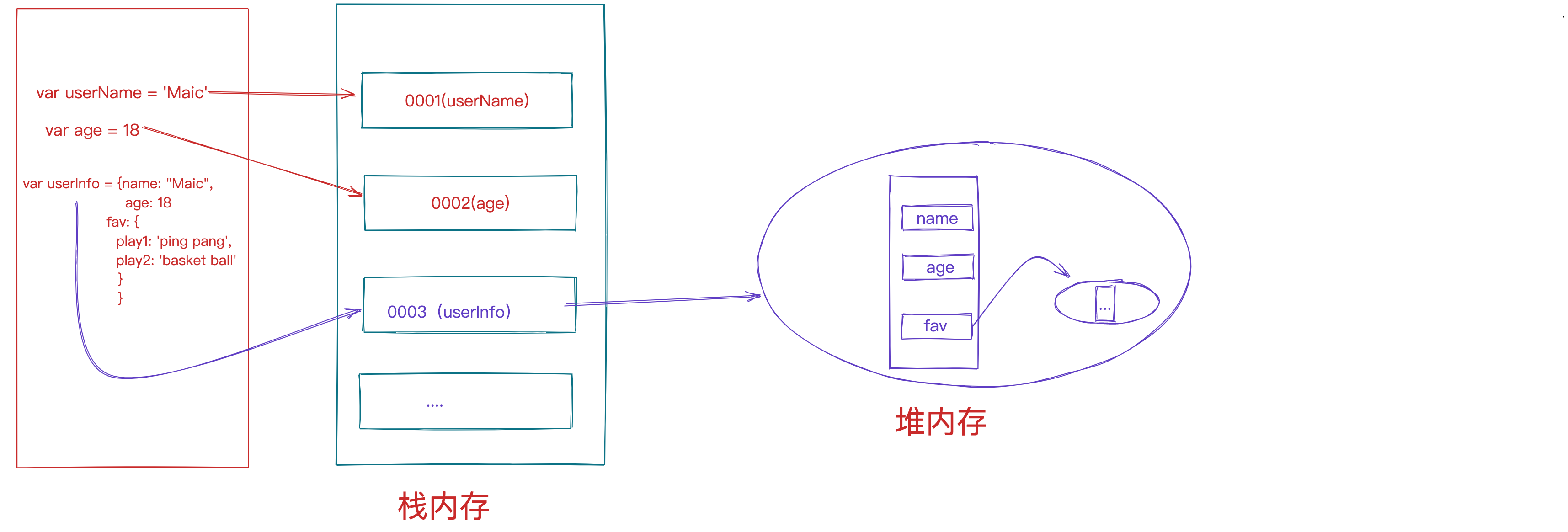
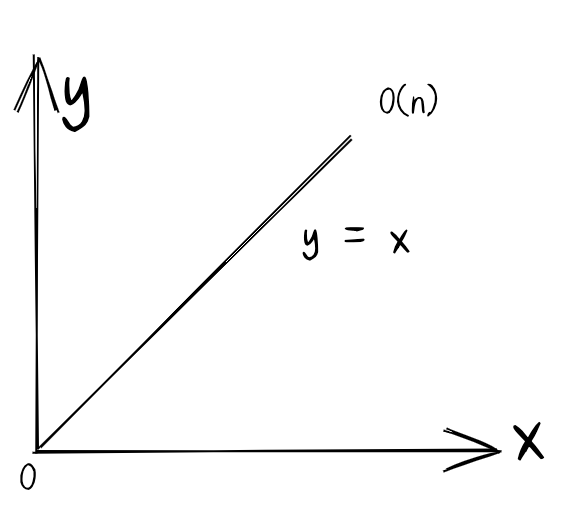- 好看影视
- web技术学学苑-uni-app版
- web技术学苑-uni-小程序
JS学习笔记
































绝大部分生产项目都是基于
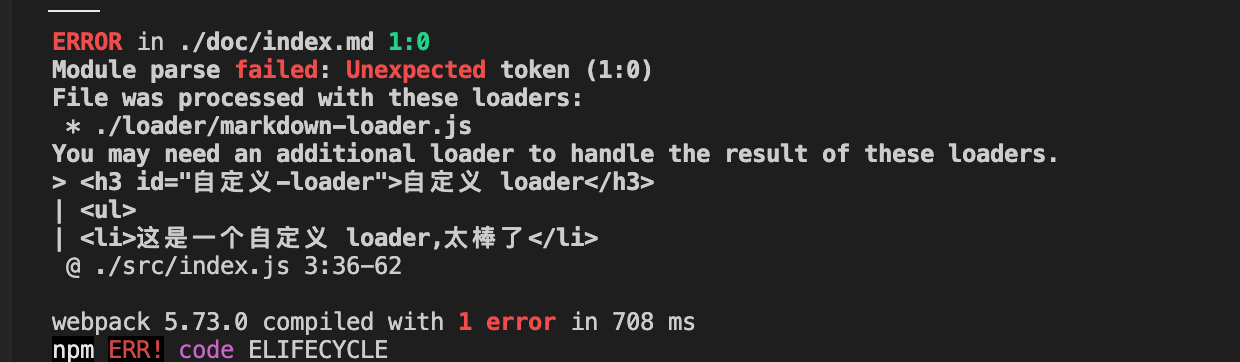
cli脚手架创建一个比较完善的项目,从早期的webpack配置工程师到后面的无需配置,大大解放了前端工程建设。但是时常会遇到,不依赖成熟的脚手架,从零搭过项目吗,有遇到哪些问题吗?或者有了解loader和plugin吗?如果只是使用脚手架,作为一个深耕业务一线的工具人,什么?还要自己搭?还要写loader,这就过分了。
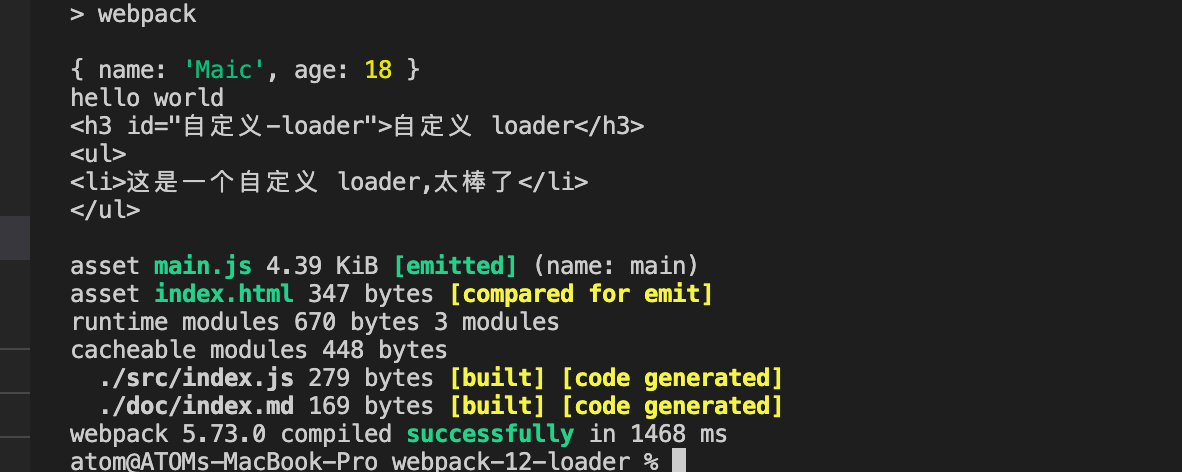
正文开始...
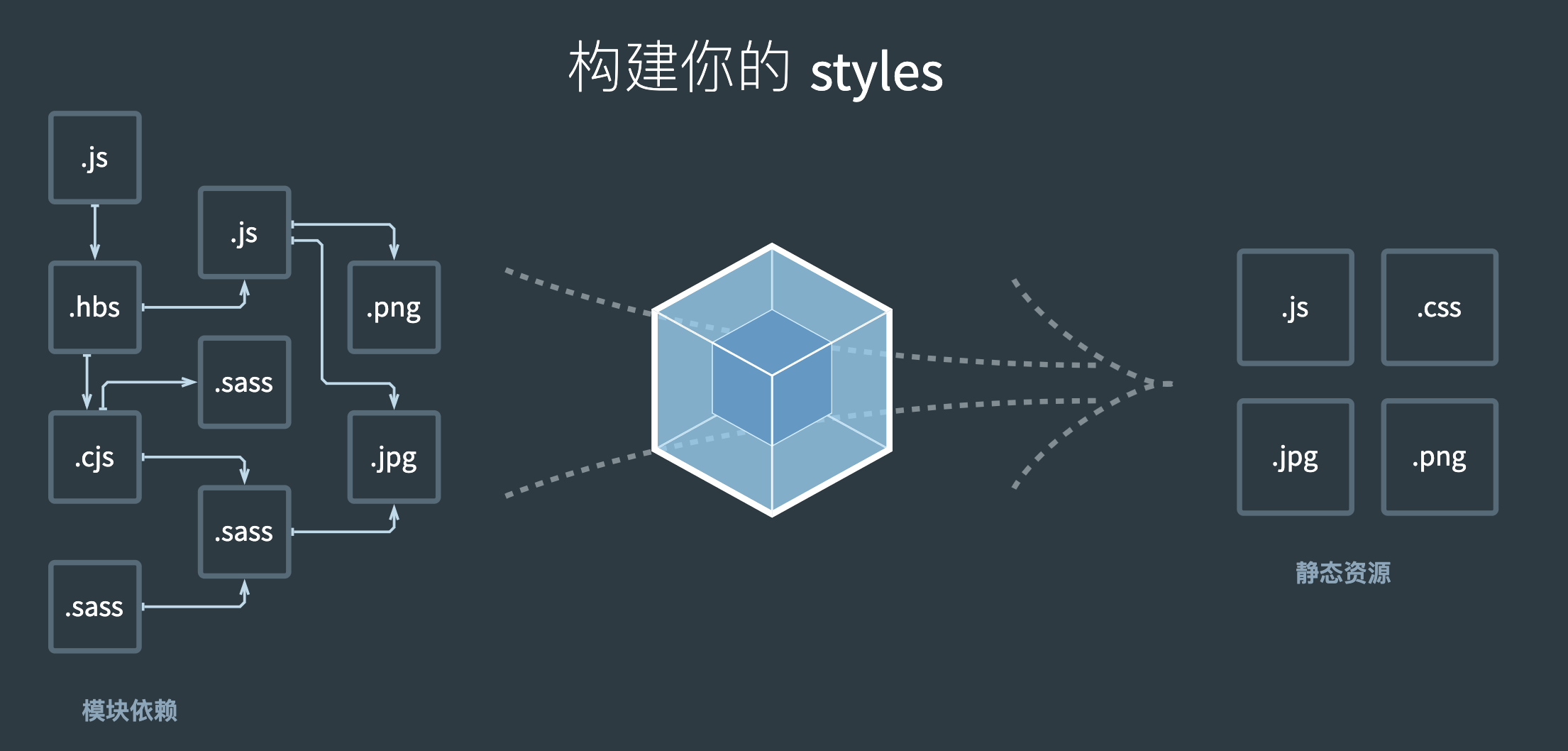
我们先了解下webpack能干什么
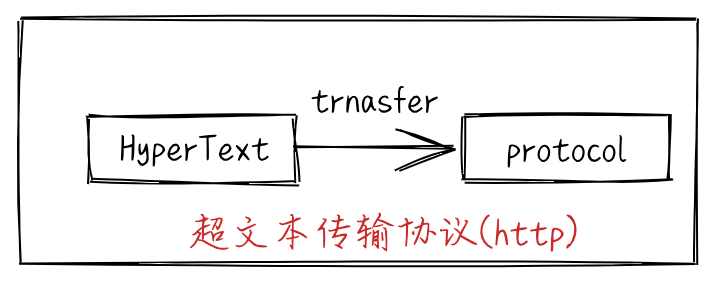
webpack是一个静态打包工具,根据入口文件构建一个依赖图,根据需要的模块组合成一个bundle.js或者多个bundle.js,用它来展示静态资源
关于webpack的一些核心概念,主要有以下,参考官网
1、entry入口(依赖入口文件,webpack 首先根据这个文件去做内部模块的依赖关系)
// webpack.config.js
module.exports = {
entry: './src/app.js'
};
// or
/*
// 是以下这种方式的简写 定义一个别名main
module.exports = {
entry: {
main: ./src/app.js'
}
}
*/也可以是一个数组
// webpack.config.js
module.exports = {
entry: ['./src/app.js', './src/b.js'],
vendor: './src/vendor.js'
};在分离应用 app.js 与第三方包时,可以将第三方包单独打包成vender.js,我们将第三方包打包成一个独立的chunk,内容hash值保持不变,这样浏览器利用缓存加载这些第三方js,可以减少加载时间,提高网站的访问速度。
不过目前webpack4.0.0已经不建议这么做,主要可以使用optimization.splitChunks选项,将app与vendor会分成独立的文件,而不是在入口处创建独立的entry
2、output输出(把依赖的文件输出一个指定的目录下)
主要会根据entry的入口文件名输出到指定的文件名目录中,默认会输出到dist文件中
const path = require('path');
// webpack.config.js
module.exports = {
entry: {
app: './src/app.js'
},
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].bundle.js'
}
};
/*
module.exports = {
entry: './src/app.js',
output: {
filename: '[name].bundle.js'
}
}
*/
// 默认输出 /dist/app.bundle.js3、module 配制loader插件,loader能让webpack处理各种文件,并把文件转换为可依赖的模块,以及可以被添加到依赖图中。其中test是匹配对应文件类型,use是该文件类型用什么loader转换,在打包前运行。
module.exports = {
module: {
rules: [
{
test: /\.less$/,
use: 'less-loader'
},
{
test: /\.ts$/,
use: 'ts-loader'
},
{
test: /\.css$/,
use: [
{
loader: 'style-loader'
},
{
loader: 'css-loader',
options: {
modules: true
}
},
{
loader: 'sass-loader'
}
]
}
]
}
};4、plugins主要是在整个运行时都会作用,打包优化,资源管理,注入环境
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
plugins: [new HtmlWebpackPlugin({ template: './src/index.html' })]
};5、mode指定打包环境,development与production,默认是production
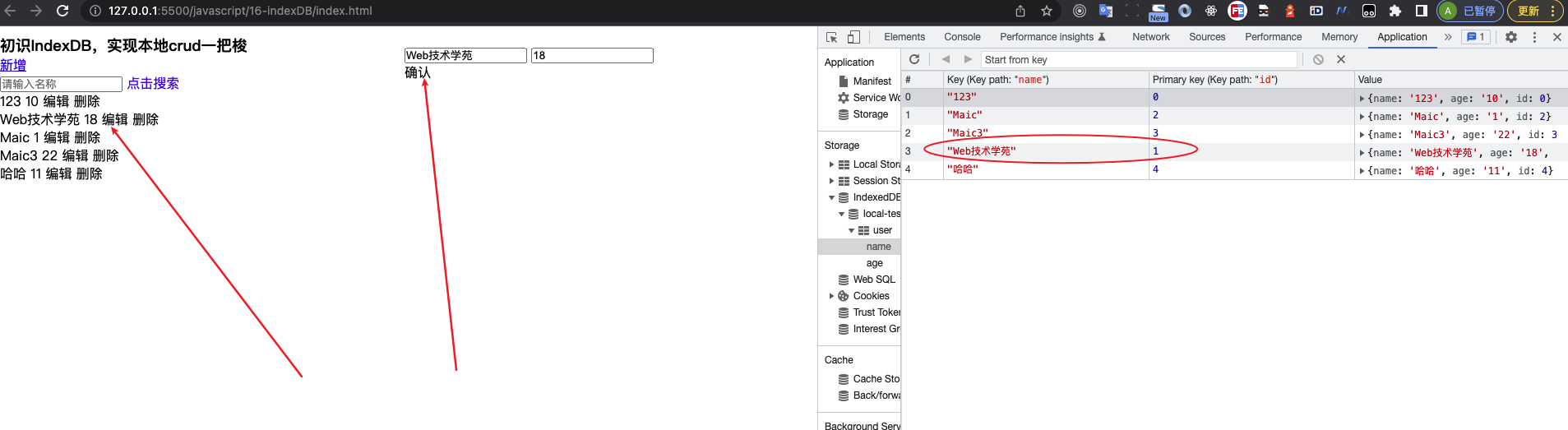
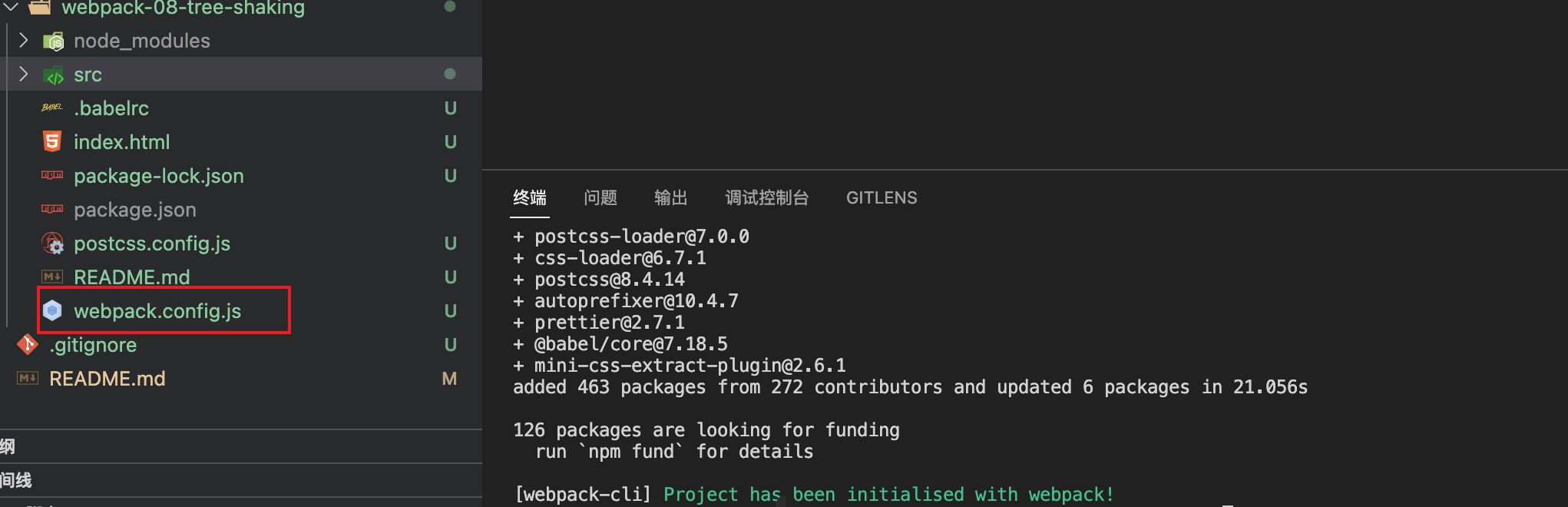
新建一个目录webpack-01,执行npm init -y
npm init -y // 生成一个默认的package.json在package.json中配置scirpt
{
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build": "webpack"
}
}首先我们在在开发依赖安装webpack与webpack-cli,执行npm i webpack webpack-cli --save-dev
在webpack5中我们默认新建一个webpack的默认配置文件webpack.config.js
const path = require('path');
module.exports = {
entry: {
app: './src/app.js'
},
output: {
filename: '[name].bundle.js',
path: path.resolve(__dirname, 'dist'),
libraryTarget: 'commonjs'
},
mode: 'production'
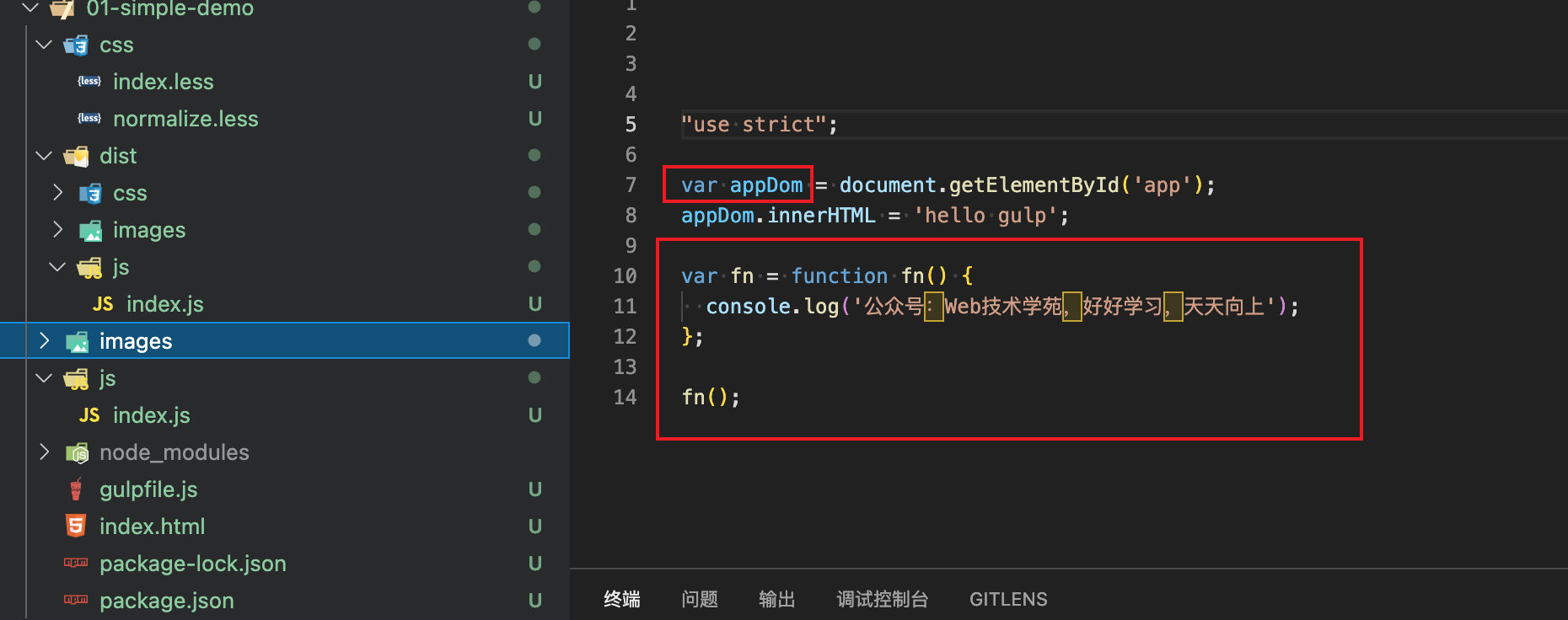
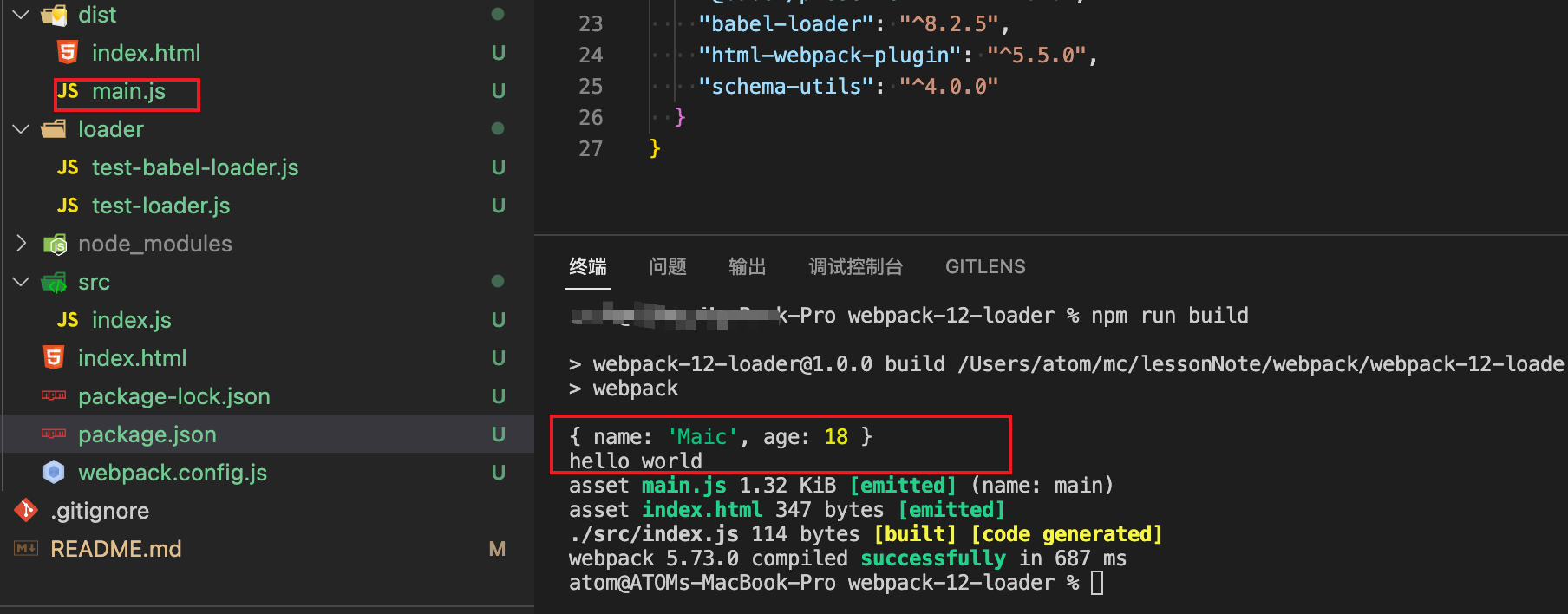
};我们在src目录下新建一个app.js并写入一段js代码
console.log('hello, webpack');在终端执行npm run build,这个命令我在package.json的script中配置
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build": "webpack",
"build:test_dev": "webpack --config webpack_test_dev_config.js",
"build:test_prd": "webpack --config webpack_test_prd_config.js",
"build:default": "webpack --config webpack.config.js",
"build:o": "webpack ./src/app.js -o dist/app.js"
},此时就会生成一个在dist文件,并且名字就是app.bundle.js
并且控制台上已经成功了
```js
> webpack
asset app.bundle.js 151 bytes [emitted] [minimized] (name: app)
./src/app.js 29 bytes [built] [code generated]
webpack 5.72.1 compiled successfully in 209 ms
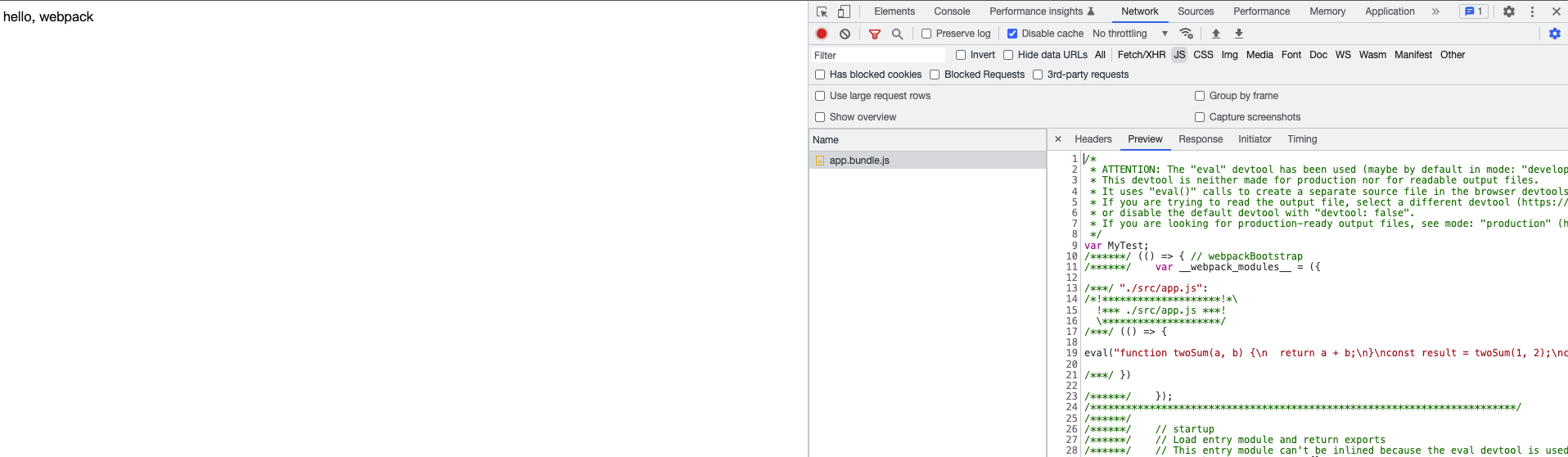
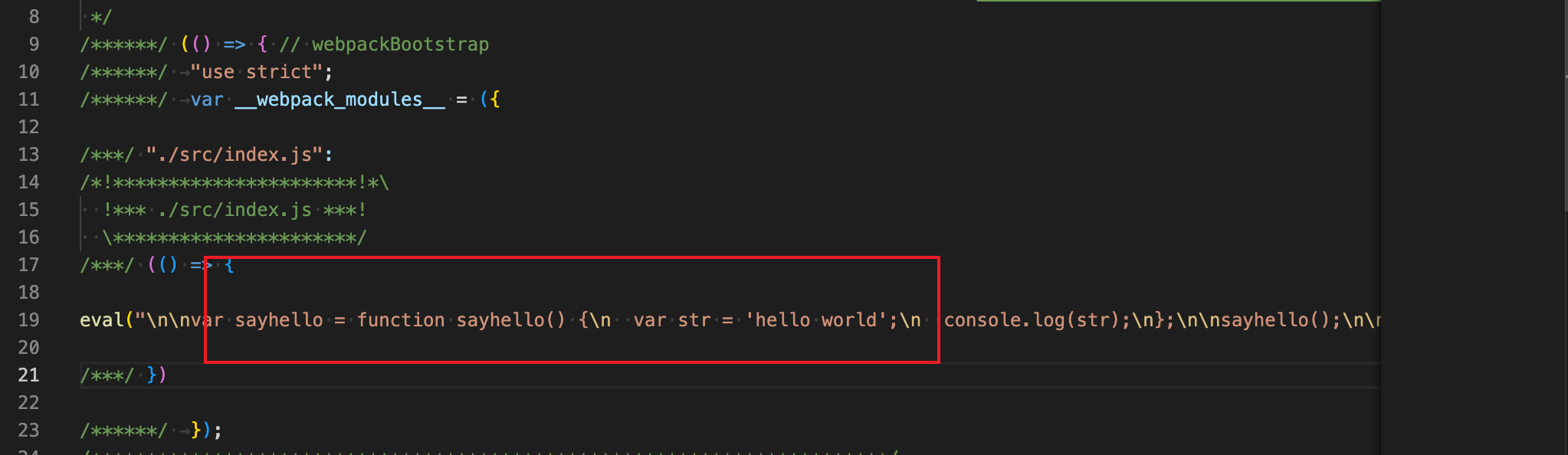
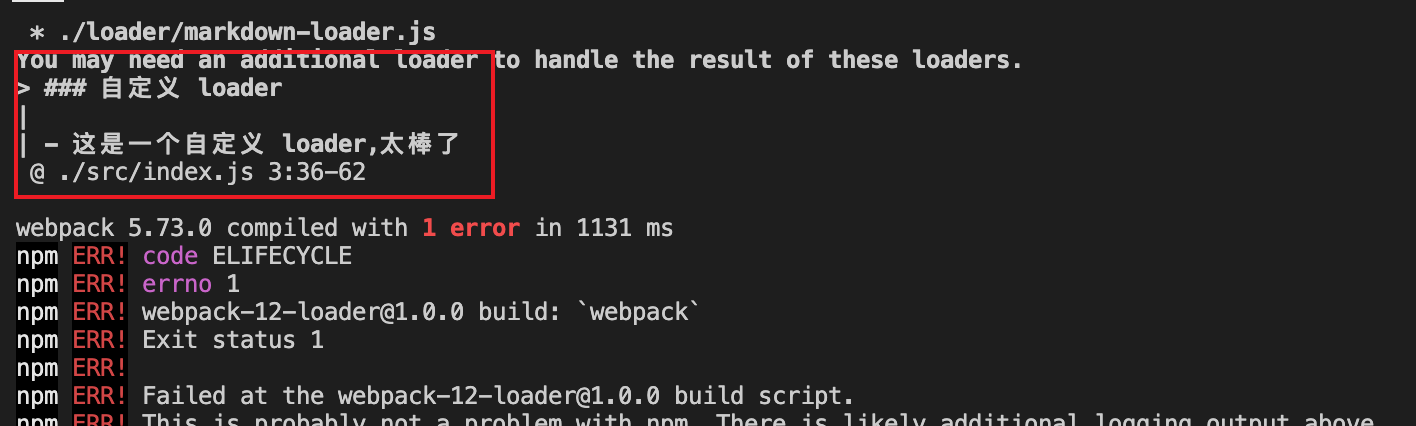
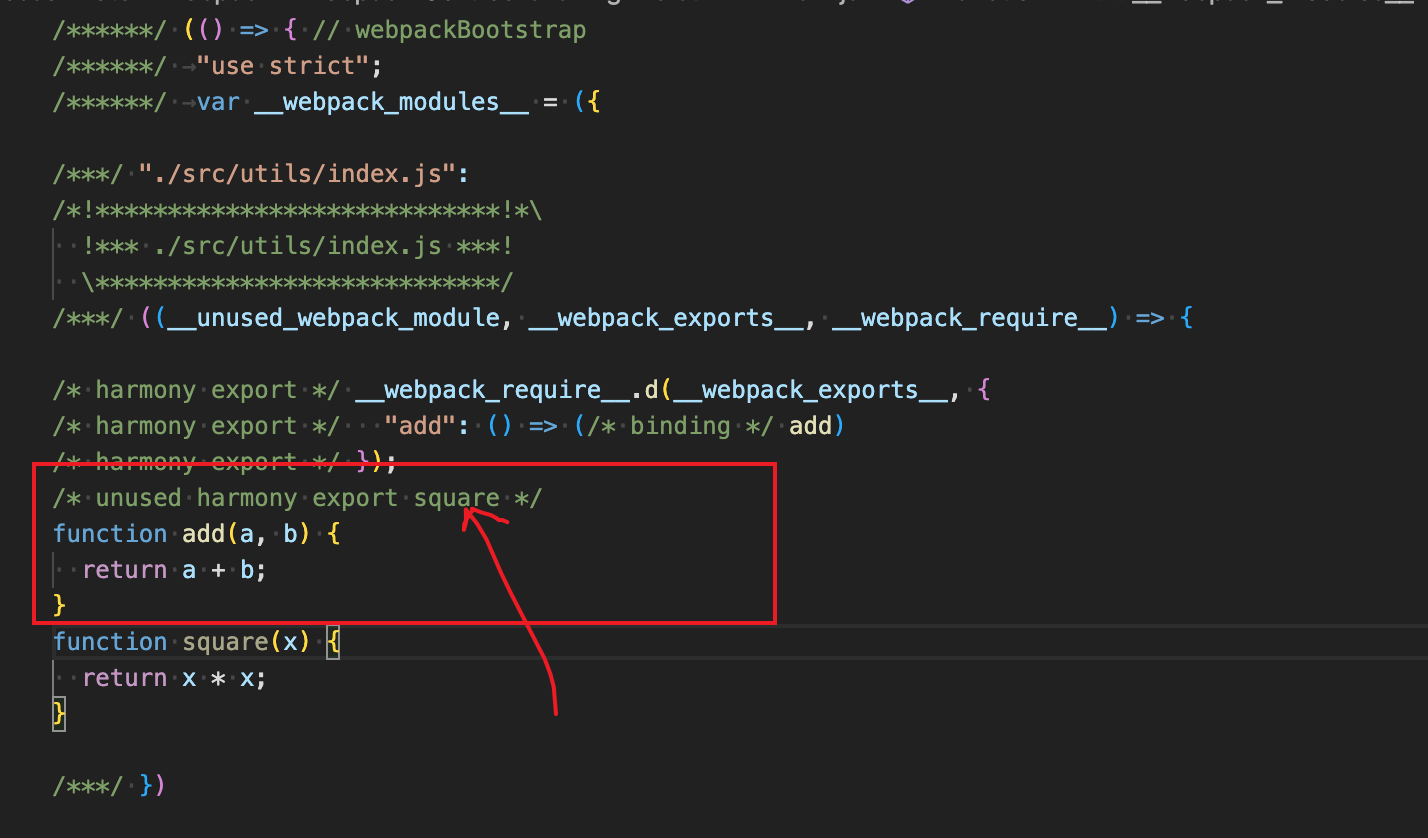
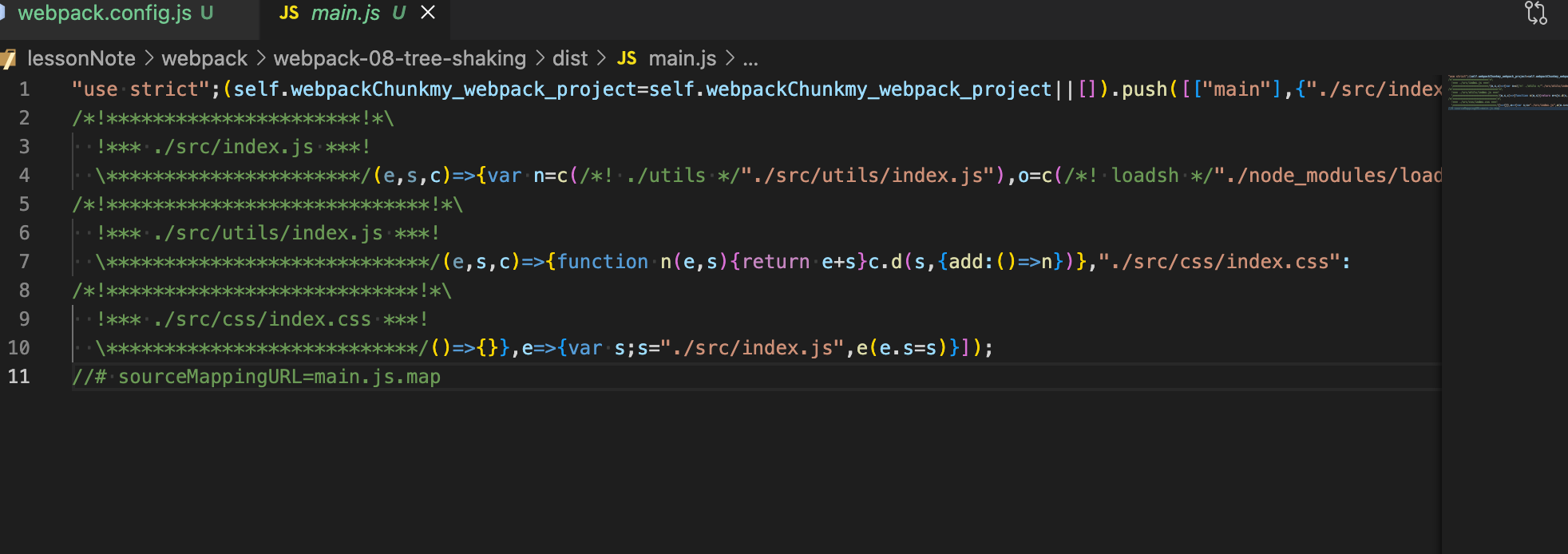
我们打开一下生成的app.bundle.js,我们发现是这样的,这是在model:production下生成的一个匿名的自定义函数。
// app.bundle.js
(() => {
var e = {};
console.log(3), console.log('hello, webpack');
var o = exports;
for (var l in e) o[l] = e[l];
e.__esModule && Object.defineProperty(o, '__esModule', { value: !0 });
})();这是生产环境输出的代码,就是在一个匿名函数中输出了结果,并且在{}上绑定了一个__esModule的对象属性,有这样一段代码var o = exports;主要是因为我们在output中新增了libraryTarget:commonjs,这个会决定js输出的结果。
我们再来看下如果mode:development那么是怎么样
// 这是在mode: development下生成一个bundle.js
/*
* ATTENTION: The "eval" devtool has been used (maybe by default in mode: "development").
* This devtool is neither made for production nor for readable output files.
* It uses "eval()" calls to create a separate source file in the browser devtools.
* If you are trying to read the output file, select a different devtool (https://webpack.js.org/configuration/devtool/)
* or disable the default devtool with "devtool: false".
* If you are looking for production-ready output files, see mode: "production" (https://webpack.js.org/configuration/mode/).
*/
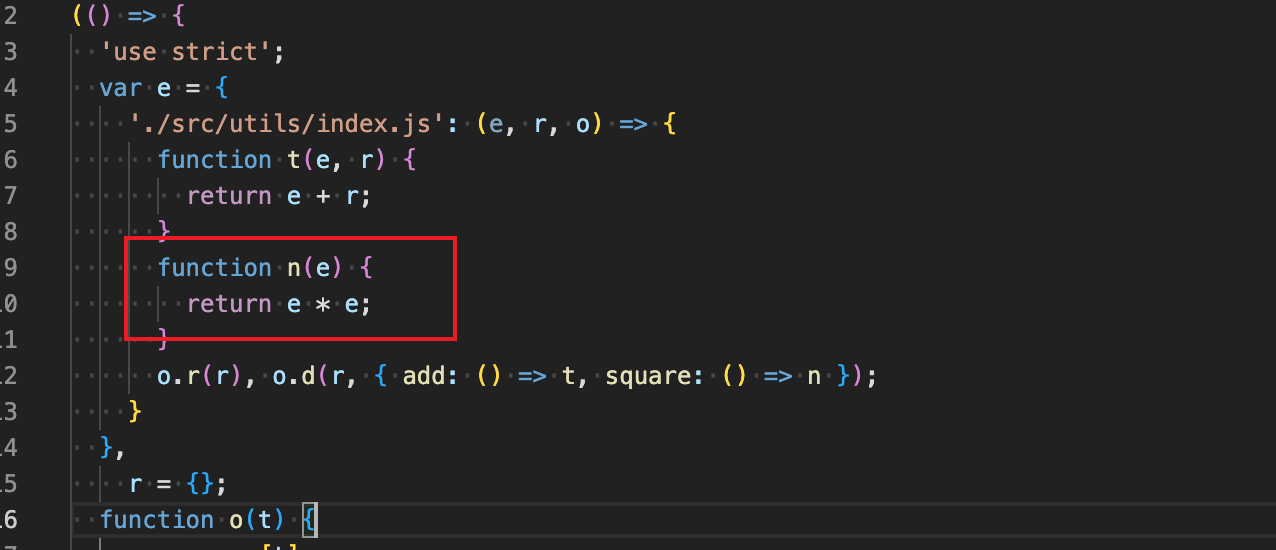
/******/ (() => { // webpackBootstrap
/******/ var __webpack_modules__ = ({
/***/ "./src/app.js":
/*!********************!*\
!*** ./src/app.js ***!
\********************/
/***/ (() => {
eval("\nfunction twoSum(a, b) {\n return a+b\n}\nconst result = twoSum(1,2);\nconsole.log(result);\nconsole.log('hello, webpack');\n\n//# sourceURL=webpack://webpack-01/./src/app.js?");
/***/ })
/******/ });
/************************************************************************/
/******/
/******/ // startup
/******/ // Load entry module and return exports
/******/ // This entry module can't be inlined because the eval devtool is used.
/******/ var __webpack_exports__ = {};
/******/ __webpack_modules__["./src/app.js"]( ""./src/app.js"");
/******/
/******/ })()
;这上面的代码就是运行mode:development模式下生成的,简化一下就是
(() => {
var webpackModules = {
'./src/app.js': () => evel('app.js内部的代码')
};
weboackModules['./src/app.js']("'./src/app.js'");
})();在开发环境就是会以文件路径为key,然后通过evel执行app.js的内容,并且调用这个webpackModules执行evel函数
注意我们默认libraryTarget如果不设置,那么就是var,主要有以下几种amd、commonjs2,commonjs,umd
通过以上,我们会发现我们可以用配置不同的命令执行打包不同的脚本,在默认情况下,npm run build与执行npm run build:default是等价的,我们会看到default用--config webpack.config.js指定了webpack打包的环境的自定义配置文件。
如果配置默认文件名就是webpack.config.js那么webpack就会根据这个文件进行打包,webpack --config xxx.js是指定自定义文件让webpack根据xxx.js输入与输出的文件进行一系列操作。
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build": "webpack",
"build:default": "webpack --config webpack.config.js",
},除了以上,我们可以不使用配置webpack --config webpack.config.js这个命令,而是直接在命令行-cli直接打包指定的文件输出到对应的文件下
"scripts": {
"build:o": "webpack ./src/app.js --output-path='./dist2' --output-filename='[name]_[hash].bundle.js'"
},会创建dist2目录并打包出来一个默认命名的main_ff7753e9dbb1e41a06a6.bundle.js的文件
我们会发现我们配置了诸如webpack_test_dev_config.js或者webpack_test_prd_config.jsz 这样的文件,通过build: test_dev与build:test_prd来区分,里面文件内容似乎大同小异,那么我可不可以复用一份文件,通过外面的环境参数来控制呢?这点在实际项目中会经常使用
我们可以通过package.json中指定的参数来确定,可以用--mode='xxx'与--env a='xxx'
"scripts": {
"build2": "webpack --mode='production' --env libraryTarget='commonjs' --config webpack.config.js"
},此时webpack.config.js需要改成函数的方式
第二参数argv能获取全部的配置的参数
// webpack.config.js
const path = require('path');
module.exports = function (env, argv) {
console.log(env, argv);
return {
entry: {
app: './src/app.js'
},
output: {
filename: '[name].bundle.js',
path: path.resolve(__dirname, 'dist'),
library: 'MyTest',
libraryTarget: argv.libraryTarget
},
mode: argv.mode
};
};因此我们就可以通过修改package.json里面的变量,从而控制webpack.config.js
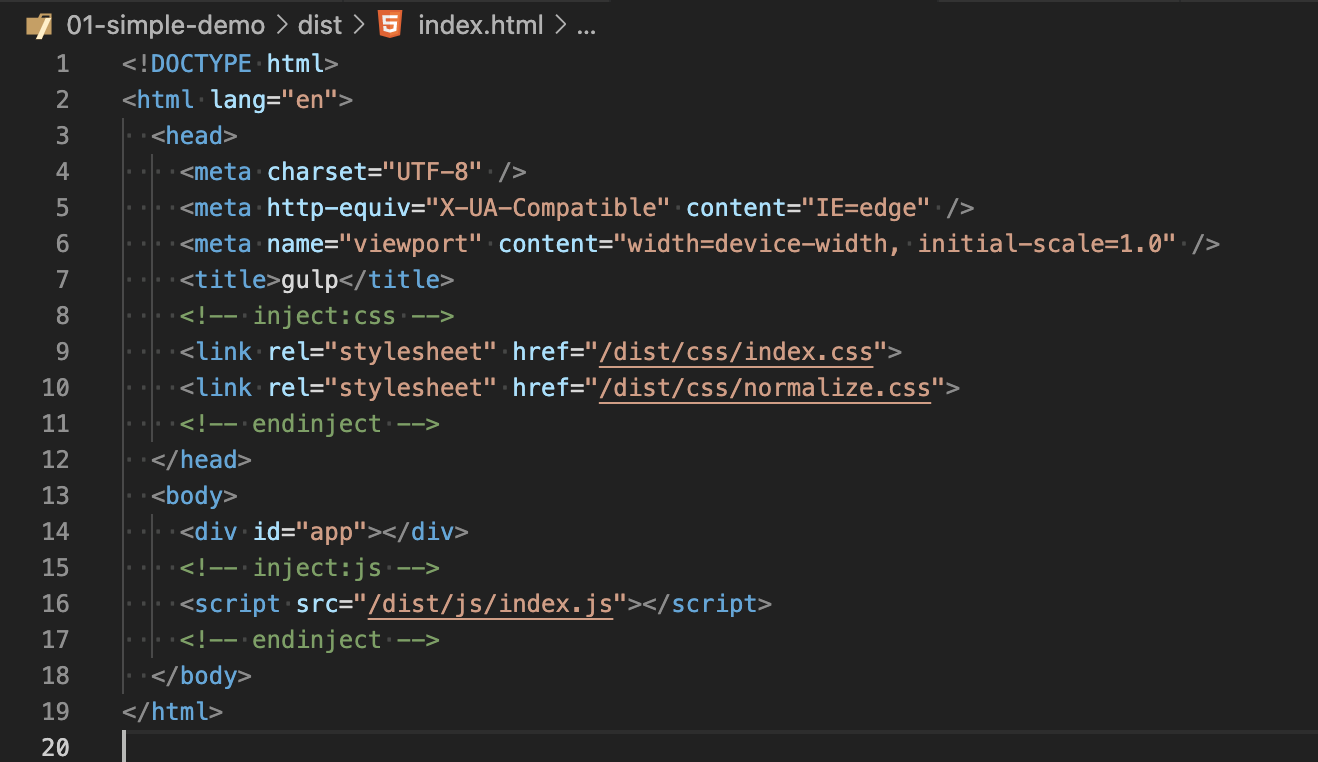
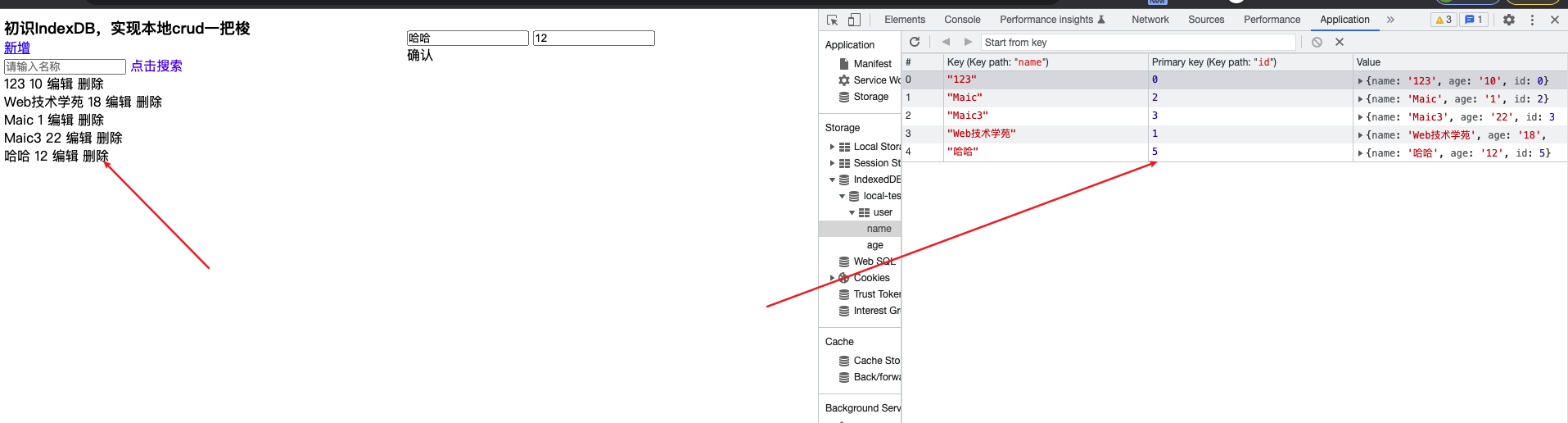
我们已经创建了一个src/app.js的入口文件,现在需要在浏览器上访问,因此需要构建一个index.html,在根目录中新建public/index.html,并且引入我刚打包的js文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>hello-webpack</title>
</head>
<body>
<div id="app"></div>
<script src="../dist/app.bundle.js"></script>
</body>
</html>终于大功告成,我打开浏览器,打开页面终于可以访问了,【我本地装了 live server】插件
但是,当我每次修改js文件,我都要每次执行npm run build这个命令,这就有些繁琐了,而且我本地是安装 vsode 插件的方式帮我打开页面的,这就有点坑了。
于是在webpack中就有一个内置cliwatch 来监听文件的变化,我们只需要加上--watch就可以了
"scripts": {
"build": "webpack --watch",
},这种方式会一直监听文件的变化,当文件发生变化时,就会重新打包,页面会重新刷新。
当然还有一种方式,就是可以在webpack.config.js中加入watch
// webpack.config.js
{
watch: true,
entry: {
app: './src/app.js'
},
}然后我们就改回原来的,将--watch去掉就行。
--watch这种方式确实提升我本地开发效率,因为只要文件一发生变化,就会重新打包编译,结合vscode的插件就会重新加载最新的文件,但是随着项目的庞大,那么这种效率就很低了,因此除了webpack自身的 watch 方案,我们需要去了解另外一个方案webpack-dev-server
我们需要借助一个非常强大的插件工具来实现本地静态服务,这个插件就是webpack-dev-server,我们常常称呼为WDS本地服务,他有热更新,并且浏览器会自动刷新页面,无需手动刷新页面
并且我们还需要引入另一个插件Html-webpack-plugins这个插件,它可以自动帮我们引入打包后的文件。当我们启动本地服务,生地文件 js 文件会在内存中生成,并且被html自动引入
我们在webpack.config.js中引入html-webpack-plugin
const path = require('path');
// 引入html-webpack-plugin
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = function (env, argv) {
console.log(env);
console.log(argv);
return {
entry: {
app: './src/app.js'
},
output: {
filename: '[name].bundle.js',
path: path.resolve(__dirname, 'dist'),
library: 'MyTest',
libraryTarget: argv.libraryTarget
},
mode: argv.mode,
plugins: [
new HtmlWebpackPlugin({
template: './public/index.html'
})
]
};
};并且在package.json中增加server命令,注意我们加了server,webpack-dev-server内部已经有对文件监听,当文件发生变化时,可以实时更新生成在内存的那个js,这个server命令就是我安装的webpack-dev-server的命令
"scripts": {
"server": "webpack server"
},控制台运行npm run server默认打开 8080 端口,已经 ok 了
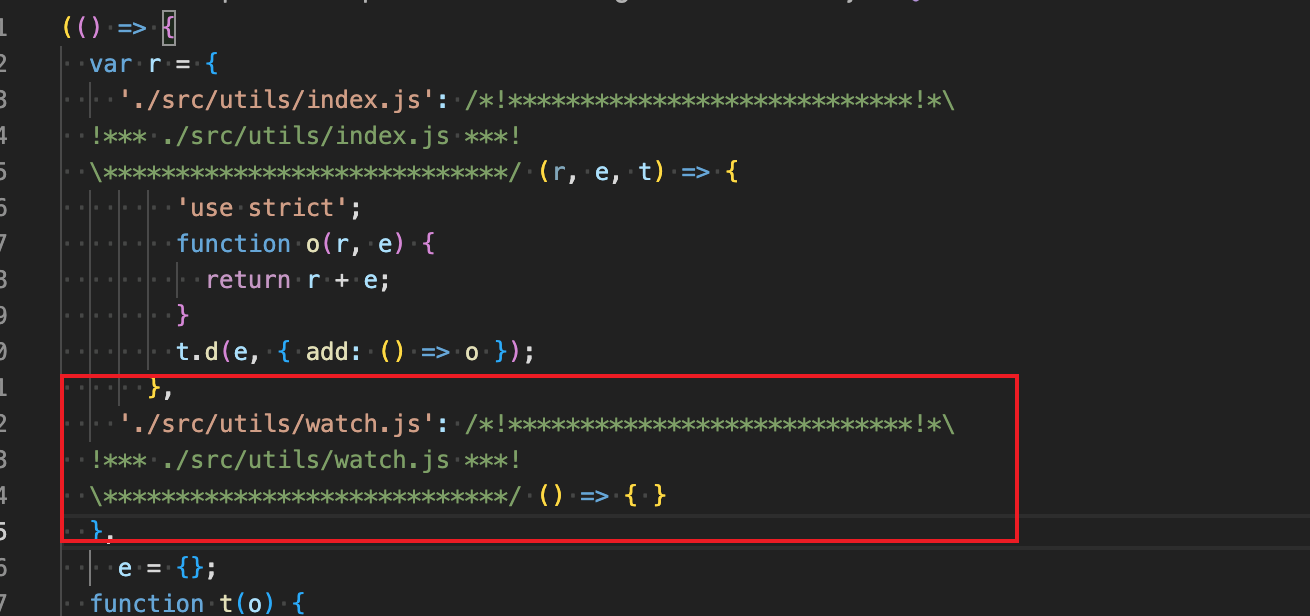
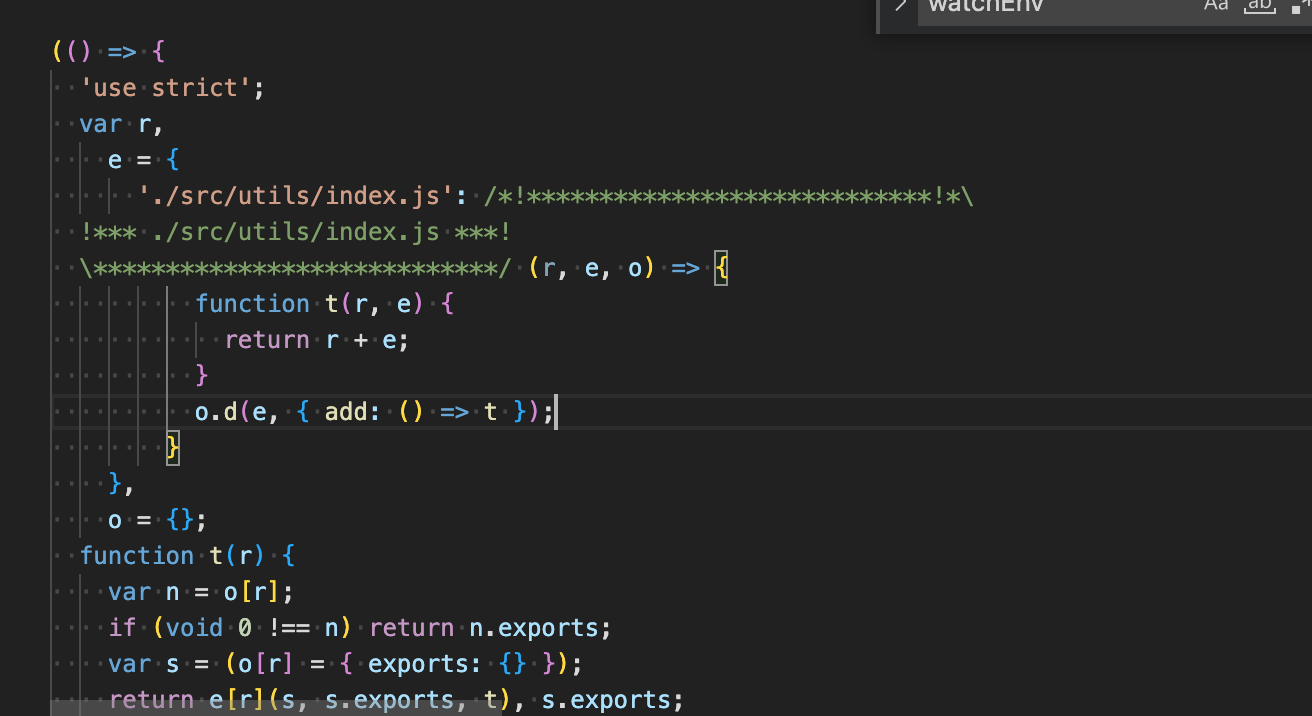
现在当我每次修改文件时,整个文件都会重新 build,并且是在虚拟内存中引入,如果修改的只是部分文件,全部文件重新加载就有些浪费了,因此需要HMR,热更新devServer hot,在运行时更新某个变化的文件模块,无需全部更新所有文件
// weboack.config.js
{
mode: argv.mode,
devServer: {
hot: true
},
}当我添加完后,发现热更新还是和以前一样,没什么用,官方这里有解释hot-module-replacement,通俗讲就是要指定某些文件要热更新,不然默认只要文件发生更改就得全部重新编译,从而全站刷新。
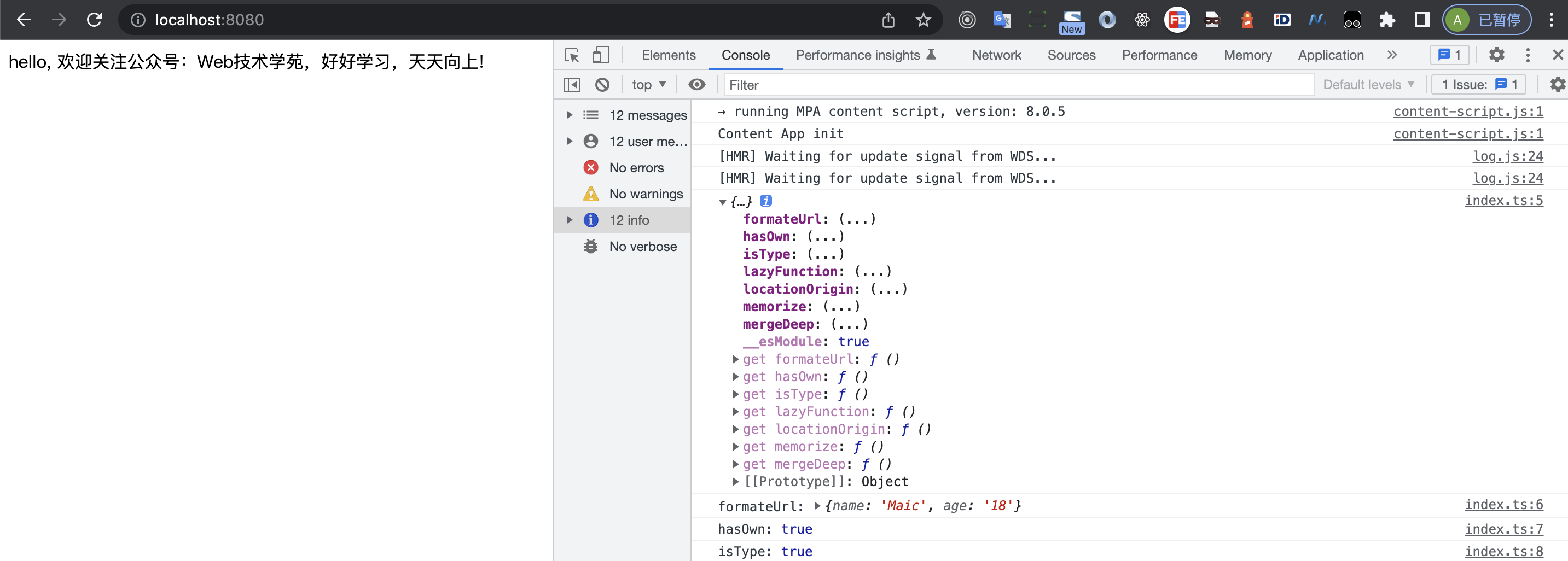
写了一段测试代码
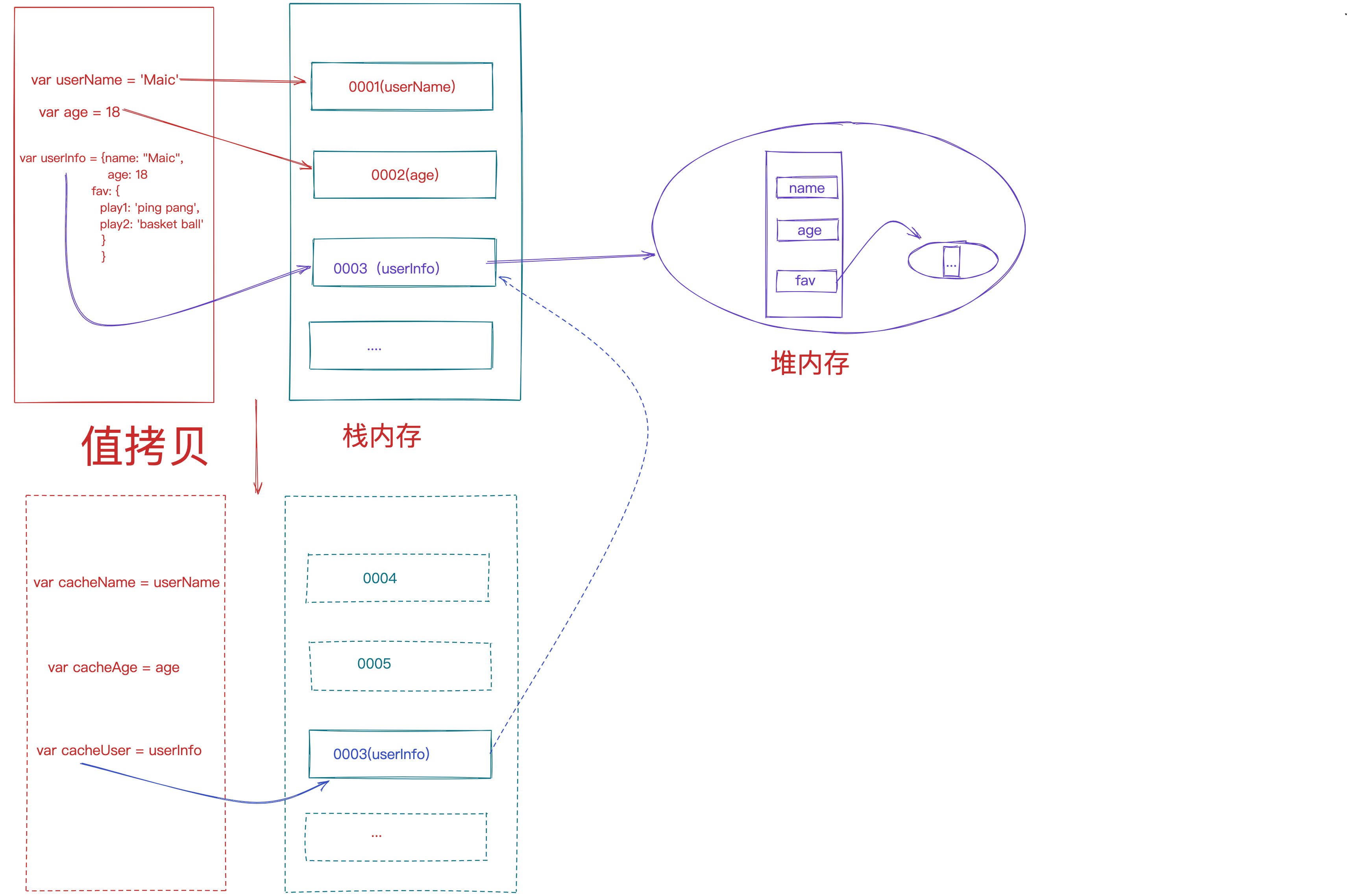
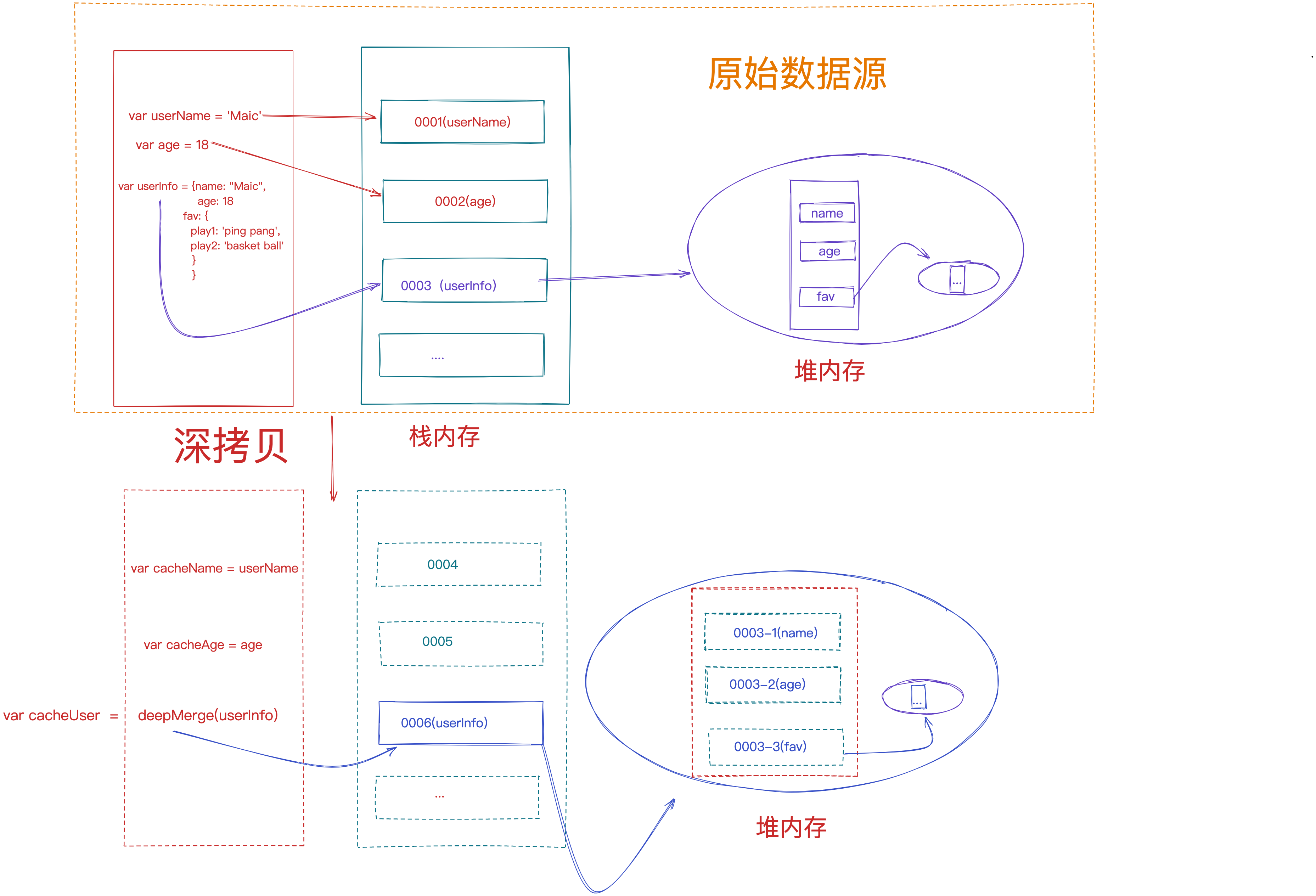
// utils/index
var str = '123';
function deepMerge(target) {
console.log(target, '=22==');
if (Array.isArray(target)) {
return target;
}
const result = {};
for (var key in target) {
if (Reflect.has(target, key)) {
if (Object.prototype.toString.call(target[key]) === '[object Object]') {
result[key] = deepMerge(target[key]);
} else {
result[key] = target[key];
}
}
}
return result;
}
console.log('深拷贝一个对象555', str);
export default deepMerge;
// module.exports = {
// deepMerge
// };在app.js中引入
import deepMerge from './utils/index';
// const { deepMerge } = require('./utils/index.js');
function twoSum(a, b) {
return a + b;
}
const userInfo = {
name: 'Maic',
age: 18,
test: {
book: 'webpack'
}
};
const result = twoSum(1, 2);
console.log(result, deepMerge(userInfo));
if (module.hot) {
// 这个文件
module.hot.accept('./utils/index.js', () => {});
}
const str = 'hello, webpack322266666';
console.log(str);
const app = document.getElementById('app');
app.innerHTML = str;注意我们加了一段代码判断指定模块是否HMR
if (module.hot) {
// 这个文件
module.hot.accept('./utils/index.js', () => {});
}这里注意一点,指定的utils/index.js必须是esModule的方式输出,要不然不会生效
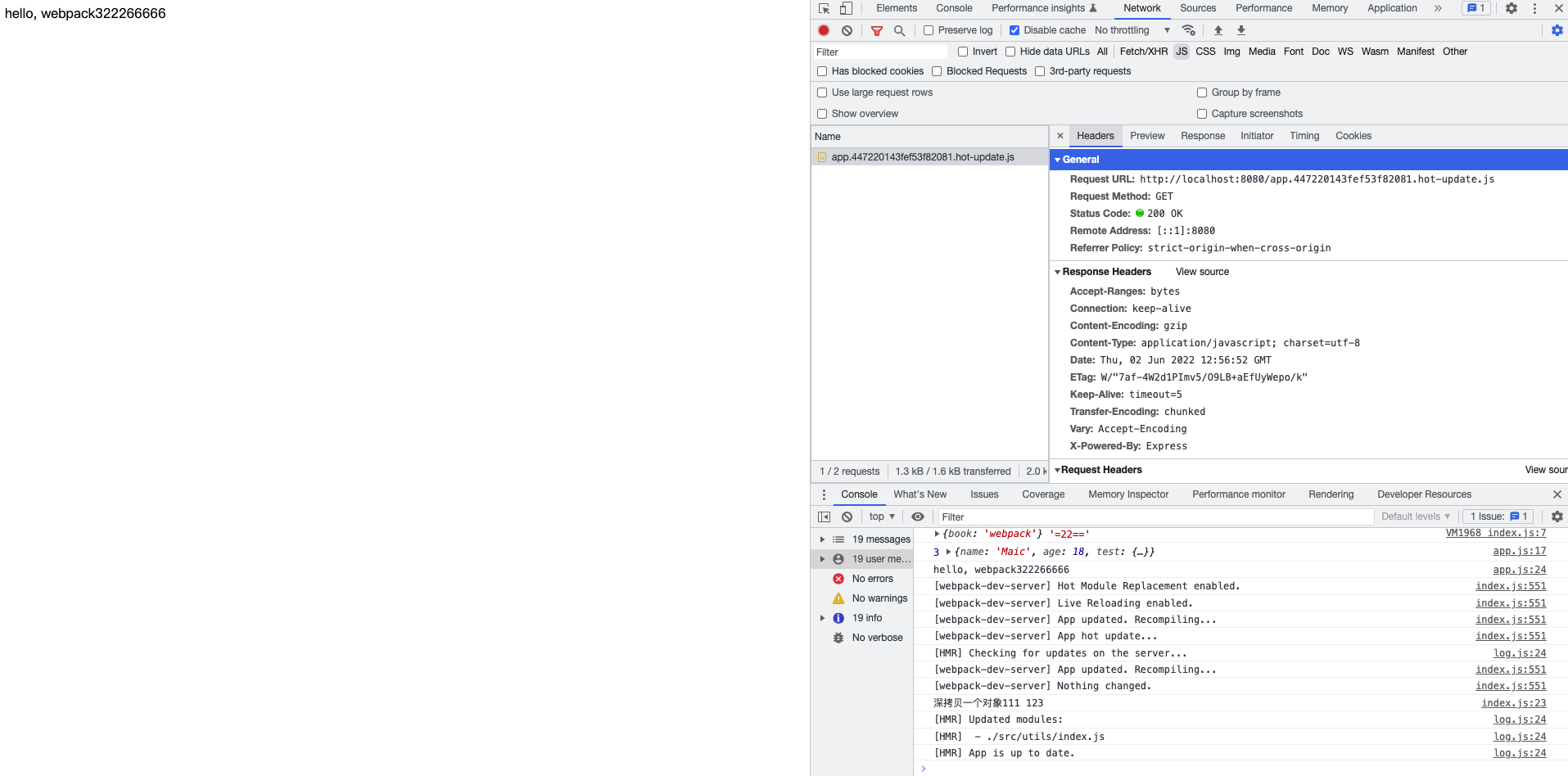
,我们会发现,当我修改utils/index.js时,会有一个请求
当你每改这个文件都会请求一个app.[hash].hot.update.js这样的一个文件。
webpack-dev-server内置了HMR,我们用webpack server这个命令就启动静态服务了,并且还内置了HMR,如果我不想用命令呢,我们可以通过 API 的方式启动dev-server,具体示例代码如下,新建一个config/server.js
const webpackDevServer = require('webpack-dev-server');
const webpack = require('webpack');
const config = require('../webpack.config.js');
const options = { hot: true, contentBase: '../dist', host: 'localhost' };
// 只能用V2版本https://github.com/webpack/webpack-dev-server/blob/v2
webpackDevServer.addDevServerEntrypoints(config, options);
const compiler = webpack(config);
const server = new webpackDevServer(compiler, options);
const PORT = '9000';
server.listen(PORT, 'localhost', () => {
console.log('server is start' + PORT);
});// config/server.js
const express = require('express');
const webpack = require('webpack');
const webpackDevMiddleware = require('webpack-dev-middleware');
const app = express();
const config = require('../webpack_test_dev_config');
const compiler = webpack(config);
// 设置静态资源目录
app.use(express.static('dist'));
app.use(webpackDevMiddleware(compiler, {}));
const PORT = 8000;
app.listen(PORT, () => {
console.log('server is start' + PORT);
});然后命令行配置node config/server.js,可以参考官网webpack-dev-middleware
npm i style-loader css-loader --save-dev配置加载 css 的loader
module: {
rules: [
{
test: /\.css$/,
use: ['style-loader', 'css-loader']
}
]
},样式是内敛在html里面的,如何提取成单个文件呢?
