Star the Repository
TODO List
- 界面优化
- 代码规范化,请求返回值规范、代码文件划分
- 实现聊天记录文件下载,以及上传合并
- 界面适应手机
- 处理聊天记录更多由本地完成,即js完成聊天记录的请求
- 添加token设置栏,按钮中设置
- 在连续对话模式下支持多人同时使用
- 重载历史记录
- 切换聊天模式和重置时提示
- 支持多对话管理
- 公式显示
- 流式拉取,逐字词动态实时显示
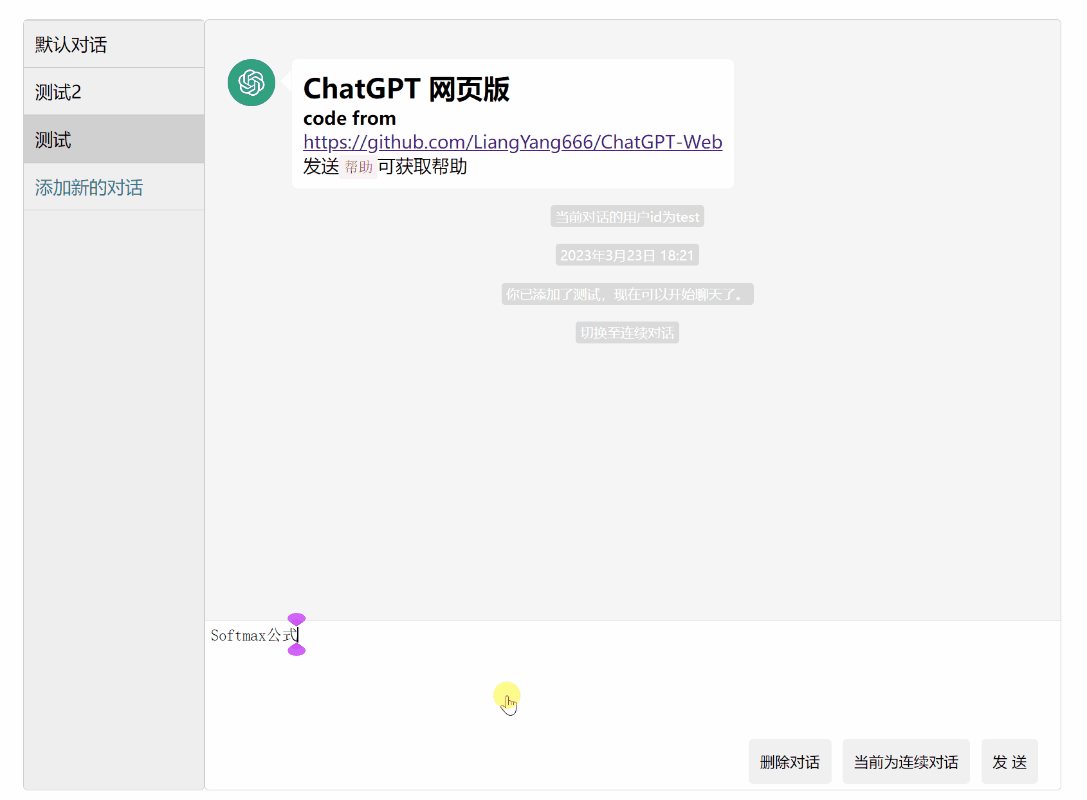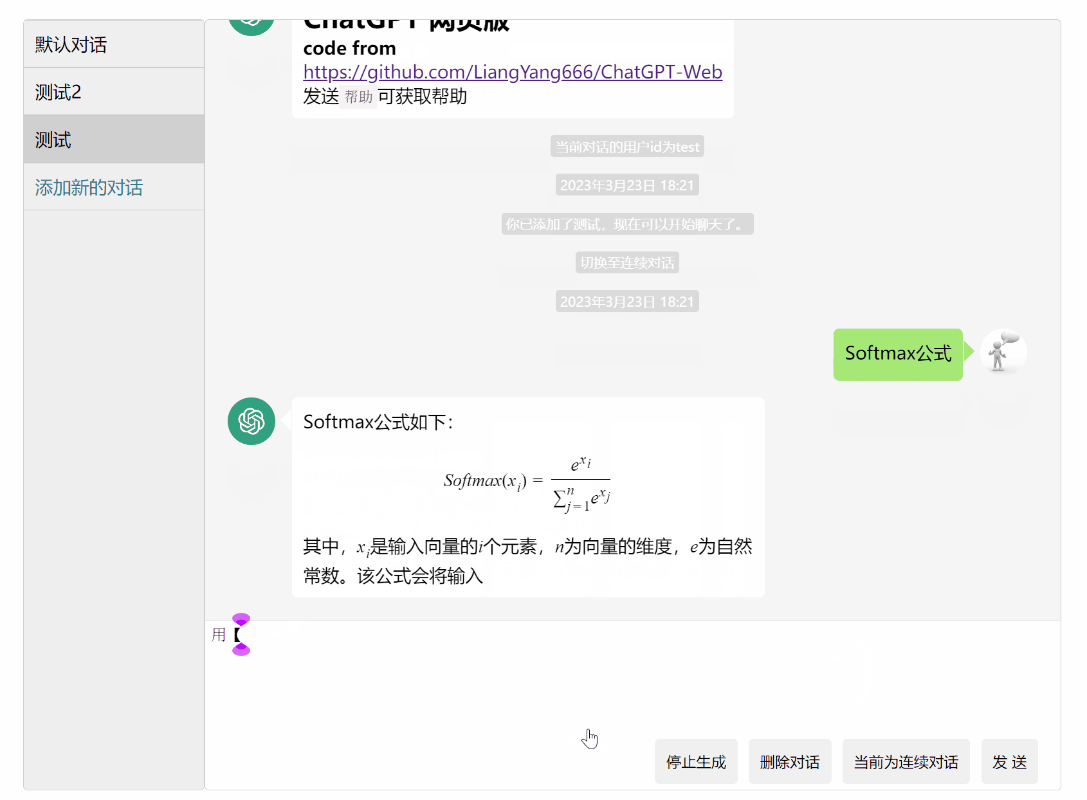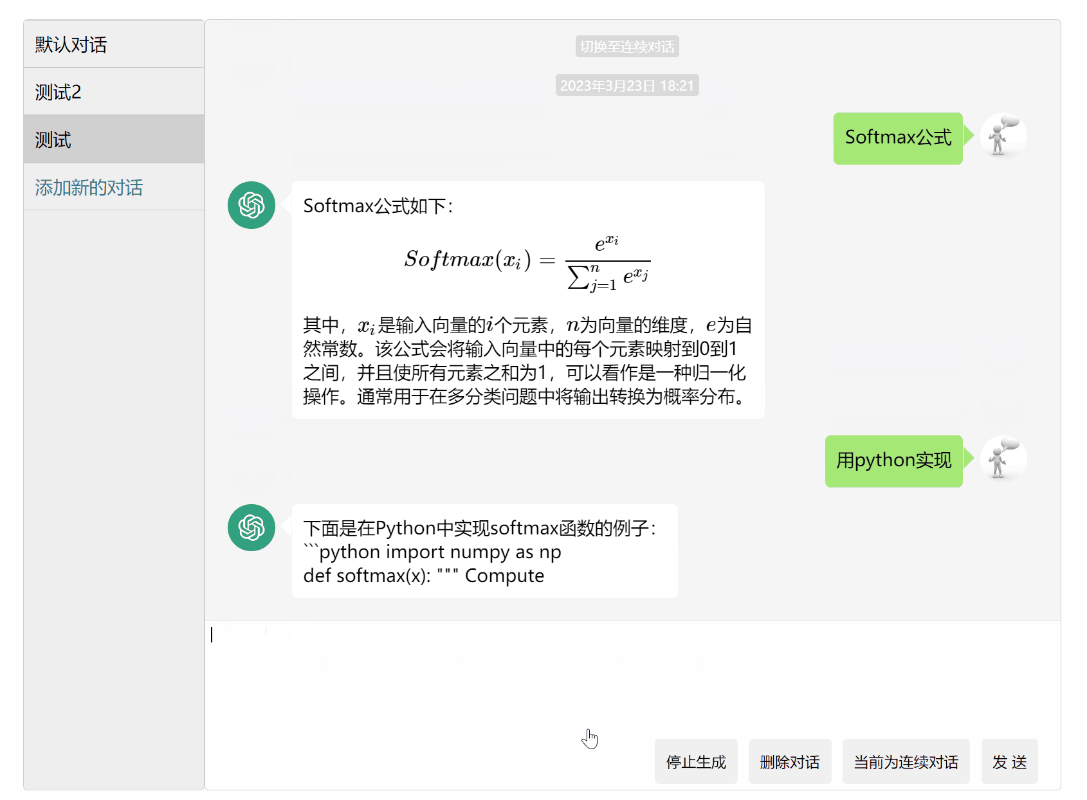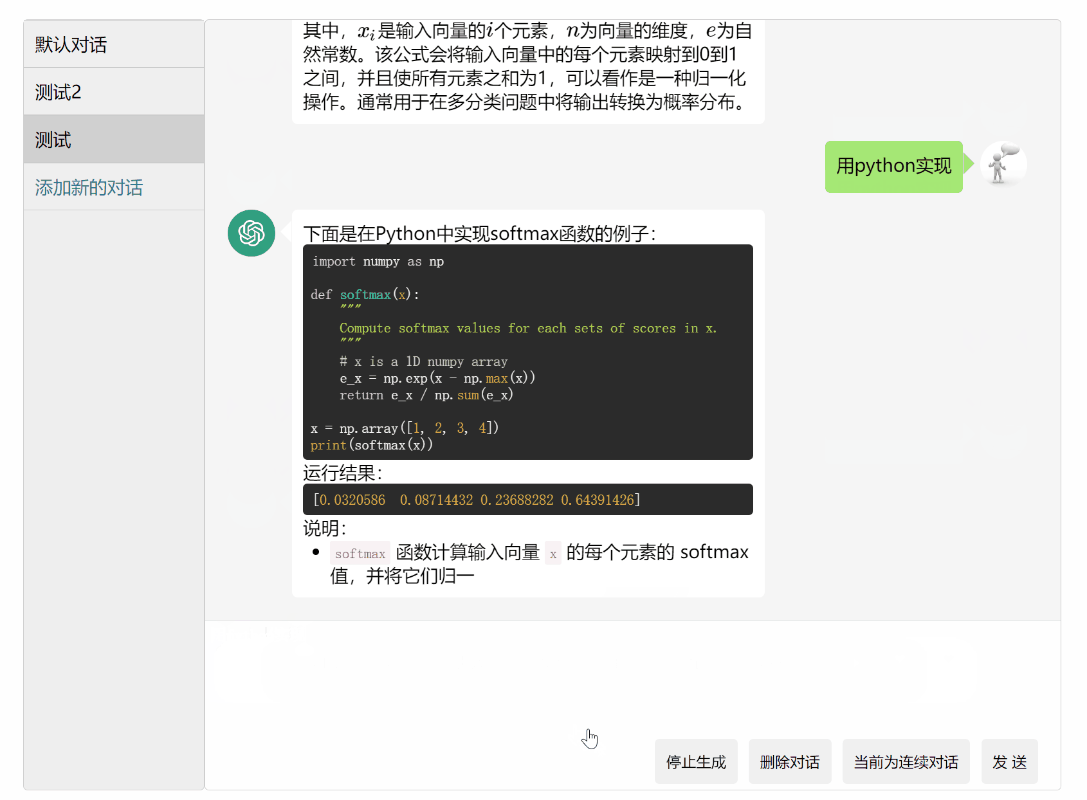
- 代码高亮显示
- 查余额
极简配置
支持Zeabur云部署(推荐,两分钟部署完成)
支持railway云部署
支持多用户使用
多对话管理
公式显示
流式逐字加载显示
代码高亮
查余额
可设置访问密码
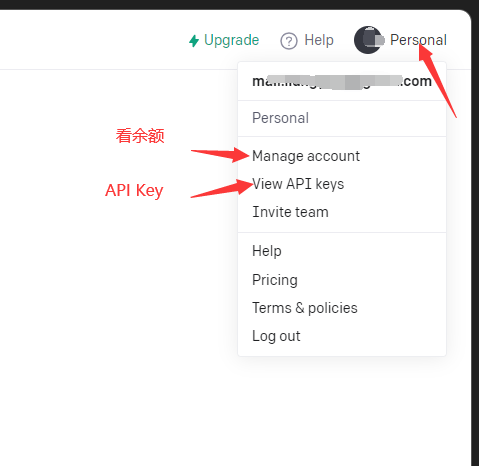
分别介绍下面几种部署方法,选择一种即可,部署完成后直接跳转至后面的使用介绍继续即可
