lf-lang / reactor-c Goto Github PK
View Code? Open in Web Editor NEWA reactor runtime written in C
License: Other
A reactor runtime written in C
License: Other































You cannot perform string comparisons with the preprocessor. I have made a fix in the LET Scheduler draft PR, hopefully will merge this in during next week and thus fix this issue
Here is the current action plan for a LET scheduler:
It would be great to track our runtime performance over time. I found this GitHub action that could help us: https://github.com/benchmark-action/github-action-benchmark
Earlier, problems were identified with the implementation of lf_timed_wait on Windows, and a fix was provided in #115. Recently, a similar test failure arose in CI on macOS: https://github.com/lf-lang/lingua-franca/actions/runs/3325260734/jobs/5497761927
The unthreaded runtime currently does not support asynchronous calls to lf_schedule and therefore does not support physical actions. This has become particularly problematic for bare-iron targets which want to call lf_schedule in interrupt service routines. The lock-time branch proposes two key new platform functions (which require different implementations for each platform) named lf_critical_section_enter and lf_critical_section_exit. On Windows, Mac, and Linux, these can be realized with mutexes similar to the threaded runtime. On bare-iron platforms, they would be realized by disabling interrupts. These functions will then need to be called by lf_schedule as well as by all accesses to the event queue and the code that increments logical time.
After updating to lf/master and reactor-c/main, the program below no longer compiles. The error is:
In file included from /Users/eal/git/examples-lingua-franca/CCpp/src-gen/DoorLock/DoorLock/core/threaded/scheduler_adaptive.c:38:
/Users/eal/git/examples-lingua-franca/CCpp/src-gen/DoorLock/DoorLock/core/../include/core/threaded/worker_assignments.h:207:20: error: implicit declaration of function 'LF_LEVEL' is invalid in C99 [-Werror,-Wimplicit-function-declaration]
size_t level = LF_LEVEL(reaction->index);
^
The program:
/**
* A simple car door lock system with a single door that can be
* controlled in any of three ways:
* 1. buttons on the physical door,
* 2. an external system (like an RFID key fob), or
* 3. a mobile device (like a phone) via a cloud service.
*
* Potentially interesting behaviors:
*
* If the door is locked and closed and receives simultaneous open
* and unlock commands, it unlocks the door, but the door remains closed.
*
* @author Ravi Akella
* @author Edward A. Lee
*/
target C {
keepalive: true,
}
import UserInteraction from "lib/UserInteraction.lf"
preamble {=
#include "types.h"
=}
reactor DoorLockController {
input door:OpenEvent;
input button:LockCommand;
input fob:LockCommand;
input mobile:LockCommand;
// FIXME: Bug: Without this reaction, none of the other reactions trigger.
// reaction(button) {= =}
initial mode ClosedLocked {
reaction(reset) {=
lf_print("*** Door is closed and locked.");
=}
reaction(button) -> ClosedUnlocked {=
if (button->value == UNLOCK) lf_set_mode(ClosedUnlocked);
=}
reaction(fob) -> ClosedUnlocked {=
if (fob->value == UNLOCK) lf_set_mode(ClosedUnlocked);
=}
reaction(mobile) -> ClosedUnlocked {=
if (mobile->value == UNLOCK) lf_set_mode(ClosedUnlocked);
=}
}
mode ClosedUnlocked {
reaction(reset) {=
lf_print("*** Door is closed and unlocked.");
=}
reaction(button) -> ClosedLocked {=
if (button->value == LOCK) lf_set_mode(ClosedLocked);
=}
reaction(fob) -> ClosedLocked {=
if (fob->value == LOCK) lf_set_mode(ClosedLocked);
=}
reaction(mobile) -> ClosedLocked {=
if (mobile->value == LOCK) lf_set_mode(ClosedLocked);
=}
reaction(door) -> Open {=
if (door->value == OPEN) lf_set_mode(Open);
=}
}
mode Open {
reaction(reset) {=
lf_print("*** Door is open.");
=}
reaction(door) -> ClosedUnlocked {=
if (door->value == CLOSE) lf_set_mode(ClosedUnlocked);
=}
}
}
main reactor {
ui = new UserInteraction()
dlc = new DoorLockController()
ui.door -> dlc.door
ui.button -> dlc.button
ui.fob -> dlc.fob
ui.mobile -> dlc.mobile
}
Currently, recompilation is required to change the log level. It would be much better if this could be done using a CLI argument.
