🌱 Learning and recording it~~
lydever / blogs Goto Github PK
View Code? Open in Web Editor NEW个人学习、记录集博客。
License: MIT License
个人学习、记录集博客。
License: MIT License




构造一个对象类型,其属性key是Keys,属性value是Type。被用于映射一个类型的属性到另一个类型。
简单来说,TypeScript中的Record可以实现定义一个对象的 key 和 value 类型,Record 后面的泛型就是对象键和值的类型。
比如我需要一个cats对象,这个对象里有三个不同的属性,且属性的值必须是数字和字符串
那么可以这样写:
interface CatInfo {
age: number;
breed: string;
}
type CatName = "mincat" | "licat" | "mordred";
const cats: Record<CatName, CatInfo> = {
mincat: { age: 10, breed: "小猫er" },
licat: { age: 5, breed: "李猫er" },
mordred: { age: 16, breed: "无名猫er" },
};
cats.licat;
const cats: Record<CatName, CatInfo>学习文档:https://www.typescriptlang.org/docs/handbook/utility-types.html#recordkeystype
在原生h5 中,拖放(drag 和 drop)是 HTML5 标准的组成部分。它常用于:抓取对象以后拖放到另一个位置。
一个元素的拖放的过程:
选中-->拖动-->释放
draggable 的语法:
<element draggable="true | false | auto" >true: 可以拖动;
false:禁止拖动
auto:跟随浏览器定义元素是否可以拖动
在web页面中,默认只有text selection,images,links(选中文本、图片、链接)可以被拖动,当一个image或link被拖动时,image或link的url会被设置到drag data中。对于其他元素,必须是selection的一部分才能被拖动。要想所有的元素都能被拖动,需要做三件事情:
1、设置draggable=“true”到元素上。
2、添加dragstart事件监听。
3、在dragstart事件中设置drag data.(通过dataTransfer对象实现)。
| 针对对象 | 事件名 | on系列事件名 | 说明 |
|---|---|---|---|
| 被拖动的元素 | drag | ondrag | 元素正在被拖动的时候触发 |
| dragend | ondragend | 拖动事件结束时触发(松开鼠标,或者按下escape键) | |
| dragstart | ondragstart | 当用户开始拖动元素或者文本selection时触发 | |
| dragexit | ondragexit | 当一个元素不在是drag的选区目标时触发。 | |
| 目的地对象 | dragleave | ondragleave | 当拖动元素或seleciton离开有效的drop元素时触发 |
| dragover | ondragover | 当拖动一个元素或seletion通过一个有效的drop元素时触发 | |
| drop | ondrop | 当元素或者文本selection在有效的drop元素中松开鼠标时触发 | |
| dragenter | ondragenter | 当拖动一个元素或者selection进入到一个有效的drop元素中时触发 |
有了这些drap&drop api事件,我们通过dataTransfer对象设置drag过程中回调函数来处理一些业务逻辑。
注意:dragenter和dragover事件的默认行为是拒绝任何被拖放的元素,因此,我们需要阻止浏览器这种默认行为:ev.preventDefault();
在drag&drop拖放操作的过程中会触发一个DragEvent对象,属于Dom event的一个子对象,这个对象有一个dataTransfer属性:该属性用于保存拖放的数据和交互信息,返回DataTransfer对象,只读,但其子属性可设置。
dataTransfer的属性:
| 属性 | 说明 |
|---|---|
| DataTransfer.dropEffect | 设置或获取当前的拖动操作的属性,值必须是下列之一:none,copy,link,move。 |
| DataTransfer.effectAllowed | 提供所有可能的操作效果类型,必须是以下的值:copyLink,copyMove,link,linkMove,all,uninitialized.这个属性应该在dragstart中设置,提供dropEffect使用。 |
| DataTransfer.files | 包含一个dataTransfer中的本地文件的文件列表,如果dragging操作中不设计文件,此属性是一个空列表。 |
| DataTransfer.types | 返回值dragstart事件中设置的拖动类型的字符串数组。 |
dataTransfer的方法:
| 方法 | 说明 |
|---|---|
| DataTransfer.clearData([format]) | 清空给定类型的数据,如果没有传入type,则清空所有数据。如果dataTransfer中没有数据,或者没有对应类型的数据,此方法没有效果。 |
| DataTransfer.getData([format]) | 返回给定类型的数据,如果dataTransfer没有此类型的数据,则返回空字符串。 |
| DataTransfer.setData(format,data) | 设置给定类型的数据,如果此类型数据不存在,就会添加到最后一列,如果此类型数据已经存在,则会替换已经存在的数据。 |
| DataTransfer.setDragImage(img,xoffset,yoffset) | 当拖动时会从拖动源创建一个半透明的图片,这个图片是自动创建的。如果需要自定义设置,需要使用这个方法,xoffset,yoffset,是图像距离鼠标指针的位置,此方法通常在dragstart事件中调用。 |
hasOwnProperty() 方法会返回一个布尔值,指示对象自身属性中是否具有指定的属性(也就是,是否有指定的键)。用通俗的话来说就是:用来判断一个属性是定义在对象本身而不是继承自原型链的。
obj.hasOwnProperty(prop)const obj = {};
obj.property1 = 88;
console.log(obj.hasOwnProperty('property1')); // true
console.log(obj.hasOwnProperty('toString')); // false
console.log(obj.hasOwnProperty('hasOwnProperty')); // false注意: 即使属性的值是 null 或 undefined,只要属性存在,hasOwnProperty 依旧会返回 true。
o = new Object();
o.lisi = null;
o.hasOwnProperty('lisi'); // 返回 true
o.lizi = undefined;
o.hasOwnProperty('lizi'); // 返回 true使用 hasOwnProperty 方法判断属性是否存在
下面的例子检测了对象 o 是否含有自身属性 prop:
o = new Object();
o.hasOwnProperty('prop'); // 返回 false
o.prop = 'exists';
o.hasOwnProperty('prop'); // 返回 true
delete o.prop;
o.hasOwnProperty('prop'); // 返回 false自身属性与继承属性
下面的例子演示了 hasOwnProperty 方法对待自身属性和继承属性的区别:
o = new Object();
o.prop = 'exists';
o.hasOwnProperty('prop'); // 返回 true
o.hasOwnProperty('toString'); // 返回 false
o.hasOwnProperty('hasOwnProperty'); // 返回 false使用 hasOwnProperty 作为属性名
JavaScript 并没有保护 hasOwnProperty 这个属性名,所以就会出现设置hasOwnProperty为函数名的情况:
var foo = {
hasOwnProperty: function() {
return false;
},
bar: 'Here be dragons'
};那么,在使用:
foo.hasOwnProperty('bar'); // 始终返回 false为解决这种情况,可以使用下面这两种方式:
// 1. 可以直接使用原型链上真正的 hasOwnProperty 方法
({}).hasOwnProperty.call(foo, 'bar'); // true
// 2. 使用 Object 原型上的 hasOwnProperty 属性
Object.prototype.hasOwnProperty.call(foo, 'bar'); // true==注意==,只有在最后一种情况下,才不会新建任何对象。
Express 是一个简洁而灵活的 node.js Web应用框架, 提供了一系列强大特性帮助你创建各种 Web 应用和丰富的 HTTP 工具,如果你不会jJava or Python等后端,使用 Express可以帮助我们快速地搭建一个完整功能的网站。
其中Express 框架核心特性:
npm install -g express-generatorexpress express-app├── app.js
├── bin
│ └── www
├── package-lock.json
├── package.json
├── public
│ ├── images
│ ├── javascripts
│ └── stylesheets
│ └── style.css
├── routes
│ ├── index.js
│ └── users.js
└── views
├── error.jade
├── index.jade
└── layout.jade之后 cd 进入到对应的目录下,然后将项目跑起来:
npm install
node bin/www
node app.js 上面通过express提供的脚手架,直接创建一个应用的骨架;现在我们自己从零搭建项目:
初始化一个新的项目:
npm init -y安装express:
npm install express新建app.js
现在搭建自己的第一个express程序:在app.js中加入如下代码
const express = require('express');
// 创建服务器
const app = express();
app.get('/',(req,res) => {
res.end("Hello World");
});
app.listen(8000,() => {
console.log("服务器启动成功~");
})进入项目根目录下,在终端中将服务器跑起来:
node app.js到浏览器:访问localhost:8000即可
请求的路径中如果有一些参数,可以这样表达:
/users/:userId;
在request对象中要获取可以通过 req.params.userId;
返回数据,我们可以方便的使用json:
res.json(数据)方式;
const express = require('express');
const app = express();
app.get('/users/:userId', (req, res, next) => {
console.log(req.params.userId);
res.json({username: "liyingxia", password: "8i8i8i8i" });
});
app.listen(8000, () => {
console.log("静态服务器启动成功~");
})Express是一个路由和中间件的Web框架,它本身的功能非常少:
Express应用程序本质上是一系列中间件函数的调用;
中间件中可以执行哪些任务?