1. Zeabur云部署(最为推荐,无需代理,云部署,通过url随时随地访问,聊天记录云同步)
- 关于Zeabur:Zeabur是云容器提供商,你能够使用它部署你的应用,并使用url链接随时随地访问你的应用,类似于Railway,但无时间限制
- 首先将代码fork到你的github中
- 点击网址注册账号,Zeabur ,绑定GitHub账号
- 进入项目创建链接,点击Create Project,输入名称 ChatGPT-Web创建项目
- 创建完成后,点击如图,添加服务
- 弹出的界面中,点击如下
- 弹出界面中,左侧选择你的GitHub,如果未绑定,请授权Zeabur访问你GitHub的所有项目,搜索ChatGPT-Web,即你clone的仓库,点击Import
- 选择分支为main,点击部署
- 等待片刻后,将显示运行中,即部署完成,但此时还需要设置一些环境变量
分别设置
DEPLOY_ON_ZEABUR为true,PORT为5000,以及OPENAI_API_KEY设置为你的apikey即可,如为保证安全性,防止他人使用还可设置PASSWORD以及ADMIN_PASSWORD环境变量(可暂不设置,有需要再设),这两个环境变量分别代表普通访问密码,以及管理员密码,设置后用户访问网页时需要使用访问密码认证,而管理员密码用于下载以及合并所有用户的聊天记录时使用- 设置访问域名,url,点击如下,再填入可用主机名保存url即可,如自己有域名,也可绑定自己的域名

