拦截,交给 Vite Worker 线程处理后再返回。最终应用中的所有模块都会被编译和执行,整个应用也就被构建完成了。
针对 npm 包依赖的请求,esm.sh 服务会将 npm 包中所有模块按照 ESM 模块化方式转换并打包,然后返回给 iframe 中的页面中执行。该步骤和步骤 7 同时进行,例如 react 包的请求 https://esm.sh/[email protected]?bundle。
随着前端应用中模块编译后的代码以及 npm 依赖代码的执行,最终该应用对应页面会在 iframe 中渲染。
Vite 沙箱方案就介绍完了,最后总结下本方案所解决的问题:
相对于 Cloud Sandbox 模式(即云端沙箱),本方案整个构建过程完全在用户的浏览器中进行,无需占用任何服务器资源;并且由于没有在服务器中初始化代码运行环境的过程,所以也不存在首次构建应用时间较长的问题。
相对于 Browser Sandbox 模式(即浏览器端沙箱)中的 CodeSandbox 方案,其本质上是模拟实现了一个运行在浏览器中的 Webpack,随着需要被构建的应用模块越来越多,整个构建时间会变长。本方案采用了基于 Vite 实现的 bundless 模式构建,可以实现对应用中模块的按需编译,只需编译当前页面所需模块,从而加快对前端应用的构建速度,使得用户更快地看到页面效果。
整个方案的主要思路来自 Vite in the browser,笔者也正是在文章中提到的 browser-vite 基础上进行开发和落地,对此十分感谢。
同时整个方案的实现代码以及使用示例代码均已开源,希望可以帮助到有相同需求的人。
仓库地址如下:
Vite 沙箱实现代码 —— vitesandbox-client
Vite 沙箱使用示例代码 —— vitesandbox-client-example
Vite 沙箱使用示例在线体验地址 —— https://mcuking.github.io/vitesandbox-client-example/
至此浏览器沙箱系列的三篇文章已经完成,撒花 🎉
文章首发于我的博客 #88
在平时的前端业务开发中,常常需要使用一些组件库里的组件开发页面。然而单单这些组件一般很难完全满足业务需求,还需要针对不同的业务场景进行开发添加业务逻辑。当随着开发的前端项目数量越来越多,就会发现很多业务场景会经常遇到,而且基本大同小异,可能只需要修改少量的代码,原来开发的代码就可以在新的项目中使用。
例如账号绑定手机号这个场景,除了使用了 input、button 等组件等,还要添加很多例如校验手机号、设置倒计时、接口校验验证码等逻辑。如果输入验证码的样式比较特别,可能还会有基于通用 input 组件二次封装出专门针对验证码的输入框。当再次遇到类似绑定手机号的需求时,大部分前端往往会直接从原有的项目中拷贝一份到新的项目,然后做一些微调即可。
这方式可能会遇到以下几个问题:
可复用的业务场景代码散落在形形色色的前端业务项目中,信息不互通,跨项目搜索很难。
往往需要问些资历比较深的开发同事,才能知道某个业务场景在哪个项目中开发过。如果刚来的开发同事并不知道之前已经开发过,而是自己闷头从零开发,就会导致开发资源浪费的问题。
相似的业务场景在不同的业务项目里有着不同的代码实现,无法做到统一标准,共同实现一个最佳实践。
平时开发时经常会有这样一个问题:在不同的业务项目中都编写过相似的业务场景的代码,但都是不同人各自维护的,之间也没有过交流。就会导致后面新的项目开发相似的业务场景时,面临有多个版本代码的选择。无法做到共同维护一个版本代码,并不断优化和改造,最终实现在这个业务场景的最佳实践。
后面的内容就是笔者为了解决上述问题,而开发的跨项目区块复用平台的实践总结。讲到这里读者可能会有个疑问:什么是区块?为什么是区块复用而不是组件复用?
为了解答这个问题,我们先明确下这些概念的定义,下面直接引用阿里飞冰相关的定义:
组件(component):功能比较确定同时复杂度较高,例如用户选择器、地址选择器等,项目中只需要引入对应的 npm 包即可,项目不关心也无法修改组件内部的代码,只能通过组件定义的 props 控制。
区块(block):一般是一个 UI 模块,使用区块时会将区块代码拷贝到项目代码中,项目里可以对区块代码进行任何改动,因此区块后续的升级也不会对项目有任何影响,这是区块跟业务组件的最大区别。
对于组件,笔者所在公司有一个非常完善的流程了:将可复用的代码抽象成基础/业务组件,然后走 npm 包发布的流程,并展示在内建的组件平台上。使用者只需要在平台上找到自己需要的组件,然后通过私有 npm 源下载到项目的依赖中即可使用。
而对于区块,一般很难抽象成组件并集成到 npm 包里,使用时往往需要直接修改区块的源码。而针对区块的复用,目前并没有合适的工具可以使用,所以才会主要针对区块实现了一个可共享复用的平台。特别说明一下,本文的区块除了包括 UI 相关的代码,也包括一些可复用的 utils 方法等等。
这个平台是基于 Bit 开发的,所以在阐述区块复用平台的实现之前,需要先介绍下 Bit 的原理。
为了避免读者的困扰,这里先提前声明一下,在这个小节里会经常出现 组件 这一词,读者可以理解成 Bit 组件--即可复用的代码片段。原因是 Bit 本身并没有区分组件和区块,凡是可复用的代码片段都可以通过 Bit 来实现复用,只是笔者主要用它来实现区块共享而已。下面是 Bit 的原理图:
Bit 是一个用于跨项目组件协作的开源 CLI 工具。使用 Bit 将分散在各个项目中的组件转化可复用的 Package,并可以跨项目使用。
你可以设置自己的用于组件协作的服务,也可以使用 Bit.dev cloud 托管组件,用于私有或共有组件的共享。
上面是 Bit 官方文档对 Bit 的定义,读者可能会觉得和 Git 有点相似。Bit 的确在实现中受到 Git 很大启发。不过区别在于 Git 是以文件为维度的,而 Bit 是以组件为维度。想了解更多内容可以点击 Bit Docs 。
关于上面定义中的提到 Bit 组件,Bit 也给出了自己的定义:
一个 React, Vue or Angular 组件
公共样式文件 (例如 CSS, SCSS)
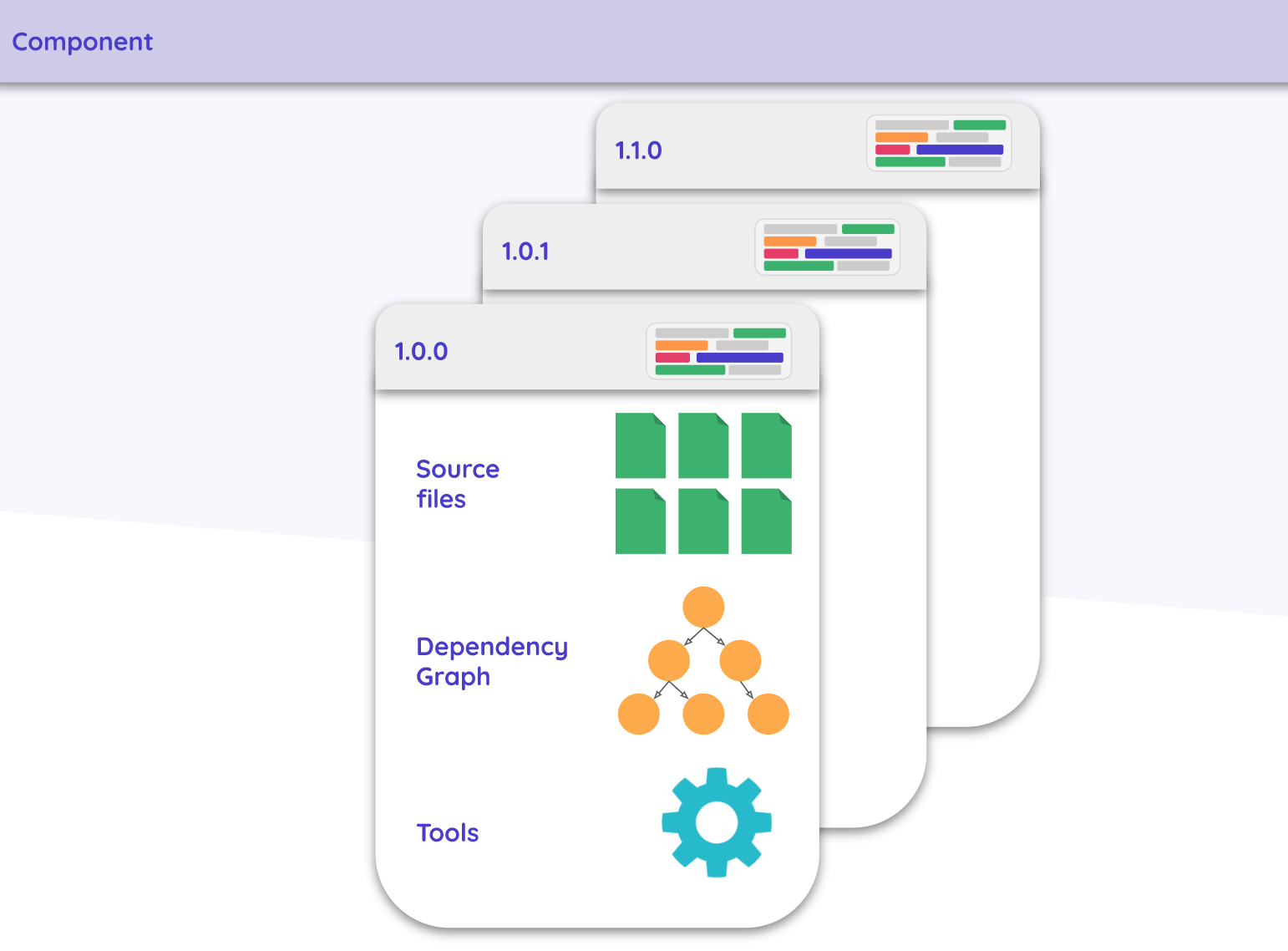
可复用的方法
针对每个组件 Bit 主要存储以下三个要素:
源代码(包括代码、测试和文档)
依赖图谱
当添加文件到 Bit 组件时,Bit 会分析该文件的引入的依赖(例如代码中的 import 或 require 语句)。依赖图谱使组件独立于项目存在,可以跨项目移动且不丢失任何引用。
需要注意的是,这里追踪的依赖项只包含使用 NPM 安装的依赖和安装的 Bit 组件。也就是说项目中直接引入的本地文件不被包含在依赖项内,例如 import { computeXXX } from '../utils'。不过不必担心,当在本地执行发布组件到远程的命令时,Bit 会检测引入的本地文件是否也被追踪,没有的话是无法发布的。
工具和配置
Bit 还会将组件特有的工具和配置保存下来,比如组件使用的编译器和测试工具等。
下面这张图生动的呈现了一个 Bit 组件的构成要素。
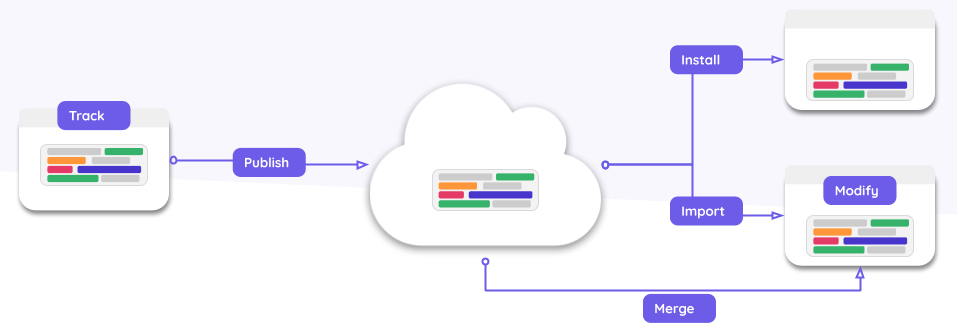