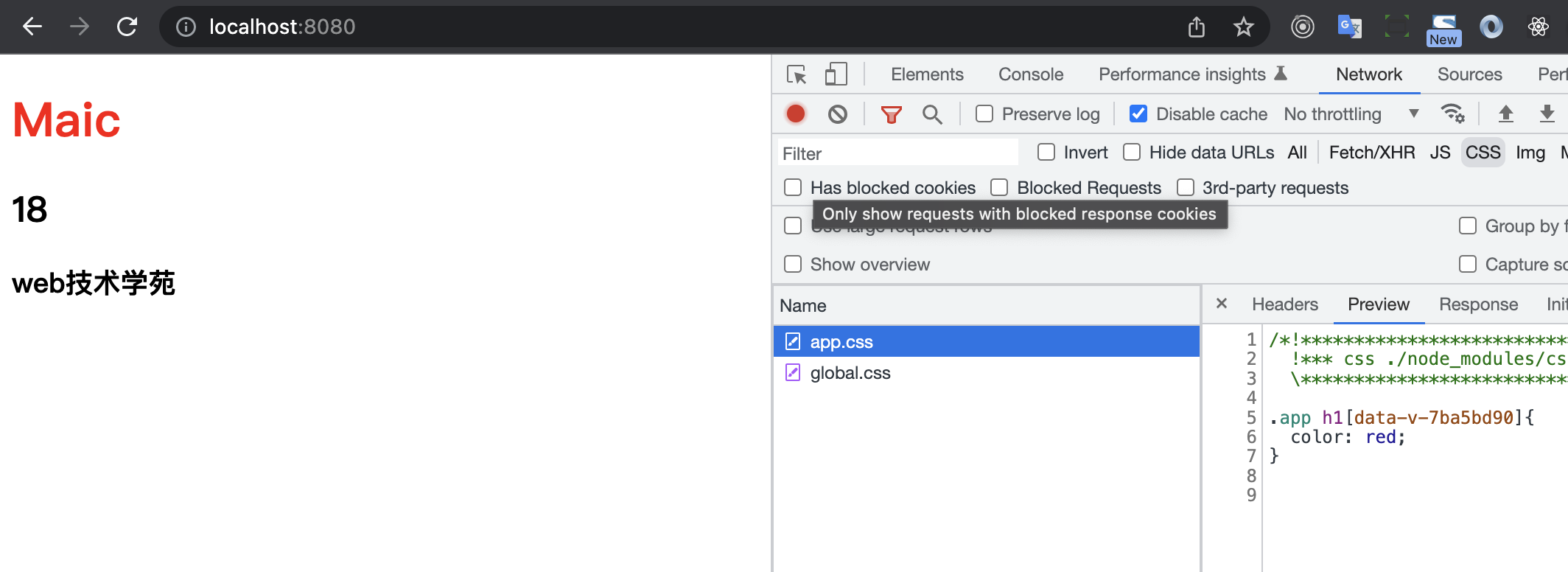
// webpack.config.js
const miniCssExtractPlugin = require('mini-css-extract-plugin');
module.exports = function (env, argv) {
return {
module: {
rules: [
{
test: /\.css$/,
// use: ['style-loader', 'css-loader']
use: [miniCssExtractPlugin.loader, 'css-loader']
}
]
},
plugins: [
new miniCssExtractPlugin({
filename: 'css/[name].css'
})
]
};
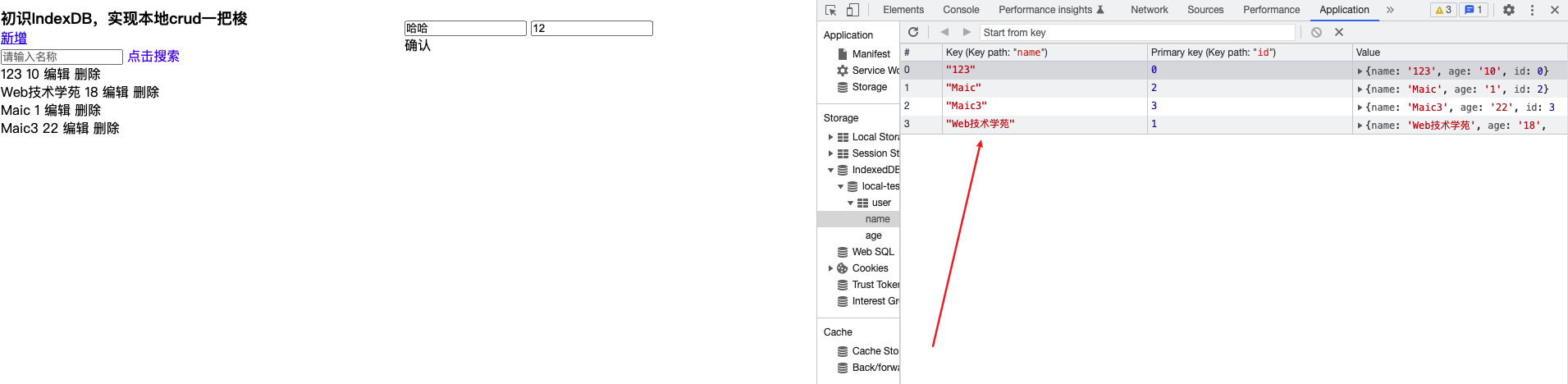
};我们把style-loader去掉了,并且换成了miniCssExtractPlugin.loader,并且在plugins中加入插件,将 css 文件提取了指定文件中,此时就会发现index.html内敛的样式就变成一个文件加载了。
我们只知道css用了css-loader与style-loader,那么图片以及特殊文件也是需要特殊loader才能使用,具体参考图片
首先需要安装file-loader执行 npm i file-loader --save-dev
// webpack.config.js
{
...
module: {
rules: [
{
test: /\.css$/,
use: [miniCssExtractPlugin.loader, 'css-loader']
},
{
test: /\.(png|svg|jpg|gif|jpeg)$/,
use: [
{
loader: 'file-loader',
options: {
outputPath: 'assets',
name: '[name].[ext]'
}
}
]
}
]
}
}可以参考file-loader,输出的图片文件可以加hash值后缀,当打包上传后,如果文件没有更改,图片更容易从缓存中获取
在app.js中加入引入图片
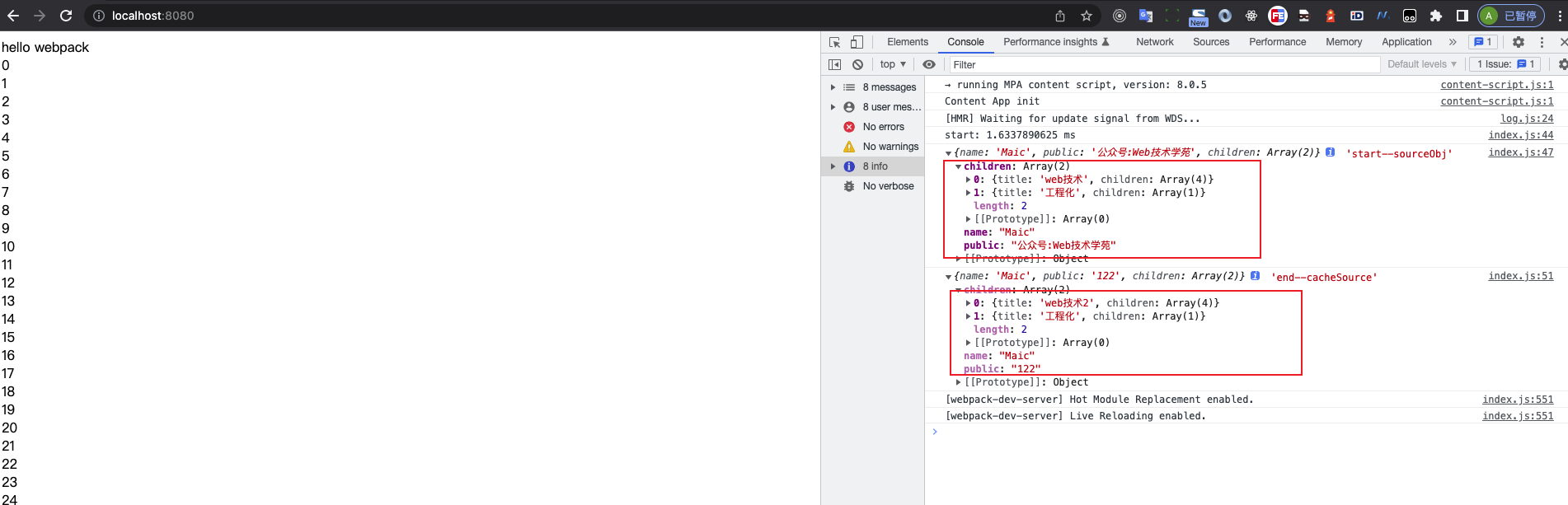
import deepMerge from './utils/index';
import '../assets/css/app.css';
import image1 from '../assets/images/1.png';
import image2 from '../assets/images/2.jpg';
// const { deepMerge } = require('./utils/index.js');
function twoSum(a, b) {
return a + b;
}
const userInfo = {
name: 'Maic',
age: 18,
test: {
book: '公众号:Web技术学苑'
}
};
const result = twoSum(1, 2);
console.log(result, deepMerge(userInfo));
if (module.hot) {
// 这个文件
module.hot.accept('./utils/index.js', () => {});
}
const str = `<div>
<h5>hello, webpack</h5>
<div>
<img src=${image1} />
</div>
<div>
<img src=${image2} />
</div>
</div>`;
console.log(str);
const app = document.getElementById('app');
app.innerHTML = str;看下引入的图片页面
大功告成,css与图片资源都已经 OK 了
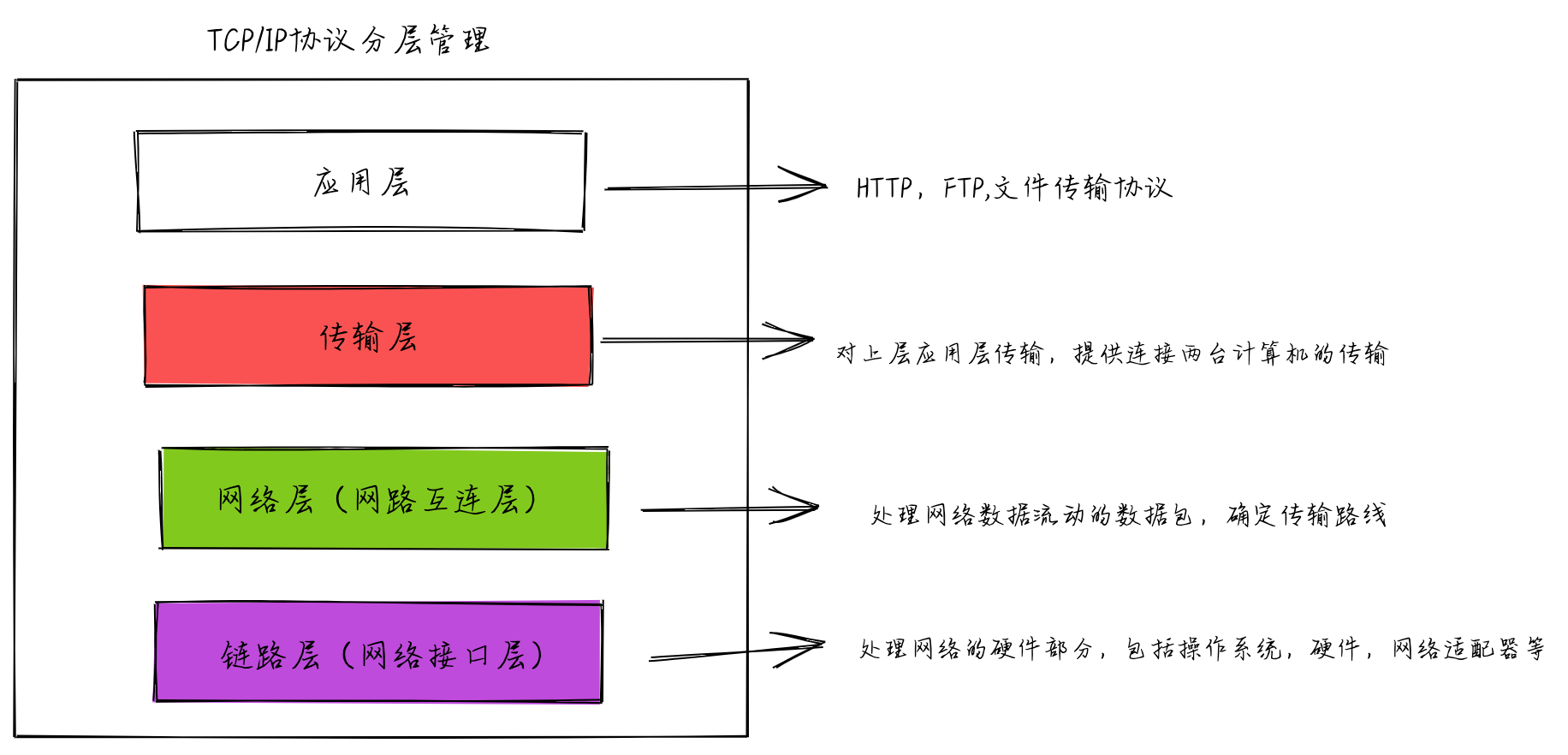
1、了解webpack是什么,它主要是前端构建工程化的一个工具,将一些譬如ts,sass,vue,tsx等等一些浏览器无法直接访问的资源,通过webpack可以打包成最终浏览器可以访问的html、css、js的文件。并且webpack通过一系列的插件方式,提供loader与plugins
这样的插件配置,达到可以编译各种文件。
2、了解webpack编译入口的基本配置,entry,output、module、plugins以及利用devServer开启热更新,并且使用module.hot.accept('path')实现HMR模块热替换功能
3、我们了解在命令行webpack --watch可以做到实时监听文件的变化,每次文件变化,页面都会重新加载
4、我们学会如何使用加载css以及图片资源,学会配置css-loader,style-loader、file-loader,以及利用min-css-extract-plugin去提取css,用html-webpack-plugin插件实现本地WDS静态文件与入口文件的映射,在html中会自动引入实时打包的入口文件的app.bundle.js
5、熟悉从 0 到 1 搭建一个前端工程化项目
6、本文示例code-example
下一节会基于这个当下项目搭建vue、react项目,以及项目的tree-shaking,懒加载、缓存,自定义loader,plugins等
最近半年项目升级 ts,一边看文档,一边实践,ts基础语法非常简单,但是写好ts就非常不简单,typescript严格来讲算是一门强类型语言,它赋予js类型体系,让开发者写js更加严谨,并且它具备强大的类型推断,并且能在node和浏览器中运行。对于项目而言,使用 typescipt 对提升项目的规范与严谨性更加友好。
本文只做笔者项目中常遇到的一些ts经验,希望在项目中你能用得到。
正文开始...
type[string|number|boolean|Array|Object|Function]
// string
type NameType = string;
const nameStr: NameType = 'Maic'; // const nameStr: string
//or
const nameStr2: string = 'tom';
// number
type AgeType = number;
const age: AgeType = 18;
// or
const age2: number = 20;
const age2: AgeType = ''; // const age: number 不能将类型“string”分配给类型“number”。
// Array<string>
type NamesType = Array<string>;
const students: NamesType = ['Maic', 'Tom'];
// or 等价于
type NamesType2 = string[];
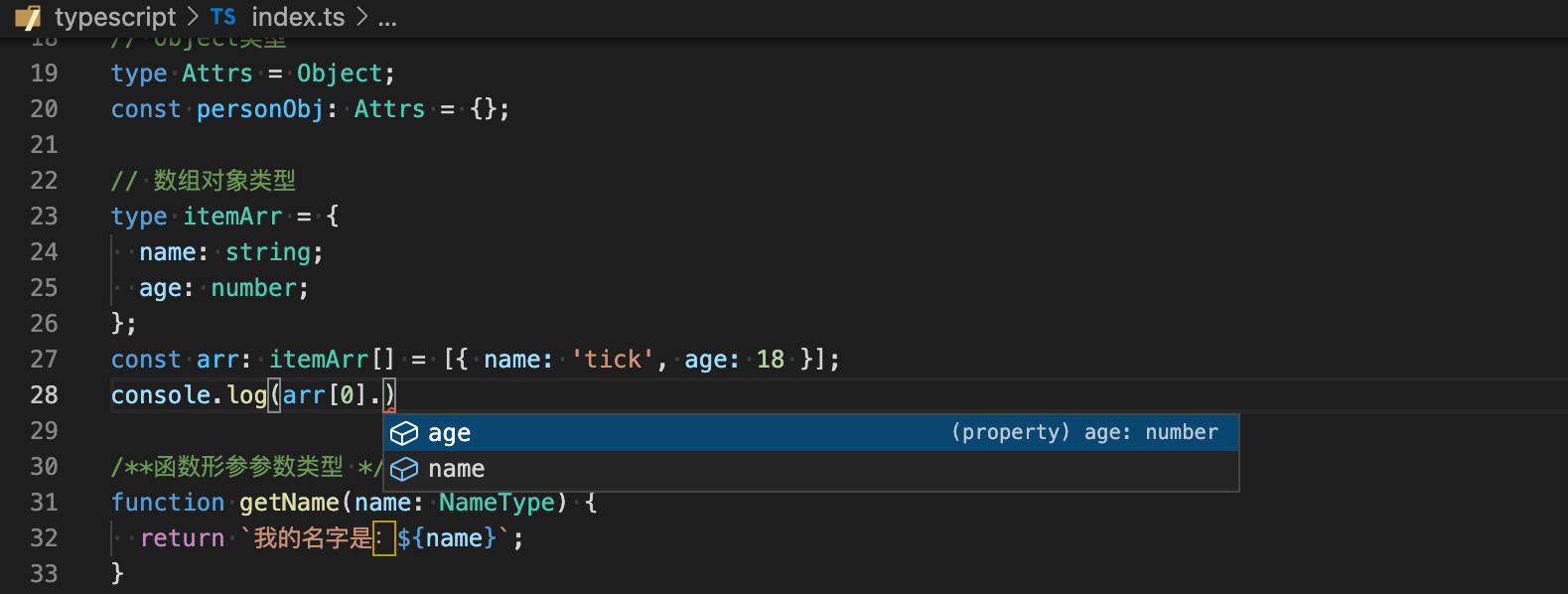
const students2: NamesType2 = ['Maic', 'Tom'];// 例如一个数组
/**
const arr = [{
name: 'Maic',
age: 18,
lovePlay: 'basketball'
}];
**/
// 如何定义该数组内部的类型
type itemArr = {
name: string;
age: number;
};
const arr: itemArr[] = [{ name: 'tick', age: 18 }];
console.log(arr[0].name);类型推断和提示
// Object
type Attrs = Object;
const personObj: Attrs = {};
// or
type nameObj = {
name: string;
age: number;
};
const personObj2: nameObj = {
name: '大大',
age: 18
};
console.log(personObj2.age);type Fn = Function;
const getAge: Fn = () => {}; // const getAge: Functiontype NameType = string;
function getName(name: NameType, age?: number) {
return `我的名字是:${name}`;
}
// or
function getName(name: string, age?: number): string {
return `我的名字是:${name}`;
}
getName('Maic');注意以上第二个形参中?age:number代表这个形参可传可不传,并且这个函数返回的值类型是一个字符串
type idTypes = string[] | number;
const ids: idTypes = '123';
// or
const ids2: string | number = 123;
function getIds(id: idTypes, name?: string) {
console.log(id.toString(), name);
// console.log(id.join(',')); 如果不判断类型,则会直接提示
// 类型“idTypes”上不存在属性“join”。
// 类型“number”上不存在属性“join”。
if (Array.isArray(id)) {
console.log(id.join(','));
}
}
getIds(['1', '2']);toString这个方法在数组和number中都有该方法,所以可以使用,如果某个方法只存在于一种类型中,则要类型收窄判断该类型
interface我们可以理解它是定义对象的一种类型,并且它具备扩展对象属性,继承对象特征
在之前我们用type定义了对象数据
type nameObj = {
name: string;
age: number;
};
const personObj2: nameObj = {
name: '大大',
age: 18
};用interface定义对象
interface personObj2 {
name: string;
age: number;
}
const personObj4: personObj2 = {
name: 'Maic',
age: 18
};如果我需要一个对象类型的属性是可选的
interface personObj2 {
name: string;
age?: number;
}只需要在定义的属性后面加个?就行
// personObj5继承personObj2属性,所以personObj5具有personObj2的所有属性
interface personObj5 extends personObj2 {}
interface personObj5 extends personObj2 {
money: number;
}
const personObj5: personObj5 = {
name: 'Tom',
money: 1000
};type通过交集扩展属性
/*** type 通过交集扩展属性 */
type personObj6 = personObj2 & { money: number };
const personObj6: personObj6 = {
name: 'Tom',
money: 100
};这里我们注意比较下type与interfance的区别
相同点
所有对象类型都可以用type或者interface来定义,type在实际项目中更广义些,而interface更多的时候描述一个对象类型更狭义一些,他们都可以定义对象类型
不同点
type 定义好了的数据,不能重载,且扩展属性需要使用交集扩展&
interface可以重载,扩展属性需使用extends
type Animal = {
name: string;
};
// 标识符“Animal”重复。ts(2300)
// type定义完了的类型,不能重复定义
// type Animal = {
// age: string;
// }
// & 扩展属性
type NewAnimal = Animal & { age: number };interface Dog {
name: string;
}
interface Dog {
age: number;
}
const dog: Dog = {
name: '',
age: 1
};
interface childDog extends Dog {
money: string;
}
const cDog: childDog = {
name: 'xx',
age: 0.5,
money: ''
};在项目中,如果你不知道该形参或者变量的类型,如果只是为了快点糊项目,不想被这个类型所拘束,那么你可以用as any
function $id(id) {
return document.getElementById(id);
}
type elm = HTMLElement;
const dom: elm = $id('app') as HTMLElement;type namesType = string | number;
function getNames(name: namesType | 'Maic') {
return name;
}
getNames('Maic'); // or getNames(123)
function handlequest(url: string, methods: string, params: Object) {
fetch(url);
}
const options = {
url: 'https://www.baidu.com',
methods: 'get',
params: {
q: 'test'
}
} as const;
handlequest(options.url, options.methods as 'get', options.params);interface shopList {
js: string;
node: string;
}
function printShop(books: shopList) {
if ('js' in books) {
console.log(`我买了 ${books['js']}`);
}
if ('node' in books) {
console.log(`这是一本 ${books['node']}书籍`);
}
}
printShop({ js: 'js设计模式', node: 'nodejs入门到放弃' });将一个的enums值的value做为另一个对象的key,将一个枚举值的key作为一个对象的value
const enum FOODS {
a = '鸭子',
b = '鸡腿'
}
console.log(FOODS.a);
type values = keyof typeof FOODS; // type values = "a" | "b"
const foods: {
[key in FOODS]: values;
} = {
[FOODS.a]: 'a',
[FOODS.b]: 'b'
};
/**
* const foods: {
鸭子: "a" | "b";
鸡腿: "a" | "b";
}
*/
console.log(foods[FOODS.a]);我们可以用instanceof收窄数据类型
function transformParams(params) {
if (params instanceof String) {
console.log(params.toLocaleLowerCase());
}
if (params instanceof Date) {
console.log(params.toLocaleDateString());
}
}
transformParams('abc');
transformParams(new Date());我么判断一个形参是否在一个类型中
/**
* is 判断参数类型
*/
interface Fish {
swim: Function;
}
interface Bird {
fly: Function;
}
function isFish(arg: Fish | Bird): arg is Fish {
return (arg as Fish).swim !== undefined;
}
const isfish = isFish({ swim: () => {} });
const isBird = isFish({ fly: () => {} });可以跟es6一样...扩展多个参数
/**
* rest params
*/
function add(num: number, ...arg: number[]) {
return arg.map((s) => s + num);
}
add(1, 2, 4, 5, 6); // [3,5,6,7]
interface params {
id: number;
name: string;
age: number;
fav: string;
}
const curentParams: params = { id: 1, name: 'Maic', age: 18, fav: 'play' };
const { id, ...arg } = curentParams;
/*
const arg: {
name: string;
age: number;
fav: string;
}
*/我们想一个对象的属性可有可无,或者一个对象属性不能修改
/***
*
* 对象属性修饰符 ? 可选 readonly 只读
*/
interface params2 {
readonly id: number;
name: string;
age?: number;
}
const curentParams2: params2 = { id: 123, name: '' }; // age 可有可无
// curentParams2.id = 456; // 无法分配到 "id" ,因为它是只读属性。 readonly id的属性不能修改通常我们一个对象的key是字符串或者是索引,那么正确定义对象索引的类型就如下面
/**
* 对象属性索引类型
*/
interface params3 {
[key: string]: string | number;
[key: number]: number;
}
const params3: params3 = {
age: 18,
1: 123
};如果我需要将一个对象key声明成另一个对象的key呢?那么我们可以使用[key in xxx]: string
enum LANGUAGE {
ru = '俄罗斯',
ch = '**',
usa = '美国'
}
type languKey = keyof typeof LANGUAGE; // type languKey = "ru" | "ch" | "usa"
/**
* const lang: {
ru: string;
ch: string;
usa: string;
}
*/
const lang: {
[key in languKey]: string;
} = {
ru: '1',
ch: '2',
usa: '3'
};/**
* 交叉类型
*/
interface span {
color: string;
}
interface a {
cursor: string;
}
type divType = span & a;
const divStyle: divType = {
color: '#111',
cursor: 'pointer'
};
console.log(divStyle.color, divStyle.cursor);注意我们使用extends也一样可以一样的效果
interface a {
cursor: string;
}
// img 类型同时拥有cursor与{color: string}两个属性类型
interface img extends a {
color: string;
}
const imgStyle: img = {
color: '#111',
cursor: 'pointer'
};通常在实际业务中, 通用的属性值可能类型不同那么我们会重复定义很多类型,比如下面
interface obj1 {
a: boolean;
}
interface obj2 {
a: string;
}
const obj1: obj1 = { a: true };
const obj2: obj2 = { a: '111' };因此我们可以这么做
// 将多行类型合并成一个
interface objType<T> {
a: T;
}
const obj3: objType<boolean> = {
a: false
};
const obj4: objType<string> = {
a: 'hello'
};当我们看到interface objType<T> { a: T },我们怎么理解,首先objType你可以把它看成一个接口名称,其实与普通申明一个普通接口名一样,T可以看成一个形参,一个占位符,我们可以在实际用的地方灵活的传入不同类型。
// Type泛型
interface obj2 {
a: string;
}
type obj4Type<Type> = {
content: Type;
};
const obj5: obj4Type<obj2> = {
content: {
a: 'hello'
}
};
console.log(obj5.content.a); // hello通常我们在项目中经常看到封装的工具函数中有泛型,那么我们可以简单的写个,具体可以看下下面简单的一个一个工具请求函数
/***
*
* 方法泛型
*/
function genterFeach<T>(url: string) {
return {
get: (params: T, config?) => {
return fetch(url, {
method: 'get',
body: JSON.stringify(params),
...config
});
},
post: (params: T, config?) => {
return fetch(url, {
method: 'post',
body: JSON.stringify(params),
...config
});
}
};
}
interface paramsF {
id: number;
password: number;
name: string;
}
const useInfo = genterFeach<paramsF>('/v1/useInfo');
const login = genterFeach<paramsF>('/v1/login');
useInfo.get({ id: 111, password: 12, name: 'Maic' });
login.post({ id: 111, password: 12, name: 'Maic' });/**
* readonly
*/
type readData = readonly [string, number];
const data: readData = ['Maic', 18];
// data[1] = 20; 无法分配到 "1" ,因为它是只读属性
type readData2<T> = T;
const data2: readData2<readonly string[]> = ['Maic'];
// data2[0] = 'tom';// 类型“readonly string[]”中的索引签名仅允许读取
console.log(data2[0]);内部元素会变成一个常量,不可修改
const strArr = ['a', 'b', 3] as const;
type strVal = typeof strArr;
const strArr2: strVal = ['a', 'b', 3];
function getStrArr([a, b, c]: [string, string, number]) {
console.log(a, b, c);
}
// getStrArr(strArr);// 类型 "readonly ["a", "b", 3]" 为 "readonly",不能分配给可变类型 "[string, string, number]"。
function getStrArr2([a, b, c]: strVal) {
console.log(a, b, c);
}
getStrArr2(strArr); // ok对于泛型在笔者初次遇见她时,还是相当陌生的,感觉这词很抽象,不好理解,光看别人写的,一堆泛型,或许增加了阅读代码的复杂度,但是泛型用好了,那么会极大的增加代码的复用度。当然,简单事情复杂化了,那么泛型也容易出错,代码也变得不易读。
我们写一个简单的例子来感受一下泛型
interface resopnseID {
id: number;
}
interface responseName {
name: string;
}
const responseId: resopnseID = {
id: 123
};
const responseName: responseName = {
name: 'Maic'
};如果我想resopnseID或者responseName高度复用呢,如果有很多类似的字段,那么我是不是要写很多这种接口类型呢
interface keysType<T, V> {
[key in T]: V;
}
const responseId2: keysType<{ id: number }, number>;
const responseName2: keysType<{ name: string }, string>;
console.log(responseName2.age); // 类型“keysType<{ name: string; }, string>”上不存在属性“age”。
console.log(responseName2.name);// 函数泛型
function setParamsType<T>(arg: T): T {
return arg;
}
console.log(setParamsType<string>('maic'));
console.log(setParamsType<number>(18));与下面等价,可以用interface申明函数类型
// 接口泛型
interface paramsType<T> {
[arg: T]: T;
}
function setParamsType<T>(arg: T): T {
return arg;
}
const myParams: parsType<number> = setParamsType;
// type 泛型
type parsType2<T> = {
[arg: T]: T;
};
const myParams2: parsType2<number> = setParamsType;我们在用class申明类时,就可以约定类中成员属性的类型以及class内部方法返回的类型
class Calculate<T> {
initNum: T;
max: string;
add: (x: T, y: T) => T;
}
const cal = new Calculate<number>();
cal.initNum = 0;
cal.add = (x, y) => x + y;
cal.add(1, 2);
// or
const cal2 = new Calculate<string>();
cal.max = '123';
cal.add = (x, y) => x + y;
cal.add(cal.max, '456'); // 123456在平时项目中我们使用泛型,我们会发现有时候,函数内部使用参数时,往往会提示属性不存在,比如
// 类型“T”上不存在属性“id”。
function getParams<T>(params: T) {
if (params.id) {
console.log('进行xxx操作');
}
}
getParams({ id: '123' });此时我们就可以利用extends约束泛型做到函数内部能正确访问
function getParams<T extends { id: string }>(params: T) {
if (params.id) {
console.log('进行xxx操作');
}
}
getParams({ id: '123' });interface parmasType {
id: string;
}
function getParams2<T extends parmasType>(params: T) {
if (params.id) {
console.log('进行xxx操作');
}
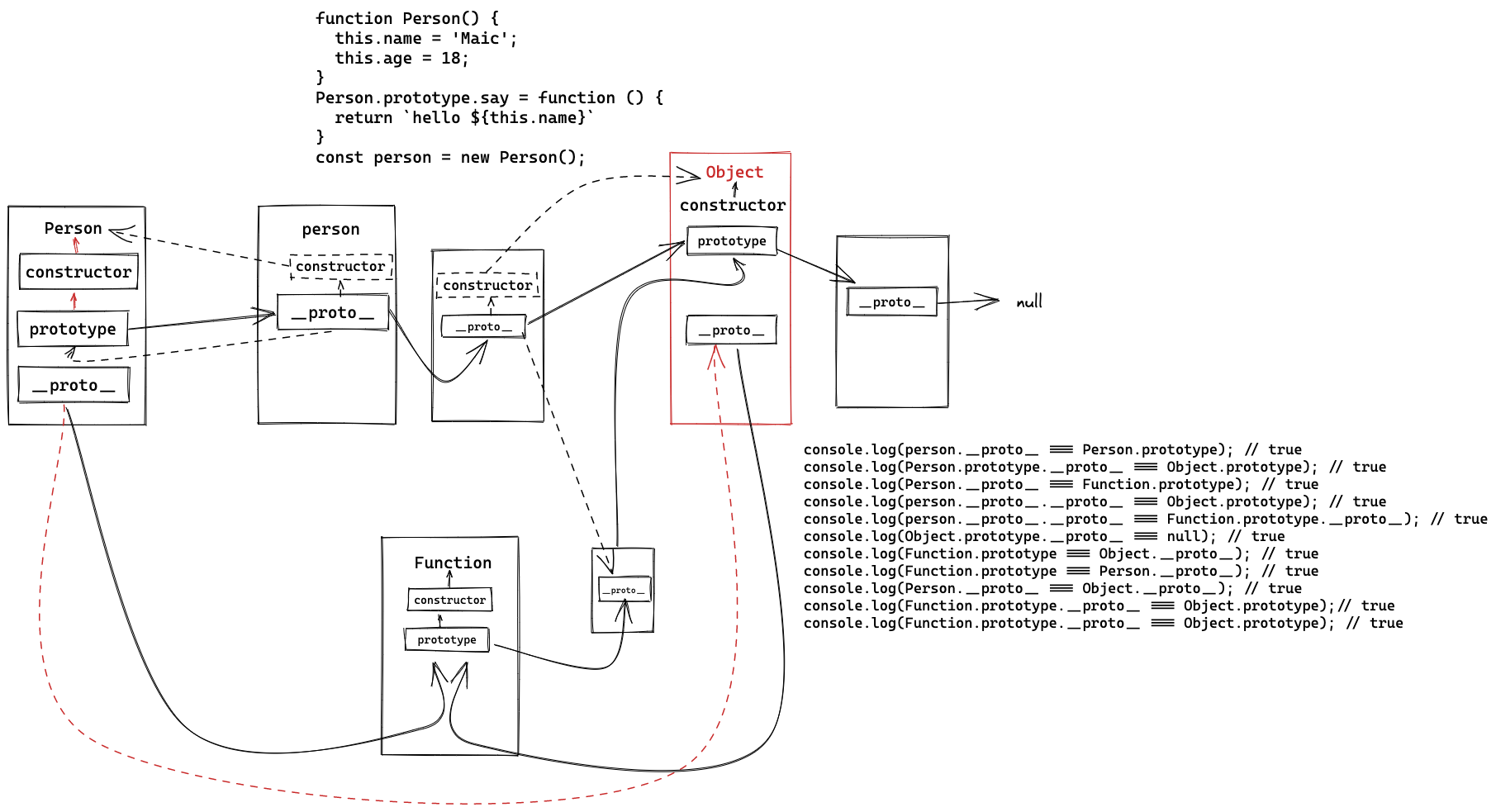
}接下来看一段原型属性推断与约束,我们可以看出构造函数与实例的关系
class Animal2 {
name: string = 'animal';
}
class Sleep {
hour: number = 10;
}
class Bee extends Animal2 {
age: number = 1;
action: Sleep = new Sleep();
}
function createInstance<T extends Animal2>(c: new () => T): T {
return new c();
}
console.log(createInstance(Bee).action.hour); // animal我们对一个对象类型接口进行keyof那么会返回对象属名组成的集合
interface keysObj {
id: string;
name: string;
date: string | number;
content: string;
}
type keytype = keyof keysObj;
// 等价于type keytype = 'id' | 'name' | 'date' | 'content'
const objkey: keytype = 'content';
// or
const objkey2: keyof keysObj = 'id';
// 简写
// const objkey: keyof keysObj = 'content'interface keysP {
[key: number]: string;
}
type keysType3 = keyof keysP; // type keysType3 = number
const objkey3: keyof keysP = 1;如何获取一个对象值的所有key
const objkey4 = {
a: '111',
b: '222',
c: 333,
d: 444
};
type result = keyof typeof objkey4; // type result = "a" | "b" | "c" | "d"
const objkey5: result = 'a'; // true通过keyof我们已经约束了一新值的所有值,那么它就再也不能赋值其他值了,比如
...
const objkey5:result = 'e'; // error 不能将类型“"e"”分配给类型“"a" | "b" | "c" | "d"”当我们对一个对一个泛型进行keyof时,此时类型会变成string | number | symbol三种类型,我们对变量进行赋值时,ts会报错
function useKey<T, Key extends keyof T>(o: T, key: Key) {
const keyName: string = key; // 不能将类型“string | number | symbol”分配给类型“string”
console.log(o[keyName]);
}那么此时我们需要借助Extract进一步进行约束
function useKey2<T, Key extends Extract<keyof T, string>>(o: T, key: Key) {
const keyName: string = key;
console.log(o[keyName]);
}注意我们看下ts全局给我们提供的这个Extract类型
type Extract<T, U> = T extends U ? T : never;我们观察到Extract就是约束了Key的类型,那么我们也可以这么写,既然我知道Key是字符串
function useKey3<T, Key extends string>(o: T, key: Key) {
const keyName: string = key;
console.log(o[keyName]);
}或者你也可以用或类型,指定keyName可以是string | number | symbol这三种类型
function useKey4<T, Key extends keyof T>(o: T, key: Key) {
const keyName: string | number | symbol = key;
console.log(o[keyName]);
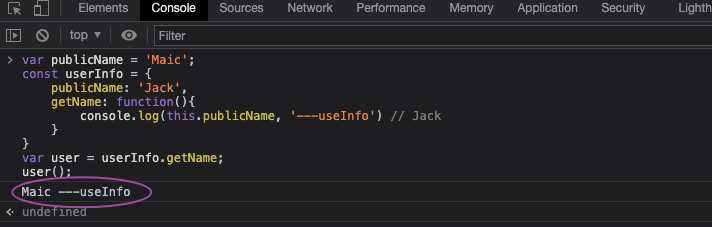
}typeof只能用于已经实际定义申明了的变量,返回该定义的变量的实际类型
let publicWebTech = '关注公众号:Web技术学苑';
type publicWeb = typeof publicWebTech;
//type publicWeb = string
const publicName: publicWeb = '';但是注意如果用const定义的变量,如果你keyof一个常量,那么就会不一样了
const publicWebAuthor = 'Maic';
// or let publicWebAuthor = 'Maic' as const;
type publicWebAuthor = typeof publicWebAuthor;
const publicAuthor: publicWebAuthor = 'Maic';获取一个对象的所有属性类型
const objResult = { a: '11', b: '222' };
type objResultType = typeof objResult;
/*
type objResultType = {
a: string;
b: string;
}
*/获取一个函数的返回类型,ReturnType
function fnTest() {
return {
a: '111',
b: '222'
};
}
type fntest = ReturnType<typeof fnTest>;
/**
type fntest = {
a: string;
b: string;
}
**/我们可以看下ReturnType的类型定义
type ReturnType<T extends (...args: any) => any> = T extends (...args: any) => infer R ? R : any;有时候我们定义一个枚举,我们想获取枚举的Key,那么可以这么做
enum SERVER {
TEST = 1,
PRD = 2,
DEV = 3
}
type serverType = keyof typeof SERVER;
// type serverType = "TEST" | "PRD" | "DEV"有时我们需要访问具体接口的某个字段的类型或者数组中的类型
interface person {
name: string;
id: number;
age: number;
}
type nametype = person['age'];
// type nametype = number
type nameOrAge = person['age' | 'name'];
// type nameOrAge = string | number
type personKeys = person[keyof person];
// type personKeys = string | number数组中的类型
const personArr = [
{
name: 'Maic',
age: 10
},
{
name: 'tom',
age: 18,
id: 189
}
];
type items = typeof personArr[number];
/*
type items = {
name: string;
age: number;
id?: undefined;
} | {
name: string;
age: number;
id: number;
}
*/// 类型“"message"”无法用于索引类型“T”。
type messageOf<T> = T['message'];此时可以用extends
type messageOf<T extends { message: string }> = T['message'];type isNumber<T> = T extends number ? number : string;
const num: isNumber<string> = '123';
// const num: string1、在ts定义基础数据类型,type与interface
2、基础使用泛型,可以在接口,函数,type使用泛型,泛型可以理解js中的形参,更加抽象和组织代码
3、extends约束泛型,并且可以在ts中做条件判断
4、使用keyof获取对象属性key值,如果需要获取一个对象定义的key,可以使用type keys = keyof typeof obj
5、有一篇笔者很早之前的一篇ts 笔记
6、本文示例code-example
更多学习ts查看TS 官方文档,也可以看对应翻译中文版https://yayujs.com/
在
vue中数据流是单向的,通常父子组件通信props或者自定义事件,或者还有provide/inject,甚至借助第三方数据流方案vuex,在通常的项目中我们会高频用到哪些通信方案?
本文是笔者总结过往项目,在vue使用到的一些数据通信方案,希望在实际项目中有些帮助和思考。
正文开始...
我们先看下在vue中我能想到的数据通信方案
1、props父传子
2、自定义事件@event="query"
3、.sync修饰符
3、vuex跨组件通信
4、Vue.observable
5、provide/inject
6、EventBus
7、$refs、$parent
基于以上几点,笔者用一个实际的todolist来举证所有的通信方式
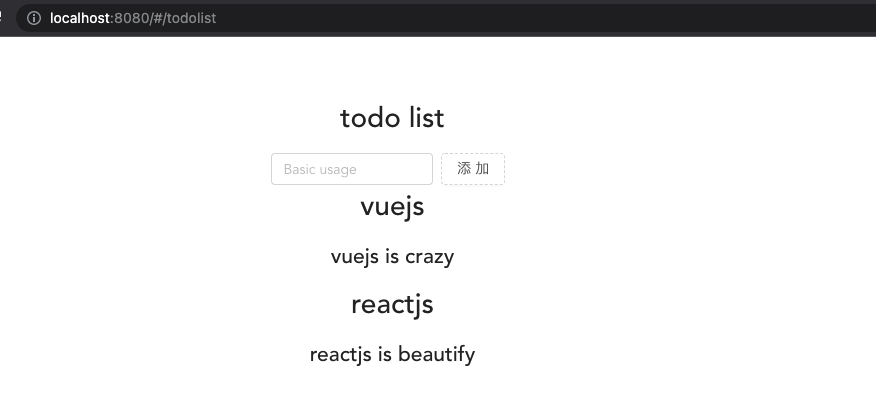
// todoList.vue
<template>
<div class="todo-list">
<h1>todo list</h1>
<Search />
<content :dataList="dataList" />
</div>
</template>
<script>
import Search from './Search.vue';
import Content from './Content.vue';
export default {
name: 'todo-list',
components: { Search, Content },
data() {
return {
dataList: [
{
title: 'vuejs',
subTitle: 'vuejs is crazy'
},
{
title: 'reactjs',
subTitle: 'reactjs is beautify'
}
]
};
},
methods: {}
};
</script>父组件以Index.vue为例,传入的子组件Content.vue的props就是:dataList="dataList"在Content.vue中我们可以看到就是通过props上的dataList获取父组件数据的。
<!--Content.vue-->
<template>
<div class="content">
<template v-for="(item, index) in dataList">
<h1 :key="index">{{item.title}}</h1>
<h2 :key="item.subTitle">{{item.subTitle}}</h2>
</template>
</div>
</template>
<script>
export default {
props: {
dataList: {
type: Array,
default: () => []
}
}
};
</script>子组件数据通过父组件传递,页面数据就显示出来了
...
<div class="todo-list">
<h1>todo list</h1>
<Search @handleAdd="handleAdd" />
<content :dataList="dataList" />
</div>
<script>
export default {
name: 'todo-list',
methods: {
handleAdd(params) {
this.dataList.push(params);
}
}
};
</script>我们看到在父组件中加入了@handleAdd自定义事件
在Search.vue中我们引入对应逻辑
<!--Search.vue-->
<div class="search">
<a-row type="flex" justify="center">
<a-col :span="4">
<a-input placeholder="Basic usage" v-model="value" @pressEnter="handleAdd"></a-input>
</a-col>
<a-col :span="2">
<a-button type="dashed" @click="handleAdd">添加</a-button>
</a-col>
</a-row>
</div>// Search.vue
export default {
name: 'search',
data() {
return {
value: '',
odd: 0
};
},
methods: {
handleAdd() {
const { value: title } = this;
if (title === '') {
return;
}
this.odd = !this.odd;
this.$emit('handleAdd', {
title,
subTitle: `${title} is ${this.odd ? 'crazy' : 'beautify'}`
});
}
}
};我们可以看到自定义事件子组件中就是这么给父组件通信的
...
this.$emit('handleAdd', {
title,
subTitle: `${title} is ${this.odd ? 'crazy' : 'beautify'}`
})在 vue 中提供了.sync修饰符,本质上就是便捷处理props单向数据流,因为有时候我们想直接在子组件中修改props,但是vue中是会警告的,如果实现props类似的双向数据绑定,那么可以借用.sync修饰符,这点项目里设计弹框时经常有用。
同样是上面todolist的例子
<template>
<div class="todo-list">
<h1>todo list-sync</h1>
<Search :dataList.sync="dataList" />
<content :dataList="dataList" />
</div>
</template>
<script>
import Search from './Search.vue';
import Content from './Content.vue';
export default {
name: 'todo-list',
components: { Search, Content },
data() {
return {
dataList: [
{
title: 'vuejs',
subTitle: 'vuejs is crazy'
},
{
title: 'reactjs',
subTitle: 'reactjs is beautify'
}
]
};
}
};
</script>我们在看下Search.vue已经通过:dataList.sync="dataList"在props上加了修饰符了
在Search.vue中可以看到
...
<script>
export default {
name: 'search',
props: {
dataList: {
type: Array,
default: () => []
}
},
data() {
return {
value: '',
odd: 0
};
},
methods: {
handleAdd() {
const { value: title, dataList } = this;
if (title === '') {
return;
}
this.odd = !this.odd;
const item = {
title,
subTitle: `${title} is ${this.odd ? 'crazy' : 'beautify'}`
};
this.$emit('update:dataList', dataList.concat(item));
}
}
};
</script>注意我们在handleAdd方法中修改了我们是用以下这种方式去与父组件通信的,this.$emit('update:dataList', dataList.concat(item))。
...
const {value: title, dataList } = this;
const item = {
title,
subTitle: `${title} is ${this.odd ? 'crazy' : 'beautify'}`
}
this.$emit('update:dataList', dataList.concat(item))sync本质也是利用自定义事件通信,上面代码就是下面的简版,我们可以利用.sync修饰符实现props的双向数据绑定,因此在实际项目中可以用.sync修饰符简化业务代码,实际与下面代码等价
<Search :dataList="dataList" @update="update" />vuex在具体业务中基本上都有用,我们看下vuex是如何实现数据通信的,关于vuex如何使用参考官方文档,这里不讲如何使用 vuex,贴上关键代码
// store/index.js
import Vue from 'vue';
import Vuex from 'vuex';
Vue.use(Vuex);
const state = {
dataList: [
{
title: 'vuejs',
subTitle: 'vuejs is crazy'
},
{
title: 'reactjs',
subTitle: 'reactjs is beautify'
}
]
};
const mutations = {
handAdd(state, payload) {
state.dataList = state.dataList.concat(payload);
}
};
export const store = new Vuex.Store({
state,
mutations
});然后在main.js中引入
// main.js
...
import {store} from '@/store/index';
...
/* eslint-disable no-new */
new Vue({
el: '#app',
store,
router,
components: { App },
template: '<App/>'
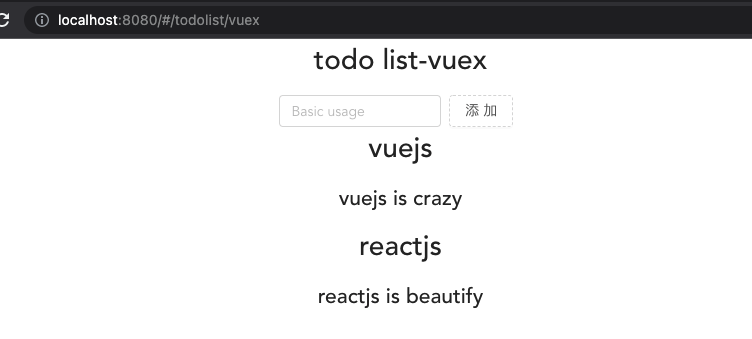
})我们看下主页面路由页面,现在变成这样了,父组件没有任何props与自定义事件,非常的干净。
<template>
<div class="todo-list">
<h1>todo list-vuex</h1>
<Search />
<content />
</div>
</template>
<script>
import Search from './Search.vue';
import Content from './Content.vue';
export default {
name: 'todo-list',
components: { Search, Content }
};
</script>然后看下Search.vue与Content.vue组件
<!--Search.vue-->
<template>
<div class="search">
<a-row type="flex" justify="center">
<a-col :span="4">
<a-input placeholder="Basic usage" v-model="value" @pressEnter="handleAdd"></a-input>
</a-col>
<a-col :span="2">
<a-button type="dashed" @click="handleAdd">添加</a-button>
</a-col>
</a-row>
</div>
</template>
<script>
export default {
name: 'search',
data() {
return {
value: '',
odd: 0
};
},
methods: {
handleAdd() {
const { value: title } = this;
if (title === '') {
return;
}
this.odd = !this.odd;
const item = {
title,
subTitle: `${title} is ${this.odd ? 'crazy' : 'beautify'}`
};
this.$store.commit('handAdd', item);
}
}
};
</script>你会发现操作数据是用$store.commit('mutationName', data)这个vuex提供的同步操作去修改数据的。
在Content.vue中就是直接从store中获取state就行了
<template>
<div class="content">
<template v-for="(item, index) in dataList">
<h1 :key="index">{{item.title}}</h1>
<h2 :key="item.subTitle">{{item.subTitle}}</h2>
</template>
</div>
</template>
<script>
export default {
computed: {
dataList() {
return this.$store.state.dataList;
}
}
};
</script>
vuex的**就是数据存储的一个仓库,数据共享,本质 store 也是一个单例模式,所有的状态数据以及事件挂载根实例上,然后所有组件都能访问和操作,但是貌似这么简单的功能引入一个状态管理工具貌似有点杀鸡用牛刀了,接下来我们用官方提供的跨组件方案。
vue 提供一个这样的一个最小跨组件通信方案,我们具体来看下,新建一个目录todoList-obsever/store/index.js,我们会借鉴vuex的一些**,具体代码如下
// store/index.js
import Vue from 'vue';
const state = {
dataList: [
{
title: 'vuejs',
subTitle: 'vuejs is crazy'
},
{
title: 'reactjs',
subTitle: 'reactjs is beautify'
}
],
commit: {
handAdd: (payload) => {
state.dataList = state.dataList.concat(payload);
},
handleDelete(index) {
state.dataList.splice(index, 1);
}
}
};
const mutations = {
commit(actionName, payload) {
if (Reflect.has(state.commit, actionName)) {
state.commit[actionName](payload);
}
},
dispatch(actionName, payload) {
mutations.commit(actionName, payload);
}
};
const store = {
state,
...mutations
};
export default Vue.observable(store);然后在Content.vue中
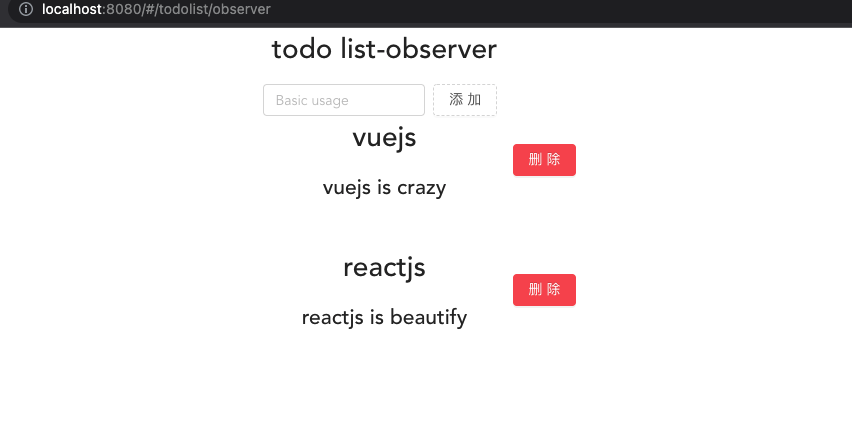
<template>
<div class="content">
<template v-for="(item, index) in dataList">
<div :key="index" class="list">
<h1 :key="index">{{ item.title }}</h1>
<h2 :key="item.subTitle">{{ item.subTitle }}</h2>
<a-button type="danger" class="del" :key="`${index}-${item.title}`" @click="handleDelete(index)">删除</a-button>
</div>
</template>
</div>
</template>
<script>
// 引入上面的store
import store from './store/index';
export default {
computed: {
dataList() {
return store.state.dataList;
}
},
methods: {
handleDelete(index) {
store.commit('handleDelete', index);
}
}
};
</script>
<style lang="scss">
.list {
.del {
position: relative;
top: -70px;
left: 160px;
}
}
</style>在Search.vue中
<template>
<div class="search">
<a-row type="flex" justify="center">
<a-col :span="4">
<a-input placeholder="Basic usage" v-model="value" @pressEnter="handleAdd"></a-input>
</a-col>
<a-col :span="2">
<a-button type="dashed" @click="handleAdd">添加</a-button>
</a-col>
</a-row>
</div>
</template>
<script>
// 引入store
import store from './store/index';
export default {
name: 'search',
data() {
return {
value: '',
odd: 0
};
},
methods: {
handleAdd() {
const { value: title } = this;
if (title === '') {
return;
}
this.odd = !this.odd;
const item = {
title,
subTitle: `${title} is ${this.odd ? 'crazy' : 'beautify'}`
};
store.commit('handAdd', item);
}
}
};
</script>ok 这种方式算是代替vuex的一种解决方案,是不是比vuex更简单呢,而且不用引入任何第三方库,因此在你的业务代码中可以用此来优化部分跨组件的数据通信。
这是一个父组件可以向子孙组件透传数据的一个属性,也就是意味着在所有子孙组件,能拿到父组件provide提供的数据,具体可以看下下面例子
<template>
<div class="todo-list">
<h1>todo list-provide</h1>
<Search @handleAdd="handleAdd" />
<content />
</div>
</template>
<script>
import Search from './Search.vue';
import Content from './Content.vue';
export default {
name: 'todo-list',
components: { Search, Content },
data() {
return {
dataList: [
{
title: 'vuejs',
subTitle: 'vuejs is crazy'
},
{
title: 'reactjs',
subTitle: 'reactjs is beautify'
}
]
};
},
provide() {
return {
newDataList: this.dataList
};
},
methods: {
handleAdd(params) {
this.dataList.push(params);
}
}
};
</script>我们在Content.vue组件中发现
<template>
<div class="content">
<template v-for="(item, index) in newDataList">
<h1 :key="index">{{item.title}}</h1>
<h2 :key="item.subTitle">{{item.subTitle}}</h2>
</template>
</div>
</template>
<script>
export default {
inject: ['newDataList']
};
</script>子组件就用inject: ['newDataList']来接收数据了。注意一点inject一定是要与provide组合使用,且必须是在父子组件,或者父孙,或者更深层的子组件中使用inject。
这种方式平时业务上也会有用得到,特别是在表单验证中就会有
// utils/eventBus.js
export default class EventBus {
constructor() {
this.events = {};
}
on(name, fn) {
if (!this.events[name]) {
this.events[name] = [];
}
this.events[name].push(fn);
}
emit(name, ...payload) {
this.events[name].forEach((v) => {
Reflect.apply(v, this, payload); // 执行回调函数
});
}
}在mian.js中挂载到prototype上
// The Vue build version to load with the `import` command
// (runtime-only or standalone) has been set in webpack.base.conf with an alias.
import Vue from 'vue';
import Antd from 'ant-design-vue';
import 'ant-design-vue/dist/antd.css';
import eventBus from '@/utils/eventBus';
import { store } from '@/store/index';
import App from './App';
import router from './router';
Vue.config.productionTip = false;
Vue.use(Antd);
/* eslint-disable no-new */
Vue.prototype.$my_event = new eventBus();
new Vue({
el: '#app',
store,
router,
components: { App },
template: '<App/>'
});然后在具体路由上我们看下
<template>
<div class="todo-list">
<h1>todo list-event-bus</h1>
<Search />
<content :dataList="dataList" />
</div>
</template>
<script>
import Search from './Search.vue';
import Content from './Content.vue';
export default {
name: 'todo-list',
components: { Search, Content },
data() {
return {
dataList: [
{
title: 'vuejs',
subTitle: 'vuejs is crazy'
},
{
title: 'reactjs',
subTitle: 'reactjs is beautify'
}
]
};
},
created() {
// 添加事件
this.$my_event.on('handleAdd', (payload) => {
this.dataList.push(payload);
});
}
};
</script>在Search.vue中我们可以看到,我们是用 this.$my_event.emit去触发事件的
<template>
<div class="search">
<a-row type="flex" justify="center">
<a-col :span="4">
<a-input placeholder="Basic usage" v-model="value" @pressEnter="handleAdd"></a-input>
</a-col>
<a-col :span="2">
<a-button type="dashed" @click="handleAdd">添加</a-button>
</a-col>
</a-row>
</div>
</template>
<script>
export default {
name: 'search',
data() {
return {
value: '',
odd: 0
};
},
methods: {
handleAdd() {
const { value: title } = this;
if (title === '') {
return;
}
this.odd = !this.odd;
this.$my_event.emit('handleAdd', { title, subTitle: `${title} is ${this.odd ? 'crazy' : 'beautify'}` });
}
}
};
</script>
<style></style>$parent或者$refs访问父组件或者调用子组件方法这是项目中比较常用粗暴的手段,用一段伪代码感受下就行,不太建议项目里用 this.$parent 操作
<template>
<div class="todo-list">
<h1>todo list-event-bus</h1>
<Search ref="search" />
<content :dataList="dataList" />
</div>
</template>
<script>
import Search from './Search.vue';
import Content from './Content.vue';
export default {
name: 'todo-list',
components: { Search, Content },
data() {
return {
dataList: [
{
title: 'vuejs',
subTitle: 'vuejs is crazy'
},
{
title: 'reactjs',
subTitle: 'reactjs is beautify'
}
]
};
},
mounted() {
// 能直接调用子组件的数据或者方法
console.log(this.$refs.search.value);
}
};
</script>在Search.vue组件中也能调用父组件的方法
<template>
<div class="search">
<a-row type="flex" justify="center">
<a-col :span="4">
<a-input placeholder="Basic usage" v-model="value" @pressEnter="handleAdd"></a-input>
</a-col>
<a-col :span="2">
<a-button type="dashed" @click="handleAdd">添加</a-button>
</a-col>
</a-row>
</div>
</template>
<script>
export default {
name: 'search',
data() {
return {
value: '',
odd: 0
};
},
methods: {
handleAdd() {
// 访问父类的初始化数据
console.log(this.$parent.dataList);
const { value: title } = this;
if (title === '') {
return;
}
this.odd = !this.odd;
this.$my_event.emit('handleAdd', { title, subTitle: `${title} is ${this.odd ? 'crazy' : 'beautify'}` });
}
}
};
</script>最后把这个todo list demo完整的完善了一下,点击路由可以切换不同todolist了
1、用具体实例手撸一个todolist把所有vue中涵盖的通信方式props,自定义事件、vuex、vue.observable、provide/inject、eventBus实践了一遍
2、明白vuex的本质,实现Vue.observable跨组件通信
3、了解事件总线的实现方式,在vue中可以使用$emit与$on方式实现事件总线
4、本文代码示例:code example
在大数据渲染中,我们往往会考虑
缓存、分页、虚拟列表方式优化大数据量渲染,通常我们会用已有的现成插件比如umy-ui(ux-table)虚拟列表 table 组件,vue-virtual-scroller以及react-virtualized这些优秀的插件快速满足业务需要。
为了理解插件背后的原理机制,我们实现一个自己简易版的虚拟列表,希望在实际业务项目中能带来一些思考和帮助。
正文开始...
在大数据渲染中,选择一段可视区域显示对应数据。
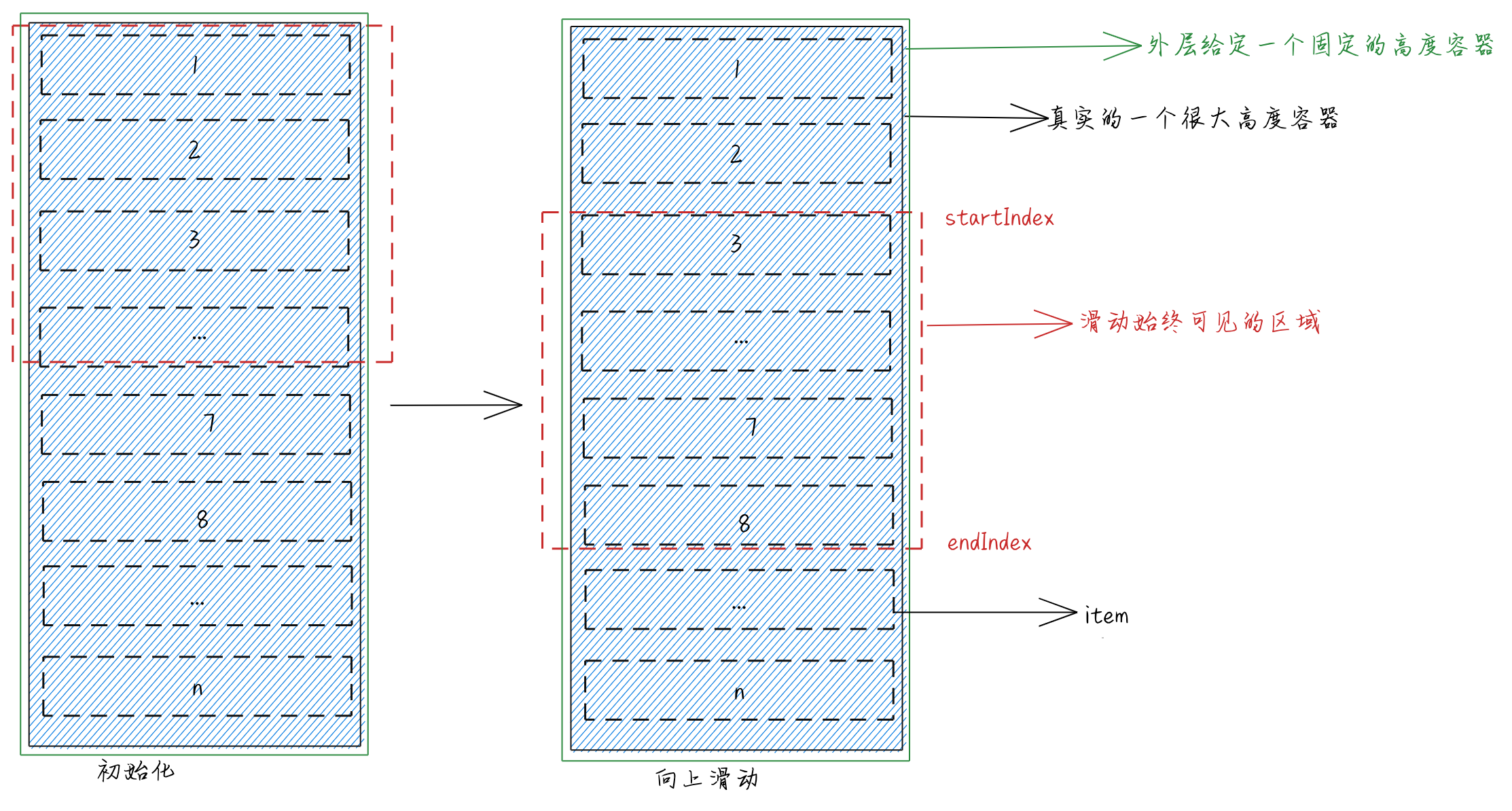
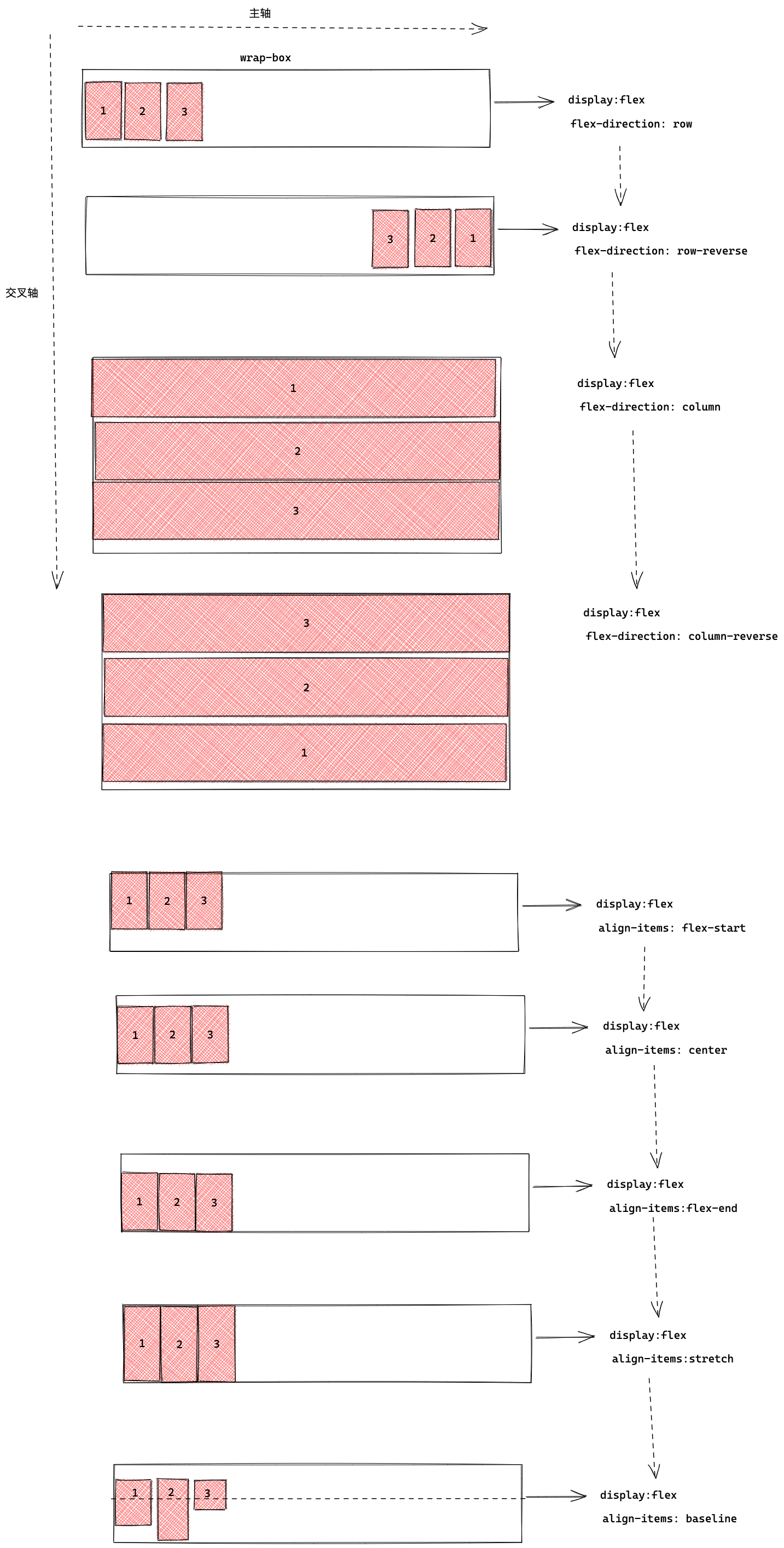
我们先初步看一个图
在这张展示图中,我们可以看到我们展示的始终是红色线虚线展示的部分,每一个元素固定高度,被一个很大高度的元素包裹着,并且最外层有一个固定的高度容器,并且设置可以滚动。
新建一个index.html对应结构如下
...
