Big O and Binary Search
Objectives
- Understand what we mean by big O
- Understand how to use approximations when considering big O
- Binary Search
Supersize it
Ok, so in our last discussion of time complexity, we said that we consider the worst case because that is when we tend to feel the costs of performance. Well, because computers are so fast, when we calculate performance we will consider the case of very large datasets. By this, we mean a size in the tens of thousands, but feel free to dream bigger.
Sometimes, time complexity is called asymptotic time complexity.
Asymptotic means:
- as n (ie. the length of our input) approaches infinity.
That is how we really calculate the cost of our function, by asking what is the worst case scenario when our input gets really large. What is the cost in terms of the size of that input.
Our second algorithm: a worthy alternative
In the last section, we answered whether a random string included a letter by considering each letter. Our function looked like the following:
let string = "banana"
let letter = "a"
function stringIncludes(string, letter){
let matches;
for(let i = 0; i < string.length; i++){
if(string[i] === letter){
matches = true
}
}
return !!matches
}
stringIncludes(string, letter)Now, let's assume that we are able to sort our letters in alphabetical order. We'll discuss the cost of sorting in a later section, but for now let's assume that we can sort for free, magically, by calling the following function:
function sortString(string){
return string.split('').sort().join('')
}
sortString("banana")
// "aaabnn"
sortString("itwasthebestoftimesitwastheworseoftimes")
// "aabeeeeeeffhhiiiimmooorsssssstttttttwww"Introduction of Binary Search
Now, if I gave you the choice between answering two questions: if the letter "u" was included in the string "itwasthebestoftimesitwastheworseoftimes" or was in that same string, but now sorted as "aabeeeeeeffhhiiiimmooorsssssstttttttwww", which would be faster for you?
Probably the second right? In answering the question, you would no longer visit each letter of the string one by one, but instead would look to the middle, see that the middle letter is "i", move further down past the t section, and at w we know that it is not there. I call our procedure the phone book method.

Phone books were how people found numbers of businesses before the Internet. Look how much fun Homer is having in comparison to the guy behind him.
If you were to look for a name in a phone book, you might flip to the center, see if your guess were too high or low, and guess again until you could answer your question. You would not flip the pages one by one. Our previous function, would still work, but would essentially be flipping our pages one by one. If you were considering whether a letter were in a string, you reduce the size of your string each time you take a guess.
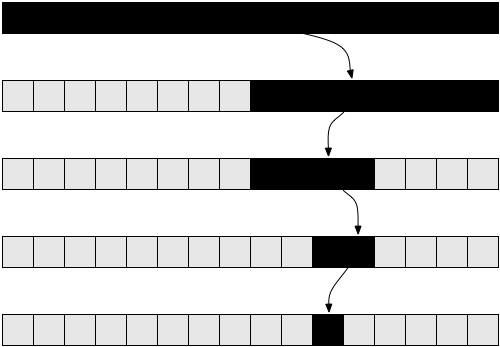
Binary search divides the dataset with each attempt to find a match.
Let's look at our old technique and our new technique side by side. Also, let's name our new function binarySearch.
// one by one
function stringIncludes(string, letter){
let matches;
for(let i = 0; i < string.length; i++){
if(string[i] === letter){
matches = true
}
}
return !!matches
}
function binarySearch(string, letter) {
var startpoint = 0
var endpoint = string.length - 1;
var guessPosition = parseInt((endpoint - startpoint)/2)
while (startpoint != endpoint) {
console.log(`start point is ${startpoint}, endpoint is ${endpoint} and guessposition is ${guessPosition}`)
if (string[guessPosition] < letter) {
console.log('too low')
startpoint = guessPosition
guessPosition = startpoint + Math.round((endpoint - startpoint)/2)
} else if(string[guessPosition] > letter) {
console.log('too high')
endpoint = guessPosition
guessPosition = startpoint + parseInt((endpoint - startpoint)/2)
} else {
console.log('just right')
return true;
}
}
if(string === letter){
return true
} else{
console.log('sorry')
return false;
}
}
let string = "aabeeeeeeffhhiiiimmooorsssssstttttttwww"Now these two different functions are vastly different in how performant they are. Let's go through our steps for calculating time complexity.
