Code for the Make Your Own Neural Network book
makeyourownneuralnetwork / makeyourownneuralnetwork Goto Github PK
View Code? Open in Web Editor NEWCode for the Make Your Own Neural Network book
License: GNU General Public License v2.0
Code for the Make Your Own Neural Network book
License: GNU General Public License v2.0
Code for the Make Your Own Neural Network book










































































































































































































Hello Rashid,
I still have some questions regarding saving a neural network.
Let's say you start with the initial code (training with dataset 60000 lines).
Everytime you run that code the time to train the network takes as in your case let's say 5 minutes.
Now let's using the code to save a neural network.
Before you have the input box "train the neural network"
you can put the code:
# load neural network weights
def load(self):
self.wih = numpy.load('saved_wih.npy')
self.who = numpy.load('saved_who.npy')
pass
After the Training part you can put the code:
# save neural network weights
def save(self):
numpy.save('saved_wih.npy', self.wih)
numpy.save('saved_who.npy', self.who)
pass
Now my questions:
1)Let's say training is bussy, and you interrupt (closing the labtob), when the neural network was bussy
with the 30000 line of the dataset.
How does the network know that he has to continue with the 30001 line from the dataset or even
know that epoch is 1,2, 3 ... etc once you run the code again?
2)Neural network has finished training (did a loop over all 60000 lines of the dataset and did this epoch
= 5 times)
When you rerun the code now, how does the network know to take the weights of the saved_wih and saved_who and not to restart the training all over again?
Thanks for clarifying!!!
1. def backquery(self, targets_list):
2. # transpose the targets list to a vertical array
3. final_outputs = numpy.array(targets_list, ndmin=2).T
4.
5. # calculate the signal into the final output layer
6. final_inputs = self.inverse_activation_function(final_outputs)
7.
8. # calculate the signal out of the hidden layer
9. hidden_outputs = numpy.dot(self.who.T, final_inputs)
10. # scale them back to 0.01 to .99
11. hidden_outputs -= numpy.min(hidden_outputs)
12. hidden_outputs /= numpy.max(hidden_outputs)
13. hidden_outputs *= 0.98
14. hidden_outputs += 0.01
15.
16. # calculate the signal into the hidden layer
17. hidden_inputs = self.inverse_activation_function(hidden_outputs)
18.
19. # calculate the signal out of the input layer
20. inputs = numpy.dot(self.wih.T, hidden_inputs)
21. # scale them back to 0.01 to .99
22. inputs -= numpy.min(inputs)
23. inputs /= numpy.max(inputs)
24. inputs *= 0.98
25. inputs += 0.01
26.
27. return inputs
why can we calculate the hidden_outputs by numpy.dot(self.who.T, final_inputs), in line 9?
why can we calculate the inputs by numpy.dot(self.wih.T, hidden_inputs), in line 20?
as we know, who*hidden_outputs = final_inputs, and wih*inputs = hidden_inputs, but line 9 and line 20 are not like this. why can we do that?
@makeyourownneuralnetwork or somebody else,
Please help. I really do not understand the difference... in way of working?
I did a small test with the own handwriting number 4 (the number you provide Rashid in your own handwriting numbers).
I did the test Rashid with your code part3_neural_network_mnist_and_own_data.ipynb (epoch = 10 and trainingset = mnist_train_100.csv
Here there is a match with the lable 4 (see attach)
Then I also did the test with your code (part2_neural_network_mnist_data.ipynb) where you provide the testset as dataset (eg: mnist_test_10.csv)
I put also the epoch = 10 and trained the network with mnist_train_100.csv
So in this case I converted the image.png into a csv file with 784 pixels and 4 in front as the correct label.
I called my testset mnist_test_03.csv
When I run the code I've got no match. (See attach)!