The tracing utility currently writes all events to a binary file. There are two potentially useful enhancements:
In line 540 of reactor_common.c, there is a check for null token if (token == NULL || ...)
If this condition is true, however, line 542 would de-reference the element_size field of the null token to create a new token.
reactor-c/core/reactor_common.c
Lines 540 to 542 in ab54ee5
The lf_nanosleep implementation in platform/lf_arduino_support.c always returns 0. This means the Arduino support will not be able to support physical actions because this function needs to return -1 to force the event queue to be checked. Somehow, this function needs to detect that lf_schedule has been called.
#16 introduced a more modular scheduling API for the C runtime and introduced three schedulers as a starting point.
To ensure that all the available runtime schedulers are correct, the full relevant C test suit is run for each scheduler.
This currently triples the total time of the C tests on GitHub Actions, both in reactor-c and in lingua-franca repositories.
To mitigate this, as discussed with @lhstrh, we should only use the default scheduler to run tests in the lingua-franca repository and limit the testing of all schedulers to just the reactor-c repo. Moreover, as an enhancement, we could create multiple CI tasks for each scheduler on GitHub Actions to speed up the total time needed to run the tests.
In our conversation with @rcakella today, it became clear that we need to enhance the token mechanism in the C infrastructure with a token that carries its own destructor. Specifically, you can currently use some of the SET functions, for example SET_NEW, to dynamically allocate memory for an outgoing message, and then a reference counting mechanism is used to later free this memory when it is no longer used. But this will not work if your message is, for example, a struct that contains pointers to dynamically allocated memory. Only the struct will be freed, not the pointed to memory. A simple solution, I think, would be to augment the token_t struct with a destructor, a function pointer. If this is NULL, then free() will be used, as now. If it is non-null, then the specified function will be invoked instead. We will then provide another variant of SET that takes the destructor as an argument.
The vector_at function in vector.h states "Return a pointer that is contained in the vector at 'idx'." But this is not what the implementation returns. The implementation returns a pointer to the pointer that is contained at idx. Is there a reason for this extra level of indirection in the implementation?
Adding this issue as a reminder to check this out. It has occurred on lock-time branch, LET branch and also currently on main. This problem quite consistently goes away if you rerun the failed tests. It is obviously a race condition, but is it in our runtime or in the test framework?
Each scheduler would benefit from an overall description of its architecture at the beginning of the file. Without such description, it is really quite difficult to figure out what's going on.
See:
We currently have a bunch of rather long functions with preprocessor commands in them. This sometimes makes the code hard to understand. Factoring code in a different way (e.g., by putting the conditional code blocks in their own function) would improve this situation.
Now that the RTI is not code generated, how should a user install it? Do they have clone the reactor-c repo and build it from source? Is there some way would bundle it with the command-line tools, at least? Is there any way to bundle it with Epoch?
As suggested by @Soroosh129, the ctarget.h file was put in include/ and ctarget.c was put in lib/. For the sake of consistency, we should probably split the files currently in core/ between include/core/ and lib/core/.
The correctness of this runtime is currently verified using code-generated integration tests in the lingua-franca repository. There are parts of the runtime that would benefit from having much smaller-scale unit tests. Now that this runtime is hosted in its own repository, I think it would make sense to start building a suite of regression tests and run them in a Github Actions workflow.
Currently, MIN_SLEEP_DURATION (used in wait_until) is the same for all platforms, but it shouldn't be. For the NRF52, for example, we found out that some careful thought needs to go into the logic for deciding whether a sleep should be entered or skipped.
Had a discussion with Edward on this and three strategies came up:
reaction_t has three fields related to STP.int flags supply macros for getting the desired fieldsRelevant CI run: https://github.com/lf-lang/reactor-c/runs/7758886688?check_suite_focus=true
This was in a refactoring branch that "should" not have caused this kind of error.
Error message (from ChainWithDelay):
Federate 2: FATAL ERROR: Attempted to insert reactions for a trigger that had an intended tag that was in the past. This should not happen under centralized coordination. Intended tag: (2500000, 0). Current tag: (3000000, 0)).
The generated C code should include code that catches signals (like control-C) and invokes shutdown reactions (probably by calling request_stop()). This should be done somewhat carefully, I think, perhaps with a timeout that exits anyway if the call to request_stop() proves ineffective.