- 点击redeploy重新部署,等待片刻后部署完成,一般一分钟以内部署完成,若未刷新可手动刷新网页查看,使用生成的url访问即可使用
- 使用new:xxx创建用户即可使用,或者上传已有聊天记录,相关使用方式见使用介绍
- 请注意,当设置密码或其它环境变量时请在设置后重新部署,每次部署后都会清除聊天记录,可先下载好已有用户记录再重新部署






2. 本地源代码部署(推荐,方便更新,需要有代理)
前提:python3.7及以上运行环境
- 执行
pip install -r requirements.txt安装必要包- 打开
config.yaml文件,配置HTTPS_PROXY和OPENAI_API_KEY,相关细节已在配置文件中描述,如果在境外部署无需代理,将HTTPS_PROXY行删除即可- 执行
python main.py运行程序.若程序中未指定apikey也可以在终端执行时添加环境变量,如执行OPANAI_API_KEY=sk-XXXX python main.py来运行,其中sk-XXXX为你的apikey- 打开本地浏览器访问
127.0.0.1:5000,部署完成- 关于更新,当代码更新时,使用git pull更新重新部署即可
- 使用linux开机自启动部署 执行
vim /etc/systemd/system/chatGpt.service,编辑内容如下
[Unit]
Description=my chat-gpt web
After=syslog.target network.target
Wants=network.target
[Service]
Environment="ADMIN_PASSWORD=123456"
Environment="OPENAI_API_KEY=sk-***"
Environment="PASSWORD=123456"
Type=simple
User=nano
WorkingDirectory=/home/nano/Project/ChatGPT-Web
ExecStart=/usr/bin/python3 main.py
Restart= always
RestartSec=1min
[Install]
WantedBy=multi-user.target最后启动
#启动
systemctl daemon-reload
systemctl start chatGpt.service
#设置为开机启动
systemctl enable chatGpt.service3. Railway部署(无需代理,云部署,通过url随时随地访问)