For once and forever can somebody do the same and debug why in one case it is working and in the other not. I'm really get disappointed in let the neural network work with data from own handwriting :-(
As you can see both labels are the same, and the network has been trained with same set of trainings data and epoch.
@makeyourownneuralnetwork can you please do the same test or can you explain. I realy like to know what is hapening. Tnx a lot.


Hi Tariq,
I watched you "gentle introduction to neural network" video and followed here. I tried the notebook, but I can't get 97% accuracy from the test set. The best I could get is 100% on training set (that needs about 10 epochs of training instead of 5), and 70% on the test set.
Another question is: I've tried to build on your code to make it work for more than 1 hidden layers, using the new version it works just as good as your original code if only 1 hidden layer of 200 nodes is used, works about OK if 2 layers of 200 nodes, but if I added up to 3 layers, the model kind of broke: it always predicts the same digit (e.g. 0) no matter what input is fed in, whether it is a training sample or a test one. I've lowered down the learning rate by several orders of magnitudes and it still behaves like that. Could you give me some hinds why this is happening?
So this is technically not an issue of the code anymore, I couldn't find your email on the internet, and twitter is just too limited to put so many texts, so I tried it here. I've been quite interested in machine learning and neural network, but there isn't nobody around me who could provide me with some guidance, so your help will be much appreciated.
I'm pasting my code below:
import numpy
import matplotlib.pyplot as plt
from scipy.special import expit
import pandas as pd
class neuralNetwork:
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
if numpy.isscalar(hiddennodes):
hiddennodes=[hiddennodes,]
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
self.n_nodes=[inputnodes,]+hiddennodes+[outputnodes,]
self.n_layers=len(self.n_nodes)
#-------------Construct weight matrix-------------
self.thetas=[]
for ii in range(self.n_layers-1):
thetaii=numpy.random.normal(0,pow(self.inodes,-0.5),[self.n_nodes[ii+1],self.n_nodes[ii]])
self.thetas.append(thetaii)
self.lr = learningrate
self.activation_function = lambda x: expit(x)
#---------------------Forward---------------------
def feedForward(self,x,y):
activations=[x,]
a1=x
for jj in range(self.n_layers-1):
if jj!=self.n_layers-2:
zjj=numpy.dot(self.thetas[jj],a1)
ajj=expit(zjj)
activations.append(ajj)
a1=ajj
else:
zjj=numpy.dot(self.thetas[jj],a1)
ajj=expit(zjj)
activations.append(ajj)
return activations
#-------------------Compute cost-------------------
def sampleCost(self,yhat,y):
jii=-numpy.dot(y,numpy.log(yhat))-numpy.dot((1-y),\
numpy.log((1-yhat)))
return jii
#---------------------Backward---------------------
def feedBackward(self,activations,y):
grads=[]
deltaL=activations[-1]-y
for jj in range(self.n_layers-2,-1,-1):
deltajj=numpy.dot(self.thetas[jj].T,deltaL)*activations[jj]*\
(1-activations[jj])
gradjj=numpy.outer(deltaL,activations[jj])
grads.append(gradjj)
deltaL=deltajj
grads=grads[::-1]
return grads
#-----------------Gradient descent-----------------
def gradientDescent(self,devs):
for l in range(self.n_layers-1):
thetal=self.thetas[l]
thetal=thetal-self.lr*devs[l]
self.thetas[l]=thetal
return
def train2(self,inputs_list,targets_list):
inputs=inputs_list
targets=targets_list
activations=self.feedForward(inputs,targets)
j=self.sampleCost(activations[-1],targets)
grads=self.feedBackward(activations,targets)
self.gradientDescent(grads)
return j
def predict(self,x):
a1=x
for jj in range(self.n_layers-1):
if jj!=self.n_layers-2:
zjj=numpy.dot(self.thetas[jj],a1)
ajj=expit(zjj)
a1=ajj
else:
zjj=numpy.dot(self.thetas[jj],a1)
ajj=expit(zjj)
return ajj
def readData(path):
data_file=pd.read_csv(path,header=None)
x_data=[]
y_data=[]
for ii in xrange(len(data_file)):
lineii=data_file.iloc[ii,:]
imgii=numpy.array(lineii.iloc[1:])/255.*0.99+0.01
labelii=numpy.zeros(10)+0.01
labelii[int(lineii.iloc[0])]=0.99
y_data.append(labelii)
x_data.append(imgii)
x_data=numpy.array(x_data)