- Consider the worse case scenario in both functions
The worst case scenario is the same for each function. The worst case would be where we have to keep guessing until we can conclude that the letter is not in our string.
- Calculate the cost as the size of our input varies
Ok, so we already concluded the cost of our first function was n + 3 where n is the size of our input string. What is the cost of our new binarySearch function?
Well, there are a couple of calculations involved in reaching a precise number, but let's focus on what is the biggest determinant: how many times we travel through the while loop above. Because the function cuts what we search through in half every time we pass through the loop, we can make the following chart:
| Input size (n) | Number of guesses |
|---|---|
| 1 | 0 |
| 2 | 1 |
| 4 | 2 |
| 8 | 3 |
| 16 | 4 |
| 1024 | 10 |
| 2048 | 11 |
| 4096 | 12 |
| 1,048,576 | 20 |
| n | log2(n) |
Ok, so as you see above, as our input size increases, the number of guesses involved increases, but very slowly. We can answer the question of whether a letter is in a sorted string over one million characters long in only twenty guesses.
Just as we could express the time complexity of our original method in terms of the size of the input string (n), we can do so with binary search as well. The time complexity of our binary search function is log₂n (log base 2 of n, also written lg(n)). Log base 2 of n means the number of times you would have to press "divided by two" on a calculator to get down to 1, starting with the number n - it's the inverse of the exponent function.
In our binary search algorithm, when the size of n gets over 1 million, it still only takes us about 20 guesses. Our other formula would have taken one million guesses for an input of that size. The table above shows that for the log₂(n) algorithm, when our input size doubles, our runtime only goes up by 1!
Simplifying Time Complexity
So at this point, it's pretty meaningless to add 3 to our cost for those first three lines in our binary search function. It's also meaningless to count up lines inside our loop and say that each time we loop through the code it costs us four and not one. The cost of binary search would still only be eighty for an input size of over one million.
Now, when we consider time complexity, we never care about how much we need to add or multiply by. Rather the only number we care about is the leading exponent of our formula. You may remember this from our Google Search a few lessons ago.
So we can now begin to understand that second sentence, "excludes coefficients and lower order terms." Coefficients just mean anything that we multiply n by, and exclude lower order terms means that we should only consider the "term" with the highest exponent. For example, let's say that the time complexity of our function is 5n^3 + n^2 + 100n + log2(n) + 100. Here n^3, n^2, 100n, log2(n) and 100 are all "terms" of the function. Excluding the lower order terms we would say that the time complexity of our function is 5n^3, and excluding n^3's coefficient of 5 we would say that the time complexity is n^3.
Ok, so the Internet told us to exclude co-efficients and lower order terms, but can we really just get get away with that?
Well let's assume the time complexity of our function and is n^3 + n^2 + n + log2(n) + 100 and assume that n is 1,000.
Now consider the following:
| Formula | log2(n) | n | n^2 | n^3 | n^3 + n^2 + n + log2(n) + 100 |
|---|---|---|---|---|---|
| n = 1000 | 9.9 | 1000 | 1,000,000 | 1,000,000,000 | 1,001,001,110 |
You can see that in our formula of n^3 + n^2 + n + log2(n) + 100, when n is 1000, the formula returns approximately 1,001,001,110.
Moreover, you can see that compared to n^3, the n^2 doesn't move the dial. It accounts for just 1,000th of our overall cost. And this is still when our n is relatively small. Imagine when our input size increases to ten thousand. So we see that the leading exponent is dominant when calculating the cost of our function.
Now if we can exclude something like n², we can also exclude any number that we multiply n by. It doesn't make enough impact that we need to count it. We care about things that change our formula by a factor of n when n approaches infinity. So compared to that, any number we multiply by won't really matter insignificant.
So in summary, when considering asymptoptic time complexity, we only look to the term with the largest exponent, we only consider the worse case scenario, and we ignore coefficients as well as any smaller terms.
We call this big O.