<div class="vitual-list-wrap" ref="listWrap">
<div class="content" :style="contentStyle">
<div class="item" v-for="(item, index) in list" :key="index" :style="item.style">{{item.content}}</div>
</div>
</div>对应的css
* {
padding: 0px;
margin: 0px;
}
#app {
width: 300px;
border: 1px solid #e5e5e5;
}
/*外部容器给一个固定的可视高度,并且设置可以滚动*/
.vitual-list-wrap {
position: relative;
height: 800px;
overflow-y: auto;
}
/*真实容器的区域*/
.content {
position: relative;
}
/*固定高度的每个元素*/
.item {
height: 60px;
padding: 10px 5px;
border-bottom: 1px solid #111;
position: absolute;
left: 0;
right: 0;
line-height: 60px;
}从对应页面结构与css中我们的思路大致是这样
有了对应设置的结构,因为我们每个元素是绝对定位的,所以我们现在的思路就是:
1、确定可视区域item显示的条数limit
2、向上滑动的当前位置起始位与最后位置,确定显示元素范围
3、确定每个元素的top,当向上滑动时,确定当前的位置与最后元素的位置索引,根据当前位置与最后元素位置,渲染可视区域
具体逻辑代码如下
<div id="app">
<h3>虚拟列表</h3>
<div class="vitual-list-wrap" ref="list-wrap">
<div class="content" :style="contentStyle">
<div class="item" v-for="(item, index) in list" :key="index" :style="item.style">{{item.content}}</div>
</div>
</div>
</div>
<!--引入vue3组件库-->
<script src="https://cdn.bootcdn.net/ajax/libs/vue/3.2.33/vue.global.min.js"></script>
<script src="./index.js"></script>我们具体看下index.js
// index.js
const { createApp, reactive, toRefs, computed, onMounted, ref } = Vue;
const vm = createApp({
setup() {
const listWrap = ref(null);
const viewData = reactive({
list: [],
total: 1000, // 数据总条数
height: 600, // 可视区域的高度
rowHeight: 60, // 每条item的高度
startIndex: 0, // 初始位置
endIndex: 0, // 结束位置
timer: false,
bufferSize: 5 // 做一个缓冲
});
const contentStyle = computed(() => {
return {
height: `${viewData.total * viewData.rowHeight}px`,
position: 'relative'
};
});
// todo 设置数据
const renderData = () => {
viewData.list = [];
const { rowHeight, height, startIndex, total, bufferSize } = viewData;
// 当前可视区域的row条数
const limit = Math.ceil(height / rowHeight);
console.log(limit, '=limit');
// 可视区域的最后一个位置
viewData.endIndex = Math.min(startIndex + limit + bufferSize, total - 1);
for (let i = startIndex; i < viewData.endIndex; i++) {
viewData.list.push({
content: i,
style: {
top: `${i * rowHeight}px`
}
});
}
};
// todo 监听滚动,设置statIndex与endIndex
const handleScroll = (callback) => {
// console.log(listWrap.value)
listWrap.value &&
listWrap.value.addEventListener('scroll', (e) => {
if (this.timer) {
return;
}
const { rowHeight, startIndex, bufferSize } = viewData;
const { scrollTop } = e.target;
// 计算当前滚动的位置,获取当前开始的起始位置
const currentIndex = Math.floor(scrollTop / rowHeight);
viewData.timer = true;
// console.log(startIndex, currentIndex);
// 做一个简单的节流处理
setTimeout(() => {
viewData.timer = false;
// 如果滑动的位置不是当前位置
if (currentIndex !== startIndex) {
viewData.startIndex = Math.max(currentIndex - bufferSize, 0);
callback();
}
}, 500);
});
};
onMounted(() => {
renderData();
handleScroll(renderData);
});
return {
...toRefs(viewData),
contentStyle,
renderData,
listWrap
};
}
});
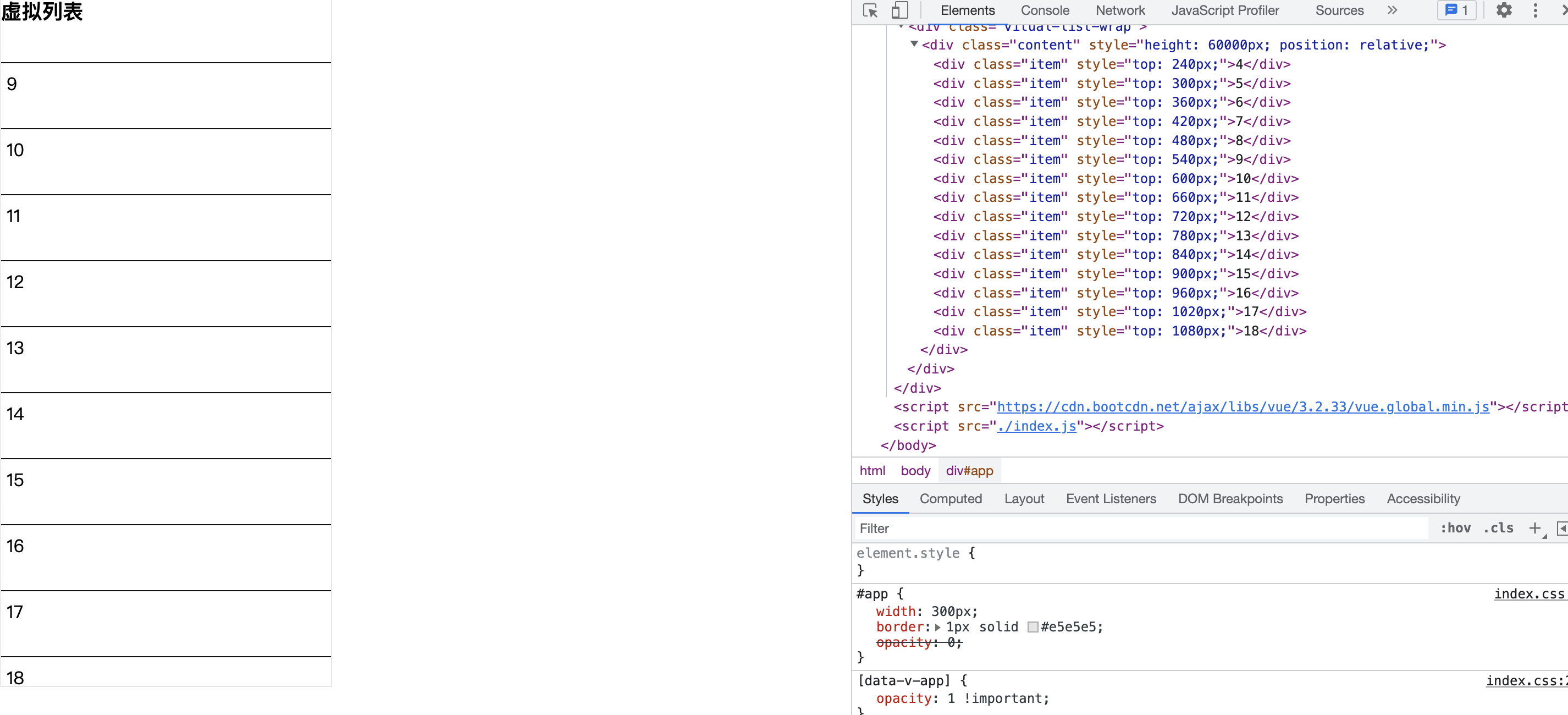
vm.mount('#app');看下页面,已经 ok 了,每次上滑都只会固定高度加载对应的数据
注意我们在css中有一段这样的代码
#app {
width: 300px;
border: 1px solid #e5e5e5;
opacity: 0;
}
... [data-v-app] {
opacity: 1 !important;
}这样处理主要是为了插值表达式在未渲染的时候,让用户看不到未渲染前的模版内容。如果不先隐藏,那么会打开页面的时候会有插值表达式,vue中提供了一个v-cloak,但是貌似这里不管用,在vue2中是可以的。
本篇是非常简易的虚拟列表实现,了解虚拟列表背后的实现**,更多可以参考vue-virtual-scroller与react-virtualized源码的实现,具体应用示例可以查看之前写的一篇偏应用的文章测试脚本把页面搞崩了 。
了解虚拟列表到底是什么,在大数据渲染中,选择一段可视区域显示对应数据
实现虚拟列表的背后原理,最外层给定一个固定的高度,然后设置纵向Y轴滚动,然后每个元素的父级设置相对定位,设置真实展示数据的高度,根据item固定高度(rowHeight),根据可视区域和rowHeight计算可显示的limit数目。
当滚动条上滑时,计算出滚动的距离scrollTop,通过currentIndex = Math.floor(scrollTop/rowHeight)计算出当前起始索引
根据endIndex = Math.min(currentIndex+limit, total-1)计算出最后可显示的索引
最后根据startIndex与结束位置endIndex,根据startIndex与endIndex渲染可视区域
本文示例code example
本文参考相关文章如何实现一个高度自适应的虚拟列表,这是react版本的
虽然平时业务接触算法不多,但是公司对于程序员的算法要求越来越高,基础不牢,地动山摇,优秀的程序员,算法是核心竞争力,也是解决复杂问题的一种必要手段。
前段时间加了一个刷算法题的群,也刷了leetcode的一些题目,今天一起学习掌握二分查找,熟记于心,触类旁通,达到真正掌握每种解题的方法,希望你在实际业务中有所帮助和思考。
正文开始...
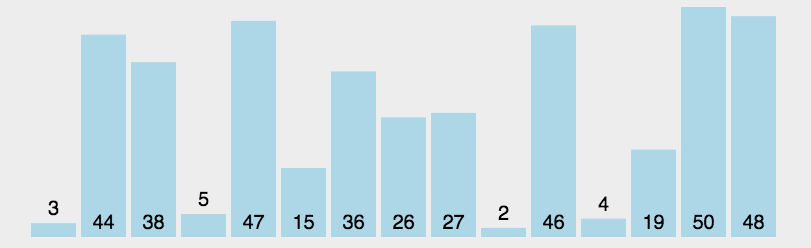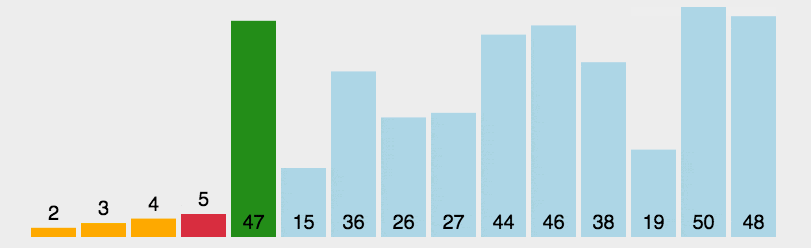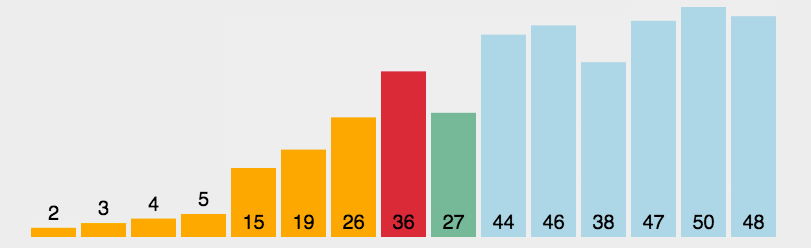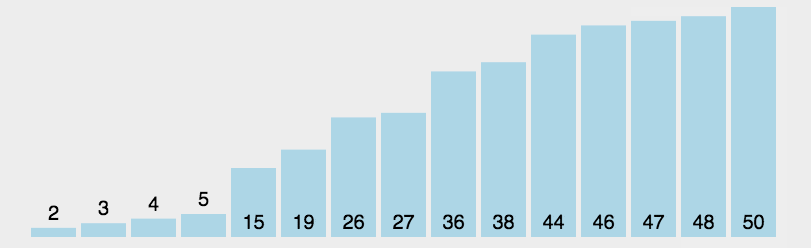
题目:给定一个有序无重复的数组arr和目标元素target,返回数组arr中target元素的下标位置
思路:在[left, right]区间中查找,指定中间位置与目标元素进行比较,如果目标元素在中间元素的左边,那么右侧区间就是[left,mid -1],如果目标元素在中间元素的右边,那么就从左侧区间开始[mid+1, right],直至找到与目标元素返回mid为止。
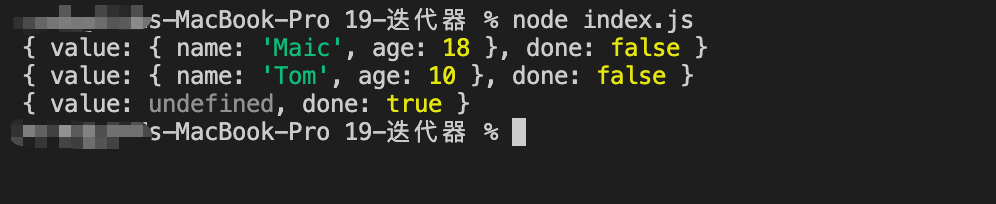
function binarySearch(arr, target) {
let left = 0; // 数组第一个位置
let right = arr.length - 1; // 数组中最后一个位置 // [left, right] 区间查找
while (left <= right) {
// 取数组中间位置
let mid = left + Math.floor((right - left) / 2); // 目标元素在中间位置的左边
if (target < arr[mid]) {
right = mid - 1; // [left, mid-1]
} else if (target > arr[mid]) {
// 目标元素在中间元素的右边,那么左区间[mid+1,right]
left = mid + 1;
} else {
return mid; // 直到找到target,相等就直接返回mid中间下标位置
}
}
return -1; // 没有找到就返回-1}binarySearch([1,3,4,5,7,8], 3); // 1
}用一张流程图描述一下上面的一段代码接下来再看下具体过程
我们会发现,二分查找实际上是从中间位置开始的,如果目标值在中间位置的左边,不断的减少
right区间,直至找到mid = right -1,当目标值target=3时,那么就返回mid的下标位置。
还有一种是左闭右开[left,right)
function binarySearch(arr, target) {
let left = 0; // 数组第一个位置
let right = arr.length - 1; // 数组中最后一个位置 // [left,right) 区间查找
while (left < right) {
// 取数组中间位置
let mid = left + Math.floor((right - left) / 2); // 目标元素在中间位置的左边
if (target < arr[mid]) {
right = mid; // [left, mid]
} else if (target > arr[mid]) {
// 目标元素在中间元素的右边,那么左区间[mid+1,right]
left = mid + 1;
} else {
return mid; // 直到找到target,相等就直接返回mid中间下标位置
}
}
return -1; // 没有找到就返回-1
}
binarySearch([1, 3, 4, 5, 7, 8], 3);巧用数组提供的api找到匹配的索引
function binarySearch(arr, target) {
return arr.findIndex((v) => v === target);
}
binarySearch([1, 3, 4, 5, 7, 8], 3); // 1你会发现原生提供的findIndex无论数组中是否有序,还是无序都可以找到target的索引,但是findIndex也有缺陷,如果数组中有重复的值,那么只会返回第一个先找到的下标索引。
function binarySearch(arr = [], target) {
let index = target ? 0 : -1;
for (let i = 0; i < arr.length; i++) {
if (target === arr[i]) {
index = i;
break;
} else {
index = -1;
}
}
return index;
}
binarySearch([1, 3, 4, 5, 7, 8], 3); // 1map 这种方式的缺陷是数组中不能有重复的值,只是针对无重复的数组
function binarySearch(arr = [], target) {
const map = new Map();
arr.forEach((v, index) => {
map.set(v, index); // 将值设置成map的key
});
return map.has(target) ? map.get(target) : -1;
}
binarySearch([1, 3, 4, 5, 7, 8], 3); // 1只针对无重复数组
function binarySearch(arr = [], target) {
const result = {};
arr.forEach((v, index) => {
result[v] = index; // 将值设置成map的key
});
return Reflect.has(result, target) ? result[target] : -1;
}
binarySearch([1, 3, 4, 5, 7, 8], 3); // 11、二分查找,将数组一分为二,确认中间位置,确定元素所在区域范围,如果是在左区间,则右区间则是mid - 1,左区间则固定[left, mid -1],如果元素所在区域是右区间,那么确定是右区间,右区间固定,左区间则是mid+1,[mid+1,right]
2、使用原生提供的findIndex快速寻找目标元素下标位置,最简单的一种方式
3、擅用map移花接木,利用map设置值方式,将元素值与索引存在map中,从而找到目标索引
4、利用对象存取数据,将元素值与索引存在result中,根据target从而找到目标索引
5、二分查找部分代码参考代码随想录[1]
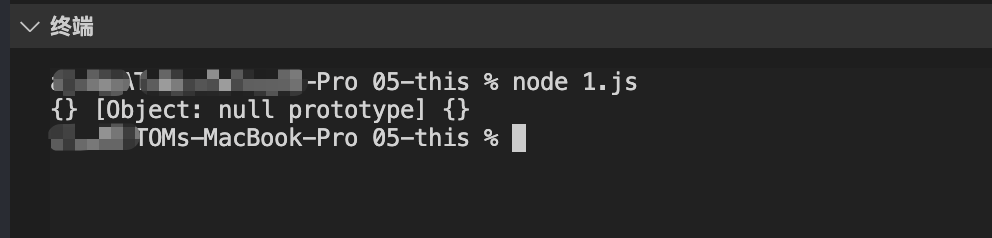
你知道 JS 中断循环有哪些吗?除了 for 循环的 break,还有哪些可以中断循环?接下来笔者以实际业务例子,分享几种能中断循环的方案,希望你在实际业务中能用得上。
在实际业务中你可能会写以下的业务代码,举个栗子,在一个循环表单域中,你需要内容为空,就禁止提交
::: details code
const shopList = [
{ title: 'Apple', price: 10 },
{ title: 'banana', price: '' },
{ title: 'orange', price: 5 }
];:::
以上是一组数组源,于是你的思路可能会这样
::: details code
const hasPriceEmpty = (arr) => {
bool = false; // 默认都不是空
arr.forEach((v) => {
if (v.price === '') {
bool = true;
break;
}
console.log(v);
});
return bool;
};
const handleSubmit = () => {
if (hasPriceEmpty(shopList)) {
return;
}
// 下面的继续业务操作
console.log('go on...');
};
handleSubmit();
:::
运行测试命令node 1.js,报错了!
于是你把 break 改成 return
::: details code
const hasPriceEmpty = (arr) => {
bool = false; // 默认都不是空
arr.forEach((v) => {
if (v.price === '') {
bool = true;
return;
}
console.log(v);
});
return bool;
};
...
:::
你会发现并没有打印go on...,确实是hasPriceEmpty这个方法已经达到了自己的业务要求,但是打印出了第一组和第三组数据。
于是mdn上关于 forEach 有这么一段话,Note: There is no way to stop or break a forEach() loop other than by throwing an exception. If you need such behavior, the forEach() method is the wrong tool.
大概意思就是除了抛出异常,break 无法中断循环,如果你想有中断行为,forEach不是一个好办法。
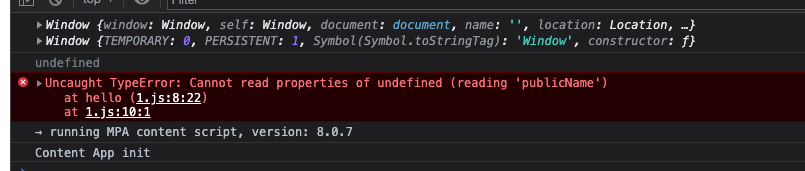
于是你想中断循环,你改了下代码
::: details code
const shopList = [
{ title: 'Apple', price: 10 },
{ title: 'banana', price: '' },
{ title: 'orange', price: 5 }
];
const hasPriceEmpty = (arr) => {
bool = false; // 默认都不是空
arr.forEach((v) => {
if (v.price === '') {
bool = true;
throw new Error('给我中断循环吧');
}
try {
console.log(v);
} catch (e) {
console.log(e);
console.log(v);
}
});
return bool;
};
const handleSubmit = () => {
if (hasPriceEmpty(shopList)) {
return;
}
// 下面的继续业务操作
console.log('go on...');
};
handleSubmit();
:::
对不起,页面只打印了第一组数据,且页面抛出了异常
我确实做到了中断 forEach 循环异常了,但是这个错误作为一个强迫症患者,我是不能接受的(throw 抛出的异常,记得 try catch 中捕获)。
这是笔者认为大部分人都能想到的办法
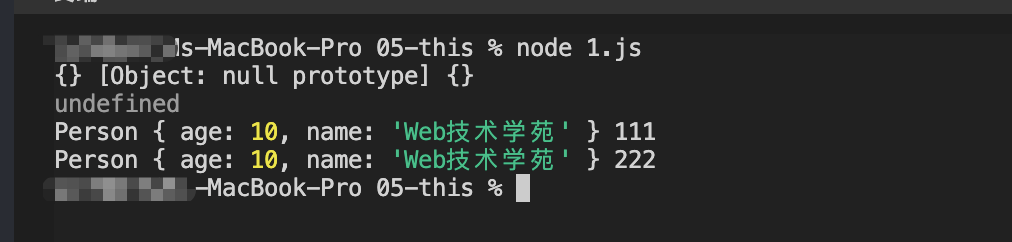
::: details code
const shopList = [
{ title: 'Apple', price: 10 },
{ title: 'banana', price: '' },
{ title: 'orange', price: 5 }
];
const hasPriceEmpty = (arr) => {
let bool = false; // 默认都不是空
for (let i = 0, len = arr.length; i < len; i++) {
if (arr[i].price === '') {
bool = true;
break;
}
console.log(arr[i]);
}
return bool;
};
const handleSubmit = () => {
if (hasPriceEmpty(shopList)) {
return;
}
// 下面的继续业务操作
console.log('go on...');
};
handleSubmit();
:::
结果很令人欢喜,完美
通常这种方式用得最多,但是作为老司机,你还需要掌握多一点其他方法。于是中断循环还有...
::: details code
const shopList = [
{ title: 'Apple', price: 10 },
{ title: 'banana', price: '' },
{ title: 'orange', price: 5 }
];
const hasPriceEmpty = (arr) => {
let bool = false; // 默认都不是空
let index = 0;
while (index < arr.length) {
index++;
console.log(arr[index], '000');
if (arr[index].price === '') {
bool = true;
break;
}
console.log(arr[index], '111');
}
return bool;
};
const handleSubmit = () => {
if (hasPriceEmpty(shopList)) {
return;
}
// 下面的继续业务操作
console.log('go on...');
};
handleSubmit();:::
结果喜大普奔,依然可以,测试结果如下
这已经达到我们想要的效果了。
利用 iterable 迭代器,for...of 中断循环
这里iterable是指具有该特性的迭代器,比如Array、Map、Set
::: details code
const shopList = [
{ title: 'Apple', price: 10 },
{ title: 'banana', price: '' },
{ title: 'orange', price: 5 }
];
const hasPriceEmpty = (arr) => {
let bool = false; // 默认都不是空
for (let item of arr) {
if (item.price === '') {
bool = true;
break;
}
console.log(item, '111');
}
return bool;
};
const handleSubmit = () => {
if (hasPriceEmpty(shopList)) {
return;
}
// 下面的继续业务操作
console.log('go on...');
};
handleSubmit();:::
于是测试结果依旧 ok
为什么数组可以用for..of循环,你可以在控制台打印注意到
原来默认申明的[]原型链上有一个这样的iterator的迭代器,所以你可以利用 iterator 的特性,用for...of中断循环
::: details code
const shopList = [
{ title: 'Apple', price: 10 },
{ title: 'banana', price: '' },
{ title: 'orange', price: 5 }
];
const hasPriceEmpty = (arr) => {
let bool = false; // 默认都不是空
const map = new Map();
// 将数据设置到Map中
arr.forEach((item) => {
map.set(item.title, item);
});
for (let s of map) {
console.log(s, '000');
if (s[1].price === '') {
bool = true;
break;
}
console.log(s, '111');
}
return bool;
};
const handleSubmit = () => {
if (hasPriceEmpty(shopList)) {
return;
}
// 下面的继续业务操作
console.log('go on...');
};
handleSubmit();:::
结果如下
以上代码也等价于
::: details code
const sourceData = [
{ title: 'Apple', price: 10 },
{ title: 'banana', price: '' },
{ title: 'orange', price: 5 }
];
const shopList = new Map([sourceData]);
const hasPriceEmpty = (arr) => {
let bool = false; // 默认都不是空
for (let s of arr) {
console.log(s, '000');
if (s[1].price === '') {
bool = true;
break;
}
console.log(s, '111');
}
return bool;
};
const handleSubmit = () => {
if (hasPriceEmpty(shopList)) {
return;
}
// 下面的继续业务操作
console.log('go on...');
};
handleSubmit();:::
验证结果如下:
利用 Map 有iterable的可迭代性,通过for...of中断循环,具体可以在控制台下验证
同样是一个栗子举证
::: details code
const shopList = [
{ title: 'Apple', price: 10 },
{ title: 'banana', price: '' },
{ title: 'orange', price: 5 }
];
const hasPriceEmpty = (arr) => {
let bool = false; // 默认都不是空
const setArr = new Set([...shopList]);
for (let s of setArr) {
console.log(s, '000');
if (s.price === '') {
bool = true;
break;
}
console.log(s, '111');
}
return bool;
};
const handleSubmit = () => {
if (hasPriceEmpty(shopList)) {
return;
}
// 下面的继续业务操作
console.log('go on...');
};
handleSubmit();:::
输出验证结果:
Set与Map一样,可以在控制台验证一下iterable属性,我就不验证了,呜呜。
1.forEach的中断循环可以抛异常来达到目的,但是不适合此业务场景
2.for 循环通用大法,break可以终止循环
3.while循环,break也可以终止循环
4.iterable特征的可迭代器,for...of,break中断循环,并且最重要的一点是在 break 后,当前索引条件不会继续执行,也就是 for...of 中,执行 break 后,后面语句都不会执行。
5.本文示例code-example
在过往中,我们都是本地配置
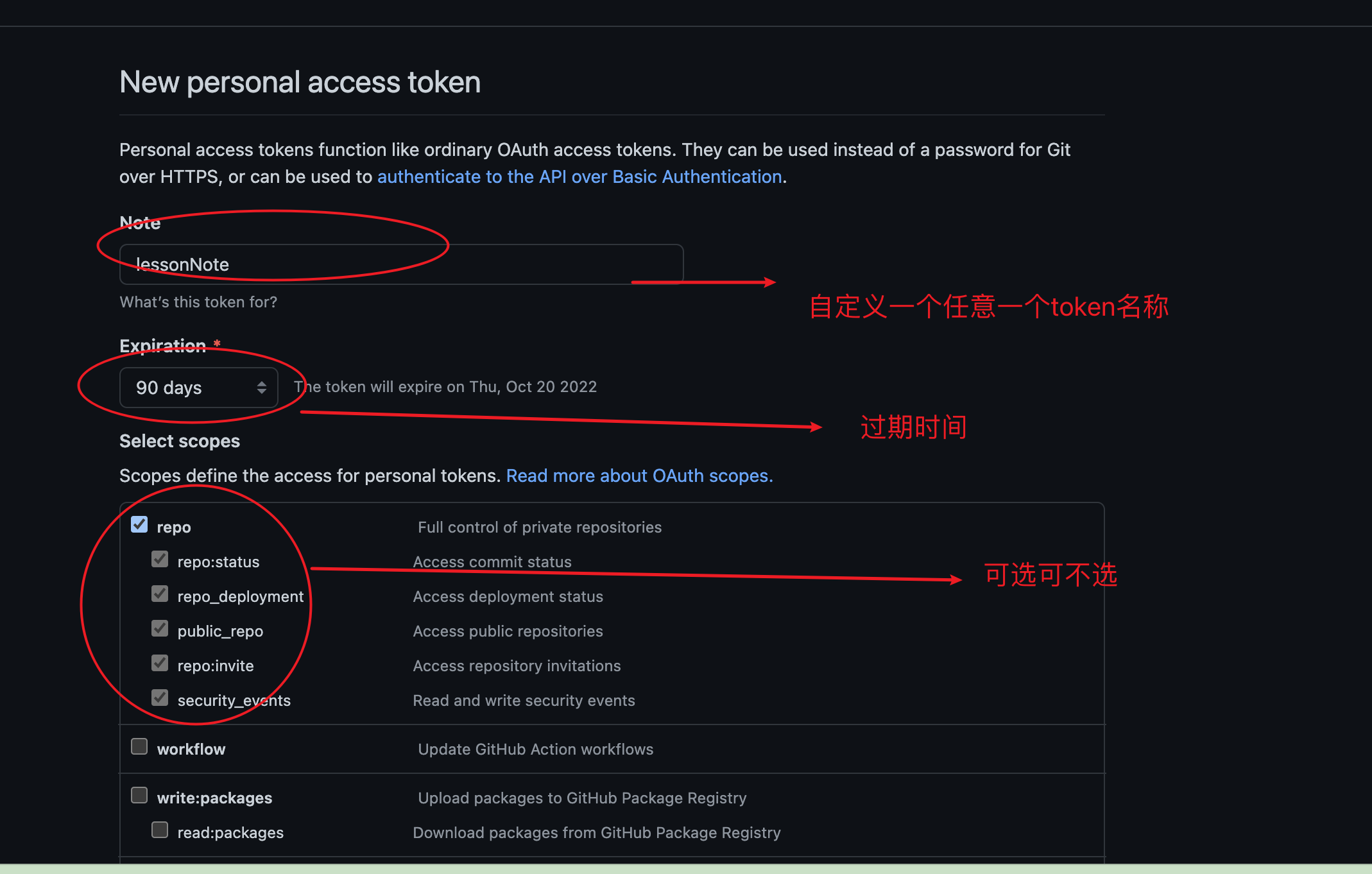
ssh生成key,然后在github的ssh中粘贴本地生成的key,这种方式其实挺繁琐的,如果我换一台电脑,貌似又需要重复一遍这样的操作,但是从2021.8.13号这天,也就是七夕节的前一天,github禁止了这种密码凭证的方式,所以有了personal access token这种方式
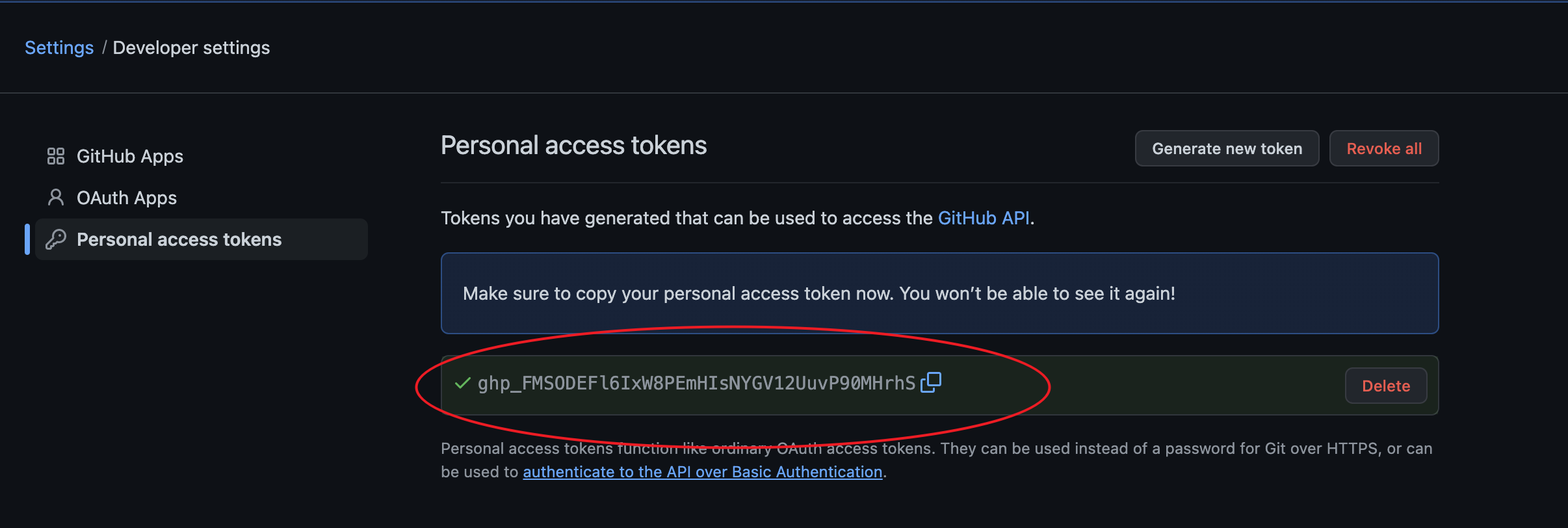
personal access token这种方式比价简单,只需要在个人账号的setPerson key
github的seting页注意这个token你需要复制出来,页面不要刷新,一刷新就没有了
在之前网上各种资料里可能都是推荐把token复制下载来,然后设置remote
比如你会像这样一样,假如你生成的token是下面这样的ghp_FMSODEFl6IxW8PEmHIsNYGV33232112UuvP90MHrhS
git remote add origin http://[email protected]/useName/xxx.git@github.com后面跟着的就是你创建项目名的具体git地址
比如我的就下面这样
你会发现这样设置,提交貌似没有问题,但是当你在另外一个仓库也是同样使用设置token时,如果你有用自动化脚本,大概率另外一个仓库一提交自动化脚本就会把这个token设置的给删除了
所以就需要设置另外一种方式
git remote rm origin添加https://username/xxx.git
git remote add origin https://xxx/xxx.gitgit add .
git commit -m 'update'
git push origin master此时你的vscode会让你输入用户名(github账号名)
当你输入完用户名后,会继续让你输入密码,此时你就需要把刚才你生成的token复制过来,填进去就可以了
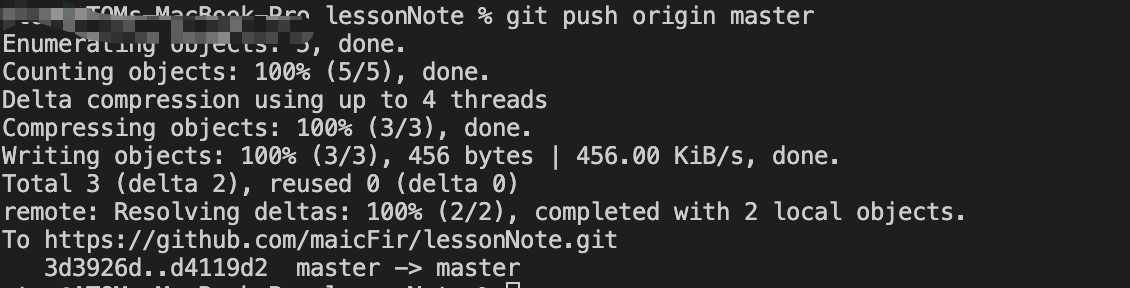
然后当你看到以下就说明已经提交成功了
至此,当你再次提交时,你不需重复以上步骤,已经可以愉快的提交你的本地仓库了
新替代原有ssh提交方案,原来那种ssh key方式官方已经不太建议了
现有person token方式更简单,安全性也很高
remote不太建议https://token/userName/xxx.git这种方式,当另外一个仓库也采用此时方式提交时,会把这个设置的token给删除掉,这个是有坑的
建议直接remote原有仓库的https方式,然后将token当成密码填入即可
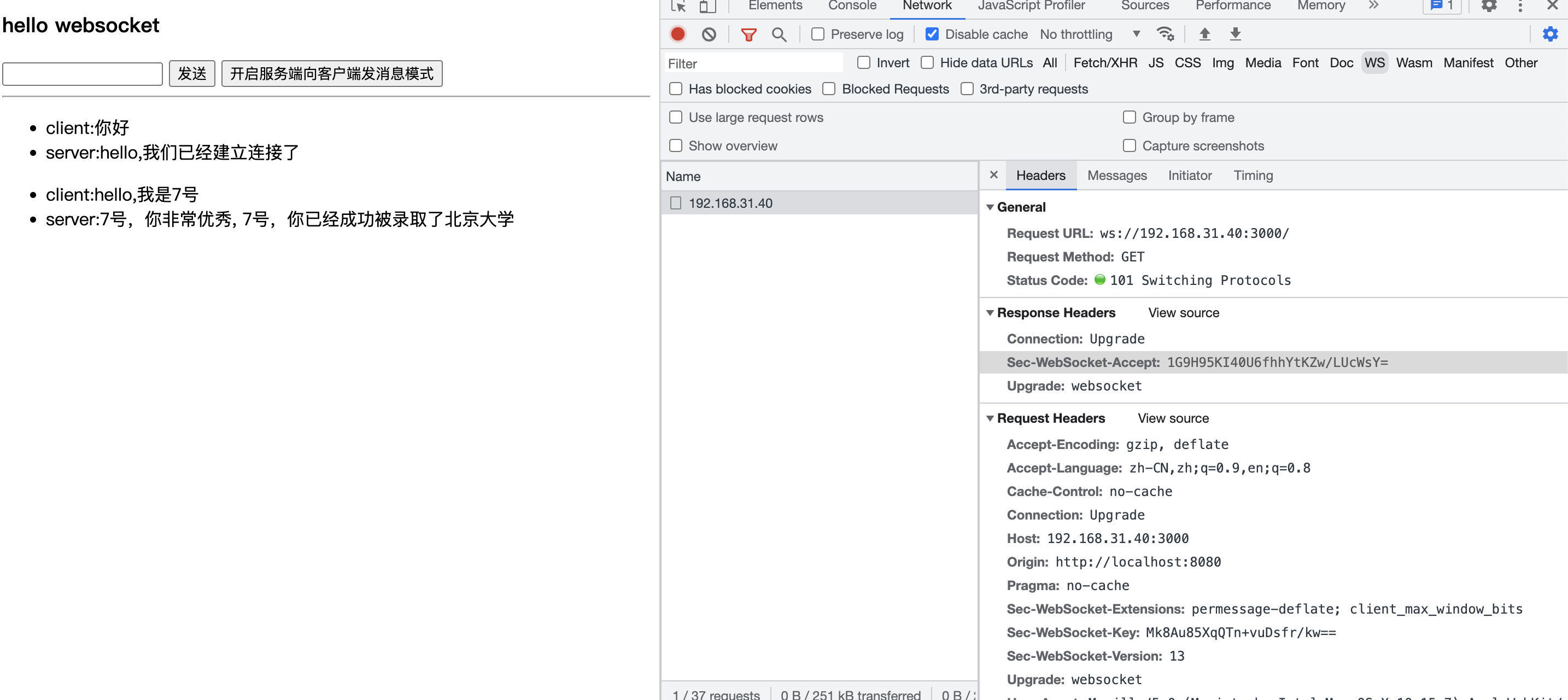
在webpack中构建本地服务,最重要的一个插件webpack-dev-server,我们俗称WDS,它承担起了在开发环境模块热加载、本地服务、接口代理等非常重要的功能。
本文是笔者对wds的一些理解和认识,希望在项目中有所帮助。
正文开始...
在阅读本文之前,本文会大概从下几个方面去了解wds
1、了解wds是什么
2、wds在 webpack 中如何使用
3、项目中使用wds是怎么样的
4、关于配置devServer的一些常用配置,代理等
5、wds如何实现模块热加载原理
webpack-dev-server顾名思义,这是一个在开发环境下的使用的本地服务,它承担了一个提供前端静态服务的作用
首先我们快速搭建一个项目,创建一个项目webpack-07-wds执行npm init -y,然后安装基础支持的插件
npm i webpack webpack-cli html-webpack-plugin webpack-dev-server -D创建一个webpack.config.js
const path = require('path');
const htmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
entry: './src/index.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'js/[name].js'
},
plugins: [
new htmlWebpackPlugin({
template: './public/index.html'
})
]
};在根目录下创建public,新建html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>webpack-for-dev-server</title>
</head>
<body>
<div id="app"></div>
</body>
</html>我们在入口文件写入一段简单的代码
// index
(() => {
const appDom = document.getElementById('app');
appDom.innerHTML = 'hello webpack for wds';
})();我们已经准备好了内容,现在需要启动wds,因此我们需要在在package.json中启动服务
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "webpack server"
},执行npm run start
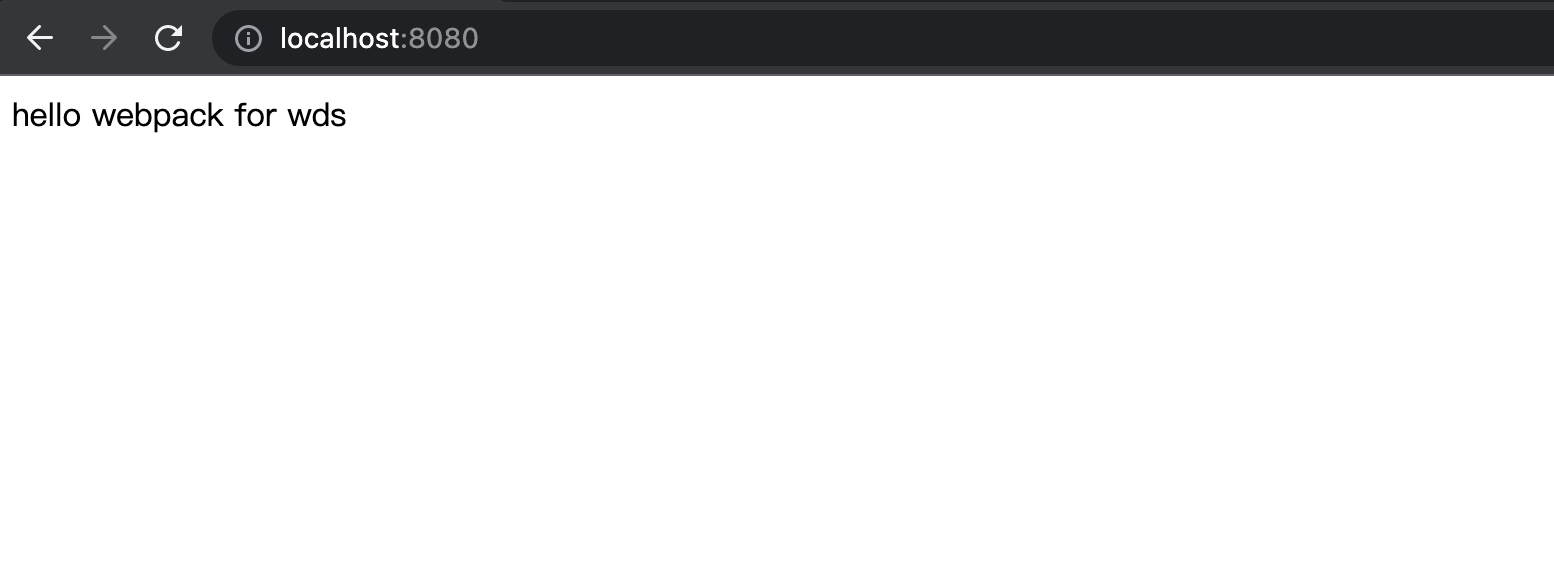
万事大吉,原来就是一行命令就可以了
但是这行命令的背后实际上有webpack-cli帮我们做了一下事情,实际上在.bin目录下,当你执行该命令时,webpack就会启用告知webpack-dev-server开启服务,通过webpack根据webpack.config.js的配置信息进行compiler,然后再交给webpack-dev-server处理
参考官方文档webpack-dev-server
根目录新建server.js
// server.js
const webpack = require('webpack');
const webpackDevServer = require('webpack-dev-server');
const webpackConfig = require('./webpack.config.js');
// webpack处理入口配置相关文件
const compiler = webpack(webpackConfig);
// devServer的相关配置
const devServerOption = {
port: 8081,
static: {
directory: path.join(__dirname, 'public')
},
compress: true // 开启gizps压缩public中的html
};
const server = new webpackDevServer(devServerOption, compiler);
const startServer = async () => {
console.log('server is start');
await server.start();
};
startServer();终端执行node server.js或者在package.json中配置,执行npm run server
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "webpack server",
"server": "node ./server.js"
}打开页面http://localhost:8081地址,发现是ok的
我们注意到可以使用webpack server启动服务,这个主要是webpack-cli的命令server
关于在命令行中设置对应的环境,在以前项目中可能你会看到,process.env.NODE_ENV这样的设置
你可以在cli命令中配置,注意只能在最前面设置,不能像以下这种方式设置webpack server NODE_ENV=test NODE_API=api,不然会无效
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "NODE_ENV=test NODE_API=api webpack server",
"server": "node ./server.js"
},在webpack.config.js中就可以看到设置的参数
// webpack.config.js
const path = require('path');
const htmlWebpackPlugin = require('html-webpack-plugin');
console.log(process.env.NODE_ENV, process.env.NODE_API); // test api
module.exports = {
entry: './src/index.js',
mode: 'development',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'js/[name].js'
},
plugins: [
new htmlWebpackPlugin({
template: './public/index.html'
})
]
};你可以设置--node-env xxx环境参数来指定环境变量
"start:test": "webpack server --node-env test",更多参数设置参考官方cli
我们上述是用一个server.js,通过命令行方式,调用webpack-dev-serverAPI 方式去启动一个本地的静态服务,但是实际上,在webpack中直接在配置devServer接口中配置就行。
了解几个常用的配置
port 指定端口打开页面client
progress 启动开发环境 gizp 压缩静态 htmlhistoryApiFallback 当使用路由模式为 history 时,必须设置这个,要不然前端刷新直接 404 页面hot模块热加载,需要结合module.hot.accept('xxx/xxx')指定某个模块热加载module.hot.acceptmodule.exports = {
...
devServer: {
port: '9000',
client: {
progress: true, // 启用gizp
overlay: {
errors: true, // 如果有错误会有蒙层
warnings: false,
},
webSocketURL: {
hostname: '0.0.0.0',
pathname: '/ws',
port: 8080,
protocol: 'ws',
}
},
historyApiFallback: true, // 使用路由模式为history时,必须设置这个,要不然前端刷新会直接404页面
hot: true, // 模块热加载,对应模块须配合module.hot.accept('xxx/xxx.js')指定模块热加载
open: true, // 当服务启动时默认自动直接打开浏览器,可以指定打开哪个页面
}
}proxy 这是项目中接触最多一点,也是初学者配置代理时常最令人头疼的事情,实际上proxy本质就是将本地的接口路由前缀代理到目标服务器环境,可以同时代理多个不同环境,具体参考以下
...
module.exports = {
...
devServer: {
...
proxy: {
'/j': {
target: 'https://movie.douban.com', // 代理豆瓣
changeOrigin: true
},
'/cmc': {
target: 'https://apps.game.qq.com', // 代理王者荣耀官网
changeOrigin: true, // 必须要加,否则代理接口直接返回html
pathRewrite: { '^/cmc': '/cmc' },
}
}
}
}我们修改index.js
(() => {
const $ = (id) => document.getElementById(id);
const appDomMovie = $('movie');
const gameDom = $('wang');
// appDom.innerHTML = 'hello webpack for wds,';
// https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=0
// 豆瓣电影
const featchMovie = async () => {
const { data = [] } = await (await fetch('/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=0')).json();
// console.log(data)
const divDom = document.createElement('div');
let str = '';
data.forEach((item) => {
const { title, rate } = item;
str += ` <span>${title},${rate}</span>`;
});
divDom.innerHTML = str;
appDomMovie.appendChild(divDom);
};
featchMovie();
const wangzherongyao = async () => {
const divDom = document.createElement('div');
// https://apps.game.qq.com/cmc/cross?serviceId=18&filter=tag&sortby=sIdxTime&source=web_pc&limit=20&logic=or&typeids=1%2C2&exclusiveChannel=4&exclusiveChannelSign=8a28b7e82d30142c1a986bb7acdcc068&time=1655732988&tagids=931
// 王者荣耀官网
const {
data: { items = [] }
} = await (
await fetch(
'/cmc/cross?serviceId=18&filter=tag&sortby=sIdxTime&source=web_pc&limit=20&logic=or&typeids=1%2C2&exclusiveChannel=4&exclusiveChannelSign=8a28b7e82d30142c1a986bb7acdcc068&time=1655732988&tagids=931'
)
).json();
let str = '';
console.log(items);
items.forEach((item) => {
const { sTitle, sIMG } = item;
str += `<div>
<img src=${sIMG} />
<div>${sTitle}</div>
</div>`;
});
divDom.innerHTML = str;
gameDom.appendChild(divDom);
};
wangzherongyao();
})();
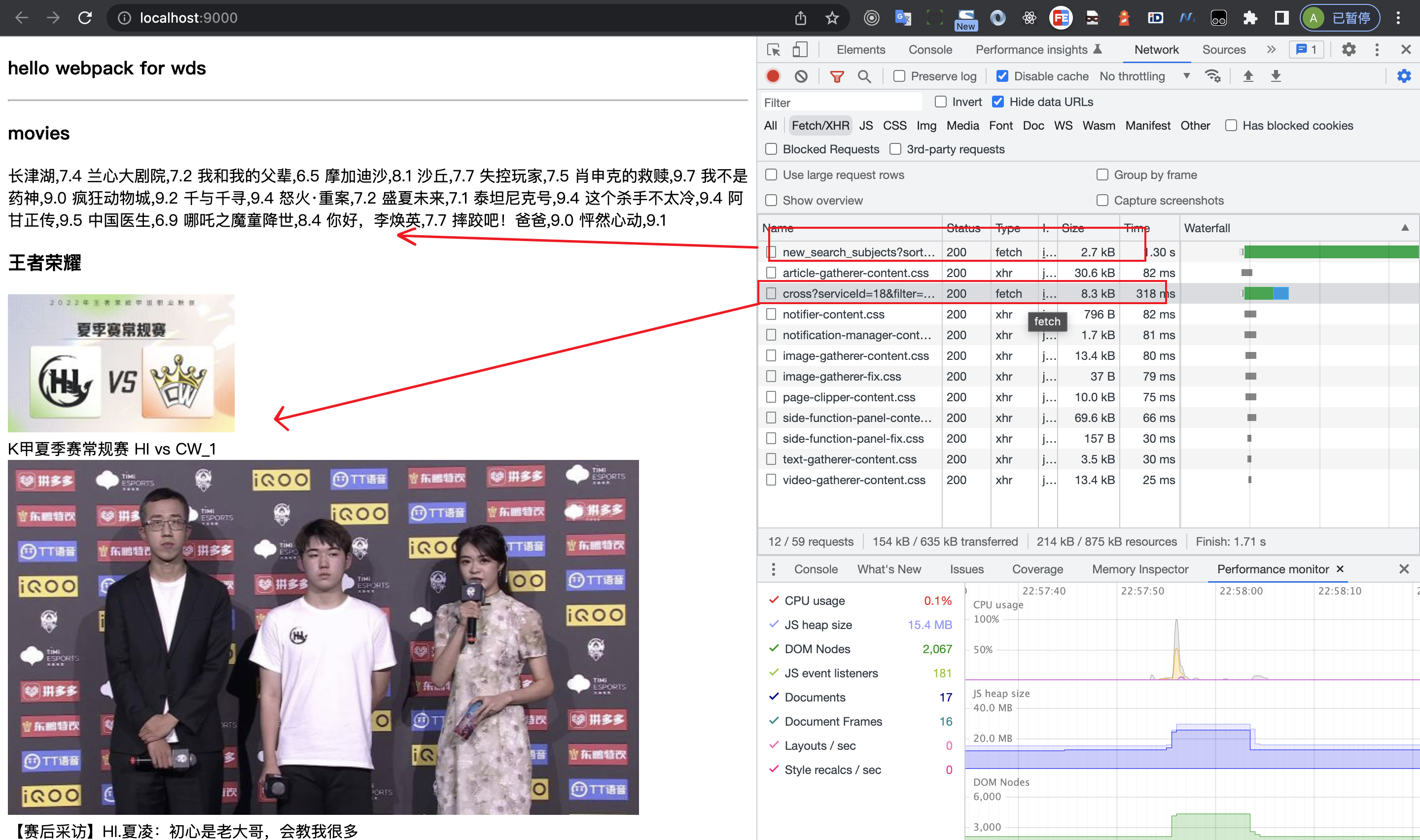
对应的两个接口数据就已经在页面上渲染出来了
对于代理我们会常常容易会犯以下几个误区
/代理,这会造成第二个代理无效,接口直接 404,优先级会先匹配第一个{
devServer: {
proxy: {
'/': {
target: 'https://movie.douban.com', // 代理豆瓣
changeOrigin: true,
},
'/cmc': {
target: 'https://apps.game.qq.com', // 代理王者荣耀官网
changeOrigin: true, // 必须要加,否则代理接口直接返回html
pathRewrite: { '^/cmc': '/cmc' },
}
}
}
}pathRewrite要不要加,什么时候该加,不知道你发现没有我第一个接口拦截并没有加pathRewrite,但是和第二个加了效果是一样的。现在有一个场景,就是你本地测试服务接口与线上接口是有区别的,一般你在本地开发是联调环境,后端的接口不按照常理出牌,假设联调环境后端就是死活不同意统一接口路径怎么办?
现在假设后端接口
联调环境:/dev/api/cmc/cross
线上环境是/api/cmc/cross
于是你想到有以下两种方案:
1、在 axios 请求拦截根据环境变量手动添加前缀,但是这不是一种很好的方案,相当于把不确定性的逻辑代码打包到线上去了,有一定风险
2、不管开发环境还是本地联调环境都是统一的路径,仅仅只是在proxy的pathRewrite做处理,这样风险很小,不容易造成线上接口 404 风险
于是这时候pathRewrite的作用就来了,重写路径,注意是pathRewrite: { '^/cmc': '/dev/cmc' }
我们仅仅是在开发环境重新了/cmc接口路径,实际上代码环境的代码并不会打包到线上
{
devServer: {
proxy: {
'/j': {
target: 'https://movie.douban.com', // 代理豆瓣
changeOrigin: true,
},
'/cmc': {
target: 'https://apps.game.qq.com', // 代理王者荣耀官网
changeOrigin: true, // 必须要加,否则代理接口直接返回html
pathRewrite: { '^/cmc': '/dev/cmc' },
}
}
}
}changeOrigin:true,像下面这种丢失了changeOrigin是不行的 devServer: {
proxy: {
'/j': {
target: 'https://movie.douban.com', // 代理豆瓣
// changeOrigin: true,
pathRewrite: { '^/j': '/j' },
},
'/cmc': {
target: 'https://apps.game.qq.com', // 代理王者荣耀官网
//changeOrigin: true,
pathRewrite: { '^/cmc': '/dev/cmc' },
}
}
}
}如果遇到有多个路由指向的是同一个服务器怎么办,别急,官网有方案,你可以这么做
{
devServer: {
proxy: [
{
context: ['/j', '/cmc'],
target: 'https://movie.douban.com'
}
];
}
}项目常用的就是以上这些了,另外拓展的,比如可以支持本地https,因为默认本地是http,还有支持当前可以开启一个websocket服务,更多配置参考官网,或者有更多特别的需求,及时翻阅官网
只更新页面模块变化的内容,无需全站刷新
本质上就是webpack-dev-server中的两个服务,一个express提供的静态服务,通过webpack去compiler入口的依赖文件,加载打包内存中的bundle.js
第二个模块热加载是一个websocket服务,通过socketio,当源码静态文件发生变化时,此时会生成一个manifest文件,这个文件会记录一个hash以及对应文件修改的chunk.js,当文件修改时websocket会单独向浏览器发送一个ws服务,从而更新页面部分模块,更多可以参考官网hot-module-replacement
了解webpack-dev-server是什么,它是一个开发环境的静态服务
webpack-dev-server在 webpack 中的使用
关于WDS一些常用的配置,比如如何配置接口代理等
浅识HMR模块热加载,原生webpack虽然也提供了模块热加载,但是webpack-dev-server可以实现模块热加载,常用框架,比如vue,内部热加载是用vue-loader实现的,在使用WDS时,默认是开启了热加载的。
可以观察
元素是否可见,由于目标元素与视口产生一个交叉区,我们可以观察到目标元素的可见区域,通常称这个API为交叉观察器
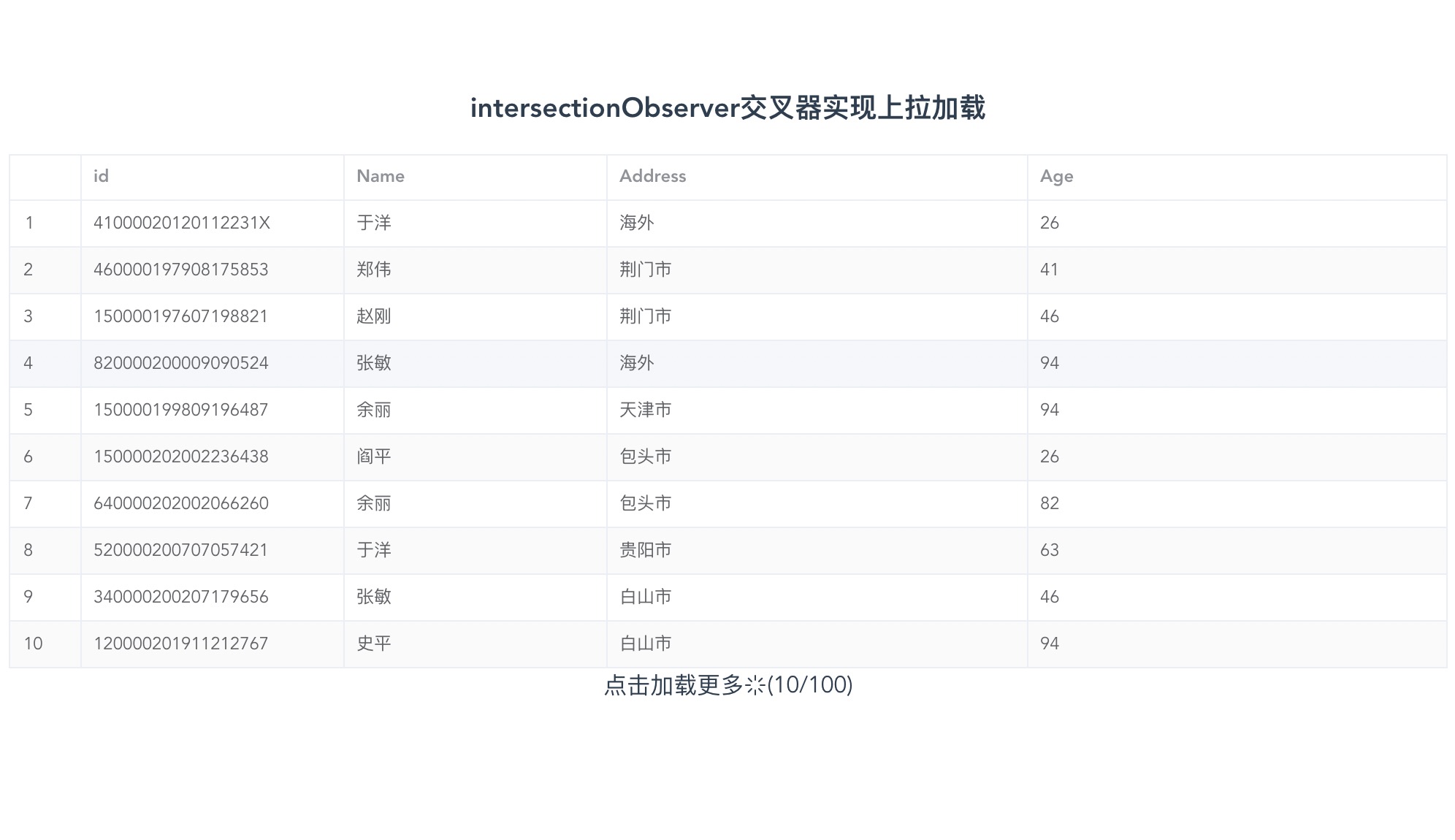
前段时间内部系统业务需要,用 IntersectionObserver实现了table中的上拉数据加载,如果有类似需求,希望本文能带给你一点思考和帮助
正文开始...
参考官网vite快速启动一个项目
::: details code
$ npm init vite@latest:::
选择一个vue模板快速初始化一个页面后,我们添加路由页面
::: details code
npm i vue-router@4:::
在已有项目上添加路由
// main.ts
import { createApp } from 'vue';
import route from './router/index';
import App from './App.vue';
const app = createApp(App);
app.use(route);
app.mount('#app');修改App模板,另外我们引入elementPlus,引入它主要是我们在实际项目中,我们用第三方 UI 库非常高频,在之前一篇文章中有提到虚拟列表优化大数据量,具体参考测试脚本把页面搞崩了。今天用交叉观察器也算是优化大数据量渲染的一种方案。
::: details code
// App.vue
<script setup lang="ts">
// This starter template is using Vue 3 <script setup> SFCs
// Check out https://v3.vuejs.org/api/sfc-script-setup.html#sfc-script-setup
import { ElConfigProvider } from 'element-plus';
import { ref } from 'vue';
const zIndex = ref(1000);
const size = ref('small');
</script>
<template>
<el-config-provider :size="size" :z-index="zIndex">
<router-view></router-view>
</el-config-provider>
</template>
<style>
#app {
font-family: Avenir, Helvetica, Arial, sans-serif;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
text-align: center;
color: #2c3e50;
margin-top: 60px;
}
</style>:::
创建router文件夹,新建index.ts,添加路由页面
::: details code
// router/index.ts
import { createWebHashHistory, createRouter } from 'vue-router';
import HelloWorld from '../components/HelloWorld.vue';
import ShopListPage from '../view/shopList/Index.vue';
const routes = [
{
path: '/hello',
component: HelloWorld
},
{
path: '/',
component: ShopListPage
}
];
const router = createRouter({
history: createWebHashHistory(),
routes
});
export default router;:::
我们新建一个view/shopList目录,在shopList中新建一个Index.vue开始今天的栗子。
本地开发环境安装mockjs模拟接口数据
npm i mockjs --save-dev新建mock我们使用它模拟接口随机数据,我们会在main.ts引入该mock/index.js
::: details code
// mock/index.ts
import Mockjs from 'mockjs';
import mockFetch from 'mockjs-fetch';
// 拦截mock
mockFetch(Mockjs);
// 生成随机长度的数组
const createMapRandom = (len: number) => {
const data = new Array(len);
return data.fill('Maic');
};
Mockjs.mock('/shoplist/list.json', () => {
return {
code: 0,
data: Mockjs.mock({
'list|10': [
{
'id|+1': createMapRandom(10).map(() => Mockjs.mock('@id')),
'adress|1': createMapRandom(10).map(() => Mockjs.mock('@city')),
'age|1': createMapRandom(10).map(() => Mockjs.mock('@integer(0,100)')),
'name|1': createMapRandom(10).map(() => Mockjs.mock('@cname'))
}
]
})
};
});:::
注意我们在使用mockjs时,我们使用了另外一个库mockjs-fetch,如果在项目中使用fetch做ajax请求,那么必须要使用这个库拦截mock请求,在默认情况下,如果你使用的是axios库,那么mock会默认拦截请求。
在view/shopList目录下,我们创建Index.vue
<template>
<div class="shopList">
<h3>intersectionObserver交叉器实现上拉加载</h3>
<el-table :data="tableData" border stripe style="width: 100%">
<el-table-column type="index" width="50" />
<el-table-column property="id" label="id" width="180" />
<el-table-column property="name" label="Name" width="180" />
<el-table-column property="adress" label="Address" />
<el-table-column property="age" label="Age" />
</el-table>
<div @click="handleMore" v-if="hasMore">点击加载更多</div>
<div v-else>没有数据啦</div>
</div>
</template>对应的js,这段js逻辑非常简单,就是请求模拟的mock数据,然后设置table所需要的数据,点击加载更多就继续请求,如果没有数据了,就显示没有数据。
::: details code
<script setup lang="ts">
import { reactive, ref, onMounted } from "vue";
import { ElTable, ElTableColumn } from "element-plus";
import "element-plus/dist/index.css";
const hasMore = ref(false);
const tableData = ref([]);
const condation = reactive({
pageParams: {
page: 1,
pageSize: 10,
},
});
// TODO 请求数据
const featchList = async () => {
const res = await fetch("/shoplist/list.json", {
method: "GET",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(condation.pageParams),
});
const json = await res.json();
tableData.value = tableData.value.concat(json.data.list);
};
onMounted(() => {
featchList();
});
// TODO 加载更多
const handleMore = () => {
featchList();
};
</script>:::
我们用vite初始化的项目是vue3,在vue3的script我们使用了setup,那么我们在script中不再用返回一个对象,申明的方法和变量可以直接在模板中使用,这里与组合式API有点区别,但是从功能上并没有什么区别。
在传统上,我们实现上拉加载,我们会监听滚动条到底部的距离,我们计算滚动条距离顶部位置、浏览器可视区域的高度、body 的高度,监听滚动事件,判断scrollTop + clientHeight > bodyScrollHeight,然后就判断是否需要加载下一页。
监听滚动事件,我们会加防抖处理事件,即使这样scroll事件也会高频触发,这样也会影响性能。
因此我们使用IntersectionObserver这个API实现上拉加载。
我们看下IntersectionObserver这个 API
// callback是一个回调函数,options是可配置的参数
var observer = new IntersectionObserver(callback, options);
// target1是一个具体的dom元素
observer.observe(target1); // 开始观察
observer.observe(target2);
observer.unobserve(target); // 停止观察
observer.disconnect(); // 停止观察我们可以在页面中用observer可以观察多个dom,同时我们也需要知道new IntersectionObserver()这个是异步的,并不会随着页面的滚动而时时触发,它只会在线程空闲下来才会执行,因此它在事件循环中,优先级很低,只有等其他任务执行完了,浏览器有了空闲才会执行它。
当目标元素可见时,会触发callback,另一次是当元素完全不可见时也会触发该callback
const options = {};
var observer = new IntersectionObserver((entries, observer) => {
console.log(entries); // entries 是一个数组,监听几个dom就会有几个
}, options);在IntersectionObserver中的entries第一个参数里,其中有几个参数我们需要了解下
::: details code
// entries
type clientRect = {
top: number;
bottom: number,
left: number,
right: number,
width: number,
height: number
}
const entriesRes = {
time: 12334,
rootBounds: {
bottom: 920,
height: 1024,
left: 0,
right: 1024,
top: 0,
width: 920
} as clientRect,
boundingClientRect: {
...
} as clientRect,
intersectionRect: {
} as clientRect,
intersectionRatio: 0,
target: dom
};
const entries = [entriesRes]
// observer
{
delay: 0
root: null
rootMargin: "0px 0px 0px 0px"
thresholds: [0]
trackVisibility: false
}:::
在第二个参数options中可配置参数
var options = {
threshold: [0, 0.5, 1],
root: document.getElementById('box1')
};threshold这个可以设置目标元素可见范围在 0,50%,100%时触发回调callback,root就是可以目标元素所在的祖先节点
我们花了一些时间了解IntersectionObserver这个API,接下来我们用它实现一个上拉加载。
// 关键代码
...
// 自定义一个上拉加载的指令
const vScrollTable = {
created: (el, binding, vnode, prevVnod) => {
handleScrollTable(el, binding);
},
};然后就是handleScrollTable这个方法
::: details code
...
// 自定义指令的created中调用该方法
const handleScrollTable = (el, binding) => {
const { infiniteScrollDisable, cb } = binding.value;
// 如果el不存在,则禁止后面IntersectionObserver的实例化
if (!el && !cb) {
return;
}
// 核心上拉加载代码
const intersectionObserver = new IntersectionObserver((enteris, observer) => {
// console.log(enteris, observer);
const [curentEnteris] = enteris;
const { intersectionRatio } = curentEnteris;
// 不可见的时候,禁止加载
if (intersectionRatio <= 0) return;
// 设置一个可以加载更多的开关
if (infiniteScrollDisable) {
cb();
}
});
// 开始监听
intersectionObserver.observe(el);
};:::
在模板里我们只需在目标元素上绑定指令就行
...