y_data=numpy.array(y_data)
return x_data,y_data
if __name__=='__main__':
#-----------------Open MNIST data-----------------
path='/home/guangzhi/codes/nn/mnist_data/mnist_train_100.csv'
x_data,y_data=readData(path)
#------------------Open test data------------------
path='/home/guangzhi/codes/nn/mnist_data/mnist_test_10.csv'
x_data_test,y_data_test=readData(path)
#------------------Create network------------------
ninnodes=784
nhidden=[200,200,100]
noutnodes=10
lr=0.1
nn=neuralNetwork(ninnodes,nhidden,noutnodes,lr)
#----------------------Train----------------------
costs=[]
epoch=60
for ii in range(epoch):
idxs=numpy.random.permutation(len(x_data))
for jj in idxs:
jjj=nn.train2(x_data[jj],y_data[jj])
costs.append(jjj)
print jjj
#----------------Plot cost function----------------
plt.plot(costs);plt.show(block=False)
#---------------Validate on train set---------------
n_test=100
n_correct=0
for ii in range(n_test):
yhat=numpy.argmax(nn.predict(x_data[ii]))
yii=numpy.argmax(y_data[ii])
if yhat==yii:
n_correct+=1
print 'yhat = %d, yii = %d' %(yhat, yii)
print n_correct/float(n_test)*100.
#---------------Validate on test set---------------
n_test=10
n_correct=0
for ii in range(n_test):
yhat=numpy.argmax(nn.predict(x_data_test[ii]))
yii=numpy.argmax(y_data_test[ii])
if yhat==yii:
n_correct+=1
print 'yhat = %d, yii = %d' %(yhat, yii)
print n_correct/float(n_test)*100.
I am using the same code for constructing a neural network with 728 input neurons. This gives me a warning message saying that "overflow encountered in exp". BTW I am not using scipy library in my code.


Error in line 30
Hello,
I copy paste the code from github.com makeyourownneuralnetwork.
Then I select the run cell select below button.
Questions:
See printscreens below!
My question in general how do I have to run my code?
Tnx
[


](url)
When initializing the weights matrix, the variance of matrix wih should be : pow(self.hnodes, -0.5)
same to the matrix who
Hello!
First of all, congratulations on writing such a great book! It helped me a lot to understand Neural Networks. For me that's exactly how learning should be! :)
Second, I have a quick question... Is it possible to adapt code for the neural network to use cross-entropy as a loss function? Would it change much in the code?
As I am still studying, I have read in some places that cross-entropy function works very well... So I would like to compare it with the performance of the one we used in the book.
Thanks in advance!
I am trying to extend the example from your book with those things, but I can't get them to work. Can you maybe show how that would be done in python?
Thanks!
This is a feature request:
I tried to save a trained neural network by pickle n.who and n.whi
f = open("nn.obj", "wb")
pickle.dump([n.who, n.wih], f)
f.close()
Then restarting the kernel and import:
with open ('nn.obj', 'rb') as f:
n.who, n.whi = pickle.load(f)
This gives me different results than an untrained network, but not the results i got with the trained network.
It would be great to have this feature explained. This is the one and only thing i miss in this great, inspiring book.
Hello does there exists a forum where we can discuss our code in ipython and then in general code about neural networking?
Hello,
what is the use of the avantage of the different inputfields in ipython. Why not put all the code in one input field? I wrote my code of the makeyourownneuralnetwork in one input field and it worked also.
Hi Tariq!
I'm enjoying your book! I just purchased it on Kindle so I assume I have the most up to date version. I'm about half of the way through, and I'm taking detailed notes on my experience, working through the examples. I have some editorial ideas for improvements. Would you like me to submit my findings to you? I do technical documentation for a living, so it may help by serving as a free, technical, editorial review for future versions of your book.
Best,
-Alexander Doak
hi
thanks for writting this sweat book,
i want to save the final weight of the neural network ,wih and who, but i am new to python and ai can you help me how to do this.
i try to save the weight but got some numbers but they does not make sense even.