如果当前中间件功能没有结束请求-响应周期,则必须调用 next()将控制权传递给下一个中间件功能,否则,请求将被挂起。
express主要提供了两种方式:app/router.use和app/router.methods这两种方式把中间件应用到我们的应用程序中;
methods指的是常用的请求方式,比如:app.get或app.post等
// express 中间件的使用
const express = require('express');
const res = require('express/lib/response');
const app = express();
app.use((req,res,next) => {
console.log("middleware");
next();
});
app.use((req,res,next) => {
console.log("middleware");
res.end("Hello Common Middleware");
})
app.listen(9000,()=>{
console.log("中间件服务器启动成功~")
})path匹配中间件:
//path 路径匹配中间件
app.use('/home',(req,res,next) => {
console.log("home middleware 中间件");
next();
});
app.use('/home',(req,res,next) => {
console.log("home middleware02");
next();
res.end("middleware");
});
app.use((req,res,next) =>{
console.log("middleware");
})path 和 method 匹配中间件
// path 和 method 匹配中间件
app.get('/home',(req,res,next) => {
console.log("home get middleware");
next();
})
app.post('/login',(req,res,next) => {
console.log("login post middleware");
next();
});
app.use((req,res,next) => {
console.log("common middleware");
})
app.use(express.json());
app.use(express.urlencoded({extended:true}));
app.post('/login',(req,res,next) => {
console.log(req.body);
res.end("登陆成功~");
});如果我们希望将请求日志记录下来,那么可以使用express官网开发的第三方库:morgan
morgan安装:
npm install morgan如何用?直接作为中间件使用即可:
const loggerWriter = fs.createWriteStream('./log/access.log', {
flags: 'a+'
})
app.use(morgan('combined', {stream: loggerWriter}));图片上传我们可以使用express官方开发的第三方库:multer
multer安装:
npm install multer上传文件:
const upload = multer({
dest: "uploads/"
})
app.post('/upload', upload.single('file'), (req, res, next) => {
console.log(req.file.buffer);
res.end("文件上传成功~");
})添加上传文件后缀名:
const storage = multer.diskStorage({
destination: (req, file, cb) => {
cb(null, "uploads/")
},
filename: (req, file, cb) => {
cb(null, Date.now() + path.extname(file.originalname));
}
})
const upload = multer({
storage
})
app.post('/upload', upload.single('file'), (req, res, next) => {
console.log(req.file.buffer);
res.end("文件上传成功~");
})上传多张图片:
app.use('/upload', upload.array('files'), (req, res, next) => {
console.log(req.files);
});客户端传递到服务器参数的方法常见的是5种:
方式一:通过get请求中的URL的params;
方式二:通过get请求中的URL的query;
方式三:通过post请求中的body的json格式;
方式四:通过post请求中的body的x-www-form-urlencoded格式;
方式五:通过post请求中的form-data格式;
方式一:params
请求地址: http://locahost:8000/login/asd/ass
获取参数:
app.use('/login/:id/:name', (req, res, next) => {
console.log(req.params);
res.json("请求成功~");
})方式二:query
请求地址:http://localhost:8000/login?username=liyingxia&password=123456
获取参数:
app.use('/login', (req, res, next) => {
console.log(req.query);
res.json("请求成功~");
})方式三:通过post请求中的body的json格式;
在客户端发送post请求时,会将数据放到body中:客户端可以通过json的方式传递,也可以通过form表单的方式传递;
自己编写中间件来解析JSON:
app.use((req, res, next) => {
if (req.headers['content-type'] === 'application/json') {
req.on('data', (data) => {
const userInfo = JSON.parse(data.toString());
req.body = userInfo;
})
req.on('end', () => {
next();
})
} else {
next();
}
})
app.post('/login', (req, res, next) => {
console.log(req.body);
res.end("登录成功~");
});适用express内置的中间件或者使用body-parser来完成:
app.use(express.json());
app.post('/login', (req, res, next) => {
console.log(req.body);
res.end("登录成功~");
});方式四:通过post请求中的body的x-www-form-urlencoded格式;
解析application/x-www-form-urlencoded:
可以使用express自带的 urlencoded函数来作为中间件:
传入的extended用于表示使用哪一种解析方式:
qs第三方模块;querystring内置模块;app.use(express.json());
app.use(express.urlencoded({extended: true}));
app.post('/login', (req, res, next) => {
console.log(req.body);
res.end("登录成功~");
});方式五:通过post请求中的form-data格式;
通过any借助multer去解析一些form-data中的普通数据:
app.use(upload.any());
app.use('/login', (req, res, next) => {
console.log(req.body);
});res.end("获取成功~")res.json({name:"liyignxia",password:"123456"});res.status(200);使用 express.Router来创建一个路由处理程序:一个Router实例拥有完整的中间件和路由系统;
// 用户相关的处理
const userRouter = express.Router();
userRouter.get('/', (req, res, next) => {
res.end("用户列表");
});
userRouter.post('/', (req, res, next) => {
res.end("创建用户");
});
userRouter.delete('/', (req, res, next) => {
res.end("删除用户");
});
app.use('/users', userRouter);Node也可以作为静态资源服务器,并且express给我们提供了方便部署静态资源的方法;
const express = require('express');
const app = express();
app.use(express.static('./build'));
app.listen(8000, () => {
console.log("静态服务器启动成功~");
})app.use((req, res, next) => {
next(new Error("USER DOES NOT EXISTS"));
});
app.use((err, req, res, next) => {
const message = err.message;
switch (message) {
case "USER DOES NOT EXISTS":
res.status(400).json({message})
}
res.status(500)
})msg:当初在数据结构课上被c语言的数据结构虐死,难。。。要想提高技术,躲不过的,还是得学造。
@TOC
数据结构研究的内容:就是如何按一定的逻辑结构,把数据组织起来,并选择适当的存储表示方法把逻辑结构组织好的数据存储到计算机的存储器里。算法研究的目的是为了更有效的处理数据,提高数据运算效率。数据的运算是定义在数据的逻辑结构上,但运算的具体实现要在存储结构上进行。一般有以下几种常用运算:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL这道题是链表中的经典题目,充分体现链表这种数据结构 操作思路简单 , 但是 实现上 并没有那么简单的特点。
那在实现上应该注意一些什么问题呢?
保存后续节点。作为新手来说,很容易将当前节点的 next 指针直接指向前一个节点,但其实当前节点下一个节点 的指针也就丢失了。因此,需要在遍历的过程当中,先将下一个节点保存,然后再操作 next指向。
链表结构声定义如下:
function ListNode(val) {
this.val = val;
this.next = null;
}实现如下:
/**
* @param {ListNode} head
* @return {ListNode}
*/
let reverseList = (head) => {
if (!head)
return null;
let pre = null, cur = head;
while (cur) {
// 关键: 保存下一个节点的值
let next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
return pre;
};let reverseList = (head) =>{
let reverse = (pre, cur) => {
if(!cur) return pre;
// 保存 next 节点
let next = cur.next;
cur.next = pre;
return reverse(cur, next);
}
return reverse(null, head);
}反转从位置 m 到 n 的链表。请使用一趟扫描完成反转。
说明: 1 ≤ m ≤ n ≤ 链表长度。
示例:
输入: 1->2->3->4->5->NULL, m = 2, n = 4
输出: 1->4->3->2->5->NULL思路:
这一题相比上一个整个链表反转的题,其实是换汤不换药。我们依然有两种类型的解法:循环解法和递归解法。
需要注意的问题就是 前后节点 的保存(或者记录),什么意思呢?看这张图你就明白了。
关于前节点和后节点的定义,大家在图上应该能看的比较清楚了,后面会经常用到。反转操作上一题已经拆解过,这里不再赘述。值得注意的是反转后的工作,那么对于整个区间反转后的工作,其实就是一个移花接木的过程,首先将**前节点的 next 指向区间终点,然后将区间起点的 next 指向后节点**。因此这一题中有四个需要重视的节点: 前节点 、 后节点 、 区间起点 和 区间终点 。接下来我们开始实际的编码操作。
循环解法:
/**
* @param {ListNode} head
* @param {number} m
* @param {number} n递归解法
对于递归解法,唯一的不同就在于对于区间的处理,采用递归程序进行处理,大家也可以趁着复习一下
递归反转的实现。
* @return {ListNode}
*/
var reverseBetween = function(head, m, n) {
let count = n - m;
let p = dummyHead = new ListNode();
let pre, cur, start, tail;
p.next = head;
for(let i = 0; i < m - 1; i ++) {
p = p.next;
}
// 保存前节点
front = p;
// 同时保存区间首节点
pre = tail = p.next;
cur = pre.next;
// 区间反转
for(let i = 0; i < count; i++) {
let next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
// 前节点的 next 指向区间末尾
front.next = pre;
// 区间首节点的 next 指向后节点(循环完后的cur就是区间后面第一个节点,即后节点)
tail.next = cur;
return dummyHead.next;
};对于递归解法,唯一的不同就在于对于区间的处理,采用递归程序进行处理,大家也可以趁着复习一下递归反转的实现。
var reverseBetween = function(head, m, n) {
// 递归反转函数
let reverse = (pre, cur) => {
if(!cur) return pre;
// 保存 next 节点
let next = cur.next;
cur.next = pre;
return reverse(cur, next);
}
let p = dummyHead = new ListNode();
dummyHead.next = head;
let start, end; //区间首尾节点
let front, tail; //前节点和后节点
for(let i = 0; i < m - 1; i++) {
p = p.next;
}
front = p; //保存前节点
start = front.next;
for(let i = m - 1; i < n; i++) {
p = p.next;
}3. 两个一组翻转链表
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例:
思路
如图所示,我们首先建立一个虚拟头节点(dummyHead),辅助我们分析。
首先让 p 处在 dummyHead 的位置,记录下 p.next 和 p.next.next 的节点,也就是 node1 和
node2。
随后让 node1.next = node2.next, 效果:
然后让 node2.next = node1, 效果:
最后,dummyHead.next = node2,本次翻转完成。同时 p 指针指向node1, 效果如下:
end = p;
tail = end.next; //保存后节点
end.next = null;
// 开始穿针引线啦,前节点指向区间首,区间首指向后节点
front.next = reverse(null, start);
start.next = tail;
return dummyHead.next;
}给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例:
给定 1->2->3->4, 你应该返回 2->1->4->3.思路
如图所示,我们首先建立一个虚拟头节点(dummyHead),辅助我们分析。
首先让 p 处在 dummyHead 的位置,记录下 p.next 和 p.next.next 的节点,也就是 node1 和
node2。
随后让 node1.next = node2.next, 效果:
然后让node2.next = node1,效果:
最后,dummyHead.next = node2,本次翻转完成。同时 p 指针指向node1, 效果如下:
依此循环,如果 p.next 或者 p.next.next 为空,也就是 找不到新的一组节点 了,循环结束。
循环解决:
var swapPairs = function(head) {
if(head == null || head.next == null)
return head;
let dummyHead = p = new ListNode();
let node1, node2;
dummyHead.next = head;
while((node1 = p.next) && (node2 = p.next.next)) {
node1.next = node2.next;
node2.next = node1;
p.next = node2;
p = node1;
}
return dummyHead.next;
};递归方式:
var swapPairs = function(head) {
if(head == null || head.next == null)
return head;
let node1 = head, node2 = head.next;
node1.next = swapPairs(node2.next);
node2.next = node1;
return node2;
};给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。
k 是一个正整数,它的值小于或等于链表的长度。
如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
示例 :
给定这个链表:1->2->3->4->5
当 k = 2 时,应当返回: 2->1->4->3->5
当 k = 3 时,应当返回: 3->2->1->4->5说明 :
思路
思路类似No.3中的两个一组翻转。唯一的不同在于两个一组的情况下每一组只需要反转两个节点,而在K 个一组的情况下对应的操作是将 K 个元素 的链表进行反转。
递归解法:
以下代码的注释中 首节点 、 尾结点 等概念都是针对反转前的链表而言的。
/**
* @param {ListNode} head
* @param {number} k
* @return {ListNode}
*/
var reverseKGroup = function(head, k) {
let pre = null, cur = head;
let p = head;
// 下面的循环用来检查后面的元素是否能组成一组
for(let i = 0; i < k; i++) {
if(p == null) return head;
p = p.next;
}
for(let i = 0; i < k; i++){
let next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
// pre为本组最后一个节点,cur为下一组的起点
head.next = reverseKGroup(cur, k);
return pre;
};循环解法
var reverseKGroup = function(head, k) {
let count = 0;
// 看是否能构成一组,同时统计链表元素个数
for(let p = head; p != null; p = p.next) {
if(p == null && i < k) return head;
count++;思路
思路一: 循环一遍,用 Set 数据结构保存节点,利用节点的内存地址来进行判重,如果同样的节点走过两
次,则表明已经形成了环。
思路二: 利用快慢指针,快指针一次走两步,慢指针一次走一步,如果 两者相遇 ,则表明已经形成了环。
可能你会纳闷,为什么思路二用两个指针在环中一定会相遇呢?