<div class="load-more-btn" @click="handleMore" v-if="hasMore" v-scroll-table="{ cb: handleMore, infiniteScrollDisable: hasMore }">
点击加载更多<el-icon :class="[loading ? 'is-loading' : '']"> <component :is="Loading"></component> </el-icon>({{ tableData.length }}/{{ total }})
</div>
<div v-else>没有数据啦</div>我们直接在元素上绑定自定义的指令v-scroll-table="{cb: handleMore,infiniteScrollDisable: hasMore}"就行
完整的全部示例见下面代码
::: details code
<!--shopList/Index.vue-->
<template>
<div class="shopList">
<h3>intersectionObserver交叉器实现上拉加载</h3>
<el-table :data="tableData" border stripe style="width: 100%" v-loading="loading">
<el-table-column type="index" width="50" />
<el-table-column property="id" label="id" width="180" />
<el-table-column property="name" label="Name" width="180" />
<el-table-column property="adress" label="Address" />
<el-table-column property="age" label="Age" />
</el-table>
<div class="load-more-btn" @click="handleMore" v-if="hasMore" v-scroll-table="{ cb: handleMore, infiniteScrollDisable: hasMore }">
点击加载更多<el-icon :class="[loading ? 'is-loading' : '']"> <component :is="Loading"></component> </el-icon>({{ tableData.length }}/{{ total }})
</div>
<div v-else>没有数据啦</div>
</div>
</template>
<script setup lang="ts">
import { reactive, ref, onMounted } from 'vue';
import { ElTable, ElTableColumn, ElIcon } from 'element-plus';
import { Loading } from '@element-plus/icons-vue';
import 'element-plus/dist/index.css';
const hasMore = ref(false);
const tableData = ref([]);
const loading = ref(false);
const condation = reactive({
pageParams: {
page: 1,
pageSize: 10
}
});
const total = ref(100);
// TODO 请求数据
const featchList = async () => {
const res = await fetch('/shoplist/list.json', {
method: 'GET',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(condation.pageParams)
});
const json = await res.json();
tableData.value = tableData.value.concat(json.data.list);
hasMore.value = true;
if (total.value === tableData.value.length) {
hasMore.value = false; // 没有更多了
}
loading.value = false;
};
onMounted(() => {
featchList();
});
// TODO 加载更多
const handleMore = () => {
loading.value = true;
// 加一个延时1s显示loading效果
setTimeout(() => {
featchList();
}, 1000);
};
const handleScrollTable = (el, binding) => {
const { infiniteScrollDisable, cb } = binding.value;
// 如果el不存在,则禁止后面IntersectionObserver的实例化
if (!el && !cb) {
return;
}
const intersectionObserver = new IntersectionObserver((enteris, observer) => {
// console.log(enteris, observer);
const [curentEnteris] = enteris;
const { intersectionRatio } = curentEnteris;
// 不可见的时候,禁止加载
if (intersectionRatio <= 0) return;
// 设置一个可以加载更多的开关
if (infiniteScrollDisable) {
cb();
}
});
// 开始监听
intersectionObserver.observe(el);
};
// 自定义一个上拉加载的指令
const vScrollTable = {
created: (el, binding, vnode, prevVnod) => {
handleScrollTable(el, binding);
}
};
</script>
<style>
.load-more-btn {
display: flex;
align-items: center;
justify-content: center;
}
</style>:::
打开页面,我们可以看到
点击加载操作就会加载更多,当滚动到底部时,就会加载更多。当数据加载完时,我们就设置hasMore = false;
核心代码非常简单,就是利用IntersectionObserver监测目标元素的可见,当目标元素可见时,我们加载更多,在目标元素不可见时,我们禁止加载更多,当数据加载完了,就禁止加载更多。
1.使用vite与vue3模板搭建一个简易的demo模板,结合vue-router、mockjs、elementPlus,fetch实现基本路由搭建,数据请求
2.了解核心IntersectionObserverAPI,用vue3指令,实现加载更多,这里用指令的原因是因为可以在多个类似模块复用指令内部那段逻辑,这样可以提高我们业务功能的复用能力
3.我们看到在vue3中script中使用了setup,在注册组件和模板上使用的变量,当前组件可以直接使用。如果你未在script中使用setup,那么就要与组合式API一样使用setup,返回模板中使用的变量以及绑定的方法,并且注册局部组件依旧要像以前方式一样在component中引入
4.更多关于IntersectionObserver的实践,我们可以用它做图片懒加载,视频播放暂停与播放等,具体可以参考这篇文章IntersectionObserver
5.本文示例源码地址intersectionObserver
项目中我们常常会接触到模块,最为典型代表的是
esModule与commonjs,在es6之前还有AMD代表的seajs,requirejs,在项目模块加载的文件之间,我们如何选择,比如常常因为某个变量,我们需要动态加载某个文件,因此你想到了require('xxx'),我们也常常会用import方式导入路由组件或者文件,等等。因此我们有必要真正明白如何使用好它,并正确的用好它们。
以下是笔者对于模块理解,希望在实际项目中能给你带来一点思考和帮助。
正文开始...
关于script加载的那几个标识,defer、async、module
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>module</title>
</head>
<body>
<div id="app"></div>
<script src="./js/2.js" defer></script>
<script src="./js/1.js" async></script>
<script src="./js/3.js">
console.log('同步加载', 3)
</script>
</body>
</html>// js/2.js
console.log('defer加载', 2);
// js/1.js
console.log('async异步加载不保证顺序', 1);
// js/3.js
console.log('同步加载', 3);我们会发现执行顺序是3,1,2
defer与async是异步的,而同步加载的 3,在页面中优先执行了。在执行顺序中,我们可以知道标识的defer是等同步的3与async的1执行后才最后执行的。
为了证明这点,我们在1.js中加入一段代码
// 1.js
console.log('没有定时器的async', 1);
setTimeout(() => {
console.log('有定时器的async,异步加载不保证顺序', 1);
}, 1000);最后我们发现打印的顺序,同步加载3,(没有定时器的async)1、defer加载2、有定时器的async,异步加载不保证顺序1
因为1.js加入了一段定时器,在事件循环中,它是一段宏任务,我们知道在浏览器处理事件循环中,同步任务>异步任务[微任务 promise>宏任务 setTimeout,事件等],在2.js中用defer标识了自己是异步,但是1.js中有定时器,2.js实际上是等了1.js执行完了,再执行的。
如果我在2.js中也加入定时器呢
console.log('没有定时器的defer加载', 2);
setTimeout(() => {
console.log('有定时器的defer加载', 2);
}, 1000);我们会发现结果依然是如此
3.js 同步加载 3
1.js 没有定时器的async 1
2.js 没有定时器的defer加载 2
1.js 有定时器的async,异步加载不保证顺序 1
2.js 有定时器的defer加载 2不难发现 defer中的定时器脚本虽然在async标识的脚本前面,但是,注意两个定时器实际上是会有前后顺序的,跟脚本的顺序没有关系
两个任务都是定时器,都是宏任务,在脚本的执行顺序中第一个定时器会先放到队列任务中,第二个定时器也会放到队列中,遵循先进先出,第一个宏任务(1.js 有定时器)先进队列,然后2.js定时器再进入队列,后面再执行。
但是注意,定时器时间短的优先进入队列。
好了,搞明白defer与async的区别了,总结一句,defer会等其他脚本加载完了再执行,而async是异步的,并不一定是在前面的就先执行。
接下来我们来看看module
module是浏览器直接加载es6,我们注意到加载module中有哪些特性?
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>module</title>
</head>
<body>
<div id="app"></div>
<script src="./js/2.js" defer></script>
<script src="./js/1.js" async></script>
<script src="./js/3.js"></script>
<script type="module">
import userInfo, { cityList } from './js/4.js';
console.log(userInfo);
// { name: 'Maic', age: 18}
console.log(cityList);
console.log(this); // undefined
/*
[ {
value: '北京',
code: 1
},
{
value: '上海',
code: 0
}
]
*/
</script>
</body>
</html>在js/4.js中,我们可以看到可以用esModule的方式输出
export default {
name: 'Maic',
age: 18
};
const cityList = [
{
value: '北京',
code: 1
},
{
value: '上海',
code: 0
}
];
export { cityList };在script用type="module"后,内部顶层this就不再是window对象了,并且引入的外部路径不能省略后缀,且脚本自动采用严格模式。
通常我们在项目中都是es6模块,在nodejs中大量模块代码都是采用commonjs的方式,既然项目里都有用到,那么我们再次回顾下他们有什么区别
参考module 加载实现中写道
1、commonjs输出的是一个值的拷贝,而es6模块输出的是一个只读值的引用
2、commonjs是在运行时加载,而es6模块是在编译时输出接口
3、commonjs的require()是同步加载,而es6的import xx from xxx是异步加载,有一个独立的模块解析阶段
另外我们还要知道commonjs的require引入的是module.exports出来的对象或者属性。而es6模块不是对象,它对外暴露的接口是一种静态定义,在代码解析阶段就已经完成。
举个例子,commonjs
// 5.js
const userInfo = {
name: 'Maic',
age: 18
};
let count = 1;
const countAge = () => {
userInfo.age += 1;
count++;
console.log(`count:${count}`);
};
module.exports = {
userInfo,
countAge,
count
};
// 6.js
const { userInfo, countAge, count } = require('./5.js');
console.log(userInfo); // {name: 'Maic', age: 18}
countAge(); // count:2
console.log(userInfo); // {name: 'Maic', age: 19}
console.log(count); // 1node 6.js
从打印里可以看出,一个原始的输出count,外部调用countAge并不会影响count输出的值,但是在内部countAge打印的仍是当前++后的值。
如果是es6模块,我们可以发现
const userInfo = {
name: 'Maic',
age: 18
};
let count = 1;
const countAge = () => {
userInfo.age += 1;
count++;
console.log('count', count);
};
export { userInfo, countAge, count };在页面中引入,我们可以发现
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>module</title>
</head>
<body>
<div id="app"></div>
...
<script type="module">
import userInfo, { cityList } from './js/4.js';
import { userInfo as nuseInfo, count, countAge } from './js/7.js';
console.log(userInfo, cityList);
console.log(this);
// { name: 'Maic', age: 18}
countAge();
console.log(nuseInfo, count);
// {name: 'Maic', age: 19} 2
</script>
</body>
</html>我们发现count导出后的值是实时的改变了。因为它是一个值的引用。
接下来有疑问,比如我有一个工具函数
function Utils() {
this.sum = 0;
this.add = function () {
this.sum += 1;
};
this.sub = function () {
this.sum-=1;
}
this.show = function () {
console.log(this.sum);
};
}
export new Utils;这工具函数,在很多地方会有引用,比如A,B,C...等页面都会引入它,那么它会每次都会实例化Utils?
接下来我们实验下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>module</title>
</head>
<body>
<div id="app"></div>
...
<script type="module">
// A
import { utils } from './js/7.js';
utils.add();
console.log(utils);
</script>
<script type="module">
// B
import { utils } from './js/7.js';
console.log('sum=', utils.sum);
console.log(utils);
</script>
</body>
</html>// 7.js
const userInfo = {
name: 'Maic',
age: 18
};
let count = 1;
const countAge = () => {
userInfo.age += 1;
count++;
console.log('count', count);
};
function Utils() {
this.sum = 0;
this.add = function () {
this.sum += 1;
};
this.sub = function () {
this.sum -= 1;
};
this.show = function () {
console.log(this.sum);
};
}
const utils = new Utils();
export { userInfo, countAge, count, utils };我们会发现在A模块里调用utils.add()后,在B中打印utils.sum是1,那么证明B引入的utils与A是一样的。
如果我输出的仅仅是一个构造函数呢?看下面
// 7.js
...
function Utils() {
this.sum = 0;
this.add = function () {
this.sum += 1;
};
this.sub = function () {
this.sum-=1;
}
this.show = function () {
console.log(this.sum);
};
}
const utils = new Utils;
const cutils = Utils;
export {
userInfo,
countAge,
count,
utils,
cutils
};页面同样引入
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>module</title>
</head>
<body>
<div id="app"></div>
...
<script type="module">
// A
import { utils, cutils } from './js/7.js';
countAge();
console.log(nuseInfo, count);
utils.add();
new cutils().add();
console.log(utils);
</script>
<script type="module">
// B
import { utils, cutils } from './js/7.js';
console.log('sum=', utils.sum);
console.log(utils);
console.log('sum2=', new cutils().sum); // 0
</script>
</body>
</html>我们会发现A中new cutils().add()在B中new cutils().sum)访问,依然是0,所以当模块中导出的是一个构造函数时,每一个模块对应new 导出的构造函数都是重新开辟了一个新的内存空间。
因此可以得出结论,在es6模块中直接导出实例化对象的性能开销比直接导出构造函数更小些。
我们初步了解下CommonJS的加载
// A.js
module.exports = {
a: 1
};
// B.js
const { a } = require('./A.js');
console.log(a); // 1在执行require时,实际上内部会在内存中生成一个对象,require是一个nodejs环境提供的一个全局函数。
{
id: '...',
exports: { ... },
loaded: true,
...
}优先会从缓存中取值,缓存中没有就直接从exports中取值。具体更多可以参考这篇文章require 源码解读
另外,我们通常项目里可能会见到下面的代码
// A
exports.a = 1;
exports.b = 2;
// B
const a = require('./A.js');
console.log(a); // {a:1, b:2}以上与下面等价
// A.js
module.exports = {
a: 1,
b: 2
};
// B.js
const a = require('./A.js');
console.log(a); // {a:1,b:2}所以我们可以看出require实际上获取就是module.exports输出{}的一个值的拷贝。
当exports.xxx时,实际上require获取的值结果依旧是module.exports值的拷贝。也就是说,在运行时,当使用exports.xx时实际上会中间悄悄转换成module.exports了。
1、比较script``type中引入的三种模式defer、async、module的不同。
2、在module下,浏览器支持es模块,import方式加载模块
3、commonjs是在运行时同步加载的,并且导出的值是值拷贝,无法做到像esMoule一样做静态分析,而且esModule导出是值是值引用。
4、esModule导出的对象,多个文件引用不会重复实例化,多个文件引入的对象是同一份对象。
5、commonjs加载原理,优先会从缓存中获取,然后再从loader加载模块
6、本文示例code example
别被标题吓到,哈哈,即使现在vite横空出世,社区光芒四射,两个字很快,但是webpack依旧宝刀未老,依然扛起前端工程化的大梁,但是今天我为啥说要拥抱gulp,因为我们经常常吃一道菜,所以要换个口味,这样才营养均衡。
gulp定义是:用自动化构建工具增强你的工作流程,是一种基于任务文件流方式,你可以在前端写一些自动化脚本,或者升级历史传统项目,解放你重复打包,压缩,解压之类的操作。
个人理解gulp是一种命令式编程的体验,更注重构建过程,所有的任务需要你自己手动创建,你会对构建流程会非常清楚,这点不像webpack,webpack就是一个开箱即用的声明式方式,webpack是一个模块化打包工具,内部细节隐藏非常之深,你也不需关注细节,你只需要照着提供的API以及引入对应的loader和plugin使用就行。
言归正传,为了饮食均衡,今天一起学习下gulpjs
正文开始...
相比较webpack,其实gulp的项目结构更偏向传统的应用,只是我们借助gulp工具解放我们的一些代码压缩、es6编译、打包以及在传统项目中都可以使用less体验。
在gulp目录下新建01-simple-demo
根目录下生成默认package.json
npm init -y然后在public目录下新建images、css、js、index.html
文件结构,大概就这样
然后在安装gulp
npm i gulp --save-dev在根目录下新建gulpfile.js
我们先在gulpfile.js中写入一点内容,测试一下
const defaultTask = (cb) => {
console.log('hello gulp')
cb();
}
exports.default = defaultTask;然后我们在命令行执行
npx gulp当我们执行npx gulp时会默认运行gulpfile.js导出的default,在gulpfile.js导出的任务会注册到gulp任务中
在gulp中任务主要分两种,一种是公开任务、另一种是私有任务
公开任务可以直接在命令执行npx gulp xxx调用执行,比如下面的defaultTask就是一个公开任务,只要被导出就是一个公开任务,没有被导出就是一个私有任务。
...
exports.default = defaultTask;公有任务taskJS
// gulpfile.js
const { src, dest } = require('gulp');
const pathDir = (dir) => {
return path.resolve(__dirname, dir);
}
// todo 执行ts任务,将js目录下的js打包到dist/js目录下
const taskJS = () => {
return src(pathDir('public/**/*.js'), { sourcemaps: true }).pipe(dest(pathDir('dist/js')))
}
exports.taskJS = taskJS;然后你在命令行执行
npx gulp taskJS
至此你会发现dist目录下就有生成的js了
npm i less gulp-less --save-dev在css/index.less中写入测试css的代码
@bgcolor: yellow;
@defaultsize: 20px;
body {
background-color: @bgcolor;
}
h1 {
font-size: @defaultsize;
}在gulpfile.js中写入编译less的任务,需要gulp-less
const { src, dest } = require('gulp');
const less = require('gulp-less');
const pathDir = (dir) => {
return path.resolve(__dirname, dir);
}
...
// todo less任务
const taskLess = () => {
// css目录洗的所有.less文件,dest输出到dist/css目录下
return src(pathDir('public/css/*.less')).pipe(less()).pipe(dest(pathDir('dist/css')))
}
exports.taskLess = taskLess;命令行运行npx gulp taskLess,结果如下
使用一个gulp-image插件对图片进行无损压缩处理
// gulpfile.js
const { src, dest } = require('gulp');
const image = require('gulp-image');
const path = require('path');
const pathDir = (dir) => {
return path.resolve(__dirname, dir);
}
...
// todo 图片资源
const taskImage = () => {
return src(pathDir('public/images/*.*')).pipe(image()).pipe(dest(pathDir('dist/images')))
}
exports.taskImage = taskImage;一顿操作发现,最新版本不支持esm,所以还是降低版本版本,这里降低到6.2.1版本
然后运行npx gulp taskImage
图片压缩得不小
在这之前,我们分别定义了三个不同的任务,gulp导出的任务有
公开任务和私有任务,多个公开任务可以串行组合使用
因此我可以将之前的介个任务组合在一起
// gulpfile.js
const { src, dest, series } = require('gulp');
const less = require('gulp-less');
const image = require('gulp-image');
const path = require('path');
const pathDir = (dir) => {
return path.resolve(__dirname, dir);
}
// todo js任务
const taskJS = () => {
return src(pathDir('public/**/*.js'), { sourcemaps: true }).pipe(dest(pathDir('dist/js')))
}
...
// series组合多个任务
const seriseTask = series(taskJS, taskLess, taskLess, taskImage)
exports.seriseTask = seriseTask;当我在命令行npx gulp seriseTask时
已经在dist生成对应的文件了
在我们index.js,很多时候是写的es6,在gulp中我们需要一些借助一些插件gulp-babel,另外我们需要安装另外两个babel核心插件@babel/core,@babel/preset-env
npm i gulp-babel @babel/core @babel/preset-env在gulpfile.js中我们需要修改下
...
const babel = require('gulp-babel');
// todo js任务
// 用babel转换es6语法糖
const taskJS = () => {
return src(pathDir('public/**/*.js'), { sourcemaps: true }).pipe(babel({
presets: ['@babel/preset-env']
})).pipe(dest(pathDir('dist/js')))
}当我们在js/index.js写入一段测试代码
js/index.js
const appDom = document.getElementById('app');
appDom.innerHTML = 'hello gulp';
const fn = () => {
console.log('公众号:Web技术学苑,好好学习,天天向上')
}
fn();运行npx gulp seriseTask
箭头函数和const申明的变量就变成了es5了
通常情况下,一般打包后的dist下的css或者js都会被压缩,在gulp中也是需要借助插件来完成
压缩js
...
const teser = require('gulp-terser');
// todo js任务
const taskJS = () => {
return src(pathDir('public/**/*.js'), { sourcemaps: true }).pipe(babel({
presets: ['@babel/preset-env']
})).pipe(teser({
mangle: {
toplevel: true // 混淆代码
}
})).pipe(dest(pathDir('dist/js')))
}
...压缩css
...
const uglifycss = require('gulp-uglifycss');
// todo less任务
const taskLess = () => {
return src(pathDir('public/css/*.less')).pipe(less()).pipe(uglifycss()).pipe(dest(pathDir('dist/css')))
}
...在这之前我们在输出dest时候我们都执向了一个具体的文件目录,在src这个api中是创建流,从文件中读取vunyl对象,本身也提供了一个base属性,因此你可以像下面这样写
const { src, dest, series } = require('gulp');
const less = require('gulp-less');
const image = require('gulp-image');
const babel = require('gulp-babel');
const teser = require('gulp-terser');
const uglifycss = require('gulp-uglifycss');
const path = require('path');
const pathDir = (dir) => {
return path.resolve(__dirname, dir);
}
// 设置base,当输出文件目标dist文件时,会自动拷贝当前文件夹到目标目录
const basePath = {
base: './public'
};
// todo js任务
const taskJS = () => {
return src(pathDir('public/**/*.js', basePath)).pipe(babel({
presets: ['@babel/preset-env']
})).pipe(teser({
mangle: {
toplevel: true // 混淆代码
}
})).pipe(dest(pathDir('dist')))
}
// todo less任务
const taskLess = () => {
return src(pathDir('public/css/*.less'), basePath).pipe(less()).pipe(uglifycss()).pipe(dest(pathDir('dist')))
}
// todo 图片资源,有压缩,并输出到对应的dist/images文件夹下
const taskImage = () => {
return src(pathDir('public/images/*.*'), basePath).pipe(image()).pipe(dest(pathDir('dist')))
}
// todo html
const taskHtml = () => {
return src(pathDir('public/index.html'), basePath).pipe(dest(pathDir('dist')))
}
const defaultTask = (cb) => {
console.log('hello gulp')
cb();
}
// series组合多个任务
const seriseTask = series(taskHtml, taskJS, taskLess, taskLess, taskImage)
exports.default = defaultTask;
exports.taskJS = taskJS;
exports.taskLess = taskLess;
exports.taskImage = taskImage;
exports.seriseTask = seriseTask;在gulp中,任务之间的依赖关系需要我们自己手动写一些执行任务流,现在一些打包后的dist的文件并不会自动注入html中。
...
const inject = require('gulp-inject');
...
// 将css,js插入html中
const injectHtml = () => {
// 目标资源
const targetSources = src(['./dist/**/*.js', './dist/**/*.css'], { read: false });
// 目标html
const targetHtml = src('./dist/*.html')
// 把目标资源插入目标html中,同时输出到dist文件下
const result = targetHtml.pipe(inject(targetSources)).pipe(dest('dist'));
return result
}
// series串行组合多个任务
const seriseTask = series(taskHtml, taskJS, taskLess, taskLess, taskImage, injectHtml)
exports.seriseTask = seriseTask;注意一个执行顺序,必须是等前面任务执行完了,再注入,所以在series任务的最后才执行injectHtml操作
并且在public/index.html下,还需要加入一段注释
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>gulp</title>
<!-- inject:css -->
<!-- endinject -->
</head>
<body>
<div id="app"></div>
<!-- inject:js -->
<!-- endinject -->
</body>
</html>当我们运行npx gulp seriseTask时
const { src, dest, series, watch } = require('gulp');
const browserSync = require('browser-sync');
...
const taskBuild = seriseTask;
// 本地服务
const taskDevServer = () => {
// 监听public所有目录下,只要文件发生改变,就重新加载
watch(pathDir('public'), taskBuild);
// 创建服务
const server = browserSync.create();
// 调用init开启端口访问
server.init({
port: '8081', //设置端口
open: true, // 自动打开浏览器
files: './dist/*', // dist文件
server: {
baseDir: './dist'
}
})
}
exports.taskDevServer = taskDevServer;当我们运行npx gulp taskDevServer时,浏览器会默认打开http://localhost:8081
我们使用了一个watch监听public目录下的所有文件,如果文件有变化时,会执行taskBuild任务会在dist目录下生成对应的文件,然后会启动一个本地服务,打开一个8081的端口就可以访问应用了。
至此一个一个用gulp搭建的前端应用终于可以了。
最后我们可以再重新组织一下gulpfile.js,因为多个任务写在一个文件里貌似不太那么好维护,随着业务迭代,会越来越多,因此,有必要将任务分解一下
在根目录新建task,我们把所有的任务如下
common.js
// task/common.js
const path = require('path');
const pathDir = (dir) => {
return path.join(__dirname, '../', dir);
}
const rootDir = path.resolve(__dirname, '../');
const basePath = {
base: './public'
};
const targetDest = 'dist';
module.exports = {
rootDir,
pathDir,
basePath,
targetDest
};injectHtml.js
// task/injectHtml.js
const { src, dest } = require('gulp');
const inject = require('gulp-inject');
const { targetDest, rootDir } = require('./common.js');
// 将css,js插入html中
const injectHtml = () => {
// 目标资源
const targetSources = src([`${rootDir}/${targetDest}/**/*.js`, `${rootDir}/${targetDest}/**/*.css`]);
// 目标html
const targetHtml = src(`${rootDir}/${targetDest}/*.html`)
// 把目标资源插入目标html中,同时输出到dist文件下
const result = targetHtml.pipe(inject(targetSources, { relative: true })).pipe(dest(targetDest));
return result
}
module.exports = injectHtml;taskDevServer.js
const { watch } = require('gulp');
const path = require('path');
const browserSync = require('browser-sync');
const { pathDir, targetDest, rootDir } = require('./common.js');
const taskDevServer = (taskBuild) => {
return (options = {}) => {
const defaultOption = {
port: '8081', //设置端口
open: true, // 自动打开浏览器
files: `${rootDir}/${targetDest}/*`, // 当dist文件下有改动时,会自动刷新页面
server: {
baseDir: `${rootDir}/${targetDest}` // 基于当前dist目录
},
...options
}
// 监听public所有目录下,只要文件发生改变,就重新加载
watch(pathDir('public'), taskBuild);
const server = browserSync.create();
server.init(defaultOption);
}
}
module.exports = taskDevServer;...
task/index.js
const injectHtml = require('./injectHtml.js');
const taskDevServer = require('./taskDevServer.js');
const taskHtml = require('./taskHtml.js');
const taskImage = require('./taskImage.js');
const taskJS = require('./taskJS.js');
const taskLess = require('./taskLess.js');
module.exports = {
injectHtml,
taskDevServer,
taskHtml,
taskImage,
taskJS,
taskLess
}在gulpfile.js中,我们修改下
// gulpfile.js
const { series } = require('gulp');
const { injectHtml, taskDevServer, taskHtml, taskImage, taskJS, taskLess } = require('./task/index.js')
// series组合多个任务
const seriseTask = series(taskHtml, taskJS, taskLess, taskLess, taskImage, injectHtml);
// 本地服务
const devServer = taskDevServer(seriseTask);
// 启动服务
const server = () => {
devServer({
port: 9000
});
}
const taskBuild = seriseTask;
const defaultTask = (cb) => {
console.log('hello gulp')
cb();
}
exports.default = defaultTask;
exports.server = server;
exports.build = taskBuild;我们在package.json中新增命令
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"server": "gulp server",
"build": "gulp build"
},npm run build
在启动server之前,我们先执行npm run build,然后再执行下面命令,保证browserSync创建的服务文件夹存在,不然页面打开就404错误
npm run server
至此gulp搭建一个简单的应该就已经完全ok了
页面背景貌似有点黄
gulpjs开发是一个任务流的开发方式,它的核心**就是用自动化构建工具增强你的工作流,所有的自动化工作流操作都牢牢的掌握在自己手上,你可以用gulp写一些自动化脚本,比如,文件上传,打包,压缩,或者改造传统的前端应用。
用gulp写了一个简单的应用,但是发现中途需要找好多gulp插件,gulp的生态还算可以,3w多个star,生态相对丰富,但是有些插件常年不更新,或者版本更新不支持,比如gulp-image,当你按照官方文档使用最新的包时,不支持esm,你必须降低版本6.2.1,改用cjs才行
使用gulp的一些常用的api,比如src、dest、series,以及browser-sync实现本地服务,更多api参考官方文档。
即使项目时间再多,也不要用gulp搭建前端应用,因为webpack生态很强大了,看gulp的最近更新还是2年前,但是写个自动化脚本,还算可以,毕竟gulp的理念就是用自动化构建工具增强你工作流程,也许当你接盘传统项目时,一些打包,拷贝,压缩文件之类的,可以尝试用用这个。
本文示例code-example
在上一篇文章中我们用
webpack与webpack-cli搭建了最简单的前端应用,通常在项目中我们会用vue或者react,我们看下如何利用我们自己搭的工程来适配react
正文开始...
首先我们要确定,react并不是在webpack中像插件一样安装就可以直接使用,我们需要支持jsx以及一些es6的一些比较新的语法,在creat-react-app这个脚手架中已经帮我们高度封装了react项目的一些配置,甚至你是看不到很多的配置,比如@babel/preset-react转换jsx等。所以我们需要知道一个react项目需要哪些插件的前提条件,本文主要参考从头开始打造工具链
安装babel相关插件
npm i @babel/core @babel/cli @babel/preset-env @babel/preset-react --save其中babel/core就是能将代码进行转换,@babel/cli允许命令行编译文件,babel/preset-env与@babel/preset-react都是预设环境,把一些高级语法转换成es5
安装好相关插件后,我们需要在根目录中创建一个.babelrc来让babel通知那两个预设的两个插件生效
// .babelrc
{
"presets": ["@babel/env", "@babel/preset-react]
}接下来我们需要安装在react中的支持的jsx,主要依赖babel-loader来编译jsx
npm i babel-loader --save-dev并且我们需要改下webpack.config.js的loader
{
module: {
rules: [
{
test: /\.css$/,
use: ['style-loader', 'css-loader']
},
{
test: /\.(png|svg|jpg|gif|jpeg)$/,
use: [
{
loader: 'file-loader',
options: {
outputPath: 'assets',
name: '[name].[ext]?[hash]'
}
}
]
},
{
test: /\.(js|jsx)$/,
loader: 'babel-loader',
exclude: /node_modules/,
options: {
presets: ['@babel/env']
}
}
]
},
}在react中我们设置HMR,我们需要结合new webpack.HotModuleReplacementPlugin(),并且在devServer中设置hot为true
module.exports = {
...
plugins: [
new HtmlWebpackPlugin({
template: './public/index.html'
}),
new miniCssExtractPlugin({
filename: 'css/[name].css'
}),
new webpack.HotModuleReplacementPlugin()
],
devServer: {
hot: true
}
}完整的配置webpack.config.js就已经 ok 了
// webpack.config.js
const path = require('path');
const webpack = require('webpack');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const miniCssExtractPlugin = require('mini-css-extract-plugin');
module.exports = {
mode: 'development',
entry: {
app: './src/app.js'
},
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].bundle.js'
},
module: {
rules: [
{
test: /\.css$/,
use: ['style-loader', 'css-loader']
},
{
test: /\.(png|svg|jpg|gif|jpeg)$/,
use: [
{
loader: 'file-loader',
options: {
outputPath: 'assets',
name: '[name].[ext]?[hash]'
}
}
]
},
{
test: /\.(js|jsx)$/,
loader: 'babel-loader',
options: {
presets: ['@babel/env']
}
}
]
},
plugins: [
new HtmlWebpackPlugin({
template: './public/index.html'
}),
new miniCssExtractPlugin({
filename: 'css/[name].css'
}),
new webpack.HotModuleReplacementPlugin()
],
devServer: {
hot: true
}
};安装react、react-dom这两个核心库
npm i react react-dom --save-dev在src目录下新建一个App.jsx
// App.jsx
import React, { Component } from 'react';
import deepMerge from './utils/index.js';
import '../src/assets/css/app.css';
import image1 from '../src/assets/images/1.png';
import image2 from '../src/assets/images/2.jpg';
class App extends Component {
constructor(props) {
super(props);
this.state = {
text: 'hello webpack for react',
name: 'Maic',
age: 18,
publicName: 'Web技术学苑',
imgSource: [image1, image2]
};
}
render() {
const { text, name, age, publicName, imgSource } = this.state;
return (
<>
<div className='app'>
<h1>{text}</h1>
<div>
<p>{name}</p>,<span>{age}</span>岁<p>{publicName}</p>
</div>
<div>
{imgSource.map((src) => (
<img src={src} key={src} />
))}
</div>
</div>
</>
);
}
}
export default App;我们在app.js中引入App.jsx
// app.js
import React from 'react';
import { createRoot } from 'react-dom/client';
import App from './App.jsx';
const appDom = document.getElementById('app');
const root = createRoot(appDom);
root.render(<App />);我们运行npm run server,浏览器打开localhost:8080
ok,用webpack搭建的一个自己的react应用就已经 ok 了
1、react 需要的一些插件,@babel/core、@babel/cli、@babel/preset-env、@babel/preset-react、babel-loader
2、设置.babelrc
3、引入react、react-dom,modules中设置babel-loader编译jsx文件
4、本文code-example
最近遇到一个 bug,测试同学用脚本添加近 1000 条数据就把页面搞崩了
真是惨重,而且chrome页面请求的接口无任何响应,后端数据有分页,前端也有分页,但是由于数据量过大,ivew的table太不经打了,因为是一个table的tree,于是这个锅,前端背了
如果你有跟笔者一样使用ivew的table经历,希望这篇文章能给你实际项目中带来一点思考和帮助。
正文开始...
table承载的数据边界是多少笔者写了一个简单的栗子来,测试页面卡顿的情况,新建一个index.html,贴上关键代码
::: details code
<html>
...
<link rel="stylesheet" type="text/css" href="http://unpkg.com/view-design/dist/styles/iview.css" />
<script type="text/javascript" src="./js/vue.min.js"></script>
<script type="text/javascript" src="./js/iview.min.js"></script>
<script type="text/javascript" src="./js/mock-min.js"></script>
<script type="text/javascript" src="./js/axios.min.js"></script>
<script type="text/javascript" src="./mockserver.js"></script>
<style>
#app {
margin: 10px;
}
</style>
<body>
<div id="app">
<Row align="middle" type="flex" gutter="10">
<i-col span="24"><h2>iview-table性能优化测试</h2></i-col>
<i-col span="3"> pageNum<i-input v-model.number="pageParams.pageNum"></i-input> </i-col>
<i-col span="3"> pageSize<i-input v-model.number="pageParams.pageSize"></i-input> </i-col>
<i-col span="3"> total<i-input v-model.number="pageParams.total"></i-input> </i-col>
<i-col span="3">
<i-button type="primary" @click="handleReflush">刷新</i-button>
</i-col>
</Row>
<i-table row-key="id" :loading="loading" :columns="columns" :data="tableData" border></i-table>
<Page :total="pageParams.total" @on-change="handleChangePage" show-sizer></Page>
</div>
</body>
</html>:::
新建一个index.js,引入页面中
::: details code
<html>
....
<body>
...
<div id="app">
...
<Page :total="pageParams.total" @on-change="handleChangePage" show-sizer></Page>
</div>
<script src="./index.js"></script>
</body>
</html>:::
我本地新建一个模拟接口数据的操作,这里笔者用了一个mockjs造数据,使用axios这个库做ajax请求
具体看下index.js这个主页面的js
::: details code
// index.js
var vm = new Vue({
el: '#app',
data: {
loading: false,
tableData: [],
pageParams: {
pageNum: 1,
pageSize: 10,
total: 10
},
columns: [
{
title: '序号',
type: 'index'
},
{
title: 'Name',
key: 'name',
tree: true
},
{
title: 'age',
key: 'age'
},
{
title: 'address',
key: 'adress'
}
]
},
methods: {
// todo 请求数据
featchData() {
const { pageParams } = this;
this.loading = true;
this.tableData = [];
let timer;
mockServer('http://test.com', pageParams).then((res) => {
const {
data: { result }
} = res;
console.log(res, '=res');
this.tableData = result;
if (timer) {
clearTimeout(timer);
}
// todo 模拟数据延时loading
timer = setTimeout(() => {
this.loading = false;
}, 2000);
});
},
// todo 点击按钮刷新操作
handleReflush() {
this.featchData();
},
// 分页参数请求
handleChangePage(pageNum) {
this.pageParams = {
...this.pageParams,
pageNum
};
this.featchData();
}
},
mounted() {
this.featchData();
}
});:::
以上代码片段有些长,但是核心**非常简单,我模拟了一个页面列表需要的数据以及入参请求的分页参数,列表会根据我设置的分页参数,请求拿到数据,渲染到页面中。
接下来看下mockserver.js这个是一个模拟接口的一个工具库,可以看下片段
::: details code
// 生成mock数据
const mockServer = (path, { pageNum, pageSize, total }) => {
// 生成随机长度的数组
const createMapRandom = (len) => {
const data = new Array(len);
return data.fill('Maic');
};
const childrenData = Mock.mock({
[`data|${Math.floor(total / pageSize)}`]: [
{
'name|1': createMapRandom(100).map(() => Mock.mock('@cname')),
'age|1': createMapRandom(100).map(() => Mock.mock('@integer(0,100)')),
'adress|1': createMapRandom(100).map(() => Mock.mock('@city')),
'id|1': createMapRandom(100).map(() => Mock.mock('@id'))
}
]
});
Mock.mock(path, {
code: 0,
message: '成功',
[`result|${pageNum * pageSize}`]: [
{
'name|+1': createMapRandom(10).map(() => Mock.mock('@cname')),
'age|1': createMapRandom(10).map(() => Mock.mock('@integer(0,100)')),
'adress|1': createMapRandom(10).map(() => Mock.mock('@city')),
'id|1': createMapRandom(10).map(() => Mock.mock('@id')),
children: childrenData.data
}
]
});
return axios.get(path);
};:::
mock数据已经准备 ok,我们看下页面就是这样的
打开控制台netWork的perfomance monitor可以看到js heap size右侧非常平稳(这里可以看到页面内存溢出情况,如果是平稳的,说明内存溢出的可能性很小),在10条数据时候,页面也非常流畅
当我把总条数调至100时
cpu在我修改总条数,然后点击刷新按钮操作,cpu和内存都有往上飙升了,但是内存溢出依然不是很明显,点击页面也并无卡顿。
当我把页面总数调至500时,此时页面内存溢出和 cpu 又是怎么样
当我点击页面刷新按钮操,然后点击列表的树操作时,页面已经有明显的卡顿了,但页面没有卡死,当我直接把总条数修改1000时,整个页面已经卡死。
500条数据就已经感受到页面卡顿了,当为1000条时,页面直接卡死,因此在测试同学极限测试的情况下,生产环境页面直接崩了,这时候,你不可能跟测试说,你为啥要造那么数据?
在极端情况下,也许就是有测试的这种情况,看了官方文档,临时做了一个补救方案,就是点击那个tree的时候,再异步加载children数据,但是...,第二天测试告诉我,页面又崩了,于是,这种方式是不行了,那么加个页面吧,把树的子集页面用一个弹框页面展示,这样首页只加载第一级数据,二级数据让后端做了个分页查询,再给前端渲染。
终于这样页面不卡顿了,测试添加1000条数据,页面不卡顿了,但是为啥ivew的 table 渲染数据,会造成页面内存溢出如此严重,去官方github上看了一下 table 组件的源码
在ivew的table组件,是用render,根据columns生成colgroup,根据data生成tr、td,具体可以看下table-body
::: details code
...
render(h) {
let $tableTrs = [];
this.data.forEach((row, index) => {
let $tds = [];
const $tableTr = h(TableTr, {
props: {
draggable: this.draggable,
row: row,
'prefix-cls': this.prefixCls
},
key: this.rowKey ? row._rowKey : index,
nativeOn: {
mouseenter: (e) => this.handleMouseIn(row._index, e),
mouseleave: (e) => this.handleMouseOut(row._index, e),
click: (e) => this.clickCurrentRow(row._index, e),
dblclick: (e) => this.dblclickCurrentRow(row._index, e),
contextmenu: (e) => this.contextmenuCurrentRow(row._index, e),
selectstart: (e) => this.selectStartCurrentRow(row._index, e)
}
}, $tds);
// 子数据
if (row.children && row.children.length) {
const $childNodes = this.getChildNode(h, row, []);
$childNodes.forEach(item => {
$tableTrs.push(item);
});
}
...
})
...
}:::
在循环data中创建tr,而且还有递归寻找getChildNode操作,tr上还绑定了许多事件,当我们点击tree时,会触发tr的 mouseenter,click 等事件,如此多的事件绑定在tr上,在数据量很大的时候,绑定的事件越多,造成内存泄漏越是严重,而且是每个tr上都是直接绑定nativeOn等这些事件。所以ivew的 table 造成内存的泄漏直接让页面卡死。
ivew的 table 既然这么不经打,那么我测试下elementUI的table是否比ivew更好。
笔者糊了一个一模一样的测试页面
::: details code
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>element-table</title>
<style>
#app {
margin: 10px;
}
</style>
<link
rel="stylesheet"
href="https://unpkg.com/element-ui/lib/theme-chalk/index.css"
/>
<script type="text/javascript" src="./js/vue.min.js"></script>
<script src="https://unpkg.com/element-ui/lib/index.js"></script>
<script type="text/javascript" src="./js/mock-min.js"></script>
<script type="text/javascript" src="./js/axios.min.js"></script>
<script type="text/javascript" src="./mockserver.js"></script>
</head>
<body>
<div id="app">
<el-row type="flex">
<el-col span="5"><h2>element-table性能优化测试</h2></el-col>
<el-col span="3">
pageNum<el-input v-model.number="pageParams.pageNum"></el-input>
</el-col>
<el-col span="3">
pageSize<el-input v-model.number="pageParams.pageSize"></el-input>
</el-col>
<el-col span="3">
total<el-input v-model.number="pageParams.total"></el-input>
</el-col>
<el-col span="3">
<el-button type="primary" @click="handleReflush">刷新</el-button>
</el-col>
</el-row>
<el-table
row-key="id"
:data="tableData"
:tree-props="{children: 'children', hasChildren: 'hasChildren'}"
border
>
<el-table-column
type="index"
label="序号"
width="50">
</el-table-column>
<el-table-column v-for="(item) in columns" :prop="item.key" :label="item.title">
</el-table-column>
</el-table-column>
</el-table>
<el-pagination
:total="pageParams.total"
:page-size="pageParams.pageSize"
:page-sizes="[10, 20, 30, 40]"
@current-change="handleChangePage"
></el-pagination>
</div>
<script>
var vm = new Vue({
el: "#app",
data: {
loading: false,
tableData: [],
pageParams: {
pageNum: 1,
pageSize: 10,
total: 10,
},
columns: [
{
title: "Name",
key: "name",
tree: true,
},
{
title: "age",
key: "age",
},
{
title: "address",
key: "adress",
},
],
},
methods: {
// todo 请求数据
featchData() {
const { pageParams } = this;
this.loading = true;
this.tableData = [];
let timer;
mockServer("http://test.com", pageParams).then((res) => {
const {
data: { result },
} = res;
console.log(res, "=res");
this.tableData = result;
if (timer) {
clearTimeout(timer);
}
// todo 模拟数据延时loading
timer = setTimeout(() => {
this.loading = false;
}, 2000);
});
},
// todo 点击按钮刷新操作
handleReflush() {
this.featchData();
},
// 分页参数请求
handleChangePage(pageNum) {
this.pageParams = {
...this.pageParams,
pageNum,
};
this.featchData();
},
},
mounted() {
this.featchData();
},
});
</script>
</body>
</html>:::
打开浏览器,直接设置1000,elementUI的table真的吊打ivew几条街
cpu 几乎没有变化多少,内存泄漏也是几乎没有,在一段时间内,几乎是保持不变的。
用5000调试,页面有稍微卡顿了,10000条数据测试,终于把页面搞崩了。点击tree页面明显卡顿,但即使是这样也比ivew1000 条的测试数据页面要好得多。
由此可见笔者已经把ivewtable 最大的问题踩了一个坑。
关于elementUI的 table 可以去官方库看下,比ivew处理要优雅得多,具体参考ele-body
看到这里,如果table大数据渲染,有没有比较好的实践方案。因为 1w 条数据的情况,即使是elementUI怎么扛打,也显得力不从心。
虚拟列表优化,这是大数据量优化的一种手段,大数据渲染 dom 导致页面卡顿,我们尝试用虚拟长列表方案去实践下
为快速实现业务table性能,我们采用第三方虚拟列表umy-ui,专门解决 table 卡顿问题
新建一个index-vitual.html
::: details code
...
<u-table
ref="table"
:data="tableData"
:height="height"
use-virtual
:row-height="rowHeight"
:treeConfig="{
children: 'children',
expandAll: false,
lazy: true
}"
row-id="id"
border
>
<u-table-column type="index" width="100" label="序号" fixed></u-table-column>
<u-table-column v-for="item in columns" :key="item.key" :prop="item.key" :tree-node="item.hasChildren" :label="item.title"> </u-table-column>
</u-table>
...:::
::: details code
// js
// 引入UMYUI 组件
const { UTable, UTableColumn } = UMYUI;
var vm = new Vue({
el: "#app",
components: {
UTable,
UTableColumn,
},
...
}):::
就是引入umy-ui的两个组件即可,主要注意u-table的几个props
1、use-virtual主要是打开虚拟列表
2、height设置一个固定的高度,或者设置一个max-height,如果不需要设置高度,内容需根据内容滚动,则关闭虚拟列表use-virtual这个参数不设置即可
3、treeConfig这个参数设置是否有tree,当设置树时u-table上必须设置row-id="id",否则树不会出来,并且cloumns上设置hasChildren标识
4、u-table-column设置:tree-node属性,指定列中哪个props展开
更多 API 可以参考官网
当我们将参数调节至首页 1000 条时,其实table的 tr 始终中 16 条左右
用该方案极大的减少了列表dom的渲染,避免了一次性渲染 1000 个tr,td。因此极大的提升了table的渲染,页面的性能也会提升不少。
最后,如果你将总条数调至 10000,你最后还是会发现页面cpu直接上升至100%,页面明显的卡顿了几秒钟,这也表明,此时无论页面是否虚拟列表方案,造成页面卡顿与js声明额数据量也有一定关系,当定义的数据过大,在内存没有释放的这段过程中,如果造成页面内存溢出或者堆栈过大,那么也会造成页面的卡死。
1、ivew的table性能很差,比较elementUI,1000数据ivew就能让你浏览器崩掉,所以慎用ivewtable 的大数据量,有坑
2、elementUI的 table 组件很优秀,1000条能扛得住,但上了5000后,就明显扛不住了,所以采用umy-ui虚拟列表渲染
3、umy-ui方案可以极大的优化大数据table渲染,但是数据量超过 1w+,甚至更多,那么虚拟列表也是没得救了,页面依然会卡顿。
因此造成页面卡顿的因素很多,我们减少事件操作、闭包、全局变量等等这些尽量减少内存的消耗,以及页面的GUI渲染,这样就可以极大提高页面的访问性能。
关于虚拟长列表方案,后续我会写一篇深究虚拟长列表的技术文章,除了这种方案优化 table,笔者想到,另外两种方案
一种是假分页,如果后端一次性返回了1000条数据,那么我在前端按照上拉滚动的方式,每次加载100条的方式去渲染,这样分10页就可以加载完毕了,比起一次性加载1w+应该会有明显的提升,后续会写个测试 demo 验证一下。
二种是增加二级页面,将大数据做本地indexDB存储,然后从indexDB中做前端分页查询。
4、本文示例code example
闭包在程序中无处不在,通俗来讲
闭包就是一个函数对其周围状态的引用并捆绑在一起的一种组合,你也可以理解成一个函数被引用包围或者是一个内部函数能够访问外部函数的作用域
闭包是面试经常考的,也是了解一个程序员基础知识一个重要点,本篇是笔着对于闭包的理解,希望在实际项目中有所思考和帮助。
正文开始...
我们可以从以下几点来理解
一个函数对其周围状态的引用并捆绑在一起的一种组合一个函数被引用包围一个内部函数能访问外部函数的作用域我们来看一张图理解下上面三句话
对应代码如下
function A() {
var name = 'Maic',
age = 0;
function B() {
console.log(name, age);
}
}
A();
// console.log(name) name is not defined我们注意到在A函数中,我们创建了两个内部的私有变量name
、age,并且我们在A函数中创建一个内部函数B,此时在B函数中,我们会发现在B内部可以访问它周围状态(变量),也就意味着在B函数内部可以访问外部函数的作用域。
至此你会发现,闭包就是在B函数一创建,并且有对周围的状态有引用,那么此时闭包就出现了,也就是说,闭包就是一座桥梁,能让B函数内部能突破自身作用域访问外部的变量。
不知道你有没有发现,我在A内部定义的变量,我在外部并不能访问,也就是说相对A的外部,A内部所有的变量都是私有的,在A定义的变量,相对于B中,又可以访问。因为B函数能访问A中的变量,也正是依靠闭包这座桥梁。
1.创建私有变量
2.延长变量的生命周期
我们知道闭包会造成内存泄露,本质上就是创建的变量一直在引用内存中,当一个普通函数被调用结束时,函数内部创建的变量就会被销毁。
但是闭包会保存其变量的引用,即便外部执行上下文被销毁,但是闭包内创建的词法环境依然还在,我们看下面代码具体理解下。
function A() {
var name = 'Maic',
age = 0;
function B() {
age++;
console.log(name, age);
}
return B;
}
var b1 = A();
b1(); // 1
b1(); // 2
b1(); // 3在A中返回了函数B,实际上就是返回了一个函数,当我们我们用var b1 = A()申明一个变量时,实际上,这里内部B还没有执行,但是在执行A()方法时,返回的是一个函数,所以我们继续执行b1(),我们尝试调用三次,我们会发现打印出来的值是1,2,3,这就说明,闭包延长了变量的生命周期,因为第三次与第二次打印出来的值就是同一个值的引用。
具体一张图可以可以理解下
当我们用var b1 = A()时,实际上,我用蓝色的方框已经标注起来了,在b1内部我们可以看到,每执行b1,实际就是执行的红色区域的函数,也就是A内部定义的函数B,但是每次调用b1,我们看到都有保留age的引用,所以你看到age依次就是1,2,3,所以也就证实了闭包能延长变量的生命周期,并且闭包创建的私有变量可以减少全局变量的使用。
通常我们知道尽量少创建全局变量,因为我们不知道这个全局变量什么时候使用,只有在被使用的时候才会被释放。闭包也是解决了全局变量命名冲突的问题,因为创建的私有变量,没法在外部访问,这样也就减少了变量名污染的问题。
等等,还有一个问题,如果我把上面的代码改成下面呢?
function A() {
var name = 'Maic',
age = 0;
function B() {
age++;
console.log(name, age);
}
return B;
}
A()(); // 1
A()(); // 1
// var b1 = A();
// b1();
// b1();
// b1();
// console.log(name)你会发现,我两次打印的都是同一个1,这是为什么呢?你有没有发现之前我们是用var b1 = A()申明的一个变量,实际上这句代码就是js新开辟暂存了一块空间,因为A内部返回的是一个函数,当我每次调用b1时,实际上是调用返回的那个函数,因为函数内部存在闭包的引用,所以一直就1,2,3,但是我这里我使用的是A()(),我们发现每次都是1,说明当我第二次调用时内部的age已经重新定义了一遍,而并没有引用上一次的值,这就说明,在A()立即调用时,闭包内部引用的变量已经被释放。由于闭包也会有缺陷,创建太多的闭包会造成消耗内存严重,影响网页性能。
柯里化函数
回调函数
计数器、延迟调用(防抖与节流)
实际上就是把一个函数的多个参数拆分成多个函数调用,主要目的是避免平繁调用具有多个相同参数函数,又可以复用相同函数,具体可以用下面代码理解下
// 未柯里化之前
function sum(a, b, c) {
return a + b + c;
}
sum(1, 2, 3);函数柯里化后
function sum(a) {
return function (b) {
return function (c) {
return a + b + c;
};
};
}
const a = sum(1);
const b = a(2);
const c = b(3);
console.log(c); // 6 or sum(1)(2)(3)上面 🌰 好像还是不太明显,在具体业务中,你可能会写出这样的代码
// 根据正则规则校验某个字段
function regKey(reg, val) {
return reg.test(val);
}
var isPhone = regKey(/^1[3,5,7,8,9]\d{9}$/, 13754123124);
const isNumber = regKey(/\d/, 'test');改成函数柯里化后
function regKey(reg) {
return (val) => {
return reg.test(val);
};
}
const checkPhone = regKey(/^1[3,5,7,8,9]\d{9}$/);
const checkNum = regKey(/\d/);
const isPhone = checkPhone(13754123124); // true
const isNumber = checkNum(123); // true我们发现改完后,貌似柯里化后,代码反而变多了,但是代码的可读性以及拓展性比以前更友好,这点因特殊业务功能而定,也不是非要把用柯里化函数去处理所有的业务,具体因情况而定,这里只是举了个简单的例子。
回调函数在业务中使用的太多了,具体可以看下下面这个简单的例子,写一段为伪代码感受一下
const request = (params) => {
const response = {
code: 0,
success: '成功',
data: []
};
return (callback) => {
callback(response);
};
};
const queryList = () => {
const getData = request({ pageIndex: 1, pageSize: 10 });
getData((res) => {
console.log(res); // {code: 0, success: '成功', data: []}
});
};这个就非常典型了,比如说一个循环里面
for (var i = 0; i < 10; i++) {
(function () {
var j = i;
setTimeout(() => {
console.log(j);
}, i * 1000);
})();
}频繁触发事件,在指定一段时间内调用函数
// 模拟数据请求伪代码
const fetchList = () => {};
let flag = false;
window.addEventListener('scroll', () => {
if (flag) {
return;
}
flag = true;
setTimeout(() => {
flag = false;
fetchList();
}, 500);
});利用定时器做缓冲器,当第二次调用时,清除上一次的定时器,在指定时间内重新调用函数
// 模拟数据请求伪代码
const fetchList = () => {};
const inputDom = document.getElementById('input');
let timer = null;
inputDom.oninput = function () {
if (!timer) {
clearTimeout(timer);
timer = setTimeout(() => {
fetchList();
}, 500);
}
};以上案例都有用到闭包,闭包的身影无处不在,只是我们用的时候,我们并没有发现。
闭包的概念,闭包是一个函数对其周围状态的引用并捆绑在一起的一种组合,或者是一个函数被引用包围,或者是一个内部函数能访问外部函数的作用域
闭包的特性,创建私有变量和延长变量的生命周期
闭包的应用场景,柯里化函数、回调函数、定时器、节流/防抖等
本文示例code example
最后,喜欢的点个赞,在看,转发,收藏等于学会,欢迎关注 Web 技术学苑,好好学习,天天向上!
别被标题吓到,哈哈,即使现在vite横空出世,社区光芒四射,两个字很快,但是webpack依旧宝刀未老,依然扛起前端工程化的大梁,但是今天我为啥说要拥抱gulp,因为我们经常常吃一道菜,所以要换个口味,这样才营养均衡。
gulp定义是:用自动化构建工具增强你的工作流程,是一种基于任务文件流方式,你可以在前端写一些自动化脚本,或者升级历史传统项目,解放你重复打包,压缩,解压之类的操作。
个人理解gulp是一种命令式编程的体验,更注重构建过程,所有的任务需要你自己手动创建,你会对构建流程会非常清楚,这点不像webpack,webpack就是一个开箱即用的声明式方式,webpack是一个模块化打包工具,内部细节隐藏非常之深,你也不需关注细节,你只需要照着提供的API以及引入对应的loader和plugin使用就行。
言归正传,为了饮食均衡,今天一起学习下gulpjs
正文开始...
相比较webpack,其实gulp的项目结构更偏向传统的应用,只是我们借助gulp工具解放我们的一些代码压缩、es6编译、打包以及在传统项目中都可以使用less体验。
在gulp目录下新建01-simple-demo
根目录下生成默认package.json
npm init -y然后在public目录下新建images、css、js、index.html
文件结构,大概就这样
然后在安装gulp
npm i gulp --save-dev在根目录下新建gulpfile.js
我们先在gulpfile.js中写入一点内容,测试一下
const defaultTask = (cb) => {
console.log('hello gulp');
cb();
};
exports.default = defaultTask;然后我们在命令行执行
npx gulp当我们执行npx gulp时会默认运行gulpfile.js导出的default,在gulpfile.js导出的任务会注册到gulp任务中
在gulp中任务主要分两种,一种是公开任务、另一种是私有任务
公开任务可以直接在命令执行npx gulp xxx调用执行,比如下面的defaultTask就是一个公开任务,只要被导出就是一个公开任务,没有被导出就是一个私有任务。
...
exports.default = defaultTask;公有任务taskJS
// gulpfile.js
const { src, dest } = require('gulp');
const pathDir = (dir) => {
return path.resolve(__dirname, dir);
};
// todo 执行ts任务,将js目录下的js打包到dist/js目录下
const taskJS = () => {
return src(pathDir('public/**/*.js'), { sourcemaps: true }).pipe(dest(pathDir('dist/js')));
};
exports.taskJS = taskJS;然后你在命令行执行
npx gulp taskJS
至此你会发现dist目录下就有生成的js了
npm i less gulp-less --save-dev在css/index.less中写入测试 css 的代码
@bgcolor: yellow;
@defaultsize: 20px;
body {
background-color: @bgcolor;
}
h1 {
font-size: @defaultsize;
}在gulpfile.js中写入编译less的任务,需要gulp-less
const { src, dest } = require('gulp');
const less = require('gulp-less');
const pathDir = (dir) => {
return path.resolve(__dirname, dir);
}
...
// todo less任务
const taskLess = () => {
// css目录洗的所有.less文件,dest输出到dist/css目录下
return src(pathDir('public/css/*.less')).pipe(less()).pipe(dest(pathDir('dist/css')))
}
exports.taskLess = taskLess;命令行运行npx gulp taskLess,结果如下
使用一个gulp-image插件对图片进行无损压缩处理
// gulpfile.js
const { src, dest } = require('gulp');
const image = require('gulp-image');
const path = require('path');
const pathDir = (dir) => {
return path.resolve(__dirname, dir);
}
...
// todo 图片资源
const taskImage = () => {
return src(pathDir('public/images/*.*')).pipe(image()).pipe(dest(pathDir('dist/images')))
}
exports.taskImage = taskImage;一顿操作发现,最新版本不支持esm,所以还是降低版本版本,这里降低到6.2.1版本
然后运行npx gulp taskImage
图片压缩得不小
在这之前,我们分别定义了三个不同的任务,gulp导出的任务有
公开任务和私有任务,多个公开任务可以串行组合使用
因此我可以将之前的介个任务组合在一起
// gulpfile.js
const { src, dest, series } = require('gulp');
const less = require('gulp-less');
const image = require('gulp-image');
const path = require('path');
const pathDir = (dir) => {
return path.resolve(__dirname, dir);
}
// todo js任务
const taskJS = () => {
return src(pathDir('public/**/*.js'), { sourcemaps: true }).pipe(dest(pathDir('dist/js')))
}
...
// series组合多个任务
const seriseTask = series(taskJS, taskLess, taskLess, taskImage)
exports.seriseTask = seriseTask;当我在命令行npx gulp seriseTask时
已经在dist生成对应的文件了
在我们index.js,很多时候是写的es6,在gulp中我们需要一些借助一些插件gulp-babel,另外我们需要安装另外两个babel核心插件@babel/core,@babel/preset-env
npm i gulp-babel @babel/core @babel/preset-env在gulpfile.js中我们需要修改下
...
const babel = require('gulp-babel');
// todo js任务
// 用babel转换es6语法糖
const taskJS = () => {
return src(pathDir('public/**/*.js'), { sourcemaps: true }).pipe(babel({
presets: ['@babel/preset-env']
})).pipe(dest(pathDir('dist/js')))
}当我们在js/index.js写入一段测试代码
js / index.js;
const appDom = document.getElementById('app');
appDom.innerHTML = 'hello gulp';
const fn = () => {
console.log('公众号:Web技术学苑,好好学习,天天向上');
};
fn();运行npx gulp seriseTask
箭头函数和const申明的变量就变成了es5了
通常情况下,一般打包后的dist下的css或者js都会被压缩,在gulp中也是需要借助插件来完成
压缩js
...
const teser = require('gulp-terser');
// todo js任务
const taskJS = () => {
return src(pathDir('public/**/*.js'), { sourcemaps: true }).pipe(babel({
presets: ['@babel/preset-env']
})).pipe(teser({
mangle: {
toplevel: true // 混淆代码
}
})).pipe(dest(pathDir('dist/js')))
}
...压缩css
...
const uglifycss = require('gulp-uglifycss');
// todo less任务
const taskLess = () => {
return src(pathDir('public/css/*.less')).pipe(less()).pipe(uglifycss()).pipe(dest(pathDir('dist/css')))
}
...在这之前我们在输出dest时候我们都执向了一个具体的文件目录,在src这个api中是创建流,从文件中读取vunyl对象,本身也提供了一个base属性,因此你可以像下面这样写
const { src, dest, series } = require('gulp');
const less = require('gulp-less');
const image = require('gulp-image');
const babel = require('gulp-babel');
const teser = require('gulp-terser');
const uglifycss = require('gulp-uglifycss');
const path = require('path');
const pathDir = (dir) => {
return path.resolve(__dirname, dir);
};
// 设置base,当输出文件目标dist文件时,会自动拷贝当前文件夹到目标目录
const basePath = {
base: './public'
};
// todo js任务
const taskJS = () => {
return src(pathDir('public/**/*.js', basePath))
.pipe(
babel({
presets: ['@babel/preset-env']
})
)
.pipe(
teser({
mangle: {
toplevel: true // 混淆代码
}
})
)
.pipe(dest(pathDir('dist')));
};
// todo less任务
const taskLess = () => {
return src(pathDir('public/css/*.less'), basePath)
.pipe(less())
.pipe(uglifycss())
.pipe(dest(pathDir('dist')));
};
// todo 图片资源,有压缩,并输出到对应的dist/images文件夹下
const taskImage = () => {
return src(pathDir('public/images/*.*'), basePath)
.pipe(image())
.pipe(dest(pathDir('dist')));
};
// todo html
const taskHtml = () => {
return src(pathDir('public/index.html'), basePath).pipe(dest(pathDir('dist')));
};
const defaultTask = (cb) => {
console.log('hello gulp');
cb();
};
// series组合多个任务
const seriseTask = series(taskHtml, taskJS, taskLess, taskLess, taskImage);
exports.default = defaultTask;
exports.taskJS = taskJS;
exports.taskLess = taskLess;
exports.taskImage = taskImage;
exports.seriseTask = seriseTask;在gulp中,任务之间的依赖关系需要我们自己手动写一些执行任务流,现在一些打包后的dist的文件并不会自动注入html中。
...
const inject = require('gulp-inject');
...
// 将css,js插入html中
const injectHtml = () => {
// 目标资源
const targetSources = src(['./dist/**/*.js', './dist/**/*.css'], { read: false });
// 目标html
const targetHtml = src('./dist/*.html')
// 把目标资源插入目标html中,同时输出到dist文件下
const result = targetHtml.pipe(inject(targetSources)).pipe(dest('dist'));
return result
}
// series串行组合多个任务
const seriseTask = series(taskHtml, taskJS, taskLess, taskLess, taskImage, injectHtml)
exports.seriseTask = seriseTask;注意一个执行顺序,必须是等前面任务执行完了,再注入,所以在series任务的最后才执行injectHtml操作
并且在public/index.html下,还需要加入一段注释
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>gulp</title>
<!-- inject:css -->
<!-- endinject -->
</head>
<body>
<div id="app"></div>
<!-- inject:js -->
<!-- endinject -->
</body>
</html>当我们运行npx gulp seriseTask时
const { src, dest, series, watch } = require('gulp');
const browserSync = require('browser-sync');
...
const taskBuild = seriseTask;
// 本地服务
const taskDevServer = () => {
// 监听public所有目录下,只要文件发生改变,就重新加载
watch(pathDir('public'), taskBuild);
// 创建服务
const server = browserSync.create();
// 调用init开启端口访问
server.init({
port: '8081', //设置端口
open: true, // 自动打开浏览器
files: './dist/*', // dist文件
server: {
baseDir: './dist'
}
})
}
exports.taskDevServer = taskDevServer;当我们运行npx gulp taskDevServer时,浏览器会默认打开http://localhost:8081
我们使用了一个watch监听public目录下的所有文件,如果文件有变化时,会执行taskBuild任务会在dist目录下生成对应的文件,然后会启动一个本地服务,打开一个8081的端口就可以访问应用了。
至此一个一个用gulp搭建的前端应用终于可以了。
最后我们可以再重新组织一下gulpfile.js,因为多个任务写在一个文件里貌似不太那么好维护,随着业务迭代,会越来越多,因此,有必要将任务分解一下
在根目录新建task,我们把所有的任务如下
common.js
// task/common.js
const path = require('path');
const pathDir = (dir) => {
return path.join(__dirname, '../', dir);
};
const rootDir = path.resolve(__dirname, '../');
const basePath = {
base: './public'
};
const targetDest = 'dist';
module.exports = {
rootDir,
pathDir,
basePath,
targetDest
};injectHtml.js
// task/injectHtml.js
const { src, dest } = require('gulp');
const inject = require('gulp-inject');
const { targetDest, rootDir } = require('./common.js');
// 将css,js插入html中
const injectHtml = () => {
// 目标资源
const targetSources = src([`${rootDir}/${targetDest}/**/*.js`, `${rootDir}/${targetDest}/**/*.css`]);
// 目标html
const targetHtml = src(`${rootDir}/${targetDest}/*.html`);
// 把目标资源插入目标html中,同时输出到dist文件下
const result = targetHtml.pipe(inject(targetSources, { relative: true })).pipe(dest(targetDest));
return result;
};
module.exports = injectHtml;taskDevServer.js
const { watch } = require('gulp');
const path = require('path');
const browserSync = require('browser-sync');
const { pathDir, targetDest, rootDir } = require('./common.js');
const taskDevServer = (taskBuild) => {
return (options = {}) => {
const defaultOption = {
port: '8081', //设置端口
open: true, // 自动打开浏览器
files: `${rootDir}/${targetDest}/*`, // 当dist文件下有改动时,会自动刷新页面
server: {
baseDir: `${rootDir}/${targetDest}` // 基于当前dist目录
},
...options
};
// 监听public所有目录下,只要文件发生改变,就重新加载
watch(pathDir('public'), taskBuild);
const server = browserSync.create();
server.init(defaultOption);
};
};
module.exports = taskDevServer;...
task/index.js
const injectHtml = require('./injectHtml.js');
const taskDevServer = require('./taskDevServer.js');
const taskHtml = require('./taskHtml.js');
const taskImage = require('./taskImage.js');
const taskJS = require('./taskJS.js');
const taskLess = require('./taskLess.js');
module.exports = {
injectHtml,
taskDevServer,
taskHtml,
taskImage,
taskJS,
taskLess
};在gulpfile.js中,我们修改下
// gulpfile.js
const { series } = require('gulp');
const { injectHtml, taskDevServer, taskHtml, taskImage, taskJS, taskLess } = require('./task/index.js');
// series组合多个任务
const seriseTask = series(taskHtml, taskJS, taskLess, taskLess, taskImage, injectHtml);
// 本地服务
const devServer = taskDevServer(seriseTask);
// 启动服务
const server = () => {
devServer({
port: 9000
});
};
const taskBuild = seriseTask;
const defaultTask = (cb) => {
console.log('hello gulp');
cb();
};
exports.default = defaultTask;
exports.server = server;
exports.build = taskBuild;我们在package.json中新增命令
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"server": "gulp server",
"build": "gulp build"
},npm run build
在启动server之前,我们先执行npm run build,然后再执行下面命令,保证browserSync创建的服务文件夹存在,不然页面打开就404错误
npm run server
至此gulp搭建一个简单的应该就已经完全 ok 了
页面背景貌似有点黄
gulpjs开发是一个任务流的开发方式,它的核心**就是用自动化构建工具增强你的工作流,所有的自动化工作流操作都牢牢的掌握在自己手上,你可以用gulp写一些自动化脚本,比如,文件上传,打包,压缩,或者改造传统的前端应用。
用gulp写了一个简单的应用,但是发现中途需要找好多gulp插件,gulp的生态还算可以,3w多个 star,生态相对丰富,但是有些插件常年不更新,或者版本更新不支持,比如gulp-image,当你按照官方文档使用最新的包时,不支持 esm,你必须降低版本6.2.1,改用cjs才行
使用gulp的一些常用的 api,比如src、dest、series,以及browser-sync实现本地服务,更多api参考官方文档。
即使项目时间再多,也不要用gulp搭建前端应用,因为webpack生态很强大了,看gulp的最近更新还是 2 年前,但是写个自动化脚本,还算可以,毕竟gulp的理念就是用自动化构建工具增强你工作流程,也许当你接盘传统项目时,一些打包,拷贝,压缩文件之类的,可以尝试用用这个。
本文示例code-example
在客户端,我们所接触到的绝大部分本地缓存方案主要有localStorage以及sessionStorage,其实Storage除了这两大高频 api,另外还有IndexDB、cookies、WebSQL,Trust Token(信任令牌),cookies相对来说在前端接触比另外几个多点,IndexDB在平常业务中肯定有所耳闻,至于其他的貌似还真没用过
本文是笔者关于IndexDB的一个简单的实践示例,一起来学习下IndexDB,因为有时候,还是真的很有用。
正文开始...
在阅读本文之前,本文主要从以下几点去探讨IndexDB
为什么会有IndexDB,本地localStorage与sessionStorage不够用吗
IndexDB有何特征
以一个示例加深对于IndexDB的理解
IndexDB在什么情况下能为我们的业务解决什么样的问题
根据官方 MDNIndex DB文档查询解释
IndexDB是浏览器提供的一种可持久化数据存储方案lcoalStorage或者seesionStorage来说,IndexDB存储数据量更大,更强大你可以把IndexDB当成一个本地的数据库,如果你要使用它。那么会有以下几个步骤
打开数据库,创建本地数据库并连接IndexDB.open('lcoal-test')
创建对象库db.createObjectStore('user')
基于事务操作本地数据库,实现增删查改
本示例主要考虑最简单方式实现,也不依赖任何工程化工具,首先新建一个index.html,在index.html中引入vue2.7,vue2.7出来了,尝下鲜,主要支持组合式 api 方式了,基本api使用上与组合式API没有啥区别。
并且,这里我没有直接用原生IndexDB,而是使用了官方文档推荐的一个库dexie.js,因为官方原生API太难用了,而这个库是对原生IndexDB的二次封装,使用起来更高效
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>初识index-db</title>
<link rel="stylesheet" href="./css/index.css" />
</head>
<body>
<div id="app">
<h3>{{lesson}}</h3>
<a href="javascript:void(0)" @click="handleAdd('add')">新增</a>
<div class="content-box">
<div class="search-bar">
<input type="text" placeholder="请输入名称" v-model="searchName" />
<span @click="handleSearch">点击搜索</span>
</div>
<template v-for="(item) in initData">
<p>
<span>{{item.name}}</span>
<span>{{item.age}}</span>
<span @click="handleAdd('edit',item)">编辑</span>
<span @click="handleDel(item)">删除</span>
</p>
</template>
</div>
<div class="wrap-modal" v-if="showDiag">
<input placeholder="请输入name" v-model="formParams.name" />
<input placeholder="请输入age" v-model="formParams.age" />
<div>
<span @click="handleSure">确认</span>
</div>
</div>
</div>
<script src="https://cdn.bootcdn.net/ajax/libs/vue/2.7.0/vue.min.js"></script>
<script src="./js/dexie.min.js"></script>
</body>
</html>然后我们引入业务js
...
<script type="module">
// 引入hooks
import { useApp, useIndexDB } from './hooks/index.js';
const { reactive, toRefs, createApp, onMounted } = Vue;
const App = {
setup() {
const { searchName, lesson, initData, showDiag, view, formParams } = useApp();
const { add_indexDB, update_indexDB, search_indexDB, del_indexDB } = useIndexDB();
// todo 查询数据
const featchList = async (searchName = '') => {
const colletion = await search_indexDB(searchName);
initData.value = colletion;
};
onMounted(() => {
featchList();
});
// todo 编辑or添加
const handleAdd = (viewType, row) => {
searchName.value = '';
view.value = viewType;
showDiag.value = true;
// 编辑
if (view.value === 'edit') {
console.log(row);
formParams.value = {
...row
};
} else {
// 添加
formParams.value.name = '';
formParams.value.age = '';
}
};
const handleSure = () => {
showDiag.value = false;
view.value === 'edit' ? update_indexDB(formParams.value, featchList) : add_indexDB(formParams.value, featchList);
};
const handleDel = (row) => {
del_indexDB(row.id, featchList);
};
// 搜索
const handleSearch = () => {
featchList(searchName.value);
};
return {
searchName,
lesson,
showDiag,
initData,
formParams,
handleAdd,
handleSure,
handleDel,
handleSearch
};
}
};
// 绑定app
const app = new Vue(App).$mount('#app');
</script>我们看下这里面引入的useApp, useIndexDB
// hooks/index.js
const { reactive, toRefs, ref } = Vue;
export const useApp = () => {
const useInfo = reactive({
lesson: '初识IndexDB,实现本地crud一把梭',
initData: [],
showDiag: false,
view: 'add',
searchName: '',
formParams: {
name: '',
age: ''
}
});
return {
...toRefs(useInfo)
};
};
// IndexDB hooks
export const useIndexDB = () => {
const db = new Dexie('local-test');
db.version(1).stores({
user: '++id, name, age'
});
// 添加数据
const add_indexDB = (params, callback) => {
db.user.add(params);
callback();
};
// 更新数据
const update_indexDB = (params, callback) => {
db.user.put(params);
callback();
};
// 查询
const search_indexDB = async (params) => {
const colletion = params ? await db.user.where('name').equals(params).toArray() : await db.user.toArray();
return colletion;
};
// 删除
const del_indexDB = (id, callback) => {
db.user.where('id').equals(id).delete();
callback();
};
return {
db,
add_indexDB,
update_indexDB,
search_indexDB,
del_indexDB
};
};页面已经搭完,我们打开页面看下
现在我们新增一条数据,在页面点击新增按钮,在applcation/Storage/IndexDB中就会保存一条数据
当我们刷新时,数据页面仍然会保留上一次的数据
在我们新增操作,然后刷新的过程中主要发生了什么呢
其实IndexDB主要做了以下几件事情
// hooks/index.js
// 1 建立连接,创建db
const db = new Dexie('local-test');
//2 创建了一个user的表名
db.version(1).stores({
user: '++id, name, age'
});
// 3 向user中添加数据
// 添加数据
const add_indexDB = (params, callback) => {
db.user.add(params);
callback();
};
//4 查询user表中的数据,并返回
const search_indexDB = async (params) => {
const colletion = params ? await db.user.where('name').equals(params).toArray() : await db.user.toArray();
return colletion;
};在点击创建时,然后点击确认操作,就是在创建数据操作
...
