Trabajo parcial para el curso de Complejidad Algorítmica. UPC - Universidad Peruana de Ciencias Aplicadas

- Manuel Alvarado Estanga
- Luis Angel Bernal
A lo largo de la existencia de las computadoras, se ha considerado a estas como herramientas de las cuales nos podemos valer para facilitar nuestras actividades. Así, se ha pensado que las computadoras nos pueden ayudar a resolver todos nuestros problemas y que poseen más poder para procesar datos que nosotros. Es raro pensar en que las computadoras poseen limites en sus facultades de cálculo, ya que muy pocas veces nos encontramos ante tales limites; de hecho, probablemente el usuario promedio no tenga que lidiar nunca en su vida con ningún problema que requiera llevar el poder de procesamiento de la computadora hasta casi el límite. Pese a esto, hasta el día de hoy existen ciertos problemas que no han podido ser resueltos ni con la ayuda de las computadoras, esto se debe a que quizás si se pueda encontrar una respuesta, pero el tiempo que le llevaría a las computadoras darnos el resultado podría ser de hasta millones de años.
Por esta razón se plantea el problema P vs. NP; este problema es considerado como uno de los tantos problemas del millón de dólares. Este problema consiste en comprobar que los problemas NP pueden ser resueltos de igual forma que los polinómicos(P) aplicando diversos conceptos que permitan facilitar el proceso de resolución. Este problema trata de aclarar que problemas pueden resolverse con la ayuda de la computadora y cuales no, para de esta forma determinar si la resolución de dichos problemas se hallará relacionada a la creación de equipos más con más potencia de análisis.
- P: Las soluciones pueden ser calculadas en un tiempo razonable
- NP: Las soluciones son muy dificiles de encontrar, pero son fáciles de comprobar
El reto es demostrar que P = NP o lo contrario; es decir, mientras no se pruebe que son diferentes podrían existir atajos que permitan resolver un problema de clase NP como uno de complejidad P. Demostrar que P = NP tendría grandes impactos en la criptografía moderna y haría vulnerables a todos los sistemas a nivel mundial en el caso que sea cierto.
Entre estos problemas de complejidad NP, se encuentra el problema del vendedor viajero (TSP, por sus siglas en ingles). Dada una colección de ciudades y las distancias entre sus conexiones (costo), el problema consiste en encontrar un camino que recorra todas las ciudades una única vez y regrese al punto inicial con la menor distancia posible.

Fuente: Wikipedia - Travelling salesman problem
- Desarrollar la competencia general de razonamiento cuantitativo y la competencia específica de uso de técnicas y herramientas acorde a los objetivos del curso.
- Desarrollar un algoritmo que permita resolver completa o parcialmente el problema del vendedor viajero.
- Establecer relaciones entre problemas de la vida diaria y problemas computacionales.
- Determinar la importancia de la aplicación de algoritmos eficientes a la hora de resolver un problema.
- Analizar la eficiencia y complejidad de los algoritmos planteados.
Este algoritmo de búsqueda consiste en recorrer los vértices de un grafo de izquierda a derecha; es decir, en lugar de recorrer una rama hacia abajo como lo hace la búsqueda por profundidad (DFS), recorre todos los nodos que se encuentran en el mismo nivel. Una posible implementación del algoritmo es la siguiente:
def bfs(grafo,inicio,meta):
cola = [(inicio,[inicio])]
visitados = set()
while len(cola) > 0:
nodo,camino = cola.pop(0)
if nodo not in visitados:
visitados.add(nodo)
for vecino in grafo.vecinos(nodo):
if vecino == meta:
return camino + [vecino]
else:
if vecino not in visitados:
visitados.add(vecino)
cola.append((vecino,camino+[vecino]))
return None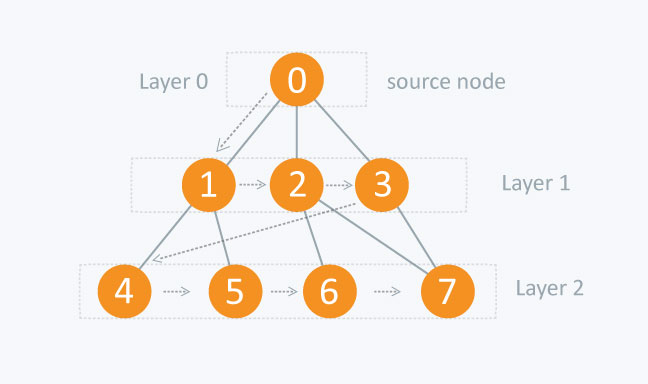
Este algoritmo de búsqueda trabaja con grafos ponderados o con pesos. En este tipo de grafos cada vértice tiene un peso y se define el costo de la arista como la distancia entre los vértices conectados. La búsqueda se realiza a partir de un punto inicial y recorre los vértices más cercanos, de tal manera que se va acumulando el costo total. Esta estrategia utiliza una cola de prioridades (Priority Queue) la cual ordena los vértices y sus respectivos costos en pares (v,c) dentro de una colección del tipo LIFO. Este tipo de colas ubica los elementos de forma ordenada según la prioridad; es decir, los elementos con menor costo estarán ubicados al final y van a ser los primeros en salir. Una posible implementación del algoritmo es la siguiente:
def ucs(grafo,inicio, meta):
visitados = set()
cola = PriorityQueue()
cola.put((0,inicio,[inicio]))
while cola:
costo,nodo,camino = cola.get()
if nodo not in visitados:
visitados.add(nodo)
for vecino in grafo.vecinos(nodo):
costo_total = costo + grafo.getPeso(nodo,vecino)
camino_total = camino + [vecino]
if vecino == meta:
return (costo_total,camino_total)
else:
if vecino not in visitados:
visitados.add(vecino)
cola.put((costo_total,vecino,camino_total))
return (None,None)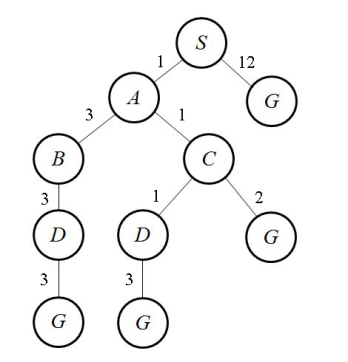
Análisis de tiempo para los algoritmos de búsqueda por anchura (BFS):
O(V+E)
Donde: V: Número de vértices en la cola
E: Número de aristas incidentes en cada vértice
Esto es de acuerdo a la estructura del grafo, en este caso se utilizará una lista de adyacencia (n + m). En una matriz de adyacencia sería n^2
Con esta estrategia buscamos encontrar los caminos más cortos desde un punto aleatorio del mapa. El camino (path) debe terminar en el mismo punto de partida para considerarlo como posible solución.
def ucs(grafo,inicio, meta):
visitados = set()
cola = PriorityQueue()
cola.put((0,inicio,[inicio]))
while cola:
costo,nodo,camino = cola.get()
if nodo not in visitados:
visitados.add(nodo)
for vecino in grafo.vecinos(nodo):
costo_total = costo + grafo.getPeso(nodo,vecino)
camino_total = camino + [vecino]
if vecino == meta:
return (costo_total,camino_total)
else:
if vecino not in visitados:
visitados.add(vecino)
cola.put((costo_total,vecino,camino_total))
return (None,None)def generarCaminos(diccionario,grafo):
n = len(diccionario)
codigos = list(diccionario)
colores = ['b','c','m','y','w']
print("Generando caminos con UCS")
for i in range(4):
indiceCP = randint(0,n-1)
codigo = codigos[indiceCP]
costo,camino = ucs(grafo,codigo,codigo) #inicia y termina en la misma ciudad (codigo inicio y fin)
nCoord = len(camino)
x1 = [0]*nCoord
y1 = [0]*nCoord
if costo and camino:
j = 0
for codigoCP in camino:
x1[j] = diccionario[codigoCP].coordX
y1[j] = diccionario[codigoCP].coordY
nombreCP = diccionario[codigoCP].nombre
plt.text(x1[j], y1[j], nombreCP, family="sans-serif", color=colores[i])
j+=1
plt.text(x1[0], y1[0] + 0.5, str(round(costo,2)), family="sans-serif", color=colores[i])
plt.plot(x1,y1,color=colores[i],marker="8",markerEdgeColor="black")
else:
continue
generarCaminos(d,grafo)
plt.show()Obtenemos como resultado los siguientes caminos:

Usamos BFS para una muestra pequeña de todos los centros poblados. El objetivo será buscar todos los caminos posibles con combinatoria de 2 sobre n, es decir tomamos dos puntos cualquiera del grafo para generar caminos. Para ello utilizaremos backtracking. Si el camino recorre todos los nodos entonces cumple con una de las condiciones del problema TSP.