- 关于Railway:Railway是云容器提供商,你能够使用它部署你的应用,并使用url链接随时随地访问你的应用,Railway使用前提是你的GitHub账号满180天,绑定并验证后每月送5美元和500小时的使用时长,大概21天,因此如果使用这种方式需要在某些不使用的时段停止你的容器
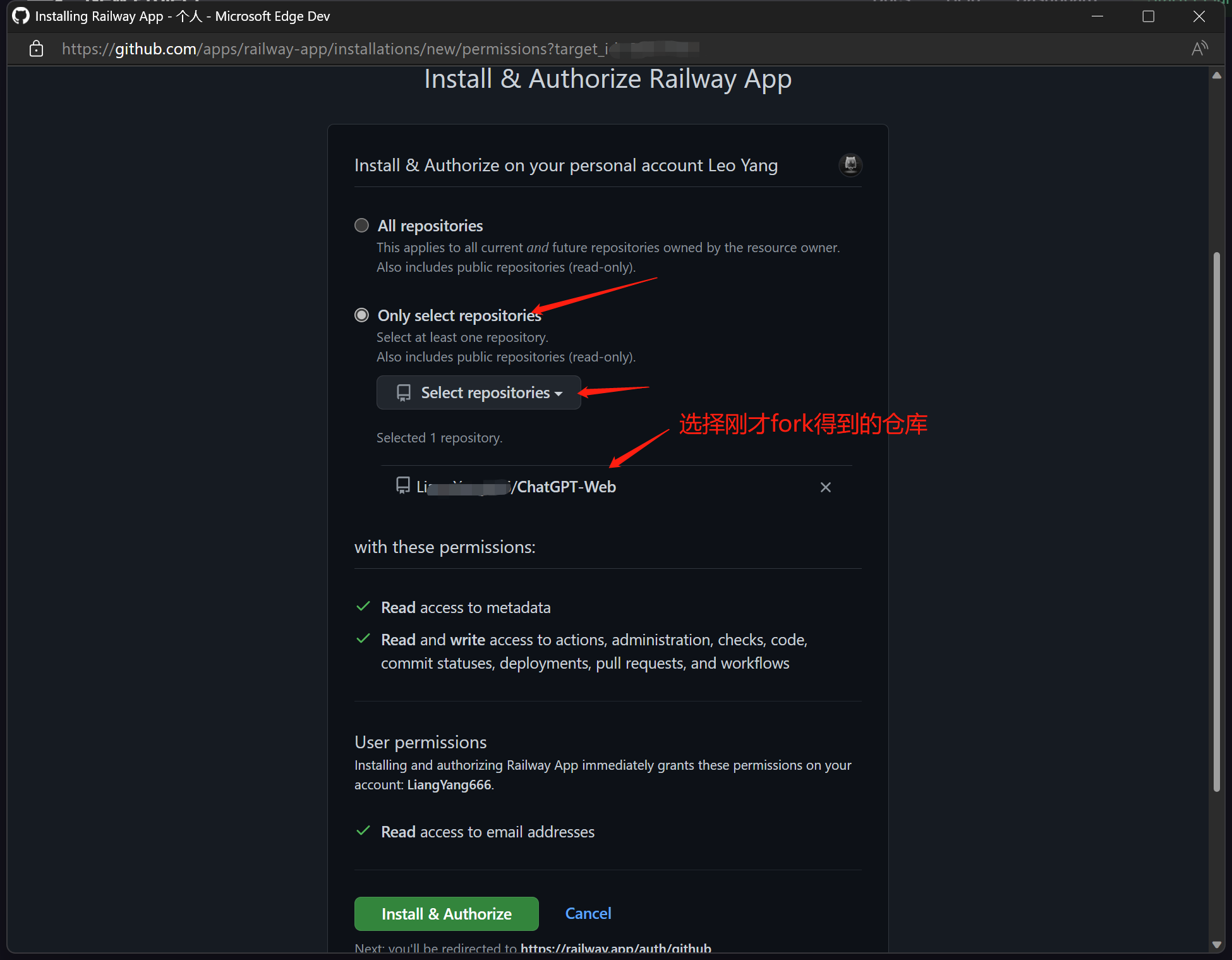
- 首先将代码fork到你的github中
- 点击右侧
,然后选择
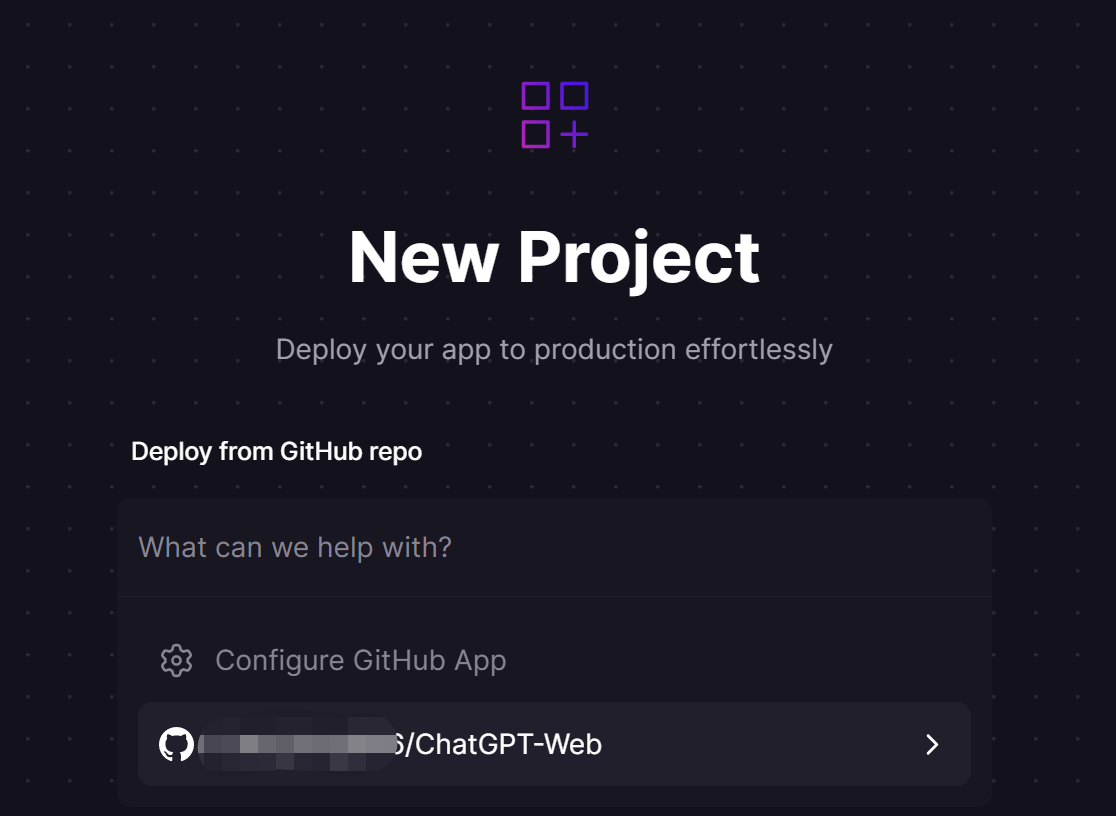
Deploy from GitHub repo,再选择Configure GitHub App,将会弹出新的窗口,在该窗口中选择Only select repositories,然后到下拉列表中选择刚才fork到你账号的仓库- 授权完成后,
Configure GitHub App下将会出现授权的项目
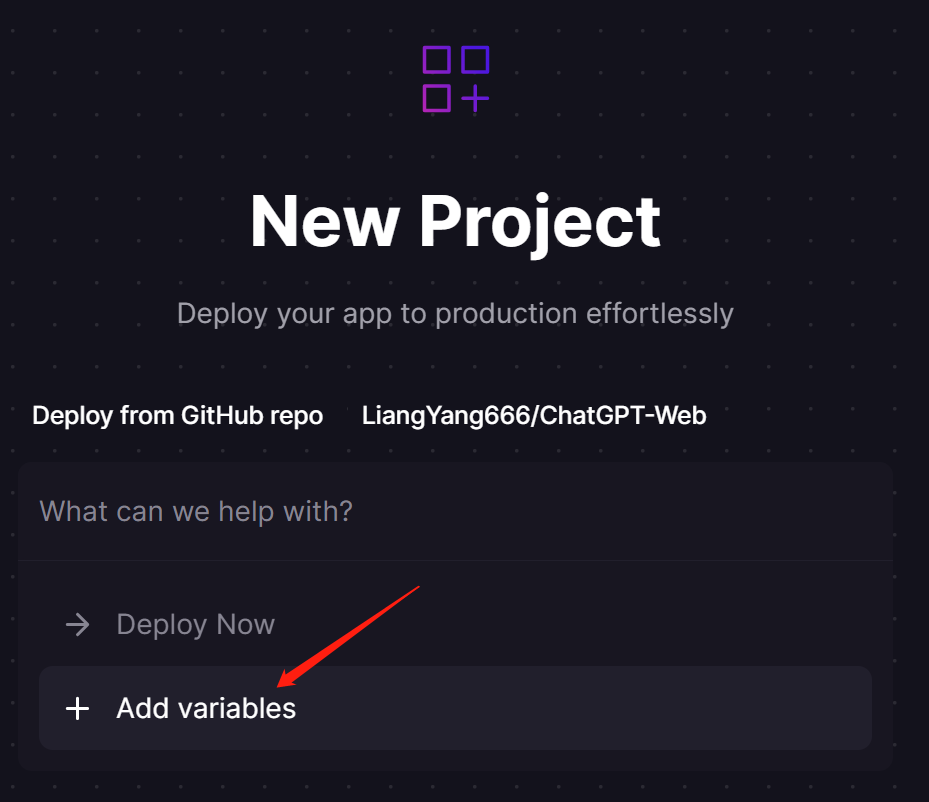
- 不要点击立即部署,点击添加变量
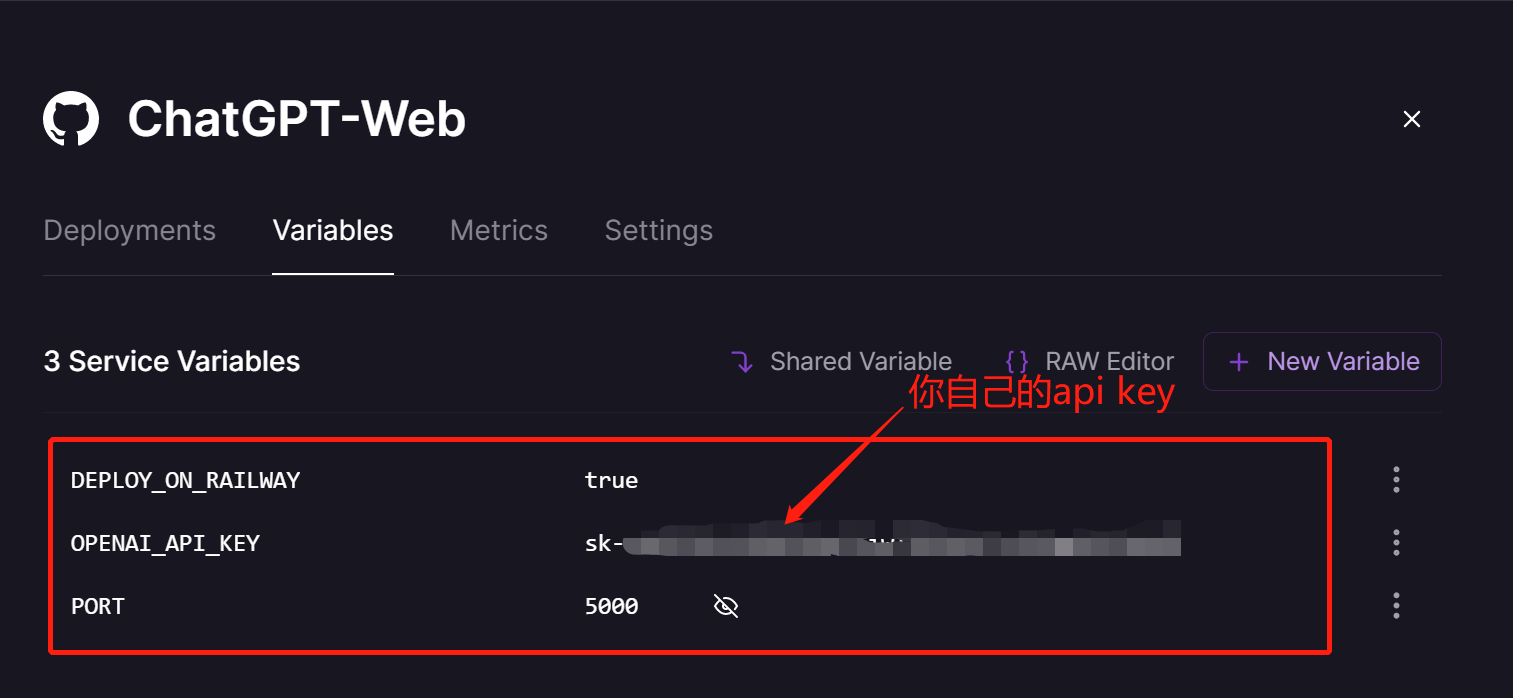
- 将会跳转至新页面,依次添加
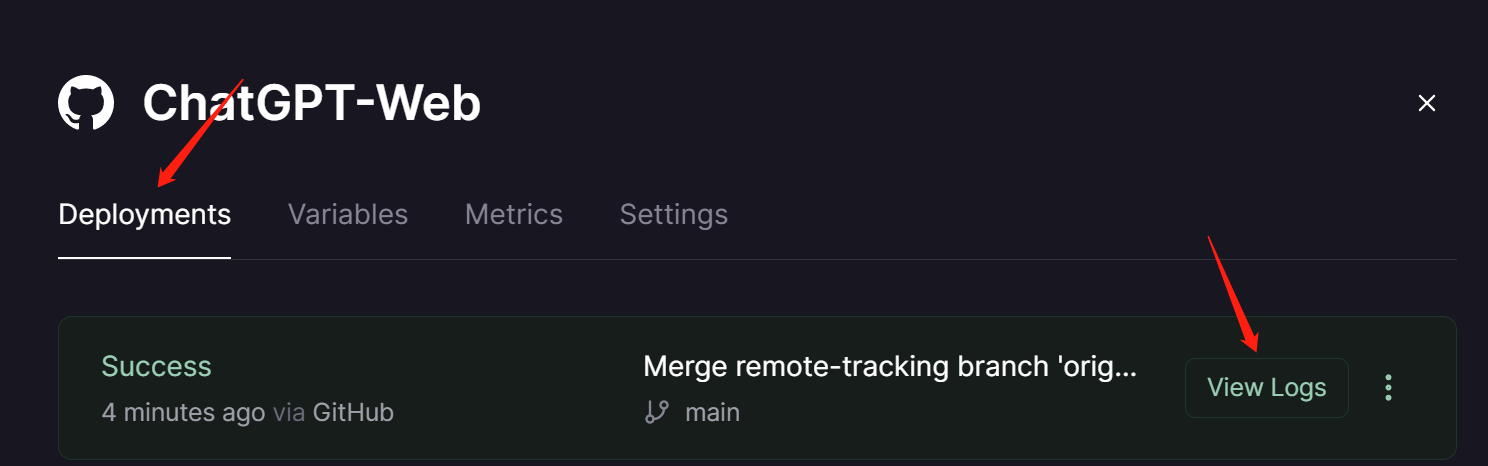