Bit 组件的发布和使用都是通过开源的 CLI 工具 bit-bin 来实现的,读者可以在自己的电脑上全局安装这个 npm 包,尝试用它发布个组件体验下。
Track: 通过指定组成组件的文件,来初始化一个 Bit 组件。同时这些文件的内容修改会被追踪。具体命令:bit add src/bindPhone/xxx -i bindPhone。
Version: 给组件标记版本,会将这个版本的组件的元数据和文件内容固化下来。具体命令:bit tag bindPhone 1.0.0。
Export: 导出组件会为组件创建一个唯一的 ID。这个唯一 ID 包含了 Remote Scope 和本地组件名称。export 指令会将组件的元数据和文件内容的拷贝推送到远程仓库。具体命令:bit export [remoteScopeName]。
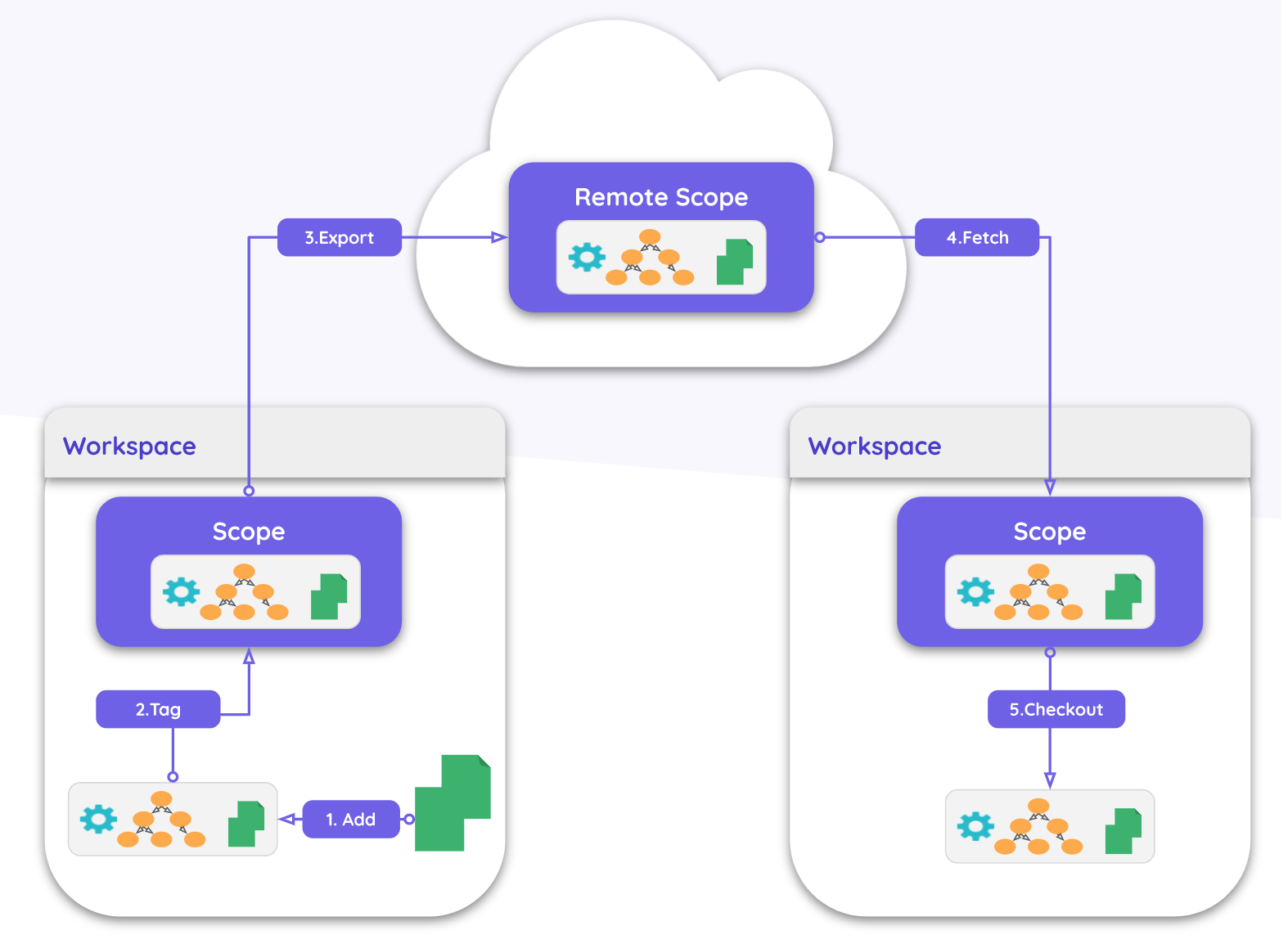
当组件被推送到服务器上的远程仓库,其他本地的 Bit WorkSpace 就可以使用这个组件了。使用的方式包括了两种:一种是 Install 方式--将组件作为一个常规的 npm 包安装到 node_modules 中,另一种方式是 Import 方式--将组件的源代码以及依赖等信息下载到本地。
读者可以再结合下面这张图来理解上面 Bit 组件生命周期的内容。
当在前端业务项目中执行 bit init 命令时,整个业务项目就变成了 workspace(工作区),类似 Git 中的工作区概念。
当在前端业务项目中执行 bit init 命令时,会生成一个 .bit目录,这个目录就是 bit scope(仓库),类似 Git 的 .git 目录就是 git repository(仓库)。
一个 scope 可以存在或者不存在 Bit 工作区中,组件通过 bit export 和 bit import 命令在不同的 scope 之间传递,另外也可以使用 bit tag 和 bit checkout 命令将单个版本的组件从本地 scope(仓库) 和本地 workspace(工作区) 之间进行转换。
组件在 scope 中是采用 CAS(content addressable storage 内容寻址存储) 存储的,关于 scope 的存储的原理后面会详细阐述。Bit 受到了 Git 的机制很大的启发,如果读者对 Git 熟悉的话,就会更容易理解 Bit。
Remote scope 是保存在服务器上的,也可以叫 bare scope,因为这个 scope(仓库) 是在 workspace(工作区) 之外的。Remote scope 是主要是用于共享组件的,也就是组件的导出/导入的地方。
通过上面的介绍,相信读者对 Bit 已经有了初步认知,其实笔者认为 Bit 非常适合跨项目区块复用平台的最主要的原因在于:发布者无需类似发布 npm 一样,需要单独创建项目并发布,而是可以直接在业务项目中发布可复用的区块代码。这一点非常适用区块的很难抽象且代码在项目中可以任意改动的特点。
那么剩下需要思考的问题就是如何在 Bit 基础上实现整个跨项目区块复用平台方案。下面这张图是整个方案的架构图,下面的小节会针对架构图中的不同部分分别做阐述。
Bit 官方已经提供了在服务器上部署远程仓库的方案,可以在远程服务器上执行 Bit 的bit init --bare 命令初始化一个远程仓库,或者直接部署 Bit 官方提供的 Docker 镜像 bit-docker。
部署完远程仓库后,使用者就可以通过 ssh 协议将本地仓库的区块代码上传到远程仓库中,或者从远程仓库中下载区块代码。
更多细节可以参考官方文档 bit-server。
上个小节中提到的上传和下载区块代码的操作都是通过 Bit 开源的 CLI 工具 bit-bin 实现的,读者可以直接在实际开发中使用。
不过如果有一些特定的需求,例如在执行 bit import 下载区块代码时,需要记录下载次数到区块平台中等,就需要定制 bit-bin。对此笔者建议直接克隆一份 Bit 源码 bit,然后进行二次定制开发,并通过在公司内部发布私有 npm 包的方式提供开发使用。
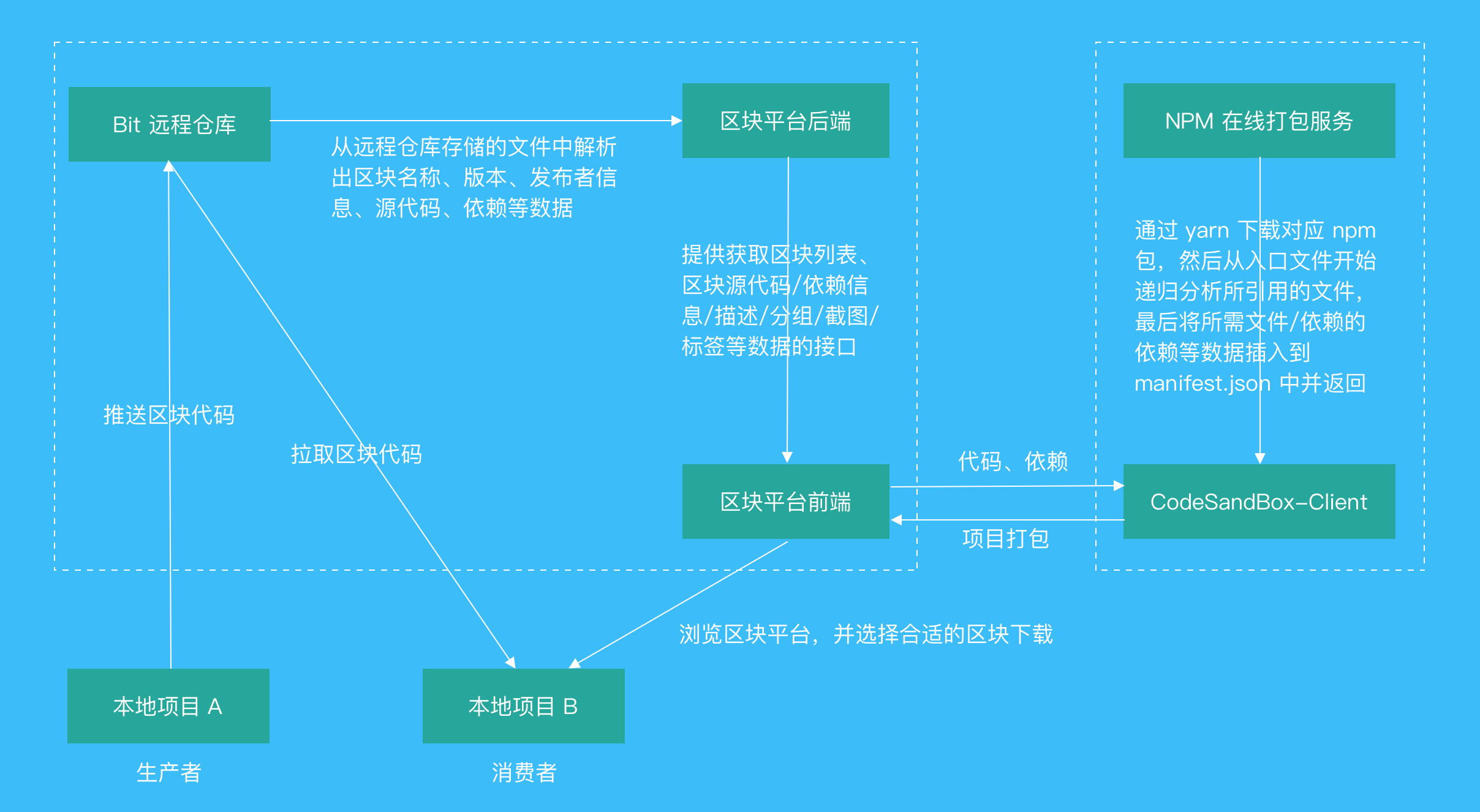
经过上面的操作,区块代码已经托管在服务器上的远程仓库(Remote Scope)中,但区块使用者还无法很直观地通过查看区块代码构建出来的视图来选择区块,也无法对区块代码进行在线调试查看效果,这对区块的使用造成了很大困扰。
而官方提供的门户站点 bit.dev 虽然有这些功能但并没有开源,所以我们需要做一个类似功能的站点。通过分析 bit.dev 站点的功能,可以发现站点实现中的两个关键点:
实时构建区块代码,然后对构建出的页面截图,展示在区块列表中。并且可以在线调试区块源码,然后实时看到调试后的构建结果;
从远程仓库存储的文件中解析出某个区块的数据(源码、依赖等等),以便在区块平台中使用。
关于第一点,主要需要一个在线 IDE 的支持,对此笔者之前已经总结了一篇文章--搭建一个属于自己的在线 IDE,这里就不再赘述了。接下来主要阐述下第二点的实现。
还记得之前有提到 Bit 的 Scope(仓库) 是采用 CAS(content addressable storage 内容寻址存储) 存储 Bit 组件的文件吗?接下来我们就详细的介绍其中的原理。
经过对 Bit 源码的分析,我们发现 Bit 组件的文件存储和 Git 非常相似,所以首先了解下 Git 是怎么做文件存储的,这里主要参考了文章 Git内部存储原理 的内容:
Git 的本质是一个文件系统,其工作空间中的所有文件的历史版本以及提交记录(Commit)、branch、tag 等信息都是以文件对象的方式保存在 .git 目录中的。在 .git 下的 objects 目录下可能会看下面这类文件:
.git/objects
├── 06
│ └── 5bcad11008c5e958ff743f2445551e05561f59
├── 3b
│ └── 18e512dba79e4c8300dd08aeb37f8e728b8dad
├── info
└── packGit Objects 目录中的文件类型主要有以下三种:
Commit: Commit 对象,记录了一个 Version 的所有目录和文件信息
Tree: 目录对象,记录了该目录下包含那些目录和文件信息
Blob: 文件对象,记录了文件内容
而 Git Objects 是通过下面的方式处理并存储在 Git 内部的文件系统中的:
首先创建一个 header,header 的值为 “对象类型 内容长度\0”;
将 header 和文件内容连接起来,计算得到其 SHA-1 hash 值(40 个十六进制的数字组成的字符串);
将连接得到的内容采用 zlib 压缩;
将压缩后的内容写入到以 “hash值前两位命令的目录/hash值后38位命令的文件” 中。
在 Bit 源码中, Bit Scope 中的 objects 文件也分成以下几种类型:
Component: 记录了 Bit 组件的相关信息,包括区块名称、历史版本等
Version: 记录了每次发布的版本信息,例如这次版本的包含的文件、依赖、发布者邮箱/用户名、发布时间等