Hi,
After training, I tried to save n (object of class neuralNetwork) with pickle but cannot reuse after saved!
Do you have any idea how to do reuse after training?
Many thanks for considering my request !
Hi, I'm interested in translating and publishing your book in Korea.
Send me an email or let me know your email and then we'll talk further.
You can contact me via [email protected].
Thank you.
used hideen instead of hidden in definition of backquery. This may be in other instances of the notebook.
Just as a reminder:
(because 37 is already closed and I don't know you still got reminder(s) to take a look at it)!
Hi,
Instead of running inside notebook, I typed in all the code to a straight Python file b/c I wanted to understand it all.
I had to change makeyourownneuralnetwork/part2_neural_network_mnist_data.ipynb, line 237 from:
print ("performance = ", scorecard_array.sum() / scorecard_array.size)
to:
print ("performance = ", scorecard_array.sum() * 1.0 / scorecard_array.size)
I'm not a Python expert, I'm sure there's a more elegant way to do this.
But, much more important, if the Notebook code does not need this coercion, this means that "Notebook Python" is subtly different from "CLI Python" !!
A More sophisticated weight initialization method is sample the weights from a normal probability distribution centered around zero and with a standard deviation that is related to the number of incoming links into a node. The implementation code is
self.wih= numpy.random.normal(0.0, pow(self.hnodes, -.5), self.hnodes, self.inode))
However, I think the code should be
self.wih= numpy.random.normal(0.0, pow(self.inodes, -.5), self.hnodes, self.inode))
because self.inode is the incoming links.
Do I understand it correctly?
Hello, (in below example for number 2 and 3)
in attach, you can see the original pictures I took with my smartpone (1512x1512 pixels).
Then I converted them to 28x28 pixels and saved in png format.
But as you can see the network doesn't guess the correct label :-(
I trained the network with the training_set (60000 examples).
As you can also see the 28x28 pixels figures are more flew but still you can correctly see the contours of the numbers.
Maybe when hou converte from 1512x1512 to 28x28 there's become to much noice arround the contours?
Is that the reason my network doesn't recognized the numbers? Is there a way to filter out the noise or can making pictures in less quality help?
Thanks for the answer,
[


](url)
_If we come back to our training, we need to run the notebook up to the point just before training. That means running the Python code that sets up the neural network class, and sets the various parameters like the number of input nodes, the data source filenames, etc.
We can then issue n.load() in a notebook cell to load the previously saved neural networks weights back into the neural network object n._
Question
How does the network known once loading the n.load() weights on which itteration step (meaning line in data set or epoch cycle) the training should continue?
In previous question I asked also how to save the weights from a fully trained network, but here too, how does the network known once the n.load() method has executed the network has been fully trained?
In the query() and train() functions, the inputs_list has a 1.0 bias constant input prepended or appended to it.
What means prepended and appended
How do you have to code this?
Hello,
even converting a picture from let's say 37K converting to a 28x28 pixel give's to much noise to let recognize the neural network the numbers correctly.
As last test did I not tested my own handwriting (because of too much noise when converting from lets say a 100x100 pixel number to a 28x28 pixel but I wrote directly in paint some numbers in 28x28 pixel format and tried to let recognize the neural network those numbers.
Eventhough here the success rate is zero too :-(
But can you tell why those numbers (see attach) are not recognized this time?
Second question, how do you succeed to convert from let's say a 37K picture to a 28x28 picture without too many noise?
[


](url)
My NN doesn't work on my own images, even when I get it to maximum accuracy(97.33%).
When I draw my images in GIMP, I start by creating a 28x28 canvas so I dont have to compress it.
Instead of scipy.misc.imread(image_file_name, flatten=True)
I have to use skimage.io.imread(image_file_name, as_grey=True) because scipy.misc is deprecated.
Is there too much noise? Is that the problem?
Order for my own images is:
my_own_3.png
my_own_4.png
my_own_6.png
my_own_7.png

suppose a network of 3 input nodes and 4 hidden layer nodes(first hidden layer), so the dimension of W is 4x3 . and W(4,1) is the link between the first input node to the fourth hidden layer. But in the book , W(4x3) refers to the link between the fourth input node to the first hidden layer. Is there something wrong OR am i mistaken?