Edward has mentioned this a few times. I put it here so I won't forget to investigate this. It seems considerably cheaper to advance to the next microstep than to advance to a new time tag (~18us vs 33us) so it might be a more performant design pattern for some throughput-oriented applications to use microsteps rather than tag advancement.
@arengarajan99 and I had a little discussion about how time should be represented in reactor-c. Lets make that discussion public here and reach a conclusion.
There are 2 options:
This is extracted from an email conversation. Just documenting it so that it does not get lost...
Bug report:
All compilations of the C target on Mac give the following warnings:
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib:
file: libcore.a(modes.c.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib:
file: libcore.a(modes.c.o) has no symbols
I think this is because there is a preprocessor command that omits everything in modes.c according the the compile definitions passed via CMake. Probably this warning will not appear in programs that use modes.
This issue is motivated by the following comment, referring to a procedure appearing in the "Remove TAN" PR:
If I understand, the reason why this procedure (and the one above it) are complicated is that pqueue priorities have to be 64 bits, which makes it hard to sort items by tag instead of time. This implementation looks like it might be complicated, and it looks like it might have suboptimal time complexity in programs that frequently schedule events a microstep in the future.
I have already suggested that attempts to cram priorities into a single word might not be serving us very well; maybe now is a good time to reconsider that?
Originally posted by @petervdonovan in #61 (comment)
I would like to emphasize that this is not the only area in which I am skeptical of our priority queue data structure. @lhstrh has, I think, mentioned calendar queues as an alternative -- if I understand, this is an exotic data structure that is fundamentally different from the traditional binary heap... I have also been unhappy with the extensive use of function pointers, which make function inlining impossible. The find_equal_same_priority function has also caused us some grief (time complexity stuff), as we have discussed in the scheduling channel on Slack... What I am saying here is that a fix for this shortcoming might as well be accompanied by an entirely new data structure, rather than just one ad hoc patch.
Hokeun's and Yunsang's recent work might be a prerequisite for this, since our benchmarks are not representative of what we expect LF programs to look like. A few days ago Soroush explained to me that typical LF programs might not actually make extensive use of the schedule(next, 0) idiom that appears in our benchmarks. Edward has also commented on our lack of representative performance assessments for the event queue.
lf_schedule_at and lf_scheduleWhile working on issue 44, I realized it might help with ease of use if we provide an alternate set of SET APIs that are defined based on the memory properties of the set data.
Instead of adding destructor variants to existing SET APIs, I propose a design that will only have two SET variants, one for static data and one for dynamic data:
SET(out, val) (implies static data)SET_DYNAMIC(out, val, destructor) (implies dynamic data)SET(out, val) is the same as the current SET.SET_DYNAMIC(out, val, destructor) is the same as SET_ARRAY except without the elem_size argument (which SET_ARRAY doesn't use in its macro body, anyway) and have an extra field for the destructor.Suppose is a struct called data:
data is static (none of its members is malloc'd), just use SET(out, data)data has dynamic members, the user would malloc the whole struct, then malloc the members. Then, use SET_DYNAMIC(out, data, &destructor), where void destructor(void* data) is a function provided by the user that takes data and frees every dynamic member of it as well as data itself. If destructor is NULL, free is used instead.The point of this API is to simplify memory management and reduce the number of assumptions the user has to make to use the dynamic memory SETs.
EDIT:
Action Items:
elem_size argument from SET_ARRAY since elem_size is already set in the default token generated by deferredCreateDefaultTokens in CTriggerObjectsGenerator.java
elem_size from _LF_SET_ARRAY and SET_ARRAYelem_size argument from API call in SetArray.lfSET_DYNAMIC API.Building the RTI results in a ton of warnings, making it difficult to address actual errors. Our code should be warning-free.
The stack trace is here: https://github.com/lf-lang/reactor-c/runs/7374143907?check_suite_focus=true#step:5:6376
All of the threads do appear to be in some sort of "waiting" function, which is why I say "deadlock" and not "abnormally bad performance due to being run on GitHub Actions."