其实很简单,如果有环,两者一定同时走到环中,那么在环中,选慢指针为参考系,快指针每次 相对参
考系 向前走一步,终究会绕回原点,也就是回到慢指针的位置,从而让两者相遇。如果没有环,则两者
的相对距离越来越远,永远不会相遇。
接下来我们来编程实现。
方法一: Set 判重
let loopCount = Math.floor(count / k);
let p = dummyHead = new ListNode();
dummyHead.next = head;
// 分成了 loopCount 组,对每一个组进行反转
for(let i = 0; i < loopCount; i++) {
let pre = null, cur = p.next;
for(let j = 0; j < k; j++) {
let next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
// 当前 pre 为该组的尾结点,cur 为下一组首节点
let start = p.next;// start 是该组首节点
// 开始穿针引线!思路和2个一组的情况一模一样
p.next = pre;
start.next = cur;
p = start;
}
return dummyHead.next;
};...
Partial 可以快速把某个接口类型中定义的所有属性变成可选的。
举个栗子:
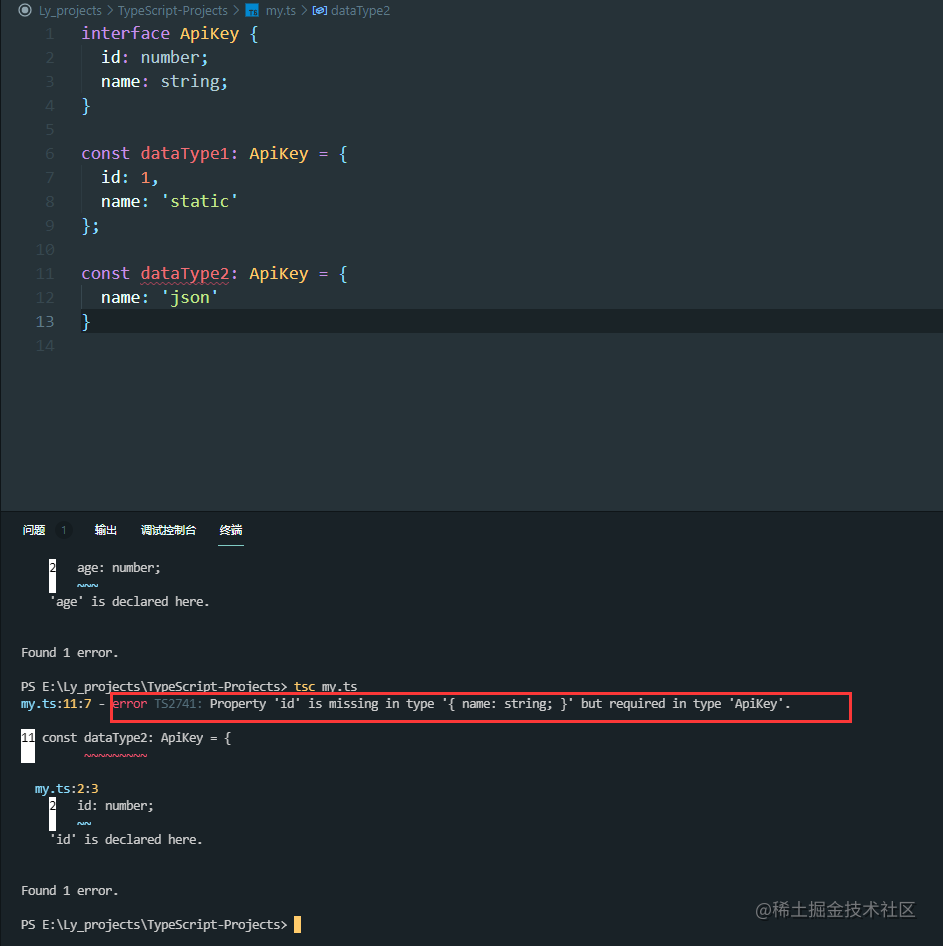
interface ApiKey {
id: number;
name: string;
}
const dataType1: ApiKey = {
id: 1,
name: 'static'
}
const dataType2: ApiKey = {
name: 'json'
}这段代码会在编译报错:
error TS2741: Property 'id' is missing in type '{ name: string; }' but required in type 'ApiKey'.Key'.因为dataType2的类型是ApiKey,ApiKey中id和name都是必选的,这导致编译报错。假如ApiKey中的参数是可选的,那么这个问题就会不复存在,而Partial的作用就在于此,它可以帮助我们把ApiKey中的所有属性都变成可选的。
我们永Partial来重写一下这个栗子:
interface ApiKey {
id: number;
name: string;
}
const dataType1: ApiKey = {
id: 1,
name: 'static'
}
const dataType2: Partial<ApiKey> = {
name: 'json'
}这个时候在运行,就不会报错了。

最近借着空闲时间断断续续两个月看完了《JavaScript权威指南(第七版)》,《JavaScript权威指南》一直以来被称为“犀牛书”,前面的第六版我大概略过一遍,由于书的厚度实在有点“厚重”,将近1000多页左右,有一些知识已经过时了,看了一下就没有细啃,随后转向新出版的第七版,第七版是是在2020年5月出版上市的,据了解,而第6版是2011年出版的,距今已经10年了,前端的技术更迭换代非常“迅速”,至少对于像我这种之前是学习后端知识的人来说,前端的技术更迭比后端的技术更新快的多,而且要求也相对“苛刻”,这怎么说呢?比如Java都更新到了16 ,但是当前大部分的Java开发者还是停留在使用Java8的阶段,前端新技术更新了,但是你还不会用,就会有种说不过去的尴尬,比如Vite构建工具,再比如Vue3新特性,TypeScript 等。
扯些没用的废话,转回来。《JavaScript权威指南》第七版中最大的变化就是删除了过时的东西,增加了 ES6 新增的语法、新的 Web API、Node、流行工具库如 Babel 等内容。相比第六版,第七版相对“友好”多了,第6版中过时的内容都被删除了,比如 EX4、Rhino、JSONP、XMLHttpRequest、关于 IE 兼容性的讨论;第6版足足300页的语言参考和客户端参考在第7版中被删除掉了。第七版书本厚度大概600页不到左右,可谓轻薄了多好,让人阅读起来也舒服。
js概述,没什么好说的。
与第6版基本相同。把对 unicode 转义的内容扩充为一个独立小节。
与第6版基本相同。增加了 Symbol 数据类型。
与第6版基本相同。增加了双引号(??)和 await 运算符。
与第6版基本相同。增加了 yield, const, let, import, export 的内容。
与第6版基本相同。增加了扩展运算符(...)的内容。
与第6版基本相同。增加了 Array.from()、flat()、flatMap()、copyWithin() 的内容。
与第6版基本相同。增加了箭头函数、参数缺省值、rest 参数的内容。
第6版的“第9章-类和模块”被拆成了2章分别讲解。
增加了 class 关键字及相关的内容。
在第6版时还没有内建的模块语法,所以在第6版第9章用一个小节讲到了模块。第7版进行了大幅扩充,分别讲解了 Node 下的模块和 ES6 的模块。
这一章是全新的,前面10章讲解的是 JavaScript 语言核心,这一章讲解语言集成的库和 API。内容包括 Set、Map、ArrayBuffer、正则匹配、日期时间类、Error 类、JSON 类、国际化 API、console API、URL API、计时器。第6版“第10章-正则表达式的模式匹配”的内容成为了本章的一个小节。
这一章是全新的的。
这一章是全新的。内容包括 callback 模式、Promise、async 和 await 等内容。
这一章是全新的,内容包括 Proxy、Reflect 对象。
介绍浏览器和js。
介绍基于 Node 的服务端开发。
当前前端开发一些重要的流行类库。比如perttier、ESlint、Babel转译器等。
@TOC
浏览器内核主要分为两个部分:渲染引擎、js引擎;
| 特性 | cookie | localSorage | sessionStorage | indexedDB |
|---|---|---|---|---|
| 数据生命周期 | 一般由服务器生成,可以设置过期时间 | 除非被清除,否则会一直存在 | 页面关闭就被清理 | 除非被清理·,否则会一直存在 |
| 数据存储大小 | 4K | 5M | 5M | 无限 |
| 与服务端通信 | 每次都会携带在header中,对于请求性能影响 | 不参与 | 不参与 | 不参与 |
localStorage 自带getItem(取数据)和setltem(存数据)来存取数据;
一般我们从浏览器地址栏输入URL后,就等待浏览器给我们返回想要的东西,而这个过程中,浏览器进行了下面一系列操作:
在浏览器地址栏输入URL后:
浏览器缓存分为强缓存和协商缓存。当客户端请求某个资源时,获取缓存的流程如下:
浏览器解析文档的过程中:
如果遇到 script 标签,会立即解析脚本,停止解析文档(因为 JS 可能会改变 DOM 和 CSS,如果继续解析会造成浪费);
如果是外部 script, 会等待脚本下载完成之后在继续解析文档。现在 script 标签增加了 defer 和 async 属性,脚本解析会将脚本中改变 DOM 和 css 的地方> 解析出来,追加到 DOM Tree 和 Style Rules 上
浏览器为了重新渲染部分或整个页面,重新计算页面元素位置和几何结构的进程叫做 reflow . 通俗点说就是当开发人员定义好了样式后(也包括浏览器的默认样式),浏览器根据这些来计算并根据结果将元素放到它应该出现的位置上,这个过程叫做 reflow . 由于reflow是一种浏览器中的用户拦截操作,所以我们了解如何减少 reflow 次数,及DOM的层级,css 效率对 refolw 次数的影响是十分有必要的。 reflow (回流)是导致DOM脚本执行效率低的关键因素之一,页面上任何一个节点触发了 reflow,会导致它的子节点及祖先节点重新渲染。 简单解释一下 Reflow:当元素改变的时候,将会影响文档内容或结构,或元素位置,此过程称为 Reflow。
首先我们在组件当中使用redux,就需要使用react-redux中的connect将该组件与store连接起来,而connect又可以接受两个参数,分别是mapStateToProps和mapDispatchToProps,前者则是获取store里面的状态,用于建立组件跟store的state的映射关系,后者则是用于建立组件跟store.dispatch的映射关系。
一、首先使用connect连接到Store
export default withRouter(connect(mapStateToProps, mapDispatchToProps)(TopNav))二、使用mapStateToProps建立组件跟store的state的映射关系
const mapStateToProps = ({user,userMessage,uploadImage}) => ({
user,userMessage,uploadImage
})
三、使用mapDispatchToProps用于建立组件跟store.dispatch的映射关系
const mapDispatchToProps = (dispatch) => ({
getMessage : (id) => dispatch(UserMessage(id)),
updateUser : (user,callback) => dispatch(updateUser(user,callback))
})
起初 Vue3.0 暴露变量必须 return 出来,template中才能使用;
Vue3.2 中 只需要在 script 标签上加上 setup 属性,组件在编译的过程中代码运行的上下文是在 setup() 函数中,无需return,template可直接使用。
<template>
// Vue2中,template标签中只能有一个根元素,在Vue3中没有此限制
// ...