Note: Mathematicians and academic computer scientists use different formal definitions for Big O than those presented here. There are two important additional concepts to note. First of all, when people colloquially say "Big O" (pronounced "big oh"), the technical term they usually mean is big ϴ ("big theta"). Big ϴ includes the concept of a "tight asymptotic bound". Using the example above, when our equation was f(n) = n^3 + n^2 + n + log2(n) + 100, ϴ requires us to describe this with an upper AND lower asymptotic bound. Thus, it would be correct for us to say that ϴ(n) = n^3, but incorrect for us to say ϴ(n) = n^2, and also incorrect for us to say ϴ(n) = n^4. Technically, big O notation would allow us to correctly say that our function f(n) is O(n) = n^3 and O(n) = n^4, and O(n) = n^5...etc. Under big O notation we are only establishing an upper asymptotic bound to our function f(n), and thus it is less precise. The formal mathematical definitions of the two concepts are:
For ϴ(g(n)) to describe a function f(n), there exist positive constants c1, c2, and n_o such that 0 <= c1 * g(n) <= f(n) <= c2 * g(n) for all n >= n_o
For O( g(n) ) to describe a function f(n), there exist positive constants c and n_o such that 0 <= f(n) <= c * g(n) for all n >= n_0
All that being said, colloquially, people say "big oh" when what they actually mean is "big theta". You can interpret all descriptions of O(n) in this text and most others as actually describing ϴ(n). But know that someone in an interview may ask you the difference between the two!
It gets better
Ok, so now we have learned that when expressing the cost of an algorithm, we only consider the term with the largest exponent. So, the next question is, is there a good technique to calculate this largest exponent. Well, yes, yes there is.
Let's look at a couple of equations:
function nSquared(string, letter){
let matches;
for(let i = 0; i < string.length; i++){ // loop 1
for(let i = 0; i < string.length; i++){ // loop 2
...
}
}
}
nSquared("abc")The big O of the above function is n squared. The reason why is because loop 2 has a cost of three (if we pass through "abc"). And then how many times does loop 1 run through innermost loop 2? Well three times. So we incur a cost of three, three times leading to a total cost is nine. So moving to a string of length n, we go through the body of loop one n times, and the cost of that is loop 2 which equals n. So total cost is n^2.
Now let's look at n^3.
function nCubed(string, letter){
let matches;
for(let i = 0; i < string.length; i++){ // loop 1
for(let i = 0; i < string.length; i++){ // loop 2
for(let i = 0; i < string.length; i++){ // loop 3
...
}
}
}
}One way of thinking about the above function is that the contents inside of loop 1 has the same big O as our nSquared function. So we have to incur the cost of our nSquared function n times. So total cost is n*n^2 or n^3.
Here's the point: to calculate the big O of a function if each loop forces you to go through your dataset n times, just count the number of nested loops.
Here is one gotcha. The big O of the below function is not n^2. It's just n. Do you see why?
function notNSquared(string, letter){
let matches;
for(let i = 0; i < string.length; i++){
if(string[i] === letter){
matches = true
}
}
for(let i = 0; i < string.length; i++){
if(string[i] === letter){
matches = true
}
}
}So in the function above, we don't go through a loop n times, we only go through a loop two times. So our cost is 2n, and because we ignore multipliers we have a big O of n. So we don't just count any loops when saying that with each loop the big O increases by a factor of n, we consider nested loops, and ONLY loops whose iterations are proportional to n (e.g. which iterate through our dataset).
Counting loops visible in your code is useful but is not a fail-safe method of determining asymptotic runtime. Among other things, you must be mindful of the runtime of built-in functions you are calling in your code. For example, my code could have a single loop, but inside that loop I sort my input array by using the built-in sort method. If the sorting algorithm used by the language is O(n * log2(n)) (which it most likely will be), I now have an overall runtime of O(n * n * log2(n)), which is O(n^2 * log2(n)) - with only a single loop in my code.
Summary
In this section we saw that when the input size is large (meaning over ten thousand or so), the leading exponent dominates our calculation of the cost of an algorithm, and so we can ignore considerations like smaller exponents, multipliers of an exponent and any number we need to add by. Then we saw that we can calculate the big O of a function by generally counting the number of nested loops that ask us to traverse through each number.
View Big O Approximation on Learn.co and start learning to code for free.





