def bfs(grafo,inicio,meta):
cola = [(inicio,[inicio])]
visitados = set()
while len(cola) > 0:
nodo,camino = cola.pop(0)
if nodo not in visitados:
visitados.add(nodo)
for vecino in grafo.vecinos(nodo):
if vecino == meta:
return camino + [vecino]
else:
if vecino not in visitados:
visitados.add(vecino)
cola.append((vecino,camino+[vecino]))
return NoneBacktracking:
#solucion = [inicio,fin]
def buscarCaminos(grafo,codigos,solucion,etapa,caminos):
n = len(solucion)
numCentrosPoblados = len(codigos)
if etapa > n: #No hay solución
return
i = 0
while True:
solucion[etapa] = codigos[i]
if etapa == n-1:
camino = bfs(grafo,solucion[0],solucion[1])
#Validar si ha recorrido todos los nodos del grafo (codigos)
if camino:
caminos.append(camino)
else:
buscarCaminos(grafo,codigos,solucion,etapa+1,caminos)
i+=1
if i == numCentrosPoblados:
breakValidamos si el camino recorre todos los nodos:
def generarCaminos(diccionario,grafo):
codigos = list(diccionario)
colores = ['r','b','c','m','y','w']
print("Generando caminos con BFS")
caminos = []
solucion = [None]*2 # [inicio,final]
buscarCaminos(grafo,codigos,solucion,0,caminos)
for c in caminos:
n = len(c)
x = [0]*n
y = [0]*n
colorC = colores[0]
encontrado = False
#Valida si el camino recorre todos los nodos
#Lo pinta de otro color
if collections.Counter(c) == collections.Counter(codigos):
colorC = colores[1]
encontrado = True
j = 0
for codigoCP in c:
x[j] = diccionario[codigoCP].coordX
y[j] = diccionario[codigoCP].coordY
plt.text(x[j], y[j], diccionario[codigoCP].nombre, family="sans-serif", color=colores[2])
j+=1
plt.plot(x,y,color=colorC,marker="8",markerEdgeColor="black")
if encontrado:
breakResultado:

- Se ha resuelto por partes el problema dado. Mediante la primera estrategia se ha logrado encontrar el camino más corto que retorne al punto de partida, mientras que con la segunda estrategia se pudo comprobar los caminos que recorren todos los centros poblados tomando una pequeña muestra.
- Si se integran ambas estrategias podría obtener una solución para un problema con pocos elementos y es fácil de comprobar; sin embargo, debido a la gran cantidad de datos a procesar los algoritmos propuestos pueden ser ineficientes.
Jiménez, A. (2006, agosto 26). P versus NP. ¿Nunca lo entendiste? Obtenido de Xataka Ciencia: https://www.xatakaciencia.com/matematicas/p-versus-np-nunca-lo-entendiste
Pavlus, J. (19 de agosto de 2010). ¿Qué significa 'P vs NP' para el resto de nosotros? Obtenido de MIT Technology review: https://www.technologyreview.es/s/1374/que-significa-p-vs-np-para-el-resto-de-nosotros
Vasiliu, A. (25 de setiembre de 2018). Uninformed search algorithms in Python. Obtenido de http://cyluun.github.io/blog/uninformed-search-algorithms-in-python
Garg, P. (25 de setiembre de 2018). Breadth First Search. Obtenido de https://www.hackerearth.com/practice/algorithms/graphs/breadth-first-search/tutorial/
Agrawal, S. (2012 de diciembre de 2012). Artificial Intelligence – Uniform Cost Search(UCS). Obtenido de https://algorithmicthoughts.wordpress.com/2012/12/15/artificial-intelligence-uniform-cost-searchucs/
Ultrablendz. (07 de agosto de 2017). ¿Por qué es la complejidad de tiempo de ambos DFS y BFS O (V + E). Obtenido de https://stackoverrun.com/es/q/3057118