// 点击确认会调用这个方法
const handleSure = () => {
// showDiag.value = false;
view.value === 'edit' ? update_indexDB(formParams.value, featchList) : add_indexDB(formParams.value, featchList);
};并且注意,我们还传入了一个featchList方法,这是在添加数据成功了,我们重新更新页面数据的一个回调
...
// todo 查询数据
const featchList = async (searchName = '') => {
const colletion = await search_indexDB(searchName);
// 页面数据赋值
initData.value = colletion;
};
...至此一个增加操作流程就已经结束
当我们点击编辑时,我们尝试修改名称,然后点击确认,那么此时就调用更新数据操作
// hooks/index.js
// 更新数据
const update_indexDB = (params, callback) => {
db.user.put(params);
callback();
};我们使用的是put方法直接就可以更新数据了
更新前
当我点击编辑
更新后
我们可以刷新右侧的刷新按钮现实对应的数据
...
// 删除
const del_indexDB = (id, callback) => {
db.user.where('id').equals(id).delete();
callback();
}
...删除前
删除后
当我们删除后,又可以重新添加
但是我们发现,每次只能添加一次,如果重复添加,那么此时会添加不了
主要原因是store中的key重复了,无法重复添加,但是你把上一条删除了,你就可以重复添加了
而且你删除后,当你刷新页面,那条数据就真的没有,当你新增一条数据,只要你不删除,那么打开页面数据就会一直在页面中。
所以IndexDB这个相当于在前端设计了一个小型数据库能力了,真的是
在上一个例子中,我们尝试用简单的一个例子去了解了IndexDB,但是在具体实际业务中,我们也很少会使用IndexDB去做这种杀鸡用牛刀的事,因为localStorage与sessionStorage也可以满足了,但如果是那种大数据量计算,如果涉及步骤操作那种,比如在这样的一个业务场景中,现在比较流行的低代码平台,拖拉拽的几个步骤就能生成一个页面,如果中途我只完成了一部分操作,页面不小心关掉了,此时如果你又让用户重新配置操作,那么体验就不会那么好,因此你可以尝试用IndexDB去做你操作流程的本地数据持久化操作,因为IndexDB可以存储足够大的数据量,你只需要保证你存的Schema数据能正常渲染你的页面就行,或者你的暂存操作也可以不用服务端处理,暂存功能完全可以依赖客户端做,这样也会减少服务端的压力。
基础的了解IndexDB,它是浏览器提供的一种可持久化缓存数据方案,相当于一个本地的数据库
写了一个简单的例子,支持IndexDB的增删查改功能
探讨了业务实际使用场景,一般用于存储大数据量,暂存操作等
本文示例code example
迭代器和生成器在前端业务里经常有用到,但是可能感受不太明显。特别是生成器,在react中如果你有用过redux中间健redux-saga那么你一定对生成器很熟悉。
本文是笔者对于迭代器与生成器的理解,希望在项目中有所帮助.
在阅读本文之前,主要会从以下几点去探讨迭代器/生成器
迭代器是什么,想想为什么会有迭代器
生成器又是什么,它解决了什么样的问题
以实际例子阐述迭代器与生成器
正文开始...
参考mdn上解释,迭代器是一个对象,每次调用next方法返回一个{done: false, value: ''},每次调用next返回当前值,直至最后一次调用时返回{value:undefined,done: true}时结束,无论后面调用next方法都只会返回{value: undefined,done:true}
在过往的业务中,你一定用过for ... of循环过数组或者Map
const arr = [
{
name: 'Maic',
age: 18
},
{
name: 'Tom',
age: 10
}
]
for (let item of arr) {
console.log(item);
/* {name: 'Maic', age:18},{name: 'Maic', age:18} */
}因为数组就是可以支持迭代器对象,并且for...of可以中断循环,关于循环中断可以参考以前写的一篇文章你不知道的JS循环中断
因为数组是支持可迭代的对象,如果使用迭代器获取每组数据应该怎么做呢?
const arr = [
{
name: 'Maic',
age: 18
},
{
name: 'Tom',
age: 10
}
]
const iterator = arr[Symbol.iterator]();
console.log(iterator.next());
console.log(iterator.next());
console.log(iterator.next());我们执行node index.js可以看到运行结果
当我们每次调用iterator.next()值时,都会返回当前的值,并且返回的值是{value: xxx, done: false},直至最后,返回的值{value: undefined, done: true }
不知道你发现没有,上面迭代器,我是通过数组访问Symbol.iterator方法,再调用返回的next方法,最后得到当前的值
我们可以在控制台看下
数组是有这个Symbol.iterator属性的
从以上迭代器特征中,我们可以得知,数组是通过一个Symbol.iterator方法,返回一个next方法,并且next方法返回{value: xx, done: false},我们模拟一个迭代器
const iteratorObj = {
value: [1, 2, 3],
count: -1,
next() {
this.count++
return {
value: this.value[this.count],
done: !this.value[this.count]
}
}
}
console.log(iteratorObj.next());
console.log(iteratorObj.next());
console.log(iteratorObj.next());
console.log(iteratorObj.next());打印的结果依次是:
{ value: 1, done: false }
{ value: 2, done: false }
{ value: 3, done: false }
{ value: undefined, done: true }此时你会发现iteratorObj就基本实现了一个迭代器的基本功能。
我们用一个对象模拟了迭代器,但是我们发现这个对象迭代器貌似没法复用
因此我们创建一个迭代器的工具函数
function createIteror(arr = []) {
let count = -1;
return {
next: function () {
count++
return {
value: arr[count],
done: count >= arr.length
}
}
}
}
const newCreateInteror = createIteror([1, 2, 3]);
console.log(newCreateInteror.next());
console.log(newCreateInteror.next());
console.log(newCreateInteror.next());
console.log(newCreateInteror.next());结果是:
{ value: 1, done: false }
{ value: 2, done: false }
{ value: 3, done: false }
{ value: undefined, done: false }因此createIteror这个方法就具备了迭代器的功能
我们在这之前用iteratorObj模拟了一个具备迭代器的功能,但是如何让真正的对象支持迭代呢
不知道你发现没有,其实数组原型上是有Symbol.iterator,所以如果要让一个对象支持迭代器功能,那么只需要遵循迭代协议即可
const coustomerInteror = {
value: [1, 2, 3],
// 让对象支持迭代器协议,需要增加一个Symbol.iterator可访问的方法,并返回一个迭代器对象,迭代器对象可以调用`next`方法,在next方法中返回一个当前对象的值
[Symbol.iterator]: function () {
let count = -1;
return {
next: () => {
count++;
return {
value: this.value[count],
done: count >= this.value.length
}
}
}
}
}
const newInter = coustomerInteror[Symbol.iterator]();
console.log(newInter.next());
console.log(newInter.next());
console.log(newInter.next());
console.log(newInter.next());
for (let item of coustomerInteror) {
console.log(item, '=result')
}可以看到打印的结果
因此让一个对象支持迭代器功能,只需要新增一个Symbol.iterator方法,遵循迭代器原则
我们从以上结果得知要想一个对象支持迭代器功能,必须要有Symbol.iterator这样的迭代器协议
因此我们可以在Object原型上新增这样的一个迭代器协议
// 在Object.prototype原型上扩展Symbol.iterator
Object.prototype[Symbol.iterator] = function () {
let count = -1;
return {
next: () => {
count++;
const keys = Object.keys(this);
return {
value: this[keys[count]],
done: count >= keys.length
}
}
}
}
const cobj = { a: 1, b: 2 };
const iteror = cobj[Symbol.iterator]();
console.log(iteror.next());
console.log(iteror.next())
console.log(iteror.next())
for (let item of cobj) {
console.log(item, '=rs')
}
const [a, b] = cobj;
console.log(a,b);执行的结果是:
{ value: 1, done: false }
{ value: 2, done: false }
{ value: undefined, done: true }
1 =rs
2 =rs
1 2你会发现当我们使用数组解构时,居然可以解构对象的值
const [a, b] = cobj;
console.log(a,b);本质上就是我们迭代器会自动调用iteror.next().value然后一一赋值返回了。
所以支持迭代器对象不仅可以for...of也可以被数组解构,这样所有var obj = {}这样类似申明的对象都可以支持迭代器了。
我们现在有个需求,需要支持通过构造函数new出来的对象支持可迭代器功能
具体我们看下代码
class Person {
constructor() {
this.name = 'Maic';
this.age = 18;
}
[Symbol.iterator]() {
let count = -1;
return {
next: () => {
count++;
// 获取对象的所有属性key
const keys = Object.keys(this);
return {
value: this[keys[count]],
done: count >= keys.length
}
}
}
}
}
const person = new Person();
const iter = person[Symbol.iterator]();
console.log(iter.next(), '==');
console.log(iter.next(), '==');
console.log(iter.next(), '==');
for (let item of person) {
if (item === 'Maic') {
break; // 可以中断循环
}
console.log(item) // 这里并不会打印
}
const [name, age] = person;
console.log(name, age)本质上也是在构造函数Person内部新增了Symbol.iterator方法,并且返回了一个迭代器对象
打印的结果如下:
{ value: 'Maic', done: false } ==
{ value: 18, done: false } ==
{ value: undefined, done: true } ==
Maic 18至此你应该非常了解迭代器的对象的特性了哈
能够for...of循环中断,且能够数组解构、扩展,所以你知道为啥会有迭代器了吗?
首先是数组Array,Map,Set
只要是有迭代器特性,那么就可以被for...of,数组解构等
这是es6新增的,参考generator解释,生成器是一种异步解决的方案,也可以理解一种函数内部的状态机,能中断函数,也就是说能够控制函数的运行
具体我们以一个实际例子看下生成器是什么
function* genter() {
yield 1;
yield 2;
}
const gen = genter();
console.log(gen);我们定义了一个普通函数,但是这个普通函数比较特殊,前面有*,这就是定义生成器函数,我们暂定把gen这个称呼为生成器对象
然后我们打印生成器对象,实际是就像函数调用一样,不过此时返回的是一个Object Generator
Object [Generator] {}但是我们继续看下
function* genter() {
yield 1;
yield 2;
}
const gen = genter();
console.log(gen.next());
console.log(gen.next());
console.log(gen.next());
for (let item of gen) {
console.log(item);
}此时打印的结果是
{ value: 1, done: false }
{ value: 2, done: false }
{ value: undefined, done: true }
1
2我们看下生成器函数内部是有yield这样的东西
实际上这就是内部函数的状态机,当你使用用生成器时,你调用next就会返回一个对象,并且像迭代器一样返回{value: xxx, done: false}
因此在使用上,我们必须认清,生成器必须是带有*定义的函数,内部是yield执行的状态机
当我们调用函数生成器时,并不会立即执行,返回一个遍历对象并返回一个next方法,当遍历对象调用next时,就会返回yield执行的状态机,并返回一个迭代器对象的值,yield会在当前状态暂停,只有调用next时,就会执行yield,yield
value表示当前yield的值,done:false表示当前遍厉没有结束,如果继续执行gen.next()那么就会返回当前的yield值,直到done:true时,表示当前遍历对象已经完全遍历完毕。
我们再来看下这段代码
function* start() {
console.log('start')
}
const genterStart = start();此时你会发现并不会调用start方法
但是你执行下面代码时,才会立即调用
function* start() {
console.log('start')
}
const genterStart = start();
setTimeout(() => {
genterStart.next();
}, 1000)我们会发现定时定时1s妙后才执行start方法,而且是通过next去执行的。
所以此时这个start变成了一个暂缓的执行函数,同时我们要注意yield只能用在*定义的生成器内部
我们在以往的业务中多少有写过扁平化数组,通常也是用递归实现多维数组的打平,现在我们尝试用生成器来实现一个扁平化数组
function* flat(arr) {
for (let i = 0; i < arr.length; i++) {
const item = arr[i];
if (Array.isArray(item)) {
// 如果是数组,则递归
yield* flat(item)
} else {
yield item
}
}
}
const sourceArr = [1, [[2, 3], 4], [5, 6]]
const result = [];
for (let item of flat(sourceArr)) {
result.push(item)
}
console.log(result)// [1,2,3,4,5,6]但是这个flat貌似不太通用,因此可不可以像原生flat方法一样,因此我们向下面这样做,在Array的原型上新增一个方法,让所有的数组都能访问这个自定义方法
// Array的prototype中绑定一个公有方法
Array.prototype.$myFlat = function () {
// 定义一个flat生成器
function* flat(arr) {
for (let i = 0; i < arr.length; i++) {
const item = arr[i];
if (Array.isArray(item)) {
// 递归当前flat
yield* flat(item);
} else {
yield item
}
}
}
const ngen = flat(this);
return [...ngen];
}
const sourceArr2 = [1, 2, [3, 4, 5, 6, [7, 8]]]
console.log(sourceArr2.$myFlat())因此$myFlat这个方法就像原生flat一样了
当我们看到用*定义的方法,就变成一个生成器,此时我们调用这个生成器方法,那么此时就可以for...of循环了
function* test() {
yield 1;
yield 2;
yield 3;
}
const gtest = test();
// gtest.next() { value:1,done: false}
// for (let item of gtest) {
// console.log(item) 这里相当于已经调用了gtest.next().value
// }
const [a, b, c, d] = gtest;
console.log('abc', a, b, c, d)打印的结果就是:
abc 1 2 3 undefined我们进一步测试一下:
function* test() {
yield 1;
yield 2;
yield 3;
}
const gtest = test();
console.log(gtest[Symbol.iterator]() === gtest) // true这里我们就会发现gtest可以通过Symbol.iterator这个方法直接调用,居然于它本身相等。
从控制台中我们可以知道gtest返回就是一个生成器对象,它的构造函数是GeneratorFunction,并且原型上有Symbol.iterator,而且是一个迭代器。
当你使用
...
gtest[Symbol.iterator]().next();
gtest[Symbol.iterator]().next()
gtest[Symbol.iterator]().next()
// 以上等价于
/*
gtest.next();
gtest.next();
gtest.next();
*/可以看下控制台打印的结果就知道了
所以大概了解生成器与迭代器的关系了么?本质上是通过生成器对象的prototype的Symbol.iterator连接了起来
当我们在生成器函数内部return时,那么当调用next迭代完所有的值时,继续调用next,则会返回return的值
什么意思,我们看下下面这段代码
function* test() {
yield 1;
yield 2;
yield 3;
return 4;
}
const gtest = test();
console.log(gtest.next());// {value: 1,done: false}
console.log(gtest.next()); // {value: 2,done: false}
console.log(gtest.next()); // {value: 3,done: false}
console.log(gtest.next()); // {value: 4,done: true}
console.log(gtest.next()); // {value: undefined,done: true}yield后面可以是变量或者具体函数返回值
你可以这么写
function* test() {
let b = 2;
const logNum = (num) => num
yield 1;
yield b;
yield logNum(5);
return 4;
}
const gtest = test();
console.log(gtest.next());
console.log(gtest.next());
console.log(gtest.next());
console.log(gtest.next()); 执行结果如下
{ value: 1, done: false }
{ value: 2, done: false }
{ value: 5, done: false }
{ value: 4, done: true }
{ value: undefined, done: true }生成器传参数
function* test() {
let b = 2;
const logNum = num => num
const n = yield 1; // n为下面第二个yield(10)这里n = 10
yield n * b; // 这个n就是第二个next传入的,会把第一个yield当返回值,传给下个yield
yield logNum(5);
return 4;
}
const gtest = test();
console.log(gtest.next());
console.log(gtest.next(10)); // 20
console.log(gtest.next());
console.log(gtest.next());
/*
{ value: 1, done: false }
{ value: 20, done: false }
{ value: 5, done: false }
{ value: 4, done: true }
{ value: undefined, done: true }
*/主要是在yield捕获异常,具体看下下面这个简单的例子
function* test() {
try {
yield 1;
} catch (error) {
console.log(error)
}
try {
yield 2;
} catch (error) {
console.log(error, '---2');
}
}
const gen = test();
console.log(gen.next())
gen.throw('错误了');
console.log(gen.next()) // 并不会运行当我们执行gen.next()时会执行yield 1此时返回{value: 1, done: false}
当我们执行gen.throw时,此时yield 2会暂停,并且就会中断了。并且后面的gen.next()就是默认返回{value: undefined, done: true}
我们在这之前都见过yield只能在生成器中使用,那到底有哪些使用,我们写个例子熟悉一下
function* a() {
yield 1;
yield 2;
}
function* b() {
yield* a();
yield 3;
}
const bGen = b();
// console.log([...bGen]); [1,2,3]
// console.log(bGen.next()) 注意这个与上面不能同时使用,不然这个bGen就是返回{value: undefined, done: true}yield后面能是函数返回值,能是变量,也可以是一个生成器函数
const obj = {
* getName() {
yield 'Maic'
}
}
const person = obj.getName();
console.log(person.next()); // {value: 'Maic', done: false}等价
const obj = {
getAge: function *() {
yield 18
}
}
const age = obj.getAge();
console.log(age.next()); // {value: 18, done: false}function* a() {
yield 1;
yield 2;
}
// new a() error在以往业务中肯定有这种场景,点击页面首先加载loading,然后请求数据,当数据请求成功后,就结束loading,我们看一段简单的伪代码
// 定义了一个获取数据的生成器方法,setTimeout模拟异步请求
function* getList() {
yield new Promise((resolve, reject) => {
setTimeout(() => {
resolve({
code: 0,
data: [
{
name: 'Maic',
age: 18
},
{
name: 'Web技术学苑',
age: 20
}
]
})
}, 1000)
})
}然后我们定义一个loadUI生成器
function* loadUI() {
console.log('正在加载中...,开启loading...');
yield* getList();
console.log('加载完成,关闭loading')
}
const loadStart = loadUI();
// 加载数据,调用next().value 获取yield的值
const currentData = loadStart.next().value;
currentData.then((res) => {
if (res) {
console.log(res);
}
loadStart.next(); // 关闭加载,加载完成,执行yield 后面的代码
});或者你可以这样
function* loadUI() {
console.log('正在加载中...,开启loading...');
const { data } = yield getList();
console.log(data);
console.log('加载完成,关闭loading')
}
const loadStart = loadUI();
function getList() {
const mockData = {
code: 0,
data: [
{
name: 'Maic',
age: 18
},
{
name: 'Web技术学苑',
age: 20
}
]
};
setTimeout(() => {
loadStart.next(mockData);// next传入数据当成yield状态机的返回值
}, 1000)
}
// 继续执行yield后面的代码
loadStart.next();运行的结果依旧是一样的,这样我就可以通过loadStart精准的控制数据请求在哪里执行了。如果我最后一行代码不执行,那么久不会执行后面的打印代码了,从而达到精准的控制函数内部的执行。
假设有一个场景,就是fn2依赖fn1的结果而决定是否是否执行,fn3依赖fn2的状态是否继续执行,那怎么设计呢?生成器可以帮我们解决这个需求问题
function fn1() {
return {
code: 1,
message: '我是fn1,你成功了,请进行下一步'
}
}
function fn2() {
return {
code: 0,
message: '我是fn2,失败了'
}
}
function fn3() {
console.log('恭喜你,闯关成功了...');
}
const source = [fn1, fn2, fn3];
function* main(arr = []) {
for (let i = 0; i < arr.length; i++) {
yield arr[i]( "i")
}
}
const it = main(source);
for (let item of it) {
console.log(item)
if (item.code === 0) {
break;
}
}结果是:
{ code: 1, message: '我是fn1,你成功了,请进行下一步' }
{ code: 0, message: '我是fn2,失败了' }当fn2返回code:0就会终止break中止,当fn2中返回的code是1时,才会进入下一个迭代
当我们for...of时,内部会依次调用next方法进行遍历数据。因为是迭代器,每次next的值返回的就是yield的值,并且返回{value: xxx, done: false},直到最后{value: undefined, done: true}
迭代器是一个对象,迭代器对象有一个next方法,当我们调用next方法时,会返回一个对象{value: xx, done: false},value就是当前迭代器迭代的具体值,当迭代器对象每调用一次next方法时,就会获取当前的值,直到迭代完全,最后返回{done: true, value: undefined}
每一个迭代器都可以被for...of、数组解构以及数组扩展
生成器函数,yield可以中断函数,当我们调用函数生成器时,实际上并不会立即执行生成器函数,这个调用的函数生成器在调用时会返回一个迭代器,每次调用next方法会返回一个对象,这个对象的值跟迭代器一样,并且返回的value是yield的值,每次调用,才会执行yield,后面的代码会中断。只有继续调用next才会继续往后执行。
生成器函数调用返回的事一个迭代器,具备迭代器所有特性,yield这个状态机只能在生成器函数内部使用
以实际例子对对象扩展支持迭代器特性,如果需要支持迭代器特征,那么必须原型上扩展Symbol.iterator方法,以$flat在数组原型上利用函数生成器实现扁平化数组等。
本文code-example
vue组合式是vue2项目过渡vue3的一种友好方案,在历史项目逐步迁移到vue3中,有项目历史包袱原因,一下子升级带来的问题可能比较多,composition-api天然兼容vue2,在vue2中使用组合式API让你提前感受vue3的各种姿势,vue3已经出来 3 年了,都2022了,vue祖师爷赏饭吃,相信你跟笔者一样早已跃跃欲试。
前段时间,笔者项目已经完成升级ts、组合式api,毕竟去年第 4 季度首要KPI便是升级项目业务引入ts和组合式API。在一边搬砖迭代业务,一边升级项目技术栈的挑战,过程虽曲折,好在组内有大佬及时解围,常常遇到奇葩问题,算是少走弯路。本篇不做组合式API语法过渡解读,因最近一个页面需求优化,以最简单的注册业务为例,在vue2与组合式API的选择中,希望给你的项目升级的过程中带来一点点帮助和思考。
正文开始...
这是一个非常普通的一个注册流程,可以看下具体页面,第一步账号注册
这是完成注册后,需要登记信息第二步信息登记
在第二步完成信息登记成功后,便等待管理员审核便可成功登陆控制台
// Index.vue
<template>
<a-base-page-layout>
<i-card class="page-content-card">
<i-steps :current="currentStep">
<i-step v-for="step of steps" :key="step.value" :title="$t(step.label)"></i-step>
</i-steps>
<i-divider></i-divider>
<!--注册-->
<a-register v-if="currentStep === 0" class="step-one" @finish="finishRegister"></a-register>
<!--信息登记-->
<a-info v-if="currentStep === 1" class="step-two" @finish="finishRegisterInfo"></a-info>
<!--等待审核-->
<a-moderation v-if="currentStep === 2" class="step-three"></a-moderation>
</i-card>
</a-base-page-layout>
</template>// Index.vue
<script>
import auth from '@/service/auth';
import { BasePageLayout } from '@/components';
import Register from './Register';
import Info from './Info';
import Moderation from './Moderation';
export default {
components: {
ABasePageLayout: BasePageLayout,
ARegister: Register,
AInfo: Info,
AModeration: Moderation,
},
data() {
return {
currentStep: 0,
steps: [
{
value: 1,
label: 'register.steps.one',
},
{
value: 2,
label: 'register.steps.two',
},
{
value: 3,
label: 'register.steps.three',
},
],
};
},
methods: {
finishRegister(result) {
if (result.developerInfo) {
if (result.developerInfo.enabled) {
this.$Message.info(this.$t('register.message.registerd'));
auth.goLogin('/');
} else {
this.currentStep = 2;
}
} else {
this.currentStep = 1;
}
},
finishRegisterInfo() {
this.currentStep = 2;
},
},
created() {
const step = +this.$route.query.step;
if (step) {
this.currentStep = step;
} else {
this.currentStep = 0;
}
},
};
</script>以上是index.vue,模板和逻辑是常用的options和template方式,在vue2中看起来似乎没毛病。
我们在继续关注第一步Register.vue,具体代码如下:
模板代码
// Register.vue
<template>
<div>
<i-alert class="warm-prompt-alert" show-icon closable>
<span class="warm-prompt-tips">{{ $t('register.warmPrompt.title') }}</span>
<span slot="desc">{{ $t('register.warmPrompt.content') }}</span>
</i-alert>
<i-row>
<i-col span="12" offset="6">
<i-tabs>
<!-- 手机号注册 -->
<i-tab-pane :label="$t('register.tabs.phone')" icon="ios-phone-portrait">
<i-form
:model="registerPhoneForm"
ref="registerPhoneForm"
:rules="phoneRuleValidate"
:label-width="140"
>
<a-fixed-autofill-password></a-fixed-autofill-password>
<i-form-item :label="$t('register.registerForm.phone.label')" prop="phone">
<i-input
v-model="registerPhoneForm.phone"
:placeholder="$t('register.registerForm.phone.placeholder')"
></i-input>
</i-form-item>
<i-form-item :label="$t('register.registerForm.password.label')" prop="password">
<i-input
type="password"
v-model="registerPhoneForm.password"
:placeholder="$t('register.registerForm.password.placeholder')"
></i-input>
</i-form-item>
<i-form-item :label="$t('register.registerForm.rpassword.label')" prop="rpassword">
<i-input
type="password"
v-model="registerPhoneForm.rpassword"
:placeholder="$t('register.registerForm.rpassword.placeholder')"
></i-input>
</i-form-item>
<i-form-item :label="$t('register.registerForm.authCode.label')" prop="authCode">
<i-row type="flex" class="authcode-row">
<i-col>
<i-input
v-model="registerPhoneForm.authCode"
:placeholder="$t('register.registerForm.authCode.placeholder')"
></i-input>
</i-col>
<i-col class="padding-left-16">
<a-vcode-button
@send-code="sendCode('phone')"
:disabled="!registerPhoneForm.phone"
></a-vcode-button>
</i-col>
</i-row>
</i-form-item>
<i-form-item>
<i-checkbox v-model="registerPhoneForm.agreeAndComply">
{{ $t('login.agreeAndComply') }}
<a @click="handleProtal('/user-agreement')" class="link">
{{ $t('login.userAgreement') }}
</a>
与
<a @click="handleProtal('/privacy-policy')" class="link">
{{ $t('login.privacyPolicy') }}
</a>
</i-checkbox>
</i-form-item>
<i-form-item>
<i-button
type="primary"
@click="submitPhoneForm"
:disabled="!registerPhoneForm.agreeAndComply"
>
{{ $t('register.registerForm.submitButtonLabel') }}
</i-button>
</i-form-item>
</i-form>
</i-tab-pane>
<!-- 邮箱注册 -->
<i-tab-pane :label="$t('register.tabs.email')" icon="ios-mail">
<i-form
:model="registerEmailForm"
ref="registerEmailForm"
:rules="emailRuleValidate"
:label-width="140"
>
<a-fixed-autofill-password></a-fixed-autofill-password>
<i-form-item :label="$t('register.registerForm.email.label')" prop="email">
<i-input
v-model="registerEmailForm.email"
:placeholder="$t('register.registerForm.email.placeholder')"
></i-input>
</i-form-item>
<i-form-item :label="$t('register.registerForm.password.label')" prop="password">
<i-input
type="password"
v-model="registerEmailForm.password"
:placeholder="$t('register.registerForm.password.placeholder')"
></i-input>
</i-form-item>
<i-form-item :label="$t('register.registerForm.rpassword.label')" prop="rpassword">
<i-input
type="password"
v-model="registerEmailForm.rpassword"
:placeholder="$t('register.registerForm.rpassword.placeholder')"
></i-input>
</i-form-item>
<i-form-item :label="$t('register.registerForm.authCode.label')" prop="authCode">
<i-row type="flex" class="authcode-row">
<i-col>
<i-input
v-model="registerEmailForm.authCode"
:placeholder="$t('register.registerForm.authCode.placeholder')"
></i-input>
</i-col>
<i-col class="padding-left-16">
<a-vcode-button
@send-code="sendCode('email')"
:disabled="!registerEmailForm.email"
></a-vcode-button>
</i-col>
</i-row>
</i-form-item>
<i-form-item>
<i-checkbox v-model="registerEmailForm.agreeAndComply">
{{ $t('login.agreeAndComply') }}
<a @click="handleProtal('/user-agreement')" class="link">
{{ $t('login.userAgreement') }}
</a>
与
<a @click="handleProtal('/privacy-policy')" class="link">
{{ $t('login.privacyPolicy') }}
</a>
</i-checkbox>
</i-form-item>
<i-form-item>
<i-button
type="primary"
@click="submitEmailForm"
:disabled="!registerEmailForm.agreeAndComply"
>
{{ $t('register.registerForm.submitButtonLabel') }}
</i-button>
</i-form-item>
</i-form>
</i-tab-pane>
</i-tabs>
</i-col>
</i-row>
</div>
</template>js代码
// Register.vue
<script>
import md5 from 'blueimp-md5';
import { commonRegexp } from '@/utils/index';
import { VcodeButton, FixedAutofillPassword } from '@/components';
import { handlegetRegistVCodeProxy, handleRegisterProxy } from '@/service/proxy/index';
export default {
components: {
AVcodeButton: VcodeButton,
AFixedAutofillPassword: FixedAutofillPassword,
},
data() {
return {
registerPhoneForm: {
phone: '',
password: '',
rpassword: '',
authCode: '',
agreeAndComply: true,
},
phoneRuleValidate: {
phone: [
{
required: true,
validator: (rule, value, callback) => {
if (value === '') {
callback(new Error(this.$t('register.registerForm.phone.emptyMessage')));
} else if (!commonRegexp.MOBILE_REG_EXP.test(value)) {
callback(new Error(this.$t('register.registerForm.phone.regCheckMessage')));
} else {
callback();
}
},
trigger: 'blur',
},
],
password: [
{
required: true,
validator: (rule, value, callback) => {
if (value === '') {
callback(new Error(this.$t('register.registerForm.password.emptyMessage')));
} else if (!commonRegexp.PASSWORD_REG_EXP.test(value)) {
callback(new Error(this.$t('register.registerForm.password.regCheckMessage')));
} else {
callback();
}
},
trigger: 'blur',
},
],
rpassword: [
{
required: true,
validator: (rule, value, callback) => {
if (value === '') {
callback(new Error(this.$t('register.registerForm.rpassword.emptyMessage')));
} else if (value !== this.registerPhoneForm.password) {
callback(new Error(this.$t('register.registerForm.rpassword.notMatchMessage')));
} else {
callback();
}
},
trigger: 'blur',
},
],
authCode: [
{
required: true,
validator: (rule, value, callback) => {
if (value === '') {
callback(new Error(this.$t('register.registerForm.authCode.emptyMessage')));
} else {
callback();
}
},
trigger: 'blur',
},
],
},
registerEmailForm: {
email: '',
password: '',
rpassword: '',
authCode: '',
agreeAndComply: true,
},
emailRuleValidate: {
email: [
{
required: true,
validator: (rule, value, callback) => {
if (value === '') {
callback(new Error(this.$t('register.registerForm.email.emptyMessage')));
} else if (!commonRegexp.EMAIL_REG_EXP.test(value)) {
callback(new Error(this.$t('register.registerForm.email.regCheckMessage')));
} else {
callback();
}
},
trigger: 'blur',
},
],
password: [
{
required: true,
validator: (rule, value, callback) => {
if (value === '') {
callback(new Error(this.$t('register.registerForm.password.emptyMessage')));
} else if (!commonRegexp.PASSWORD_REG_EXP.test(value)) {
callback(new Error(this.$t('register.registerForm.password.regCheckMessage')));
} else {
callback();
}
},
trigger: 'blur',
},
],
rpassword: [
{
required: true,
validator: (rule, value, callback) => {
if (value === '') {
callback(new Error(this.$t('register.registerForm.rpassword.emptyMessage')));
} else if (value !== this.registerEmailForm.password) {
callback(new Error(this.$t('register.registerForm.rpassword.notMatchMessage')));
} else {
callback();
}
},
trigger: 'blur',
},
],
authCode: [
{
required: true,
validator: (rule, value, callback) => {
if (value === '') {
callback(new Error(this.$t('register.registerForm.authCode.emptyMessage')));
} else {
callback();
}
},
trigger: 'blur',
},
],
},
};
},
methods: {
handleProtal(path) {
this.$router.push(path);
},
async sendCode(type) {
const params = {};
if (type === 'phone') {
params.phoneNum = this.registerPhoneForm.phone;
params.countryCode = '+86';
} else if (type === 'email') {
params.email = this.registerEmailForm.email;
}
params.authCodeType = 0; // 0 注册 1验证码登陆 2 找回密码
try {
await handlegetRegistVCodeProxy(params);
this.$Message.success({
content: this.$t('common.message.success'),
});
} catch (err) {
throw err;
}
},
async _doRegister(params) {
const res = await handleRegisterProxy(params);
console.log(res, 'register');
this.$emit('finish', res);
},
submitPhoneForm() {
const {
registerPhoneForm: { phone: account, password, authCode },
} = this;
this.$refs.registerPhoneForm.validate(valid => {
if (valid) {
const params = {
account,
password: md5(password),
authCode,
};
this._doRegister(params);
}
});
},
submitEmailForm() {
const {
registerEmailForm: { email: account, password, authCode },
} = this;
this.$refs.registerEmailForm.validate(valid => {
if (valid) {
const params = {
account,
password: md5(password),
authCode,
};
this._doRegister(params);
}
});
},
},
};
</script>这个页面代码如此冗余,我们发现有非常多重复的东西,用了两个tab切换两种不同方式注册,但实际上发现手机注册、邮箱注册最后调用接口都是一样的,所以冗余代码有些多,代码虽长了些,好在能改得动。
用jsx与composition-api重构了这个页面,减少了很多不必要的代码
新重构Index.vue模板代码
// Index.vue
<script lang="tsx">
import { defineComponent, SetupContext, watch, onMounted } from '@vue/composition-api';
import Qs from 'qs';
import auth from '@/service/auth';
import { BasePageLayout } from '@/components';
import { useStepConfig } from './hooks';
import Register from './Register.vue';
import Info from './Info.vue';
import Moderation from './Moderation.vue';
import AuditFail from './AuditFail.vue';
export default defineComponent({
components: {
ABasePageLayout: BasePageLayout,
ARegister: Register,
AInfo: Info,
AModeration: Moderation,
AuditFail,
},
setup(props, ctx: SetupContext) {
const { currentStep, steps } = useStepConfig();
const { root } = ctx;
// 完成注册
const finish = (result: PlainObj, setType: string) => {
if (setType === 'regiter') {
if (result.developerInfo) {
if (result.developerInfo.enabled) {
root.$Message.info(root.$t('register.message.registerd'));
auth.goLogin('/');
} else {
root.$router.replace('/register?step=2');
}
} else {
root.$router.replace('/register?step=1');
}
} else {
// const { step, status } = result;
const params = Qs.stringify(result, { addQueryPrefix: true });
root.$router.push(`/register${params}`);
}
};
watch(
() => root.$route,
(val): void => {
const {
query: { step = 0 },
} = val;
currentStep.value = step ? Number(step) : 0;
}
);
onMounted(() => {
const step = +root.$route.query.step;
currentStep.value = step || 0;
});
return {
currentStep,
steps,
finish,
};
},
render() {
const { currentStep, steps, finish } = this;
const CurentComponent: any = (): JSX.Element => {
const ret: {
[key: number]: JSX.Element;
} = {
0: <a-register class="step-one" onFinish={finish}></a-register>,
1: <a-info class="step-two" onFinish={finish}></a-info>,
2: <a-moderation class="step-three"></a-moderation>,
};
return ret[currentStep];
};
return (
<div class="register">
<a-base-page-layout>
<a-card class="page-content-card">
{currentStep === 3 ? (
<audit-fail onFinish={finish}></audit-fail>
) : (
<div>
<i-steps current={currentStep}>
{steps.map(v => (
<i-step key={v.value} title={v.label.value}></i-step>
))}
</i-steps>
{[1, 2].includes(currentStep) ? (
<i-divider style="width:auto;min-width:80%;margin:30px 60px;"></i-divider>
) : null}
<CurentComponent />
</div>
)}
</a-card>
</a-base-page-layout>
</div>
);
},
});
</script>由页面结构来看,其实与未升级前并没有发生多大变化,就是第一步注册操作、第二步信息登记,第三部等待审核。不过注意页面上还有一个状态currentStep=3的条件,这是一个等待审核被拒绝的页面状态。页面每个步骤的阶段显示都是通过路由的currentStep来做判断标识。
重构后后新注册页面模板代码
// Register.vue
<template>
<div>
<i-alert class="warm-prompt-alert">
<span slot="desc">
{{ $t('register.warmPrompt.title') }}{{ $t('register.warmPrompt.content') }}
<a href="javascript:void(0)" style="color: #4754ff" @click="handleLogin">
{{ $t('register.warmPrompt.accountLogin') }}
</a>
</span>
</i-alert>
<i-row>
<i-col span="12" offset="6">
<i-form :model="formParams" :rules="rulesConfig" ref="form" :label-width="140">
<a-fixed-autofill-password></a-fixed-autofill-password>
<i-form-item :label="$t('register.registerForm.useServer.label')" prop="useServer">
<i-select
style="width: 320px"
v-model="formParams.useServer"
:placeholder="$t('register.registerForm.useServer.placeholder')"
>
<i-option
v-for="item in useServerListOption"
:value="item.value"
:key="item.value"
:label="$t(item.label)"
></i-option>
</i-select>
</i-form-item>
<i-form-item :label="$t('register.registerForm.account.label')" prop="account">
<i-input
v-model.trim="formParams.account"
clearable
:placeholder="$t('register.registerForm.account.placeholder')"
></i-input>
</i-form-item>
<i-form-item :label="$t('register.registerForm.password.label')" prop="password">
<i-input
type="password"
clearable
v-model.trim="formParams.password"
:placeholder="$t('register.registerForm.password.placeholder')"
></i-input>
</i-form-item>
<i-form-item :label="$t('register.registerForm.rpassword.label')" prop="rpassword">
<i-input
type="password"
clearable
v-model="formParams.rpassword"
:placeholder="$t('register.registerForm.rpassword.placeholder')"
></i-input>
</i-form-item>
<i-form-item :label="$t('register.registerForm.authCode.label')" prop="authCode">
<i-row type="flex" class="authcode-row">
<i-col>
<i-input
v-model="formParams.authCode"
clearable
:placeholder="$t('register.registerForm.authCode.placeholder')"
></i-input>
</i-col>
<i-col class="padding-left-16">
<a-vcode-button
:sendCode="sendCode"
:disabled="!formParams.account"
></a-vcode-button>
</i-col>
</i-row>
</i-form-item>
<i-form-item>
<i-checkbox v-model="formParams.agreeAndComply">
{{ $t('login.agreeAndComply') }}
<a @click="handleProtal('/user-agreement')" class="link">
{{ $t('login.userAgreement') }}
</a>
与
<a @click="handleProtal('/privacy-policy')" class="link">
{{ $t('login.privacyPolicy') }}
</a>
</i-checkbox>
</i-form-item>
<i-form-item>
<i-button
style="width: 100%"
type="primary"
@click="handleSubmit"
:disabled="!formParams.agreeAndComply"
>
{{ $t('register.registerForm.submitButtonLabel') }}
</i-button>
</i-form-item>
</i-form>
</i-col>
</i-row>
</div>
</template>我们发现模板页面少了邮箱与手机号的区别,这是因为把手机号与邮箱统称为账号了,笔者认为在需求阶段应该就能考虑到,由于接口设计原因,邮箱和手机号为一个字段,但是前端表现形式不一样,譬如涉及邮箱和手机号的正则校验,因此,在需求与编码阶段,你是否会走第一种方案?还是说以后端一个字段设计为准,在视图层里,你不要那么明确的给用户两种方式选择。有更好的选择,如果设计如此,我们可以与产品设计沟通,因为只要你有理由说服了他们,那么就会增加代码的可复用度,降低冗余代码的堆积,从而减少维护成本。
重构后新注册js代码
// Register.vue
<script lang="tsx">
import { defineComponent, SetupContext, computed } from '@vue/composition-api';
import { Form } from 'view-design';
import md5 from 'blueimp-md5';
import { commonRegexp } from '@/utils/index';
import { VcodeButton, FixedAutofillPassword } from '@/components';
import useServerListOptionMinx from '@/mixins/useServerListOptionMinx';
import { handlegetRegistVCodeProxy, handleRegisterProxy } from '@/service/proxy/index';
import { useRegister } from './hooks';
interface formParamsType {
account: string;
password: string;
authCode: string | number;
useServer: number | string;
}
export default defineComponent({
components: {
AVcodeButton: VcodeButton,
AFixedAutofillPassword: FixedAutofillPassword,
},
mixins: [useServerListOptionMinx],
setup(props: any, ctx: SetupContext) {
const { formParams, rules } = useRegister();
const { refs, emit, root } = ctx;
const rulesConfig = computed(() => rules.value);
const doRegister = async (params: formParamsType) => {
const res = await handleRegisterProxy(params);
emit('finish', res, 'regiter');
};
const handleProtal = (path: string) => {
root.$router.push(path);
};
const handleSubmit = () => {
const { account, password, authCode, useServer } = formParams.value;
(refs.form as InstanceType<typeof Form>).validate((valid: Boolean) => {
if (valid) {
const params: formParamsType = {
account,
password: md5(password),
authCode,
useServer,
};
doRegister(params);
}
});
};
// 发送验证码
const sendCode = async (callback: Function) => {
const { account } = formParams.value;
const params: {
phoneNum?: string | number;
email?: string;
authCodeType: number;
} = {
authCodeType: 0, // 0 注册 1验证码登陆 2 找回密码
};
if (commonRegexp.PHONE_REG_EXP.test(account)) {
params.phoneNum = account;
// params.countryCode = '+86';
} else if (commonRegexp.EMAIL_REG_EXP.test(account)) {
params.email = account;
}
try {
await handlegetRegistVCodeProxy(params);
root.$Message.success({
content: root.$t('common.message.success'),
} as any);
callback(true);
} catch (err) {
callback(false);
throw err;
}
};
const handleLogin = () => {
root.$router.push('/login');
};
return {
formParams,
rulesConfig,
handleSubmit,
handleProtal,
sendCode,
handleLogin,
};
},
});
</script>不知道你注意一段代码没有,以前的表单校验rule与formParams全部从useRegister解构了出来,在vue3大量的api都是用hooks的**写的,与react越来越相似,在react中,函数式组件,hooks极大的解耦了业务组件,React 构建的页面**就是像搭积木一样,每个视图模块就是一个组件,在vue2之前虽然提供了render渲染组件,但是对于像react一样天然支持jsx的能力还是非常欠缺,虽然在vue也可以申明函数组件,也提供的template模板的方式。但是composition-api除了支持jsx,有更大的ts能力,让你组织你的代码,更强壮,可维护性更强,业务逻辑能进一步复用并减少耦合。
接下来我们来看下useRegister这个引入的hook,我们通常把这个方法有个更优雅的名字来定义它useXXXX,也就是类比 react 中的hook
// hooks/index.ts
import { reactive, toRefs, computed } from '@vue/composition-api';
import i18n from '@/i18n/index';
import { commonRegexp } from '@/utils/index';
// step进度条
export const useStepConfig = () => {
const setUpConfig = reactive({
currentStep: 0,
steps: [
{
value: 1,
label: computed(() => i18n.t('register.steps.one')),
},
{
value: 2,
label: computed(() => i18n.t('register.steps.two')),
},
{
value: 3,
label: computed(() => i18n.t('register.steps.three')),
},
],
});
return {
...toRefs(setUpConfig),
};
};
// 账号注册
export const useRegister = () => {
const registeConfig = reactive({
formParams: {
account: '',
password: '',
rpassword: '',
authCode: '',
agreeAndComply: true,
useServer: '',
},
rules: {
useServer: [
{
required: true,
trigger: 'change',
validator: (_rule: any, value: string, callback: Function) => {
if (value === '') {
callback(new Error(i18n.t('register.registerForm.useServer.message')));
} else {
callback();
}
},
},
],
account: [
{
required: true,
trigger: 'blur',
validator: (_rule: any, value: string, callback: Function) => {
if (value === '') {
callback(new Error(i18n.t('register.registerForm.account.emptyMessage')));
} else if (
!commonRegexp.MOBILE_REG_EXP.test(value) &&
!commonRegexp.EMAIL_REG_EXP.test(value)
) {
callback(new Error(i18n.t('register.registerForm.account.message')));
} else {
callback();
}
},
},
],
password: [
{
required: true,
validator: (_rule: any, value: string, callback: Function) => {
if (value === '') {
callback(new Error(i18n.t('register.registerForm.password.emptyMessage')));
} else if (!commonRegexp.PASSWORD_REG_EXP.test(value)) {
callback(new Error(i18n.t('register.registerForm.password.regCheckMessage')));
} else {
callback();
}
},
trigger: 'blur',
},
],
rpassword: [
{
required: true,
validator: (_rule: any, value: string, callback: Function) => {
if (value === '') {
callback(new Error(i18n.t('register.registerForm.rpassword.emptyMessage')));
} else if (value !== registeConfig.formParams.password) {
callback(new Error(i18n.t('register.registerForm.rpassword.notMatchMessage')));
} else {
callback();
}
},
trigger: 'blur',
},
],
authCode: [
{
required: true,
validator: (_rule: any, value: string, callback: Function) => {
if (value === '') {
callback(new Error(i18n.t('register.registerForm.authCode.emptyMessage')));
} else {
callback();
}
},
trigger: 'blur',
},
],
},
});
return {
...toRefs(registeConfig),
};
};
// 信息填写
export const userRegistInfo = () => {
...
return {
}
}这个hook文件已经把三个步奏用到的数据层已经高度的分离了出去,在实际业务中,你并不一定需要写在一个文件中,如果涉及多人合作,那么你可以把index里面拆分得更细些,比如这里你差分成三个不同ts文件userRegistInfo.ts、useRegister.ts、useStepConfig.ts,我们把每一块自己需要数据写入自己相关的hooks中,这样每个人只需要维护自己那份代码就行。
看到这里你是否感受到composition-api的**呢,在vue3中,所有的api用法几乎与composition-api用法一样,在官方有这么一段话,当迁移到 Vue 3 时,只需简单的将 @vue/composition-api 替换成 vue 即可。你现有的代码几乎无需进行额外的改动。。看到这里,你情不自禁的发出尖叫,vue3向下兼容了vue2,并且当你用composition-api过渡vue3时,我只需要全局替换一下@vue/composition-api这个就可以全量升级到vue3了。
此时你心中有没有被震惊到,赶紧升级你项目的vue2,让你自己在vue2的项目中也能畅游vue3的各种姿势,哈哈。
1.在 vue2 中使用options面条方式编码,业务页面有冗余代码,当我们发现字段设计与交互有差别时,可以与产品设计沟通,用你的理由说服他
2.在 vue2 中用composition-api方式组织你的业务代码时,明显感受到业务逻辑比以前更清晰,并且天然支持ts,让你的代码更安全,更强壮 💪
3.类似 react 的hook**,高度解耦业务视图层的数据逻辑,让你更专注解决疑难杂症,或者有更多的时间轻松聊天喝茶摸鱼。
4.更多关于composition-api,更多 vue3 参考官网
http这道八股文在面试中屡见不鲜,也是屡战屡败,今天卷http也是让自己重新回顾http,虽然在实际项目中,你不需要像面试一样被刨根问底,来自灵魂的拷问,但是,高端岗位,高端面试总会让你欲罢不能,说下http的理解,这道看似简单的菜,但是当你吃的时候,总会耐人寻味。
正文开始....
从http四个字母来讲,它是Hypter transfer protocol超文本传输协议。
超文本传输协议,你告诉面试官,他首先是超文本,不是普通文本,然后它是一种传输协议。下面一张图再次印在脑壳里
首先我们知道http它是一种计算机通信的协议,它是在计算机之间通信的协议,你可以把它看成计算机之间通信的规范,能处理各种网上信息的媒介。
然后我们知道它能传输,互联网上所有的文本,图片,视频以及文件都是能传输的,我们之所以能看网上的所有任何信息,这些信息都离不开传输。那么传输就靠它,遵循 A->B 或者 B->A,它是一个双向的通信。在 A->B 两点之间可以加许多约束,比如加密,安全认证、压缩数据等等,但是始终得遵循http传输的规范。
最后我们知道它是超文本,既然是超文本,那么它是一定不同寻常。所有数据文本格式在http眼里统称为超文本【文字、图片,视频、文件等】
以上说了那么多,那么http既然是超文本传输协议,那么它是类似应用软件、操作系统或者是apache、nginx、tomact那样的服务器吗?以上都不是,它是一种计算机通信的规范,是一种动态的存在,与应用软件、操作系统,以及web服务器息息相关,我们可以用编程语言去操作http进而操作应用软件、操作系统等等。
在互联网的世界里,http协议并不是孤立存在的,它在tcp/ip协议栈的上层,通过ip协议实现寻址和路由,通过tcp协议实现可靠的数据传输,DNS协议实现域名解析,SSL/TLS实现安全通信,有些其他通信协议甚至是依赖它的,比如websocket协议、HTTPDNS,这些协议组成一个协议网,而http处于中心位置,它们有机组合。
通常来讲,问这问题,似乎有点超越我知识边界啊,此时脑子里一片空白,心中已是万马奔腾....
http0.9版本
只支持GET请求方式,仅支持请求HTML格式资源。
http1.0版本
1、增加了HEAD、POST请求方法
2、增加了status状态码,字符集,内容编码
3、增加了请求头,请求体,响应体,支持长链接keep-alive
4、支持了多种文本格式传输,不仅限html格式文本
5、引入协议版本号
6、增加了缓存机制
http1.1版本
1、增加了PUT、DELETE、OPTION等方法
2、增加了缓存管理与控制
3、默认长链接connection:keep-alive
5、运行响应数据分块、利于传输大文件
6、强制要求Host头,增加管道机制,同时支持多个请求并行发送【把多个请求放到队列中,一个一个请求的同时,接收对应的响应】
7、增加了身份认证机制,新增 24 个错误码
http2.0版本
延续了http1.0所有的特性,增加以下新功能
1、二进制协议,不再是纯文本
2、可以发个多个请求,废除 1.1 的管道
3、专用的算法压缩头部,减少数据量的传输
4、允许服务器向客户端推送消息
5、增加了安全性,要求安全加密
6、增加了双工模式【客户端发送多个请求,服务端同时处理多个请求】
http位于 TCP/IP 上层,准确的说,http是TCP/IP协议的子集,TCP/IP 协议按层次分层管理
简单的来说就是发送SYN标识、确认SYN/ACK标识、回传ACK标识
首先 DNS 同属于应用层协议,它是域名->ip 之间的解析服务
通常我们访问一个类似www.baidu.com的网站,这是域名,通过访问域名,浏览器响应的页面在客户端中,在访问域名时,DNS 是帮我们解析了该域名的地址,实际上百度的 IP 地址可能是类似220.181.38.251这样的 ip,这也是服务器的ip地址。
在 DNS 解析只是为了让用户不用记住这串ip,用域名映射了ip地址,IP 协议会在你当前的固定的MAC地址(相当于电脑端的门牌号)上与ip地址进行发送数据与接收数据操作。
随便淘宝输入一个地址https://www.taobao.com/?spm=a2107.1.0.0.5c9511d9IYcDK4
我们快速使用express搭建一个服务器,并指定ip访问
npm init -y // 生成package.json
npm i express // 安装expresstouch server.js 创建服务端代码
// server.js
const express = require('express');
const app = express();
const PORT = '8081';
app.get('/', (req, res) => {
res.send('hello server');
});
app.listen(PORT, () => {
console.log('server is start' + PORT);
});运行命令node server.js,打开浏览器访问localhost:8081,这里的localhost之所以可以这么访问,是因为我们本地host映射的本地 ip 域名就是localhost,如果你查看你本地的ip也可以用ip访问,比如我的本地ip是192.168.1.6,具体查看mac,终端输入ifconfig即可查看本机的ip,如果你用ip访问那么就是http://192.168.1.6:8081
从这段简单的服务端代码我们可以知道,打开network我们来仔细回顾下http到底有哪些信息
General通用首部字段类型urlRequest URL 地址,GET请求,Status,还有Remote Address远程地址。strict-origin-when-cross-origin,对于同源的请求,会发送完整的 URL 作为引用地址Request URL: http://192.168.1.6:8081/
Request Method: GET
Status Code: 200 OK
Remote Address: 192.168.1.6:8081
Referrer Policy: strict-origin-when-cross-origin有http的版本,状态是200
X-Powered-By:Express这是可以看出是哪个服务器开发的。
Content-Type: text/html;charset=utf-8对应的网络类型语言和语言编码。
Content-Length: 12报文的实体长度。
ETag:W/"c-KpI5DocyxPM9FaJeckcyQoImh1k 服务器返回的一段标识,web端缓存验证。
Connection:keep-alive设置客户端长链接。Keep-Alive: timeout=5
HTTP/1.1 200 OK
X-Powered-By: Express
Content-Type: text/html; charset=utf-8
Content-Length: 12
ETag: W/"c-KpI5DocyxPM9FaJeckcyQoImh1k"
Date: Wed, 27 Apr 2022 13:04:19 GMT
Connection: keep-alive
Keep-Alive: timeout=5Accept服务器返回的语言Accept-Encoding: gzip, deflate,默认gzip与deflate,表示http响应是否进行压缩。Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,表示支持的语言
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cache-Control: no-cache
Connection: keep-alive
Cookie: sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2217af9c0b6845ce-07835609215c5b4-35637203-1296000-17af9c0b685d5f%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22url%E7%9A%84domain%E8%A7%A3%E6%9E%90%E5%A4%B1%E8%B4%A5%22%2C%22%24latest_search_keyword%22%3A%22url%E7%9A%84domain%E8%A7%A3%E6%9E%90%E5%A4%B1%E8%B4%A5%22%2C%22%24latest_referrer%22%3A%22url%E7%9A%84domain%E8%A7%A3%E6%9E%90%E5%A4%B1%E8%B4%A5%22%7D%2C%22%24device_id%22%3A%2217af9c0b6845ce-07835609215c5b4-35637203-1296000-17af9c0b685d5f%22%7D; _ga=GA1.1.1843623571.1627687795; Hm_lvt_c090ced1a911ebae432278eea5465028=1627687795; _hjid=0262b7cd-3d01-48d6-bf20-77b938e07cbf
Host: 192.168.1.6:8081
Pragma: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36因为http是无状态的的协议,它不会对之前的请求和响应进行管理,也就是无法根据之前的请求,判断当前的请求操作。虽然http是无状态的,也因此减少了服务器资源与CPU的内存消耗。但是可以通过cookie记录请求的状态,当一个网站需要登录后再次访问,不需要登录时,当我们登录后,服务端会在请求头里设置cookie,当客户端再次请求时,会携带这个之前设置好的cookie给后端,然后后端会在cookie设置uid等之类标识,前端也会根据这个设置标识不用重复登录操作。其实接口的鉴权也是这么这么做的,通常登录后,会在报文的请求头里设置token,所有接口请求头里都会带cookie标识给后端做验证,并且会设置当前cookie字段HttpOnly=true状态,在前端js是读取不到的。这是防御xss攻击的一种手段。
客户端HTTP的返回结果,标记服务端处理是否正常。
status大体分五类
1xx 信息状态码 接受请求正在处理
2xx 成功状态码 请求处理完毕 200
3xx 重定向状态码 需要加以附加操作才能完成请求 302 重定向
4xx 客户端状态码 服务器无法处理请求 404资源无法找到, 403访问资源被服务器拒绝
5xx 服务器错误状态码 服务器处理请求错误 500,503等请求头 cookie 部分字段设置HttpOnly,Set-Cookie: token=123;HttpOnly,js 是无法读取cookie设置的属性值的,防止 xss 利用 js 劫持 cookie
X-Frame-Options: DENY / SAMEORGIN 属于http响应首部,控制网站内容 Frame,防止点击劫持,`
X-XSS-Protection: 1 属于http响应首部,主要针对跨站脚本攻击, 1:xss 过滤设置成无效状态, 0:将 xss 过滤设置成有效状态
相比较http,https主要增强了安全性,http协议有很多的优点,但是也有缺点
1、首先http是明文通信,内容没有加密,有可能会被篡改
2、不会验证身份信息,因此可能会遭伪装
3、无法保护请求报文的完整性,报文有可能会被篡改。
因为以上种种,所以有了SSL(Secure Socket Layer)/TSL(Transport Layer Security)安全套接层/安全传输层协议
https通常会通过证书手段判断服务器和客户端的真实性,并且SSL会加密,意味报文不会轻易被窃取,一张图简单描述一下https
本质上https是套了一层SSL/TSL协议的外壳,增强了http协议的安全性
主要分为 3 类
Module Federation官方称为模块联邦,模块联邦是webpack5支持的一个最新特性,多个独立构建的应用,可以组成一个应用,这些独立的应用不存在依赖关系,可以独立部署,官方称为微前端。
什么模块联邦,微前端,瞬间高大上了,但是官方那解释和示例似乎看起来还是似懂非懂。
正文开始...
在阅读本文前,本文将会从以下几点去探讨MDF
MDFMDF给我解决了什么样的问题MDF在多个应用中如何使用MDF的强大我们先看一下图
在以前,我们每一个项目都会是一个独立的仓库,一个独立项目,一个独立的应用,多个项目应用之间都是互相独立,独立构建,独立部署。
现在假设application-a项目有一个组件是Example,假设application-b中也有一个组件需要这个组件Example
我们之前的做法就是把a项目的Example拷贝到b项目中,如果这个Example组件有依赖第三方插件,那么我们在b项目也需要安装对应的第三方插件,而且有一种场景,就是哪天这个Example组件需要更新了,那么两个应用得重复修改两次。
于是你想到另外一种方案,我是不是可以把这个独立的组件可以抽象成一个独立的组件仓库,用npm去管理这个组件库,而且这样有组件的版本控制,看起来是一种非常不错的办法。
但是...,请看下面,MDF 解决的问题
webpack5升级了,module Federation允许一个应用可以动态的加载另一个应用的代码,而且共享依赖项
现在就变成了一个项目 A 中可以动态加载项目 B,项目 B 也可以动态加载项目 A,A 应用的任何应用可以通过MFD共享给其他应用使用。
我们可以用下面一张图理解下
甚至你可以把B应用利用模块联邦导出,在A应用中使用。
现在终于明白为啥会有module federation了吧,本质上就是多个独立的应用之间,可以相互引用,可以减少重复的代码,更好的维护多个应用。我在 A 项目写的一个组件,我发现 B 项目也有用,那么我可以把这个组件共享给 B 使用。而不是 cv 操作,或者把这个组件搞个独立 npm 仓库(这也是一种比较可靠的方案)
新建一个目录module-federation,然后新建一个packages目录,对应的目录结构如下
|---packages
|
|-----application-a
|---src
|---App.jsx
|---app.js
|---public
|---index.js
|---...
|---package.json
|-----application-b
|---...
|----package.json我们在application-a与application-b中新建一个package.json,我们使用一个工具wsrun,可以批量启动或者打包多个应用
{
"name": "module-federation",
"version": "1.0.0",
"description": "模块联邦demo测试",
"main": "index.js",
"private": true,
"workspaces": ["packages/*"],
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "wsrun --parallel start",
"build": "yarn workspaces run build",
"dev": "wsrun --parallel dev"
},
"keywords": [],
"author": "maicFir",
"license": "ISC",
"devDependencies": {
"wsrun": "^5.2.4"
}
}在application-a应用中,我们主要看下以下几个文件
{
"name": "application_a",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "webpack server --port=8081 --open",
"build": "webpack"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"@babel/core": "^7.18.2",
"@babel/preset-env": "^7.18.2",
"@babel/preset-react": "^7.17.12",
"babel-loader": "^8.2.5",
"html-webpack-plugin": "^5.5.0",
"webpack": "^5.73.0",
"webpack-cli": "^4.10.0",
"webpack-dev-server": "^4.9.3"
},
"dependencies": {
"react": "^18.2.0",
"react-dom": "^18.2.0"
}
}// application-a/webpack.config.js
const path = require('path');
const webpack = require('webpack');
const HtmlWebpackPlugin = require('html-webpack-plugin');
// 引入moduleFed插件
const ModuleFederationPlugin = require('webpack/lib/container/ModuleFederationPlugin');
const { dependencies } = require('./package.json');
module.exports = {
mode: 'development',
entry: './index.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].bundle.js'
},
resolve: {
extensions: ['.jsx', '.js', '.json']
},
module: {
rules: [
{
test: /\.(js|jsx)$/,
loader: 'babel-loader',
options: {
presets: ['@babel/env']
}
}
]
},
plugins: [
new ModuleFederationPlugin({
name: 'application_a',
library: { type: 'var', name: 'application_a' },
// 另外一个应用html中引入的模块联邦入口文件
filename: 'remoteEntry.js',
// 选择暴露当前应用需要给外部使用的组件,供其他应用使用
exposes: {
'./Example': './src/compments/Example'
},
// 这里是选择关联其他应用的组件
remotes: {
application_b: 'application_b'
},
// react react-dom会独立分包加载
shared: {
...dependencies,
react: {
singleton: true,
requiredVersion: dependencies['react']
},
'react-dom': {
singleton: true,
requiredVersion: dependencies['react-dom']
}
}
// shared: ['react', 'react-dom'], 这样会error
}),
new HtmlWebpackPlugin({
template: './public/index.html'
}),
// 热加载
new webpack.HotModuleReplacementPlugin()
],
devServer: {
hot: true
}
};我们在看下入口entry文件
// application-a/index.js
import('./src/app.js');app.js
// application-a/src/app.js
import React from 'react';
import { createRoot } from 'react-dom/client';
import App from './App.jsx';
const appDom = document.getElementById('app');
const root = createRoot(appDom);
root.render(<App />);在App.jsx
// application-a/src/App.jsx
import React from 'react';
// 引入application_b应用的Example,Example2组件
// import Example1 from 'application_b/Example';
// import Example2 from 'application_b/Example2';
//or
const Example1 = React.lazy(() => import('application_b/Example'));
const Example2 = React.lazy(() => import('application_b/Example2'));
function App() {
return (
<div>
<p>this is applicatin a</p>
<Example1 />
<Example2 />
</div>
);
}
export default App;Example.jsx
// application-a/src/compments/Example.jsx
import React from 'react';
export default function Example1() {
return <h1>我是A应用的一个组件-example1</h1>;
}至此我们application-a这个项目已经 ok 了
我们再看下application-b
// application-b/webpack.config.js
const path = require('path');
const webpack = require('webpack');
const HtmlWebpackPlugin = require('html-webpack-plugin');
// 引入moduleFederation
const ModuleFederationPlugin = require('webpack/lib/container/ModuleFederationPlugin');
const { dependencies } = require('./package.json');
module.exports = {
mode: 'development',
entry: './index.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].bundle.js'
},
module: {
rules: [
{
test: /\.(js|jsx)$/,
loader: 'babel-loader',
options: {
presets: ['@babel/env']
}
}
]
},
resolve: {
extensions: ['.jsx', '.js', '.json']
},
plugins: [
new ModuleFederationPlugin({
name: 'application_b',
library: { type: 'var', name: 'application_b' },
filename: 'remoteEntry.js',
// 当前组件需要暴露出去的组件
exposes: {
'./Example': './src/compments/Example',
'./Example2': './src/compments/Example2'
},
// 关联需要引入的其他应用
remotes: {
application_a: 'application_a'
},
shared: {
...dependencies,
react: {
singleton: true,
requiredVersion: dependencies['react']
},
'react-dom': {
singleton: true,
requiredVersion: dependencies['react-dom']
}
}
// shared: ['react', 'react-dom'],
}),
new HtmlWebpackPlugin({
template: './public/index.html'
}),
new webpack.HotModuleReplacementPlugin()
],
devServer: {
hot: true
}
};我们在application-b/src/compments新建了两个组件
Example
import React from 'react';
export default function Example() {
return <h1>我是B应用-example1</h1>;
}Example1
import React from 'react';
export default function Example2() {
return <h1>我是B应用-example2</h1>;
}在webpack.config.js中我们在exposes中导出了,这样能给其他应用使用
...
plugin: [
new ModuleFederationPlugin({
name: 'application_b',
library: { type: 'var', name: 'application_b' },
filename: 'remoteEntry.js',
exposes: {
'./Example': './src/compments/Example',
'./Example2': './src/compments/Example2',
},
...
}),
]remoteEntry.js由于我需要在application-a中使用application-b暴露出来的组件
因此我需要在application-a的模版页面中引入
<!--application-a/public/index.html-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>application-a</title>
<script src="http://localhost:8082/remoteEntry.js"></script>
</head>
<body>
<div id="app"></div>
</body>
</html>如果我需要在application-b中需要application-a中的组件,同样需要引入
<!--application-b/public/index.html-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>application-b</title>
<script src="http://localhost:8081/remoteEntry.js"></script>
</head>
<body>
<div id="app"></div>
</body>
</html>在根目录下执行npm run start,注意子应用里面的名字也必须是start,相当于批量开启应用
application-a
application-b
至此你会发现application-a需要application-b应用的两个组件就已经无缝的应用到了自己应用中去
我们会发现,在application-a应用共享出来的模块,在application-b中的要提前在html中下载引入。
// error
exposes: {
'Example': './src/compments/Example',
},这样会导致在application-a中的 Example`无法使用
正确的做法是
exposes: {
'./Example': './src/compments/Example',
/*
'./App': './src/App' // 这样会报错,另外一个应用引入会报错
*/
},另外exposes只能暴露内部jsx的组件,不能是js文件,不能是整个App.jsx应用。主要是App.jsx有引用application-a的引用
如果application-b中,App.jsx改成以下
import React from 'react';
function App() {
return (
<div>
<h3>hello application B</h3>
</div>
);
}
export default App;那么此时我可以把整个application-b应用当成组件在application-a中使用,但是得把当前应用暴露出去
// application-b/webpack.config.js
exposes: {
'./Example': './src/compments/Example',
'./Example2': './src/compments/Example2',
'./App': './src/App'
},在application-a的App.jsx
// application-a/src/App.jsx
import React from 'react';
// import Example1 from 'application_b/Example';
// import Example2 from 'application_b/Example2';
// or
const Example1 = React.lazy(() => import('application_b/Example'));
const Example2 = React.lazy(() => import('application_b/Example2'));
const AppFromB = React.lazy(() => import('application_b/App'));
function App() {
return (
<div>
<p>this is applicatin a</p>
<Example1 />
<Example2 />
<p>下面是从另外一个应用动态加载过来的</p>
<AppFromB></AppFromB>
</div>
);
}
export default App;
握草,真是感叹,MDF 真的是太强了,这不是妥妥的可以替代传统的那种iframe嵌套另外一个独立的项目
...
shared: ['react', 'react-dom'],正确做法
const { dependencies } = require("./package.json");
...
shared: {
...dependencies,
react: {
singleton: true,
requiredVersion: dependencies["react"],
},
"react-dom": {
singleton: true,
requiredVersion: dependencies["react-dom"],
},
},另外推荐几篇关于MDF的参考资料以及文章
喝水不忘挖井人,参照官网以及以上一些资料,经本地不断的测试,终于了解webpack5 MDF的一些使用场景以及它在具体业务使用的可能性,更多关于 MDF 信息参考官方文档
了解module federation,官方解释就是模块联邦,主要依赖内部 webpack 提供的一个插件ModuleFederationPlugin,可以将内部的组件共享给其他应用使用
MDF解决了什么样的问题,允许一个应用 A 加载另外一个应用 B,并且依赖共享,两个独立的应用之间互不影响
写了一个例子,进一步理解MDF
本文示例code example
深度优先遍历与广度优先遍历,不刷算法题不知道这两个概念,虽然平时业务也有写过这种场景,但是一遇到这两词就感觉高大上了
深度优先遍历就是当我们搜索一个树的分支时,遇到一个节点,我们会优先遍历它的子节点,直到最后根节点为止,最后再遍历兄弟节点,从兄弟子节点寻找它的子节点,直到搜索到最后结果,然后结束。
首先我们从上面一段话中,我们知道遍历的对象是树,树是一种数据结构,我们在 js 中可以模拟它,具体我们画一个图
以上就是一个基本的树结构,在 js 中我们可以用以下结构去描述
const root = {
name: '1',
children: [
{
name: '2-1',
children: [
{
name: '3-1',
children: [
{
name: '4-2',
children: null
},
{
name: '4-1',
children: null
}
]
},
{
name: '3-2',
children: null
}
]
},
{
name: '2-2',
children: null
}
]
};我们理解上面那句话,深度优先遍历,就是当我搜索一个树分支,遇到一个节点,我就搜索她的子节点,直到搜索完了,再去搜索兄弟节点,我们用代码来验证一下
// 深度优先遍历
const deepDFS = (root, nodeList = []) => {
if (root) {
nodeList.push(root.name);
// 递归root.children,找root的子节点
root.children && root.children.forEach((v) => deepDFS(v, nodeList));
}
return nodeList;
};
const result = deepDFS(root, []);
console.log(JSON.stringify(result, null, 2));
/**
[
"1",
"2-1",
"3-1",
"4-2",
"4-1",
"3-2",
"2-2"
]
*/从结果上来看发现从最开始的分支,从第一个分支开始,找到一个节点就一直找到最深的那个节点为止,然后再找父级兄弟节点,最后再从根子节点的兄弟节点去寻找子节点。
搜索树分支时,从根节点开始,当访问子节点时,先遍历找到兄弟节点,再寻找对应自己的子节点
我们用一个图来还原一下搜索过程
对应的代码如下
// 广度优先遍历
const deepBFS = (root, nodeList = []) => {
const queue = [root];
// 循环判断队列的长度是否大于0
while (queue.length > 0) {
// 取出队列添加的节点
const p = queue.shift();
nodeList.push(p.name);
// 根据节点是否含有children,如果有子节点则添加到队列中
p.children && p.children.forEach((v) => queue.push(v));
}
return nodeList;
};
console.time('BFS-start');
const result = deepBFS(root, []);
console.log(JSON.stringify(result, null, 2));
console.timeEnd('BFS-start');
/*
[
"1",
"2-1",
"2-2",
"3-1",
"3-2",
"4-2",
"4-1"
]
*/广度优先遍历的主要**是将一个树放到一个队列中,我们循环这个队列,判断该队列的长度是否大于 0,我们不断循环队列,shift出队列操作,然后判断节点children,循环children,然后将子节点添加到队列中,一旦队列的长度为 0,那么就终止循环了。
我们测试一下两者哪种搜索时间效率更高
// BFS 广度优先遍历
console.time('BFS-start');
const result = deepBFS(root, []);
console.log(JSON.stringify(result, null, 2));
console.timeEnd('BFS-start');// DFS 深度优先遍历
console.time('DFS-start');
console.log(JSON.stringify(deepDFS(root, []), null, 2));
console.timeEnd('DFS-start');最后发现
广度优先遍历的时间明显比深度优先的时间效率要高,广度优先遍历是用队列记录了每一个节点的位置,所以会占用内存更多点,由于深度优先遍历是从根节点往子节点依次递归查询,当子节点查询完了,就从根的节点的兄弟节点依次往下搜索,所以比较耗时,搜索效率上广度优先遍历更高。
1、理解深度优先遍历与广度优先遍历是什么
深度优先遍历就是从上到下,当我们搜索一个树时,我们从根开始,遇到一个节点,就先查询的它的子节点,如果子节点还有子节点就继续往下寻找直到最后没有为止,再从根子节点的兄弟节点开始依次向下寻找节点。
而广度优先遍历遍历就是从根节点开始,寻找子节点,先遍历寻找兄弟节点,依次从上往下,按层级依次搜索。
2、用具体代码实现深度优先遍历与广度优先遍历
3、深度优先遍历比广度优先遍历更耗时
4、本文示例代码 code example
在 vue 中,我们知道它的核心**是数据驱动视图,表现层我们知道在页面上,当数据发生变化,那么视图层也会发生变化。这种数据变化驱动视图背后依靠的是什么?