PORT,DEPLOY_ON_RAILWAY以及OPENAI_API_KEY三个环境变量,相应值如下PORT为5000,DEPLOY_ON_RAILWAY为true- 修改变量后会自动部署,可点击
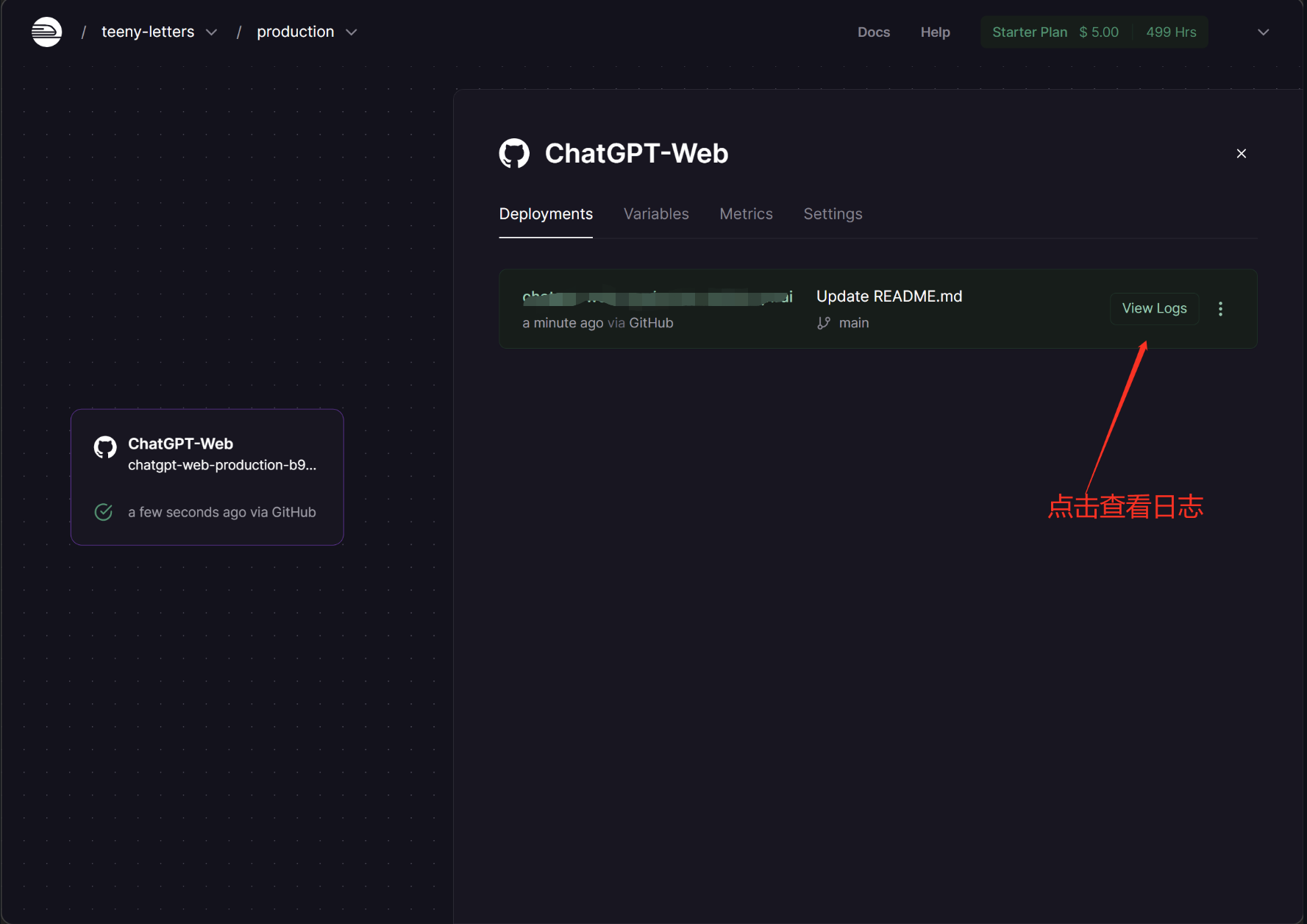
Deployments查看,还可以点击查看日志
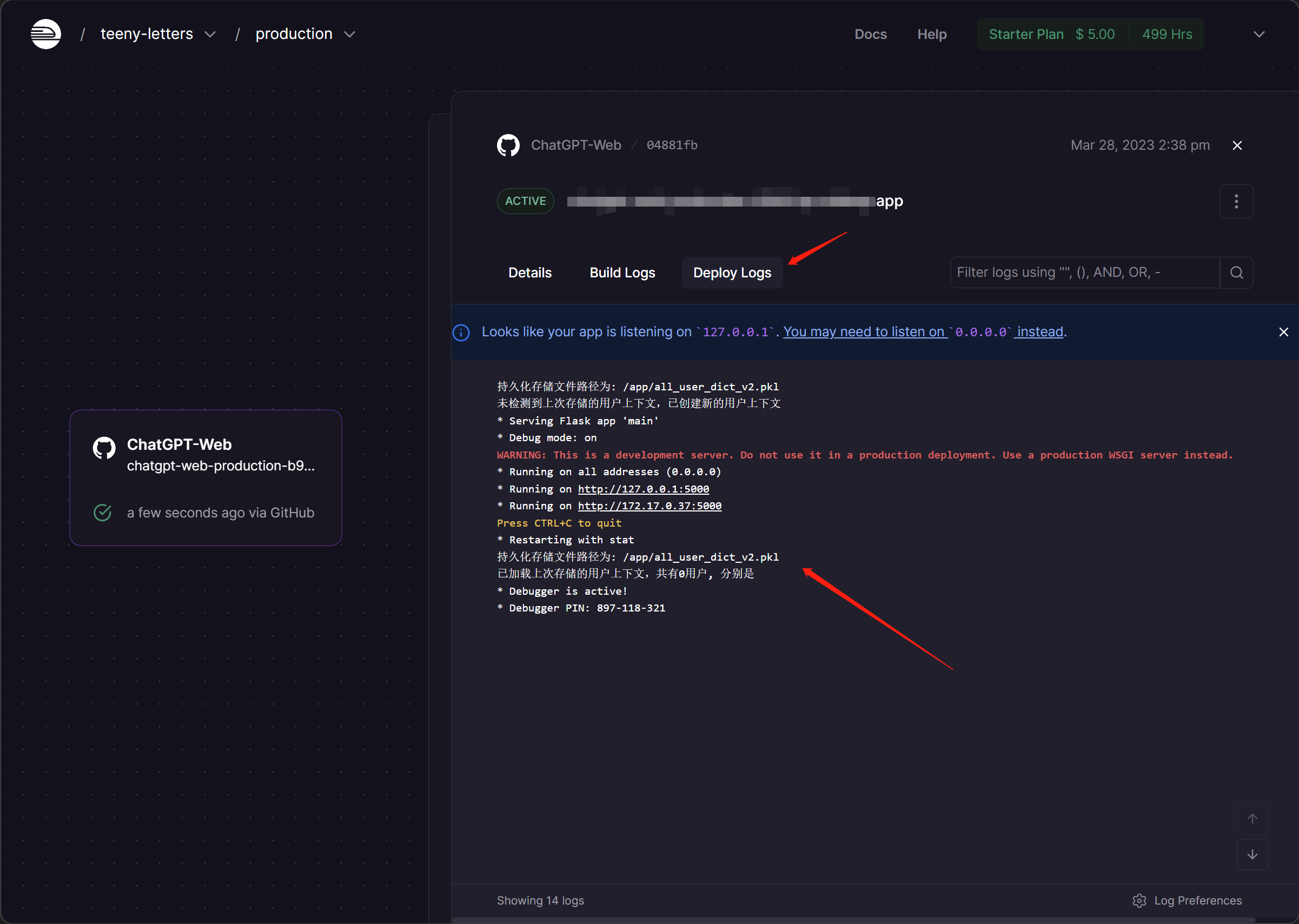
- 点击查看日志,成功的一般显示如下
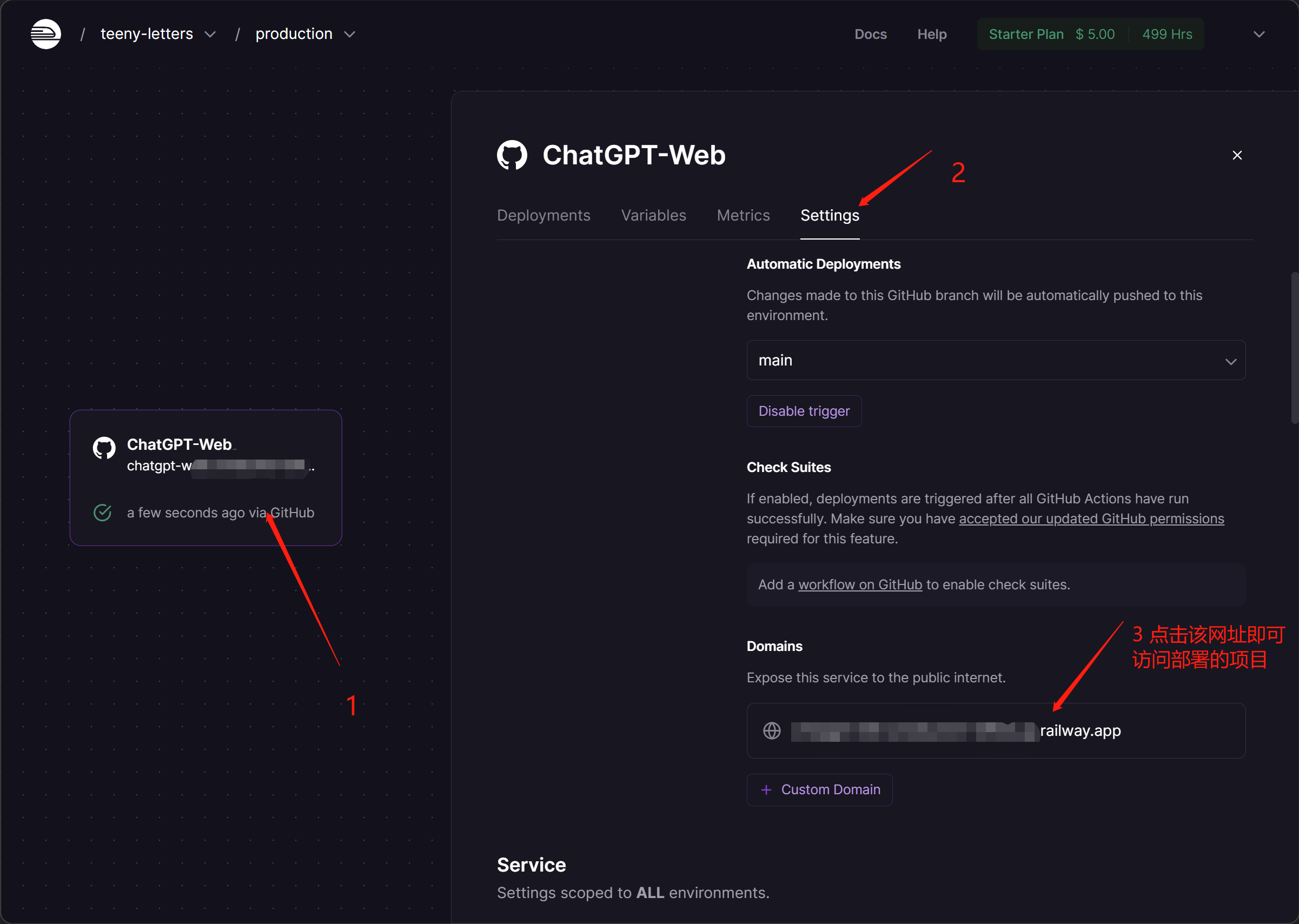
- 查看访问url,未生成可点击Generate Domain生成即可,当然如果你自己有域名,还可以添加你自己的自定义域名
- 进入后如图,任何网络环境下只要输入url即可访问
- 关于更新,当源仓库更新时,只需要将fork下来的仓库同步更新,railway将会自动部署更新的代码

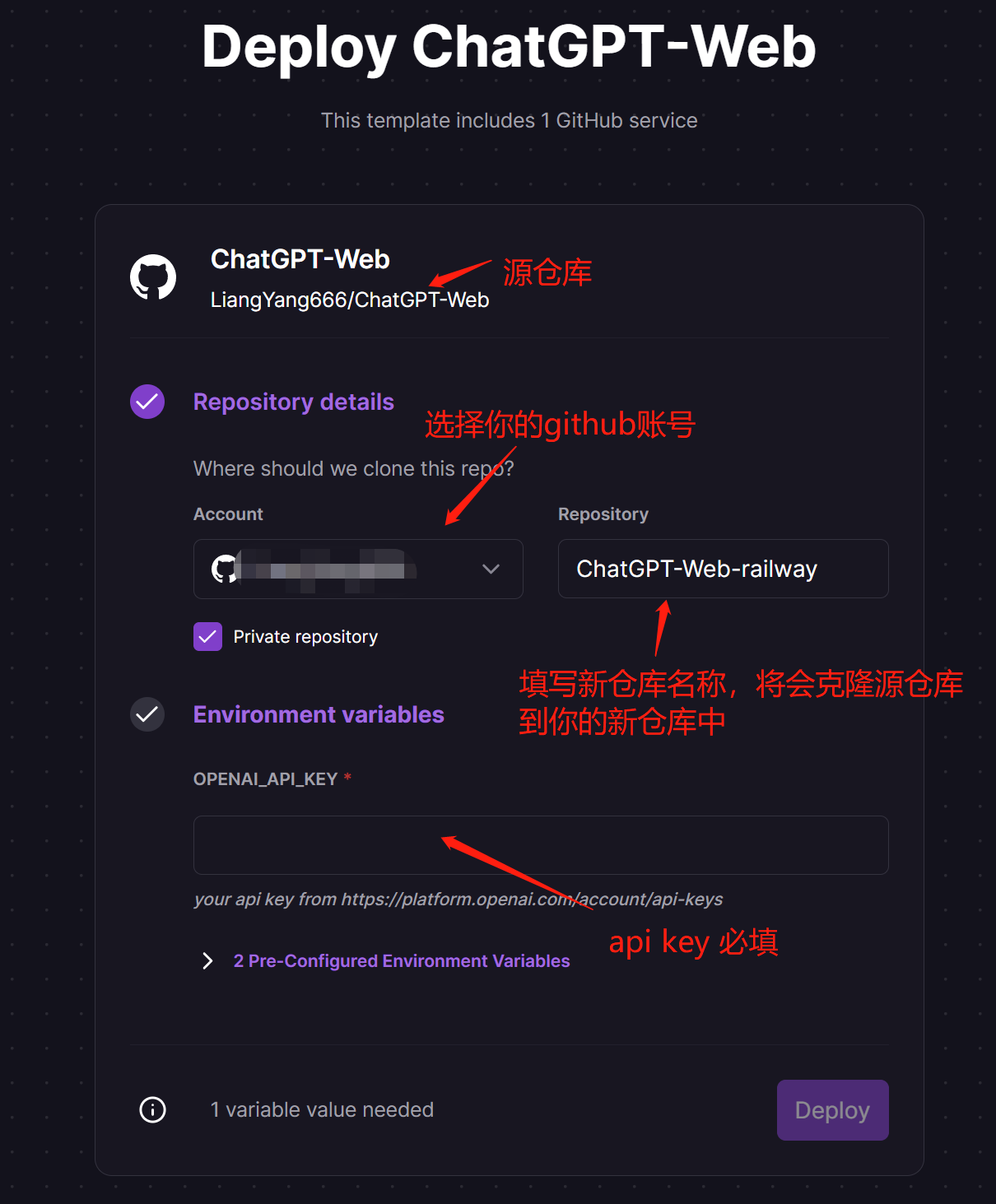
4. Railway template部署(不推荐,代码迟滞高)
- 点击右侧按钮进行部署
- 点击部署后,会自动跳转,等待部署完成即可,如图为部署完成
- 点击查看日志,成功的一般显示如下
- 查看访问url,使用该url即可访问