Source: 记录了文件内容
Symlink: 暂时无用
Scope: 暂时无用
而 Bit Objects 在处理和存储上面这些信息的方式也和 Git 大同小异:
首先根据文件内容计算得到其 SHA-1 hash 值(40 个十六进制的数字组成的字符串);
然后创建一个 header,header 的值为 “对象类型 文件内容的SHA-1 hash值 内容长度\0”;
将 header 和文件内容连接起来;
将连接得到的内容采用 zlib 压缩;
将压缩后的内容写入到以 “hash值前两位命令的目录/hash值后38位命令的文件” 中。
区别在于两点:一个是 Git 是根据 header + 文件内容 两者相加组成的完整内容计算的 SHA-1 hash 值,而 Bit 仅仅根据文件内容计算 SHA-1 hash 值;另一个点是 Bit 的 header 中还额外包括文件内容的 SHA-1 hash 值。
既然我们知道了数据是如何被处理和存储成这些文件,那么就可以反过来从这些文件中解析出这些数据,下面就是解析文件的方法:
const zlib = require('zlib');
const fs = require('fs-extra');
const SPACE_DELIMITER = ' ';
const NULL_BYTE = '\u0000';
const inflate = (buffer) => {
return new Promise((resolve, reject) => {
zlib.inflate(buffer, (err, res) => {
if (err) return reject(err);
return resolve(res);
});
});
}
// 将对象转化成 buffer const buf = Buffer.from(JSON.stringify(obj));
// 将 buffer 转化成对象 const temp = JSON.parse(buf.toString());
const parse = (buffer) => {
// 使用分隔符号 '\u0000' 将文件内容分成 header 和 content 两部分
const firstNullByteLocation = buffer.indexOf(NULL_BYTE);
// 头部部分
const headers = buffer.slice(0, firstNullByteLocation).toString();
// 内容部分
const contents = buffer.slice(firstNullByteLocation + 1, buffer.length);
const [type] = headers.split(SPACE_DELIMITER);
console.log('file type is:', headers);
if (type === 'Source') {
return contents.toString();
}
return JSON.parse(contents.toString());
}
const parseObject = async (path) => {
const contents = await fs
.readFile(path)
.then(fileContents => {
return inflate(fileContents);
})
.then(buffer => parse(buffer));
console.log('file contents is:', contents);
return contents;
}
parseObject('/Users/xxx/bit/common/objects/03/3cb8b37245cf0cfbde2495d5d88c1324234e96');然后就可以调用 parseObject 方法去解析不同类型文件的内容,例如 Component 文件的示例内容如下:
{
name: 'button',
scope: 'common',
versions: {
'1.0.0': '4873cd3d4efdd585ee9a960bdfb16f2ee986ab14',
'1.0.1': 'e1e8280f56c5bfca8640e186f5667286b2023927'
},
lang: 'javascript',
deprecated: false,
bindingPrefix: '@bit',
remotes: [
{
url: 'file:///Users/xxx/bit/common',
name: 'common',
date: '1599218799176'
}
]
}Version 文件示例内容如下:
{
files: [
{
file: '0b8b28f212101ef236744a25bfa085a00d0e7a63',
relativePath: 'src/components/button/index.js',
name: 'index.js',
test: false
}
],
mainFile: 'src/components/button/index.js',
bindingPrefix: '@bit',
log: {
message: '',
date: '1599218793164',
username: 'xxx',
email: '[email protected]'
},
ci: {},
docs: [],
dependencies: [],
devDependencies: [],
flattenedDependencies: [],
flattenedDevDependencies: [],
extensions: [],
packageDependencies: { react: '^16.13.1' },
devPackageDependencies: {},
...
}Source 文件内容其实就是区块的源码,这里就不展示了。
接下来的分析中又发现本地 scope 中(即 .bit 目录中)的 index.json 文件中记录了 Bit 组件的对应的 Component 文件的 SHA-1 hash 值。如下所示:
[
{
"id": {
"scope": "common",
"name": "button"
},
"isSymlink": false,
"hash": "2179ca06272f0962fafd793abdf27a553fd9b418" // 对应组件的 Component 文件
}
]根据以上分析到的知识点,我们就可以找出从远程仓库 Scope 的 Objects 中解析出我们需要的区块源代码的方法了,大致步骤如下:
首先从 scope 中的 index.json 中找到对应区块名称,并获取到区块对应的 Component 文件的 hash 值;
使用上面的 parseObject 方法解析出 Component 文件的内容,并从 Component 文件内容中的 versions 字段找到区块最新版本对应的 Version 文件的 hash 值;