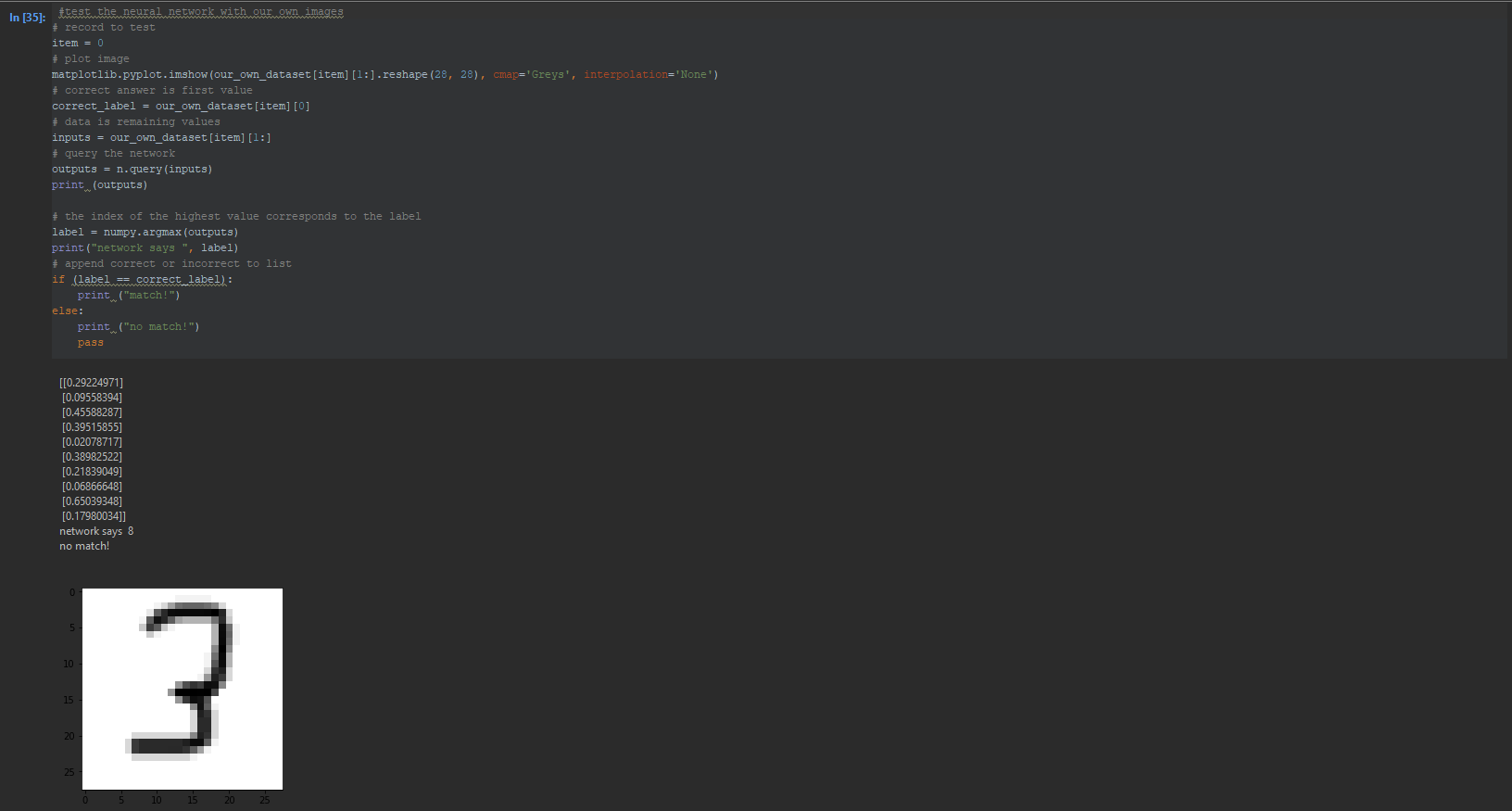
Hello,
in the code part 'test the neural network' I put code to print also my number the network has to guess (the images itself)
_# test the neural network
_# scorecard for how well the network performs, initially empty
scorecard = []
_# go through all the records in the test data set
for record in test_data_list:
# split the record by the ',' commas
all_values = record.split(',')
# correct answer is first value
correct_label = int(all_values[0])
print(correct_label, "is correct label")
image_array = numpy.asfarray(all_values[1:]).reshape(28,28)
matplotlib.pyplot.imshow(image_array, cmap='Greys',interpolation='None')
# scale and shift the inputs
inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
# query the network
outputs = n.query(inputs)
# the index of the highest value corresponds to the label
label = numpy.argmax(outputs)
print(label, "network's answer")
# append correct or incorrect to list
if (label == correct_label):
# network's answer matches correct answer, add 1 to scorecard
**scorecard.append(1)**
else:
# network's answer doesn't match correct answer, add 0 to scorecard
scorecard.append(0)
pass
pass
However when I run the code only the last record is printed as an image. But the code is put into the loop. How comes only my last record of the test set has been printed? See attach!