Consider the simple program
target C;
reactor Source {
output out:int
timer t(0,10 msec)
reaction(t) -> out {=
lf_set(out,1);
=}
}
reactor Sink {
input in:int
reaction(in) {==}
}
main reactor {
a = new Source()
b = new Sink()
a.out->b.in after 10 msec
}
I am working with such a program on the zephyr-port and noticed that we run out of memory. When running it on Linux with valgrind I also get this suspicious output:
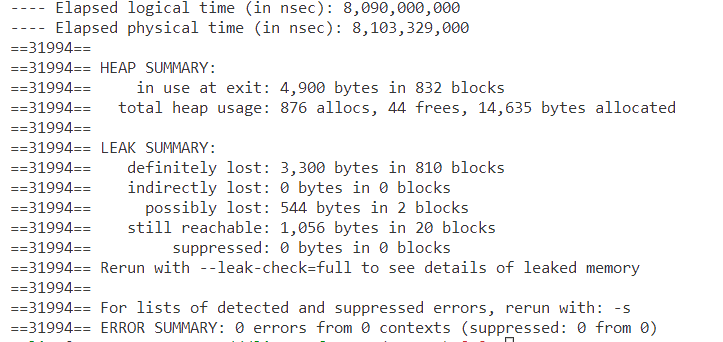
Without the after-delay I get:
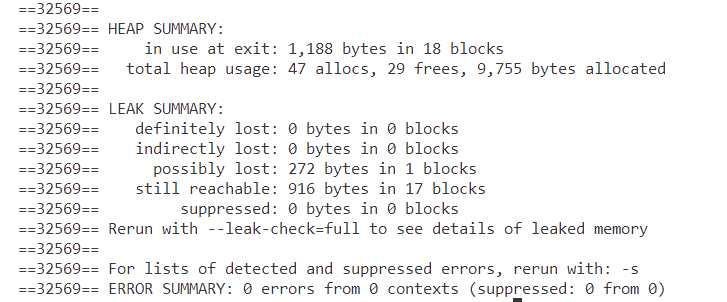
I believe the memory leak is related to the fact that the AfterDelay reactor calls lf_schedule_copy on its action to create the delay. This will use malloc to dynamically allocate memory for the token, and for some reason it is not freed
When building trace_to_csv and trace_to_chrome, the following error appears:
gcc -c -o trace_to_csv.o trace_to_csv.c -I../../org.lflang/src/lib/c/reactor-c/core/ -Wall
trace_to_csv.c:33:10: fatal error: reactor.h: No such file or directory
33 | #include "reactor.h"
| ^~~~~~~~~~~
The fix is to update CFLAGS to be:
CFLAGS=-I../../org.lflang/src/lib/c/reactor-c/include/core/ -Wall
This fix, however, generates the following error:
gcc -o trace_to_csv trace_to_csv.o trace_util.o
/usr/bin/ld: trace_to_csv.o: in function `lf_thread_create':
trace_to_csv.c:(.text+0x2b): undefined reference to `thrd_create'
/usr/bin/ld: trace_to_csv.o: in function `lf_thread_join':
trace_to_csv.c:(.text+0x79): undefined reference to `thrd_join'
/usr/bin/ld: trace_to_csv.o: in function `lf_mutex_init':
trace_to_csv.c:(.text+0x9c): undefined reference to `mtx_init'
/usr/bin/ld: trace_to_csv.o: in function `lf_mutex_lock':
trace_to_csv HelloWorld.lft says:Start time is 1666806776059282403.
There are 1 objects traced.
------- objects traced:
pointer = 0x563b805c2870, trigger = (nil), type = reactor: HelloWorld
-------
corrupted size vs. prev_size
Aborted (core dumped)
The csv file is generated though.
On reflection, it seems like capitalizing functions isn't so easy on the eyes. We did this to bring attention to the fact that these functions are defined by macros, but, in retrospect, this isn't really much of interested to users of this API. I propose we end this convention and bring all names down to lowercase. Any objections?
We have an automated documentation system based on Doxygen + Breathe + Sphinx, contributed by @arengarajan99.
There are still some missing features/issues. Here are tasks left to complete:
extern functions with multiple implementations generate readable documentationREADME.mdREADME.mdI am working on this Reactor in single-threaded mode.