正文开始...
// src/core/instance/observer/index.js
/**
* Define a reactive property on an Object.
*/
export function defineReactive(obj: Object, key: string, val: any, customSetter?: ?Function, shallow?: boolean) {
const dep = new Dep();
const property = Object.getOwnPropertyDescriptor(obj, key);
if (property && property.configurable === false) {
return;
}
// cater for pre-defined getter/setters
const getter = property && property.get;
const setter = property && property.set;
if ((!getter || setter) && arguments.length === 2) {
val = obj[key];
}
let childOb = !shallow && observe(val);
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
const value = getter ? getter.call(obj) : val;
if (Dep.target) {
dep.depend();
if (childOb) {
childOb.dep.depend();
if (Array.isArray(value)) {
dependArray(value);
}
}
}
return value;
},
set: function reactiveSetter(newVal) {
const value = getter ? getter.call(obj) : val;
/* eslint-disable no-self-compare */
if (newVal === value || (newVal !== newVal && value !== value)) {
return;
}
/* eslint-enable no-self-compare */
if (process.env.NODE_ENV !== 'production' && customSetter) {
customSetter();
}
// #7981: for accessor properties without setter
if (getter && !setter) return;
if (setter) {
setter.call(obj, newVal);
} else {
val = newVal;
}
childOb = !shallow && observe(newVal);
dep.notify();
}
});
}我们会发现其实在vue2源码中,本质上就是利用Object.defineProperty来劫持对象。
每劫持一组对象,首先会实例化一个Dep对象,每个拦截的对象属性都会动态添加get和set将传入的data或者prop变成响应式,在Object.defineProperty的get中,当我们访问对象的某个属性时,就会先调用get方法,依赖收集调用dep.depend(),当我们设置该属性值时就会调用set方法调用dep.notify()``派发更新所有的数据,在调用notify时会调用实例Watch的run,从而执行watch的回调方法。
在vue2源码中劫持对象实现数据驱动视图,那么我们依葫芦画瓢,化繁为简,实现一个自己的数据劫持吧。
新建一个index.js
// index.js
var options = {
name: 'Maic',
age: 18,
from: 'china'
};
const renderHtml = (data, key) => {
const appDom = document.getElementById('app');
appDom.innerHTML = `<div>
<p>options:${JSON.stringify(options)}</p>
<p>${key}: ${JSON.stringify(data)}</p>
</div>`;
};
const defineReactive = (target, key) => {
let val = target[key];
Object.defineProperty(target, key, {
enumerable: true,
configurable: true,
get: function () {
return val;
},
set: function (nval) {
console.log(nval, '==nval');
val = nval;
renderHtml(nval, key);
}
});
};
Object.keys(options).forEach((key) => {
defineReactive(options, key);
});
renderHtml(options, 'name');再新建一个html引入index.js
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>vue2-reactive</title>
</head>
<body>
<div id="app"></div>
<script src="./index.js"></script>
</body>
</html>直接打开index.html
当我们大开控制台时,我们直接修改options.age = 10此时会触发拦截器的set方法,从而进行更新页面数据操作。
在源码里里面处理是相当复杂的,我们可以看到访问数据时,会先调用get方法,在dep.depend()进行依赖收集,然后再设置对象的值时,会调用set方法,派发更新操作。更多关于vue2响应式原理可以参考这篇文章响应式原理
vue3主要利用Proxy这个API来实现对象劫持的,关于Proxy可以看下阮一峰老师的 es6 教程proxy,全网讲解Proxy最好的教程了。
继续用个例子来感受下
var options = {
name: 'Maic',
age: 18,
from: 'china'
};
const renderHtml = (data, key) => {
const appDom = document.getElementById('app');
appDom.innerHTML = `<div>
<p>options:${JSON.stringify(options)}</p>
<p>${key}: ${JSON.stringify(data)}</p>
</div>`;
};
renderHtml(options, 'name');
var proxy = new Proxy(options, {
get: function (target, key, receiver) {
console.log(key, receiver);
return Reflect.get(target, key);
},
set: function (target, key, val, receiver) {
console.log(key, val, receiver);
renderHtml(val, key);
return Reflect.set(target, key, val);
}
});当我们在控制输入proxy.name = 111时,此时就会触发new Proxy()内部的set方法,而我们此时采用的是利用Reflect.set(target,key,val)成功的设置了,在get中,我们时用Relect.get(target, key)获取对应的属性值。
这点与vue2中劫持数据的方式比较大,具体可以看下vue3源码响应式reactive实现
// package/reactivity/src/reactive.ts
function createReactiveObject(target: Target, isReadonly: boolean, baseHandlers: ProxyHandler<any>, collectionHandlers: ProxyHandler<any>, proxyMap: WeakMap<Target, any>) {
if (!isObject(target)) {
if (__DEV__) {
console.warn(`value cannot be made reactive: ${String(target)}`);
}
return target;
}
// target is already a Proxy, return it.
// exception: calling readonly() on a reactive object
if (target[ReactiveFlags.RAW] && !(isReadonly && target[ReactiveFlags.IS_REACTIVE])) {
return target;
}
// target already has corresponding Proxy
const existingProxy = proxyMap.get(target);
if (existingProxy) {
return existingProxy;
}
// only a whitelist of value types can be observed.
const targetType = getTargetType(target);
if (targetType === TargetType.INVALID) {
return target;
}
const proxy = new Proxy(target, targetType === TargetType.COLLECTION ? collectionHandlers : baseHandlers);
proxyMap.set(target, proxy);
return proxy;
}从源码中我们可以看出在vue3使用reative初始化响应式数据时,实际上它就是就是一个被proxy代理后的数据,并且使用WeakMap来存储响应式数据的。
相比较vue2的defineProperty,vue3的Proxy更加强大,因为代理对象对劫持的对象动态新增属性也一样有检测,而defineProperty就没有这种特性,它只能劫持已有的对象属性。
在vue2中数据劫持是用Object.defineProperty,当访问对象属性时会触发get方法进行依赖收集,当设置对象属性时会触发set方法进行派发更新操作。
在vue3中数据劫持时用new Proxy()来做的,可以动态的监测对象的属性新增与删除操作,效率高,实用简单。
本文示例code example
跨域产生的原因首先是受浏览器的安全性设计影响,由于浏览器同源策略的设计,所以产生了跨域。
在项目中,我们常常遇到跨域的问题,虽然在你的项目里,脚手架已经 100%做好了本地代理、或者运维老铁在nginx中也已经给你做了接口代理,所以你遇到跨域的概率会少了很多,但是在传统的项目中,在那个jquery的横行时代,或者你接手了一个祖传项目时,跨域问题会是时有发生,本文只做笔者了解跨域的通用解决方案,希望在实际项目中对你有些思考和帮助。
正文开始...
非同源是无法彼此访问cookie,dom操作,ajax、localStorage、indexDB操作
但是非同源可以访问以下一些属性
window.postMessage();
window.location
window.frames
window.parent
...对于非同源网站跨域通信,我们可以采用以下几种方案
通过在url上放入#type,利用hashchange事件,获取父页面的相关hash数据
// parent
const type = 'list';
const originUrl = originUrl + '#' + type;
const iframe = document.getElementById('iframe');
iframe.src = originUrl;在子iframe中,我们可以监听hashchange事件
// iframe
window.addEventListener('hashchange', (evt) => {
console.log(evt); // 获取片段标识符的相关数据
});子页面可以利用window.postMessage向父页面发送信息,父页面监听message接收子页面发送的消息,通常这种方式在iframe通信中用得做多,也是跨域通信的一种解决方案
// parent
window.addEventListener('message', (evt) => {
const data = evt.data;
console.log(data);
});// child
const origin = '*'; // 这里一般是父页面的域名,但是也可以是*
const data = {
text: 'hello, world'
};
window.postMessage(data, origin);利用script标签,向服务端发送一个get请求,url上绑定一个callback=fn,这个fn通常是与后端约束好,fn是客户端执行的函数名。
用一个简单的例子来解释下jsonp
客户端示例
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>jsonp</title>
</head>
<body>
<h3>jsonp</h3>
<div id="app"></div>
<script>
var script = document.createElement('script');
script.setAttribute('type', 'text/javascript');
script.src = 'http://192.168.31.40:8080/api?callback=jsonp';
document.body.appendChild(script);
const renderHtml = ({ name, age }, dom) => {
dom.innerHTML = `<div>我的名字 ${name},今年 ${age}岁了</div>`;
};
function jsonp(data) {
console.log(data);
const app = document.getElementById('app');
const { name, age } = data;
renderHtml({ name, age }, app);
}
</script>
</body>
</html>服务端示例代码
// server.js
const http = require('http');
const fs = require('fs');
const path = require('path');
const PORT = '8080';
const server = http.createServer((req, res) => {
res.statusCode = 200;
// console.log(req.url);
res.setHeader('Content-Type', 'text/html');
fs.readFile(path.resolve(__dirname, '../', 'index.html'), (err, data) => {
if (err) {
res.end('404');
return;
}
res.end(data);
});
const data = {
name: 'Maic',
age: Math.floor(Math.random() * 20)
};
if (req.url.includes('/api')) {
res.end(`jsonp(${JSON.stringify(data)})`);
}
});
server.listen(PORT, () => {
console.log('server is start' + PORT);
});注意我们看到有这样的一段判断req.url.includes('/api'),然后我们res.end(jsonp(JSON.stringify(data))),返回的就是jsonp这个回调函数,把数据当形参传给前端,在客户端定义的jsonp方法就能获取对应的数据。
执行node server.js打开http://localhost:8080我们会发现
返回的数据就是fn({name: 'xx',age: 'xx'})
我们看下请求头
浏览器会发送一个get请求,所携带的参数就是callback: jsonp,而我们在客户端确实是通过jsonp这个方法拿到对应的数据了。
所以我们可以知道jsonp实际上就是利用一个客户端发送的get请求携带一个后端服务的返回的回调函数,在客户端,我们定义这个回调函数就可以获取后端返回的形参数据了。
从jsonp这种跨域通信来看,其实有也它的缺点和优点
1、它的安全性会有一定风险,因为依赖的结果就是那个回调函数的形参内容,如果被人劫持修改返回数据,那可能会造成安全性问题
2、仅支持get请求,不支持其它http请求方式,我们发现jsonp这种通信就是利用script标签请求了一个url,url上携带了一个可执行的回调函数,进而通过后端给回调函数传递数据的。
3、没有任何状态码,数据丢给客户端,如果有失败情况,不会有像http状态码一样
能解决跨域通信问题,兼容性比较好,不受同源策略的影响,对后端来说实现也简单。
在以前比较久远的项目中,你可能是直接使用jquery,jsonp就ok了,大概的代码就是长这样的
$.ajax({
url: 'xxx',
dataType: 'jsonp',
jsonp: 'successCallback',
success: (data) => {
console.log(data);
},
error: (err) => {
console.log(err);
}
});successCallback这个就是与服务端约束的回调函数,一般与服务端沟通一致就行,那么简单的jsonp就已经完成了,是不是感觉很简单呢?
由于WebSocket不受同源策略的限制,因此WebSocket也是可以实现跨域通信的。这里就不举例子了,具体可以参考之前写的一篇浅谈 websocket这篇文章
这种方式是在服务端进行控制,允许任何资源请求。其实在浏览器端,即使跨域,还是会正常请求,只是请求非同源环境的后端服务,浏览器禁止请求访问,更多可以参考这篇文章cors
我们写个例子具体测试一下,在客户端加入这段代码
const send = document.getElementById('send');
send.onclick = function () {
if (!window.fetch) {
return;
}
fetch('http://localhost:8081/list.json')
.then((res) => res.json())
.then((result) => {
console.log(result);
const contentDom = document.querySelector('.content');
renderHtml(result, contentDom);
});
};服务端代码,我们新建一个index2.js服务端代码,并执行node index2.js
const http = require('http');
const PORT = '8081';
const server = http.createServer((req, res) => {
res.statusCode = 200;
// // console.log(req.url);
res.setHeader('Content-Type', 'application/json');
if (req.url.includes('/list.json')) {
res.end(
JSON.stringify({
name: 'maic',
age: Math.ceil(Math.random() * 20)
})
);
}
});
server.listen(PORT, () => {
console.log('server is start' + PORT);
});我们注意到请求的端口是8081,打开8080页面
点击按钮,发送fetch请求,我们发现浏览器报了这样你常常看到的跨域信息as been blocked by CORS policy: No 'Access-Control-Allow-Origin' header...,因为跨域了
紧接着我们在服务端设置下Access-Control-Allow-Origin: *
const http = require('http');
const PORT = '8081';
const server = http.createServer((req, res) => {
res.statusCode = 200;
// // console.log(req.url);
res.setHeader('Content-Type', 'application/json');
res.setHeader('Access-Control-Allow-Origin', '*');
if (req.url.includes('/list.json')) {
res.end(
JSON.stringify({
name: 'maic',
age: Math.ceil(Math.random() * 20)
})
);
}
});
server.listen(PORT, () => {
console.log('server is start' + PORT);
});此时再次访问时,已经 ok 了
注意我们可以看下Response Headers
HTTP/1.1 200 OK
Content-Type: application/json
Access-Control-Allow-Origin: *
Date: Sun, 01 May 2022 14:23:59 GMT
Connection: keep-alive
Content-Length: 24Access-Control-Allow-Origin:*这是我们服务的设置响应请求头,设置允许所有域名请求。
因此cors跨域其实在服务端设置Access-Control-Allow-Origin: *也就完美的解决了跨域问题。
跨域产生的原因,主要受同源策略的影响,非同源环境,无法相互访问cookie、localStorage、dom操作等
解决跨域的方案主要有片段标识符、iframe通信postMessage,jsonp、WebSocket、cors
用具体实际例子深入了解几种跨域模式,比如jsonp,实际上是利用script发送一个get请求,在get请求的参数中传入一个可执行的回调函数,服务根据请求,将返回一个前端可执行的回调函数,并且将数据当成该回调函数的形参,在前端定义该回调函数,从而获取调函数传入的数据。
用具体 🌰 看到服务端设置cors,主要是在后端接口返回响应头里设置Access-Control-Allow-Origin:*允许所有不同源网站访问,这种方法也是比较粗暴的解决跨域问题。
本文示例代码code example
在项目中你有优化过自己写过的代码吗?或者在你的项目中,你有用过哪些技巧优化你的代码,比如常用的函数防抖、节流,或者异步懒加载等。
今天一起学习一下如何利用函数缓存优化你的业务项目代码。
正文开始...
我们还是快速初始化一个项目
npm init -y
npm i webpack webpack-cli webpack-dev-server html-webpack-plugin --save-dev然后新建webpack.config.js并且配置对应的内容
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
entry: {
app: './src/index.js'
},
output: {
path: path.resolve(__dirname, 'dist')
},
plugins: [
new HtmlWebpackPlugin({
template: './index.html'
})
]
};然后新建index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>缓存函数</title>
</head>
<body>
<div id="app"></div>
</body>
</html>对应的src/index.js
const appDom = document.getElementById('app');
console.log('hello');
appDom.innerText = 'hello webpack';对应package.json配置执行脚本命令
{
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start:dev": "webpack serve --mode development",
"build": "webpack --config ./webpack.config.js --mode production"
}
}执行npm run start:dev,浏览器打开http://localhost:8080
至此这个前端的简单应用已经 ok 了
现在页面我需要一个需求,我要在页面中插入1000条数据
在这之前我们使用过一个分时函数**来优化加载数据
现在我们把这个分时函数写成一个工具函数
// utils/timerChunks.js
// 分时函数
module.exports = (sourceArr = [], callback, count = 1, wait = 200) => {
let ret,
timer = null;
const renderData = () => {
for (let i = 0; i < sourceArr.length; i++) {
// 取出数据
ret = sourceArr.shift();
callback(ret);
}
};
return () => {
if (!timer) {
// 利用定时器每隔200ms取出数据
timer = setInterval(() => {
// 如果数据取完了,就清空定时器
if (sourceArr.length === 0) {
clearInterval(timer);
ret = null;
return;
}
renderData();
}, wait);
}
};
};由于代码中使用了es6,因此还需要配置babel-loader将es6转换成es5
npm i @babel/core @babel/cli @babel/preset-env babel-loader --save-dev以上几个通常是babel需要安装的,修改下的webpack.config.js的module.rules
{
...
module: {
rules: [
{
test: /\.js$/,
use: [
{
loader: 'babel-loader',
options: {
presets: ['@babel/env'] // 设置预设,这个会把es6转换成es5
}
}
]
}
]
},
}我们修改下index.js
const timerChunk = require('./utils/timerChunk');
class renderApp {
constructor(dom) {
this.dom = dom;
this.sourceArr = [];
this.appDom = new WeakMap().set(dom, dom);
}
init() {
this.createData();
// 页面创建div,然后为div内容赋值
this.createElem('hello webpack');
const curentRender = this.render();
curentRender();
}
createData() {
const arr = [],
max = 100;
for (let i = 0; i < max; i++) {
arr.push(i);
}
this.sourceArr = arr;
}
createElem(res) {
const divDom = document.createElement('div');
divDom.innerText = res;
this.appDom.get(this.dom).appendChild(divDom);
}
render() {
const { sourceArr } = this;
return timerChunk(sourceArr, (res) => {
this.createElem(res);
});
}
}
new renderApp(document.getElementById('app')).init();ok,我们看下页面
好像以上代码没有什么可以优化的了,并且渲染大数据做了分时函数处理。
并且我们可以测试一下代码运行的时间
console.time('start');
const timerChunk = require('./utils/timerChunk');
...
new renderApp(document.getElementById('app')).init();
console.timeEnd('start');浏览器打印出来的大概是:start: 1.07177734375 ms
缓存函数其实就是当我们第二次加载的时,我们会从缓存对象中获取函数,这是一个常用的优化手段,在webpack源码中也有大量的这样的缓存函数处理
首先我们创建一个memorize工具函数
// utils/memorize.js
/**
* @desption 缓存函数
* @param {*} callback
* @returns
*/
export const memorize = (callback) => {
let cache = false;
let result = null;
return () => {
// 如果缓存标识存在,则直接返回缓存的结果
if (cache) {
return result;
} else {
// 将执行的回调函数赋值给结果
result = callback();
// 把缓存开关打开
cache = true;
// 清除传入的回调函数
callback = undefined;
return result;
}
};
};
/**
* 懒加载可执行函数
* @param {*} factory
* @returns
*/
export const lazyFunction = (factory) => {
const fac = memorize(factory);
const f = (...args) => fac()(...args);
return f;
};我们在index.js中修改下代码
console.time('start');
const { lazyFunction } = require('./utils/memorize.js');
// const timerChunk = require('./utils/timerChunk.js')
const timerChunk = lazyFunction(() => require('./utils/timerChunk.js'));
...
new renderApp(document.getElementById('app')).init();
console.timeEnd('start');我们看下测试结果,控制台上打印时间是start: 0.72607421875 ms
因此时间上确实是要小了不少。
那为什么memorize这个工具函数可以优化程序的性能
当我们看到这段代码是不是感觉很熟悉
export const memorize = (callback) => {
let cache = false;
let result = null;
return () => {
// 如果缓存标识存在,则直接返回缓存的结果
if (cache) {
return result;
} else {
// 将执行的回调函数赋值给结果
result = callback();
// 把缓存开关打开
cache = true;
// 清除传入的回调函数
callback = null;
return result;
}
};
};没错,本质上就是利用闭包缓存了回调函数的结果,当第二次再次执行时,我们用了一个cache开关的标识直接返回上次缓存的结果。并且我们手动执行回调函数后,我们手动释放了callback。
并且我们使用了一个lazyFunction的方法,实际上是进一步包了一层,我们将同步引入的代码,通过可执行回调函数去处理。
所以你看到的这行代码,lazyFunction传入了一个函数
const { lazyFunction } = require('./utils/memorize.js');
// const timerChunk = require('./utils/timerChunk.js')
const timerChunk = lazyFunction(() => require('./utils/timerChunk.js'));实际上你也可以不需要这么做,因为timerChunk.js本身就是一个函数,memorize只要保证传入的形参是一个函数就行
所以以下也是等价的,你也可以像下面这样使用
console.time('start');
const { lazyFunction, memorize } = require('./utils/memorize.js');
const timerChunk = memorize(() => require('./utils/timerChunk.js'))();
...为此这样的一个memorize的函数就可以当成业务代码的一个通用的工具来使用了
我们再来看另外一个例子,深拷贝对象,这是一个业务代码经常有用的一个函数,我们可以用memorize来优化,在webpack源码中合并内部plugins、chunks处理啊,参考webpack.js,等等都有用这个memorize,具体我们写个简单的例子感受一下
在utils目录下新建merge.js
// utils/merge.js
const { memorize } = require('./memorize');
/**
* @desption 判断基础数据类型以及引用数据类型,替代typeof
* @param {*} val
* @returns
*/
export const isType = (val) => {
return (type) => {
return Object.prototype.toString.call(val) === `[object ${type}]`;
};
};
/**
* @desption 深拷贝一个对象
* @param {*} obj
* @param {*} targets
*/
export const mergeDeep = (obj, targets) => {
const descriptors = Object.getOwnPropertyDescriptors(targets);
// todo 针对不同的数据类型做value处理
const helpFn = (val) => {
if (isType(val)('String')) {
return val;
}
if (isType(val)('Array')) {
const ret = [];
// todo 辅助函数,递归数组内部, 这里递归可以考虑用分时函数来代替优化
const loopFn = (val) => {
val.forEach((item) => {
if (isType(item)('Object')) {
ret.push(auxiFn(item));
} else if (isType(item)('Array')) {
loopFn(item);
} else {
ret.push(item);
}
});
};
loopFn(val);
return ret;
}
if (isType(val)('Object')) {
return Object.assign(Object.create({}), val);
}
};
for (const name of Object.keys(descriptors)) {
// todo 根据name取出对象属性的每个descriptor
let descriptor = descriptors[name];
if (descriptor.get) {
const fn = descriptor.get;
Object.defineProperty(obj, name, {
configurable: false,
enumerable: true,
writable: true,
get: memorize(fn) // 参考https://github.com/webpack/webpack/blob/main/lib/index.js
});
} else {
Object.defineProperty(obj, name, {
value: helpFn(descriptor.value),
writable: true
});
}
}
return obj;
};在index.js中引入这个merge.js,对于的source.js数据如下
// source.js
export const sourceObj = {
name: 'Maic',
public: '公众号:Web技术学苑',
children: [
{
title: 'web技术',
children: [
{
title: 'js'
},
{
title: '框架'
},
{
title: '算法'
},
{
title: 'TS'
}
]
},
{
title: '工程化',
children: [
{
title: 'webpack'
}
]
}
]
};index.js
const { mergeDeep } = require('./utils/merge.js');
import { sourceObj } from './utils/source.js'
...
console.log(sourceObj, 'start--sourceObj')
const cacheSource = mergeDeep({}, sourceObj);
cacheSource.public = '122';
cacheSource.children[0].title = 'web技术2'
console.log(cacheSource, 'end--cacheSource')我们可以观察出前后数据修改的变化
因此一个简单的深拷贝就已经完成了
使用memorize缓存函数优化代码,本质缓存函数就是巧用闭包特性,当我们首次加载回调函数时,我们会缓存其回调函数并会设置一个开关记录已经缓存,当再次使用时,我们会直接从缓存中获取函数。在业务代码中可以考虑缓存函数**优化以往写过的代码
利用缓存函数在对象拦截中使用memorize优化,主要参考webpack源码合并多个对象
写了一个简单的深拷贝,主要是helpFn这个方法对不同数据类型的处理
本文示例code-example
在上一篇中我们利用
webpack从 0 到 1 搭建了一篇最基本的react应用,而vue在团队项目里也是用得非常之多,我们如何不依赖vue-cli脚手架搭建一个自己的vue工程化项目呢?
相比较react,vue所需要的插件要少得多,我们知道在vue中,大多数是以.vue的模版组件,因此关键是我们可以用webpack的相关loader能够解析.vue文件即可,在vue项目中解析单文件组件,热加载,css 作用域等全部依赖于这个插件vue-loader,因此vue-loader算是vue工程化中必不可少的一个插件。
正文开始...
新建一个webpack-03-vue目录,执行npm init -y
安装相关基础配置插件
npm i webpack webpack-cli fs-loader css-loader style-loader html-webpack-plugin mini-css-extract-plugin -D安装vue最新版本,执行以下命令
npm i vue -s安装解析.vue文件的loader
npm i vue-loader -D// webpack.config.js
module.exports = {
...
module: {
rules: [
{
test: /\.css$/,
use: ['style-loader', 'css-loader']
},
{
test: /\.vue$/,
loader: 'vue-loader' // 与 use: ['vue-loader']等价
}
]
},
}除了设置loader,我们还需要引入另外一个插件VueLoaderPlugin,不然运行项目加载template时就会报错。
// webpack.config.js
const HtmlWebpackPlguins = require('html-webpack-plugin');
const miniCssExtractPlugin = require('mini-css-extract-plugin');
// 引入VueLoaderPlugin 必不可少
const { VueLoaderPlugin } = require('vue-loader');
module.exports = {
...
plugins: [
new HtmlWebpackPlguins({
template: './public/index.html'
}),
new miniCssExtractPlugin({
filename: 'css/[name].css'
}),
new VueLoaderPlugin(),
]
}如果我们需要提取css,我们需要把style-loader换成miniCssExtractPlugin.loader即可
// webpack.config.js
const miniCssExtractPlugin = require('mini-css-extract-plugin');
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: [miniCssExtractPlugin.loader, 'css-loader']
},
...
]
}所有配置完成后,看下最终的webpack.config.js完整配置
const path = require('path');
const HtmlWebpackPlguins = require('html-webpack-plugin');
const miniCssExtractPlugin = require('mini-css-extract-plugin');
const { VueLoaderPlugin } = require('vue-loader');
module.exports = {
entry: {
app: './src/index.js'
},
output: {
filename: '[name][hash].js',
path: path.resolve(__dirname, 'dist')
},
mode: 'development',
module: {
rules: [
{
test: /\.css$/,
use: [miniCssExtractPlugin.loader, 'css-loader']
},
{
test: /\.vue$/,
loader: 'vue-loader'
},
{
test: /\.less$/,
use: [
miniCssExtractPlugin.loader,
'css-loader',
{
loader: 'less-loader'
},
{
loader: 'postcss-loader'
// options: {
// postcssOptions: {
// plugins: [['postcss-preset-env']]
// }
// }
}
]
},
{
test: /\.(js|jsx)$/,
loader: 'babel-loader'
}
]
},
plugins: [
new HtmlWebpackPlguins({
template: './public/index.html'
}),
new miniCssExtractPlugin({
filename: 'css/[name].css'
}),
new VueLoaderPlugin()
]
};我们在src目录下新建一个index.js与App.vue文件
<!--App.vue-->
<template>
<div class="app">
<h1>{{name}}</h1>
<h2>{{age}}</h2>
<h3>{{publicText}}</h3>
</div>
</template>
<script>
import { reactive, toRefs } from 'vue';
export default {
name: 'App',
setup() {
const info = reactive({
name: 'Maic',
age: 18,
publicText: 'web技术学苑'
});
return {
...toRefs(info)
};
}
};
</script>
<style scoped>
.app h1 {
color: red;
}
</style>我们在index.js中引入App.vue文件
import { createApp } from 'vue';
import App from './App.vue';
createApp(App).mount('#app');运行npm run server,打开地址localhost:8080访问
在vue中会用less,因此我们看下less在vue中的运用
在项目中,我们会用less,scss或者stylus这样的第三方css编译语言,在vue项目中需要有对应的loader加载才行
安装npm i less less-loader -d,并设置loader
// webpack.config.js
module.exports = {
module: {
rules: [
...{
test: /\.less$/,
use: [miniCssExtractPlugin.loader, 'css-loader', 'less-loader']
}
]
}
};在App.vue中设置 less
<style lang="less" scoped>
.app{
h1 {
color: red;
& {
font-size:30px;
}
}
h2 {
display: flex;
}
}
</style>ok 页面已经支持less了,我们知道css有很多特性需要些支持多个浏览器的兼容性,因此会有很多的前缀,譬如--webkeit--,--ms--等等,那么这些前缀,我能否利用插件来支持呢,因此我们需要了解一个插件postcss
postcss有很多可配置的参数,更多参考可以查看官网webpack-postcss,也可以查看更详细 api 文档github-postcss实现更多的功能
npm install --save-dev postcss-loader postcss postcss-preset-env我们在loader上加上postcss-loader
module.exports = {
module: {
rules: [
...{
test: /\.less$/,
use: [
miniCssExtractPlugin.loader,
'css-loader',
{
loader: 'less-loader'
},
{
loader: 'postcss-loader',
options: {
postcssOptions: {
plugins: [['postcss-preset-env']]
}
}
}
]
}
]
}
};我们注意到官方提供了一个autoprefixer,但是我们这里使用的是postcss-preset-env,实际上这个插件已经有了autoprefixer的功能。
从官网了解到,你可以在webpack.config.js的loader中设置postcss-preset-env,你也可以在根目录新建一个文件postcss.config.js以此来代替loader的设置
// postcss.config.js
module.exports = {
plugins: [['postcss-preset-env']]
};因此你就会看到样式user-select加了前缀
但是你会发现,为啥display:flex没有前缀,因此有一个对浏览器兼容性设置的配置,实际上安装webpack时就已经给我们自动安装了,主要依靠.browserslist来设置支持浏览器的前缀 css
这个插件主要是可以让你的样式兼容多个不同版本的浏览器,如果指定的版本浏览器比较高,那么一些支持的特性就会自动支持,所以就不会设置前缀,具体可以参考browserslist
你可以在package.json中设置,比如像下面这样
{
...
"dependencies": {
"vue": "^3.2.36"
},
"browserslist": [
"> 1%",
"last 2 versions"
]
}当你设置完后,你会发现,重新执行npm run server,对应的display:flex就已经加了前缀了。
或者你可以在根目录新建一个.browserslistrc文件,与package.json设置的等价
> 1%
last 2 versions终于关于用 webpack 搭建vue的min工程版已经可以了,项目还有一些图片加载,字体图标啊这些都是file-loader插件的事情,后续有用上的时候就安装支持配置一下,具体也可参考这一篇文章webpack 从 0 到 1 构建也有相关file-loader的设置
看完是不是觉得webpack配置vue没那么难了
安装webpack,webpack-cli等基础插件,支持vue核心插件vue-loader
.vue文件需要vue-loader编译,需要配置对应loader,在webpack.config.js中需要加入VueLoaderPlugin插件,一定要引入,不然会直接报错。
less与postcss的安装,主要依赖less,less-loader, postcss,posscss-loader,postcss-preset-env这些插件支持,既可以在loader中支持配置postcss-preset-env,可以用postcss.config.js来代替设置
browserslist 配置设置,内部主要是依赖 caniuse-lite 与Can I Use 来做浏览器兼容性查询的
栈是一种数据结构,在 js 中我们知道,基础数据类型是存放在栈内存中的,引用数据类型是存放在栈中的一个地址引用,实际上是存放在堆内存中,今天我们看一道 leetcode 题目,加深对栈的理解,匹配有效括号,这是栈的应用
题目意思是: 给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
要求:
1、左括号必须用相同类型的右括号闭合
2、左括号必须正确的顺序闭合
题目考察核心关于栈的使用场景,以及我们可以利用栈来解决这道题
我们先抛开这个道算法题,什么是栈,理解栈,用一个图来理解下
在js中我们可以用数组来模拟栈所具备的特性,入栈与出栈,我们常常能听到栈是先进后出,后进先出的特性,怎么理解这看着似乎都认识,但总是很烧壳的一个概念
我们用一个数组来模拟栈
// 构造一个栈结构,定义一个数组
var stack = [];
// 入栈
stack.push(1);
// 不断的入栈,有时也叫压栈
stack.push(2);
stack.push(3,4);
console.log(stack) // [1,2,3,4]...
let value = null;
value = stack.pop(); // 4 被弹出来了
console.log(stack); // [1,2,3];
value = stack.pop(); // 3 被弹出来了
console.log(stack); // [1,2];
value = stack.pop(); // 2 被弹出来了
console.log(stack); // [1];
value = stack.pop(); // 1 被弹出来了
console.log(stack); // []; // 最后栈的长度就是空了可以结合上面一张图再理解下上面入栈和出栈的代码,当每次执行出栈操作时,后面添加进来的数组依次被弹出去了。用一个比较形象的比喻就是,先上车的坐在车子尾巴上,后面上车的,站在车门口,当车子每停一次,后面进来的,站在门口的就先出去了。
言归正传,理解了栈结构特性,那么这道题就可以利用栈来解决
const isValid = (s) => {
var stack = [];
for (let i = 0; i < s.length; i++) {
const val = s[i];
// 入栈操作
if (val === '(') {
stack.push(')');
} else if (val === '[') {
stack.push(']'); // 入栈操作
} else if (val === '{') {
stack.push('}'); // 入栈操作
} else if (val !== stack.pop()) {
// pop取出值,后面依次比较,如果与取出的值不相等,那么就是不匹配的,返回false
return false;
}
}
return stack.length === 0; // 最后全部pop出来了,数组是空,证明全部匹配上了
};除了这种方式还有没有其他解?我们看下其他方式
const isValid2 = (s) => {
const stack = [];
const map = new Map([
['(', ')'],
['[', ']'],
['{', '}']
]);
for (let i = 0; i < s.length; i++) {
const c = s[i];
if (map.has(c)) {
// 判断map中有key值,入栈操作
stack.push(c);
} else {
// 获取栈的值
const mapKey = stack[stack.length - 1];
// 获取map的值
if (map.get(mapKey) === c) {
stack.pop();
} else {
return false;
}
}
}
return stack.length === 0;
};1、理解栈结构特性,先进后出,后进先出特性
2、数组模拟栈特性,push入栈,pop出栈
3、符号匹配的应用,在循环中判断是否是(,[,{,然后入栈操作对应的对称符号,判断当前值是否不等于出栈值,那么返回false,直到stackpop 出所有的值,栈长度为空,证明所有符号都匹配上了。
4、利用map映射对应的符号匹配,循环字符串,如果map有 key,就把当前 key 添加到栈中,如果没有,那么就先在取出对应栈的 key,然后用当前的 key,去 map.get(key)获取的值与当前值是否相等,如果相等,就 pop 出该值,如果不相等就直接返回 false,直到循环结束,栈的长度为 0,证明所有符号都匹配上了。
5、本文示例代码code example
6、本题来源leetcode-20
BFC(
Block Formatting Context)俗称块级格式上下文,初次看到这词似乎有点不是很理解,通俗解释就是一个独立区域决定了内部元素的排放,以及内部元素与外部元素的相互作用关系
正文开始...
俗称块级格式上下文,一块独立的区域决定了内部元素的位置排列,以及内部元素与外部元素的作用关系
我们先了解下BFC有什么特点
1、垂直方向,相邻BFC的块级元素会产生外边距合并
2、BFC 包含浮动元素,浮动会触发新的 BFC 产生
3、已经确定的 BFC 区域不会与相邻 BFC 的浮动元素边距发生重合
针对以上几点我来具体深究一下 BFC 的特性到底有何区别,在什么样的场景下会比较触发BFC
新建一个index.html测试
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>BFC</title>
<style>
* {
padding: 0;
margin: 0;
}
.wrap-box {
width: 300px;
}
.inner-box {
width: 100px;
height: 50px;
}
.inner-box:nth-of-type(2n + 1) {
background-color: red;
}
</style>
</head>
<body>
<div class="wrap-box">
<div class="inner-box">1</div>
<div class="inner-box">2</div>
<div class="inner-box">3</div>
</div>
</body>
</html>不出意外在wrap-box这个 BFC 中,内部元素垂直单行排列
这说明块级格式上下文,在wrap-box这个元素决定了内部的元素排放,因为子元素始终是被包裹起来的,因为是块级元素,所以单行排列。
接下来我们将子元素添加外边距margin:10px 0;
* {
padding: 0;
margin: 0;
}
.wrap-box {
width: 300px;
}
.inner-box {
width: 100px;
height: 50px;
margin: 10px 0;
}
另外我们看下wrap-box的盒子模型
在子元素inner-box我们加了外边距margin,我们从已知的BFC特点知道相邻的BFC外边距会合并。
因为被包裹的inner-box是三个块级元素,在wrap-box内部来说,这三个内部div形成独立的BFC,所以相邻的1-2,2-3的外边距就合并了。
现在我有个需求,我不想让他们合并,我要破坏内部的三个 BFC 结构怎么办?
因此我需要将第二个inner-box改造成一个新的 BFC 结构
<div class="wrap-box">
<div class="inner-box">1</div>
<div class="inner-box-2">
<div class="inner-box">2</div>
</div>
<div class="inner-box">3</div>
</div>注意我在第二个元素多加了一层结构
因此结构变成下面这样,主要看第三个图,我用虚线标出了表明第二元素已经被加了一层结构,貌似外边距还是会合并,这是为啥?
从新的结构我们可以知晓,相邻块级元素的BFC会使边距发生合并,以前的内部的 BFC 是123,现在新的 BFC 是143,2已经被4包裹独立出来了,在 2 内部的margin会作用到父级,从而作用到父级相邻的 BFC 结构。
我们继续在4上添加一个margin:10px 0,神奇的事情发生了,居然还是一样边距被合并了,具体看下代码
.wrap-box {
width: 300px;
}
.inner-box {
width: 100px;
height: 50px;
margin: 10px 0;
overflow: hidden;
}
.inner-box:nth-of-type(2n + 1) {
background-color: red;
}
.inner-box-2 {
margin: 10px 0;
}
你会发现居然在2的外层加了magrin,居然不会影响整个盒模型的高度。
因此你再细品那句话相邻块级格式上下文的上下边距会产生重叠,于是你恍然大悟,143是三个 BFC 结构,所以 4 设置margin自然就被重合了。
但是我要破坏这种相邻 BFC 结构,因此触发 BFC 结构的机会来了。我给inner-box-2加个样式,用overflow:hidden触发生成一个新的 BFC;
现在就变成了这样了
没错,盒子模型高度变成了190了,中间的4外边距没有合并了。
由于在4不是虽然不是根元素,但是身上加了overflow:hidden触发4形成一个新的 BFC,那么触发 BFC 还有其他什么方式吗?
我们了解到除了overflow:hidden,还有以下几种方式
overflow: auto;display: flex; display: table;display: -webkit-box; float: left;
.inner-box-2 {
margin: 10px 0;
overflow: hidden;
/* overflow: auto; */
/* display: flex; */
/* display: table; */
/* display: -webkit-box; */
/* float: left; */
}当我们把inner-box-2设置为浮动后,边距就不会合并了。这也证实了相邻 BFC 与已经设置的浮动元素边距并不会合并,但inner-box-2与inner-box-1始终在一个大的BFC包裹着,而每一个自身元素又形成一个独立的BFC。
:::: code-group
::: code-group-item html
<div class="wrap-box">
<div class="inner-box inner-box-1">1</div>
<div class="inner-box inner-box-2">2</div>
</div>:::
::: code-group-item css
<style>
*{
padding: 0;
margin: 0;
}
.wrap-box {
width: 300px;
border: 1px solid #111;
overflow: hidden;
}
.inner-box {
width: 100px;
height: 50px;
margin: 10px 0;
overflow: hidden;
}
.inner-box-2 {
float: left;
}
.inner-box:nth-of-type(2n+1) {
background-color: red;
}
.inner-box:nth-of-type(2n) {
background-color: yellow;
}
</style>:::
::::
我们知道相邻的 BFC 结构垂直方向外边距会合并,利用这点,我们实现九宫格布局
:::: code-group
::: code-group-item html
<div class="wrap-box">
<div class="inner-box">1</div>
<div class="inner-box">2</div>
<div class="inner-box">3</div>
<div class="inner-box">4</div>
<div class="inner-box">5</div>
<div class="inner-box">6</div>
<div class="inner-box">7</div>
<div class="inner-box">8</div>
<div class="inner-box">9</div>
</div>:::
::: code-group-item css
* {
padding: 0;
margin: 0;
}
.wrap-box {
width: 300px;
border: 1px solid #111;
display: flex;
flex-wrap: wrap;
}
.inner-box {
width: 100px;
height: 50px;
margin: 10px 0;
overflow: hidden;
float: left;
}
.inner-box:nth-of-type(2n + 1) {
background-color: red;
}
.inner-box:nth-of-type(2n) {
background-color: yellow;
}:::
::::
注意我们给所有的子元素加了浮动,那么此时会造成父元素高度坍塌,因此父级元素必须要加上overflow:hidden或者设置display: inlie-block或者position: absolute;这样才可以导致父级元素不坍塌。
貌似456中间元素因为设置浮动破坏了BFC,所以我们需要给456设置特殊margin才行,于是乎你给 456 加一层 div,然后设置margin: -10px 0并且要设置左浮动
:::: code-group
::: code-group-item css
.item-2 {
float: left;
margin: -10px 0;
}:::
::: code-group-item html
<div class="wrap-box">
<div class="inner-box">1</div>
<div class="inner-box">2</div>
<div class="inner-box">3</div>
<div class="item-2">
<div class="inner-box">4</div>
<div class="inner-box">5</div>
<div class="inner-box">6</div>
</div>
<div class="inner-box">7</div>
<div class="inner-box">8</div>
<div class="inner-box">9</div>
</div>:::
::::
OK 已经可以了
此时我们这样改 dom 结构似乎有点不是很好,因为可能数据是从后端接口返回并不是写死的数据结构,因此我们再改下结构布局
:::: code-group
::: code-group-item html
<div class="wrap-box">
<div class="item">
<div class="inner-box">1</div>
<div class="inner-box">2</div>
<div class="inner-box">3</div>
</div>
<div class="item">
<div class="inner-box">4</div>
<div class="inner-box">5</div>
<div class="inner-box">6</div>
</div>
<div class="item">
<div class="inner-box">7</div>
<div class="inner-box">8</div>
<div class="inner-box">9</div>
</div>
</div>:::
::: code-group-item css
* {
padding: 0;
margin: 0;
}
.wrap-box {
width: 300px;
border: 1px solid #111;
overflow: hidden;
}
.inner-box {
width: 100px;
height: 50px;
overflow: hidden;
float: left;
}
.inner-box:nth-of-type(2n + 1) {
background-color: red;
}
.inner-box:nth-of-type(2n) {
background-color: yellow;
}
.item {
margin: 10px 0;
overflow: hidden;
}:::
::::
我们最初把margin作用在每个小元素下,现在我们利用BFC的特性,我们把margin作用在item上,因为三个item就是相邻垂直方向的 BFC 结构,边距会产生合并,也正是利用边距合并巧妙的解决了保持边距相等的问题。
具体可以看下效果
由于不同的布局方式,因此写出来的页面拓展性是完全不一样,拓展性强的布局方式,对于后期的维护是相当有益。因此不推荐第一种方式改结构,然后特殊设置456的父边距,虽然效果能达到一致,但是后期维护性与拓展性不高。
有时候左侧固定,右侧自适应这种页面结构时常会有,这种布局方案有哪些可以实现呢
:::: code-group
::: code-group-item html
<h1>左边固定,右边自适应,右边随着左边的宽度而自适应</h1>
<div class="wrap-box">
<div class="slide-left">left</div>
<div class="main">main</div>
</div>:::
::: code-group-item css
* {
padding: 0;
margin: 0;
}
.wrap-box {
width: 300px;
border: 1px solid #111;
overflow: hidden;
resize: horizontal;
}
.slide-left {
width: 100px;
height: 100px;
background-color: red;
}
.main {
height: 100px;
background-color: yellow;
}:::
::::
此时发现页面不尽人意,肯定是下面这样的
但是当我们给slide-left设置float:left后,我们会发现,此时slide-left的文档流被破坏,main会紧贴着slide-left排列
.slide-left {
width: 100px;
height: 100px;
background-color: red;
resize: horizontal;
float: left;
}此时我们可以观察到main贴着slide-left,宽度就是父级的宽度
但实际上main是需要剩下的宽度,他需要根据左侧的slide-left的宽度而自适应
因此你可以,让main成为一个独立 BFC,我们需要设置它oveflow:hidden就行
那么此时就会变成
完整的 css 如下
* {
padding: 0;
margin: 0;
}
.wrap-box {
width: 300px;
border: 1px solid #111;
overflow: hidden;
resize: horizontal;
}
.slide-left {
width: 100px;
height: 100px;
background-color: red;
float: left;
}
.main {
height: 100px;
background-color: yellow;
overflow: hidden;
}OK,现在就实现了右侧根据左侧宽度的大小自适应了。
更多关于 BFC 可以参考MDN BFC
了解什么是 BFC,BFC 简称块级格式上下文,它是一块独立的区域影响子元素的排列,相邻区域的 BFC 边距会产生重合
触发 BFC 条件有,display: flex、display: inline-block、display:box,position:absolute,或者oveflow: hidden/auto,float:left;
利用 BFC 实现九宫布局,本质利用相邻 BFC 外边距合并
左侧固定,右侧自适应布局
本文 code example
选择排序是一种简单的排序,时间复杂度是 O(n^2),在未排序的数组中找到最小的那个数字,然后将其放到起始位置,从剩下未排序的数据中继续寻找最小的元素,将其放到已排序的末尾,以次类推,直到所有元素排序结束为止。
我们先看下选择排序的一段代码
function selectSort(arr) {
const len = arr.length;
var minIndex, temp;
for (let i = 0; i < len; i++) {
minIndex = i; //假设当前循环索引是最小元素
for (let j = i + 1; j < len; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j; // 寻找最小的值
}
}
// 交换minIndex与i元素的值
temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
return arr;
}
selectSort([6, 12, 80, 91, 8, 0]);我们画个图还原排序所有过程,具体如下
从每次循环中我们可以知道选择排序,实际上就是先确认起始位置的索引,假设第一个是最小位置,从剩余元素中找到比第一个位置小的值,如果剩余的元素有比它小,那么确认当前索引为最小索引值,并交换两个元素的位置。
然后再从第二元素开始,假设第二元素是最小值,然后从剩余元素中找最小的元素,如果剩余元素有比它小就交换位置,如果没有,就正常不交换位置,直到循环到最后一个元素为止。
再言简意赅点,选择排序就是
1、假设第一个元素是最小值
2、从剩余元素中选择与第一个元素比较元素大小,确认最小索引值,然后交换位置
3、从剩余位置依次循环,假设剩余位置为最小值,然后从剩余元素中选择与之进行比较,然后确认是否交换位置
4、直到循环到最后一个索引为止
最后看一张图
1、选择排序时间复制度是 O(n^2)
2、假设首个元素是最小的元素,在剩余未排序的元素中与之进行比较,如果比它小,就确认最小位置索引,与之交换位置
3、在剩余未排序的所有的元素中,假设首个元素是最小值,然后与剩余元素进行依次比较,确认元素当前最小最小索引,交换位置,依次循环,直到最后循环结束为止
为组内实现一个私有通用的组件库,解放重复劳动力,提高效率,让你的代码被更多小伙伴使用。
本文是笔者总结的一篇关于构建组件库的一些经验和思考,希望在项目中有所帮助。
正文开始...
生成基础package.json
npm init -y安装项目指定需要的插件
npm i webpack webpack-cli html-webpack-plugin @babel/core @babel/cli @babel/preset-env webpack-dev-server --save-devwebpack官方支持ts编写配置环境,不过需要安装几个插件支持,参考官网configuration-languages,我们今天使用ts配置webpack。
npm install --save-dev typescript ts-node @types/node @types/webpack修改tsconfig.json
{
"compilerOptions": {
...
"module": "commonjs",
"target": "es5",
...
}
}在.eslintrc.js中的相关配置,配置env.node:true,具体参考如下
module.exports = {
env: {
browser: true,
es2021: true,
node: true
},
extends: ['eslint:recommended', 'plugin:@typescript-eslint/recommended'],
parser: '@typescript-eslint/parser',
parserOptions: {
ecmaVersion: 'latest',
sourceType: 'module'
},
plugins: ['@typescript-eslint'],
rules: {
'@typescript-eslint/no-var-requires': 0,
'@typescript-eslint/no-non-null-assertion': 0
}
};在根config目录新建webpack.common.ts、webpack.dev.ts、webpack.prod.ts
// webpack.common.ts
import * as path from 'path';
import * as webpack from 'webpack';
// 配置devServer
import 'webpack-dev-server';
const configCommon: webpack.Configuration = {
entry: {
app: path.join(__dirname, '../src/index.ts')
},
output: {
path: path.join(__dirname, '../dist')
// clean: true
},
module: {
rules: [
{
test: /\.js$/,
use: ['babel-loader'],
exclude: /node_modules/
},
{
test: /\.ts(x?)$/,
use: [
{
loader: 'babel-loader'
},
{
loader: 'ts-loader'
}
],
exclude: /node_modules/
}
]
},
resolve: {
extensions: ['.tsx', '.ts', '.js']
},
devServer: {
static: {
directory: path.join(__dirname, '../example') // 修改默认静态服务访问public目录
}
}
};
module.exports = configCommon;webpack.dev.ts
// config/webpack.dev.ts
import * as path from 'path';
import * as webpack from 'webpack';
const { merge } = require('webpack-merge');
const HtmlWebpackPlguin = require('html-webpack-plugin');
const webpackCommon = require('./webpack.common');
const devConfig: webpack.Configuration = merge(webpackCommon, {
devtool: 'inline-source-map',
plugins: [
new HtmlWebpackPlguin({
inject: true,
filename: 'index.html', // 只能是文件名,不能是xxx/index.html 会造成页面模版加载ejs解析错误
template: path.resolve(__dirname, '../example/index.html'),
title: 'example'
})
]
});
module.exports = devConfig;webpack.prod.ts
// webpack.prod.ts
const { merge } = require('webpack-merge');
import * as webpack from 'webpack';
const commonConfig = require('./webpack.common');
const prodConfig: webpack.Configuration = merge(commonConfig, {
mode: 'production'
});
module.exports = prodConfig;我们在根目录下创建webpack.config.ts
// webpack.config.ts
type PlainObj = Record<string, any>;
const devConfig = require('./config/webpack.dev');
const prdConfig = require('./config/webpack.prod');
module.exports = (env: PlainObj, argv: PlainObj) => {
// 开发环境 argv会获取package.json中设置--mode的值
if (argv.mode === 'development') {
return devConfig;
}
return prdConfig;
};在package.json中
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "webpack serve --mode development",
"build": "webpack --mode production"
},运行npm run start
我们看下src/index.ts
const domApp = document.getElementById('app');
console.log(11122);
domApp!.innerHTML = 'hello word';以上所有的这些基本都是为了支持ts环境,还有支持ts可配置webpack环境
现在我们试图将一些通用的工具函数贡献给其他小伙伴用了。
在src新建其他工具函数,例如在之前我们所用到的timerChunk分时函数
timerChunk.ts分时函数
// timerChunk.ts
// 分时函数
module.exports = (sourceArr: any[] = [], callback: (args: unknown) => void, count = 1, wait = 200) => {
let ret: any,
timer: any = null;
const renderData = () => {
for (let i = 0; i < Math.min(count, sourceArr.length); i++) {
// 取出数据
ret = sourceArr.shift();
callback(ret);
}
};
return () => {
if (!timer) {
// 利用定时器每隔200ms取出数据
timer = setInterval(() => {
// 如果数据取完了,就清空定时器
if (sourceArr.length === 0) {
clearInterval(timer);
ret = null;
return;
}
renderData();
}, wait);
}
};
};memorize缓存函数
// src/memorize.ts
/**
* @desption 缓存函数
* @param {*} callback
* @returns
*/
export const memorize = (callback: callBack) => {
let cache = false;
let result: unknown = null;
return () => {
// 如果缓存标识存在,则直接返回缓存的结果
if (cache) {
return result;
} else {
// 将执行的回调函数赋值给结果
result = callback();
// 把缓存开关打开
cache = true;
// 清除传入的回调函数
callback = null;
return result;
}
};
};isType.ts检测数据类型
/**
* @desption 判断基础数据类型以及引用数据类型,替代typeof
* @param {*} val
* @returns
*/
export const isType = (val: string | object | number | any[]) => {
return (type: string) => {
return Object.prototype.toString.call(val) === `[object ${type}]`;
};
};formateUrl.ts获取url参数
import { isType } from './isType';
/**
* @desption 将url参数转换成对象
* @param params
* @returns
*/
export const formateUrl = (params: string) => {
if (isType(params)('String')) {
if (/^http(s)?/.test(params)) {
const url = new URL(params);
// 将参数转换成http://localhost:8080?a=1&b=2 -> {a:1,b:2}
return Object.fromEntries(url.searchParams.entries());
}
// params如果为a=1&b=2,则转换成{a:1,b:2}
return Object.fromEntries(new URLSearchParams(params).entries());
}
};lazyFunction.ts懒加载函数
import { memorize } from './memorize';
/**
* @desption 懒加载可执行函数
* @param {*} factory
* @returns
*/
export const lazyFunction = (factory: callBack) => {
const fac: any = memorize(factory);
const f = (...args: unknown[]) => fac()(...args);
return f;
};hasOwn.ts判断一个对象的属性是否存在
const has = Reflect.has;
const hasOwn = (obj: Record<string, any>, key: string) => has.call(obj, key);
export { hasOwn };mergeDeep.ts深拷贝对象
import { isType } from './isType';
import { memorize } from './memorize';
/**
* @desption 深拷贝一个对象
* @param {*} obj
* @param {*} targets
*/
export const mergeDeep = (obj: object, targets: object) => {
const descriptors = Object.getOwnPropertyDescriptors(targets);
// todo 针对不同的数据类型做value处理
const helpFn = (val: any) => {
if (isType(val)('String')) {
return val;
}
if (isType(val)('Object')) {
return Object.assign(Object.create({}), val);
}
if (isType(val)('Array')) {
const ret: any[] = [];
// todo 辅助函数,递归数组内部, 这里递归可以考虑用分时函数来代替优化
const loopFn = (curentVal: any[]) => {
curentVal.forEach((item) => {
if (isType(item)('Object')) {
ret.push(helpFn(item));
} else if (isType(item)('Array')) {
loopFn(item);
} else {
ret.push(item);
}
});
};
loopFn(val);
return ret;
}
};
for (const name of Object.keys(descriptors)) {
// todo 根据name取出对象属性的每个descriptor
const descriptor = descriptors[name];
if (descriptor.get) {
const fn = descriptor.get;
Object.defineProperty(obj, name, {
configurable: false,
enumerable: true,
writable: true,
get: memorize(fn) // 参考https://github.com/webpack/webpack/blob/main/lib/index.js
});
} else {
Object.defineProperty(obj, name, {
value: helpFn(descriptor.value),
writable: true
});
}
}
return obj;
};我们在src中创建了以上所有的工具函数
我们在src/index.ts将上面所有的工具函数导入
// const domApp = document.getElementById('app');
// console.log(11122);
// domApp!.innerHTML = 'hello word';
export * from './memorize';
export * from './lazyFunction';
export * from './hasOwn';
export * from './getOrigin';
export * from './formateUrl';
export * from './mergeDeep';
export * from './isType';现在需要打包不同环境的lib,通用就是umd,cjs,esm这三种方式
主要要是修改下webpack.config.output的library.type,参考官方outputlibrary
我们在config目录下新建一个webpack.target.ts
import * as webpack from 'webpack';
const prdConfig = require('./webpack.prod');
const { name } = require('../package.json');
enum LIBARY_TARGET {
umd = 'umd',
cjs = 'cjs',
esm = 'esm'
}
const targetUMD: webpack.Configuration = {
...prdConfig,
output: {
...prdConfig.output,
filename: 'umd/index.js',
library: {
name,
type: 'umd'
}
}
};
const targetCJS: webpack.Configuration = {
...prdConfig,
output: {
...prdConfig.output,
filename: 'cjs/index.js',
library: {
name,
type: 'commonjs'
}
}
};
const targetESM: webpack.Configuration = {
...prdConfig,
experiments: {
outputModule: true
},
output: {
...prdConfig.output,
filename: 'esm/index.js',
library: {
type: 'module',
export: 'default'
}
}
};
const libraryTargetConfig = new Map([
[LIBARY_TARGET.umd, targetUMD],
[LIBARY_TARGET.cjs, targetCJS],
[LIBARY_TARGET.esm, targetESM]
]);
module.exports = libraryTargetConfig;在webpack.config.ts引入webpack.target.ts
// webpack.config.ts
type PlainObj = Record<string, any>;
const devConfig = require('./config/webpack.dev');
const libraryTargetConfig = require('./config/webpack.target');
module.exports = (env: PlainObj, argv: PlainObj) => {
console.log(argv);
// 开发环境 argv会获取package.json中设置--mode的值
if (argv.mode === 'development') {
return devConfig;
}
return libraryTargetConfig.has(argv.env.target) ? libraryTargetConfig.get(argv.env.target) : libraryTargetConfig.get('umd');
};然后我们在package.json中配置不同模式打包
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "webpack serve --mode development",
"build:umd": "webpack --mode production --env target=umd",
"build:esm": "webpack --mode production --env target=esm",
"build:cjs": "webpack --mode production --env target=cjs",
"build": "npm run build:umd && npm run build:esm && npm run build:cjs"
},当我们依次执行npm run build
在example目录下新建测试index.ts,同时记得修改webpack.dev.ts的entry入口文件
// example/index.ts
// ok
import * as nice_utils from '../src/index';
// umd
// const nice_utils = require('../dist/umd/index.js');
// cjs
// const { nice_utils } = require('../dist/cjs/index.js');
// esm error
// import nice_utils from '../dist/esm/index.js';
const appDom = document.getElementById('app');
appDom!.innerHTML = 'hello, 欢迎关注公众号:Web技术学苑,好好学习,天天向上!';
console.log(nice_utils);
console.log('formateUrl:', nice_utils.formateUrl('http://www.example.com?name=Maic&age=18'));
console.log('hasOwn:', nice_utils.hasOwn({ publictext: 'Web技术学苑' }, 'publictext'));
console.log('isType:', nice_utils.isType('Web技术学苑')('String'));我们运行npm run start,测试运行下example是否ok
我发现esm打包出来的居然用不了,这就很坑了,难道是模块使用的问题?
但是其他两种貌似是ok的
我们现在将这包发布到npm上吧
npm run build生成dist包,并且修改package.json文件的main,指定到dist/umd/index.js下
{
"name": "@maicfir/nice_utils",
"version": "1.0.4",
"description": "一个好用的工具类库",
"main": "dist/umd/index.js",
"types": "src/types/global.d.ts",
...
}npm login
npm账户和密码code,把code输入即可npm publish
查看 npm 上是否成功,具体可以查看nice_utils
利用webpack5配置打包ts环境,主要是让webpack5配置文件支持ts
组织webpack5打包不同library.type,支持打包成不同type,umd,cjs,ejs三种类型
编写具体工具类函数
将自己写的工具类发布到npm或者私服上,让工具类变成通用工具代码
本文示例code-example
this是一个比较迷惑的人是东西,尽管你对this有很多的了解,但是面试题里面考察this指向总会让你有种猜谜的感觉,知道一些,但是还是会出错,或许你猜对了,但是又好像解释不太清楚。
嗯,不是你一个人这样,很多人都这样,包括我自己,本质上就是面试埋下的坑,让你跳进去,你想跳过去,那还是不太容易,真正对知识的理解与应用,绝不只是停留在概念与理念,也不是为了完成一道面试题,答不对也没关系,如果面试官给你耐心解释了这道题,那也是一次不错的学习机会。
正文开始...
在阅读本文之前,主要会从以下几点对this的思考
this 是什么时候产生的this在函数中的指向问题箭头函数中thisthis的指向方案为了了解this,我们先看下this,新建一个index.html与1.js
console.log(this, Object.getPrototypeOf(this));index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>this</title>
</head>
<body>
<div id="app"></div>
<script src="./1.js"></script>
</body>
</html>当我们在浏览器打开时,我们会发现this是一个window对象
如果我们在终端直接运行1.js呢
{} [Object: null prototype] {}在node环境下,全局的this居然是一个{}对象
this现在我们在js的最顶部使用use strict采用严格模式。
我们在函数内部写一个this
"use strict"
console.log(this, Object.getPrototypeOf(this));
var publicName = "Maic";
function hello() {
console.log(this) // undefined
console.log(this.publicName) // undefined
}
hello();在严格模式下函数内部会是undefined,并且访问publicName会直接报错
为啥use strict严格模式下全局this无法访问
于是查找资料寻得,严格模式主要有以下特征
未提前申明的变量不能使用,会报错
不能用delete删除对象的属性
定义的变量名不能重复申明
函数内部的this不再指向全局对象
还有其他的更多的参考js-script
在这之前我们很基础的了解到在非严格模式下this指向的是window或者{}对象,在普通函数中this的指向是window全局对象
而你通常会看到this的指向并不都是指向全局对象,而是动态变化的,正因为它会变化,所以令人十分费脑壳
this指向function hello() {
console.log(this) // window
// console.log(this.publicName);
}
hello();在普通函数内部this指向的是window对象
this指向...
function Person() {
this.age = 10;
this.name = 'Web技术学苑';
console.log(this, '111')
}
const person = new Person();
console.log(person, '222'); // Person { age: 10, name: 'Web技术学苑' }至此你会发现,构造函数内部的this居然就是实例化的那个对象person
const userInfo = {
publicName: 'Jack',
getName: function () {
console.log(this.name, '--useInfo') // Jack
}
}
userInfo.getName();不出意外打印都知道肯定publicName肯定是Jack,内部的this也是指向userInfo
但是如果改成下面这种呢
var publicName = "Maic";
const userInfo = {
publicName: 'Jack',
getName: () => {
console.log(this.publicName, '---useInfo')
}
}
userInfo.getName();这是一个很迷惑的问题,箭头函数不是没有自己的this吗,而且这里是userInfo.getName()这不是一个隐式调用吗?应也是userInfo这个对象才对,但是并不是,当改成箭头函数后,内部的this居然变成了全局的window对象了
我们看下babel对上面一段代码编译成es5的代码
es6代码
var publicName = 'Maic';
const userInfo = {
publicName: 'Jack',
getName: () => {
console.log(this.publicName, '---useInfo')
}
}
userInfo.getName();编译后的代码,大概就是下面这样的了
var _this = this;
var publicName = "Maic";
var userInfo = {
publicName: "Jack",
getName: function getName() {
console.log(_this.publicName, "---useInfo");
}
};
userInfo.getName();其实箭头函数是非常迷惑人的,而且外面是一个被调用的是一个对象,所以时常会给人一种幻觉,我们常听到一句this指向的是被调用的那个对象,那么这里箭头函数的this指向的是window,而const定义的变量会被转换成var
那怎么能让getName指向的是本身自己的useInfo呢
var publicName = 'Maic';
const userInfo = {
publicName: 'Jack',
getName: function(){
console.log(this.publicName, '---useInfo') // Jack
}
}
userInfo.getName();你看当我把箭头函数改成普通函数,这个普通函数内部的this就指向userInfo了
this指向被调用的那个对象貌似这句话后又在此时好像又是正确的
我们接下来看下下面一种情况
var publicName = 'Maic';
const userInfo = {
publicName: 'Jack',
getName: function(){
console.log(this.publicName, '---useInfo') // Jack
}
}
var user = userInfo.getName;
user();那么此时getName内部的this又是谁呢?
此时你会发现打印的是Maic
此时会发现this指向的是window,也就是说指向的那个被调用者,那被调用者是谁?
上面那段代码同等于下面,你仔细看
var publicName = 'Maic'; // var 定义,实际上等同于window.publicName = publicName
function getName () {
console.log(this.publicName, '---useInfo') // Jack
}
const userInfo = {
publicName: 'Jack',
getName
}
// var user = userInfo.getName;
// or 等价于
// window.user = userInfo.getName;
// or 进一步等价
window.user = function getName () {
console.log(this.publicName, '---useInfo') // Jack
}
// user();
// or 等价于
window.user();所以你现在是不是很清晰明白this指向的也是被调用的那个对象window了
但是有一点必须申明,必须在非严格模式下,此时的this才会指向window。
在这之前我们了解到非严格模式下
this指向的是window对象this指向的是实例化的那个对象this指向的是全局对象,如果不是那么指向的是被调用本身的那个对象我们再来看下那些面试题中很迷惑的this
var user = {
name: 'Maic',
a: {
name: 'Tom',
b: function () {
console.log(this.name)
}
}
}
console.log(user.a.b()) // Tom没错,你看到的这个打印是Tom,这里直接调用的是b这个方法,被调用的是user.a这个对象,所以在b这个方法内部的this指向了a对象
如果是箭头函数呢
var publicName = "Maic";
...
var user = {
name: 'Jack',
a: {
name: 'Tom',
b: () => {
console.log(this.name)
}
}
}
console.log(user.a.b()) // Maic我们会发现通过babel转换后会是这样的
var _this = this;
var user = {
name: "Jack",
a: {
name: "Tom",
b: function b() {
console.log(_this.name);
}
}
};所以依然箭头函数内部依然是个全局对象window
我们接下来看一道真实的面试题
var obj = {
a: 1,
b: function () {
console.log(this.a)
},
c: () => {
console.log(this.a)
}
}
var a = 2;
var objb = obj.b;
var objc = {
a: 3
}
objc.b = obj.b;
const t = objc.b;
obj.b(); // 1
obj.c(); // 2
objb(); // 2
objc.b(); // 3
obj.b.call(null); // 2
obj.b.call(objc); // 3
t() // 2我想信绝大大部分第一个obj.b()肯定是可以正确答出来,但是后面的貌似有些迷惑人,时常会让你掉进坑里
我们先看结论打印的依次肯定是
1
2
2
3
2
3
2obj.b()的调用实际上在之前例子已经有讲,b方法是一个普通方法,内部this指向的就是被调用的obj对象,所以此时内部访问的a属性就是对象obj
var objb = obj.b,当我们看到这样的代码时,其实这段代码可以拆分以下
function b() {
console.log(this.b)
}
window.objb = b;本质上就是将对象obj的一个方法b赋值给了window.objb的一个属性
所以objb()的调用也是window.objb(),objb方法内部this自然指向的就是window对象,而我们用var a = 2这个默认会绑定在window对象上
obj.c(),因为c是一个箭头函数,所以内部的this就是指向的全局对象
obj.b.call(null)这个null是非常迷惑人,通常来说call不是改变函数内部this的指向吗,但是这里,如果call(null)实际上会默认指向window对象
objc.b()这打印的是3,其实与objb的赋值有异曲同工之笔
...
var objc = {
a: 3
}
objc.b = obj.b;本质上就在objc动态的新增了一个属性b,而这个属性b赋值了一个方法,也就是下面这样
objc.b = function() {
console.log(this.a)
}
objc.b() // 3如果是const t = objc.b,至此你会发现,当我们执行t()时,此时打印的却是2那是因为const t定义的变量会编译成var从而t变量变成一个全局的window对象下的属性,本质上等价下面
...