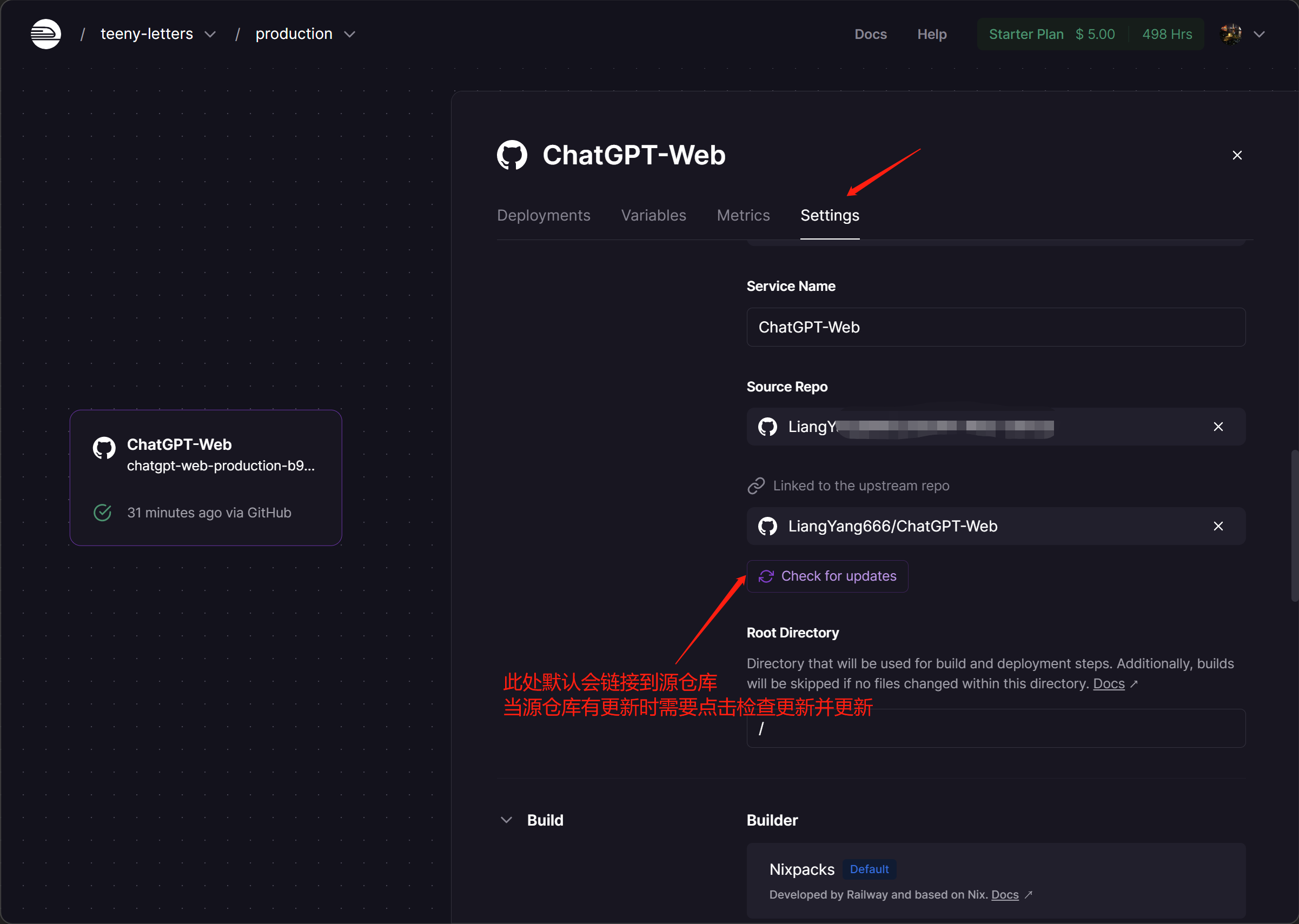
- 关于更新,点击如下进行更新即可,由Dashboard进入选择如下,但该种方式检查更新的迟滞似乎太高
5. 可执行文件部署(推荐无python运行环境使用,需要自己有代理)
待补充
6. Docker部署(需要自己有代理)
待补充
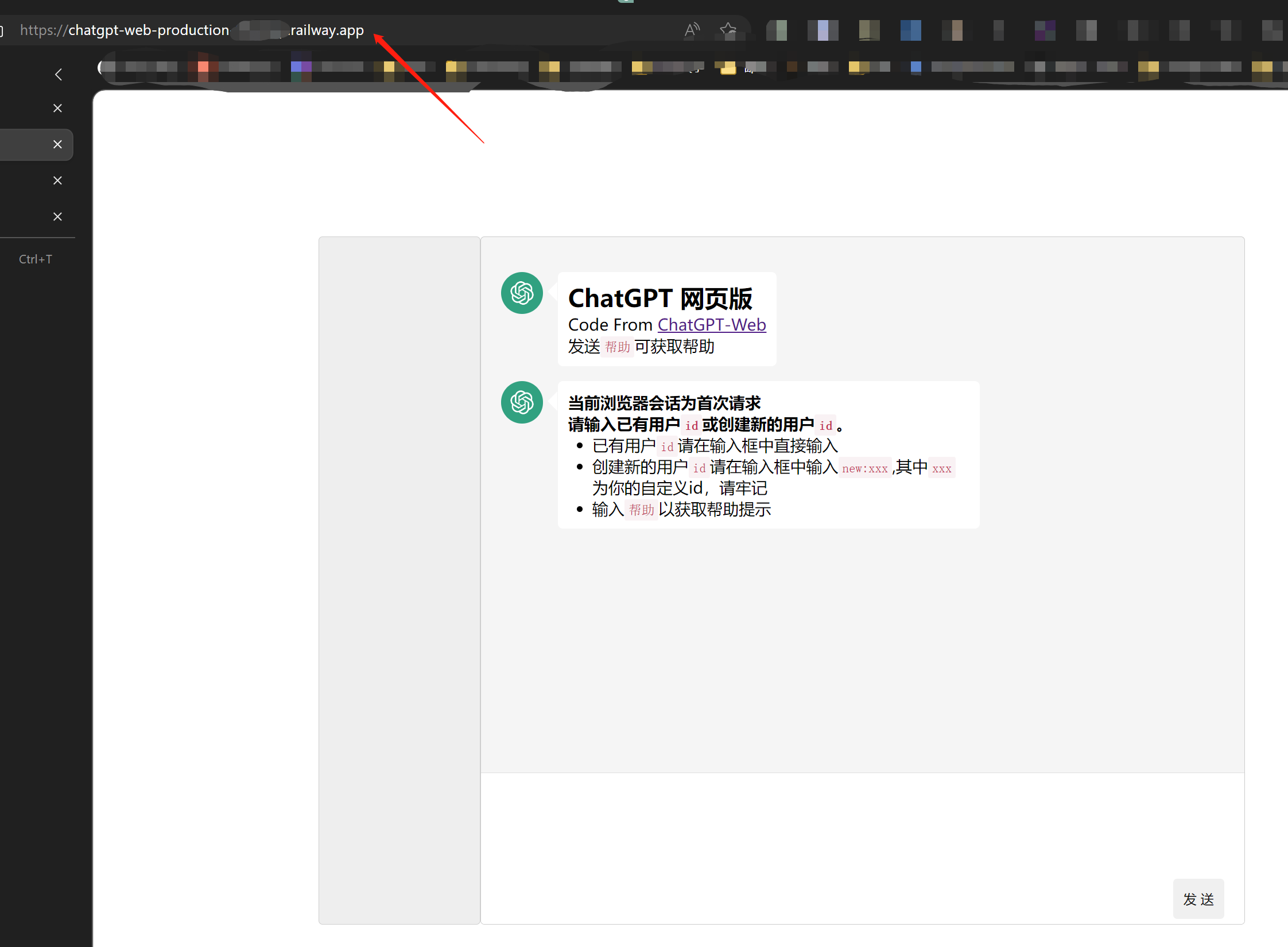
- 开启程序后进入如下页面
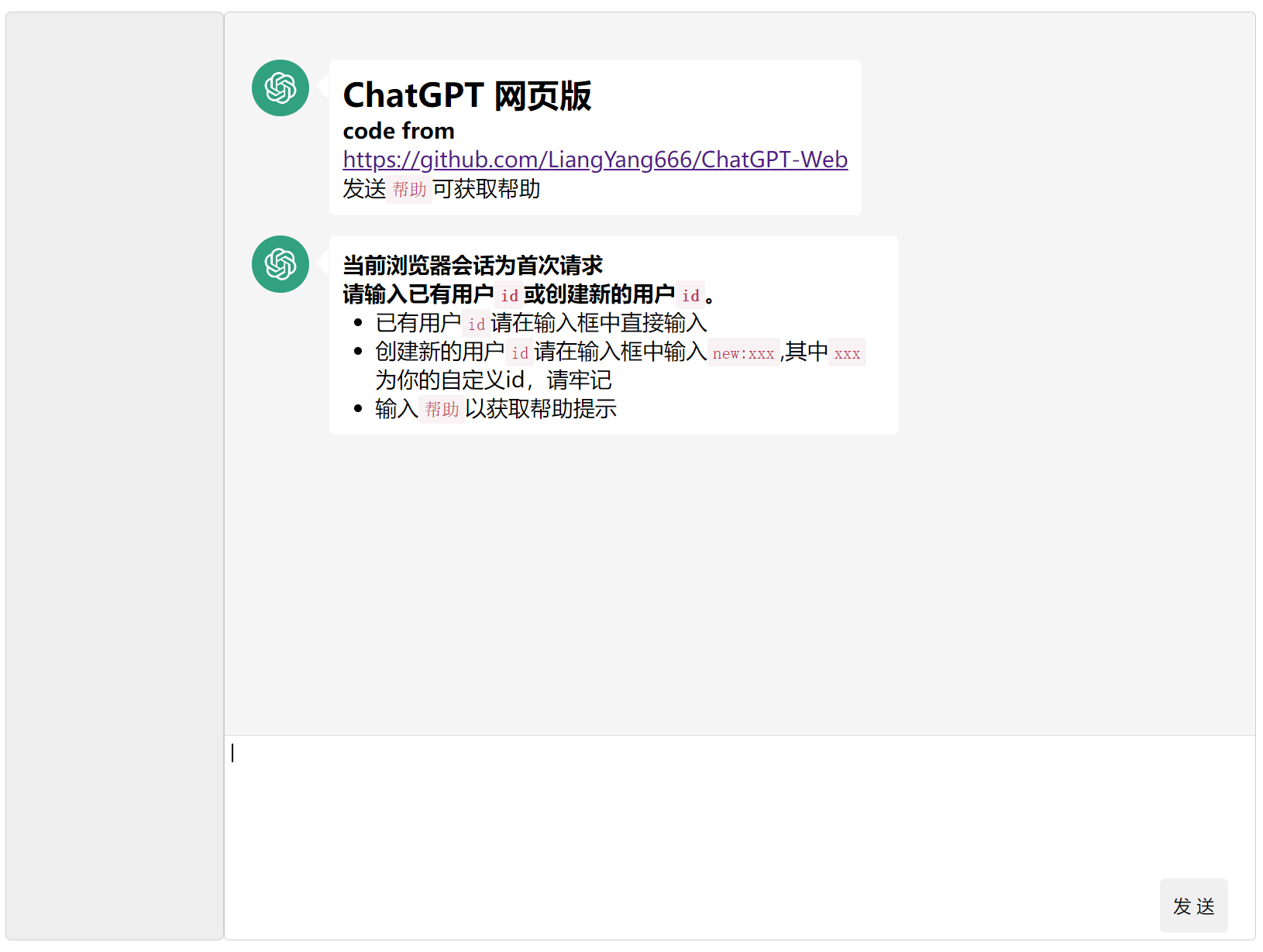
- 直接输入已有用户id,或者输入new:xxx创建新id,这个id用于绑定会话,下次不同浏览器打开都可以恢复用户的聊天记录,一个浏览器31天内一般不会要求再次输入用户id,如下为创建一个新id,名为zs,下图为发送完成后自动刷新的用户页面,左侧会有一个默认对话

- 代码中已经设置了apikey,但如果开放给别人用针对个别用户也可以按照说明设置用户专属apikey,这里就暂不设置专属的
- 默认为普通对话模式,即每次发送都是仅对于该提问回答,可点击切换为连续对话模式,chatgpt将会联系上下文(之前的对话,程序中设置了最大5条记录)回复你,但意味着花费会更多money
- 用python写一个冒泡算法试试看,回车发送,shift+回车换行,然后问用java呢?会联系上下文回答