`# test the neural network
scorecard = []
for record in test_data_list:
# split the record by the ',' commas
all_values = record.split(',')
# correct answer is first value
correct_label = int(all_values[0])
# scale and shift the inputs
inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
# query the network
outputs = n.query(inputs)
# the index of the highest value corresponds to the label
label = numpy.argmax(outputs)
# append correct or incorrect to list
if (label == correct_label):
# network's answer matches correct answer, add 1 to scorecard
scorecard.append(1)
else:
# network's answer doesn't match correct answer, add 0 to scorecard
scorecard.append(0)
pass
pass`
After writing code on test set it says:
ValueError: shapes (200,784) and (342,1) not aligned: 784 (dim 1) != 342 (dim 0)
Can you help fix it?
IndexError Traceback (most recent call last)
in ()
1 item = 2
----> 2 matplotlib.pyplot.imshow(our_own_dataset[item][1:].reshape(28,28), cmap='Greys', interpolation='None')
3 correct_label = our_own_dataset[item][0]
4 inputs = our_own_dataset[item][1:]
5 outputs = n.query(inputs)
IndexError: list index out of range
The [item] is giving me an index error. Please, can someone help me fix this?
Hi Tariq,
I really like your book. Thanks.
Can you help me please? I'm new to Python and I get the following error when I try to run the code:
FileNotFoundError Traceback (most recent call last)
in ()
1 # load the mnist test data CSV file into a list
----> 2 test_data_file = open("mnist_dataset/mnist_test_100.csv", 'r')
3 test_data_list = test_data_file.readlines()
4 test_data_file.close()
FileNotFoundError: [Errno 2] No such file or directory: 'mnist_dataset/mnist_test_100.csv'
Thank you,
Kate
Hello,
I do not understad the part:
inputs = numpy.array(inputs_list, ndmin=2).T
Will it automatically converted in a two dimensional 28x28 array.
But in the inputs_list you still have also the label no?
Hi Rashid,
can you recommend a book (i)python used to create a neural network?
Hello Rashid,
I see you made a separate blog to describe and how to adapt your current code for how to save your network.
Is it possible to do the same for how to adapt and use your network with bias as well in input as hidden layer?
Thank you very much,
Gerrit
Will the code also run when I should only make use of python (anaconda)? In stead of using Ipython?
This is regarding the above file.
On line In [75], the code gives an error "TypeError: Image data can not convert to float". Please help me get through this error.
Sorry, I can't find your email in the ebook, so if I can ask here :):
P/S: you know what, during asking this, I think I just solve the thing, but it much worth pointing out:
It a bit blurry on page 93 to the rest of the chapter, I'm working on it, on page 95:
Page 95, I will assume that:
(E/O)' = -2.(T - O) // but why?
I think I just solve it:
On some previous page, we do agree E function is (target - output)^2 or ( T - O )^2, so:
[ (T-O)^2 ] ' = [ T^2 -2.T.O + O^2 ] ' // and we differential by O, also T is a constant, so we will have
= 2.O - 2.T = -2.(T-O) // Am I correct?
But why you skip this, if this is a homework, then must have a link or the answer somewhere 👎
@makeyourownneuralnetwork
I'm wondering, can you send the numbers you create your own via attach or via mail?