// const t = objc.b
var a = 2;
/*
等价于下面
var t = function() {
console.log(this.a)
}
*/
// 本质上就是
window.t = function() {
console.log(this.a)
}thisvar nobj = {
name: '1',
a: {
name: '2',
b: {
name: '3',
c: function () {
console.log(this.name)
}
}
}
}
console.log(nobj.a.b.c()); //3以上的结果是3,实际上我们从之前案例中明白,非严格模式下this指向被调用那个对象
所以你可以把上面那段代码看成下面这样
...
console.log((nobj.a.b).c()); //3
//or 相当于
/*
*
var n = nobj.a.b;
n.c()
*/这个相信很多小伙伴已经耳熟能祥了,call,apply,bind,能手撕call,apply,bind的文章已经不计其数
这里就只讲解如何使用,以及他们在业务中的一些具体使用场景
用一段伪代码举证以下
// index.vue
import configOption from './config'
export default {
name: 'index',
computed: {
optionsBtnGroup() {
return configOption.call(this)
}
},
methods: {
handleEdit(id) {
console.log(id)
},
handleDelete(id) {
console.log(id)
}
}
}对应的template可能就是下面这样几个按钮
<div>
<a href="javascript:void(0)" v-for="(item, index) in optionsBtnGroup" :key="index" @click="item.handle(item.id)">{{item.text}}</a>
</div>我们再来看下config.js
export default () => {
const options = [
{
text: '编辑',
id: 123,
handle: (id) => {
this.handleEdit(id)
}
},
{
text: '删除',
id: 234,
handle: (id) => {
this.handleDelete(id)
}
}
]
}正因为在计算属性中用了call所以在config.js中才能访问外部methods的方法,有些人看到这样的代码肯定会说,两个按钮这么搞配置,代码反而多了这么多,还不如模版上放两个按钮完事
是的,确实是,当我们为了使用call而使用反而增加了业务代码的维护成本,正常情况还是建议不要写出上面那段坏代码的味道,我们只要明白在什么时候可以用,什么可以不用就行,不要为了使用而使用,反而本末倒置。
但是有时候如果业务复杂,你想隔离业务的耦合,达到通用,call能帮你减少不少代码量
apply也是可以改变this对象
const userInfo = {
publicName: 'Jack',
getName: () => {
console.log(this.publicName, '---useInfo')
}
}
function test(...args) {
console.log(args); // ['hello', 'world']
console.log(this.publicName);
}
test.apply(userInfo, ['hello', 'world'])apply会立即执行该函数,如果传入的首个参数是null或者undefined,那么此时内部this指向的是window
另外还有一个方法可以让函数立即执行,也能改变当前函数this指向
...
var publicName = 'Maic';
function test(...args) {
console.log(args);
console.log(this.publicName);
}
Reflect.apply(test, {publicName: 'aaa'}, [1,2,3]) // aaa [1,2,3]
Reflect.apply(test, window, ['a', 'b', 'c']) // Maic ['a', 'b', 'c']这也是可以改变this指向,不过会返回一个新函数,我们常常在react中发现这样用bind显示绑定方案。
我们写个简单的例子,尝试改变页面背景,切换肤色
document.body.addEventListener('click', function () {
console.log(this) // body
if (this.style.backgroundColor === 'red') {
this.style.backgroundColor = 'green'
} else {
this.style.backgroundColor = 'red';
}
})
可以切换背景肤色
以上貌似没有问题,但是你可能会写这样的代码
document.body.addEventListener('click', () => {
console.log(this)
if (this.style.backgroundColor === 'red') {
this.style.backgroundColor = 'green'
} else {
this.style.backgroundColor = 'red';
}
})此时内部的this一定指向的window,而且内部访问style报错
于是你会改成这样
const fn = function () {
if (this.style.backgroundColor === 'red') {
this.style.backgroundColor = 'green'
} else {
this.style.backgroundColor = 'red';
}
}
document.body.addEventListener('click', fn)是的,这样是可以的,本质上就是一个fn的形参,内部this指向仍然是document.body
于是为了借助bind,你可以这么做
const body = document.body;
const fn = function () {
if (this.style.backgroundColor === 'red') {
this.style.backgroundColor = 'green'
} else {
this.style.backgroundColor = 'red';
}
}.bind(body)
body.addEventListener('click', fn)这么做也是ok的
不知道你有没有疑问,为什不像下面这么做呢?
const body = document.body;
const fn = function () {
if (this.style.backgroundColor === 'red') {
this.style.backgroundColor = 'green'
} else {
this.style.backgroundColor = 'red';
}
}
body.addEventListener('click', fn.bind(this))如果你仔细看下,其实fn内部this指向是window,所以这是一个常会犯的错误。
还有为啥不是像下面这样
const body = document.body;
const fn = function () {
if (this.style.backgroundColor === 'red') {
this.style.backgroundColor = 'green'
} else {
this.style.backgroundColor = 'red';
}
}
body.addEventListener('click', fn.bind(body))以上功能没有任何问题,但是我们每次点击都会调用bind,从而返回一个新的函数,所以这种方式虽然效果一样,但是性能远不如第一种,为了更好理解,你可以写成下面这样
const body = document.body;
const fn = function () {
if (this.style.backgroundColor === 'red') {
this.style.backgroundColor = 'green'
} else {
this.style.backgroundColor = 'red';
}
}
const callback = fn.bind(body)
body.addEventListener('click', callback)了解this怎么产生的,通常情况this在非严格模式下,指向的是全局window对象,在严格模式下,普通函数内的this不是全局对象
迷惑的this指向问题,正常情况this指向的是被调用的那个对象,但是如果是箭头函数,那么指向的是全局对象window
bind,call, apply改变this指向
推举一篇关于阮一峰老师this的博文
面向对象的三大特征、封装、继承、多肽,
js中同样有这三种特征,js是一门弱语言,俗称解释性语言,通常来说比起高级语言,他没有严格的类型约束,为了让代码写得更健壮,维护性更强,因此有了ts约束,而继承是能让代码更加通用,让你的代码更加的抽象。
往往在项目中都会看到有用class,或者OOP**去组织业务代码,本篇只做项目中常用到的继承以及对不同继承方式的回顾,也是再次加深对继承的一些理解,希望你在项目中有些帮助和思考。
正文开始...
我们通过构造函数构建对象
function Animal(name) {
this.name = name;
this.getName = function () {
return this.name;
};
}
const tigger = new Animal('tigger');
const cat = new Animal('cat');我们通过new 构造函数()方式新建了两个对象tigger、cat,其实我们会发现,相当于有多少对象,我就要实例化多少个对象。并且实例化的对象都相互独立,互不影响。现在我想trigger与cat拥有同样的属性或者方法呢?
可以利用原型链prototype共享方法,
...
Animal.prototype.say = function() {
console.log('hello,'+this.name);
}
cat.say(); // hello, cat
tigger.say(); // hello,trigger当使用new Animal('cat')或者new Animal('tigger'),你会发现同样的事情,我们实例化了多次,因为这样做,tigger与cat并不相等,那么如何可减少内存开销呢。
我们可以利用单件模式一个全局变量去处理,举个例子
let instance;
function Animal(name) {
this.name = name;
this.getName = function () {
return this.name;
};
if (!instance) {
instance = this;
}
this.getInstance = function () {
return instance;
};
}
const cat = new Animal('cat').getInstance();
const trigger = new Animal('trigger').getInstance();
console.log(cat === trigger); // true或者在构造函数上绑定一个静态属性,这样比定义全局变量要好得多,推荐下面这种方式
function Animal(name) {
this.name = name;
this.getName = function () {
return this.name;
};
if (!Animal.instance) {
Animal.instance = this;
}
return Animal.instance;
}
const cat = new Animal('cat');
const trigger = new Animal('trigger');
console.log(cat === trigger); // true但是这样我们会发现const trigger = new Animal('trigger')实际上无论实例化多少个,都只会返回首次实例化的对象,对于不同场景还是得特殊处理。
自定义一个数组,完全继承数组所有特性
function MyArray() {
this.ret = [];
}
MyArray.prototype = new Array();
// 指定构造函数
MyArray.prototype.constructor = MyArray;
var mine = new MyArray();
console.log(mine instanceof Array); // true
// 以上等价
MyArray.prototype.isPrototypeOf(mine); // true查找对象的构造函数
function Print() {}
const print = new Print();
console.log(Print.prototype.constructor === print.constructor); // true
console.log(Object.getPrototypeOf(print) === Print.prototype); // true判断print的构造函数是不是Print
...
print instanceof Print // true也可以用这个来代替
...
Print.prototype.isPrototypeOf(print); // true所有对象共享一个原型对象,基于构建器工作模式,将父类的prototype直接赋值给子类的prototype
// 父构造函数
function Parent() {
this.ParentName = 'parent';
}
Parent.prototype.cname = '123';
Parent.prototype.getName = function () {
console.log(this.cname); // 666
};
// 子构造函数
function Child() {
this.childname = 'childname';
// this.ParentName = '888';
}
Child.prototype = Parent.prototype;
// Child.prototype.cname = '666'; 会修改父类的cname
const c = new Child();
console.log(c.ParentName, c.childname, c.cname);
// undefined childname 123从打印里我们可以看出,子类可以访问父类prototype上的属性或者prototype方法,但是父类自身属性或者自身方法不能访问,但是,我们注意到如果子类prototype属性有父类相同的prototype属性名时,此时子类会覆盖父类prototype的属性。子类自身属性与父类自身属性同名时,此时子类访问就会有值,访问的是自身属性,c.ParentName打印就会是888
于此同时子类prototype修改会同时修改父类的prototype
现在我有一个需求,子类只继承父类的prototype,不需要继承父类自身本身的属性,举个栗子佐证下
function extends(Child, Parent) {
const F = function() {};
F.prototype = Parent.prototype;
Child.prototype = new F();
// 将Child的构造函数指定成Child
Child.prototype.constructor = Child;
}
function Parent() {
this.parentName = '123'
}
Parent.prototype.age = 18;
function Child() {
this.childName = 'childname'
}
// Child.prototype.age = 666; // 并不会修改父类age属性
extend(Child, Parent);
const c = new Child();
console.log(c.age, c.childName, c.parentName)
// 18, childname,undefined我们可以发现实际上利用extends方法,利用了一个中间的F构造函数,通过F.prototype = Parent.prototype,然后将Child.prototype = new F(),与上面原型继承不同的是,修改子类prototype与父类相同的属性时,并不会修改父类prototype的属性。本质上就是借鸡生蛋,借用了F的prototype,不直接修改父类的prototype
将父类的prototype属性值拷贝给子类
function extends(Child, Parent) {
const c_proto = Child.prototype;
const p_proto = Parent.prototype;
for (let key in p_proto) {
c_proto[key] = p_proto[key]
}
}
function Child () {
this.name = 'child'
}
function Parent() {
this.name = 'parent'
}
Parent.prototype.money = 100;
extends(Child, Parent);
const c = new Child();
console.log(c.money, c.name) // 100, child注意,只会继承父类prototype属性,父类自身属性并不会继承,因此这种与临时构造器功能上如出一辙,子类并不能修改父类自身的属性。
function extends2(target) {
const F = function () {};
F.prototype = target;
return new F();
}
function Parent() {
this.name = 'parent';
}
Parent.prototype.age = 100;
const child = extends2(Parent.prototype);
const parent = new Parent();
// child.__protototype__.age = 88;
console.log(child.age, child.name); // 100, undefined
console.log(parent.age, parent.name); // 100, parent这种继承本质上仍然是用利用父类的prototype赋值给了一个中间构造函数F的prototype,他的弊端是并不能访问父类的自身属性与自身方法,
但是child.__protototype__.age会修改父类的prototype上的同名属性。
// 父构造函数
function Parent() {
this.name = 'parent';
this.say = function () {
console.log('hello,' + this.name);
};
}
Parent.prototype.age = 10;
// 子构造函数
function Child() {
Parent.call(this);
}
const c = new Child();
console.log(c.name); // parent
console.log(c.age); // undefined
console.log(c.say()); // hello parent我们注意到c.age返回的是undefined,因为age不是构造函数本身的属性或者方法,在构造函数prototype的方法或者属性无法访问,如果我需要访问呢?
function Parent() {
this.name = 'parent';
this.say = function () {
console.log('hello,' + this.name);
};
}
Parent.prototype.age = 10;
function Child() {
Parent.call(this);
}
Child.prototype = Object.create(Parent.prototype);
Child.prototype.age = 888;
const c = new Child();
const p = new Parent();
console.log(c.age); // 888
console.log(c.name); // parent
console.log(p.age); // 10我们就加了一行代码实现了Child.prototype = Object.create(Parent.prototype),这种方式子类与父类的耦合非常低,子类修改与父类同名prototype的属性并不会影响父类。
实际上还有一种更简单的继承,让子类的prototype等于父类的实例,也称为原型链继承
function Parent() {
this.name = 'parent';
this.say = function () {
console.log('hello,' + this.name);
};
}
function Child() {}
Child.prototype = new Parent();
const c = new Child();
const p = new Parent();
console.log(c.name); // 'parent'function A() {
this.a = 11;
}
function B() {
this.b = 22;
}
function C() {
A.call(this);
B.call(this);
}
C.prototype = Object.create(A.prototype);
C.prototype.constructor = C;
// 合并B的prototype
Object.assigin(C.prototype, B.prototype);
const c = new C();class Parent {
constructor() {
this.name = 'Maic';
}
getName() {
return this.name;
}
}
class Child extends Parent {
constructor() {
super();
this.age = 10;
}
}
const c = new Child();
console.log(c.name); // Maic
console.log(c.getName()); // Maic
console.log(c.age); // 10注意constructor中有super()调用
// utils.js
class Utils {
static instance = null;
formateDate() {}
formateUrl() {
console.log('formateUrl');
}
static getInstance() {
if (!this.instance) {
this.instance = new Utils();
}
return this.instance;
}
}
export default Utils.getInstance();引入utils.js
import Utils from './utils';
console.log(Utils.formateUrl());1、obj instanceof A判断一个对象的构造函数(A 是否是 obj 的构造函数),如果是则返回true、不是返回false
2、A.prototype.isPrototypeOf(obj)判断构造函数A是不是obj实例对象的构造函数
3、常用的几种继承、原型继承法、临时构造器、原型属性拷贝继承、寄生继承、构造器继承【call】、原型链继承、extends继承
4、call父类构造函数在子类构造函数调用call实现继承,父类除了了自身属性和自身方法能被继承访问,父类原型的方法子类无法访问
5、Child.prototype = Object.create(Parent.prototype)实现继承父类
npm是一个包管理工具,当我们安装nodejs时,这个命令会默认安装。你可能非常熟悉npm run xxx这个命令,每次上线前你都在执行npm run build,甚至你常常在npm i的等待中摸鱼。
当某一天你的同事在你电脑输入了一行命令...,npm view typescript versions,你脑壳里想着,这
于是乎,你去官方文档查了下这个命令,原来npm view xx versions是查询 xx 包所有可用版本。为了不拘泥于npm run start与npm run build这两行命令,于是笔者总结了这篇没有深度,但是很广度的npm命令大全,希望你能在你实际项目中能用得上。
正文开始...
::: details code
npm init
// or npm init -y:::
该命令意思是初始化一个包项目,生成一个package.json文件
可以一直enter键下去,你也可以按你心情在控制台输入一些信息,然后enter下去
later...
最后在你目录下生成了一个package.json文件
::: details code
{
"name": "npm-know",
"version": "1.0.0",
"description": "My first encounter with npm",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"npm"
],
"author": "Maic",
"license": "ISC", // 以上都是默认的配置
}:::
另外如果你想在指定的目录中生成package.json,那么你你只需执行下面一行命令
npm init -w 01, 01是你当前已存在的目录,如果01不存在,则会在你得根目录.Trash中创建一个01/package.json
package.json的一些解释::: details code
// name 包名,如果你需要发布一个npm包,那么这是必须的
// version 版本 同上,你需要发布一个包,那么版本是必须的 包名+版本构成一个包的唯一标识
// description 包名的描述,npm能根据这个描述检索你得包名
// main 程序的主要入口,默认index.js
// scripts 可以执行npm 指定运行的别名
// keywords 关键字,便于别人搜索关联找到你发布的包名
// author 发布该包的作者名
// license 许可证 通常是ISC或者MIT,便于开发者知道这是个开源可免费试用的包:::
关于package.json的默认的配置就是这么多,接下来,你感兴趣的来了,她来了,她就是
bin...
::: details code
{
...,
license: 'ISC',
"bin": {
"maic-app-cli": "./cli.js"
}
}:::
在官方解释这个bin有点绕,我的理解的就是,提供一个可执行的接口命令,让你可以运行你写的包,能关联到当前的项目,不管是全局还是局部安装,npm可以通过这个bin的别名命令,执行指定包内的脚本,从而进行一系列的初始化工作。比如大名鼎鼎的vue-cli和create-react-app脚手架,当你看到[email protected]版本package.json时,可以看到vue命令的操作
::: details code
{
"name": "vue-cli",
"version": "2.9.6",
"description": "A simple CLI for scaffolding Vue.js projects.",
"preferGlobal": true,
"bin": {
"vue": "bin/vue",
"vue-init": "bin/vue-init",
"vue-list": "bin/vue-list"
},
...
}:::
前往bin/vue目录你可以看到
::: details code
#!/usr/bin/env node
const program = require('commander');
program
.version(require('../package').version)
.usage('<command> [options]')
.command('init', 'generate a new project from a template')
.command('list', 'list available official templates')
.command('build', 'prototype a new project')
.command('create', '(for v3 warning only)');
program.parse(process.argv);:::
这里就是熟悉的脚手架vue create xx,vue init的一些 xxx项目的脚手架工作了,具体可以查看vue-cli 源码
关于bin的实际操作,后续会专门写一个自己的脚手架,再来细细了解下这些知识。
conig,这个配置可以在你指定包名,版本升级时,一些特殊值可以保持不变。
dependencies这是一个开发依赖,当你在你得cmd控制台输入npm i ramda -s时
package.json中dependencies生成了一个依赖文件"ramda": "^0.27.1"。
devDependencies是一个在生产环境需要依赖的包,dependencies与devDependencies的区别是:npm i xx -s和npm i xx --save-dev,在实际项目开发中,你可以把dependencies安装的开发环境依赖包,在你打包的时候利用webpack的externals外部扩展特性分离出去,也就是将开发环境的包可以用cdn加载,这样减少你生产环境的bundle.js的体积,开发环境那部分依赖的包就可以单独cdn引入,进而提升你项目的打包速度。
打开node_modules/ramda,我们能从这个优秀的ramda包中发现些什么,
注意scripts
在scripts配置中有一个"build": "npm run build:es && npm run build:cjs && npm run build:umd && npm run build:umd:min && npm run build:mjs",ramda
是用rollup打包的,这行命令可以将你的ramda打包成了不同模式,支持按需引入还是script标签引用的多种方式。关于rollup打包,可以参考官网学习rollup.js。
现在我们测试下自己配置的scripts,当前目录下新建一个文件index.js,并控制台运行npm run start
::: details code
{
"name": "npm-know",
"version": "1.0.0",
"description": "My first encounter with npm",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node index.js"
},
...
}:::
index.js写入测试代码
::: details code
// 由于刚项目已经安装ramda,所以直接require该包
const R = require('ramda');
const cityMap = [
{
city: '北京'
},
{
city: '上海'
},
{
city: '深圳'
}
];
// 找到上海
const shanghaiCity = R.find(R.propEq('city', '上海'))(cityMap);
console.log(shanghaiCity);:::
测试结果如下:
在你执行npm run start时,它与npm start也是等价的,实际上当我们执行这行命令时本质上在执行node index.js,前者相当于就是一个命令的别名,所以你看到ramda的scripts上配置了多行命令,"build": "npm run build:es && npm run build:cjs && npm run build:umd && npm run build:umd:min && npm run build:mjs",,在ramda中,这行命令执行了多行配置
在npm init生成的package.json内部还有其他的字段,更多可以参考官方文档pckage.json,你已经了解npm最硬核的一些知识了,其他的,你就熟悉下些配置时,比如支持操作系统、node 指定环境版本等等,巴拉巴拉...
::: details code
npm - h;:::
这是一个查看npmcmmand 有那些指令,等价于npm help,如果你记不起 npm 有哪些命令,那么你可以用这个查看她的全家桶
::: details code
npm i
// npm i -g 全局安装
// npm i xx@latest 安装最新xx版本的包
// npm i [email protected] 安装指定版本的包
// npm i [email protected] -s or npm i [email protected] -d 安装到开发环境,包名会在dependencies
// npm i [email protected] --save-dev 安装到生产环境,包名会在devDependencies:::
如果你package.json的dependencies或者devDependencies有对应的包了,那么你执行该命令后,会在你当前项目中生成一个node_modules文件夹,该文件下会下载你需要的包,应有尽有。
::: details code
npm cache clear:::
清除缓存包,在你运行项目,莫名其妙的报错的时候,除了删除node_modules,有时候你执行这个命令,可能能帮助到你
::: details code
npm bugs ramda:::
这是一个很有用的命令,快速链接到你这个包的issue,在issue中会找到你遇到的一些问题,例如:cd node_modules/ramda,执行命令npm bugs,浏览器自动给你打开了该包issue地址。(如果只是在你自己的项目根目录里,执行这个命令,这个命令会把以当前package.json的 name,在 npm 官网当成一个路由地址打开,那么就是 404 了,不信你可以试试)。
查看 ramda 所有版本包
::: details code
npm view ramda versions
// npm view ramda version 查看当前项目ramda版本
// npm view ramda@* 查看当前包的基本信息:::
如果你本地想安装一个vue指定的版本,那么你可以先npm view vue versions 查到所有的版本,然后命令安装npm i [email protected] -s那么就会安装该版本。就是这么简单,这个命令用起来,你终于不用去官网看版本了。
::: details code
npm diff --diff=ramda@0.0.1 --diff=ramda@0.1.0:::
比较两个版本的不同,用到少。
::: details code
npm docs ramda:::
这个命令打开ramda的官方文档,就是package.json里面的那个homepage地址
更新 xxx 包
::: details code
npm update ramda // 更新ramda包:::
卸载 xxx 包
::: details code
npm uninstall ramda
// 简写,等价于下面 npm un ramda or npm rm ramda or npm r ramda:::
::: details code
npm pkg get name version
:::
读取包名、版本等信息
接下来说几个关于npm发包的几个关键命令
::: details code
npm login:::
这中途需要npm官方会给你发个邮箱的验证码,收到npm注册的邮箱,输入就 OK 了,这里以笔者 n 年前上传的一个包eazyutils包为例。
::: details code
npm publish:::
(注意修改下package.json的版本),否则提交不上
更多npm命令参考npm commands了,不常用的就没写了,因为那些不常用的,笔者也没用过,哈哈。更多关于npm的命令最好就是找官方文档查询,本来以为你看到这里,以为已经总结了所有npm命令,但是....,笔者文章已经覆盖了项目里所用到的绝大部分场景。
1.npm 常用的command命令,譬如高频命令npm view xxx versions,npm update@lastest、npm un xxx、npm i xx -s,常用的增删查改基本以及涵盖了。
2.了解package.json关键的几个字断意思,但是bin这个你必须要知道,因为她,你可以任性创建一个自己的xx-cli了
3.npm如何发布一个全世界都能看到,全世界都能下载的npm包,以 n 年前的一个简单eazyutils包为例
最后,喜欢的点个赞,在看,收藏等于学会,我会以循序渐进的方式一直分享下去。
在上一节中我们初步了解了webpack可以利用内置静态模块类型(asset module type)来处理资源文件,我们所知道的本地服务,资源的压缩,代码分割,在webpack构建的工程中有一个比较显著的特征是,模块化,要么commonjs要么esModule,在开发环境我们都是基于这两种,那么通过webpack打包后,如何让其支持浏览器能正常的加载两种不同的模式呢?
接下来我们一起来探讨下webpack中打包后代码的原理
正文开始...
新建一个文件夹webpack-05-module,
npm init -y我们安装项目一些基础支持的插件
npm i webpack webpack-cli webpack-dev-server html-webpack-plugin babel-loader @babel
l/core -D在根目录新建webpack.config.js,配置相关参数,为了测试 webpack 打包cjs与esModule我在entry写了两个入口文件,并且设置mode:development与devtool: 'source-map',设置source-map是为了更好的查看源代码
::: details code
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const { CleanWebpackPlugin } = require('clean-webpack-plugin');
module.exports = {
entry: {
cjs: './src/commonjs_index.js',
esjs: './src/esmodule_index.js'
},
devtool: 'source-map',
output: {
filename: 'js/[name].js',
path: path.resolve(__dirname, 'dist'),
assetModuleFilename: 'images/[name][ext]'
},
mode: 'development',
module: {
rules: [
{
test: /\.js$/,
loader: 'babel-loader',
options: {
presets: ['@babel/env']
}
},
{
test: /\.(png|jpg)$/i,
type: 'asset/resource'
// generator: {
// // filename: 'images/[name][ext]',
// publicPath: '/assets/images/'
// }
}
]
},
plugins: [
new CleanWebpackPlugin(),
new HtmlWebpackPlugin({
template: './public/index.html'
})
]
};:::
在src目录下新建commonjs_index.js, esmodule_index.js文件
// commonjs_index.js
const { twoSum } = require('./utils/common.js');
import imgSrc from './assets/images/1.png';
console.log('cm_sum=' + twoSum(1, 2));
const domApp = document.getElementById('app');
var img = new Image();
img.src = imgSrc;
domApp.appendChild(img);引入的common.js
// utils/common.js
function twoSum(a, b) {
return a + b;
}
module.exports = {
twoSum
};// esmodule_index.js
import twoSumMul from './utils/esmodule.js';
console.log('es_sum=' + twoSumMul(2, 2));引入的esmodule.js
// utils/esmodule.js
function twoSumMul(a, b) {
return a * b;
}
// esModule
export default twoSumMul;当我们运行npm run build命令,会在根目录dist/js文件夹下打包入口指定的两个文件
我把对应注释去掉后就是下面这样的
::: details code
// cjs.js
(() => {
var __webpack_modules__ = {
'./src/utils/common.js': (module) => {
function twoSum(a, b) {
return a + b;
}
module.exports = {
twoSum: twoSum
};
},
'./src/assets/images/1.png': (module, __unused_webpack_exports, __webpack_require__) => {
'use strict';
module.exports = __webpack_require__.p + 'images/1.png';
}
};
var __webpack_module_cache__ = {};
function __webpack_require__(moduleId) {
var cachedModule = __webpack_module_cache__[moduleId];
if (cachedModule !== undefined) {
return cachedModule.exports;
}
var module = (__webpack_module_cache__[moduleId] = {
exports: {}
});
__webpack_modules__[moduleId](module, module.exports, __webpack_require__ "moduleId");
return module.exports;
}
(() => {
__webpack_require__.g = (function () {
if (typeof globalThis === 'object') return globalThis;
try {
return this || new Function('return this')();
} catch (e) {
if (typeof window === 'object') return window;
}
})();
})();
(() => {
__webpack_require__.r = (exports) => {
if (typeof Symbol !== 'undefined' && Symbol.toStringTag) {
Object.defineProperty(exports, Symbol.toStringTag, { value: 'Module' });
}
Object.defineProperty(exports, '__esModule', { value: true });
};
})();
(() => {
var scriptUrl;
if (__webpack_require__.g.importScripts) scriptUrl = __webpack_require__.g.location + '';
var document = __webpack_require__.g.document;
if (!scriptUrl && document) {
if (document.currentScript) scriptUrl = document.currentScript.src;
if (!scriptUrl) {
var scripts = document.getElementsByTagName('script');
if (scripts.length) scriptUrl = scripts[scripts.length - 1].src;
}
}
if (!scriptUrl) throw new Error('Automatic publicPath is not supported in this browser');
scriptUrl = scriptUrl
.replace(/#.*$/, '')
.replace(/\?.*$/, '')
.replace(/\/[^\/]+$/, '/');
__webpack_require__.p = scriptUrl + '../';
})();
var __webpack_exports__ = {};
(() => {
'use strict';
__webpack_require__.r(__webpack_exports__);
var _assets_images_1_png__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(/*! ./assets/images/1.png */ './src/assets/images/1.png');
var _require = __webpack_require__(/*! ./utils/common.js */ './src/utils/common.js'),
twoSum = _require.twoSum;
console.log('cm_sum=' + twoSum(1, 2));
var domApp = document.getElementById('app');
var img = new Image();
img.src = _assets_images_1_png__WEBPACK_IMPORTED_MODULE_0__;
domApp.appendChild(img);
})();
})();:::
初次看,感觉webpack打包cjs的代码太长了,但是删除掉注释后,我们仔细分析发现,并没有那么复杂
首先是该模块采用 IFEE 模式,一个匿名的自定义自行函数内包裹了几大块区域
::: details code
var __webpack_modules__ = {
'./src/utils/common.js': (module) => {
function twoSum(a, b) {
return a + b;
}
// 当在执行时,返回这个具体函数体内容
module.exports = {
twoSum: twoSum
};
},
'./src/assets/images/1.png': (module, __unused_webpack_exports, __webpack_require__) => {
'use strict';
// 每一个对应的模块对应的内容
module.exports = __webpack_require__.p + 'images/1.png';
}
};:::
我们发现webpack是用模块引入的路径当成key,然后value就是一个函数,函数体内就是引入的具体代码内容,并且内部传入了一个形参module,实际上这个module就是为{exports: {}}定义的对象,把内部函数twoSum绑定了在对象上
::: details code
var __webpack_module_cache__ = {};
// moduleId 就是引入的路径
function __webpack_require__(moduleId) {
// 根据moduleId优先从缓存中获取__webpack_modules__中绑定的值 {twoSum: TwoSum}
var cachedModule = __webpack_module_cache__[moduleId];
if (cachedModule !== undefined) {
return cachedModule.exports;
}
// 传入__webpack_modules__内部value的形参 module
var module = (__webpack_module_cache__[moduleId] = {
exports: {}
});
__webpack_modules__[moduleId](module, module.exports, __webpack_require__ "moduleId");
// 根据moduleId依次返回 {twoSum: twoSum}、__webpack_require__.p + 'images/1.png‘图片路径
return module.exports;
}:::
__webpack_require__.p图片地址::: details code
(() => {
__webpack_require__.g = (function () {
if (typeof globalThis === 'object') return globalThis;
try {
return this || new Function('return this')();
} catch (e) {
if (typeof window === 'object') return window;
}
})();
})();
(() => {
var scriptUrl;
if (__webpack_require__.g.importScripts) scriptUrl = __webpack_require__.g.location + '';
var document = __webpack_require__.g.document;
if (!scriptUrl && document) {
if (document.currentScript) scriptUrl = document.currentScript.src;
if (!scriptUrl) {
var scripts = document.getElementsByTagName('script');
if (scripts.length) scriptUrl = scripts[scripts.length - 1].src;
}
}
if (!scriptUrl) throw new Error('Automatic publicPath is not supported in this browser');
scriptUrl = scriptUrl
.replace(/#.*$/, '')
.replace(/\?.*$/, '')
.replace(/\/[^\/]+$/, '/');
// 获取图片路径
__webpack_require__.p = scriptUrl + '../';
})();:::
esModule转换,用Object.defineProperty拦截exports(module.exports)对象添加__esModule属性(() => {
__webpack_require__.r = (exports) => {
if (typeof Symbol !== 'undefined' && Symbol.toStringTag) {
Object.defineProperty(exports, Symbol.toStringTag, { value: 'Module' });
}
Object.defineProperty(exports, '__esModule', { value: true });
};
})();__webpack_require__(moduleId)执行获取对应的内容::: details code
var __webpack_exports__ = {};
(() => {
'use strict';
// 在步骤4中做对象拦截,添加__esMoules属性
__webpack_require__.r(__webpack_exports__);
//根据路径获取对应module.exports的内容也就是__webpack_require__中的module.exports对象的数据
var _assets_images_1_png__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(/*! ./assets/images/1.png */ './src/assets/images/1.png');
var _require = __webpack_require__(/*! ./utils/common.js */ './src/utils/common.js'),
twoSum = _require.twoSum;
console.log('cm_sum=' + twoSum(1, 2));
var domApp = document.getElementById('app');
var img = new Image();
img.src = _assets_images_1_png__WEBPACK_IMPORTED_MODULE_0__;
domApp.appendChild(img);
})();
})();:::
我们看下具体代码
::: details code
// esjs.js
(() => {
// webpackBootstrap
'use strict';
var __webpack_modules__ = {
'./src/utils/esmodule.js': (__unused_webpack_module, __webpack_exports__, __webpack_require__) => {
__webpack_require__.r(__webpack_exports__);
function twoSumMul(a, b) {
return a * b;
}
const __WEBPACK_DEFAULT_EXPORT__ = twoSumMul;
__webpack_require__.d(__webpack_exports__, {
default: () => __WEBPACK_DEFAULT_EXPORT__
});
}
};
// The module cache
var __webpack_module_cache__ = {};
// The require function
function __webpack_require__(moduleId) {
// Check if module is in cache
var cachedModule = __webpack_module_cache__[moduleId];
if (cachedModule !== undefined) {
return cachedModule.exports;
}
// Create a new module (and put it into the cache)
var module = (__webpack_module_cache__[moduleId] = {
// no module.id needed
// no module.loaded needed
exports: {}
});
// Execute the module function
__webpack_modules__[moduleId](module, module.exports, __webpack_require__ "moduleId");
// Return the exports of the module
return module.exports;
}
(() => {
// define getter functions for harmony exports
__webpack_require__.d = (exports, definition) => {
for (var key in definition) {
if (__webpack_require__.o(definition, key) && !__webpack_require__.o(exports, key)) {
Object.defineProperty(exports, key, { enumerable: true, get: definition[key] });
}
}
};
})();
/* webpack/runtime/hasOwnProperty shorthand */
(() => {
__webpack_require__.o = (obj, prop) => Object.prototype.hasOwnProperty.call(obj, prop);
})();
/* webpack/runtime/make namespace object */
(() => {
// define __esModule on exports
__webpack_require__.r = (exports) => {
if (typeof Symbol !== 'undefined' && Symbol.toStringTag) {
Object.defineProperty(exports, Symbol.toStringTag, { value: 'Module' });
}
Object.defineProperty(exports, '__esModule', { value: true });
};
})();
/************************************************************************/
var __webpack_exports__ = {};
(() => {
__webpack_require__.r(__webpack_exports__);
var _utils_esmodule_js__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(/*! ./utils/esmodule.js */ './src/utils/esmodule.js');
console.log('es_sum=' + (0, _utils_esmodule_js__WEBPACK_IMPORTED_MODULE_0__['default'])(2, 2));
})();
})();:::
看着代码似乎与cjs大体差不多,事实上有些不一样
当我们执行_utils_esmodule_js__WEBPACK_IMPORTED_MODULE_0__这个方法时,实际会在__webpack_modules__方法会根据moduleId执行 value 值的函数体,而函数体会被__webpack_require__.d这个方法进行拦截,会执行 Object.defineProperty的get方法,返回绑定在__webpack_exports__对象的值上
主要看以下两段代码
var __webpack_modules__ = {
'./src/utils/esmodule.js': (__unused_webpack_module, __webpack_exports__, __webpack_require__) => {
// 这里定义模块时就已经先进行了拦截,这里与cjs有很大的区别
__webpack_require__.r(__webpack_exports__);
function twoSumMul(a, b) {
return a * b;
}
const __WEBPACK_DEFAULT_EXPORT__ = twoSumMul;
__webpack_require__.d(__webpack_exports__, {
default: () => __WEBPACK_DEFAULT_EXPORT__
});
}
};
...
(() => {
// define getter functions for harmony exports
__webpack_require__.d = (exports, definition) => {
for (var key in definition) {
if (__webpack_require__.o(definition, key) && !__webpack_require__.o(exports, key)) {
Object.defineProperty(exports, key, { enumerable: true, get: definition[key] });
}
}
};
})();在 webpack 转换esModule代码中,同样会是有优先从缓存对象中获取,通过调用 __webpack_modules__[moduleId](module, module.exports, __webpack_require__ "moduleId"); 这个方法,改变module.exports根据moduleId获取函数体内的值twoSumMul函数
最后画了一张简易的图,文字理解还是有点多,纸上得来终学浅,绝知此事要躬行,还是得写个简单的demo自己深深体会下,具体参考文末的code example
webpack 打包cjs与esModule的区别,本质上就是为了在浏览器支持 webpack 中使用export default {}与module.exports 在浏览器定义了一个全局变量__webpack_modules__根据引入的模块路径变成key,value就是在webpack中的cjs或者esModule中函数体。
当我们在cjs使用require('/path')、或者在esModule中使用import xx from '/path'时,实际上webpack把requireorimport转变成了一个定义的函数__webpack_require__('moduleId')的可执行函数。
cjs是在执行__webpack_require__.r(__webpack_exports__)是就已经预先将__webpack_require__返回的函数体内容进行了绑定,只有在执行_webpack_require__(/*! ./utils/common.js */ './src/utils/common.js')返回函数体,本质上就是在运行时执行
esMoule实际上是在定义时就已经进行了绑定,在定义__webpack_exports__时,执行了 __webpack_require__.r(__webpack_exports__);动态添加__esModule属性,根据moduleId定义模块时,执行了 __webpack_require__.d(__webpack_exports__, { default: () => __WEBPACK_DEFAULT_EXPORT__});,将对应模块函数体会直接用对象拦截执行Object.defineProperty的get方法,执行definition[key]从而返回函数体。本质上就是在编译前执行,而不是像cjs一样在函数体执行阶段直接输出对应内容。
他们相同点就是优先会从缓存__webpack_module_cache__对象中根据moduleId直接获取对应的可执行函数体
js 的浅拷贝与深拷贝在业务中时常有用到,关于浅拷贝与深拷贝的剖析文章层出不穷,本文是笔者对于深拷贝与浅拷贝的理解,一起来夯实 js 语言基础知识的理解吧。
正文开始...
在阅读文章之前,本文主要从以下几个方面去探讨
为什么会有浅拷贝与深拷贝
浅拷贝是什么,深拷贝又是什么
浅拷贝与深拷贝有何区别
写一个例子佐证以上所有的观点
我们知道在js中基础数据类型是存放在栈内存中的,而引用数据类型是存放在栈地址引用的一个堆内存中。为什么两种数据会存放方式不同?这是一个值的思考的问题?我的猜想,引用数据类型是复杂的数据结构,本质上也是存放栈地址的引用,只是这个地址指向了另外一个堆内存空间,如果他们都是放在一起的话,就不太好区分你是基础数据类型,还是引用数据类型了。
首先它们都是拷贝,一个是浅,一个是深,我们先说结论,浅拷贝是基础数据类型的拷贝,只会拷贝一层,如果遇到拷贝的数据是引用数据,那么浅拷贝的数据与原有数据是同一份引用。
而深拷贝是遇到引用数据类型会创建一个新的对象,遍历原有对象,对新对象进行动态赋值,修改新对象引用不影响原有对象的属性值
我们用一个图来解释上面两段比较长的话
基础数据类型直接存放在栈地址内存中,而引用数据类型是存放在栈内存地址的引用中,这个引用实际上指向的区域是一块堆内存空间
在了解浅拷贝与深拷贝之前,我们先来了解下值拷贝
当我对原有基础数据类型与引用数据类型进行赋值时
用下面代码示例上图
var userName = 'Maic';
var age = 18;
var userInfo = {
name: 'Maic',
age: 18,
fav: {
play1: 'ping pang',
play2: 'basket ball'
}
};
var cacheUserName = userName;
var cacheAge = age;
// 对象值拷贝
var cacheUserInfo = userInfo;
cacheUserName = 'Tom';
cacheAge = 20;
cacheUserInfo.name = 'jake';
cacheUserInfo.age = 10;
cacheUserInfo.fav.play1 = 'swim';
console.log(userName, age, userInfo, '------', cacheUserName, cacheAge, cacheUserInfo);然后运行node index.js
从执行结果上来看
Maic 18 { name: 'jake', age: 10, fav: { play1: 'swim', play2: 'basket ball' } }
------
Tom 20 { name: 'jake', age: 10, fav: { play1: 'swim', play2: 'basket ball' } }因此可以得出结论
基础数据类型的赋值,是值的拷贝,会重新开辟一个栈空间,新拷贝的值修改不会影响原有数据类型
引用数据类型的赋值,原有引用数据与新赋值的数据指向的是同一份地址,修改引用数据的属性会影响原来的
以上是两种数据类型值的拷贝,貌似与浅拷贝还有离得有点远
于是我们看下对象扩展的浅拷贝
...
// 对象浅拷贝
var cacheUserInfo = { ...userInfo }
// 与下面等价
// var cacheUserInfo = Object.assign({}, userInfo);
// 修改值拷贝后值
cacheUserName = 'Tom';
cacheAge = 20;
cacheUserInfo.name = 'jake';
cacheUserInfo.age = 10;
cacheUserInfo.fav.play1 = 'swim';
console.log(userName, age, userInfo, '------', cacheUserName, cacheAge, cacheUserInfo);我使用了es6对象扩展对原有对象进行拷贝,那么此时结果是怎么样
Maic 18 { name: 'Maic', age: 18, fav: { play1: 'swim', play2: 'basket ball' } }
------
Tom 20 { name: 'jake', age: 10, fav: { play1: 'swim', play2: 'basket ball' } }不知道注意到没有,在引用数据类型的第一级如果这个属性是基础数据类型,那么修改并不会影响原有的值,如果属性是引用数据类型,那么这层结构会是一个值拷贝,修改新赋值属性,会影响到原有的对象属性
我们看下图理解下
因此我们可以得出结论,浅拷贝如果遇到基础数据类型,那么修改新值,不会影响原有的值,但是如果数据是引用数据类型,那么新修改的值会影响原有的值,因为新修改的与原修改的是同一份引用。
所以浅拷贝只会拷贝一层,如果数据是引用数据类型,实际上会直接引用同一份数据。
深拷贝顾名思义,从表现层来看就是,就是为了修改新数据而不影响原有数据而产生的。
我们举个栗子
var userInfo = {
name: 'Maic',
age: 18,
fav: {
play1: 'ping pang',
play2: 'basket ball'
}
};当我需要修改userInfo.fav.play1的值,而不想影响原有userInfo对象的值,那么此时你就会想到深拷贝,那怎么深拷贝呢。
利用JSON.stringify(data)拷贝对象
...
const newUseInfo = JSON.parse(JSON.stringify(userInfo));
newUseInfo.fav.play1 = 'hello';
console.log(userInfo, '----', newUseInfo);结果:
{
name: 'Maic',
age: 18,
fav: { play1: 'ping pang', play2: 'basket ball' }
}
----------
{
name: 'Maic',
age: 18,
fav: { play1: 'hello', play2: 'basket ball' }
}但是我们得考虑到JSON.stringify这种有种缺陷,必须是json对象,有其他比如方法这种会被自动过滤处理。而且如果json对象格式错误,就会抛出异常,所以我们看下另外一种方案。
使用代理对象**,将原有对象拷贝一份,然后再赋值
var userInfo = {
name: 'Maic',
age: 18,
fav: {
play1: 'ping pang',
play2: 'basket ball'
},
fav2: [
{
a: 1,
b: 2
},
{
a: 3,
b: 4
}
]
};
const isType = (val) => {
return (type) => Object.prototype.toString.call(val) === `[object ${type}]`;
};
function deepMerge(target = {}) {
const ret = {};
for (let key in target) {
if (target.hasOwnProperty(key)) {
if (isType(target[key])('Object')) {
ret[key] = deepMerge(target[key]);
} else {
ret[key] = target[key];
}
}
}
return ret;
}
const cacheObj = deepMerge(userInfo);
cacheObj.fav.play1 = '111';
cacheObj.fav2[0].a = '666';
console.log(userInfo, '-----', cacheObj);最终结果是
{
name: 'Maic',
age: 18,
fav: { play1: 'ping pang', play2: 'basket ball' },
fav2: [ { a: '666', b: 2 }, { a: 3, b: 4 } ]
}
-------
{
name: 'Maic',
age: 18,
fav: { play1: '111', play2: 'basket ball' },
fav2: [ { a: '666', b: 2 }, { a: 3, b: 4 } ]
}但是如果数据中有数组,貌似数组的这种情况还是同一份值,那是因为直接赋值了
...
function deepMerge(target = {}) {
const ret = {};
for (let key in target) {
if (target.hasOwnProperty(key)) {
if (isType(target[key])('Object')) {
ret[key] = deepMerge(target[key])
} else {
// 是因为这里直接赋值了操作
ret[key] = target[key];
}
}
}
return ret;
}于是需要多加一个条件,需要对数组进行判断
const isType = (val) => {
return (type) => Object.prototype.toString.call(val) === `[object ${type}]`;
};
function deepMerge(target) {
const ret = Array.isArray(target) ? [] : {};
for (let key in target) {
if (target.hasOwnProperty(key)) {
if (isType(target[key])('Object')) {
ret[key] = deepMerge(target[key]);
} else if (isType(target[key])('Array')) {
// 判断数组,并再次递归,用数组concat方法添加该数据
ret[key] = [].concat([...deepMerge(target[key])]);
} else {
ret[key] = target[key];
}
}
}
return ret;
}
const cacheObj = deepMerge(userInfo);
cacheObj.fav.play1 = '111';
cacheObj.fav2[0].a = '666';
console.log(userInfo, '----', cacheObj);此时结果
{
name: 'Maic',
age: 18,
fav: { play1: 'ping pang', play2: 'basket ball' },
fav2: [ { a: 1, b: 2 }, { a: 3, b: 4 } ],
fav3: [ 1, 2, 3 ]
}
-------
{
name: 'Maic',
age: 18,
fav: { play1: '111', play2: 'basket ball' },
fav2: [ { a: '666', b: 2 }, { a: 3, b: 4 } ],
fav3: [ 1, 2, 3 ]
}以上用一个图来进一步理解下
真是人才,深拷贝原来是这样的
通过以上例子,我们已经知道
浅拷贝如果拷贝对象内部的数据是基础数据类型,那么直接拷贝,新对象修改值,不会影响原有的值,如果拷贝的对象是一个引用数据类型,那么会是一个值的引用,此时新拷贝对象修改其值会影响原有的值。浅拷贝只会拷贝一层,拷贝的内部引用数据类型是同一份。
深拷贝本质上就是无论原对象值是基础数据类型,还是引用数据类型,我新拷贝的对象修改对象内部的值,并不会影响原有对象的值
另外还要有一点值拷贝,也是赋值,基础数据类型赋值,新修改的数据不会影响原有的数据,但是如果是引用数据类型,那么新拷贝的值修改会影响原有数据
值拷贝(直接赋值操作),主要区分基础数据类型与引用数据类型,如果是基础数据类型,那么新值修改不会影响原有的值,但是如果引用数据类型,那么新修改的值会影响原有数据类型
浅拷贝,如果拷贝的对象内部属性是引用数据类型,那么像es6中的对象扩展符或者Object.assign都是浅拷贝操作,新拷贝的基础数据类型修改不会影响原有值,但是如果拷贝的是引用数据类型,那么新拷贝的值与原有值是同一份引用,新值修改会影响原有的值
深拷贝,一句话,新拷贝的对象修改值不会影响原有值
本文示例code example
平时项目中我们绝大部分都是用bash命令行,或者用GUI可视化工具,无论是小乌龟还是gui工具,如果是工具比较推荐sourceTree,但是我更推荐git-fork,工具因人而已,无论习惯命令行还是工具,寻得自己喜欢的方式就行,没有好坏之分,也没有高低之分。
如果你常常用gui,或者你常常用命令行,那么不妨用用脚本来解放你的双手。
正文开始...
正常情况下,我们知道我们bash中,我们使用git pull、git add .、git commit、git push等这些命令实际是在git bash环境下执行的命令。相当于DOS环境或者shell执行git命令。
在git bash也是可以执行.sh的xshell脚本
我们在bash新建一个index.sh文件测试一下
touch index.sh在index.sh中输入一段打印脚本
echo 'hello bash'在命令行中输入bash index.sh
我们在index.sh中新增一个命令
echo 'hello bash'
# 删除test.txt
rm test.txt
# 删除test目录
rm -rf test
# 打开xx文件修改
vim test2.txt在终端中你需要用i插入,修改后执行:wq!就可以保存退出了
ls -a# 将当前的test2.txt复制成test2_blank.txt
cp test2.txt test2_blank.txt以上是一些常用的xshell命令,更多命令可以参考xshell
以上基础的了解一些常用的xshell命令,现在我们可以编写一个xshell脚本了
首先我们在我们项目根目录新建一个deplop.sh文件
touch deplop.sh
对应的deplop.sh
# 如果项目已经初始化后,已经init 那么不用加这个
# git init
# 更新your对应分支
git pull origin your_branch
# 查看本地状态
git status
# 添加本地修改的文件
git add .
# 提交
git commit -m 'add xx'
# 添加远程remote 如果项目已经remote,可以省略
# git remote add origin https://github.com/xx.git
# 推送到指定分支
git push origin your_branch然后我们在根目录下创建一个package.json
npm init -y然后在package.json中,添加命令
{
"name": "lessonNote",
"version": "1.0.0",
"description": "lessonNote-js 学习笔记",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"push": "bash deplop.sh"
},
...
}然后我们运行命令npm run push
至此你就可以愉快的用一行命令了,但是正常情况下你每次得修改commit的信息,而不是写死在deplop.sh脚本里面
于是你可以这样
# 如果项目已经初始化后,已经init 那么不用
# git init
# 更新your_branch
git pull origin your_branch
# 查看本地状态
git status
# 添加本地修改的文件
git add .
# 读取终端输入的信息
read -p "input your commit message: " msg
# 提交
git commit -m "$msg"
# 添加远程remote 如果项目已经remote,可以省略
# git remote add origin https://github.com/xx.git
# 推送到指定分支
git push origin your_branch当你运行npm run push后,就会执行上面你编辑的脚本,就可以快速的提交到自己仓库了
如果你是想推一个你打包后的项目到指定仓库,可以参考deplop.sh
# deploy.sh
#!/usr/bin/env sh
# 确保脚本抛出遇到的错误
set -e
# 生成静态文件
npm run build
# 进入生成的文件夹目录
cd docs/.vuepress/dist
git init
# 添加当前文件
git add .
# 读取终端输入的信息
read -p "input commit message: " msg
git commit -m "$msg"
# remote 指定仓库
git remote add origin https://github.com/xxx.git
# 推送到指定仓库
git push -f origin your_branch
echo 'push success'然后执行npm run push这样就可以一行命令替代你提交的所有操作了
了解一些常用的xshell脚本命令,在xx.sh这样的文件,你可以编写一些脚本,对文件进行删除,修改等操作
新建一个deplop.sh文件,编写git提交本地文件,解放git add 、git commit、git push操作
本文示例code example
websocket 是一种基于
http的通信协议,服务端可以主动推送信息给客户端,客户端也可以像服务端发送请求,Websocket允许服务端与客户端进行全双工通信。
基于tcp协议之上,服务端实现比较容易
默认端口是80(ws)或者443(wss),握手阶段采用的http协议
数据格式比较轻量,性能开销小,通信高效
可以发送文本或者二进制数据
没有同源限制,客户端可以像任意服务发送信息
协议标识符是ws,如果加密,那么是wss,
新建一个html文件客户端代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>websocket</title>
</head>
<body>
<h3>hello websocket</h3>
<input type="number" id="textContent" />
<button id="handleSend">发送</button>
<button id="auto-send">开启服务端向客户端发消息模式</button>
<hr />
<div id="app"></div>
</body>
</html>在html中引入下面一段 js
// index.js
const sendDom = document.getElementById('send');
const appDom = document.getElementById('app');
const autoDom = document.getElementById('auto-send');
const inputContent = document.getElementById('textContent');
const socketPath = 'ws://192.168.31.40:3000';
let timer = null;
let num = 0;
const result = [];
// 建立连接
const ws = new WebSocket(socketPath);
const sendMyNum = (isSetInterval = false, to = 'client', val) => {
const setNum = () => {
num = val || Math.ceil(Math.random() * 10);
ws.send(
JSON.stringify({
clientText: `client:hello,我是${num}号`,
num,
to
})
);
};
if (isSetInterval) {
timer = setInterval(() => {
setNum();
}, 1000);
} else {
setNum();
}
};
const renderHtml = (data) => {
const { serverText, clientText } = JSON.parse(data);
appDom.innerHTML = '';
result.push({
serverText,
clientText
});
console.log(result);
if (result.length > 0) {
let str = '';
result.forEach((v) => {
str += `<ul>
<li>${v.clientText}</li>
<li>${v.serverText}</li>
</ul>`;
});
appDom.innerHTML = str;
}
};
// 发送数据
ws.onopen = function () {
console.log('websocket connection start');
sendMyNum(false);
};
// 接收服务端发送的消息
ws.onmessage = function (evt) {
console.log(`receive:${evt.data}`);
if (evt.data) {
renderHtml(evt.data);
// 接收数据后关闭定时器
clearInterval(timer);
// sendMyNum(true)
}
};
// 关闭连接
ws.onclose = function () {
console.log('关闭了');
};
// 手动向客户端发送消息
handleSend.onclick = function () {
const val = inputContent.value;
if (val === '') {
alert('请输入你的编号');
return;
}
sendMyNum(false, 'client', val);
};
// 自动开启向客户端发送消息
autoDom.onclick = function () {
sendMyNum(true, 'server');
};新建一个server目录,新建创建服务端代码,主要依赖nodejs-websocket这个库是服务端websocket代码。
var ws = require('nodejs-websocket');
var http = require('http');
const fs = require('fs');
const path = require('path');
const PORT = 8080;
var server = http.createServer(function (request, response) {
response.statusCode = 200;
response.setHeader('Content-Type', 'text/html');
fs.readFile(path.resolve(__dirname, '../', 'index.html'), (err, data) => {
if (err !== null) {
response.end('404');
return;
}
response.end(data);
});
});
server.listen(PORT, function (evt) {
console.log(new Date() + ' Server is listening on port 8080');
});
// websocket
const tcp = ws
.createServer(function (connection) {
console.log('New connection');
connection.on('text', function (data) {
const { clientText, num, to } = JSON.parse(data);
if (to === 'server') {
connection.sendText(
JSON.stringify({
serverText: `server:${num}号,恭喜你,你太幸运了,你已经被清华录取了`,
clientText: `${num}号`
})
);
} else {
if (num > 6) {
connection.sendText(
JSON.stringify({
clientText,
serverText: `server:${num}号,你非常优秀, ${num}号,你已经成功被录取了北京大学`
})
);
} else {
connection.sendText(
JSON.stringify({
serverText: `server: ${num}号,非常遗憾,${num}号,你落榜了,再接再厉`,
clientText
})
);
}
}
});
connection.sendText(
JSON.stringify({
serverText: `server:hello,我们已经建立连接了`,
clientText: `client:你好`
})
);
connection.on('close', function (code, reason) {
console.log('Connection closed');
console.log(code, reason);
});
})
.listen(3000);
tcp.on('error', (err) => {
console.log(err);
});我们可以执行命令node server.js,打开浏览器http://localhost:8080/
打开network,ws下面可以看到有客户端向服务端发送的消息,也有服务端向客户端发送的两条信息。
我们看到请求头的一些信息
我们可以看到请求头里
Request URL: ws://192.168.31.40:3000/
Request Method: GET
Status Code: 101 Switching ProtocolsAccept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cache-Control: no-cache
Connection: Upgrade
Host: 192.168.31.40:3000
Origin: http://localhost:8080
Pragma: no-cache
Sec-WebSocket-Extensions: permessage-deflate; client_max_window_bits
Sec-WebSocket-Key: Mk8Au85XqQTn+vuDsfr/kw==
Sec-WebSocket-Version: 13
Upgrade: websocket
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36当输入数字,向服务端发送消息时,服务端会返回对应信息。通常来讲,服务端会不定时的向前端推送信息,前端拿到推送信息进行一系列的页面状态展示等。
通过以上的例子,我们基础的了解到websocket的使用
websocket其实需要客户端对websocket处理主要是这三个步骤
更多websocket可以参考websocket
flex在css布局中的是一个经常考察的知识点,虽然垂直居中问题已经问得快烂大街了,flex你虽然总是在用,但是总会有你不知道的盲点
本文是一篇关于flex布局相关的总结笔记,遇到比较刁钻的问题,当个知识拓展吧
在阅读本文之前,主要从以下几个方向去探讨flex
flex如何实现垂直居中,如何实现一个对角排列布局当我们对一个元素设置flex后,其子元素所有的float,clean、vertical-align属性都会失效,并且默认水平排列,并且宽度由自身元素内容决定。
主要影响水平轴排列还是交叉轴排列
.wrap-box {
display: flex;
// flex-direction: row; 默认从左往右
flex-direction: row-revers; 顺序从右往左
flex-direction: column; 从上往下
flex-direction: column-reverse; 从下往上
}flex-wrap:nowrap.wrap-box {
display: flex;
flex-direction: row;
flex-wrap: nowrap // 不换行
// flex-wrap: wrap // 换行
// flex-wrap: wrap-reverse 换行从下往上依次排列
}这个属性主要是flex-direction与flex-wrap的结合体
.wrap-box {
display: flex;
flex-flow: row nowrap // 默认
}主要影响水平主轴的排列顺序
.wrap-box {
display: flex;
justify-content: flex-start // 左对齐排列
// justify-content: center // 居中排列
// justify-content: space-between // 两端对齐排列
// justify-content: space-around // 间隔相等排列
// justify-content: flex-end // 居右排列
}主要影响交叉轴垂直方向的排列
.wrap-box {
display: flex;
align-items: flex-start; // 垂直方向从上往下排列
// align-items: center 垂直方向居中排列
// align-items: flex-end 垂直方向从下往上排列
// align-items: stretch 会将子元素高度拉伸父元素一致(子元素未设置高度)
}决定子项目的顺序,order越小,越是排列在最前面
假设现在有个需求,css实现简单的跑马灯
:::: code-group
::: code-group-item html
<div class="wrap-box">
<div class="item-1">1</div>
<div class="item-2">2</div>
<div class="item-3">3</div>
</div>:::
::: code-group-item css
@keyframes ani-1 {
0% {
order: 0;
}
50% {
order: 1;
}
100% {
order: 2;
}
}
@keyframes ani-2 {
0% {
order: 1;
}
50% {
order: 0;
}
100% {
order: 1;
}
}
@keyframes ani-3 {
0% {
order: 2;
}
50% {
order: 2;
}
100% {
order: 0;
}
}
.wrap-box {
width: 500px;
height: 500px;
overflow: hidden;
display: flex;
background-color: green;
align-items: stretch;
}
.wrap-box .item-1,
.wrap-box .item-2,
.wrap-box .item-3 {
width: 100px;
height: 100px;
background-color: red;
}
.wrap-box .item-1 {
animation: ani-1 5s infinite;
transition: order 1s ease;
}
.wrap-box .item-2 {
animation: ani-2 5s infinite;
transition: order 1s ease;
}
.wrap-box .item-3 {
animation: ani-3 5s infinite;
transition: order 1s ease;
}:::
::::
我们利用css3的动画帧,改变order的顺序,因此一个简易的css跑马灯就实现了,而且并没有改变dom的结构和顺序
设置当前的item的固定宽度
.wrap-box .item-3{
flex-basis: 200px;
}该属性是决定当前item的放大比例,默认是0
比如三个div,左右固定,中间内容自动撑开
当前item的缩小比例,默认的是0
能控制单个item的排列,这个属性通常不是很常用,面试曾被这个css的属性布局问题给跪了
面试题大概是这样的,3个子div实现一个对角线布局,用flex布局,如果没想到这个align-self大概是实现不了
.wrap-box {
width: 500px;
height: 500px;
overflow: hidden;
background-color: green;
display: flex;
justify-content: space-between;
}
.wrap-box .item-1,
.wrap-box .item-2,
.wrap-box .item-3 {
width: 100px;
height: 100px;
background-color: red;
}
.wrap-box .item-2 {
align-self: center; // 垂直居中
}
.wrap-box .item-3 {
align-self: flex-end; // 靠右
}设置对应的item大概就是下面这样了
通常我们设置flex:1,其实本质上是替代了以下几个参数
.item3 {
flex-grow:1;
flex-shrink:1;
flex-basis: 0%;
}以下是一个基本的页面结构
:::: code-group
::: code-group-item html
<div class="wrap">
<div class="inner-box"></div>
</div>:::
::: code-group-item css
.wrap {
width: 100px;
height: 100px;
display: flex;
justify-content: center;
align-items: center;
background-color: red;
}
.wrap .inner-box {
width: 50px;
height: 50px;
background: green;
}:::
::::
了解flex基本特征,影响水平轴与交叉轴的的属性主要受flex-direction这个属性的,默认水平row排列
当一个父级元素设置flex后,子级的浮动、clear,vertain-align属性都会失效,默认所有子级元素水平排列
flex的一些特性,比如放大flex-glow、缩小flex-shrink,还有影响水平轴排列just-content,以及交叉轴排列align-items属性的设置
align-self 这个属性可以单独控制当前元素的位置
flex实现一个垂直居中
面向对象对每一个程序员来说,非常熟悉,在 C 语言里,我们说它是面向过程,在java中我们熟悉的面向对象的三大特征中封装、继承、多态,java是高级语言,在BS架构中,后端语言用java等语言运行在服务器上,而在离用户端最近的B端,js中也有面相对象。
今年回家又相亲吗?在过年回家的路上,我们来聊聊我理解中的面相对象,这个对象比较轻松,那个悲伤的话题打住,正文开始...
在js中申明一个对象我们可以 🈶️ 以下几种方式:
::: details code
// 1:申明一个对象
var person = {}
// 2:构造函数new
function Animal {}
var animal = new Animal();
// 3:new Object
var cat = new Object();
// 4: class
class Maic {
constructor(name){
super();
this.name = name;
}
getName() {
return `我的名字:${this.name}`
},
eat() {
console.log('吃饭了');
},
say() {
console.log('说话了');
}
}
// 5.Object.create({})
var jd = Object.create({}):::
我们用以上申明对象,其实第一种与第三种是一样的,通常来讲第一种方式用的多,两者构造函数都是Object,你可以理解第一种方式是第三种方式的简写。
而第二种方式function Animal这是申明一个构造函数,一般构造函数都是大写字母开头,为了与普通函数的区别,在我没有new的时候,它就是个普通函数,但是如果我对它进行了new Animal操作,那么此时,性质就变味了,此时我变成了一个对象。
第四种是es6的一种新的方式,本质上可以理解为定义构造函数的变体。但是class这种方式让你组织你的代码更加优雅。
js语言借鉴了java**,但又与java还是有些不同,有人把js定义为解释性语言,就是不需要编译,直接在浏览器端引入一段脚本就能跑,当然底层的那些是chrome内核帮我们做了解析。对于web开发者来说,我只要保证写的js脚本能跑通就行。
既然借鉴了java的对象**,那么又是如何体现?
设计语言的大师把现实中所有物质,一切皆可用对象来描述。我们可以把这个对象理解成一个抽象的空间,而这个空间里有人,人有名字,可以吃饭,可以说话等等。
在代码中,我是如何去描述呢?我们先用用第二种方式构造函数去描述
::: details code
// 定义空间
function Person(name) {
this.name = name; // 人的名字
// 可以说话
this.say = function () {
console.log(`我的名字:${this.name}`);
};
// 可以吃饭
this.eat = function () {
console.log(`今天我要吃黄焖鸡`);
};
}
var person = new Person('Maic');
var person2 = new Person('张三');:::
我们可以测试一下脚本,将这段代码 copy 到控制台上可以知道
::: details code
:::
在控制台上,我们可以验证对象的构造函数是谁?
::: details code
// 获取person的构造函数
console.log(person.constructor.name); //Person
console.log(person2.constructor.name); //Person
// 我们每new一个构造函数,实际上person2和person就是不一样的,但是他们属性和方法却可以是一样的:::
从上面例子我们已经知道构造函数有个特点:
1、内部有this,这个this其实指向的就 new 操作后的实例对象
2、生成对象时,必须new构造函数
在我们用new操作后,这个person对象就具备了空间属性,有名字,可以说话,可以吃饭,而通常我们把名字比喻成属性,说话和吃饭就是动作,可以比作方法。在面相对象中,描述一个事物的特征有两个特性,对象属性和方法。
而对象属性和方法,在面相对象中有私有属性、公有属性、私有方法,公用方法、以及静态方法、并且还可以继承,有了这些、从而实现了封装、继承、多肽。从而让代码变得更抽象、更模块化、更易于维护。
有人说代码写得好的,就像是在写诗,因为没有一句废话、高度复用,可扩展性强,健壮、抽象,在你读优秀框架作者的源码时,你会就发现,世界就是你,你就是世界。
在我们new构造函数后,我们探究下,这个new背后做了啥?
::: details code
function Person(name) {
this.name = name; // 人的名字
this.say = function () {
console.log(`我的名字:${this.name}`);
};
return this;
}
var person = Person('Maic');:::
没有new时,直接把Person当方法了,我们看下打印结果
不可思议的就是这个方法内部的this指向的是全局window对象。
这里扩展一点,我们用var person = Person('Maic');实际上就是用var这个关键词在全局作用域下开辟了一块空间。其实function fnName()也是开辟了一个局部作用域空间。用不同的关键词定义就形成特殊的空间,因为还有块级作用域一说。
在这个未使用new操作符的普通函数,内部的this指向就是那个被调用者。在你定义函数,定义变量时,我们可以看下那个隐藏的被调用者究竟是谁?
::: details code
function Person() {
console.log('这里的this是啷个' + this, 'this是window唛:' + window === this);
if (Person in window) {
console.log('function 定义Person就是window里面');
}
var xiaobai = '大佬666';
this.xiaoqi = '大佬777';
console.log(window.xiaobai, '111'); // undefined 111
console.log(window.xiaoqi, '222'); // 大佬777 222
}
var person;
Person();
console.log('var person', person in window);
/*
打印的结果下面:
1 '这里的this是啷个[object Window]' false
3 'var person' true
*/:::
我们发现 3 打印的是true,但是函数内部打印的 this 并不等于window
我们要知道函数内就是一个独立的作用域,在函数内var定义变量就是一个私有的,如果你想在函数外部访问,对不起,没门,函数内部可以访问外部变量,但是函数内部变量不能在外部访问,举个例子,理解下
::: details code
function test() {
var actions = '完美世界';
}
console.log(actions); // Uncaught ReferenceError: actions is not defined:::
不出意外,actions提示为未定义,因为函数内作用域的属性,无法直接被外部访问。
但是函数外部变量,却可以在内部访问,因为函数外部的变量能被局部作用域访问。
你可以把定义函数的区域理解成一个独立城堡,而函数外部就是城门外面,只进不出。
::: details code
var actionsA = '星辰变';
function test() {
var actions = '完美世界';
console.log(actionsA); // 星辰变
}
test();
console.log(actions); // Uncaught ReferenceError: actions is not defined:::
我们举例这么多就是为了验证函数那句window === this为false,其实函数内部的this不是由函数自己内部而定义,它的指向是函数真正被调用那个对象。
::: details code
function test() {}
test();:::
等价于
::: details code
function test() {}
window.test();:::
所以函数内部指向的是 window,所以你可以看到,window.xiaoqi就是函数内部的this.xiaoqi,而内部定义的局部变量var xiaobai打印却是undefined,后续可以写一篇关于作用域的理解。这里发散得有点远。
::: details code
function Person() {
console.log('这里的this是啷个' + this, 'this是window唛:' + window === this);
if (Person in window) {
console.log('function 定义Person就是window里面');
}
var xiaobai = '大佬666';
this.xiaoqi = '大佬777';
console.log(window.xiaobai, '111'); // undefined 111
console.log(window.xiaoqi, '222'); // 大佬777 222
}
var person;
Person();:::
如果我想要一个函数可以当成一个正常的对象用,那要怎么办呢?
::: details code
function Person(name, leavel) {
// 如果错误把构造函数当成方法使用了,判断当前函数内部的this的构造函数是否是Person
if (!(this instanceof Person)) {
return new Person(name, leavel);
}
this.name = name;
this.leavel = leavel;
}
const t = Person('石昊', 1);
const t2 = new Person('澜叔', 10000);
console.log(t.name); // 石昊
console.log(t.leavel); // 1:::
另外有一点要注意,在严格模式下,函数内部this不能指向全局那个被调用的对象,因为此时this指向的是undefined,而undefined不能动态添加属性。
::: details code
function test() {
'use strict';
this.name = '大佬';
}
test(); // Cannot set properties of undefined (setting 'name'):::
在了解没有new操作背后,那个this就是指向函数的被调用者。那么用new后呢。
我们打印一下new Person('石昊',1)
我们仔细发现,t这个实例对象的构造函数就是Person,我们可以总结以下几点
1、创建一个空间、返回一个对象实例
::: details code
function Person() {}:::
2、将空间对象的原型指向构造函数的prototype
::: details code
var t = new Person(); // t.__prototype ==== Person.prototype true
// Person.prototype.constructor === t.__proto__.constructor true:::
3、指定内部this对象,构造函数内部的this就是t
::: details code
function Person() {
this.name = 'hello'; // this ==== 外面的t
}
var t = new Person();:::
4、执行构造函数体内部代码
在构造函数内部,我们没有任何返回值,当实例化后,当前构造函数的 this 就是那个实例对象,如果我返回是其他对象呢?
::: details code
function Person(name) {
this.name = name;
return {
shop: '沃尔玛',
address: '福田路38号'
};
}
const t = new Person('唐三');
console.log(t.__proto__.constructor.name); // Object
console.log(Person.prototype.constructor.name); // Person:::
在new构造函数,如果构造函数没有返回任何值,那么就是new实例返回始终是一个对象。如果返回的是非对象,那么会忽略。
::: details code
function Person(name) {
this.name = name;
return 'hello';
}
const t = new Person('唐三');
console.log(t.name); //唐三:::
以上我们已经知晓了new的操作步骤,现在有个面试题,实现一个new操作符。
笔者在以前面试题被问了这个问题后,曾经一脸懵,我回答面试官,new就是一个关键字,怎么实现,这是他语法规定的啊?我心中万马奔腾,但是这肯定不是他想要的答案,直到今日终于可以手写一个了new操作符了。
我们仔细观察下下面的原生new的过程
::: details code
function Person(name) {
this.name = name;
}
const t = new Person();:::
下面开始了
::: details code
// constructor是构造函数类比Person
// params是参数类比name
function mynew(constructor, params) {
// 获取参数集合,将参数slice复制操作,转换成数组
const args = [].slice.call(arguments);
// 获取构造函数,第一个参数
var curentConstrouctor = args.shift();
// 需要创建一个空间对象,继承构造函数的prototype属性
var ctx = Object.create(curentConstrouctor.prototype);
// todo 等价下面
/*
const ctx = Object.create({});
ctx.__prototype__ = curentConstrouctor.prototype;
// or ctx.__prototype__ = curentConstrouctor.prototype.constructor
*/
// 执行构造函数,改变构造函数内部的this
const ret = curentConstrouctor.call(ctx, ...args);
if (typeof ret === 'object' && ret !== null) {
return ret;
}
return ctx;
}
function Person(name, age) {
this.name = name;
this.age = age;
}
var t = mynew(Person, '唐三', 18);
// console.log(t) Person {name: '唐三', age: 18}:::
new操作后,实际上实例对象的隐式__prototype__指向的就是构造函数Person的Prototype
说完了new操作符,来了解下项目中高频创建对象
::: details code
// 1
var obj = {
name: 'Maic',
age: '18',
say() {
console.log('说话了');
},
eat() {
console.log('吃饭了');
}
};
// 2
var obj2 = Object.create(obj);
// 3
class Parent {
constructor(name, age) {
this.name = name;
this.age = age;
}
static test = 'TEST';
static getName() {
return this;
}
}
const parent = new Parent('Maic', 18);
console.log(Parent.getName(), 'name');:::
1、面向对象**,具有一个抽象事物描述事情的特征,属性方法。有java继承、封装**。
2、函数作用域概念,在函数作用域内部,可以访问外部函数变量,但是函数外部无法访问函数内部变量。
3、构造函数内部 this 指向,在new后,对象实例的__prototype__指向的就是构造函数的prototype,当前构造函数内部this指向的就是构造函数的实例对象。
4、new实现原理,本质上就是返回一个对象,将该对象的隐式原型指向构造函数。
5、常见的几种申明对象。
6、本文示例code-example
eslint在项目里并不太陌生,通常在使用脚手架时,会默认让你安装执行的eslint,公司项目比较规范时,常常会配置组内统一的eslint规则,eslint帮助我们在开发阶段检查代码是否符合标准规范,统一了我们组内不同项目代码风格,也可以帮助我们养成良好的代码习惯,统一eslint对于项目的可维护性必不可少,今天我们一起学习一下如果改进你项目的规范。
正文开始...