使用上面的 parseObject 方法解析出 Version 文件的内容,从 Version 文件内容中的 files 字段就可以找到该区块包含的所有源码文件名称、相对路径、hash 值等,从 dependencies、devDependencies 等字段中就可以获取区块所有的依赖;
将上个步骤中获取到的区块源代码/依赖等数据,按照一定的格式返回给区块平台即可。
这样就达到了从 Bit 远程仓库中解析出某个区块的源码和依赖等数据,并返回给区块平台的目的。由于篇幅有限,具体代码就不在这里展示了。
到此整个架构的实践就已将介绍完了。
如果做个类比的话,区块复用平台就像冶金设备,而前端的业务项目就像一座座矿山,区块复用平台的使命就是从这么多前端项目中冶炼出有复用价值的金子--区块,并将这些金子直观地展示给开发者,使其尽可能复用这些区块,以提升开发效率。
文章首发于我的博客 #86
这几个月在公司内做一个跨前端项目之间共享组件/区块的工程,主要思路就是在 Bit 的基础上进行开发。Bit 主要目的是实现不同项目 共享 与 同步 组件/区块,大致思路如下:
在 A 项目中通过执行 Bit 提供的命令行工具将需要共享的组件/区块的源码推送到远端仓库,然后在 B 项目中就可以同样通过 Bit 提供的命令行工具拉取存储在 Bit 远程仓库的组件/区块。听起来比较像 Git,主要的区别是 Bit 除了推送源码之外,还会包括组件的依赖图谱分析、组件的版本管理等功能。下面这张图就描述了 Bit 的实现思路。更多细节可以参考 Bit 官方文档 Bit-Docs
虽然 Bit 开源了命令行工具,但并没有开源共享组件/区块的展示站点,类似 Bit 官方提供的网站 bit.dev。也就是说使用者无法通过浏览组件/区块的构建后的视图的方式,来查找保存在 Bit 远程仓库的组件/区块代码。Bit 网站效果如下图:
接下来就需要自己实现一个类似的网站,进而就会发现其中最难的部分就是实现一个在线 IDE,用于展示组件/区块代码,并支持代码实时构建以及获取构建后的页面截图等功能。效果如下图:
看到这里你可能会有个疑问,为什么不能直接使用现有免费的在线 IDE?例如 CodeSandbox、CodePen、Stackblitz 等。主要有如下原因:
对于稍具一定规模的公司,都会有自己的私有 npm 源,而在线 IDE 无法获取到这些 npm 包;
前端项目构建中一些特定的配置,而现有的在线 IDE 无法支持;
例如 CodeSandbox 只能设置构建模板的类型--create-react-app 等,并没有提供外部修改具体的构建配置的 API。假设项目中用到了 less 文件,选择 create-react-app 模板是无法构建的该类型文件的。
特殊的功能无法实现,例如点击页面的按钮,可以实现对在线 IDE 右侧构建出来的页面进行截图,并将图片数据传输出来;
使用在线 IDE 提供的服务,一般意味着你的组件/区块是暴露在公网上的,然而可能有些代码涉密,是不能上传到公网上的。
部分构建工具依赖 node_modules 等文件,无法在没有 node_modules 的浏览器中正常工作。例如 babel 插件等。这个在后面的定制 CodeSandbox 功能部分会举个例子细说。
所以我们需要搭建一个属于自己的在线 IDE ,以解决上面提的几个问题。那么接下来有两种方式:一种是完全从零开发一个在线 IDE,另一种是找到一个开源的项目,并在此基础上进行定制。
最开始笔者选择了自己开发,但是开发一段时间后,发现花费了大量精力实现出来 IDE 和已有的产品相比,不论是从功能丰富度还是易用性上,都完全落败。再加上笔者主要想实现的是一个跨前端项目区块复用的平台,在线 IDE 只是其中一个非必要的组成部分(注:其实也可以将共享的组件/区块的源代码直接在页面上展示,通过组件/区块命称来区分,虽然这种方式确实很 low)。所以最终还是选择在已经开源的在线 IDE 基础上二次开发。
笔者主要研究的是 Codesandbox 以及 Stackblitz 。这两个都是商业化的项目,其中 Stackblitz 的核心部分并没有开源出来,而 CodeSandbox 绝大部分的功能都已经开源出来了,所以最终选择了 CodeSandbox。
为了方便后续讲解如何定制和部署 CodeSandbox,这里大概说一下它的基本原理(下面主要引用了CodeSandbox 如何工作? 上篇 的部分内容):
CodeSandbox 最大的特点是采用在浏览器端做项目构建,也就是说打包和运行不依赖服务器。由于浏览器端并没有 Node 环境,所以 CodeSandbox 自己实现了一个可以跑在浏览器端的简化版 webpack。
如下图所示,CodeSandbox 主要包含了三个部分:
Editor 编辑器:主要用于编辑代码,代码变动后会通知 Sandbox 进行转译
Sandbox 代码运行沙盒:在一个单独的 iframe 中运行,负责代码的编译 Transpiler 和运行 Evaluation
Packager npm 在线打包器:给 Sandbox 提供 npm 包中的文件内容
构建过程主要包括了三个步骤:
Packager--npm 包打包阶段:下载 npm 包并递归查找所有引用到的文件,然后提供给下个阶段进行编译
Transpilation--编译阶段:编译所有代码, 构建模块依赖图
Evaluation--执行阶段:使用 eval 运行编译后的代码,实现项目预览
Packager 阶段的代码实现是在 CodeSandbox 托管在 GitHub 上的仓库 dependency-packager 里,这是一个基于 express 框架提供的服务,并且部署采用了 Serverless(基于 AWS Lambda) 方式,让 Packager 服务更具伸缩性,可以灵活地应付高并发的场景。(注:在私有化部署中如果没有 Serverless 环境,可以将源码中有关 AWS Lambda 部分全部注释掉即可 )
以 react 包为例,讲解下 Packager 服务的原理,首先 express 框架接收到请求中的包名以及包版本,例如 [email protected]。然后通过 yarn 下载 react 以及 react 的依赖包到磁盘上,通过读取 npm 包的 package.json 文件中的 browser、module、main、unpkg 等字段找到 npm 包入口文件,然后解析 AST 中所有的 require 语句,将被 require 的文件内容添加到 manifest 文件中,并且递归执行刚才的步骤,最终形成依赖图。这样就实现将 npm 包文件内容转移到 manifest.json 上的目的,同时也实现了剔除 npm 模块中多余的文件的目的。最后返回给 Sandbox 进行编译。下面是一个 manifest 文件的示例:
{
// 模块内容
"contents": {
"/node_modules/react/index.js": {
"content": "'use strict';↵↵if ....", // 代码内容
"requires": [ // 依赖的其他模块
"./cjs/react.development.js",
],
},
//...
