MapReduce implementations of random oversampling, random undersampling and ‘‘Synthetic Minority Oversampling TEchnique’’ (SMOTE) algorithms using Hadoop
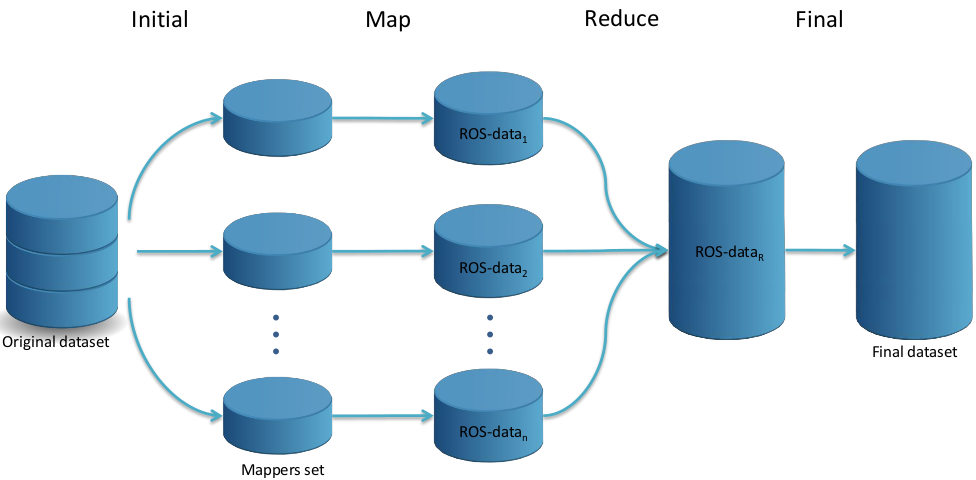
The Random Oversampling (ROS) algorithm has been adapted to deal with big data following a MapReduce design where each Map process is responsible for adjusting the class distribution in a mapper’s partition through the random replication of minority class instances and the Reduce process is responsible for collecting the outputs generated by each mapper to form the balanced dataset. This process is illustrated in Figure 1 and consists of four steps: Initial, Map, Reduce and Final.
Figure 1: A flowchart of how the ROS MapReduce design works.
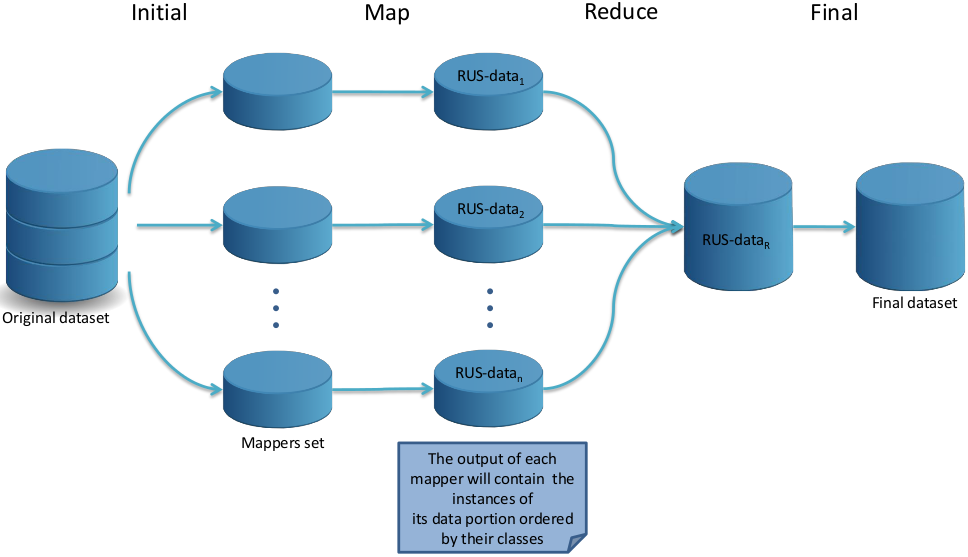
The Random Undersampling (RUS) version adapted to deal with big data follows a MapReduce design where each Map process is responsible for grouping by classes all the instances in its data partition and the Reduce process is responsible for collecting the output by each mapper and equilibrating the class distribution through the random elimination of majority class instances to form the balanced dataset. This process is illustrated in Figure 2 and consists of four steps: Initial, Map, Reduce and Final.
Figure 2: A flowchart of how the RUS MapReduce design works.
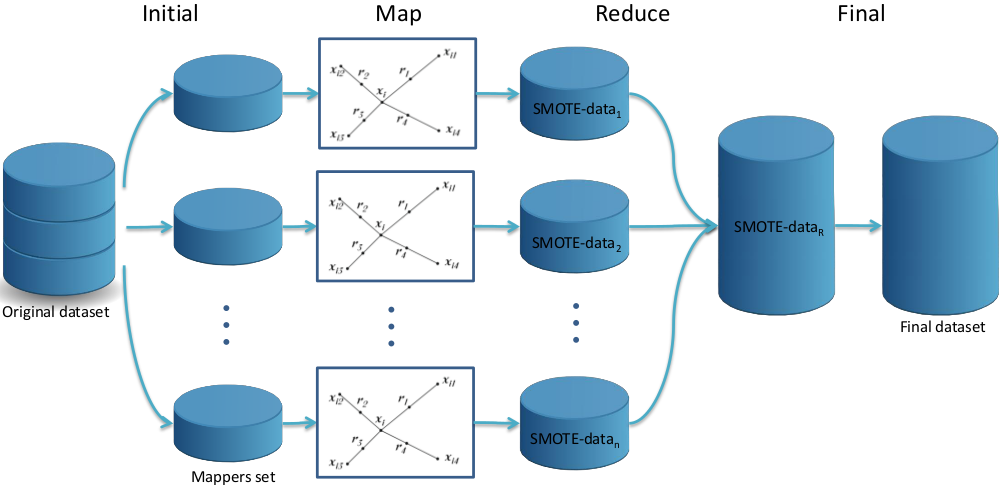
The SMOTE algorithm has been adapted to deal with big data following a MapReduce design where each Map process oversamples the minority class and the Reduce process randomizes the output generated by each mapper to form the balanced dataset. This process is illustrated in Figure 3 and consists of four steps: Initial, Map, Reduce and Final.
Figure 3: A flowchart of how the SMOTE MapReduce design works.
S. Río, V. López, J.M. Benítez, F. Herrera. On the use of MapReduce for Imbalanced Big Data using Random Forest. Information Sciences 285 (2014) 112-137. doi: 10.1016/j.ins.2014.03.043 link to pdf file
