Source code and dataset for The WebConf 2018 (WWW 2018) paper: CESI: Canonicalizing Open Knowledge Bases using Embeddings and Side Information.
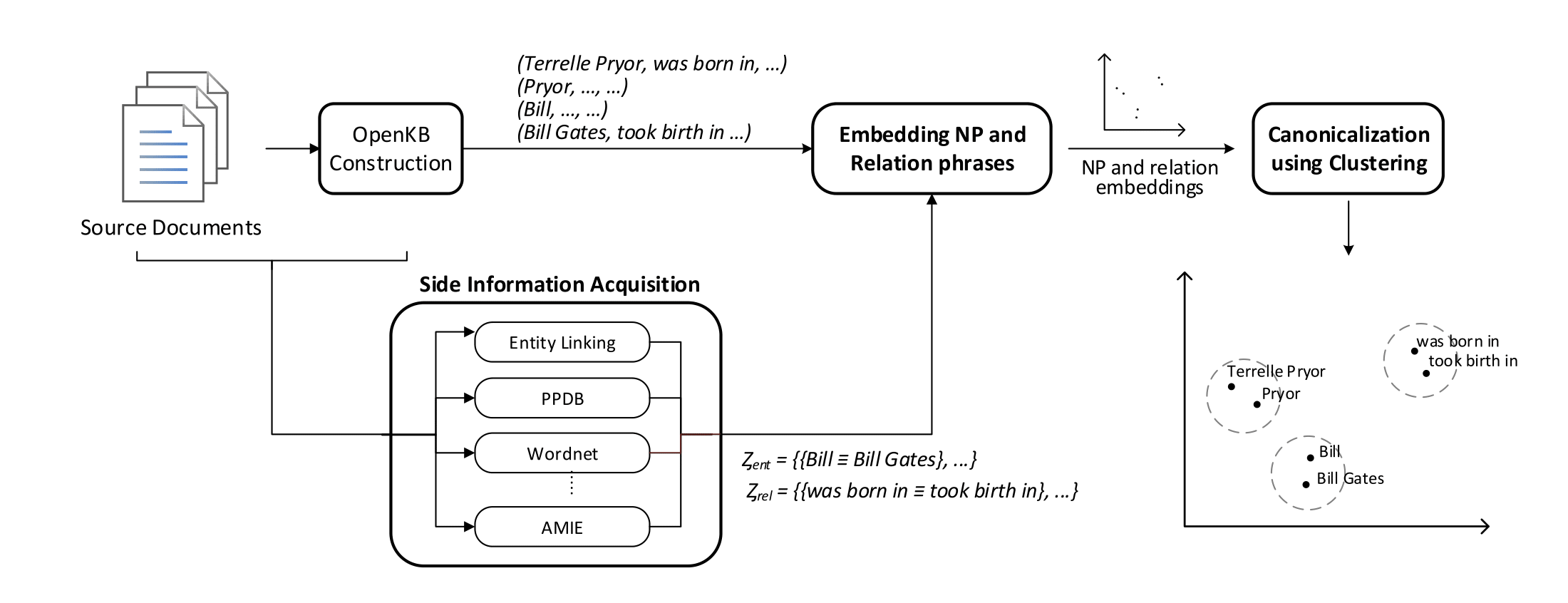 Overview of CESI. CESI first acquires side information of noun and relation phrases of Open KB triples. In the second step, it learns embeddings of these NPs and relation phrases while utilizing the side information obtained in previous step. In the third step, CESI performs clustering over the learned embeddings to canonicalize NP and relation phrases. Please refer paper for more details
Overview of CESI. CESI first acquires side information of noun and relation phrases of Open KB triples. In the second step, it learns embeddings of these NPs and relation phrases while utilizing the side information obtained in previous step. In the third step, CESI performs clustering over the learned embeddings to canonicalize NP and relation phrases. Please refer paper for more details
- Compatible with both Python 2.7/3.x
- Dependencies can be installed using
requirements.txt
- Datasets ReVerb45k, Base and Ambiguous are included with the repository.
- The input to CESI is a KG as list of triples. Each triple is stored as a json in a new line. An example entry is shown below:
{
"_id": 36952,
"triple": [
"Frederick",
"had reached",
"Alessandria"
],
"triple_norm": [
"frederick",
"have reach",
"alessandria"
],
"true_link": {
"subject": "/m/09w_9",
"object": "/m/02bb_4"
},
"src_sentences": [
"Frederick had reached Alessandria",
"By late October, Frederick had reached Alessandria."
],
"entity_linking": {
"subject": "Frederick,_Maryland",
"object": "Alessandria"
},
"kbp_info": []
} _idunique id of each triple in the Knowledge Graph.tripledenotes the actual triple in the Knowledge Graphtriple_normdenotes the normalized form of the triple (after lemmatization, lower casing ...)true_linkis the gold canonicalization of subject and object. For relations gold linking is not available.src_sentencesis the list of sentences from which the triple was extracted by Open IE algorithms.entity_linkingis the Entity Linking side information which is utilized by CESI.kbp_infoKnowledge-Base Propagation side information used by CESI.
- After installing python dependencies, execute
sh setup.shfor setting up required things. - Pattern library is required to run the code. Please install it from Python 2.x/Python 3.x.
- Running PPDB server is essential for running the main code.
- To start the server execute:
python ppdb/ppdb_server.py -port 9997(Let the server run in a separate terminal)
python src/cesi_main.py -name reverb45_test_run- On executing the above command, all the output will be dumped in
output/reverb45_test_rundirectory. -nameis an arbitrary name assigned to the run.
Please cite the following paper if you use this code in your work.
@inproceedings{cesi2018,
author = {Vashishth, Shikhar and Jain, Prince and Talukdar, Partha},
title = {{CESI}: Canonicalizing Open Knowledge Bases Using Embeddings and Side Information},
booktitle = {Proceedings of the 2018 World Wide Web Conference},
series = {WWW '18},
year = {2018},
isbn = {978-1-4503-5639-8},
location = {Lyon, France},
pages = {1317--1327},
numpages = {11},
url = {https://doi.org/10.1145/3178876.3186030},
doi = {10.1145/3178876.3186030},
acmid = {3186030},
publisher = {International World Wide Web Conferences Steering Committee},
address = {Republic and Canton of Geneva, Switzerland},
keywords = {canonicalization, knowledge graph embeddings, knowledge graphs, open knowledge bases},
}

























































































