</template>
<script setup>
// ...
</script>
<style lang="scss" scoped>
// 支持CSS变量注入v-bind(color)
</style><script setup>
import { reactive, ref, toRefs } from 'vue'
// ref声明响应式数据,用于声明基本数据类型
const name = ref('Jerry')
// 修改
name.value = 'Tom'
// reactive声明响应式数据,用于声明引用数据类型
const state = reactive({
name: 'Jerry',
sex: '男'
})
// 修改
state.name = 'Tom'
// 使用toRefs解构
const {name, sex} = toRefs(state)
// template可直接使用{{name}}、{{sex}}
</script><template>
// 调用方法
<button @click='changeName'>按钮</button>
</template>
<script setup>
import { reactive } from 'vue'
const state = reactive({
name: 'Jery'
})
// 声明method方法
const changeName = () => {
state.name = 'Tom'
}
</script><script setup>
import { computed, ref } from 'vue'
const count = ref(1)
// 通过computed获得doubleCount
const doubleCount = computed(() => {
return count.value * 2
})
</script><script setup>
import { watch, reactive } from 'vue'
const state = reactive({
count: 1
})
// 声明方法
const changeCount = () => {
state.count = state.count * 2
}
// 监听count
watch(
() => state.count,
(newVal, oldVal) => {
console.log(state.count)
console.log(`watch监听变化前的数据:${oldVal}`)
console.log(`watch监听变化后的数据:${newVal}`)
},
{
immediate: true, // 立即执行
deep: true // 深度监听
}
)
</script>子组件:
<template>
<span>{{props.name}}</span>
// 可省略【props.】
<span>{{name}}</span>
</template>
<script setup>
// import { defineProps } from 'vue'
// defineProps在<script setup>中自动可用,无需导入
// 需在.eslintrc.js文件中【globals】下配置【defineProps: true】
// 声明props
const props = defineProps({
name: {
type: String,
default: ''
}
})
</script>父组件:
<template>
<child name='Jerry'/>
</template>
<script setup>
// 引入子组件(组件自动注册)
import child from './child.vue'
</script>子组件:
<template>
<span>{{props.name}}</span>
// 可省略【props.】
<span>{{name}}</span>
<button @click='changeName'>更名</button>
</template>
<script setup>
// import { defineEmits, defineProps } from 'vue'
// defineEmits和defineProps在<script setup>中自动可用,无需导入
// 需在.eslintrc.js文件中【globals】下配置【defineEmits: true】、【defineProps: true】
// 声明props
const props = defineProps({
name: {
type: String,
default: ''
}
})
// 声明事件
const emit = defineEmits(['updateName'])
const changeName = () => {
// 执行
emit('updateName', 'Tom')
}
</script>父组件:
<template>
<child :name='state.name' @updateName='updateName'/>
</template>
<script setup>
import { reactive } from 'vue'
// 引入子组件
import child from './child.vue'
const state = reactive({
name: 'Jerry'
})
// 接收子组件触发的方法
const updateName = (name) => {
state.name = name
}
</script>子组件:
<template>
<span @click="changeInfo">我叫{{ modelValue }},今年{{ age }}岁</span>
</template>
<script setup>
// import { defineEmits, defineProps } from 'vue'
// defineEmits和defineProps在<script setup>中自动可用,无需导入
// 需在.eslintrc.js文件中【globals】下配置【defineEmits: true】、【defineProps: true】
defineProps({
modelValue: String,
age: Number
})
const emit = defineEmits(['update:modelValue', 'update:age'])
const changeInfo = () => {
// 触发父组件值更新
emit('update:modelValue', 'Tom')
emit('update:age', 30)
}
</script>父组件:
<template>
// v-model:modelValue简写为v-model
// 可绑定多个v-model
<child
v-model="state.name"
v-model:age="state.age"
/>
</template>
<script setup>
import { reactive } from 'vue'
// 引入子组件
import child from './child.vue'
const state = reactive({
name: 'Jerry',
age: 20
})
</script><script setup>
import { nextTick } from 'vue'
nextTick(() => {
// ...
})
</script>在标准组件写法里,子组件的数据都是默认隐式暴露给父组件的,但在 script-setup 模式下,所有数据只是默认 return 给 template 使用,不会暴露到组件外,所以父组件是无法直接通过挂载 ref 变量获取子组件的数据。
如果要调用子组件的数据,需要先在子组件显示的暴露出来,才能够正确的拿到,这个操作,就是由 defineExpose 来完成。
子组件:
<template>
<span>{{state.name}}</span>
</template>
<script setup>
import { reactive, toRefs } from 'vue'
// defineExpose无需引入
// import { defineExpose, reactive, toRefs } from 'vue'
// 声明state
const state = reactive({
name: 'Jerry'
})
// 将方法、变量暴露给父组件使用,父组件才可通过ref API拿到子组件暴露的数据
defineExpose({
// 解构state
...toRefs(state),
// 声明方法
changeName () {
state.name = 'Tom'
}
})
</script>父组件:
<template>
<child ref='childRef'/>
</template>
<script setup>
import { ref, nextTick } from 'vue'
// 引入子组件
import child from './child.vue'
// 子组件ref
const childRef = ref('childRef')
// nextTick
nextTick(() => {
// 获取子组件name
console.log(childRef.value.name)
// 执行子组件方法
childRef.value.changeName()
})
</script>子组件:
<template>
// 匿名插槽
<slot/>
// 具名插槽
<slot name='title'/>
// 作用域插槽
<slot name="footer" :scope="state" />
</template>
<script setup>
import { useSlots, reactive } from 'vue'
const state = reactive({
name: '张三',
age: '25岁'
})
const slots = useSlots()
// 匿名插槽使用情况
const defaultSlot = reactive(slots.default && slots.default().length)
console.log(defaultSlot) // 1
// 具名插槽使用情况
const titleSlot = reactive(slots.title && slots.title().length)
console.log(titleSlot) // 3
</script>父组件:
<template>
<child>
// 匿名插槽
<span>我是默认插槽</span>
// 具名插槽
<template #title>
<h1>我是具名插槽</h1>
<h1>我是具名插槽</h1>
<h1>我是具名插槽</h1>
</template>
// 作用域插槽
<template #footer="{ scope }">
<footer>作用域插槽——姓名:{{ scope.name }},年龄{{ scope.age }}</footer>
</template>
</child>
</template>
<script setup>
// 引入子组件
import child from './child.vue'
</script><script setup>
import { useRoute, useRouter } from 'vue-router'
// 必须先声明调用
const route = useRoute()
const router = useRouter()
// 路由信息
console.log(route.query)
// 路由跳转
router.push('/newPage')
</script><script setup>
import { onBeforeRouteLeave, onBeforeRouteUpdate } from 'vue-router'
// 添加一个导航守卫,在当前组件将要离开时触发。
onBeforeRouteLeave((to, from, next) => {
next()
})
// 添加一个导航守卫,在当前组件更新时触发。
// 在当前路由改变,但是该组件被复用时调用。
onBeforeRouteUpdate((to, from, next) => {
next()
})
</script>*Vue3 中的Vuex不再提供辅助函数写法
<script setup>
import { useStore } from 'vuex'
import { key } from '../store/index'
// 必须先声明调用
const store = useStore(key)
// 获取Vuex的state
store.state.xxx
// 触发mutations的方法
store.commit('fnName')
// 触发actions的方法
store.dispatch('fnName')
// 获取Getters
store.getters.xxx
</script><template>
<span>Jerry</span>
</template>
<script setup>
import { reactive } from 'vue'
const state = reactive({
color: 'red'
})
</script>
<style scoped>
span {
// 使用v-bind绑定state中的变量
color: v-bind('state.color');
}
</style>man.js
import { createApp } from 'vue'
import App from './App.vue'
const app = createApp(App)
// 获取原型
const prototype = app.config.globalProperties
// 绑定参数
prototype.name = 'Jerry'组件内使用
<script setup>
import { getCurrentInstance } from 'vue'
// 获取原型
const { proxy } = getCurrentInstance()
// 输出
console.log(proxy.name)
</script>不必再配合 async 就可以直接使用 await 了,这种情况下,组件的 setup 会自动变成 async setup 。
<script setup>
const post = await fetch('/api').then(() => {})
</script>用单独的<script>块来定义
<script>
export default {
name: 'ComponentName',
}
</script>父组件:
<template>
<child/>
</template>
<script setup>
import { provide } from 'vue'
import { ref, watch } from 'vue'
// 引入子组件
import child from './child.vue'
let name = ref('Jerry')
// 声明provide
provide('provideState', {
name,
changeName: () => {
name.value = 'Tom'
}
})
// 监听name改变
watch(name, () => {
console.log(`name变成了${name}`)
setTimeout(() => {
console.log(name.value) // Tom
}, 1000)
})
</script>子组件:
<script setup>
import { inject } from 'vue'
// 注入
const provideState = inject('provideState')
// 子组件触发name改变
provideState.changeName()
</script>浅拷贝是指,一个新的对象对原始对象的属性值进行精确地拷贝,如果拷贝的是基本数据类型,拷贝的就是基本数据类型的值;如果拷贝的是引用数据类型,拷贝的就是内存地址。如果其中一个对象的引用内存地址发生改变,另一个对象也会发生变化。