},
// 模块具体安装版本号
"dependencies": [{
name: "@babel/runtime",
version: "7.3.1"
}, /*…*/ ],
// 模块别名, 比如将react作为preact-compat的别名
"dependencyAliases": {},
// 依赖的依赖, 即间接依赖信息. 这些信息可以从yarn.lock获取
"dependencyDependencies": {
"object-assign": {
"entries": ["object-assign"], // 模块入口
"parents": ["react", "prop-types", "scheduler", "react-dom"], // 父模块
}
//...
}
}值得一提的是为了提升 npm 在线打包的速度,CodeSandbox 作者使用了 AWS 提供的 S3 云存储服务。当某个版本的 npm 包已经打包过一次的话,会将打包的结果 -- manifest.json 文件存储到 S3 上。在下一次请求同样版本的包时,就可以直接返回储存的 manifest.json 文件,而不需要重复上面的流程了。在私有化部署中可以将 S3 替换成你自己的文件存储服务。
当 Sandbox 从 Editor 接收到前端项目的源代码、npm 依赖以及构建模板 Preset。Sandbox 会初始化配置,然后从 Packager 服务下载 npm 依赖包对应的 manifest 文件,接着从前端项目的入口文件开始对项目进行编译,并解析 AST 递归编译被 require 的文件,形成依赖图(注:和 webpack 原理基本一致)。
注意 CodeSandbox 支持外部预定义项目的构建模板 Preset。Preset 规定了针对某一类型的文件,采用哪些 Transpiler(相当于 Webpack 的 Loader)对文件进行编译。目前可供选择的 Preset 选项有: vue-cli 、 create-react-app、create-react-app-typescript、 parcel、angular-cli、preact-cli。但是不支持修改某个 Preset 中的具体配置,这些都是内置在 CodeSandbox 源码中的。Preset 具体配置示例如下:
import babelTranspiler from "../../transpilers/babel";
...
const preset = new Preset(
"create-react-app",
["web.js", "js", "json", "web.jsx", "jsx", "ts", "tsx"], {
hasDotEnv: true,
setup: manager => {
const babelOptions = {...};
preset.registerTranspiler(
module =>
/\.(t|j)sx?$/.test(module.path) && !module.path.endsWith(".d.ts"),
[{
transpiler: babelTranspiler,
options: babelOptions
}],
true
);
...
}
}
);Evaluation 执行阶段是从项目入口文件对应的编译后的模块开始,递归调用 eval 执行所有被引用到的模块。
由于本文主要是阐述如何搭建自己的在线 IDE,所以 CodeSandbox 更多的实现细节可以参考如下文章:
了解完 CodeSandbox 基本原理后,接下来就到了本文的核心内容:如何私有化部署 CodeSandbox。
首先是 npm 在线打包服务 dependency-packager。笔者是通过镜像部署到自己的服务器上的。
接着是将 npm 源改成公司的私有 npm 源,可以通过两种方式,一种是在镜像中通过 npm config 命令全局修改,例如如下 Dockerfile:
FROM node:12-alpine
COPY . /home/app
# 设置私有 npm 源
RUN cd /home/app && npm config set registry http://npm.xxx.com && npm install -f
WORKDIR /home/app
CMD ["npm", "run", "dev"]第二种方式是在源码中通过 yarn 下载 npm 包的命令后面添加参数 --registry=http://npm.xxx.com ,相关代码在 functions/packager/dependencies/install-dependencies.ts 文件中。
另外该服务依赖了 AWS 的 Lambda 提供的 Serverless,并采用 AWS 提供的 S3 存储服务缓存 npm 包的打包结果。如果读者没有这些服务的话,可以将源码中这部分内容注释掉或者换成对应的其他云计算厂商的服务即可。dependency-packager 本质上就是一个基于 express 框架的 node 服务,可以简单地直接跑在服务器中。
在 CodeSandbox-client 工程中的 standalone-packages/react-sandpack 项目,就是 CodeSandbox 提供的基于 react 实现的的编辑器项目。区别于主项目实现的编辑器,这个编辑器主要是为了给使用者进行定制,所以实现的比较简陋,使用者可以根据自己的需求在这个编辑器的基础上加入自己需要的功能。当然如果没有自定义编辑器的需求,可以直接使用 react-sandpack 项目对应的 npm 包 react-smooshpack,使用方式如下:
import React from 'react';
import { render } from 'react-dom';
import {
FileExplorer,
CodeMirror,
BrowserPreview,
SandpackProvider,
} from 'react-smooshpack';
import 'react-smooshpack/dist/styles.css';
const files = {
'/index.js': {
code: "document.body.innerHTML = `<div>${require('uuid')}</div>` ",
},
};
const dependencies = {
uuid: 'latest',
};
const App = () => (
<SandpackProvider
files={files}
dependencies={dependencies}
entry="/index.js"
bundlerURL= `http://sandpack-${version}.codesandbox.io` >
<div style={{ display: 'flex', width: '100%', height: '100%' }}>
<FileExplorer style={{ width: 300 }} />
<CodeMirror style={{ flex: 1 }} />
<BrowserPreview style={{ flex: 1 }} />
</div>
</SandpackProvider>
);
render(<App />, document.getElementById('root'));其中子组件 FileExplorer、CodeMirror、BrowserPreview 分别是左侧的文件目录树、中间的代码编辑区和右侧的项目构建后的页面预览区。
通过查看这个独立库的源码,可以知道除了这三个子组件之外,SandpackProvider 还会再插入一个 iframe 标签,主要用于显示项目构建后的页面,而右侧预览区组件 BrowserPreview 中的 Preview 组件会将这个 ifame 插入到自己的节点,这样就实现了将项目构建的页面实时显示出来的目的。
而 iframe 加载的 bundlerUrl 默认是官方提供的地址 http://sandpack-${version}.codesandbox.io ,其中这个域名对应的服务其实就是 CodeSandbox 的核心--在浏览器端构建前端项目的服务,大致原理刚刚已经阐述过了。下一小节会阐述如何将官方提供的构建服务替换成自己的。
至于代码编辑区的代码/依赖如何同步到 iframe 中加载的构建服务,其实它依赖了另一个独立库 sandpack(和 react-sandpack 同级目录),其中有一个 Manager 类就是在代码编辑区和右侧预览区的构建服务之间搭建桥梁,主要是用了 codesandbox-api 包提供的 dispatch 方法进行编辑器和构建服务之间的通信。
怕大家误解先提前说明下,上一小节提到的构建服务并不是后端服务,这个服务其实就是 CodeSandbox 构建出来的前端页面。基本原理部分已经阐述了 CodeSandbox 实际上在浏览器里实现了一个 webpack,项目的构建全部是在浏览器中完成的。
而 CodeSandbox 前端构建的核心部分的目录在 CodeSandbox-client 工程中 packages/app 项目,其中的原理已经在上面阐述过了,这里只需要将该项目构建出来的 www 文件夹部署到服务器即可。由于该核心库又依赖了其他库,所以也需要先构建下依赖库。下面笔者写了一个 build.sh 文件,放置在整个项目的一级目录即可。
# 运行和构建需要 Node 10 环境
nvm use 10
# 安装依赖
yarn
# 如果是第一次构建,需要先将整个项目构建一次,后面需要使用其中的构建产物
# 如果已经整体项目构建过一次,则无需重新构建
yarn run build
# 构建依赖库
yarn run build:deps
# 进入到核心库 packages/app 进行构建
cd packages/app
yarn run build:sandpack-sandbox
# 由于一些原因,一些需要的静态文件需要从整体项目的构建目录中获取
# 因此需要在执行该 shell 脚本之前,将整个项目构建一次,即执行 yarn run build 即可(这个构建的时间会比较久)
cp -rf ../../www/static/* ./www/static当执行完上面的 shell 脚本之后,就可以将 packages/app 目录下构建的产物 www 部署到服务器上,笔者采用的是容器部署,下面是 dockerfile 文件内容。
FROM node:10.14.2 as build
WORKDIR /
ADD . .