I'd like to experiment also with those.
It's a pritty that it is so hard to create 28x28 pixels images because of that low pixel rate.
A picture taken with a modern smartphone or camera is soon 1 Mbyte and more and if you want to convert to 28x28 the noise becomes really a lot.
Even if you do it eg with paint, you can define the area as 28x28 but that is so small area you can hardly drawn a number (see my last images) :-( a sent few post agoo.
Hi Tariq, in your notebooks, you refer to the data sets as mnist_train.csv and mnist_test.csv, but the files in mnist_dataset are named differently, as they are subsets of the original data. Should the notebooks use the subset or the full CSV files should be downloaded?
I am really impressed with the literary and technical content of your book. Even the style you use for your graphics and equations is inspired - a work of art.
Two issues:
Thanks again for a really wonderful introduction to neural nets.
Hi, first of all I want to mention this is a great book and good reading.
Though when running the code I run into some trouble.
I set up a docker ubuntu image, so I'm not running the code with the notebook but manually from console. It seems that there is a problem with numpy's array class. I doesn't matter whether i run it with python3 or python 2.7 --> same issue
When running the code i get the following issue (numpy 1.13). Could you give any hint how to solve this?
python3 neuralNetwork.py Traceback (most recent call last): File "neuralNetwork.py", line 141, in <module> main() File "neuralNetwork.py", line 105, in main n.train(inputs, targets) File "neuralNetwork.py", line 38, in train inputs = numpy.array(inputs_list, ndim=2).T TypeError: 'ndim' is an invalid keyword argument for this function
Source code attached as txt file, since it breaks formatting.
I get error:
TypeError: Cannot cast array from dtype('float64') to dtype('S32) according to rule 'safe'
on the line:
hidden_inputs = numpy.dot(self.wih, inputs)
in method "query"
on training set:
mnist_train_100.csv
Hello,
probably one of my last questions I have about this book "Make your own neural network" !
In most lecture about neural networks (even about image or label recognition) they talk also about a bias.
So a bias node will be foreseen in input and hidden nodes.
How comes, in this example no bias has been used and still the performance is very high?
What I understand is a bias will never change (even the weights connected to that bias) during the learning cycle of the
neural network. Let's say you want make use of a bias (in the input layer and hidden layer) in your example, how will this influence the code and result, because as if
I understand now, within each itteration or learning cycle, here all the nodes and weights will be adapted?
Hello, I just recently got access to a HPC where I can get large amounts of resources for programs. Recently the HPC started to implement Jupyter-notebooks. Considering that training these neural nets can be quite resource-heavy, how can I make the code work with Message Passing Interface(MPI)?
Hello @makeyourownneuralnetwork ,
somewhere in your book you described the output as function.
You described 3 chooses.
error = target - output
error = |target - output|
error = (target - output)^2
As for several reasons (I will not repeat here) the best choise you can take is the last one.
However in your code you use output_errors = targets - final_outputs
why not error = (target - output)^2 ? And can't we improve the performance of the network by coding error = (target - output)^2
hello Rashid,
one more question.
If we use the training_100 set we have a performance arround 0,6 a 0,7.
But can we improve the learning of the neural network when we keep using the training_100 set but in stead increasing
the epochs to let's say 1000 in stead of 5.
So in stead of incrementing the cycles by making use of bigger training examples, make less use of training examples but
increase the epochs?
Hi,
Thanks for the material. Why are the Hidden Nodes take as 200 ?
I'm aware this is hardly the right place to post this issue, but I'm eager to get back to reading this great book:
I bought the Kindle version on Amazon, and the URL links on pages 132+133 (and possibly more?) don't work. Don't know if it's a limitation of the Kindle software or not, but regardless, a footnote with the verbatim URL wouldn't hurt.
Thanks for this book, I'm finally starting to have the pieces fall into place!
However I can't run this example. When I run it, I've got a message:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-11-54d918467417> in <module>()
6
7 # use the filename to set the correct label
----> 8 label = int(image_file_name[-5:-4])
9
10 # load image data from png files into an array
ValueError: invalid literal for int() with base 10: 'e'
Everything looks fine after that but at the end the code tells
('network says ', 6)
no match!
oh sorry I made a wrong question
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.