object.assign 是 ES6 中 object 的一个方法,该方法可以用于 JS 对象的合并。我们可以使用它来实现浅拷贝。
该方法的参数 target 指的是目标对象,sources指的是源对象。使用形式如下:
Object.assign(target, ...sources)使用实例:
let target = {a: 1};
let object2 = {b: {d : 2}};
let object3 = {c: 3};
Object.assign(target, object2, object3);
console.log(target); // {a: 1, b: {d : 2}, c: 3}这里通过 Object.assign 将 object2 和 object3 拷贝到了 target 对象中,下面来尝试将 object2 对象中的 b 属性中的d属性由 2 修改为 666:
object2.b.d = 666;
console.log(target); // {a: 1, b: {d: 666}, c: 3}可以看到,target的b属性值的d属性值变成了666,因为这个b的属性值是一个对象,它保存了该对象的内存地址,当原对象发生变化时,引用他的值也会发生变化。
==注意:==
实际上,Object.assign 会循环遍历原对象的可枚举属性,通过复制的方式将其赋值给目标对象的相应属性。
使用扩展运算符可以在构造字面量对象的时候,进行属性的拷贝。使用形式如下:
let cloneObj = { ...obj };使用实例:
let obj1 = {a:1,b:{c:1}}
let obj2 = {...obj1};
obj1.a = 2;
console.log(obj1); //{a:2,b:{c:1}}
console.log(obj2); //{a:1,b:{c:1}}
obj1.b.c = 2;
console.log(obj1); //{a:2,b:{c:2}}
console.log(obj2); //{a:1,b:{c:2}}扩展运算符... 和 object.assign 实现的浅拷贝的功能差不多,如果属性都是基本类型的值,使用扩展运算符进行浅拷贝会更加方便。
slice()方法是JavaScript数组方法,该方法可以从已有数组中返回选定的元素,不会改变原始数组。使用方式如下:
array.slice(start, end)该方法有两个参数,两个参数都可选:
-1 指最后一个元素,-2 指倒数第二个元素,以此类推。如果两个参数都不写,就可以实现一个数组的浅拷贝:
let arr = [1,2,3,4];
console.log(arr.slice()); // [1,2,3,4]
console.log(arr.slice() === arr); //falseslice 方法不会修改原数组,只会返回一个浅拷贝了原数组中的元素的一个新数组。原数组的元素会按照下述规则拷贝:
slice 会拷贝这个对象引用到新的数组里。两个对象引用都引用了同一个对象。如果被引用的对象发生改变,则新的和原来的数组中的这个元素也会发生改变。字符串、数字及布尔值来说,slice 会拷贝这些值到新的数组里。在别的数组里修改这些字符串或数字或是布尔值,将不会影响另一个数组。如果向两个数组任一中添加了新元素,则另一个不会受到影响。
concat() 方法用于合并两个或多个数组,此方法不会更改原始数组,而是返回一个新数组。使用方式如下:
arrayObject.concat(arrayX,arrayX,......,arrayX)该方法的参数arrayX是一个数组或值,将被合并到arrayObject数组中。如果省略了所有 arrayX 参数,则concat会返回调用此方法的现存数组的一个浅拷贝:
let arr = [1,2,3,4];
console.log(arr.concat()); // [1,2,3,4]
console.log(arr.concat() === arr); //falseconcat方法创建一个新的数组,它由被调用的对象中的元素组成,每个参数的顺序依次是该参数的元素(参数是数组)或参数本身(参数不是数组)。它不会递归到嵌套数组参数中。
concat方法不会改变this或任何作为参数提供的数组,而是返回一个浅拷贝,它包含与原始数组相结合的相同元素的副本。 原始数组的元素将复制到新数组中,如下所示:
concat将对象引用复制到新数组中。 原始数组和新数组都引用相同的对象。 也就是说,如果引用的对象被修改,则更改对于新数组和原始数组都是可见的。 这包括也是数组的数组参数的元素。concat将字符串和数字的值复制到新数组中。根据以上对浅拷贝的理解,实现浅拷贝的思路:
代码实现:
// 浅拷贝的实现;
function shallowCopy(object) {
// 只拷贝对象
if (!object || typeof object !== "object") return;
// 根据 object 的类型判断是新建一个数组还是对象
let newObject = Array.isArray(object) ? [] : {};
// 遍历 object,并且判断是 object 的属性才拷贝
for (let key in object) {
if (object.hasOwnProperty(key)) {
newObject[key] = object[key];
}
}
return newObject;
}这里用到了hasOwnProperty()方法,该方法会返回一个布尔值,指示对象自身属性中是否具有指定的属性。所有继承了 Object 的对象都会继承到 hasOwnProperty() 方法。这个方法可以用来检测一个对象是否是自身属性。
可以看到,所有的浅拷贝都只能拷贝一层对象。如果存在对象的嵌套,那么浅拷贝就无能为力了。深拷贝就是为了解决这个问题而生的,它能解决多层对象嵌套问题,彻底实现拷贝。
深拷贝是指,对于简单数据类型直接拷贝他的值,对于引用数据类型,在堆内存中开辟一块内存用于存放复制的对象,并把原有的对象类型数据拷贝过来,这两个对象相互独立,属于两个不同的内存地址,修改其中一个,另一个不会发生改变。
JSON.parse(JSON.stringify(obj))是比较常用的深拷贝方法之一,它的原理就是利用JSON.stringify 将JavaScript对象序列化成为JSON字符串),并将对象里面的内容转换成字符串,再使用JSON.parse来反序列化,将字符串生成一个新的JavaScript对象。
使用示例:
let obj1 = {
a: 0,
b: {
c: 0
}
};
let obj2 = JSON.parse(JSON.stringify(obj1));
obj1.a = 1;
obj1.b.c = 1;
console.log(obj1); // {a: 1, b: {c: 1}}
console.log(obj2); // {a: 0, b: {c: 0}}这个方法虽然简单粗暴,但也存在一些问题,在使用该方法时需要注意:
函数,undefined,symbol,当使用过JSON.stringify()进行处理之后,都会消失。Date 引用类型会变成字符串;RegExp 引用类型会变成空对象;NaN、Infinity 以及 -Infinity,JSON 序列化的结果会变成 null; (obj[key] = obj)。在日常开发中,上述几种情况一般很少出现,所以这种方法基本可以满足日常的开发需求。如果需要拷贝的对象中存在上述情况,还是要考虑使用下面的几种方法。
该函数库也有提供_.cloneDeep用来做深拷贝,可以直接引入并使用:
var _ = require('lodash');
var obj1 = {
a: 1,
b: { f: { g: 1 } },
c: [1, 2, 3]
};
var obj2 = _.cloneDeep(obj1);
console.log(obj1.b.f === obj2.b.f);// false实现深拷贝的思路就是,使用for in来遍历传入参数的属性值,如果值是基本类型就直接复制,如果是引用类型就进行递归调用该函数,实现代码如下:
function deepClone(source) {
//判断source是不是对象
if (source instanceof Object == false) return source;
//根据source类型初始化结果变量
let target = Array.isArray(source) ? [] : {};
for (let i in source) {
// 判断是否是自身属性
if (source.hasOwnProperty(i)) {
//判断数据i的类型
if (typeof source[i] === 'object') {
target[i] = deepClone(source[i]);
} else {
target[i] = source[i];
}
}
}
return target;
}
console.log(clone({b: {c: {d: 1}}})); // {b: {c: {d: 1}}})这样虽然实现了深拷贝,但也存在一些问题:
上面只是实现了一个基础版的深拷贝,对于上面存在的几个问题,可以尝试去解决一下:
使用 Reflect.ownKeys() 方法来解决不能复制不可枚举属性以及 Symbol 类型的问题。
Reflect.ownKeys() 方法会返回一个由目标对象自身的属性键组成的数组。它的返回值等同于:
Object.getOwnPropertyNames(target).concat(Object.getOwnPropertySymbols(target));当参数值为 Date、RegExp 类型时,直接生成一个新的实例并返回;
利用 Object.getOwnPropertyDescriptors() 方以获得对象的所有属性以及对应的特性。简单来说,这个方法返回给定对象的所有属性的信息,包括有关getter和setter的信息。它允许创建对象的副本并在复制所有属性(包括getter和setter)时克隆它。
使用 Object.create() 方法创建一个新对象,并继承传入原对象的原型链。Object.create()方法会创建一个新对象,使用现有的对象来提供新创建的对象的__proto__。
使用 WeakMap 类型作为 Hash 表,WeakMap 是弱引用类型,可以防止内存泄漏,所以可以用来检测循环引用,如果存在循环,则引用直接返回 WeakMap 存储的值。WeakMap的特性就是,保存在其中的对象不会影响垃圾回收,如果WeakMap保存的节点,在其他地方都没有被引用了,那么即使它还在WeakMap中也会被垃圾回收回收掉了。
在深拷贝的过程当中,里面所有的引用对象都是被引用的,为了解决循环引用的问题,在深拷贝的过程中,希望有个数据结构能够记录每个引用对象有没有被使用过,但是深拷贝结束之后这个数据能自动被垃圾回收,避免内存泄漏。
代码实现:
function deepClone (obj, hash = new WeakMap()) {
// 日期对象直接返回一个新的日期对象
if (obj instanceof Date){
return new Date(obj);
}
//正则对象直接返回一个新的正则对象
if (obj instanceof RegExp){
return new RegExp(obj);
}
//如果循环引用,就用 weakMap 来解决
if (hash.has(obj)){
return hash.get(obj);
}
// 获取对象所有自身属性的描述
let allDesc = Object.getOwnPropertyDescriptors(obj);
// 遍历传入参数所有键的特性
let cloneObj = Object.create(Object.getPrototypeOf(obj), allDesc)
hash.set(obj, cloneObj)
for (let key of Reflect.ownKeys(obj)) {
if(typeof obj[key] === 'object' && obj[key] !== null){
cloneObj[key] = deepClone(obj[key], hash);
} else {
cloneObj[key] = obj[key];
}
}
return cloneObj
}可以使用下面数据进行测试:
let obj = {
num: 1,
str: 'str',
boolean: true,
und: undefined,
nul: null,
obj: { name: '对象', id: 1 },
arr: [0, 1, 2],
func: function () { console.log('函数') },
date: new Date(1),
reg: new RegExp('/正则/ig'),
[Symbol('1')]: 1,
};
Object.defineProperty(obj, 'innumerable', {
enumerable: false, value: '不可枚举属性'
});
obj = Object.create(obj, Object.getOwnPropertyDescriptors(obj))
obj.loop = obj // 将loop设置成循环引用的属性
let cloneObj = deepClone(obj)
console.log('obj', obj)
console.log('cloneObj', cloneObj)Array.prototype.reduce()
reduce() 方法接收一个函数作为累加器,为数组中的每一个元素执行回调函数,并将其回调的的结果值作为返回值。
语法:
arr.reduce(callback(priviousValue,currentValue,currentIndex,sourceArray),[initValue])reduce 函数接收四个参数:
callback:reduce得回调函数,接收四个参数:
initValue:作为第一次调用callback得第一个参数的初始值。(可选)
返回值
回调函数累计处理的结果
从MDN文档描述中:
回调函数第一次执行时,priviousValue 和currentValue的取值有两种情况:如果调用reduce()时提供了initValue,priviousValue取值为initValue,currentValue取数组中的第一个值;如果没有提供 initValue,那么priviousValue取数组中的第一个值,currentValue取数组中的第二个值。
解释:也就是说如果没有我们没有给出初始值,开始执行时,数组中被处理的取值索引是1,而不是从0开始的。这会导致数组中第一个元素(即索引为0没有被处理,因为数组的元素索引是从0开始的)
大白话显得苍白无力,实践出真知。我们来实践一下:
第一个例子:没有initValue 时
let array = [1,2,3,4,5];
let sum = array.reduce((preValue,curValue,curIndex,array) => {
console.log(preValue,curValue,curIndex);
return preValue + curValue;
})
console.log(array,sum);
打印结果:
1 2 1
3 3 2
6 4 3
10 5 4
[1,2,3,4,5] 15
从打印的结果来看,我的数组长度是5,但是reduce()循环打印的次数只有4次,函数开始执行的数组索引是从index为1开始的,第一次的preValue值是数组的第一个值1
第二个例子:有initValue 时:
我们在第一个例子的基础上,修改一下:
let array = [1,2,3,4,5];
let sum = array.reduce((preValue,curValue,curIndex,array) => {
console.log(preValue,curValue,curIndex);
return preValue + curValue;
},0) //与上个例子相比,这里设置初始值0
console.log(array,sum);这时候的打印结果:
0 1 0
1 2 1
3 3 2
6 4 3
10 5 4
[1,2,3,4,5] 15这时候的函数的执行是从index为0开始的,第一次执行回调函数时,preValue的值是我们设置的初始值0,回调函数执行5次,数组长度为5.