RUN /bin/sh build.sh
FROM nginx:1.16.1-alpine
COPY --from=build /packages/app/www /usr/share/nginx/html/注意这里采用了分阶段构建镜像,即先构建 CodeSandbox 项目,再构建镜像。但在实践中发现 CodeSandbox 项目放在服务器上构建不是很顺利,所以最终还是选择在本地构建该项目,然后将构建产物一并上传到远程 git 仓库,这样在打包机上只需要构建镜像并运行即可。
整个部署的灵感来自 GitLab 的官方仓库的一个 issue: GitLab hosted Codesandbox
上个小节读者可能会有个疑问,为什么直接使用 CodeSandbox 提供的默认构建服务?其实就是为了对 CodeSandbox 的构建流程进行定制,接下来举四个例子来说明下。
针对公司自建的组件库,一般都会开发类似 babel-plugin-import 这样的插件,以便在代码中使用组件时无需额外再引入组件的样式文件,babel-plugin-import 插件会在 js 编译阶段自动插入引入样式的代码。但这种插件可能会需要遍历组件的 package.json 中的依赖中是否有其他组件,如果有也要把其他组件的样式文件的引入写到编译后的 js 中,并递归执行刚才的过程。这里就需要读入 node_modules 中的相关文件。但是诸如 CodeSandbox、Stackblitz 等都是在浏览器中进行构建,并没有 node_modules。
针对这个问题,笔者最终放弃了利用 babel 插件在 js 编译阶段进行插入引入样式文件代码的方式,而是在代码运行阶段从 npm 在线打包服务中获取组件的样式文件,然后将样式文件内容通过 style 标签动态插入到 head 标签上面。下面是具体改动:
在线 npm 打包服务侧
在线 npm 打包服务一般只会返回 js 文件,所以需要在该服务基础上增加一个功能:当判断请求的 npm 包为内建组件,则还要额外返回样式文件。下面是 dependence-packager 项目中添加的核心代码:
为了提供获取私有组件样式文件的方法,可以在 functions/packager/utils 目录下新建一个文件 fetch-builtin-component-style.ts ,核心代码如下:
// 根据组件 npm 包名以及通过 yarn 下载到磁盘上的 npm 包路径,读入对应的样式文件内容,并写入到 manifest.json 的 contents 对象上
const insertStyle = (contents: any, packageName: string, packagePath: string) => {
const stylePath = `/node_modules/${packageName}/dist/index.css`;
const styleFilePath = join(
packagePath,
`/node_modules/${packageName}/dist/index.css` ,
);
if (fs.existsSync(styleFilePath)) {
contents[stylePath] = {
content: fs.readFileSync(styleFilePath, "utf-8"),
isModule: false,
};
}
};
// 获取内建组件的样式文件,并写入到返回给 Sandbox 的 manifest.json 文件中
const fetchBuiltinComponentStyle = (
contents: any,
packageName: string,
packagePath: string,
dependencyDependencies: any,
) => {
// 当 npm 包或者其依赖以及依赖的依赖中有内建组件,则将该内建组件对应的样式文件写入到 manifest.json 文件中
if (isBuiltinComponent(packageName)) {
insertStyle(contents, packageName, packagePath);
}
Object.keys(dependencyDependencies.dependencyDependencies).forEach(
(pkgName) => {
if (isBuiltinComponent(pkgName)) {
insertStyle(contents, pkgName, packagePath);
}
},
);
};并在 functions/packager/index.ts 文件中调用该方法。代码如下:
+ // 针对私有组件,将组件样式文件也写到返回给浏览器的 manifest.json 文件中
+ fetchBuiltinComponentStyle(
+ contents,
+ dependency.name,
+ packagePath,
+ dependencyDependencies,
+ );
// 作为结果返回
const response = {
contents,
dependency,
...dependencyDependencies,
};浏览器 CodeSandbox 侧
浏览器 CodeSandbox 侧需要提供处理私有组件样式的方法,主要是在 Evaluation 执行阶段将样式文件内容通过 style 标签动态插入到 head 标签上面,可以在 packages/app/src/sandbox/eval/utils 目录下新建一个文件 insert-builtin-component-style.ts ,下面是核心代码:
// 基于样式文件内容创建 style 标签,并插入到 head 标签上
const insertStyleNode = (content: string) => {
const styleNode = document.createElement('style');
styleNode.type = 'text/css';
styleNode.innerHTML = content;
document.head.appendChild(styleNode);
}
const insertBuiltinComponentStyle = (manifest: any) => {
const { contents, dependencies, dependencyDependencies } = manifest;
// 从依赖以及依赖的依赖中根据 npm 包名筛选出内建组件
const builtinComponents = Object.keys(dependencyDependencies).filter(pkgName => isBuiltinComponent(pkgName));
dependencies.map((d: any) => {
if (isBuiltinComponent(d.name)) {
builtinComponents.push(d.name);
}
});
// 根据基于内建组件 npm 名称拼装成的 key 查找到具体的文件内容,并调用 insertStyleNode 方法插入到 head 标签上
builtinComponents.forEach(name => {
const styleContent = contents[`/node_modules/${name}/dist/index.css`];
if (styleContent) {
const { content } = styleContent;
if (content) {
insertStyleNode(content);
}
}
});
}并在 Evaluation 执行阶段调用该方法,相关文件在 packages/sandpack-core/src/manager.ts ,具体修改如下:
...
setManifest(manifest?: Manifest) {
this.manifest = manifest || {
contents: {},
dependencies: [],
dependencyDependencies: {},
dependencyAliases: {},
};
+ insertBuiltinComponentStyle(this.manifest);
...
}
...在区块复用平台项目中,在点击保存按钮时,不仅要保存编辑好的代码,还需要对构建好的右侧预览区域进行截图并保存。如下图所示:

右侧预览区域所展示的内容是 SandpackProvider 组件插入的 iframe,所以只需要找到这个 iframe,然后通过 postMessage 与 iframe 内页面进行通信。当 iframe 内部页面接收到截图指令后,对当前 dom 进行截图并传出即可,这里笔者用的是 html2canvas 进行截图的。下面是 CodeSandbox 侧的代码改造,文件在 packages/app/src/sandbox/index.js 中,主要是在文件结尾处添加如下代码:
const fetchScreenShot = async () => {
const app = document.querySelector('#root');
const c = await html2canvas(app);
const imgData = c.toDataURL('image/png');
window.parent.postMessage({
type: 'SCREENSHOT_DATA',
payload: {
imgData
}
}, '*');
};
const receiveMessageFromIndex = (event) => {
const {
type
} = event.data;
switch (type) {
case 'FETCH_SCREENSHOT':
fetchScreenShot();
break;
default:
break;
}
};
window.addEventListener('message', receiveMessageFromIndex, false);在 CodeSandbox 使用侧,则需要在需要截图的时候,向 iframe 发送截图指令。同时也需要监听 iframe 发来的消息,从中筛选出返回截图数据的指令,并获取到截图数据。由于实现比较简单,这里就不展示具体代码了。
主要是对 create-react-app 这个 preset 的配置做一些修改,文件地址 packages/app/src/sandbox/eval/presets/create-react-app/v1.ts。修改代码如下:
...
+ import lessTranspiler from '../../transpilers/less';
+ import styleProcessor from '../../transpilers/postcss';
export default function initialize() {
...
+ preset.registerTranspiler(module => /\.less$/.test(module.path), [
+ { transpiler: lessTranspiler },
+ { transpiler: styleProcessor },
+ {
+ transpiler: stylesTranspiler,
+ options: { hmrEnabled: true },
+ },
+ ]);
...
}可以将打包 npm 的服务换成上面私有化部署的服务,以解决无法获取私有 npm 包等问题。相关文件在 packages/sandpack-core/src/npm/preloaded/fetch-dependencies.ts 。修改代码如下:
const PROD_URLS = {
...