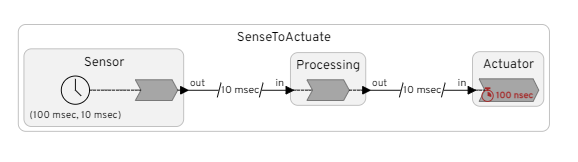
From observing the debug output it seems as if the after-delay events are not passed through the event queue. It seems like it works like this:
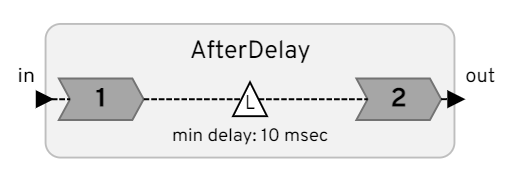
The problem here is that any downstream reaction with a deadline will get stuck behind reaction2. But reaction2 currently does not inherit the downstream deadlines. So, in effect, an after-delay breaks the EDF scheduling. A solution is that the second reactions in the AfterDelays calculates its index (i.e. priority) based on the deadline of its immediate downstream reactor.
I have found a few more functions that probably need the lf_ prefix:
Also, reactor.h seems to have a get_start_time that is neither deprecated nor implemented.
As pointed out in the discussion in #66, the current structure of files could be improved.
It used to be that events were not posted on the event queue after the timeout time. This seems to no longer work. See for example the warnings below:
> cd lingua-franca/test/C
> bin/BankGangedConnections
---- Start execution at time Fri Mar 11 18:51:56 2022
---- plus 817463000 nanoseconds.
---- Using 16 workers.
Received 1.
Shutdown invoked.
WARNING: ---- There are 1 unprocessed future events on the event queue.
WARNING: ---- The first future event has timestamp 1000000000 after start time.
---- Elapsed logical time (in nsec): 0
---- Elapsed physical time (in nsec): 919,000
After seeing this commit from @petervdonovan in the benchmark repository, I remembered that I implemented a simple optimization in the C++ runtime that completely avoids the overhead for reading physical time in the scheduler. The idea is to keep a cached value of the last read physical time. Let's call it last_pt. If the current logical time (let's call it lt) is smaller than last_pt, then there is no need to read the physical time again since we already know that whatever reading we will get, will be larger than lt. Only if lf > last_pt we read the current physical time and update last_pt.
Surely such an optimization could also be implemented in the C runtime. With this optimization, there is no measurable difference between benchmarks run with fast=true and without.
Some of the header files have very common names like "platform.h" and "port.h". This is already causing problems when porting it to XMOS. Likely this will cause problems when integrating reactor-c with other libraries and projects. There seems to be two ways to solve this.
Renaming:
platform -> lf_platform, port -> lf_port etc.
Use paths (thanks Christian :))
We can move all the header files out of the "core" folder and into the "include" folder. We put them like this:
core
include
-- reactor-c
---- platform.h
---- port.h
---- platform
------ lf_arduino.h
Then we put ~/include on the include path. This means that you have to do #include "reactor-c/platform.h" for all includes. I.e. you have to prepend reactor-c to all your includes. I think this latter solution is cleanest. We can at the same remove the symlink from include/core to core.
Since the RTI stands own its own now, we should move it to its own repository. This is important especially for pre-build releases of lfc and Epoch. Currently, we point users to a directory in our LF source tree to build the RTI, but in a pre-build release, that directory is not easily accessible. It would be easier to point users directly to a GitHub page and tell them to download and build the project.
Currently we use a symlink include/core -> ../core. We should reorganize the directory layout instead.
Such as the case that was identified in #54.
We should create a workflow that:
lingua-francagit checkout origin <branch> inside the reactor-c directory (this is helpful)This way, it is clear that runtime changes don't break any tests.
Optionally, we could create a workflow that, upon a push to main, updates the version module pointer in lingua-franca so that we always have the latest version of reactor-c in master.
In master together with reactor-c/main, in test/C/src/DelayArrayWithAfter.lf, we get this message
WARNING: Token being freed that has already been freed
This indicates the reference counting is not working correctly with after delays. At some point, it did work. I don't now when this error crept in. The tests DelayStructWithAfter.lf and DelayStructWithAfterOverlapped.lf also exhibit the same problem.
I think that some things in reactor_common.c would be better split off into a separate modal.c. I'm OK with merging (the pull request) now and doing a refactoring later.
Originally posted by @lhstrh in #6 (review)
@cmnrd pointed out during today's weekly meeting that instead of copying the C runtime each time code is generated, we can provide a way to install the C runtime as a library and dynamically (or even statically) link to it. This would be somewhat similar to our current way of handling the RTI, where we ask the user to centrally install the RTI instead of generating it for each LF program.
I believe we need at least three versions of the C runtime library: unthreaded, threaded, federated.
The biggest obstacle to implementing this feature is the fact that the C runtime contains the int main() function.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.