总之:如果没有提供initValue,reduce 会从索引1的地方开始执行 callback 函数,直接跳过第一个索引。如果提供initialValue,从索引0开始。
还有一个值得注意的是:
如果没有提供初始值,可能会有下面这四种输出的可能:
var maxCallback = ( acc, cur ) => Math.max( acc.x, cur.x );
var maxCallback2 = ( max, cur ) => Math.max( max, cur );
// reduce() 没有初始值
[ { x: 2 }, { x: 22 }, { x: 42 } ].reduce( maxCallback ); // NaN
[ { x: 2 }, { x: 22 } ].reduce( maxCallback ); // 22
[ { x: 2 } ].reduce( maxCallback ); // { x: 2 }
[ ].reduce( maxCallback ); // TypeError
// map/reduce; 这是更好的方案,即使传入空数组或更大数组也可正常执行
[ { x: 22 }, { x: 42 } ].map( el => el.x )
.reduce( maxCallback2, -Infinity );如果数组为空且没有提供initialValue,会抛出TypeError 。如果数组仅有一个元素(无论位置如何)并且没有提供initialValue, 或者有提供initialValue但是数组为空,那么此唯一值将被返回并且callback不会被执行。因此提供初始值通常更安全。
(1)计算数组中每个元素出现的次数
// 计算数组中每个元素出现的次数
let nums = ["01","02","03","01","05","04","02"];
let count = nums.reduce((preV,currentV) => {
if (currentV in preV) {
preV[currentV] ++
} else {
preV[currentV] = 1
}
return preV
},{})
console.log(count);
(2) 数组去重
// 数组去重
let nums = ["01","02","03", ,"04","02","01","05"];
let newArr = nums.reduce((preV,currentV) => {
if (!preV.includes(currentV)) {
return preV.concat(currentV)
} else {
return preV
}
},[])
console.log(newArr);(3)数组扁平化:将多维数组转化为一维数组:
// 数组扁平化运用:将二维数组转化为一维
let arr = [[0,1],[2,3,4],[5,6,7,8]]
let newArr = arr.reduce((preV,currentV) => {
return preV.concat(currentV)
},[])
console.log(newArr);打印结果:
(4)对象里的属性求和
// 对象里的属性求和
let items = [
{
id: 1,
name: 'python',
count: 20
},
{
id: 2,
name: 'javascript',
count: 30
},
{
id: 3,
name: 'java',
count: 50
}
];
let total = items.reduce((preV,currentV) => {
return currentV.count +preV;
},0);
console.log("总统计人数:" + total)打印结果:
@TOC
Michael Widenius "Monty"是一位编程天才。19 岁的时候,他从赫尔辛基理工大学辍学开始全职工作,因为大学已经没有什么东西可以教他了。33 岁时,他发布了MySQL,成为了全世界最流行的开源数据库。并以 10亿美元的价格,将自己创建的公司 MySQL AB卖给了 SUN,此后,Oracle 收购了 SUN。
Widenius 离开了 Sun 之后,觉得依靠 Sun/Oracle 来发展 MySQL,实在很不靠谱,于是决定另开分支,这个分支的名字叫做 MariaDB。MariaDB名称来自他的女儿Maria的名字。
MariaDB跟 MySQL在绝大多数方面是兼容的,对于开发者来说,几乎感觉不到任何不同。目前 MariaDB 是发展最快的 MySQL 分支版本,新版本发布速度已经超过了 Oracle官方的 MySQL版本。
关系型数据库以行和列的形式存储数据,这一系列的行和列被称为表,一组表组成了数据库。
表与表之间的数据记录有关系。
数据保存在表内,行(记录)用于记录数据,列(字段)用于规定数据格式
show databases;# 如果没有修改 my.ini 配置文件的默认字符集,在创建数据库时,指定字符集
create database db_name character set 'utf8';
# 特殊字符(关键字)用反引号
create database `create`;MySQL\data 目录下将自动生成一个对应名称的目录,目录内部有一个 db.opt 文件
show create database db_name; # db_name 即你的数据库名drop database db_name; # db_name 即你的数据库名use database;select database();create table 表名(字段 字段类型,....)
MySQL\data目录下的数据库目录中将自动生成一个对应名称的.frm 文件
drop table 表名;show tables;
# 查看字母是'l'开头的表
show tables like 'l%'; # %是通配符show create table 表名;desc 表名;MySQL 是基于C/S 架构,必须在客户端通过终端窗口,连接MySQL 服务器进行操作
mysql -h host -u user -p
Enter password:*********## DOS命令下修改,将 root 账号密码修改为 123456
mysqladmin -u root password 1234 ##语句最后不要加分号,否则密码就是 “123456;”
##mysql 命令
set password for 'root'@'localhost'= password('123456');create user 'username'@'host' identified by 'password';参数说明:
create user 'zhangsan'@'localhost' identified by '123456';drop user 'username'@'host';字符集
MySQL默认字符集是 latin( 拉丁 ),改变为 utf8 才能正确显示中文
[mysqld] 下添加
character-set-server=utf8
init-connect='\set NAMES utf8'
修改默认引擎
InnoDB 优于 MYISAM
default-storage-engine=MYISAM 修改为 default-storage-engine=InnoDB
化 个性化 mysql 提示符
MySQL默认提示符是” mysql>“ ,可以个性化定制,例如:"mysql(数据库)>"
[mysql]下添加
prompt="mysql(\d)>"SQL(Structured Query Language)是用于访问和处理数据库的 标准计算机语言。使用SQL 访问和处理数据系统中的数据,这类数据库包括:Oracle,mysql,Sybase, SQLServer, DB2, Access 等等。
mysql> select 1+1; # 这个注释直到该行结束
mysql> select 1+1; -- 这个注释直到该行结束
mysql> select 1 /* 这是一个在行中间的注释 */ + 1;
mysql> select 1+
/*
这是一个
多行注释的形式
*/
1;数据类型是指列、存储过程参数、表达式和局部变量的数据特征,它决定了数据的存储方式,代表了不同的信息类型。不同的数据库,数据类型有所不同,MySQL数据库有以下几种数据类型:
| 类型 | 字节 | 大小 | 说明 |
|---|---|---|---|
| char | 1 | 0-255 字符 (2^8) | 定长字符串 |
| varchar | 2 | 0-65 535 字符 (2^16) | 变长字符串 |
| tinytext | 1 | 0-255 字符 (2^8) | 短文本(与 char存储形式不同) |
| text | 2 | 0-65 535 字符(2^16) | 文本 |
| mediumtext | 3 | 0-16 777 215字符 (2^24) | 中等长度文本 |
| longtext | 4 | 0-4 294 967 295字符(2^32) | 极大文本 |
注意:char 和 和 varchar 需要指定长度,例如:char(10)
| 类型 | 字节 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| tinyint | 1 | (-128,127) | (0,255) | 很小整数值 |
| smallint | 2 | (-32 768,32 767) | (0,65 535) | 小整数值 |
| mediumint | 3 | (-8 388 608,8 388 607) | (0,16 777 215) 中整数值 | |
| int 或integer | 4 | (-2 147 483 648,2 147 483647) | (0,4 294 967 295) | 整数值 |
| bigint | 8 | (-9 233 372 036 854 775 808,9 223 372 036 854 775 807) | (0,18 446 744073 709 551 615) | 很大的整数值 |
很多人喜欢在定义数据时,这样写:
create table tbl_name(
age int(10)
);int 后面()中的数字,不代表占用空间容量。而代表最小显示位数。这个东西基本没有意义,除非你对字段指定 zerofill。mysql 会自动分配长度:int(11)、tinyint(4)、smallint(6)、mediumint(9)、bigint(20)。所以,建议在使用时,就用这些默认的显示长度就可以了。不用再去自己填长度(比如:int(10)、tinyint(1)之类的基本没用)。
| 类型 | 字节 | 范围 | 用途 |
|---|---|---|---|
| float(M,D) | 4 | 23bit(约 6~7位 10进制数字) | 单精度浮点数 值绝对能保证精度为 6~7位有效数字 |
| double(M,D) | 8 | 52bit(约 15~16位10 进制数字) | 双精度浮点数值 精度为15~16位有效数字 |
| decimal(M,D) | M+2 | 依赖于 M 和 D的值 | 定点型 |
M(精度),代表总长度(整数位和小数位)限制
D(标度),代表小数位的长度限制。
M 必需大于等于 D
| 数字的修饰符 | 功能 | 说明 |
|---|---|---|
| unsigned | 无符号 | 非负数 |
| zerofill | 前导 0 | 整形前加 0(自动添加 unsigned) |
| 类型 | 字节 | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| date | 3 | 1000-01-01---9999-12-31 | YYYY-MM-DD | 日期值 |
| time | 3 | -838:59:59---838:59:59 | HH:MM:SS | 时间值或持续时间 |
| year | 1 | 1901---2155 | YYYY | 年份值 |
| datetime | 8 | 1000-01-01 00:00:00---9999-12-3123:59:59 | YYYY-MM-DDHH:MM:SS | 混合日期和时间值 |
| timestamp | 4 | 1970-01-01 00:00:00/2038 | 结束时间是第 2147483647 秒,北京时间2038-1-19 11:14:07,格林尼治时间2038 年 1 月 19日 凌晨 03:14:07 | YYYYMMDDHHMMSS |
| 名称 | 字节 | 说明 |
|---|---|---|
| set | 1、2、3、4或 8 | 列举:可以取 SET列表中的一个或多个元素(多选) |
| enum | 1或 2 | 枚举:可以取 ENUM 列表中的一个元素(单选) |
create table students(
id tinyint, # 微小整型
name varchar(10), #变长字符
sex enum('m','w'), #单选
birthday date, # 日期型
tel char(11), # 定长字符
city char(1), # 城市
hobby set('1','2','3','4'), #多选
introduce text # 个人介绍
);| 属性 | 功能 | 说明 |
|---|---|---|
| not null | 非空 | 必须有值,不允许为 null |
| default | 默认值 | 当插入记录时没有赋值,自动赋予默认值(允许为null) |
| primary key | 主键 | 惟一标识一行数据的字段(主键自动为 not null) |
| auto_increment | 自动增量 | 不能单独使用,必须与 primary key 一起定义 |
| unique(uniquekey) | 唯一 | 记录不能重复(一张表可以有多个 unique,允许为null) |
# 方法 1:指定字段
insert into students(name,age) values('张三','20');
# 方法 2: 省略字段名,字段位要一一对应,不能跳过(auto_increment 字段,可以使用 null 或 default)
insert into students values(null,'张三','20');
# 方法 3:批量增加数据
insert into students(name,age) values('张三','20'),('李四','21'),('王五','22') ……# 用 delete删除记录,一定要加 where条件,否则表数据全部删除!!