// 替换成自己的在线 npm 打包服务即可
- bucket: 'https://prod-packager-packages.codesandbox.io',
+ bucket: 'http://packager.igame.163.com'
};
...
function dependencyToPackagePath(name: string, version: string) {
- return `v${VERSION}/packages/${name}/${version}.json` ;
+ return `${name}@${version}` ;
}这四个例子就讲完了,读者可以根据自己的需求进行更多的定制。当你明白了整个 CodeSandbox 的运行机制后,就会发现定制并没有那么难。
到此为止,私有化部署一个属于自己并且可以任意定制的在线 IDE 的目标就已经达成了。当然在线 IDE 的项目构建不仅仅局限在浏览器中,还可以将整个构建过程放在服务端,借助于云+容器化的能力,使得在线 IDE 有着跟本地IDE几乎完全一样的功能。其实这两者应用的场景不多,完全基于浏览器构建更适用于单一页面项目的实时预览,而基于服务端构建是完全可以适用于真实的项目开发的,并且不仅仅局限于前端项目。笔者也在尝试探索基于服务端构建 IDE 的可能性,期待后面能够有些产出分享给大家。
接下来如果读者感兴趣的话,可以继续阅读基于 Bit 和 CodeSandbox 实现的区块平台项目--跨项目区块复用方案实践
文章首发于我的博客 #63
在 H5 + Native 的混合开发模式中,让人诟病最多的恐怕就是加载 H5 页面过程中的白屏问题了。下面这张图描述了从 WebView 初始化到 H5 页面最终渲染的整个过程。
其中目前主流的优化方式主要包括:
针对 WebView 初始化:该过程大致需耗费 70~700ms。当客户端刚启动时,可以先提前初始化一个全局的 WebView 待用并隐藏。当用户访问了 WebView 时,直接使用这个 WebView 加载对应网页并展示。
针对向后端发送接口请求:在客户端初始化 WebView 的同时,直接由 Native 开始网络请求数据,当页面初始化完成后,向 Native 获取其代理请求的数据。
针对加载的 js 动态拼接 html(单页面应用):可采用多页面打包, 服务端渲染,以及构建时预渲染等方式。
针对加载页面资源的大小:可采用懒加载等方式,将需要较大资源的部分分离出来,等整体页面渲染完成后再异步请求分离出来的资源,以提升整体页面加载速度。
当然还有很多其它方面的优化,这里就不再赘述了。本文重点讲的是,在与静态资源服务器建立连接,然后接收前端静态资源的过程。由于这个过程过于依赖用户当前所处的网络环境,因此也成了最不可控因素。当用户处于弱网时,页面加载速度可能会达到 4 到 5 s 甚至更久,严重影响用户体验。而离线包方案就是解决该问题的一个比较成熟的方案。
首先阐述下大概思路:
我们可以先将页面需要的静态资源打包并预先加载到客户端的安装包中,当用户安装时,再将资源解压到本地存储中,当 WebView 加载某个 H5 页面时,拦截发出的所有 http 请求,查看请求的资源是否在本地存在,如果存在则直接返回资源。
下面是整体技术方案图,其中 CI/CD 我默认使用 Jenkins,当然也可以采用其它方式。
相关代码:
离线包打包插件:https://github.com/mcuking/offline-package-webpack-plugin
应用插件的前端项目:https://github.com/mcuking/mobile-web-best-practice
首先需要在前端打包的过程中同时生成离线包,我的思路是 webpack 插件在 emit 钩子时(生成资源并输出到目录之前),通过 compilation 对象(代表了一次单一的版本构建和生成资源)遍历读取 webpack 打包生成的资源,然后将每个资源(可通过文件类型限定遍历范围)的信息记录在一个资源映射的 json 里,具体内容如下:
资源映射 json 示例
{
"packageId": "mwbp",
"version": 1,
"items": [
{
"packageId": "mwbp",
"version": 1,
"remoteUrl": "http://122.51.132.117/js/app.67073d65.js",
"path": "js/app.67073d65.js",
"mimeType": "application/javascript"
},
...
]
}
其中 remoteUrl 是该资源在静态资源服务器的地址,path 则是在客户端本地的相对路径(通过拦截该资源对应的服务端请求,并根据相对路径从本地命中相关资源然后返回)。
最后将该资源映射的 json 文件和需要本地化的静态资源打包成 zip 包,以供后面的流程使用。
相关代码:
离线包管理平台前后端:https://github.com/mcuking/offline-package-admin
文件差分工具:https://github.com/Exoway/bsdiff-nodejs
从上面有关离线包的阐述中,有心者不难看出其中有个遗漏的问题,那就是当前端的静态资源更新后,客户端中的离线包资源如何更新?难不成要重新发一个安装包吗?那岂不是摒弃了 H5 动态化的特点了么?
而离线包平台就是为了解决这个问题。下面我以 mobile-web-best-practice 这个前端项目为例讲解整个过程:
mobile-web-best-practice 项目对应的离线包名为 main,第一个版本可以如上文所述先预置到客户端安装包里,同时将该离线包上传到离线包管理平台中,该平台除了保存离线包文件和相关信息之外,还会生成一个名为 packageIndex 的 json 文件,即记录所有相关离线包信息集合的文件,该文件主要是提供给客户端下载的。大致内容如下:
{
"data": [
{
"module_name": "main",
"version": 2,
"status": 1,
"origin_file_path": "/download/main/07eb239072934103ca64a9692fb20f83",
"origin_file_md5": "ec624b2395a479020d02262eee36efe4",
"patch_file_path": "/download/main/b4b8e0616e75c0cc6f34efde20fb6f36",
"patch_file_md5": "6863cdacc8ed9550e8011d2b6fffdaba"
}
],
"errorCode": 0
}
其中 data 中就是所有相关离线包的信息集合,包括了离线包的版本、状态、以及文件的 url 地址和 md5 值等。
当 mobile-web-best-practice 更新后,会通过 offline-package-webpack-plugin 插件打包出一个新的离线包。这个时候我们就可以将这个离线包上传到管理平台,此时 packageIndex 中离线包 main 的版本就会更新成 2。
当客户端启动并请求最新的 packageIndex 文件时,发现离线包 main 的版本比本地对应离线包的版本大时,会从离线包平台下载最新的版本,并以此作为查询本地静态资源文件的资源池。
讲到这里读者可能还会有一个疑问,那就是如果前端仅仅是改动了某一处,客户端仍旧需要下载完整的新包,岂不是很浪费流量同时也延长了文件下载的时间?
针对这个问题我们可以使用一个文件差分工具 - bsdiff-nodejs,该 node 工具调用了 c 语言实现的 bsdiff 算法(基于二进制进行文件比对算出 diff/patch 包)。当上传版本为 2 的离线包到管理平台时,平台会与之前保存的版本为 1 的离线包进行 diff ,算出 1 到 2 的差分包。而客户端仅仅需要下载差分包,然后同样使用基于 bsdiff 算法的工具,和本地版本 1 的离线包进行 patch 生成版本 2 的离线包。
到此离线包管理平台大致原理就讲完了,但仍有待完善的地方,例如:
增加日志功能
增加离线包达到率的统计功能
...