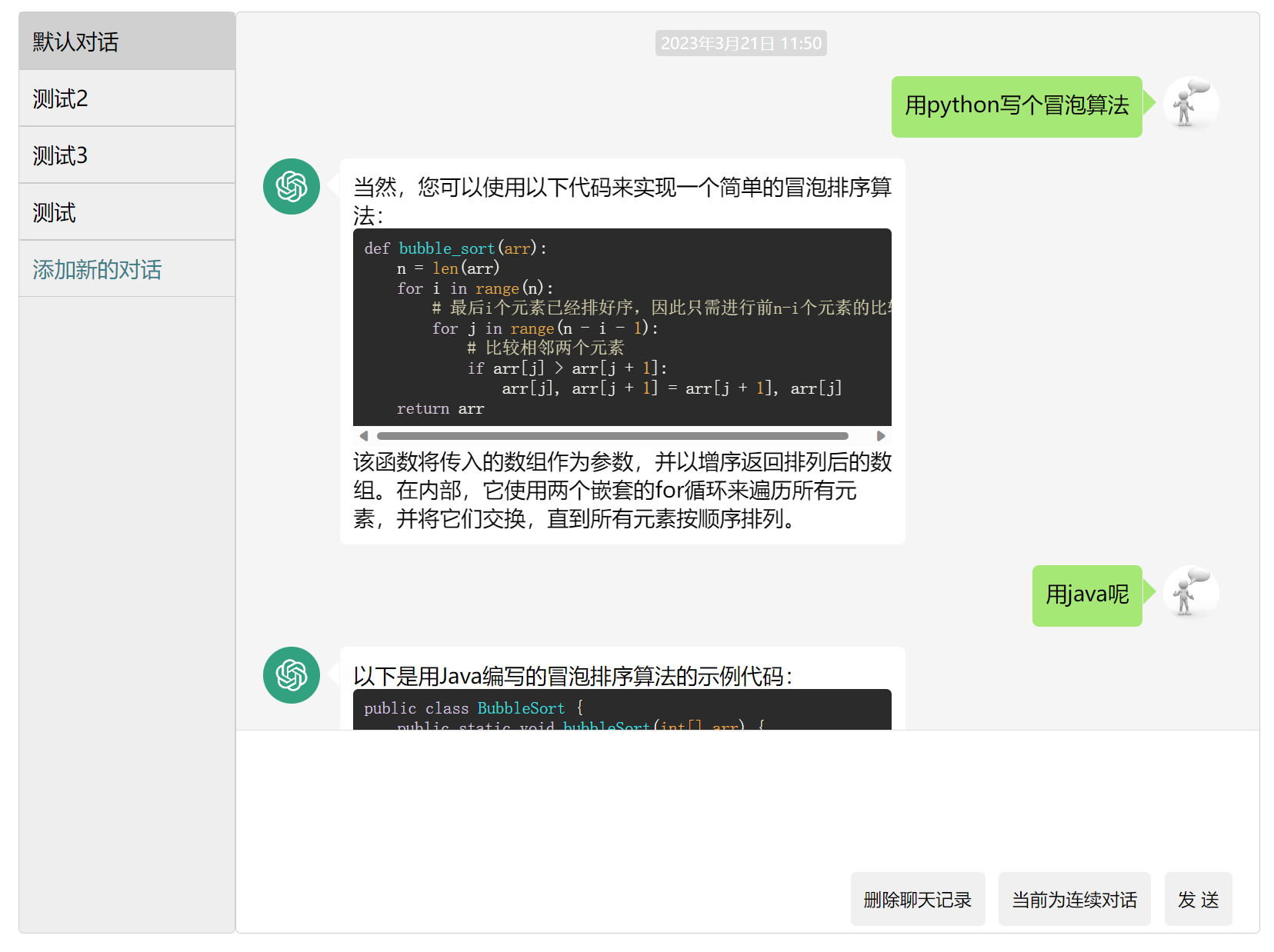
- 还可以按如下添加对话
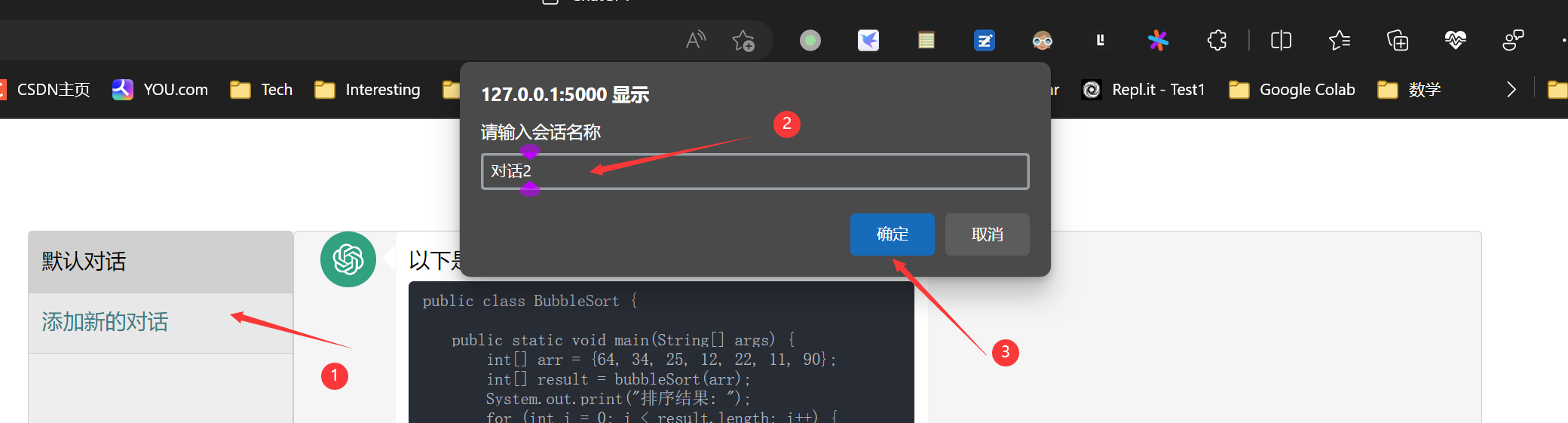
- 对话管理,当不使用该对话时,可以点击删除对话,若当前为默认对话,则只可删除聊天记录
2023.05.14 支持访问密码,支持Zeabur部署
2023.3.19: 代码高亮显示
2023.3.17: 显示公式
2023.3.17: 类似于chatgpt官网,支持实时流获取,即逐字获取动态加载显示
2023.3.13: 类似于chatgpt官网,支持新建对话,单个用户可以管理多个对话
2323.3.6: 会话与用户id绑定并保存用户信息,同一浏览器下次登陆时自动进入绑定的id,其余设备输入用户id后依然可以重载聊天记录
2323.3.6: 支持保存历史聊天记录,当重新打开会话时自动恢复聊天记录,使用pickle持久化存储,程序重启时依然可加载各用户聊天记录
2023.3.5: 支持markdown内容显示



























































































