delete from 表名 where xx=xxx;
# 用 truncate删除记录,不能加 where条件,直接删除全部记录,id索引重新从 1开始
truncate table 表名;单条修改
update 表名 set xx=xx,xxx=xx where xxx=xxx and xxx=xxx;
#多条修改
update students
set name = case id # id 字段
when 1 then 'zhangsan'
when 2 then 'lisi'
when 3 then 'wangwu'
when 4 then 'zhaoliu'
end,
city = case id
when 1 then '2'
when 2 then '4'
when 3 then '1'
when 4 then '2'
end
where id in (1,2,3,4);查询比较繁杂,单拎出来
SELECT 语句用于从表中选取数据。结果被存储在一个结果表中(称为*结果集*)。
# 当前使用的数据库
select database();
# 查看当前 MySQL版本
select version();
# 查看当前用户
select user();
# 查看运算结果
select 1+2;# 字段用','隔开,至少有一个字段,最终结果集按照这个这个顺序显示
select 字段 1,字段 2... from 表名;
# *代表所有字段
select * from 表名;# 去重后的结果,distinct 必须紧接在 select 后面
select distinct 字段 from 表名;
# 统计不重复的个数
select count(distinct 字段) from 表名;| 类型 | 运算符 |
|---|---|
| 算术 | + - * / % |
| 比较 | > < >= <= != = |
| 逻辑 | or |
| 提升优先级 | ( ) |
# 搜索 id<20的所以数据
select * from students where id<20;
# 搜索 id 编号为偶数的数据
select * from students where id%2=0;# 搜索 id 在(1,3,7)之中的数据
select * from students where id=1 || id=3 || id=7;
select * from students where id in(1,3,7);
# 一次删除多条记录
delete from students where id=3 || id=15 || id=23;
delete from students where id in(3,15,23);# 搜索 id 在 20-40之间的数据
select * from students where id>20 && id<40;
select * from students where id between 20 and 40;
# 删除 id 在 20-40之间的数据
delete from students where id between 20 and 40;# 搜索 id 除了 20-40之间的数据
select * from students where id not between 30 and 40;用于模糊查询 %:任意字符长度 _ :一个字符长度
# 搜索 name名字以 5 结尾的数据
select * from students where name like '张%';
# 搜索 name名字包含字母 s 的数据
select * from students where name like '%二%';
# 搜索 id 以 5结尾的两位数 数据
select * from students where id like '_5';控制查询记录条数,数据表中的记录,从 索引从 0 开始
select * from students limit 2 # 返回两条记录
select * from students limit 3,4 # 从索引为 3的记录开始,返回 4条记录
# php中的分页功能,偏移值的计算:(当前页-1) * 每页记录数
select name from student limit 4 offset 3
# 还可以使用 offset(偏移):从索引为 3的记录开始,返回 4 条根据 给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表利用 group by分组信息进行统计,常见的是配合 max 等聚合函数筛选数据后分析。
select 指定的字段要么作为分组的依据(Group By 语句的后面),要么就要被包含在聚合函数中。
# 简单分组
select sex from students group by sex;
+-----+
| sex |
+-----+
| m |
| w |
+-----+
# 聚合函数分组
select count(*),city from students group by city;
+----------+----------+
| count(*) | livecity |
+----------+----------+
# 结果
| 7 | 1 |
| 8 | 2 |
| 1 | 3 |
| 3 | 4 |
| 2 | 5 |
+----------+----------+按照给定的字段进行排序,asc:升序(默认) desc:降序
如果同时选择多个字段,先按第一个字段排序,如果第一个字段值相等,再尝试第二个字段,以此类推
# 默认升序
select * from students order by birthday;
# 降序
select * from students order by birthday desc;select → 字段→ from→ 表名→where→group by→order by→limit
例如这里有三个表:
从姓名表中查询为id为6,成绩表中他课程号为4,科目表中id为4的所有信息:
select a.name,c.name,b.score from students as a,score as b,course as c where b.user_id=6 and b.course_id=4 and a.id=b.user_id and c.id=b.course_id;有时为了得到完整的结果,我们需要从两个或更多的表中获取结果。我们就需要执行 join
select a.*,b.name from students as a [inner] join city as b on a.livecity=b.id;select a.*,b.name from students as a left join city as b on a.livecity=b.id;select a.*,b.name from students as a right join city as b on a.livecity=b.id;# 带有连接的分组
select city.name, count(*) from students,city where students.livecity=city.id group by st
udents.livecity;
+--------+----------+
| name | count(*) |
+--------+----------+
| 北京 | 7 |
| 上海 | 8 |
| 杭州 | 1 |
| 深圳 | 3 |
+--------+----------+子查询(subquery)是指出现在其他 SQL语句内的 select 子句(嵌套在查询内部,且必须始终出现在圆括号内)
# 查找城市名称是北京的
# 普通方式查询
select * from students where livecity=1;
# 子查询方式
select * from students where livecity=(select id from city where name='北京');视图是从一个或几个基本表(或视图)中导出的虚拟的表。在系统的数据字典中仅存放了视图的定义,不存放视图对应的数据。视图是原始数据库数据的一种变换,是查看表中数据的另外一种方式。可以将视图看成是一个移动的窗口,通过它可以看到感兴趣的数据。 视图是从一个或多个实际表中获得的,这些表的数据存放在数据库中。那些用于产生视图的表叫做该视图的基表。一个视图也可以从另一个视图中产生。
数据库中视图是一个重要的概念,其优势在于:
CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE conditi
on;
参数说明:
# ALTER 语句:
ALTER VIEW view_name AS SELECT column_name(s) FROM table_name WHERE c
ondition;
# CREATE OR REPLACE 语句:
ALTER VIEW view_name AS SELECT column_name(s) FROM table_name WHERE c
ondition;DROP view_name;SHOW TABLES;
SHOW TABLE STATUS;这两个命令不仅可以显示表名及表信息,而且会显示出所有视图名称及视图信息。除此之外,使用 SHOW CREATE VIEW 命令可以查看某个视图的定义,格式如下:
SHOW CREATE VIEW view_name;关系数据库表是用于存储和组织信息的数据结构,数据结构的不同,直接影响操作数据的效率和功能,对于 MySQL来说,它提供了很多种类型的存储引擎,可以根据对数据处理的需求,选择不同的存储引擎,从而最大限度的利用 MySQL强大的功能。
MyISAM 表是独立于操作系统的,这说明可以轻松地将其从 Windows 服务器移植到 Linux 服务器,建立一个 MyISAM 引擎的 tb_Demo 表,就会生成以下三个文件:
MyISAM 无法处理事务 ,特别适合以下几种情况下使用:
InnoDB是一个健壮的事务型存储引擎,InnoDB还引入了外键约束,在以下场合下,使用 InnoDB是最理想的选择:
以银行转账业务为例,张三→李四转账 100 元,这是一个完整事务,需要两步操作:
如果在 1步完成后,操作出现错误(断电、操作异常等),使 2步没有完成,此时,张三减去了 100元,而张三却没有收到 100 元
为了避免这种情况的发生,就将整个操作定义为一个事务,任何操作步骤出现错
误,都会回滚到上一次断点位置,避免出现其他错误。
语法:
# 开始
begin;
update tbl_a set money=money-100 where name='zhangsan';
update tbl_b set money=money+100 where name='lisi';
# 提交
commit;
# 回滚
rollback;索引是帮助 MySQL高效获取数据的数据结构
数据库在保存数据之外,还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。索引可以大大提高 MySQL的检索速度。
在 MySQL中,对于一个 Primary Key的列,MySQL已经自动对其建立了 Unique和 Index。
# 创建索引
create table 表名(
id int not null,
username varchar(16) not null,
index(username(length)) ### 用 username字段作为索引
);# 显示索引
show index from 表名;# 删除索引
alter table 表名 drop index name;约束保证数据的完整性和一致性,根据约束的字段数目的多少,约束又分为表级约束和列级约束
约束类型包括:
注意: 每个表可以有多个 unique约束,但是每个表只能有一个 primary key 约束。# 第一种方式
create table persons(
id_p int not null,
address varchar(255),
city varchar(255),
phone varchar(11) unique # 定义字段的同时,定义约束
);
# 第二种方式
create table persons(
id_p int not null,
address varchar(255),
city varchar(255),
phone varchar(11),
unique phone(phone) # 单独一行命令,定义约束
# 第三种方式
alter table persons add unique city(city); #修改表用于约束对应列中的值的默认值(除非默认为空值,否则不可插入空值)
create table persons(
id tinyint primary key auto_increment,
name varchar(30),
sex enum('m','w') default 'm', # 定义 sex 默认值为:'m'
)每张数据表只能存在一个主键,主键保证记录的唯一性,主键自动为 not null(同时作为表的索引)。
# 为没有主键的表添加主键
alter table 表名 add primary key (字段名)外键约束是为了保持数据一致性,完整性,实现一对一或一对多关系
innoDB。# 先建父表 子表才能建外键 父表和子表必须都是 innodb 引擎
# city父表
create table city(
id tinyint primary key,
name varchar(10) not null
)engine=INNODB;
# students 子表
create table students(
id tinyint primary key auto_increment, #id
# 定义字段时同时定义
city tinyint, # 外键字段类型要与主表相同