相关项目:
集成离线包库的安卓项目:https://github.com/mcuking/mobile-web-best-practice-container
客户端的离线包库目前仅开发了 android 平台,该库是在
webpackagekit(个人开发的安卓离线包库)基础上进行的二次开发,主要实现了一个多版本文件资源管理器,可以支持多个前端离线包预置到客户端中。其中拦截请求的源码如下:
public class OfflineWebViewClient extends WebViewClient {
@TargetApi(Build.VERSION_CODES.LOLLIPOP)
@Override
public WebResourceResponse shouldInterceptRequest(WebView view, WebResourceRequest request) {
final String url = request.getUrl().toString();
WebResourceResponse resourceResponse = getWebResourceResponse(url);
if (resourceResponse == null) {
return super.shouldInterceptRequest(view, request);
}
return resourceResponse;
}
/**
* 从本地命中并返回资源
* @param url 资源地址
*/
private WebResourceResponse getWebResourceResponse(String url) {
try {
WebResourceResponse resourceResponse = PackageManager.getInstance().getResource(url);
return resourceResponse;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}通过对 WebviewClient 类的 shouldInterceptRequest 方法的复写来拦截 http 请求,并从本地查找是否有相应的前端静态资源,如果有则直接返回。
当前端资源通过 CI 机自动打包后部署到静态资源服务器,那么又如何上传到离线包平台呢?我曾经考虑过当前端资源打包好时,通过接口自动上传到离线包平台。但后来发现可行性不高,因为我们的前端资源是需要经过测试阶段后,通过运维手动修改 docker 版本来更新前端资源。如果自动上传,则会出现离线包平台已经上传了了未经验证的前端资源,而静态资源服务器却没有更新的情况。因此仍需要手动上传离线包。当然读者可以根据实际情况选择合适的上传方式。
在上传的离线包填写信息的时候,增加了 appName 字段。当请求离线包列表 json 文件时,在 query 中添加 appName 字段,离线包平台会只返回属于该 App 的离线包列表。
当然可以做的更丰富些,比如可以选择在客户端连接到 Wi-Fi 的时候,或者从后台切换到前台并超过 10 分钟时候。该设置项可以放在离线包平台中进行配置,可以做成全局有效的设置或者针对不同的离线包进行个性化设置。
这个大可不必担心,上面的代码中如果 http 请求没有命中任何前端资源,则会放过该请求,让它去请求远端的服务器。因此即使本地离线包资源没有及时更新,仍然可以保证页面的静态资源是最新的。也就是说有一个兜底的方案,出了问题大不了回到原来的请求服务器的加载模式。
笔者开发的离线包平台目前仅对相邻版本进行了差分,所以如果客户端本地离线包版本和离线包平台最新版本不相邻,会下载最新版本的全量包。当然,各位可以根据需要,可以将上传的离线包和过去 3 个版本或者更多版本进行差分,这样客户端可以选择下载对应版本的差分包即可,例如下载 1->3 的差分包。
这里笔者举个例子方便阐述,假设客户端请求线上离线包版本的时机是在 app 启动时和定时每两个小时请求一次。当 app 刚刚请求线上离线包版本完没多久,线上的前端页面资源更新了,同时线上离线包也会更新。这个时候用户访问页面时,客户端并不知道线上资源已经更新,所以仍旧会拦截 html 资源请求,并从本地离线包中查找。由于 html 文件名中没有 hash,即使页面更新内容变化,文件名称仍然不变,所以还是可以从本地离线包中找到对应的 html 文件并返回,虽然这个 html 文件相对于线上已经是较旧的文件了。而旧的 html 中引用的 js/css 等资源也会是旧的资源,由此便导致用户看到的页面始终是旧的。只有等到 app 重新启动或者等待将近两个小时后,客户端重新请求线上离线包版本后,才能更新到最新的页面。
对此主要问题根源在于,客户端并不知道线上资源的更新时机,只能通过定时轮询。如果服务端主动通知客户端,例如通过推送方式,当线上离线包一更新,便通知客户端请求最新版本离线包,就可以保证尽量的及时更新。(当然下载离线包也会需要一些时间)
讲到这里读者可以思考一个问题,前端的页面更新是否及时真的是非常重要的事情么?这里涉及到用户打开页面的体验和页面及时更新两者的取舍问题,可以类比下原生 app,原生 app 一般只有用户同意更新之后才会下载更新,很多用户使用的版本可能并不是最新的。所以笔者认为,只要能够做好后端接口的兼容性,不至于出现页面不更新的话,请求的线上接口参数变更甚者被废除,导致页面报错这种情况,页面的无法及时更新还是可以容忍的。
况且一般用户使用 app 的时间不会太长,当下一次再打开的时候客户端就会下载最新的离线包了。笔者所在公司也有这样的问题,但并没有影响到用户的实际使用。所以还是建议离线 html 文件,以彻底提升页面的打开速度。
笔者询问了下云音乐的 iOS 端离线包方案,是通过私有 API -- registerSchemeForCustomProtocol 注册了 http(s) scheme,进而可以获取到所有的 http(s) 请求,更多信息可参考下面这篇文章:
http://nanhuacoder.top/2019/04/11/iOS-WKWebView02/
文中提到因为WKWebView 在独立于主进程 NSURLProtocol 进程 Network Process 里执行网络请求,正常情况 NSURLProtocol 进程是无法拦截到 webview 中网页发起的请求的。(注:UIWebView 发出的 request,NSURLProtocol 是可以拦截到的)
如果通过 registerSchemeForCustomProtocol 注册了 http(s) scheme, 那么由 WKWebView 发起的所有 http(s)请求都会通过 IPC 从 网络进程 Network Process 传给主进程 NSURLProtocol 处理,就可以拦截所有的网络请求了。
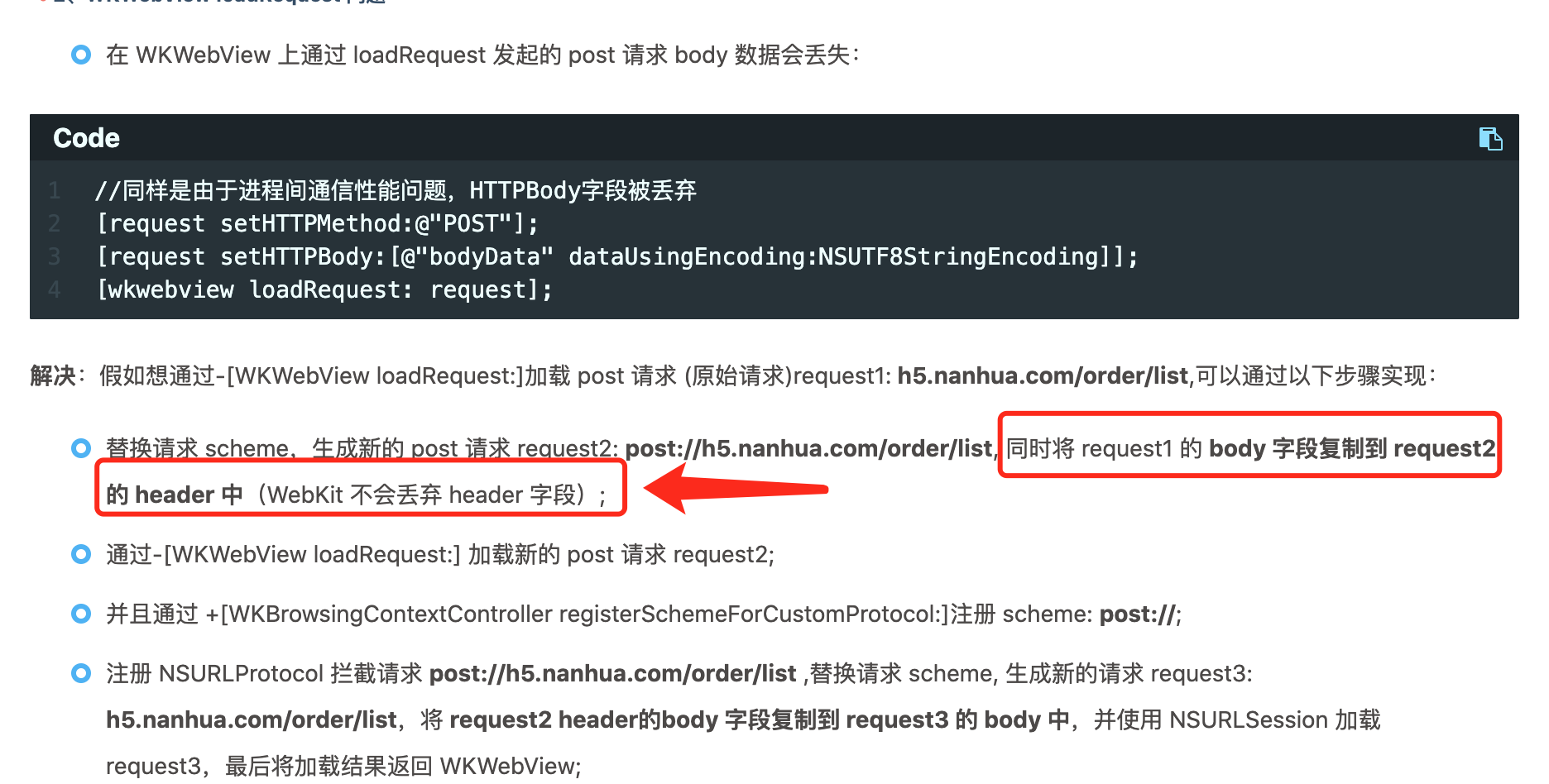
但是进程之间的通信使用了 MessageQueue,网络进程 Network Process 会将请求 encode 成一个 Message,然后通过 IPC(进程间通信) 发送给 主进程 NSURLProtocol。出于性能的原因,encode 的时候 将 HTTPBody 和 HTTPBodyStream 这两个字段丢弃掉。
文中提到里一个解决办法,如下所示:
但是还是会遇到一个问题,那就是 http 的 header 本身的大小会有限制,导致例如上传图片等场景会失败。笔者这里提一个可以走通的方式:
在初始化 wkWebview 的时候,注入并执行一段 js,这段 js 主要逻辑是复写挂载在全局上的 XMLHttpRequest 原型上的 open 和 send 方法。
在 open 方法里基于时间戳生成一串字符串 identifier,挂载到 XMLHttpRequest 的实例对象上,同时添加到第二个参数 Url 上,然后再执行原有的 open 方法。
至于 send 方法,主要是拿到 http 请求的 body,以及 open 方法中挂载到实例对象的 identifier 属性,组合成一个对象并调用原生方法保存到客户端的存储中。
当在主进程 NSURLProtocol 中拦截到 XHR 请求时,先从请求的 Url 获取到 identifier,然后根据 identifier 从客户端的存储中找到之前保存的 body。这样就解决了 body 丢失的问题。
当然如果项目中用到了浏览器原生提供的 fetch 方法的话,记得也要将 fetch 方法复写下哦。
至此整个方案的大致原理已经阐述完了,更多细节问题读者可以参考文中提供的项目链接,所有端的代码都已经托管到了我的 github 上了。
这也算完成了我一个夙愿:实现一套离线包方案并且完全开源出来。最后希望对大家有所帮助~
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.