首先我们还是用之前搭建vue的一个项目做从 0 到 1 开始配置eslint
npm i eslint --save-dev然后我们执行初始化eslint命令
npm init @eslint/config此时会让我们选择第三个,并且选择js modules, vue
当你默认选择后就会生成一个文件.eslintrc.js,由于我添加了ts所以默认也会添加@typescript-eslint,我们会发现package.json多了几个插件@typescript-eslint/eslint-plugin、@typescript-eslint/parser,并且要安装npm i typescript --save-dev
eslint规则是自己默认选择的配置
module.exports = {
env: {
browser: true,
es2021: true
},
extends: ['eslint:recommended', 'plugin:vue/essential', 'plugin:@typescript-eslint/recommended'],
parserOptions: {
ecmaVersion: 'latest',
parser: '@typescript-eslint/parser',
sourceType: 'module'
},
plugins: ['vue', '@typescript-eslint'],
rules: {
indent: ['error', 'tab'],
'linebreak-style': ['error', 'unix'],
quotes: ['error', 'single'],
semi: ['error', 'never']
}
};默认生成的规则就是以上
我们运行npx eslint ./src/index.js
执行该命令就会检测对于的文件是否符合eslint默认配置的规则
在.eslintrc.js中
module.exports = {
env: {
browser: true,
es2021: true
},
extends: ['eslint:recommended', 'plugin:vue/essential', 'plugin:@typescript-eslint/recommended'],
parserOptions: {
ecmaVersion: 'latest',
parser: '@typescript-eslint/parser',
sourceType: 'module'
},
plugins: ['vue', '@typescript-eslint'],
rules: {
indent: ['error', 'tab'],
'linebreak-style': ['error', 'unix'],
quotes: ['error', 'single'],
semi: ['error', 'always']
}
};主要由以下 5 个部分
.browserslistrc浏览器预设的环境预设对应的规则module.exports = {
env: {
browser: true,
es2021: true,
es6: true
}
};module.exports = {
extends: ['eslint:recommended']
};module.exports = {
parserOptions: {
ecmaVersion: 'latest',
parser: '@typescript-eslint/parser',
sourceType: 'module'
}
};module.exports = {
plugins: ['vue', '@typescript-eslint']
};module.exports = {
rules: {
semi: 0 // 0 off,1 warn,2 error
}
};参考一段之前业务有用用到的统一eslint配置
::: details code
// eslint配置
module.exports = {
root: true,
env: {
node: true
},
parserOptions: {
parser: '@typescript-eslint/parser'
},
extends: ['plugin:vue/essential', 'plugin:prettier/recommended', '@vue/airbnb', '@vue/typescript'],
rules: {
'no-undef': 0, // 由于eslint无法识别.d.ts声明文件中定义的变量,暂时关闭
'no-console': process.env.NODE_ENV === 'production' ? 2 : 0,
'no-debugger': process.env.NODE_ENV === 'production' ? 2 : 0,
indent: 0,
'linebreak-style': 0,
'no-trailing-spaces': 0,
'class-methods-use-this': 0,
'import/prefer-default-export': 0,
'no-restricted-syntax': 0,
'no-tabs': 0,
'import/no-unresolved': 0,
'no-underscore-dangle': 0,
'comma-dangle': 'off',
'max-len': 'off',
camelcase: 'off',
'object-curly-newline': 0,
'operator-linebreak': 0,
'guard-for-in': 0,
'import/no-webpack-loader-syntax': 0,
// 不安全项
'no-param-reassign': 0,
'no-dupe-class-members': 0,
'no-unused-vars': 0, // ts里面有校验,可以把eslint 的校验关闭
// 提示警告
'no-return-await': 1,
'import/no-cycle': 1,
'no-nested-ternary': 1,
'no-new-func': 1,
'vue/no-side-effects-in-computed-properties': 1,
'vue/no-multiple-template-root': 'off', // vue3 模板可以有多个根结点
'vue/valid-template-root': 'off',
'vue/no-v-for-template-key': 'off', // vue3 v-for 中template 可以设置key
'vue/no-v-model-argument': 0,
'vue/no-use-v-if-with-v-for': 0,
'import/no-extraneous-dependencies': 1,
'no-continue': 1,
'operator-assignment': 1,
'no-bitwise': 1,
'prefer-destructuring': 2,
'array-callback-return': 2,
'func-names': 2,
'no-plusplus': 2,
'no-shadow': 2,
'no-mixed-operators': 2,
'no-fallthrough': 2,
'default-case': 2,
'no-useless-constructor': 2,
'no-unused-expressions': ['error', { allowShortCircuit: true }],
// 关闭iview input组件,col组件个别标签报错
'vue/no-parsing-error': [2, { 'x-invalid-end-tag': false }],
// 保证js、ts项目arrow风格一致
'arrow-parens': [2, 'always', { requireForBlockBody: false }],
'implicit-arrow-linebreak': [0, 'beside'],
// ts 任意枚举报错问题
'no-shadow': 'off',
'@typescript-eslint/no-shadow': ['error']
},
overrides: [
{
files: ['**/__tests__/*.{j,t}s?(x)', '**/tests/unit/**/*.spec.{j,t}s?(x)'],
env: {
jest: true
}
}
]
};:::
在自定义自己的rules,也可以执行npm init @eslint/config配置社区比较流行的自定义风格,使用Airbnb
当我们选择airbnb风格后,执行npx eslint ./src/index.js
提示index.js有一个规则错误
Expected 1 empty line after import statement not followed by another import import/newline-after-import
我们将第三行换行就行
import { createApp } from 'vue';
import App from './App.vue';
createApp(App).mount('#app');我们看下生成的.eslintrc.js这个一般在你项目中多少有看到也可以是 json 类型
module.exports = {
env: {
browser: true,
es2021: true
},
extends: ['plugin:vue/essential', 'airbnb-base'],
parserOptions: {
ecmaVersion: 'latest',
sourceType: 'module'
},
plugins: ['vue'],
rules: {}
};rules有很多的配置,可以参考官方
一般正常情况当我们启动服务时,如果我们代码有写得不规范,开发工具就终端就会给我们提示警告,此时我们需要eslint-loader,只需要这样配置即可
module.exports = {
module: {
rules: [
{
test: /\.(js|jsx)$/,
use: ['babel-loader', 'eslint-loader']
}
]
}
};但是官方已经不建议这么用了eslint-loader已经停止了维护,官方建议使用eslint-webpack-plugin
在webpack.config.js我们可以这么做
const ESLintPlugin = require('eslint-webpack-plugin');
module.exports = {
plugins: [new ESLintPlugin()]
};当我们运行npm run server时就会检查代码错误
提示在utils/index.js中不能使用console,很显然,这条规则并不符合我们的初衷,我只需要在生成环境环境不打印console才行
当我们修改.eslintrc.js时,
module.exports = {
rules: {
'no-console': 0,
'import/extensions': ['error', 'always']
}
};我们将rules规则的noconsole: 0允许使用console,当我修改完时,再次运行,终端就不会报错了
我们再加个规则,max-params:2,函数形参不能到过三个,如果超过三个就会报错
module.exports = {
rules: {
'no-console': 0,
'import/extensions': ['error', 'always'],
'max-params': 2
}
};// utils/index.js
function test(a, b, c, d) {
console.log('hello', a, b, c, d);
}
test(1, 2, 3, 4);
因为默认max-params默认最多就是 3 个参数,所以在运行时就提示报错了。
于是你改成下面这样就可以了
// utils/index.js
function test(a, ...rest) {
console.log('hello', ...rest);
}
test(1, 2, 3, 4);除了eslint-webpack-plugin的插件帮我们在代码运行时就可以检测出代码的一些不规范问题,我们通常可以结合vscode插件帮我更友好的提示,我们需要在写代码的时候,编辑器就已经给我们提示错误。
安装完后,打开对应文件,就会有对应的提示
并且你可以通过提示跳转到对应的eslint
在vscode中装上插件Prettier code formatter
然后在根目录下创建.prettierrc.json文件
{
"singleQuote": true,
"printWidth": 150
}设置编辑器的代码长度 printWidth 是 150,设置 singleQuote 单引号。
我们也需要设置一下vscode的settings.json,主要设置参照如下
然后添加一行自动保存功能,这样我们就可以保存时,自动格式化自己的代码
{
"editor.codeActionsOnSave": {
"source.fixAll.eslint": true
}
}因为eslint既检查了代码又可以根据.eslintrc.js美化代码,但是prettierrc有时会与eslint的配置格式有冲突,所以此时 vscode 格式化的状态就是混乱的,因此有时候很奇怪,所以你需要改settings.json默认改成eslint,具体可以参考知乎这篇文章prettierrc
网上关于prettierrc的配置有很多,具体上还是看组内统一的规范,这里我贴一份之前项目格式化所用的,估计不同团队的配置绝大数是大同小异。
// .prettierrc.json
{
"eslintIntegration": true,
"printWidth": 100,
"tabWidth": 2,
"useTabs": false,
"semi": true,
"singleQuote": true,
"proseWrap": "preserve",
"arrowParens": "avoid",
"bracketSpacing": true,
"disableLanguages": [
"vue"
],
"endOfLine": "auto",
"htmlWhitespaceSensitivity": "ignore",
"ignorePath": ".prettierignore",
"jsxBracketSameLine": false,
"jsxSingleQuote": false,
"requireConfig": false,
"trailingComma": "es5"
}eslint在项目中的配置,主要利用npm init @eslint/config快速初始化一份eslint配置,在试用前先进行安装npm i eslint --save-dev
开发环境使用eslint-loader,现在采用更多的是eslint-webpack-plugins
采用Airbnb风格格式校验代码
.prettierrc.json 格式化代码,不过注意与eslint格式冲突的问题。
本文示例code example
在我们的业务中我们会经常遇到大数据渲染,很早之前我们考虑到有用到虚拟列表,
IntersectionObserver 交叉观察器,前端分页查询来优化大数据量渲染
最近在读《javascripts设计模式与开发实践》发现有了另外一种方案分时函数
正文开始...
假设现在后端给了1000条数据,现在前端需要展示
这不简单吗,不考虑性能情况下,直接循环创建 dom 渲染不就可以了吗?
于是你写了demo测试一下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>大数据</title>
<style>
* {
padding: 0px;
margin: 0px;
}
</style>
</head>
<body>
<div id="app"></div>
</body>
</html>引入js
// arr后端mock数据
var arr = [];
var max = 1000;
for (let i = 0; i < max; i++) {
arr.push(i);
}
function renderList(sourceData) {
const domApp = document.getElementById('app');
const len = sourceData.length;
for (let i = 0; i < len; i++) {
const divDom = document.createElement('div');
divDom.innerHTML = sourceData[i];
domApp.appendChild(divDom);
}
}
console.time('start');
renderList(arr);
console.timeEnd('start');在控制台打印发现执行时间start: 5.104248046875 ms
以上是比较粗暴的方式,拿到后端数据直接在前端循环数据,然后渲染,但是这种性能非常的低。
参考《javascript设计模式与开发实践》,分时函数主要**是利用定时器,在一次性渲染 1000 条数据,我把这 1000 条数据分割成若干份,在指定时间内分片渲染完
具体参考下以下代码
var arr = [];
var max = 1000;
for (let i = 0; i < max; i++) {
arr.push(i);
}
// 创建一个分时函数
const timerChunk = (sourceArr, callback, count = 1, wait = 200) => {
let ret,
timer = null;
const renderData = () => {
for (let i = 0; i < Math.min(count, sourceArr.length); i++) {
// 取出数据
ret = sourceArr.shift();
callback(ret);
}
return function () {
if (!timer) {
timer = setInterval(() => {
// 如果数据取完了,清空定时器
if (sourceArr.length === 0) {
clearInterval(timer);
return;
}
renderData();
}, wait);
}
};
};
};
const createElem = (res) => {
const appDom = document.getElementById('app');
const divDom = document.createElement('div');
divDom.innerHTML = res;
appDom.appendChild(divDom);
};
var curentRender = timerChunk(
arr,
(res) => {
createElem(res);
// 每次取10条数据,200ms
},
10,
200
);
console.time('start');
curentRender(); // start: 0.0341796875 ms
console.timeEnd('start');我们通过分时函数处理后,时间大概就是start: 0.037841796875 ms
对比以上两种,使用分时函数后,速度提高了近 120 倍,因此使用分时函数优化大数据量渲染是很有必要的。
1、大数据量渲染暴力循环直接渲染性能差
2、分时函数处理大数据量渲染页面性能高
3、本文示例code
webpack的loader本质上是一个导出的函数,loader runner会调用该函数,在loader函数内部,this的上下文指向是webpack,通常loader内部返回的是一个string或者Buffer。当前loader返回的结果,会传递给下一个执行的loader
今天一起学习一下webpack5中的loader,让我们进一步加深对webpack的理解
正文开始...
loader首先我们看下,通常情况下loader是怎么使用的
module.exports = {
...
module: {
rules: [
{
test: /\.js$/,
use: [
{
loader: 'babel-loader',
options: {
presets: ['@babel/env']
}
},
]
}
]
},
}在module.rules下,use是一个数组,数组中是可以有多个loader
默认情况loader:'babel-loader'会从node_modules中的lib/index.js中执行内部的_loader函数,然后通过内部@babel/core这个核心库对源代码进行ast转换,最终编译成es5的代码
现在需要自己写个loader,参考官方文档writing loader
我们在新建一个loader目录,然后新建test-loader
module.exports = function (source) {
console.log('hello world');
return source;
};在rules中我们修改下
const path = require('path');
module.exports = {
module: {
rules: [
{
test: /\.js$/,
use: [
{
loader: path.resolve(__dirname, 'loader/test-loader.js')
}
]
}
]
}
};当我运行npm run start时,我们会发现loader中加载的自定义test-loader已经触发了。
但是官方提供另外一种方式
在resolveLoader中可以给加载loader快捷的注册路径,这样就可以像官方一样直接写test-loader了,这个是文件名,文件后缀名默认可以省略。
module.exports = {
module: {
rules: [
{
test: /\.js$/,
use: [
{
loader: 'test-loader'
}
]
}
]
},
resolveLoader: {
modules: ['node_modules', './loader']
}
};我们知道loader中可以设置options,而在自定义loader是如何获取options的参数呢?
官方提供了loader的一些接口api-loader
获取 loader 传过来的options
// loader/test-loader.js
module.exports = function (source) {
const options = this.getOptions();
console.log(options);
console.log('hello world');
return source;
};我们可以看到以下options传入的参数
...
use: [
{
loader: 'test-loader',
options: {
name: 'Maic',
age: 18
}
}
]在官方提供了一个简单的例子,主要是用schema-utils验证options传入的数据格式是否正确
安装schema-utils
npm i schema-utils --save-dev在test-loader中引入schema-utils
// 定义schema字段数据类型
const schema = {
type: 'object',
properties: {
name: {
type: 'string',
description: 'name is require string'
},
age: {
type: 'number',
description: 'age is require number'
}
}
};
// 引入validate
const { validate } = require('schema-utils');
module.exports = function (source) {
// 获取loader传入的options
const options = this.getOptions();
validate(schema, options);
console.log(options);
console.log('hello world');
return source;
};当我把rules中options修改类型时
{
use: [
{
loader: 'test-loader',
options: {
name: 'Maic',
age: '18'
}
}
];
}运行npm run start
直接提示报错了,相当于validate这个方法帮我们验证了loader传过来的options,如果传入的options类型不对,那么直接报错了,我们可以用此来检验参数的类型。
babel-loader在之前的所有项目中,我们都会使用这个babel-loader,那我们能不能自己实现一个自定义的babel-loader呢?
首先我们要确定,babel转换es6,我们需要安装依赖两个插件,一个是@babel/core核心插件,另一个是@babel/preset-env预设插件
修改rules,我们现在使用一个test-babel-loader插件
...
{
module: {
rules: [
{
test: /\.js$/,
use: [
{
loader: 'test-babel-loader',
options: {
presets: ['@babel/preset-env'] // 预设
}
},
{
loader: 'test-loader',
options: {
name: 'Maic',
age: 18
}
}
]
}
]
},
resolveLoader: {
modules: ['node_modules', './loader']
},
}修改test-babel-loader
// 引入@babel/core核心库
const babelCore = require('@babel/core');
module.exports = function (content) {
// 获取options
const options = this.getOptions();
// 必须异步方式
const callback = this.async();
// 转换es6
babelCore.transform(content, options, (err, res) => {
if (err) {
callback(err);
} else {
callback(null, res.code);
}
})在index.js中写入一些 es6 代码
const sayhello = () => {
const str = 'hello world';
console.log(str);
};
sayhello();然后在package.json写入打包命令
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "webpack server --port=8081",
"build": "webpack"
},我们执行npm run build
test-loader与test-babel-loader都会执行,而且生成的main.js源代码的es6已经被转换成es5了。
markdown-loader首先我们在loader目录下新建一个markdown-loader.js
// markdown-loader.js
module.exports = function (content) {
console.log(content);
return content;
};然后在rules中加入自定义loader
{
test: /\.md$/,
loader: 'markdown-loader'
}
...我们需要在src/index.js中引入md文件
import md from '../doc/index.md';
const sayhello = () => {
const str = 'hello world';
console.log(str);
};
sayhello();我们运行npm run build
已经获取到了doc/index.md的内容了
在 loader 中我需要解析md的内容,此时我们需要借助一个第三方的md解析器marked
npm i marked --save-dev详细使用文档参考markedjs
const { marked } = require('marked');
module.exports = function (content) {
// 解析md
const ret = marked.parse(content);
console.log(ret);
return ret;
};我们运行npm run build
此时依然报错,错误提示You may need an additional loader to handle the result of these loaders.
所以需要解析html,那么此时需要另外一个loader来解决,html-loader
npm i html-loader --save-dev然后添加html-loader
{
test: /\.md$/,
use: ['html-loader', 'markdown-loader']
}我们在看下index.js
import md from '../doc/index.md';
console.log(md);
const sayhello = () => {
const str = 'hello world';
console.log(str);
};
sayhello();我们在index.js打印引入的md就一段html-loader转换过的最终代码
import md from '../doc/index.md';
const sayhello = () => {
const str = 'hello world';
console.log(str);
};
sayhello();
const renderMd = () => {
const app = document.getElementById('app');
const div = document.createElement('div');
div.innerHTML = md;
app.appendChild(div);
};
renderMd();我么最终就看到md文件就成功通过我们自己写的 loader 给转换了
本质上就是将md转换成html标签,然后再渲染到页面上了
了解loader的本质,实际上就是一个导出的函数,该函数只能返回字符串或者Buffer,内部提供了很多钩子,比如getOptions可以获取loader中的options
loader的执行顺序是从下往上或者从右往左,在后一个 loader 中的content是前一个loader返回的结果
loader 有两种类型,一种是同步this.callback,另一种是异步this.async
了解自定义babel转换,通过@bable/core,@babel/preset-env实现 es6 转换
实现了一个自定义markdown转换器,主要是利用marked.js这个对md文件转换成 html,但是html标签进一步需要html-loader
本文示例code-example
原型链是一个比较抽象的概念,每当被问起这个问题时,总会回答得不是那么准确,好像懂,但自己好像又不太懂,真是尴尬了
正文开始...
我们知道每一个函数都有一个自身的prototype,每一个对象都有__proto__对象,而这个__proto__我们常称之为隐式原型,正因为它连接起了对象与构造函数的关系
当我们访问一个对象时,首先会在自身属性上找,当自身属性找不到时,会到对象的隐士链上去找,如果隐式链上还没有,那么会构造函数的原型上找,当原型上没有时,会到原型的隐式__proto__上去找,当这个属性还找不到时,就直接返回undefined了,因此才形成了一条原型链。
针对以上一段常常的话,我们用实际例子来佐证一下
function Person() {
this.name = 'Maic';
this.age = 18;
}
Person.prototype.say = function () {
return `hello ${this.name}`
}
const person = new Person();我们访问
console.log(person.name); // Maic现在我在原型上找
function Person() {
// 1 this.name = 'Maic';
this.age = 18;
}
// 3 Person.prototype.name = 'Test';
// 4 Person.prototype.__proto__.name = '999'
Person.prototype.say = function () {
return `hello ${this.name}`
}
const person = new Person();
// 2 person.__proto__.name = '8888'
console.log(person.say());从结果上来看,会是依次从1,2,3,4依次查找下去,直到最后找不到name为止,然后就打印undefined
当我们对构造函数实例化的时候,此时就会返回一个对象person,然后这个person对象就可以访问构造函数内部的属性,以及原型上的方法了。
这个person对象为什么可以访问构造函数的属性?以及构造函数原型上的方法?
那是因为通过__proto__这个隐式原型指向的构造函数的prototype
在面试中常有问题到,new的过程中发生了啥?
1、创建了一个对象
2、将这个对象的__proto__指向了构造函数的prototype
3、执行构造函数内部方法,并改变构造函数内部的this指向到新对象中
4、返回该构造函数的结果
我们根据以上几点,实现一个类似new的操作,从而真正理解new原生的实现
function mynew(Fn, ...arg) {
// 1、创建一个对象
const ret = {};
// 2 将这个对象__proto__执行构造函数的prototype
ret.__proto__ = Fn.prototype
// or
// Object.setPrototypeOf(ret, Fn.prototype);
const result = Fn.call(ret, ...arg);
return typeof result === 'object' ? result : ret;
}我们再重新看下这段代码
function Person() {
this.name = 'Maic';
this.age = 18;
}
Person.prototype.say = function () {
return `hello ${this.name}`
}
const person = new Person();看下下面的几个判断
...
console.log(person.__proto__ === Person.prototype) // true
console.log(Person.__proto__ === Function.prototype) // true
console.log(Person.__proto__ === Object.__proto__); // true
console.log(Function.prototype === Object.__proto__); // true
console.log(Person.prototype.__proto__ === Object.prototype) // true
console.log(Object.prototype.__proto__ === null); // true
console.log(person.__proto__.__proto__ === Object.prototype) // true
console.log(Function.prototype.__proto__ === Object.prototype); // true上面的关系画了一个图, 可能更直观点
这个图看起来貌似还是不太容易记住,多理解几遍,应该会掌握八九不离十
另外还有一篇github上关于伢羽老师的原型链文章可以一同参考
理解原型链,每一个函数都有一个原型prototype,每一个对象都有自己的隐式__proto__,当我们访问对象属性时,会优先在自己内部属性寻找,然后会找__proto__上的属性,然后会去构造函数的prototype上寻找,如果构造函数的prototype找不到,会到到构造函数prototype的__proto__上寻找,最后找不到该属性就返回undefined
了解new操作背后的本质
了解构造函数与实例对象的关系
本文示例code example
在前面几篇文章中,我们已经基础的如何运用一个webpack与webpack-cli从 0 到 1 搭建一个简单的react或者vue工程应用,其中我们使用了加载文件,我们在之前处理文件使用file-loader或者url-loader处理,url-loader主要是可以针对图片文件大小进行有选择的base64压缩,在webpack5中可以用内置的Asset Modules来处理图片资源
接下来我们一起来探讨下webpack5中关于Asset Modules的那些事
正文开始...
新建一个文件夹webpack-04-resource,
npm init -y我们安装项目一些基础支持的插件
npm i webpack webpack-cli webpack-dev-server html-webpack-plugin babel-loader @babel
l/core -D在根目录新建webpack.config.js
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const { CleanWebpackPlugin } = require('clean-webpack-plugin');
module.exports = {
entry: './src/index.js',
output: {
filename: 'js/[name].js',
path: path.resolve(__dirname, 'dist')
},
mode: 'development',
module: {
rules: [
{
test: /\.js$/,
loader: 'babel-loader',
options: {
presets: ['@babel/env']
}
},
{
test: /\.(png|jpg)$/i,
type: 'asset/resource'
}
]
},
plugins: [
new CleanWebpackPlugin(),
new HtmlWebpackPlugin({
template: './public/index.html'
})
]
};注意我们加载图片没有使用file-loader与url-loader,我们使用的是webpack5内置的asset/rosource这个来处理
module.exports = {
module: {
rules: [
{
test: /\.(png|jpg)$/i,
type: 'asset/resource'
}
]
}
};在index.js中我们插入一张图片
import img1Src from '../assets/images/1.png';
var appDom = document.getElementById('app');
const img = new Image();
img.src = img1Src;
appDom.appendChild(img);ok,运行npm run server,打开浏览器localhost:8080
我们会发现,生成的图片地址就是<img src="http://localhost:8080/js/../b1640e009cff6a775ce5.png">
现在我想配置图片的默认输出地址与名字,在module.rules中有一个generator的属性可以配置匹配图片输出的文件
// webpack.config.js
module.exports = {
module: {
rules: [
...{
test: /\.(png|jpg)$/i,
type: 'asset/resource',
generator: {
filename: 'images/[name][ext]'
}
}
]
}
};此时页面加载图片的路径就变成<img src="http://localhost:8080/js/../images/1.png">了
如果你的图片地址是上传到cdn上的,那么你可以这么做,但是这种做法是不是在项目中真的需要,还有待商榷,因为这样会导致应用所有的所有图片用cdn方式加载,如果项目中只是部分图片按需 cdn 加载,那么这种做法是不可取的。
{
test: /\.(png|jpg)$/i,
// type: 'asset/resource'
type: 'asset',
parser: {
dataUrlCondition: {
maxSize: 40 * 1024
}
},
generator: {
publicPath: 'https://cdn/assets', // cdn域名前缀
filename: 'images/[name][ext]'
}
}自此页面的加载的图片就是<img src="https://cdn/assets/images/3.png">
除了generator.filename方式,你也可以在output中加入assetModuleFilename配置来修改图片默认的地址,不过注意这个属性只能是针对rule中设置的 type''asset/resource' | 'asset'类型才生效。
module.exports = {
output: {
filename: 'js/[name].js',
path: path.resolve(__dirname, 'dist'),
assetModuleFilename: 'images/[name][ext]'
}
};通常项目里我们会把比较小的图片直接坐base64加载,大的图片就直接输出加载,或者上传到cdn直接加载图片地址,你可以在rules的generator.publicPath设置地址图片地址。
因此我引入两张大小不一样的图片测试,修改一下index.js
import img1Src from '../assets/images/1.png';
import img3Src from '../assets/images/3.png';
function renderImage(imageSource) {
const weakMap = new WeakMap();
var appDom = document.getElementById('app');
imageSource.forEach((src) => {
const img = new Image();
weakMap.set(img, img);
if (weakMap.has(img)) {
weakMap.get(img).src = src;
appDom.appendChild(img);
}
});
}
renderImage([img1Src, img3Src]);我们再修改下webpack.config.js
module.exports = {
module: {
rules: [
...{
test: /\.(png|jpg)$/i,
// type: 'asset/resource'
type: 'asset',
parser: {
dataUrlCondition: {
maxSize: 40 * 1024
}
}
}
]
}
};在rules中增加parser属性,并且将type改成asset,当我们设置一个dataUrlCondition: {maxSize: 40 * 1024},小于KB就用base64加载了,大于40KB就直接用图片路径加载
因此我们可以看到两张图片,一张图片是base64一张图片就走文件路径了。
所以在你的项目中你可以利用这个parser.dataUrlCondition.maxSize特性来优化图片资源,有些资源小图片就可以用base64来加载,这样可以减少页面图片的资源请求
但是并不是所有的图片都要base64,base64生成的字符串非常大,同时也是增加了html的体积,无法利用缓存机制加载图片。
所以在优化的网页加载过程中,并不是全部都用base64来加载图片。
主要参考官网asset-modules
webpack5 之前
Data Url嵌入到打包后bundle.js中,比如base64文件webpack5 现在
用asset module type通过添加以下四种类型来代替以上loader
url,是file-loader的替代品url-loader的替代品row-loader的替代品url-loader和file-loader中选择,配置parse.dataUrlCondition.maxSizebase64输出相比较webpack5之前我们加载图片资源文件使用file-loader或者url-loader在webpack5中可以使用内置模块type: 'assets/resource'
基于 webpack5 内置模块asset module type来设置资源的加载
图片资源base64处理,根据图片资源的大小parse.dataUrlCondition.maxSize来限制是否需要base64输出
比较asset module type几种模式区别,代替以前row-loader、file-loader、url-loader方案,但是这仅仅是你的webpack版本在 5 以后。
es6 在项目中用得非常多,浏览器也支持了很多 es6 写法,通常为了兼容性,我们会用
babel将一些比较高级的语法进行转换,比如箭头函数、Promise、对象解构等等,那么我们项目中有哪些你经常用的es6呢?
本篇是笔者根据以往项目总结所用的es6,希望在项目中有所思考和帮助。
正文开始...
const/let)这是一个百分百有用,是一个闭着眼睛都会的用法,不过我们注意const/let是 es6 引入的一个块级作用域的关键字,在{}中定义变量{}外部不能访问,并且不存在变量的提升, let与const定义的变量,不能重复定义,用const申明的变量不能重新赋值。
const STATUS = {
0: '未开始',
1: '进行中',
2: '结束了'
};
let userName = 'Maic';项目中会用得非常多,告别那种一一取值再赋值吧
const userInfo = {
name: 'Maic',
age: 18,
number: 10
}
const {name,age} = userInfo;
console.log(name, age);
const {name: nname, ...rests } = userInfo
console.log(nname, rests): // Maic {age: 18, number: 10}
const url = new URL('https://github.com/type-challenges/type-challenges/issues?q=label%3A5+label%3Aanswer');
const search = url.search;
const [, params] = search.split('?');
console.log(params) // q=label%3A5+label%3Aanswer
const arr = [1,2,3,4];
const [first, ...rest] = arr;
console.log(first, rest); // 1 [2,3,4]var key = 'test';
var obj = {
[key]: 'test'
};const objs = { name: 'Tom', age: 10 };
const merge = (target, options) => {
const ret = Object.assign(Object.create({}), target, options);
return ret;
};
const nobj = merge(objs, { age: 18 });
// or
const nobj2 = { ...objs, age: 18 };const arr = [1, 2, 3];
// 复制操作
const narr = [...arr];
// or
const [...n2arr] = arr;
// 合并数组
const barr = [4, 5, 6];
const carr = [...arr, ...barr];Map也俗称集合,项目中你可以用此来维护一组if的条件判断,或是以前策略模式的一组数据,可以用此来优化代码,让业务代码可拓展性更强,从此告别冗余的if else,switch case,这个会用得比较多,用下面一段伪代码来感受一下,
const queryDetail = () => {
console.log('query detail');
};
const queryList = () => {
console.log('query list');
};
const queryPic = () => {
console.log('query pic');
};
const request = new Map([
['getDetail', queryDetail],
['queryList', queryList]
]);
if (request.has('getDetail')) {
request.get('getDetail')();
}
if (!request.has('queryPic')) {
request.set('queryPic', queryPic);
}
// or 循环执行
request.forEach((fn) => {
fn();
});
request.get('queryPic')();
console.log(request.entries(request));
// 获取所有的值
console.log(request.values(request));
// 获取所有的key
console.log(request.keys(request));
/*
[Map Entries] {
[ 'getDetail', [Function: queryDetail] ],
[ 'queryList', [Function: queryList] ],
[ 'queryPic', [Function: queryPic] ]
}
*/const map = new Map();
Reflect.ownKeys(map.__proto__);
/**
[
0: "constructor"
1: "get"
2: "set"
3: "has"
4: "delete"
5: "clear"
6: "entries"
7: "forEach"
8: "keys"
9: "size"
10: "values"
11: Symbol(Symbol.toStringTag)
12: Symbol(Symbol.iterator)
]
*/const obj = { a: 1, b: 2 };
const map = new Map(Object.entries(obj));
/*
等价于
const map = new Map([
['a',1],
['b',2]
]);
*/
console.log(map); // Map(2) { 'a' => 1, 'b' => 2 }var map2 = new Map([
['a', '123'],
['b', '234']
]);
Object.fromEntries(map2.entries()); // {a: '123', b: '234'}与Map的区别是WeakMap是一种弱引用,WeakMap的key必须是非基础数据类型。WeakMap没有遍历的entries、keys、values、size方法,只有get、set、has、delete方法。
const bodyDom = document.getElementsByTagName('body')[0];
const weakMap = new WeakMap();
weakMap.set(bodyDom, 'bodyDom');
console.log(weakMap.get(bodyDom));一般我们在项目常用去重操作,或者过滤数据处理
var newset = [...new Set([1, 1, 2, 3])];
console.log(newset); // 1,2,3
var arrsSet = new Set();
arrsSet.add({ name: 'Maic' }).add({ name: 'Tom' });
console.log([...arrsSet]); // [ { name: 'Maic' }, { name: 'Tom' } ]
console.log(newset.has(1)); // true根据某个字段找出两组数据中相同的数据,并合并
const data1 = [
{price:100,attr: 'nick'},
{price: 200,attr: '领带'}
];
const data2 = [
{price:200,attr: '眼镜'},
{price: 5000,attr: '戒子'},
{price:100,attr: 'nick'}
];
const findSomeByKey = (target1, target2, key) => {
const target2Set = new Set([...target2]);
const ret = [];
const tagret = target1.map(v => v[key]);
target2.forEach(v => {
Object.entries(v).forEach(s => {
const [, val] = s;
if (tagret.includes(val)) {
const curent = target1.find(v => v[key] === val);
ret.push(v, curent)
}
})
})
return ret
}
findSomeByKey(data1, data2, 'price');
/*
[
{price: 200, attr: '眼镜'},
{price: 200, attr: '领带'},
{price: 100, attr: 'nick'},
{price: 100, attr: 'nick'}
]const nset = new Set();
console.log(Reflect.ownKeys(nset.__proto__));
/*
[
0: "constructor"
1: "has"
2: "add"
3: "delete"
4: "clear"
5: "entries"
6: "forEach"
7: "size"
8: "values"
9: "keys"
10: Symbol(Symbol.toStringTag)
11: Symbol(Symbol.iterator)
]
*/没有循环,没有 get,不太常用
const nweakSet = new WeakSet([
['name', 'Maic'],
['age', 18]
]);
console.log(nweakSet);
console.log(Reflect.ownKeys(nweakSet.__proto__));
/**
"constructor"
1: "delete"
2: "has"
3: "add"
4: Symbol(Symbol.toStringTag)
*/这是es6中比较新的 api
// 判断对象熟悉是否存在
const nobj = { a: 1 };
if ('a' in nobj) {
console.log('存在');
} else {
console.log('不存在');
}
// or
console.log(nobj.hasOwnProperty('a'));
// or
console.log(Object.hasOwn(nobj, 'a'));
// now
Reflect.has(nobj, 'a');
// 向对象中添加属性
Reflect.defineProperty(obj, 'b', { value: 22 });
console.log(nobj); // {a:1,v:2}
// 删除对象属性
Reflect.deleteProperty(nobj, 'a');
console.log(nobj); // {b:22}
// 调用函数
function f() {
this.age = 18;
this.arg = [...arguments];
console.log(this.arg, this.age); // [1,2] 18
}
Reflect.apply(f, this, [1, 2]);
// 相当于过去这个
Function.prototype.apply.call(f, this, [1, 2]);
// 遍厉对象,获取key
console.log(Reflect.ownKeys(nobj)); // ['a', 'b']es6对象代理,劫持对象,在vue3中实现双向数据绑定,用Proxy实现一个观察者模式
var bucket = new Set();
var effect = (fn) => {
bucket.add(fn);
};
const proxyOption = {
set(target, key, val, receiver) {
const result = Reflect.set(target, key, val, receiver);
bucket.forEach((item) => {
Reflect.apply(item, this, []);
});
return result;
},
get(target, key, receiver) {
return Reflect.get(target, key);
}
};
// 创建观察器
const observer = (obj) => new Proxy(obj, proxyOption);
const obj = {
name: 'Maic',
age: 18
};
// 将obj添加到观察器中
const userInfo2 = observer(obj);
effect(() => {
console.log(userInfo2.name, userInfo2.age);
});
userInfo2.name = 'Tom'; // 触发Proxy这个用得太多了,异步变成同步操作,async定义的一个函数,会默认返回一个Promise,注意async中不一定有await,但是有await一定得有async。
const featchList = () =>
new Promise((resolve, reject) => {
resolve({ code: 0, message: '成功' });
});
const requests = async () => {
try {
const { code } = await featchList();
} catch (error) {
throw error;
}
console.log(code, '=code');
};
requests();class Utils {
constructor(name, age) {
Object.assign(this, { name, age });
// or
/*
this.name = name;
this.age = age;
*/
}
}
const utils = new Utils('utils', 18);function test(name = 'Maic') {
console.log(name);
}不过要注意箭头函数的一些特性,比如没有没有自己的this,不能被实例化,也不能用bind,call之类的
const request = () => {};
// 以前
const requestFn = function () {};1、常用的let、const
2、对象解构,扩展运算符,数组解构等
3、Map,Set,Reflect,Proxy、class、箭头函数等常见的运用
4、本文示例code example
webpack如何打包资源优化你有了解吗?或者一个经常被问的面试题,首屏加载如何优化,其实无非就是从http请求、文件资源、图片加载、路由懒加载、预请求,缓存这些方向来优化,通常在使用脚手架中,成熟的脚手架已经给你做了最大的优化,比如压缩资源,代码的tree shaking等。
本文是笔者根据以往经验以及阅读官方文档总结的一篇关于webpack打包方面的长文笔记,希望在项目中有所帮助。
正文开始...
在阅读之前,本文将从以下几个点去探讨 webpack 的打包优化
1、webpack如何做treeShaking
2、webpack的 gizp 压缩
3、css如何做treeShaking,
4、入口依赖文件拆包
5、图片资源加载优化
在官网中有提到treeShaking,从名字上中文解释就是摇树,就是利用esModule的特性,删除上下文未引用的代码。因为 webpack 可以根据esModule做静态分析,本身来说它是打包编译前输出,所以webpack在编译esModule的代码时就可以做上下文未引用的删除操作。
那么如何做treeshaking?我们来分析下
在之前我们都是手动配置搭建webpack项目,webpack官方提供了cli快速构建基本模版,无需像之前一样手动配置entry、plugins、loader等
首先安装npm i webpack webpack-cli,命令行执行`
npx webpack init一系列初始化操作后,就生成以下代码了
默认的webpack.config.js
// Generated using webpack-cli https://github.com/webpack/webpack-cli
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const MiniCssExtractPlugin = require('mini-css-extract-plugin');
const WorkboxWebpackPlugin = require('workbox-webpack-plugin');
const isProduction = process.env.NODE_ENV == 'production';
const stylesHandler = MiniCssExtractPlugin.loader;
const config = {
entry: './src/index.js',
output: {
path: path.resolve(__dirname, 'dist')
},
devServer: {
open: true,
host: 'localhost'
},
plugins: [
new HtmlWebpackPlugin({
template: 'index.html'
}),
new MiniCssExtractPlugin()
// Add your plugins here
// Learn more about plugins from https://webpack.js.org/configuration/plugins/
],
module: {
rules: [
{
test: /\.(js|jsx)$/i,
loader: 'babel-loader'
},
{
test: /\.less$/i,
use: [stylesHandler, 'css-loader', 'postcss-loader', 'less-loader']
},
{
test: /\.css$/i,
use: [stylesHandler, 'css-loader', 'postcss-loader']
},
{
test: /\.(eot|svg|ttf|woff|woff2|png|jpg|gif)$/i,
type: 'asset'
}
// Add your rules for custom modules here
// Learn more about loaders from https://webpack.js.org/loaders/
]
}
};
module.exports = () => {
if (isProduction) {
config.mode = 'production';
config.plugins.push(new WorkboxWebpackPlugin.GenerateSW());
} else {
config.mode = 'development';
}
return config;
};运行命令npm run serve
现在修改一下index.js,并在src中增加utils目录
// utils/index.js
export function add(a, b) {
return a + b;
}
export function square(x) {
return x * x;
}index.js
import { add } from './utils';
console.log('Hello World!');
console.log(add(1, 2));在index.js中我只引入了add,相当于square这个函数在上下文中并未引用。
不过我还需要改下webpack.config.js
...
module.exports = () => {
if (isProduction) {
config.mode = "production";
config.plugins.push(new WorkboxWebpackPlugin.GenerateSW());
} else {
config.mode = "development";
config.devtool = 'source-map'
config.optimization = {
usedExports: true
}
}
return config;
};注意我只增加了devtool:source-map与optimization.usedExports = true
我们看下package.json
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build": "webpack --mode=production --node-env=production",
"build:dev": "webpack --mode=development",
"build:prod": "webpack --mode=production --node-env=production",
"watch": "webpack --watch",
"serve": "webpack serve"
},默认初始化已经给们预设了多个不同的打包环境,因此我只需要运行下面命令就可以选择开发环境了
npm run build:dev
此时我们看到打包后的代码未引入的square有一行注释
/* unused harmony export square */
function add(a, b) {
return a + b;
}
function square(x) {
return x * x;
}square上下文未引用,虽然给了标记,但是未真正清除。
光使用usedExports:true还不行,usedExports 依赖于 terser 去检测语句中的副作用,因此需要借助terser插件一起使用,官方webpack5提供了TerserWebpackPlugin这样一个插件
在webpack.config.js中引入
...
const TerserPlugin = require("terser-webpack-plugin");
...
module.exports = () => {
if (isProduction) {
config.mode = "production";
config.plugins.push(new WorkboxWebpackPlugin.GenerateSW());
} else {
config.mode = "development";
config.devtool = 'source-map'
config.optimization = {
usedExports: true, // 设置为true 告诉webpack会做treeshaking
minimize: true, // 开启terser
minimizer: [new TerserPlugin({
extractComments: false, // 是否将注释剥离到单独文件,默认是true
})]
}
}
return config;
};你会发现,那个square函数就没有了
如果我将usedExports.usedExports = false,你会发现square没有被删除。
官方解释,当我们设置optimization.usedExports必须为true,当我们设置usedExports:true,且必须开起minimize: true,这样才会把上下文未使用的代码给清除掉,如果minimize: false,那么压缩插件将会失效。
当我们设置usedExports: true
此时生成打包的代码会有一个这样的魔法注释,square未使用
/* unused harmony export square */
function add(a, b) {
return a + b;
}
function square(x) {
return x * x;
}当我们设置minimize: true时,webpack5会默认开启terser压缩,然后发现有这样的unused harmony export square就会删掉对应未引入的代码。
这个是usedExports摇树的另一种方案,usedExports是检查上下文有没有引用,如果没有引用,就会注入魔法注释,通过terser压缩进行去除未引入的代码
而slideEffects是对没有副作用的代码进行去除
首先什么是副作用,这是一个不太好理解的词,在react中经常有听到
其实副作用就是一个纯函数中存在可变依赖的因变量,因为某个因变量会造成纯函数产生不可控的结果
举个例子
没有副作用的函数,输入输出很明确
function watchEnv(env) {
return env === 'prd' ? 'product' : 'development';
}
watchEnv('prd');有副作用,函数体内有不确定性因素
export function watchEnv(env) {
const num = Math.ceil(Math.random() * 10);
if (num < 5) {
env = 'development';
}
return env === 'production' ? '生产环境' : '测试开发环境';
}我们在index.js中引入watch.js
import { add } from './utils';
import './utils/watch.js';
console.log('Hello World!');
console.log(add(1, 2));然后运行npm run build:dev,打包后的文件有watch的引入
在index.js中引入watch.js并没有什么使用,但是我们仍然打包了进去
为了去除这引入但未被使用的代码,因此你需要在optimization.sideEffects: true,并且要在package.json中设置sideEffects: false,在optimization.sideEffects设置 true,告知 webpack 根据 package.json 中的 sideEffects 标记的副作用或者规则,从而告知 webpack 跳过一些引入但未被使用的模块代码。具体参考optimization.sideEffects
module.exports = () => {
if (isProduction) {
config.mode = 'production';
config.plugins.push(new WorkboxWebpackPlugin.GenerateSW());
} else {
config.mode = 'development';
(config.devtool = 'source-map'),
(config.optimization = {
sideEffects: true, // 开启sideEffects
usedExports: true,
minimize: true, // 开启terser
minimizer: [
new TerserPlugin({
extractComments: false // 是否将注释剥离到单独文件,默认是true
})
]
});
}
return config;
};{
"name": "my-webpack-project",
"version": "1.0.0",
"description": "My webpack project",
"main": "index.js",
"sideEffects": false,
...
}此时你运行命令npm run build:dev,查看打包文件
我们就会发现,引入的watch.js就没有了
在官方中有这么一段话使用 mode 为 "production" 的配置项以启用更多优化项,包括压缩代码与 tree shaking。
因此在webpack5中只要你设置mode:production那些代码压缩、tree shaking通通默认给你做了做了最大的优化,你就无需操心代码是否有被压缩,或者tree shaking了。
对于能否被tree shaking还补充几点
1、一定是esModule方式,也就是export xxx或者import xx from 'xxx'的方式
2、cjs方式不能被tree shaking
3、线上打包生产环境mode:production自动开启多项优化,可以参考生产环境的构建production
首先是是在devServer下提供了一个开发环境的compress:true
{
devServer: {
open: true,
host: "localhost",
compress: true // 启用zip压缩
}
}需要安装对应插件
npm i compression-webpack-plugin --save-devwebpack.config.js中引入插件
// Generated using webpack-cli https://github.com/webpack/webpack-cli
...
const CompressionWebpackPlugin = require('compression-webpack-plugin');
const config = {
...
plugins: [
new HtmlWebpackPlugin({
template: "index.html",
}),
new MiniCssExtractPlugin(),
new CompressionWebpackPlugin(),
// Add your plugins here
// Learn more about plugins from https://webpack.js.org/configuration/plugins/
],
...
};当你运行命令后,你就会发现打包后的文件有gzip的文件了
但是我们发现html以及map.js.map文件也被gizp压缩了,这是没有必要的
官方提供了一个exclude,可以排除某些文件不被gizp压缩
{
plugins: [
new HtmlWebpackPlugin({
template: "index.html",
}),
new MiniCssExtractPlugin(),
new CompressionWebpackPlugin({
exclude: /.(html|map)$/i // 排除html,map文件
})
// Add your plugins here
// Learn more about plugins from https://webpack.js.org/configuration/plugins/
],
}对比开启gizp压缩与未压缩,加载时间很明显有提升
主要删除未使用的样式,如果样式未使用,就删除掉。
现在修改下index.js
我在body中插入一个class
import { add } from './utils';
import './utils/watch';
import './css/index.css';
console.log('Hello World!');
console.log(add(1, 2));
// /*#__PURE__*/ watchEnv(process.env.NODE_ENV)
const bodyDom = document.getElementsByTagName('body')[0];
const divDom = document.createElement('div');
divDom.setAttribute('class', 'wrap-box');
bodyDom.appendChild(divDom);对应的 css 如下
.wrap-box {
width: 100px;
height: 100px;
background-color: red;
}执行npm run serve
但是我们发现,样式居然没了
于是苦思瞑想,不得其解,于是一顿排查,当我们把sideEffects: false时,神奇的是,样式没有被删掉
原来是sideEffects:true把引入的 css 当成没有副作用的代码给删除了,此时,你需要告诉webpack不要删除我的这有用的代码,不要误删了,因为import 'xxx.css'如果设置了sideEffects: true,此时引入的css会被当成无副作用的代码,就给删除了。
// package.json
{
"sideEffects": ["**/*.css"]
}当你设置完后,页面就可以正常显示 css 了
官方也提供了另外一种方案,你可以在module.rules中设置
{
module: {
rules: [
{
test: /\.css$/i,
sideEffects: true,
use: [stylesHandler, "css-loader", "postcss-loader"],
},
]
}
}以上与在package.json设置一样的效果,都是让webpack不要误删了无副作用的 css 的代码
但是现在有这样的css代码
.wrap-box {
width: 100px;
height: 100px;
background-color: red;
}
.title {
color: green;
}title页面没有被引用,但是也被打包进去了
此时需要一个插件来帮助我们来完成 css 的摇树purgecss-webpack-plugin
const path = require("path");
...
const glob = require('glob');
const PurgeCSSPlugin = require('purgecss-webpack-plugin');
const PATH = {
src: path.resolve(__dirname, 'src')
}
const config = {
...
plugins: [
...
new PurgeCSSPlugin({
paths: glob.sync(`${PATH.src}/**/*`, { nodir: true }),
})
// Add your plugins here
// Learn more about plugins from https://webpack.js.org/configuration/plugins/
],
...
};未引用的 css 就已经被删除了
主要是减少入口依赖文件包的体积,如果不进行拆包,那么我们根据entry的文件打包就很大。那么也会影响首页加载的性能。
官方提供了两种方案:
引入loadsh
// index.js
import { add } from './utils';
import _ from 'loadsh';
import './utils/watch';
import './css/index.css';
console.log('Hello World!');
console.log(add(1, 2));
// /*#__PURE__*/ watchEnv(process.env.NODE_ENV)
const bodyDom = document.getElementsByTagName('body')[0];
const divDom = document.createElement('div');
divDom.setAttribute('class', 'wrap-box');
divDom.innerText = 'wrap-box';
bodyDom.appendChild(divDom);
console.log(_.last(['Maic', 'Web技术学苑']));
main.js中将loadsh打包进去了,体积也非常之大72kb
我们现在利用entry进行分包
const config = {
entry: {
main: { import: ['./src/index'], dependOn: 'loadsh-vendors' },
'loadsh-vendors': ['loadsh']
}
};此时我们再次运行npm run build:dev
此时main.js的大小1kb,但是loadsh已经被分离出来了
生成的loadsh-vendors.js会被单独引入
可以看下打包后的index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>Webpack App</title>
<script defer src="main.js"></script>
<script defer src="loadsh-vendors.js"></script>
<link href="main.css" rel="stylesheet" />
</head>
<body>
<h1>Hello world!</h1>
<h2>Tip: Check your console</h2>
</body>
<script>
if ('serviceWorker' in navigator) {
window.addEventListener('load', () => {
navigator.serviceWorker
.register('service-worker.js')
.then((registration) => {
console.log('Service Worker registered: ', registration);
})
.catch((registrationError) => {
console.error('Service Worker registration failed: ', registrationError);
});
});
}
</script>
</html>optimzation.splitChunks对于动态导入模块,在webpack4+就默认采取分块策略const config = {
// entry: {
// main: { import: ['./src/index'], dependOn: 'loadsh-vendors' },
// 'loadsh-vendors': ['loadsh']
// },
entry: './src/index.js',
...
}
module.exports = () => {
if (isProduction) {
config.mode = "production";
config.plugins.push(new WorkboxWebpackPlugin.GenerateSW());
} else {
config.mode = "development";
config.devtool = 'source-map',
config.optimization = {
splitChunks: {
chunks: 'all' // 支持异步和非异步共享chunk
},
sideEffects: true,
usedExports: true,
minimize: true, // 开启terser
minimizer: [new TerserPlugin({
extractComments: false, // 是否将注释剥离到单独文件,默认是true
})]
}
}
return config;
};当optimization.splitChunks.chunks:'all',此时可以把loash分包出来了
关于optimization.splitChunks的设置非常之多,有对缓存的设置,有对chunk大小的限制,最常用的还是设置chunks:all,建议SplitChunksPlugin多读几遍,一定会找到不少收获。
optimization.runtimeChunk时,运行时依赖的代码会独立打包成一个runtime.xxx.js...
config.optimization = {
runtimeChunk: true, // 减少入口文件打包的体积,运行时代码会独立抽离成一个runtime的文件
splitChunks: {
minChunks: 1, // 默认是1,可以不设置
chunks: 'all', // 支持异步和非异步共享chunk
},
sideEffects: true,
usedExports: true,
minimize: true, // 开启terser
minimizer: [new TerserPlugin({
extractComments: false, // 是否将注释剥离到单独文件,默认是true
})]
}main.js有一部分代码移除到一个独立的runtime.js中
webpack提供了一个外部扩展,将输出的bundle.js排除第三方的依赖,参考Externalsconst config = {
// entry: {
// main: { import: ['./src/index'], dependOn: 'loadsh-vendors' },
// 'loadsh-vendors': ['loadsh']
// },
entry: './src/index.js',
...,
externals: /^(loadsh)$/i,
/* or
externals: {
loadsh: '_'
}
*/
};
module.exports = () => {
if (isProduction) {
config.mode = "production";
config.plugins.push(new WorkboxWebpackPlugin.GenerateSW());
} else {
config.mode = "development";
config.devtool = 'source-map',
config.optimization = {
runtimeChunk: true, // 减少入口文件打包的体积,运行时代码会独立抽离成一个runtime的文件
// splitChunks: {
// minChunks: 1,
// chunks: 'all', // 支持异步和非异步共享chunk
// },
sideEffects: true,
usedExports: true,
minimize: true, // 开启terser
minimizer: [new TerserPlugin({
extractComments: false, // 是否将注释剥离到单独文件,默认是true
})]
}
}
return config;
};但是此时loash已经被我们移除了,我们还需在HtmlWebpackPlugin中加入引入的cdn地址
...
plugins: [
new HtmlWebpackPlugin({
template: "index.html",
inject: 'body', // 插入到body中
cdn: {
basePath: 'https://cdn.bootcdn.net/ajax/libs',
js: [
'/lodash.js/4.17.21/lodash.min.js'
]
}
}),
]修改模版,由于模版内容是ejs,所以我们循环取出js数组中的数据
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>Webpack App</title>
</head>
<body>
<h1>Hello world!</h1>
<h2>Tip: Check your console</h2>
<% for (var i in htmlWebpackPlugin.options.cdn && htmlWebpackPlugin.options.cdn.js) { %>
<script src="<%= htmlWebpackPlugin.options.cdn.basePath %><%= htmlWebpackPlugin.options.cdn.js[i] %>"></script>
<% } %>
</body>
<script>
if ('serviceWorker' in navigator) {
window.addEventListener('load', () => {
navigator.serviceWorker
.register('service-worker.js')
.then((registration) => {
console.log('Service Worker registered: ', registration);
})
.catch((registrationError) => {
console.error('Service Worker registration failed: ', registrationError);
});
});
}
</script>
</html>此时你运行命令npm run build:dev,然后打开 html 页面
但是我们发现当我们运行npm run serve启动本地服务,此时页面还是会引入loadsh,在开发环境,其实并不需要引入,本身生成的bundle.js就是在内存中加载的,很显然不是我们需要的
此时我需要做几件事
1、开发环境我不允许引入externals
2、模版html中需要根据环境判断是否需要插入cdn
const isProduction = process.env.NODE_ENV == "production";
const stylesHandler = MiniCssExtractPlugin.loader;
const PATH = {
src: path.resolve(__dirname, 'src')
}
const config = {
// entry: {
// main: { import: ['./src/index'], dependOn: 'loadsh-vendors' },
// 'loadsh-vendors': ['loadsh']
// },
entry: './src/index.js',
output: {
path: path.resolve(__dirname, "dist"),
},
devServer: {
open: true,
host: "localhost",
compress: true
},
plugins: [
new HtmlWebpackPlugin({
env: process.env.NODE_ENV, // 传入模版中的环境
template: "index.html",
inject: 'body', // 插入到body中
cdn: {
basePath: 'https://cdn.bootcdn.net/ajax/libs',
js: [
'/lodash.js/4.17.21/lodash.min.js'
]
}
}),
new MiniCssExtractPlugin(),
new CompressionWebpackPlugin({
exclude: /.(html|map)$/i // 排除html,map文件不做gizp压缩
}),
new PurgeCSSPlugin({
paths: glob.sync(`${PATH.src}/**/*`, { nodir: true }),
})
// Add your plugins here
// Learn more about plugins from https://webpack.js.org/configuration/plugins/
],
...
// externals: /^(loadsh)$/i,
externals: isProduction ? {
loadsh: '_'
} : {}
};根据传入模版的env判断是否需要插入 cdn
... <% if (htmlWebpackPlugin.options.env === 'production') { %> <% for (var i in htmlWebpackPlugin.options.cdn && htmlWebpackPlugin.options.cdn.js) { %>
<script src="<%= htmlWebpackPlugin.options.cdn.basePath %><%= htmlWebpackPlugin.options.cdn.js[i] %>"></script>
<% } %> <% } %>主要是有选择的压缩图片资源,我们可以看下module.rules.parser
module: {
rules: [
{
test: /\.(png|svg|jpg|jpeg|gif)$/i,
type: 'asset/resource',
parser: {
dataUrlCondition: {
maxSize: 4 * 1024 // 小于4kb将会base64输出
}
}
},
],
},官方提供了一个ImageMinimizerWebpackPlugin
我们需要安装
npm i image-minimizer-webpack-plugin imagemin --save-dev在webpack.config.js中引入image-minimizer-webpack-plugin,并且在plugins中引入这个插件,注意webpack5官网那份文档很旧,参考npm上npm-image-minimizer-webpack-plugin
按照官网的,就直接报错一些配置参数不存在,我估计文档没及时更新
...
const ImageMinimizerPlugin = require('image-minimizer-webpack-plugin');
const config = {
plugins: [
...
new ImageMinimizerPlugin({
minimizer: {
// Implementation
implementation: ImageMinimizerPlugin.squooshMinify,
},
})
// Add your plugins here
// Learn more about plugins from https://webpack.js.org/configuration/plugins/
],
}未压缩前
压缩后
使用压缩后,图片无损压缩体积大小压缩大小缩小一半,并且网络加载图片时间从18.87ms减少到4.81ms,时间加载上接近 5 倍的差距,因此可以用这个插件来优化图片加载。
这个插件可以将图片转成webp格式,具体参考官方文档效果测试一下
1、webpack如何做treeShaking,主要是两种
usedExports:true,但是要配合terser压缩插件才会生效sideEffects: true,在package.json中设置sideEffects:false去除无副作用的代码,但是注意css引入会当成无副作用的代码,此时需要在 rules 的 css 规则中标记sideEffects: true,这样就不会删除 css 了2、webpack的 gizp 压缩
主要是利用CompressionWebpackPlugin官方提供的这个插件
3、css如何做treeShaking,
主要是利用PurgeCSSPlugin这个插件,会将没有引用 css 删除
4、入口依赖文件拆包
entry中分包处理,将依赖的第三方库独立打包成一个公用的bundle.js,入口文件不会把第三方包打包到里面去optimization.splitChunks设置chunks:'all'将同步或者异步的esModule方式的代码进行分包处理,会单独打成一个公用的 jsexternals将第三方包分离出去,此时第三方包不会打包到入口文件中去,不过注意要在ejs模版中进行单独引入图片资源加载优化image-minimizer-webpack-plugin做图片压缩处理通常在实际项目中,无论操作数据、或是dom,我们需要熟悉一些浏览器的API,或是js原生给我们扩展的API,我们熟悉了这些API,某种意义上来说,一些高效的API和方法常常会解惑你项目中遇到的很多疑难杂症。
本文只作一些笔者项目中关于URL常用到的API,希望在你项目中能带来一点思考和帮助。
正文开始...
控制台下,window.location获取浏览器地址 URL 相关信息
// window.location
/*
https://www.baidu.com/s?wd=Reflect.%20defineProperty&rsv_spt=1#123
*/
const { href, origin, host, port, protocol, pathname, hash, search } = window.location;
console.log(href); // 获取整个URL xxx
console.log(origin); // 协议+域名+端口 https://www.baidu.com
console.log(host); // 主机名+端口号(http或者https会省略端口号) www.baidu.com
console.log(port); // '' http默认端口80 https默认端口443
console.log(protocol); // 协议 https:
console.log(pathname); // 除了域名的路由地址路径
console.log(hash); // 路径带#的参数
console.log(search); // 地址?后面所有参数在location.search、location.hash、location.origin、location.href是通常项目中几个比较高频的获取当前地址的一些参数方法,不过注意只有location.origin这个是只读的,其他API都是可读可写
在js中创建一个地址,使用场景,举个栗子,我们用URL模拟当前页面的地址
const url = new URL('https://www.baidu.com/s?wd=Reflect.%20defineProperty&rsv_spt=1#123');
console.log(url.search); // ?wd=Reflect.%20defineProperty&rsv_spt=1
console.log(url.hash); // #123
console.log(url.origin); // https://www.baidu.com
console.log(url.href); // 'https://www.baidu.com/s?wd=Reflect.%20defineProperty&rsv_spt=1#123'URL这个原生构造的地址中属性与location获取地址上的通用属性都基本一样。唯一的区别是,location多了replace与reload方法,URL除了拥有location的通用属性,没有replace与reload方法,但是他具备一个获取参数的一个searchParamsAPI
...
console.log(url.searchParams);
// { 'wd' => 'Reflect. defineProperty', 'rsv_spt' => '1' }
console.log(url.searchParams.toString());
// wd=Reflect.+defineProperty&rsv_spt=1快速获取URL中携带参数的方法,这个在URL构建的地址中非常方便。比如现在有一个需求,我需要将一个地址的参数转换成key与value的键值对。
以前我们的做法是这样的
function formateQueryUrl() {
const { search } = window.location;
// 以?分割,获取url上的真正的参数
const [, searchStr] = search.split('?');
// 以&分割前后参数
const arr = searchStr.split('&');
const ret = {};
arr.forEach((v) => {
const [key, val] = v.split('=');
ret[key] = val;
});
return ret;
}现在我们可以更高效的利用URL的searchParams
// 与上面formateQueryUrl方法等价
function eazyFormateQueryUrl() {
const url = new URL(window.location);
return Object.fromEntries(url.searchParams.entries());
}
// 如果当前浏览器地址 https://www.badu.com?a=1&b=2
// {a:1,b:2}这个eazyFormateQueryUrl方法是不是很简单,两行代码就搞定了格式化url中的参数,并且将一串字符串参数轻松的转换成了对象
注意上面的方法我们使用了Object.fromEntries与url.searchParams.entries(),其实url.searchParams的构造函数就是URLSearchParams,而URLSearchParams是一个具有可迭代器功能的 API,所以你可以for...of或者entries操作。
同时我们注意fromEntries,我们看下这个API,通常我们不常用,一般我们都是entries操作得多,但是实际上fromEntries就是还原对象的entries操作,这里我们就是利用了这一点。
举个栗子
const ret = { name: 'Maic', public: 'Web技术学苑' };
const arr = Object.entries(ret);
console.log(arr);
// [['name', 'Maic'], ['public', 'Web技术学苑']]如果你想将arr还原成以前的对象,那么你肯定想到循环的做法,像下面这样
...
const target = {};
arr.forEach(item => {
const [key, val] = item;
target[key] = val;
});
console.log(target);
// {name: 'Maic', public: 'Web技术学苑'}其实不用循环,原生 Object 提供了一个API,它可以将entries数据还原成以前的。那么我们可以简单实现
const ret = { name: 'Maic', public: 'Web技术学苑' };
const arr = Object.entries(ret);
/* const target = {};
arr.forEach(item => {
const [key, val] = item;
target[key] = val;
});
*/
// 与下面等价
const target = Object.fromEntries(arr);
// {name: 'Maic', public: 'Web技术学苑'}正因为如此,我们利用了fromEntries的这点特性,巧妙的将原数据进行转对象了。
对于URL,我们还需要可以动态的添加路径,比如下面一个栗子
function locationByNamePath(path) {
const { origin } = window.location;
const url = new URL(path, origin);
window.location.href = url.href;
}
locationByNamePath('/index.html');
// https://www.baidu.com/index.html
locationByNamePath('/about.html');
// https://www.baidu.com/about.html这个API是一个原生的构造函数,可以获取地址?后面的参数信息
举个栗子
var urlSearch = new URLSearchParams(window.location.search);
console.log(`${urlSearch}`);
// 打开百度,在控制台随便输入关键字搜索,控制台复制该断代码,就可以看到
URLSearchParams传入字符串
const search = new URLSearchParams('a=1&b=2&c=3');
console.log(search.toString()); // a=1&b=2&c=3等价于
const search = new URLSearchParams(window.location.search);
console.log(search.toString()); // a=1&b=2&c=3URLSearchParams传入数组,将一个对象转换成url参数,通常在ajaxget 请求拼接参数时,可能很有用
const obj = { a: 1, b: 2, c: 3 };
const search2 = new URLSearchParams(Object.entries(obj));
console.log(search2.toString());
//a=1&b=2&c=3
$.ajax({
url: `xxxx?${search2}`,
methods: 'get'
});当我们使用fetch原生api请求时,new URLSearchParams可以作为body参数
const params = {
name: 'maic',
password: '123456'
};
fetch('https://baidu.com', {
methods: 'POST',
body: new URLSearchParams(params)
});我们知道URLSearchParams具有可迭代器属性的特征,因此它像Map、Set一样具有增删查改的特性
查get 获取参数值
const obj = { a: 1, b: 2, c: 3 };
const search2 = new URLSearchParams(Object.entries(obj));
console.log(search2.get('a')); // 1
console.log(search2.get('b')); // 2
console.log(search2.get('c')); // 3增append,添加某个参数
...
search2.append('d', 'hello')
// a=1&b=2&c=3&d=hello删delete 删除某个参数
...
search2.delete('a');
console.log(search2.toString());
//b=2&c=3改set 修改参数
const obj = { a: 1, b: 2, c: 3 };
const search2 = new URLSearchParams(Object.entries(obj));
search2.set('a', '666');
console.log(`${search2}`);
// a=666&b=2&c=3&d=hello是否存在has 判断有没有key
...
console.log(search2.has('a')); // true获取URLSearchParams所有的key或者value
new URLSearchParams({a:1,b:2,c:3}).keys(),new URLSearchParams({a:1,b:2,c:3}).values()
const obj = { a: 1, b: 2, c: 3 };
const search2 = new URLSearchParams(Object.entries(obj));
const keys = Array.from(search2.keys());
console.log(keys);
// ['a', 'b', 'c']
const values = Array.from(search2.values());
// ['1', '2', '3']对于URLSearchParams可以传字符串,可以是对象或是数组,当我们获取URLSearchParams的 key,直接调用xxx.keys()或者是xxx.values(),不过这样取出的值是一个迭代器,还需要用Array.from中转一下。
还原URLSearchParams参数
...
Object.fromEntries(search2.entries());
// {a:1,b:2,c:3}location常用获取hostname、origin、search、hash等
URL创建 url,并且拥有searchParams获取 url 中的?后面的参数
利用URLSearchParams高效格式化url参数,两行代码实现了格式化?参数
URLSearchParams这个API可以直接获取 url 参数,并提供增删查改[append、delete、get、set、has]方法
给定一个长度为 n 的数组
nums,数组nums[1,n]内出现的重复的元素,请你找出所有出现两次的整数,并以数组形式返,你必须设计并实现一个时间复杂度为 O(n) 且仅使用常量额外空间的算法解决此问题。
解题思路
复杂度 O(n),首先肯定只能循环一次数组,且数组中有重复的元素,并且找出重复的元素并返回。
具体实现代码示例:
var findDuplicates = (nums) => {
const result = [];
const arr = new Array(nums.length).fill(0);
for (let i = 0; i < arr.length; i++) {
if (!arr[nums[i]]) {
arr[nums[i]] = 1;
continue;
}
result.push(nums[i]);
}
return result;
};
const res = findDuplicates([4, 3, 2, 7, 8, 2, 3, 1]);
console.log(res); // [2,3]首先以上代码块已经实现了寻找数组中的重复数字了。
但是我们要具体分析下时间复杂度为什么是 O(n)
解释一下什么是时间复杂度O(n)
百度相关资料解释,O(n)实际上是一个线性的一次函数,可以看成 y = x;y 随着 x 的增长而增长,具体一张图加深下印象
另外还有一个比较费脑壳的词空间复杂度O(1)
不管x怎么变化,y始终是一个定值
在时间复杂度 O(n)具体是怎么样
我们会发现 n=10,下面循环就循环的 10 次,如果 n=100,那么就会循环 100 次。,所以y是随着n呈线性变化的。
var n = 10;
var y = 0;
for (let x = 0; x < n; x++) {
console.log(x);
y += x;
}如果是双层循环呢,那么此时时间复杂度就是 O(n^2),比如
var n = 10;
for (let i = 0; i < n; i++) {
for (let j = 0; j < b; j++) {
console.log(j);
}
}因为双层循环,那么时间复杂循环就是 100 次了,所以复杂度就 O(n^2)了
如果没有循环,在数组中寻找指定元素呢,那么复杂度就 O(1);
总结以上时间复杂度,有一层循环就是O(n),如果没有循环,在数组中找值O(1),如果是双层循环那么时间复杂度就是O(n^2);
很显然我们这道题使用的是一层循环,那么复杂度就是 O(n),我们借用了一个arr = new Array(n).fill(0)其实是在n长度的数组中快速拷贝赋值一n个长度的 0。
但是我们发现在循环中,我们使用了continue,continue在for循环的作用是跳过本次循环,也正是利用这一点,我们将当下数组值作为arr的索引,并设置一个值。
关于continue跳过本次循环,我们可以写个简单的例子测试一下
当i===2时,跳过当前循环,那么此时后面的result.push(i)自然就不会有效了。
const result = [];
for (let i = 0; i < 5; i++) {
if (i === 2) {
continue;
}
result.push(i);
}
console.log(result); // [0,1,3,4]另外一个对应就是break;
很显然break是中止循环,当i=2时,整个循环就结束了。
const result = [];
for (let i = 0; i < 5; i++) {
if (i === 2) {
break;
}
result.push(i);
}
console.log(result); // [0,1]再来分析,其实我们会发现,很有意思就是
默认情况数组中arr所有数据都是 0,我们用nums[i]也就是目标元素的值作为arr索引,并且标记为 1,当下次有重复的值时,其实此时,就取反操作了。所以就不会走continue了,那么此时push就是获取对应之前的重复值了。
...
if (!arr[nums[i]]) {
arr[nums[i]] = 1;
continue;
}
result.push(nums[i]);另外在leetcode评论区里也有比较好的解法,具体**可以参考下
给对应下标数字取反,如果已经时负数,那证明之前出现过了,那么就将该元素添加到数组中去。
function findDuplicates(nums) {
let result = [];
for (let i = 0; i < nums.length; i++) {
let num = Math.abs(nums[i]);
if (nums[num - 1] > 0) {
nums[num - 1] *= -1;
} else {
result.push(num);
}
}
return result;
}webpack官方提供了分析打包的一些工具,我们在开发打包后,我们可以利用webpack给我们提供的一些工具去分析包的大小,从而对打包输出文件进行优化,通常我们都会用webpack-bundle-analyzer这个插件去分析,除了这种,我们看下官方提供的另外几种工具。
正文开始...
在开始本文之前,首先会从以下几点去利用工具分析打包dist,参考官方文档bundle-analysis
webpack-chart: webpack stats 交互饼图,主要是利用命令行webpack --profile --json=stats.json 本地生成json,然后根据生成的json显示包的信息
webpack-bundle-analyzer是一个插件,只要打包成功后,会自动打开一个界面分析 dist 包
webpack bundle optimize helper 分析打包后的bundle.js,减少bundle大小
bundle-stats生成一个 bundle 报告,比较不同构建之间的结果
我们打开webpack-chart
然后在我们的项目命令行里输入
npx webpack --profile --json=stats.json
或者在package.json
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"server": "webpack server",
"async": "webpack --profile --json=stats.json"
},将生成的stats.json在指定打开的那个网站上上传上去
但是这个图貌似并没有那么明显
打开webpack-visualizer
将生成的stats.json上传后
能分析哪个文件包含的一些依赖包的关系
直接安装webpack-bundle-analyzer插件
npm i webpack-bundle-analyzer --save-dev// webpack.config.js
const { BundleAnalyzerPlugin } = require('webpack-bundle-analyzer')
...
module.exports = {
plugins: [
...
new BundleAnalyzerPlugin()
]
}当我们运行npx webpack时,就会自动打开本地8888端口了
通常来说,这种方式效果最好,可以非常清楚的看到文件包之间的依赖关系
另外还有一种方式,就是可以用命令行方式,前提是先生成stats.json
npx webpack-bundle-analyzer stats.json
打开地址helper,上传生成的stats.json
在这之前我们webpack.config.js的mode:development此时我们改成mode:production
相比较之前要小得多,并且告诉我们一些可以改进的意见
直接打开analyse,把生成的stats.json上传上去即可
不过这个信息貌似只能分析包文件的一些大小,包之间的依赖关系并没有那么明显
webpack几种不同分析包的工具,每一种都有不同的特点webpack --profile --json=stats.json生成stats.json文件,然后利用工具上传stats.json,分析包数据webpack-bundle-analyzer用得比较多点A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.