foreign key(city) references city(id), # city 字段作为外键 ,引用 city表中的 id
)engine=INNODB;
-----------------------------------------------------------------------------
# 主表的数据可以修改,但不能删除
# 删除 city中的记录
delete from city where id=1;
# 创建外键以后,再删除 city记录,就会报错:
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fail
s (`hxsd`.`students`, CONSTRAINT `students_ibfk_1` FOREIGN KEY (`city`) REFERE
NCES `city` (`id`))alter table 表名 drop primary key;alter table 表名 drop index index_name;alter table 表名 drop foreign key FK_ID;索引是面向数据库本身的,用于查询优化等操作。约束则更多的是业务上的关系。
通常,创建唯一约束就自动获取唯一索引,是因为数据库认为对数据库进行唯一检查时,如果该字段上有索引会很快,所以创建唯一约束就默认创建唯一索引。同样,常见的主键即是唯一性的约束,也是个索引。但对于 not null 这样的约束,数据库是不会创建索引的。
如果一张表的数据量太大,不仅查找数据的效率低下,而且难以找到一块集中的存储来存放。为了解决这个问题,数据库推出了分区的功能。MySQL 表分区主要有以下四种类型:
create table test(
id int DEFAULT null,
name char(30),
datedata date
)
PARTITION BY RANGE (year(datedata)) (
PARTITION part1 VALUES LESS THAN (1990) ,
PARTITION part2 VALUES LESS THAN (1995) ,
PARTITION part3 VALUES LESS THAN (2000) ,
PARTITION part4 VALUES LESS THAN MAXVALUE ); create table test1(
id int not null,
name char(30),
career VARCHAR(30)
)
PARTITION BY LIST (id) (
PARTITION part0 VALUES IN (1,5) ,
PARTITION part1 VALUES IN (11,15) ,
PARTITION part2 VALUES IN (6,10) ,
PARTITION part3 VALUES IN (16,20)
);CREATE TABLE employees (
id INT NOT NULL,
firstname VARCHAR(30),
lastname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH(store_id) PARTITIONS 4;
CREATE TABLE tk (
col1 INT NOT NULL,
col2 CHAR(5),
col3 DATE,
PRIMARY KEY(col1)
)
PARTITION BY KEY (col1) PARTITIONS 3;
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。(*)
存储过程是为了完成特定功能的 SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程**上很简单,就是数据库 SQL 语言层面的代码封装与重用。
优点:
存储过程就是具有名字的一段代码,用来完成一个特定的功能。
创建的存储过程保存在数据库的数据字典中。
语法:
create procedure 存储过程名称(in|out|inout 参数名称 参数类型,......)
begin
过程体;
end实例:
create procedure getStudentCount()
begin
select count(*) as num from student where classid=8;
end查看所有存储过程状态:
SHOW PROCEDURE STATUS;查看对应数据库下所有存储过程状态:
SHOW PROCEDURE STATUS WHERE DB='数据库名';查看名称包含 Student 的存储过程状态:
SHOW PROCEDURE STATUS WHERE name LIKE '%Student%';查询存储过程详细代码:
SHOW CREATE PROCEDURE 过程名;ALTER PROCEDURE 过程名 ([过程参数[,...]]) 过程体;DROP PROCEDURE 过程名;==注意:不能在一个存储过程中删除另一个存储过程,只能调用另一个存储过程。==
MySQL存储过程用 call 和过程名以及一个括号,括号里面根据需要,加入参数,参数包括输入参数、输出参数、输入输出参数调用,格式如下:
CALL存储过程名 ([过程参数[,...]])触发器(trigger),也叫触发程序,是与表有关的命名数据库对象,是 MySQL中提供给程序员来保证数据完整性的一种方法,它是与表事件 INSET、UPDATE、DELETE相关的一种特殊的存储过程,它的执行是由事件来触发,比如当对一个表
进行 INSET、UPDATE、DELETE 事件时就会激活它执行。因此,删除、新增或者修改操作可能都会激活触发器,所以不要编写过于复杂的触发器,也不要增加过多的触发器,这样会对数据的插入、修改或者删除带来比较严重的影响,同时也会带来可移植性差的后果,所以在设计触发器的时候一定要有所考虑。
CREATE TRIGGER trigger_name trigger_time trigger_event ON tb_name FOR EACH ROW tri
gger_stmt参数说明:
| 事件 | 描述 |
|---|---|
| INSERT型触发器 | 插入某一行时激活触发器,可能通过 INSERT、LOADDATA、REPLACE 语句触发 |
| UPDATE型触发器 | 更改某一行时激活触发器,可能通过 UPDATE 语句触发 |
| DELETE型触发器 | 删除某一行时激活触发器,可能通过 DELETE、REPLACE语句触发 |
我们想要使班级表中的班内学生数随着学生的添加自动更新,则采用触发器来实现
最为合适,创建触发器如下:
CREATE trigger tri_stuInsert after insert
on student for each row
BEGIN
declare c int;
set c = (select stuCount from class where classID=new.classID);
update class set stuCount = c + 1 where classID = new.classID;
END
从需求我们可以得知,班内学生数的变化是在插入学生记录之后发生的,所以创建的触发器类型为 after insert 类型。
SHOW TRIGGERS;DROP TRIGGER [IF EXISTS] trigger_name日常开发中创建的数据库通常都是 InnoDB 数据库,在数据库上建立的表大都是事务性表,也就是事务安全的,这时触发器的执行顺序主要是:
如果是对数据库的非事务表进行操作,当触发器执行顺序中的任何一步执行出错,那么就无法回滚了,数据可能会出错。
# concat
insert into tbl_name values( concat('abc','def') );# count 统计总记录数
select count(*) from tbl_name;
# sum 年龄总和
select sum(age) from tbl_name;
# avg 平均年龄
select avg(age) from tbl_name;
# 最大年龄
select min(birthday) from tbl_name; # 日期最小的FOUND_ROWS 函数配合 SQL_CALC_FOUND_ROWS 用于获取总记录数(忽略limit)
select SQL_CALC_FOUND_ROWS * from qa_list limit 3;
select FOUND_ROWS();第一个 sql 里面的 SQL_CALC_FOUND_ROWS 不可省略,它表示需要取得结果数,也是后面使用 FOUND_ROWS()函数的铺垫。
FOUND_ROWS()返回的结果是临时的。如果程序往后会用到这个数字,必须提前它保存在一个变量中待用。
FOUND_ROWS()与 count()的区别:
1、当 SQL限制条件太多时, count()的执行效率不是很高,最好使用 FOUND_RO
WS()
2、当 SQL查询语句没有 where等条件限制时,使用 count()函数的执行效率较高。
mysqldump -u [用户名] -p [密码] [数据库名] > [path]/[名称].sqlmysql>source c:\system.sql..................
防抖:在第一次触发事件时,不立即执行函数,而是给出一个限定值,比如200ms,然后:
应用场景:
效果:如果短时间内大量触发同一件事,只会执行一次函数。
防抖函数的核心思路如下:
接下来,就是将思路转成代码:
定义debounce函数要求传入两个参数
通过定时器来延迟传入函数fn的执行
自定义防抖函数:
function debounce(fn, delay) {
var timer = null;
return function () {
if (timer) clearTimeout(timer);
timer = setTimeout(function () {
fn();
},delay)
}
}假如我们需要获取input框中输入的值,如何获取?我们知道在oninput事件触发时会有参数传递,并且触发的函数中this是指向当前的元素节点的
目前我们fn的执行是一个独立函数调用,它里面的this是window,我们需要将其修改为对应的节点对象,而返回的function中的this指向的是节点对象;
目前我们的fn在执行时是没有传递任何的参数的,它需要将触发事件时传递的参数传递给fn,而我们返回的function中的arguments正是我们需要的参数;
所以我们的代码可以进行如下的优化:
function debounce(fn, delay) {
var timer = null;
return function() {
if (timer) clearTimeout(timer);
// 获取this和argument
var _this = this;
var _arguments = arguments;
timer = setTimeout(function() {
// 在执行时,通过apply来使用_this和_arguments
fn.apply(_this, _arguments);
}, delay);
}
}节流:
效果:
应用场景:
监听页面的滚定事件
鼠标移动事件
搜索框input事件,要支持实时搜索可以使用节流方案
用户频繁点击按钮操作
游戏中的一些设计
总结:同样是密集的事件触发,但是这次密集事件触发的过程,不会等待最后一次才进行函数调用,而是会按照一定的频率进行调用。
节流函数的默认实现思路采用时间戳的方式来完成:
我们使用一个last来记录上一次执行的时间
每次准备执行前,获取一下当前的时间now:now - last > interval,函数执行,并且将now赋值给last即可。
基础版:
function throttle(fn, interval) {
var last = 0;
return function () {
// this和arugments
var _this = this;
var _arguments = arguments;
var now = new Date().getTime();
if (now - last > interval) {
fn.apply(_this, _arguments);
last = now;
}
}
}优化最后执行:
默认情况下,我们的防抖函数最后一次是不会执行的
now - last > interval满足不了的代码实现:
function throttle(fn, interval) {
var last = 0;
var timer = null; // 记录定时器是否已经开启
return function () {
// this和arguments;
var _this = this;
var _arguments = _arguments;
var now = new Date().getTime();
if (now - last > interval) {
if (timer) { //若已经开启,则不需要开启另外一个定时器了
clearTimeout(timer);
timer = null;
}
fn.apply(_this, _arguments);
last = now;
} else if (timer === null) { // 没有立即执行的情况下,就会开启定时器
//只是最后一次开启
timer = setTimeout(function () {
timer = null; // 如果定时器最后执行了,那么timer需要赋值为null
fn.apply(_this, _arguments);
},interval)
}
}
}A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.