![]()
(Framework for Adapting Representation Models)



FARM makes cutting edge Transfer Learning for NLP simple. It is a home for all species of pretrained language models (e.g. BERT) that can be adapted to different down-stream tasks. The aim is to make it simple to perform document classification, NER and question answering, for example, using the one language model. The standardized interfaces for language models and prediction heads allow flexible extension by researchers and easy adaptation for practitioners. Additional experiment tracking and visualizations support you along the way to adapt a SOTA model to your own NLP problem and have a very fast proof-of-concept.
- Easy adaptation of language models (e.g. BERT) to your own use case
- Fast integration of custom datasets via Processor class
- Modular design of language model and prediction heads
- Switch between heads or just combine them for multitask learning
- Smooth upgrading to new language models
- Powerful experiment tracking & execution
- Simple deployment and visualization to showcase your model
- Full Documentation
- Intro to Transfer Learning (Blog)
- Tutorial (Jupyter notebook)
- Tutorial (Colab notebook)
Recommended (because of active development):
git clone https://github.com/deepset-ai/FARM.git cd FARM pip install -r requirements.txt pip install --editable .
If problems occur, please do a git pull. The --editable flag will update changes immediately.
From PyPi:
pip install farm
FARM offers two modes for model training:
Option 1: Run experiment(s) from config

Use cases: Training your first model, hyperparameter optimization, evaluating a language model on multiple down-stream tasks.
Option 2: Stick together your own building blocks
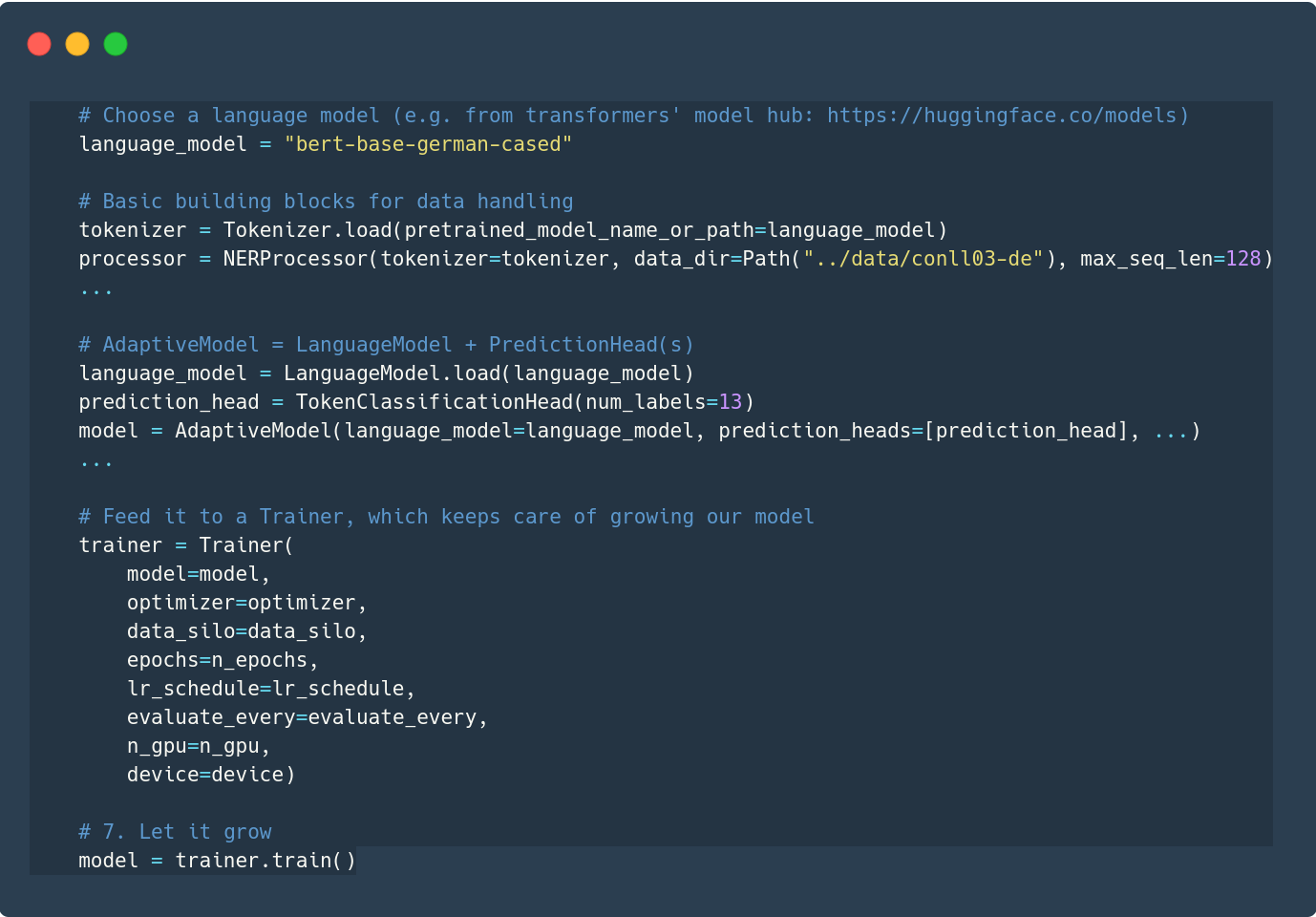
Usecases: Custom datasets, language models, prediction heads ...
Metrics and parameters of your model training get automatically logged via MLflow. We provide a public MLflow server for testing and learning purposes. Check it out to see your own experiment results! Just be aware: We will start deleting all experiments on a regular schedule to ensure decent server performance for everybody!
- Run
docker-compose up - Open http://localhost:3000 in your browser

One docker container exposes a REST API (localhost:5000) and another one runs a simple demo UI (localhost:3000). You can use both of them individually and mount your own models. Check out the docs for details.
- More pretrained models XLNet, XLM ...
- SOTA adaptation strategies (Adapter Modules, Discriminative Fine-tuning ...)
- Enabling large scale deployment for production
- Additional Visualizations and statistics to explore and debug your model